referrnces:
上述写的很详细,大家可以看看,我也是学习后的笔记~
不断更新完善ing ~~~
文章目录
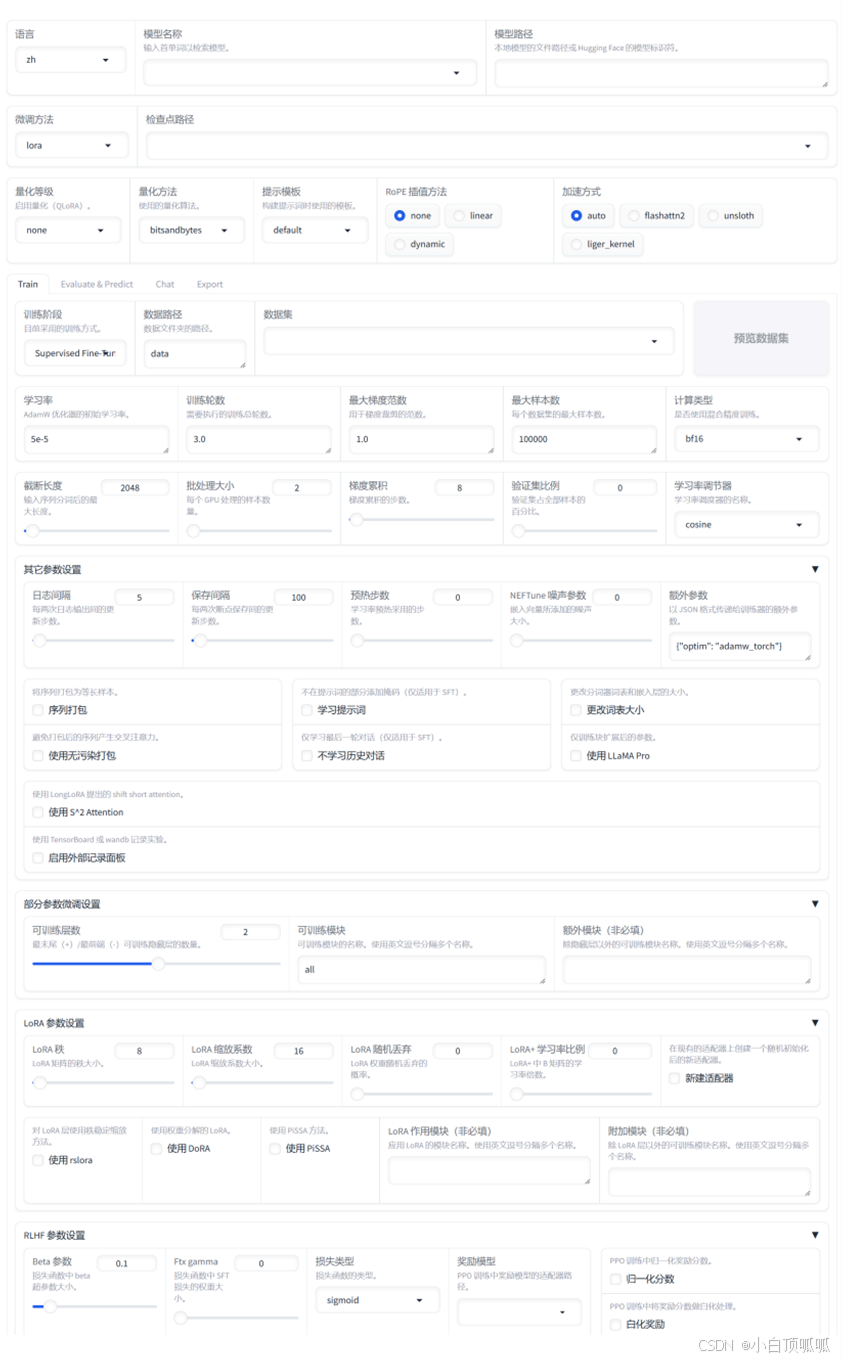
一、界面
启动界面(第一个选项切换语言为中文):
1、基础部分
1.1 语言:
1.2 模型名称、模型路径:
点击模型名称,会自动弹出可选择的模型,同时模型路径会显示出对应的hugging face上的模型标识符(就是默认的模型文件夹路径地址),但是一般我们不这么做,一般做法为:从hugging face/model scope将模型参数下载到本地,然后再在模型路径中粘贴本地的绝对地址,例如:C:\Users\chen\Desktop\copy\chatglm3 ,绝对地址!绝对地址!OK?

1.3量化等级、量化方法、提示模板、RoPE插值方法、加速方式
一般来说入门这里保持默认就行,不需要调整填写。

解释:
量化是指将神经网络中的权重和激活值从高精度(如32位浮点数)转换为低精度(如8位整数或更低)的过程。这一技术的主要目的是减少模型的内存占用和计算需求,从而加速推理过程并降低硬件成本,一般默认是 INT8 和 INT4 两种量化。
量化方法:

加速方式:
auto:自动选择最佳的加速方式。flashattn2:全称是FlashAttention,2是指第二代,FlashAttention的主要作用是全面降低显存读写,旨在减少计算复杂度并加快推理速度。unsloth:开源的加速微调项目,地址:https: / github.com/unslothai/unslothliger_kernel:也是加速训练的项目,地址: https: / github.com/linkedin/Liger-Kernel
2、Train
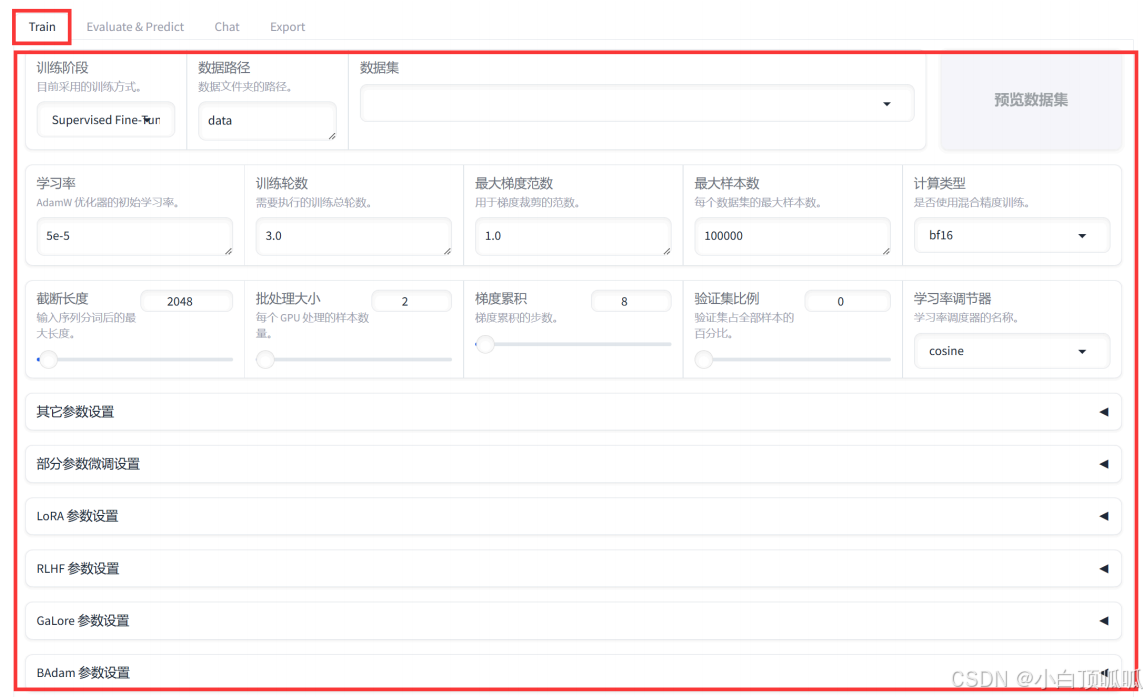
2.1 训练阶段
- Supervised Fine-Tuning:
监督微调是一种迁移学习技术,首先在一个预训练模型上进行无标签的数据集训练,然后在这个预训练模型的基础上,用带标签的新数据进行进一步的训练,以适应新的任务需求。 - Reward Modeling:
奖励建模是强化学习的一部分,目标是预测环境对代理行动的奖励信号。通过预测奖励,模型可以更好地理解哪些动作会导致更好的结果。 - PPO:
PP0(Proximal Policy Optimization)是一种强化学习算法,它通过限制新旧策略之间的差异来优化策略梯度。这种方法可以保证每次迭代更新后的策略不会偏离太多,从而稳定地提升性能。 - DPO:
DPO(Decoupled Policy Optimization)是一种强化学习算法,它将策略优化和价值估计解耦开来,分别进行独立的更新。这种方式可以避免策略和价值函数之间的相互影响,从而提高学习效率。 - KTO:
KTO(Knowledge Transfer for Optimal Learning)是一种知识转移方法,它试图从源任务中学到的知识转移到目标任务中,以加速学习过程并提高最终性能 - Pre-Training:
预训练是一种先在大规模无标签数据集上训练模型的技术(例如我们在模型名称中选择的chatglm3-6b、llama3等),然后再将其用于特定任务的微调。预训练可以帮助模型捕获通用的语义信息,从而提高下游任务的表现。
2.2 数据路径
默认为data,不需要更改。我们也把训练数据放在data文件夹下即可:
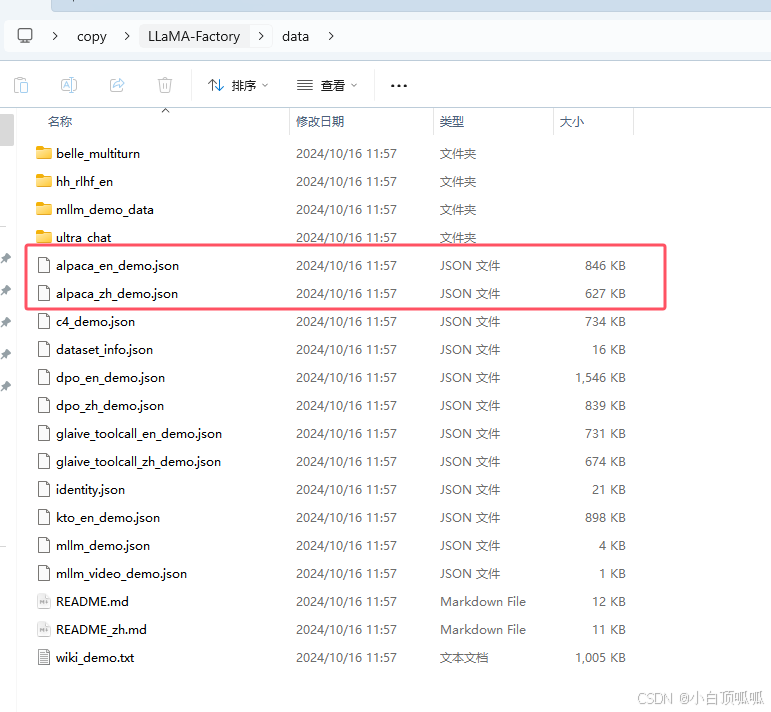
2.3 数据集
需要在LLaMA-Factory\data路径下(上图)的dataset_info.json文件中添加我们添加的文件信息,具体方法我的另一篇文章(windows系统从0开始配置llamafactory微调chatglm3-6b(环境版本、数据配置、webui、命令行))写了。添加成功可点右侧预览数据集成功预览。
2.4 学习率
控制模型学习速度的参数,学习率高时模型学习速度快,但可能导致学习过程不稳定;学习
率低时,模型学习速度慢,训练时间长,效率低。
1e-1(0.1):相对较大的学习率,用于初期快速探索,1e-2(0.01):中等大小的学习率,常用于许多标准模型的初始学习率1e-3(0.001):较小的学习率,适用于接近优化目标时的细致调整。1e-4(0.0001):更小的学习率,用于当型接近收敛时的微调。默认值
-5e-5(0.00005):非常小的学习率,常见于预训练模型的微调阶段,例如在自然语言
处理中微调BERT模型
2.5 训练轮次
2.6 最大梯度范数
最大梯度范数(Maximum Gradient Norm)也叫梯度裁剪,用于防止梯度爆炸,通常在0.1-10之间,太小会限制模型学习,太大无法有效防止梯度爆炸。是在深度学习中用来衡量模型参数更新过程中梯度大小的一种指标。它通常用于优化算法中,以控制梯度的规模,防止在训练过程中出现梯度爆炸的问题。
梯度提供了损失函数如何随着参数变化而变化的信息,因此它指示了参数应该调整的方向和幅度。
2.7 最大样本数
2.8 计算类型
- 若硬件支持bf16,且希望最大化内存效率和计算速度,可优先选择bf16。
30以前显卡不支持bf16计算,例如2080,可以退而求其次选择fp16 - 若硬件支持fp16,希望加速训练过程且能接受较低的数值精度,可选择fp16。
- 如果不确定硬件支持哪些类型,或需要高精度计算,可以选择fp32
2.9 截断长度
指在处理输入时,模型能够接受的最大标记(token)数量,若输入序列超过这个长度,多余的部分将会被截断,确保输入长度不会超出模型的处理能力。对于文本分类任务,通常截断到128或256个标记就足够了,而对于更复杂的任务,如文本生成或翻译,可能需要更长的长度。
一般填1024(默认)、2048、4096(chatglm36b的最大)
2.10 批处理大小
指在每次迭代中输入到模型中的样本数量。批处理太大会占用更多的内存(显存)。
2.11 梯度累积
用于在受限地GPU内存情况下,模拟更大的批处理大小。
例:
Gradient Accumulation steps = 2
仍然保持梯度累积步数为2,意味着每累积2个批次的梯度后,才会进行一次梯度更新。
2.12 验证集比例
在全量数据集中按比例抽出一部分数据作为验证集。默认是0。一般可取0.1、0.2 等。
2.13 学习率调节器
各种优化算法中最关键的参数之一,直接影响网络的训练速度和收敛情况。 用来调节学习率,能够在训练过程中根据预先定义的结构来调整学习率。 在训练初期,我们希望使用较大的学习率,使模型能快速地收敛到一个合理的解。在训练后期,我们希望使用较小的学习率,使模型能够更精细地优化解。一般默认使用cosine。
3 、其它参数设置
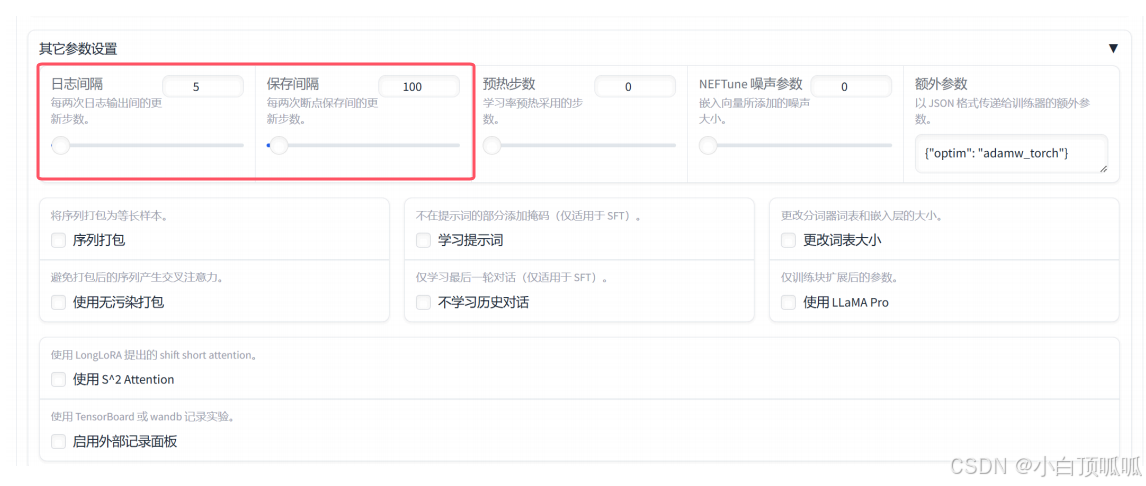
3.1 日志间隔
设定每隔多少步输出一次日志 = 黑窗口每隔多少步(steps)打印一次训练的日志。
训练完成后后续也会保存为一个文件trainer_log.jonl,例如每隔10步(steps)打印一次训练的日志:
{"current_steps": 10, "total_steps": 9370, "loss": 0.2888, "learning_rate": 1.0672358591248667e-06, "epoch": 0.010665244634048793, "percentage": 0.11, "elapsed_time": "0:00:29", "remaining_time": "7:45:30"}
{"current_steps": 20, "total_steps": 9370, "loss": 0.3181, "learning_rate": 2.1344717182497334e-06, "epoch": 0.021330489268097587, "percentage": 0.21, "elapsed_time": "0:00:57", "remaining_time": "7:31:16"}
{"current_steps": 30, "total_steps": 9370, "loss": 0.2964, "learning_rate": 3.2017075773746e-06, "epoch": 0.031995733902146384, "percentage": 0.32, "elapsed_time": "0:01:28", "remaining_time": "7:41:09"}
3.2 保存间隔
用于定期保存模型以防止意外丢失训练成果,例如每隔500步保存一次:
3.3 预热步数
在训练过程中,学习率逐步增加到初始设定值之前的步数。
3.4 NEFTune噪声参数
嵌入向量所添加的噪声大小,用于正则化和提升模型泛化能力。
3.5 优化器

4、部分微调参数设置
简单运行可以不调整不填这一块。

4.1 可训练层数
这个滑块控制了模型中可以进行训练的层数。在微调过程中,你可以选择只对模型的部分层级进行训练,而不是全部。这可能是因为你想保留预训练模型的一些知识,或者因为你的数据集较小,全量训练可能导致过拟合。
4.2 可训模块
在这个文本框中,你可以指定要训练的具体模块名称。如果输入"all",则表示所有模块都将被训练。否则,你需要提供一个逗号分隔的列表来指明哪些模块需要训练。这在一些复杂的模型结构中非常有用,比如Transformer模型,其中包含多个不同的组件,如自注意力层、多头注意力层等。通过选择特定的模块进行训练,你可以更好地控制模型的学习过程,避免过度训练某些部分并提高效率。
4.3 额外模块(非必须域)
这个字段允许你添加除隐藏层之外的其他可训练模块。这些可能是模型中的特殊组件,如嵌入层、池化层或其他特定于任务的层。如果你想要微调的模块不是默认的隐藏层,那么在这里列出它们可以帮助你精确地控制哪些部分应该被更新。
5、LoRA参数设置 ★★★
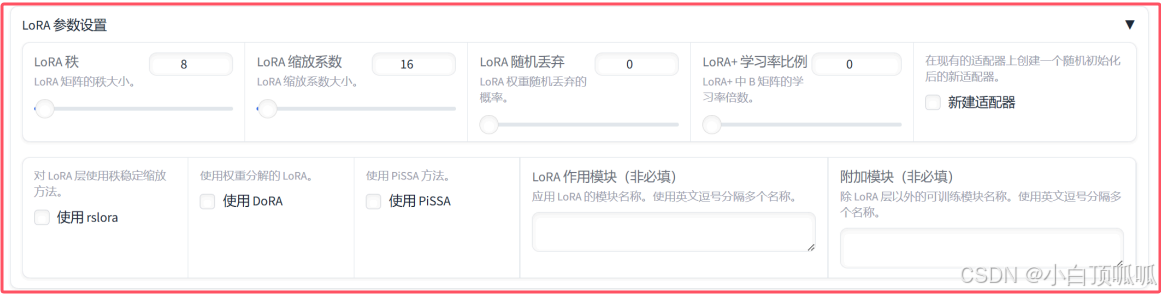
5.1 LoRA秩(LoRA rank)
LoRA秩决定了LoRA矩阵的大小,即LoRA矩阵的行数和列数。较大的LoRA秩意味着更大的适应空间,但也增加了计算负担。这个值越高,LoRA矩阵的维度就越大,能够捕捉到的模式也就越多,但是也会导致更高的计算和存储升本。
5.2 LoRA收缩系数(LoRA expansion factor)
LoRA收缩系数是指LoRA矩阵相对于原权重矩阵的扩展程度。较高的收缩系数会导致更大的LoRA矩阵,理论上能捕获更多的模式,但同样会增加计算和存储成本。
5.3 LoRA随机丢弃(LoRA dropout)
这是一个概率值,用于在训练过程中随机丢弃LoRA矩阵的一部分元素。类似于Dropout技术,它可以用来防止过拟合,增加模型的鲁棒性。将其设置为0表示不应用随机丢弃。
5.4 LoRA+学习率比例(LoRA+learning rate multiplier)
LoRA+是一种改进的LoRA方法,它在LoRA矩阵上使用单独的学习率。这个参数定义了LoRA+中B矩阵的学习率倍数,即B矩阵的学习率是基础学习率的多少倍。适当调整这个值有助于找到合适的优化速度。
5.5 对LoRA层使用稳态压缩方法(Use rsLoRA)
使用rsLoRA(Stable LoRA)是一种稳定LoRA的方法,旨在解决LoRA在训练过程中可能出现的数值稳定性问题。启动该选项可以确保LoRA矩阵的正定性,从而提高训练的稳定性。
5.6 使用权重分解的LoRA(Use DoRA)
DoRA是一种LoRA的变体,它将LoRA矩阵分解成两个较小的矩阵相乘形式,降低了计算复杂度。
5.7 使用PiSSA方法(Use PiSSA)
PiSSA是一种优化方法,用于改善LoRA的性能。它通过分段平方根缩放来调整LoRA矩阵,以实现更好的收敛性和泛化能力。
5.8 LoRA作用模块(LoRA modules)
这里可以指定LoRA应用于哪个模块。如果输入“all”,则表示LoRA将在所有的模块上应用。否则,你需要提供一个逗号分隔的列表来智能哪些模块需要应用LoRA。这让你可以选择性的在模型的不同部分应用LoRA,以达到最佳效果。
5.9 附加模块(Additional modules)
这个字段允许你添加除LoRA层以外的其他可训练模块。这些可能是模型的特殊组件,如嵌入层、池化层或其他特定于任务的层。如果你想要微调的模块不是LoRA层,那么在这里累出他们可以帮助你精确的控制哪些部分应该被更新。
6、Evaluate & Predict
这里使用测试集进行验证。
7、Chat
在线使用大模型进行测试,实验下模型加载是否成功以及对话效果。
8、Export
Export模块是用于导出训练好的模型以便在其他地方使用或分享:
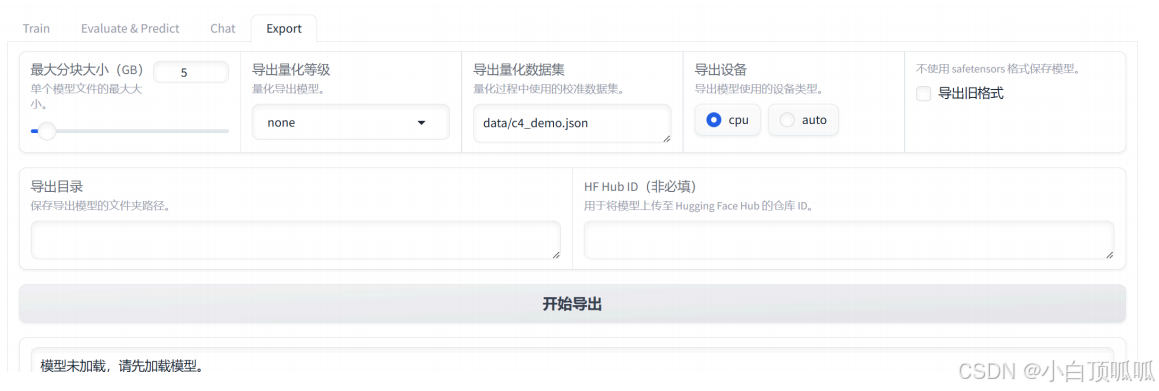
最大分块大小(GB): 这个滑块用于设置导出文件的最大大小。这对于上传到某些平台(如Hugging Face Hub)有限制的文件大小很有用。你可以调整此值以确保导出的文件不会超过所选的最大大小。导出量化等级: 这里可以选择是否要对模型进行量化。选择 “none” 表示不进行量化,而选择其他选项可能会导致模型尺寸减小,但在某些情况下可能会影响准确率。导出量化数据集: 如果选择了量化级别,你可以在这里选择用于量化评估的数据集。这通常是训练或验证数据的一个子集,用于评估和微调量化后的模型性能。导出设备类型: 这个下拉菜单让你选择模型将被导出到什么类型的设备上。CPU选项表示模型将被优化以在CPU上运行,而auto选项让系统自动决定最适合的设备类型。这取决于你的目标环境和可用硬件。不使用safetensors格式保存模型: 这个复选框用于选择是否使用safetensors格式保存模型。safetensors是一种安全的张量格式,可以保护模型免受恶意攻击。取消勾选该选项表示将使用标准格式保存模型。导出目录: 在这里,你可以指定一个路径来保存导出的模型文件。这是模型及其相关文件将被保存的位置。HF Hub ID: 如果你想将模型上传到Hugging Face Hub,你可以在此处输入仓库ID。这是一个可选字段,如果你不想上传模型,则可以留空。