引言
刚玩完ChatGPT,看着最近大火的AI绘画、赛博coser,还不时给我推送教程视频,我本来就喜欢折腾些新鲜事物,于是心动打算入坑。但Mac作为一个被孤立党(ps.小群体),现在的大环境下都是win的教程,仅有的几篇mac教程文章又因为是某些程序猿大佬随手记录写的[[1]],我的代码水平就只会抄抄改改,阅读门槛太高根本看不懂,频频碰壁,借助国内国外资源整合后我终于在M1 Mac上成功本地部署并运行stable-diffusion-webui了
在本地的效果就只能说能用,正常情况下提示词(prompt)少一点是能半分钟出图,不过毕竟集显的算力摆在那,我的是M1 Pro 16G,扒拉别人分享图的参数来生成一张图,需要6、7分钟甚至更久(速度感人…),所以如果你的使用需求不高可以试着搞搞,如果追求出图效率的话可以考虑云端部署,文末会细讲。目前,Web UI 中的大多数功能都可以在 macOS 上正常运行,但不能用来训练模型,尽管可以训练,但速度非常慢并且消耗过多的内存。
08-06更新:距离第一次写这篇文章已经6个月了,虽然6月份时我编辑过一次,但只是对文章表达作适当修改,没有新增内容。这次更新连续写了3天,我重新部署了SD, 顺利地走完安装过程,也发现了一些细节(新内容)可以拿出来讲讲,对文章结构优化和插图更新,提升了阅读体验。
这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

‼️阅前须知:
本指南是关于Mac系统本地部署Stable- diffusion[3]的教程,还包括入门使用。
- 如果您想要简单体验AI绘画,目前有很多免费的在线使用服务,请尝试跳转到“拓展阅读:在线服务”。
- 如果您想要高效率制图、提升使用体验,或者作为生产力,请尝试跳转到“拓展阅读:云端部署”。
- 如果您希望在 macOS 上获得最大的可配置性,并且愿意安装一堆软件,那么请尝试本指南。
本指南篇幅较长(1.4万字),分多步讲解,希望帮助更多的人取得成功,特别是第一次尝试安装此类软件的人。
①受众:本文是面向纯小白的手把手教学,官方的教程非常简单清晰[4],有能力者建议直接看原文档;本文是针对国内适配化的教程,一些步骤也可以学习参考。

②配置:亲测适用于M1芯片及以上的Macbook(⬇️我的配置)
| MacBook Pro | 2021款 |
|---|---|
| 芯片 | Apple M1 Pro |
| 内存 | 16GB |
| 储存 | 512GB |
| CPU | 8核 |
| GPU | 14核 |
| macOS | Ventura 13.4.1 © |
intel芯片一方面性能已经落后了即使成功部署使用体验也不好所以不推荐,如果实在热爱那也不是不行,部分网友也有反馈成功部署,证明教程是可行的;另一方面可能需要额外安装特定的显卡驱动(CUDA),自行搜索安装。
③网络:必须要有一个稳定的网络代理(科学上网)
这个最关键!懂的都懂。稳定的网络代理可以杜绝98%的报错信息,剩下1%的个人操作问题和1%的发现新问题。
④Python环境:该程序经过测试可在 Python 3.10.6 上运行。除非您自找麻烦,否则不要使用其他版本
安装程序会创建一个 python 虚拟环境,因此安装的任何模块都不会影响 python 的现有系统安装[5]。
请确保你已了解并具备这些条件再入门,如果具备了我所提到的条件、按照我的每一步标准来,基本上可以无惧报错、无痛完成本地部署。如果你还在犹豫,不妨再看看目录,你会发现一个小惊喜;“国内环境安装、别怕折腾,坑都帮你填好了”,下面开始教学~
准备工作
配置Git代理
安装中使用git clone指令来克隆一些GitHub仓库项目到本地,包括以后安装插件、更新都需要用到git指令,因为网络原因,虽然开启了网络代理,但git并没有走代理,需要在git 里面进行配置。[6]
①打开你的代理工具,在设置中的找到代理端口号

②输入命令行修改⬇️
(xxxx修改为你的代理端口号)
git config --global http.proxy "http://127.0.0.1:xxxx"
git config --global https.proxy "https://127.0.0.1:xxxx"
③输入指令检查一下修改成功了没有⬇️
git config --list --show-origin

不会修改也没啥问题就是速度慢了亿点点(20~60kb/s),这样子设置好了之后,下载速度嗖嗖的提升,减少等待时间和报错。
下载Homebrew
官方方案:
“如果您使用的是 macOS,请尝试我们的新.pkg安装程序。”[7]
直接下载Homebrew-4.1.3.pkg,然后按照安装向导的指示进行即可
⬇️或者复制以下代码到终端中运行
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
国内方案:
官方的可能因为网络问题无法下载,我们也可以下载国内大学在码云分享的homebrew[8][9]
打开终端,一般在启动台的“其他”文件夹里,或者使用commond+空格搜索“终端”,⬇️运行以下代码:
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"

①输入“1”选择中科大版本,然后输入Y(YES),直接输入开机密码(不显示)然后回车确认,开始下载
②首次下载它弹窗让你先下载Git,我们点击同意,然后等待下载

③Git下载完重新运行一遍代码和重复①的操作,这次就开始下载brew本体了
④可以选择(输入Y回车),想省时间也可不选,直接回车(非必须模块。可以忽略)

⑤下载完成,提示今后下载还是输入“1”,提示安装完成,复制它给你的指令运行

补充:brew常用指令
-
- 查看版本:
brew -v - 更新 brew 版本:
-brew update - 查找:
brew search xxx(其中 xxx 替换为要查找的关键字) - 安装:
-brew install xxx - 安装完成输入
xxx -h查看 - 查看本地软件库列表:
brew ls
- 查看版本:
⑥我们使用brew -v,看到brew版本和安装日期就说明成功了
brew -v

Homebrew报错,Error: Command failed with exit 128: git[10]
①执行brew -v命令看看是不是有两个提示:大概就是要你手动添加homebrew-core和homebrew-cask目录
brew -v
②分别执行这两个指令手动添加
把绿色框选的路径地址,直接复制替换到代码中的“你的homebrew-core路径”
git config --global --add safe.directory 你的homebrew-core路径
git config --global --add safe.directory 你的homebrew-cask路径

下载Python
接着使用brew install下载Python等依赖项,新建一个终端执行命令⬇️
brew install cmake protobuf rust [email protected] git wget
等待下载完成。
下载stable-diffusion-webui
首选方案:
这种方式是首选,因为它允许您通过运行git pull来更新
⬇️使用git clone指令来克隆stable-diffusion-webui项目到本地
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui

你也可以先cd (打开指定目录命令)[11]到自己想要的文件目录下,然后再执行git clone指令
可以直接把文件夹拖到终端窗口里,他就会自动填充路径,不需要自己打长长的路径(本来准备个GIF图演示一下但是上传不了)
cd 文件目录路径(/Users/用户名/xxx)
备用方案:
直接在项目主页打包下载.zip文件解压到自己想要的路径
要更新,您必须再次下载 zip 并替换文件。

安装和配置
在stable- diffusion中,目前共有 5 种模型。
- 基础底模型(单独使用):checkpoint
- 辅助模型(配合底模使用):Embedding,lora,Hypernetwork
- 美化模型:VAE
对于这几种的区别和使用方式随着你后面使用就会慢慢了解,简单的说基础底模型就是基础,基于它生成图片,而辅助模型可以对大模型进行微调(是建立在大模型基础上的,不能单独使用)、最后美化模型则是更细节的方式,如图片色调(滤镜)等。
基础底模型只能有一种,而辅助模型(如lora)的则没有限制,可以没有,也可以是一种或多种。
首先必须要一个基础底模型来正常启动,建议先从官方模型运行测试一下是否部署成功(建议使用v1.5,v2.0要改文件而且性能要求高要改设置挺麻烦不推荐新手),以后再去探索其他模型。
一些流行的官方Stable Diffusion模型是:
- Stable DIffusion 1.4 (sd-v1-4.ckpt)
- Stable Diffusion 1.5 (v1-5-pruned-emaonly.ckpt)
- Stable Diffusion 1.5 Inpainting (sd-v1-5-inpainting.ckpt)【推荐】
Stable Diffusion 2.0和2.1需要模型和配置文件搭配使用,生成图像时图像宽度和高度需要设置为768或更高:
配置文件请按住键盘上的Option键点击此处下载v2-inference-v.yaml(可能下载为v2-inference-v.yaml.yml)
例如,如果您下载了768-v-ema.ckpt模型,请将其重命名为768-v-ema.yaml并将其与模型一起放入stable-diffusion-webui/models/Stable-diffusion

模型下载
①可以从Hugging Face[12]下载模型。
一个大牛们分享各种AI模型的网站,分享包括AI绘画、gpt、AI变声等模型,因为界面比较专业下载操作可能会有点麻烦。
要下载,请选择模型,然后单击标题Files and versions。查找带有“.ckpt”或“.safetensors”扩展名的文件,然后单击文件大小右侧的下载图标来下载它们。

②墙裂推荐,AI绘画圈的C站:https://civitai.com/[13]
早期国内能直连下载速度很可观,现在得挂代理才能用了
最火的AI绘画分享社区,在这个网站你可以直观的看到模型的生成效果,还可以复制别人的参数生成接近一样的图;轻松下载模型,通过筛选根据分类来下载对应的模型。

③国内下载:
这两个是有体验过的AI绘画在线服务网站,可以下载模型也可以在线体验,不过现在模型比较少社区也没咋有热度。
哩布哩布:LiblibAI·哩布哩布AI-中国领先原创AI模型分享社区[14]

电子羊eSheep:eSheep - 一站式的AIGC社区[15]

因为审美追求不同,我个人就不推荐哪个模型浪费大家流量了,具体的一些模型推荐:
出图效率倍增!47个高质量的 Stable Diffusion 常用模型推荐www.uisdc.com/47-stable-diffusion-models

模型安装
⚠️根据自己下载的文件夹路径,教程按默认路径演示
如果使用git clone指令是默认下载在-Users/用户名/目录下,需要使用open .(中间是空格)来打开⬇️。接下来的教程演示默认都是在这个路径下完成。
open .
⚠️模型名称不能带中文和空格,建议尽量不要修改模型名称
①**基础模型:**将“.ckpt”或“.safetensors”文件放到文件路径:stable-diffusion-webui/models/Stable-diffusion

②**辅助模型:**将“.ckpt”或“.safetensors”文件放到文件路径:stable-diffusion-webui/models/Lora
(⚠️等你运行./webui.sh后才会有这个文件夹)

③**美化模型VAE:**将“.ckpt”或“.safetensors”文件放到文件路径:stable-diffusion-webui/models/Vae

运行./webui.sh文件
新开一个终端,运行这两个指令:
⚠️根据自己下载的文件夹路径,教程按默认路径演示
(记住这两个指令,最好是自己打熟练,中途报错、以后每次运行都会再用到)
cd stable-diffusion-webui/
./webui.sh
如果一开始你将stable-diffusion-webui文件夹放在其他路径,则按前面提到的cd指令打开文件目录
cd 文件目录路径(/Users/用户名/xxxx/stable- diffusion-webui)
运行之后他就开始下载一些需要的依赖,耐心等待
⚠️中途看到“Installing gfpgan”或者其他的卡住没反应,不要关闭!不要关闭!(除非有error报错信息)
如果你的代理工具有显示实时网络速率功能或者使用第三方监测网速工具就会看到其实是有在下载的,只是下载过程不展示进度,耐心等待就行

这个环节就是报错最多的环节,其实根本就不算问题,如果安装出现报错,使用万能重启大法,可以切换梯子重新执行指令多尝试几次,每次它都是从上次失败的地方继续下载,不需要担心它会从头开始。
到这里Mac本地部署Stable diffusion教程就结束了,相信大家最终都到达这个界面了吧:

复制链接127.0.0.1:7860在浏览器中打开就可以美美地食用了~
(这个链接只是本地离线的链接、终端关闭也就不能访问,看自己情况地址可能跟我的不一样)
⬇️要创建一个分享链接就在启动时加上描述[16]
./webui.sh --share
error:Something went wrong Expecting value: line1 column1 (char 0)[17]
这是因为你开着代理进去了,关闭代理,关闭终端重新运行./webui.sh再进去就正常了

故障排除和常见问题:
文章中讲到的都是安装过程中常见甚至是固定出现的报错,方便你顺畅的完成部署,其他可能遇到的问题我将其汇总写了另外一篇补充文章《Mac本地部署Stable-diffusion故障排除和常见问题》方便大家检索参考,后续维护也比较方便,没有回答到的问题还请移步官方:Issues · AUTOMATIC1111/stable-diffusion-webui,或者善用Google大法,祝福各位~
外笛:Mac本地部署Stable-diffusion故障排除和常见问题28 赞同 · 119 评论文章
界面基本操作[18]
现在让我们来检验一下软件是否安装成功,准备好开始绘制你的第一个AI绘画作品了吗?
首先了解一下界面基本布局和操作吧
(⚠️建议先跳转到下面安装界面中文汉化插件后再看)
界面设置(绿色区域)

**文生图:**根据文本提示生成图像
**图生图:**图像生成图像;功能很强大,自己在后续使用中探索。
**后期处理:**图片处理;功能很强大,自己在后续使用中探索。
**PNG信息:这是一个快速获取图片生成参数的便捷功能。如果图像是在SD里生成的,您可以使用“发送到”**按钮将参数快速复制到各个页面。
**模型融合:**您最多可以组合 3 个模型来创建新模型。它通常用于混合两个或多个模型的风格。但是,不能保证合并结果。它有时会产生不需要的伪影。
**训练:**训练页面用于训练模型。它目前支持textual inversion(embedding) 和hypernetwork。Mac不能用来训练模型,所以我不会介绍这一部分。
**设置:**设置里面的具体选项就不详细讲了,大家在后续使用中自行探索
更改任何设置后,记得单击**“保存设置”**后再重载界面。
**扩展:**安装扩展插件,下一步有详细讲。
生成参数设置(红色区域)

①左上角是选择基础模型,基于这个模型生成图片。
下拉菜单选择您想要的模型。首次使用的用户建议使用v1.5 基础模型。
下拉菜单旁边的刷新按钮用于刷新模型列表。当您刚刚将新模型放入模型文件夹需要更新列表时使用它。
②右边生成按钮下的按钮,从左到右:
1.读取最后一个参数:一般用于复制别人参数然后自动填充所有字段,以便您在按下“生成”按钮时生成相同的图像。请注意,将设置种子和模型覆盖。如果这不是您想要的,请将种子设置为 -1 并删除覆盖。
2.垃圾桶图标:删除当前提示和反向提示。
3.模型图标:显示额外的模型。此按钮用于将hypernetworks、embeddings和LoRA模型插入提示中。
4.加载样式:您可以从下面的样式下拉菜单中选择多种样式。使用此按钮将它们插入提示和反向提示中。
5.保存方式:保存提示和反向提示。您需要为样式命名。
③文本输入框,描述您想在图像中看到的内容。
- **正向提示词:**指定你想看到的内容
- **反向提示词:**指定你不想看到的内容
下面是一个例子(使用chatGPT生成):
(fantasy:1.5), (enchanted forest), (mysterious atmosphere), (magical creatures), (glowing flowers), (ethereal:0.8), (twinkling stars), (floating islands)

④采样方法:去噪过程的算法。(具体使用方法看这个:链接)
⑤采样步骤:去噪过程的采样步骤数。越多越好,但也需要更长的时间。25 个步骤适用于大多数情况。
⑥宽度和高度:输出图像的尺寸。使用 v1 模型时,您应该至少将一侧设置为 512 像素。例如,对于长宽比为 2:3 的肖像图像,将宽度设置为 512,高度设置为 768。
⑦批次计数:运行图像生成管道的次数。
⑧批量大小:每次运行管道时生成的图像数量。
生成的图像总数等于批次乘以批数。您通常会更改批量大小,因为它更快。仅当遇到内存问题时,您才会更改批次计数。
⑨CFG 比例:提示词引导系数 是一个参数,用于控制模型遵守您的提示词的程度。(提示词权重)
- 1 – 大多忽略您的提示。
- 3 – 更加自由更有创意。
- 7 – 遵循提示和自由之间的良好平衡。
- 15 – 更加遵守提示。
- 30 – 严格按照提示操作。
下图显示了使用固定种子值更改 CFG 的效果。您不想将 CFG 值设置得太高或太低。如果 CFG 值太低,稳定扩散将忽略您的提示。太高时图像的颜色会饱和。

⑩种子Seed:用于在潜在空间中生成初始随机张量的种子值。实际上,它控制图像的内容。生成的每个图像都有自己的种子值。如果设置为 -1,AUTOMATIC1111 将使用随机种子值。
使用回收按钮复制种子值。

使用骰子图标将种子设置回 -1(随机)。

⑪面部修复需要应用一个额外的模型,该模型经过训练可以恢复面部缺陷。
在使用面部修复之前,您必须指定要使用的面部恢复模型。首先,访问**“设置”选项卡。导航至面部恢复部分。选择面部修复模型。CodeFormer是一个不错的选择。将 CodeFormer 权重设置为 0 以获得最大效果。请记住单击“应用设置”**按钮来保存设置!

⑫使用**“平铺”**选项可生成可平铺的周期性图像。就是由重复有规律图案拼成的图像。
⑬高分辨率修复选项应用upscaler来放大图像。因为稳定扩散的原始分辨率是 512 像素(或某些 v2 模型为 768 像素)。对于许多用途而言,图像太小了。(具体使用方法看这个:链接)
⑭最后,点击右边的生成按钮。稍等片刻后,您将获得图像!
生成图像操作(蓝色区域)
①图片生成后展示在这里

②您会发现下面一排按钮,用于对生成的图像执行各种功能。从左到右…
打开文件夹:打开图像输出文件夹。
保存:保存图像。点击后,按钮下方会显示下载链接。如果您选择图像网格,它将保存所有图像。
Zip:压缩打包图像以供下载。
**发送到图生图:**将选定的图像发送到图生图选项卡。
发送到重绘:将所选图像发送到图生图选项卡中的修复选项卡。
发送到后期处理:将选定的图像发送到后期处理选项卡。
扩展插件安装
一般有三种安装方式,具体还要看插件提供哪些方式
- 第一种是官方提供的在设置"Extensions"选项卡中搜索下载,因为网络问题即使挂了代理也连不上,不推荐
- 第二种是手动“git clone”克隆想要安装插件的GitHub项目到本地手动放置,但是后续更新需要重新克隆,不推荐
- 第三种是在里面通过复制插件的GitHub项目地址在"Extensions"中下载,推荐,操作简单一键更新
推荐几个入门必备插件,现在让我们通过具体插件安装来掌握方法,每个插件都有提供官方项目地址,不清楚或者想了解更多的请阅读官方文档。
1.界面中文汉化包
官方的SD界面默认是是英文的,我们需要自己下载插件来进行中文替换(习惯英语操作的可以忽略本条)
(也可以选择另一个支持中英双语的插件:https://github.com/VinsonLaro/stable-diffusion-webui-chinese)
①点击“extensions”选项
②点击“install from URL”
③复制粘贴这个地址:https://github.com/hanamizuki-ai/stable-diffusion-webui-localization-zh_Hans
④点击“install”,等待下载

⑤完成点击“installed”,点击“apply and restart UI”

回到界面设置中文:
①点击“settings”
②点击“user interface”
③点击“localization”,下拉菜单选择zh-cn
④点击“apply settings”保存
⑤最后“reload UI”,重载界面

再次进入就是中文了!可能有些地方翻译不全,但也适配了一些常用插件的翻译。
2.提示词自动补全/翻译
一个类似输入法英文补全的功能,它是帮你补全大数据词库里的prompt(生成提示词),方便了我们英文不熟悉者和懒人用户
插件介绍还有个翻译功能,但用不明白(不知道),翻译的还是推荐下一个插件
①按照前面的方法复制链接下载然后重载界面生效
复制地址:https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
②现在我们在输入时下方就有提示词,可以选择自动补全

3.prompt翻译
一个提供多个接口可选择的免费翻译prompt插件,我们输入中文就能转化为英文了,完美解决语言差异。
①按照前面的方法复制链接下载然后重载界面生效
复制地址:https://github.com/Physton/sd-webui-prompt-all-in-one
②在正向提示词输入框右下方输入框输入文字然后回车确定/自动翻译


③自行根据需要配置翻译接口,进阶使用你还可以搭配chatgpt的api key来辅助生成prompt。
4.反推提示词
一个比默认图片提取prompt更精准的插件,功能也更强大
①按照前面的方法复制链接下载然后重载界面生效
原来项目的主支已经不更新了,原地址:https://github.com/toriato/stable-diffusion-webui-wd14-tagger
而且这个项目在MAC上安装还有Bug[19][20],我喜欢折腾所以下载了原始版本。
推荐使用这个继承分支的⬇️
复制地址:https://github.com/picobyte/stable-diffusion-webui-wd14-tagger
②安装成功会看到上面的设置栏多了一个“WD 1.4标签器 (Tagger)”,点击进入界面
③上传一张图片让它分析,首次运行会下载一些依赖,可以在终端窗口查看进度

④上面就是分析出来的提示词,下面是每个提示词对应的权重,越高就越接近,你还可以自己设定权重值范围,超过此权重值的提示词才会显示出来。

⑤使用结束后,记得点击下方的“卸载所有反推模型”,不然模型会占用很高的显存。
5.图库浏览器
我们之前生成的图片后老是需要打开文件夹去查看,而且管理起来很不方便,可以使用这个插件来浏览和管理图片。
①按照前面的方法复制链接下载然后重载界面生效
复制地址:GitHub - AlUlkesh/stable-diffusion-webui-images-browser: an images browse for stable-diffusion-webui
点一下“首页”它就自动获取所有生成的图片

在这里可以看到图片信息和保存路径

上面可以进行筛选和文件名关键词、提示词搜索,还可以打分后续根据评分搜索

可以收藏来单独管理,快速文生图、图生图等等

6.防止爆显卡
你可能遇到过这样的报错提示,原因是我们显卡内存不够了
RuntimeError: MPS backend out of memory (MPS allocated: 5.05 GB, other allocations: 2.28 GB, max allowed: 6.80 GB). Tried to allocate 1024.00 MB on private pool. Use PYTORCH_MPS_HIGH_WATERMARK_RATIO-0.0 to disable upper limit for memory allocations (may cause system failure).
启用 Tiled VAE 插件后,它会先生成一个个小的图块,然后再组合在一起形成高分辨率图像,这样就有效防止爆显存情况的出现,不过生成时间会更长一些。
①按照前面的方法复制链接下载然后重载界面生效
复制地址:https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
进阶使用你还可以搭配controlNet模型来放大图像,生成更高分辨率(6K)等。
N.主题美化包
(不感兴趣可忽略本条)
仔细审视自己的SD界面,你可能在疑惑为什么自己的界面和其他博主的不一样?(没ta那么好看)
其实大部分博主用的都是这个(之前叫kitchen,现在叫lobe theme)美化主题:


①同样的复制地址下载然后重载界面生效
复制地址:https://github.com/canisminor1990/sd-webui-lobe-theme
有亮色、深色两个主题可选择,还可以自定义
Tip: 右上角⚙图标打开设置面板(记得先开启简体中文哦),当前可用设置如下:
-
主题[21]
-
-
原色:目前提供
13主题色搭配 -
中性色:目前提供
6不同色彩倾向灰阶搭配 -
标志类型:
Lobe,Kitchen,Custom -
- 自定义徽标:支持
img url、base64、 和emoji。当输入单个表情符号时,它将自动替换为 3D Fluent Emoji。 - 自定义标题:自定义站点名称。
- 自定义徽标:支持
-
我们还可以在Chrome浏览器中安装Web应用程序,这样下次我们启动webui后直接打开,不需要手动复制本地链接到浏览器了。

最后其实还有大家最关心的controlNet插件[22]没讲到,因为这个插件不算入门,要讲的点很多(不太想),单独拿出来才能讲明白。感兴趣的可以先去学习一下,我在文章后面也有推荐一些其他的学习资源。
AI绘画神级插件 Controlnet 连续更新!手把手教你安装体验新功能(附模型资源)www.uisdc.com/controlnet-v1-1

使用和优化
日常使用
我们关闭终端SD程序就终止运行了,再次使用还是执行这两个指令:
cd stable-diffusion-webui/
./webui.sh
更新方法:
⬇️输入以下指令:
git pull https://github.com/AUTOMATIC1111/stable-diffusion-webui
⚠️如果要从头开始重新安装,请删除目录:venv, repositories。
性能优化:[24]
目前 macOS 上的 GPU 加速会占用大量内存。如果性能较差(如果使用任何采样器生成 20 个步骤的 512x512 图像需要超过一分钟)
①--opt-split-attention-v1尝试从命令行选项(即)开始./webui.sh --opt-split-attention-v1,看看是否有帮助。
②没有太大区别吗?
打开“活动监视器”应用程序,然后检查“内存”选项卡下的内存压力图。生成图像时内存压力显示为红色
关闭 Web UI 进程,然后添加--medvram命令行选项(即./webui.sh --opt-split-attention-v1 --medvram)。
③使用该选项时性能仍然很差并且内存压力仍然红色?
尝试--lowvram(即./webui.sh --opt-split-attention-v1 --lowvram)
④使用任何采样器仍需要几分钟以上的时间才能通过 20 个步骤生成 512x512 图像?
您可能需要关闭 GPU 加速。
webui-user.sh在 Xcode 中打开
更改#export COMMANDLINE_ARGS=""为export COMMANDLINE_ARGS="--skip-torch-cuda-test --no-half --use-cpu all".
进阶学习
为了避免篇幅太长主题不明,本文只分享了部署方面的知识,一些进阶操作如其他插件、训练模型、AI动画(视频)、生产力方式的知识还不足以教学分享。作为学生大部分时间都在学习(玩乐),不能够像职业人和自媒体博主一样持续输出教学知识,那就分享一些我认为优质的进阶学习资源,让我们共同进步~
文章推荐:
因为优设是个设计师分享社区,里面的教程文章都比较详细好懂、配图设计精美,阅读起来也很舒服。还讲到AI绘画的生产力变现。
Stable Diffusion 入门和进阶指南www.uisdc.com/zt/stable-diffusion

视频推荐:
这位B站UP主讲的一系列AI绘画课程质量都很高,可以持续订阅,同样详细好懂、视频风格很有美感。
Nenly同学的个人空间-Nenly同学个人主页-哔哩哔哩视频space.bilibili.com/1814756990
拓展阅读:
在线服务
国外的Stable Diffusion Online,国内的前面介绍模型有提到,用过esheep电子羊、小程序(也有网页版)的MewXAI,目前国内的AI绘画服务网站没有本地资源丰富,模型比较少社区也没咋有热度,基本上都是一个套路——(每天)只有一定的免费体验次数,生图需求高就需要付费,就不多说了;如果感兴趣,轻度体验一下玩玩还不错。
【重要的事情说三遍】不是打广告!不是打广告!不是打广告~
电子羊eSheep:eSheep - 一站式的AIGC社区

云端部署
本地部署的优点就是可以随时自由使用,不需要网络,生成一些比较好玩的图片啊(懂的都懂);云端部署就是自己可以选择更好的虚拟GPU性能、生成更快更好的质量,还可以训练模型。不过谷歌免费的**Colab已经识别禁用SD webui程序了(有办法解决,上一阵子用过),也可以选择花钱租用,像国内的AutoDL、百度飞桨、腾讯云**等等,使用别人分享整合好的资源就要遵循相关使用规则和平台的规则,也就是没有本地自由。也可以做到鱼和熊掌兼得——本地和云端协调,高效率、高自由度制图。
表:本地部署和云端部署优缺点对比
| 部署方式 | 优点 | 缺点 |
|---|---|---|
| 本地部署 | 1. 控制权更高,可以直接访问硬件资源。 2. 不需要网络连接。 3. 无需担心云服务费用。 | 1. 需要自己管理和维护设备。 2. 扩展性差,如果需要更多资源可能需要购买新的硬件。 3. 如果设备发生故障,可能会导致服务中断。 |
| 云端部署 | 1. 高度可扩展,可以根据需求随时增加或减少资源。 2. 无需担心硬件维护和升级。 3. 可以从任何地方访问。 | 1. 需要网络连接。 2. 数据安全性和隐私可能需要额外考虑。 3. 可能需要支付高昂的服务费用。 |
表:本地部署和云端部署综合对比
| MAC / 云计算服务 | 本地部署 | 云端部署 |
|---|---|---|
| 价格 | 免费 | 花钱租用 |
| 安装难度 | 难 | 容易 |
| 生图速度 | 取决于自己的电脑配置 | 可选择好的性能设备 |
| 是否支持训练模型 | 不支持或者速度很慢 | 支持 |
| 能否自由使用 | 离线自由使用 | 遵守相关条款使用 |
引言
刚玩完ChatGPT,看着最近大火的AI绘画、赛博coser,还不时给我推送教程视频,我本来就喜欢折腾些新鲜事物,于是心动打算入坑。但Mac作为一个被孤立党(ps.小群体),现在的大环境下都是win的教程,仅有的几篇mac教程文章又因为是某些程序猿大佬随手记录写的[1],我的代码水平就只会抄抄改改,阅读门槛太高根本看不懂,频频碰壁,借助国内国外资源整合后我终于在M1 Mac上成功本地部署并运行stable-diffusion-webui了[2]。
在本地的效果就只能说能用,正常情况下提示词(prompt)少一点是能半分钟出图,不过毕竟集显的算力摆在那,我的是M1 Pro 16G,扒拉别人分享图的参数来生成一张图,需要6、7分钟甚至更久(速度感人…),所以如果你的使用需求不高可以试着搞搞,如果追求出图效率的话可以考虑云端部署,文末会细讲。目前,Web UI 中的大多数功能都可以在 macOS 上正常运行,但不能用来训练模型,尽管可以训练,但速度非常慢并且消耗过多的内存。
08-06更新:距离第一次写这篇文章已经6个月了,虽然6月份时我编辑过一次,但只是对文章表达作适当修改,没有新增内容。这次更新连续写了3天,我重新部署了SD, 顺利地走完安装过程,也发现了一些细节(新内容)可以拿出来讲讲,对文章结构优化和插图更新,提升了阅读体验。
‼️阅前须知:
本指南是关于Mac系统本地部署Stable- diffusion[3]的教程,还包括入门使用。
- 如果您想要简单体验AI绘画,目前有很多免费的在线使用服务,请尝试跳转到“拓展阅读:在线服务”。
- 如果您想要高效率制图、提升使用体验,或者作为生产力,请尝试跳转到“拓展阅读:云端部署”。
- 如果您希望在 macOS 上获得最大的可配置性,并且愿意安装一堆软件,那么请尝试本指南。
本指南篇幅较长(1.4万字),分多步讲解,希望帮助更多的人取得成功,特别是第一次尝试安装此类软件的人。
①受众:本文是面向纯小白的手把手教学,官方的教程非常简单清晰[4],有能力者建议直接看原文档;本文是针对国内适配化的教程,一些步骤也可以学习参考。

②配置:亲测适用于M1芯片及以上的Macbook(⬇️我的配置)
| MacBook Pro | 2021款 |
|---|---|
| 芯片 | Apple M1 Pro |
| 内存 | 16GB |
| 储存 | 512GB |
| CPU | 8核 |
| GPU | 14核 |
| macOS | Ventura 13.4.1 © |
intel芯片一方面性能已经落后了即使成功部署使用体验也不好所以不推荐,如果实在热爱那也不是不行,部分网友也有反馈成功部署,证明教程是可行的;另一方面可能需要额外安装特定的显卡驱动(CUDA),自行搜索安装。
③网络:必须要有一个稳定的网络代理(科学上网)
这个最关键!懂的都懂。稳定的网络代理可以杜绝98%的报错信息,剩下1%的个人操作问题和1%的发现新问题。
④Python环境:该程序经过测试可在 Python 3.10.6 上运行。除非您自找麻烦,否则不要使用其他版本
安装程序会创建一个 python 虚拟环境,因此安装的任何模块都不会影响 python 的现有系统安装[5]。
请确保你已了解并具备这些条件再入门,如果具备了我所提到的条件、按照我的每一步标准来,基本上可以无惧报错、无痛完成本地部署。如果你还在犹豫,不妨再看看目录,你会发现一个小惊喜;“国内环境安装、别怕折腾,坑都帮你填好了”,下面开始教学~
准备工作
配置Git代理
安装中使用git clone指令来克隆一些GitHub仓库项目到本地,包括以后安装插件、更新都需要用到git指令,因为网络原因,虽然开启了网络代理,但git并没有走代理,需要在git 里面进行配置。[6]
①打开你的代理工具,在设置中的找到代理端口号

②输入命令行修改⬇️
(xxxx修改为你的代理端口号)
git config --global http.proxy "http://127.0.0.1:xxxx"
git config --global https.proxy "https://127.0.0.1:xxxx"
③输入指令检查一下修改成功了没有⬇️
git config --list --show-origin

不会修改也没啥问题就是速度慢了亿点点(20~60kb/s),这样子设置好了之后,下载速度嗖嗖的提升,减少等待时间和报错。
下载Homebrew
官方方案:
“如果您使用的是 macOS,请尝试我们的新.pkg安装程序。”[7]
直接下载Homebrew-4.1.3.pkg,然后按照安装向导的指示进行即可
⬇️或者复制以下代码到终端中运行
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
国内方案:
官方的可能因为网络问题无法下载,我们也可以下载国内大学在码云分享的homebrew[8][9]
打开终端,一般在启动台的“其他”文件夹里,或者使用commond+空格搜索“终端”,⬇️运行以下代码:
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"

①输入“1”选择中科大版本,然后输入Y(YES),直接输入开机密码(不显示)然后回车确认,开始下载
②首次下载它弹窗让你先下载Git,我们点击同意,然后等待下载

③Git下载完重新运行一遍代码和重复①的操作,这次就开始下载brew本体了
④可以选择(输入Y回车),想省时间也可不选,直接回车(非必须模块。可以忽略)

⑤下载完成,提示今后下载还是输入“1”,提示安装完成,复制它给你的指令运行

补充:brew常用指令
-
- 查看版本:
brew -v - 更新 brew 版本:
-brew update - 查找:
brew search xxx(其中 xxx 替换为要查找的关键字) - 安装:
-brew install xxx - 安装完成输入
xxx -h查看 - 查看本地软件库列表:
brew ls
- 查看版本:
⑥我们使用brew -v,看到brew版本和安装日期就说明成功了
brew -v

Homebrew报错,Error: Command failed with exit 128: git[10]
①执行brew -v命令看看是不是有两个提示:大概就是要你手动添加homebrew-core和homebrew-cask目录
brew -v
②分别执行这两个指令手动添加
把绿色框选的路径地址,直接复制替换到代码中的“你的homebrew-core路径”
git config --global --add safe.directory 你的homebrew-core路径
git config --global --add safe.directory 你的homebrew-cask路径

下载Python
接着使用brew install下载Python等依赖项,新建一个终端执行命令⬇️
brew install cmake protobuf rust [email protected] git wget
等待下载完成。
下载stable-diffusion-webui
首选方案:
这种方式是首选,因为它允许您通过运行git pull来更新
⬇️使用git clone指令来克隆stable-diffusion-webui项目到本地
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui

你也可以先cd (打开指定目录命令)[11]到自己想要的文件目录下,然后再执行git clone指令
可以直接把文件夹拖到终端窗口里,他就会自动填充路径,不需要自己打长长的路径(本来准备个GIF图演示一下但是上传不了)
cd 文件目录路径(/Users/用户名/xxx)
备用方案:
直接在项目主页打包下载.zip文件解压到自己想要的路径
要更新,您必须再次下载 zip 并替换文件。

安装和配置
在stable- diffusion中,目前共有 5 种模型。
- 基础底模型(单独使用):checkpoint
- 辅助模型(配合底模使用):Embedding,lora,Hypernetwork
- 美化模型:VAE
对于这几种的区别和使用方式随着你后面使用就会慢慢了解,简单的说基础底模型就是基础,基于它生成图片,而辅助模型可以对大模型进行微调(是建立在大模型基础上的,不能单独使用)、最后美化模型则是更细节的方式,如图片色调(滤镜)等。
基础底模型只能有一种,而辅助模型(如lora)的则没有限制,可以没有,也可以是一种或多种。
首先必须要一个基础底模型来正常启动,建议先从官方模型运行测试一下是否部署成功(建议使用v1.5,v2.0要改文件而且性能要求高要改设置挺麻烦不推荐新手),以后再去探索其他模型。
一些流行的官方Stable Diffusion模型是:
- Stable DIffusion 1.4 (sd-v1-4.ckpt)
- Stable Diffusion 1.5 (v1-5-pruned-emaonly.ckpt)
- Stable Diffusion 1.5 Inpainting (sd-v1-5-inpainting.ckpt)【推荐】
Stable Diffusion 2.0和2.1需要模型和配置文件搭配使用,生成图像时图像宽度和高度需要设置为768或更高:
配置文件请按住键盘上的Option键点击此处下载v2-inference-v.yaml(可能下载为v2-inference-v.yaml.yml)
例如,如果您下载了768-v-ema.ckpt模型,请将其重命名为768-v-ema.yaml并将其与模型一起放入stable-diffusion-webui/models/Stable-diffusion

模型下载
①可以从Hugging Face[12]下载模型。
一个大牛们分享各种AI模型的网站,分享包括AI绘画、gpt、AI变声等模型,因为界面比较专业下载操作可能会有点麻烦。
要下载,请选择模型,然后单击标题Files and versions。查找带有“.ckpt”或“.safetensors”扩展名的文件,然后单击文件大小右侧的下载图标来下载它们。

②墙裂推荐,AI绘画圈的C站:https://civitai.com/[13]
早期国内能直连下载速度很可观,现在得挂代理才能用了
最火的AI绘画分享社区,在这个网站你可以直观的看到模型的生成效果,还可以复制别人的参数生成接近一样的图;轻松下载模型,通过筛选根据分类来下载对应的模型。

③国内下载:
这两个是有体验过的AI绘画在线服务网站,可以下载模型也可以在线体验,不过现在模型比较少社区也没咋有热度。
哩布哩布:LiblibAI·哩布哩布AI-中国领先原创AI模型分享社区[14]

电子羊eSheep:eSheep - 一站式的AIGC社区[15]

因为审美追求不同,我个人就不推荐哪个模型浪费大家流量了,具体的一些模型推荐:
出图效率倍增!47个高质量的 Stable Diffusion 常用模型推荐www.uisdc.com/47-stable-diffusion-models

模型安装
⚠️根据自己下载的文件夹路径,教程按默认路径演示
如果使用git clone指令是默认下载在-Users/用户名/目录下,需要使用open .(中间是空格)来打开⬇️。接下来的教程演示默认都是在这个路径下完成。
open .
⚠️模型名称不能带中文和空格,建议尽量不要修改模型名称
①**基础模型:**将“.ckpt”或“.safetensors”文件放到文件路径:stable-diffusion-webui/models/Stable-diffusion

②**辅助模型:**将“.ckpt”或“.safetensors”文件放到文件路径:stable-diffusion-webui/models/Lora
(⚠️等你运行./webui.sh后才会有这个文件夹)

③**美化模型VAE:**将“.ckpt”或“.safetensors”文件放到文件路径:stable-diffusion-webui/models/Vae

运行./webui.sh文件
新开一个终端,运行这两个指令:
⚠️根据自己下载的文件夹路径,教程按默认路径演示
(记住这两个指令,最好是自己打熟练,中途报错、以后每次运行都会再用到)
cd stable-diffusion-webui/
./webui.sh
如果一开始你将stable-diffusion-webui文件夹放在其他路径,则按前面提到的cd指令打开文件目录
cd 文件目录路径(/Users/用户名/xxxx/stable- diffusion-webui)
运行之后他就开始下载一些需要的依赖,耐心等待
⚠️中途看到“Installing gfpgan”或者其他的卡住没反应,不要关闭!不要关闭!(除非有error报错信息)
如果你的代理工具有显示实时网络速率功能或者使用第三方监测网速工具就会看到其实是有在下载的,只是下载过程不展示进度,耐心等待就行

这个环节就是报错最多的环节,其实根本就不算问题,如果安装出现报错,使用万能重启大法,可以切换梯子重新执行指令多尝试几次,每次它都是从上次失败的地方继续下载,不需要担心它会从头开始。
到这里Mac本地部署Stable diffusion教程就结束了,相信大家最终都到达这个界面了吧:

复制链接127.0.0.1:7860在浏览器中打开就可以美美地食用了~
(这个链接只是本地离线的链接、终端关闭也就不能访问,看自己情况地址可能跟我的不一样)
⬇️要创建一个分享链接就在启动时加上描述[16]
./webui.sh --share
error:Something went wrong Expecting value: line1 column1 (char 0)[17]
这是因为你开着代理进去了,关闭代理,关闭终端重新运行./webui.sh再进去就正常了

故障排除和常见问题:
文章中讲到的都是安装过程中常见甚至是固定出现的报错,方便你顺畅的完成部署,其他可能遇到的问题我将其汇总写了另外一篇补充文章《Mac本地部署Stable-diffusion故障排除和常见问题》方便大家检索参考,后续维护也比较方便,没有回答到的问题还请移步官方:Issues · AUTOMATIC1111/stable-diffusion-webui,或者善用Google大法,祝福各位~
外笛:Mac本地部署Stable-diffusion故障排除和常见问题28 赞同 · 119 评论文章
界面基本操作[18]
现在让我们来检验一下软件是否安装成功,准备好开始绘制你的第一个AI绘画作品了吗?
首先了解一下界面基本布局和操作吧
(⚠️建议先跳转到下面安装界面中文汉化插件后再看)
界面设置(绿色区域)

**文生图:**根据文本提示生成图像
**图生图:**图像生成图像;功能很强大,自己在后续使用中探索。
**后期处理:**图片处理;功能很强大,自己在后续使用中探索。
**PNG信息:这是一个快速获取图片生成参数的便捷功能。如果图像是在SD里生成的,您可以使用“发送到”**按钮将参数快速复制到各个页面。
**模型融合:**您最多可以组合 3 个模型来创建新模型。它通常用于混合两个或多个模型的风格。但是,不能保证合并结果。它有时会产生不需要的伪影。
**训练:**训练页面用于训练模型。它目前支持textual inversion(embedding) 和hypernetwork。Mac不能用来训练模型,所以我不会介绍这一部分。
**设置:**设置里面的具体选项就不详细讲了,大家在后续使用中自行探索
更改任何设置后,记得单击**“保存设置”**后再重载界面。
**扩展:**安装扩展插件,下一步有详细讲。
生成参数设置(红色区域)

①左上角是选择基础模型,基于这个模型生成图片。
下拉菜单选择您想要的模型。首次使用的用户建议使用v1.5 基础模型。
下拉菜单旁边的刷新按钮用于刷新模型列表。当您刚刚将新模型放入模型文件夹需要更新列表时使用它。
②右边生成按钮下的按钮,从左到右:
1.读取最后一个参数:一般用于复制别人参数然后自动填充所有字段,以便您在按下“生成”按钮时生成相同的图像。请注意,将设置种子和模型覆盖。如果这不是您想要的,请将种子设置为 -1 并删除覆盖。
2.垃圾桶图标:删除当前提示和反向提示。
3.模型图标:显示额外的模型。此按钮用于将hypernetworks、embeddings和LoRA模型插入提示中。
4.加载样式:您可以从下面的样式下拉菜单中选择多种样式。使用此按钮将它们插入提示和反向提示中。
5.保存方式:保存提示和反向提示。您需要为样式命名。
③文本输入框,描述您想在图像中看到的内容。
- **正向提示词:**指定你想看到的内容
- **反向提示词:**指定你不想看到的内容
下面是一个例子(使用chatGPT生成):
(fantasy:1.5), (enchanted forest), (mysterious atmosphere), (magical creatures), (glowing flowers), (ethereal:0.8), (twinkling stars), (floating islands)

④采样方法:去噪过程的算法。(具体使用方法看这个:链接)
⑤采样步骤:去噪过程的采样步骤数。越多越好,但也需要更长的时间。25 个步骤适用于大多数情况。
⑥宽度和高度:输出图像的尺寸。使用 v1 模型时,您应该至少将一侧设置为 512 像素。例如,对于长宽比为 2:3 的肖像图像,将宽度设置为 512,高度设置为 768。
⑦批次计数:运行图像生成管道的次数。
⑧批量大小:每次运行管道时生成的图像数量。
生成的图像总数等于批次乘以批数。您通常会更改批量大小,因为它更快。仅当遇到内存问题时,您才会更改批次计数。
⑨CFG 比例:提示词引导系数 是一个参数,用于控制模型遵守您的提示词的程度。(提示词权重)
- 1 – 大多忽略您的提示。
- 3 – 更加自由更有创意。
- 7 – 遵循提示和自由之间的良好平衡。
- 15 – 更加遵守提示。
- 30 – 严格按照提示操作。
下图显示了使用固定种子值更改 CFG 的效果。您不想将 CFG 值设置得太高或太低。如果 CFG 值太低,稳定扩散将忽略您的提示。太高时图像的颜色会饱和。

⑩种子Seed:用于在潜在空间中生成初始随机张量的种子值。实际上,它控制图像的内容。生成的每个图像都有自己的种子值。如果设置为 -1,AUTOMATIC1111 将使用随机种子值。
使用回收按钮复制种子值。

使用骰子图标将种子设置回 -1(随机)。

⑪面部修复需要应用一个额外的模型,该模型经过训练可以恢复面部缺陷。
在使用面部修复之前,您必须指定要使用的面部恢复模型。首先,访问**“设置”选项卡。导航至面部恢复部分。选择面部修复模型。CodeFormer是一个不错的选择。将 CodeFormer 权重设置为 0 以获得最大效果。请记住单击“应用设置”**按钮来保存设置!

⑫使用**“平铺”**选项可生成可平铺的周期性图像。就是由重复有规律图案拼成的图像。
⑬高分辨率修复选项应用upscaler来放大图像。因为稳定扩散的原始分辨率是 512 像素(或某些 v2 模型为 768 像素)。对于许多用途而言,图像太小了。(具体使用方法看这个:链接)
⑭最后,点击右边的生成按钮。稍等片刻后,您将获得图像!
生成图像操作(蓝色区域)
①图片生成后展示在这里

②您会发现下面一排按钮,用于对生成的图像执行各种功能。从左到右…
打开文件夹:打开图像输出文件夹。
保存:保存图像。点击后,按钮下方会显示下载链接。如果您选择图像网格,它将保存所有图像。
Zip:压缩打包图像以供下载。
**发送到图生图:**将选定的图像发送到图生图选项卡。
发送到重绘:将所选图像发送到图生图选项卡中的修复选项卡。
发送到后期处理:将选定的图像发送到后期处理选项卡。
扩展插件安装
一般有三种安装方式,具体还要看插件提供哪些方式
- 第一种是官方提供的在设置"Extensions"选项卡中搜索下载,因为网络问题即使挂了代理也连不上,不推荐
- 第二种是手动“git clone”克隆想要安装插件的GitHub项目到本地手动放置,但是后续更新需要重新克隆,不推荐
- 第三种是在里面通过复制插件的GitHub项目地址在"Extensions"中下载,推荐,操作简单一键更新
推荐几个入门必备插件,现在让我们通过具体插件安装来掌握方法,每个插件都有提供官方项目地址,不清楚或者想了解更多的请阅读官方文档。
1.界面中文汉化包
官方的SD界面默认是是英文的,我们需要自己下载插件来进行中文替换(习惯英语操作的可以忽略本条)
(也可以选择另一个支持中英双语的插件:https://github.com/VinsonLaro/stable-diffusion-webui-chinese)
①点击“extensions”选项
②点击“install from URL”
③复制粘贴这个地址:https://github.com/hanamizuki-ai/stable-diffusion-webui-localization-zh_Hans
④点击“install”,等待下载

⑤完成点击“installed”,点击“apply and restart UI”

回到界面设置中文:
①点击“settings”
②点击“user interface”
③点击“localization”,下拉菜单选择zh-cn
④点击“apply settings”保存
⑤最后“reload UI”,重载界面

再次进入就是中文了!可能有些地方翻译不全,但也适配了一些常用插件的翻译。
2.提示词自动补全/翻译
一个类似输入法英文补全的功能,它是帮你补全大数据词库里的prompt(生成提示词),方便了我们英文不熟悉者和懒人用户
插件介绍还有个翻译功能,但用不明白(不知道),翻译的还是推荐下一个插件
①按照前面的方法复制链接下载然后重载界面生效
复制地址:https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
②现在我们在输入时下方就有提示词,可以选择自动补全

3.prompt翻译
一个提供多个接口可选择的免费翻译prompt插件,我们输入中文就能转化为英文了,完美解决语言差异。
①按照前面的方法复制链接下载然后重载界面生效
复制地址:https://github.com/Physton/sd-webui-prompt-all-in-one
②在正向提示词输入框右下方输入框输入文字然后回车确定/自动翻译


③自行根据需要配置翻译接口,进阶使用你还可以搭配chatgpt的api key来辅助生成prompt。
4.反推提示词
一个比默认图片提取prompt更精准的插件,功能也更强大
①按照前面的方法复制链接下载然后重载界面生效
原来项目的主支已经不更新了,原地址:https://github.com/toriato/stable-diffusion-webui-wd14-tagger
而且这个项目在MAC上安装还有Bug[19][20],我喜欢折腾所以下载了原始版本。
推荐使用这个继承分支的⬇️
复制地址:https://github.com/picobyte/stable-diffusion-webui-wd14-tagger
②安装成功会看到上面的设置栏多了一个“WD 1.4标签器 (Tagger)”,点击进入界面
③上传一张图片让它分析,首次运行会下载一些依赖,可以在终端窗口查看进度

④上面就是分析出来的提示词,下面是每个提示词对应的权重,越高就越接近,你还可以自己设定权重值范围,超过此权重值的提示词才会显示出来。

⑤使用结束后,记得点击下方的“卸载所有反推模型”,不然模型会占用很高的显存。
5.图库浏览器
我们之前生成的图片后老是需要打开文件夹去查看,而且管理起来很不方便,可以使用这个插件来浏览和管理图片。
①按照前面的方法复制链接下载然后重载界面生效
复制地址:GitHub - AlUlkesh/stable-diffusion-webui-images-browser: an images browse for stable-diffusion-webui
点一下“首页”它就自动获取所有生成的图片

在这里可以看到图片信息和保存路径

上面可以进行筛选和文件名关键词、提示词搜索,还可以打分后续根据评分搜索

可以收藏来单独管理,快速文生图、图生图等等

6.防止爆显卡
你可能遇到过这样的报错提示,原因是我们显卡内存不够了
RuntimeError: MPS backend out of memory (MPS allocated: 5.05 GB, other allocations: 2.28 GB, max allowed: 6.80 GB). Tried to allocate 1024.00 MB on private pool. Use PYTORCH_MPS_HIGH_WATERMARK_RATIO-0.0 to disable upper limit for memory allocations (may cause system failure).
启用 Tiled VAE 插件后,它会先生成一个个小的图块,然后再组合在一起形成高分辨率图像,这样就有效防止爆显存情况的出现,不过生成时间会更长一些。
①按照前面的方法复制链接下载然后重载界面生效
复制地址:https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
进阶使用你还可以搭配controlNet模型来放大图像,生成更高分辨率(6K)等。
N.主题美化包
(不感兴趣可忽略本条)
仔细审视自己的SD界面,你可能在疑惑为什么自己的界面和其他博主的不一样?(没ta那么好看)
其实大部分博主用的都是这个(之前叫kitchen,现在叫lobe theme)美化主题:


①同样的复制地址下载然后重载界面生效
复制地址:https://github.com/canisminor1990/sd-webui-lobe-theme
有亮色、深色两个主题可选择,还可以自定义
Tip: 右上角⚙图标打开设置面板(记得先开启简体中文哦),当前可用设置如下:
-
主题[21]
-
-
原色:目前提供
13主题色搭配 -
中性色:目前提供
6不同色彩倾向灰阶搭配 -
标志类型:
Lobe,Kitchen,Custom -
- 自定义徽标:支持
img url、base64、 和emoji。当输入单个表情符号时,它将自动替换为 3D Fluent Emoji。 - 自定义标题:自定义站点名称。
- 自定义徽标:支持
-
我们还可以在Chrome浏览器中安装Web应用程序,这样下次我们启动webui后直接打开,不需要手动复制本地链接到浏览器了。

最后其实还有大家最关心的controlNet插件[22]没讲到,因为这个插件不算入门,要讲的点很多(不太想),单独拿出来才能讲明白。感兴趣的可以先去学习一下,我在文章后面也有推荐一些其他的学习资源。
AI绘画神级插件 Controlnet 连续更新!手把手教你安装体验新功能(附模型资源)www.uisdc.com/controlnet-v1-1

使用和优化
日常使用
我们关闭终端SD程序就终止运行了,再次使用还是执行这两个指令:
cd stable-diffusion-webui/
./webui.sh
更新方法:
⬇️输入以下指令:
git pull https://github.com/AUTOMATIC1111/stable-diffusion-webui
⚠️如果要从头开始重新安装,请删除目录:venv, repositories。
性能优化:[24]
目前 macOS 上的 GPU 加速会占用大量内存。如果性能较差(如果使用任何采样器生成 20 个步骤的 512x512 图像需要超过一分钟)
①--opt-split-attention-v1尝试从命令行选项(即)开始./webui.sh --opt-split-attention-v1,看看是否有帮助。
②没有太大区别吗?
打开“活动监视器”应用程序,然后检查“内存”选项卡下的内存压力图。生成图像时内存压力显示为红色
关闭 Web UI 进程,然后添加--medvram命令行选项(即./webui.sh --opt-split-attention-v1 --medvram)。
③使用该选项时性能仍然很差并且内存压力仍然红色?
尝试--lowvram(即./webui.sh --opt-split-attention-v1 --lowvram)
④使用任何采样器仍需要几分钟以上的时间才能通过 20 个步骤生成 512x512 图像?
您可能需要关闭 GPU 加速。
webui-user.sh在 Xcode 中打开
更改#export COMMANDLINE_ARGS=""为export COMMANDLINE_ARGS="--skip-torch-cuda-test --no-half --use-cpu all".
进阶学习
为了避免篇幅太长主题不明,本文只分享了部署方面的知识,一些进阶操作如其他插件、训练模型、AI动画(视频)、生产力方式的知识还不足以教学分享。作为学生大部分时间都在学习(玩乐),不能够像职业人和自媒体博主一样持续输出教学知识,那就分享一些我认为优质的进阶学习资源,让我们共同进步~
文章推荐:
因为优设是个设计师分享社区,里面的教程文章都比较详细好懂、配图设计精美,阅读起来也很舒服。还讲到AI绘画的生产力变现。
Stable Diffusion 入门和进阶指南www.uisdc.com/zt/stable-diffusion

视频推荐:
这位B站UP主讲的一系列AI绘画课程质量都很高,可以持续订阅,同样详细好懂、视频风格很有美感。
Nenly同学的个人空间-Nenly同学个人主页-哔哩哔哩视频space.bilibili.com/1814756990
拓展阅读:
在线服务
国外的Stable Diffusion Online,国内的前面介绍模型有提到,用过esheep电子羊、小程序(也有网页版)的MewXAI,目前国内的AI绘画服务网站没有本地资源丰富,模型比较少社区也没咋有热度,基本上都是一个套路——(每天)只有一定的免费体验次数,生图需求高就需要付费,就不多说了;如果感兴趣,轻度体验一下玩玩还不错。
【重要的事情说三遍】不是打广告!不是打广告!不是打广告~
电子羊eSheep:eSheep - 一站式的AIGC社区


云端部署
本地部署的优点就是可以随时自由使用,不需要网络,生成一些比较好玩的图片啊(懂的都懂);云端部署就是自己可以选择更好的虚拟GPU性能、生成更快更好的质量,还可以训练模型。不过谷歌免费的**Colab已经识别禁用SD webui程序了(有办法解决,上一阵子用过),也可以选择花钱租用,像国内的AutoDL、百度飞桨、腾讯云**等等,使用别人分享整合好的资源就要遵循相关使用规则和平台的规则,也就是没有本地自由。也可以做到鱼和熊掌兼得——本地和云端协调,高效率、高自由度制图。
表:本地部署和云端部署优缺点对比
| 部署方式 | 优点 | 缺点 |
|---|---|---|
| 本地部署 | 1. 控制权更高,可以直接访问硬件资源。 2. 不需要网络连接。 3. 无需担心云服务费用。 | 1. 需要自己管理和维护设备。 2. 扩展性差,如果需要更多资源可能需要购买新的硬件。 3. 如果设备发生故障,可能会导致服务中断。 |
| 云端部署 | 1. 高度可扩展,可以根据需求随时增加或减少资源。 2. 无需担心硬件维护和升级。 3. 可以从任何地方访问。 | 1. 需要网络连接。 2. 数据安全性和隐私可能需要额外考虑。 3. 可能需要支付高昂的服务费用。 |
表:本地部署和云端部署综合对比
| MAC / 云计算服务 | 本地部署 | 云端部署 |
|---|---|---|
| 价格 | 免费 | 花钱租用 |
| 安装难度 | 难 | 容易 |
| 生图速度 | 取决于自己的电脑配置 | 可选择好的性能设备 |
| 是否支持训练模型 | 不支持或者速度很慢 | 支持 |
| 能否自由使用 | 离线自由使用 | 遵守相关条款使用 |
如果你对云端部署感兴趣,可以看看这些:
Colab:
AutoDL(炼丹)和百度飞桨:
小李xiaolxl的个人空间-小李xiaolxl个人主页-哔哩哔哩视频space.bilibili.com/34590220
腾讯云:

【玩转 GPU】StableDiffusion腾讯云快速部署,全网最详细保姆级教程(AI绘画、技术小白必看)-腾讯云开发者社区-腾讯云

基于ChatGPT+Stable Diffusion实现AI绘画-腾讯云开发者社区-腾讯云cloud.tencent.com/developer/article/2308252?source=t

一键安装包
很喜欢知友们的一句话:啊?!——我看到最后你才告诉我原来还有一键安装包这回事。没错,不是只有Windows才有Stable diffusion一键安装包,其实Mac早就有了SD一键安装包(AI绘画启动器)——不!是 魔法与巫术课程标准书籍[25],只不过没啥热度,因为名字听起来奇奇怪怪,还是说不好用?也有可能遭受同行打击?所以我还是推荐文章这种“古法炮制”SD部署(因为自己淋过雨所以不让别人撑伞)。

如果你真的不想自己动手,感兴趣的话可以看看他们的最新视频,下载和使用方法我就不细讲了,我目前也就只知道这么一个Mac能用的AI启动器,如果还有了解的小伙伴欢迎提醒我,这一区域还等人填补,希望将来有更多开发大佬(赛博佛祖)贡献更多更好的Mac SD本地部署一键安装包(启动器),造福人类~
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
👉[[CSDN大礼包:《StableDiffusion安装包&AI绘画入门学习资料》免费分享]](安全链接,放心点击)
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。
2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。
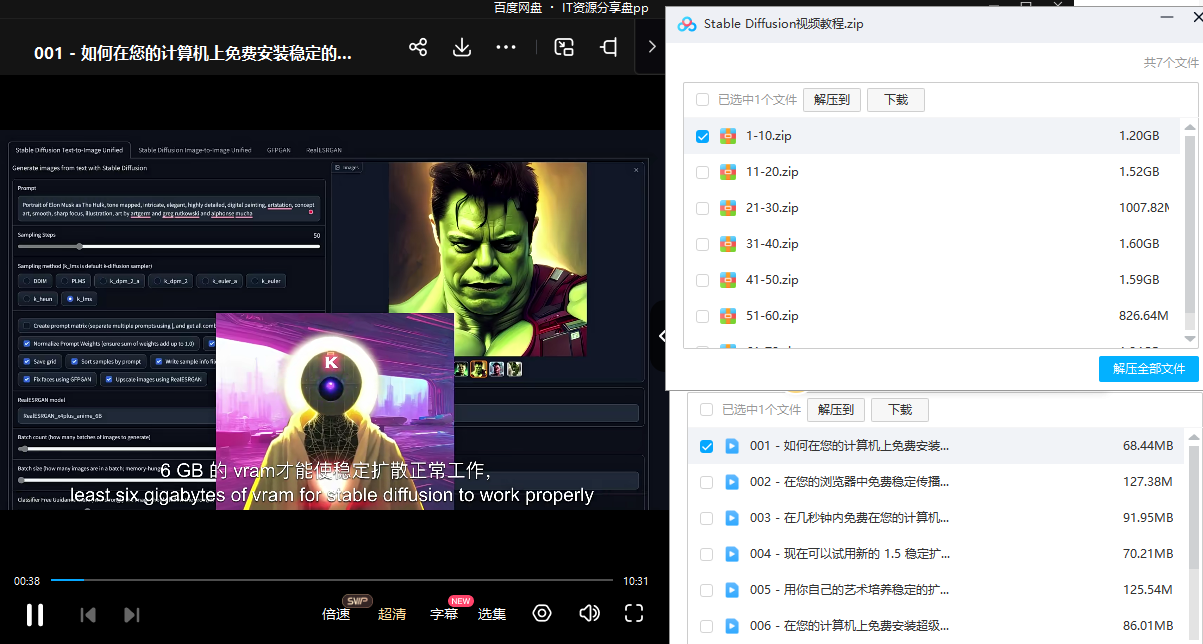
3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。
4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】