1.Anaconda的简单介绍和理解
首先在做项目的时候,涉及到使用anaconda。我脑子里面一头雾水,不知道anaconda是什么有什么用,对这个东西完全没有认识。
我现在简单的谈谈我的认识
1.1 自带各种包的python解释器
首先anaconda可以把它看做是一个自带的很多包的python解释器,比如我们一般使用纯净的python
比如python3.12
我们如果需要使用python的某些库和功能,我们一般需要先pip install xxx,比如如果你要安装numpy包,你需要在pycharm的终端里面输入如下命令。
pip install numpy这种就是在终端里面输入命令行来安装包,然后你需要在你的代码里面做一个import导入,这样就可以使用numpy包了,如下面所示。
#import导入你已经安装好的numpy包
import numpy as np
# 创建一维数组
arr_1d = np.array([1, 2, 3, 4, 5])
print("一维数组:", arr_1d)
# 创建二维数组
arr_2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print("二维数组:\n", arr_2d)
# 数组的加法运算
arr_add = arr_1d + 2
print("一维数组每个元素加2后的结果:", arr_add)
# 二维数组的乘法运算(对应元素相乘)
arr_mul = arr_2d * 2
print("二维数组每个元素乘以2后的结果:\n", arr_mul)
那么anaconda首先你可以理解为,自带某些数据分析包的python解释器,不用你自己去装和数据分析领域相关的包了
以下大致是anaconda涉及到的包
数据分析与科学计算领域
- Numpy:基础的科学计算库,提供了高性能的多维数组对象以及对这些数组进行操作的各种函数。可用于数学运算、线性代数、随机数生成等。广泛应用于数据分析、机器学习、科学研究等领域,如在数据预处理阶段对数据进行归一化、计算均值方差等统计量.
- Pandas:用于数据处理和分析的强大库,提供了数据结构如
DataFrame和Series,方便进行数据读取、清洗、转换、合并等操作。常用于数据分析流程中的数据整理和初步探索,如处理 CSV、Excel 等格式的数据文件,进行数据筛选、排序、分组聚合等操作. - Scipy:在 Numpy 基础上构建的科学计算库,包含了众多的数学算法和工具,如数值积分、优化、信号处理、图像处理等。在科学研究和工程领域中,用于解决复杂的数学问题和数据处理任务,如物理模型的数值模拟、信号滤波等.
- Matplotlib:用于绘制各种静态、动态和交互式图表的绘图库,支持折线图、散点图、柱状图、热图等多种图形。适用于数据可视化,能够将数据分析结果以直观的图形形式呈现,帮助用户更好地理解和解释数据,常用于科研报告、数据分析展示、工程分析等场景.机器学习与
机器学习与数据挖掘领域
- Scikit-learn:提供了丰富的机器学习算法和工具,包括分类、回归、聚类、降维等算法,如决策树、支持向量机、朴素贝叶斯、K-Means 聚类等。可用于数据挖掘、预测分析、模式识别等任务,帮助开发人员快速构建和评估机器学习模型.
- TensorFlow:一个广泛使用的深度学习框架,用于构建和训练各种神经网络模型,如卷积神经网络(CNN)、循环神经网络(RNN)及其变体。在图像识别、自然语言处理、语音识别等领域有广泛应用,可用于开发图像分类器、机器翻译系统、语音助手等人工智能应用.
- Keras:基于 TensorFlow 等后端的高级神经网络 API,提供了简洁易用的接口,方便快速搭建和实验深度学习模型。适合初学者快速上手深度学习,能够快速构建和训练神经网络,如构建简单的手写数字识别模型等.
- PyTorch:另一个流行的深度学习框架,以其动态计算图和简洁的编程风格受到欢迎。在学术界和工业界都有广泛应用,尤其在自然语言处理领域表现出色,可用于开发语言模型、文本生成、情感分析等应用.
其他领域
- Biopython:用于计算分子生物学的工具和库,可进行DNA、RNA和蛋白质序列的读取、写入、比对和分析,以及蛋白质结构的预测、模拟和可视化等。应用于生物信息学、结构生物学、系统生物学等领域,帮助研究人员处理和分析生物学数据.
- Requests:用于发送 HTTP 请求的库,简单易用,能够方便地与 Web 服务进行交互,获取网页数据、调用 API 等。在网络爬虫、数据采集、Web 开发等场景中经常使用,如爬取网页内容、获取天气预报数据等。
- BeautifulSoup:用于解析 HTML 和 XML 文档的库,能够方便地从网页中提取所需的信息。常与 Requests 库配合使用,在网络爬虫中用于解析网页结构,提取文本、链接、图片等信息.
- Jupyter Notebook:一种交互式的文档格式和开发环境,支持以单元格为单位的代码编写、运行和结果展示,能够实时查看代码的输出和修改代码。广泛应用于数据科学、教学、科研等领域,方便数据分析师、研究人员和教师记录和分享代码、数据和分析过程.
1.2 自动分析依赖
然后Anaconda可以自动分析相关依赖,自动安装各种组件,不容易报错。
这句话是什么意思?我来给你解释一下
比如我们平时在安装python的各种包的时候我们可以看到,它存在各种版本。但是每个软件包之间可能都会有若干个版本,比如A包版本是3.2,最新是4.0,然后B包最新版是1.3,这个时候你说我直接pip安装B包,然后再次运行程序,有可能就会报错。为什么?有可能你的B包版本太高,和解释器里面的A包发生了冲突,又或者你的python版本太低,兼容不了B包。
有非常多的可能性,我们需要一个个排查,那有没有一个软件,能够自动去帮我选择我应该安装哪个版本的B包呢?能够不仅匹配我的Python版本,而且还不会和我的A包版本发生冲突。
当然有啦,这就是Anaconda的conda安装功能。
自带的 conda 包管理器强大且智能,能够快速、准确地安装、更新和卸载库,并在处理库之间的依赖关系时表现出色。当安装一个新的库时,conda 会自动检测并安装该库所依赖的其他库,且确保它们的版本兼容性,节省了用户手动解决依赖问题的时间和精力,降低了由于依赖错误而导致的安装失败和运行时错误的风险
假如你要用Conda安装numpy,命令如下所示
conda install numpy
例如,要安装numpy包,可以在命令行(在 Windows 中是 “命令提示符” 或 “PowerShell”,在 Linux 和 macOS 中是 “终端”)中输入以下命令:
conda 会自动从 Anaconda 的软件包仓库中查找numpy包及其依赖项,并将它们下载并安装到当前激活的 Anaconda 环境中。杜绝了自己安装,然后报错版本等各种问题。
1.3 创建隔离环境,方便直接删除各种包
然后Anaconda还有一个功能,就是创建独立的隔离环境。(但这个不是独有的,其实pycharm自己就有一个类似的功能,pycharm也可以创建隔离的环境)
所以什么是独立环境,我最直观的感受就是:
首先,在独立环境下我们的解释器可以有两种,一种是全局的解释器(默认状态),一种是虚拟环境的解释器(需要创立虚拟环境然后我们设置)。
两种有什么区别呢?
比如全局下的解释器,你有一个毕业设计项目A,还有一个公司的项目B,你这个A项目用的解释器是python3.12(全局,安装在C盘一个默认的 ),含有numpy包,你在你的毕业设计项目中pip install numpy过后,B项目也可以用。
如果是conda或者pycharm虚拟环境下的解释器,那么所有安装的包和相关的解释器都在一个虚拟环境目录下,你所有和这个项目相关的包都在里面。
影响不了其他项目(比如你安装了numpy在这个虚拟环境里面),其他项目也就无法识别numpy包了,除非你手动设置其他项目也使用这个虚拟环境。所以如果你的C盘满了,你的某个项目也不用了,你可以直接删除这个项目的虚拟环境(包含各种包,某个版本的python解释器加起来可能占用若干个GB空间),释放空间。
具体如何激活CONDA或者pycharm虚拟环境就自己搜索一下吧。这里只是帮你理解。
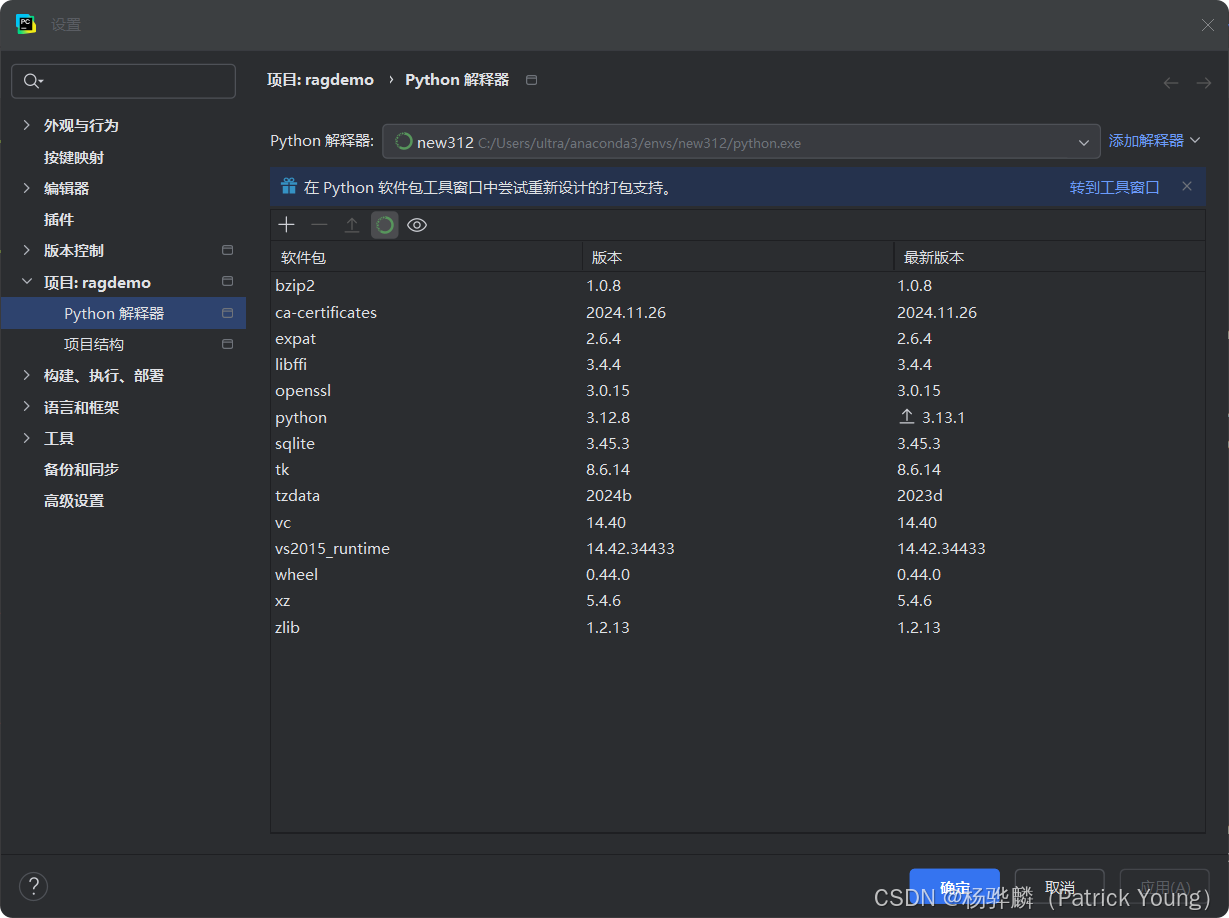
下面展示一下如何调用conda或者pycharm env虚拟环境下的解释器和相关包。
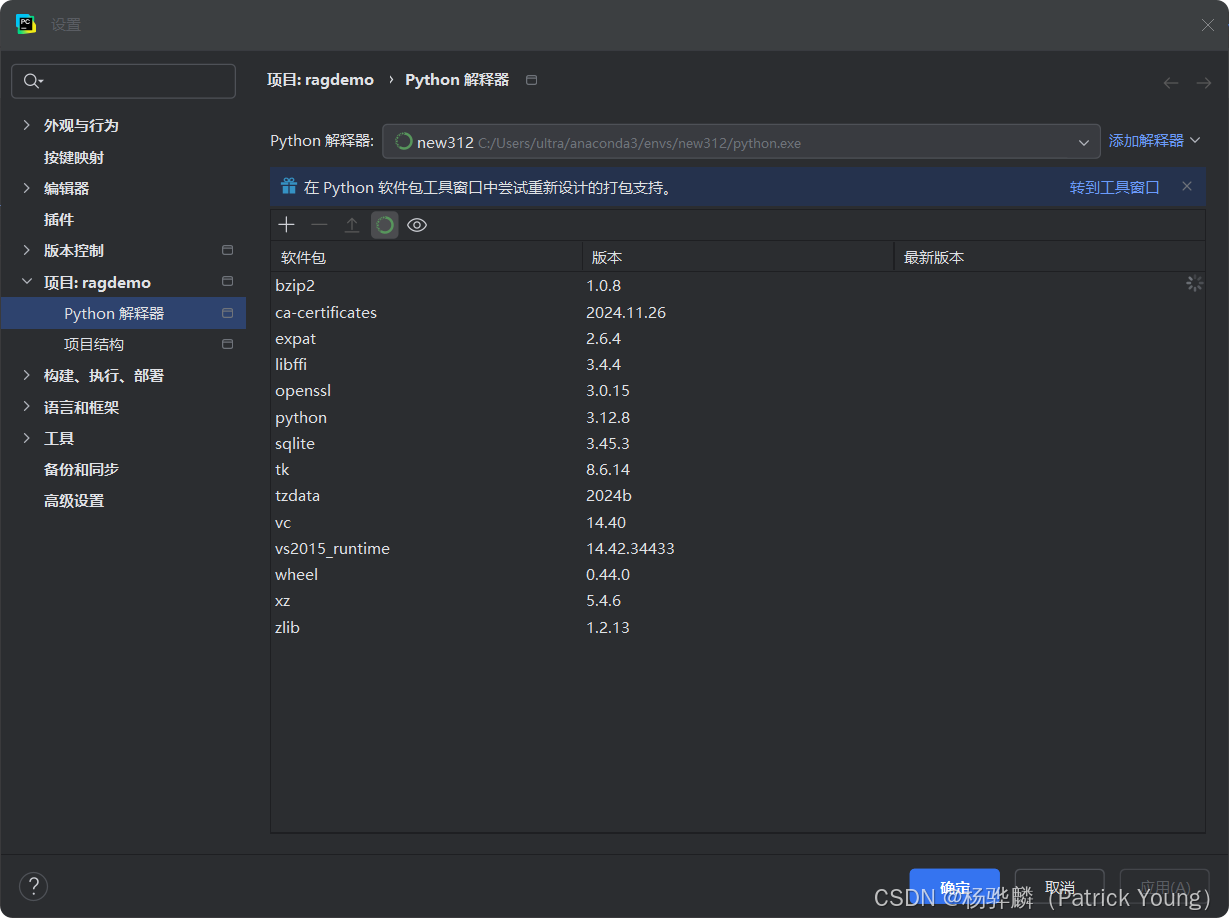
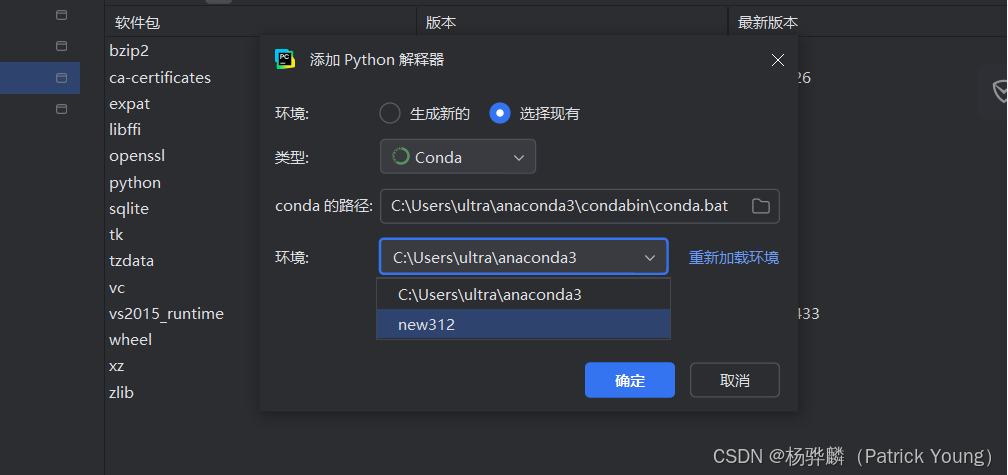
打开pycharm设置,点击解释器这里,然后点击添加本地解释器。
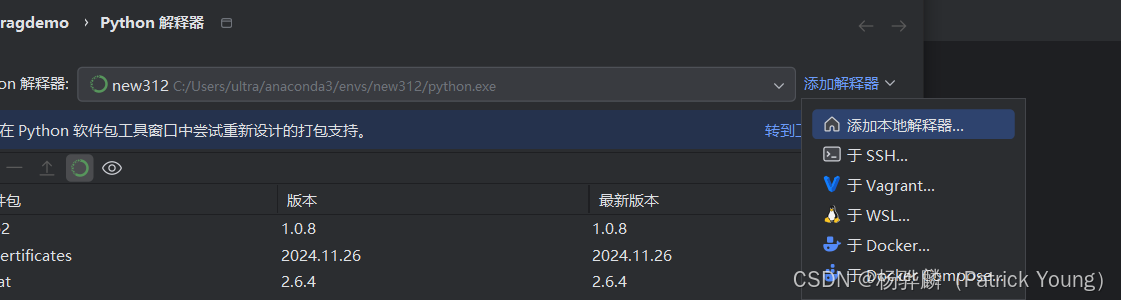
然后这里你可以选是conda的虚拟环境还是pycharm自带的。我这里用的是conda,然后我就选择了我自己的conda环境
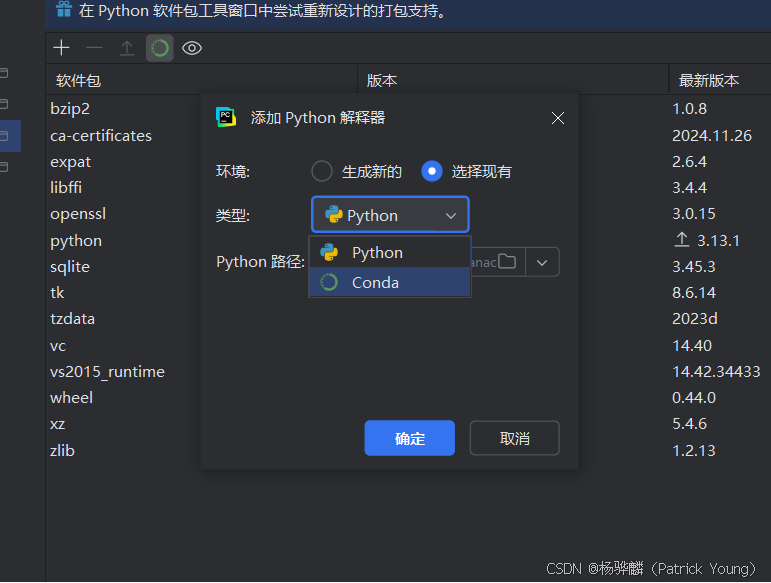
然后我们可以看到我自己的new312环境,点击即可重新加载解释器,完成虚拟环境解释器的选择。
--------------------------------------------------------------
2.安装xinference的思路和出现的问题
我的安装思路是
2.1 安装Anaconda
2.2 进入目标项目,创建单独的conda环境,选择python3.12
conda create --name yourname python=3.122.3 激活conda环境.
conda activate yourname
2.4 安装Pytorch(GPU CUDA版本)
进入pytorch官网安装相关包(自带了CUDA)。(或者用Conda安装),建议用pytorch官网安装,之前用Conda安装发生了报错,并且装成了CPU版本,我们需要的是带CUDA驱动的GPU版本。所以我这里就提供去官网安装的方法。如果你要知道conda安装方法,建议询问GPT获得命令行。
 https://pytorch.org/
https://pytorch.org/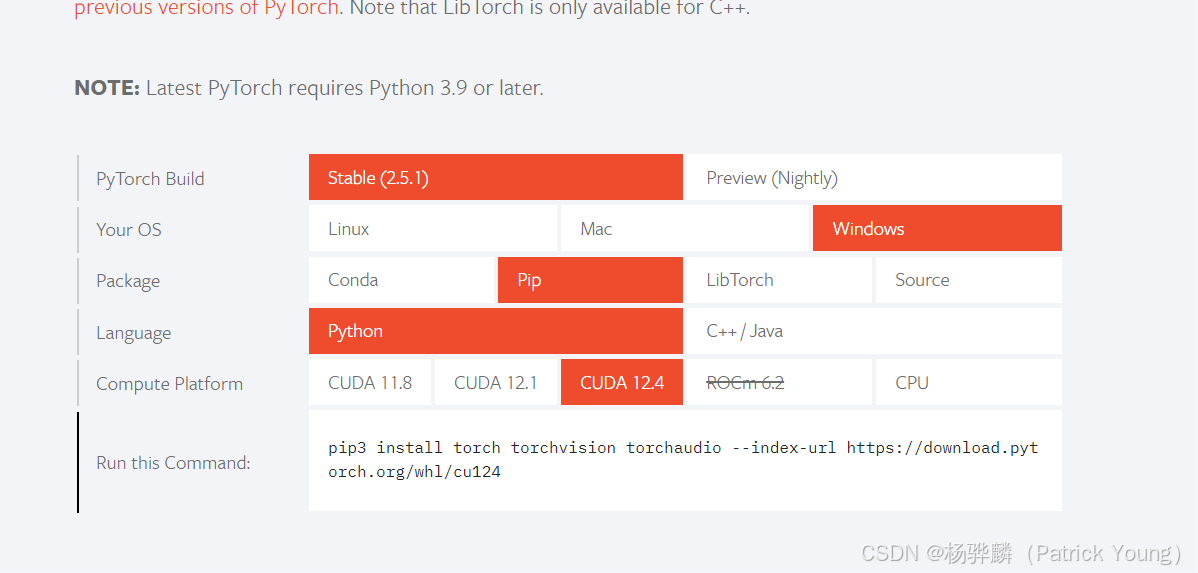
我这里安装的是CUDA12.4,版本太低了(CUDA11.8)的话,我的电脑上后续安装Xinference会报错。
先查看你的nvdia版本(如果你没有独立显卡的就不要看这个了,你直接安装CPU版本的cuda驱动)
具体安装步骤可以查看这个帖子,教你如何安装pytorch,但是帖子里面是安装的低版本,我建议直接跟着我来安装高版本。
//打开powershell或者cmd输入命令行
nvidia-smi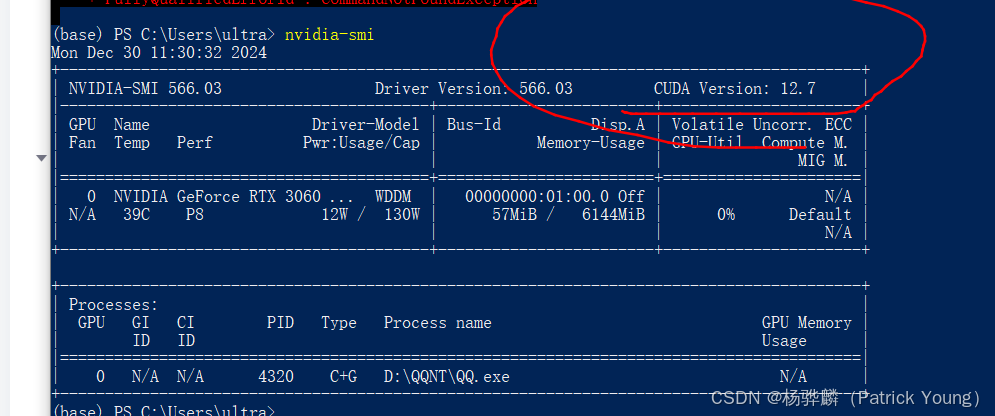
其中CUDA Version后是指最高支持的cuda版本,所以你要安装的pytorch能够调用的cuda不能超过这个地方12.7版本。所以我直接安装了12.4版本的pytorch。
复制最下面的RUN this command 到pycharm的终端里面安装就可以了(注意这个时候你的conda环境是激活的,不然你就直接安装到全局解释器去了,到时候删除环境的时候不会连着删除这个包,可能长时间占用c盘空间)。

如果你看不懂我的 你可以再看看下面这个帖子
2.5 安装xinference(这一步报错UDA_HOME environment variable is not set. )
这一步我们在pycharm终端里面输入
pip install xinference[all]
由于conda库里面没有xinference,所以我们只能通过pip安装,所以conda不能帮我们解析依赖自动配置,防止报错。但是果不其然,用pip安装的下场,还是出现了报错(并且困扰了我很久)。
报错原因如图所示:
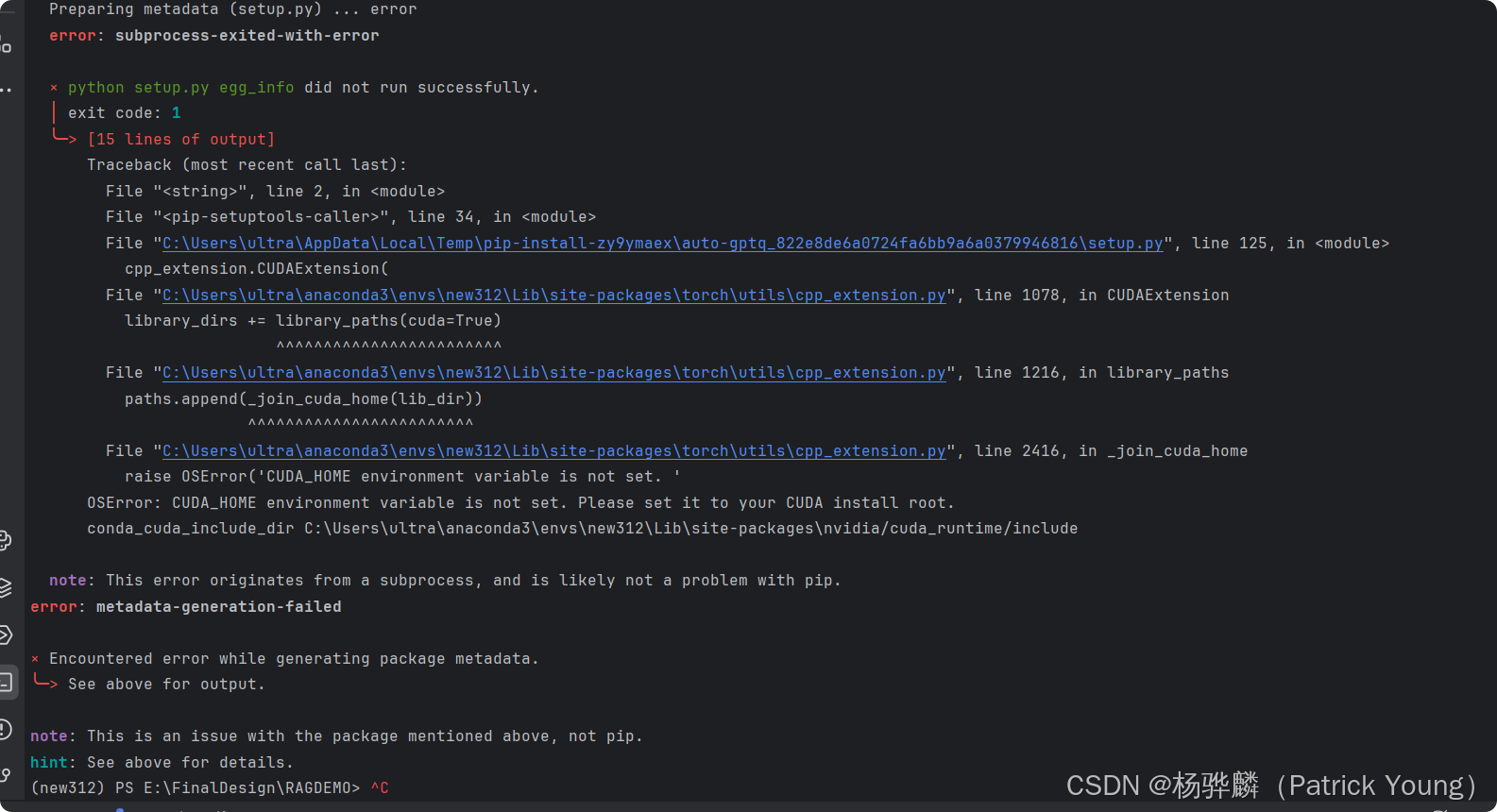
error: subprocess-exited-with-error
raise OSError('CUDA_HOME environment variable is not set. '
OSError: CUDA_HOME environment variable is not set. Please set it to your CUDA install root.
conda_cuda_include_dir C:\Users\ultra\anaconda3\envs\new312\Lib\site-packages\nvidia/cuda_runtime/include
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed翻译一下就是CUDA_HOME 环境变量未设置。请将其设置为你的 CUDA 安装根目录
可是我们在2.4步骤的时候不是已经安装带有CUDA版本的pytorch了吗,按理来说cuda的路径是已经配置好了,不用我们再去设置了,所以是为什么呢?
然后我去看了下面这篇帖子。
解决OSError: CUDA_HOME environment variable is not set. Please set it to your CU_cuda home environment variable is not set-CSDN博客文章浏览阅读1.3w次,点赞12次,收藏25次。在大多数情况下,上述 cudatoolkit 是可以满足 Pytorch 等框架的使用需求的。但对于一些特殊需求,如需要为 Pytorch 框架添加 CUDA 相关的拓展时( Custom C++ and CUDA Extensions ),需要对编写的 CUDA 相关的程序进行编译等操作,则需安装完整的 Nvidia 官方提供的 CUDA Toolkit.C++Extension有对CUDA的依赖,并且此cuda需要是电脑安装的而不是使用anaconda下载的cudatookit。重启计算机,即可解决。_cuda home environment variable is not set
意思就是我们还要去NVDIA官网再安装一个官方驱动。然后配置环境变量,才能解决问题。
CUDA Toolkit - Free Tools and Training | NVIDIA Developer
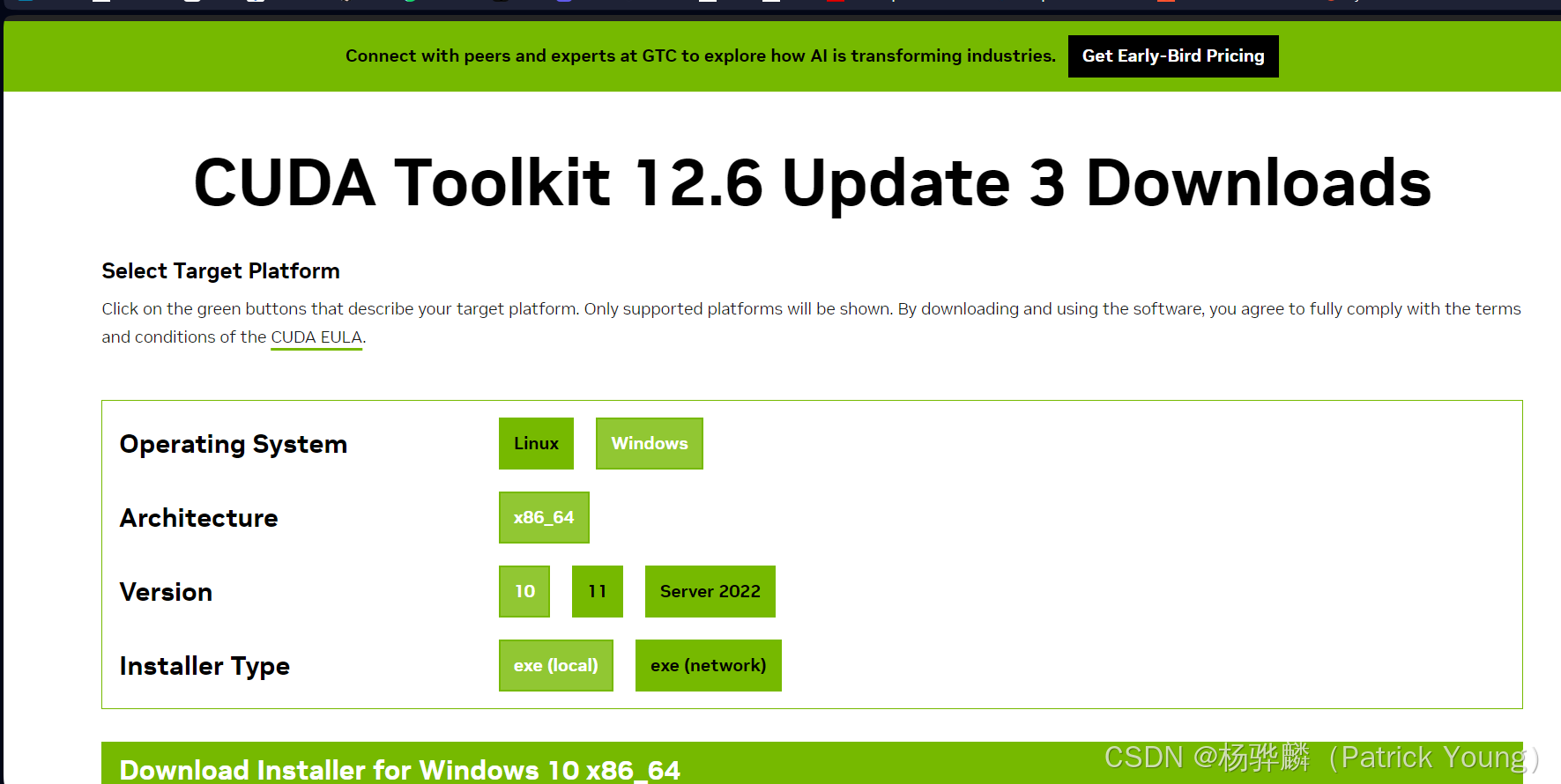
下载CUDA,然后安装,可以先不配置系统变量,因为一般会自动配置,驱动请安装在C盘默认地址,不然后面又要报错。
然后继续安装xinference试试
pip install xinference
如果实在还是配置有问题,可以进行下面的设置(如果上一部运行成功可以直接忽略):
1. 安装后在系统环境变量设置可以看到(路径为默认安装路径)
2. 再添加一个与CUDA_PATH相同路径的CUDA_HOME
重启计算机,即可解决


2.6 安装NVDIA驱动后,重新安装xinference又出现llama-cpp-python报错
Building wheel for llama-cpp-python (pyproject.toml) did not run successfully.
2024-01-15 02:55:12,546 - scikit_build_core - WARNING - Can't find a Python library, got libdir=None, ldlibrary=None, multiarch=None, masd=None
loading initial cache file C:\Windows\TEMP\tmpyjbtivnu\build\CMakeInit.txt
-- Building for: NMake Makefiles
CMake Error at CMakeLists.txt:3 (project):
Running
'nmake' '-?'
failed with:
no such file or directory
CMake Error: CMAKE_C_COMPILER not set, after EnableLanguage
CMake Error: CMAKE_CXX_COMPILER not set, after EnableLanguage
error: subprocess-exited-with-error
× Building wheel for llama-cpp-python (pyproject.toml) did not run successfully.
│ exit code: 1
╰─> [20 lines of output]
*** scikit-build-core 0.7.1 using CMake 3.28.1 (wheel)
*** Configuring CMake...
2024-01-15 02:55:12,546 - scikit_build_core - WARNING - Can't find a Python library, got libdir=None, ldlibrary=None, multiarch=None, masd=None
loading initial cache file C:\Windows\TEMP\tmpyjbtivnu\build\CMakeInit.txt
-- Building for: NMake Makefiles
CMake Error at CMakeLists.txt:3 (project):
Running
'nmake' '-?'
failed with:
no such file or directory
CMake Error: CMAKE_C_COMPILER not set, after EnableLanguage
CMake Error: CMAKE_CXX_COMPILER not set, after EnableLanguage
-- Configuring incomplete, errors occurred!
*** CMake configuration failed
[end of output]
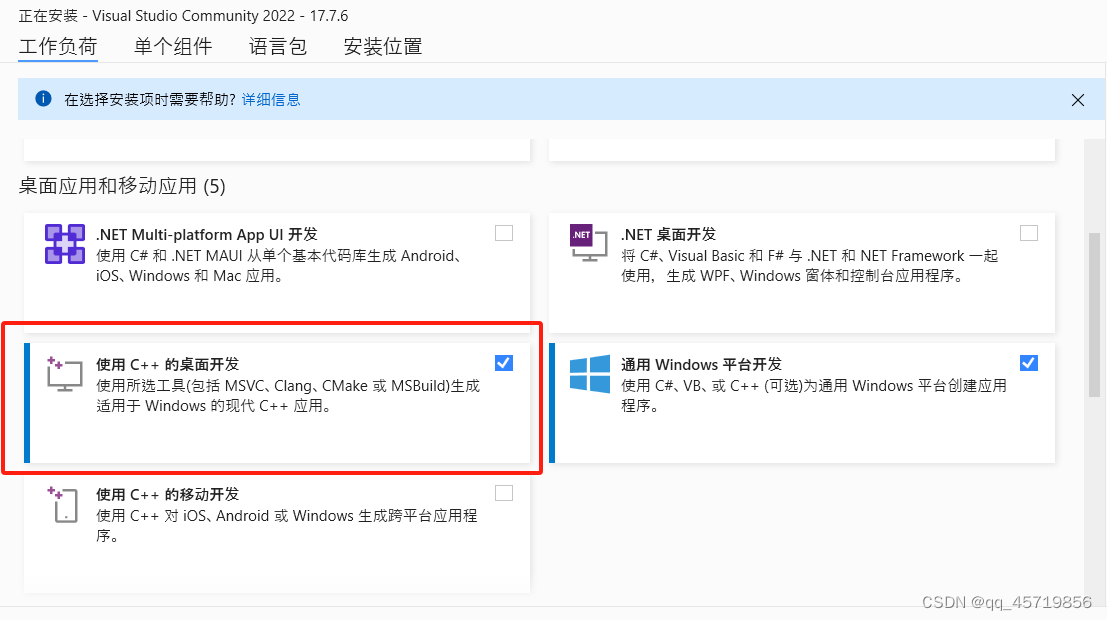
在安装llama-cpp-python包时遇到的错误,涉及到CMake配置失败和需要VisualStudio2022+C++构建工具的情况。
解决方法是安装VisualStudio2022全版,包括C++桌面开发组件。具体可以参考下面这个文章
Could not build wheels for llama-cpp-python, which is required to install pyproject.toml-based proj_error: could not build wheels for llama-cpp-python-CSDN博客文章浏览阅读7.2k次,点赞16次,收藏15次。文章描述了用户在安装llama-cpp-python包时遇到的错误,涉及到CMake配置失败和需要VisualStudio2022+C++构建工具的情况。解决方法是安装VisualStudio2022全版,包括C++桌面开发组件。
必须勾选C++桌面开发(10G+),没错就是这么大
然后安装完毕后再运行,xinference的安装代码
pip install xinference[all]按理说这样就应该能成功运行了吧。但是(想骂人),我又出现了一个错误,但一般你们不会再出现了。所以后面如果你也出现了,可以看2.7 module 'pkgutil' has no attribute 'ImpImporter'. Did you mean: 'zipimporter'?
2.7 module 'pkgutil' has no attribute 'ImpImporter'. Did you mean: 'zipimporter'?,安装完VSCODE后可能还会出现的错误(可选阅读)
error: subprocess-exited-with-error
× pip subprocess to install build dependencies did not run successfully.
│ exit code: 1
╰─> [63 lines of output]
Collecting setuptools
Downloading setuptools-75.6.0-py3-none-any.whl.metadata (6.7 kB)
Collecting wheel
Downloading wheel-0.45.1-py3-none-any.whl.metadata (2.3 kB)
Collecting cython==0.29.35
Downloading Cython-0.29.35-py2.py3-none-any.whl.metadata (3.1 kB)
Collecting numpy==1.24.3
Downloading numpy-1.24.3.tar.gz (10.9 MB)
---------------------------------------- 10.9/10.9 MB 4.1 MB/s eta 0:00:00
Installing build dependencies: started
Installing build dependencies: finished with status 'done'
Getting requirements to build wheel: started
Getting requirements to build wheel: finished with status 'error'
error: subprocess-exited-with-error
Getting requirements to build wheel did not run successfully.
exit code: 1
[33 lines of output]
Traceback (most recent call last):
File "C:\Users\ultra\anaconda3\envs\new312\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 353, in <module>
main()
File "C:\Users\ultra\anaconda3\envs\new312\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 335, in main
json_out['return_val'] = hook(**hook_input['kwargs'])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\ultra\anaconda3\envs\new312\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 112, in get_requires_for_build_wheel
backend = _build_backend()
^^^^^^^^^^^^^^^^
File "C:\Users\ultra\anaconda3\envs\new312\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 77, in _build_backend
obj = import_module(mod_path)
^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\ultra\anaconda3\envs\new312\Lib\importlib\__init__.py", line 90, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<frozen importlib._bootstrap>", line 1387, in _gcd_import
File "<frozen importlib._bootstrap>", line 1360, in _find_and_load
File "<frozen importlib._bootstrap>", line 1310, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 488, in _call_with_frames_removed
File "<frozen importlib._bootstrap>", line 1387, in _gcd_import
File "<frozen importlib._bootstrap>", line 1360, in _find_and_load
File "<frozen importlib._bootstrap>", line 1331, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 935, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 999, in exec_module
File "<frozen importlib._bootstrap>", line 488, in _call_with_frames_removed
File "C:\Users\ultra\AppData\Local\Temp\pip-build-env-sbi2vlun\overlay\Lib\site-packages\setuptools\__init__.py", line 16, in <module>
import setuptools.version
File "C:\Users\ultra\AppData\Local\Temp\pip-build-env-sbi2vlun\overlay\Lib\site-packages\setuptools\version.py", line 1, in <module>
import pkg_resources
File "C:\Users\ultra\AppData\Local\Temp\pip-build-env-sbi2vlun\overlay\Lib\site-packages\pkg_resources\__init__.py", line 2172, in <module>
register_finder(pkgutil.ImpImporter, find_on_path)
^^^^^^^^^^^^^^^^^^^
AttributeError: module 'pkgutil' has no attribute 'ImpImporter'. Did you mean: 'zipimporter'?
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: subprocess-exited-with-error
Getting requirements to build wheel did not run successfully.
exit code: 1
See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.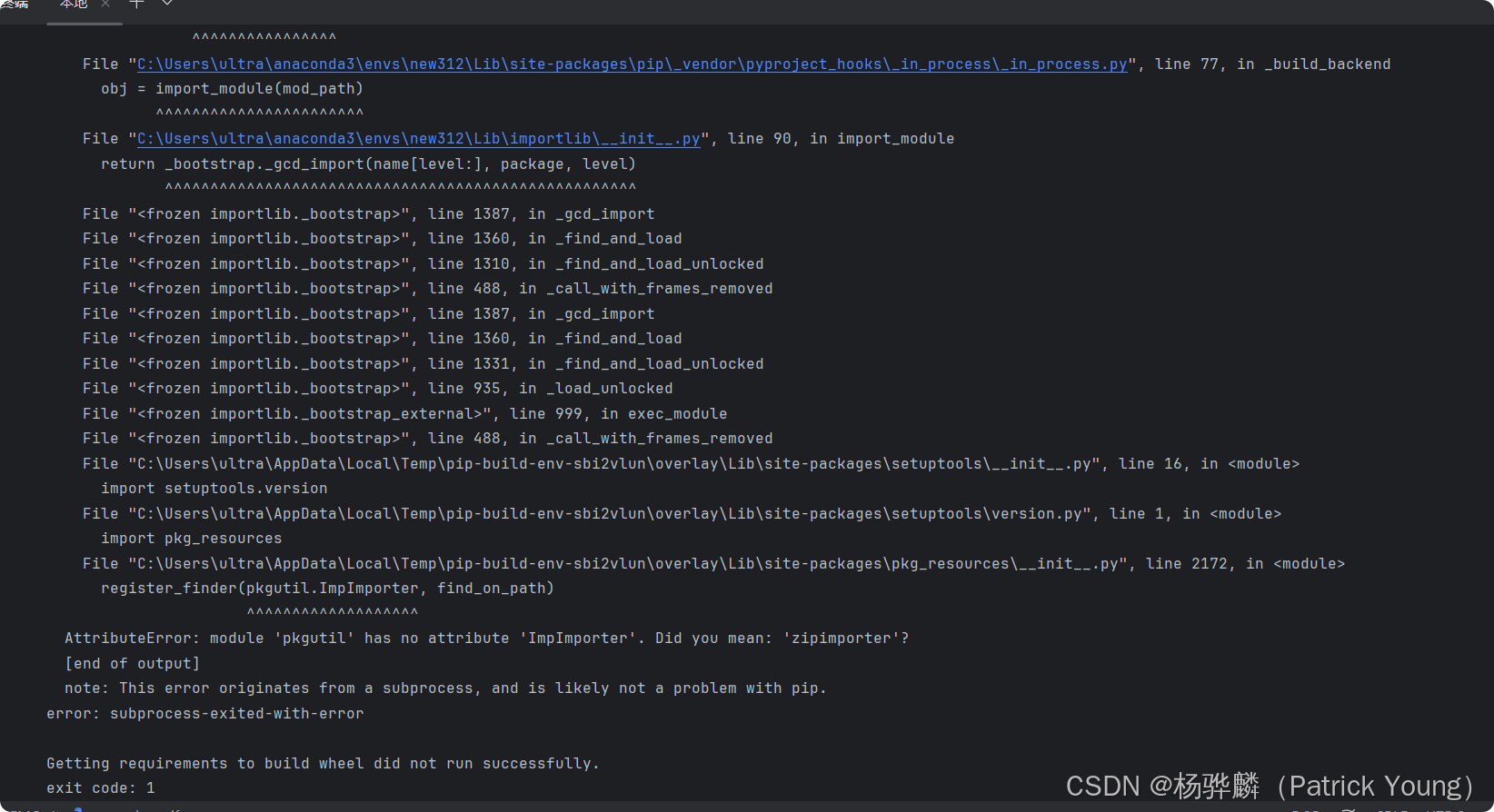
 解决该问题的步骤:
解决该问题的步骤:解决步骤:
这是关于在 Python 3.12 环境下安装工具时,遇到的 pkgutil 和 distutils 相关的兼容性问题。以下是总结和解决方案:
问题分析
-
错误信息:
- AttributeError: module 'pkgutil' has no attribute 'ImpImporter'. Did you mean: 'zipimporter'?
- 这个错误是由于 Python 3.12 开始,
pkgutil模块不再包含ImpImporter,导致某些安装包的处理出现问题。
-
ModuleNotFoundError: No module named 'distutils':
- 在 Python 3.12 中,
distutils被移除,很多工具和包(如setuptools)依赖于distutils,因此会遇到缺少distutils的问题。
- 在 Python 3.12 中,
解决方案
1. 升级 pip:
-
通过
ensurepip来确保 pip 是最新版本,这有助于解决某些安装包的兼容性问题。 -
对于 macOS/Unix/Linux:
python -m ensurepip --upgrade -
对于 Windows:
py -m ensurepip --upgrade
2. 安装 setuptools:
-
setuptools是一个处理 Python 软件包的工具包,它依赖于distutils。在 Python 3.12 中,由于没有distutils,你需要安装setuptools来间接解决这个问题。 -
安装
setuptools:pip install setuptools -
如果提示已经安装了,可以先卸载旧版本再重新安装:
pip uninstall setuptools pip install setuptools
3. 安装其他工具:
- 如果安装时遇到
distutils缺失,可以使用setuptools替代,setuptools会自动解决相关依赖问题。
总结
- Python 3.12 中移除了
distutils,导致一些包(如setuptools)无法正常安装或执行。安装或升级setuptools可以解决大部分问题。 - 升级 pip 并安装或重新安装
setuptools是解决该问题的主要方法。
2.8 重新再安装Xinference
pip install xinference解决所有问题!!