【题目】:LoFLAT: Local Feature Matching using Focused Linear Attention Transformer
【中文题目】:LoFLAT:使用聚焦线性注意力变换器进行局部特征匹配
【引用格式】:Cao N, He R, Dai Y, et al. LoFLAT: Local Feature Matching using Focused Linear Attention Transformer[J]. arXiv preprint arXiv:2410.22710, 2024.
【网址】:https://arxiv.org/pdf/2410.22710
目录
一、瓶颈问题
- Transformer 的注意力机制(SoftMax)具有二次复杂度,在处理高分辨率图像时会导致计算成本过高
- 现有的基于线性注意力机制的方法虽然降低了计算成本,但难以捕捉像素标签之间的详细局部交互,从而影响了精确局部对应关系的准确性和鲁棒性
二、本文贡献
- 提出了使用聚焦线性注意力变换器的新型局部特征匹配算法 LoFLAT
- 提出了聚焦线性注意力,通过聚焦映射函数细化注意力分布,并通过深度卷积增强特征多样性
三、解决方案
LoFLAT 方法主要由三个模块组成:特征提取模块 (FEM)、特征 Transformer 模块 (FTM) 和匹配模块 (MM)。特征提取模块首先采用ResNet作为特征提取的backbone,另外为了提取不同分辨率的特征,文中还加入了特征金字塔网络,来构建多尺度特征金字塔。然后,特征Transformer模块通过使用自注意力和交叉注意力捕捉与上下文相关且位置相关的局部特征。最后,匹配模块通过一个从粗到细的过程,输出精确而稳健的特征匹配结果。整体架构如下图:
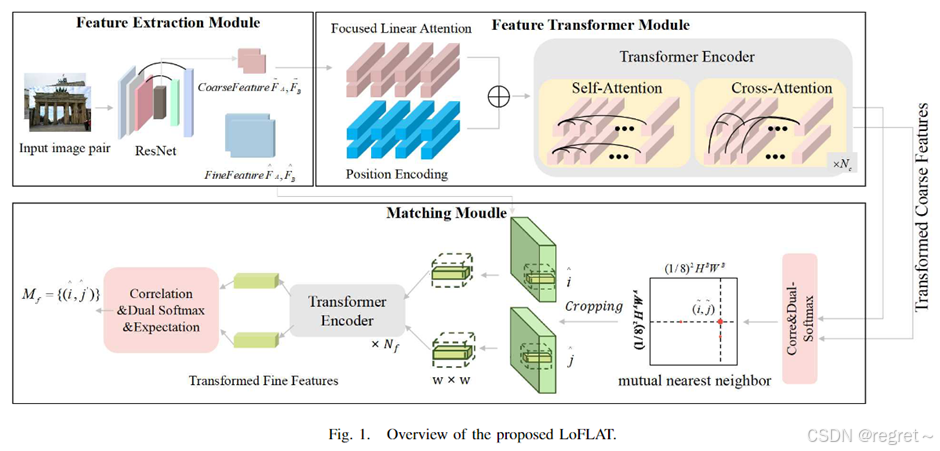
1 特征提取模块
文中使用了ResNet和多层金字塔来提取多尺度特征。其中粗特征表示为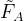
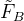
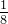
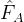
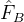
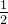
2 特征Transformer模块
在特征提取之后,特征Transformer模块会整合位置和上下文信息,将

和
视觉Transformer的核心部件是Transformer编码器,由多个自注意力层和前馈神经网络层组成,旨在捕捉全局上下文信息,能够整合整个图像的信息并与之互动,从而超越局部感受野的限制。通常,这些注意力层采用的是Softmax注意或线性注意力。
2.1 Softmax注意力
Softmax注意力是Transformer中最基本的注意力形式,通过Queries和keys之间的相似性为值元素分配权重,生成输出向量,是模型能够并行处理信息并捕捉全局上下文信息。计算公式如下所示:
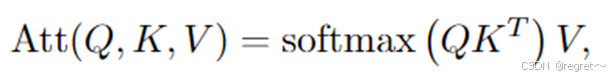
然而,在实践中直接使用Softmax注意力具有挑战性,并且由于具有全局感受野的Softmax注意力的二次复杂性,会导致过高的计算成本。因此,大多是方法主要采用线性注意力作为有效的代替方法,其具有更高的计算效率、更低的内存要求以及实时处理的有效性。
2.2 线性注意力
线性注意力的计算复杂度为O(N)而Softmax的计算复杂度为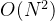
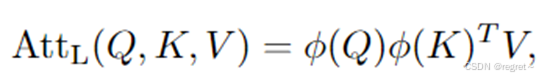
其中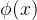
2.3 基于聚焦线性的Transformer
以往的研究表明,与 Softmax 注意力相比,线性注意的分布相对更平滑。这表明线性注意力中的注意力权重在多个输入特征中的分布更为均匀。然而,对于粗匹配来说,Softmax 注意力更锐利的分布特点使模型能够关注较少的一组关键特征,从而增强其分辨能力。
文中为了解决模型复杂性和表征有效性这两个问题,提出了聚焦线性注意力。首先采用聚焦映射函数,从Queries和keys中提炼出关键特征;随后,遵循线性注意力原则,在保持注意力层输出准确性的同时降低计算成本。同时,将深度卷积应用于Values,来捕捉详细的局部特征,从而提高模型对细粒度信息的敏感度;最终,文中整合了两个过程的输出结果,生成了一个兼顾全局背景和丰富局部细节的特征表征。具有框架及公式如下:
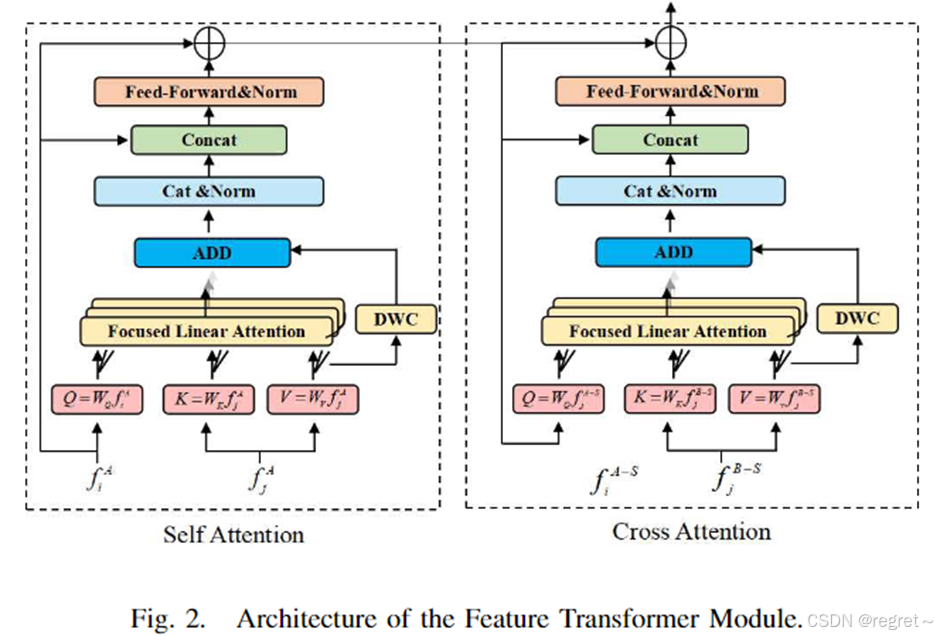
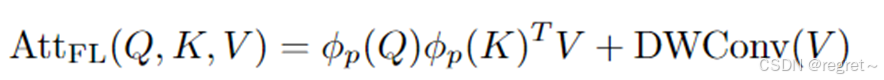
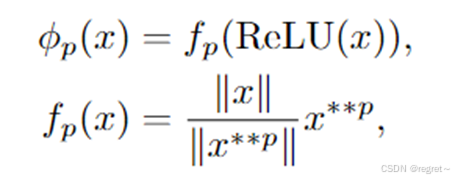
在核函数中,ReLU函数用于确保所有输入值都是非负和有效的。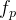
深度卷积(DWConv)用于进一步提高模型捕捉局部特征和增加特征多样性的能力。DWConv 部分作为一种局部关注机制,使每个查询只关注其空间邻域内有限的一组特征,而不是全局性地考虑所有特征。这种局部关注的好处在于,即使两个查询在传统的线性关注机制中获得相同的关注权重,DWConv 也能确保它们从不同的局部特征子集中提取信息。
3 匹配模块
有了与位置和上下文相关的局部特征,就可以通过一个从粗到细的过程来建立精确而稳健的匹配对。具体来说,首先应用双Softmax 算子,通过估计概率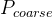
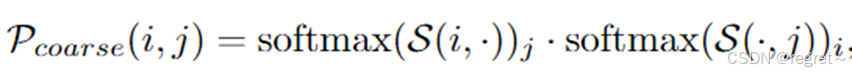
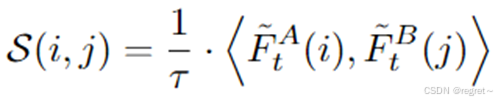
粗匹配最初是根据概率矩阵
四、实验结果
数据集:MegaDepth数据集
指标:文中使用 5◦、10◦ 和 20◦ 阈值下姿态误差的 AUC。.姿态误差以旋转和平移角度误差的最大值来衡量。为了确定摄像机的姿态,文中使用 RANSAC 从预测的匹配中估算出基本矩阵
实验环境:使用了4个英伟达显卡(NVIDIA GeForce RTX 3090 GPUs),每台上的batch size 为1,即有效批次规模为4。文中共花费69小时训练30轮。
参数设置:权重衰减为0.1的AdamW优化器;初始学习率为0.006,并在运行过程中动态调整实际学习率。防止梯度爆炸,使用了梯度裁剪法,阈值为0.5。
实验结果:文中重新训练了LoFTER作为baseline,并将原始图像的大小调整为500×500像素。

(a)和(b)中,可以看出,在视角变化较小的情况下,两种方法都能获得高密度的匹配结果。不过文中提出的方法匹配的特征带你更多而且准确性更高。(c)和(d)中,在视角变化较大的场景中,LoFTER的准确度明显下降,导致错误匹配的数量增加。
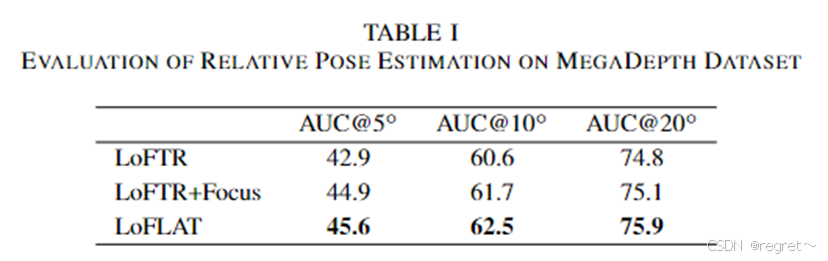
这里进一步比较了 LoFTR 和文中提出的 LoFLAT 在不同角度误差阈值(5◦、10◦ 和 20◦)下的 AUC 指标性能。从表中可以看出,在三个阈值下,文中的模型都优于基准方法 LoFTR,分别提高了 2.7%、1.9% 和 0.9%。在更严格的阈值条件下(即更小的角度误差),性能提升更为明显。文中的方法可能在需要精确匹配的任务中表现尤为出色。