之前看深度学习的文章,基本都在数据预处理部分进行了数据增强。

什么旋转、跳跃、我不停歇~
不对,不对。是旋转、平移、裁剪等操作。
所以最近在做目标检测时,废话不多说,先把数据增强的代码整上去!
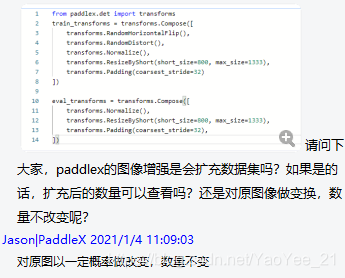
from paddlex.det import transforms
train_transforms = transforms.Compose([
transforms.RandomDistort(),
#transforms.RandomExpand(),
transforms.RandomCrop(),
transforms.RandomHorizontalFlip(),
transforms.Normalize(),
#transforms.ResizeByShort(short_size=800, max_size=1333),
transforms.Padding(coarsest_stride=32)
])
eval_transforms = transforms.Compose([
transforms.Normalize(),
#transforms.ResizeByShort(short_size=800, max_size=1333),
transforms.Padding(coarsest_stride=32),
])
上面这段代码是 paddle 框架中的数据增强接口,用了几天发现有点不对劲,这货一通操作后,具体把样本扩充到多少张了?
这是个问题。
所以咨询了 paddle 的开发人员后,发现这个数据增强接口 并没有做数据扩充,只是对图片进行变换,你大妈已经不是你大妈了,但是你最终还是只有一个大妈。
如果数量不变的话,数据增强有什么意义呢?菜鸡的我又去 Github 上问了下。
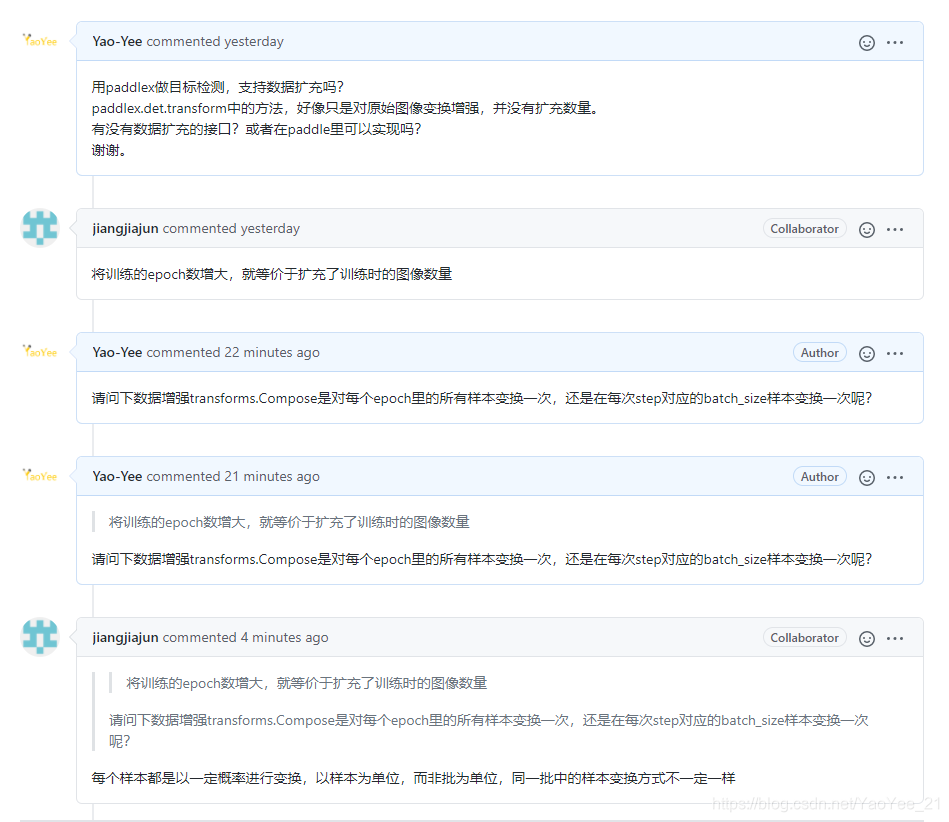
“将训练的epoch数增大,就等价于扩充了训练时的图像数量”,这句话很有哲理。
在一番搜索之后,这其实说的是 在线数据增强,一般常见的是 离线数据增强,也是就一次性把数据扩充好,用这个大数据集进行模型训练。
而这样的方式,在数据集很大时,就比较耗费空间,所以这时就可以采用 “在线数据增强”,也就是说在每个epoch进行训练前,对数据集进行旋转、平移等变换。等到下一次epoch时,只要数据增强方式够多,并且每个方式都包含随机因子,那么就可以保证每个epoch训练的数据都是不一样的,也就是说有多少轮epoch,我们就把数据扩充了多少倍。
本节炼丹小课堂就结束了,同学们下节课见~
猜你喜欢:👇🏻
⭐【算法】深度学习神经网络都调哪些参数?
⭐【总结】一文了解所有的机器学习评价指标
⭐【总结】机器学习划分数据集的几种方法
