目录
注:下面的这些操作都是在上一篇文章的基础上去做细化的。包括数据库的创建以及表的创建都在上一篇文章中全部讲述到了,请大家先去把上一篇文章【《数据库操作基础》】阅读完毕后再来阅读这一篇文章。
1.新增
insert into 表名 values(值,值...);
insert into student values(1,"zhangsan");insert into student values(2,'李四');注:当我们要插入的数据是中文时,必须要注意我们在创建库的时候是否指定字符集是utf8。
特殊情况:
1.指定列插入:
insert into 表名(列名,列名...) values(值,值...);
注:所以指定列就填充相对应的值,没有被指定的列就会被填充默认值null;
2.一次插入多行数据
insert into 表名 values(值,值...),(值,值...)...;
注:其实一次插入多行数据相比于一次分多次插入要快不少;问:那到底是哪个环节导致了多次插入更快呢?答:因为MySQL是一个客户端服务器结构的程序,当我们要插入数据的时候,我们需要通过网络完成客户端与服务器之间的交互。当我们一次插入多条数据的时候只需要完成一次交互;但是当我们分多次插入的时候,就需要客户端与服务器之间完成多次的交互;
3.查询表中的数据
select * from 表名;
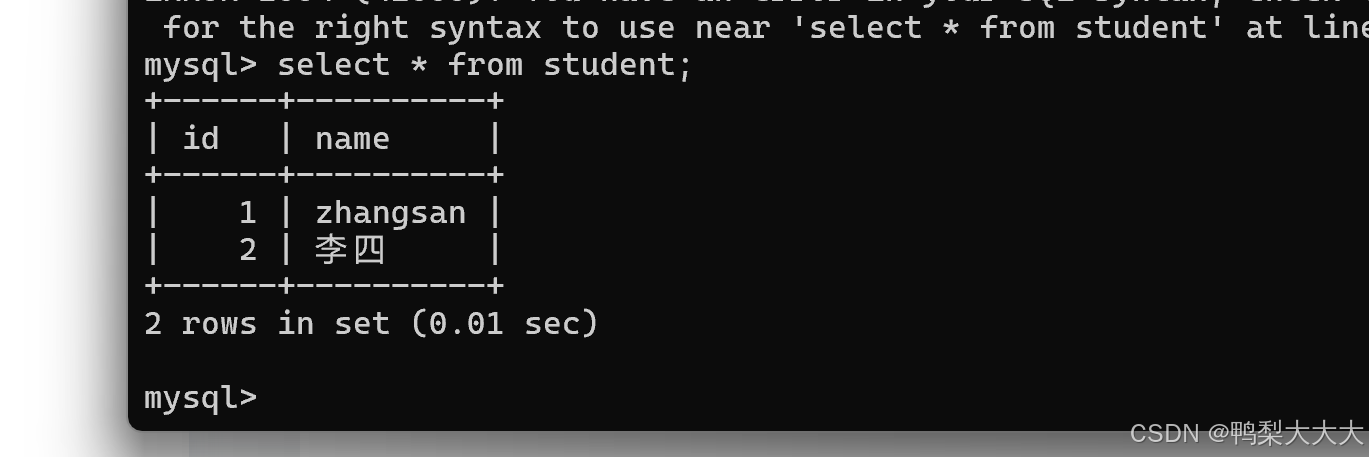
4.时间日期类的插入
1)先创建出一个新的表
create table student(id int,name varchar(20),birthday datetime);2)插入数据
注:那这里这个datetime类型的数据应该怎么插入呢?是可以用一个固定格式的字符串来表示时间日期的。
insert into student values(1,'张三','2004-11-25 12:00:00');※如果想填写的时间日期就是当前时刻:sql提供了一个现成的函数【now()】;例如:
insert into student values(2,'list',now());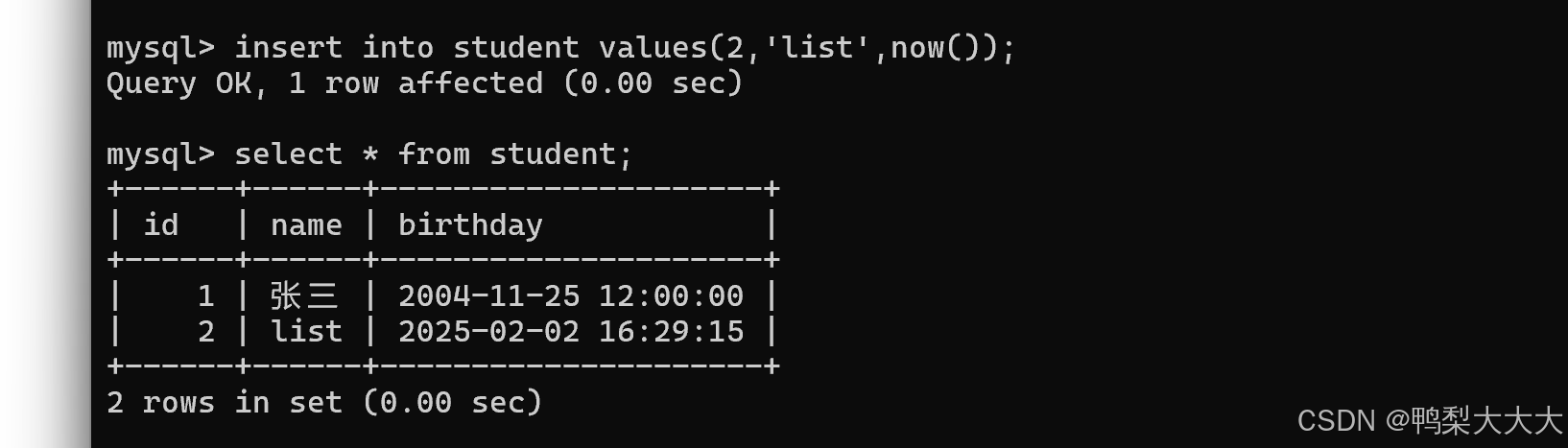
3)查询验证
select * from student;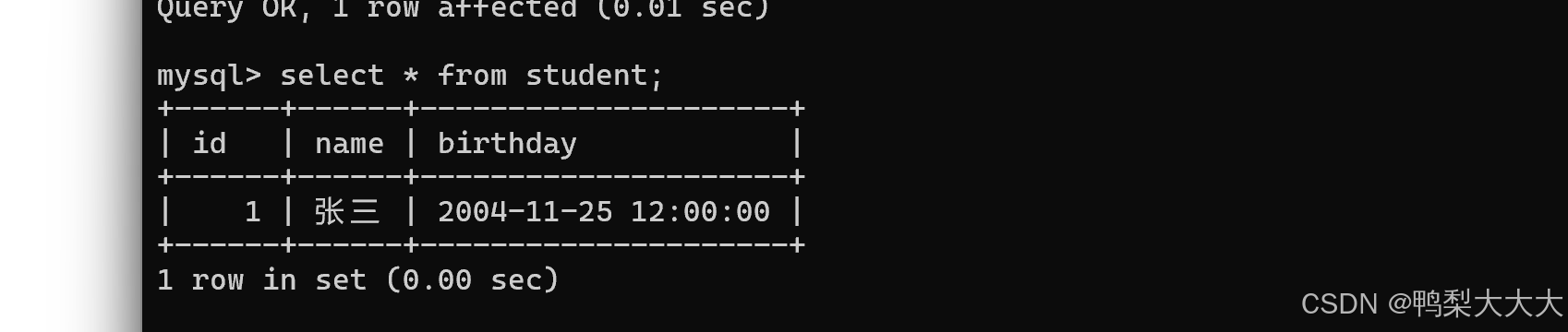
2.查询
注:在MySQL的增删改查中,最复杂的花样玩的最多的就是查询了;所以在这篇学习笔记中,查询时我们学习的重中之重;
准备工作:
1)先构造一个表
我们先构造一个表,然后基于这个表对这个表进行查询的各种操作;例如:
-- 创建考试成绩表
DROP TABLE IF EXISTS exam_result;
CREATE TABLE exam_result (
id INT,
name VARCHAR(20),
chinese DECIMAL(3,1),
math DECIMAL(3,1),
english DECIMAL(3,1)
);
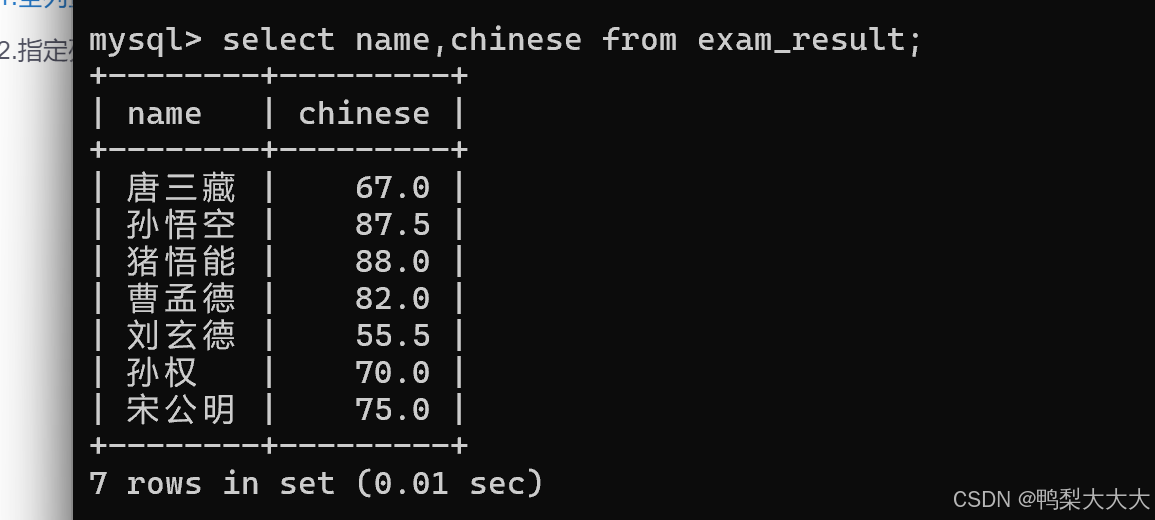
2)再来构造一个测试数据
-- 插入测试数据
INSERT INTO exam_result (id,name, chinese, math, english) VALUES
(1,'唐三藏', 67, 98, 56),
(2,'孙悟空', 87.5, 78, 77),
(3,'猪悟能', 88, 98.5, 90),
(4,'曹孟德', 82, 84, 67),
(5,'刘玄德', 55.5, 85, 45),
(6,'孙权', 70, 73, 78.5),
(7,'宋公明', 75, 65, 30);
查询方式:
1.全列查询
全列查询就是把这个表中所有行所有列都查询出来。
select * from 表名;
select * from exam_result;
这里是查询出来之后,服务器通过网络把这些数据返回给客户端的,并且在客户端以表格的形式打印出来。
select * 操作其实是一个危险操作;
MySQL是一个“客户端-服务器”结构的程序,客户端这里进行的操作就都会通过请求发送给服务器,而服务器查询的结果也就会通过响应返回给客户端。而我们在可以涉及到的请求和响应都是通过网络来进行的,而如果数据库当前这个表中的数据特别多就可能会产生问题;例如,1.读取硬盘,把硬盘的IO给跑满了,此时程序的其他部分想访问硬盘就会非常慢;2.操作网络,也可能把网卡的带宽跑满,此时其他客户端想通过网络访问服务器也会非常慢;
这样的拥堵就可能导致客户端无法顺利访问到数据库,进一步也就对整个系统造成影响(就是相当于数据库服务器挂了)
2.指定列查询
select 列名,列名... from 表名;
3.查询字段为表达式
顾名思义就是一边查询一边进行计算,即在查询的时候写作有列名构成的表达式,把这一列中的所有行都带入表达式中参与运算;
例如:想查询所有同学语文成绩都减10分之后的分数;
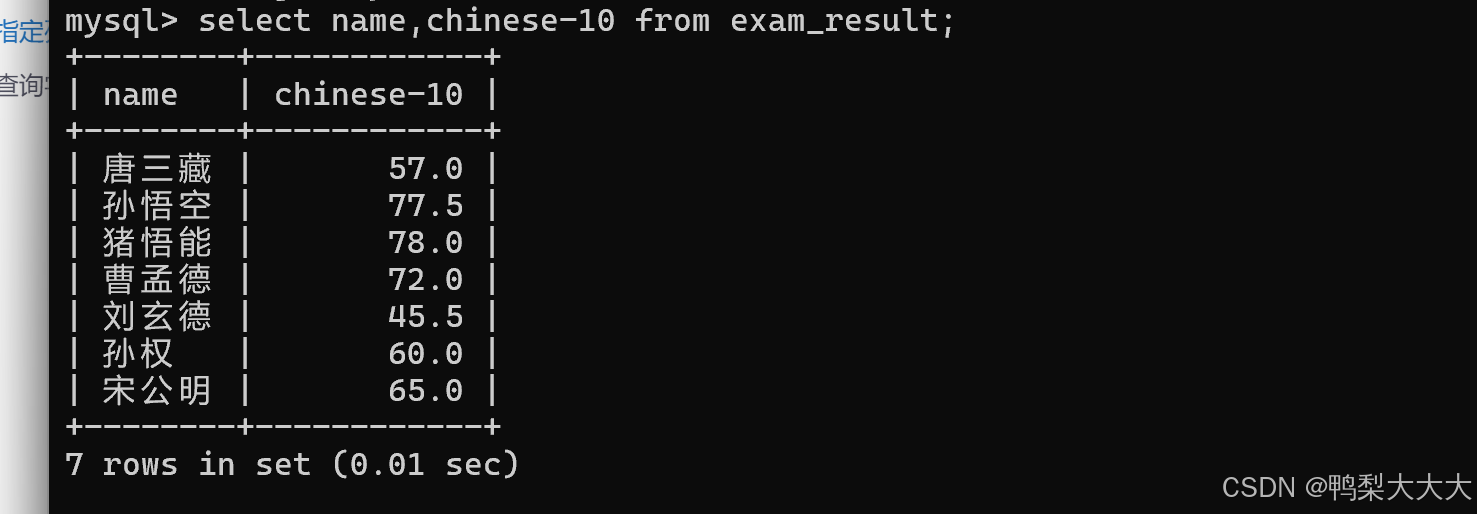
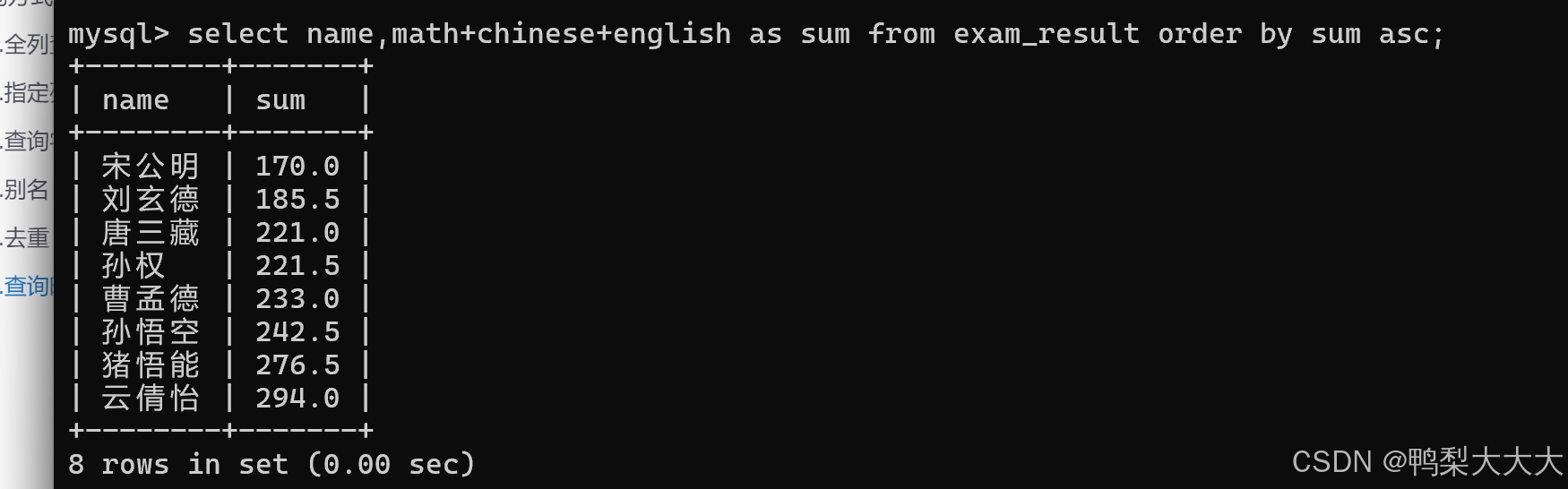
例如:计算所有同学三科的总成绩
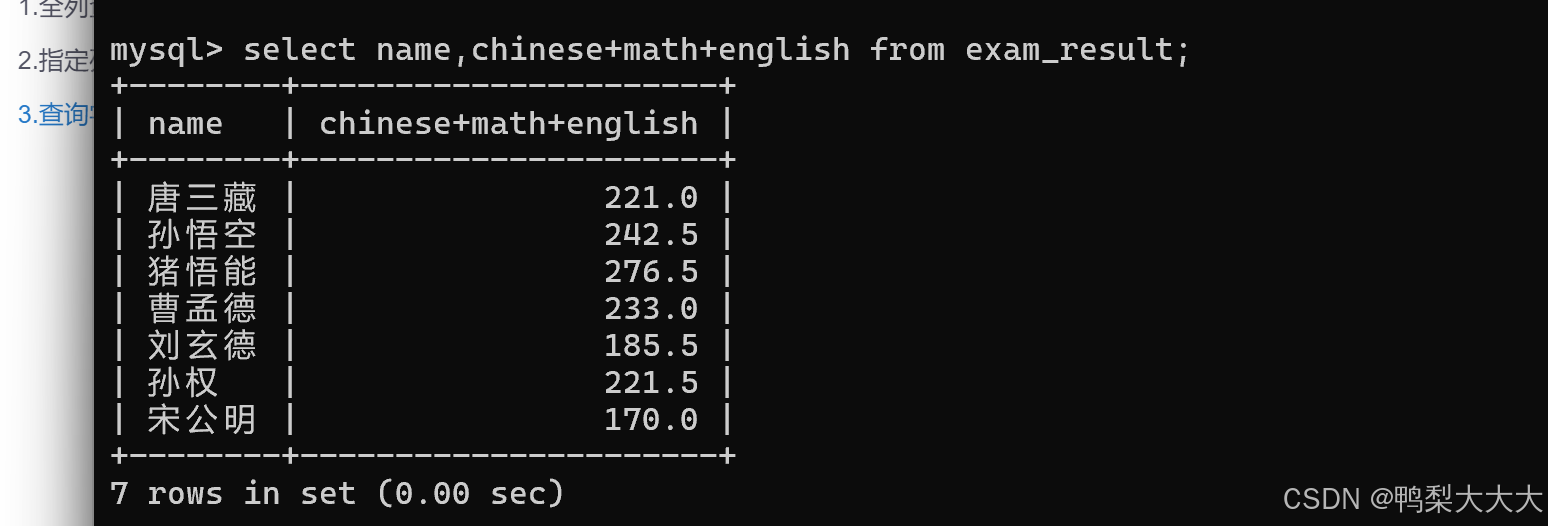
注意:这里的操作并不会修改数据库服务器上的原始数据,只是在最终响应里的“临时结果”中做了计算。
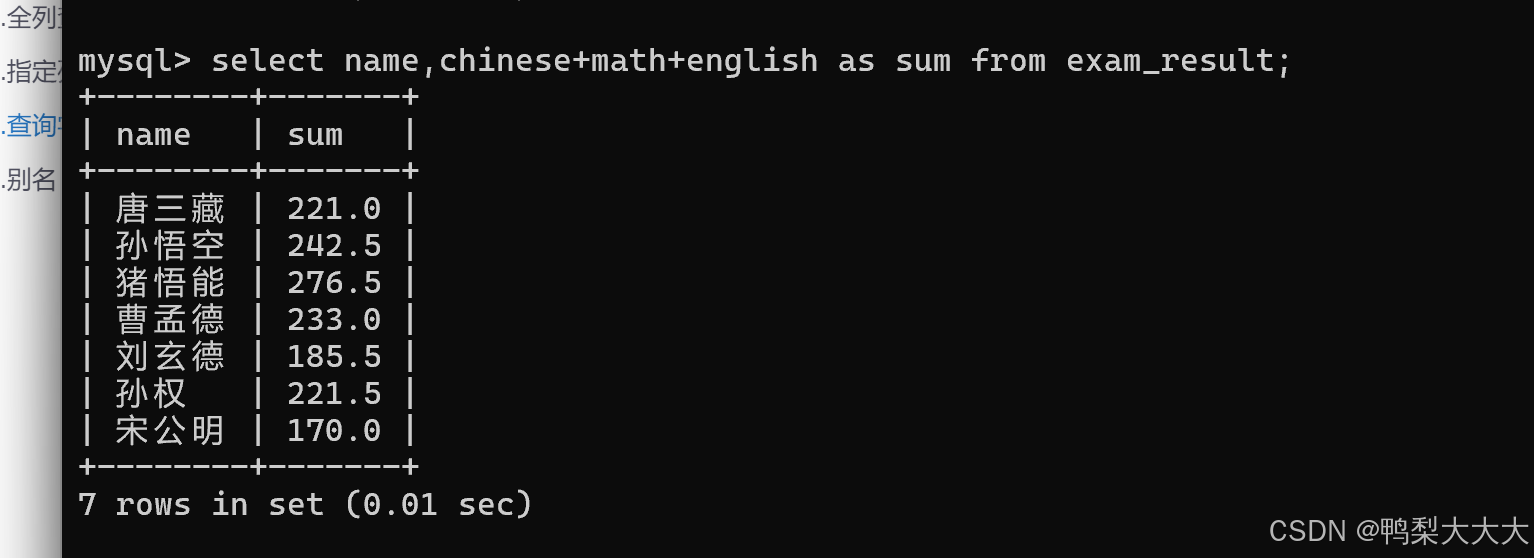
4.别名
查询的时候给 列/表达式 指定别名;【也能给表指定别名】
select 表达式 as 别名 from 表名;
例如:我将上述的Chinese+math+english 改成 sum 这个名字
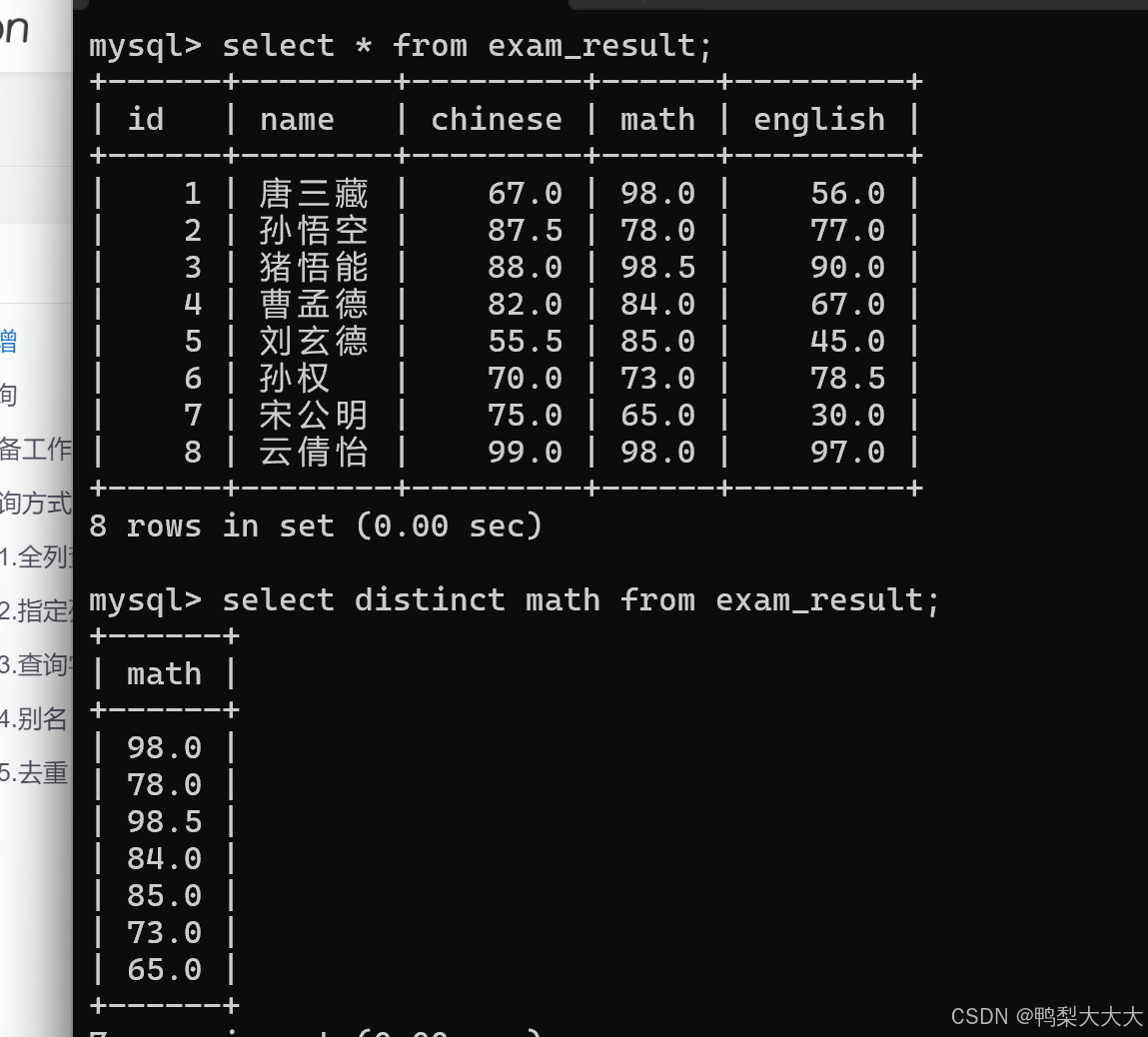
5.去重(distinct)
即用distinct修饰某个列/多个列,值相同的行只保留一个;例如:比较下图的不同之处
例如:去掉math那一列重复的行
例如:去除math和name同时重复的行

6.查询时排序
这里查询的时候排序是指把行进行排序;对于排序,我们主要是要明确排序规则:1.针对哪个列进行排序;2.排序的时候是降序还是升序;
select 列名 from 表名 order by 列名 asc/desc;
[asc:升序/desc:降序] 如果省略就是默认升序排序
升序:

降序:
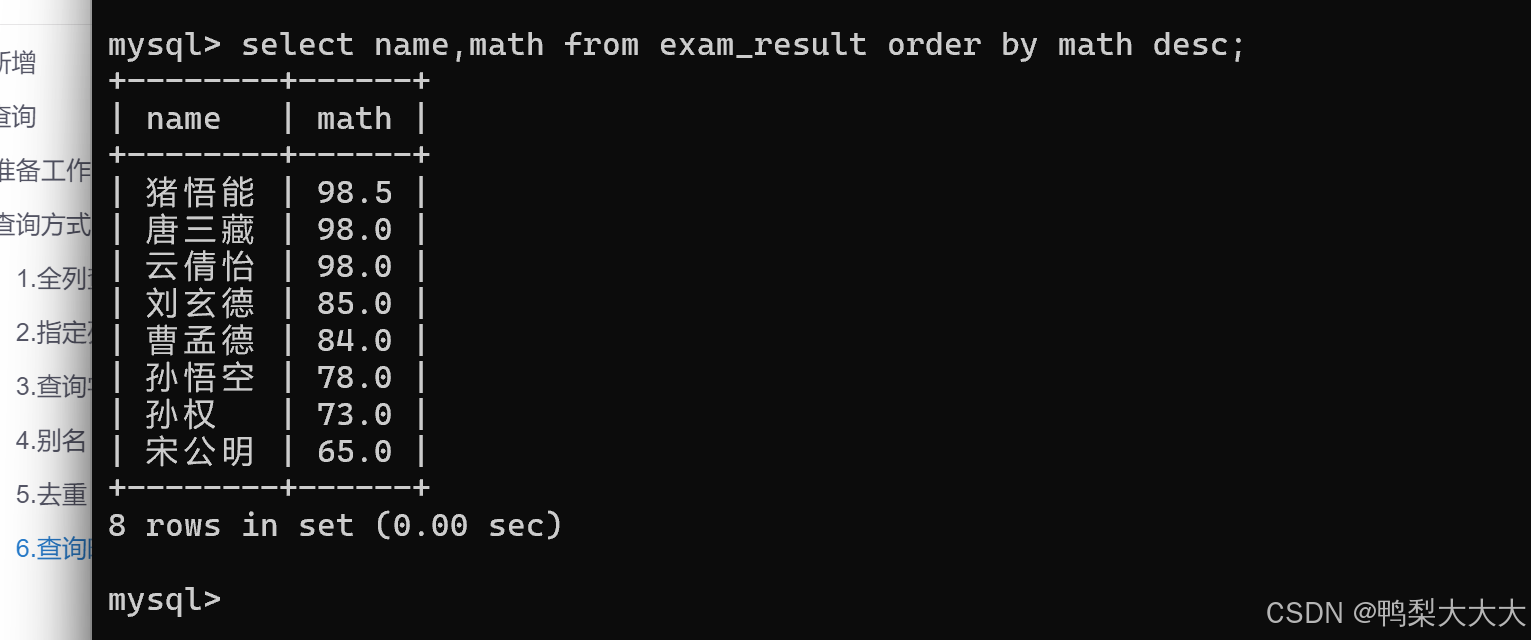
按照表达式升序:
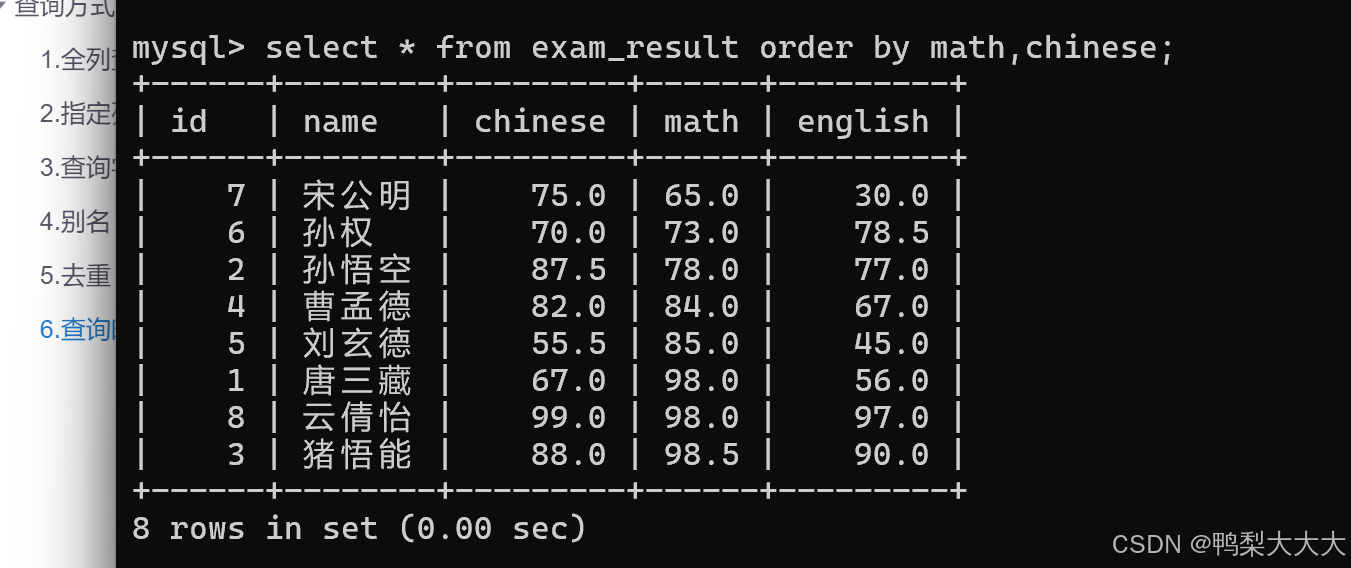
先按照数学成绩升序排名,在数学成绩相同的情况下按照语文成绩排名:
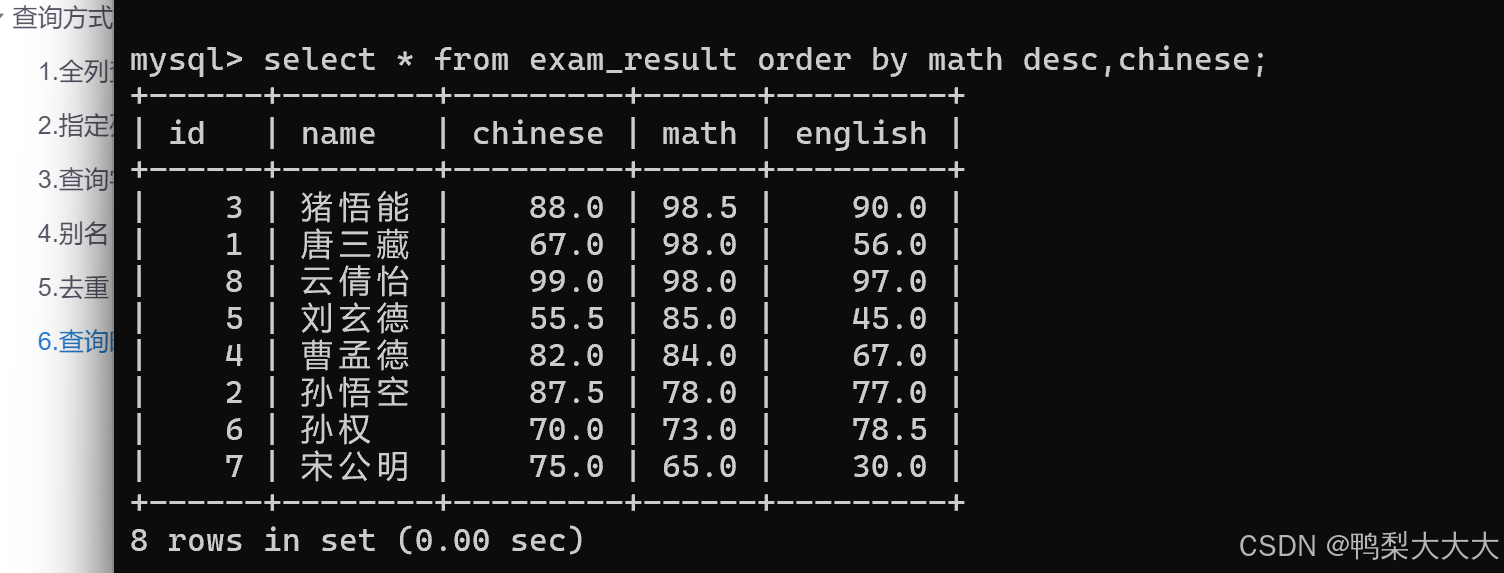
先按照数学降序排序,如果数学成绩相同的情况下再按照语文成绩升序排序:
7.条件查询(where)
所谓的条件查询就是指定具体的条件,按照指定的条件对数据进行筛选。
select 列名 from 表名 where 条件;

下面来找一些简单的例子:
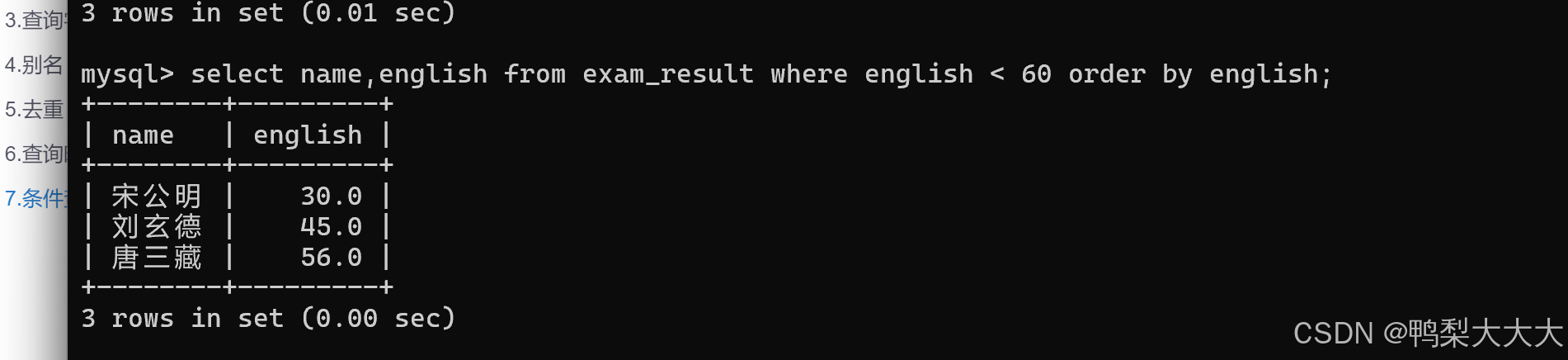
1.查询英语不及格的同学的英语成绩:
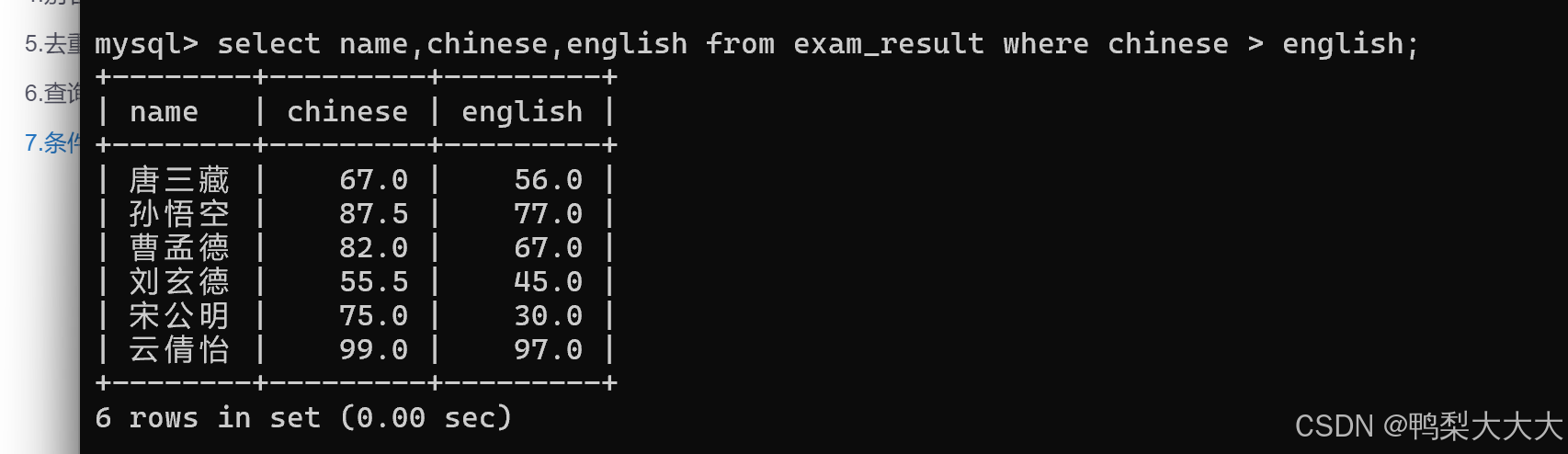
2.语文成绩好于英语成绩的同学:
3.总成绩在200分以下的同学:

4.查询语文成绩大于80分,且英语成绩大于80分的同学:

5.查询语文成绩大于80分,或者英语成绩大于80分的同学:
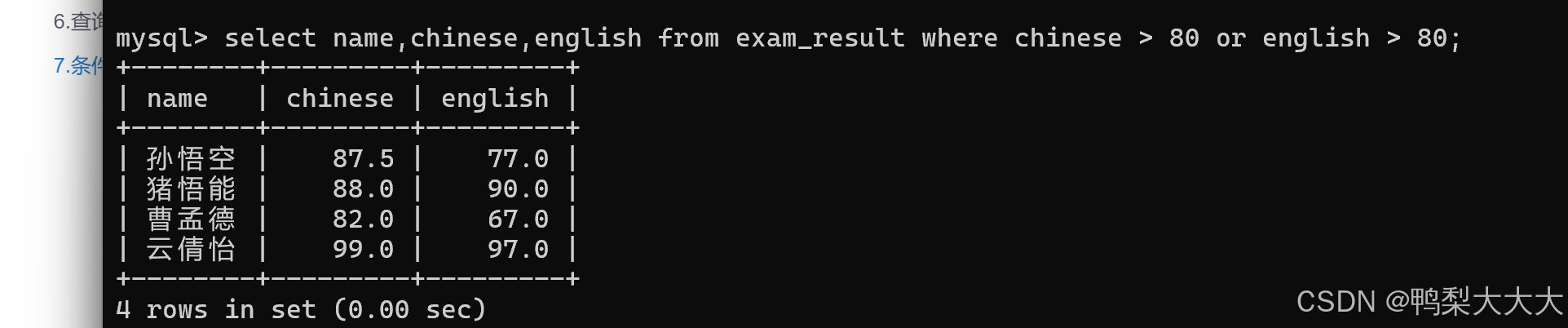
注意:在SQL语句中,and的优先级比or高
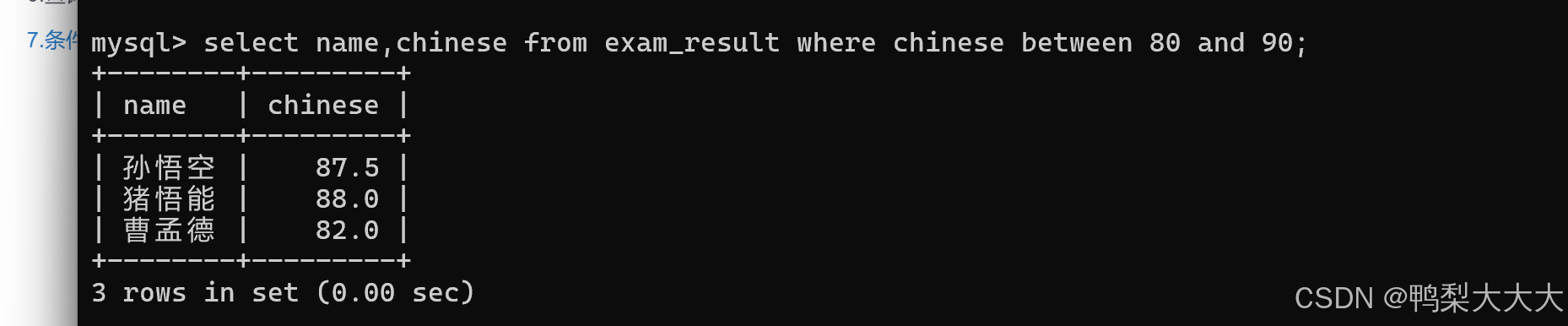
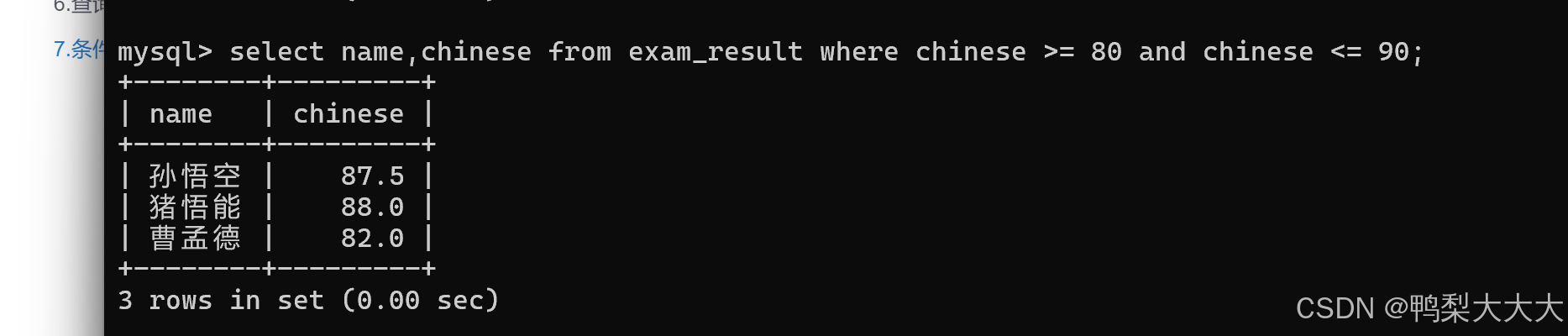
6.查询语文成绩在 [80, 90] 分的同学及语文成绩:
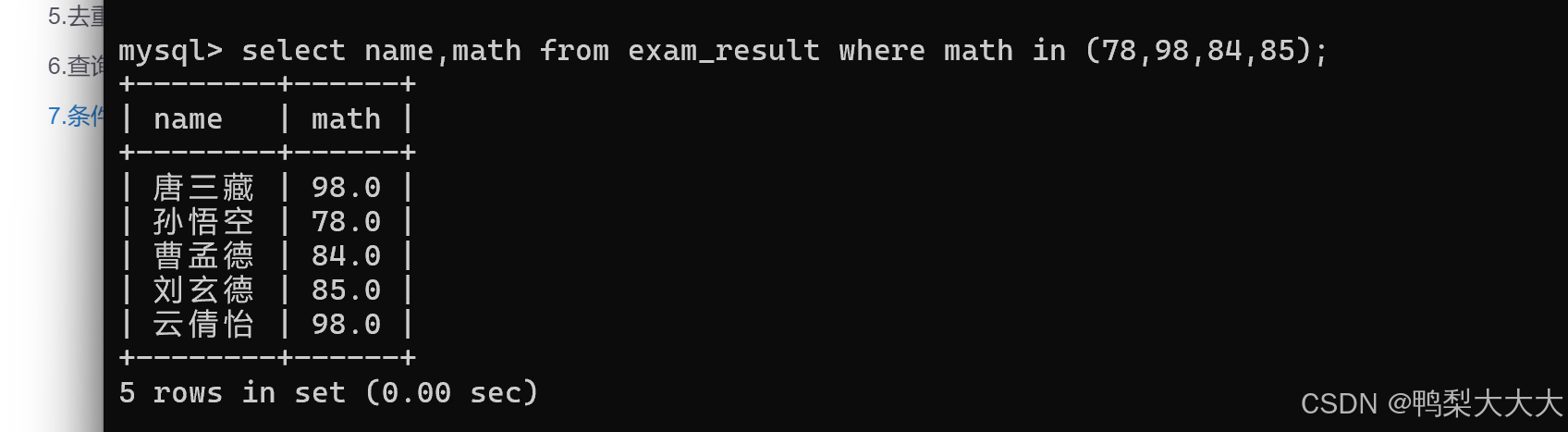
7.查询数学成绩是 78 或者 84 或者 98 或者 85 分的同学及数学成绩:
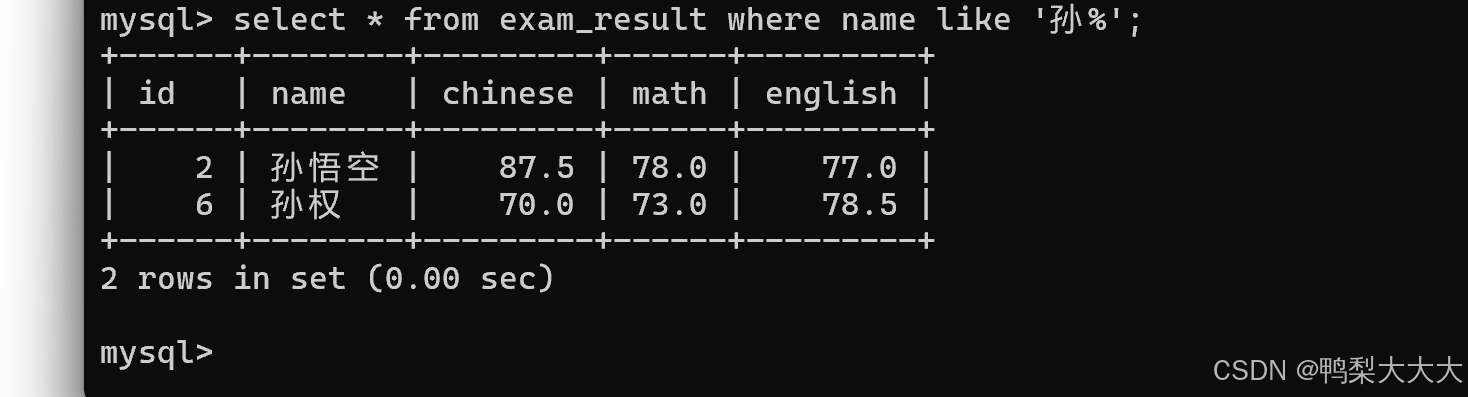
8.模糊查询:
1)% 匹配任意多个(包括 0 个)字符
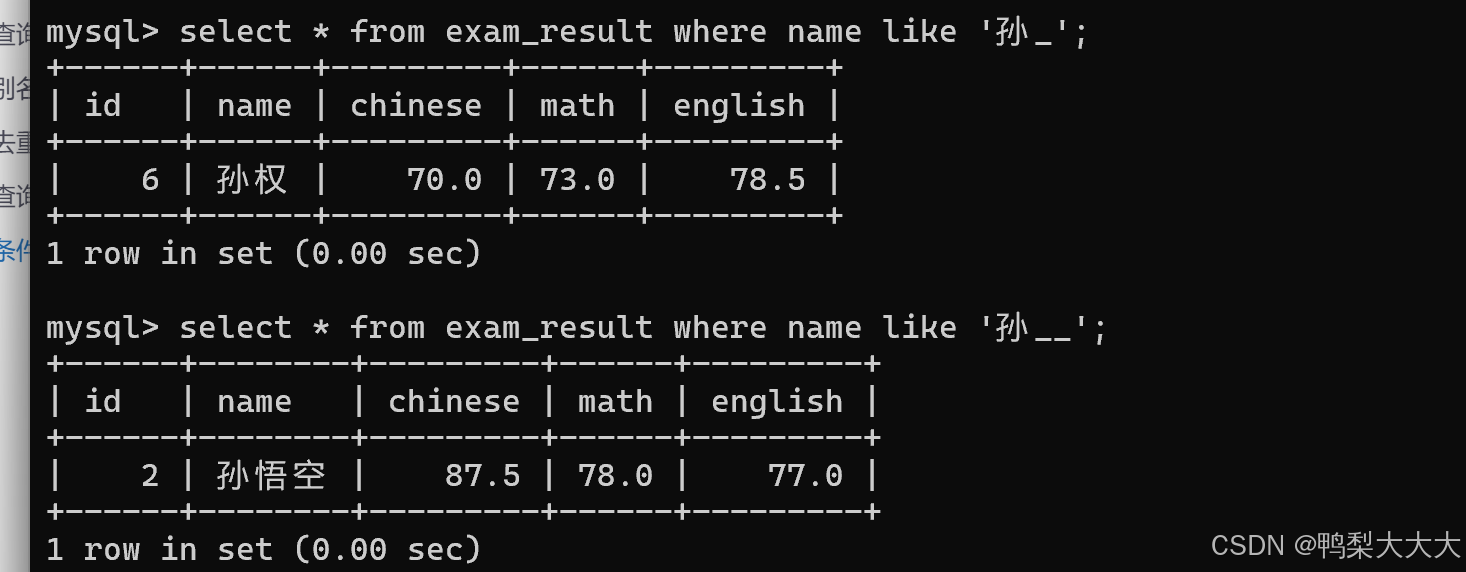
2)_ 匹配严格的一个任意字符
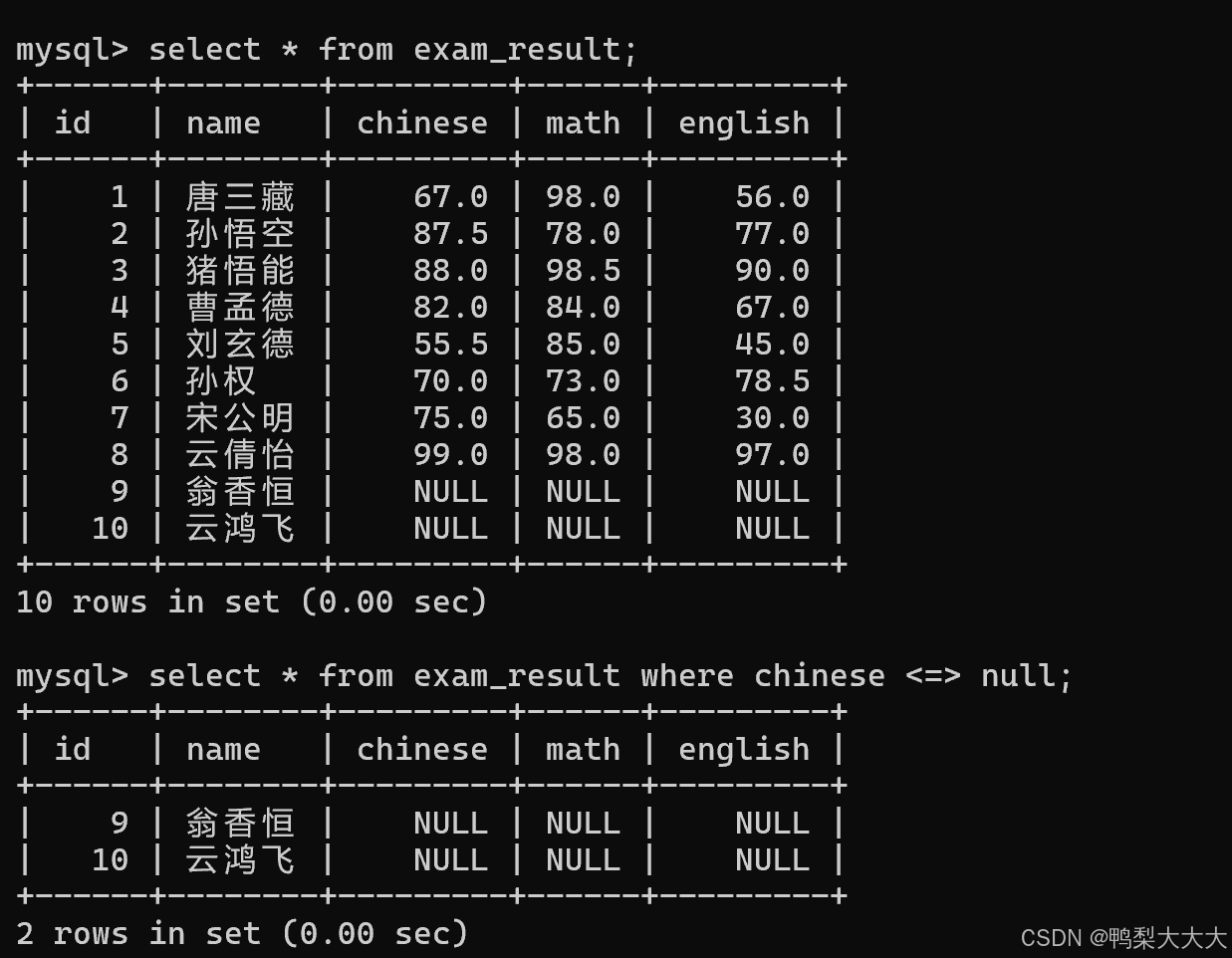
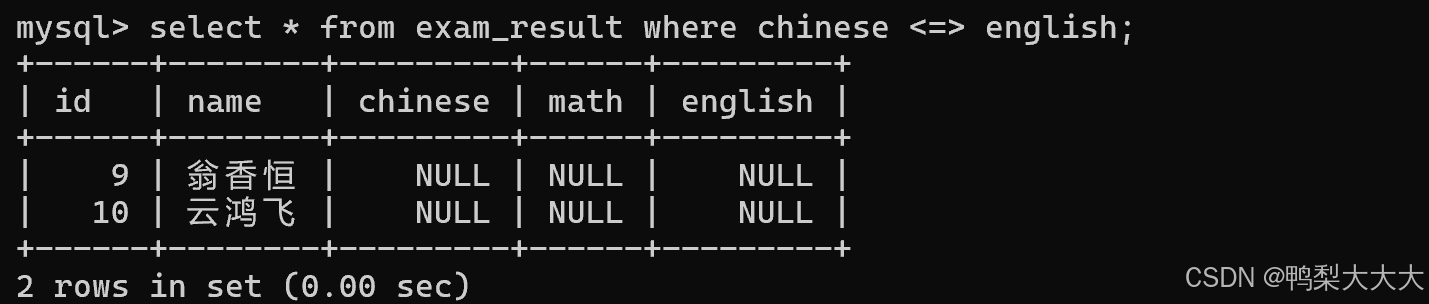
9.NULL 的查询:IS [NOT] NULL
错误做法:

正确做法:

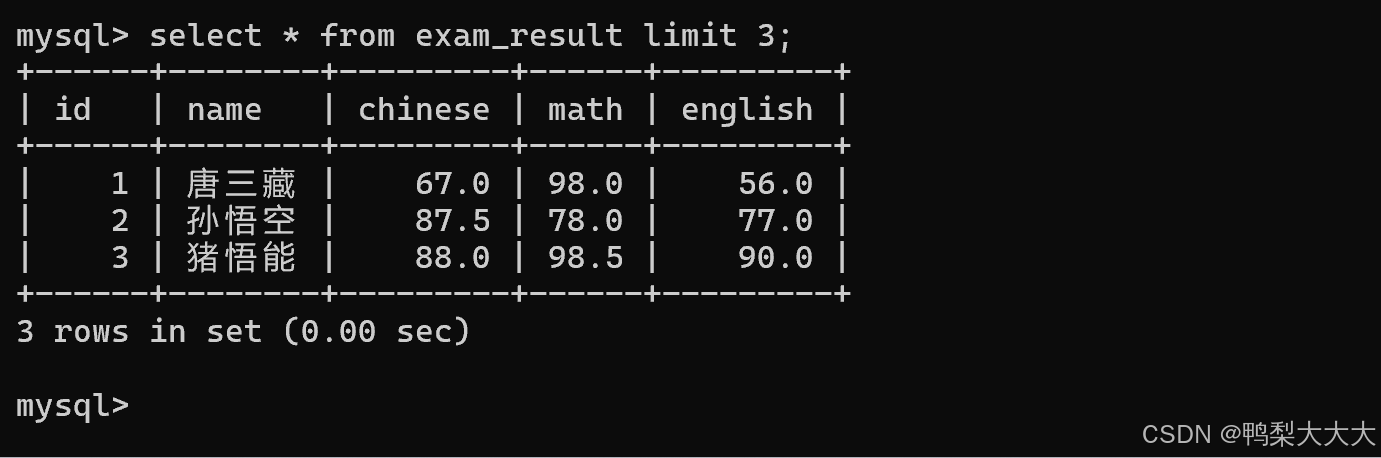
8.分页查询:LIMIT
在这篇文章的刚开始,我们有提到到表中的数据太多的时候,如果使用select * 这种方式进行查询是比较危险的。因为较多的数据很容易把硬盘占满,导致服务器崩塌的情况出现。
而分页查询就可以保证一次查询,不要查出太多的东西。即通过limit可以限制这个查询结果最多能查出多少个结果。
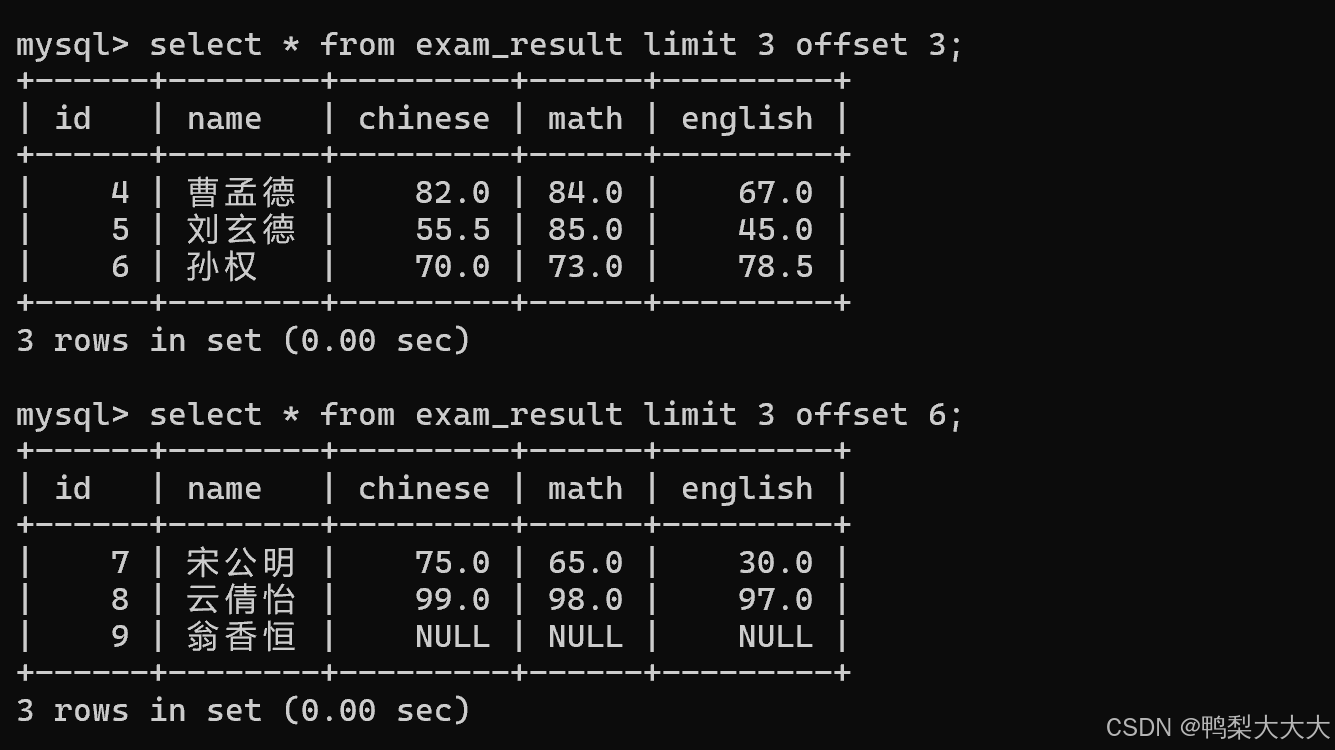
offset的作用:即偏移量【即下标】
3.修改
update 表名 set 列名 = 值 where 条件;
下面我们通过几个例子来”感受“一下这里的用法:
1.将孙悟空同学的数学成绩变更为 80 分::
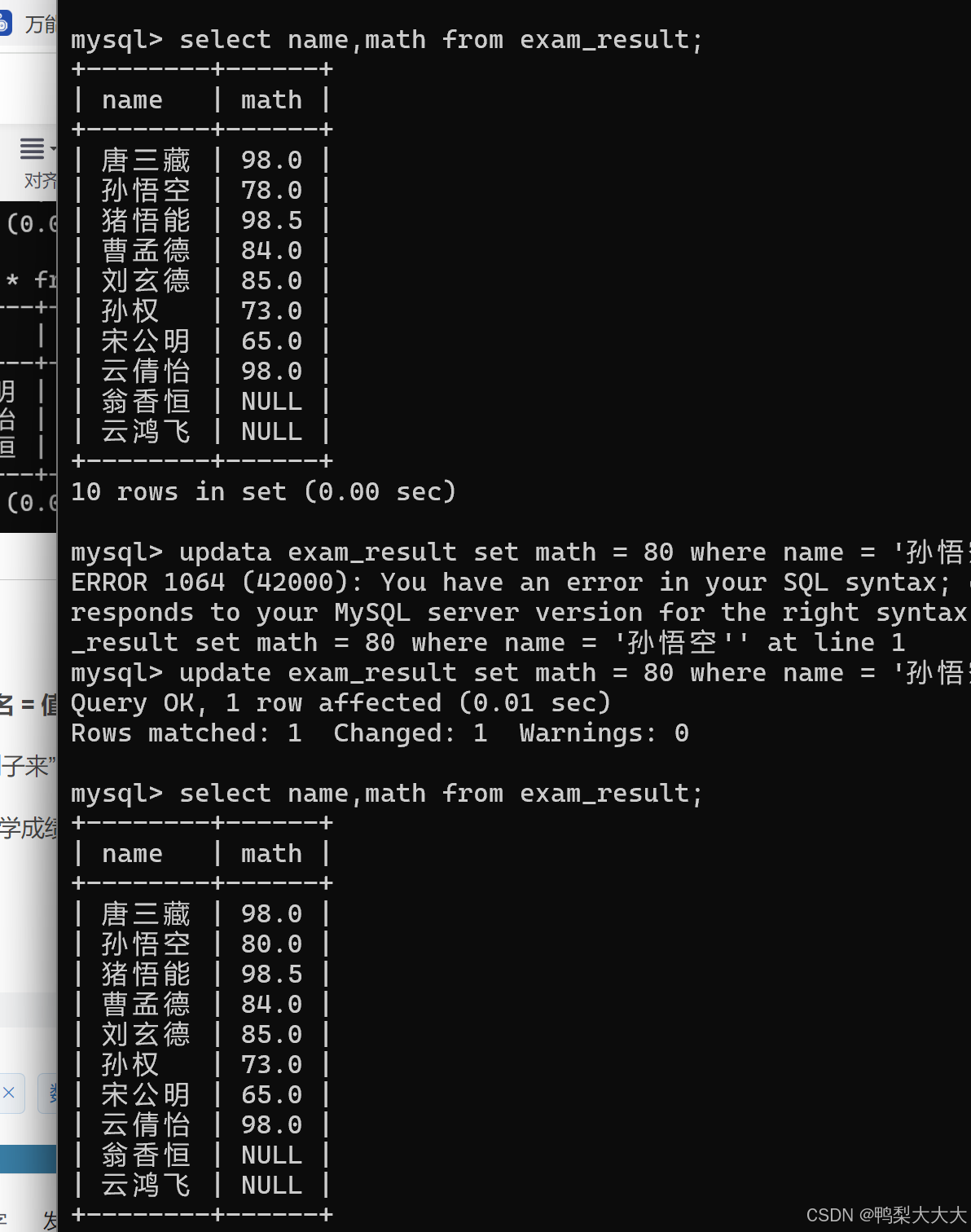
由上图可以看出,孙悟空原本的数学成绩是78分,修改之后变为了80分。
注:使用update可以一次修改多个列;set 列 = 值 ,列 = 值...【此处的等号就是赋值的意思】

2.将总成绩倒数前三的 3 位同学的数学成绩减 30 分:

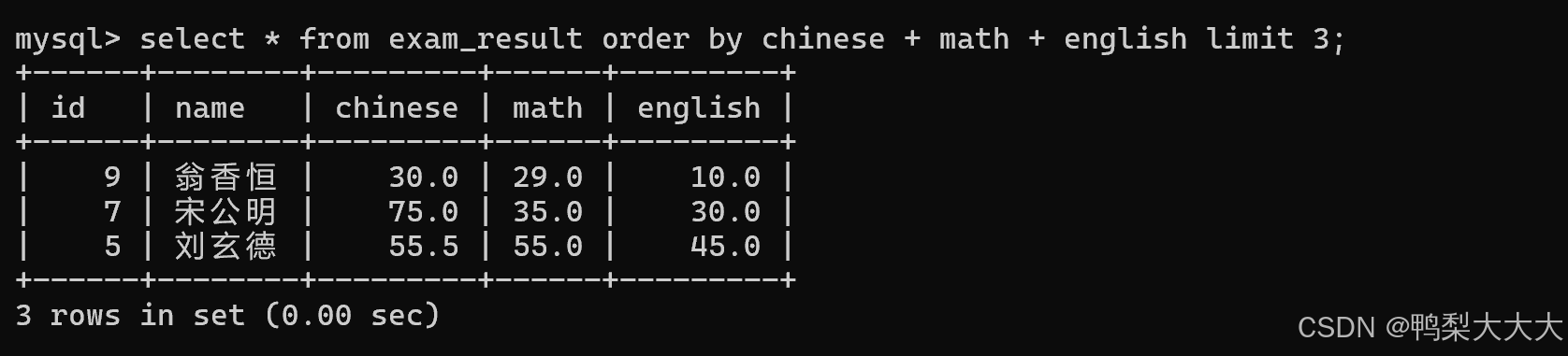
如上图所示,总分倒数的三名同学数学都被减了30分;
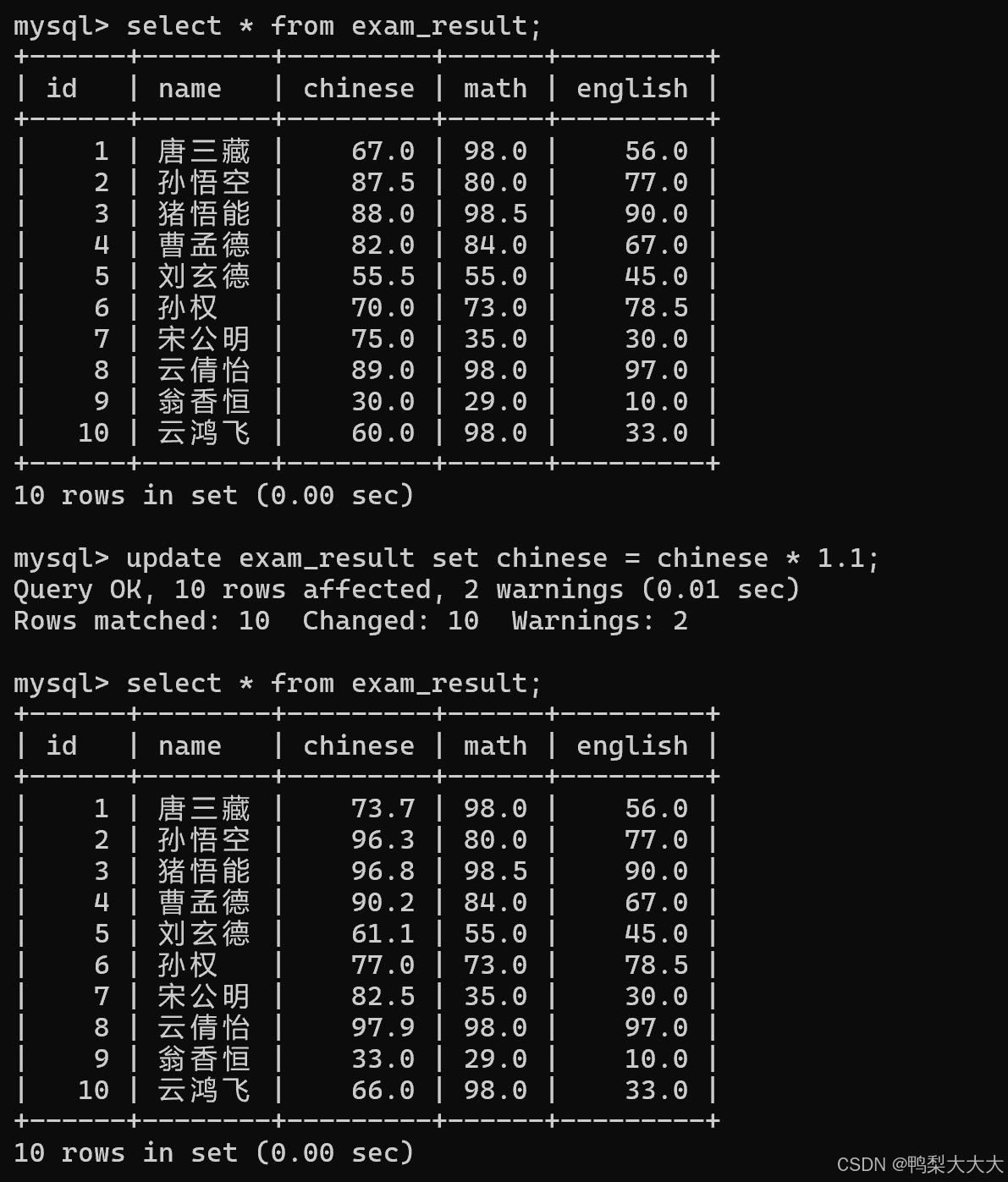
3.将所有同学的语文成绩更新为原来的 1.1倍:
如下图所示,修改后的语文成绩是原来的1.1倍【注意:使用update后面没有where就是对所有行进行修改;如果是有where就是对满足条件的所有行进行修改】
注意:上述修改并不一定都能成功,像空值就不会被修改,还有一些不符合建表时规定的数据;
4.删除
delete from 表名 where 条件;
作用:把对应表中的行删除掉;下面我们将举一些例子来加深对这里的理解:
注:不指定任何条件就是删除整张表;
1.删除孙悟空同学的考试成绩:
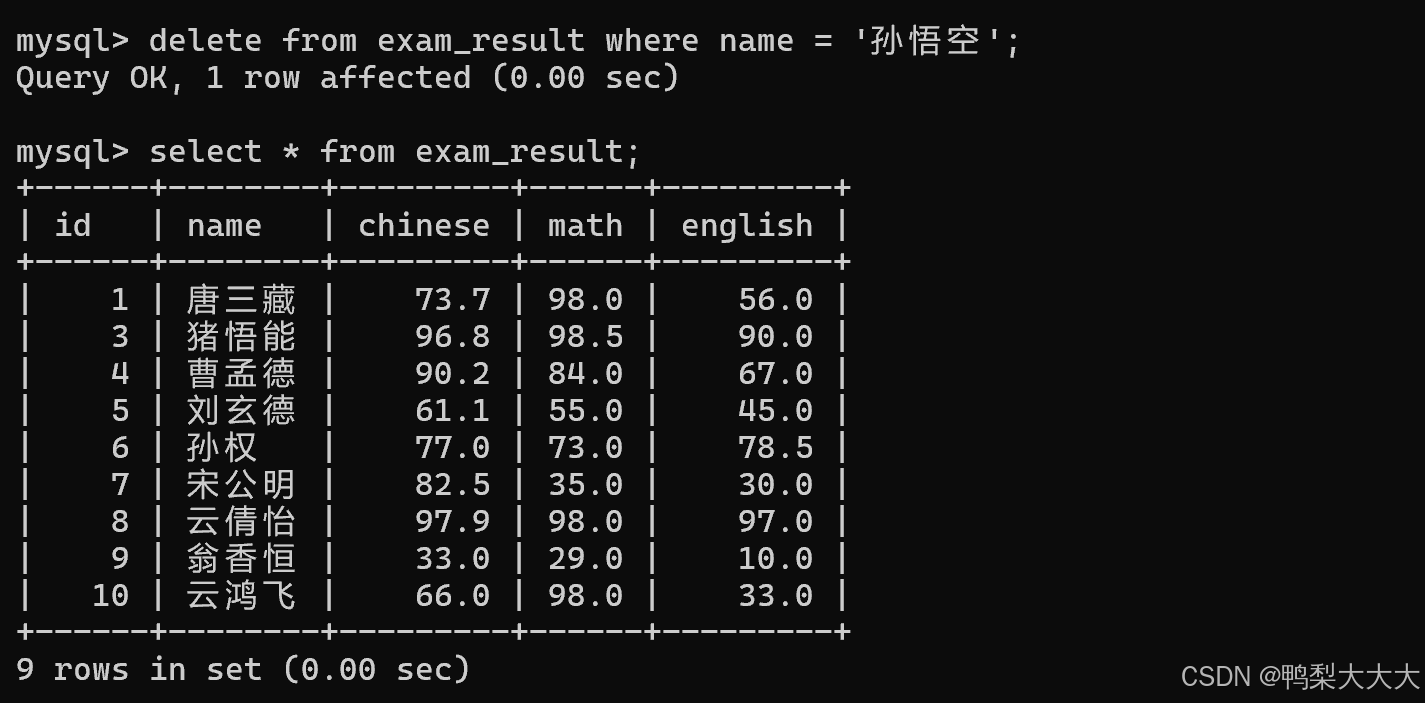
2.删除整张表:

注:drop和delete是有区别的;delete只是删除表中的数据,drop是删除了表也删除的表中的数据