目录
1:简介
Numpy(Numerical Python的简称)是高性能科学计算和数据分析的基础包,提供了矩阵运算的功能。Numpy提供了一下几个主要功能:
- ndarray————一个具有向量算数运算和复杂广播能力的多维数组对象。
- 用于对数组数据进行快速晕眩的标准数学函数。
- 用于读写磁盘数据的工具以及用户操作内存映射文件的工具。
- 非常有用的线性代数,傅里叶变换和随机数操作。
- 用于集成C/C++和Fortran代码的工具。
除明显的科学用途之外,Numpy也可以用作通用数据的高效多维容器,可以定义任意的数据类型。
这使Numpy可以无缝,快速的与各种数据库集成。
2:Numpy要点
2.1:创建数组
在Numpy中,最核心的数据结构是ndarray,ndarray代表的数多维数组,数组指的是数据的集合。
举例:
(1) 一个班级里学生的学号可以通过一维数组来表示:数组名叫a,在a中存储的是数值类型的数据,分别是1,2,3,4
| 索引 | 学号 |
| 0 | 1 |
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
其中a[0]代表的是第一个学生的学号1,a[1]代表第二个学生的学号2,以此类推。
(2)一个班级李学生的学号和姓名,则可以用二维数值来表示:数组名叫b
| 1 | 上官婉儿 |
| 2 | 工藤新一 |
| 3 | 赵云 |
| 4 | 马超 |
类似,其中b[0,0] 代表的就是学号1,b[0,1]代表的就是上官婉儿(学号为1的学生的名字)。以此类推。
借用线性代数的说法,一维数组通常称为常量(vector),二维数组通常称为矩阵(matrix)。
程序中实现:
import numpy as np
vector = np.array([1,2,3,4])
matrix = np.array([[1,'上官婉儿'],[2,'工藤新一'],[3,'赵云'],[4,'马超']])
print(vector)
print(matrix)输出:
[1 2 3 4]
[['1' '上官婉儿']
['2' '工藤新一']
['3' '赵云']
['4' '马超']]2.2:获取Numpy中数据的维度
a = np.arange(20).reshape(4, 5)
print(a)
print(a.shape)np.arange(n)方法,可以生成0到n-1的数组。
例如:b = np.arange(12) 输出: [ 0 1 2 3 4 5 6 7 8 9 10 11]
reshape(row,column)方法,可以自动构架一个多行多列的array对象。
shape属性可以获取Numpy数组的维度。
所以上程序输出:
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
(4, 5)2.3:获取本地数据
创建一个csv文件,如下:
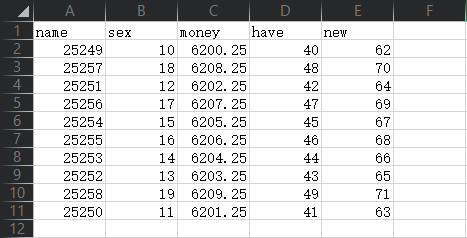
代码获取本地文件数据:
import numpy as np nfl = np.genfromtxt("C:/Users/longYsuaiZzz/Desktop/1.csv", dtype='U75', skip_header=1, delimiter=",") print(nfl)输出[['25249' '10' '6200.25' '40' '62'] ['25257' '18' '6208.25' '48' '70'] ['25251' '12' '6202.25' '42' '64'] ['25256' '17' '6207.25' '47' '69'] ['25254' '15' '6205.25' '45' '67'] ['25255' '16' '6206.25' '46' '68'] ['25253' '14' '6204.25' '44' '66'] ['25252' '13' '6203.25' '43' '65'] ['25258' '19' '6209.25' '49' '71'] ['25250' '11' '6201.25' '41' '63']]
np.genfromtxt()获取本地文件,dtype关键字设定为'U75',表示每个值都是75byte的unicode,skip_header关键字值为整数,表示跳过开头对应的行数。
2.4:Numpy数组索引
import numpy as np
nfl = np.genfromtxt("C:/Users/longYsuaiZzz/Desktop/1.csv", dtype='U75', skip_header=1, delimiter=",")
print(nfl)
print(nfl[0,1])输出结果:10。数组索引 nfl[0,1]。0代表的是行,1代表的是列
2.5:切片
import numpy as np
matrix = np.array([
[2, 4, 5],
[1, 3, 7],
[8, 6, 3]])
print(matrix[:, 1])
print(matrix[:, 0:2])
print(matrix[1:3, :])
print(matrix[1:3, 0:2])print(matrix[:, 1])代表选择所有的行,但是列的索引是1的数据
print(matrix[:, 0:2])代表选择所有的行,但是列的索引是0和1。
print(matrix[1:3, :])代表选择索引是1和2的行的所有列。
print(matrix[1:3, 0:2])代表所选索引是1和2的行,索引是0和1的列的所有数据。
2.6:数据比较
Numpy强大的地方是数组和矩阵的比较,数据比较之后会产生boolean值。
例如:
import numpy as np
matrix = np.array([[2, 4, 5], [1, 3, 7], [8, 6, 3]])
m = (matrix == 5)
print(m)输出:
[[False False True]
[False False False]
[False False False]]复杂一点的:
import numpy as np
matrix = np.array([[2, 4, 5], [1, 3, 7], [8, 6, 3]])
second_column_5 = (matrix[:, 2] == 5)
print(second_column_5)
print(matrix[second_column_5, :])输出:
[ True False False]
[[2 4 5]]其中:second_column_5 = (matrix[:, 2] == 5) 表示 matrix 这个数组所有的行,以及索引是2的列==>>[5,7,3],然后和5 进行比较,得到的就是 true false false。matrix[second_column_5, :] 表示的是 返回是true的 哪一行数据。
2.7:代替值
Numpy是可以运用布尔值来替换值。
在数组中:
import numpy as np
vector = np.array([5, 10, 15, 20, 25])
equal = (vector == 10) | (vector == 25)
vector[equal] = 50
print(vector)输出:
[ 5 50 15 20 50]个人理解,equal是 比较之后得到的一个布尔值数组,然后在数组中是true的替换成新的值。
在矩阵中:
import numpy as np
matrix = np.array([
[5, 10, 15],
[20, 25, 30],
[35, 25, 45]
])
second_column_25 = matrix[:, 1] == 25
matrix[second_column_25, 1] = 10
print(matrix)输出:
[[ 5 10 15]
[20 10 30]
[35 10 45]]先创建数组matrix。讲matrix的第二列与25比较,得到一个布尔值数组。second_column_25将matrix第二列值为25的替换成10
2.8:数据类型转换
通过astype转换类型。
例如:
import numpy as np
vector = np.array(["1", "2", "3"])
print(vector)
vector = vector.astype(float)
print(vector)返回:
['1' '2' '3']
[1. 2. 3.]2.9:Numpy的统计计算方法
sum():计算数组元素的和;对于矩阵计算结果为一个一位数组,需要制定行或列。
mean():计算数据元素的平均值;对于矩阵计算结果为一个一维数组,需要制定行或列。
max():计算数组元素的最大值;对于矩阵计算结果为一个一维数组,需要制定行或列。
例如:
import numpy as np
vector = np.array([4,5,6])
print(vector.sum())
matrix = np.array([
[5, 10, 15],
[20, 25, 30],
[35, 25, 25]
])
print(matrix.sum(axis=1))
print(matrix.sum(axis=0))输出:
15
[30 75 85]
[60 60 70]axis = 1 计算的是行的和。axis = 0 计算的是列的和。