【深度学习】 TensorFlow命令笔记
- tf.argmax
- tf.clip_by_value
- tf.concat
- tf.constant
- tf.contrib.layers.l1_regularizer和tf.contrib.layers.l2_regularizer
- tf.contrib.slim.conv2d
- tf.contrib.slim.fully_connected
- tf.contrib.slim.l2_regularizer
- tf.contrib.slim.max_pool2d
- tf.convert_to_tensor
- tf.device
- tf.equal
- tf.expand_dims
- tf.flags
- tf.gfile.Exists
- tf.gfile.GFile
- tf.gfile.FastGFile
- tf.GPUOptions和tf.ConfigProto
- tf.greater
- tf.image.sample_distorted_bounding_box
- tf.layers.dropout
- tf.less
- tf.logging.set_verbosity
- tf.logical_and
- tf.logical_or
- tf.name_scope
- tf.nn.conv2d
- tf.nn.max_pool和tf.nn.avg_pool
- tf.nn.softmax
- tf.nn.softmax_cross_entropy_with_logits和tf.nn.sparse_softmax_cross_entropy_with_logits
- tf.placeholder
- tf.python_io.TFRecordWriter
- tf.reduce_mean
- tf.Session和tf.global_variables_initializer
- tf.shape和get_shape
- tf.slice
- tf.split
- TensorFlow中的常用Optimizer
- tf.train.batch和tf.train.shuffle_batch
- tf.train.Example
- tf.train.exponential_decay
- tf.train.polynomial_decay
- tf.train.Saver
- tf.train.slice_input_producer
- tf.truncated_normal
- tf.unstack
- tf.Variable和tf.get_variable
- tf.variable_scope
- tf.where
- 结语
tf.argmax
返回最大值
tf.argmax(input, axis)
- input:一个多维数据
- axis:根据axis取值的不同返回按input某一维度依次取得的最大值的索引
- 返回一个向量,每个元素是按顺序得到的最大值的索引
tf.clip_by_value
对tensor进行值域控制
将指定张量中,小于最小值阈值的值变为最小值阈值,大于最大值阈值的值变为最大值阈值,返回转换后的张量
tf.clip_by_value(tensor, min, max)
- tensor:待转换的tensor
- min:最小值阈值
- max:最大值阈值
tf.concat
张量拼接
tf.concat([tensor1, tensor2, tensor3,...], axis)
- [tensor1, tensor2, tensor3,…]:多个张量,每个张量的shape必需相同
- axis:根据axis取值的不同,将多个张量按某一维度拼接在一起
- 返回拼接后的张量
tf.constant
创建常数张量
tf.constant(value, dtype=None, shape=None, name=None, verity_shape=False)
- value:可以是一个数值,也可以是一个列表list。如果是一个数,那么这个常量中所有值的按该数来赋值。如果是list,那么len(value)一定要小于等于shape展开后的长度。赋值时,先将value中的值逐个存入。不够的部分,则全部存入value的最后一个值。
- dtype:表示数据类型,一般是tf.float32、tf.float64或tf.int32、tf.int64
- shape:表示张量形状
- verity_shape:默认是False,如果为True会检查value和shape是否相符,不相符则报错
tf.contrib.layers.l1_regularizer和tf.contrib.layers.l2_regularizer
L1正则和L2正则,一般在损失函数后添加
正则化的目的是限制参数过多或者过大,避免模型更加复杂,避免过拟合
L1正则:
L2正则:
其中,
E
i
n
E_{in}
Ein 是未包含正则化项的训练样本误差,
λ
λ
λ 是可调的正则化参数
L1正则可以保证模型的稀疏性,也就是某些参数等于0;L2正则可以保证模型的稳定性,也就是参数的值不会太大或太小
L1的公式不可导,L2的公式可导,优化带L1正则化的损失函数要更加复杂
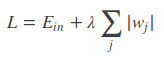
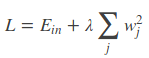
tf.contrib.layers.l1_regularizer(lambda)(weights)
tf.contrib.layers.l2_regularizer(lambda)(weights)
- lambda是正则化权重系数
- weights是参数
当参数很多时,每组参数每组参数的加正则项很不方便,通过下面的代码简化
import tensorflow as tf
def get_weight(shape, lambda):
var = tf.Variable(tf.random_normal(shape), dtype = tf.float32)
tf.add_to_collection(
"losses", tf.contrib.layers.l2_regularizer(lambda)(var))
# 参数正则的结果加入集合“losses”
return var
x = tf.placeholder(tf.float32, shape=(None, 2))
# 输入特征占位 shape=None * 2
y_ = tf.placeholder(tf.float32, shape=(None, 1))
# label占位 shape=None * 1
batch_size = 8
layer_dimension = [2, 10, 10, 10, 1]
n_layers = len(layer_dimension)
cur_layer = x
in_dimension = layer_dimension[0]
for i in range(1, n_layers):
# 从第二层起每一层循环
out_dimension = layer_dimension[i]
weight = get_weight([in_dimension, out_dimension], 0.001)
bias = tf.Variable(tf.constant(0.1, shape=[out_dimension]))
cur_layer = tf.nn.relu(tf.matmul(cur_layer, weight) + bias)
# 完成一次正向传播
in_dimension = layer_dimension[i]
mse_loss = tf.reduce_mean(tf.square(y_ - cur_layer))
# 损失函数
tf.add_to_collection("losses", mse_loss)
# 损失函数加入集合losses
loss = tf.add_n(tf.get_collection("losses"))
# 损失函数加所有参数的正则结果,得到最终的带正则化的损失函数
tf.contrib.slim.conv2d
创建卷积层
tf.contrib.slim.conv2d(inputs, num_outputs, kernel_size, stride=1, padding='SAME', data_format=None, rate=1, activation_fn=nn.relu, normalizer_fn=None, normalizer_params=None, weights_initializer=initializers.xavier_initializer(), weights_regularizer=None, biases_initializer=init_ops.zeros_initializer(), biases_regularizer=None, reuse=None, variables_collections=None, outputs_collections=None, trainable=True, scope=None)
- inputs:输入卷积层的张量
- num_outputs:指定卷积核的个数,也就是输出张量的channel数
- kernel_size:卷积核尺寸
- stride:步长,默认为1
- padding:padding的方式选择,默认为SAME
- data_format:指定输入的input的格式,inputs的形状为[batch_size, height, width, channels]和data_format 是NHWC相匹配,[batch_size, channels, height, width]和NCHW 相匹配
- rate:使用空洞卷积的膨胀率,默认为1,即为普通卷积,rate=n代表卷积核中相邻两两数之间插入了n-1个0,注意卷积核边界点外圈也插入n-1个零,这样组成新kernel_size的卷积核
- activation_fn:激活函数的指定,默认为ReLU函数
- normalizer_fn:指定正则化函数
- normalizer_params:指定正则化函数的参数
- weights_initializer:指定权重的初始化方式
- weights_regularizer:权重正则化方式
- biases_initializer:指定biase的初始化方式
- biases_regularizer:biases正则化方式
- reuse:指定是否共享层或者变量
- variable_collections:指定所有变量被添加的集合
- outputs_collections:指定输出被添加的集合
- trainable:卷积层的参数是否可被训练,默认为True,也就是可训练
- scope:共享变量所指的variable_scope
tf.contrib.slim.fully_connected
创建全连接层
tf.contrib.slim.fully_connected(inputs, num_outputs, activation_fn=nn.relu, normalizer_fn=None, normalizer_params=None, weights_initializer=initializers.xavier_initializer(), weights_regularizer=None, biases_initializer=init_ops.zeros_initializer(), biases_regularizer=None, reuse=None, variables_collections=None, outputs_collections=None, trainable=True, scope=None)
- inputs:至少秩为2的张量,最后一个维度为静态值;即:"[batch_size, depth]", “[None, None, None, channels]”
- num_output:全连接层输出单元的数量
- activation_fn:激活函数。默认值为ReLU函数。显式地将其设置为None以跳过它并保持线性激活
- normalizer_fn:用来代替“偏差”的归一化函数。如果提供“normalizer_fn”,则忽略“biases_initializer”和“biases_regularizer”,并且不会创建或添加“bias”。默认设置为None
- normalizer_params:规范化函数参数
- weights_initializer:权值的初始化器
- weights_regularizer:可选的权重正则化器
- biases_initializer:用于偏差的初始化器。如果没有人跳过bias
- biases_regularizer:可选的偏差调整器
- reuse:是否应该重用层及其变量。如果为了能够重用层范围,则必须给出
- variables_collections:所有变量的可选集合列表,或包含每个变量的不同集合列表的字典
- outputs_collections:用于添加输出的集合
- trainable:如果“True”则参数可训练
- scope:variable_scope的可选作用域
- 返回值:一系列运算结果的张量变量
tf.contrib.slim.l2_regularizer
用于对权重应用L2正则化
tf.contrib.slim.l2_regularizer(weight_decay)
- weight_decay:l2正则项的系数
tf.contrib.slim.max_pool2d
创建最大池化层
tf.contrib.slim.max_pool2d(inputs, kernel_size, stride=2, padding='VALID', data_format=DATA_FORMAT_NHWC, outputs_collections=None, scope=None)
- inputs:输入池化层的张量
- kernel_size:滤波核尺寸
- stride:步长,默认为2
- padding:padding的方式选择,默认为VALID
- data_format:指定输入的input的格式,inputs的形状为[batch_size, height, width, channels]和data_format 是NHWC相匹配,[batch_size, channels, height, width]和NCHW 相匹配
- outputs_collections:指定输出被添加的集合
- scope:共享变量所指的variable_scope
对于池化层,滤波核要移动到滤波核范围内无元素为止
tf.convert_to_tensor
将python的某一数据类型转化成TensorFlow的张量
tf.convert_to_tensor(data, dtype)
- data:转化成张量的数据
- dtype:是data的数据类型
- 比如:tf.convert_to_tensor(str, dtype=tf.string) 将字符串类型的数据str转化为张量
tf.device
指定session在第几块可见的GPU上运行
with tf.device('/gpu:0'):
...
在第一块可见的GPU上运行
with tf.device('/gpu:1'):
...
在第二块可见的GPU上运行
tf.equal
逐个元素进行判断是否相等
tf.equal(x, y, name=None)
- 如果相等就是True,不相等,就是False
tf.expand_dims
tensorflow张量增加维度
tf.expand_dims(tensor, axis)
- axis:指定维度
- axis为0时,在最前面加一个维度
- axis为1时,在第一个维度后面加一个维度,以此类推
- axis为-1时,在最后加一个维度
tf.flags
用于传递和解析命令行参数,相当于python的argparse
tf.flags.DEFINE_string("str_name", "str", "str_descrip")
- 定义一个字符串类型的参数
- 括号中第一个参数是定义的这个参数的名称,第二个是默认值,第三个是描述
tf.flags.DEFINE_boolean("bool_name", True, "bool_descrip")
- 定义一个布尔类型的参数
tf.flags.DEFINE_integer("int_name", num, "int_descrip")
- 定义一个整形类型的参数
FLAGS = tf.flags.FlAGS
- 使定义的参数生效,并通过FLAGS使用
FLAGS.str_name
# 值为"str"
FLAGS.bool_name
# 值为True
FLAGS.int_name
# 值为num
tf.gfile.Exists
判断目录或文件是否存在
tf.gfile.Exists(filename)
- filename:文件或路径
- 如果filename存在,返回True,否则返回False
tf.gfile.GFile
获取文本操作句柄,类似于python提供的文本操作open()函数
tf.gfile.GFile(filename, mode)
- 使用方法.read()实现读取文件
- filename:要打开的文件名
- mode:以何种方式去读写
- 返回一个文本操作句柄
tf.gfile.FastGFile
无阻赛以较快的方式获取文本操作句柄
tf.gfile.FastGFile(filename, mode)
tf.GPUOptions和tf.ConfigProto
限制GPU资源的使用
- 方法一
gpu_options=tf.GPUOptions(per_process_gpu_memory_fraction=0.7)
# 设置GPU显存使用率为70%
config=tf.ConfigProto(gpu_options=gpu_options)
session = tf.Session(config=config)
- tf.ConfigProto参数allow_soft_placement:设置为True,会在终端打印出各项操作是在哪个设备上运行的
- 方法二
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.7
# 设置GPU显存使用率为70%
session = tf.Session(config=config)
申请动态显存
- 方法一
gpu_options=tf.GPUOptions(allow_growth = True)
config=tf.ConfigProto(gpu_options=gpu_options)
session = tf.Session(config=config)
- 方法二
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.Session(config=config)
设置使用哪些GPU
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# 使用GPU编号0
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
# 使用GPU编号0,1
tf.greater
比较大小
tf.greater(a, b)
- a:tensor
- b:tensor
输入a、b是两个张量,这个函数会比较两个输入张量中每一个对应元素的大小,然后返回一个bool类型的tensor。a中元素大的返回True,b中元素大的返回False。
tf.image.sample_distorted_bounding_box
根据设置,在原图上随机生成边界框,用于图像数据加强
sample_distorted_bounding_box(
image_size,
bounding_boxes,
seed=None,
seed2=None,
min_object_covered=0.1,
aspect_ratio_range=(0.75, 1.33),
area_range=(0.05, 1),
max_attempts=100,
use_image_if_no_bounding_boxes=None,
name=None
)
- image_size:一个原图像size的tensor,可以使用tf.shape(image)获得
- bounding_boxes:是一个 shape 为(batch, N, 4)的tensor,数据类型为float32,第一个batch是因为函数是处理一组图片的,N表示描述与图像相关联的N个ground truth box的形状,而每一个ground true box由4个数字(y_min, x_min, y_max, x_max)表示。注意这个bounding_boxes的值应该是归一化后的。
- min_object_covered:默认为 0.1。图像上随机生成的边界框必须与原图ground truth box有重叠的数量和ground truth box的数量的比例。当为0时,边界框不必与提供的任何ground truth box有重叠部分。
- aspect_ratio_range:默认为(0.75, 1.33)。生成的图像的裁剪区域边界框的宽高比的范围
- area_range:默认为(0.05, 1)。生成的图像边界框区域的面积和原图面积的比例的范围
- max_attempts:默认为100。尝试生成图像指定约束的裁剪区域的次数。经过 max_attempts 次失败后,将返回整个图像
- 返回值一:一个和image_size各个维度对应的tensor。作为tf.slice的第二个输入参数(begin)。
- 返回值二:一个和image_size各个维度对应的tensor。作为tf.slice的第三个输入参数(size)。
- 返回值三:可以作为tf.image.draw_bounding_boxes 的输入,用于在原图上画出剪裁的边界框(box)。
tf.layers.dropout
dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。
dropout是CNN中防止过拟合提高效果的一个大杀器
tf.layers.dropout(inputs, rate=0.5, noise_shape=None, seed=None, training=False, name=None)
- inputs:输入张量
- rate:在训练的时候拿掉神经元的比例
- training:如果是False,就是在推断中使用,dropout不起作用;如果是True,就是在训练中使用,dropout起作用
tf.less
比较大小
tf.less(a, b)
- a:tensor
- b:tensor
输入a、b是两个张量,这个函数会比较两个输入张量中每一个对应元素的大小,然后返回一个bool类型的tensor。a中元素小的返回True,b中元素小的返回False。
和tf.greater正好相反
tf.logging.set_verbosity
设置输出日志最低等级
tf.logging.set_verbosity(tf.logging.DEBUG)
- 输出DEBUG级别,以及高于DEBUG级别的日志信息
在TensorFlow中有函数可以直接log打印。
TensorFlow使用五个不同级别的日志消息,按照上升的顺序它们是:
- DEBUG
- INFO
- WARN
- ERROR
- FATAL
tf.logical_and
逻辑与
tf.logical_and(a, b, name)
- a:布尔型tensor
- b:布尔型tensor
tf.logical_or
逻辑或
tf.logical_or(a, b, name)
- a:布尔型tensor
- b:布尔型tensor
tf.name_scope
解决命名冲突问题
with tf.name_scope("name"):
或
with tf.name_scope("name") as scope:
- name:该命名区域的名称
- 在某个tf.name_scope()指定的区域中定义的所有对象及各种操作,他们的“name”属性上会增加该命名区的区域名,用以区别对象属于哪个区域
tf.nn.conv2d
卷积计算
卷积核虽然是3x3、5x5之类,但是一个卷积核用在一个多channel的张量上时,卷积核对应每个channel的值是不同的。比如一个5x5x5的张量,3x3的卷积核做卷积,卷积核实际维度是3x3x5,卷积核的5个channel的值各不相同。
对卷积的理解
从函数(或者说映射、变换)的角度理解。 卷积过程是在图像每个位置进行线性变换映射成新值的过程,将卷积核看成权重,若拉成向量记为 w w w,图像对应位置的像素拉成向量记为 x x x,则该位置卷积结果为 y = w T x + b y=w^Tx+b y=wTx+b,即向量内积+偏置,将 x x x变换为 y y y。从这个角度看,多层卷积是在进行逐层映射,整体构成一个复杂函数,训练过程是在学习每个局部映射所需的权重,训练过程可以看成是函数拟合的过程。
从模版匹配的角度理解,认为卷积核定义了某种模式,卷积运算是在计算每个位置与该模式的相似程度,或者说每个位置具有该模式的分量有多少,当前位置与该模式越像,响应越强。
一个卷积核代表一种模式,缺乏泛化能力。通过多层卷积,来将简单模式组合成复杂模式,通过这种灵活的组合来保证具有足够的表达能力和泛化能力。
浅层layer学到的特征为简单的边缘、角点、纹理、几何形状、表面等,到深层layer学到的特征则更为复杂抽象,为狗、人脸、键盘等等。
卷积神经网络每层的卷积核权重是由数据驱动学习得来。
数据驱动卷积神经网络逐层学到由简单到复杂的特征,复杂模式是由简单模式组合而成。
以上内容参考自卷积神经网络之卷积计算、作用与思想
关于zero-padding
如果使用了zero-padding,输出的尺寸计算方式如下:
- out-length = |in-length/stride-length|,即:输出长度等于输入长度除以步长,然后向上取整
如果不使用zero-padding,遵循:
- 不足一次移动了就扔掉的原则
tensorflow相关命令
filter_weight = tf.get_variable("weights", [5, 5, 3, 16], initializer = tf.truncated_normal_initializer(stddev=0.1))
# 5x5的卷积核,输入的深度为3,输出深度为16
biases = tf.get_variable("biases", [16], initializer = tf.constant_initializer(0.1))
# 偏置
conv = tf.nn.conv2d(input, filter_weight, strides = [1, 1, 1, 1], padding="SAME")
# input是输入卷积核的张量, strides第一个元素和最后一个元素必须是1,分别对应batch维度的步长和输入深度维度的步长
# tensorflow中padding有两种选择,“SAME”是使用zero-padding,“VALID”是不使用zero-padding
bias = tf.nn.bias_add(conv, biases)
#
actived_conv = tf.nn.relu(bias)
#
tf.nn.max_pool和tf.nn.avg_pool
卷积层使用的滤波器是横跨整个深度的,池化层使用的滤波器只影响一个深度上的节点
pool = tf.nn.max_pool(actived_conv, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding="SAME")
# tf.nn.max_pool是最大池化
# tf.nn.avg_pool是平均池化
tf.nn.softmax
计算分类网络输出的softmax结果
tf.nn.softmax(logits, name)
- logits:网络输出的结果
tf.nn.softmax_cross_entropy_with_logits和tf.nn.sparse_softmax_cross_entropy_with_logits
交叉熵损失函数,多用于分类问题
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=None, logits=None)
- labels:真实标签(one-hot处理过)
- logits:网络输出的结果
具体的执行流程分为两步:
- 先对网络最后一层的输出做一个softmax,这一步通常是求取输出属于某一类的概率,对于单label样本而言,输出就是一个num_classes大小的向量([Y1, Y2, Y3…]其中Y1,Y2,Y3…分别代表了是属于该类的概率)
softmax的公式是:
- softmax的输出向量[Y1, Y2, Y3…]和样本的实际标签做一个交叉熵,公式如下:
其中 y i , y_i^, yi,是真实标签, y i y_i yi是softmax的输出结果
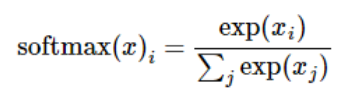
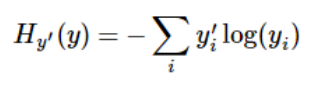
显而易见,预测越准确,结果的值越小,最后求一个平均,得到我们想要的loss
注意,这个函数的返回值并不是一个数,而是一个向量,如果要求交叉熵,我们要再做一步tf.reduce_sum操作,就是对向量里面所有元素求和,最后才得到 H y , ( y ) H_{y^,}(y) Hy,(y)
如果求loss,则要做一步tf.reduce_mean操作,对向量求均值
tf.nn.sparse_softmax_cross_entropy_with_logits(labels=None, logits=None)
- labels:真实标签(未经one-hot处理)
- logits:网络输出的结果
回归问题多使用均方误差(MSE)
mse = tf.reduce_mean(tf.square(y_ - y))
# MSE
tf.placeholder
在神经网络构建graph时在模型中占位,分配必要的内存
tf.placeholder(dtype, shape, name)
- dtype:数据类型,常用tf.float32或tf.float64等
- shape:数据形状
- name:数据名称
- tf.placeholder占位的变量,需要在sess.run()中使用一个名为feed_dict的字典赋初始值,否则会报错
tf.python_io.TFRecordWriter
TFRecordWriter类,将记录写入TFRecords文件的类
with tf.python_io.TFRecordWriter(tf_filename) as tfrecord_writer:
- tf_filename:TFRecords文件的路径
tfrecord_writer.write(str)
- str:要写入tf-record文件的字符串
tf.reduce_mean
计算张量沿指定轴的平均值
tf.reduce_mean(input_tensor, axis=None, keep_dims=False, name=None, reduction_indices=None)
- axis:指定的轴,如果不指定,则计算所有元素的均值
- keep_dims:是否降维度,设置为True,输出的结果保持输入tensor的形状,设置为False,输出结果会降低维度
tf.Session和tf.global_variables_initializer
会话
- 方式一
sess = tf.Session()
sess.run(...)
sess.close()
- 方式二
with tf.Session() as sess:
sess.run(...)
- 关于tf.global_variables_initializer()
sess.run(tf.global_variables_initializer())
# 初始化所有变量
仅仅是初始化变量
tf.shape和get_shape
查看tenosr的维度
tf.shape(input, name=None, out_type=tf.int32)
- input:tensor
- out_type:返回值类型
- 返回一个tensor
测试程序:
import tensorflow as tf
A = tf.constant([[[1, 1, 1],
[2, 2, 2]],
[[3, 3, 3],
[4, 4, 4]],
[[5, 5, 5],
[6, 6, 6]]])
x = tf.shape(A)
y = tf.shape(A)[0]
with tf.Session() as sess:
print("x = ", sess.run(x))
print(type(x))
print("y = ", sess.run(y))
print(type(y))
sess.run(A)
print(A.get_shape())
print(type(A.get_shape()))
print(A.get_shape().as_list())
print(type(A.get_shape().as_list()))
输出如下:
x = [3 2 3]
<class 'tensorflow.python.framework.ops.Tensor'>
y = 3
<class 'tensorflow.python.framework.ops.Tensor'>
(3, 2, 3)
<class 'tensorflow.python.framework.tensor_shape.TensorShapeV1'>
[3, 2, 3]
<class 'list'>
tf.slice
张量切片
tf.slice(input, begin, size, name=None)
- input:是你输入的tensor,就是被切的那个
- begin:是每一个维度的起始位置
- size:相当于问每个维度拿几个元素出来
参考博客:https://www.jianshu.com/p/71e6ef6c121b
tf.split
张量拆分,不改变维度
tf.split(value, num_or_size_splits, axis=0)
- value:原始张量
- num_or_size_splits:拆分的份数
- axis:指定维度
- 返回一个list,里面是拆分后的每个张量
TensorFlow中的常用Optimizer
- tf.train.GradientDescentOptimizer
梯度下降算法,该方法学习率恒定
tf.train.GradientDescentOptimizer(learning_rate).minimize(cost_function, global_step=global_step)
- learning_rate:学习率
- cost_function:要优化的损失函数
- global_step:一个计数器,global_step自动更新为执行该命令的次数
- 列子:
global_step = tf.get_variable("step", [], initializer=tf.constant_initializer(0.0), trainable=False)
# 初始化global_step为0
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(loss, global_step=global_step)
...
_, step = sess.run(optimizer, global_step)
# step是执行次数
- 方法一:minimize函数:处理了梯度计算和参数更新两个操作,上面例子用的就是minimize函数
- 方法二:compute_gradients函数:用于获取梯度,参数是要优化的损失函数,返回的是当前梯度
- 方法三:apply_gradients函数:用于更新参数,参数是compute_gradients返回的梯度
- tf.train.MomentumOptimizer
引入一个积攒历史梯度信息动量来加速梯度下降
tf.train.MomentumOptimizer(learning_rate, momentum, use_locking=False, use_nesterov=False, name='Momentum')
- learning_rate::学习率,张量或者浮点数
- momentum:动量,张量或者浮点数
- use_locking:为True时锁定更新
- use_nesterov:为True时,使用 Nesterov Momentum
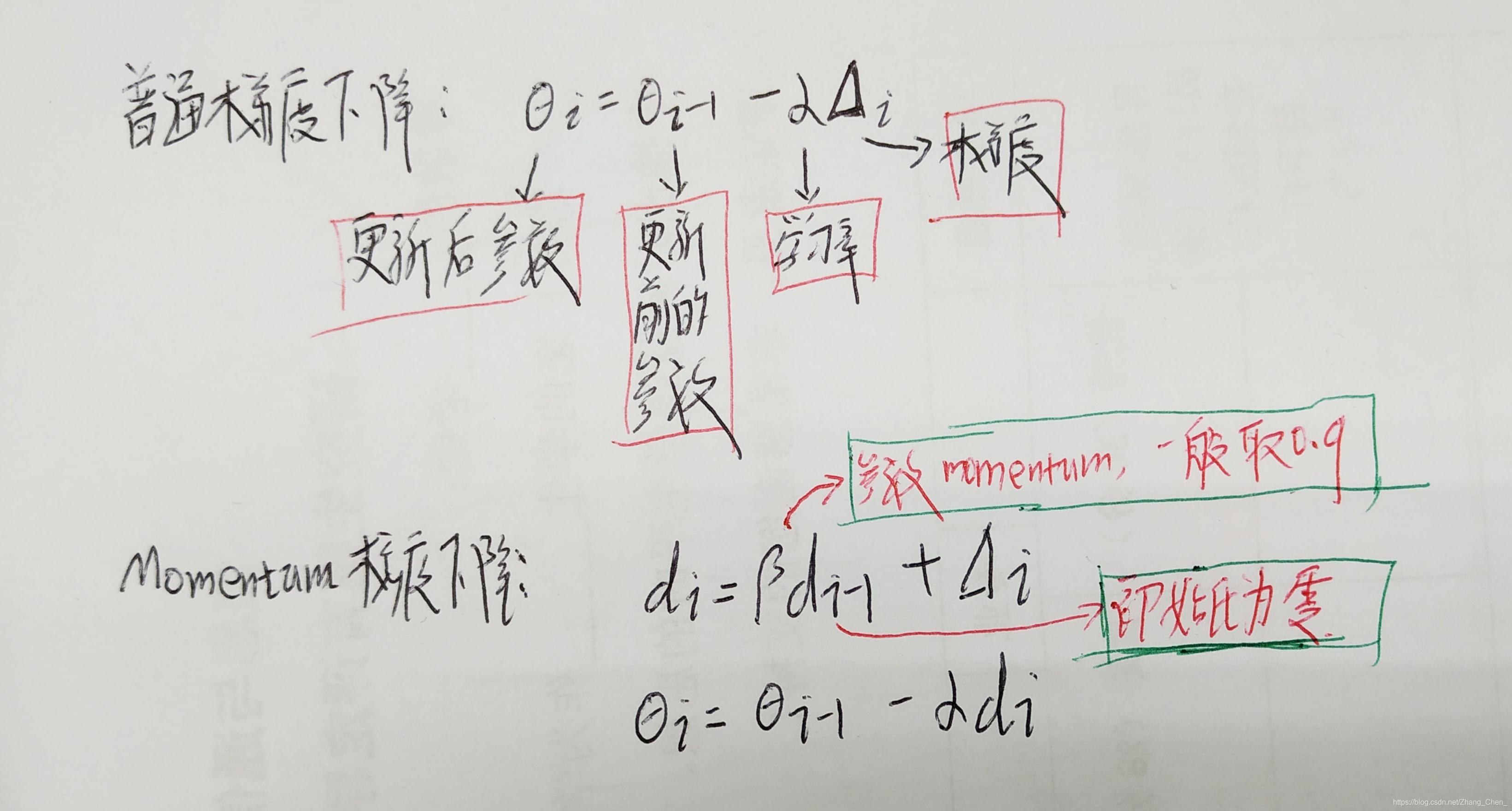
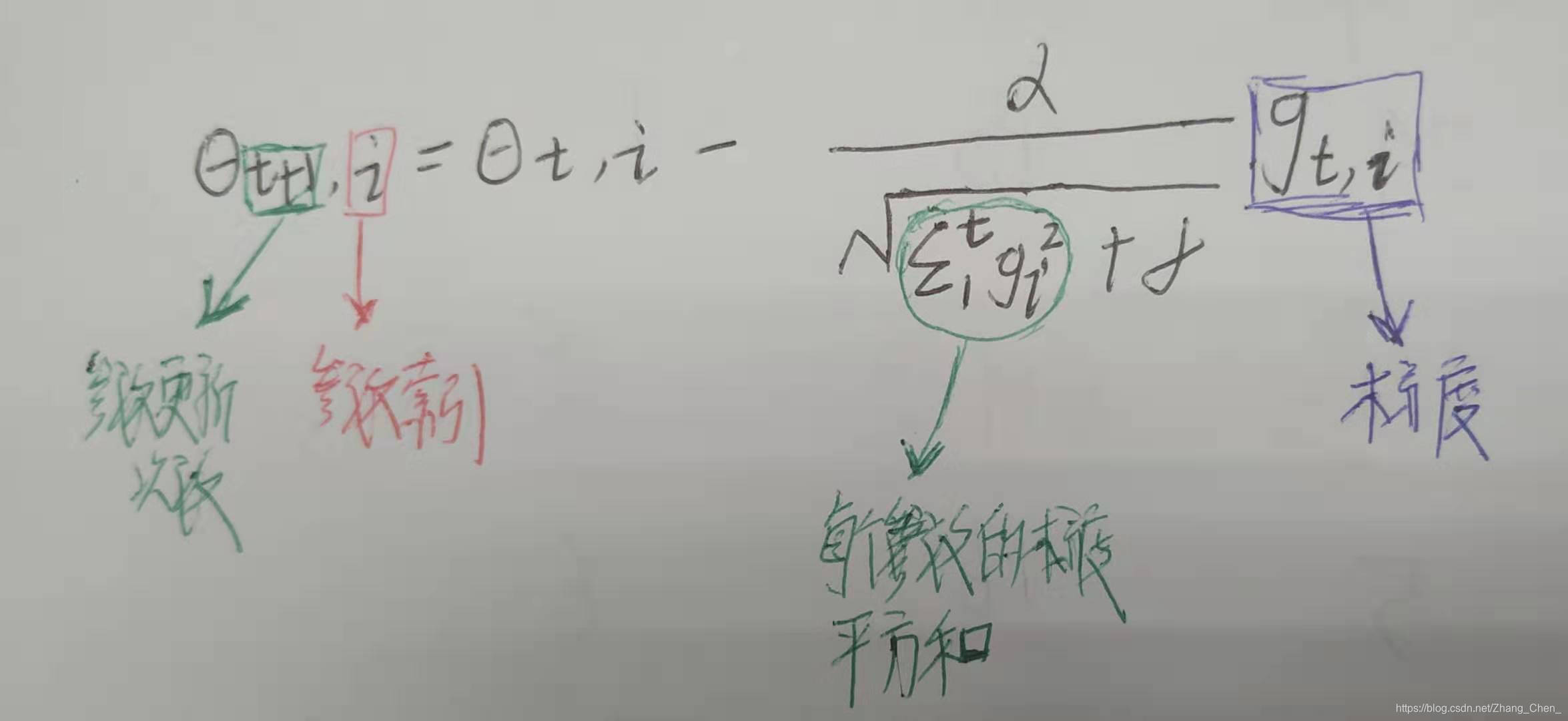
- tf.train.AdagradOptimizer
独立地适应所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平均值总和的平方根。具有代价函数较大梯度的参数相应地有个较小的学习率,而具有小梯度的参数在学习率上有相对较大的学习率
tf.train.AdagradOptimizer(learning_rate, initial_accumulator_value=0.1)
- tf.train.AdadeltaOptimizer
tf.train.AdadeltaOptimizer(learning_rate, rho=0.95, epsilon=1e-08)
- tf.train.RMSPropOptimizer
tf.train.RMSPropOptimizer(learning_rate, decay=0.9, momentum=0.0, epsilon=1e-10)
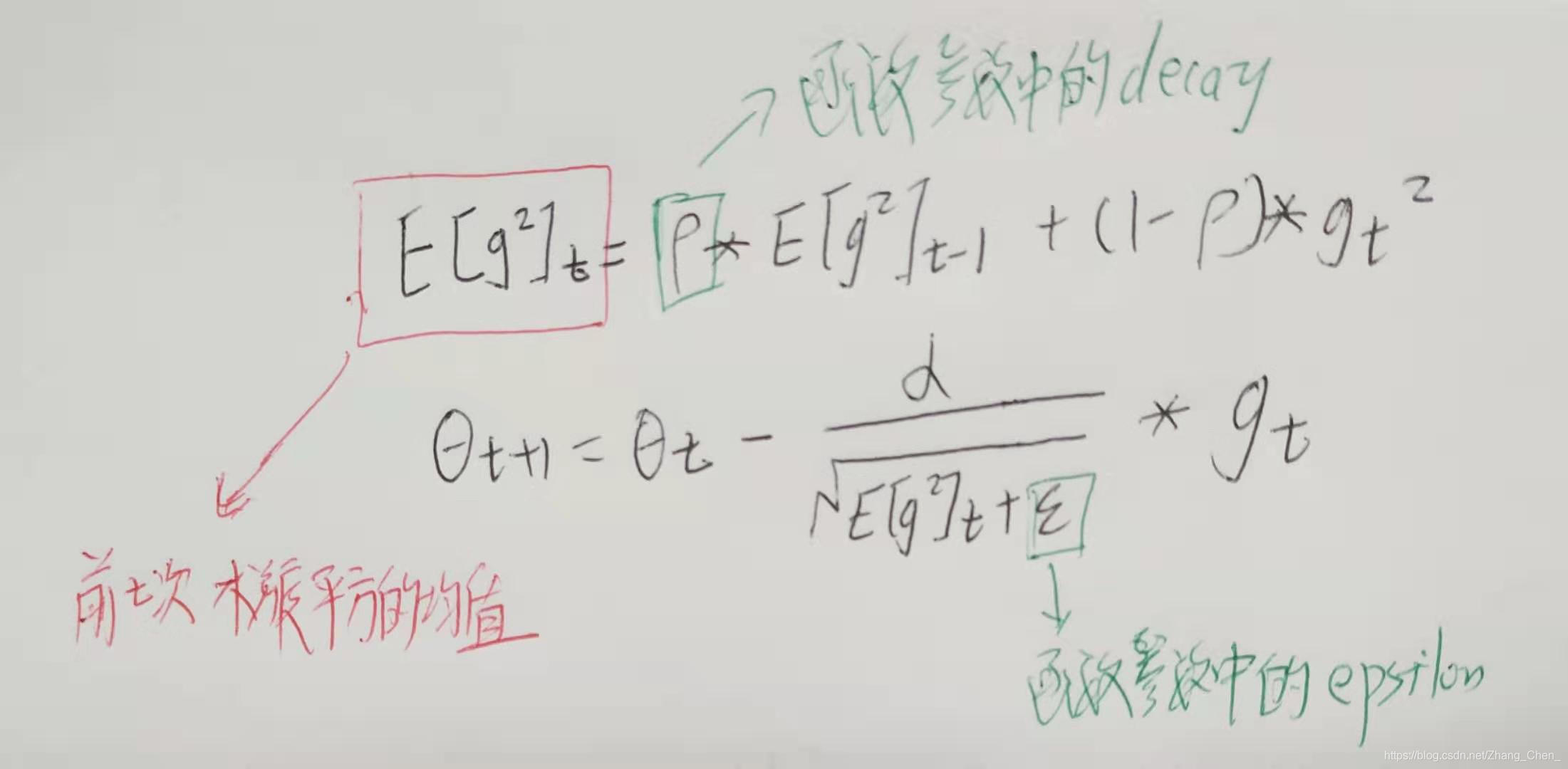
- tf.train.AdamOptimizer
Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率
tf.train.AdamOptimizer(learning_rate, beta1=0.9, beta2=0.999, epsilon=1e-08, use_locking=False, name='Adam')

- tf.train.FtrlOptimizer
tf.train.FtrlOptimizer(learning_rate, learning_rate_power=-0.5, initial_accumulator_value=0.1, l1_regularization_strength=0.0, l2_regularization_strength=0.0)
tf.train.batch和tf.train.shuffle_batch
tf.train.batch是一个tensor队列生成器,作用是按照给定的tensor顺序,把batch_size个tensor推送到文件队列,作为训练一个batch的数据,等待tensor出队执行计算
tf.train.batch(tensors, batch_size, num_threads=1, capacity=32, enqueue_many=False, shapes=None, dynamic_pad=False, allow_smaller_final_batch=False, shared_name=None, name=None)
- tensor:tensor序列或tensor字典,可以是含有单个样本的序列
- batch_size:设置batch size值
- num_threads:执行tensor入队操作的线程数量,可以设置使用多个线程同时并行执行,提高运行效率,但也不是数量越多越好
- capacity:定义生成的tensor序列的最大容量
- enqueue_many:定义第一个传入参数tensors是多个tensor组成的序列,还是单个tensor
- shapes:默认是推测出的传入的tensor的形状
- dynamic_pad:定义是否允许输入的tensors具有不同的形状,设置为True,会把输入的具有不同形状的tensor归一化到相同的形状
- allow_smaller_final_batch,设置为True,表示在tensor队列中剩下的tensor数量不够一个batch_size的情况下,允许最后一个batch的数量少于batch_size, 设置为False,则不管什么情况下,生成的batch都拥有batch_size个样本
tf.train.shuffle_batch和tf.train.batch的区别仅仅是前者会将数据集随机打乱
tf.train.Example
将数据处理成二进制
tf.train.Int64List、tf.train.FloatList和tf.train.BytesList
tf.train.Int64List(value)
tf.train.FloatList(value)
tf.train.BytesList(value)
- value:用于将值传进去,可以是一个值,也可以是一个列表
- 一般tf.train.Int64List、tf.train.FloatList对应处理整数和浮点数,tf.train.BytesList用于处理其他类型的数据
tf.train.Feature和tf.train.Features
tf.train.Feature(int64_list)
tf.train.Feature(float_list)
tf.train.Feature(bytes_list)
- int64_list等:tf.train.Int64List等的结果
- 如:tf.train.Feature(int64_list=tf.train.Int64List(value))
tf.train.Features(feature)
- feature:一般设置方法是传入一个字典,字典的key是字符串(feature名),而值是tf.train.Feature对象
tf.train.Example
tf.train.Example(features)
- features:tf.train.Features对象
- 有方法SerializeToString:把tf.train.Example对象序列化为字符串,因为写入文件的时候不能直接处理对象,需要将其转化为字符串才能处理
tf.train.exponential_decay
指数衰减法改变学习率
learning_rate = tf.train.exponential_decay(base_learning_rate, global_step, decay_step, decay_rate, staircase = False)
# 学习率计算公式:
learning_rate = base_learning_rate * decay_rate ^ (global_step / decay_step)
# staircase为True时,global_step / decay_step会被转化为整数
tf.train.polynomial_decay
多项式衰减法改变学习率
定义一个初始的学习率,一个最低的学习率,按照设置的衰减规则,学习率从初始学习率逐渐降低到最低的学习率,并且可以定义学习率降低到最低的学习率之后,是一直保持使用这个最低的学习率,还是到达最低的学习率之后再升高学习率到一定值,然后再降低到最低的学习率(反复这个过程)
learning_rate = tf.train.polynomial_decay(learning_rate, global_step, decay_steps, end_learning_rate=0.0001, power=1.0, cycle=False, name=None)
- learning_rate:初始学习率
- global_step:当前训练迭代次数
- decay_step:定义学习率下降在迭代次数为多少时下降
- end_learning_rate:最小的学习率,默认值是0.0001
- power: 多项式的幂,默认值是1,即线性的
- cycle: 定义学习率是否到达最低学习率后升高,然后再降低,默认False,保持最低学习率
# 学习率计算公式:
global_step = min(global_step, decay_steps)
learning_rate = (learning_rate - end_learning_rate) * (1 - global_step / decay_steps) ^ (power) + end_learning_rate
# cycle为False时
# 学习率计算公式:
decay_steps = decay_steps * ceil(global_step / decay_steps)
# ceil是向上取整
learning_rate = (learning_rate - end_learning_rate) * (1 - global_step / decay_steps) ^ (power) + end_learning_rate
# cycle为True时
tf.train.Saver
保存和还原一个神经网络模型
tf.train.Saver(max_to_keep=5, keep_checkpoint_every_n_hours=1.0)
- max_to_keep:表示要保留的最近文件的最大数量,创建新文件时,将删除旧文件
- keep_checkpoint_every_n_hours:除了保留最新的 max_to_keep检查点文件之外,还可以每N小时的训练保留一个checkpoint文件。如果想分析模型在长时间训练期间的进展情况,这将非常有用
import tensorflow as tf
...
saver = tf.train.Saver()
with tf.Session() as sess:
...
saver.save(sess, "/path/to/model/model.ckpt")
TensorFlow模型将保存到/path/to/model/model.ckpt文件中。
/path/to/model路径下会保存三个文件:
- model.ckpt.meta 这个文件保存了TensorFlow计算图的结构,可以理解为神经网络的网络结构
- model.ckpt 这个文件保存了TensorFlow程序中每一个变量的取值
- checkpoint 这个文件保存了一个目录下所有的模型文件列表
import tensorflow as tf
...
saver = tf.train.Saver()
with tf.Session() as sess:
...
saver.restore(sess, "/path/to/model/model.ckpt")
加载保存后的模型
比如,可能有一个之前训练好的五层神经网络模型,但现在想尝试一个六层的神经网络,那么可以将前面五层神经网络中的参数直接加载到新的模型,而仅仅将最后一层神经网络重新训练
为了保存或者加载部分变量,在声明tf.train.Saver类时可以提供一个列表来指定需要保存或者加载的变量
saver = tf.train.Saver([v1])
# 只有变量v1会被加载尽量
# 注意要将其他变量也初始化,否则将报错初始化错误
tf.train.slice_input_producer
TensorFlow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算。具体来说就是使用一个线程源源不断的将硬盘中的图片数据读入到一个内存队列中,另一个线程负责计算任务,所需数据直接从内存队列中获取。
TF在内存队列之前,还设立了一个文件名队列,文件名队列存放的是参与训练的文件名,要训练 N个epoch,则文件名队列中就含有N个批次的所有文件名。
而创建TF的文件名队列就需要使用到 tf.train.slice_input_producer 函数
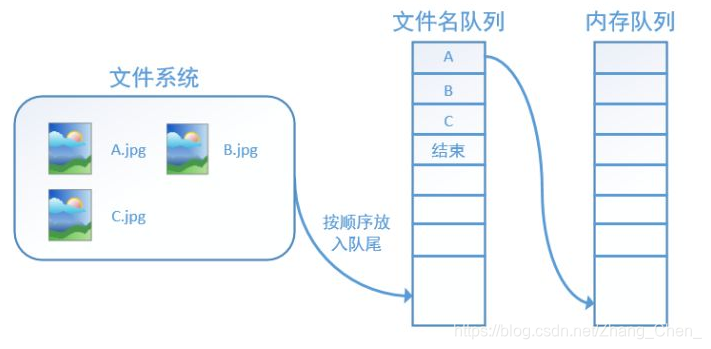
每次从一个tensor列表中按顺序或者随机抽取出一个tensor放入文件名队列
在N个epoch的文件名最后是一个结束标志,当TF读到这个结束标志的时候,会抛出一个OutofRange的异常,外部捕获到这个异常之后就可以结束程序了
tf.train.slice_input_producer(tensor_list, num_epochs=None, shuffle=True, seed=None, capacity=32, shared_name=None, name=None)
- tensor_list:一个列表,两个元素,第一个是全部数据,第二个是顺序对应的全部标签,比如:[image, labels]
- num_epochs:训练epoch个数
- shuffle:布尔类型,设置是否随机打乱数据集
- seed:可选的整数,是生成随机数的种子,在第三个参数设置为shuffle=True的情况下才有用
- capacity:第一个参数中tensor列表的容量
- shared_name:如果设置一个‘shared_name’,则在不同的上下文环境(Session)中可以通过这个名字共享生成的tensor
- name:设置操作的名称
这个命令返回的就是这个文件名队列,队列中每一项包括两个元素,第一个元素是数据名,第二个元素是label。
该命令的输出,常作为tf.train.batch命令的输入
tf.truncated_normal
产生截断正态分布随机数
tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
- shape:输出张量的维度
- mean:均值
- stddev:标准差
- dtype:输出数据类型
- seed:随机种子,若 seed 赋值,每次产生相同随机数
- name:名称
- 取值范围为 [ mean - 2 * stddev, mean + 2 * stddev ]
tf.unstack
张量拆分,拆分后降低维度
tf.unstack(value, num_or_size_splits, axis=0)
- value:原始张量
- num_or_size_splits:拆分的份数
- axis:指定维度
- 返回一个list,里面是拆分后的每个张量
tf.Variable和tf.get_variable
- tf.Variable
设定一个初始化参数
tf.Variable(initializer, name, trainable)
- initializer:初始化参数
- name:这个参数的自定义名称
- trainable:如果为True,则将变量添加到图形集合GraphKeys.TRAINABLE_VARIABLES
- 通过tf.Variable设定的初始化参数,需要在session中sess.run()才能使用
- 可以通过tf.global_variables_initializer()全部初始化
- tf.get_variable
获取一个已经存在的变量或者创建一个新的变量
tf.get_variable(name, shape, dtype, ininializer, trainable)
- ininializer:如果创建新的变量,则用它来初始化变量
- trainable:如果为True,则将变量添加到图形集合GraphKeys.TRAINABLE_VARIABLES
例子 1:
global_step = tf.get_variable("step", [], initializer=tf.constant_initializer(0.0), trainable=False)
例子2:
v = tf.Variable(tf.constant(1.0, shape=[1], name="v"))
v = tf.get_variable("v", shape=[1], initializer=tf.constant_initializer(1.0))
例子2中两个定义是等价的
tf.variable_scope
声明变量作用域
with tf.variable_scope(name_or_scope, default_name=None, values=None, reuse=None)
- name_or_scope:变量空间的名称,一般为字符串类型
- default_name:当name_or_scope 使用时,它可以忽略。如果name_or_scope是None,则其值赋给空间变量名称
- values:一个Tensor的列表,是传入该scope的tensor参数
- reuse:三种取值,None、False和True。当值为True时,tf.get_variable()不是创建变量,而是获取已有变量
with tf.variable_scope("foo"):
v = tf.get_variable("v", [1], initializer=tf.constant_initializer(1.0))
# 在命名空间“foo”中,定义一个名字为“v”的变量
# --------------------------------------------------------------------------------------------------------------------
with tf.variable_scope("foo"):
v = tf.get_variable("v", [1])
# 因为命名空间中已经有“v”,所以上面命令报错
# --------------------------------------------------------------------------------------------------------------------
with tf.variable_scope("foo", resue=True):
v1 = tf.get_variable("v", [1])
print v == v1
# 上述命令打印“True”
# 当“resue”参数设置为True时,tf.get_variable()不是创建变量,而是获取已有变量
# --------------------------------------------------------------------------------------------------------------------
with tf.variable_scope("bar", resue=True):
v1 = tf.get_variable("v", [1])
# 上面命令报错,因为在命名空间“bar”中不存在变量“v”
tf.variable_scope函数嵌套使用时,reuse的确定:
新建一个嵌套的上下文管理器但不指定reuse,这是reuse的取值会和外面一层保持一致
tf.where
根据第一个条件是否成立,当成立(为True)的时候选择第二个参数中对应的值,否则使用第三个参数中对应的值
tf.where(condition, x=None, y=None, name=None)
- condition:条件
- x:tensor
- y:tensor
结语
如果您有修改意见或问题,欢迎留言或者通过邮箱和我联系。
手打很辛苦,如果我的文章对您有帮助,转载请注明出处。