目标检测评价指标之——Precision,Recall,IOU,AP,mAP
看了一些介绍目标检测评价指标的文章,在此做一个小总结,供大家参考。
文章目录
一、置信度是什么?
不是在讲目标检测评价指标吗?怎么又在说置信度了?博主莫不是在逗我们玩?不看了,下一篇!(客官别急,容我慢慢道来)
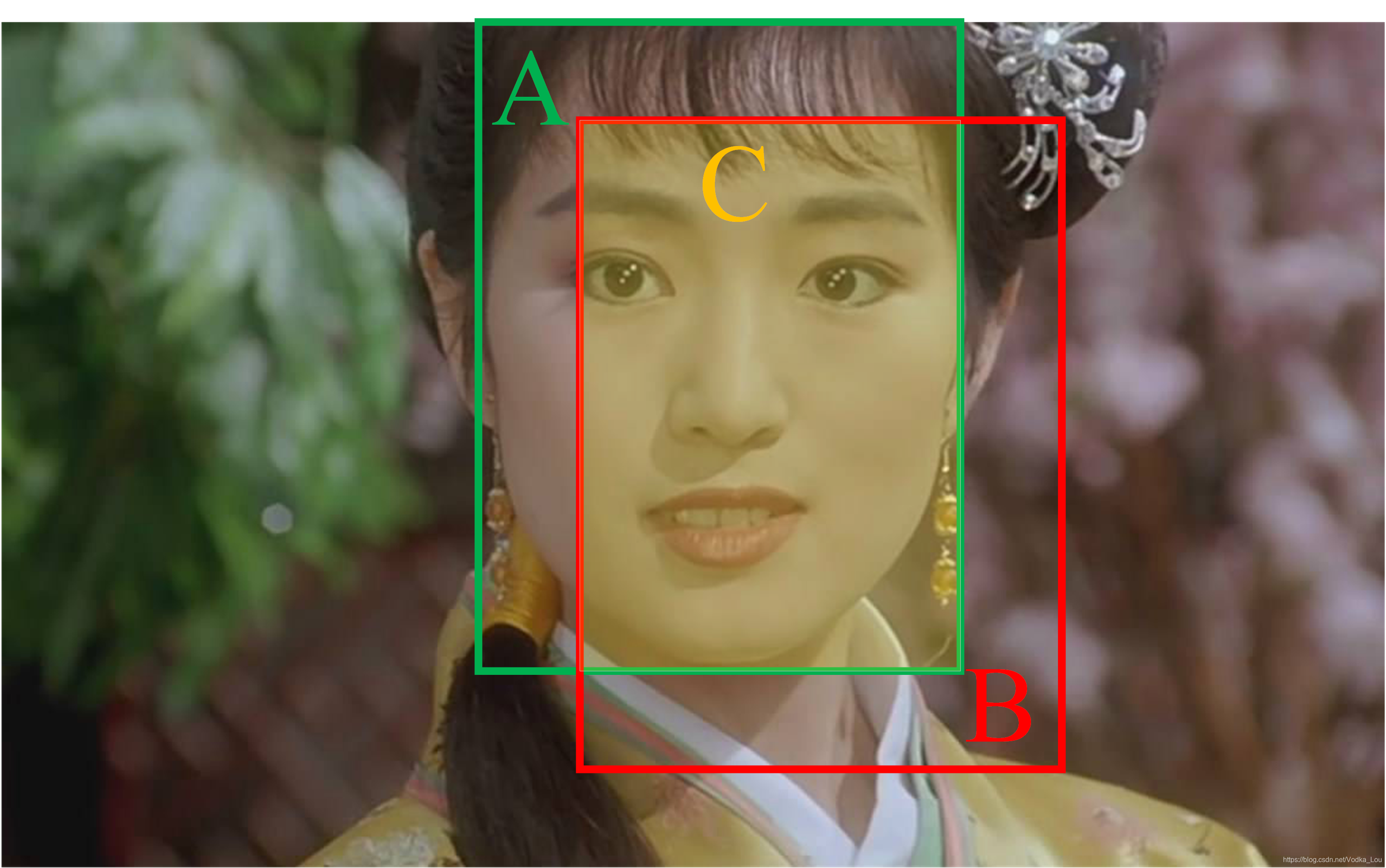
作为补偿,先给大家看个秋香压压惊,假设现在你是唐伯虎,你需要在一群人中找到秋香(检测人脸)。你们应该都已经找到了,并且很自信地肯定,绿色框内的人脸就是秋香本香,但是计算机没有这么自信呀,它只能够生成一系列预测框(红色框),每个框有一个置信度。这时候有小伙伴要问了,什么是置信度?
这里给一个通俗的解释,置信度可以暂时理解为自信程度,类比到你自己,你们是不是很自信地认为绿色框框就是秋香的脸,如果你百分百肯定这个框就是秋香,那好,这个框框的置信度就为1。但是有些人没看过《唐伯虎点秋香》(给大家放个链接,欢迎大家试看五分钟,ps:腾讯打钱),只是听大家说秋香长得很漂亮,这时候有些人会觉得黄色框框里的人长得也挺漂亮,我觉得黄色框框内的人是秋香,但是又看看绿色框框,好像这个才是秋香,纠结来纠结去,一下子拿不定主意,所以现在的他显得有点不够自信了,不过他最终还是做出了如下判断。


他认为,绿色框的人脸更漂亮一些,且又站在C位,所以有80%的信心认为此人是秋香,而黄色框的也有可能是秋香,但是他的信心没有那么足了,只有60%的信心认为黄色框内的人脸是秋香本人。想必现在大家对置信度有那么点概念了吧,没有概念的也没关系,慢慢听我道来。
暂时先不看秋香,现在重新回到目标检测(秋香可以晚上在被窝慢慢看),目标检测过程中,往往最后会生成很多的预测框,每个预测框自身都会带一个置信度,用来衡量预测框内为目标(秋香)的自信程度,置信度越高,说明当前训练的模型对于这个框的结果越认可。这个认可的程度就被称为置信度。当然最权威的还是从统计学角度对置信度进行解释,这里给大家放一个传送门。
二、IOU与TP、FP、FN
看到标题的小伙伴顿时不高兴了,不是说目标检测评价指标吗?不是说一文看懂吗?怎么又在说一些我不关心的事情,于是乎反手一个叉叉。(别急,再往下看看可以吗?我把美丽的秋香给你看!)
上图中,绿色框A表示Ground Truth,也称GT,GT就是正确的标注。这个标注是由标注员进行标注的,就好比是期末考试的参考答案,老师告诉你这个A就是正确答案,因此所有答题结果都要往这个正确答案上靠,这样子你才能拿高分,对于目标检测任务来说,就是检测效果好。当然,不可能所有的答案都和参考答案一样,就好比我们上学的时候,不可能人人都拿100分,总有几个调皮捣蛋的孩子会不及格。因此将检测框和GT进行比较,就能够衡量一个模型好不好。那具体怎么比呢?这里就要引入一个IOU的概念了,什么是IOU(Intersection over Union),IOU中文也叫交并比,拿上图举例,就是A和B的交集C :A和B的并集,数学公式如下:
也就是上图中黄色区域C除以A和B所占的区域,IOU的值越大,说明预测结果与参考答案越接近,值越小说明检测结果越差。那IOU到底多大才好呢?当然根据不同的任务,IOU的阈值是可调的,如果你的要求比较严格,那么就可以把IOU的阈值调的大一些,要求比较低,可以把IOU调小一点。为了便于解释,本文取IOU = 0.5,如果预测框与真实框的IOU > 0.5,那么此预测框归为TP,如果0 < IOU <= 0.5,那么此预测框归为FP,如果IOU < 0 ,那么此预测框归为FN(计算IOU的Python代码看这)。可能现在有小伙伴蒙了,不着急,接着往下看。
如上图所示,==注意:检测到同一个GT的多余检测框也归为FP,怎么解释呢?对于秋香图来说,只有秋香一个GT,可能这时候有若干个预测框都符合IOU > 0.5,那么此时只能取其中一个框作为TP,而剩余的检测框只能够归为FP。这是为什么呢?答:秋香只能属于唐伯虎一个人!
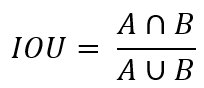

三、Precision、Recall、AP和mAP
敲黑板,进入正题!进入正题!进入正题!(重要的事情说三遍)
1.Precision
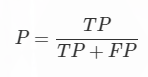
其中P代表Precision,可以翻译为精确率。有些小伙伴可能有点晕字母,什么TP,FP,TN,FN一股脑的过来,把人都整蒙了。首先我们需要弄清楚,英文首字母代表的是哪个单词。先记住P和N,P代表Positive,N代表Negative,中文的含义是正和负,正样本:Positive Samples,负样本:Negative Samples。其次是T和F,不是TFBoy啊!T代表True,F代表False。Positive是参考答案,那么True代表你做对了,False代表你做错了。做对了你就找到了秋香,没做对你可能找到的就是秋香的丫鬟!至于他们之间的具体关系,如果忘了的话,回过头去第二节再理理,反复几次就记住啦!
2.Recall
其中R代表Recall,中文是召回率的意思,具体的字母含义同上。可能有人会问了,这两个指标之间有什么关系呢?单单有Precision难道不能评价目标检测的性能吗?其实Precision还有另一种翻译,叫做查准率,而Recall也叫查全率。Precision重点倾向于准不准(我能不能准确找到秋香),而Recall,举个不恰当的例子,当发生严重事故的时候,有许多不同程度受伤的人,那么这时候Precision就表示准确的判断这个人受了什么伤,更倾向于准确确定伤员病情。而Recall是查全率,表示查找这一个区域里到底有多少成员受伤了。毕竟在这种危急时刻,查找所有受伤的成员,并把他们解救出来是摆在首要位置的,这时候Recall的作用可能更为重要。这两个评价指标之间并没有孰好孰坏之分,只是在不同的场景之下,各有侧重罢了。
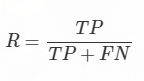
3.AP值和PR曲线
在讲AP(Average Precision)之前想说说PR曲线,有了上节的铺垫,我们知道了P(Precision)和R(Recall)之间的关系。通过评价,我们可以得到一组PR值,反映在平面直角坐标系中,就是坐标系中的一个点。这里我引用一篇讲述PR曲线的博文。如下图所示:
Inst#是样本序号,图中有20个样本。Class是Ground Truth 标签,p是Positive样本(正例),n当然就是Negative(负例) Score是检测器对于该样本属于正例的可能性的打分。也就是我们所说的置信度。因为一般模型输出的不是0,1的标注,而是小数。
然后设置一个从高到低的阈值y,大于等于阈值y的被我正式标注为正例,小于阈值y的被我正式标注为负例。显然,我设置n个阈值,我就能得到n种标注结果,评判我的模型好不好使。
比如阈值0.9,只有第一个样本被我判断为正例,那么我的查准率precision就是100%,但是查全率Recall就是10%。阈值0.1,所有样本都被我判断为正例,查全率是100%,查准率就是50%。最后我能得到若干对precision,recall值(P,R) : (1, 0.1),… ,(0.5,1),将这若干对画在图上,再连接起来就是这个PR曲线了。
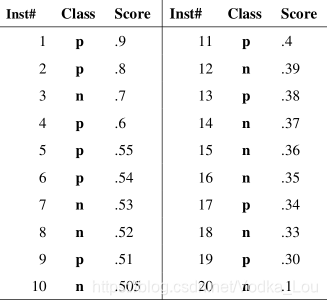
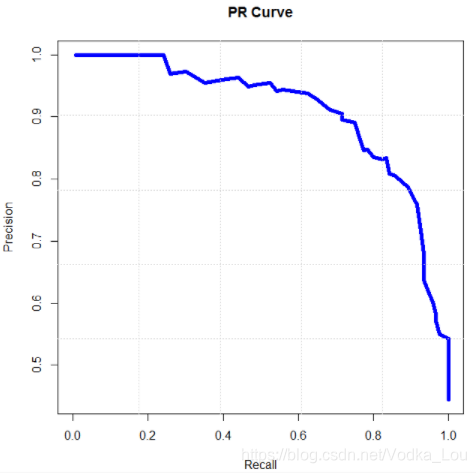
那么PR曲线所包含的左下角区域的面积就是AP值的大小。
4.mAP值
有了AP的介绍,那mAP就很简单了。可以这么理解,AP就是大家找到秋香的平均准确率,那么大家找到春香,夏香,秋香,冬香的平均准确率就是AP1,AP2,AP3,AP4,除以四就是mAP的值了。
总结
唐伯虎点秋香的故事今天就讲到这,目标检测评价指标的解释今天就讲到这,熬夜写博不易,欢迎在评论区交流讨论。