文章目录
前言
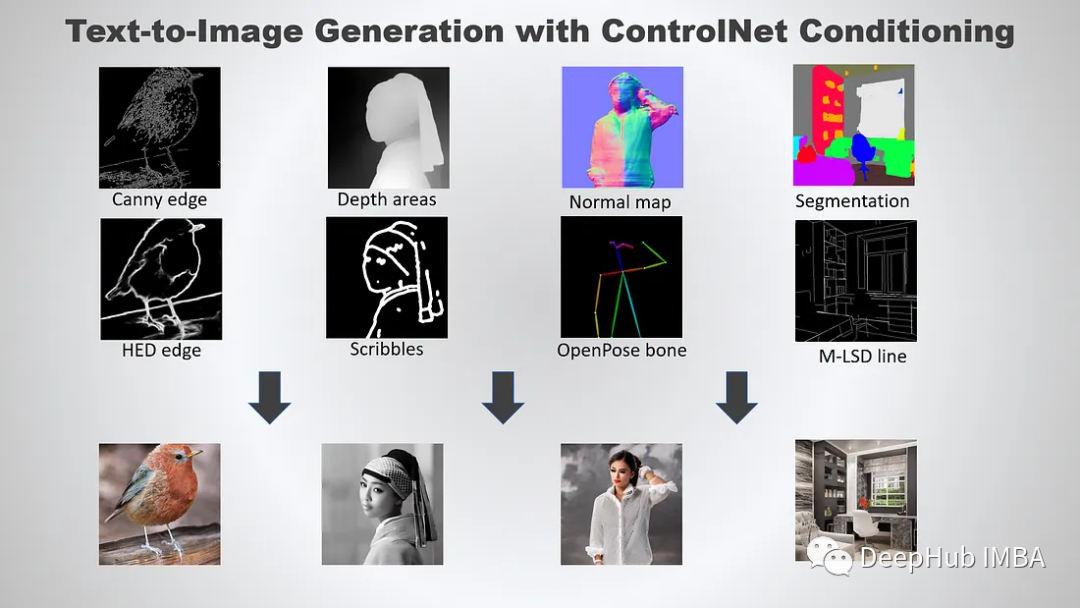
Stable Diffusion是目前图像生成领域的大杀器,ControlNet的目标就是添加额外的条件来控制最后的生成图像,包括边缘检测、深度估计、分割、姿势估计、涂鸦等功能。
Stable diffusion WebUI
配置环境
首先需要安装 Anacomda或者Miniconda软件,方便管理我们的虚拟环境,这里默认大家都已经装好这个软件。
打开Anaconda Prompt或者Miniconda,新建一个名为sd_webui的虚拟环境,这里python版本必须是3.10.6,否则有可能失败。这里需要配置镜像源,给大家看一下我的C://user/***/.condarc文件里的内容。
channels:
- https://mirrors.ustc.edu.cn/anaconda/cloud/msys2/
- https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/
- https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
- https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
- defaults
show_channel_urls: true
没有配置镜像源的可以直接替换原来的内容即可,接下来创新虚拟环境。
conda create -n sd_webui python=3.10.6
中途会提示y/n,这里输入y后回车即可。
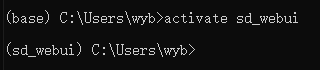
等待虚拟环境创建成功后进入环境。

activate sd_webui
升级pip
python.exe -m pip install --upgrade pip
更改pip的默认下载路径为清华源镜像,这里镜像源很多,可以根据实际情况更改。
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
此外,需要安装CUDA,这里我没有安装,因为我这个电脑之前跑深度学习本身就有CUDA。相信配置过深度学习的同学应该很快就能装好。需要注意的是,我的CUDA版本是11.1,虽然安装的过程中下载的是与CUDA11.7对应的pytorch,却依旧可以运行成功。
下载stable diffusion webui
安装Git,默认大家已经安装好这个软件,官网:https://git-scm.com/download/win
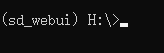
利用Git从官网克隆stable diffusion webui仓库,这个代码不需要在Git中运行,直接在Anaconda Prompt或者Miniconda里使用Git命令也可以。此时会默认克隆仓库到当前路径下,比如下边的情况下会克隆到H盘根目录下。
克隆stable diffusion webui仓库,当然一般克隆的时候得科学上网。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
等待下载到本地即可,过程中可能会出现以下几种错误:
OpenSSL SSL_read: Connection was reset, errno 10054
fatal: unable to access ‘https://github.com/AUTOMATIC1111/stable-diffusion-webui.git’: Failed to connect to github.com port 443: Connection refused
Failed to connect to github.com port 443 after 21100 ms: Timed out
或者就是克隆过程很慢
此时可以尝试的方法包括但不限于以下几种:
# 关闭证书校验
git config --global http.sslverify "false"
# 取消全局代理
git config --global --unset http.proxy
git config --global --unset https.proxy
# 换服务器的节点
# 配置Git的端口号
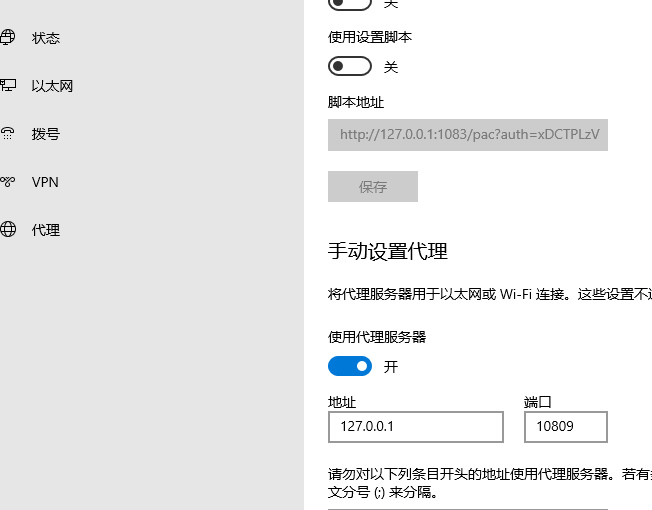
解释一下最后一个方法,这个方法可以解决就算科学上网了依旧克隆非常缓慢的问题。首先这里由于我们使用了代理服务器,打开网络设置到代理,可以发现这里有地址和端口两个信息。
记住地址和端口,利用下边的代码配置Git。
git config --global http.proxy 127.0.0.1:10809
随后可以发现Git克隆的速度直接拉满,相比之前的几十kb属实令人赏心悦目不少。
显示done则表示克隆成功。当然以上的方法也未必能够解决所有问题,大家在实际过程中遇到不能解决的问题或解决方案欢迎告知我。
现在打开自己刚开克隆的H盘根目录就会发现已经出现文件夹stable-diffusion-webui,具体的盘符或者路径根据实际情况修改。

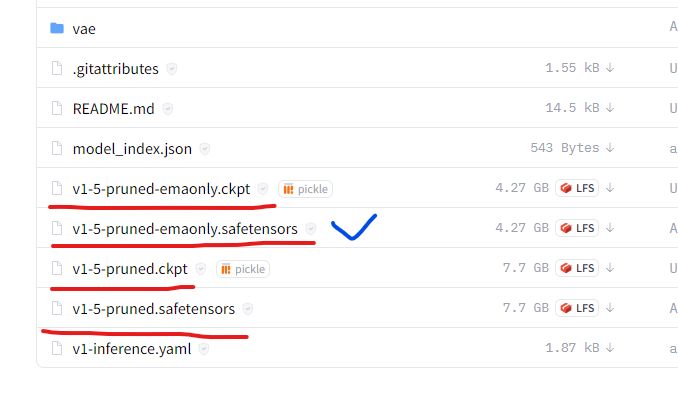
接下来下载stable diffusion的预训练模型,官网:https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main,点击Files and versions,下载红线画出来的文件,任意一个应该都可以。这里我下载的是蓝色标出的文件。
下载完成后,放在D:\stable-diffusion-webui\models\Stable-diffusion路径下。
安装torch和torchvision
在Anaconda Prompt或者Miniconda中进入到stable diffusion webui的路径下
D:
cd stable-diffusion-webui
运行webui-user.bat文件
此时会首先执行stable diffusion webui下的launch.py文件,就是安装torch,torchvision,其他的一些包以及克隆一些github仓库。因为这个过程肯定不会一次成功,因此先说明一下,在windows的命令行运行过程中,可以使用两下CTRL+C来退出进程。
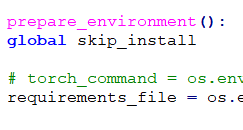
打开launch.py到prepare_envitonment函数可以发现要求的torch和torchvision版本是

pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117
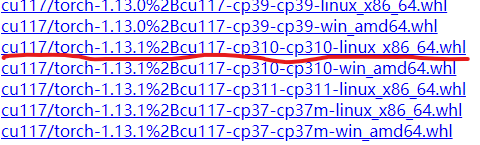
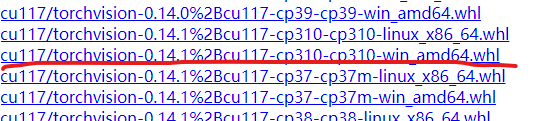
由于torch这个包比较大,如果在线安装不能成功的话,也可以离线安装,即先下载对应的 .whl 文件,官网:https://download.pytorch.org/whl/torch_stable.html,找到cu117开头的路径,下载对应的python3.10的torch和torchvision。
下载完成后就放在stable diffusion webui路径下,使用pip安装即可,注意要先装torch再装torchvision。
pip install torch-1.13.1+cu117-cp310-cp310-win_amd64.whl
pip install torchvision-0.14.1+cu117-cp310-cp10-win_amd64.whl
在线安装还是离线安装可以根据实际情况来定,安装完成后再次运行webui-user.bat如果还是会进入安装torch和itorchvision的步骤,就前往launch.py文件注释掉这一行即可。
如果以上做完后,运行webui-user.bat后会先安装一些别的包,随后出现Installing gfpgan则表明上述的安装已经成功。
克隆GFPGAN、CLIP、open_clip、stable_diffusion、taming-transformers、k-diffussion、CodeFormer、BLIP等仓库
一般在运行到安装这些仓库的时候大概率不成功,但如果前边已经将Git克隆的诸多问题都解决了的话应该可以一次成功。
这里说明一下不成功的时候该如何解决,不成功的报错就是:
RuntimeError: Couldn't install ***
这里我之前尝试之前的设置Git端口的形式解决了。如果不能解决,这里有两种解决办法,建议先看完再尝试。
1. 我们可以先采用Git克隆下来的方式一将这些包克隆下来再复制到D:\stable-diffusion-webui\repositories路径下,这里必须按照launch.py文件里的安装顺序来,如下
Xformer是一个选装的包,可装可不装,应该是显卡显存不大的话装一下比较好。这里只说后边的包。这些语句的后边都跟着对应的github链接,如果对应的链接后边有一个@**************,就把@连同后边的字符串全部删掉,记得保存一下。
全部使用Git克隆下来,如下


git clone https://github.com/TencentARC/GFPGAN.git
git clone https://github.com/openai/CLIP.git
git clone https://github.com/mlfoundations/open_clip.git
git clone https://github.com/Stability-AI/stablediffusion.git
git clone https://github.com/CompVis/taming-transformers.git
git clone https://github.com/crowsonkb/k-diffusion.git'
git clone https://github.com/sczhou/CodeFormer.git'
git clone https://github.com/salesforce/BLIP.git'
如果在Git里没有修改当前路径的话会默认全部克隆到C:\Users\***路径下。
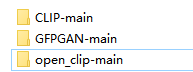
由于直接克隆下来的文件夹名字与launch.py文件里的不一致,因此,这里还需要改一下文件夹名字,如图
修改完名字后复制将图片中的几个包复制到D:\stable-diffusion-webui\repositories路径下即可。需要注意的是,这里没有复制GFPGAN、CLIP和open_clip三个包,因为这三个包的安装方式不太一样。
首先将着三个包复制到D:\stable-diffusion-webui\venv\Scripts路径下:
在Anaconda Prompt或者Miniconda里cd到三个包的路径下,比如GFPGAN的路径就是:D:\stable-diffusion-webui\venv\Scripts\GFPGAN,分别输入
cd D:\stable-diffusion-webui\venv\Scripts\GFPGAN
D:\\stable-diffusion-webui\venv\Scripts\python.exe setup.py build install
cd D:\stable-diffusion-webui\venv\Scripts\CLIP
D:\\stable-diffusion-webui\venv\Scripts\python.exe setup.py build install
cd D:\stable-diffusion-webui\venv\Scripts\open_clip
D:\\stable-diffusion-webui\venv\Scripts\python.exe setup.py build install
这样就安装好了所有的包。
2. 以上使用Git克隆的包实际上都不需要采用clone的方式,也可以直接下载.zip解压即可。使用Git的原因是为了方便后续更新。
但是需要注意的是直接下载的.zip文件解压后包的名字会多出来一个-main或者-master,比如
在进入路径的时候与之前的名字就存在区别。
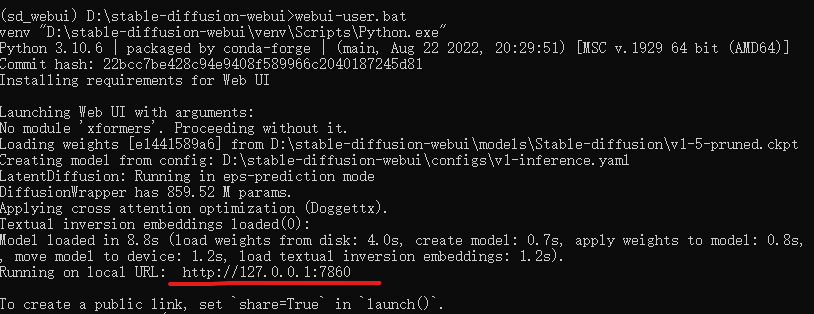
此时再次运行webui-user.bat就会完成安装这些大包的环节,而是去安装一些其他的依赖。等待安装完成后就会输出当前权重加载的路径、配置文件等信息。
如果出现一个本地端口号则表示整个安装过程已经成功,此时最麻烦的部分就结束了。
复制这个本地连接到浏览器打开,就会进入webui的界面。
D:\stable-diffusion-webui\models\Stable-diffusion下。
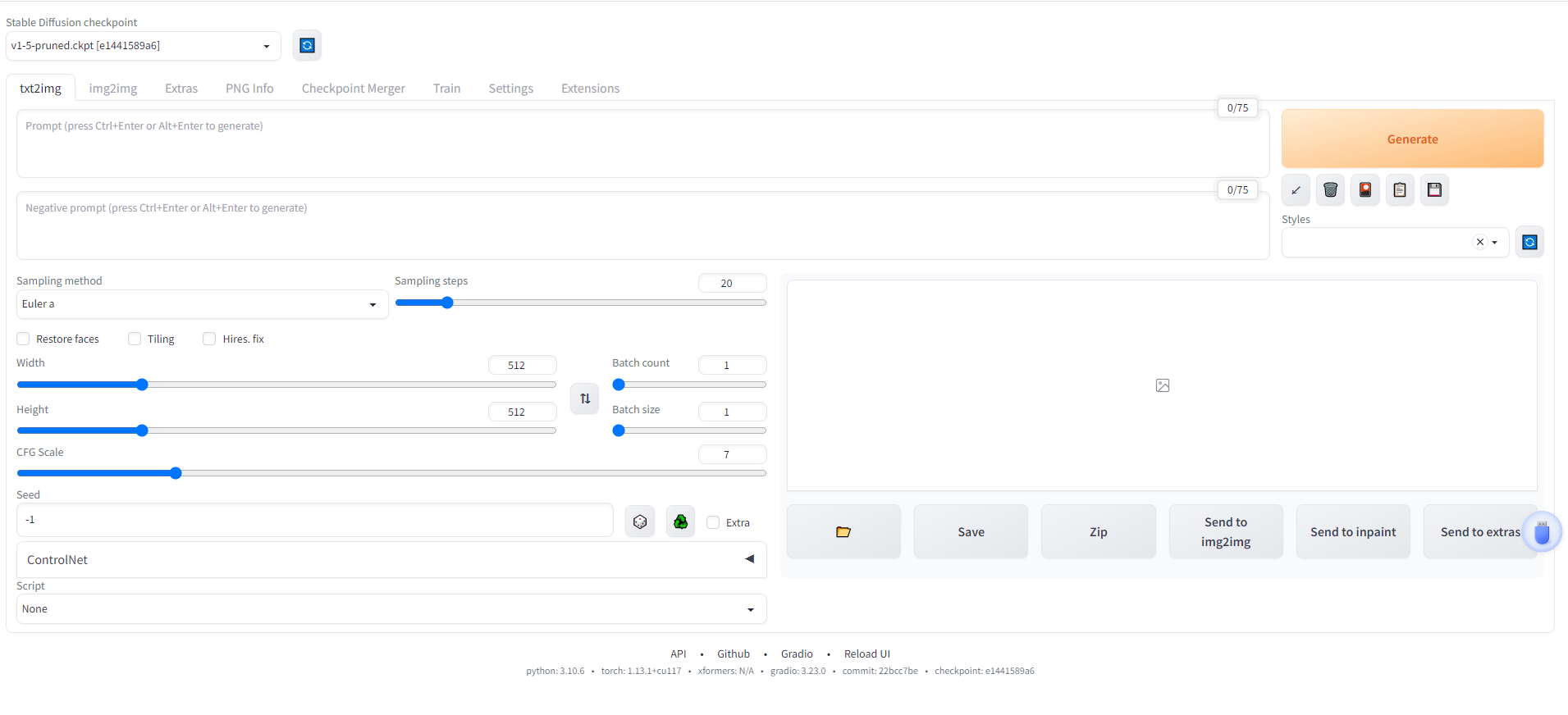
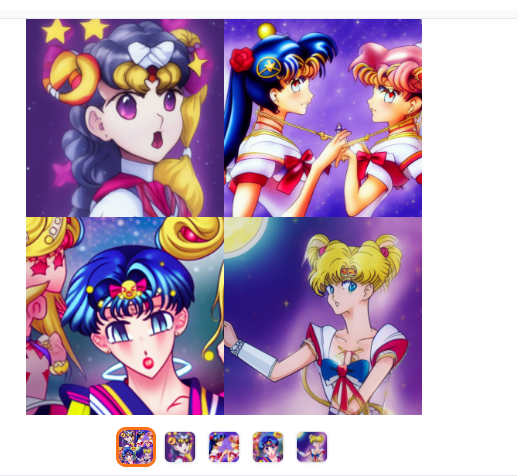
我们先来小试牛刀一下,看看能否成功生成图片。在txt2img框里输入Sailor Moon ,这个是美少女战士的意思,点击右边的Generate按钮开始生成,看看生成的结果如何。如果显卡的配置较差可能整个过程耗时比较久。
实测发现整个生成过程中需要使用大约6.3g的显存,空间状态下占用5.1g左右的显存。如果想要一次性生成多张图片,可以修改batch count参数的值,比如我这里设置为4。
所有的结果会保存在D:\stable-diffusion-webui\outputs路径下,比如我这里是2023年4月1日利用txt2img生成图片,那么结果就会保存在D:\stable-diffusion-webui\outputs\txt2img-images\2023-04-01路径下。因此,可以直接去这里复制图片,同时如果生成次数太多要注意清理这些输出。


安装ControlNet插件
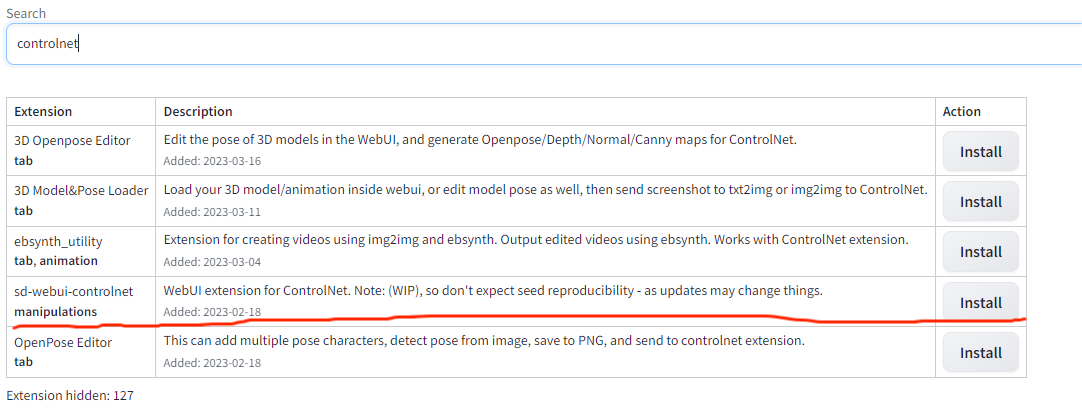
在webui界面点击extensions,再点击Available,在下边的搜索框输入controlnet回车。
找到sd-webui-controlnet manipulations,点击右边的install安装插件。
安装完成后点击最下边的 Reload UI重新加载页面
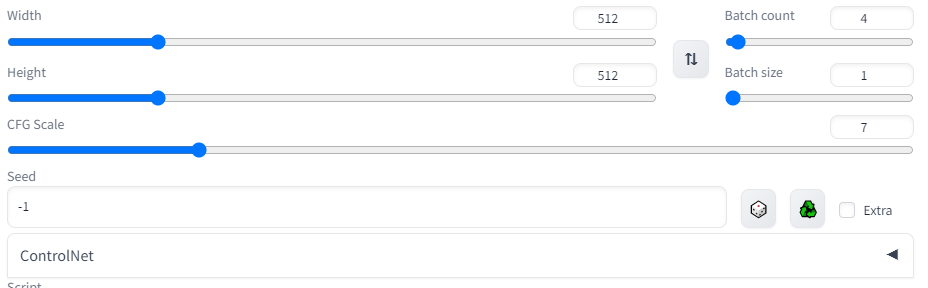
重新打开页面后可以发现在原来的seed参数下多了一行ControlNet,点击右边的小箭头就可以使用ControlNet了。
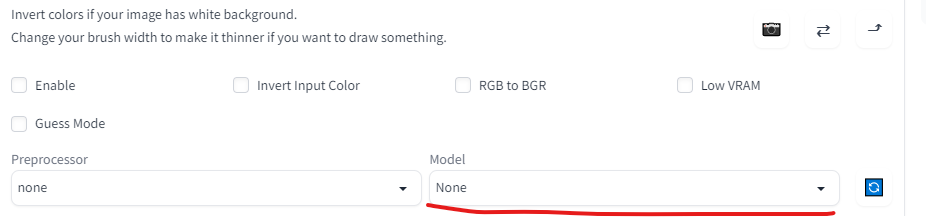
但是这时还没办法直接使用,可以发现Model这个参数为空。
因为ControlNet还需要下载专门的模型,否则就没办法来引导专门的这些绘画功能。这里我们先以Scribbles为例,即利用一幅黑色背景的白色轮廓图来涂鸦。
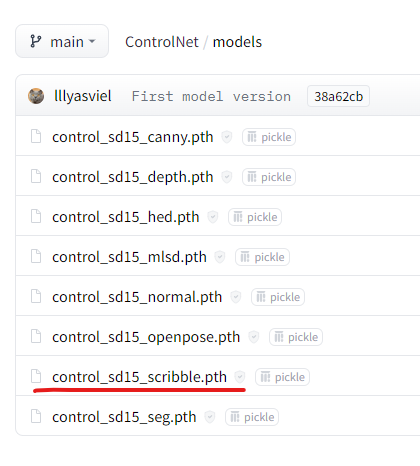
进入模型下载官网:https://huggingface.co/lllyasviel/ControlNet/tree/main/models,选择control_sd15_scribble.pth
文件点击下载。可以选择的模型共8个,每个参数文件大小都是5.71g。
进入下一页面后点击download开始下载。
下载完成后,先在D:\stable-diffusion-webui\models路径下新建一个ControlNet文件夹,如果这个文件夹已经存在那更好。然后将刚才下载所得的参数文件放到这个文件夹里边。
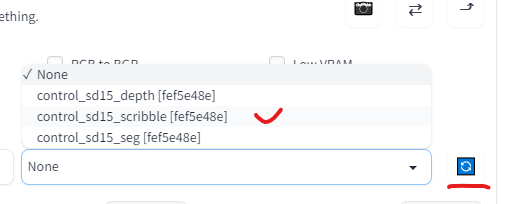
返回到webui的controlnet中,点击右边蓝色的按钮刷新参数文件,在更新的列表里选择我们想用来做涂鸦的参数文件。
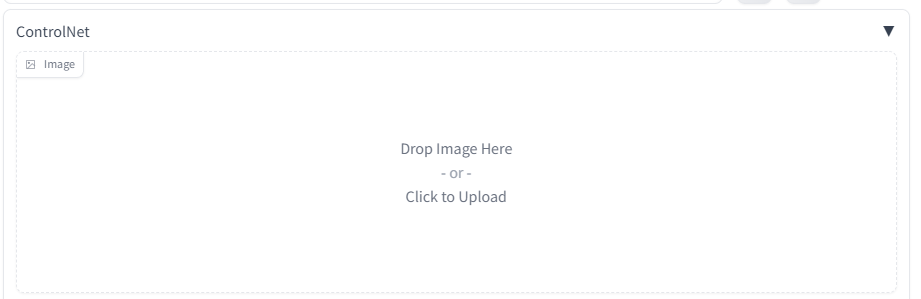
这里我从网上找了一个美少女战士的轮廓图,直接拖动到这里或者点击上传我们的图片。

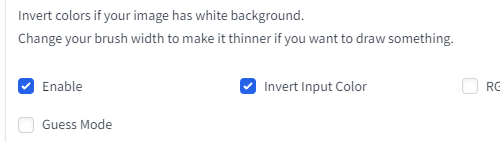
在生成之前需要设置几个参数,Enable,inver input color必须选中,
这里我在txt2img框里写的是girl, amine。一般将batch count设置得多一点,因为不是所有的图片都能令人满意。看一看这里输出的结果吧。
总体上来说还行,我们再利用另一幅线稿生成一下。
有的图片里会把耳朵也当成一个眼睛,属实有点吓人。实际生成过程中还可以控制画布大小,图像大小等。当然也有汉化包可以汉化使用,但有时候汉化后反倒不太容易理解本来的意思,因此我这里就不汉化了,有需求的可以前往别处找找教程。
好了,到此为止我们的教程已经结束了。