本文主要阐述了如何使用第二代6B模型进行对话训练,以及如何通过微调来提高大模型的性能。文中提到了在8501端口上启动第二代6B模型,并使用极简模板进行请求。与第一代模型相比,第二代6B模型具有更强的对话能力,并且可以通过微调来适应特定任务。此外,本文还介绍了如何使用ChatGLM-6B模型进行调用,以及如何使用gradio进行环境隔离和客户端创建。最后,文中提到了向量数据库和基于大模型的RAG或chatbot等检索方法。
ChatGLM3-6B 模型私有化部署
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
使用 Transformers 库加载模型
可以通过如下代码调用 ChatGLM-6B 模型来生成对话:
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
模型的实现仍然处在变动中。如果希望固定使用的模型实现以保证兼容性,可以在 from_pretrained 的调用中增加 revision=“v1.1.0” 参数。以上代码会由 transformers 自动下载模型实现和参数。完整的模型实现可以在 Hugging Face Hub。如果你的网络环境较差,下载模型参数可能会花费较长时间甚至失败。此时可以先将模型下载到本地,然后从本地加载。
使用 Gradio WebUI 启动模型(Basic Demo)
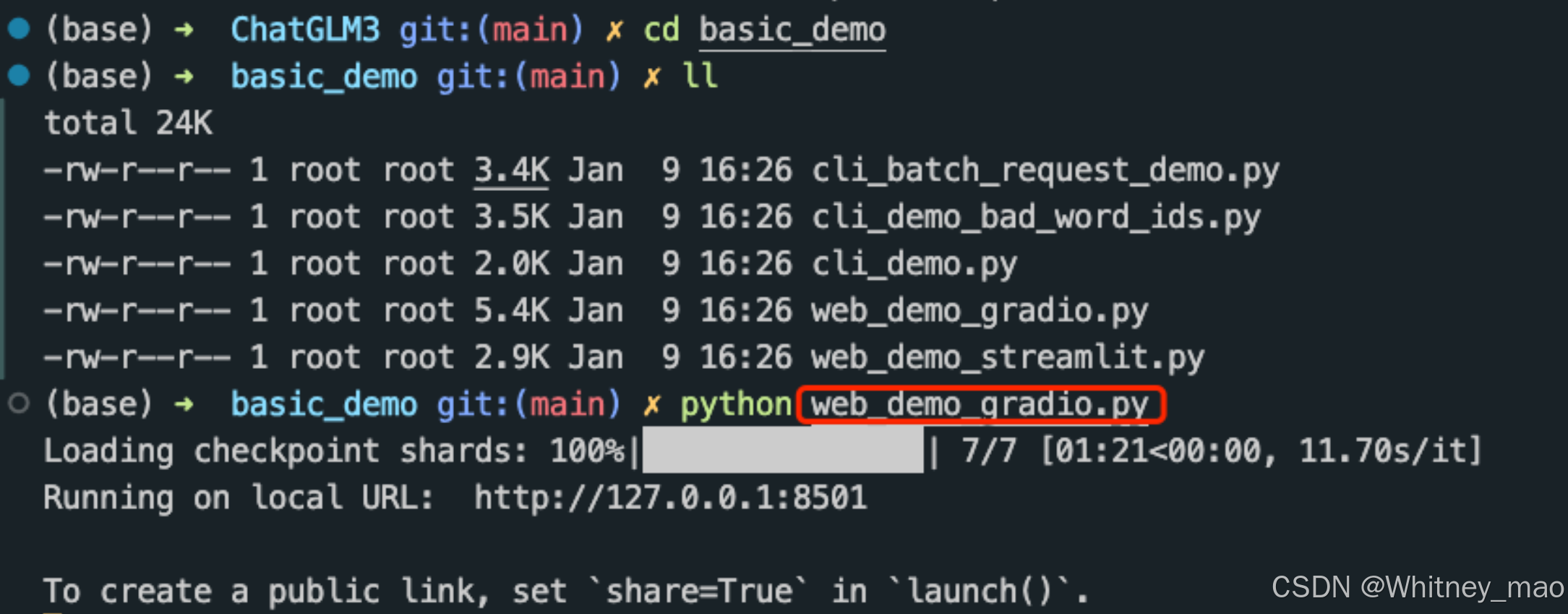
首先安装 Gradio:pip install gradio,然后运行仓库中的 web_demo.py:
git clone https://github.com/THUDM/ChatGLM-6B
cd ChatGLM-6B
程序会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。最新版 Demo 实现了打字机效果,速度体验大大提升。
2024年的 PR 更新改变了 ChatGLM3 代码结构,相关DEMO启动文件均移动到 *_demo目录下。
README.md 还未及时更新,如下所示:
通过GradIO和LangChain,可以将ChatGLM模型转换为有界面的应用。
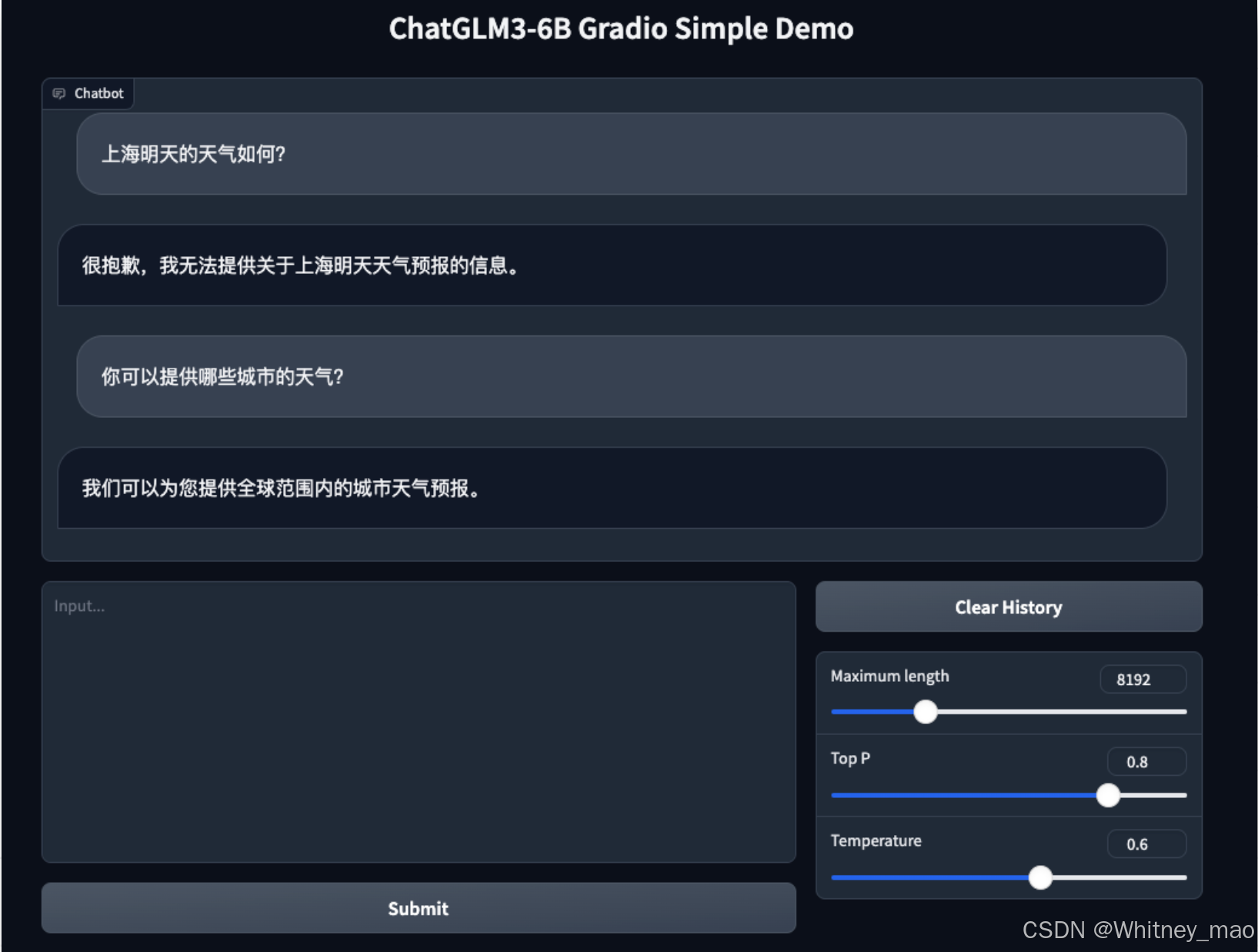
使用 Streamlit WebUI 启动模型(Composite Demo)
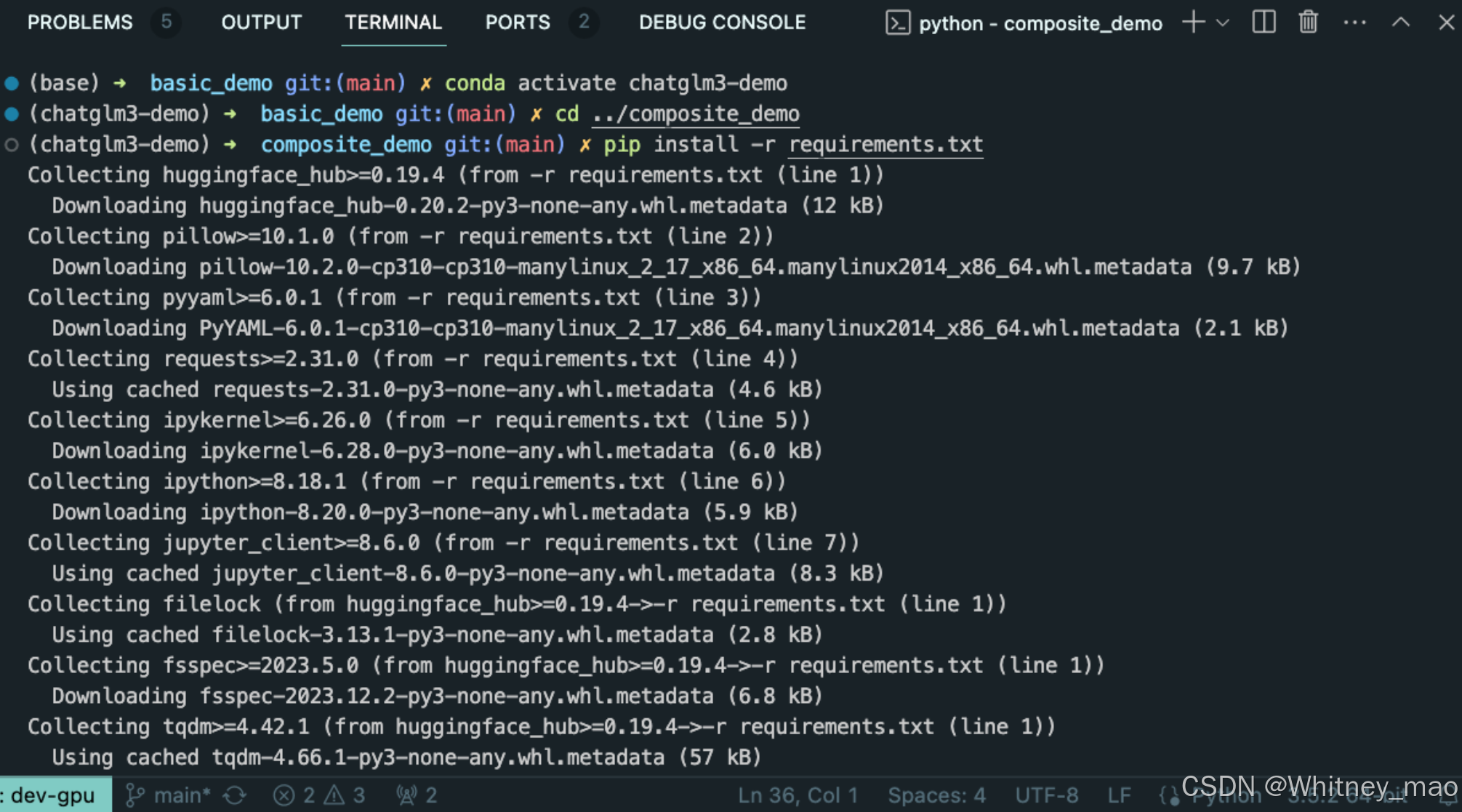
建议将 ChatGLM3 的依赖包都安装在此隔离环境中:
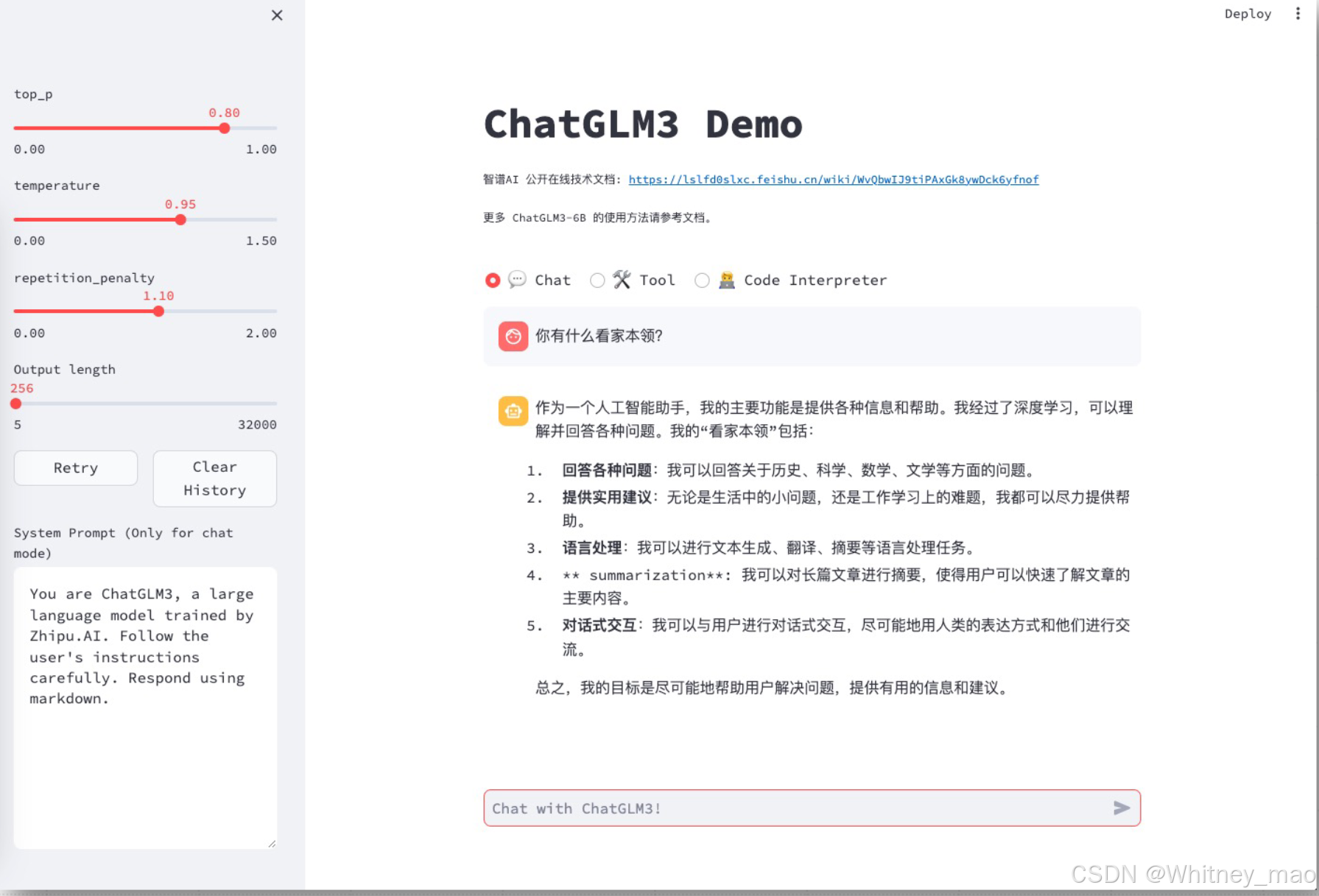
使用 Streamlit Web UI 部署 ChatGLM3-6B(对话 + 工具模式 + 代码解释器)
使用 Streamlit Web UI 部署 ChatGLM3-6B(对话)
使用 Streamlit Web UI 部署 ChatGLM3-6B(后台日志)
局限性
由于 ChatGLM-6B 的小规模,其能力仍然有许多局限性。以下是我们目前发现的一些问题:
- 模型容量较小:6B 的小容量,决定了其相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息;它也不擅长逻辑类问题(如数学、编程)的解答。
- 产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。
- 英文能力不足:ChatGLM-6B 训练时使用的指示/回答大部分都是中文的,仅有极小一部分英文内容。因此,如果输入英文指示,回复的质量远不如中文,甚至与中文指示下的内容矛盾,并且出现中英夹杂的情况。
- 易被误导,对话能力较弱:ChatGLM-6B 对话能力还比较弱,而且 “自我认知” 存在问题,并很容易被误导并产生错误的言论。例如当前版本的模型在被误导的情况下,会在自我认知上发生偏差。
LangChain 与 ChatGLM 生态集成
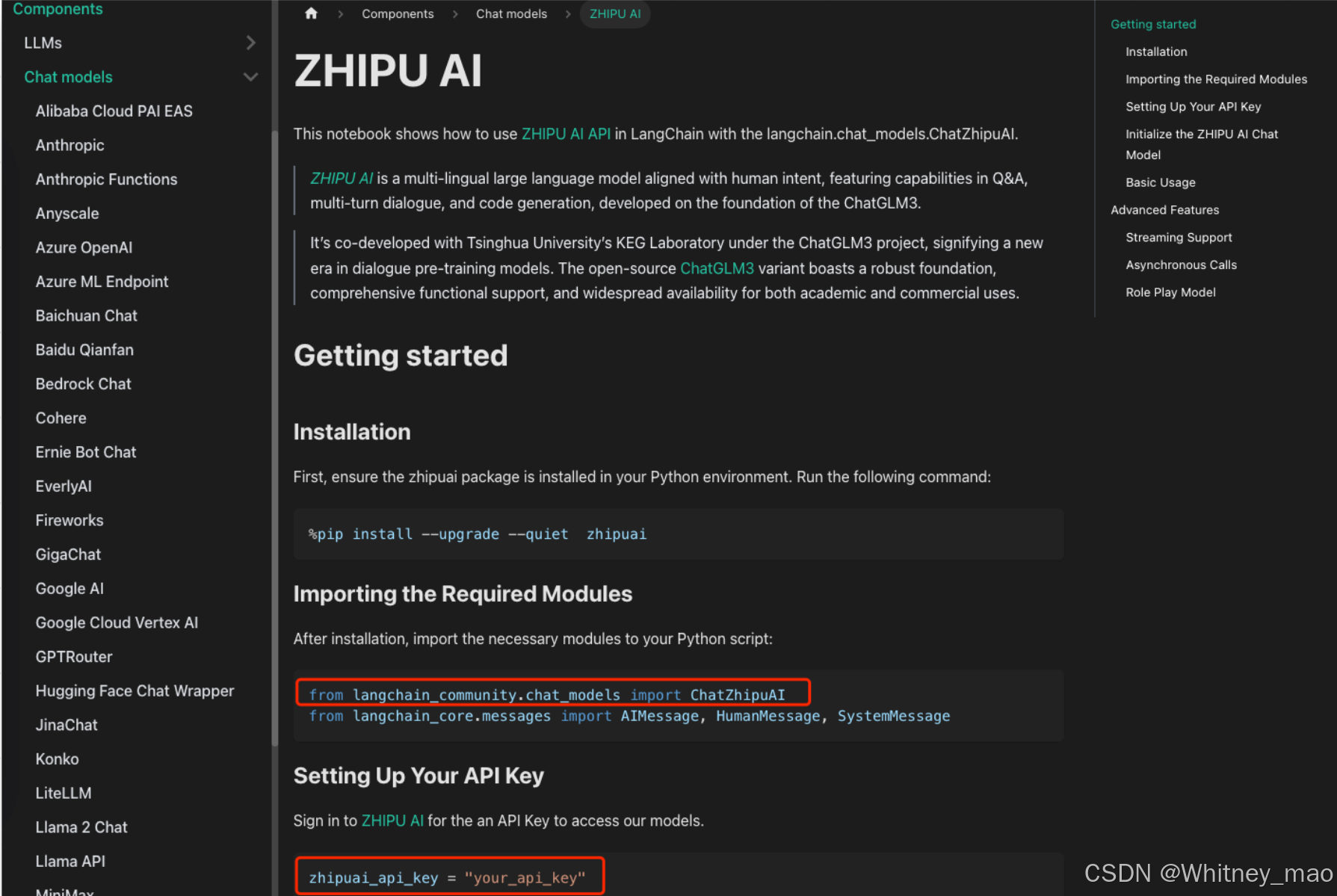
使用 LangChain 调用 ZHIPU AI 模型服务(API KEY)
https://python.langchain.com/docs/integrations/chat/zhipuai
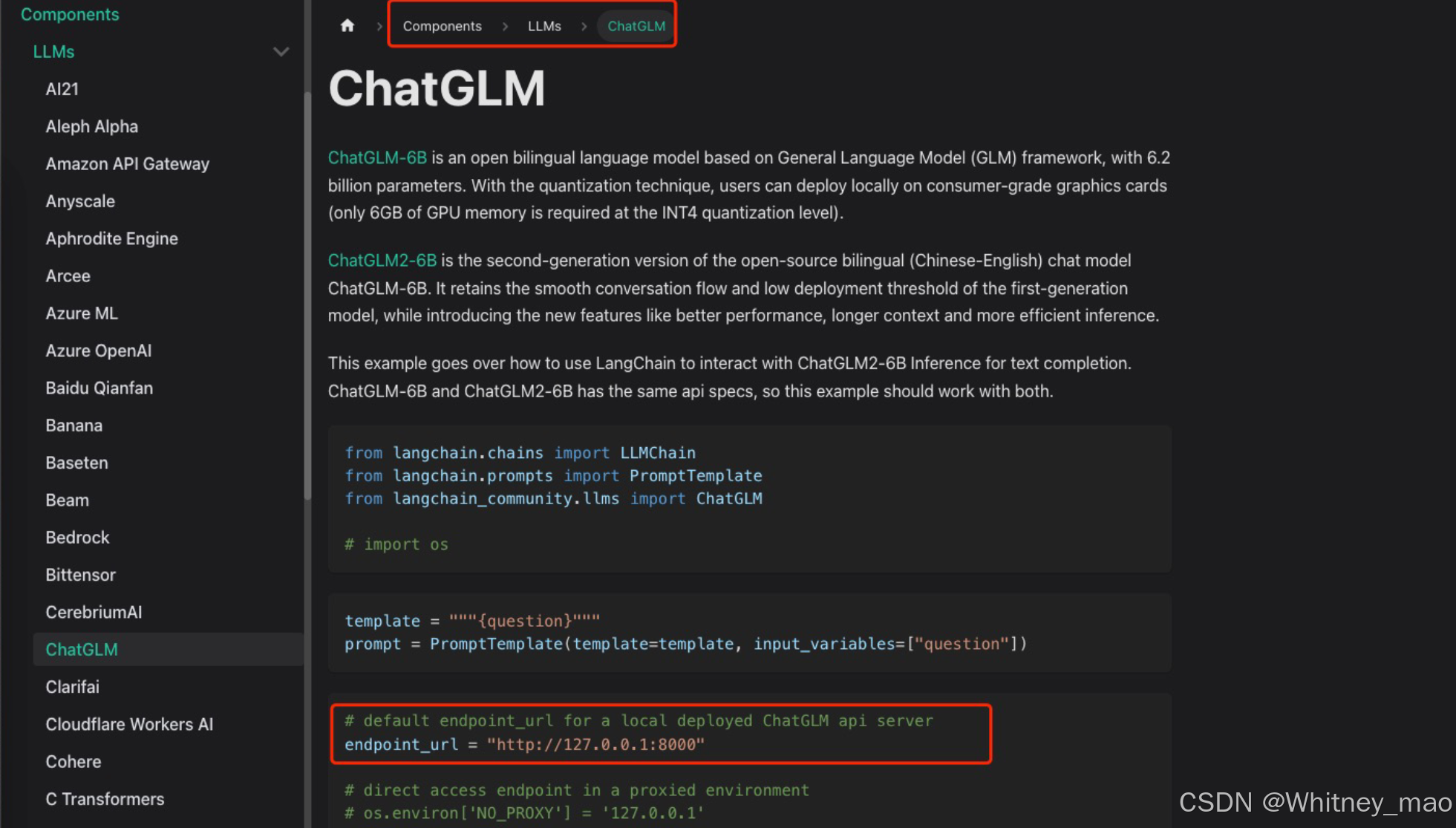
私有化部署 ChatGLM2-6B API Server(LLM Mode)
https://python.langchain.com/docs/integrations/llms/chatglm
ChatGLM模型优化方法
使用 LangChain LLMChain 调用 ChatGLM2-6B 模型服务
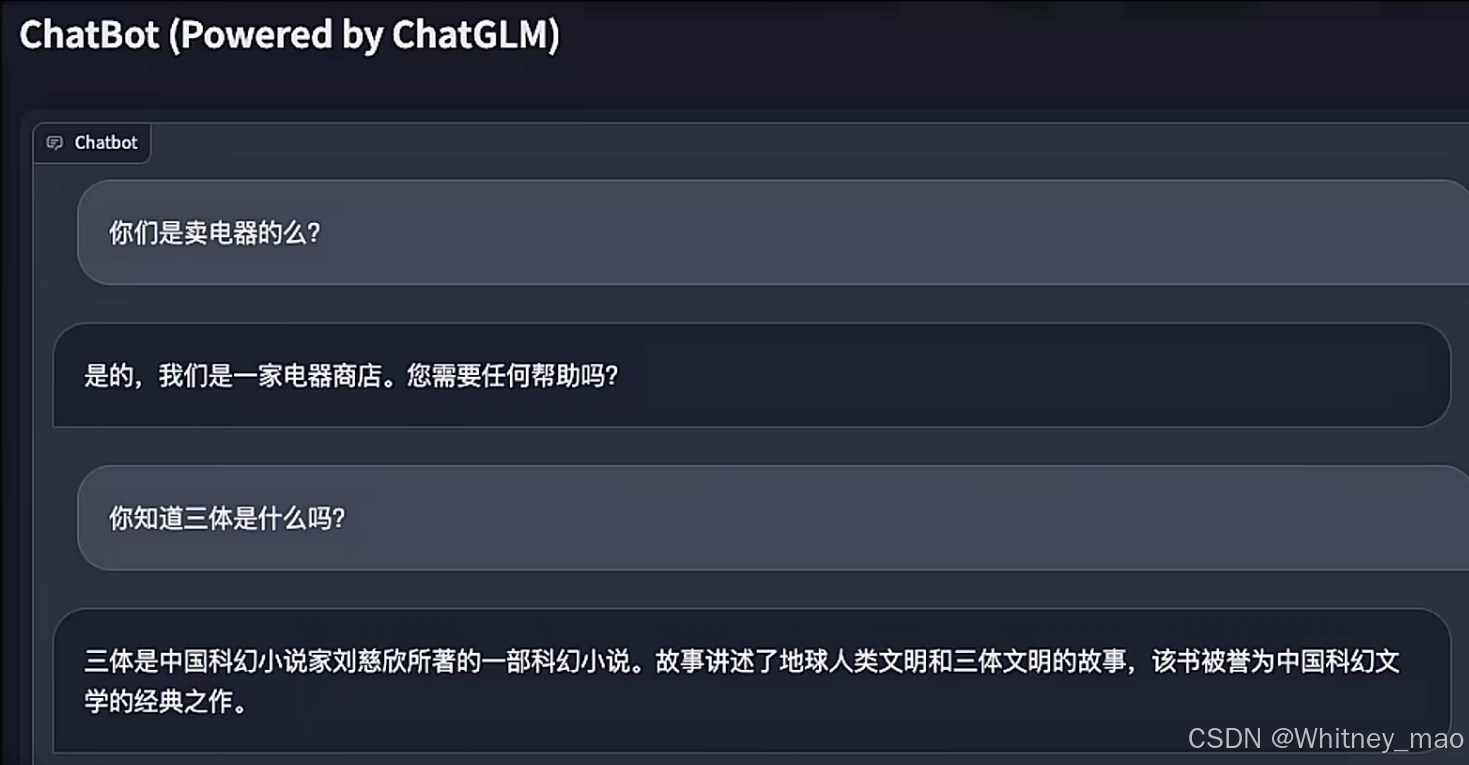
gradio就是在ConversationChain外面套上一层Web UI,并采用history这种记录方式记录对话内容。LangChain调用ChatGLM模型服务的pipeline,形成如下图的基础框架,并基于此框架,内嵌向量知识库库以及查询功能,从而形成各种垂类聊天类型的机器人。
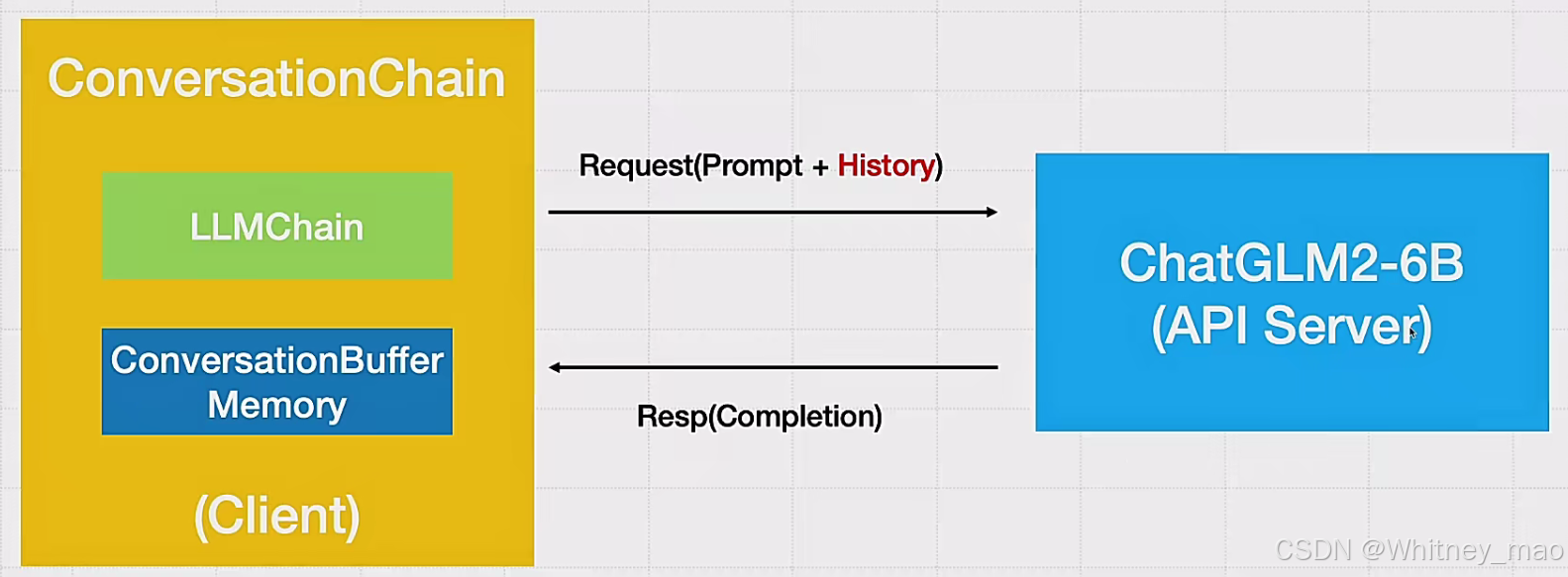
使用 LangChain ConversationChain 调用 ChatGLM2-6B 模型服务
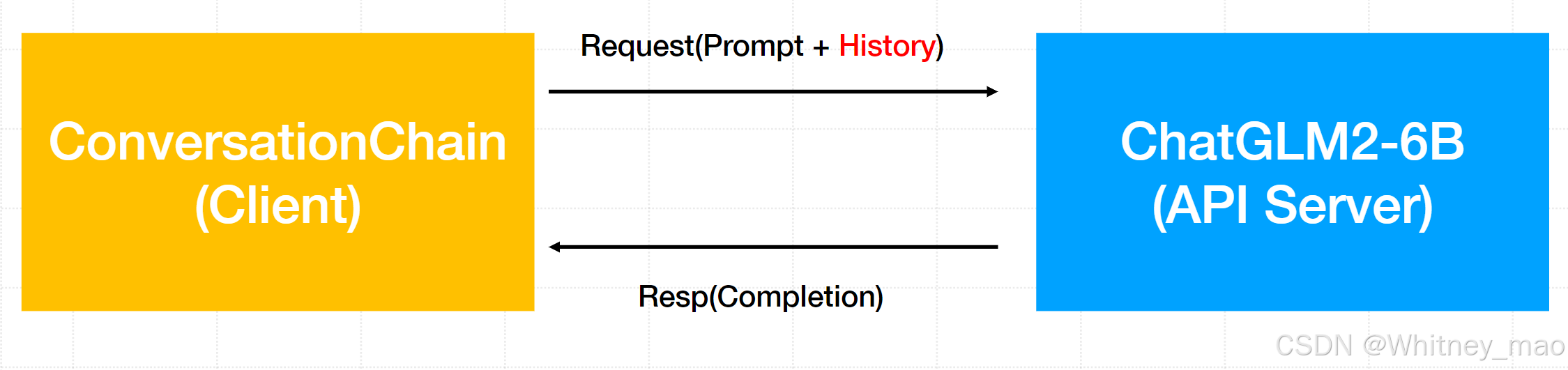
LLMChain 实现单轮对话
from langchain_community.llms import ChatGLM
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# ChatGLM 私有化部署的 Endpoint URL
endpoint_url = "http://127.0.0.1:8001"
实例化 ChatGLM 大模型
llm = ChatGLM(
endpoint_url=endpoint_url,
max_token=80000,
history=[
["你是一个专业的销售顾问", "欢迎问我任何问题。"]
],
top_p=0.9,
model_kwargs={"sample_model_args": False},
)
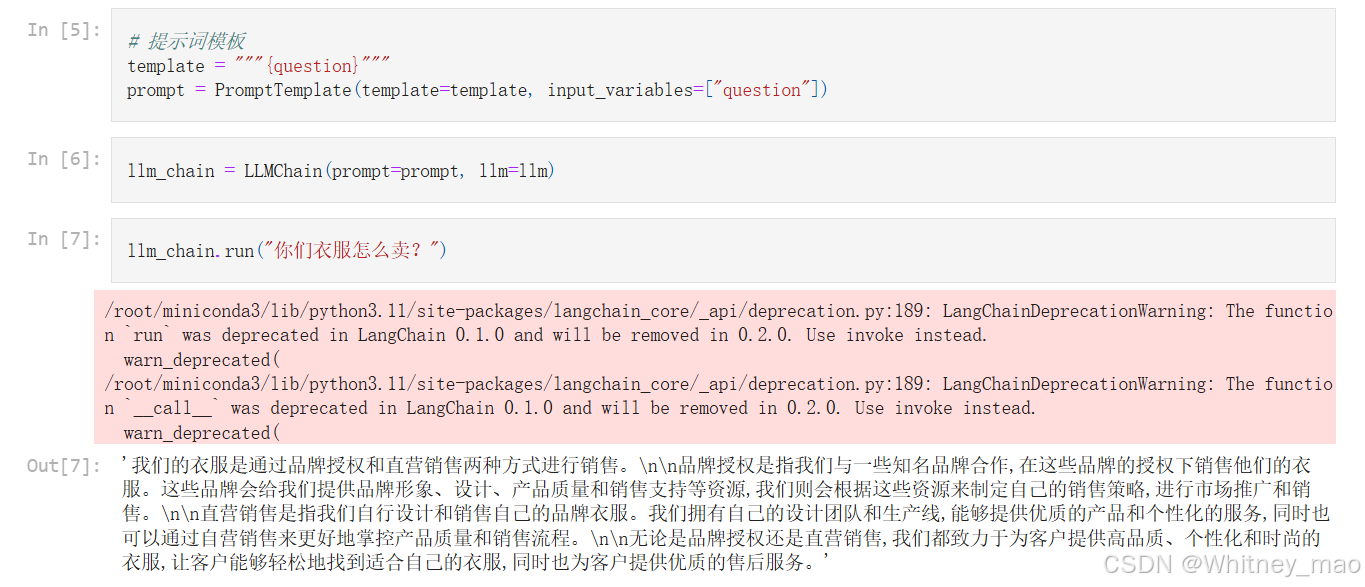
提示词模板
template = """{question}"""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm_chain = LLMChain(prompt=prompt, llm=llm)
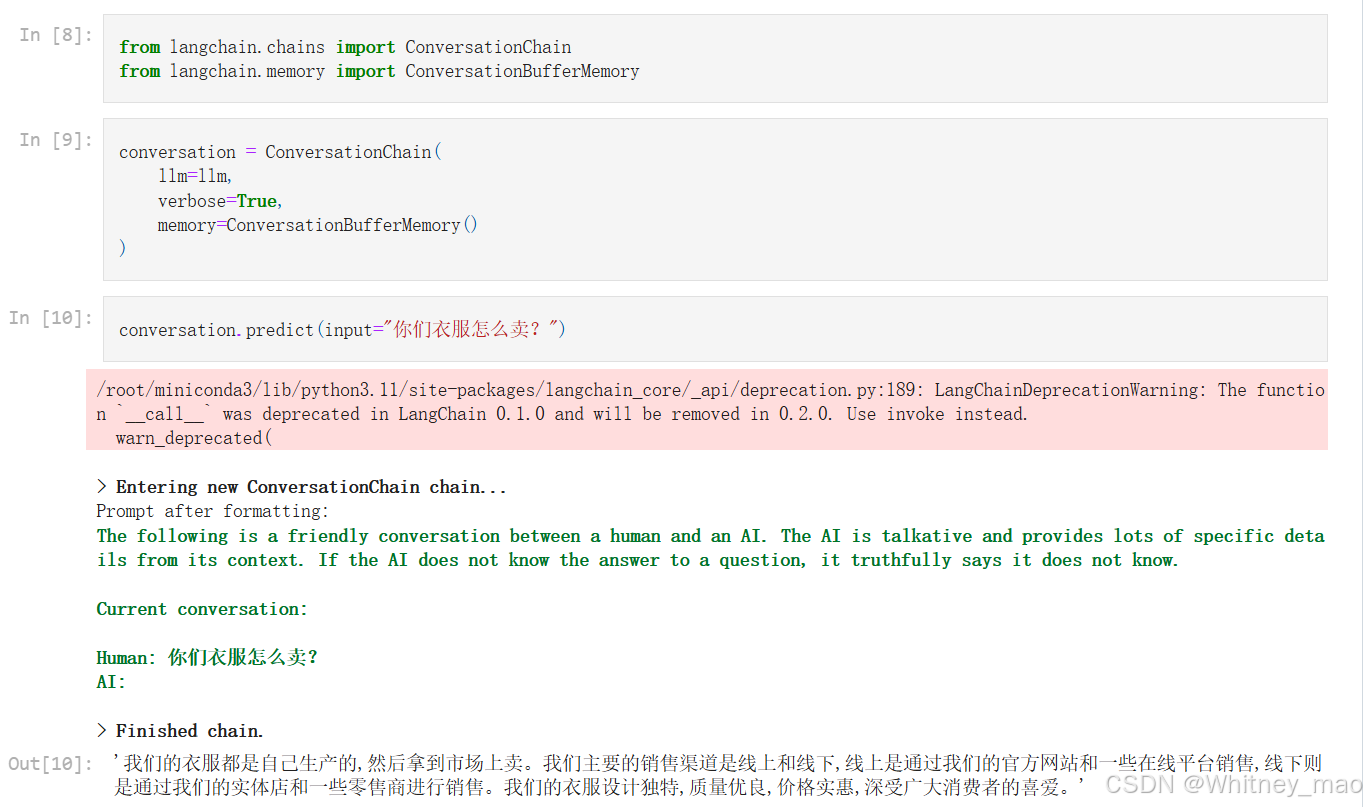
llm_chain.run("你们衣服怎么卖?")
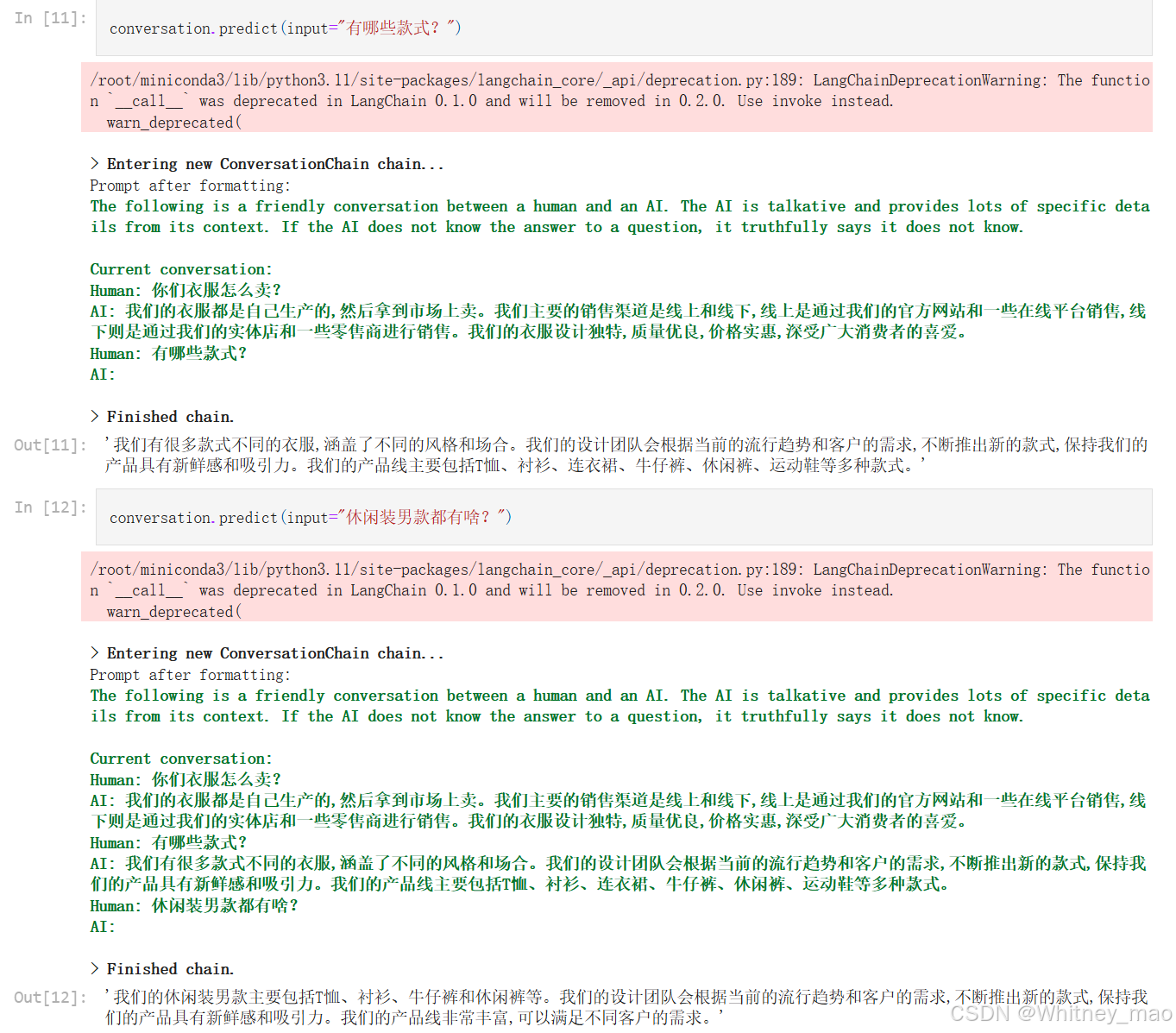
带记忆功能的聊天对话
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
conversation = ConversationChain(
llm=llm,
verbose=True,
memory=ConversationBufferMemory()
)