了解了图数据库的计算与存储原理,大家一定会提出一个问题,图数据库该如何操作和查询呢?我们知道关系型数据库用的是SQL,它也是数据库领域第一个国际标准,在今年的4月,GQL图数据库语言标准正式与大家见面了。(嬴图| ISO/IEC-GQL国际图语言标准发布,图技术开启新纪元_图数据库 国际标准-CSDN博客)
在过去大数据库和NoSQL风起云涌的10年中,尽管SQL是被广泛兼容的,但是通过API的方式来调用也越来越常见。相比SQL而言,API/SDK调用的方式非常简单,例如键值数据库(KV Store),几乎只能通过简单的API来调用,也因此很多人认为键值数据库不是完整的数据库。
换个角度问个问题:人类终极的数据库是什么?或许你不会反对这个答案:人脑!人类的大脑到底是什么样的数据库技术?笔者以为是图数据库,至少在概率上它远远高于关系型数据库、列数据库、键值库或任何文档数据库,又或许是我们还没有发明的一种数据库。但是图数据库是最接近终极数据库的,毋庸置疑。
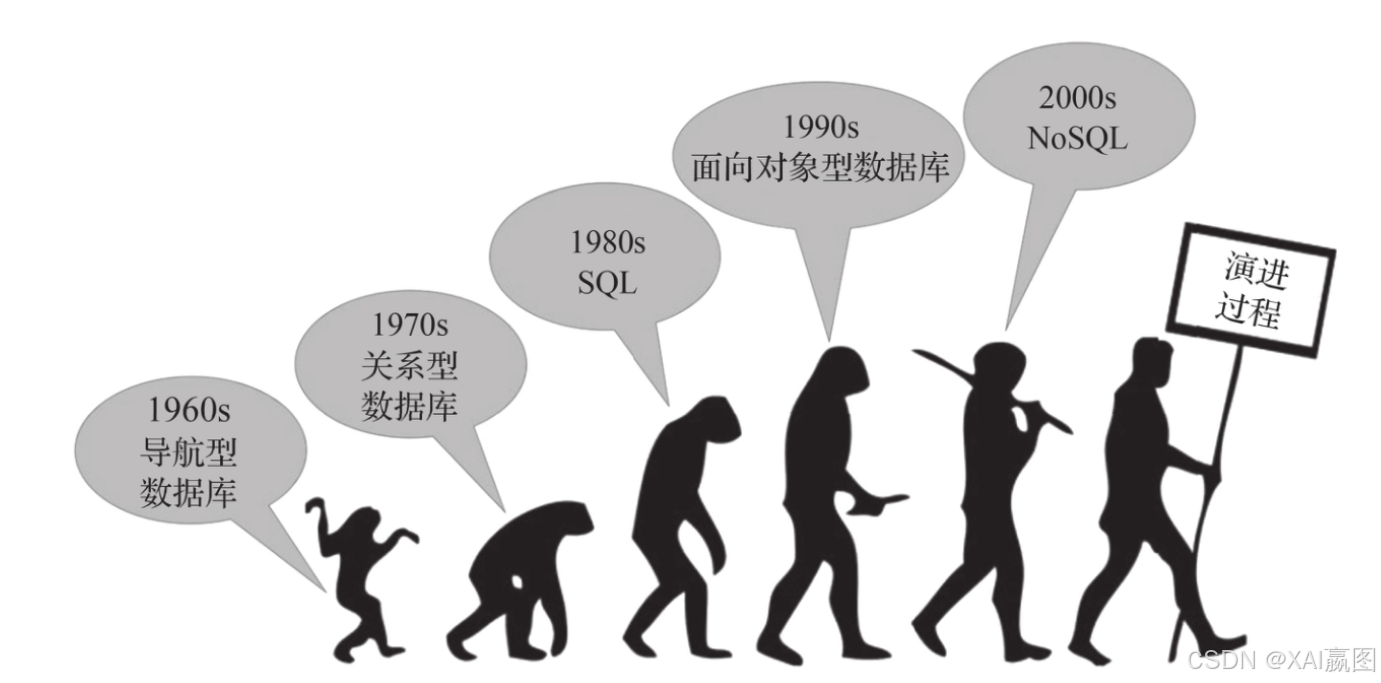
如果读者对于SQL语言的演进有所了解,知道它直接推动了关系型数据库的崛起(如果诸位还能回忆起在SQL语言出现之前的数据库使用是如何笨拙与痛苦的话)。互联网的崛起催生了NoSQL的诞生和崛起,其中很大的一个原因是关系型数据库无法很好地应对数据处理速度、数据建模灵活性的诉求。NoSQL数据库一般被分为以下4或5大类,每一类都有其各自的特性。
·键值(key-value):性能和简易性。
·宽列(wide-column):体量与性能。
·文档(document):数据多样性。
·图(graph):深数据与快数据。
·(可选的)时序(time series):IOT数据、时序优先性能。
从查询语言(或者API)的复杂度来看,数据处理能力也存在着一条进化路径。图2-34形象地表达了NoSQL类数据库和以SQL为中心的关系型数据库之间的区别。
·相对原始的键值库API→有序键值库(ordered key-value)。
·有序键值库→大表(一种典型的宽列库)。
·大表→文档数据库(例如MongoDB),并带有全文搜索能力(搜索引擎)。
·文档数据库→图数据库。
·图数据库→SQL中心化的关系型数据库。
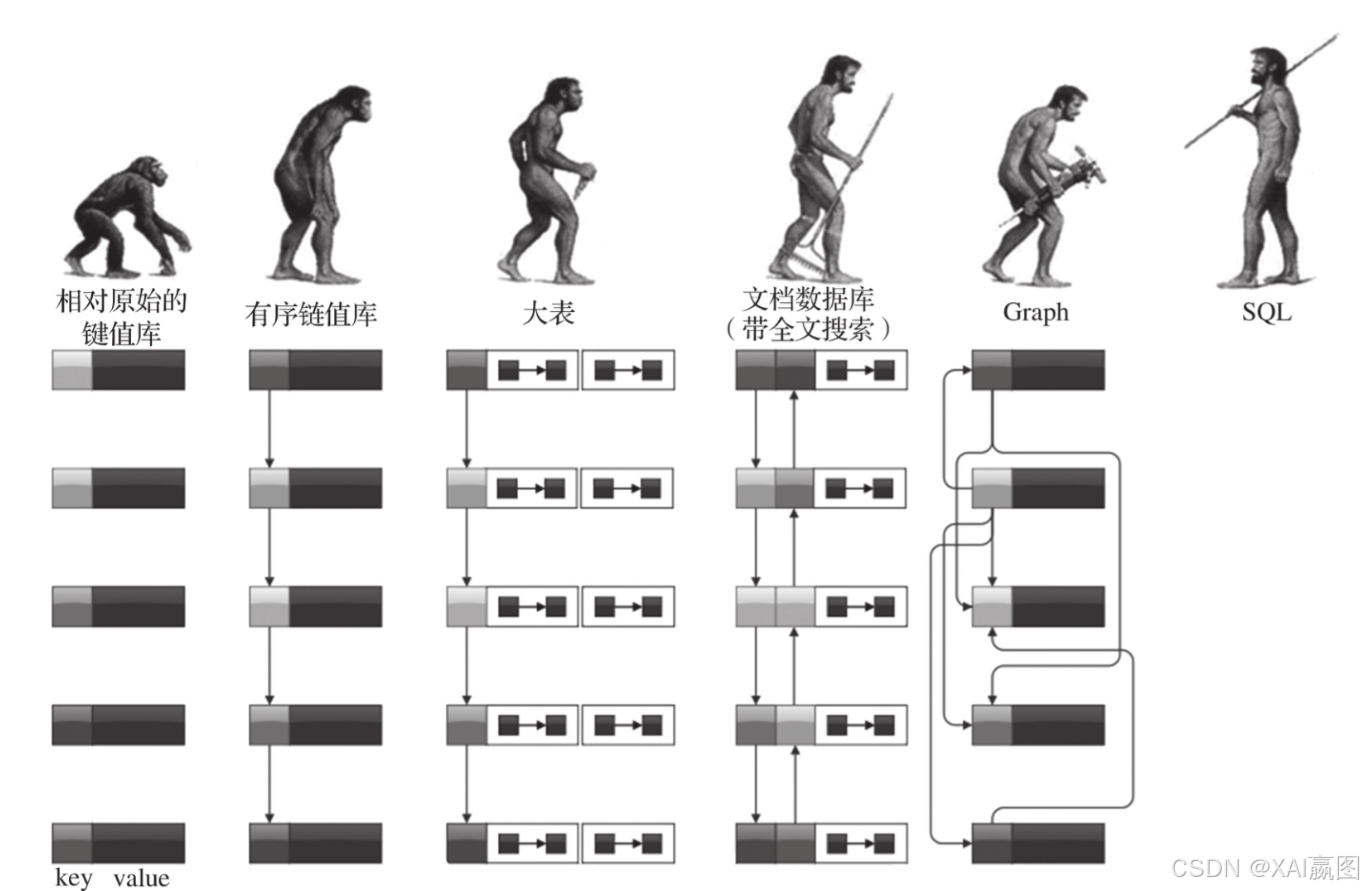
如图2-34所示,SQL被认为是最先进的数据处理与查询语言。下面稍微深入地研究一下SQL的演化历史,让我们有个更全局化的概念。
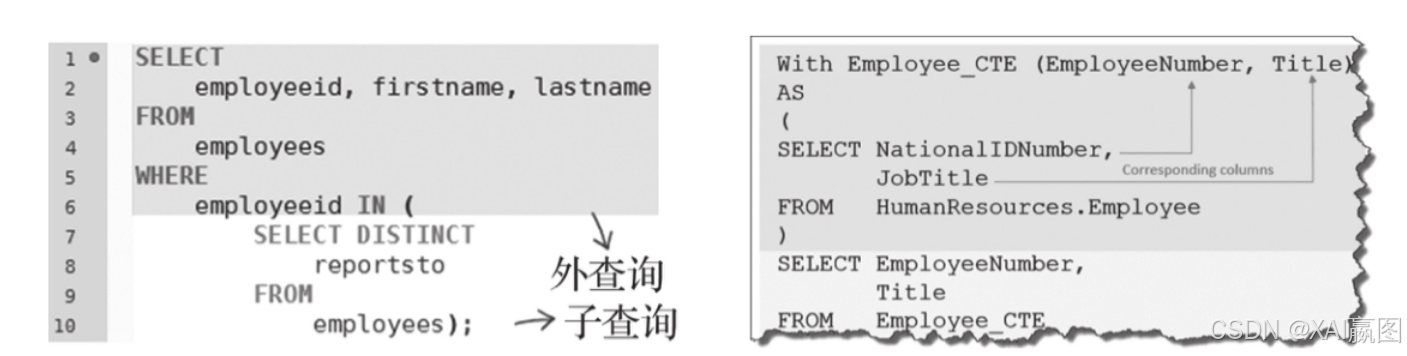
SQL的出现已将近50年了,并且迭代了很多版本(平均3~4年一次大迭代),其中最知名的非SQL-92、SQL-99莫属,例如在92版本的FROM语句中增加了子查询(subquery)功能;在99年版本中增加了CTE(Common Table Expression)功能。这些功能极大地增加了关系型数据库的灵活性,如图2-35所示。
然而,关系型数据库始终存在一个“弱点”,那就是不支持递归型数据结构。所谓递归数据结构(recursive data structures),指的是有向关系图的功能实现。讽刺的是,关系型数据库的名字虽然包含了关系,但是它在设计之初就很难支持关联关系的查询。为了实现关联查询,关系型数据库不得不依赖表连接操作——每一次表连接都意味着潜在的表扫描操作,随之而来的是性能指数级下降,以及SQL语句、代码复杂度的直线上升。
表连接操作的性能损耗是直接源自关系型数据库的基础设计思想的:
·数据正则化;
·固定化的、预先设定的表模式。
回顾一下NoSQL的核心理念,它在数据建模中突出了数据去正则化。所谓数据正则化,指的是用空间换取时间(牺牲空间来换取更高的性能)。在NoSQL(也包括Hadoop等,例如典型的3、5、7份拷贝的理念)中,数据经常被以多份拷贝的方式存储,而这样做的好处在于数据可以以近邻计算资源的方式被处理。这种理念和SQL中的只存一份正则化设计思路是截然相反的——后者或许可以节省一些存储空间,但是对于复杂的SQL操作而言,带来的是性能损耗。
预先定义数据的表模式理念是SQL与NoSQL的另一大差异。对于初次接触这一概念的读者而言,理解这个点会有些困难,它实际上指的是SQL中模式第一、数据第二,而在NoSQL中数据先行、模式第二。
在关系型数据库中,系统管理员(DBA)需要先定义表的结构(schema),然后才会加载第一行数据进入数据库,他不可能动态地更改表的结构。这种僵化性对于固定模式、一成不变的数据结构和业务需求而言或许不是什么大问题。但是,让我们想象一下,如果数据模式可以自我调整,并能根据流入的数据动态调整,这就给我们带来了极大的灵活性。对于强SQL背景的人而言,这是很难想象的。但是,我们需要暂时抛弃僵化的、限制性的思维,以一种成长性的思维方式来看待。我们所要达成的目标是一种schema-free或schemaless的数据模式,也就是无需预先设定数据模式,数据之间的关联性不需要预先定义和了解,随着数据的流入,它们会自然形成某种关联关系。而数据库所需要做的是对应这些数据“因地制宜”来处理如何查询与计算。
在过去几十年中,数据库程序员已经被训练得一定要先了解数据模型,不论它是关系型表结构还是实体E-R模式图。了解数据模型当然有它的优势,但这也让开发流程变得更加复杂和缓慢。程序员读者们,你还记得上一次参与的交钥匙解决方案的开发周期是多长时间吗?一个季度、半年、一年还是更久?在一个有8 000张表的Oracle数据库中,没有任何一个DBA可以完全掌握所有表之间的关联关系。这个时候,我们更愿意把这套脆弱的系统比作一个定时炸弹,而你的所有业务都绑定在其上。
关于无模式(schema-free),在文档型数据库或宽列数据库中已经有了这一概念,尽管它们多少有一些和图数据库相似的设计理念。下面通过一些图数据库的具体例子来帮助读者理解无模式。
(文/Ricky - HPC高性能计算与存储专家、大数据专家、数据库专家及学者)
· END ·