目录
Pandas是Python中用于数据处理和分析的核心库,提供了快速、灵活且明确的数据结构,主要包括一维的Series和二维的DataFrame。它支持从CSV、Excel、SQL等多种数据源导入数据,并具备数据清洗、合并、重塑、分组统计、时间序列分析等功能。Pandas还易于与其他Python数据分析库集成,是金融、统计、社会科学和工程等领域进行数据分析和处理的强大工具。
一、配置环境
在命令行中运行以下命令:
pip show pandas
如果为以下内容,则表示未安装pandas库
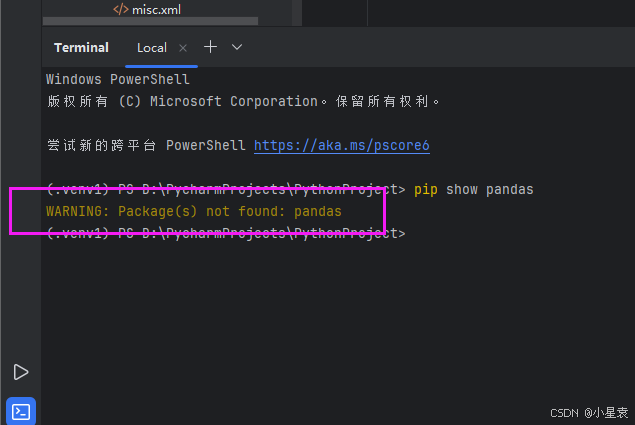
要安装Pandas库,你可以使用Python的包管理工具
pip。在命令行界面(例如终端、命令提示符或Anaconda Prompt,取决于你的操作系统和Python安装方式)中,输入以下命令:
pip install pandas
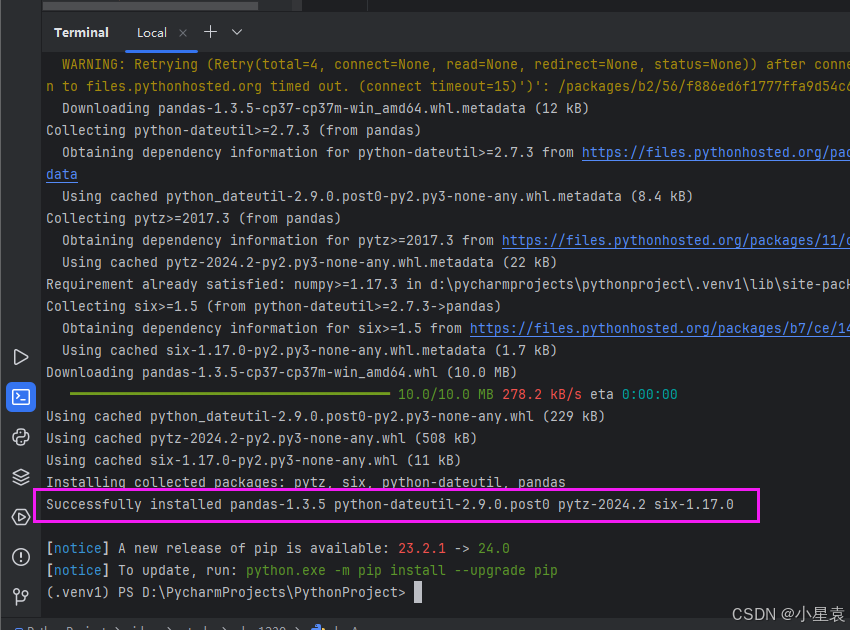
安装成功展示图:
二、序列和数据表
2.1 初始化
Series可以存储任何数据类型,例如整数、浮点数、字符串、python对象等,每个元素都有一个索引。
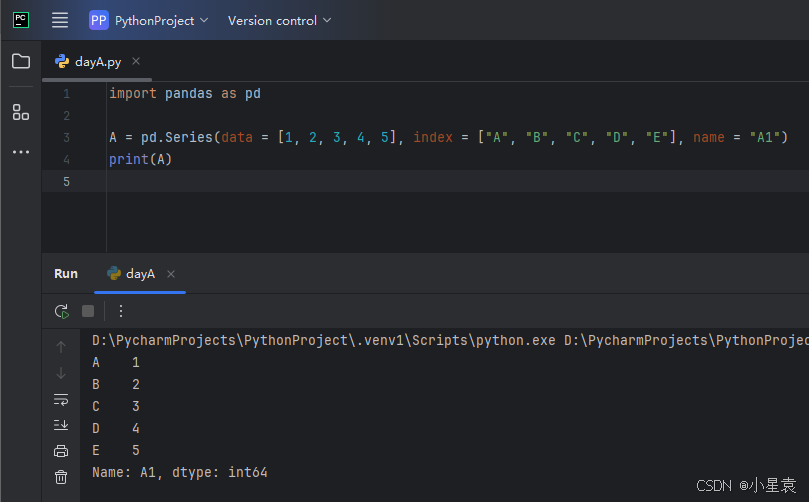
import pandas as pd
A = pd.Series(data = [1, 2, 3, 4, 5], index = ["A", "B", "C", "D", "E"], name = "A1")
print(A)
2.2 获取数值
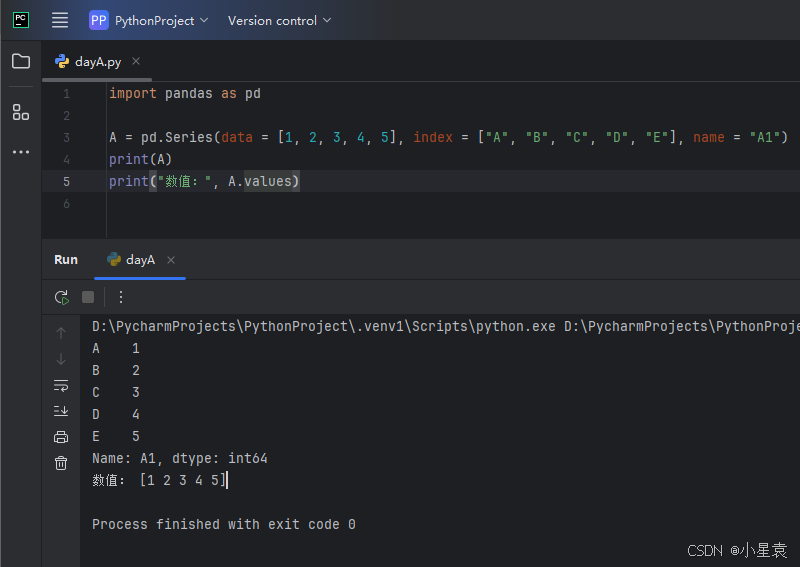
import pandas as pd
A = pd.Series(data = [1, 2, 3, 4, 5], index = ["A", "B", "C", "D", "E"], name = "A1")
print(A)
print("数值:", A.values)
2.3 获取索引
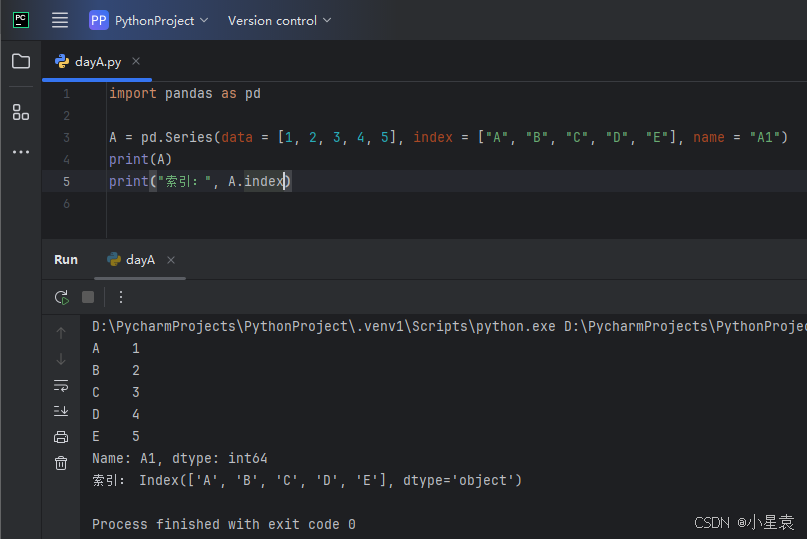
import pandas as pd
A = pd.Series(data = [1, 2, 3, 4, 5], index = ["A", "B", "C", "D", "E"], name = "A1")
print(A)
print("索引:", A.index)
2.4 索引取内容
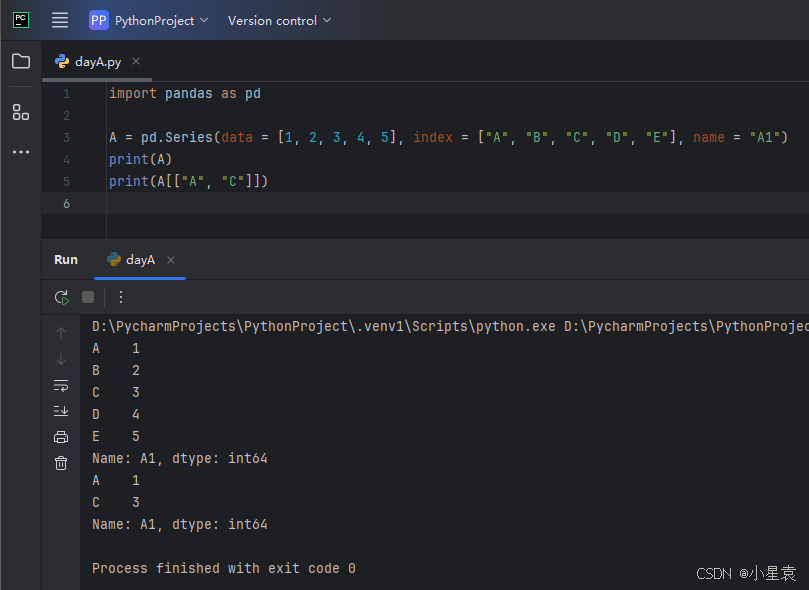
import pandas as pd
A = pd.Series(data = [1, 2, 3, 4, 5], index = ["A", "B", "C", "D", "E"], name = "A1")
print(A)
print(A[["A", "C"]])
2.5 索引改变取值
import pandas as pd
A = pd.Series(data = [1, 2, 3, 4, 5], index = ["A", "B", "C", "D", "E"], name = "A1")
print(A)
A[["A", "C"]] = [11, 12]
print(A)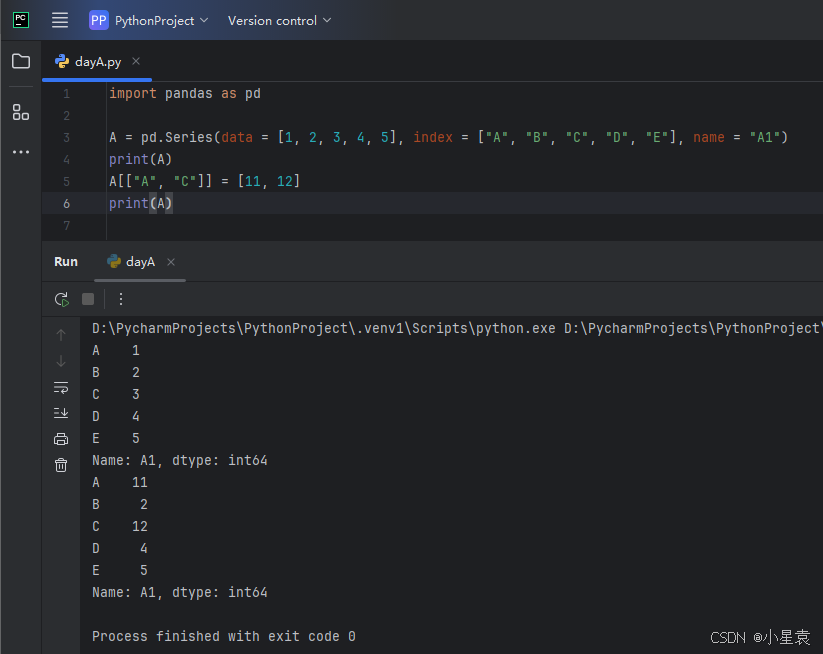
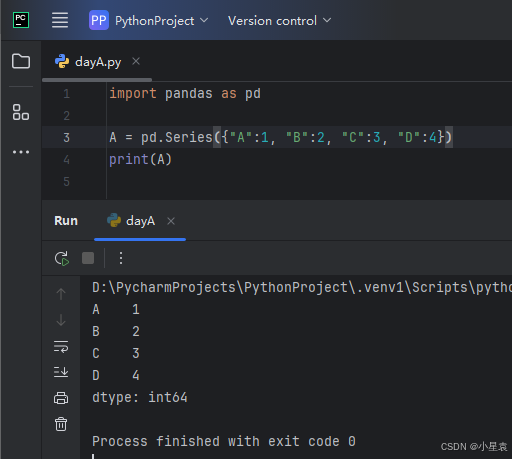
2.6 字典生成序列
import pandas as pd
A = pd.Series({"A":1, "B":2, "C":3, "D":4})
print(A)
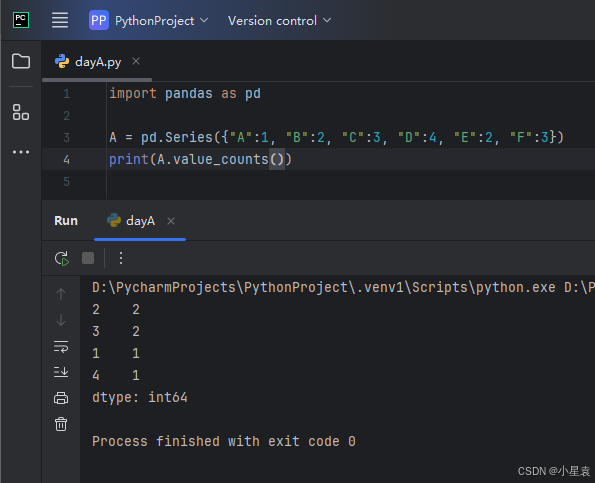
2.7 计算取值出现次数
import pandas as pd
A = pd.Series({"A":1, "B":2, "C":3, "D":4, "E":2, "F":3})
print(A.value_counts())
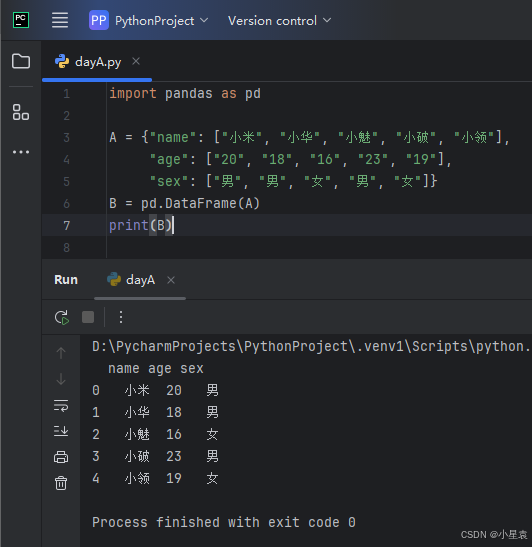
2.8 数据表
import pandas as pd
A = {"name": ["小米", "小华", "小魅", "小破", "小领"],
"age": ["20", "18", "16", "23", "19"],
"sex": ["男", "男", "女", "男", "女"]}
B = pd.DataFrame(A)
print(B)
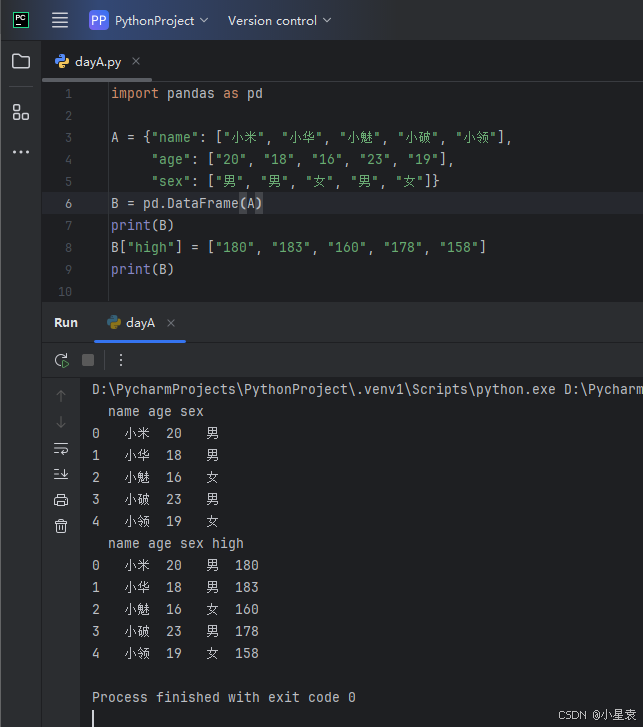
2.9 数据表添加新变量
import pandas as pd
A = {"name": ["小米", "小华", "小魅", "小破", "小领"],
"age": ["20", "18", "16", "23", "19"],
"sex": ["男", "男", "女", "男", "女"]}
B = pd.DataFrame(A)
print(B)
B["high"] = ["180", "183", "160", "178", "158"]
print(B)
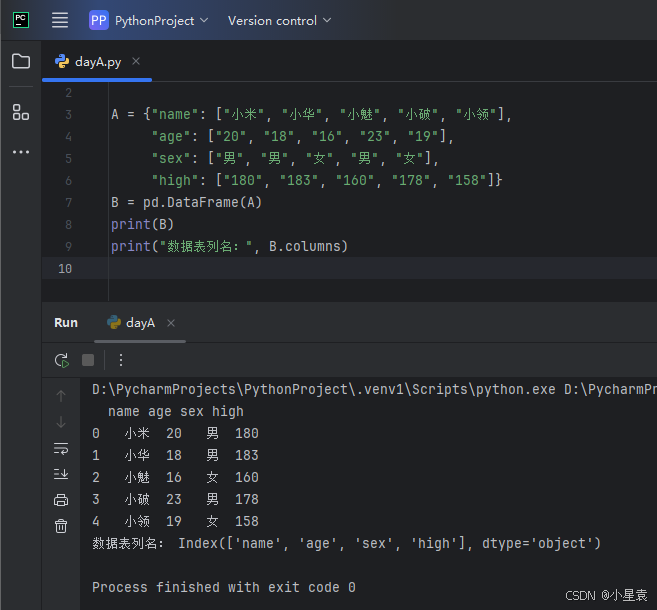
2.10 获取列名
import pandas as pd
A = {"name": ["小米", "小华", "小魅", "小破", "小领"],
"age": ["20", "18", "16", "23", "19"],
"sex": ["男", "男", "女", "男", "女"],
"high": ["180", "183", "160", "178", "158"]}
B = pd.DataFrame(A)
print(B)
print("数据表列名:", B.columns)
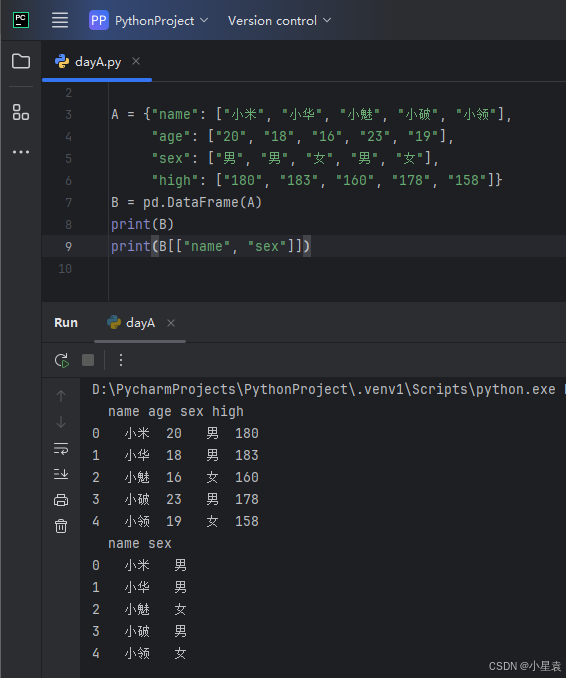
2.11 根据列名获取数据
import pandas as pd
A = {"name": ["小米", "小华", "小魅", "小破", "小领"],
"age": ["20", "18", "16", "23", "19"],
"sex": ["男", "男", "女", "男", "女"],
"high": ["180", "183", "160", "178", "158"]}
B = pd.DataFrame(A)
print(B)
print(B[["name", "sex"]])
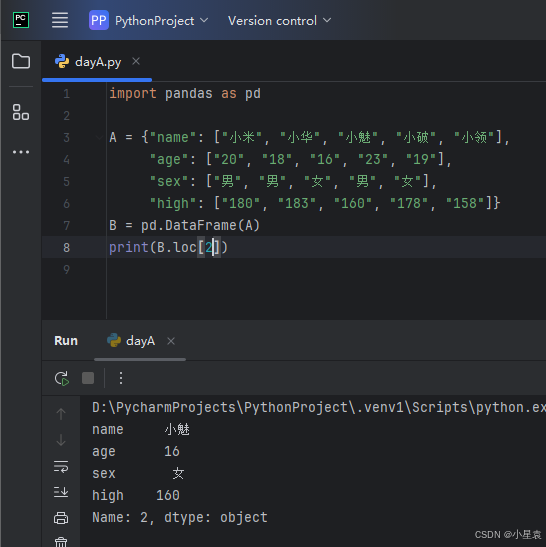
2.12 输出固定行
import pandas as pd
A = {"name": ["小米", "小华", "小魅", "小破", "小领"],
"age": ["20", "18", "16", "23", "19"],
"sex": ["男", "男", "女", "男", "女"],
"high": ["180", "183", "160", "178", "158"]}
B = pd.DataFrame(A)
print(B.loc[2])
2.13 输出多行
import pandas as pd
A = {"name": ["小米", "小华", "小魅", "小破", "小领"],
"age": ["20", "18", "16", "23", "19"],
"sex": ["男", "男", "女", "男", "女"],
"high": ["180", "183", "160", "178", "158"]}
B = pd.DataFrame(A)
print(B.loc[2 : 4])

2.14 输出指定行和列
import pandas as pd
A = {"name": ["小米", "小华", "小魅", "小破", "小领"],
"age": ["20", "18", "16", "23", "19"],
"sex": ["男", "男", "女", "男", "女"],
"high": ["180", "183", "160", "178", "158"]}
B = pd.DataFrame(A)
print(B.loc[2 : 4, ["name", "high"]])
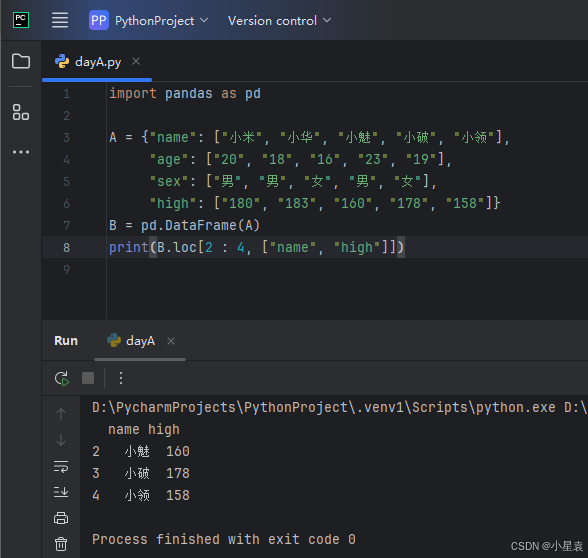
2.15 输出性别为“男”的行和列
import pandas as pd
A = {"name": ["小米", "小华", "小魅", "小破", "小领"],
"age": ["20", "18", "16", "23", "19"],
"sex": ["男", "男", "女", "男", "女"],
"high": ["180", "183", "160", "178", "158"]}
B = pd.DataFrame(A)
print(B.loc[B.sex == "男", ["name", "sex"]])
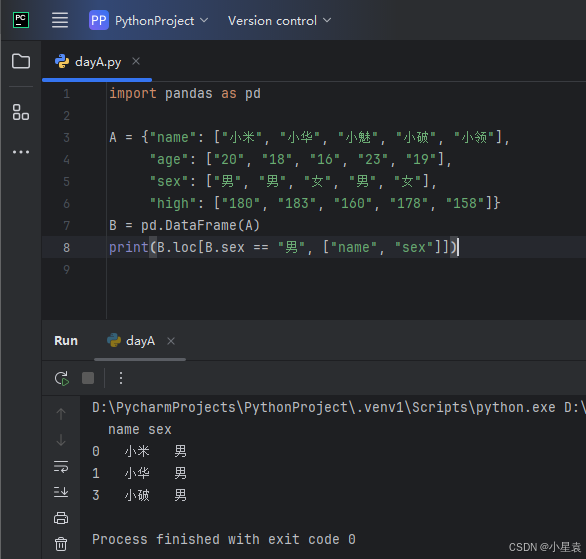
2.16 获取指定行
import pandas as pd
A = {"name": ["小米", "小华", "小魅", "小破", "小领"],
"age": ["20", "18", "16", "23", "19"],
"sex": ["男", "男", "女", "男", "女"],
"high": ["180", "183", "160", "178", "158"]}
B = pd.DataFrame(A)
print(B.iloc[0 : 2])
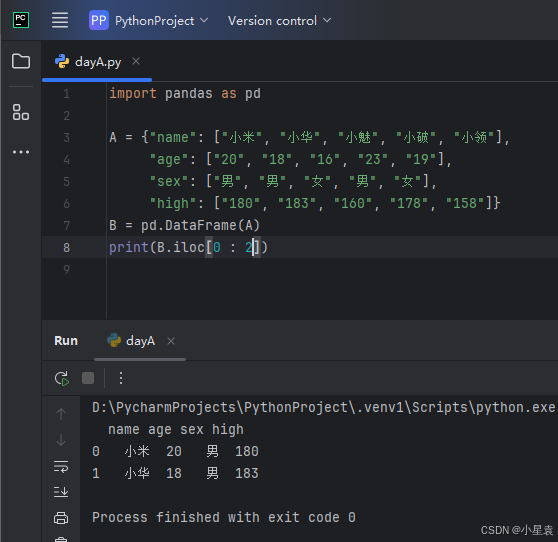
2.17 获取指定列
import pandas as pd
A = {"name": ["小米", "小华", "小魅", "小破", "小领"],
"age": ["20", "18", "16", "23", "19"],
"sex": ["男", "男", "女", "男", "女"],
"high": ["180", "183", "160", "178", "158"]}
B = pd.DataFrame(A)
print(B.iloc[ : , 0 : 2])
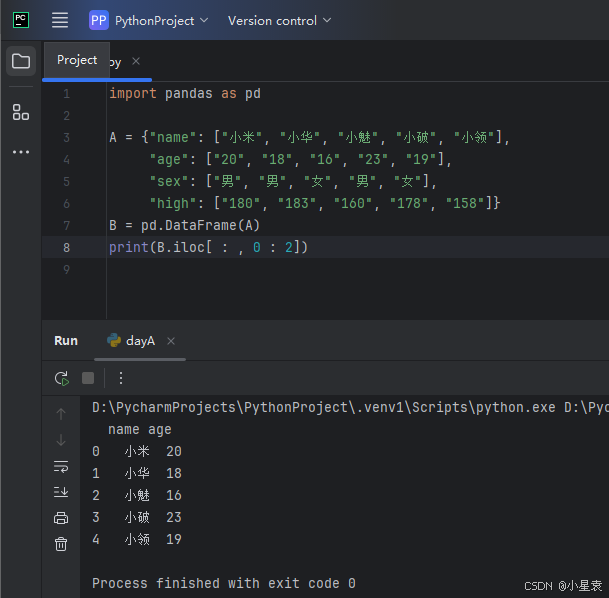
2.18 获取指定位置数据
import pandas as pd
A = {"name": ["小米", "小华", "小魅", "小破", "小领"],
"age": ["20", "18", "16", "23", "19"],
"sex": ["男", "男", "女", "男", "女"],
"high": ["180", "183", "160", "178", "158"]}
B = pd.DataFrame(A)
print(B.iloc[0 : 2, 0 : 2])
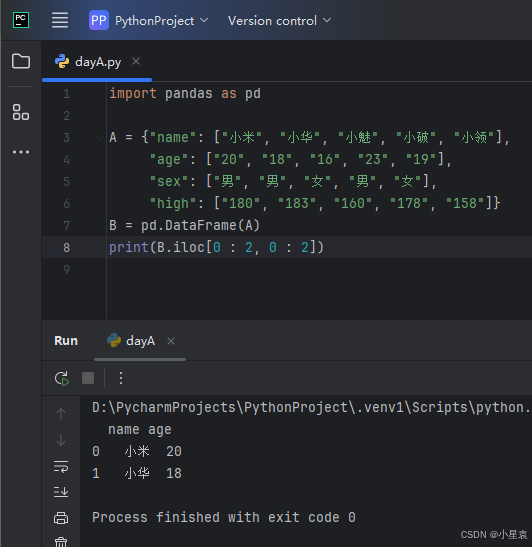
2.19 索引转化
import numpy as np
import pandas as pd
A = {"name": ["小米", "小华", "小魅", "小破", "小领"],
"age": ["20", "18", "16", "23", "19"],
"sex": ["男", "男", "女", "男", "女"],
"high": ["180", "183", "160", "178", "158"]}
B = pd.DataFrame(A)
# 转换为列表
print(B.iloc[list(B.sex == "男"), 0 : 3])
# 转换为数组
print(B.iloc[np.array(B.sex == "男"), 0 : 3])
2.20 判断条件
import numpy as np
import pandas as pd
A = {"name": ["小米", "小华", "小魅", "小破", "小领"],
"age": ["20", "18", "16", "23", "19"],
"sex": ["男", "男", "女", "男", "女"],
"high": ["180", "183", "160", "178", "158"]}
B = pd.DataFrame(A)
print(list(B.age >= "18"))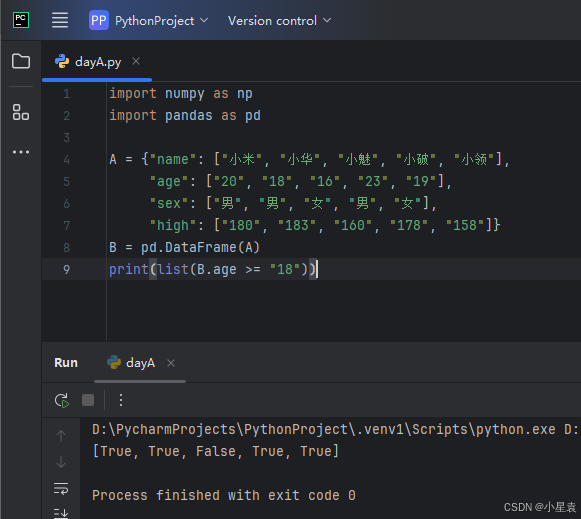
2.21 重新赋值
import numpy as np
import pandas as pd
A = {"name": ["小米", "小华", "小魅", "小破", "小领"],
"age": ["20", "18", "16", "23", "19"],
"sex": ["男", "男", "女", "男", "女"],
"high": ["180", "183", "160", "178", "158"]}
B = pd.DataFrame(A)
B.high = ["179", "186", "168", "183", "160"]
print(B)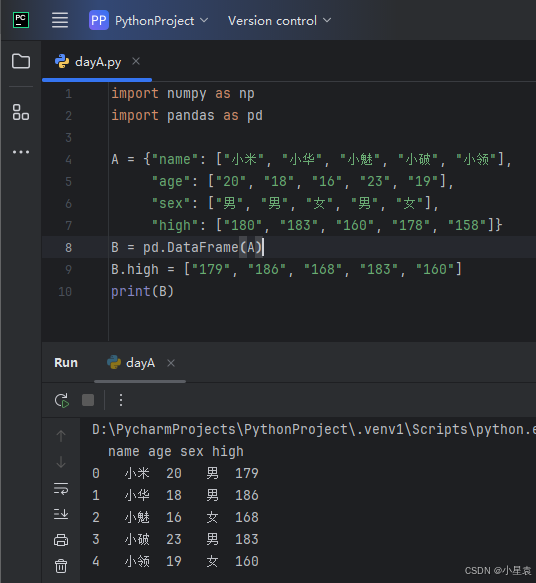
三、数据聚合和分组运算
3.1 获取数据集
iris.csv(iris数据集、鸢尾花数据集)资源-CSDN文库
3.2 读取数据集
鸢尾花数据集(Iris Dataset),又称安德森鸢尾花卉数据集(Anderson’s Iris Data Set),是数据科学与机器学习领域中最著名的经典数据集之一。
鸢尾花数据集可以通过多种方式获取,如Scikit-learn提供的内置数据集,以及UCI机器学习库等。获取后,可以使用Python等编程语言进行数据加载、预处理和模型训练等操作。
鸢尾花数据集以其简洁明了的数据结构和广泛的应用场景,成为了机器学习初学者的首选案例。通过学习和实践这一数据集,初学者可以逐步掌握机器学习的基础知识和技能。
import numpy as np
import pandas as pd
iris = pd.read_csv("D:/iris.csv")
print(iris.head())
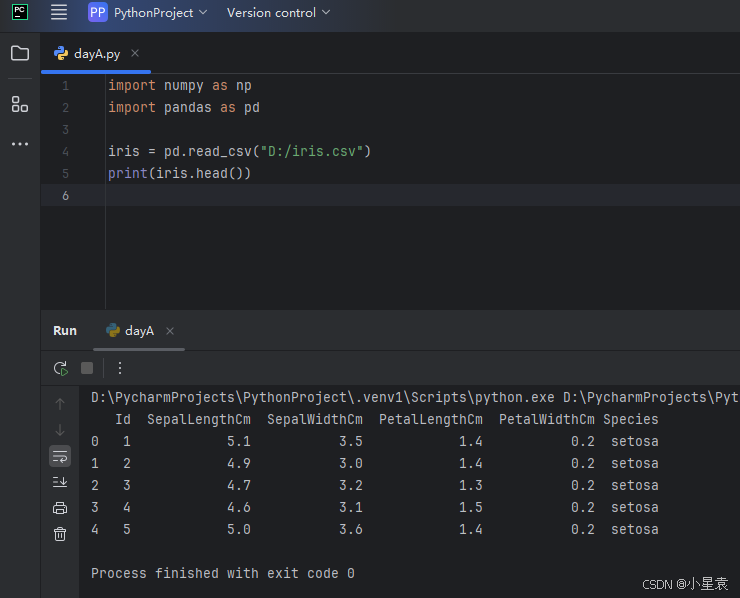
3.3 计算每列均值
import numpy as np
import pandas as pd
iris = pd.read_csv("D:/iris.csv")
print(iris.iloc[ : , 1 : 5].apply(func = np.mean, axis = 0))
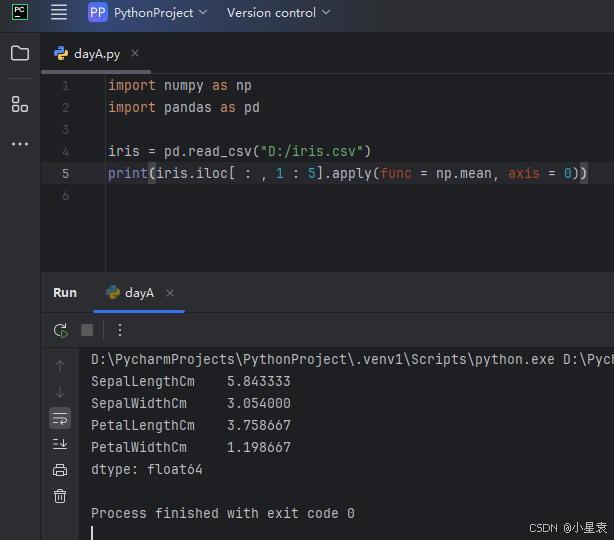
3.4 计算每列的最小值
import numpy as np
import pandas as pd
iris = pd.read_csv("D:/iris.csv")
min = iris.iloc[ : , 1 : 5].apply(func = np.min , axis = 0)
print(min)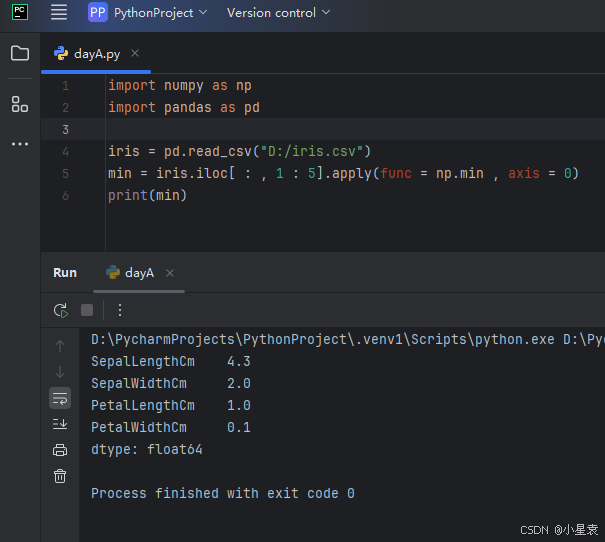
3.5 计算每列的最大值
import numpy as np
import pandas as pd
iris = pd.read_csv("D:/iris.csv")
max = iris.iloc[ : , 1 : 5].apply(func = np.max , axis = 0)
print(max)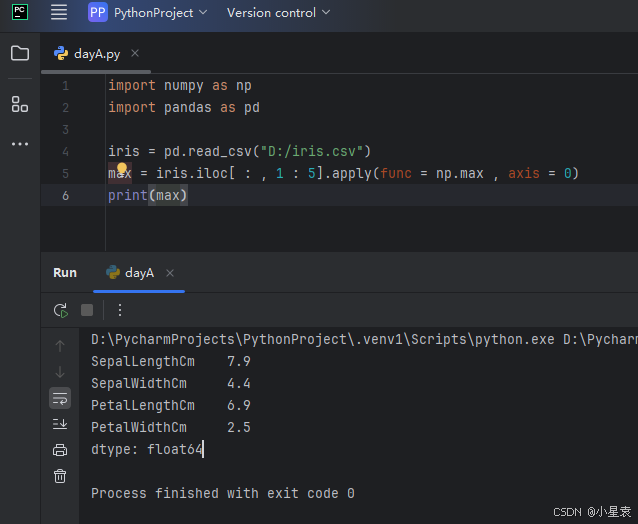
3.6 计算每列的样本数量
import numpy as np
import pandas as pd
iris = pd.read_csv("D:/iris.csv")
size = iris.iloc[ : , 1 : 5].apply(func = np.size , axis = 0)
print(size)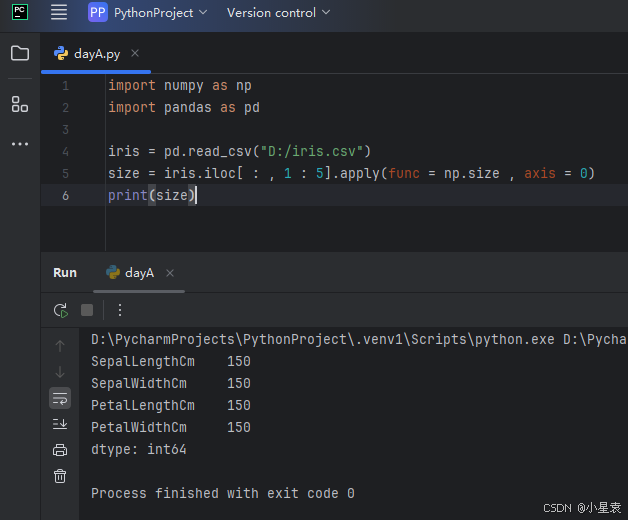
3.7 行计算
只展示前五行
其中代码的axis=0要改成axis=1
import numpy as np
import pandas as pd
iris = pd.read_csv("D:/iris.csv")
data = iris.iloc[0 : 5, 1 : 5].apply(func = (np.min, np.max, np.mean, np.std, np.var) , axis = 1)
print(data)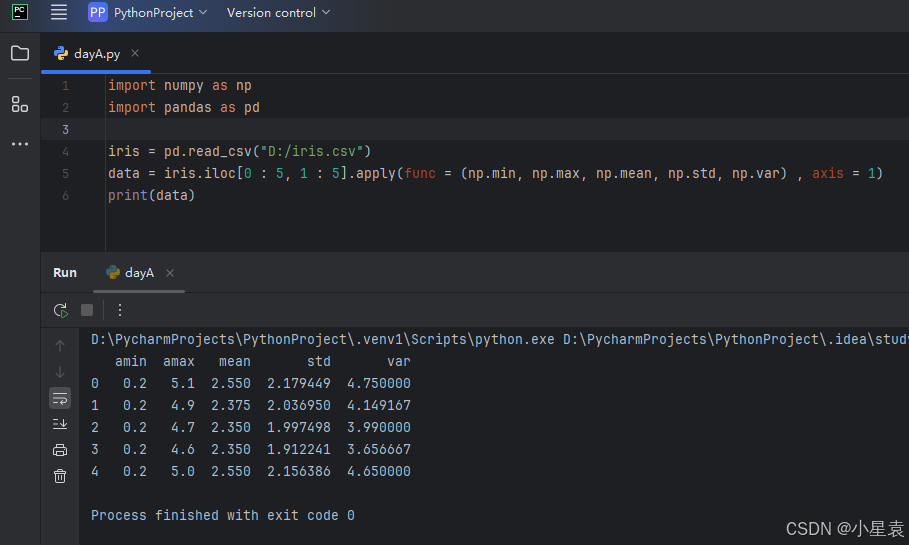
3.8 分组计算均值
import numpy as np
import pandas as pd
iris = pd.read_csv("D:/iris.csv")
res = iris.drop("Id", axis = 1).groupby(by = "Species").mean()
print(res)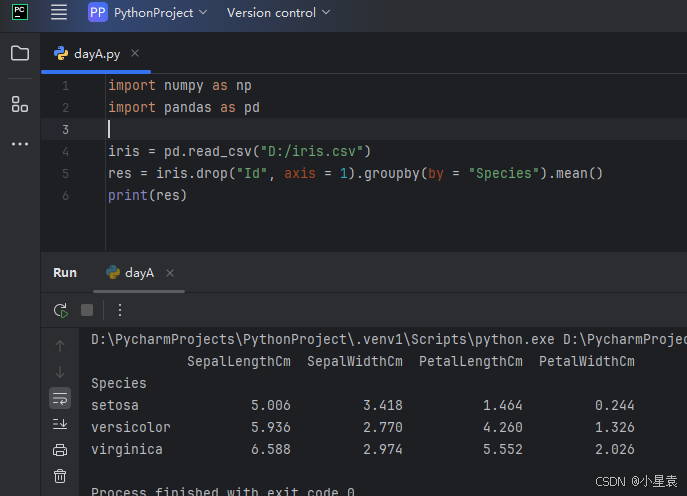
3.9 分组计算偏度
import numpy as np
import pandas as pd
iris = pd.read_csv("D:/iris.csv")
res = iris.drop("Id", axis = 1).groupby(by = "Species").skew()
print(res)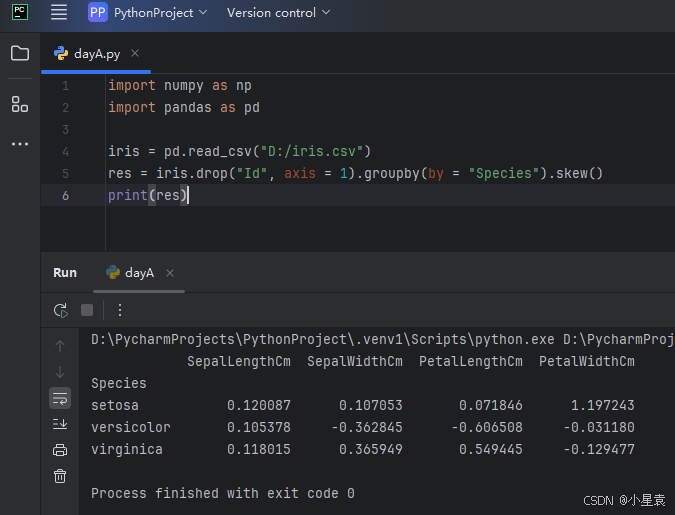
3.10 聚合运算
3.10.1 分组前
import numpy as np
import pandas as pd
iris = pd.read_csv("D:/iris.csv")
res = iris.drop("Id", axis = 1).agg({"SepalLengthCm" : ["min", "max", "mean"],
"SepalWidthCm" : ["min", "max", "mean"],
"PetalLengthCm" : ["min", "max", "mean"]})
print(res)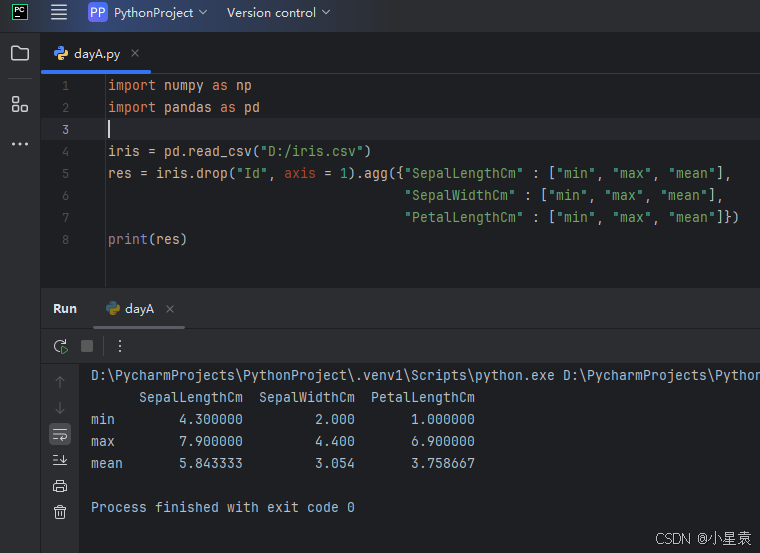
3.10.2 分组后
import numpy as np
import pandas as pd
iris = pd.read_csv("D:/iris.csv")
res = (iris.drop("Id", axis = 1).groupby(by = "SepalLengthCm")
.agg({"SepalLengthCm" : ["min", "max", "mean"],
"SepalWidthCm" : ["min"],
"PetalLengthCm" : ["skew"]}))
print(res)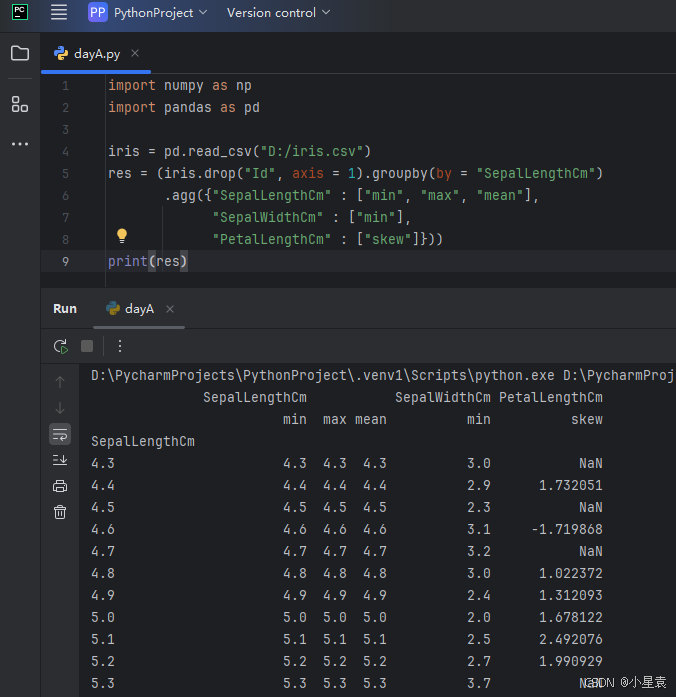
四、数据可视化
Mtplotlib是Python中一个广泛使用的绘图库,它提供了一个类似于MATLAB的绘图框架。Mtplotlib可以生成高质量的图表,这些图表可以用于数据可视化、科学研究、教育以及出版等领域。
4.1 安装matplotlib库
pip install matplotlib
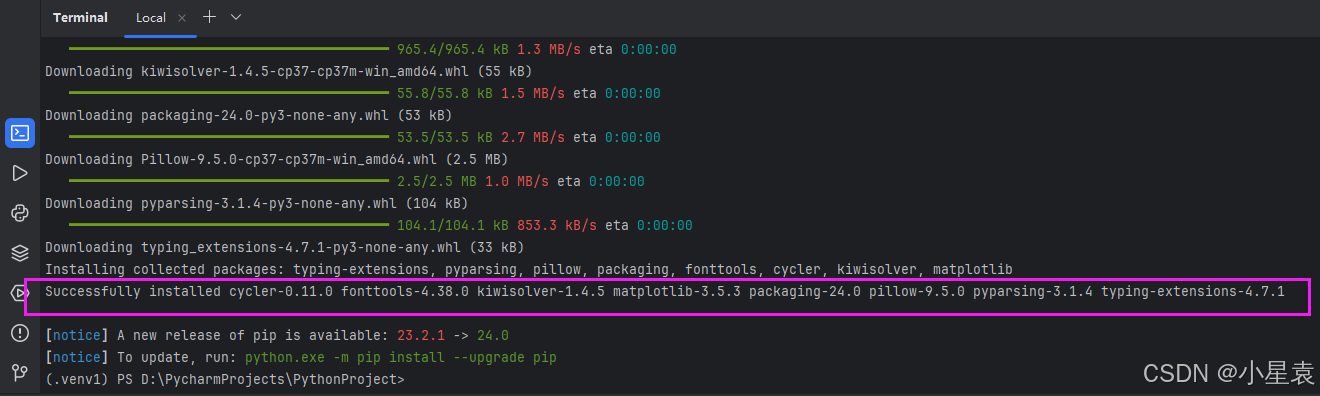
安装成功展示图:
4.2 检测matplotlib库
pip show matplotlib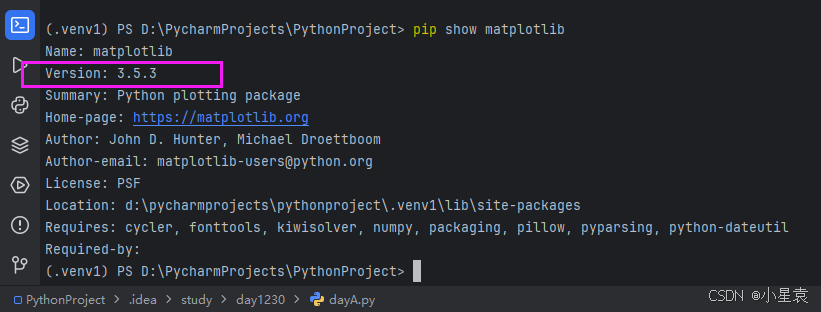
4.3 箱线图
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
iris = pd.read_csv("D:/iris.csv")
iris.iloc[ : , 1 : 6].boxplot(column = ["SepalLengthCm", "SepalWidthCm", "PetalLengthCm", "PetalWidthCm"], by = "Species", figsize=(10,10))
plt.show()
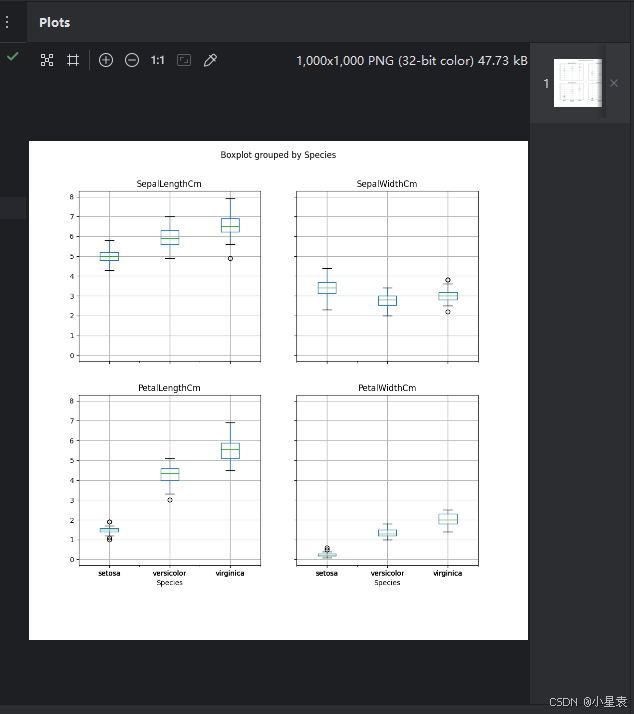
4.4 散点图
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
iris = pd.read_csv("D:/iris.csv")
color = iris.Species.map({"setosa" : "blue", "versicolor" : "green", "virginica" : "red"})
iris.plot(kind = "scatter" , x = "SepalLengthCm", y = "SepalWidthCm", s = 30, c = color, figsize = (10,10))
plt.show()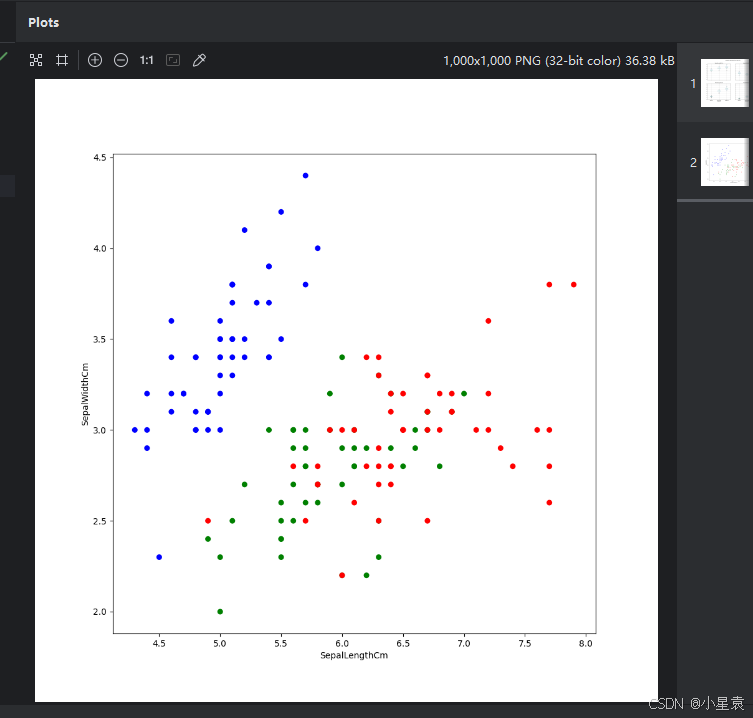
4.5 六边形热力图
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
iris = pd.read_csv("D:/iris.csv")
iris.plot(kind = "hexbin" , x = "SepalLengthCm", y = "SepalWidthCm", gridsize = 15, figsize = (10,7), sharex = False)
plt.show()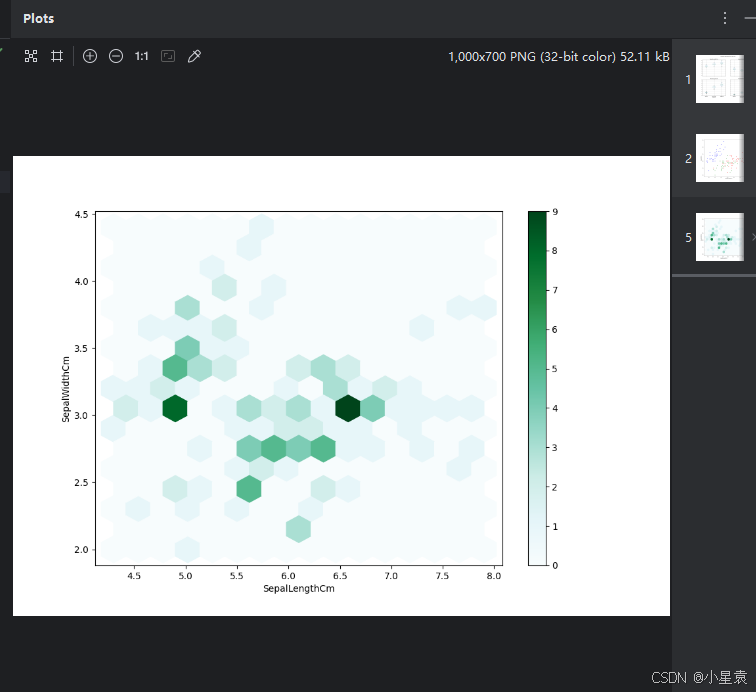
4.6 折线图
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
iris = pd.read_csv("D:/iris.csv")
iris.iloc[ : , 0 : 5].plot(kind = "line", x = "Id", figsize = (12, 8))
plt.show()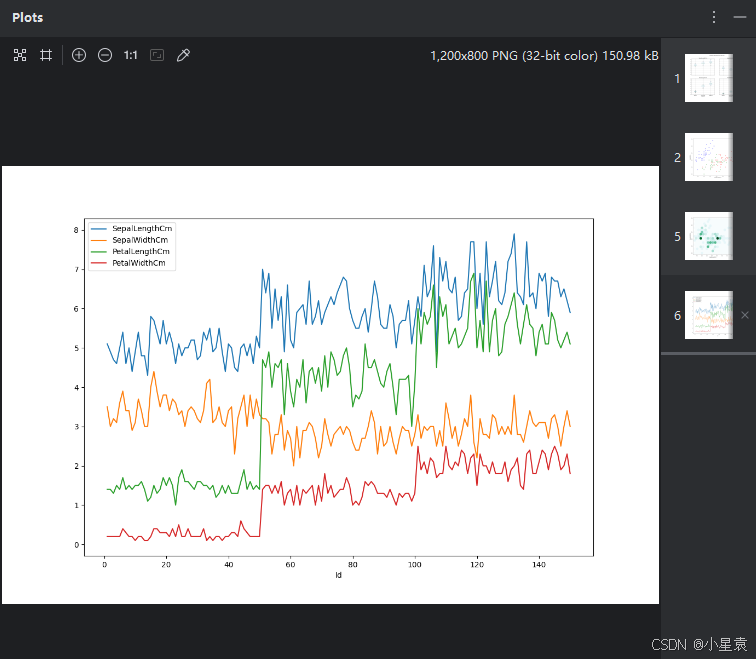
上一篇文章:Python的Numpy库应用入门(超详细教程)-CSDN博客