目录
1 NDArray 的背景介绍
在Python的世界,调用NDArray的标准包叫做NumPy。为了给Java开发者创造同一种工具,亚马逊云服务开源了DJL,一个基于Java的深度学习库。尽管它包含了深度学习模块,但是它最核心的NDArray库可以被用作NumPy的java替代工具库。


同时它具备优良的可扩展性,全平台支持,以及强大的后端引擎支持 TensorFlowPaddlePaddle, PyTorch, Apache MXNet等)。无论是CPU还是GPU, PC还是安卓,DJL都可以轻而易举的完成任务。
1.1 架构
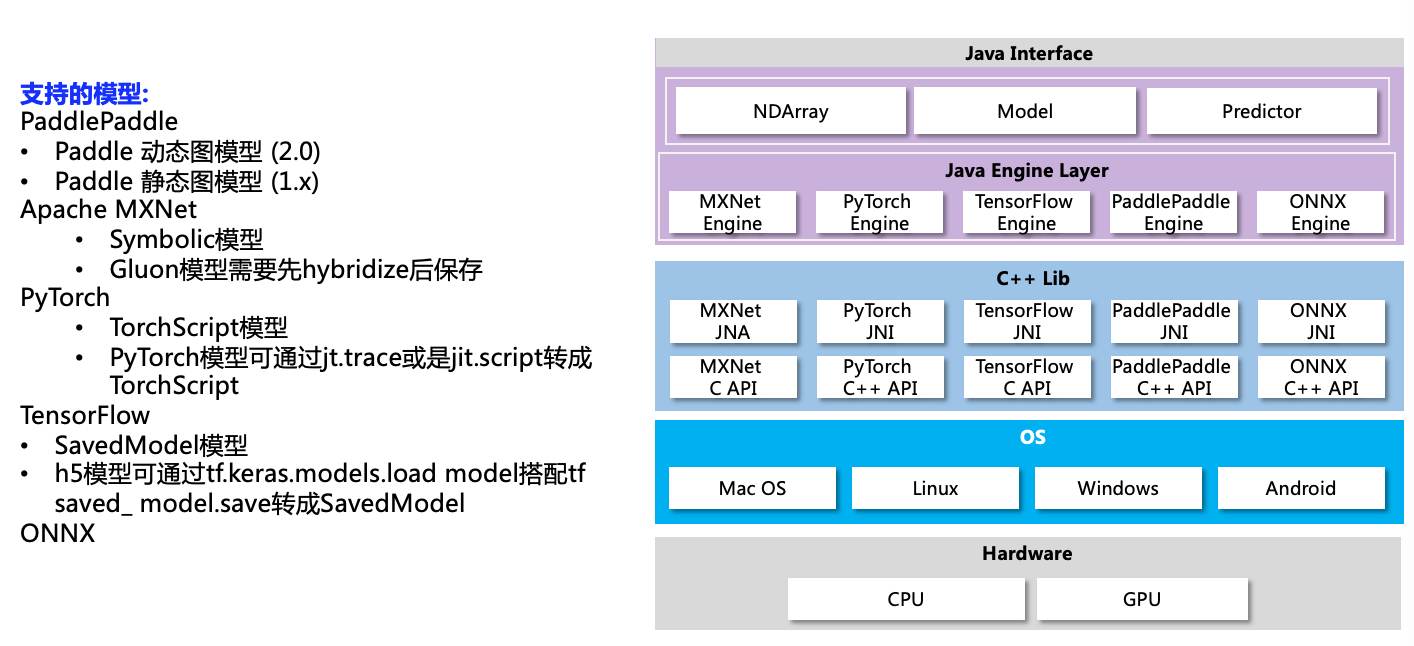
在这个系列文章中,我们将带你了解NDArray,并且教你如何写与Numpy同样简单的Java代码以及如何将NDArray使用在现实中的应用之中。
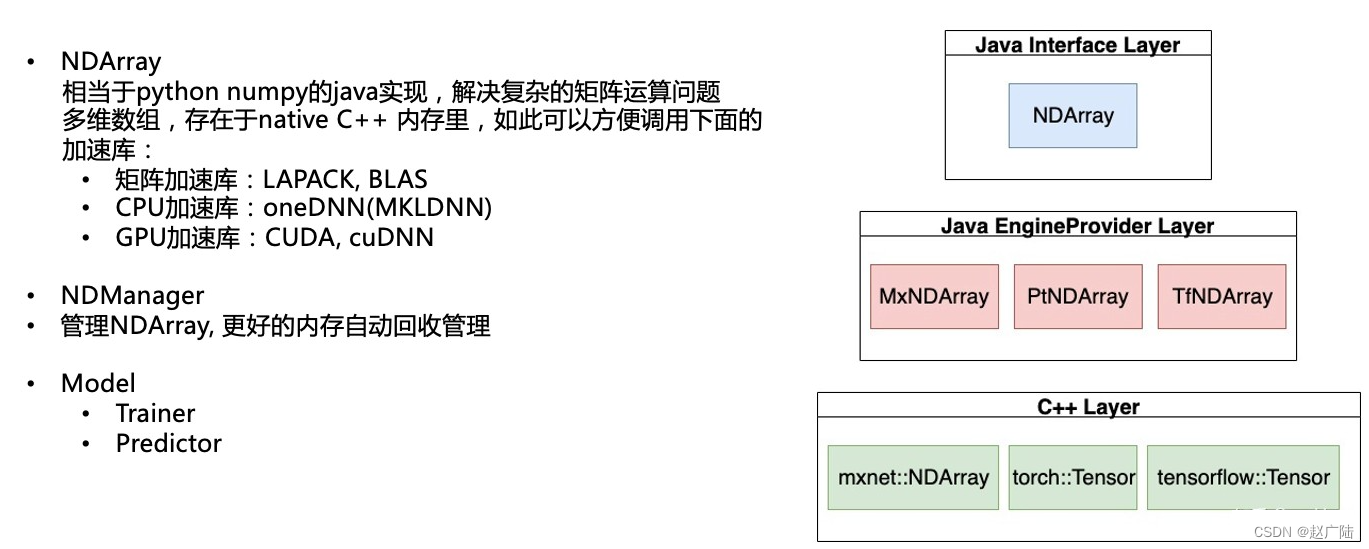
NDArray相当于python numpy的java实现,解决复杂的矩阵运算问题。多维数组存在于native C++ 内存里,如此可以方便调用下面的加速库:
- 矩阵加速库:LAPACK, BLAS
- CPU加速库:oneDNN(MKLDNN)
- GPU加速库:CUDA, cuDNN
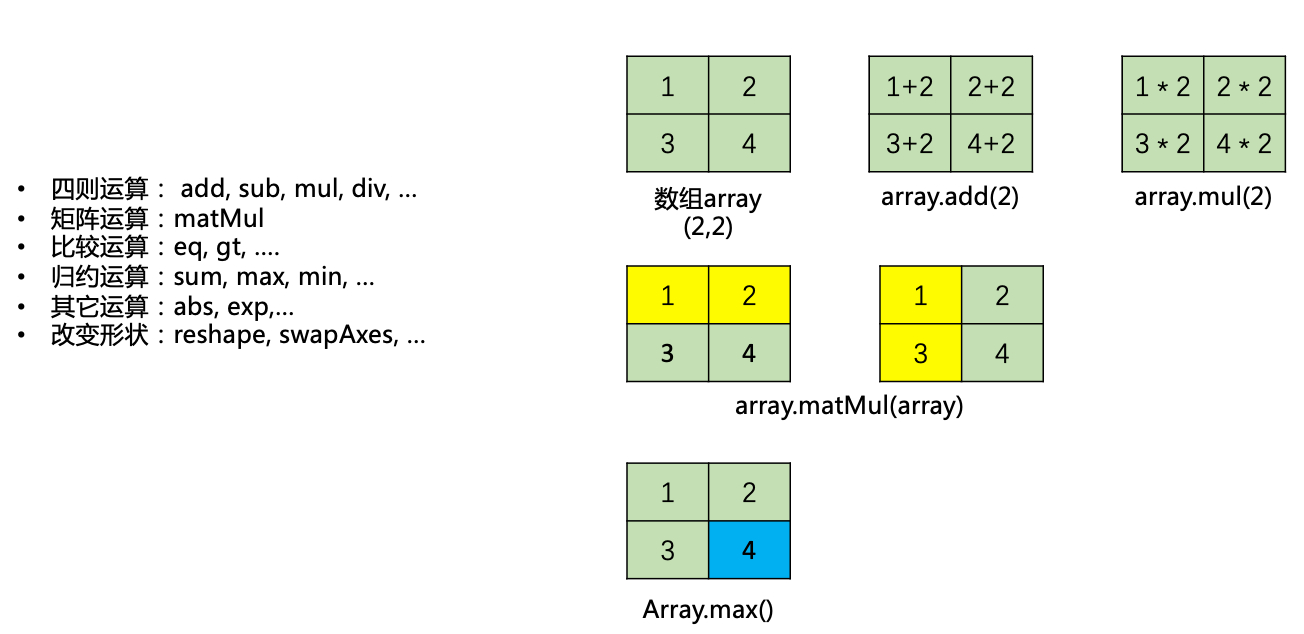
NDArray提供了丰富的api,如:
四则运算: add, sub, mul, div, …
矩阵运算:matMul
比较运算:eq, gt, ….
归约运算:sum, max, min, …
其它运算:abs, exp,…
改变形状:reshape, swapAxes, …
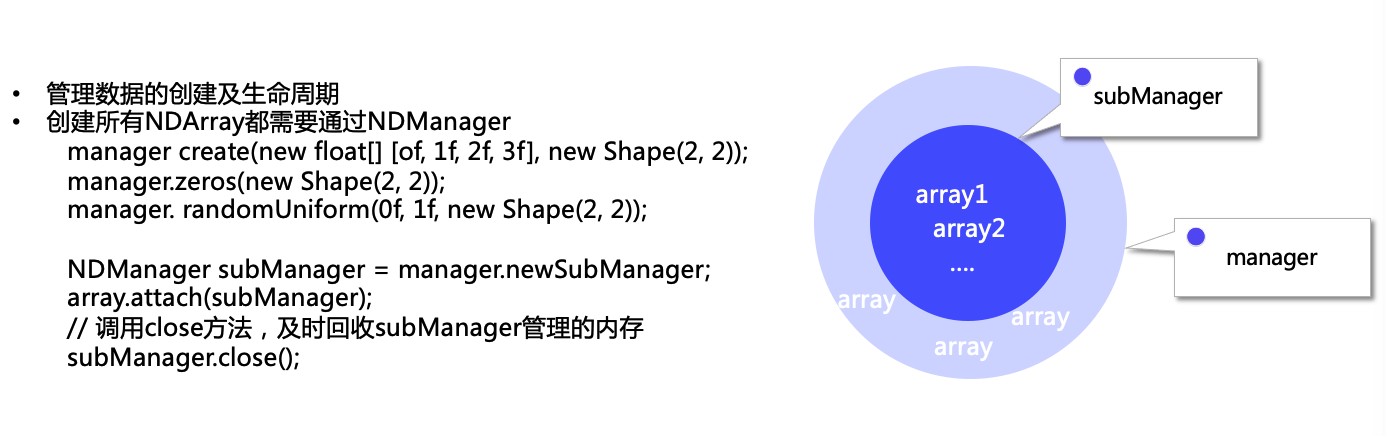
为了更好的管理NDArray,管理数据的创建及生命周期, 创建所有NDArray都需要通过NDManager。如此可以高效的利用内存,防止内存泄露等问题。
NDManager是DJL中的一个class可以帮助管理NDArray的内存使用。通过创建NDManager,可以及时的对内存进行清理。当这个block里的任务运行完成时,内部产生的NDArray都会被清理掉。这个设计保证了我们在大规模使用NDArray的过程中,可以更高效的利用内存。
try (NDManager manager = NDManager.newBaseManager()) {
...
}
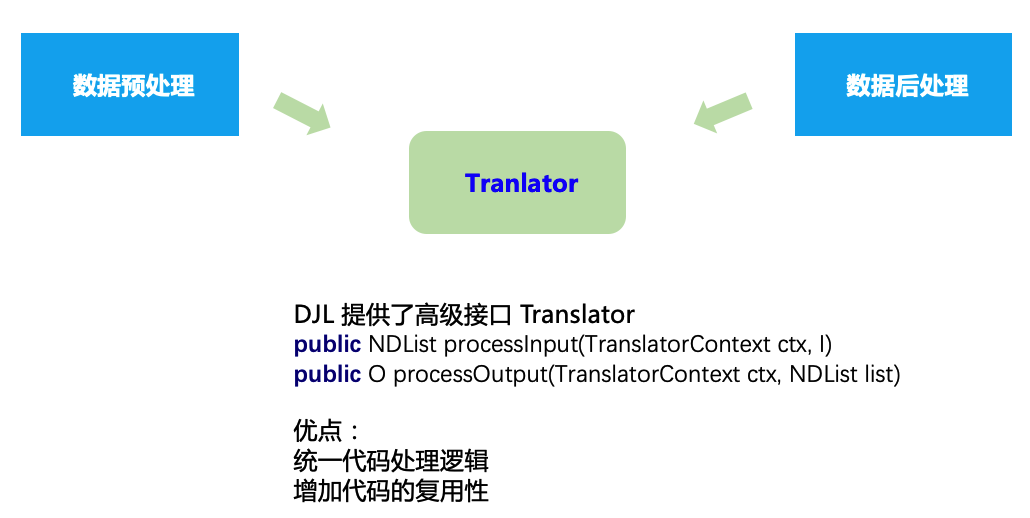
熟练掌握了NDArray的使用后,除了可以完成复杂的矩阵处理,计算外,如何用于模型的推理部署呢?
模型的推理可以概括为三个步骤:
- 数据预处理
- 推理
- 数据后处理
在预处理过程中,我们需要完成把图片转成RGB数组,把文字转换成索引id,把音频转换成float数组,数据归一化等操作。
在后处理过程中,我们需要完成把概率转换为对应的标签,把文字索引转换回文字等操作。
在数据预处理/数据后处理过程中,NDArray起了最关键的作用。

DJL为了统一代码处理逻辑,增加代码的复用性,提供了高级接口Translator:
public NDList processInput(TranslatorContext ctx, I)
public O processOutput(TranslatorContext ctx, NDList list)
12
对NDArray有了基本的了解后,通过学习后续的教程,可以进一步掌握NDArray的使用。
2 JavaDJL使用
随着数据科学在生产中的应用逐步增加,使用N维数组灵活的表达数据变得愈发重要。我们可以将过去数据科学运算中的多维循环嵌套运算简化为简单几行。由于进一步释放了计算并行能力,这几行简单的代码运算速度也会比传统多维循环快很多。这种数学计算的包已经成为于数据科学,图形学以及机器学习领域的标准。同时它的影响力还在不断的扩大到其他领域。
在Python的世界,调用NDArray的标准包叫做NumPy。但是如今在Java领域中,并没有与之同样标准的库。为了给Java开发者创造同一种使用环境,亚马逊云服务开源了DJL,一个基于Java的深度学习库。尽管它包含了深度学习模块,但是它最核心的NDArray系统可以被用作N维数组的标准。它具备优良的可扩展性,全平台支持,以及强大的后端引擎支持(TensorFlow、PyTorch、Apache MXNet)。无论是CPU还是GPU,PC还是安卓,DJL都可以轻而易举的完成任务。
2.1 安装DJL
可以通过下方的配置来配置gradle项目,或者也可以跳过设置直接使用我们的
plugins {
id 'java'
}
repositories {
jcenter()
}
dependencies {
implementation "ai.djl:api:0.6.0"
// PyTorch
runtimeOnly "ai.djl.pytorch:pytorch-engine:0.6.0"
runtimeOnly "ai.djl.pytorch:pytorch-native-auto:1.5.0"
}
然后,我们就可以开始上手写代码了。
2.2 基本操作
首先尝试建立一个Try block来包含我们的代码(如果使用在线JShell可跳过此步):
try(NDManager manager = NDManager.newBaseManager()) {
}
NDManager是DJL中的一个Class,可以帮助管理NDArray的内存使用。通过创建NDManager,我们可以更及时地对内存进行清理。当这个Block里的任务运行完成时,内部产生的NDArray都会被清理掉。这个设计保证了我们在大规模使用NDArray的过程中,可以通过清理其中的NDManager来更高效地利用内存。为了做对比,我们可以参考NumPy在Python之中的应用。
import numpy as np
2.3 创建NDArray
Ones是一个创建全是1的N维数组操作。
Python (Numpy)
nd = np.ones((2, 3))
[[1. 1. 1.]
[1. 1. 1.]]
Java (DJL NDArray)
NDArray nd = manager.ones(new Shape(2, 3));
/*
ND: (2, 3) cpu() float32
[[1., 1., 1.],
[1., 1., 1.],
]
*/
我们也可以尝试生成随机数。比如需要生成一些从0到1的随机数:
Python (Numpy)
nd = np.random.uniform(0, 1, (1, 1, 4))
# [[[0.7034806 0.85115891 0.63903668 0.39386125]]]
Java (DJL NDArray)
NDArray nd = manager.randomUniform(0, 1, new Shape(1, 1, 4));
/*
ND: (1, 1, 4) cpu() float32
[[[0.932 , 0.7686, 0.2031, 0.7468],
],
]
*/
这只是简单演示一些常用功能。现在NDManager支持多达20种在NumPy中创建NDArray的方法。
2.4 数学运算
我们可以使用NDArray进行一系列数学操作。假设想对数据做一个转置操作,然后对所有数据加一个数的操作。可以参考如下的实现:
Python (Numpy)
nd = np.arange(1, 10).reshape(3, 3)
nd = nd.transpose()
nd = nd + 10
[[11 14 17]
[12 15 18]
[13 16 19]]
Java (DJL NDArray)
NDArray nd = manager.arange(1, 10).reshape(3, 3);
nd = nd.transpose();
nd = nd.add(10);
/*
ND: (3, 3) cpu() int32
[[11, 14, 17],
[12, 15, 18],
[13, 16, 19],
]
*/
DJL现在支持60多种不同的NumPy数学运算,基本涵盖了大部分的应用场景。
2.5 Get和Set
其中一个对于NDArray最重要的亮点就是它轻松简单的数据设置/获取功能。我们参考了NumPy的设计,将Java过去对于数据表达中的困难做了精简化处理。假设想筛选一个N维数组所有小于10的数:
Python (Numpy)
nd = np.arange(5, 14)
nd = nd[nd >= 10]
# [10 11 12 13]
Java (DJL NDArray)
NDArray nd = manager.arange(5, 14);
nd = nd.get(nd.gte(10));
/*
ND: (4) cpu() int32
[10, 11, 12, 13]
*/
是不是非常简单?接下来,我们看一个稍微复杂一些的应用场景。假设现在有一个3×3的矩阵,然后我们想把第二列的数据都乘以2:
Python (Numpy)
nd = np.arange(1, 10).reshape(3, 3)
nd[:, 1] *= 2
[[ 1 4 3]
[ 4 10 6]
[ 7 16 9]]
Java (DJL NDArray)
NDArray nd = manager.arange(1, 10).reshape(3, 3);
nd.set(new NDIndex(":, 1"), array -> array.mul(2));
/*
ND: (3, 3) cpu() int32
[[ 1, 4, 3],
[ 4, 10, 6],
[ 7, 16, 9],
]
*/
在上面的案例中,我们在Java引入了一个NDIndex的Class。它复刻了大部分在NumPy中对于NDArray支持的get/set操作。只需要简单的放进去一个字符串表达式,开发者在Java中可以轻松玩转各种数组的操作。
现实中的应用场景
上述的操作对于庞大的数据集是十分有帮助的。现在我们来看一下这个应用场景:基于单词的分类系统训练。在这个场景中,开发者想要利用从用户中获取的数据来进行情感分析预测。NDArray被应用在了对于数据进行前后处理的工作中。
2.6 分词操作
在输入到NDArray数据前,我们需要对于输入的字符串进行分词操作并编码成数字。下面代码中看到的Tokenizer是一个Map<String, Integer>。它是一个单词到字典位置的映射。
String text = "The rabbit cross the street and kick the fox";
String[] tokens = text.toLowerCase().split(" ");
int[] vector = new int[tokens.length];
/*
String[9] { "the", "rabbit", "cross", "the", "street",
"and", "kick", "the", "fox" }
*/
for (int i = 0; i < tokens.length; i++) {
vector[i] = tokenizer.get(tokens[i]);
}
vector
/*
int[9] { 1, 6, 5, 1, 3, 2, 8, 1, 12 }
*/
2.7 NDArray处理
经过编码操作后,我们创建了NDArray。然后需要转化数据的结构:
NDArray array = manager.create(vector);
array = array.reshape(new Shape(vector.length, 1)); // form a batch
array = array.div(10.0);
/*
ND: (9, 1) cpu() float64
[[0.1],
[0.6],
[0.5],
[0.1],
[0.3],
[0.2],
[0.8],
[0.1],
[1.2],
]
*/
最后,我们将数据传入深度学习模型中。如果使用Java要达到这些需要更多的工作量:如果需要实现类似于Reshape的方法,我们需要创建一个N维数组:List<List<List<…List…>>>来保证不同维度的可操作性。同时我们需要能够支持插入新的List来创建最终的数据格式。