
- 博主简介:努力学习的22级计算机科学与技术本科生一枚🌸
- 博主主页: @Yaoyao2024
- 往期回顾: 【论文精读】上交大、上海人工智能实验室等提出基于配准的少样本异常检测框架超详细解读(翻译+精读)
- 每日一言🌼: 人只有知道自己无知后,才能从骨子里谦和起来,不再恃才傲物,不再咄咄逼人。 – 莫言
一、第一章:算法概述
1.1:算法的概念
算法(Algorithm)
- 抽象概念: 算法是 解决问题的一种方法or一种过程
- 具体到基于计算机设计的算法:组成: 若干指令的有穷序列。有以下四个性质
- 输入:是算法解决问题的对象,即外部提供的量作为算法的输出
- 输出:算法解决问题的结果,即算法至少输出一个值。
- 确定性:每条指令的含义是没有歧义的(即我们需要的是一个确定的明确的无歧义的解决方法)。
- 有限性:每条指令执行的次数、时间是有限的。即在有限时间内,这个问题肯定有解。
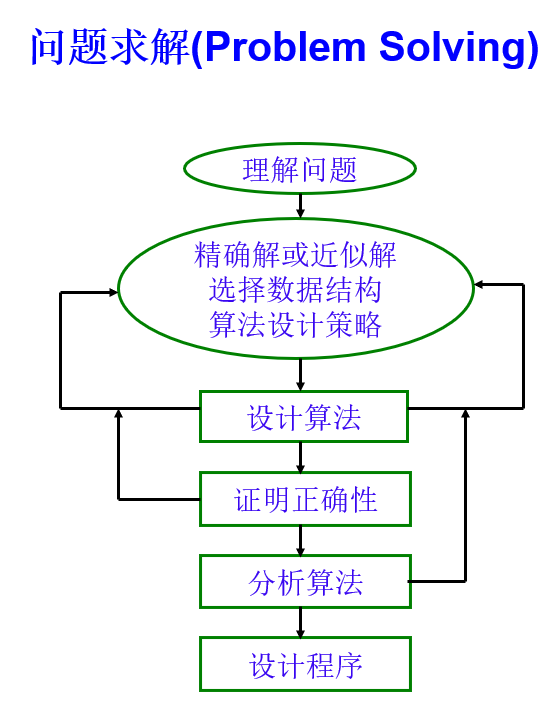
1.2:算法描述的方式
- 自然语言
- 表格
- 伪代码
1.3:程序的概念
定义:是算法基于某种程序设计语言的具体实现,程序≠算法,程序可以不满足有限性。
举例:
- 操作系统:启动后便无限循环执行的程序,它不是算法
- 操作系统中执行的各种任务(是子程序):通过特定的算法实现,得到输出结果后便终止->是算法
1.4:算法的复杂性
-
定义&分类(2个):
算法的复杂性是衡量该算法所需计算机资源的高低: 复杂性越高,则花费的计算机资源越高;复杂性越低,则花费的计算机资源越低。
而计算机的资源主要体现在两个方面:时间、空间(存储)。
因此,算法的复杂性主要分为以下两方面去衡量- 时间复杂性:运行时所需要的时间资源的量
- 空间复杂性:运行时所需要的存储资源的量
-
复杂性的依赖(取决):
上面讲到,算法的复杂性主要是指花费计算机资源的量,那么这个量取决于什么呢?主要是以下三点:- 问题的规模
- 问题的实际输入
- 算法本身设计的求解函数
-
算法追求的目标:设计出复杂性尽可能低的算法。
-
算法的时间复杂性(3种)体现在三个方面:
- 最坏情况下的时间复杂性 T m a x ( n ) = m a x { T ( I ) ∣ s i z e ( I ) = n } T_{max} (n) = max\left \{ T(I)| size(I)= n \right \} Tmax(n)=max{T(I)∣size(I)=n}
- 最好情况下的时间复杂性 T m i n ( n ) = m i n { T ( I ) ∣ s i z e ( I ) = n } T_{min} (n) = min\left \{ T(I)| size(I)= n \right \} Tmin(n)=min{T(I)∣size(I)=n}
- 平均情况下的时间复杂性 T a v g ( n ) = ∑ s i z e ( I ) = n P ( I ) T ( I ) T_{avg} (n) = \sum_{size(I) = n}^{}P(I)T(I) Tavg(n)=size(I)=n∑P(I)T(I)
可操作性最好的是:最好、最坏
- 渐近复杂性分析的记号(5个)
规定:f(n)是算法的实际复杂性计算得到的值(eg:3N, N^2),g(n)是我们需要确定的,渐进记号里的值,渐进记号+g(n)= 渐进复杂性表示,它是在问题规模重发大时,重点考虑算法复杂性的阶数。-
渐进上界O: f ( n ) = O ( g ( n ) ) f(n) = O(g(n)) f(n)=O(g(n)) ⭐
(当存在正常数c和n0使得所有n>=n0有:0<= f(n) <= cg(n),eg : 3N = O(N),即取f(n)中最高的那个阶数)
等价于f(n)/g(n)→1,as n→∞。 -
渐进下界O: f ( n ) = Ω ( g ( n ) ) f(n) = Ω(g(n)) f(n)=Ω(g(n))⭐
(当存在正常数c和n0使得所有n>=n0有:0<=cg(n)<= f(n),取f(n)中最低的那个阶数) -
非紧上界o: f ( n ) = o ( g ( n ) ) f(n) = o(g(n)) f(n)=o(g(n))
o(g(n))={f(n)|对于任何正常数c>0,存在正数和n0使得对所有n≥n有:0 ≤ f(n) < cg(n)}
等价于f(n)/g(n)→0,as n→∞。 -
非紧下界ω: f ( n ) = ω ( g ( n ) ) f(n) = ω(g(n)) f(n)=ω(g(n))
ω(g(n)={fn)|对于任何正常数c>0,存在正数和no0使得对所有n≥n有:0 ≤ cg(n) < f(n)}
等价于f(n)/g(n)→∞,as n→o。
f(n)∈o(g(n)<->g(n)∈o(fn) -
紧渐进界θ: f ( n ) = θ ( g ( n ) ) f(n) = θ(g(n)) f(n)=θ(g(n)) ⭐
存在正常数c1,c2和n0使得对所有n>=n0,有:c1g(n) <= f(n) <= c2g(n)。
-
🪧渐近分析中函数类比⭐
- f(n)=O(g(n)) ≈ a≤b;
- f(n)=Ω(g(n)) ≈ a≥b;
- f(n)=Θ(g(n)) ≈ a=b;
- f(n)=o(g(n)) ≈ a<b;
- f(n)=ωg(n)) ≈ a>b.
- 渐进记号的若干性质(通过上面的类比来记忆)
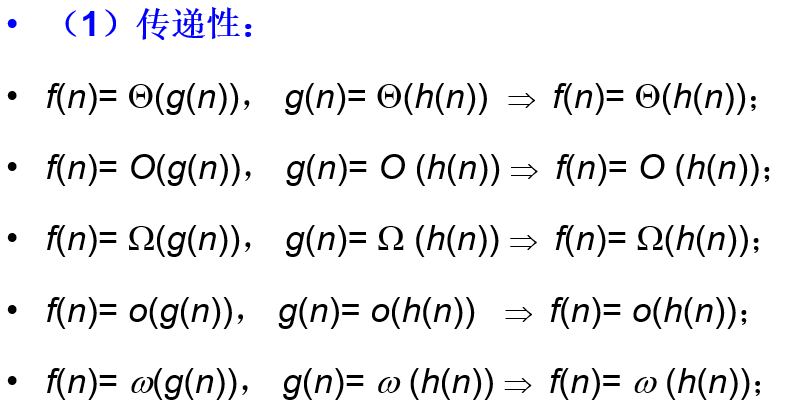

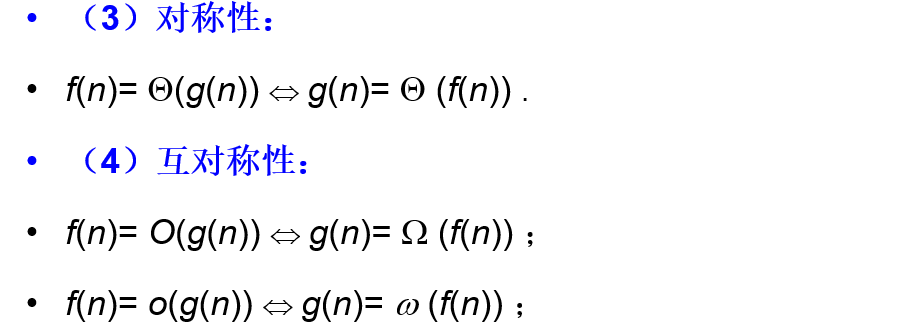

二、递归与分治
2.1:分治的基本思想和与递归的关系
-
设计思想:
将一个难以解决的大问题分解成规模较小的子问题,以便各个击破,分而治之。
如果原问题可以分解为k个子问题,1<=k<=n,且这些子问题相互独立并且与原问题相同,并且可以通过合并子问题的解来求得原问题的解,这个时候,分治就是可行的。 -
与递归的关系:
分治的核心就是问题不变,只是将问题规模减小,这恰巧与递归技术的理念相符(函数自身调用自身,原问题的解来源于子问题的解),因此,可以理解成,分治是一种算法思想,和递归是具体实现的手段,二者密不可分。 -
递归算法的概念:
直接或间接地调用自身算法,用函数给出定义的函数称为递归函数。
Tips:使用递归函数不是递归算法实现的唯一途径,像二叉树这种数据结构本身具有递归特性。
2.2:4个基础递归算法
⭐必须记住的4个基础递归算法
-
阶乘函数
n ! = { 1 n = 0 n ( n − 1 ) ! n > 0 n!=\begin{cases}\quad1&n=0\\n(n-1)!&n>0&\end{cases} n!={1n(n−1)!n=0n>0
函数定义(n的阶乘):int fac(int n) { if(n = 0 ) return 1; return n*fac(n-1); } -
Fibonacci数列
无穷数列1,1,2,3,5,8,13,21,34,55,…,称为Fibonacci数列。它可以递归地定义为:
F ( n ) = { 1 n = 0 1 n = 1 F ( n − 1 ) + F ( n − 2 ) n > 1 F(n)=\begin{cases}1&n=0\\[2ex]1&n=1\\[2ex]F(n-1)+F(n-2)&n>1\end{cases} F(n)=⎩ ⎨ ⎧11F(n−1)+F(n−2)n=0n=1n>1
函数定义(第n个Fibonacci数):int fibonacci(int n) { if (n <= 1) return 1; return fibonacci(n-1) + fibonacci(n-2); } -
n个数的全排列
//产生list[k:m]的所有全排列 void Perm(Type list[], int k, int m){ //只剩下一个元素 if(k == m){ for (int i = 0; i < m; i++){ cout << list[i]; } cout << endl; } for(int i = k; i <=m; i++){ Swap(list[k], list[i]); Perm(list, k+1, m); Swap(list[k], list[i]); } } -
汉诺塔Hanoi问题
问题描述:把a塔座上的n个圆盘,借助c,移动到b(移动过程中,圆盘必须始终在塔座上是从上到下从小到大)

void hanoi (int n, int a, int b, int c){
{
if(n > 0){
hanoi(n-1, a, c, b);
move(a, b);
hanoi(n-1, c, b, a);
}
}
2.3:递归的优缺点
- 优点:结构清晰,可读性强,正确性可以用数学归纳法证明;算法的设计和调试方便。
- 缺点:运行效率低:时间消耗和空间占用高
2.4:递归转为非递归的3个方法
- 用户自己定义栈结构,本质上还是递归,优化效果不明显
- 递推(循环迭代) 来实现递归函数
- 通过变换将一些递归转换为尾递归;尾递归是一种特殊的递归形式,其中递归调用是函数中的最后一个操作。尾递归可以很容易地转换为迭代,从而优化时空复杂度。许多编程语言和编译器对尾递归有特殊的优化处理。
2.5:分治策略的设计模式(基本步骤)
分治的基本思想在2.1已经讲过,
这里写一下代码的设计模式
divide-and-conquer(P){
if(|P| <= n0) adhoc(P); //解决这个特定的可以解决的小规模问题
//分解问题
divide P into subinstances P1,P2,...,Pk;//分解问题
//分别递归地解决各个子问题
for(int i = 1; i <=k; i++){
yi = divide-and-conquer(Pi);
}
//将子问题合并
return merge(y1,...yk);
}
2.6:分治法使用条件的问题4个特征
- 小规模可行性
- 最优子结构(原问题能够分解为若干个规模较小的子问题)
- 合并
- 相互独立(和最优子结构的独立性不同,这里是指子问题之间不包含公共子问题)
3,4是分治和递归的最大区别

2.7:子问题分割原则
分治算法是不断往下把问题进行k等分(平衡子问题的思想),那么这个k到底取多少呢?
一般取k=2。
2.8:基础分治算法⭐
1. 二分搜索
template <class Type>
int BinarySearch(Type a[], cons Type& x, int l, int r)
{
while(r >= l){
int mid = (l+r)/2;
if(x == a[m]) return m;
if(x < a[m]) r = mid-1;
else l = mid+1;
}
return -1;
}
时间复杂度:
O(logn)
2. 大整数乘法:目的:减少乘法次数

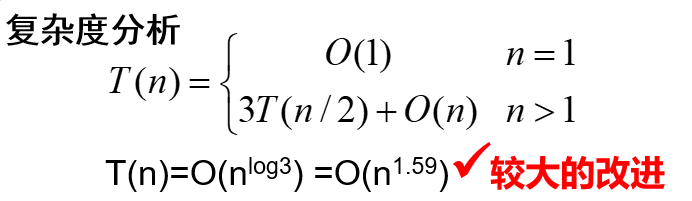
3. 矩阵乘法:分治+减少乘法次数
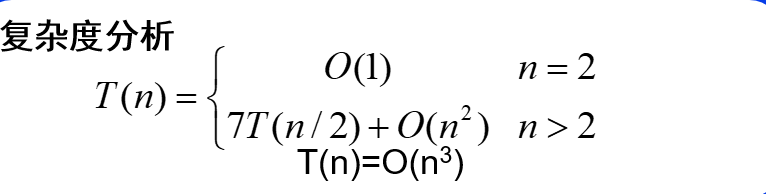
4.棋盘覆盖⭐必考:核心算法

<
//tr,tc(top_row,top_col):代表棋盘左上角坐标
//sr,sc(special_row, special_col):代表特殊点坐标
//size:棋盘的大小
//递归
void chessBoard(int tr, int tc, int sr, int sc, int size);
#include <stdio.h>
#include <stdlib.h>
#include <cstring> // Include for memset
int nCount = 0;
int Matrix[100][100];
void chessBoard(int tr, int tc, int sr, int sc, int size);
int main()
{
int size,r,c,row,col;
std::memset(Matrix,0,sizeof(Matrix)); // Use std:: prefix for memset
scanf("%d",&size);
scanf("%d%d",&row,&col);
chessBoard(0,0,row,col,size);
for (r = 0; r < size; r++)
{
for (c = 0; c < size; c++)
{
printf("%2d ",Matrix[r][c]);
}
printf("\n");
}
return 0;
}
void chessBoard(int tr, int tc, int sr, int sc, int size)
{
//tr and tc represent the top left corner's coordinate of the matrix
if (1 == size) return;
int s,t;
s = size/2; //The number of grid the matrix's edge
t = ++ nCount;
//locate the special grid on bottom right corner
if (sr < tr + s && sc < tc +s)
{
chessBoard(tr,tc,sr,sc,s);
}
else
{
Matrix[tr+s-1][tc+s-1] = t;
chessBoard(tr,tc,tr+s-1,tc+s-1,s);
}
//locate the special grid on bottom left corner
if (sr < tr + s && sc >= tc + s )
{
chessBoard(tr,tc+s,sr,sc,s);
}
else
{
Matrix[tr+s-1][tc+s] = t;
chessBoard(tr,tc+s,tr+s-1,tc+s,s);
}
//locate the special grid on top right corner
if (sr >= tr + s && sc < tc + s)
{
chessBoard(tr+s,tc,sr,sc,s);
}
else
{
Matrix[tr+s][tc+s-1] = t;
chessBoard(tr+s,tc,tr+s,tc+s-1,s);
}
//locate the special grid on top left corner
if (sr >= tr + s && sc >= tc + s)
{
chessBoard(tr+s,tc+s,sr,sc,s);
}
else
{
Matrix[tr+s][tc+s] = t;
chessBoard(tr+s,tc+s,tr+s,tc+s,s);
}
}
5.合并排序(归并排序):核心算法

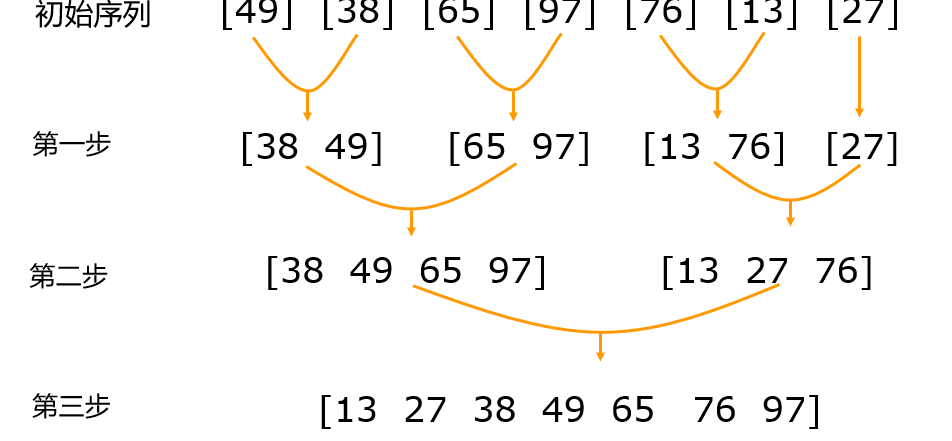



基本思想:将待排序元素分为大小大致相等的2个子集,分别对子集进行相同的划分和排序,最后在进行合并得到最终的排序结果。
void MergeSort(Type a[], int l, int r)
{
//先划分
if(left >= right) return;
//保证至少有两个元素
int m = (l+r)/2;
MergeSort(a, l, m);
MergeSort(a, m+1, r);
//合并到数组b
merge(a,b,left,m,right);
//复制回数组a
copy(a, b, left, right);
}
}
6.快速算法:核心算法
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
快速排序算法通过多次比较和交换来实现排序,其排序流程如下:
1、首先设定一个分界值,通过该分界值将数组分成左右两部分。
2、将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于或等于分界值,而右边部分中各元素都大于或等于分界值。
3、然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
4、重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
概括来说为 挖坑填数 + 分治法。

//下面这个代码中的分界值总是选择第一个即a[l]
void QuickSort(Type a[], int l, int r)
{
if(l <r){
int q = Partition(a, l, r);// 划分,得到分解值的新位置q,此时q左边都<q,右边都>q
//对左半段排序
QuickSort(a,l, q -1);
//对右边半段排序
QuickSort(a,q+1, r); //注意,q位置的数已经排好了,不要动了
}
}
三、动态规划
3.1:基本思想
和分治算法类似,都是把原问题分解为规模较小的子问题,子问题都可解(最优子结构)。与分治不同的是,子问题在求解过程中是不独立的,如果不进行优化,很多子问题将被重复计算。
如果能够保存已解决的子问题的答案,而在需要时再找出已求得的答案,就可以避免大量重复计算,从而得到多项式时间算法。
3.2:基本步骤(必须搞清楚,4个步骤
- 分析最优解的结构:判断是否具有最优子结构,能否用DP
- 定义递推公式(状态转移方程
- 自底向上递推计算子问题的最优值
- 根据第三步记录的最优值信息,构造最优解
3.3:矩阵连乘

-
分析是否具有最优子结构
特征:计算A[i:j]的最优次序所包含的计算矩阵子链A[i:k]和A[k+1:j]的次序也是最优的 -
递归关系
可以递归地定义m[i,j]为: m [ i , j ] = { 0 i = j min i ≤ k < j { m [ i , k ] + m [ k + 1 , j ] + p i − 1 p k p j } i < j k 的位置只有 j − i 种可能 \begin{aligned}&\text{可以递归地定义m[i,j]为:}\\&m[i,j]=\begin{cases}0&i=j\\\min_{\mathrm{i\leq k<j}}\{m[i,k]+m[k+1,j]+p_{i-1}p_kp_j\}&i<j\end{cases}\\&k\text{ 的位置只有 }j-i\text{ 种可能}\end{aligned} 可以递归地定义m[i,j]为:m[i,j]={0mini≤k<j{m[i,k]+m[k+1,j]+pi−1pkpj}i=ji<jk 的位置只有 j−i 种可能
∙ 分别计算完两个部分后,我们需要将它们合并成一个矩阵。 ∙ A i 到 A k 的结果矩阵维度为 p i − 1 × p k 。 ∙ A k + 1 到 A j 的结果矩阵维度为 p k ⋅ p j 。 ∙ 将这两个矩阵相乘需要 p i − 1 ⋅ p k ⋅ p j 次标量乘法。 \begin{aligned}&\bullet\text{ 分别计算完两个部分后,我们需要将它们合并成一个矩阵。}\\&\bullet A_i\text{ 到 }A_k\text{ 的结果矩阵维度为 }p_{i-1}\times p_k\text{。}\\&\bullet A_{k+1}\text{ 到 }A_j\text{ 的结果矩阵维度为 }p_k\cdot p_j\text{。}\\&\bullet\text{ 将这两个矩阵相乘需要 }p_{i-1}\cdot p_k\cdot p_j\text{ 次标量乘法。}\end{aligned} ∙ 分别计算完两个部分后,我们需要将它们合并成一个矩阵。∙Ai 到 Ak 的结果矩阵维度为 pi−1×pk。∙Ak+1 到 Aj 的结果矩阵维度为 pk⋅pj。∙ 将这两个矩阵相乘需要 pi−1⋅pk⋅pj 次标量乘法。
- 计算最优值(记住)
看这篇文章理解https://blog.csdn.net/qq_44755403/article/details/105015330
矩阵连乘问题是一个经典的动态规划问题,用于确定如何以最低的计算代价将一组矩阵连乘起来。为了更好地理解和记忆这段代码,可以按照以下步骤进行分解和解释:

代码分解及解释
-
初始化对角线
for (i = 0; i <= n; i++) { m[i][i] = 0; }- 这段代码初始化矩阵
m的对角线元素为零,即单个矩阵的乘积代价为零。
- 这段代码初始化矩阵
-
外层循环:矩阵链长度
for (r = 2; r <= n; r++) {r表示当前考虑的矩阵链长度,从2开始到n。
-
中间循环:矩阵链起点
for (i = 1; i <= n - r + 1; i++) {i表示矩阵链的起点,范围从1到n - r + 1。
-
确定矩阵链的终点
j = i + r - 1;j是矩阵链的终点。
-
初始化
m[i][j]的值m[i][j] = m[i][i] + m[i + 1][j] + p[i - 1] * p[i] * p[j]; //将矩阵链 (i) 和矩阵链 (i+1,j) 分别计算的最小代价。 s[i][j] = i;- 这段代码的目的是为 m[i][j] 赋一个初始值,假设第一个切分点就是 i。这里的 m[i][i] 和 m[i + 1][j] 都是已经计算过的子问题的最优解。
-
内层循环:寻找最优切分点
for (k = i + 1; k < j; k++) { int t = m[i][k] + m[k + 1][j] + p[i - 1] * p[k] * p[j]; if (t < m[i][j]) { m[i][j] = t; s[i][j] = k; } }k表示当前测试的切分点。- 计算在
k处切分的代价t,如果t小于当前最小值,则更新m[i][j]和s[i][j]。
m [ 2 ] [ 5 ] = min { m [ 2 ] [ 2 ] + m [ 3 ] [ 5 ] + p 1 p 2 p 5 = 0 + 2500 + 35 × 15 × 20 = 13000 m [ 2 ] [ 3 ] + m [ 4 ] [ 5 ] + p 1 p 3 p 5 = 2625 + 1000 + 35 × 5 × 20 = 7125 m [ 2 ] [ 4 ] + m [ 5 ] [ 5 ] + p 1 p 4 p 5 = 4375 + 0 + 35 × 10 × 20 = 11375 m[2][5]=\min\begin{cases}m[2][2]+m[3][5]+p_1p_2p_5=0+2500+35\times15\times20=13000\\m[2][3]+m[4][5]+p_1p_3p_5=2625+1000+35\times5\times20=7125\\m[2][4]+m[5][5]+p_1p_4p_5=4375+0+35\times10\times20=11375\end{cases} m[2][5]=min⎩ ⎨ ⎧m[2][2]+m[3][5]+p1p2p5=0+2500+35×15×20=13000m[2][3]+m[4][5]+p1p3p5=2625+1000+35×5×20=7125m[2][4]+m[5][5]+p1p4p5=4375+0+35×10×20=11375
3.4:动态规划的两个基本要素
- 最优子结构(问题的最优解包含了子问题的最优解),自底向上求解,由子问题的最优解构造出原问题的最优解
- 重叠子问题(解决方法:对每个子问题只算一次,记录下来,填到表格中,只是用常数时间去看一下子问题结果)
3.5:备忘录方法的概念记住
是动态规划算法的变形
备忘录法的控制结构和递归相同,但是备忘录是自顶向下(因为本质还是递归),而动态规划是自底向上。
3.6:动态规划和分治比较
- 相同点:都是将原问题分解为规模较小的子问题,然后再将由子问题合并or构造得到原问题的解
- 不同点:动态规划分解出来的子问题往往在求解时不是相互独立的(重复),而递归分解出来的子问题是相互独立的。
- 控制结构不同:分治是自顶向下,动态规划是自底向上
本质是分治是递归实现,一般,递归的过程就是首先自顶向下然后再自底向上,而动态规划为了避免重叠子问题,利用迭代循环,即没有递的过程(自顶向下)只有归(自底向上)的过程
3.7:备忘录和动态规划的区别
- 相同点:都是利用表格(数组)保存子问题的结果,避免重复计算
- 不同点:备忘录本质还是递归(自顶向下),动态规划是自底向上
3.8:重点算法:最长公共子序列
基本思想
- 最优子结构分析
- 递归结构
c [ i ] [ j ] = { 0 i = 0 , j = 0 c [ i − 1 ] [ j − 1 ] + 1 i , j > 0 ; x i = y j max { c [ i ] [ j − 1 ] , c [ i − 1 ] [ j ] } i , j > 0 ; x i ≠ y j c[i][j]=\begin{cases}\quad0&\quad i=0,j=0\\\quad c[i-1][j-1]+1&\quad i,j>0;x_i=y_j\\\max\{c[i][j-1],c[i-1][j]\}&\quad i,j>0;x_i\neq y_j\end{cases} c[i][j]=⎩ ⎨ ⎧0c[i−1][j−1]+1max{c[i][j−1],c[i−1][j]}i=0,j=0i,j>0;xi=yji,j>0;xi=yj - 55页核心算法

函数 LCSLength
这个函数用于计算两个序列 x 和 y 的最长公共子序列的长度,并填充矩阵 c 和 b。
6. // 动态规划计算LCS的长度
7. vector<vector<int>> lcsLength(const string& X, const string& Y) {
8. int m = X.size();
9. int n = Y.size();
10. vector<vector<int>> dp(m + 1, vector<int>(n + 1, 0));
11.
12. for (int i = 1; i <= m; i++) {
13. for (int j = 1; j <= n; j++) {
14. if (X[i - 1] == Y[j - 1])
15. dp[i][j] = dp[i - 1][j - 1] + 1;
16. else
17. dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
18. }
19. }
20. return dp;
21. }
c[i][j] 表示 x[1…i] 和 y[1…j] 的最长公共子序列的长度。
b[i][j] 用来记录在计算 c[i][j] 时,是从哪个子问题转移过来的。
b[i][j] = 1 表示 c[i][j] 是由 c[i-1][j-1] + 1 转移过来的,即 x[i] == y[j]。
b[i][j] = 2 表示 c[i][j] 是由 c[i-1][j] 转移过来的,即 x[i] != y[j] 且从上方转移。
b[i][j] = 3 表示 c[i][j] 是由 c[i][j-1] 转移过来的,即 x[i] != y[j] 且从左方转移。
- 56页构造最优值
根据上一个过程的记录信息,得到最长公共子序列
void LCS(int i, int j, char *x, int **b) {
if (i == 0 || j == 0) return;
if (b[i][j] == 1) {
LCS(i-1, j-1, x, b);
cout << x[i];
} else if (b[i][j] == 2) {
LCS(i-1, j, x, b);
} else {
LCS(i, j-1, x, b);
}
}
递归终止条件:i == 0 或 j == 0,即到达矩阵的边界。
根据 b[i][j] 的值,决定递归调用的方向。
b[i][j] == 1:表示当前字符 x[i] 和 y[j] 是 LCS 的一部分,递归调用 LCS(i-1, j-1, x, b) 并输出 x[i]。
b[i][j] == 2:表示当前字符 x[i] 不在 LCS 中,递归调用 LCS(i-1, j, x, b)。
b[i][j] == 3:表示当前字符 y[j] 不在 LCS 中,递归调用 LCS(i, j-1, x, b)。
四、贪心
4.1:基本思想
顾名思义,贪心算法总是作出在当前看来最好的选择。也就是说贪心算法并不从整体最优考虑,它所作出的选择只是在某种意义上的局部最优选择。当然,希望贪心算法得到的最终结果也是整体最优的。虽然贪心算法不能对所有问题都得到整体最优解,但对许多问题它能产生整体最优解。如单源最短路经问题,最小生成树问题等。在一些情况下,即使贪心算法不能得到整体最优解,其最终结果却是最优解的很好近似。
4.2:基础算法——活动安排算法
注意:按照互动开始时间进行排序
目的:使尽可能多的活动使用同一个资源(尽可能多的活动在一天中不相交)
思路:每次选择结束时间尽可能早的活动加结果集合A,在选择之前确保当前选择的要与上一个选择的兼容(否则排除
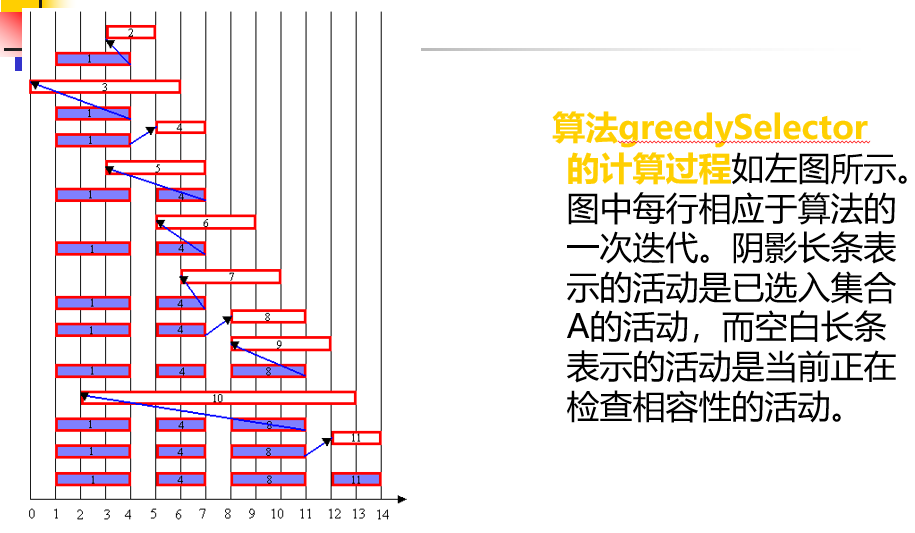

4.3:贪心算法的要素
- 贪心选择性
基本定义(一定要记住):整体最优解可以由局部最优得到(即贪心选择),这也是贪心算法与动态规划算法的主要区别 - 最优子结构
4.4:贪心和动态规划的对比
- 相同点:都具有最优子结构
- 不同点:贪心选择性;动态规划是自底向上,贪心自顶向下;
4.5:背包问题(不能解决0,1背包问题)
- 基本步骤:首先计算每种物品单位重量的价值VⅵWi,然后,依贪心选择策略,将尽可能多的单位重量价值最高的物品装入背包。若将这种物品全部装入背包后**,背包内的物品总重量未超过C,则选择单位重量价值次高的物品并尽可能多地装入背包**。依此策略一直地进行下去,直到背包装满为止。

4.6:哈夫曼编码
- 前缀码:每个字符都用
0,1串进行编码,并且任意字符的代码都不是其他字符代码的前缀,这种编码称为前缀码。可以使译码过程简单;最优前缀码总是一棵完全二叉树。 - 构造哈夫曼编码:给你字母频次,构造出哈夫曼树,进行编码,画哈夫曼树
4.7:最小生成树
- 最小生成树的性质(MST性质):最小生成树(Minimum Spanning Tree,简称 MST)是图论中的一个重要概念。给定一个连通的、无向的加权图,最小生成树是该图的一个子图,它包含了所有的顶点,并且边的总权值最小,同时保证没有环。
1.Prim算法:基于一个点,贪心取选边 O(n^2)
- Prim算法:操作对象是点,首先基于一个点,选取最短的边,然后继续基于已经选的顶点集合选短的边。
- 每次将离连通部分的最近的点和点对应的边加入的连通部分,连通部分逐渐扩大,最后将整个图连通起来,并且边长之和最小。

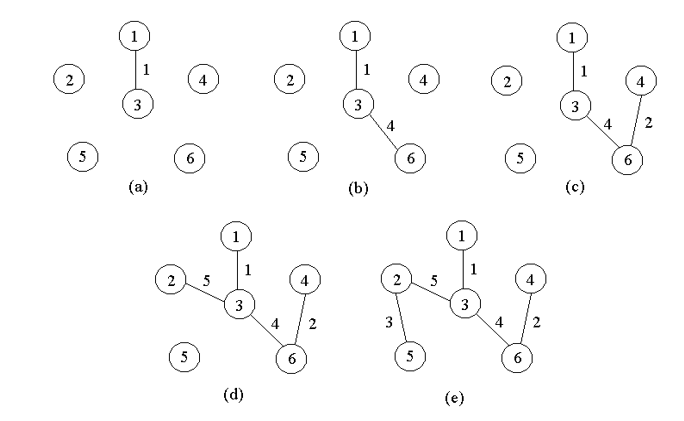
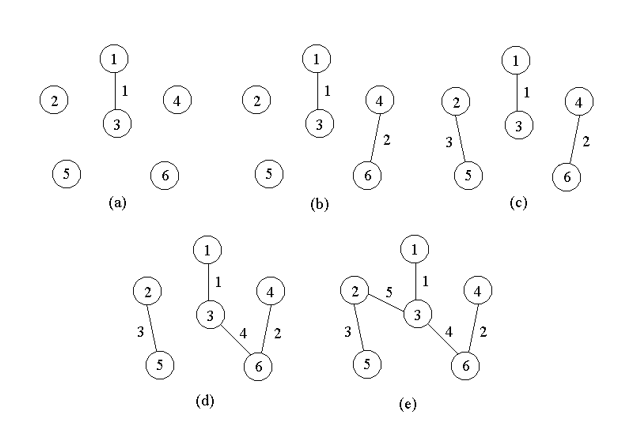
2. Kruskal算法:直接选边(eloge)
-
核心思想:所有边能小则小,算法的实现方面要用到并查集判断两点是否在同一集合
-
首先,将所有边,按照权重大小,从小到大排序
-
构造一个只含 n 个顶点、而边集为空的子图,把子图中各个顶点看成各棵树上的根结点
-
从边集 E 中选取一条权值最小的边,若该条边的两个顶点分属不同的树(保证了最后是联通且没有环的图,即树),则将其加入子图;即把两棵树合成一棵树;
-
反之,若该条边的两个顶点已落在同一棵树上,则不可取(取了的话会形成环!),而应该取下一条权值最小的边再试之
-
依次类推,直到森林中只有一棵树,也即子图中含有 n-1 条边为止。
4.8:多机调度——了解基本思想
-
问题描述:有m台相同的机器,需要处理n个独立的作业,作业i所需的处理时间为t[i]。 每个作业都可以在任何一台机器上加工处理,但未完工之前不允许中断处理。任何作业不能拆分成更小的作业。 如何对作业进行调度,使得所给的n个作业由m台机器在尽可能短的时间内加工处理完成。
-
解题方法
- 当机器数m>=作业数n时,只要将机器 i 的[0,t[i]]时间区间分配给作业 i 即可。这种情况下,耗时最长的作业的处理时间就是所求的最短时间。
- 当机器数m<作业数n时,按照如下步骤处理:
第1步:将n个作业按其所需处理时间从大到小降序排列;
第2步:将m个机器按照工作时长从小到大升序排列;
第3步:将“耗时最长的作业”分配给“最先空闲的机器”,增加该机器的工作时长。
重复第二步和第三步,直到所有作业都被处理。这种情况下,累加耗时最长的机器的工作时长就是所求的最短时间。

五、回溯
5.1:基本思想

- 基本步骤(3大步骤)

5.2:显著特征
整个树形解空间都是动态生成过程,主要保存从根节点开始到当前节点的扩展路径。
5.3:扩展结点、活结点、死节点

5.4:限界函数->剪枝


- 可行性约束函数:就像迷宫中的墙壁,告诉你哪些方向是走不通的,避免浪费时间。
- 限界函数:就像地图应用,提前告诉你某条路径是否比你已经找到的路径更长,避免走冤枉路。
5.5:解空间解向量

5.6:四大框架⭐
1. 递归回溯
void backTrack(int depth){
if(depth >= depthMax) Output(path);// 到达叶子节点,输出当前路径上收集到的答案
else{
//进行深度搜索,遍历第一层叶子节点
for(int i = firstNode(depthMax, depth); i <= lastNode(depthMax,depth); i++){
//把当前节点加入当前路径
x[depth] = node[i];
//判断是否要继续向下
if(Constraint(depth) && Bound(depth)) backTrack(depth+1);
}
}
}
2. 迭代回溯

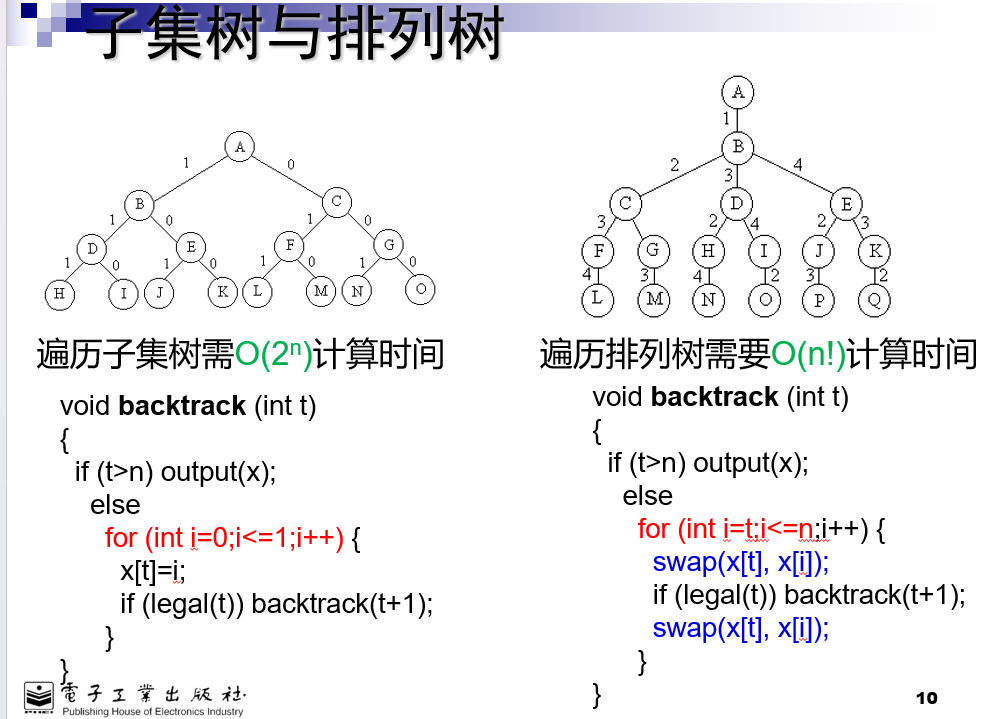
3. 子集树和排列树
t总表示处于第几层x[t]总是表示当前这一层做出的选择,整个x数组表示当前路径
5.7:子集树的应用:0,1背包问题(会写回溯过程)
void backTrack(int i) {
//到达叶子节点
if( i > n ) {
//当前最优值 = 当前价值
bestp = cp;
return;
}
//约束条件(可行性限制)——遍历左子树
if( cw + w[i] <= c) {
cw += w[i];
cp += p[i];
backTrack(i+1);
cw -= w[i];
cp -= p[i];
}
//限界函数,遍历右子树
if(Bound(i+1) > bestp)
backTrack(i+1);
}
}
5.8:排列树应用(n后问题)
- 用n元组
x[1:n]表示n后的解。其中x[i]表示皇后i放在棋盘的第x[i]列。
//检查当前第k行是否安全
bool Queen::Place(int k)
{
for(int j = 1; j < k; j++)
//判断当前第k行(在backtrack里已经放置了这行的皇后)是否合法
//1.不能处于对角线 || 同一列
if( abs(k-j) == abs(x[j]-x[k]) || (x[j] == x[k]) ) return false;
return true;
}
//回溯函数,依次在每一行进行放置函数
void Queen::backTrack(int t)//在第t行的每一列放置皇后,判断是否可行
{
if(t > n) sum++;
else
for(int i = 1; i <= n; i++)
{
x[t] = i; // 将t行的皇后放置在第i列
if(Palace(t)) backTrack(t+1); //如果可以放置,则从这个分支向下深搜
}
}
5.9:批处理作业调度
六、BFS(分支限界)
6.1:和回溯法的差异
- 相同点:都是在解空间中搜索解决问题
- 不同点:
- 求解目标:回溯->找到解空间中满足约束的所有解,分支限界->求解到某种意义的最优解
- 搜索方式:DFS\BFS
- 对扩展结点的扩展方式不同
- 存储空间要求不同
6.2: 基本思想

分支限界法设计算法的步骤是:
(1)针对所给问题,定义问题的解空间(对解进行编码);分
(2)确定易于搜索的解空间结构(按树或图组织解) ;
(3)以广度优先或以最小耗费(最大收益)优先的方式搜索解空间,并在搜索过程中用剪枝函数避免无效搜索。
6.3:从活结点中选扩展结点的方法:2类分支限界法
- 队列式
- 优先队列
6.4:基本算法
1. 01背包

2. 最大团问题
最大团也就是该图中最大的完全图(各顶点之间都有边)
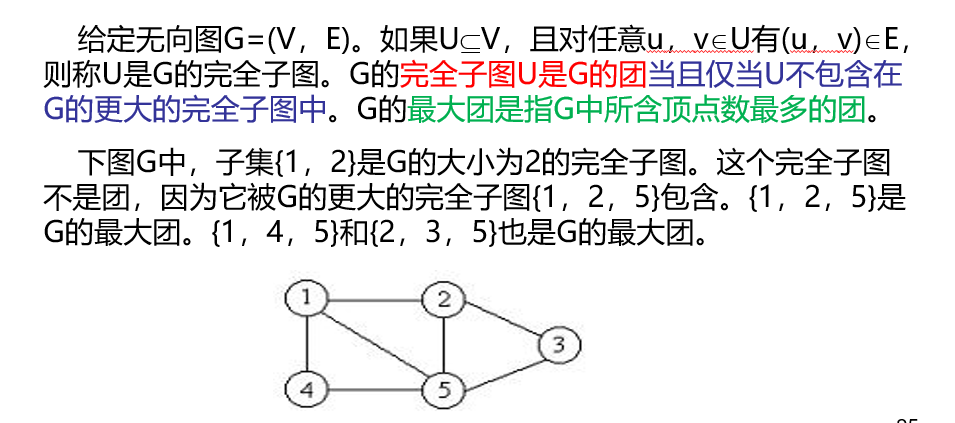

七、随机
好的,让我们总结一下这四种随机化算法的特征及其主要思想。
1. 数值概率算法
- 主要思想:利用随机化方法求得近似解(非精确解)。
- 特征:
- 通过多次随机试验,得到一个近似的解。
- 适用于求解复杂问题,特别是那些没有快速精确解法的问题。
- 结果的准确性依赖于试验次数,试验次数越多,结果越接近真实值。
- 典型例子:模拟退火算法(Simulated Annealing)、遗传算法(Genetic Algorithm)。
2. 舍伍德思想(Sherwood’s Idea)
- 主要思想:利用随机化方法解决特定问题,求得应该解。
- 特征:
- 舍伍德思想通常用于优化问题,通过随机化方法找到一个接近最优的解。
- 通过随机选择和调整,逐步逼近最优解。
- 适用于大规模优化问题,特别是那些传统方法难以处理的问题。
- 典型例子:随机梯度下降(Stochastic Gradient Descent)。
3. 拉斯维加斯算法(Las Vegas Algorithm)
- 主要思想:利用随机化方法求解问题,但有可能得不到解。
- 特征:
- 保证解的正确性,但不保证在有限时间内找到解。
- 如果找到解,解一定是正确的;如果没有找到解,算法可能会继续运行或终止。
- 适用于那些解唯一且难以找到的复杂问题。
- 典型例子:快速选择算法(Quickselect)用于找到数组的第 k 大元素。
4. 蒙特卡罗算法(Monte Carlo Algorithm)
- 主要思想:在 P 正确一致的前提下,通过随机化方法求得正确解。
- 特征:
- 通过随机试验和统计方法,得到问题的解。
- 解的正确性依赖于试验次数和概率分布。
- 适用于数值积分、优化、统计模拟等问题。
- 解的准确性可以通过增加试验次数来提高。
- 典型例子:蒙特卡罗积分(Monte Carlo Integration)、蒙特卡罗模拟(Monte Carlo Simulation)。
总结
- 数值概率算法:通过多次随机试验,得到近似解,适用于复杂问题。
- 舍伍德思想:通过随机化方法解决特定问题,逐步逼近最优解。
- 拉斯维加斯算法:保证解的正确性,但不保证在有限时间内找到解。
- 蒙特卡罗算法:在 P 正确一致的前提下,通过随机试验和统计方法,得到正确解。
希望这个总结能帮助你更好地理解这四种随机化算法的特征及其主要思想。如果有任何疑问,请随时提问。
置信度:[95]
时间越长次数越多,越精确
八、第八章:线性规划算法
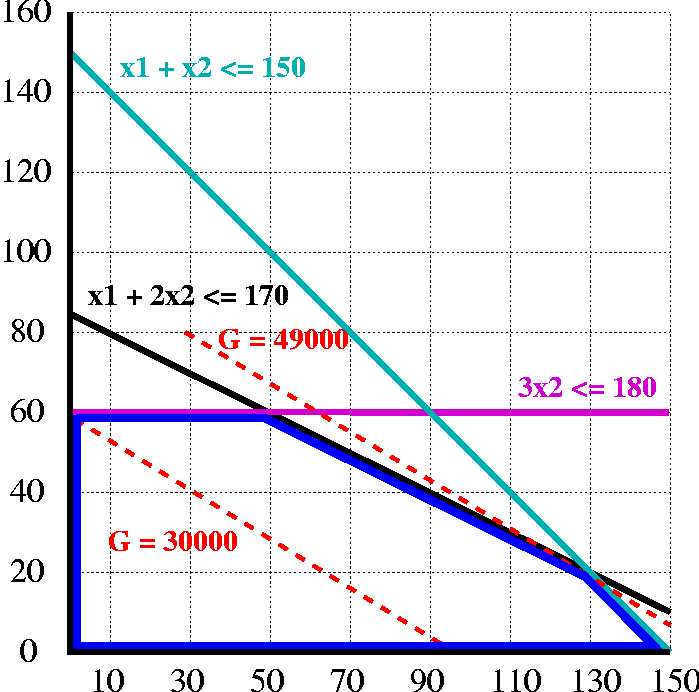
8.1:线性规划问题的基本形式
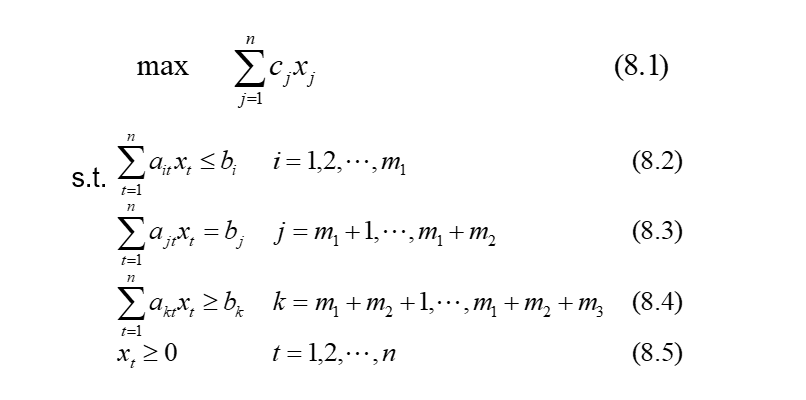
8.2:可行解的定义、可行区域的定义4个定义
- 可行解
- 可行区域
- 最优解的定义
- 最优值的定义

8.3:两种情况不存在最优解
- 约束条件相互排斥,根本没有解->可行区域为空
- 目标函数无极值、无界(目标函数没有约束)

8.4:线性规划的基本定理

8.5:单纯形算法
-
两个特点
- 测试,每个测试使目标函数增大
- 经过多少次测试,则可以得到目标函数的解
-
基本的步骤


m个也是约束方程的个数

选取,怎么钻取?
怎么选取立即变量?
专注变换,
要稍微解释一下!
- 第一步:生成一个初始单纯形表,纵坐标是基本可行解,横坐标是非基本可行解,具体的值是对应到对应约束式的系数。(注意,化成右侧的式子再进行填表
- 选出使目标函数增加的非基本变量作为入基变量
- 选择标准:z行中的正系数非基本变量都满足要求,选择Z行整数对应的非基本变量即可


- 第三步:选出一个基本变量作为离基变量
-
出发点:我们希望入基变量越大越好,但是入基变量受基本变量(或者说离基变量)的影响,所以我们要找到对入基变量有影响的基本变量进行离基
-
选择标注:比较入基变量和离基基本变量的符号关系,以及大小关系
-
符号选择:
入基变量所在的列与基本变量所在的行交叉处元素为负数;该元素无限制,不选
入基变量所在列全部都为负数,那么目标函数无界,得到问题的无界解
入基变量所在列中有多个元素是正数,选择限制比值最小的基本变量作为离基变量(将最左边的常数列除以交叉值,就为最终的结果)
-
- 第四步,转轴变换。横竖兑换

- 解离基变量所对应的方程,将入基变量用离基变量表示,再将其带入其他的基本变量和所在行消去其中的入基变量。生成新的单纯形表
- 离基变量对于入基变量的影响最大,限制了入基变量的增加,离基变量等于零的时候,即最小的时候,入基变量最大
- 第五步:转回并重复第一步,进一步改进目标函数值。不断重复上述过程,直到Z行所有的非基本变量系数都变成负值为止。
这一步已经新生成了一个单纯形表格,如下。目标式子中,不完全都是自变量了,还有常数

下述步骤是对上述三个步骤的重复
- 表上找一横
- 一横上找一竖
- 横竖交叉,进行交换
8.6:网络流
重点
-
基本概念:什么是网络
-
什么是网络流
-
什么是可行流,可行流,满足的2个条件
- 容量约束
- 平衡约束
定义是什么
-
边流
-
最大流





-
流的费用
-
残留网络


