多目标跟踪 YOLOv4+Deep Sort
主要工作
本文主要是记录一下最近做的一些关于多目标跟踪的学习,难免以后忘记了,在这儿记录一下。首先,参考的是本站大佬Bubbliiiing的yolov4检测算法部分,然后结合了一下Deep Sort算法,原始的Deep Sort算法是没有类别显示得嘛,所以,我做了点修改,把类别显示出来了。最后,在某大佬指导下完成了被跟踪目标的速度计算,后续如果有时间的话,或者有心思的话,还会接着做下去的。
一、YOLOv4部分
这部分没啥好说的了,用的气泡大神的源码,只是加了点东西,这里贴一个链接吧,需要的话去它的github可以下载的,记得有用的话,给大佬点一个小星星。
数据集训练部分
这部分是采用的BDD 100k数据集做的,这个数据集介绍也不多说了,我上一篇文章写了,在这儿有数据集介绍,也介绍了怎么把那个Json文件的标签转换出来,变成XML的格式去训练。需要的去看一下就懂了,再强调一次哈,这个BDD 100K数据集不仅仅是用来做目标检测部分的,他还可以做其他的工作,我对那些部分标签是没有处理的。
二、Deep Sort目标跟踪部分
1.算法来源
这部分代码来源于另外一个大佬,它的位置是这儿,但是这儿得到的结果是没有跟踪类别显示的,然后结合出来的代码之前看过的一篇文章,那位作者也已经完成了的,我也看了那位作者的代码,在它的基础上给出了改进。
2.整个算法部分解读
我的能力有限,只可以解释一部分的东西,将就看一下,嘿嘿
import os
import cv2
import time
import argparse
import torch
import warnings
import numpy as np
from detector import build_detector
from deep_sort import build_tracker
from utils.draw import draw_boxes
from utils.parser import get_config
from utils.log import get_logger
from utils.io import write_results
from matrix_transpose import get_real_postion
from get_v import get_distance
from PIL import Image
class VideoTracker(object):
def __init__(self, args, video_path):
self.args = args
self.video_path = video_path
self.logger = get_logger("root") # 好像是和时间有关
use_cuda = args.use_cuda and torch.cuda.is_available()
if not use_cuda:
warnings.warn("Running in cpu mode which maybe very slow!", UserWarning)
if args.display:
cv2.namedWindow("test", cv2.WINDOW_NORMAL)
cv2.resizeWindow("test", args.display_width, args.display_height)
if args.cam != -1:
print("Using webcam " + str(args.cam))
self.vdo = cv2.VideoCapture(args.cam)
else:
self.vdo = cv2.VideoCapture()
self.detector = build_detector()
self.deepsort = build_tracker(use_cuda=True)
self.class_names = self.detector.class_names
def __enter__(self):
if self.args.cam != -1:
ret, frame = self.vdo.read()
assert ret, "Error: Camera error"
self.im_width = frame.shape[0]
self.im_height = frame.shape[1]
else:
assert os.path.isfile(self.video_path), "Path error"
self.vdo.open(self.video_path)
self.im_width = int(self.vdo.get(cv2.CAP_PROP_FRAME_WIDTH))
self.im_height = int(self.vdo.get(cv2.CAP_PROP_FRAME_HEIGHT))
assert self.vdo.isOpened()
if self.args.save_path:
os.makedirs(self.args.save_path, exist_ok=True)
# path of saved video and results
self.save_video_path = os.path.join(self.args.save_path, "results03.avi")
self.save_results_path = os.path.join(self.args.save_path, "results.txt")
# create video writer
fourcc = cv2.VideoWriter_fourcc(*'MJPG')
self.writer = cv2.VideoWriter(self.save_video_path, fourcc, 20, (self.im_width, self.im_height))
# logging
self.logger.info("Save results to {}".format(self.args.save_path))
return self
def __exit__(self, exc_type, exc_value, exc_traceback):
if exc_type:
print(exc_type, exc_value, exc_traceback)
def run(self):
pos_and_id = []
results = []
idx_frame = 0
while self.vdo.grab():
idx_frame += 1
if idx_frame % self.args.frame_interval:
continue
start = time.time()
ref, ori_im = self.vdo.retrieve() # ref是bool类型, ori_im是图片
if ref is True:
im = cv2.cvtColor(ori_im, cv2.COLOR_BGR2RGB)
# ----- do detection
frame = Image.fromarray(np.uint8(im))
bbox_xywh, cls_conf, cls_ids = self.detector.new_detect(frame) # 这里是目标检测开始的地方,拿到目标框,
# 拿到类别置信度,拿到所属类别索引
new_bbox = np.array(bbox_xywh).astype(np.float32) # 拿出来了需要转换格式
# -----#-----
# 这里开始就是目标跟踪部分了哈
outputs = self.deepsort.update(new_bbox, cls_conf, im, cls_ids) # 既然是要显示类别,那就要把类别部分传入进去,对吧
if len(outputs) > 0: # 判断输出是否跟踪到了,提示一下,在本算法中,前面两帧的结果都是空的,因为在初始化目标跟踪算法
temp = np.zeros(len(outputs))
outputs = np.insert(outputs, 6, values=temp, axis=1)
bbox_xyxy = outputs[:, :4] # 网络输出前4个部分的都是位置坐标
bbox_xyxy_1 = get_real_postion(bbox_xyxy) # 得到真实坐标 这里是速度测试部分的代码,意思是把当前像素坐标转换为真实坐标
identities = outputs[:, 4:5] # 拿到每个跟踪标号
pos_and_id.append((bbox_xyxy_1, identities)) # 为了测速,把目标位置和编号一一保存在一起
if idx_frame >= 20: # 测速采用的是每20帧计算一次距离
_x1 = pos_and_id[idx_frame - 20]
_x2 = pos_and_id[idx_frame - 3]
dis, id_num = get_distance(_x1, _x2) # 拿到两帧对应跟踪到的目标之间的距离,其实就是欧氏距离
sudu = []
for dis_num in dis:
if dis_num < 0:
sudu.append(float(0.0)) # 目标没移动,速度为0
else:
sudu.append(float(0.001 * dis_num / args.time)) # 根据标号的计算得到速度
for i, k in enumerate(id_num):
if int(k) in outputs[..., 4]:
ind = list(outputs[..., 4]).index(int(k))
outputs[..., 6][ind] = sudu[i] # 给outputs增加一列,也就是速度列,他和每个跟踪编号是一一对应的哈
# print(sudu[i])
# print(outputs[..., 6][ind])
if len(outputs) > 0: # 在这里开始把一一输出拿出来画图
bbox_tlwh = []
bbox_xyxy = outputs[:, :4]
identities = outputs[:, 4:5]
cls_ids = outputs[:, 5:6]
sudu_value = outputs[:, -1]
ori_im = draw_boxes(ori_im, bbox_xyxy, identities, cls_ids, sudu_value) # 加入了类别,速度进去
for bb_xyxy in bbox_xyxy:
bbox_tlwh.append(self.deepsort._xyxy_to_tlwh(bb_xyxy))
results.append((idx_frame - 1, bbox_tlwh, identities))
end = time.time()
if self.args.display:
cv2.imshow("test", ori_im)
cv2.waitKey(1)
if self.args.save_path:
self.writer.write(ori_im)
# save results
write_results(self.save_results_path, results, 'mot')
# logging
self.logger.info("time: {:.03f}s, fps: {:.03f}, detection numbers: {}, tracking numbers: {}" \
.format(end - start, 1 / (end - start), new_bbox.shape[0], len(outputs)))
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("--display", action="store_true", default=True)
parser.add_argument("--frame_interval", type=int, default=1)
parser.add_argument("--display_width", type=int, default=800)
parser.add_argument("--display_height", type=int, default=600)
parser.add_argument("--save_path", type=str, default="./output/")
parser.add_argument("--cpu", dest="use_cuda", action="store_false", default=True)
parser.add_argument("--camera", action="store", dest="cam", type=int, default="-1")
parser.add_argument("--time", type=float, default=1.94444 * 0.00001)
return parser.parse_args()
if __name__ == "__main__":
args = parse_args()
# D:/python_learning/yolo4/video_dec/video06.mp4
# D:\python_learning\yolov4-deepsort_1\video_dec\cesu.mp4
with VideoTracker(args, video_path='D:/python_learning/yolov4-deepsort_1/video_dec/video-8.mp4') as vdo_trk:
vdo_trk.run()
重要的部分都是在后面写了注释的,关于代码中的类别是怎么加进去的,其实就是在目标跟踪算法中初始化轨迹的时候,对应着也加入类别这一个属性,如下:
在Track类别中,这个类挺长的,我只粘贴了一部分,但是self.cls_id = cls_id这一行,也就是这个意思。其他地方我都加了注释的。其实你只要懂了这个算法,你也就知道其他的有几个地方也要加,代码很多,而且分布不均匀,这儿就不贴出来了。
class Track:
"""
Track类主要存储的是轨迹信息,mean和covariance是保存的框的位置和速度信息,
track_id代表分配给这个轨迹的ID。state代表框的状态,有三种:
Tentative: 不确定态,这种状态会在初始化一个Track的时候分配,并且只有在连续匹配上n_init帧才会转变为确定态。
如果在处于不确定态的情况下没有匹配上任何detection,那将转变为删除态。
Confirmed: 确定态,代表该Track确实处于匹配状态。如果当前Track属于确定态,
但是失配连续达到max age次数的时候,就会被转变为删除态。
Deleted: 删除态,说明该Track已经失效。
"""
def __init__(self, mean, covariance, track_id, n_init, max_age,
feature=None, cls_id=None):
self.mean = mean
self.covariance = covariance
self.track_id = track_id
self.hits = 1
# hits和n_init进行比较
# hits每次update的时候进行一次更新(只有match的时候才进行update)
# hits代表匹配上了多少次,匹配次数超过n_init就会设置为confirmed状态
self.age = 1 # 没有用到,和time_since_update功能重复
self.time_since_update = 0
# 每次调用predict函数的时候就会+1
# 每次调用update函数的时候就会设置为0
self.state = TrackState.Tentative
self.cls_id = cls_id
self.features = []
# 每个track对应多个features, 每次更新都将最新的feature添加到列表中
if feature is not None:
self.features.append(feature)
# if cls_id is not None:
# self.cls_id.append(cls_id)
self._n_init = n_init # 如果连续n_init帧都没有出现失配,设置为deleted状态
self._max_age = max_age # 上限
'''
max_age代表一个Track存活期限,他需要和time_since_update变量进行比对。time_since_update是每次轨迹调用predict函数的时候
就会+1,
每次调用predict的时候就会重置为0,也就是说如果一个轨迹长时间没有update(没有匹配上)的时候,就会不断增加,
直到time_since_update超过max age(默认70),将这个Track从Tracker中的列表删除。
hits代表连续确认多少次,用在从不确定态转为确定态的时候。
每次Track进行update的时候,hits就会+1, 如果hits>n_init(默认为3),也就是连续三帧的该轨迹都得到了匹配,
这时候才将不确定态转为确定态。
需要说明的是每个轨迹还有一个重要的变量,features列表,存储该轨迹在不同帧对应位置通过ReID提取到的特征。
为何要保存这个列表,而不是将其更新为当前最新的特征呢?这是为了解决目标被遮挡后再次出现的问题,
需要从以往帧对应的特征进行匹配。另外,如果特征过多会严重拖慢计算速度,所以有一个参数budget用来控制特征列表的长度
,取最新的budget个features,将旧的删除掉。
'''
3.测速部分
这部分下一篇文章单独写吧,其实我自己都不知道我做的对不对,也是根据大佬指导了一下,看了下论文,自己想着想着编写的代码,纯原创。贴两张运行结果图,之后更新具体怎么做的:


界面编写部分
这部分是采用pyqt5简单写了一个界面,可视化一下,主要用的工具是 Qt designer,然后,就酱~~~~~
界面代码如下:
from PyQt5.QtGui import *
from PyQt5.QtWidgets import *
import sys
from PyQt5 import QtCore, QtGui, QtWidgets
from threading import Thread
from detector.YOLOV4 import YOLO
from yolo3.yolo import YOLO3
from PIL import Image
import numpy as np
import cv2
import time
from deep_sort import build_tracker
from utils.draw import draw_boxes
from matrix_transpose import get_real_postion
from get_v import get_distance
class Ui_MainWindow(object):
def setupUi(self, MainWindow):
MainWindow.setObjectName("MainWindow")
MainWindow.resize(1127, 864)
self.centralwidget = QtWidgets.QWidget(MainWindow)
MainWindow.setStyleSheet("#MainWindow{border-image:url(img/previewFix.jpg);}")
self.centralwidget.setObjectName("centralwidget")
self.textBrowser = QtWidgets.QTextBrowser(self.centralwidget)
self.textBrowser.setGeometry(QtCore.QRect(210, 10, 631, 51))
self.textBrowser.setObjectName("textBrowser")
self.total_label = QtWidgets.QLabel(self.centralwidget)
self.total_label.setGeometry(QtCore.QRect(220, 90, 861, 671))
self.total_label.setText("")
self.total_label.setObjectName("total_label")
self.verticalLayoutWidget = QtWidgets.QWidget(self.centralwidget)
self.verticalLayoutWidget.setGeometry(QtCore.QRect(40, 90, 141, 191))
self.verticalLayoutWidget.setObjectName("verticalLayoutWidget")
self.verticalLayout = QtWidgets.QVBoxLayout(self.verticalLayoutWidget)
self.verticalLayout.setContentsMargins(0, 0, 0, 0)
self.verticalLayout.setObjectName("verticalLayout")
self.load_img = QtWidgets.QPushButton(self.verticalLayoutWidget)
self.load_img.setObjectName("load_img")
self.verticalLayout.addWidget(self.load_img)
self.label = QtWidgets.QLabel(self.verticalLayoutWidget)
self.label.setObjectName("label")
self.verticalLayout.addWidget(self.label)
self.yolo3 = QtWidgets.QPushButton(self.verticalLayoutWidget)
self.yolo3.setObjectName("yolo3")
self.verticalLayout.addWidget(self.yolo3)
self.yolo4 = QtWidgets.QPushButton(self.verticalLayoutWidget)
self.yolo4.setObjectName("yolo4")
self.verticalLayout.addWidget(self.yolo4)
self.verticalLayoutWidget_2 = QtWidgets.QWidget(self.centralwidget)
self.verticalLayoutWidget_2.setGeometry(QtCore.QRect(30, 340, 161, 421))
self.verticalLayoutWidget_2.setObjectName("verticalLayoutWidget_2")
self.verticalLayout_2 = QtWidgets.QVBoxLayout(self.verticalLayoutWidget_2)
self.verticalLayout_2.setContentsMargins(0, 0, 0, 0)
self.verticalLayout_2.setObjectName("verticalLayout_2")
self.load_cam = QtWidgets.QPushButton(self.verticalLayoutWidget_2)
self.load_cam.setObjectName("load_cam")
self.verticalLayout_2.addWidget(self.load_cam)
self.load_video = QtWidgets.QPushButton(self.verticalLayoutWidget_2)
self.load_video.setObjectName("load_video")
self.verticalLayout_2.addWidget(self.load_video)
self.load_track = QtWidgets.QPushButton(self.verticalLayoutWidget_2)
self.load_track.setObjectName("load_track")
self.verticalLayout_2.addWidget(self.load_track)
self.obj_cesu = QtWidgets.QPushButton(self.verticalLayoutWidget_2)
self.obj_cesu.setObjectName("obj_cesu")
self.verticalLayout_2.addWidget(self.obj_cesu)
self.exit = QtWidgets.QPushButton(self.verticalLayoutWidget_2)
self.exit.setObjectName("exit")
self.verticalLayout_2.addWidget(self.exit)
MainWindow.setCentralWidget(self.centralwidget)
self.menubar = QtWidgets.QMenuBar(MainWindow)
self.menubar.setGeometry(QtCore.QRect(0, 0, 1127, 23))
self.menubar.setObjectName("menubar")
MainWindow.setMenuBar(self.menubar)
self.statusbar = QtWidgets.QStatusBar(MainWindow)
self.statusbar.setObjectName("statusbar")
MainWindow.setStatusBar(self.statusbar)
self.retranslateUi(MainWindow)
self.exit.clicked.connect(MainWindow.close)
QtCore.QMetaObject.connectSlotsByName(MainWindow)
def retranslateUi(self, MainWindow):
_translate = QtCore.QCoreApplication.translate
MainWindow.setWindowTitle(_translate("MainWindow", "空间信息1.1"))
self.textBrowser.setHtml(_translate("MainWindow", "<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.0//EN\" \"http://www.w3.org/TR/REC-html40/strict.dtd\">\n"
"<html><head><meta name=\"qrichtext\" content=\"1\" /><style type=\"text/css\">\n"
"p, li { white-space: pre-wrap; }\n"
"</style></head><body style=\" font-family:\'SimSun\'; font-size:9pt; font-weight:400; font-style:normal;\">\n"
"<p align=\"center\" style=\" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"><span style=\" font-size:26pt; font-weight:600; font-style:italic;\">智能交通检测与跟踪系统</span></p></body></html>"))
self.load_img.setText(_translate("MainWindow", "请选择检测图片"))
self.load_img.setToolTip('~~~~~请选一张用来检测的图片~~~~~')
self.label.setText(_translate("MainWindow", "请选择检测模型:"))
self.yolo3.setText(_translate("MainWindow", "yolo3"))
self.yolo3.setToolTip('~~~~~yolov3模型~~~~~')
self.yolo4.setText(_translate("MainWindow", "yolo4"))
self.yolo4.setToolTip('~~~~~yolov4模型~~~~~')
self.load_cam.setText(_translate("MainWindow", "加载摄像头检测"))
self.load_cam.setToolTip('~~~~~请注意要打开摄像头哦~~~~~')
self.load_video.setText(_translate("MainWindow", "加载视频检测"))
self.load_video.setToolTip('~~~~~选择要检测视频路径~~~~~')
self.load_track.setText(_translate("MainWindow", "目标跟踪"))
self.load_track.setToolTip('~~~~~选择要跟踪的视频路径~~~~~')
self.obj_cesu.setText(_translate("MainWindow", "目标测速"))
self.obj_cesu.setToolTip('~~~~~选择要测速的视频路径~~~~~')
self.exit.setText(_translate("MainWindow", "退出系统"))
self.exit.setToolTip('~~~~~点一下就知道了~~~~~')
class Mywindow(QMainWindow, Ui_MainWindow):
def __init__(self, yolo, yolo3, deepsort):
super(Mywindow, self).__init__()
self.threadstop = False
self.threadstop01 = False
self.threadstop02 = False
self.threadstop03 = False
self.setupUi(self)
self.yolov4 = yolo
self.deepsort = deepsort
self.yolov3 = yolo3
self.file_path = None
self.load_img.clicked.connect(self.opendir)
self.load_cam.clicked.connect(self.load) # 打开摄像头检测
self.yolo3.clicked.connect(self.pre_yolo3) # 加载yolo3模型
self.yolo4.clicked.connect(self.pre_yolo4) # 加载yolo4模型
self.load_video.clicked.connect(self.load_1) # 加载视频检测
self.load_track.clicked.connect(self.load_2) # 加载视频跟踪
# self.obj_cesu.clicked.connect(self.load_3) # 加载目标测速
def load(self):
self.th = Thread(target=ui.load_cam_dec)
self.th.start()
def load_1(self):
self.threadstop = True
self.threadstop01 = False
self.th.join(0)
self.th1 = Thread(target=ui.load_video_dec)
self.th1.start()
def load_2(self):
self.threadstop01 = True
self.threadstop02 = False
self.th1.join(0)
self.th2 = Thread(target=ui.load_video_track)
self.th2.start()
def load_3(self):
self.threadstop02 = True
self.threadstop03 = False
self.th2.join()
self.th3 = Thread(target=ui.video_cesu)
self.th3.start()
def opendir(self):
filename, filetype = QFileDialog.getOpenFileName(self, "打开文件", "F:/Yan_yi/yolov4-deepsort_1/detector/YOLOV4/img",
"Image Files(*.jpg)") # 拿到路径
self.file_path = filename
def pre_yolo3(self):
image = Image.open(self.file_path)
r_image = self.yolov3.detect_image(image)
r_image.save('./img_output/result_yolo3.jpg')
self.total_label.setPixmap(QPixmap('./img_output/result_yolo3.jpg'))
self.total_label.setScaledContents(True)
def pre_yolo4(self):
image = Image.open(self.file_path)
r_image_ = self.yolov4.detect_image(image)
r_image_.save('./img_output/result_yolo4.jpg')
self.total_label.setPixmap(QPixmap("")) # 移除label上的图片
self.total_label.setPixmap(QPixmap('./img_output/result_yolo4.jpg'))
self.total_label.setScaledContents(True)
def load_cam_dec(self):
fps = 0
self.cap = cv2.VideoCapture(0)
while self.cap.isOpened():
t1 = time.time()
ret, frame = self.cap.read()
if self.threadstop:
return
if ret == False:
continue
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = Image.fromarray(np.uint8(frame))
# 进行检测
frame = np.array(self.yolov4.detect_image(frame))
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
fps = (fps + (1. / (time.time() - t1))) / 2
print("fps= %.2f" % (fps))
frame = cv2.putText(frame, "fps= %.2f" % (fps), (0, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
outImage = QImage(frame, frame.shape[1], frame.shape[0], QImage.Format_RGB888)
self.total_label.setPixmap(QPixmap.fromImage(outImage))
self.total_label.setScaledContents(True)
cv2.waitKey(1)
def load_video_dec(self):
filename, filetype = QFileDialog.getOpenFileName(self, "打开文件", "F:/Yan_yi/yolov4-deepsort_1/video_dec",
"Image Files(*.mp4 *.avi)") # 拿到路径
fps = 0
self.cap2 = cv2.VideoCapture(filename)
while self.cap2.isOpened():
t1 = time.time()
ret, frame = self.cap2.read()
if self.threadstop01:
return
if ret == False:
continue
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = Image.fromarray(np.uint8(frame))
# 进行检测
# frame = np.array(self.yolov4.detect_image(frame))
# frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
fps = (fps + (1. / (time.time() - t1))) / 2
print("fps= %.2f" % (fps))
frame = cv2.putText(frame, "fps= %.2f" % (fps), (0, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# print(type(frame))
outImage = QImage(frame, frame.shape[1], frame.shape[0], QImage.Format_RGB888)
self.total_label.setPixmap(QPixmap.fromImage(outImage))
self.total_label.setScaledContents(True)
cv2.waitKey(1)
def load_video_track(self):
filename, filetype = QFileDialog.getOpenFileName(self, "打开文件", "F:/Yan_yi/yolov4-deepsort_1/video_dec",
"Image Files(*.mp4 *.avi)") # 拿到路径
self.cap = cv2.VideoCapture(filename)
pos_and_id = []
idx_frame = 0
while self.cap.isOpened():
idx_frame += 1
ret, ori_im = self.cap.read()
if self.threadstop02:
return
if ret == False:
continue
im = cv2.cvtColor(ori_im, cv2.COLOR_BGR2RGB)
frame = Image.fromarray(np.uint8(im))
bbox_xywh, cls_conf, cls_ids = self.yolov4.new_detect(frame)
new_bbox = np.array(bbox_xywh).astype(np.float32)
# -----#-----
# do tracking
outputs = self.deepsort.update(new_bbox, cls_conf, im, cls_ids) # 应该是从这里进去修改!一定要理解这个算法才可以
# draw boxes for visualization
if len(outputs) > 0: # 判断输出是否跟踪到了,提示一下,在本算法中,前面两帧的结果都是空的,因为在初始化目标跟踪算法
temp = np.zeros(len(outputs))
outputs = np.insert(outputs, 6, values=temp, axis=1)
bbox_xyxy = outputs[:, :4] # 网络输出前4个部分的都是位置坐标
bbox_xyxy_1 = get_real_postion(bbox_xyxy) # 得到真实坐标 这里是速度测试部分的代码,意思是把当前像素坐标转换为真实坐标
identities = outputs[:, 4:5] # 拿到每个跟踪标号
pos_and_id.append((bbox_xyxy_1, identities)) # 为了测速,把目标位置和编号一一保存在一起
if idx_frame >= 20: # 测速采用的是每20帧计算一次距离
_x1 = pos_and_id[idx_frame - 20]
_x2 = pos_and_id[idx_frame - 3]
dis, id_num = get_distance(_x1, _x2) # 拿到两帧对应跟踪到的目标之间的距离,其实就是欧氏距离
# print(dis)
sudu = []
for dis_num in dis:
if dis_num < 0:
sudu.append(float(0.0)) # 目标没移动,速度为0
else:
sudu.append(float(0.001 * dis_num / 0.0003)) # 根据标号的计算得到速度
for i, k in enumerate(id_num):
if int(k) in outputs[..., 4]:
ind = list(outputs[..., 4]).index(int(k))
outputs[..., 6][ind] = sudu[i] # 给outputs增加一列,也就是速度列,他和每个跟踪编号是一一对应的哈
# print(sudu[i])
# print(outputs[..., 6][ind])
if len(outputs) > 0: # 在这里开始把一一输出拿出来画图
# print('--------------------')
bbox_xyxy = outputs[:, :4]
identities = outputs[:, 4:5]
cls_ids = outputs[:, 5:6]
sudu_value = outputs[:, -1]
# print(sudu_value)
# print('-------------', type(ori_im))
ori_im = draw_boxes(ori_im, bbox_xyxy, identities, cls_ids, sudu_value) # 加入了类别,速度进去
# print('-------------', type(ori_im))
# ori_im = cv2.cvtColor(ori_im, cv2.COLOR_BGR2RGB)
# ori_im = np.array(ori_im)
# print('-------------', type(ori_im))
outImage = QImage(ori_im, ori_im.shape[1], ori_im.shape[0], QImage.Format_RGB888)
self.total_label.setPixmap(QPixmap.fromImage(outImage))
self.total_label.setScaledContents(True)
cv2.waitKey(1)
def video_cesu(self):
filename, filetype = QFileDialog.getOpenFileName(self, "打开文件", "D:/",
"Image Files(*.mp4 *.avi)") # 拿到路径
self.cap = cv2.VideoCapture(filename)
while self.cap.isOpened():
ret, frame = self.cap.read()
if self.threadstop03:
return
if ret == False:
continue
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
outImage = QImage(frame, frame.shape[1], frame.shape[0], QImage.Format_RGB888)
self.total_label.setPixmap(QPixmap.fromImage(outImage))
self.total_label.setScaledContents(True)
cv2.waitKey(1)
if __name__ == "__main__":
app = QtWidgets.QApplication(sys.argv)
app.setWindowIcon(QIcon('./images/cartoon2.ico'))
yolo = YOLO()
yolo3 = YOLO3()
deepsort = build_tracker(use_cuda=True)
ui = Mywindow(yolo, yolo3, deepsort)
ui.show()
sys.exit(app.exec_())
界面很粗糙,但是勉强每个功能都可以运行,问题也有,就是速度慢,多线程那部分,写的很勉强,我也不知道怎么去修改,如果有Python大佬的话,欢迎指导一下我。到底怎么用多线程加载视频。放两张运行结果图:
先是主界面
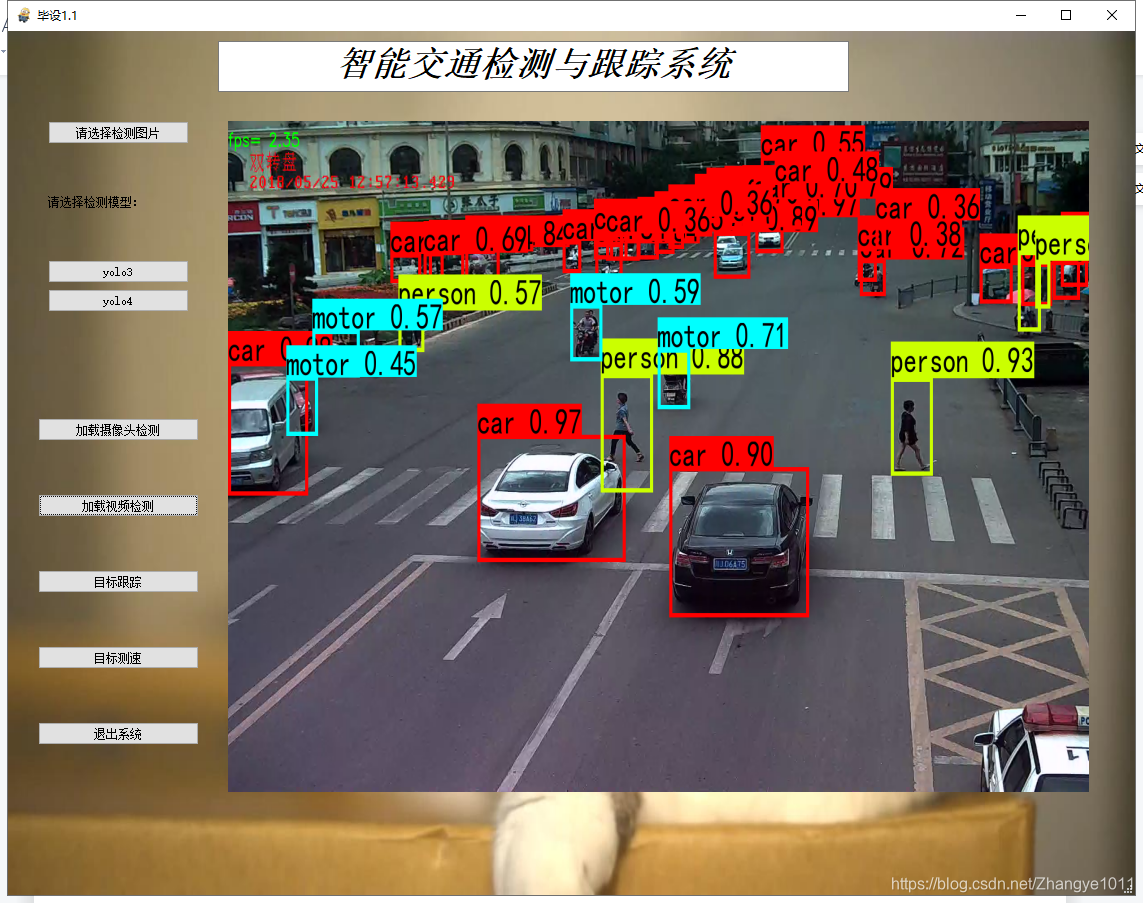
目标检测:
目标跟踪:
代码粗糙,轻喷~~~~~

总结
这就是最近做的事儿,好多不足之处等待着改进,脑瓜疼,加油,一起学习吧,冲冲冲!然后就是整个程序,我后面陆陆续续做了改进,加了很多注释,很多地方都修复了,包括界面,自主训练reid权重等,还有就是加载视频跟踪闪退的问题,基本上现在是完整了。==如果想根据我的代码改成其他的版本的yolo,结合deepsort,其实很简单,可以照着我的程序写,思路大差不差,==我这儿也有yolox+deepsot的版本。
有时候有人找我要整个程序,先说,是有偿的,因为我做这个也做了很久,很辛苦。我把它上传到资源网站了,你们确实需要的话就自己下载吧,这个程序是我调试后的最终版本,有运行问题可以加我Q1790604735。我很乐意和你讨论任何bug,以及程序问题,并且帮你解决。然后就是,其实整个关键代码都被我粘贴在本博文了,你认真看看,跟着改也能改出来的,能自己做才是做好的,加油!