文章目录
kafka每个分区下使用多副本冗余实现高可用性,多副本之间有一个leader,多个follower,它们之间的数据同步依赖3个重要属性:
- LEO:日志末端的位移(log end offset),标识当前日志文件中下一条待写入的消息的offset
- HW:高水位值(High Watermark),定义了消息可见性,标识了一个特定的消息偏移量(offset),消费者只能拉取到这个水位 offset 之前的消息;帮助Kafka完成副本同步
- leader epoch:leader的任期,每一个Leader副本时代分配一个标识符,由领导将其添加到每个消息中,当follower副本需要截断日志时,替代高位水作为其截断操作的参照数据
kafka刷盘策略
- log.flush.interval.messages=10000
达到消息数量时,会将数据flush到日志文件中。默认10000
- log.flush.interval.ms=1000
间隔多少时间(ms),执行一次强制的flush操作。interval.ms和interval.messages无论哪个达到,都会flush。若未设置,则使用则使用log.flush.scheduler.interval.ms中的值
- log.flush.scheduler.interval.ms=3000
检查是否需要将所有日志刷新到磁盘的频率,默认3000
在Linux系统中,当我们把数据写入文件系统之后,其实数据在操作系统的pagecache里面,并没有刷到磁盘上。如果操作系统挂了,数据就丢失了。一方面,应用程序可以调用fsync这个系统调用来强制刷盘,另一方面,操作系统有后台线程,定时刷盘。频繁调用fsync会影响性能,需要在性能和可靠性之间进行权衡。实际上,官方不建议通过上述的三个参数来强制写盘,认为数据的可靠性通过replica来保证,而强制flush数据到磁盘会对整体性能产生影响。
副本同步
leader副本有属性 HW、LEO、Remote LEO(所有其它follower副本的LEO)
HW = Math.max[currentHW, min(LEO1,LEO2…LEOn)]
follower副本有属性 HW、LEO
HW = Math.min(currentHW,currentLEO)
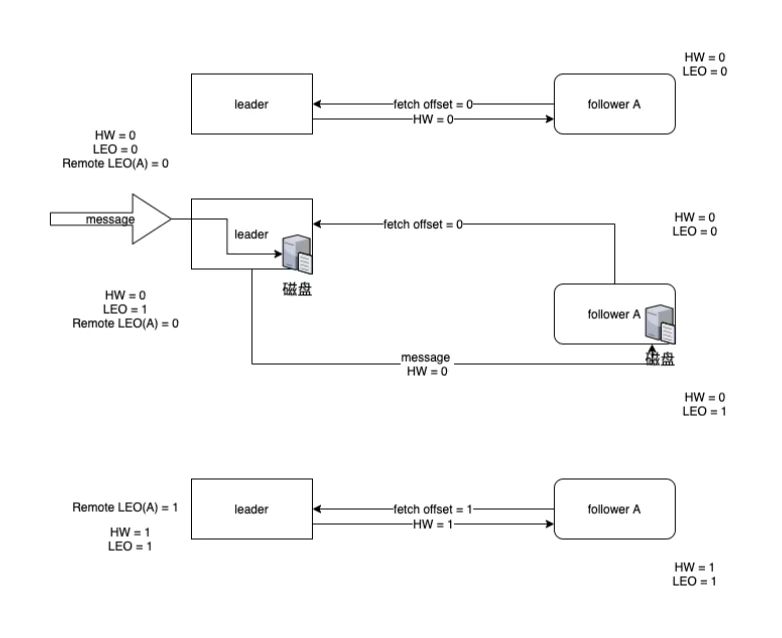
- follower副本会定时拉取leader副本内容,保持副本在ISR列表中,初始时都为0
- 生产者发送一条消息leader持久化到磁盘后,leader的LEO位移+1,HW=Math.max(0, min(0))=0
- follower同步leader新数据且持久化到自己的磁盘后,自身的LEO+1,HW=Math.min(0,1)=0
- follower再次同步leader,leader的RemoteLEO更新为1,更新HW=Math.max(0, min(1))=1, follower收到leader的HW=1,更新HW = Math.min(1, 1) = 1
HW类似二阶段提交,leader在所有(ISR列表副本)都同步持久化后,表示消息在所有副本都可见,才去更新值。
最少同步副本min.insync.replicas,代表 ISR列表中至少要有几个可用副本,当小于该值时,就认为整个分区处于不可用状态
follower在leader更新后,下一次的同步拉取最新的HW值,这将导致一些问题:
消息丢失
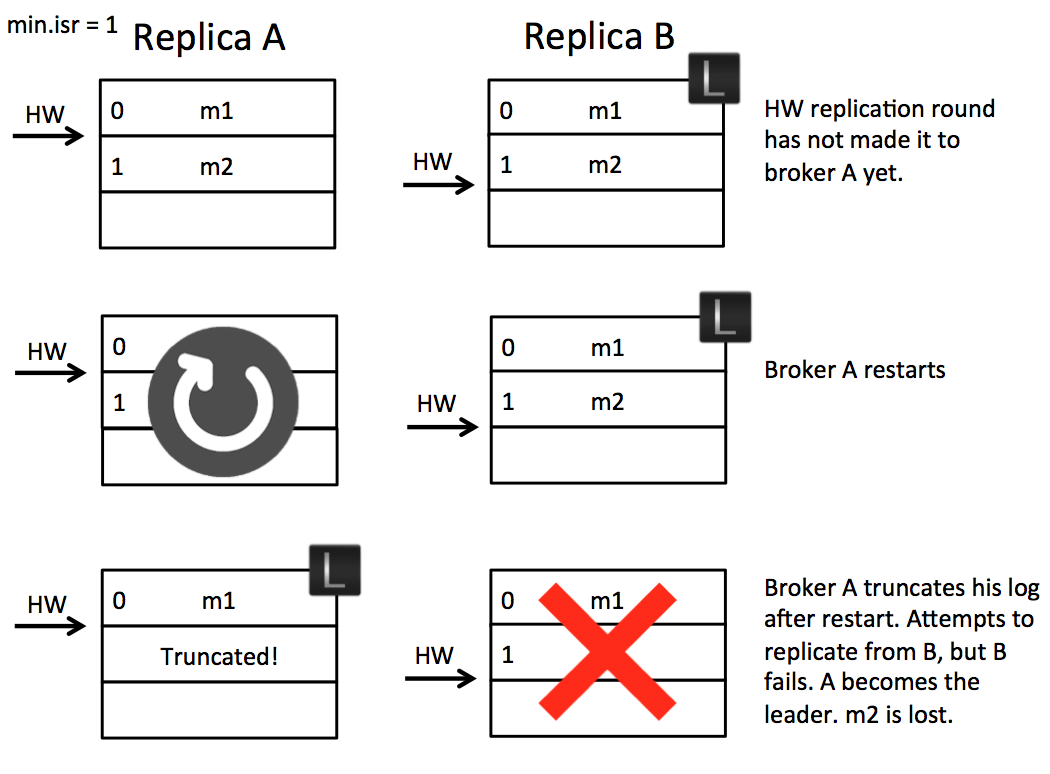
- 现有2个副本,follower A持久化m2后,向leader B发送同步请求,leader B的HW更新
- followerA 的response还未接收时A重启了,或者是A在其更新HW前进行了重启操作导致HW还没有更新到,重启后初始化会根据其记录的高水位HW来进行日志的截断保证数据的同步
- A的日志被truncated后,去从leader B同步数据,这个时候B又宕机了,followerA被选举成leaderA,消息m2则丢失
消息错乱
考虑到上述情况是,A重启后初始化会根据其记录的高水位HW来进行日志的截断导致后续问题发生,现在修改成从leader副本中获取HW执行日志的截断操作,看下是否正常
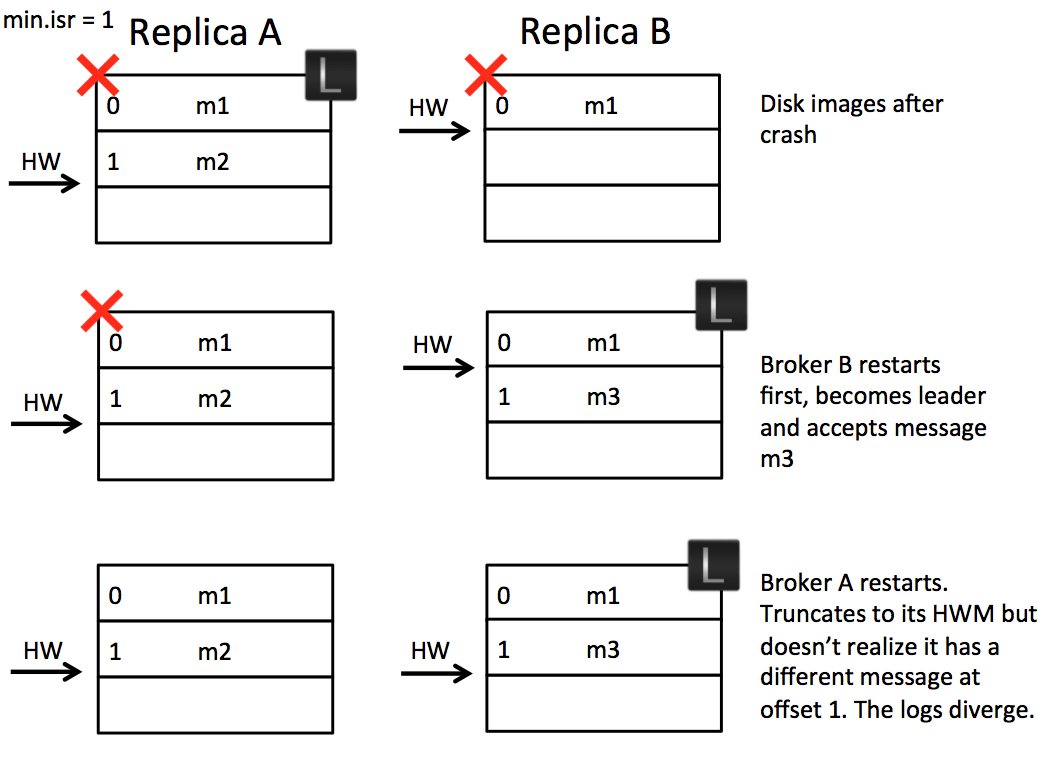
- follower B同步leader A的m2数据时,2个broker都宕机了
- B先重启后成为leader,生产者新产生一个消息m3,并更新了自己的HW
- A现在重启完成,成为follow,在同步之前不按自身的HW进行日志的截断。
- 同步到leader的HW与自身是一致,不进行截断操作,导致2个副本上的数据不一致
解决方案:
解决消息丢失
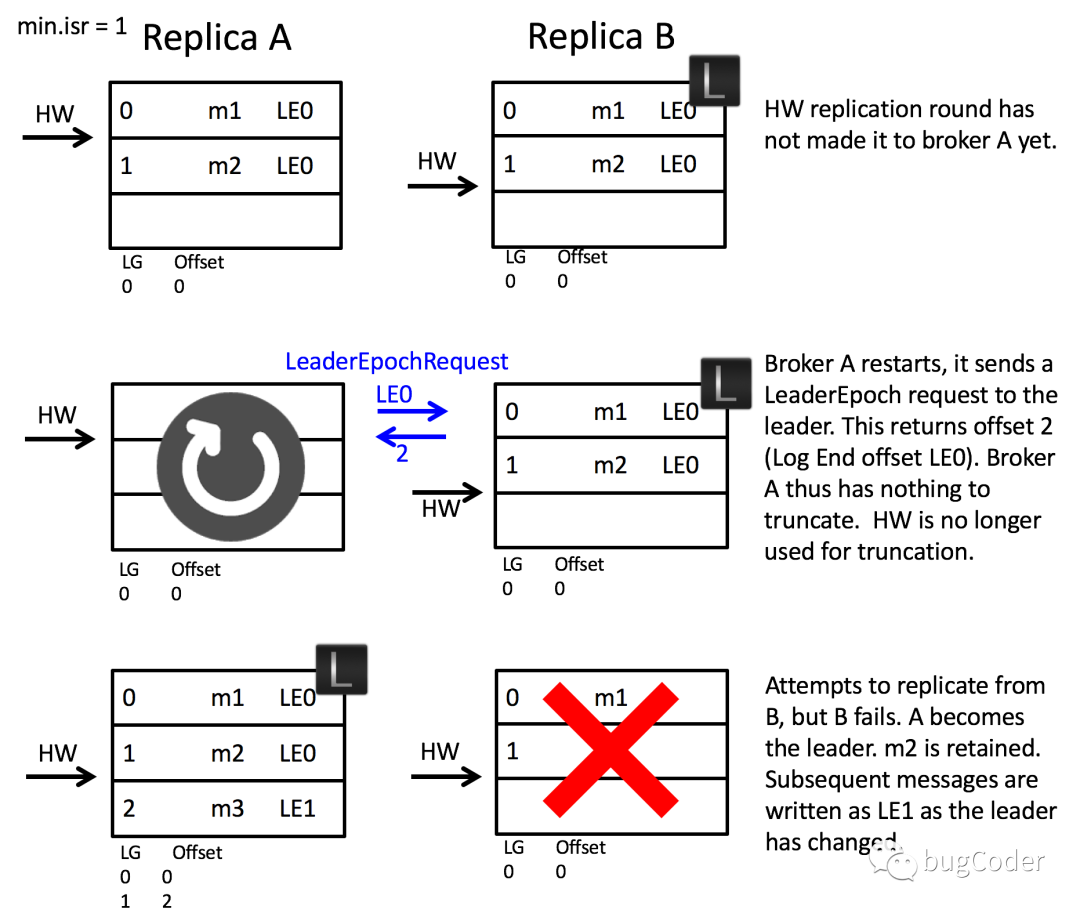
- 当A重启后,初始化时,向leader发送LeaderEpochRequest请求获取和自身一样的leader epoch值的最新的LEO
- A发现同一时期的LEO比自己的大,不需要进行日志截断,保留当前数据
- 当A从B同步数据时,B宕机了,A选举为leader,m2数据未丢失
解决消息错乱
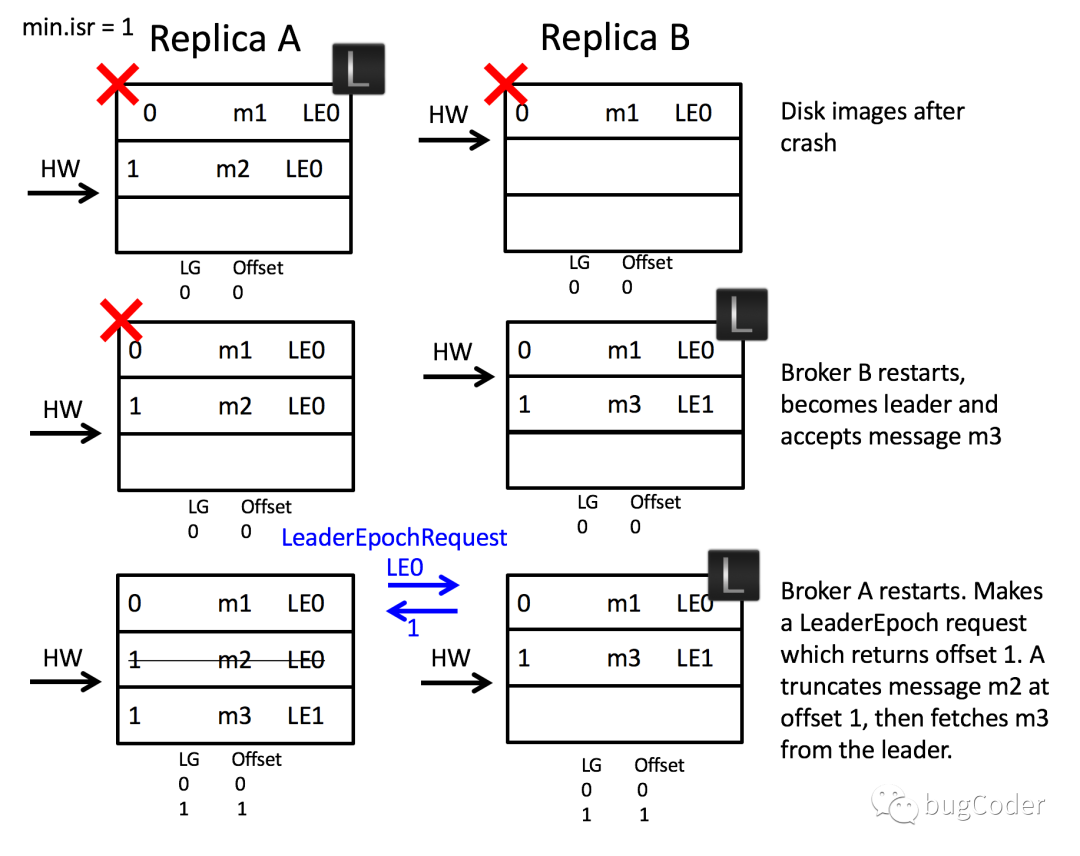
- follower B同步leader A的m2数据时,2个broker都宕机了
- B先重启后成为leader,并增大一个leader任期,生产者新产生一个消息m3,并更新了自己的HW
- A现在重启完成,成为follow,向leader B发送一个LeaderEpoch request请求,用来确定自己应该处于哪个leader epoch
- 根据Follower副本请求中携带的LeaderEpoch,在Leader副本中查找对应的最大偏移量,作为Follower副本日志截断的位置
- 此处例子中,A的LeaderEpoch request请求中任期为0,返回任期为1, EndOffset=1,A从位移1遗弃截断日志、再同步日志
LeaderEpochRequest
kafka副本截断,副本同步机制
abstract class AbstractFetcherThread(...) {
...
override def doWork(): Unit = {
//日志截断
maybeTruncate()
//日志同步
maybeFetch()
}
}
日志截断
private def maybeTruncate(): Unit = {
// 将所有处于截断中状态的分区依据有无Leader Epoch值进行分组
val (partitionsWithEpochs, partitionsWithoutEpochs) = fetchTruncatingPartitions()
// 对于有Leader Epoch值的分区,按Leader Epoch逻辑进行日志截断
if (partitionsWithEpochs.nonEmpty) {
truncateToEpochEndOffsets(partitionsWithEpochs)
}
// 对于没有Leader Epoch值的分区,按HightWatermark进行日志截断
if (partitionsWithoutEpochs.nonEmpty) {
truncateToHighWatermark(partitionsWithoutEpochs)
}
}
按HightWatermark进行日志截断
private[server] def truncateToHighWatermark(partitions: Set[TopicPartition]): Unit = inLock(partitionMapLock) {
val fetchOffsets = mutable.HashMap.empty[TopicPartition, OffsetTruncationState]
// 遍历每个要执行截断操作的分区对象
for (tp <- partitions) {
val partitionState = partitionStates.stateValue(tp)
// 获取分区的分区读取状态
if (partitionState != null) {
val highWatermark = partitionState.fetchOffset
val truncationState = OffsetTruncationState(highWatermark, truncationCompleted = true)
info(s"Truncating partition $tp to local high watermark $highWatermark")
// 执行截断到高水位值
if (doTruncate(tp, truncationState))
//保存分区和对应的截取状态
fetchOffsets.put(tp, truncationState)
}
}
// 更新这组分区的分区读取状态
updateFetchOffsetAndMaybeMarkTruncationComplete(fetchOffsets)
}
按LeaderEpoch逻辑进行日志截断
private def truncateToEpochEndOffsets(latestEpochsForPartitions: Map[TopicPartition, EpochData]): Unit = {
// 实现类ReplicaFetcherThread:向leader发送OffsetsForLeaderEpochRequest,返回每个Partition对应的EpochEndOffset的MAP
val endOffsets = fetchEpochEndOffsets(latestEpochsForPartitions)
//Ensure we hold a lock during truncation. 加锁保证leader在truncate执行期间不改变
inLock(partitionMapLock) {
//Check no leadership and no leader epoch changes happened whilst we were unlocked, fetching epochs
// 检验leader是否发生变化
val epochEndOffsets = endOffsets.filter { case (tp, _) =>
val curPartitionState = partitionStates.stateValue(tp)
val partitionEpochRequest = latestEpochsForPartitions.getOrElse(tp, {
throw new IllegalStateException(
s"Leader replied with partition $tp not requested in OffsetsForLeaderEpoch request")
})
val leaderEpochInRequest = partitionEpochRequest.currentLeaderEpoch.get
curPartitionState != null && leaderEpochInRequest == curPartitionState.currentLeaderEpoch
}
val ResultWithPartitions(fetchOffsets, partitionsWithError) = maybeTruncateToEpochEndOffsets(epochEndOffsets, latestEpochsForPartitions)
handlePartitionsWithErrors(partitionsWithError, "truncateToEpochEndOffsets")
updateFetchOffsetAndMaybeMarkTruncationComplete(fetchOffsets)
}
}
class ReplicaFetcherThread(...)extends AbstractFetcherThread(...){
override def fetchEpochEndOffsets(partitions: Map[TopicPartition, EpochData]): Map[TopicPartition, EpochEndOffset] = {
if (partitions.isEmpty) {
debug("Skipping leaderEpoch request since all partitions do not have an epoch")
return Map.empty
}
//封装OffsetsForLeaderEpochRequest请求, 该副本的 Leader Epoch、 Leader 副本所在的节点
val epochRequest = OffsetsForLeaderEpochRequest.Builder.forFollower(offsetForLeaderEpochRequestVersion, partitions.asJava, brokerConfig.brokerId)
debug(s"Sending offset for leader epoch request $epochRequest")
try {
//向Leader副本所在节点发送OffsetsForLeaderEpochRequest请求并接受响应
val response = leaderEndpoint.sendRequest(epochRequest)
val responseBody = response.responseBody.asInstanceOf[OffsetsForLeaderEpochResponse]
debug(s"Received leaderEpoch response $response")
responseBody.responses.asScala
} catch {
case t: Throwable =>
warn(s"Error when sending leader epoch request for $partitions", t)
// if we get any unexpected exception, mark all partitions with an error
val error = Errors.forException(t)
partitions.map { case (tp, _) =>
tp -> new EpochEndOffset(error, UNDEFINED_EPOCH, UNDEFINED_EPOCH_OFFSET)
}
}
}
}
发送RPC请求
kafka中所有的RPC请求都是通过KafkaApis.handle() 方法进行处理的
class KafkaApis(...){
case ApiKeys.OFFSET_FOR_LEADER_EPOCH => handleOffsetForLeaderEpochRequest(request)
}
def handleOffsetForLeaderEpochRequest(request: RequestChannel.Request): Unit = {
...
val endOffsetsForAuthorizedPartitions = replicaManager.lastOffsetForLeaderEpoch(authorizedPartitions)
...
}
class ReplicaManager{
def lastOffsetForLeaderEpoch(requestedEpochInfo: Map[TopicPartition, OffsetsForLeaderEpochRequest.PartitionData]): Map[TopicPartition, EpochEndOffset] = {
requestedEpochInfo.map { case (tp, partitionData) =>
val epochEndOffset = getPartition(tp) match {
case HostedPartition.Online(partition) =>
partition.lastOffsetForLeaderEpoch(partitionData.currentLeaderEpoch, partitionData.leaderEpoch,
fetchOnlyFromLeader = true)
case HostedPartition.Offline =>
new EpochEndOffset(Errors.KAFKA_STORAGE_ERROR, UNDEFINED_EPOCH, UNDEFINED_EPOCH_OFFSET)
case HostedPartition.None if metadataCache.contains(tp) =>
new EpochEndOffset(Errors.NOT_LEADER_OR_FOLLOWER, UNDEFINED_EPOCH, UNDEFINED_EPOCH_OFFSET)
case HostedPartition.None =>
new EpochEndOffset(Errors.UNKNOWN_TOPIC_OR_PARTITION, UNDEFINED_EPOCH, UNDEFINED_EPOCH_OFFSET)
}
tp -> epochEndOffset
}
}
}
class Partition{
def lastOffsetForLeaderEpoch(currentLeaderEpoch: Optional[Integer],
leaderEpoch: Int,
fetchOnlyFromLeader: Boolean): EpochEndOffset = {
inReadLock(leaderIsrUpdateLock) {
val localLogOrError = getLocalLog(currentLeaderEpoch, fetchOnlyFromLeader)
localLogOrError match {
case Left(localLog) =>
localLog.endOffsetForEpoch(leaderEpoch) match {
case Some(epochAndOffset) => new EpochEndOffset(NONE, epochAndOffset.leaderEpoch, epochAndOffset.offset)
case None => new EpochEndOffset(NONE, UNDEFINED_EPOCH, UNDEFINED_EPOCH_OFFSET)
}
case Right(error) =>
new EpochEndOffset(error, UNDEFINED_EPOCH, UNDEFINED_EPOCH_OFFSET)
}
}
}
}
class Log{
def endOffsetForEpoch(leaderEpoch: Int): Option[OffsetAndEpoch] = {
leaderEpochCache.flatMap { cache =>
val (foundEpoch, foundOffset) = cache.endOffsetFor(leaderEpoch)
if (foundOffset == EpochEndOffset.UNDEFINED_EPOCH_OFFSET)
None
else
Some(OffsetAndEpoch(foundOffset, foundEpoch))
}
}
}
偏移量计算逻辑
class LeaderEpochFileCache{
/**
* 按requestedEpoch计算应返回的偏移量
*/
def endOffsetFor(requestedEpoch: Int): (Int, Long) = {
inReadLock(lock) {
val epochAndOffset =
if (requestedEpoch == UNDEFINED_EPOCH) {
// This may happen if a bootstrapping follower sends a request with undefined epoch or
// a follower is on the older message format where leader epochs are not recorded
(UNDEFINED_EPOCH, UNDEFINED_EPOCH_OFFSET)
} else if (latestEpoch.contains(requestedEpoch)) {// 如果请求的Leader Epoch 就是Leader副本当前的Leader Epoch,则返回(请求Epoch,Leader副本LEO)
// For the leader, the latest epoch is always the current leader epoch that is still being written to.
// Followers should not have any reason to query for the end offset of the current epoch, but a consumer
// might if it is verifying its committed offset following a group rebalance. In this case, we return
// the current log end offset which makes the truncation check work as expected.
(requestedEpoch, logEndOffset())
} else {
val higherEntry = epochs.higherEntry(requestedEpoch)//比requestedEpoch大的最小epoch
if (higherEntry == null) {// 请求的epoch比当前leader最大的还大
// The requested epoch is larger than any known epoch. This case should never be hit because
// the latest cached epoch is always the largest.
(UNDEFINED_EPOCH, UNDEFINED_EPOCH_OFFSET)
} else {
val floorEntry = epochs.floorEntry(requestedEpoch)//比requestedEpoch小的最大epoch
if (floorEntry == null) {// 请求的epoch比当前leader最小的还小
// The requested epoch is smaller than any known epoch, so we return the start offset of the first
// known epoch which is larger than it. This may be inaccurate as there could have been
// epochs in between, but the point is that the data has already been removed from the log
// and we want to ensure that the follower can replicate correctly beginning from the leader's
// start offset.
(requestedEpoch, higherEntry.getValue.startOffset)
} else {
// We have at least one previous epoch and one subsequent epoch. The result is the first
// prior epoch and the starting offset of the first subsequent epoch.
(floorEntry.getValue.epoch, higherEntry.getValue.startOffset)
}
}
}
debug(s"Processed end offset request for epoch $requestedEpoch and returning epoch ${epochAndOffset._1} " +
s"with end offset ${epochAndOffset._2} from epoch cache of size ${epochs.size}")
epochAndOffset
}
}
}
如果Follower副本请求中的 Leade Epoch 值等于Leader副本端的LeaderEpoch,那么就返回 Leader 副本的LEO
如果Follower副本请求中的 LeaderEpoch值小于Leader副本端的LeaderEpoch,说明发生过leader副本的切换。
- 对于LeaderEpoch,返回Leader副本端保存的不大于Follower副本请求中LeaderEpoch 的最大LeaderEpoch
max(<= LeaderEpoch request 请求参数的LeaderEpoch)
- 对于EndOffset,返回 Leader 副本端保存的第一个比 Follower 副本请求中LeaderEpoch大的 LeaderEpoch 对应StartOffset
min(> LeaderEpoch request 请求参数的LeaderEpoch. StartOffset)
举个例子,假设Follower副本请求的LeaderEpoch = 2。Leader 副本保存的LeaderEpoch -> StartOffset 对应关系为:(其中 StartOffset 是对应的 LeaderEpoch 第一条写入消息的偏移量,相当于上一任 LeaderEpoch 的 LEO 值)
LeaderEpoch:2 -> StartOffset:30
LeaderEpoch:3 -> StartOffset:50
LeaderEpoch:4 -> StartOffset:70
那么给Follower副本返回的是:(LeaderEpoch:2,EndOffset:50)
副本日志同步
private def maybeFetch(): Unit = {
val fetchRequestOpt = inLock(partitionMapLock) {
//构造一个fetch请求
val ResultWithPartitions(fetchRequestOpt, partitionsWithError) = buildFetch(partitionStates.partitionStateMap.asScala)
handlePartitionsWithErrors(partitionsWithError, "maybeFetch")
if (fetchRequestOpt.isEmpty) {
trace(s"There are no active partitions. Back off for $fetchBackOffMs ms before sending a fetch request")
partitionMapCond.await(fetchBackOffMs, TimeUnit.MILLISECONDS)
}
fetchRequestOpt
}
fetchRequestOpt.foreach { case ReplicaFetch(sessionPartitions, fetchRequest) =>
processFetchRequest(sessionPartitions, fetchRequest)
}
}
fetch同步,看不懂看着就头大,复制过来有空再看吧
private def processFetchRequest(sessionPartitions: util.Map[TopicPartition, FetchRequest.PartitionData],
fetchRequest: FetchRequest.Builder): Unit = {
val partitionsWithError = mutable.Set[TopicPartition]()
var responseData: Map[TopicPartition, FetchData] = Map.empty
try {
trace(s"Sending fetch request $fetchRequest")
responseData = fetchFromLeader(fetchRequest)
} catch {
case t: Throwable =>
if (isRunning) {
warn(s"Error in response for fetch request $fetchRequest", t)
inLock(partitionMapLock) {
partitionsWithError ++= partitionStates.partitionSet.asScala
// there is an error occurred while fetching partitions, sleep a while
// note that `ReplicaFetcherThread.handlePartitionsWithError` will also introduce the same delay for every
// partition with error effectively doubling the delay. It would be good to improve this.
partitionMapCond.await(fetchBackOffMs, TimeUnit.MILLISECONDS)
}
}
}
fetcherStats.requestRate.mark()
if (responseData.nonEmpty) {
// process fetched data
inLock(partitionMapLock) {
responseData.forKeyValue { (topicPartition, partitionData) =>
Option(partitionStates.stateValue(topicPartition)).foreach { currentFetchState =>
// It's possible that a partition is removed and re-added or truncated when there is a pending fetch request.
// In this case, we only want to process the fetch response if the partition state is ready for fetch and
// the current offset is the same as the offset requested.
val fetchPartitionData = sessionPartitions.get(topicPartition)
if (fetchPartitionData != null && fetchPartitionData.fetchOffset == currentFetchState.fetchOffset && currentFetchState.isReadyForFetch) {
val requestEpoch = if (fetchPartitionData.currentLeaderEpoch.isPresent) Some(fetchPartitionData.currentLeaderEpoch.get().toInt) else None
partitionData.error match {
case Errors.NONE =>
try {
// Once we hand off the partition data to the subclass, we can't mess with it any more in this thread
val logAppendInfoOpt = processPartitionData(topicPartition, currentFetchState.fetchOffset,
partitionData)
logAppendInfoOpt.foreach { logAppendInfo =>
val validBytes = logAppendInfo.validBytes
val nextOffset = if (validBytes > 0) logAppendInfo.lastOffset + 1 else currentFetchState.fetchOffset
val lag = Math.max(0L, partitionData.highWatermark - nextOffset)
fetcherLagStats.getAndMaybePut(topicPartition).lag = lag
// ReplicaDirAlterThread may have removed topicPartition from the partitionStates after processing the partition data
if (validBytes > 0 && partitionStates.contains(topicPartition)) {
// Update partitionStates only if there is no exception during processPartitionData
val newFetchState = PartitionFetchState(nextOffset, Some(lag), currentFetchState.currentLeaderEpoch, state = Fetching)
partitionStates.updateAndMoveToEnd(topicPartition, newFetchState)
fetcherStats.byteRate.mark(validBytes)
}
}
} catch {
case ime@( _: CorruptRecordException | _: InvalidRecordException) =>
// we log the error and continue. This ensures two things
// 1. If there is a corrupt message in a topic partition, it does not bring the fetcher thread
// down and cause other topic partition to also lag
// 2. If the message is corrupt due to a transient state in the log (truncation, partial writes
// can cause this), we simply continue and should get fixed in the subsequent fetches
error(s"Found invalid messages during fetch for partition $topicPartition " +
s"offset ${currentFetchState.fetchOffset}", ime)
partitionsWithError += topicPartition
case e: KafkaStorageException =>
error(s"Error while processing data for partition $topicPartition " +
s"at offset ${currentFetchState.fetchOffset}", e)
markPartitionFailed(topicPartition)
case t: Throwable =>
// stop monitoring this partition and add it to the set of failed partitions
error(s"Unexpected error occurred while processing data for partition $topicPartition " +
s"at offset ${currentFetchState.fetchOffset}", t)
markPartitionFailed(topicPartition)
}
case Errors.OFFSET_OUT_OF_RANGE =>
if (handleOutOfRangeError(topicPartition, currentFetchState, requestEpoch))
partitionsWithError += topicPartition
case Errors.UNKNOWN_LEADER_EPOCH =>
debug(s"Remote broker has a smaller leader epoch for partition $topicPartition than " +
s"this replica's current leader epoch of ${currentFetchState.currentLeaderEpoch}.")
partitionsWithError += topicPartition
case Errors.FENCED_LEADER_EPOCH =>
if (onPartitionFenced(topicPartition, requestEpoch)) partitionsWithError += topicPartition
case Errors.NOT_LEADER_OR_FOLLOWER =>
debug(s"Remote broker is not the leader for partition $topicPartition, which could indicate " +
"that the partition is being moved")
partitionsWithError += topicPartition
case Errors.UNKNOWN_TOPIC_OR_PARTITION =>
warn(s"Received ${Errors.UNKNOWN_TOPIC_OR_PARTITION} from the leader for partition $topicPartition. " +
"This error may be returned transiently when the partition is being created or deleted, but it is not " +
"expected to persist.")
partitionsWithError += topicPartition
case _ =>
error(s"Error for partition $topicPartition at offset ${currentFetchState.fetchOffset}",
partitionData.error.exception)
partitionsWithError += topicPartition
}
}
}
}
}
}
if (partitionsWithError.nonEmpty) {
handlePartitionsWithErrors(partitionsWithError, "processFetchRequest")
}
}
参考:
https://blog.csdn.net/m0_60992470/article/details/120102171
https://www.modb.pro/db/131817