CloudCanal 是一款 数据同步、迁移 工具,帮助企业构建高质量数据管道,具备实时高效、精确互联、稳定可拓展、一站式、混合部署、复杂数据转换等优点。
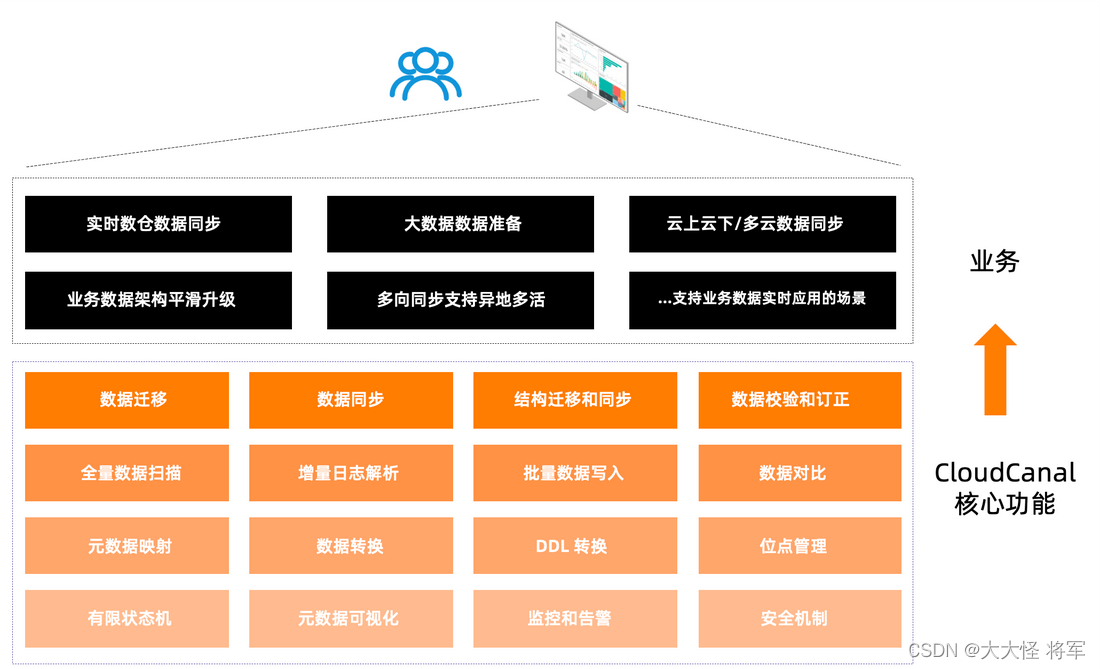
数据迁移
将指定数据源数据全量搬迁到目标数据源,支持多种数据源,具备断点续传、顺序分页扫描、并行扫描、元数据映射裁剪、自定义代码数据处理、批量写入、并行写入、数据条件过滤等特点,对源端数据源影响小且性能好,同时满足数据轻度处理需求。
可选搭配结构迁移、数据校验和订正,满足结构准备或数据质量的需求。
数据同步
通过消费源端数据源增量操作日志,准实时在对端数据源重放,以达到数据同步目的,具备断点续传、DDL 同步、元数据映射裁剪、自定义代码数据处理、操作过滤、数据条件过滤、高性能对端写入等特点。
可选搭配结构迁移、数据初始化(全量迁移)、单次或定时数据校验与订正,满足数据准备和业务长周期数据同步对于数据质量的要求。
结构迁移和同步
帮助用户快速将源端结构执行到对端的功能,具备类型转换、数据库方言转换、命名映射等特点,可独立使用,也可作为数据迁移或数据同步准备步骤。
数据校验和订正
将源端和对端数据分别取出,逐字段对比,可选择差异数据订正,功能可单独使用,也可配合数据迁移或数据同步使用,满足用户数据质量验证与修复的需求。
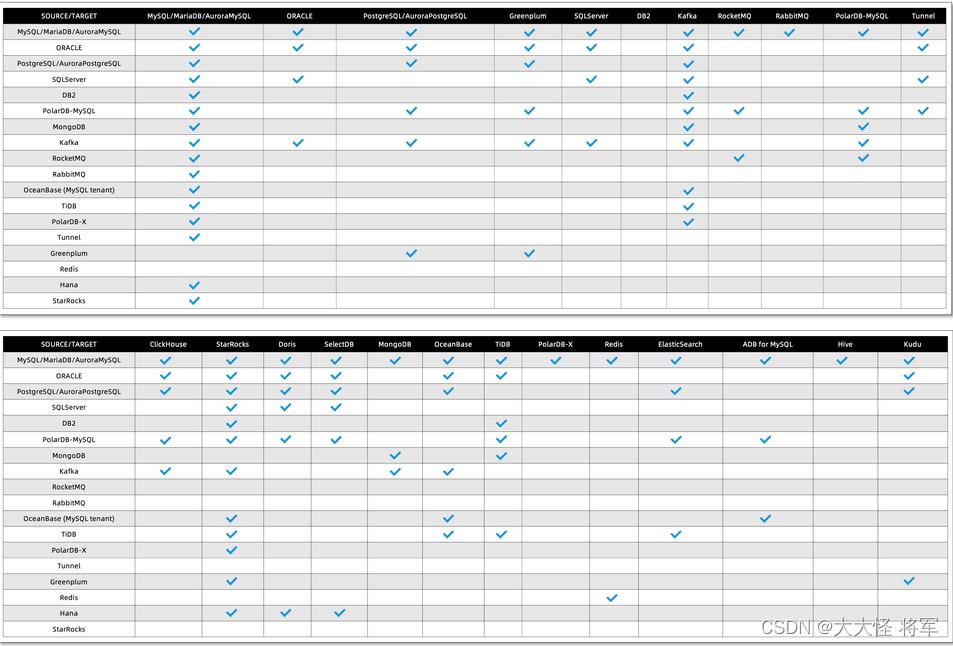
数据源互通拓扑
纵向为源端,横向为目标端(因数据源较多,分为两部分)
产品场景
本文主要介绍 CloudCanal 产品的应用场景,帮助业务落地数据应用需求。
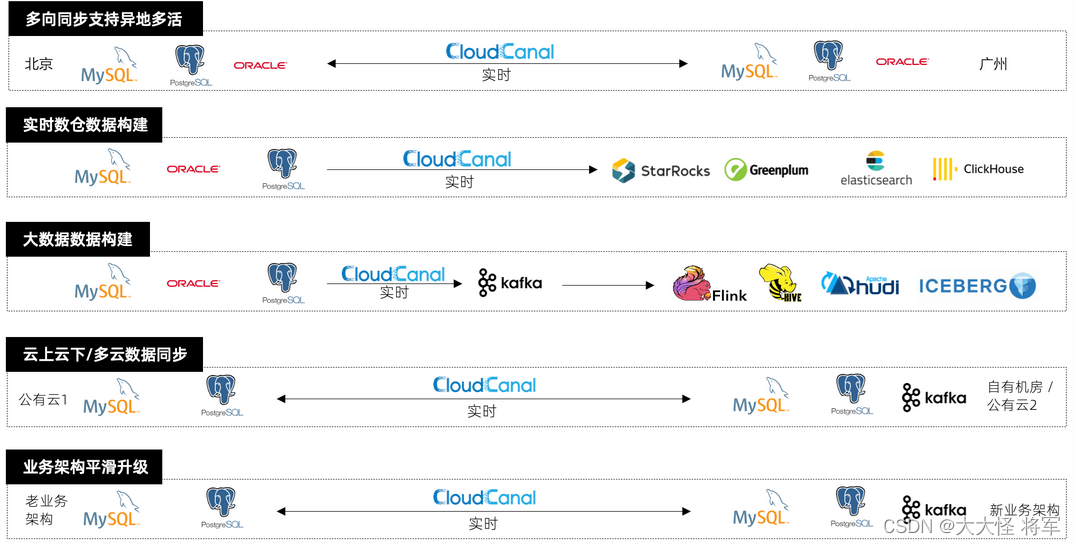
数据库多向同步
帮助业务双向/多向同步数据库、消息中间件数据之间数据,并消除同步循环,达成 业务异地多活、数据容灾备份 业务目标。
参考样例: MySQL 双向数据同步
实时数仓数据同步
通过实时同步,让数据既满足业务流程的刚性需求,同时具备更多的应用,包括但不限于数据复杂检索(多维度筛选、聚合、连接等)、模糊搜索、子业务流程触发、数据共享、数据挖掘等。
参考样例: MySQL 到 ClickHouse 同步
大数据数据准备
通过消息中间件解耦在线业务和大数据分析,在线数据实时出现在消息中间件中,下游流、批处理数据,构建数据平台。
参考样例: MySQL 到 Kafka 同步
云上云下/多云数据同步
公有云与公有云、公有云与私有机房、跨地域远距离数据迁移和同步,增量同步节省业务带宽,CloudCanal Tunnel 数据源让 两端数据库都不暴露公网,并且默认附带鉴权、加密传输,让数据同步更安全。
参考样例: 跨互联网数据同步
业务数据架构平滑升级
自定义代码上传让业务有机会进行复杂的数据迁移同步,通过实现 clougence-sdk 接口,接受迁移或同步数据,再进行变换处理甚至调用远程服务,最后将结果返回 CloudCanal 。
此能力让用户对老业务数据结构进行彻底变化,并且完成 新老业务不停机过渡 成为可能。
参考样例: 数据同步脱敏
更多场景和样例
CloudCanal 能够极大丰富业务的数据应用场景,充分发挥数据本来的价值,更多场景应用不断丰富中。
参考样例: 数据校验与订正
产品优势
CloudCanal 具备实时高效、精确互联、稳定可拓展、一站式、混合部署、复杂数据转换等优点,相比同类产品,更加专注、细致、专业。
实时高效
数据同步功能 延迟普遍小于 5 秒 , 期间完成增量数据解析、攒批、操作过滤、数据转换、元数据映射、数据写入等动作。
精确互联
对于数据链路两端的数据类型、结构规范、读写特点做了精确匹配与转换,让每一个数据源种类、版本差异 得到妥善解决。
稳定可扩展
产品内核精简,单进程架构,系统分布式、高可用部署。产品通过组合各个职能的任务进程,实现大规模、分布式、高质量数据管道集群。
一站式
汇集结构迁移、数据迁移、数据同步、数据校验与订正、修改订阅等功能,通过有限状态机让功能自动流转和运行。一站式支持用户数据准备与长期同步过程的一系列工作。
混合部署
支持各个公有云、本地机房私有部署,首要关注用户数据安全,有效支持异地、云上云下、多云之间数据安全同步需求。
复杂数据转换
产品默认包含元数据映射、裁剪、过滤等标准能力,同时支持 用户上传业务代码 进行数据复杂处理。
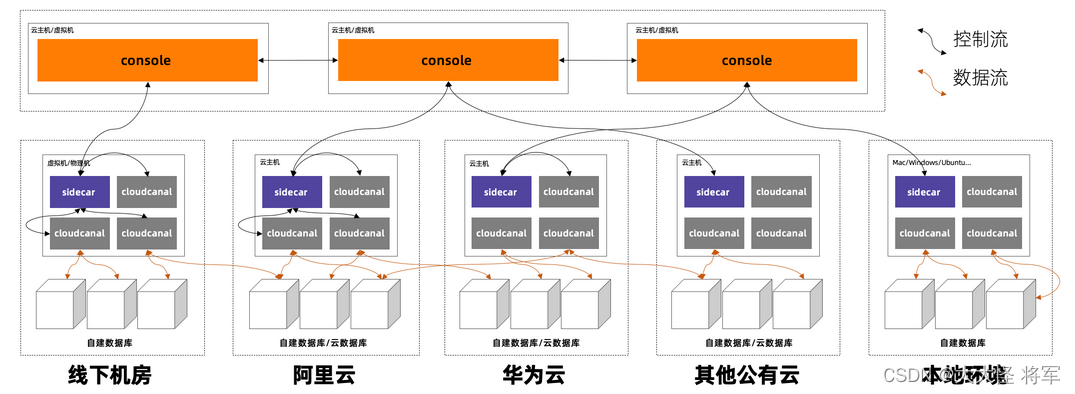
产品架构
本文主要介绍 CloudCanal 技术架构,包括产品架构、内核架构、容灾方案、混合云网络方案 4 个部分。
-
Console
- 集中化的管控服务,以 web 服务集群存在。
- 承载产品化功能,包括数据源/机器/数据任务生命周期管理、容灾调度、监控告警、元数据管理等。
-
Sidecar
- 部署于具体数据迁移同步机器上。
- 承担包括获取需要运行的任务配置、启停数据任务进程、收集和上报任务状态、执行任务的健康检查等工作。
-
CloudCanal Core
- 部署于具体数据迁移同步机器上。
- 执行具体的数据迁移、同步、校验、订正任务。
内核架构

-
数据源插件
- 包含各个数据库、消息、数据仓库等数据源数据读写、元数据获取逻辑和对应驱动。
- 各个插件通过 Java 类加载机制隔离,任务运行时只加载对应数据源插件。
-
核心
- 包含内核代码骨架、操作过滤、元数据映射、DDL 转换、自定义数据处理等部分。
-
支撑
- 包含元数据、任务配置、位点、监控指标,以及和管控交互的逻辑。
容灾方案
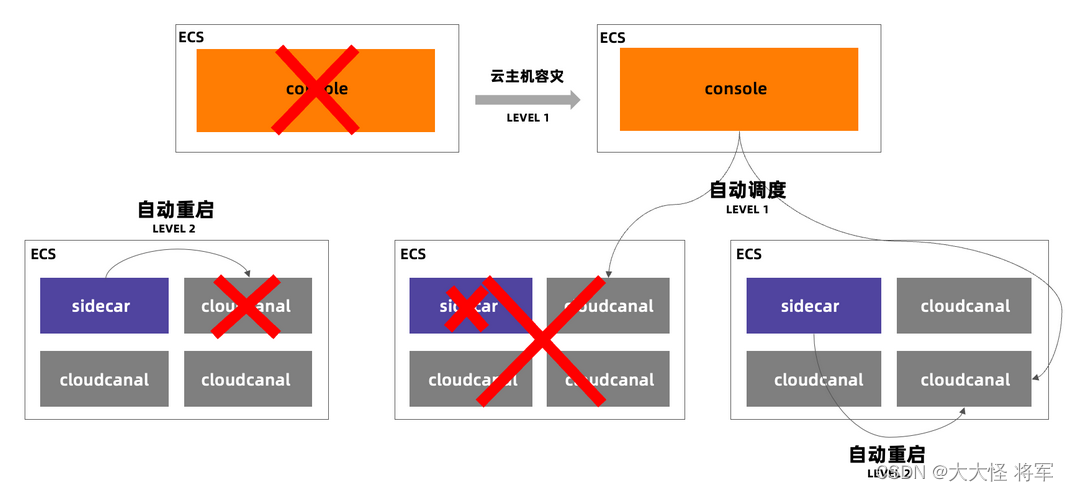
-
管控容灾
- 通过集群化部署解决,有状态部分交由元数据库解决。
-
任务 1 级容灾
- Sidecar 进程退出或机器不正常以及网络隔离情况下,Console 根据租期和 Sidecar 链接状态,进行主动容灾调度。
-
任务 2 级容灾
- Sidecar 进程正常,任务进程不正常,Sidecar 通过健康监测保障其负责的任务按照管控指定的状态运行,保活或保死。
混合云网络方案
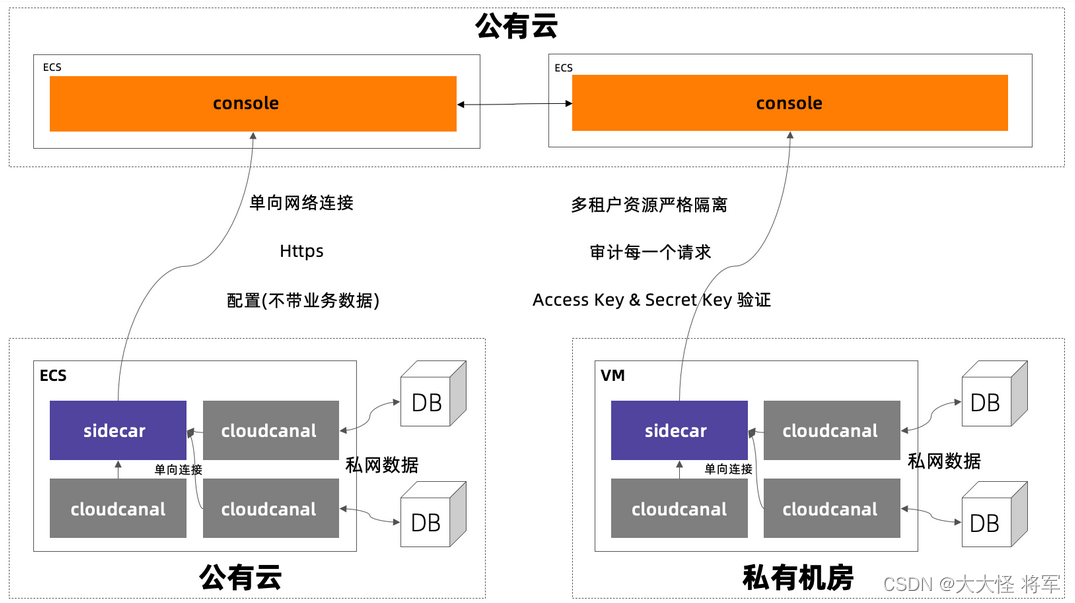
CloudCanal 为了适应多租户、分布式系统部署要求,采用了多种网络安全措施,确保用户数据和信息安全。
-
单向链接
- Sidecar 节点反向链接 Console , Sidecar 节点不主动暴露网络信息。
-
HTTPS 协议
- Sidecar 节点和 Console 通信采用 HTTPS 协议,防止盗取并篡改信息。
-
数据不出网络
- 所有数据流转均发生在用户内网,数据不流出泄漏。CloudCanal 所有针对数据源的动作均发生在用户网络环境。
-
长连接 AccessKey SecurityKey 认证
- 采用 TCP 长连接,每一次连接经过用户独有的 AccessKey 和 SecurityKey 认证。
-
请求验证
- Sidecar 每一次请求都经过资源归属验证。
-
操作审计
- Sidecar 节点请求 Console 的操作均做审计,可追踪溯源。
-
产品术语
本文主要介绍 CloudCanal 产品中包含的专业术语。
数据源
可以为关系型数据库( MySQL/PostgreSQL/Oracle 等)、消息中间件( Kafka/RocketMQ 等)、缓存( Redis 等)、实时数仓( Greenplum/Doris/StarRocks 等)、大数据产品( Hive/Kudu 等)等或者它们对应的云托管产品配置, 一般包含 链接地址、登录认证信息 等属性。
一个数据源一般以 my-59bi20aqxxxxx96 类似的 id 表示。
数据作业
完成一项数据迁移、同步工作的配置,可能包含一组先后或同时运行的结构迁移、全量迁移、增量同步、数据校验进程(数据任务)。
一个数据作业最大同步数据表范围,关系型数据库为单/多 Schema ,消息为同一个消息中间件多个 Topic。
一个数据作业一般以 canal7yr4y7xxxx3 类似的实例id表示。
数据任务
一个数据作业包含多个步骤,比如结构迁移、全量迁移、增量同步、数据校验、数据订正等,一个步骤即一个数据任务。
结构迁移
数据作业范围之内,将数据源的结构定义拷贝到对端数据源,对于异构数据源,通常存在类型或特定方言转换。
全量迁移
数据作业范围之内数据单次/定时搬迁,顺序扫描源端数据源数据,批量、并发写入对端数据源,通常需要秒~小时级别时间完成此类操作。
增量同步
数据作业范围内持续增量错做同步,利用源端数据库变更日志、触发器类增量数据、消息等准实时采集变化数据并写入到对端数据库,对端数据库在具备实时写入能力的情况下,可以做到增量数据的亚秒级别延迟的增量同步。
数据校验和订正
数据作业范围内数据单次/定时校验和差异订正。
其中数据校验指批量扫描源端和对端数据库的数据,在内存中逐行逐列对比数据,报告数据缺失、不一致情况,记录到 diff.log 和 compare_rs.log 文件中。
数据订正根据数据校验差异数据 compare_rs.log 逐条扫描源端数据源中最新数据行,并覆盖式写入对端数据源中,达成数据订正的效果。
自定义代码
全量迁移和增量同步过程中,CloudCanal 允许用户上传业务代码(Java 代码,jar 包形式上传),对数据进行转换、过滤、补充等操作。
集群
数据任务在机器间调度的基本单元(数据任务只在单个集群中调度),可跨机架、机房、可用区,甚至地域,一般建议将物理距离相近的机器放于一个集群中。
一个集群一般以 clusterl79txxxxku 类似的集群名称表示。
机器
用来运行 数据任务,可以是自建虚拟机( VM )、物理机、云托管虚拟机( ECS,EC2 等)、开发机( Mac 等)。
一个机器只属于一个集群。
异步任务
异步任务是 CloudCanal 管控的基础组件,针对长流程、需要重试、需要状态等待等业务逻辑。
一个异步任务一般由 1~n 个步骤组成,每一个步骤完成一项特定工作,当步骤失败时,该异步任务将停止继续往下运行,直到问题被消除再重试或取消执行。
快速开始
本文主要介绍 CloudCanal 快速上手,以 Linux 机器全新部署 Docker 版 CloudCanal 为例
机器准备
准备一台 Linux(CentOS 7/8) 虚拟机,硬件规格
- CPU核数:4核
- 内存:8 GB
CloudCanal 安装与激活
- 参考 全新安装(Linux/MacOS) 文档安装并激活 CloudCanal
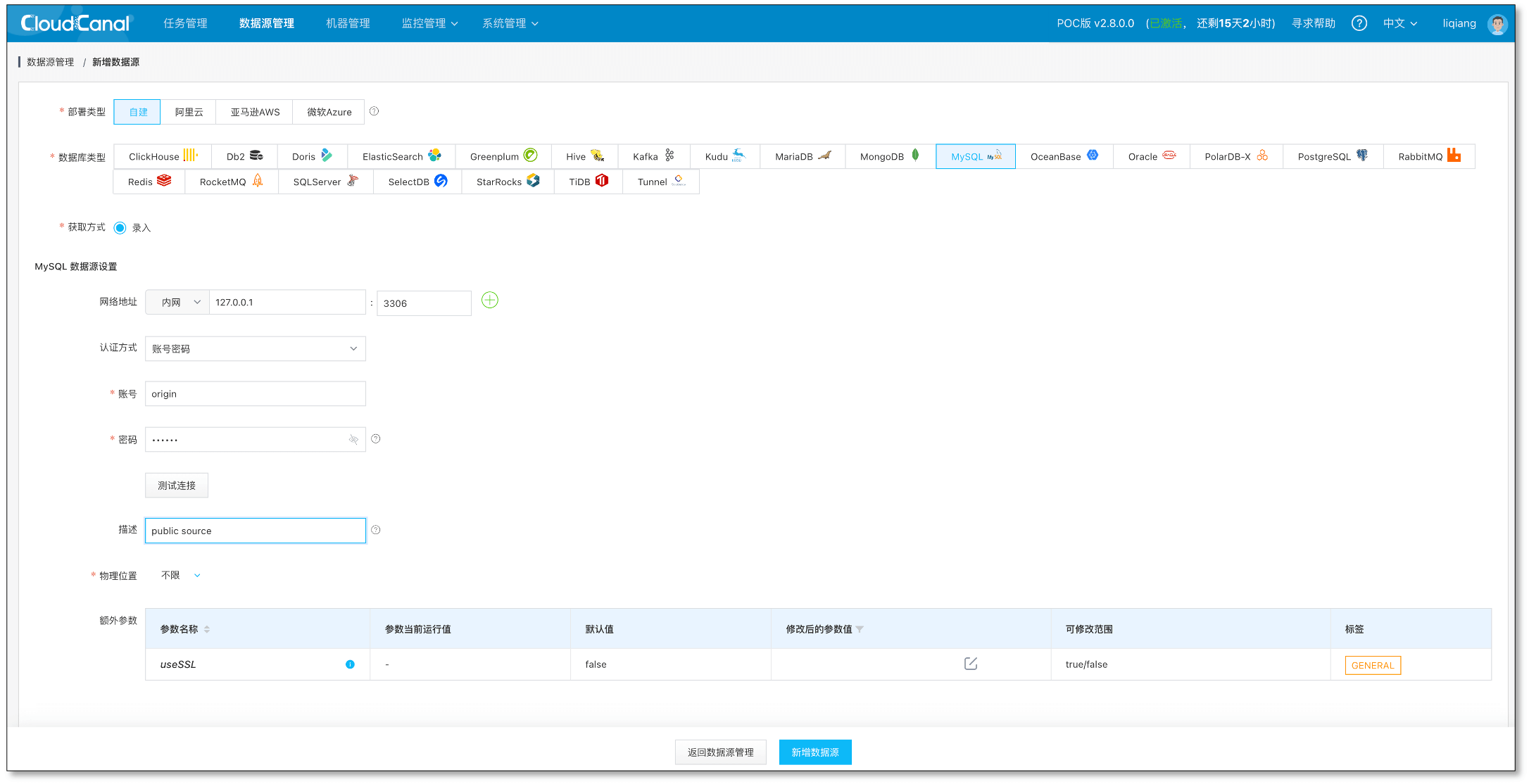
数据源添加
-
登录 CloudCanal 控制台,数据源管理 > 新增数据源
- 选择 自建
- 选择数据库类型 MySQL
- 填写网络地址、账号密码等必要信息并 测试连接
- 点击 新增数据源 按钮即可完成添加
-
数据源管理页面可以查看刚刚添加的数据源

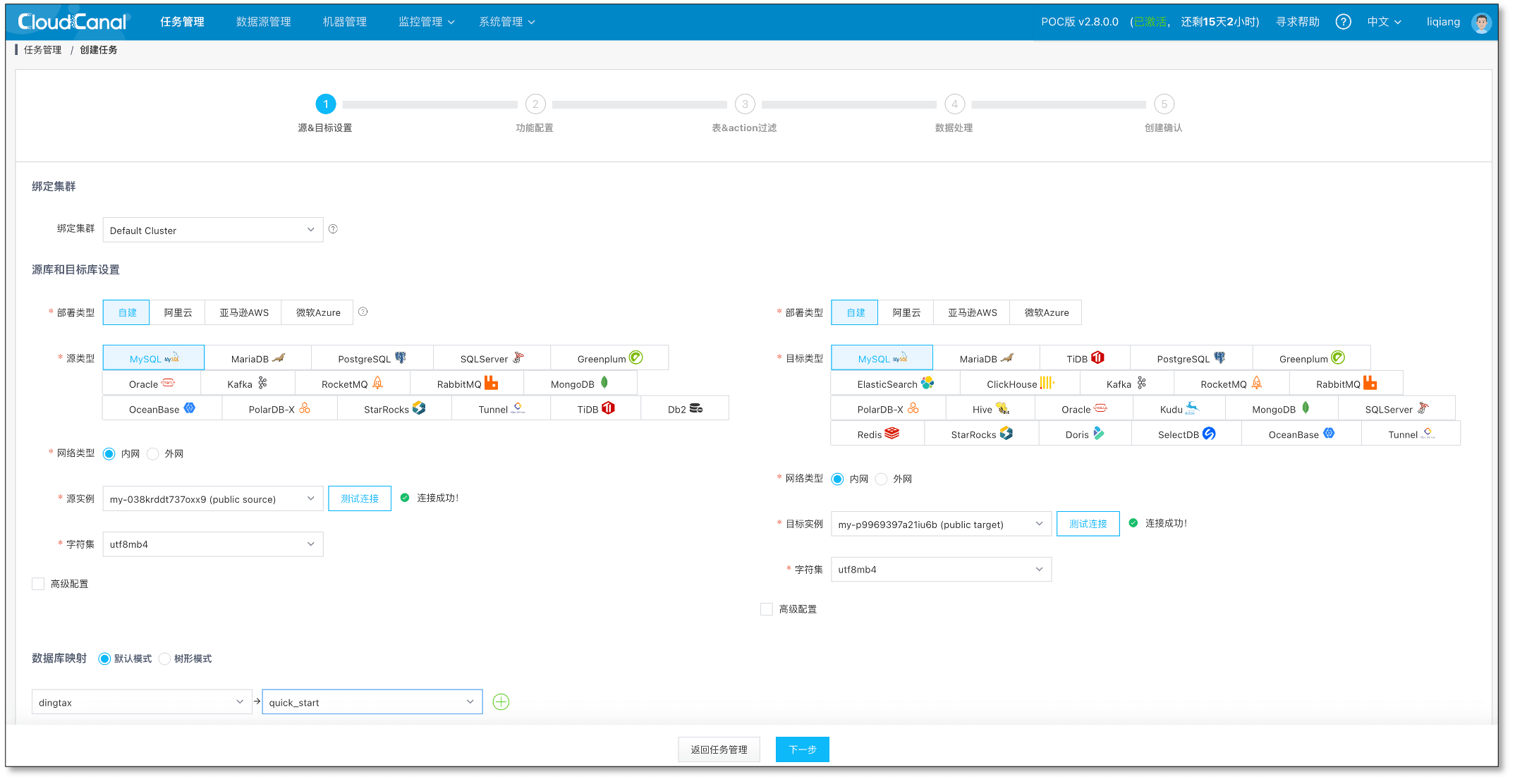
任务创建与运行
-
登录添加好的 MySQL 数据库,执行以下脚本准备测试库表
# source database create database sample_src; # target database create database sample_dst; # prepare table and data for migration and sync use sample_src; CREATE TABLE IF NOT EXISTS `sample_src`.`test_table`( `id` INT UNSIGNED AUTO_INCREMENT, `name` VARCHAR(32) NOT NULL, `age` int not null , PRIMARY KEY ( `id` ) )ENGINE=InnoDB DEFAULT CHARSET=utf8; # prepare test data insert into `sample_src`.`test_table`(id,name,age) values(1,'hello',18); insert into `sample_src`.`test_table`(id,name,age) values(2,'world',18); insert into `sample_src`.`test_table`(id,name,age) values(3,',',18); insert into `sample_src`.`test_table`(id,name,age) values(4,'cloudcanal',18);
-
CloudCanal控制台,任务管理 > 创建任务
-
选择添加的数据源作为 源 和 目标 并点击 测试连接 , 点击 下一步
-
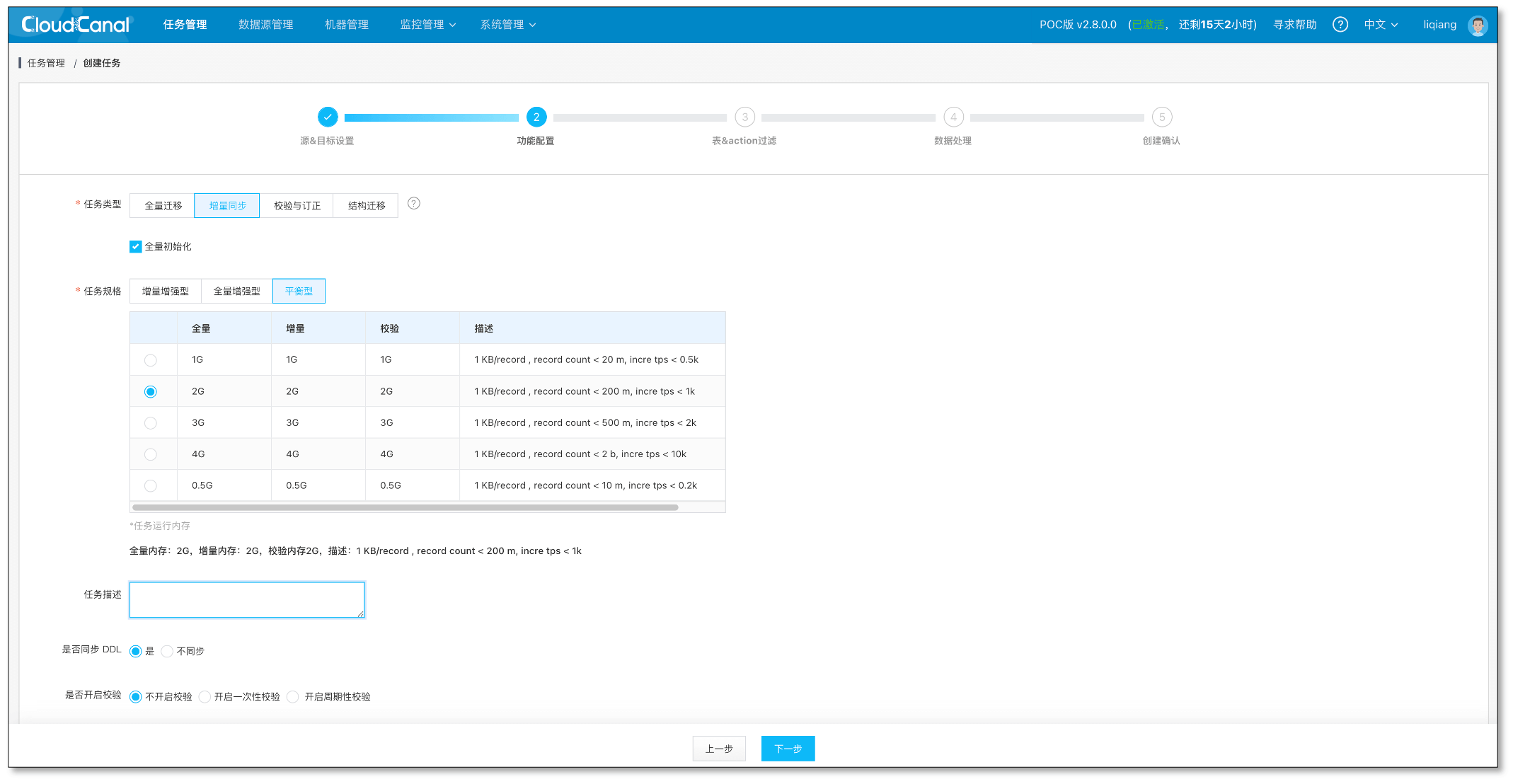
选择数据业务类型为 数据同步,并且勾选 数据初始化 , 点击 下一步
-
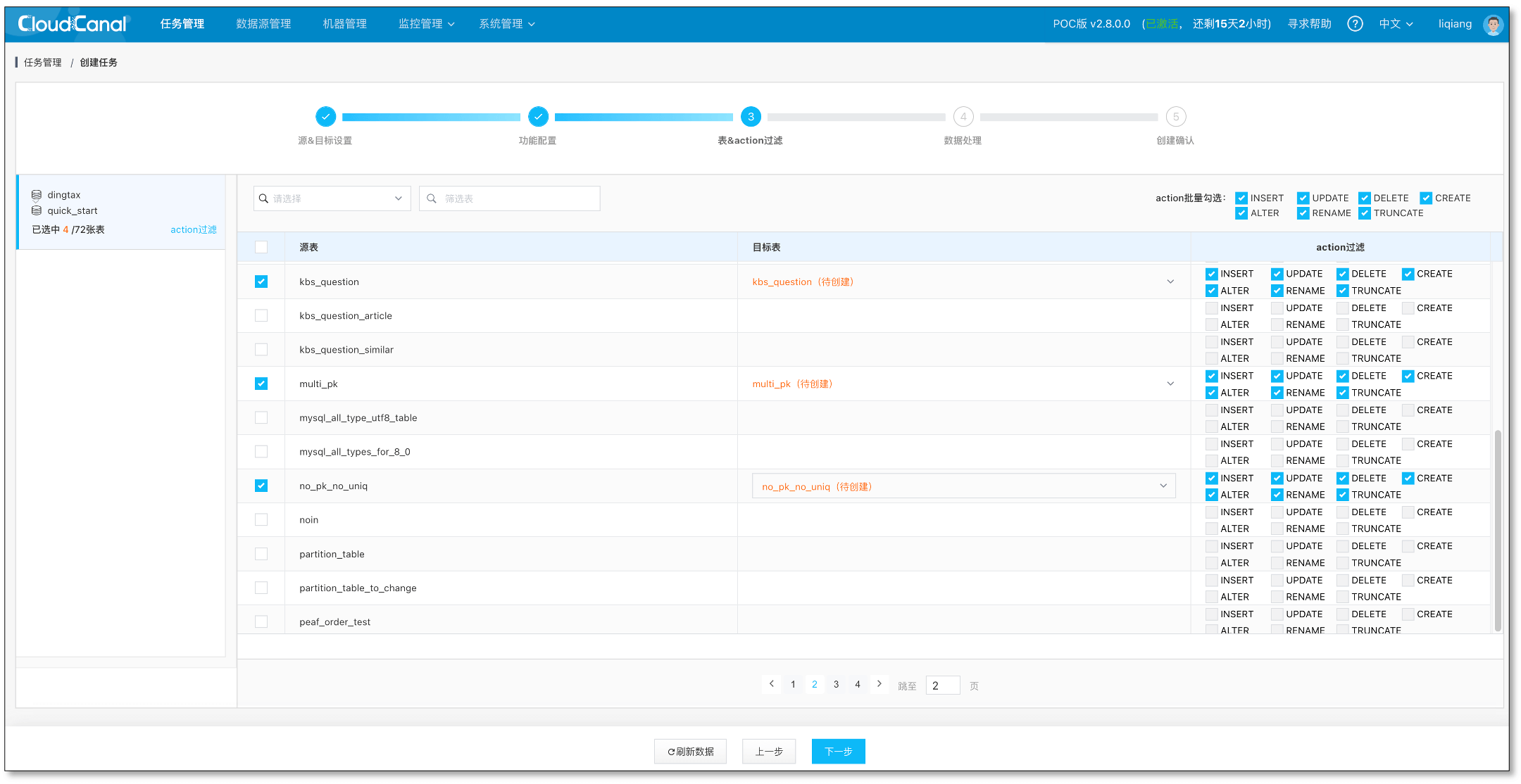
选择需要订阅的源端表 test_table , 并点击 下一步
-
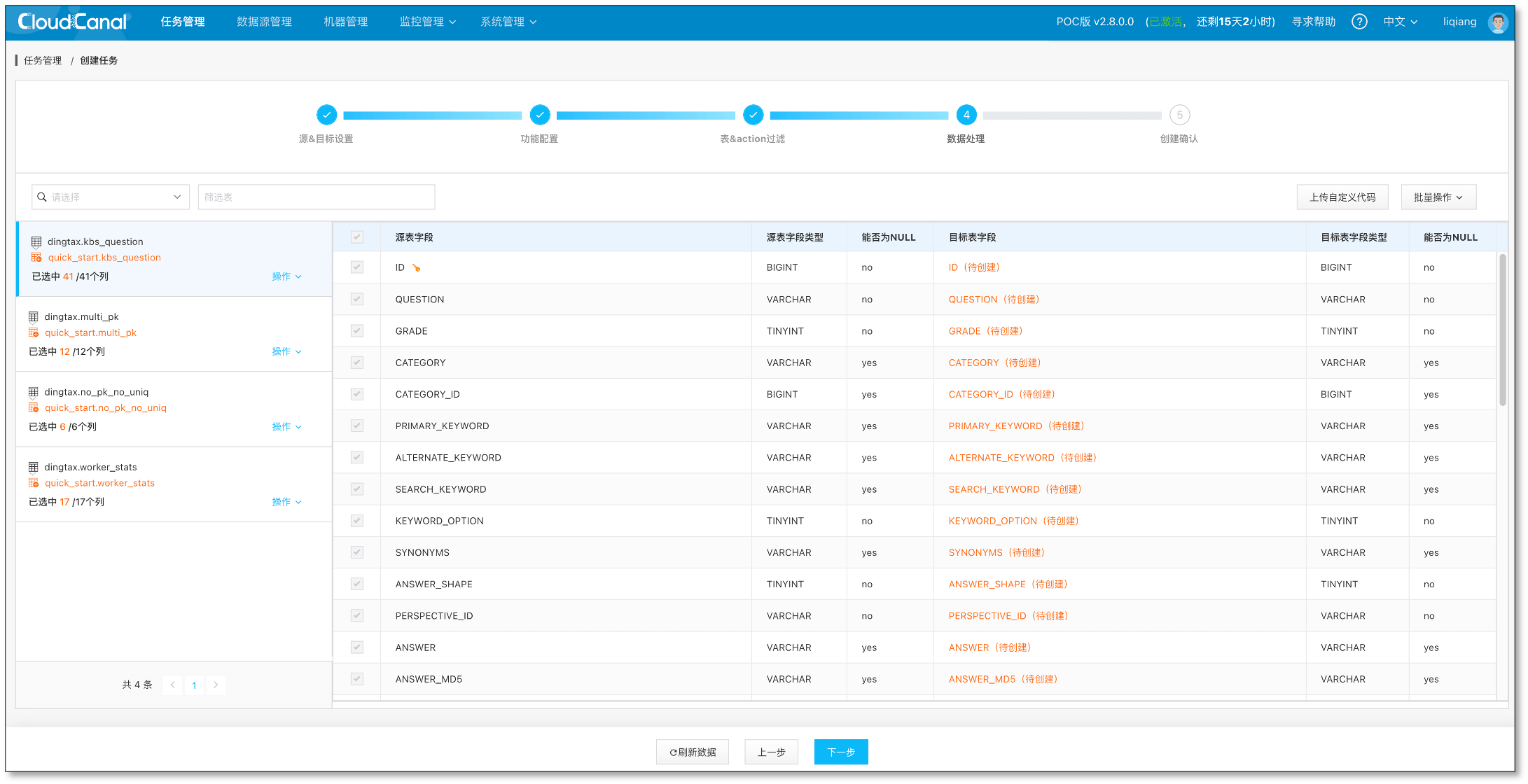
选择全部列,并点击 下一步
-
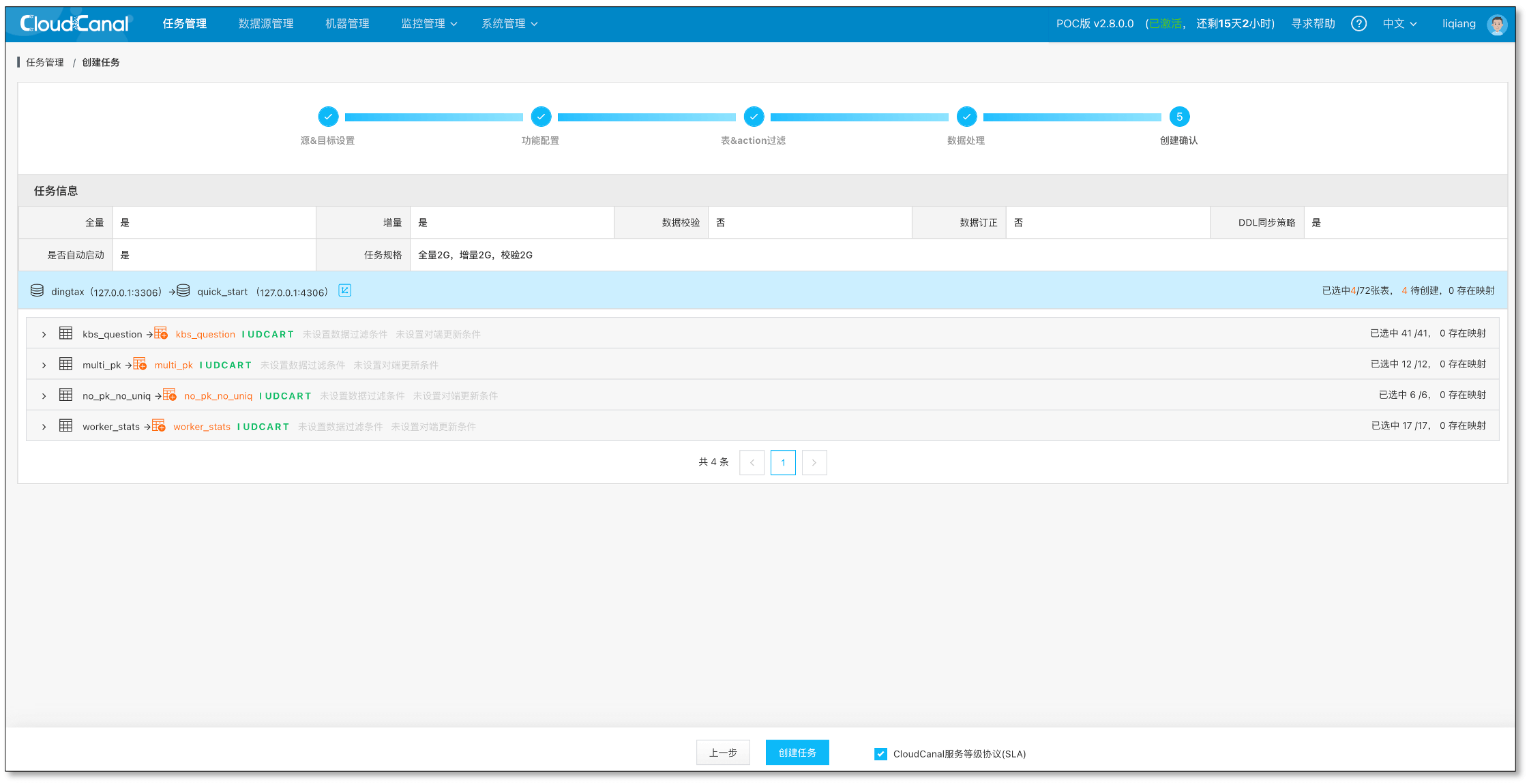
确认 创建任务
-
任务正常运行
- 任务自动进行初始化、迁移、同步,进度条逐步发生变化
-
数据验证
- 源端造一些增删改数据,可在对端表中查到一致的数据

总结
通过机器准备、软件安装与激活、数据源添加、任务创建与运行4步,可快速使用 CloudCanal 进行数据迁移与同步。