机器学习——XGBoost原理笔记
(之前搞课设的时候弄过,在这里简记一下hhh)
1 XGBoost原理阐述
1.1 关于决策树与集成模型
将决策树与集成学习框架进行结合的常用模型包括:
- B a g g i n g Bagging Bagging + 决策树 = 随机森林( R a n d o m F o r e s t Random Forest RandomForest)
- A d a B o o s t AdaBoost AdaBoost + 决策树 = 提升树( B o o s t i n g D e c i s i o n T r e e Boosting Decision Tree BoostingDecisionTree)
- G r a d i e n t B o o s t i n g Gradient Boosting GradientBoosting + 决策树 = 梯度提升树( G r a d i e n t B o o s t i n g D e c i s i o n T r e e Gradient Boosting Decision Tree GradientBoostingDecisionTree)
其中 XGBoost 就是梯度提升树(GBDT)的实现库,所以在搞清楚 XGBoost 之前需要先理解 GBDT。
1.2 梯度提升树
GBDT 又叫 MART(Multiple Additive Regression Tree),是一种基于 B o o s t i n g Boosting Boosting 的集成思想的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终的答案,GBDT 集成模型简要示意图如下所示:
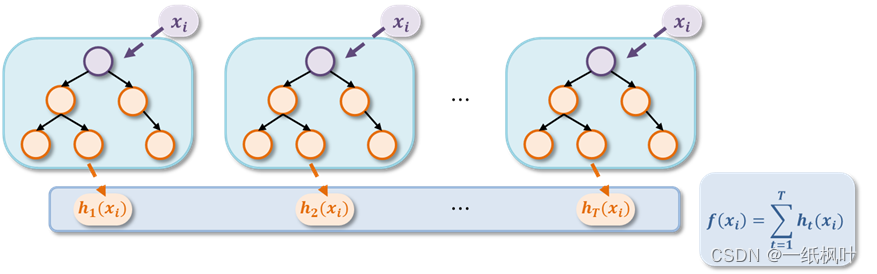
1.2.1 回归决策树(regression Decision Tree)
对比分类决策树与回归决策树:
- 分类 DT:通过 最大化熵 的思想划分属性分支,叶子节点的值是类别。
- 回归 DT:通过 最小化均方差 的思想,且每个节点的值都是预测值而非类别。
1.2.2 梯度迭代(Gradient Boosting)
GB 的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。
例如取预测值与真实值的误差作为下一棵树的输入,此时梯度迭代的示意图如下所示:

在此基础上,引入损失函数,将损失函数的值作为每一轮次决策树估计结果的残差,此时梯度迭代的示意图如下所示:

1.2.3 梯度提升树(GBDT)的迭代目标
GBDT 的每一轮迭代目标:找到一个 CART 回归树模型的弱学习器 h t ( x ) h_t(x) ht(x),让本轮的损失函数 L ( y , f t ( x ) ) = L ( y , f t − 1 ( x ) + h t ( x ) ) L\left(y, f_t(x)\right)=L\left(y, f_{t-1}(x)+h_t(x)\right) L(y,ft(x))=L(y,ft−1(x)+ht(x)) 最小。
1.2.4 如何拟合损失函数
在文献中,
F
r
i
d
e
m
a
n
Frideman
Frideman 提出了利用损失函数的负梯度值来近似拟合本轮损失函数值,进而拟合一个 CART 回归树。设第
t
t
t 轮中样本
x
i
x_i
xi 的损失函数负梯度表达式为:
r
t
i
=
−
[
∂
L
(
y
i
,
f
(
x
i
)
∂
f
(
x
i
)
]
f
(
x
)
=
f
t
−
1
(
x
)
(1)
r_{t i}=-\left[\frac{\partial L\left(y_i, f\left(\boldsymbol{x}_i\right)\right.}{\partial f\left(\boldsymbol{x}_i\right)}\right]_{f(\boldsymbol{x})=f_{t-1}(\boldsymbol{x})} \tag{1}
rti=−[∂f(xi)∂L(yi,f(xi)]f(x)=ft−1(x)(1)
其中 f ( x ) f(\boldsymbol{x}) f(x) 取上一轮生成的强学习器 f t − 1 ( x ) f_{t-1}(\boldsymbol{x}) ft−1(x)。在此基础上,利用所有样本的损失函数负梯度 ( x i , r t i ) , ( i = 1 , 2 , ⋯ , m ) \left(\boldsymbol{x}_i, r_{t i}\right),(i=1,2, \cdots, m) (xi,rti),(i=1,2,⋯,m) 可以拟合出整个CART回归树:
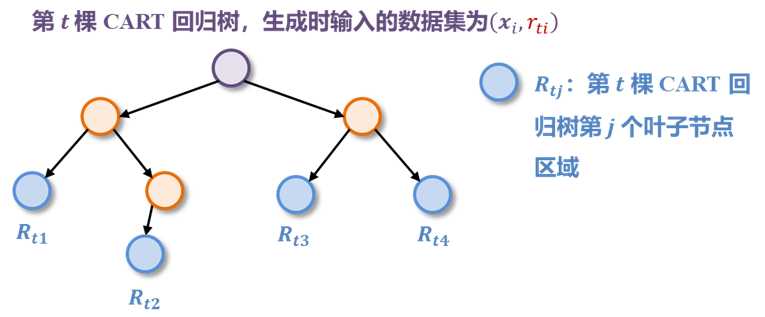
使用损失函数的负梯度值作为 CART 回归树的输入,此时单棵 CART 回归树的生成步骤如下所示:
每一轮树的生成需要明确两个关键点:
- 从备选的属性集合中选择一个属性 A A A
- 在该属性中找出一个最佳划分点 s s s
对应的生成原则为:要使得划分后两个集合 D 1 \boldsymbol{D_1} D1 和 D 2 \boldsymbol{D_2} D2 中样本的样本均方误差和最小 & 两个集合的均方误差和最小,即:
min A , s { min D 1 ∑ x i ∈ D 1 ( A , s ) ( r t i − c t 1 ) 2 + min D 2 ∑ x i ∈ D 2 ( A , s ) ( r t i − r t 2 ) 2 } (2) \min _{\boldsymbol{A, s}}\left\{\min _{\boldsymbol{D_1}} \sum_{\boldsymbol{x_i} \in \boldsymbol{D_1(A, s)}}\left(\textcolor{red}{r_{t i}}-\textcolor{red}{c_{t 1}}\right)^2+\min _{D_2} \sum_{x_i \in D_2(A, s)}\left(\textcolor{red}{r_{t i}}-\textcolor{red}{r_{t 2}}\right)^2\right\} \tag{2} A,smin⎩ ⎨ ⎧D1minxi∈D1(A,s)∑(rti−ct1)2+D2minxi∈D2(A,s)∑(rti−rt2)2⎭ ⎬ ⎫(2)
其中 c t 1 \textcolor{red}{c_{t 1}} ct1 , c t 2 \textcolor{red}{c_{t 2}} ct2 是经过 ( A , s ) (A, s) (A,s) 划分之后两块区域的输出值 / 叶子节点值。按照该原则划分会将训练集中的样本划分成两个区域: R t 1 ( A , s ) = { x ∣ x ( A ) ≤ s } R_{t 1}(A, s)=\left\{x \mid x^{(A)} \leq s\right\} Rt1(A,s)={x∣x(A)≤s} 和 R t 2 ( A , s ) = { x ∣ x ( A ) > s } R_{t 2}(A, s)=\left\{x \mid x^{(A)}>s\right\} Rt2(A,s)={x∣x(A)>s},而 c t 1 \textcolor{red}{c_{t 1}} ct1 , c t 2 \textcolor{red}{c_{t 2}} ct2 计算表达式为:
c
t
1
=
1
R
1
中样本个数
∑
x
i
∈
R
t
1
(
A
,
s
)
r
t
i
(3)
\textcolor{red}{c_{t 1}}=\frac{1}{R_1 \text { 中样本个数 }} \sum_{x_i \in R_{t 1}(A, s)} \textcolor{red}{r_{t i}} \tag{3}
ct1=R1 中样本个数 1xi∈Rt1(A,s)∑rti(3)
c
t
2
=
1
R
2
中样本个数
∑
x
i
∈
R
t
2
(
A
,
s
)
r
t
i
(4)
\textcolor{red}{c_{t 2}}=\frac{1}{R_2 \text { 中样本个数 }} \sum_{x_i \in R_{t 2}(A, s)} \textcolor{red}{r_{t i}} \tag{4}
ct2=R2 中样本个数 1xi∈Rt2(A,s)∑rti(4)
通过上述方式,逐步对回归树进行分裂,到最终会得到一共 J J J 个划分区域 / 叶子节点 R t j R_{tj} Rtj ,每个区域都会被分到若干个训练集样本 ( x i , r t i ) \left(\boldsymbol{x}_i, r_{t i}\right) (xi,rti) ,而每个叶子节点的输出值就是落在这些节点上的所有样本的标签值的均值:
c t j = 1 N u m R t j ∑ x i ∈ R t j r t i (5) \textcolor{red}{c_{t j}}=\frac{1}{N u m_{\textcolor{blue}{R_{t j}}}} \sum_{x_i \in \textcolor{blue}{R_{t j}}} \textcolor{red}{r_{t i}} \tag{5} ctj=NumRtj1xi∈Rtj∑rti(5)
当所有区域的输出值都求出来后,这一棵 CART 回归树也就构建完成了。对于一个未知样本 x x x 而言,该 CART 回归树的预测结果为:
h t ( x ) = ∑ j = 1 J [ c t j ⋅ I ( x ∈ R t j ) ] (6) h_t(\boldsymbol{x})=\sum_{j=1}^J\left[c_{t j} \cdot I\left(x \in R_{t j}\right)\right] \tag{6} ht(x)=j=1∑J[ctj⋅I(x∈Rtj)](6)
其中 I ( x ∈ R t j ) I\left(x \in R_{t j}\right) I(x∈Rtj) 是指标函数,即只有 x \boldsymbol{x} x 样本被划分到的那个对应区域 R t j R_{tj} Rtj 中 I ( x ∈ R t j ) = 1 I\left(x \in R_{t j}\right)=1 I(x∈Rtj)=1,其余清空下 I ( x ∈ R t j ) = 0 I\left(x \in R_{t j}\right)=0 I(x∈Rtj)=0
1.2.5 GBDT回归算法思路
综合以上,GBDT 的算法设计思路如下所示:
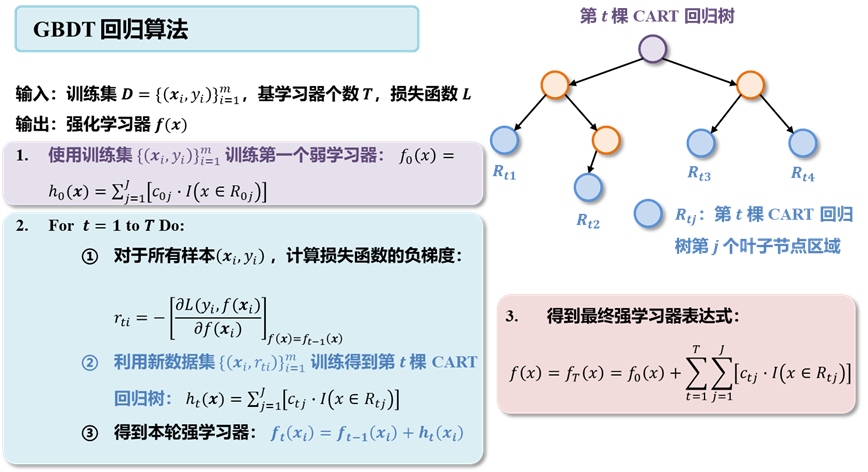
1.3 XGBoost 原理
XGBoost(Extreme Gradient Boosting regression Decision Tree)是 GBDT 模型的一种高效的改进实现算法,其设计思想主要在于改进 GBDT中单颗 CART 回归树的生成步骤。
在 CART 回归树的生成步骤中,有两步比较关键:
- 对输入数据集做若干次划分,得到若干个最优划分区域/叶子节点 R t j R_{t j} Rtj
- 计算出各个区域 / 叶子节点的输出值 c t j c_{t j} ctj
在 GBDT 模型中,上述两个步骤是分开逐个求解的,而在 XGBoost 中,上述两个步骤将会合并求解,即一步同时求出划分区域以及区域最佳输出值,同时优化了 GBDT 的损失函数。上述两个步骤将会合并求解,即一步同时求出划分区域以及区域最佳输出值,同时优化了 GBDT 的损失函数。
1.3.1 XGBoost 损失函数设计
GBDT 的损失函数为(第
t
t
t 轮迭代时):
L
t
=
L
(
y
,
f
t
(
x
i
)
)
=
L
(
y
,
f
t
−
1
(
x
i
)
+
h
t
(
x
i
)
)
=
L
(
y
,
∑
t
=
1
t
−
1
h
t
(
x
i
)
)
(7)
L_t=L\left(y, f_t\left(\boldsymbol{x}_i\right)\right)=L\left(y, f_{t-1}\left(\boldsymbol{x}_i\right)+h_t\left(\boldsymbol{x}_i\right)\right)=L\left(y, \sum_{t=1}^{t-1} h_t\left(\boldsymbol{x}_i\right)\right) \tag{7}
Lt=L(y,ft(xi))=L(y,ft−1(xi)+ht(xi))=L(y,t=1∑t−1ht(xi))(7)
在此基础上,加入正则化项:
Ω
(
h
t
)
=
γ
J
+
λ
2
∑
j
=
1
J
ω
t
j
2
(8)
\Omega\left(h_t\right)=\gamma J+\frac{\lambda}{2} \sum_{j=1}^J \omega_{t j}^2 \tag{8}
Ω(ht)=γJ+2λj=1∑Jωtj2(8)
其中
ω
t
j
2
\omega_{t j}^2
ωtj2 为第
t
t
t 棵回归树中第
j
j
j 个叶子节点的输出值(和前面
c
t
j
2
c_{t j}^2
ctj2 一致→ 为了和原论文保持一致换的),
J
J
J 是 CART 树中叶子节点数,而
γ
\gamma
γ 和
λ
\lambda
λ 是正则化系数。
加入正则化项之后的损失函数为:
L
t
=
∑
i
=
1
m
L
(
y
,
∑
t
=
1
t
−
1
h
t
(
x
i
)
)
⏟
L
(
y
,
f
t
−
1
(
x
i
)
+
h
t
(
x
i
)
)
+
γ
J
+
λ
2
∑
j
=
1
J
ω
t
j
2
⏟
Ω
(
h
t
)
(9)
L_t=\underbrace{\sum_{i=1}^m L\left(y, \sum_{t=1}^{t-1} h_t\left(\boldsymbol{x}_i\right)\right)}_{L\left(y, f_{t-1}\left(\boldsymbol{x}_i\right)+h_t\left(\boldsymbol{x}_i\right)\right)}+\underbrace{\gamma J+\frac{\lambda}{2} \sum_{j=1}^J \omega_{t j}^2}_{\Omega\left(h_t\right)} \tag{9}
Lt=L(y,ft−1(xi)+ht(xi))
i=1∑mL(y,t=1∑t−1ht(xi))+Ω(ht)
γJ+2λj=1∑Jωtj2(9)
该函数也是 XGBoost 要最小化的单回归树损失函数。通过求解上述函数的最小值,得到第
t
t
t 个决策树最优的所有
J
J
J 个叶子节点区域
{
R
t
j
∣
1
≤
j
≤
J
}
\left\{R_{t j} \mid 1 \leq j \leq J\right\}
{Rtj∣1≤j≤J} 和每个叶子节点区域的最优解
ω
t
j
2
\omega_{t j}^2
ωtj2:
argmin { R t j ∣ 1 ≤ j ≤ J } , ω t j 2 [ ∑ i = 1 m L ( y , ∑ t = 1 t − 1 h t ( x i ) ) ⏟ L ( y , f t − 1 ( x i ) + h t ( x i ) ) + γ J + λ 2 ∑ j = 1 J ω t j 2 ⏟ Ω ( h t ) ] (10) \underset{\left\{R_{t j} \mid 1 \leq j \leq J\right\}, \quad \omega_{t j}^2}{\operatorname{argmin}}[\underbrace{\sum_{i=1}^m L\left(y, \sum_{t=1}^{t-1} h_t\left(\boldsymbol{x}_i\right)\right)}_{L\left(y, f_{t-1}\left(\boldsymbol{x}_i\right)+h_t\left(\boldsymbol{x}_i\right)\right)}+\underbrace{\gamma J+\frac{\lambda}{2} \sum_{j=1}^J \omega_{t j}^2}_{\Omega\left(h_t\right)}] \tag{10} {Rtj∣1≤j≤J},ωtj2argmin[L(y,ft−1(xi)+ht(xi)) i=1∑mL(y,t=1∑t−1ht(xi))+Ω(ht) γJ+2λj=1∑Jωtj2](10)
对损失函数进行2阶泰勒展开:
L
t
=
∑
i
=
1
m
L
(
y
i
,
f
t
−
1
(
x
i
)
+
h
t
(
x
i
)
)
+
γ
J
+
λ
2
∑
j
=
1
J
ω
t
j
2
(11)
L_t=\sum_{i=1}^m L\left(y_i, f_{t-1}\left(\boldsymbol{x}_i\right)+h_t\left(\boldsymbol{x}_i\right)\right)+\gamma J+\frac{\lambda}{2} \sum_{j=1}^J \omega_{t j}^2 \tag{11}
Lt=i=1∑mL(yi,ft−1(xi)+ht(xi))+γJ+2λj=1∑Jωtj2(11)
进一步展开:
L
t
≈
∑
i
=
1
m
L
(
y
i
,
f
t
−
1
(
x
i
)
)
+
∂
L
(
y
i
,
f
t
−
1
(
x
i
)
)
∂
f
t
−
1
(
x
i
)
⋅
h
t
(
x
i
)
+
1
2
⋅
∂
L
t
−
1
2
(
y
i
,
f
t
−
1
(
x
i
)
)
∂
f
t
−
1
2
(
x
i
)
⋅
[
h
t
(
x
i
)
]
2
+
γ
J
+
λ
2
∑
j
=
1
J
ω
t
j
2
(12)
L_t\approx \sum_{i=1}^m L\left(y_i, f_{t-1}\left(\boldsymbol{x}_i\right)\right)+\frac{\partial L\left(y_i, f_{t-1}\left(\boldsymbol{x}_i\right)\right)}{\partial f_{t-1}\left(\boldsymbol{x}_i\right)} \cdot h_t\left(\boldsymbol{x}_i\right)+\frac{1}{2} \cdot \frac{\partial L_{t-1}^2\left(y_i, f_{t-1}\left(\boldsymbol{x}_i\right)\right)}{\partial f_{t-1}^2\left(\boldsymbol{x}_i\right)} \cdot\left[h_t\left(\boldsymbol{x}_i\right)\right]^2+\gamma J+\frac{\lambda}{2} \sum_{j=1}^J \omega_{t j}^2 \tag{12}
Lt≈i=1∑mL(yi,ft−1(xi))+∂ft−1(xi)∂L(yi,ft−1(xi))⋅ht(xi)+21⋅∂ft−12(xi)∂Lt−12(yi,ft−1(xi))⋅[ht(xi)]2+γJ+2λj=1∑Jωtj2(12)
为了简化运算,令:
g
t
i
=
∂
L
(
y
i
,
f
t
−
1
(
x
i
)
)
∂
f
t
−
1
(
x
i
)
(13)
g_{t i}=\frac{\partial L\left(y_i, f_{t-1}\left(\boldsymbol{x}_i\right)\right)}{\partial f_{t-1}\left(\boldsymbol{x}_i\right)} \tag{13}
gti=∂ft−1(xi)∂L(yi,ft−1(xi))(13)
h
t
i
=
∂
L
t
−
1
2
(
y
i
,
f
t
−
1
(
x
i
)
)
∂
f
t
−
1
2
(
x
i
)
(14)
h_{t i}=\frac{\partial L_{t-1}^2\left(y_i, f_{t-1}\left(\boldsymbol{x}_i\right)\right)}{\partial f_{t-1}^2\left(\boldsymbol{x}_i\right)} \tag{14}
hti=∂ft−12(xi)∂Lt−12(yi,ft−1(xi))(14)
此时损失函数的近似表达式为:
L
t
≈
∑
i
=
1
m
[
L
(
y
i
,
f
t
−
1
(
x
i
)
)
+
g
t
i
⋅
h
t
(
x
i
)
+
1
2
⋅
h
t
i
⋅
[
h
t
(
x
i
)
]
2
]
+
γ
J
+
λ
2
∑
j
=
1
J
ω
t
j
2
(15)
L_t \approx \sum_{i=1}^m\left[L\left(y_i, f_{t-1}\left(\boldsymbol{x}_i\right)\right)+g_{t i} \cdot h_t\left(\boldsymbol{x}_i\right)+\frac{1}{2} \cdot h_{t i} \cdot\left[h_t\left(\boldsymbol{x}_i\right)\right]^2\right]+\gamma J+\frac{\lambda}{2} \sum_{j=1}^J \omega_{t j}^2 \tag{15}
Lt≈i=1∑m[L(yi,ft−1(xi))+gti⋅ht(xi)+21⋅hti⋅[ht(xi)]2]+γJ+2λj=1∑Jωtj2(15)
在上述的损失函数的泰勒近似中,
L
(
y
i
,
f
t
−
1
(
x
i
)
)
L\left(y_i, f_{t-1}\left(\boldsymbol{x}_i\right)\right)
L(yi,ft−1(xi)) 是固定常数,可以去掉,同时由于每个回归树的第
j
j
j 个叶子节点的取值最终会是同一个值
ω
t
j
\omega_{t j}
ωtj,故抛掉该项后继续化简该式子:
L
t
≈
∑
i
=
1
m
[
g
t
i
⋅
h
t
(
x
i
)
+
1
2
⋅
h
t
i
⋅
[
h
t
(
x
i
)
]
2
]
+
γ
J
+
λ
2
∑
j
=
1
J
ω
t
j
2
(16)
L_t \approx \sum_{i=1}^m\left[g_{t i} \cdot h_t\left(\boldsymbol{x}_i\right)+\frac{1}{2} \cdot h_{t i} \cdot\left[h_t\left(\boldsymbol{x}_i\right)\right]^2\right]+\gamma J+\frac{\lambda}{2} \sum_{j=1}^J \omega_{t j}^2 \tag{16}
Lt≈i=1∑m[gti⋅ht(xi)+21⋅hti⋅[ht(xi)]2]+γJ+2λj=1∑Jωtj2(16)
其中:
∑
i
=
1
m
[
g
t
i
⋅
h
t
(
x
i
)
]
=
∑
i
=
1
m
[
g
t
i
⋅
∑
j
=
1
J
[
ω
t
j
⋅
I
(
x
∈
R
t
j
)
]
]
=
∑
j
=
1
J
(
∑
x
i
∈
R
t
j
g
t
i
⋅
ω
t
j
)
(17)
\sum_{i=1}^m\left[g_{t i} \cdot h_t\left(\boldsymbol{x}_i\right)\right]=\sum_{i=1}^m\left[g_{t i} \cdot \sum_{j=1}^J\left[\omega_{t j} \cdot I\left(x \in R_{t j}\right)\right]\right]=\sum_{j=1}^J\left(\sum_{\boldsymbol{x}_i \in R_{t j}} g_{t i} \cdot \omega_{t j}\right) \tag{17}
i=1∑m[gti⋅ht(xi)]=i=1∑m[gti⋅j=1∑J[ωtj⋅I(x∈Rtj)]]=j=1∑J
xi∈Rtj∑gti⋅ωtj
(17)
∑
i
=
1
m
[
h
t
i
⋅
[
h
t
(
x
i
)
]
2
]
=
∑
i
=
1
m
{
h
t
i
⋅
[
∑
j
=
1
J
[
ω
t
j
⋅
I
(
x
∈
R
t
j
)
]
]
2
}
=
∑
j
=
1
J
(
∑
x
i
∈
R
t
j
g
t
i
⋅
ω
t
j
2
)
(18)
\sum_{i=1}^m\left[h_{t i} \cdot\left[h_t\left(\boldsymbol{x}_i\right)\right]^2\right]=\sum_{i=1}^m\left\{h_{t i} \cdot\left[\sum_{j=1}^J\left[\omega_{t j} \cdot I\left(x \in R_{t j}\right)\right]\right]^2\right\}=\sum_{j=1}^J\left(\sum_{\boldsymbol{x}_i \in R_{t j}} g_{t i} \cdot \omega_{t j}^2\right) \tag{18}
i=1∑m[hti⋅[ht(xi)]2]=i=1∑m⎩
⎨
⎧hti⋅[j=1∑J[ωtj⋅I(x∈Rtj)]]2⎭
⎬
⎫=j=1∑J
xi∈Rtj∑gti⋅ωtj2
(18)
将上述结果代入式子中有:
L
t
≈
∑
i
=
1
m
[
g
t
i
⋅
h
t
(
x
i
)
+
1
2
⋅
h
t
i
⋅
[
h
t
(
x
i
)
]
2
]
+
γ
J
+
λ
2
∑
j
=
1
J
ω
t
j
2
≈
∑
j
=
1
J
(
∑
x
i
∈
R
t
j
g
t
i
⋅
ω
t
j
+
1
2
∑
x
i
∈
R
t
j
h
t
i
⋅
ω
t
j
2
)
+
γ
J
+
λ
2
∑
j
=
1
J
ω
t
j
2
≈
∑
j
=
1
J
[
(
∑
x
i
∈
R
t
j
g
t
i
)
⋅
ω
t
j
+
1
2
(
∑
x
i
∈
R
t
j
h
t
i
+
λ
)
⋅
ω
t
j
2
]
+
γ
J
L_t \approx \sum_{i=1}^m\left[g_{t i} \cdot h_t\left(\boldsymbol{x}_i\right)+\frac{1}{2} \cdot h_{t i} \cdot\left[h_t\left(\boldsymbol{x}_i\right)\right]^2\right]+\gamma J+\frac{\lambda}{2} \sum_{j=1}^J \omega_{t j}^2\\ \approx \sum_{j=1}^J\left(\sum_{\boldsymbol{x}_i \in R_{t j}} g_{t i} \cdot \omega_{t j}+\frac{1}{2} \sum_{\boldsymbol{x}_i \in R_{t j}} h_{t i} \cdot \omega_{t j}^2\right)+\gamma J+\frac{\lambda}{2} \sum_{j=1}^J \omega_{t j}^2\\ \approx \sum_{j=1}^J\left[\left(\sum_{\boldsymbol{x}_i \in R_{t j}} g_{t i}\right) \cdot \omega_{t j}+\frac{1}{2}\left(\sum_{\boldsymbol{x}_i \in R_{t j}} h_{t i}+\lambda\right) \cdot \omega_{t j}^2\right]+\gamma J
Lt≈i=1∑m[gti⋅ht(xi)+21⋅hti⋅[ht(xi)]2]+γJ+2λj=1∑Jωtj2≈j=1∑J
xi∈Rtj∑gti⋅ωtj+21xi∈Rtj∑hti⋅ωtj2
+γJ+2λj=1∑Jωtj2≈j=1∑J
xi∈Rtj∑gti
⋅ωtj+21
xi∈Rtj∑hti+λ
⋅ωtj2
+γJ
为了进一步简化运算,继续对式子中的元素进行换元:
{
G
t
i
=
(
∑
x
i
∈
R
t
j
g
t
i
)
H
t
i
=
(
∑
x
i
∈
R
t
j
h
t
i
)
(19)
\left\{\begin{aligned} G_{t i} & =\left(\sum_{x_i \in R_{t j}} g_{t i}\right) \\ H_{t i} & =\left(\sum_{\boldsymbol{x}_i \in R_{t j}} h_{t i}\right) \end{aligned}\right. \tag{19}
⎩
⎨
⎧GtiHti=
xi∈Rtj∑gti
=
xi∈Rtj∑hti
(19)
将换元结果代入损失函数表达式有:
L
t
≈
∑
j
=
1
J
[
G
t
i
⋅
ω
t
j
+
1
2
(
H
t
i
+
λ
)
⋅
ω
t
j
2
]
+
γ
J
(20)
L_t \approx \sum_{j=1}^J\left[G_{t i} \cdot \omega_{t j}+\frac{1}{2}\left(H_{t i}+\lambda\right) \cdot \omega_{t j}^2\right]+\gamma J \tag{20}
Lt≈j=1∑J[Gti⋅ωtj+21(Hti+λ)⋅ωtj2]+γJ(20)
该表达式就是 XGBoost 最终构造的损失函数。
1.3.2 XGBoost 目标函数建立与求解
经过上述推导,XGBoost 的优化目标函数为:
argmin
{
R
t
j
∣
1
≤
j
≤
J
}
,
ω
t
j
2
[
∑
j
=
1
J
[
G
t
i
⋅
ω
t
j
+
1
2
(
H
t
i
+
λ
)
⋅
ω
t
j
2
]
+
γ
J
]
(21)
\underset{\left\{R_{t j} \mid 1 \leq j \leq J\right\}, \quad \omega_{t j}^2}{\operatorname{argmin}}\left[\sum_{j=1}^J\left[G_{t i} \cdot \omega_{t j}+\frac{1}{2}\left(H_{t i}+\lambda\right) \cdot \omega_{t j}^2\right]+\gamma J\right] \tag{21}
{Rtj∣1≤j≤J},ωtj2argmin[j=1∑J[Gti⋅ωtj+21(Hti+λ)⋅ωtj2]+γJ](21)
优化求解目标函数,XGBoost 设计了一种可以同时求出回归树最优的所有
J
J
J 个叶子节点区域和每个叶子节点区域的最优解,这个设计可以拆成2个部分:
- 如果已经求出了第 t t t个回归树的 J J J 个最优的叶子节点区域,如何求出每个叶子节点区域最优解 ω t j \omega_{t j} ωtj?
- 对当前回归树做子树分裂决策时,应该如何选择属性 A A A 和对应的属性值 s s s 进行分裂,使得损失函数 L t L_t Lt 最小?
问题 1:求解最优 ω t j \boldsymbol{\omega_{t j}} ωtj
求解方法:直接在损失函数
L
t
L_t
Lt上对求
ω
t
j
\omega_{tj}
ωtj 的偏导数,并取其偏导数为 0 时
ω
t
j
\omega_{tj}
ωtj 的值为最优解:
∂
L
t
∂
ω
t
j
=
0
→
ω
t
j
=
−
G
t
j
H
t
j
+
λ
(22)
\frac{\partial L_t}{\partial \omega_{t j}}=0 \quad \rightarrow \quad \omega_{t j}=-\frac{G_{t j}}{H_{t j}+\lambda} \tag{22}
∂ωtj∂Lt=0→ωtj=−Htj+λGtj(22)
问题 2:构建回归树时分裂规则设计 (求解最优 { R t j ∣ 1 ≤ j ≤ J } \left\{\boldsymbol{R}_{\boldsymbol{t} j} \mid \mathbf{1} \leq \boldsymbol{j} \leq \boldsymbol{J}\right\} {Rtj∣1≤j≤J} )
在 GBDT 中,使用 CART 回归树,节点属性选择和最佳分裂点选择都是基于均方误差最小的思想设计的,通过这种均方误差最小的分裂方式,间接的降低了每一轮迭代中损失函数的值,最后成功实现损失函数最小的目标。
在 XGBoost 中则不再单纯使用均方误差最小化的思路来设计回归树,而是使用了贪心法,即每次分裂都期望直接最小化总损失函数 / 目标函数的误差。
假设
ω
t
j
\omega_{tj}
ωtj 的值已经是最优解,将最优解代入到损失函数有:
L
t
=
−
1
2
∑
j
=
1
J
(
G
t
j
2
H
t
j
+
λ
+
γ
J
)
(23)
L_t=-\frac{1}{2} \sum_{j=1}^J\left(\frac{G_{t j}^2}{H_{t j}+\lambda}+\gamma J\right) \tag{23}
Lt=−21j=1∑J(Htj+λGtj2+γJ)(23)
设计思路:在左右子树分裂时,最大程度减少上面损失函数的损失。
假设某个数据集节点被某个属性的某个取值标准分成左右子树,且对应的1阶和2阶导数和值为:
G
L
G_L
GL,
H
L
H_L
HL,
G
R
G_R
GR,
H
R
H_R
HR,则对应有:
- 分裂之前的损失函数值:
L B e f o r e = − 1 2 ⋅ ( G L + G R ) 2 ( H L + H R ) + λ + γ J (24) L_{Before}=-\frac{1}{2} \cdot \frac{\left(G_L+G_R\right)^2}{\left(H_L+H_R\right)+\lambda}+\gamma J \tag{24} LBefore=−21⋅(HL+HR)+λ(GL+GR)2+γJ(24) - 左子树损失函数值:
L L e f t = − 1 2 ⋅ G L 2 H L + λ + γ J (25) L_{Left}=-\frac{1}{2} \cdot \frac{G_L^2}{H_L+\lambda}+\gamma J \tag{25} LLeft=−21⋅HL+λGL2+γJ(25) - 右子树损失函数值:
L R i g h t = − 1 2 ⋅ G R 2 H R + λ + γ J (25) L_{Right}=-\frac{1}{2} \cdot \frac{G_R^2}{H_R+\lambda}+\gamma J \tag{25} LRight=−21⋅HR+λGR2+γJ(25)
损失函数的损失最小化即为让树节点分裂后的损失函数和减去分裂前的损失函数和这个差值最小,即:
m
i
n
\boldsymbol{min}
min(分裂后的损失函数和 – 分裂前的损失)
min
Δ
=
min
[
(
L
L
e
f
t
+
L
Right
)
−
L
Before
]
=
min
{
[
(
−
1
2
⋅
G
L
2
H
L
+
λ
+
γ
J
)
+
(
−
1
2
⋅
G
R
2
H
R
+
λ
+
γ
J
)
]
−
(
−
1
2
⋅
(
G
L
+
G
R
)
2
(
H
L
+
H
R
)
+
λ
+
γ
J
)
}
(26)
\begin{aligned} \min \Delta&=\min \left[\left(L_{L e f t}+L_{\text {Right }}\right)-L_{\text {Before }}\right] \\ & =\min \left\{\left[\left(-\frac{1}{2} \cdot \frac{G_L^2}{H_L+\lambda}+\gamma J\right)+\left(-\frac{1}{2} \cdot \frac{G_R^2}{H_R+\lambda}+\gamma J\right)\right]-\left(-\frac{1}{2} \cdot \frac{\left(G_L+G_R\right)^2}{\left(H_L+H_R\right)+\lambda}+\gamma J\right)\right\} \end{aligned} \tag{26}
minΔ=min[(LLeft+LRight )−LBefore ]=min{[(−21⋅HL+λGL2+γJ)+(−21⋅HR+λGR2+γJ)]−(−21⋅(HL+HR)+λ(GL+GR)2+γJ)}(26)
经过化简,将最小化转为最大化:
max
{
1
2
⋅
[
G
L
2
H
L
+
λ
+
G
R
2
H
R
+
λ
−
(
G
L
+
G
R
)
2
(
H
L
+
H
R
)
+
λ
−
γ
]
}
(27)
\max \left\{\frac{1}{2} \cdot\left[\frac{G_L^2}{H_L+\lambda}+\frac{G_R^2}{H_R+\lambda}-\frac{\left(G_L+G_R\right)^2}{\left(H_L+H_R\right)+\lambda}-\gamma\right]\right\} \tag{27}
max{21⋅[HL+λGL2+HR+λGR2−(HL+HR)+λ(GL+GR)2−γ]}(27)
综合以上,在构造一棵回归树时,每一轮在选择 以何种属性(
A
A
A) 和 该属性中哪个划分点值(
s
s
s) 对回归树进行划分,只需要找到一对
(
A
,
s
)
(A,s)
(A,s)组合,使得下面的表达式值最大即可:
argmax
(
A
,
s
)
{
1
2
⋅
[
G
L
2
H
L
+
λ
+
G
R
2
H
R
+
λ
−
(
G
L
+
G
R
)
2
(
H
L
+
H
R
)
+
λ
−
γ
]
}
(27)
\underset{(A, s)}{\operatorname{argmax}}\left\{\frac{1}{2} \cdot\left[\frac{G_L^2}{H_L+\lambda}+\frac{G_R^2}{H_R+\lambda}-\frac{\left(G_L+G_R\right)^2}{\left(H_L+H_R\right)+\lambda}-\gamma\right]\right\} \tag{27}
(A,s)argmax{21⋅[HL+λGL2+HR+λGR2−(HL+HR)+λ(GL+GR)2−γ]}(27)
2 XGBoost 算法设计思路
XGBoost 算法设计思路如下所示:
