1、redis相关面试题。
(1)redis数据类型用过哪些?
String(字符串)、Hash(哈希)、List(列表)、Set(集合)、Zset(sort set有序集合)。
String(字符串)
- 常用命令: set,get,decr,incr,mget 等。
- String类型时二进制安全的,也就是说String包含了任何类型,如int、序列化对象、jpg等。最大存储为512MB。
Hash(哈希)
- 常用命令:hget,hset,hgetall 等。
- Hash是键值对(key-value)集合,特别适合存储对象。
List(列表)
- 常用命令:lpush(添加头部),rpush(添加尾部),lpop,rpop,lrange key start stop(获取指定范围的元素)等。
- List是简单的字符串列表,按照插入的顺序排序,可以添加一个元素到列表头部(lpush)或尾部(rpush)。
Set(集合)
- 常用命令:sadd,spop,smembers,sunion 等。
- Set是String类型的无序集合,通过哈希表实现,其添加、删除、查找复杂度都是O(1)。
Zset(sort set有序集合)
- 常用命令:zadd,zrange,zrem,zcard等。
- Zset是String类型有序集合,允许键key重复,但不允许成员value重复(后面添加的成员元素与集合中的相同,则替换集合中的元素)。每个元素都会关联一个double类型的score,通过score来为成员的元素从小到大排序。
(2)追问1:
- 缓存时缓存的是什么东西?
答 主要是缓存从数去库中查询的数据,第二次查询时直接获取redis缓存的数据。 - 怎么保证缓存与数据库的一致性?
答:1.读写分离,即读只访问缓存,写只访问数据库,若更新数据库成功,写入缓存失败,则进行数据回滚。2.队列存储请求,将读或写操作放入队列中,直到完成该操作才执行下一个读写操作。3.设置定时缓存同步。
(3)追问2:
Hash这个数据类型有用过吗?它是怎么扩容的?
(4)追问3:
- Hash冲突是怎么解决的?
答:通过链表解决hash冲突,数组类型为链表,即相同的Hash码存入到相同数组下标中链表的尾部。
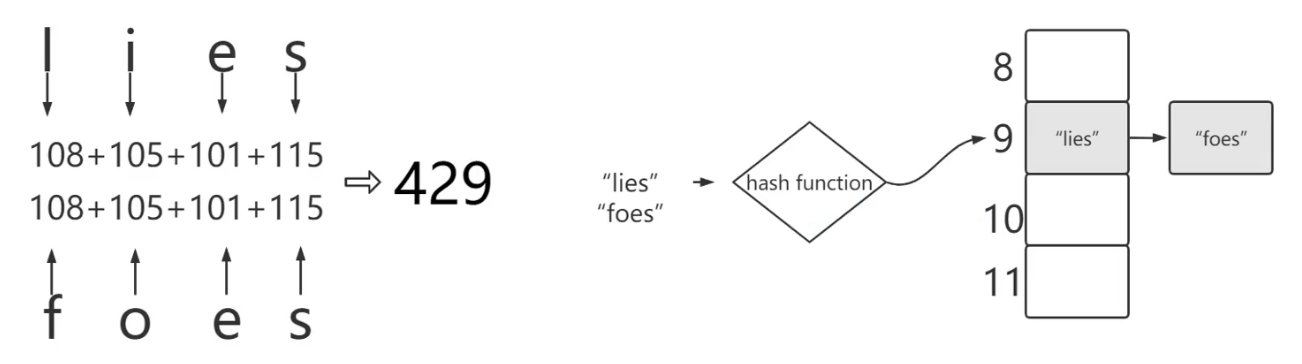
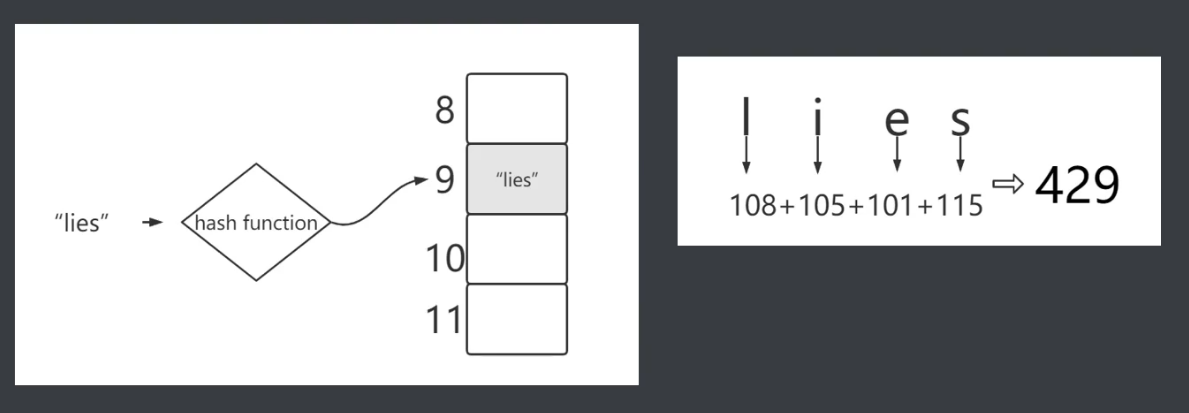
- 哈希码是如何实现的?
哈希码是哈希表的下标,通过算法计算出字符串的哈希码(HashCode),该算法不唯一。
如:算出字符串每个字符的ASCII码,然后进行相加再取模,得出哈希表的下标(Hashcode)。
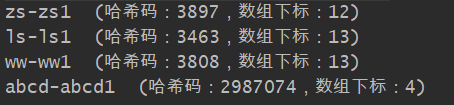
通过获取key的hashCode,并对其取模,发现其恒定不变:
public class Main extends HashMap {
public static void main(String args[]) {
Main map = new Main();
map.put("zs", "zs1");
map.put("ls", "ls1");
map.put("ww", "ww1");
map.put("abcd", "abcd1");
}
static void put(String key, String val) {
System.out.println(key + "-" + val + "(哈希码:" + key.hashCode()
+ ",数组下标:" + Math.abs(key.hashCode() % 15) + ")");
}
}
以上代码输出如下:
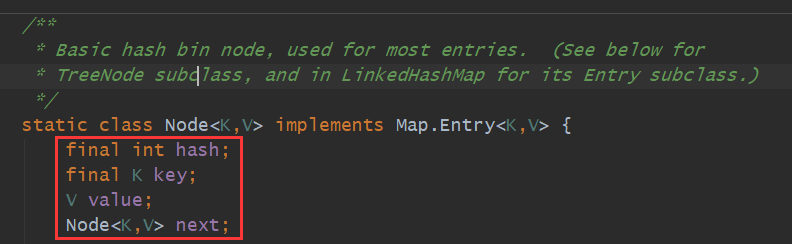
- put操作最终保存的是什么值?
当进行put操作时,会将要put的值放入对应下标数组的链表中,存放的值有:key、value、hash、next,如下所示:
- get操作:
先是计算出key的哈希值,然后在再通过哈希值算出数组下标,然后在该数组下标遍历查找链表中的元素,比较hash和key是否相等。
2、HashMap相关面试题:
(1)模拟源码实现HashMap。
Map接口代码如下:
public interface Map<K, V> {
// 存
V put(K key, V value);
// 取
V get(K key);
// 长度
int size();
interface Node<K, V> {
K getKey();
V getValue();
}
}
HashMap接口代码如下:
public class HashMap<K, V> implements Map<K, V> {
private Node<K, V>[] hashTable = null;
private int size;
public HashMap() {
hashTable = new Node[16];
}
/**
* 1.通过key进行hs算法得出hashCode
* 2.通过hashCode算出数组下标
* 3.判断该数组下标元素是否为空,不为空直接存储
* 4.若不为空进行链表存储,返回
* @param key
* @param value
* @return
*/
@Override
public V put(K key, V value) {
int hashCode = key.hashCode();
// 获取hash下标
int index = getHash(hashCode);
// 获取该下标的链表
Node<K, V> linked = hashTable[index];
if (linked == null) {
// 直接存储
hashTable[index] = new Node<>(key, value, hashCode, null);
size++;
} else {
// 头插法,将新元素插入到原来链表的头部
hashTable[index] = new Node<>(key, value, hashCode, linked);
}
return hashTable[index].getValue();
}
/**
* 通过key获取hashCode,进行取模获取数组下标
* @param hashCode
* @return
*/
private int getHash(int hashCode) {
int index = hashCode % 16;
return index >= 0 ? index : -index;
}
/**
* 1.获取key的hashCode,并通过hashCode获取数组下标
* 2.通过下标获取对应的链表
* 3.循环遍历链表,若key和hashCode相等,返回value,否则返回null
* @param key
* @return
*/
@Override
public V get(K key) {
if (size() == 0)
return null;
int hashCode = key.hashCode();
// 获取hash下标
int index = getHash(hashCode);
// 获取该下标的链表,并查找链表中对应的value
return getValue(hashTable[index], key, hashCode);
}
private V getValue(Node<K, V> linked, K key, int hashCode) {
// 若key相等且hashCode相等
if (key.equals(linked.getKey()) && linked.getHash() == hashCode) {
return linked.getValue();
}
// 若链表的下一个节点不为null,递归遍历
if (linked.next != null)
return getValue(linked.next, key, hashCode);
return null;
}
@Override
public int size() {
return size;
}
class Node<K, V> implements Map.Node<K, V> {
K key;
V value;
int hash;
Node<K, V> next;
public Node(K key, V value, int hash, Node<K, V> next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}
@Override
public K getKey() {
return key;
}
@Override
public V getValue() {
return value;
}
public int getHash() {
return hash;
}
}
}
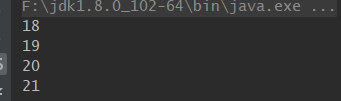
代码测试:
public class Test {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("zs", "18");
map.put("ls", "19");
map.put("ww", "20");
map.put("zl", "21");
System.out.println(map.get("zs"));
System.out.println(map.get("ls"));
System.out.println(map.get("ww"));
System.out.println(map.get("zl"));
}
}
输出结果如下:
(2)为什么HashMap要用红黑树
因为链表插入删除效率高,查找元素慢,所以需要将链表构建成红黑树来提高查询效率。
当阈值(TREEIFY_THRESHOLD)值大于8时,采用红黑树,否则采用普通方法(数组和链表方式)。
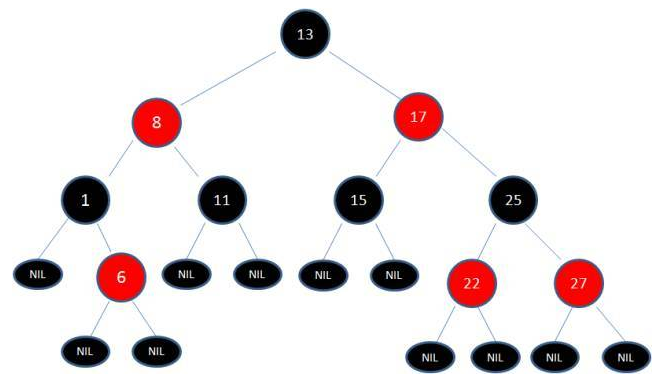
红黑树定义:
- 节点是红色或者黑色。
- 根节点是黑色。
- 每个叶子节点都是黑色的空节点。
- 每个红色节点的两个子节点都是黑色(不能有两个连续的红色节点)。
- 任意每个节点到叶子节点路径所包含相同数量的黑色节点。
除此之外,最长路径不能超过最短路径2倍。
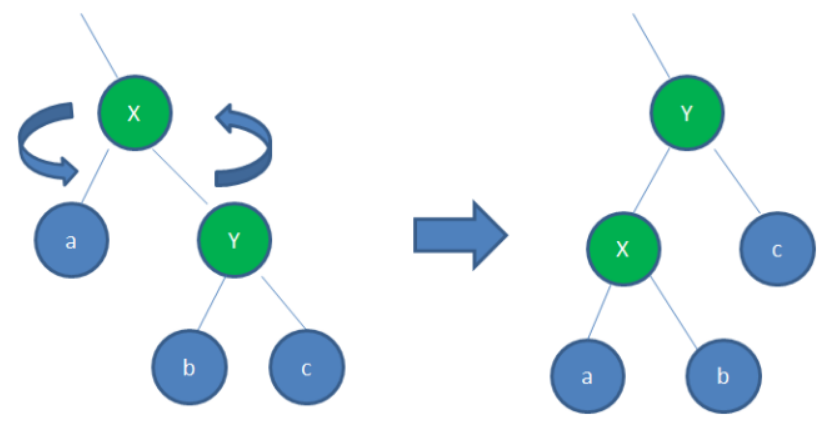
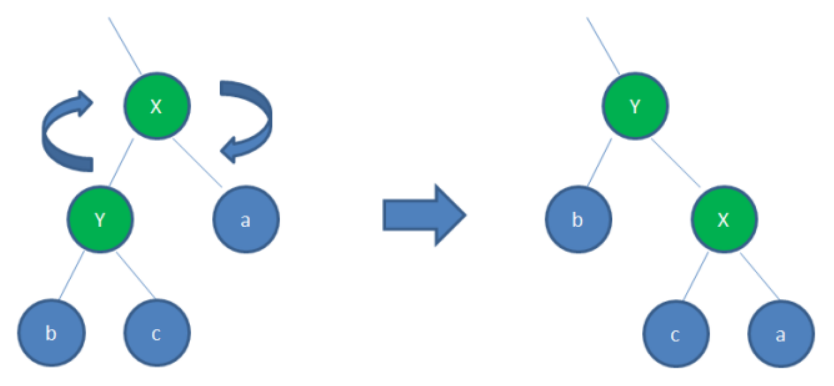
在每次插入或删除的时候可能会打乱原来红黑树的结构,所以需要进行调整,调整的方法有:左旋转、右旋转、节点变色。这个过程中比较消耗性能的,所以需要结合链表结构进行操作。
如图为左旋转:
如图为右旋转:
(3)说说HashMap、TreeMap和LinkedHashMap的区别。
HashMap:数组 + 链表(单向) + 红黑树。实现了Map接口。非线程安全,且不保持元素顺序。
TreeMap:数组 + 红黑树。非线程安全,所有元素都保持着固定的顺序。
LinkedHashMap:数组 + 链表(双向) + 红黑树。非线程安全,实现了Map接口并继承了HashMap,保证了插入元素的有序。
(4)ConcurrentHashMap和HashTable的区别。
参考链接:HashMap、ConcurrentHashMap和HashTable的区别
- ConcurrentHashMap:线程安全,采用分段锁的方式,不会造成线程堵塞、效率高,但是不保证操作原子性。
- HashTable:线程安全,采用syncronized同步锁方式,会造成线程堵塞,效率低
3、TCP/IP传输协议
1.TCP/IP三次握手、四次挥手
描述:
- TCP/IP是计算机网络需要遵守的网络传输控制协议,使得不同的计算机按照一定的规则进行通信。
- TCP/IP协议定义了一个在因特网上传输的包,称为IP数据包,它由首部报头和数据两部分组成。
为什么是三次握手?而不是两次?四次?
- 三次握手是在安全可靠的基础上,握手次数最少的方案。
- 两次握手并不能保证安全可靠,四次握手会、效率较低,在考虑高安全的情况下,可以有N次握手的协议。
TCP/IP连接的精髓
TCP连接的一方A,由操作系统动态随机选取一个32位长的序列号(InitialSequence Number),假设A的初始序列号为1000,以该序列号为原点,对自己将要发送的每个字节的数据进行编号,1001,1002,1003…,并把自己的初始序列号ISN告诉B,让B有一个思想准备,什么样编号的数据是合法的,什么编号是非法的,比如编号900就是非法的,同时B还可以对A每一个编号的字节数据进行确认。如果A收到B确认编号为2001,则意味着字节编号为1001-2000,共1000个字节已经安全到达。同理B也是类似操作。
参考连接:https://www.zhihu.com/question/24853633
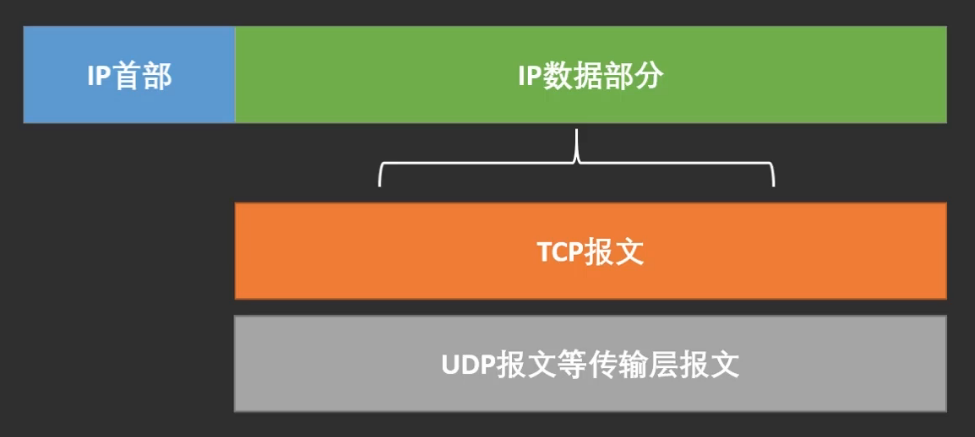
- 首部IP报头:包含源IP地址、目的IP地址、数据包长度、IP版本号等。
- 数据:保存了TCP、UDP、ICMP等传输层报文。
TCP报文:
TCP报文由首部和数据部分组成,其中首部主要的描述如下:

- 序号:又称seq序号,占32bit,TCP连接传送的数据流中每一个字节都有一个序号。
- 确认号:通讯的任何一方在收到对方的报文后,都需要发送一个对应的报文表示确认收到,其中就包含了确认号,表示收到对方的下一个报文段的序号值。如何标识是一个确认报文,需要关注6个标志位,,主要关注3个标志位(ACK、SYN、FIN),次要3个标志位(RST复位标志、URG紧急标志、PSH推送标志)。
- ACK确认标志(Acknowledgement):当ACK = 1时确认号字段才会有效。当ACK = 0时,确认号无效。
- SYN同步标志(Synchronize):设置SYN = 1,标识连接请求或连接接受报文。
- FIN结束标志(Finish):释放一个连接,当FIN = 1时,表示该报文段发送端的数据已发送完毕。
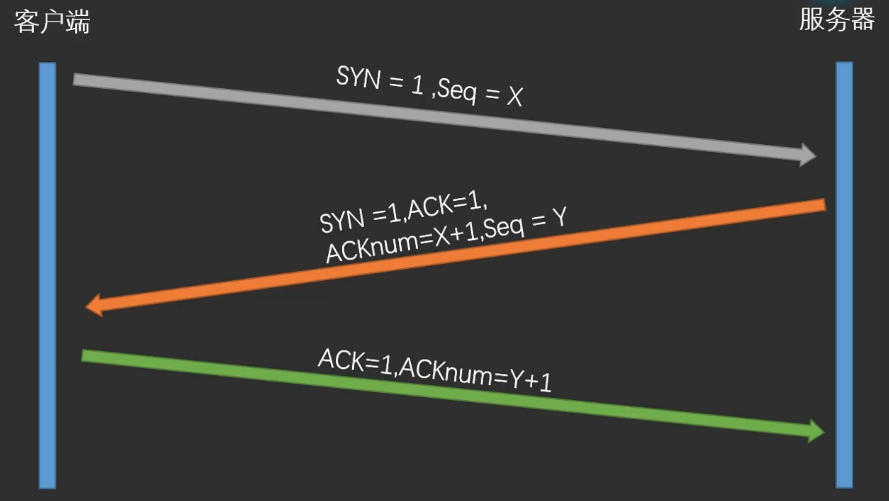
(1)三次报文握手:一次握手,交换三次报文。
- 第一次握手:客户端向服务端发送一个连接请求,设置SYN = 1(表示连接请求),发送自己的序列号seq = x。
- 第二次握手:经客户端的发送后,服务端返回发送一个确认报文,表示收到。设置ACK = 1,接着发送一个确认号ACKnum,该确认号表示期望收到对方下一个报文段数据的第一个字节序号,确认号为ACKnum = x + 1,+ 1表示收到FIN的标识。还需要发送SYN = 1表示连接请求,以及自己的序列号seq = y。
- 第三次握手:向服务端发送一个确认报文ACK = 1,以及确认号ACKnum = y + 1,这样就完成了TCP的三次握手。
总结:
- 第一次(Client - Server):SYN = 1,seq = x。
- 第二次(Server - Client):SYN = 1,ACK = 1,ACKnum = x + 1,seq = y。
- 第三次(Client - Server):ACK = 1,ACKnum = y + 1。
以上三次握手可以想象为平常生活中家人喊吃饭:
- 第一次:家人喊,小明啊,小明…
- 第二次:小明回应,干嘛呢?
- 第三次:家人说,快点过来吃饭。结束,过去吃饭。
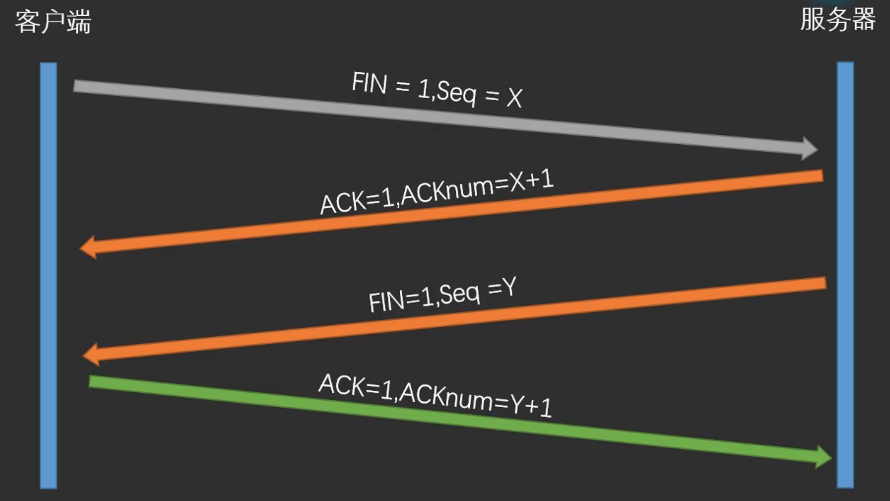
(2)四次挥手:TCP连接的释放
- 第一次挥手:客户端发送一个FIN = 1的包,请求释放报文,seq = x。
- 第二次挥手:服务端确认客户端的FIN包,表明收到客户端的关闭请求,同时发送一个确认报文,ACK = 1,ACKnum = x + 1。这时还没准备好关闭连接。
- 第三次挥手:当做好准备关闭连接时,向客户端发送结束连接请求FIN = 1,seq = y。
- 第四次挥手:客户端收到服务端的关闭请求,发送一个确认包ACK = 1,ACKnum = y + 1。服务器关闭连接,进入CLOSED状态,服务端将不再回应客户端。服务端等待某个固定时间后自行关闭,进入CLOSED状态。
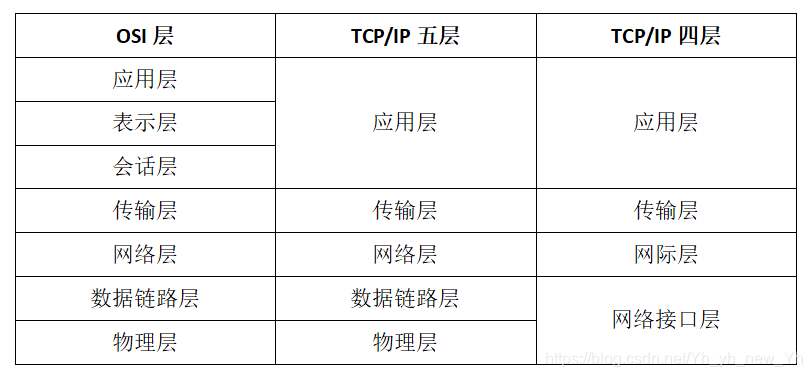
2.OSI模型和TCP/IP五(四)层模型
(1)OSI七层模型
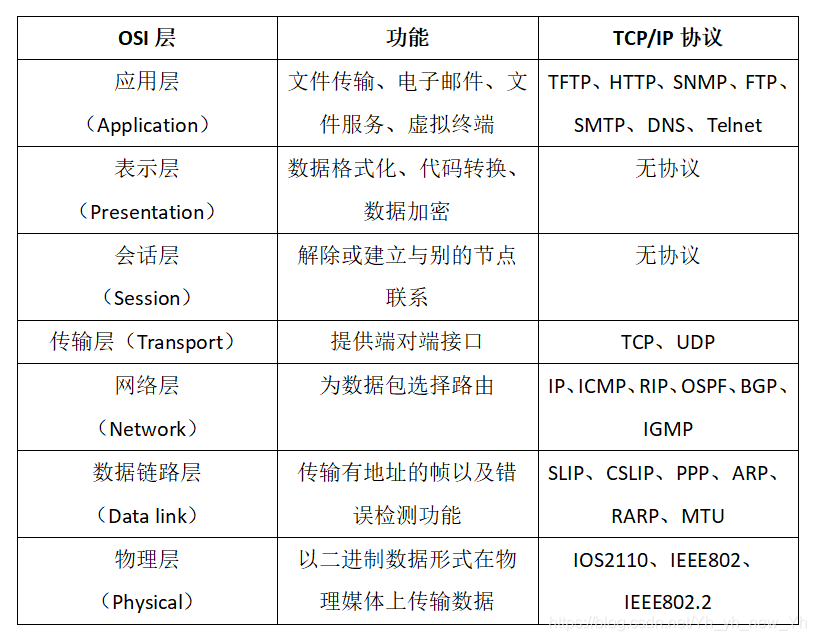
- 应用层:针对你特定的应用协议。
- 表示层:设备固定的数据格式和网络标准数据格式之间的转化
- 会话层:通信管理,负责建立和单开通信连接,管理传输层 以下分层
- 传输层:管理两个节点之间的数据传递。负责可靠传输。
- 网络层:地址管理和路由选择。
- 数据链接层:互联设备之间传送和识别数据帧。
- 物理层:界定连接器和网线之间的规格。
OSI的7层协议体系结构的概念很清楚,理论也比较完整,但是即复杂又不实用。
(2)TCP/IP五(四)层结构
TCP/IP四层结构从实质上来讲,TCP/IP只有上面三层,因为最下面的网络接口层没有什么具体内容。因此通常建议采用TCP/IP五层结构来学习。
- 应用层:负责应用进程之间通信。
- 传输层:两台主机之间的数据交换服务。
- 网络层:负责地址管理和路由选择。
- 数据链路层:设备之间数据帧的传输和识别,将网络层交下来的IP数据组装成帧。
- 物理层:光电信号传递方式,以比特为单位的数据传输。
4、docker网络模型
参考链接:https://zhuanlan.zhihu.com/p/98788162
(1)Bridge模式
docker默认的网络模式,为容器创建独立的网络命名空间。当docker进程启动时,会在主机上创建一个docker0虚拟网桥,主机上创建的容器就会链接到这个虚拟网桥上。
(2)None模式
为容器创建独立的网络命名空间,但不分配任何网络配置。也就是说容器没有网卡、IP、路由等,需要自己手动添加。
(3)Host模式
容器和宿主机使用同一个网络。
(4)Container模式
指定新创建的容器和已经存在的一个容器共享一个网络。
(5)跨主机通信(Pipework)
Pipework是一个docker容器网络配置工具。使用新建的bri0网桥代替缺省的docker0网桥。bri0网桥与缺省的docker0网桥的区别:bri0和主机eth0之间是weth pair。
5、浅拷贝和深拷贝
参考链接:https://www.jianshu.com/p/94dbef2de298
- 浅拷贝:
- 浅拷贝是按位拷贝对象,它会创建一个新对象。
- 拷贝的对象引用指向原对象的引用,当拷贝对象的值修改时,原对象的值也会被修改。
- 深拷贝:
- 不仅会创建对象,还会开辟一个独立的内存空间,实现真正的内容拷贝。
6.布隆过滤器
参考链接:https://zhuanlan.zhihu.com/p/94433082
- 基于哈希表的实现,传统的哈希表为单函数存储,而布隆过滤器是哈希表的多函数存储,即每次计算哈希值的方式不一样,这样会导致查询时存在一定误区。
- 由单个m长度的向量表(包含0和1)组成,默认为0。通过k个函数来计算哈希值,将向量表中置为1。
- 通过函数计算哈希值,只要哈希值中存在0,表示不存在,若全为1,表示存在。