1 spark on yarn常用属性介绍
| 属性名 | 默认值 | 属性说明 |
|---|---|---|
spark.yarn.am.memory | 512m | 在客户端模式(client mode)下,yarn应用master使用的内存数。在集群模式(cluster mode)下,使用spark.driver.memory代替。 |
spark.driver.cores | 1 | 在集群模式(cluster mode)下,driver程序使用的核数。在集群模式(cluster mode)下,driver程序和master运行在同一个jvm中,所以master控制这个核数。在客户端模式(client mode)下,使用spark.yarn.am.cores控制master使用的核。 |
spark.yarn.am.cores | 1 | 在客户端模式(client mode)下,yarn应用的master使用的核数。在集群模式下,使用spark.driver.cores代替。 |
spark.yarn.am.waitTime | 100ms | 在集群模式(cluster mode)下,yarn应用master等待SparkContext初始化的时间。在客户端模式(client mode)下,master等待driver连接到它的时间。 |
spark.yarn.submit.file.replication | 3 | 文件上传到hdfs上去的replication次数 |
spark.yarn.preserve.staging.files | false | 设置为true时,在job结束时,保留staged文件;否则删掉这些文件。 |
spark.yarn.scheduler.heartbeat.interval-ms | 3000 | Spark应用master与yarn resourcemanager之间的心跳间隔 |
spark.yarn.scheduler.initial-allocation.interval | 200ms | 当存在挂起的容器分配请求时,spark应用master发送心跳给resourcemanager的间隔时间。它的大小不能大于spark.yarn.scheduler.heartbeat.interval-ms,如果挂起的请求还存在,那么这个时间加倍,直到到达spark.yarn.scheduler.heartbeat.interval-ms大小。 |
spark.yarn.max.executor.failures | numExecutors * 2,并且不小于3 | 在失败应用程序之前,executor失败的最大次数。 |
spark.executor.instances | 2 | Executors的个数。这个配置和spark.dynamicAllocation.enabled不兼容。当同时配置这两个配置时,动态分配关闭,spark.executor.instances被使用 |
spark.yarn.executor.memoryOverhead | executorMemory * 0.10,并且不小于384m | 每个executor分配的堆外内存。 |
spark.yarn.driver.memoryOverhead | driverMemory * 0.10,并且不小于384m | 在集群模式下,每个driver分配的堆外内存。 |
spark.yarn.am.memoryOverhead | AM memory * 0.10,并且不小于384m | 在客户端模式下,每个driver分配的堆外内存 |
spark.yarn.am.port | 随机 | Yarn 应用master监听的端口。 |
spark.yarn.queue | default | 应用提交的yarn队列的名称 |
spark.yarn.jar | none | Jar文件存放的地方。默认情况下,spark jar安装在本地,但是jar也可以放在hdfs上,其他机器也可以共享。 |
2 客户端模式和集群模式的区别
这里我们要区分一下什么是客户端模式(client mode),什么是集群模式(cluster mode)。
我们知道,当在YARN上运行Spark作业时,每个Spark executor作为一个YARN容器(container)运行。Spark可以使得多个Tasks在同一个容器(container)里面运行。
yarn-cluster和yarn-client模式的区别其实就是Application Master进程的区别,在yarn-cluster模式下,driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行。然而yarn-cluster模式不适合运行交互类型的作业。
在yarn-client模式下,Application Master仅仅向YARN请求executor,client会和请求的container通信来调度他们工作,也就是说Client不能离开。下面的图形象表示了两者的区别。
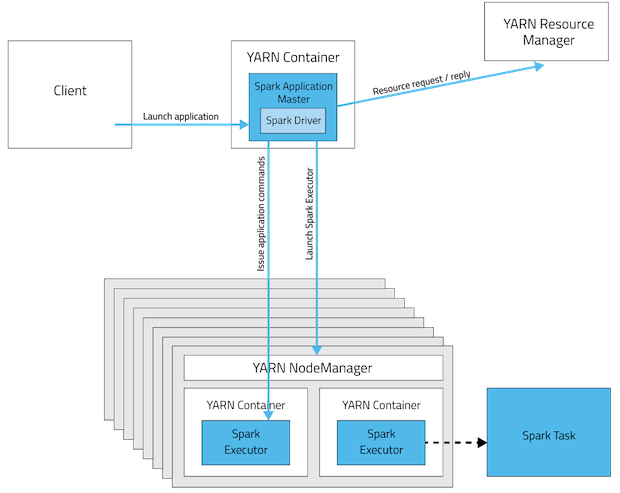

2.1 Spark on YARN集群模式分析
2.1.1 客户端操作
1、根据
yarnConf来初始化yarnClient,并启动yarnClient;2、创建客户端
Application,并获取Application的ID,进一步判断集群中的资源是否满足executor和ApplicationMaster申请的资源,如果不满足则抛出IllegalArgumentException;3、设置资源、环境变量:其中包括了设置
Application的Staging目录、准备本地资源(jar文件、log4j.properties)、设置Application其中的环境变量、创建Container启动的Context等;4、设置
Application提交的Context,包括设置应用的名字、队列、AM的申请的Container、标记该作业的类型为Spark;5、申请
Memory,并最终通过yarnClient.submitApplication向ResourceManager提交该Application。
当作业提交到YARN上之后,客户端就没事了,甚至在终端关掉那个进程也没事,因为整个作业运行在YARN集群上进行,运行的结果将会保存到HDFS或者日志中。
2.1.2 提交到YARN集群,YARN操作
1、运行
ApplicationMaster的run方法;2、设置好相关的环境变量。
3、创建
amClient,并启动;4、在
Spark UI启动之前设置Spark UI的AmIpFilter;5、在
startUserClass函数专门启动了一个线程(名称为Driver的线程)来启动用户提交的Application,也就是启动了Driver。在Driver中将会初始化SparkContext;6、等待
SparkContext初始化完成,最多等待spark.yarn.applicationMaster.waitTries次数(默认为10),如果等待了的次数超过了配置的,程序将会退出;否则用SparkContext初始化yarnAllocator;7、当
SparkContext、Driver初始化完成的时候,通过amClient向ResourceManager注册ApplicationMaster;8、分配并启动
Executeors。在启动Executeors之前,先要通过yarnAllocator获取到numExecutors个Container,然后在Container中启动Executeors。
如果在启动Executeors的过程中失败的次数达到了maxNumExecutorFailures的次数,maxNumExecutorFailures的计算规则如下:
// 默认为numExecutors * 2,最少为3
private val maxNumExecutorFailures = sparkConf.getInt("spark.yarn.max.executor.failures",
sparkConf.getInt("spark.yarn.max.worker.failures", math.max(args.numExecutors * 2, 3)))那么这个Application将失败,将Application Status标明为FAILED,并将关闭SparkContext。其实,启动Executeors是通过ExecutorRunnable实现的,而ExecutorRunnable内部是启动CoarseGrainedExecutorBackend的。
- 9、最后,
Task将在CoarseGrainedExecutorBackend里面运行,然后运行状况会通过Akka通知CoarseGrainedScheduler,直到作业运行完成。
2.2 Spark on YARN客户端模式分析
和yarn-cluster模式一样,整个程序也是通过spark-submit脚本提交的。但是yarn-client作业程序的运行不需要通过Client类来封装启动,而是直接通过反射机制调用作业的main函数。下面是流程。
1、通过
SparkSubmit类的launch的函数直接调用作业的main函数(通过反射机制实现),如果是集群模式就会调用Client的main函数。2、而应用程序的
main函数一定都有个SparkContent,并对其进行初始化;3、在
SparkContent初始化中将会依次做如下的事情:设置相关的配置、注册MapOutputTracker、BlockManagerMaster、BlockManager,创建taskScheduler和dagScheduler;4、初始化完
taskScheduler后,将创建dagScheduler,然后通过taskScheduler.start()启动taskScheduler,而在taskScheduler启动的过程中也会调用SchedulerBackend的start方法。
在SchedulerBackend启动的过程中将会初始化一些参数,封装在ClientArguments中,并将封装好的ClientArguments传进Client类中,并client.runApp()方法获取Application ID。5、
client.runApp里面的做的和上章客户端进行操作那节类似,不同的是在里面启动是ExecutorLauncher(yarn-cluster模式启动的是ApplicationMaster)。6、在
ExecutorLauncher里面会初始化并启动amClient,然后向ApplicationMaster注册该Application。注册完之后将会等待driver的启动,当driver启动完之后,会创建一个MonitorActor对象用于和CoarseGrainedSchedulerBackend进行通信(只有事件AddWebUIFilter他们之间才通信,Task的运行状况不是通过它和CoarseGrainedSchedulerBackend通信的)。
然后就是设置addAmIpFilter,当作业完成的时候,ExecutorLauncher将通过amClient设置Application的状态为FinalApplicationStatus.SUCCEEDED。7、分配
Executors,这里面的分配逻辑和yarn-cluster里面类似。8、最后,
Task将在CoarseGrainedExecutorBackend里面运行,然后运行状况会通过Akka通知CoarseGrainedScheduler,直到作业运行完成。9、在作业运行的时候,
YarnClientSchedulerBackend会每隔1秒通过client获取到作业的运行状况,并打印出相应的运行信息,当Application的状态是FINISHED、FAILED和KILLED中的一种,那么程序将退出等待。10、最后有个线程会再次确认
Application的状态,当Application的状态是FINISHED、FAILED和KILLED中的一种,程序就运行完成,并停止SparkContext。整个过程就结束了。
3 spark submit 和 spark shell参数介绍
| 参数名 | 格式 | 参数说明 |
|---|---|---|
| –master | MASTER_URL | 如spark://host:port |
| –deploy-mode | DEPLOY_MODE | Client或者master,默认是client |
| –class | CLASS_NAME | 应用程序的主类 |
| –name | NAME | 应用程序的名称 |
| –jars | JARS | 逗号分隔的本地jar包,包含在driver和executor的classpath下 |
| –packages | 包含在driver和executor的classpath下的jar包逗号分隔的”groupId:artifactId:version”列表 | |
| –exclude-packages | 用逗号分隔的”groupId:artifactId”列表 | |
| –repositories | 逗号分隔的远程仓库 | |
| –py-files | PY_FILES | 逗号分隔的”.zip”,”.egg”或者“.py”文件,这些文件放在python app的PYTHONPATH下面 |
| –files | FILES | 逗号分隔的文件,这些文件放在每个executor的工作目录下面 |
| –conf | PROP=VALUE | 固定的spark配置属性 |
| –properties-file | FILE | 加载额外属性的文件 |
| –driver-memory | MEM | Driver内存,默认1G |
| –driver-java-options | 传给driver的额外的Java选项 | |
| –driver-library-path | 传给driver的额外的库路径 | |
| –driver-class-path | 传给driver的额外的类路径 | |
| –executor-memory | MEM | 每个executor的内存,默认是1G |
| –proxy-user | NAME | 模拟提交应用程序的用户 |
| –driver-cores | NUM | Driver的核数,默认是1。这个参数仅仅在standalone集群deploy模式下使用 |
| –supervise | Driver失败时,重启driver。在mesos或者standalone下使用 | |
| –verbose | 打印debug信息 | |
| –total-executor-cores | NUM | 所有executor总共的核数。仅仅在mesos或者standalone下使用 |
| –executor-core | NUM | 每个executor的核数。在yarn或者standalone下使用 |
| –driver-cores | NUM | Driver的核数,默认是1。在yarn集群模式下使用 |
| –queue | QUEUE_NAME | 队列名称。在yarn下使用 |
| –num-executors | NUM | 启动的executor数量。默认为2。在yarn下使用 |
你可以通过spark-submit --help或者spark-shell --help来查看这些参数。