0 前言
facebookresearch SlowFast :https://github.com/facebookresearch/SlowFast
b站视频:https://www.bilibili.com/video/BV1Uh4y1q7R2/
1 准备
平台:Autodl:https://www.autodl.com/
环境:
PyTorch 1.8.1
Python 3.8(ubuntu18.04)
Cuda 11.1
需要先将这两个权重下载到AI平台的:/root/slowfastFile
model_final_280758.pkl:https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_FPN_3x/137849458/model_final_280758.pkl
SLOWFAST_32x2_R101_50_50.pkl:https://dl.fbaipublicfiles.com/pyslowfast/model_zoo/ava/SLOWFAST_32x2_R101_50_50.pkl
2 安装与运行
2.1 基础环境
pip install 'git+https://gitee.com/YFwinston/fvcore'
pip install simplejson
conda install av -c conda-forge -y
conda install x264 ffmpeg -c conda-forge -y
pip install -U iopath
pip install psutil
pip install opencv-python
// pip install torchvision
pip install tensorboard
pip install moviepy
pip install pytorchvideo
pip install 'git+https://gitee.com/YFwinston/fairscale'
2.2 detectron2_repo 安装
// pip install -U torch torchvision cython
pip install -U cython
pip install -U 'git+https://gitee.com/YFwinston/fvcore.git' 'git+https://gitee.com/YFwinston/cocoapi.git#subdirectory=PythonAPI'
git clone https://gitee.com/YFwinston/detectron2 detectron2_repo
pip install typing-extensions==4.3.0
pip install -e detectron2_repo
pip install pillow
pip install pyyaml
pip install scipy
pip install pandas
pip install scikit-learn
2.3 slowfast 安装
git clone https://gitee.com/YFwinston/slowfast
export PYTHONPATH=/root/slowfast:$PYTHONPATH
cd slowfast
python setup.py build develop
cd /root
cd /root/slowfast/demo/AVA
cp /root/autodl-nas/slowfast/ava.json ./
cp /root/autodl-nas/slowfast/SLOWFAST_32x2_R101_50_50s.yaml ./
cd /root
cd /root
git clone https://gitee.com/YFwinston/pytorchvideo.git
cd pytorchvideo
pip install -e .
cd /root
2.4 相关文件
2.4.1 ava.json
然后在/root/slowfast/demo/AVA下面的ava.json写入:
{"bend/bow (at the waist)": 0, "crawl": 1, "crouch/kneel": 2, "dance": 3, "fall down": 4, "get up": 5, "jump/leap": 6, "lie/sleep": 7, "martial art": 8, "run/jog": 9, "sit": 10, "stand": 11, "swim": 12, "walk": 13, "answer phone": 14, "brush teeth": 15, "carry/hold (an object)": 16, "catch (an object)": 17, "chop": 18, "climb (e.g., a mountain)": 19, "clink glass": 20, "close (e.g., a door, a box)": 21, "cook": 22, "cut": 23, "dig": 24, "dress/put on clothing": 25, "drink": 26, "drive (e.g., a car, a truck)": 27, "eat": 28, "enter": 29, "exit": 30, "extract": 31, "fishing": 32, "hit (an object)": 33, "kick (an object)": 34, "lift/pick up": 35, "listen (e.g., to music)": 36, "open (e.g., a window, a car door)": 37, "paint": 38, "play board game": 39, "play musical instrument": 40, "play with pets": 41, "point to (an object)": 42, "press": 43, "pull (an object)": 44, "push (an object)": 45, "put down": 46, "read": 47, "ride (e.g., a bike, a car, a horse)": 48, "row boat": 49, "sail boat": 50, "shoot": 51, "shovel": 52, "smoke": 53, "stir": 54, "take a photo": 55, "text on/look at a cellphone": 56, "throw": 57, "touch (an object)": 58, "turn (e.g., a screwdriver)": 59, "watch (e.g., TV)": 60, "work on a computer": 61, "write": 62, "fight/hit (a person)": 63, "give/serve (an object) to (a person)": 64, "grab (a person)": 65, "hand clap": 66, "hand shake": 67, "hand wave": 68, "hug (a person)": 69, "kick (a person)": 70, "kiss (a person)": 71, "lift (a person)": 72, "listen to (a person)": 73, "play with kids": 74, "push (another person)": 75, "sing to (e.g., self, a person, a group)": 76, "take (an object) from (a person)": 77, "talk to (e.g., self, a person, a group)": 78, "watch (a person)": 79}
2.4.2 SLOWFAST_32x2_R101_50_50s.yaml
然后在/root/slowfast/demo/AVA下面的SLOWFAST_32x2_R101_50_50s.yaml 写入:
TRAIN:
ENABLE: False
DATASET: ava
BATCH_SIZE: 1
EVAL_PERIOD: 1
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: /root/autodl-nas/slowfast/SLOWFAST_32x2_R101_50_50.pkl #path to pretrain model
CHECKPOINT_TYPE: pytorch
DATA:
NUM_FRAMES: 16
SAMPLING_RATE: 2
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 256
INPUT_CHANNEL_NUM: [3, 3]
DETECTION:
ENABLE: True
ALIGNED: False
AVA:
BGR: False
DETECTION_SCORE_THRESH: 0.8
TEST_PREDICT_BOX_LISTS: ["person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 5
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 101
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[6, 13, 20], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
OPTIMIZING_METHOD: sgd
MODEL:
NUM_CLASSES: 80
ARCH: slowfast
MODEL_NAME: SlowFast
LOSS_FUNC: bce
DROPOUT_RATE: 0.5
HEAD_ACT: sigmoid
TEST:
ENABLE: False
DATASET: ava
BATCH_SIZE: 1
DATA_LOADER:
NUM_WORKERS: 1
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: .
#TENSORBOARD:
# MODEL_VIS:
# TOPK: 2
DEMO:
ENABLE: True
LABEL_FILE_PATH: "demo/AVA/ava.json" # Add local label file path here.
INPUT_VIDEO: "/root/autodl-nas/slowfast/1.mp4"
OUTPUT_FILE: "/root/autodl-nas/slowfast/1_1.mp4"
DETECTRON2_CFG: "COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml"
DETECTRON2_WEIGHTS: "/root/autodl-nas/slowfast/model_final_280758.pkl"
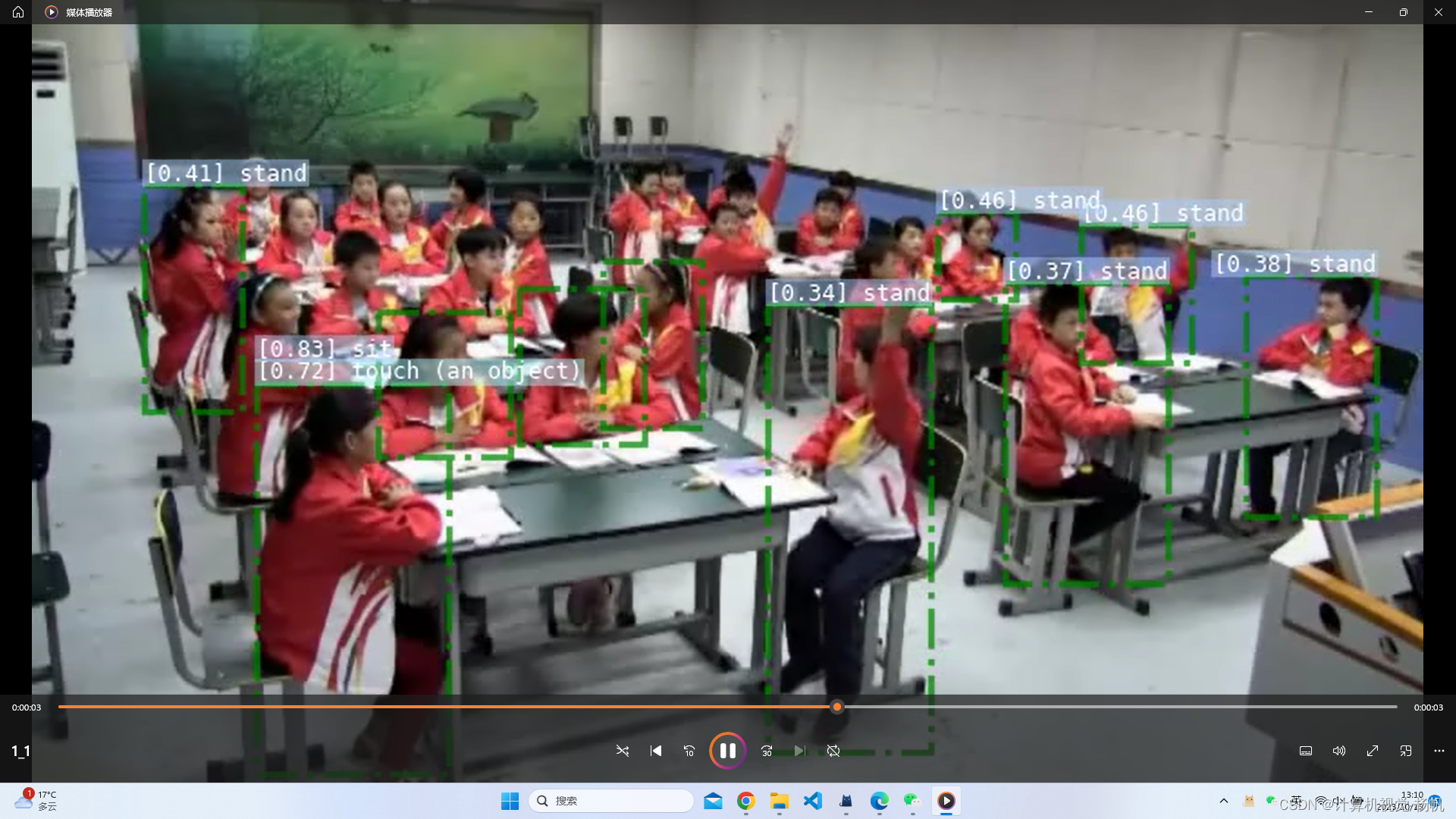
2.5 demo测试
在/home/slowfast/demo/中传入一个视频:1.mp4
执行:
cd /root/slowfast/
python tools/run_net.py --cfg demo/AVA/SLOWFAST_32x2_R101_50_50s.yaml
2.6 相关报错
2.6.1 报错1
This maybe due to another process holding this lock file. If you are sure no other Matplotlib process is running, remove this file and try again.
2.6.1 解决1
pip install --upgrade matplotlib
2.6.2 报错2
ModuleNotFoundError: No module named ‘torch._six’
2.6.2 解决2
vim /root/slowfast/slowfast/datasets/multigrid_helper.py
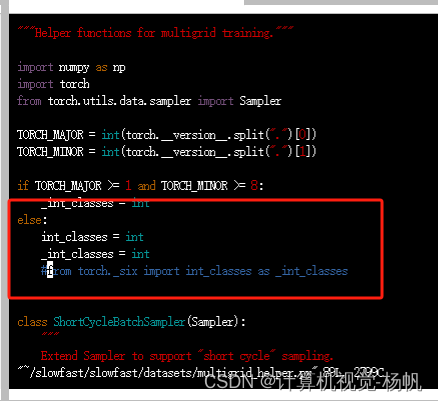
if TORCH_MAJOR >= 1 and TORCH_MINOR >= 8:
_int_classes = int
else:
int_classes = int
_int_classes = int
#from torch._six import int_classes as _int_classes
2.6.3 报错3
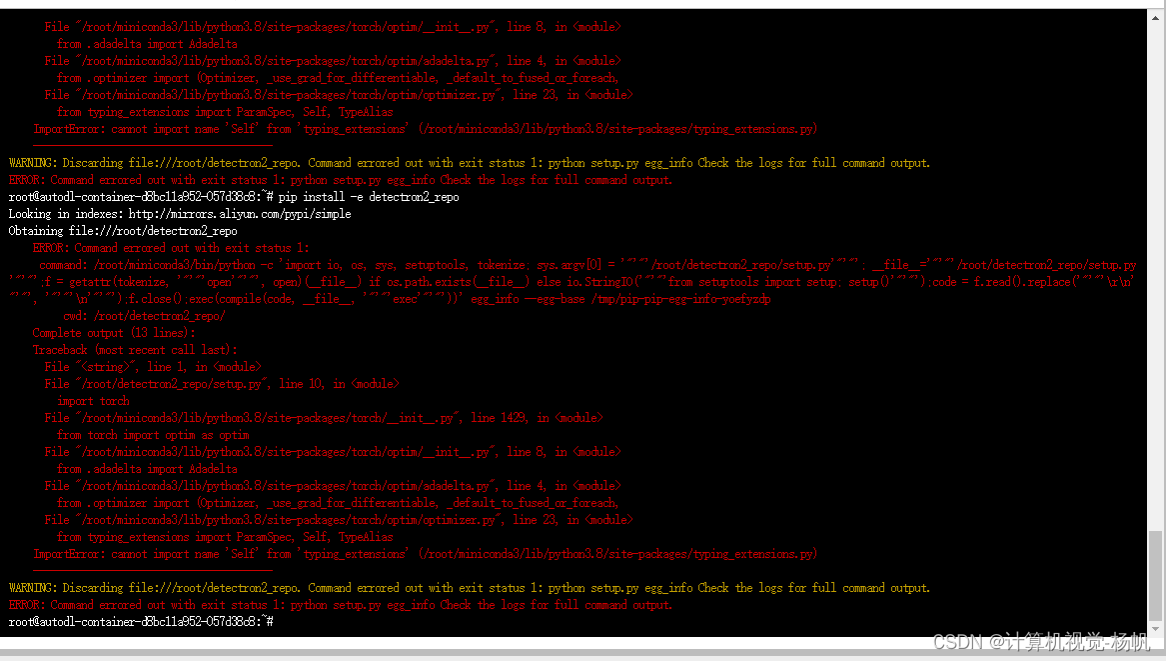
报错:
ERROR: Command errored out with exit status 1:
command: /root/miniconda3/bin/python -c 'import io, os, sys, setuptools, tokenize; sys.argv[0] = '"'"'/root/detectron2_repo/setup.py'"'"'; __file__='"'"'/root/detectron2_repo/setup.py'"'"';f = getattr(tokenize, '"'"'open'"'"', open)(__file__) if os.path.exists(__file__) else io.StringIO('"'"'from setuptools import setup; setup()'"'"');code = f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' egg_info --egg-base /tmp/pip-pip-egg-info-yoefyzdp
cwd: /root/detectron2_repo/
Complete output (13 lines):
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/root/detectron2_repo/setup.py", line 10, in <module>
import torch
File "/root/miniconda3/lib/python3.8/site-packages/torch/__init__.py", line 1429, in <module>
from torch import optim as optim
File "/root/miniconda3/lib/python3.8/site-packages/torch/optim/__init__.py", line 8, in <module>
from .adadelta import Adadelta
File "/root/miniconda3/lib/python3.8/site-packages/torch/optim/adadelta.py", line 4, in <module>
from .optimizer import (Optimizer, _use_grad_for_differentiable, _default_to_fused_or_foreach,
File "/root/miniconda3/lib/python3.8/site-packages/torch/optim/optimizer.py", line 23, in <module>
from typing_extensions import ParamSpec, Self, TypeAlias
ImportError: cannot import name 'Self' from 'typing_extensions' (/root/miniconda3/lib/python3.8/site-packages/typing_extensions.py)
----------------------------------------
WARNING: Discarding file:///root/detectron2_repo. Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.
ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.
2.6.3 解决3
pip install typing-extensions==4.3.0
2.6.4 报错4
Traceback (most recent call last):
File "tools/run_net.py", line 6, in <module>
from slowfast.utils.misc import launch_job
File "/root/slowfast/slowfast/utils/misc.py", line 19, in <module>
import slowfast.utils.logging as logging
File "/root/slowfast/slowfast/utils/logging.py", line 15, in <module>
import slowfast.utils.distributed as du
File "/root/slowfast/slowfast/utils/distributed.py", line 12, in <module>
from pytorchvideo.layers.distributed import ( # noqa
ImportError: cannot import name 'cat_all_gather' from 'pytorchvideo.layers.distributed' (/root/miniconda3/lib/python3.8/site-packages/pytorchvideo/layers/distributed.py)
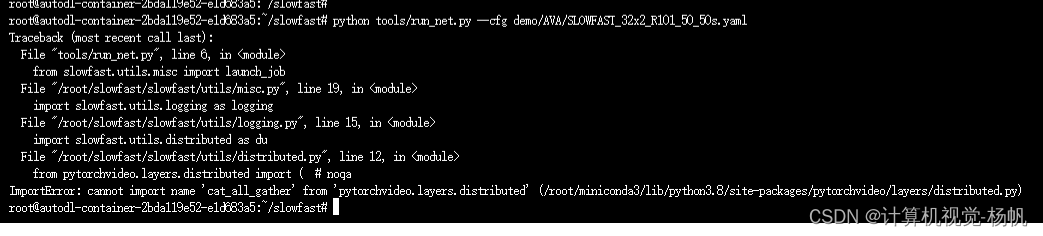
2.6.4 解决4
cd /root
git clone https://gitee.com/YFwinston/pytorchvideo.git
cd pytorchvideo
pip install -e .
cd /root
3 yolo数据集转ava数据集
https://github.com/Whiffe/SCB-dataset/tree/main/yolo2ava
python yolo2ava.py --yolo_path /root/5k_HRW_yolo_Dataset --ava_path /root/autodl-tmp/SCB-ava-Dataset4
执行后的目录结构
SCB-ava-Dataset4
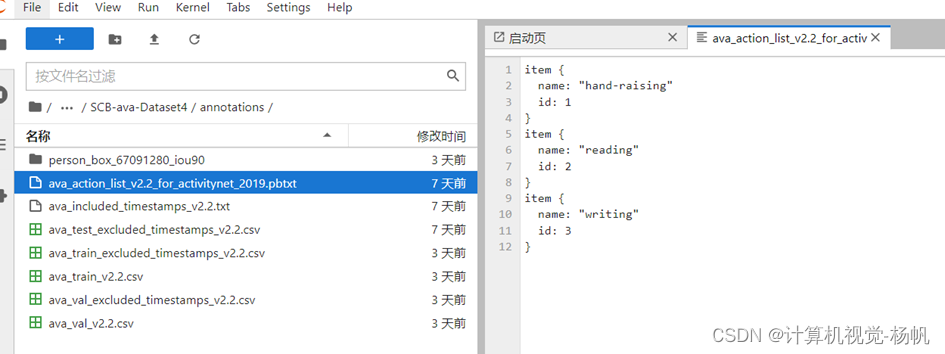
├── annotations
│ ├── ava_action_list_v2.2_for_activitynet_2019.pbtxt
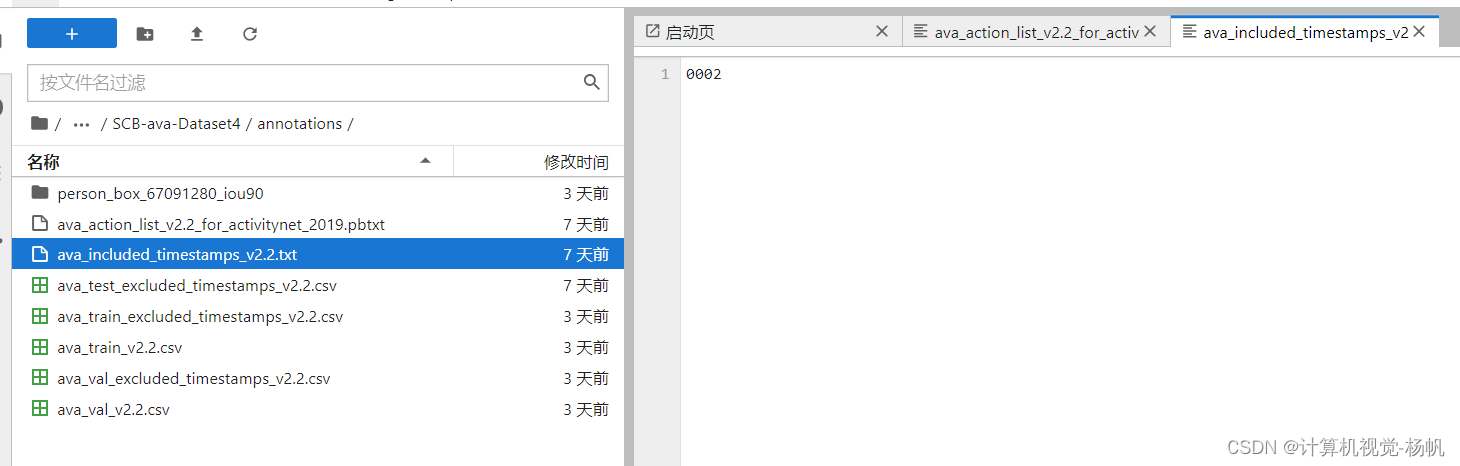
│ ├── ava_included_timestamps_v2.2.txt
│ ├── ava_test_excluded_timestamps_v2.2.csv
│ ├── ava_train_excluded_timestamps_v2.2.csv
│ ├── ava_train_v2.2.csv
│ ├── ava_val_excluded_timestamps_v2.2.csv
│ ├── ava_val_v2.2.csv
│ └── person_box_67091280_iou90
│ ├── ava_detection_train_boxes_and_labels_include_negative_v2.2.csv
│ └── ava_detection_val_boxes_and_labels.csv
├── frame_lists
│ ├── train.csv
│ └── val.csv
└── frames
├── 0001001
│ ├── 0001001_000001.png
│ ├── 0001001_000002.png
│ ├── …
│
├── 0001002
│ ├── 0001002_000001.png
│ ├── 0001002_000002.png
│ ├── …
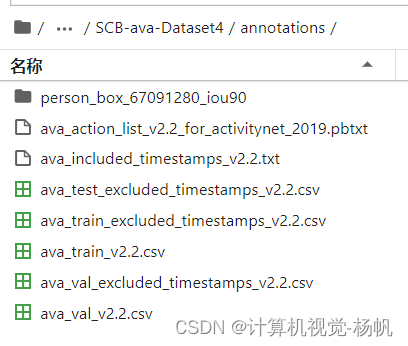
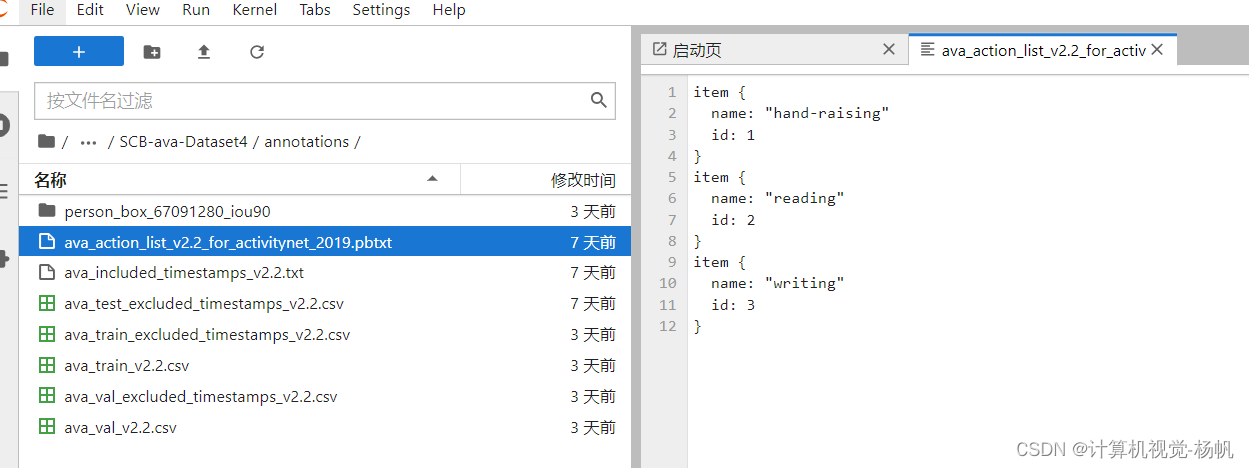


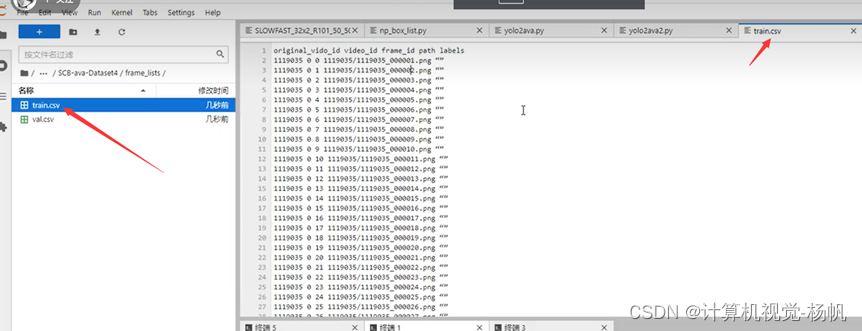
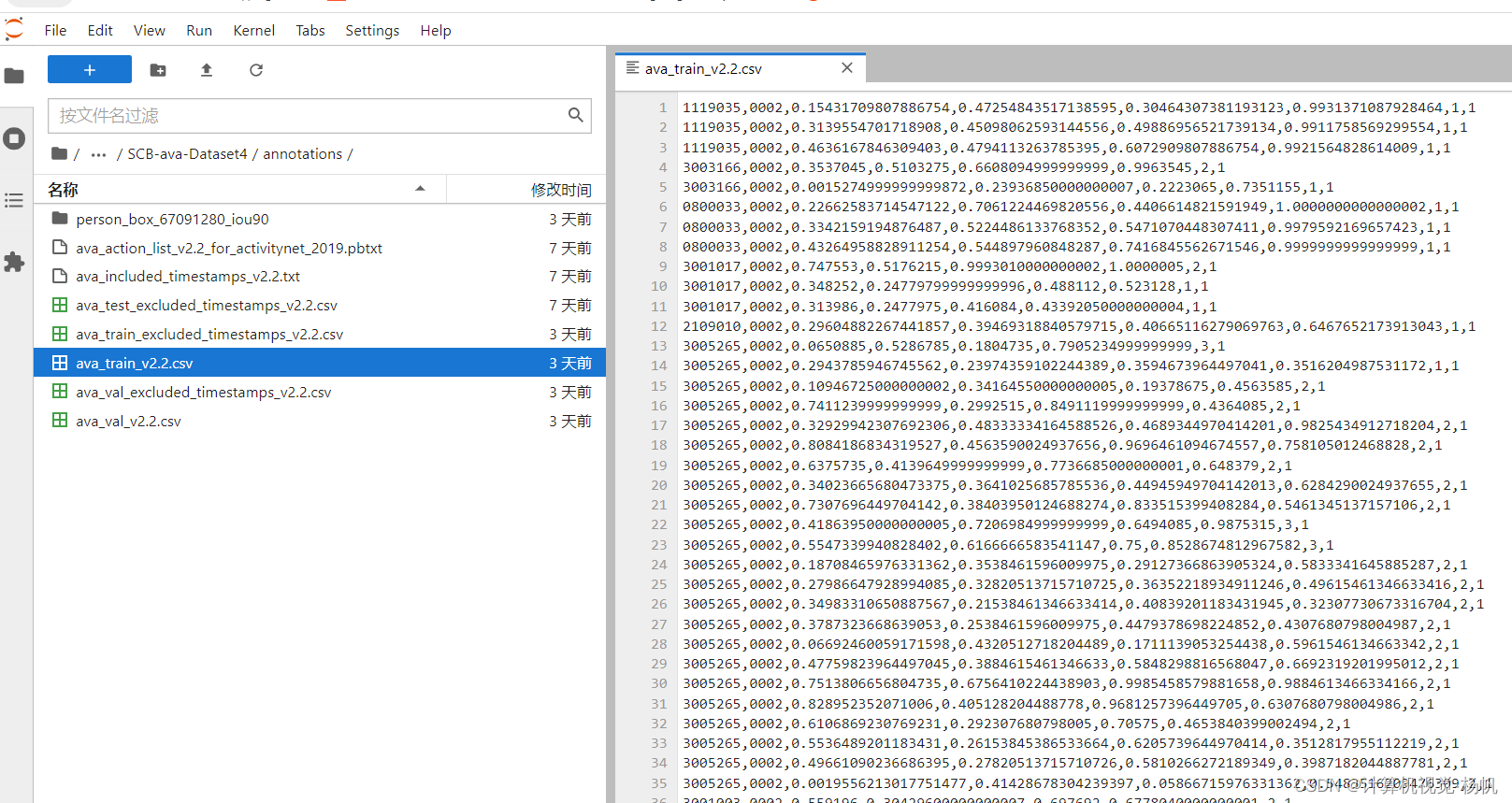
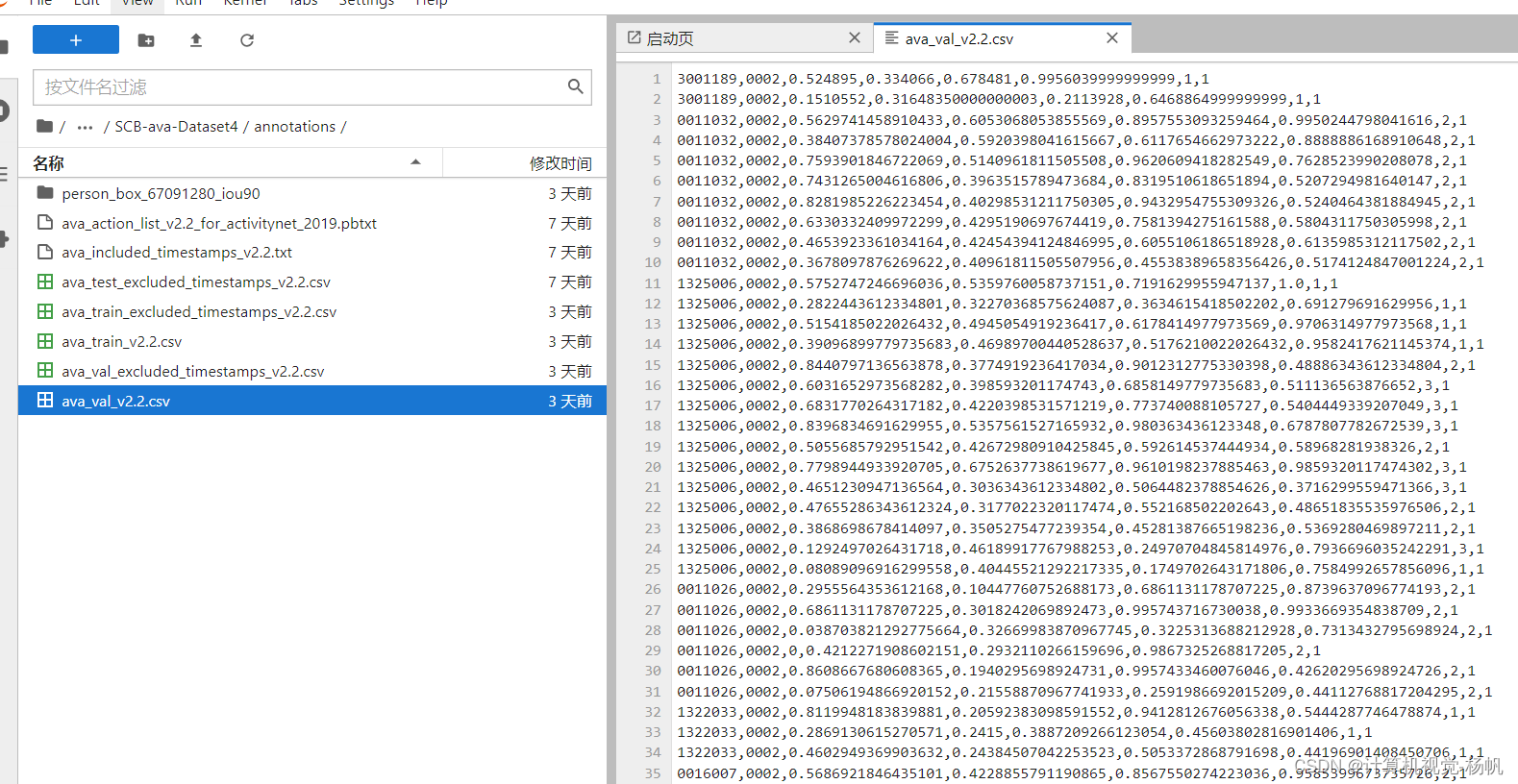
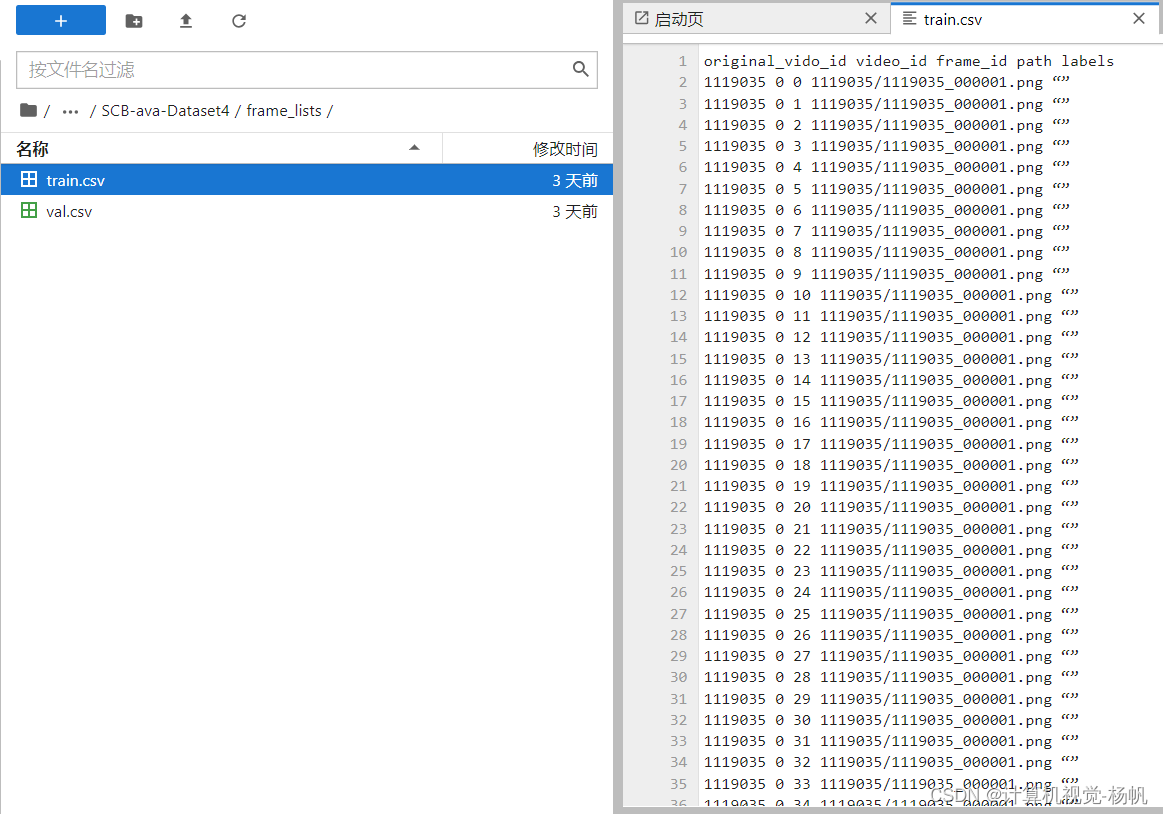
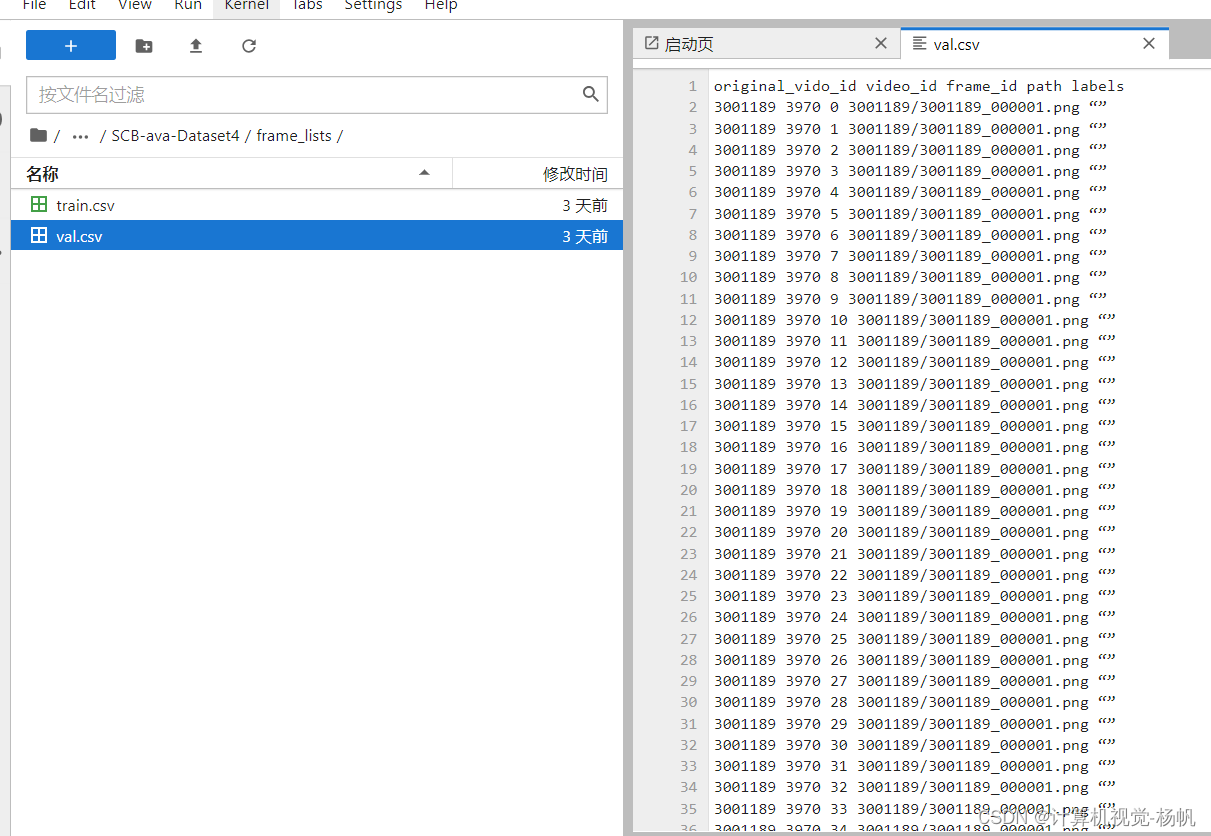
可以用下面的命令查看当前路径的文件占了多少空间
du -sh
4 训练
3.1 训练的相关配置文件
3.1.1 SLOWFAST_32x2_R101_50_50s.yaml
configs/AVA/c2/SLOWFAST_32x2_R101_50_50s.yaml
TRAIN:
ENABLE: True
DATASET: ava
BATCH_SIZE: 4
EVAL_PERIOD: 1
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: /root/autodl-nas/slowfast/SLOWFAST_32x2_R101_50_50.pkl
CHECKPOINT_TYPE: pytorch
DATA:
NUM_FRAMES: 32
SAMPLING_RATE: 2
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 256
INPUT_CHANNEL_NUM: [3, 3]
PATH_TO_DATA_DIR: '/root/autodl-tmp/SCB-ava-Dataset4'
DETECTION:
ENABLE: True
ALIGNED: False
AVA:
FRAME_DIR: '/root/autodl-tmp/SCB-ava-Dataset4/frames'
FRAME_LIST_DIR: '/root/autodl-tmp/SCB-ava-Dataset4/frame_lists'
ANNOTATION_DIR: '/root/autodl-tmp/SCB-ava-Dataset4/annotations'
DETECTION_SCORE_THRESH: 0.8
TRAIN_PREDICT_BOX_LISTS: [
"ava_train_v2.2.csv",
"person_box_67091280_iou90/ava_detection_train_boxes_and_labels_include_negative_v2.2.csv",
]
TEST_PREDICT_BOX_LISTS: [
"person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]
FULL_TEST_ON_VAL: True
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 5
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 101
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[6, 13, 20], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
OPTIMIZING_METHOD: sgd
MODEL:
NUM_CLASSES: 80
ARCH: slowfast
MODEL_NAME: SlowFast
LOSS_FUNC: bce
DROPOUT_RATE: 0.5
HEAD_ACT: sigmoid
TEST:
ENABLE: True
DATASET: ava
BATCH_SIZE: 8
DATA_LOADER:
NUM_WORKERS: 2
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: '/root/autodl-tmp/'
3.1.2 ava_action_list_v2.2_for_activitynet_2019.pbtxt
SCB-ava-Dataset4/annotations/ava_action_list_v2.2_for_activitynet_2019.pbtxt
item {
name: "hand-raising"
id: 1
}
item {
name: "reading"
id: 2
}
item {
name: "writing"
id: 3
}
3.1.3 ava_included_timestamps_v2.2.txt
SCB-ava-Dataset4/annotations/ava_included_timestamps_v2.2.txt
0002
3.1.4 ava_train/test_excluded_timestamps_v2.2.csv
空
SCB-ava-Dataset4/annotations/ava_test_excluded_timestamps_v2.2.csv
SCB-ava-Dataset4/annotations/ava_train_excluded_timestamps_v2.2.csv
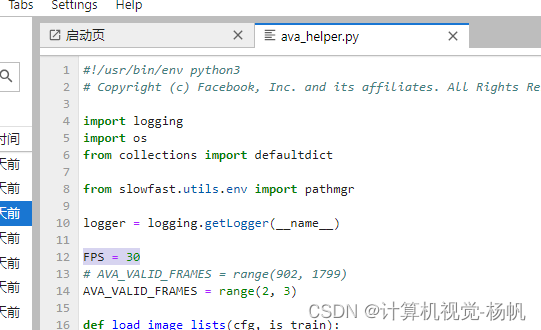
ava_helper.py
ava默认是从902帧开始,我们可以从第1帧开始,不过需要修改代码,位置在slowfast/slowfast/datasets/ava_helper.py,
AVA_VALID_FRAMES = range(2, 3)
3.2 训练
python tools/run_net.py \
--cfg configs/AVA/c2/SLOWFAST_32x2_R101_50_50s.yaml
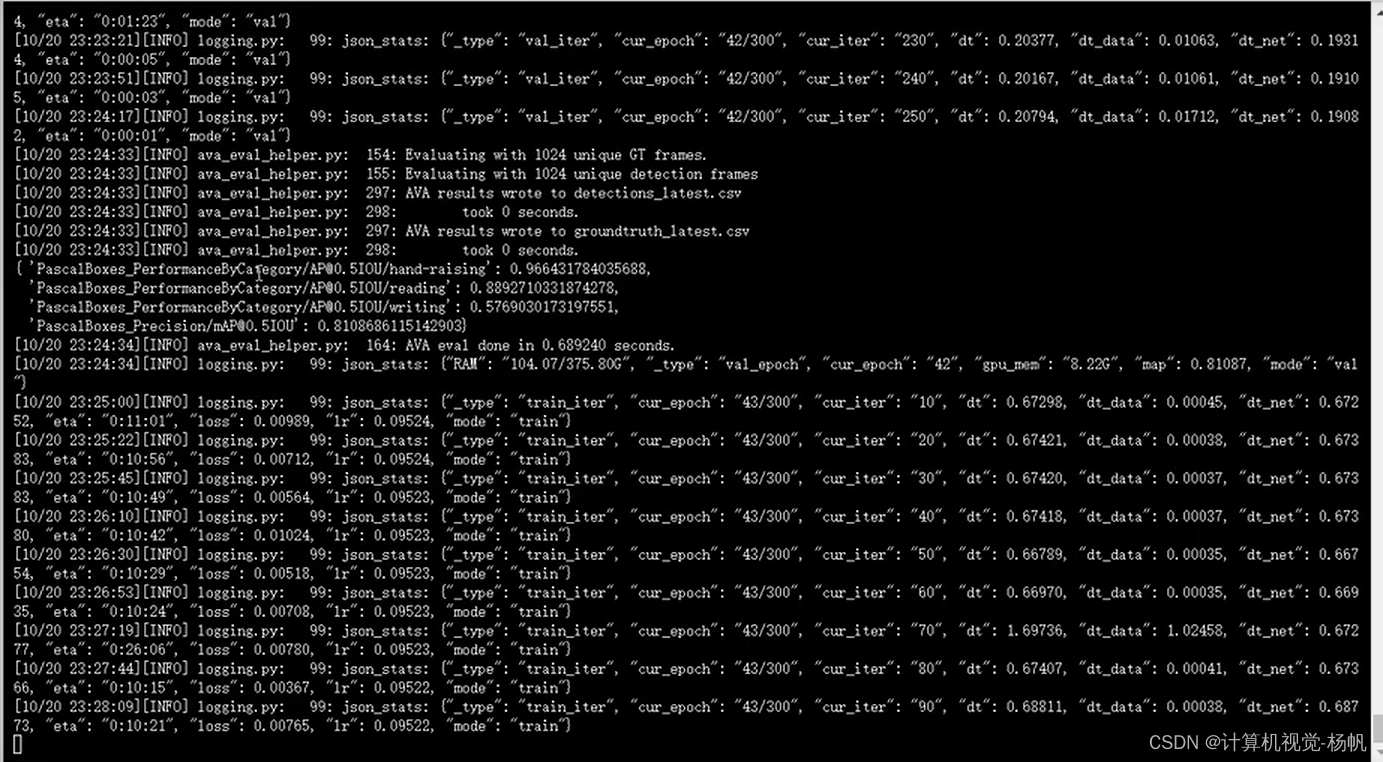
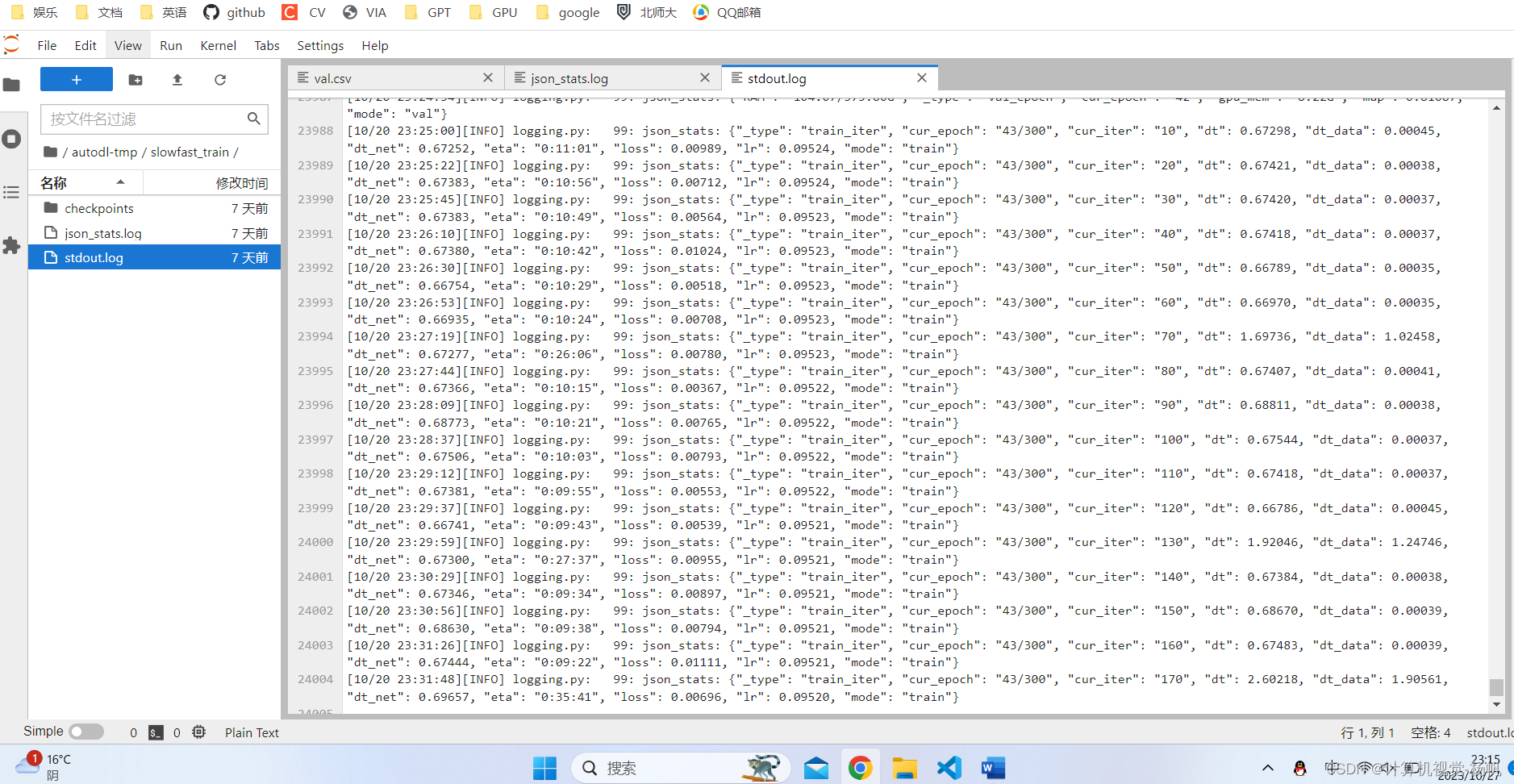
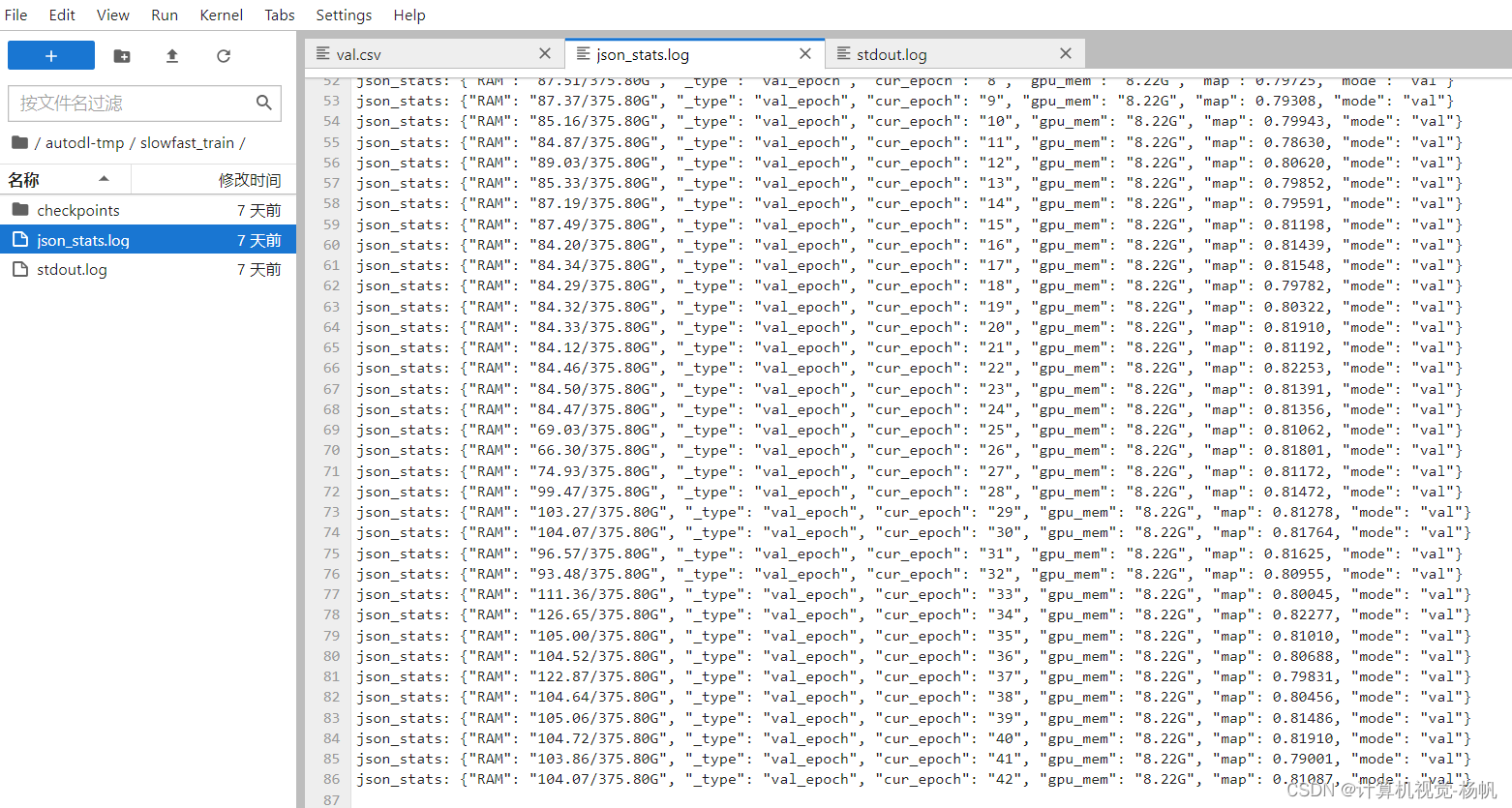

3.3 相关报错
3.3.1 报错1
报错:
Traceback (most recent call last):
File “tools/run_net.py”, line 52, in
main()
File “tools/run_net.py”, line 27, in main
launch_job(cfg=cfg, init_method=args.init_method, func=train)
File “/root/slowfast/slowfast/utils/misc.py”, line 430, in launch_job
func(cfg=cfg)
File “/root/slowfast/tools/train_net.py”, line 681, in train
train_epoch(
File “/root/slowfast/tools/train_net.py”, line 276, in train_epoch
del inputs
UnboundLocalError: local variable ‘inputs’ referenced before assignment
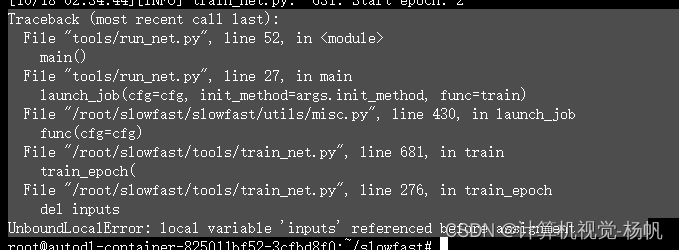
3.3.1 解决1
解决:
https://github.com/facebookresearch/SlowFast/issues/547
更改batch_size的大小,报错是因为batch_size大于视频数量
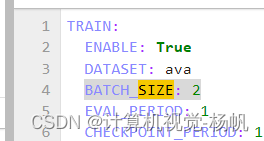
3.3.2 报错2
报错:
Traceback (most recent call last):
File “tools/run_net.py”, line 52, in
main()
File “tools/run_net.py”, line 27, in main
launch_job(cfg=cfg, init_method=args.init_method, func=train)
File “/root/slowfast/slowfast/utils/misc.py”, line 430, in launch_job
func(cfg=cfg)
File “/root/slowfast/tools/train_net.py”, line 681, in train
train_epoch(
File “/root/slowfast/tools/train_net.py”, line 110, in train_epoch
optim.set_lr(optimizer, lr)
File “/root/slowfast/slowfast/models/optimizer.py”, line 267, in set_lr
param_group[“lr”] = new_lr * param_group[“layer_decay”]
KeyError: ‘layer_decay’
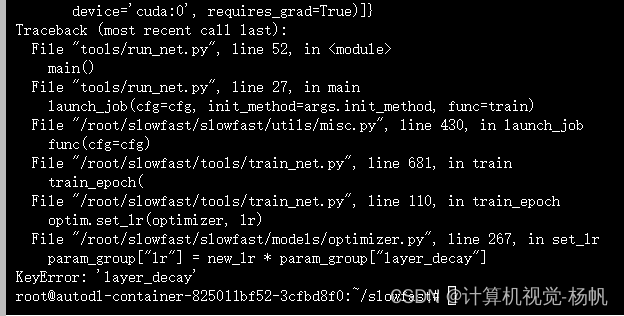
3.3.2 解决2
解决:
https://github.com/facebookresearch/SlowFast/issues/654
slowfast/slowfast/models/optimizer.py

def set_lr(optimizer, new_lr):
"""
Sets the optimizer lr to the specified value.
Args:
optimizer (optim): the optimizer using to optimize the current network.
new_lr (float): the new learning rate to set.
"""
for param_group in optimizer.param_groups:
try:
param_group["lr"] = new_lr * param_group["layer_decay"]
except:
param_group["lr"] = new_lr * 1.0
3.3.3 报错3
错误:
/root/slowfast/ava_evaluation/metrics.py:41: FutureWarning: In the future `np.bool` will be defined as the corresponding NumPy scalar.
or labels.dtype != np.bool
Traceback (most recent call last):
File "tools/run_net.py", line 52, in <module>
main()
File "tools/run_net.py", line 27, in main
launch_job(cfg=cfg, init_method=args.init_method, func=train)
File "/root/slowfast/slowfast/utils/misc.py", line 430, in launch_job
func(cfg=cfg)
File "/root/slowfast/tools/train_net.py", line 748, in train
eval_epoch(
File "/root/miniconda3/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/root/slowfast/tools/train_net.py", line 420, in eval_epoch
val_meter.log_epoch_stats(cur_epoch)
File "/root/slowfast/slowfast/utils/meters.py", line 235, in log_epoch_stats
self.finalize_metrics(log=False)
File "/root/slowfast/slowfast/utils/meters.py", line 208, in finalize_metrics
self.full_map = evaluate_ava(
File "/root/slowfast/slowfast/utils/ava_eval_helper.py", line 162, in evaluate_ava
results = run_evaluation(categories, groundtruth, detections, excluded_keys)
File "/root/slowfast/slowfast/utils/ava_eval_helper.py", line 238, in run_evaluation
metrics = pascal_evaluator.evaluate()
File "/root/slowfast/ava_evaluation/object_detection_evaluation.py", line 307, in evaluate
) = self._evaluation.evaluate()
File "/root/slowfast/ava_evaluation/object_detection_evaluation.py", line 799, in evaluate
precision, recall = metrics.compute_precision_recall(
File "/root/slowfast/ava_evaluation/metrics.py", line 41, in compute_precision_recall
or labels.dtype != np.bool
File "/root/miniconda3/lib/python3.8/site-packages/numpy/__init__.py", line 305, in __getattr__
raise AttributeError(__former_attrs__[attr])
AttributeError: module 'numpy' has no attribute 'bool'.
`np.bool` was a deprecated alias for the builtin `bool`. To avoid this error in existing code, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here.
The aliases was originally deprecated in NumPy 1.20; for more details and guidance see the original release note at:
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
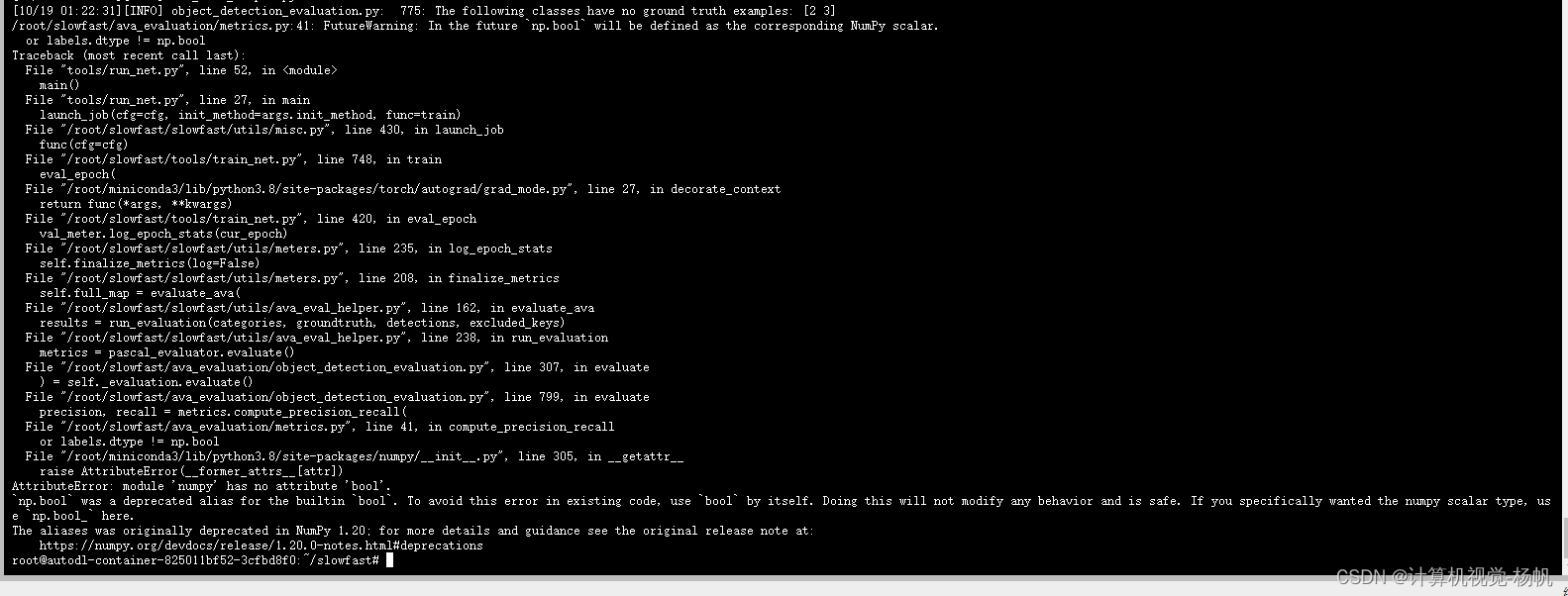
3.3.3 解决3
成功解决AttributeError: module ‘numpy‘ has no attribute ‘bool‘.
pip uninstall numpy
pip install numpy==1.23.2
报错:
Traceback (most recent call last):
File "tools/run_net.py", line 52, in <module>
main()
File "tools/run_net.py", line 27, in main
launch_job(cfg=cfg, init_method=args.init_method, func=train)
File "/root/slowfast/slowfast/utils/misc.py", line 430, in launch_job
func(cfg=cfg)
File "/root/slowfast/tools/train_net.py", line 748, in train
eval_epoch(
File "/root/miniconda3/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/root/slowfast/tools/train_net.py", line 420, in eval_epoch
val_meter.log_epoch_stats(cur_epoch)
File "/root/slowfast/slowfast/utils/meters.py", line 235, in log_epoch_stats
self.finalize_metrics(log=False)
File "/root/slowfast/slowfast/utils/meters.py", line 208, in finalize_metrics
self.full_map = evaluate_ava(
File "/root/slowfast/slowfast/utils/ava_eval_helper.py", line 162, in evaluate_ava
results = run_evaluation(categories, groundtruth, detections, excluded_keys)
File "/root/slowfast/slowfast/utils/ava_eval_helper.py", line 221, in run_evaluation
pascal_evaluator.add_single_detected_image_info(
File "/root/slowfast/ava_evaluation/object_detection_evaluation.py", line 275, in add_single_detected_image_info
self._evaluation.add_single_detected_image_info(
File "/root/slowfast/ava_evaluation/object_detection_evaluation.py", line 710, in add_single_detected_image_info
) = self.per_image_eval.compute_object_detection_metrics(
File "/root/slowfast/ava_evaluation/per_image_evaluation.py", line 114, in compute_object_detection_metrics
scores, tp_fp_labels = self._compute_tp_fp(
File "/root/slowfast/ava_evaluation/per_image_evaluation.py", line 210, in _compute_tp_fp
scores, tp_fp_labels = self._compute_tp_fp_for_single_class(
File "/root/slowfast/ava_evaluation/per_image_evaluation.py", line 310, in _compute_tp_fp_for_single_class
) = self._get_overlaps_and_scores_box_mode(
File "/root/slowfast/ava_evaluation/per_image_evaluation.py", line 253, in _get_overlaps_and_scores_box_mode
gt_non_group_of_boxlist = np_box_list.BoxList(
File "/root/slowfast/ava_evaluation/np_box_list.py", line 58, in __init__
raise ValueError(
ValueError: Invalid box data. data must be a numpy array of N*[y_min, x_min, y_max, x_max]
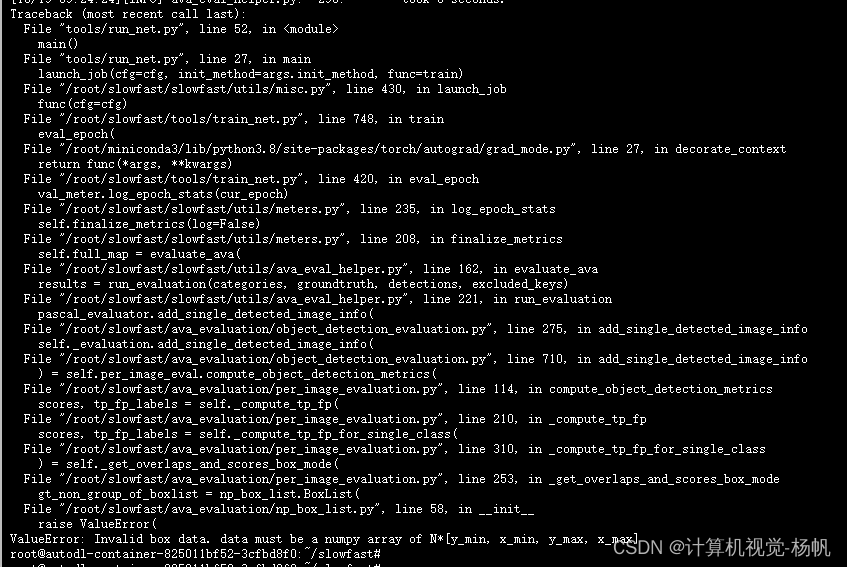
3.3.4 问题4
Traceback (most recent call last):
File "tools/run_net.py", line 52, in <module>
main()
File "tools/run_net.py", line 27, in main
launch_job(cfg=cfg, init_method=args.init_method, func=train)
File "/data/SCB/slowfast/slowfast/utils/misc.py", line 430, in launch_job
func(cfg=cfg)
File "/data/SCB/slowfast/tools/train_net.py", line 681, in train
train_epoch(
File "/data/SCB/slowfast/tools/train_net.py", line 176, in train_epoch
scaler.step(optimizer)
File "/root/miniconda3/envs/slowfast/lib/python3.8/site-packages/torch/cuda/amp/grad_scaler.py", line 315, in step
return optimizer.step(*args, **kwargs)
File "/root/miniconda3/envs/slowfast/lib/python3.8/site-packages/torch/optim/optimizer.py", line 280, in wrapper
out = func(*args, **kwargs)
File "/root/miniconda3/envs/slowfast/lib/python3.8/site-packages/torch/optim/optimizer.py", line 33, in _use_grad
ret = func(self, *args, **kwargs)
File "/root/miniconda3/envs/slowfast/lib/python3.8/site-packages/torch/optim/sgd.py", line 76, in step
sgd(params_with_grad,
File "/root/miniconda3/envs/slowfast/lib/python3.8/site-packages/torch/optim/sgd.py", line 222, in sgd
func(params,
File "/root/miniconda3/envs/slowfast/lib/python3.8/site-packages/torch/optim/sgd.py", line 306, in _multi_tensor_sgd
torch._foreach_add_(bufs, device_grads, alpha=1 - dampening)
RuntimeError: The size of tensor a (80) must match the size of tensor b (3) at non-singleton dimension 0
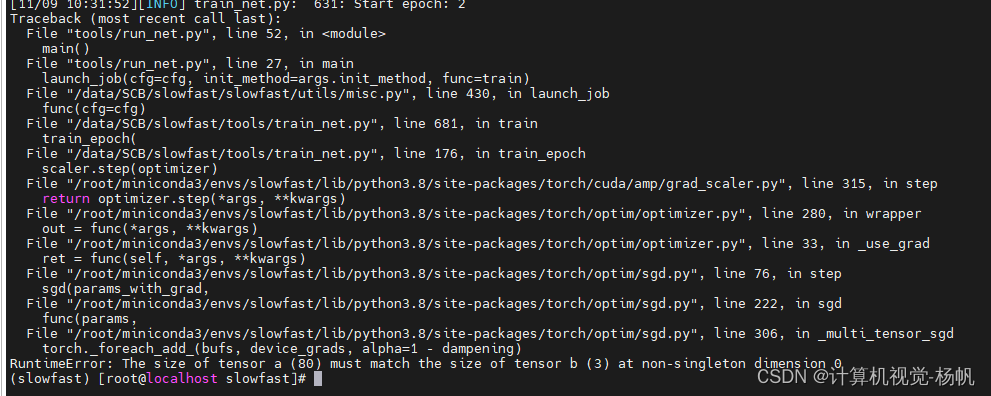
解决:
这里报错的原因是预训练模型的原因,不应该加载预训练模型,注释TRAIN.CHECKPOINT_FILE_PATH即可
4 测试
4.1 配置文件
slowfast/configs/AVA/c2/SLOWFAST_32x2_R101_50_50s2.yaml
TRAIN:
ENABLE: False
DATASET: ava
BATCH_SIZE: 4
EVAL_PERIOD: 1
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: /root/autodl-nas/slowfast/SLOWFAST_32x2_R101_50_50.pkl
CHECKPOINT_TYPE: pytorch
DATA:
NUM_FRAMES: 32
SAMPLING_RATE: 2
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 256
INPUT_CHANNEL_NUM: [3, 3]
PATH_TO_DATA_DIR: '/root/autodl-tmp/SCB-ava-Dataset4'
DETECTION:
ENABLE: True
ALIGNED: False
AVA:
FRAME_DIR: '/root/autodl-tmp/SCB-ava-Dataset4/frames'
FRAME_LIST_DIR: '/root/autodl-tmp/SCB-ava-Dataset4/frame_lists'
ANNOTATION_DIR: '/root/autodl-tmp/SCB-ava-Dataset4/annotations'
DETECTION_SCORE_THRESH: 0.8
TRAIN_PREDICT_BOX_LISTS: [
"ava_train_v2.2.csv",
"person_box_67091280_iou90/ava_detection_train_boxes_and_labels_include_negative_v2.2.csv",
]
TEST_PREDICT_BOX_LISTS: [
"person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]
FULL_TEST_ON_VAL: True
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 5
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 101
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[6, 13, 20], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
OPTIMIZING_METHOD: sgd
MODEL:
NUM_CLASSES: 80
ARCH: slowfast
MODEL_NAME: SlowFast
LOSS_FUNC: bce
DROPOUT_RATE: 0.5
HEAD_ACT: sigmoid
TEST:
ENABLE: True
DATASET: ava
BATCH_SIZE: 1
CHECKPOINT_FILE_PATH: /root/autodl-tmp/slowfast_train/checkpoints/checkpoint_epoch_00034.pyth
DATA_LOADER:
NUM_WORKERS: 2
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: '/root/autodl-tmp/'
4.2 测试
python tools/run_net.py \
--cfg configs/AVA/c2/SLOWFAST_32x2_R101_50_50s2.yaml \
错误:
Traceback (most recent call last):
File "tools/run_net.py", line 52, in <module>
main()
File "tools/run_net.py", line 37, in main
launch_job(cfg=cfg, init_method=args.init_method, func=test)
File "/root/slowfast/slowfast/utils/misc.py", line 430, in launch_job
func(cfg=cfg)
File "/root/slowfast/tools/test_net.py", line 252, in test
test_meter = perform_test(test_loader, model, test_meter, cfg, writer)
File "/root/miniconda3/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/root/slowfast/tools/test_net.py", line 129, in perform_test
test_meter.iter_toc()
File "/root/slowfast/slowfast/utils/meters.py", line 159, in iter_toc
self.iter_timer.pause()
File "/root/miniconda3/lib/python3.8/site-packages/fvcore/common/timer.py", line 30, in pause
raise ValueError("Trying to pause a Timer that is already paused!")
ValueError: Trying to pause a Timer that is already paused!
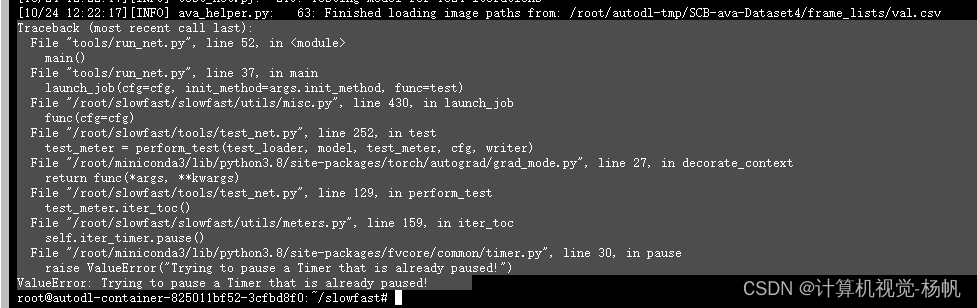
解决:
https://github.com/facebookresearch/SlowFast/issues/599#ref-issue-1441689338
https://github.com/facebookresearch/SlowFast/issues/623
修改test_net.py中的内容,加两组try except
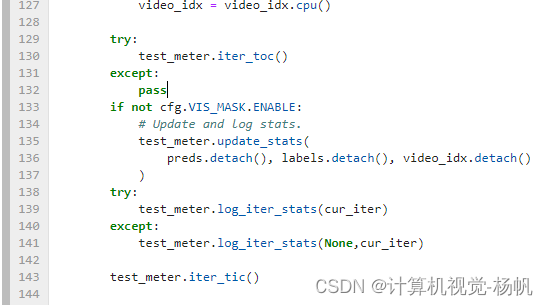
if cfg.NUM_GPUS > 1:
preds, labels, video_idx = du.all_gather([preds, labels, video_idx])
if cfg.NUM_GPUS:
preds = preds.cpu()
labels = labels.cpu()
video_idx = video_idx.cpu()
try:
test_meter.iter_toc()
except:
pass
if not cfg.VIS_MASK.ENABLE:
# Update and log stats.
test_meter.update_stats(
preds.detach(), labels.detach(), video_idx.detach()
)
try:
test_meter.log_iter_stats(cur_iter)
except:
test_meter.log_iter_stats(None,cur_iter)
test_meter.iter_tic()
报错:
Traceback (most recent call last):
File "tools/run_net.py", line 52, in <module>
main()
File "tools/run_net.py", line 37, in main
launch_job(cfg=cfg, init_method=args.init_method, func=test)
File "/root/slowfast/slowfast/utils/misc.py", line 430, in launch_job
func(cfg=cfg)
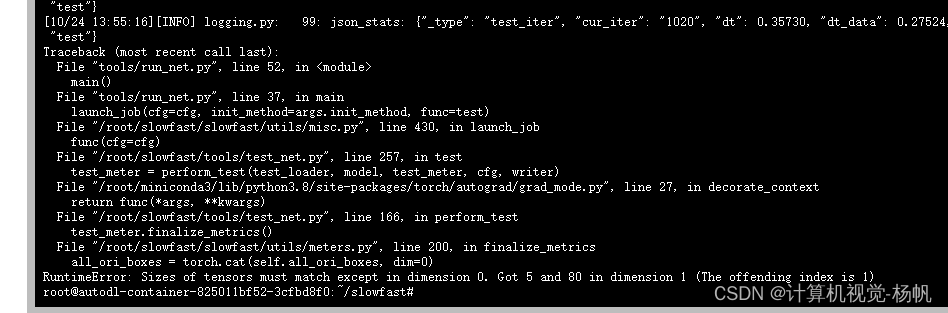
File "/root/slowfast/tools/test_net.py", line 257, in test
test_meter = perform_test(test_loader, model, test_meter, cfg, writer)
File "/root/miniconda3/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/root/slowfast/tools/test_net.py", line 166, in perform_test
test_meter.finalize_metrics()
File "/root/slowfast/slowfast/utils/meters.py", line 200, in finalize_metrics
all_ori_boxes = torch.cat(self.all_ori_boxes, dim=0)
RuntimeError: Sizes of tensors must match except in dimension 0. Got 5 and 80 in dimension 1 (The offending index is 1)
这个错误是在运行PyTorch代码时出现的,它指的是你在进行张量(tensor)操作时,试图将两个维度(dimension)大小不匹配的张量进行相加或其他操作。
具体来说,错误消息"Sizes of tensors must match except in dimension 0. Got 5 and 80 in dimension 1 (The offending index is 1)"告诉我们,你正在试图将一个在第一个维度大小为5的张量和第一个维度大小为80的张量进行相加。这是不允许的,因为在除第一个维度之外的所有维度上,两个输入张量的大小必须完全相同。
为了解决这个问题,你需要确保你正在操作的两个张量在所有维度上的大小都相同,或者至少在需要进行操作的维度上相同。
例如,如果你有两个大小为(5, 80)和(80, 80)的张量,你不能直接将它们相加,因为它们的第二个维度大小不匹配。你需要确保它们的大小相同,比如通过调整你的数据或者改变你的操作。
如果你能提供更多关于你遇到这个错误的上下文信息(比如你的代码片段和你的数据),我可能能提供更具体的建议。
Traceback (most recent call last):
File "tools/run_net.py", line 52, in <module>
main()
File "tools/run_net.py", line 37, in main
launch_job(cfg=cfg, init_method=args.init_method, func=test)
File "/data/SCB/slowfast/slowfast/utils/misc.py", line 430, in launch_job
func(cfg=cfg)
File "/data/SCB/slowfast/tools/test_net.py", line 262, in test
test_meter = perform_test(test_loader, model, test_meter, cfg, writer)
File "/root/miniconda3/envs/slowfast/lib/python3.8/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/data/SCB/slowfast/tools/test_net.py", line 171, in perform_test
test_meter.finalize_metrics()
File "/data/SCB/slowfast/slowfast/utils/meters.py", line 204, in finalize_metrics
all_ori_boxes = torch.cat(self.all_ori_boxes, dim=0)
RuntimeError: Sizes of tensors must match except in dimension 0. Expected size 5 but got size 3 for tensor number 1 in the list.
解决:
报错的原因如下:
维度不匹配,
下面内容导致了维度不匹配(test_net.py)
if not cfg.VIS_MASK.ENABLE:
# Update and log stats.
# print("labels.detach():",labels.detach())
test_meter.update_stats(
preds.detach(), labels.detach(), video_idx.detach()
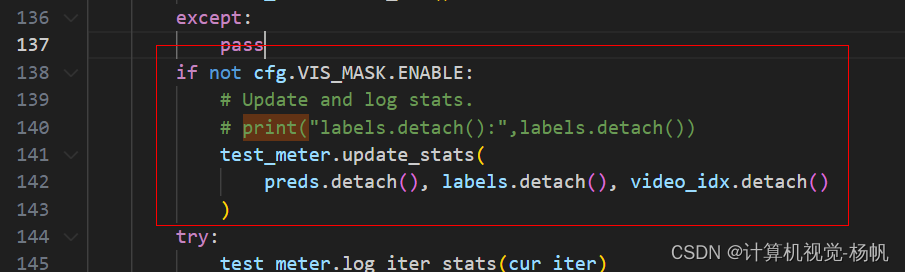
需要添加配置文件SLOWFAST_32x2_R101_50_50s.yaml中添加如下东西
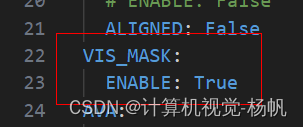
VIS_MASK:
ENABLE: True
4.2 demo测试
4.2.1 配置文件
slowfast/demo/AVA/SLOWFAST_32x2_R101_50_50s2.yaml
TRAIN:
ENABLE: False
DATASET: ava
BATCH_SIZE: 1
EVAL_PERIOD: 1
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: /root/slowfast_train/checkpoints/checkpoint_epoch_00034.pyth #path to pretrain model
CHECKPOINT_TYPE: pytorch
DATA:
NUM_FRAMES: 16
SAMPLING_RATE: 2
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 256
INPUT_CHANNEL_NUM: [3, 3]
DETECTION:
ENABLE: True
ALIGNED: False
AVA:
BGR: False
DETECTION_SCORE_THRESH: 0.8
TEST_PREDICT_BOX_LISTS: ["person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 5
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 101
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[6, 13, 20], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
OPTIMIZING_METHOD: sgd
MODEL:
NUM_CLASSES: 80
ARCH: slowfast
MODEL_NAME: SlowFast
LOSS_FUNC: bce
DROPOUT_RATE: 0.5
HEAD_ACT: sigmoid
TEST:
ENABLE: False
DATASET: ava
BATCH_SIZE: 1
DATA_LOADER:
NUM_WORKERS: 1
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: .
#TENSORBOARD:
# MODEL_VIS:
# TOPK: 2
DEMO:
ENABLE: True
LABEL_FILE_PATH: "demo/AVA/student_behaviors.json" # Add local label file path here.
INPUT_VIDEO: "/root/autodl-tmp/0_0_0.mp4"
OUTPUT_FILE: "/root/autodl-tmp/0_1_1.mp4"
DETECTRON2_CFG: "COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml"
DETECTRON2_WEIGHTS: "/root/autodl-nas/slowfast/model_final_280758.pkl"
4.2.2 student_behaviors.json
slowfast/demo/AVA/student_behaviors.json
{"hand-raising": 0, "reading": 1, "writing": 2}
4.2.2 demo测试
cd /root/slowfast/
python tools/run_net.py --cfg demo/AVA/SLOWFAST_32x2_R101_50_50s2.yaml

5 在非云平台安装SlowFast(本地机器上)
5.1 基础环境
torch版本:
2.0.0+cu117
torchvision版本
0.15.1+cu117
pip install 'git+https://gitee.com/YFwinston/fvcore'
pip install simplejson
conda install av -c conda-forge -y
conda install x264 ffmpeg -c conda-forge -y
pip install -U iopath
pip install psutil
pip install opencv-python
// pip install torchvision
pip install tensorboard
pip install moviepy
pip install pytorchvideo
pip install 'git+https://gitee.com/YFwinston/fairscale'
cd /data/SCB/
git clone https://gitee.com/YFwinston/pytorchvideo.git
cd pytorchvideo
pip install -e .
/data/SCB/
5.2 detectron2_repo 安装
// pip install -U torch torchvision cython
// pip install -U cython
pip install cython
pip install -U 'git+https://gitee.com/YFwinston/fvcore.git' 'git+https://gitee.com/YFwinston/cocoapi.git#subdirectory=PythonAPI'
git clone https://gitee.com/YFwinston/detectron2 detectron2_repo
pip install typing-extensions==4.3.0
pip install -e detectron2_repo
pip install pillow
pip install pyyaml
pip install scipy
pip install pandas
pip install scikit-learn
5.3 slowfast 安装
git clone https://gitee.com/YFwinston/slowfast
export PYTHONPATH=/data/SCB/slowfast:$PYTHONPATH
cd slowfast
python setup.py build develop
cd ..
5.4 相关文件
ava.json
cd /data/SCB/slowfast/demo/AVA
vim ava.json
{"bend/bow (at the waist)": 0, "crawl": 1, "crouch/kneel": 2, "dance": 3, "fall down": 4, "get up": 5, "jump/leap": 6, "lie/sleep": 7, "martial art": 8, "run/jog": 9, "sit": 10, "stand": 11, "swim": 12, "walk": 13, "answer phone": 14, "brush teeth": 15, "carry/hold (an object)": 16, "catch (an object)": 17, "chop": 18, "climb (e.g., a mountain)": 19, "clink glass": 20, "close (e.g., a door, a box)": 21, "cook": 22, "cut": 23, "dig": 24, "dress/put on clothing": 25, "drink": 26, "drive (e.g., a car, a truck)": 27, "eat": 28, "enter": 29, "exit": 30, "extract": 31, "fishing": 32, "hit (an object)": 33, "kick (an object)": 34, "lift/pick up": 35, "listen (e.g., to music)": 36, "open (e.g., a window, a car door)": 37, "paint": 38, "play board game": 39, "play musical instrument": 40, "play with pets": 41, "point to (an object)": 42, "press": 43, "pull (an object)": 44, "push (an object)": 45, "put down": 46, "read": 47, "ride (e.g., a bike, a car, a horse)": 48, "row boat": 49, "sail boat": 50, "shoot": 51, "shovel": 52, "smoke": 53, "stir": 54, "take a photo": 55, "text on/look at a cellphone": 56, "throw": 57, "touch (an object)": 58, "turn (e.g., a screwdriver)": 59, "watch (e.g., TV)": 60, "work on a computer": 61, "write": 62, "fight/hit (a person)": 63, "give/serve (an object) to (a person)": 64, "grab (a person)": 65, "hand clap": 66, "hand shake": 67, "hand wave": 68, "hug (a person)": 69, "kick (a person)": 70, "kiss (a person)": 71, "lift (a person)": 72, "listen to (a person)": 73, "play with kids": 74, "push (another person)": 75, "sing to (e.g., self, a person, a group)": 76, "take (an object) from (a person)": 77, "talk to (e.g., self, a person, a group)": 78, "watch (a person)": 79}
SLOWFAST_32x2_R101_50_50s.yaml
cd /data/SCB/slowfast/demo/AVA
vim SLOWFAST_32x2_R101_50_50s.yaml
TRAIN:
ENABLE: False
DATASET: ava
BATCH_SIZE: 1
EVAL_PERIOD: 1
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: /data/SCB/slowfast/mywork/SLOWFAST_32x2_R101_50_50.pkl #path to pretrain model
CHECKPOINT_TYPE: pytorch
DATA:
NUM_FRAMES: 16
SAMPLING_RATE: 2
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 256
INPUT_CHANNEL_NUM: [3, 3]
DETECTION:
ENABLE: True
ALIGNED: False
AVA:
BGR: False
DETECTION_SCORE_THRESH: 0.8
TEST_PREDICT_BOX_LISTS: ["person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 5
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 101
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[6, 13, 20], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
OPTIMIZING_METHOD: sgd
MODEL:
NUM_CLASSES: 80
ARCH: slowfast
MODEL_NAME: SlowFast
LOSS_FUNC: bce
DROPOUT_RATE: 0.5
HEAD_ACT: sigmoid
TEST:
ENABLE: False
DATASET: ava
BATCH_SIZE: 1
DATA_LOADER:
NUM_WORKERS: 1
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: .
#TENSORBOARD:
# MODEL_VIS:
# TOPK: 2
DEMO:
ENABLE: True
LABEL_FILE_PATH: "demo/AVA/ava.json" # Add local label file path here.
INPUT_VIDEO: "/data/SCB/slowfast/mywork/1.mp4"
OUTPUT_FILE: "/data/SCB/slowfast/mywork/1_1.mp4"
DETECTRON2_CFG: "COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml"
DETECTRON2_WEIGHTS: "/data/SCB/slowfast/mywork/model_final_280758.pkl"
5.5 demo测试
在/data/SCB/slowfast/mywork/中传入一个视频:1.mp4
执行:
cd /data/SCB/slowfast/
python tools/run_net.py --cfg demo/AVA/SLOWFAST_32x2_R101_50_50s.yaml
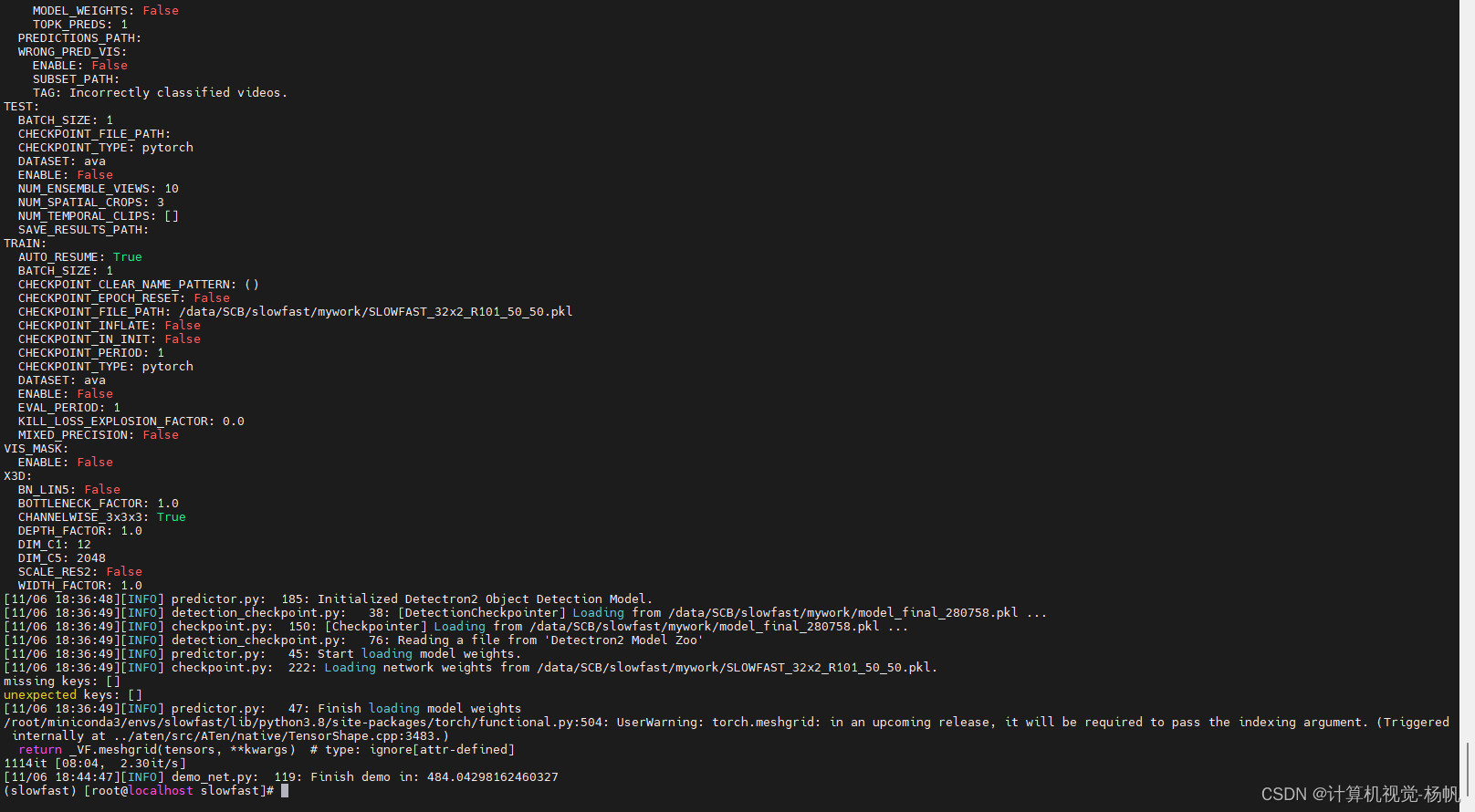
5.6 训练
训练的配置文件 SLOWFAST_32x2_R101_50_50s.yaml
slowfast/configs/AVA/c2/SLOWFAST_32x2_R101_50_50s.yaml
TRAIN:
ENABLE: True
DATASET: ava
BATCH_SIZE: 8
EVAL_PERIOD: 1
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
# CHECKPOINT_FILE_PATH: /data/SCB/slowfast/mywork/SLOWFAST_32x2_R101_50_50.pkl
CHECKPOINT_TYPE: pytorch
DATA:
NUM_FRAMES: 32
SAMPLING_RATE: 2
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 256
INPUT_CHANNEL_NUM: [3, 3]
PATH_TO_DATA_DIR: '/data/SCB/Dataset/SCB-ava-Dataset4'
DETECTION:
ENABLE: True
# ENABLE: False
ALIGNED: False
VIS_MASK:
ENABLE: True
AVA:
FRAME_DIR: '/data/SCB/Dataset/SCB-ava-Dataset4/frames'
FRAME_LIST_DIR: '/data/SCB/Dataset/SCB-ava-Dataset4/frame_lists'
ANNOTATION_DIR: '/data/SCB/Dataset/SCB-ava-Dataset4/annotations'
DETECTION_SCORE_THRESH: 0.8
TRAIN_PREDICT_BOX_LISTS: [
"ava_train_v2.2.csv",
"person_box_67091280_iou90/ava_detection_train_boxes_and_labels_include_negative_v2.2.csv",
]
TEST_PREDICT_BOX_LISTS: [
"person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]
FULL_TEST_ON_VAL: True
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 5
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 101
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[6, 13, 20], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
BASE_LR: 0.01
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
OPTIMIZING_METHOD: sgd
MAX_EPOCH: 50
MODEL:
# NUM_CLASSES: 80
NUM_CLASSES: 3
ARCH: slowfast
MODEL_NAME: SlowFast
# LOSS_FUNC: bce
LOSS_FUNC: cross_entropy
# LOSS_FUNC: F_BCE
DROPOUT_RATE: 0.5
# HEAD_ACT: sigmoid
TEST:
ENABLE: True
DATASET: ava
BATCH_SIZE: 1
DATA_LOADER:
NUM_WORKERS: 2
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: '/data/SCB/slowfast/mywork/out/'
注意 NUM_GPUS 和 TEST.BATCH_SIZE 要保持一致
训练
python tools/run_net.py \
--cfg configs/AVA/c2/SLOWFAST_32x2_R101_50_50s.yaml
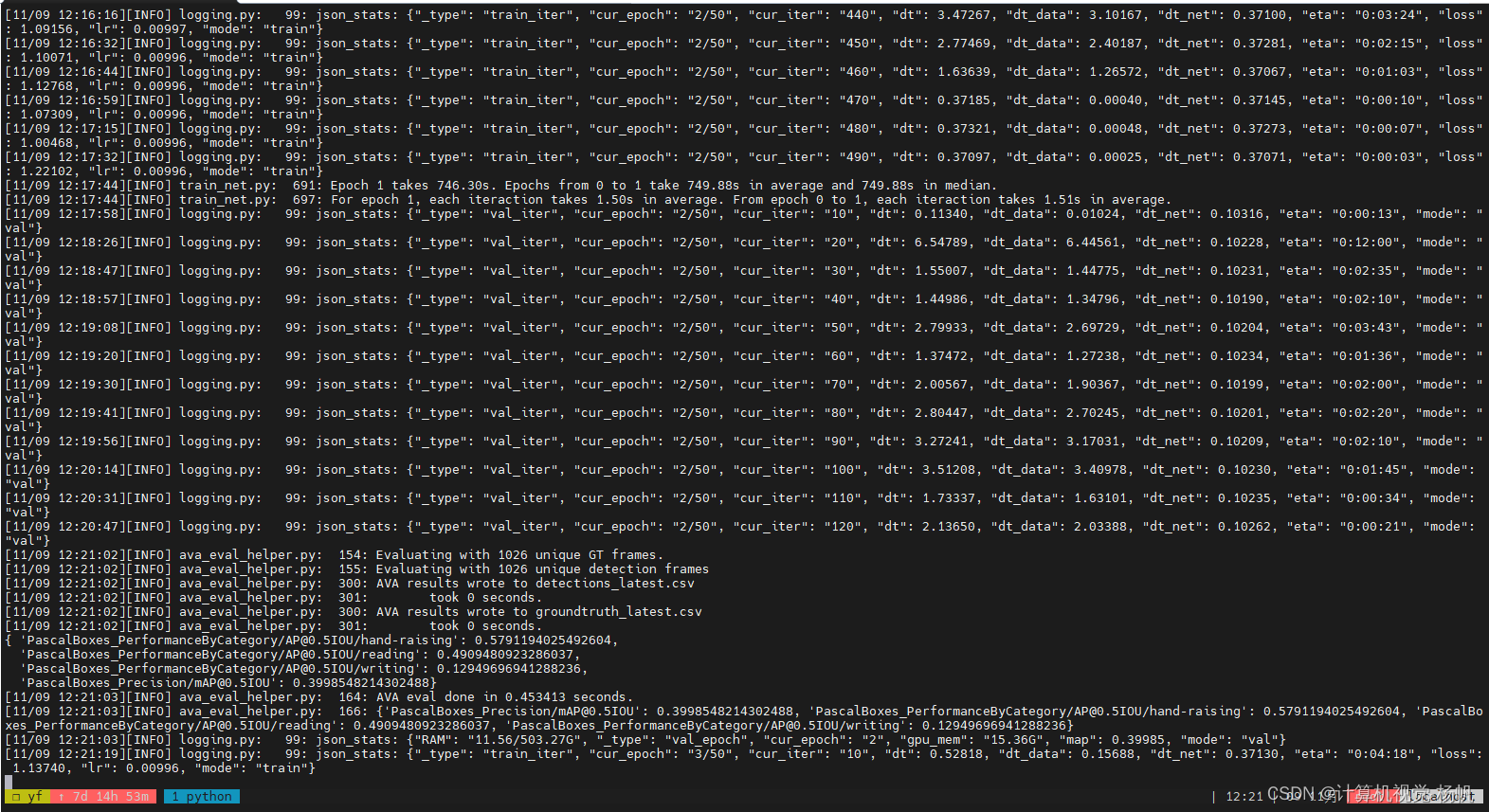
6 其他
6.1 日志文件修改
在日志文件中添加类似如下内容:
{ 'PascalBoxes_PerformanceByCategory/[email protected]/hand-raising': 0.9341844125742432,
'PascalBoxes_PerformanceByCategory/[email protected]/reading': 0.29780414588177817,
'PascalBoxes_PerformanceByCategory/[email protected]/writing': 0.375,
'PascalBoxes_Precision/[email protected]': 0.5356628528186738}
在"slowfast/slowfast/utils/ava_eval_helper.py"
添加:
logger.info("AVA eval done in %f seconds." % (time.time() - eval_start))
logger.info(results)
return results["PascalBoxes_Precision/[email protected]"]
结果如下:
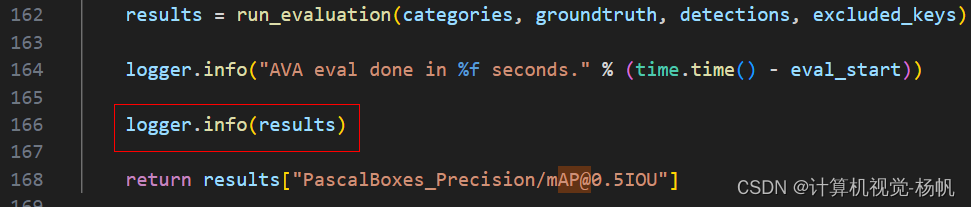

相关参考
[深度学习][原创]slowfast的demo跑起来的正确方法
[深度学习][原创]使用labelImg+yolov5完成所有slowfast时空动作检测项目-开山篇
[深度学习][原创]使用labelImg+yolov5完成所有slowfast时空动作检测项目-流程篇
[深度学习][原创]使用labelImg+yolov5完成所有slowfast时空动作检测项目-配置文件篇
[深度学习][原创]使用labelImg+yolov5完成所有slowfast时空动作检测项目-训练测试篇
[深度学习][原创]mmaction2时空动作检测过滤成自己想要的类别