中文分词、命名实体识别、语义词性标注、语句逻辑推理、文本摘要、机器翻译、文本情感分析、内容创作
1 实验介绍
1.1 实验背景
中文分词、命名实体识别、语义词性标注、语句逻辑推理是自然语言处理领域中的重要任务。中文分词是将连续的汉字序列切分成有意义的词语序列的过程。命名实体识别是指在文本中识别出具有特定意义的实体,如人名、地名、机构名等。语义词性标注是将词语标注为其在句子中的语法和语义角色。语句逻辑推理是指根据语句中的逻辑关系,推导出新的结论。利用 ChatGLM3 进行这些任务的实验可以帮助我们更好地理解和掌握自然语言处理技术,提高我们对自然语言处理应用的理解和能力。
ChatGLM3是一个基于 GPT-3的自然语言处理模型,它具有强大的文本生成和理解能力,可以应用于文本摘要、机器翻译、文本情感分析、内容创作等多个领域。
在文本摘要方面,ChatGLM3可以根据输入的文本内容,自动提取出其中的关键信息,生成简洁准确的摘要,帮助用户快速了解文章主题和要点。
在机器翻译方面,ChatGLM3可以将一种语言翻译成另一种语言,支持多种语言的翻译,为跨语言交流提供了便利。在文本情感分析方面,ChatGLM3可以分析文本中的情感倾向,包括积极、消极和中性等情感类型,帮助用户了解文本的情感色彩和情感倾向。
在内容创作方面,ChatGLM3可以根据用户输入的关键词和主题,自动生成文章、新闻、广告等多种文本内容,为用户提供创作灵感和快速撰写文本的工具。
1.2 实验原理
中文分词是将一段中文文本切分成一系列有意义的词语的过程。ChatGLM3 使用了基于统计学习的分词方法,通过学习大量的中文文本,自动构建出一个词语库,并使用隐马尔可夫模型(HMM)对文本进行分词。命名实体识别是指在文本中识别出具有特定含义的实体,如人名、地名、组织机构名等。ChatGLM3 使用了基于条件随机场(CRF)的方法,通过学习大量的标注数据,自动构建出一个命名实体识别模型,对文本进行命名实体识别。语义词性标注是指为文本中的每个词语标注其词性,并给出其在句子中的语义角色。ChatGLM3 使用了基于深度学习的方法,通过学习大量的标注数据,自动构建出一个语义词性标注模型,对文本进行语义词性标注。语句逻辑推理是指根据前提条件和逻辑规则,推导出结论的过程。ChatGLM3使用了基于逻辑回归的方法,通过学习大量的逻辑规则和标注数据,自动构建出一个逻辑推理模型,对文本进行逻辑推理。
文本摘要:利用 ChatGLM3 生成摘要,可以通过输入一段长文本,让模型自动生成一段简短的摘要。实验原理是ChatGLM3通过学习大量的文本数据,能够理解文本的主题和关键信息,从而生成简洁准确的摘要。
机器翻译;利用 ChatGLM3 实现机器翻译,可以输入一句话或一段文本,让模型自动将其翻译成另一种语言。实验原理是,ChatGLM3 通过学习大量的双语语料库,能够理解不同语言之间的语法、词汇和语义,从而实现准确的翻译
文本情感分析:利用 ChatGLM3 进行文本情感分析,可以输入一段文本,让模型自动判断文本的情感倾向,如积极消极或中性。实验原理是,ChatGLM3通过学习大量的情感标注数据,能够理解文本中的情感色彩和情感表达方式,从而实现准确的情感分析。
内容创作:利用 ChatGLM3进行内容创作,可以输入一些关键词或主题,让模型自动生成一篇文章、一段对话或首诗歌等。实验原理是,ChatGLM3 通过学习大量的文本数据,能够理解文本的主题和结构,从而生成符合主题和结构的内容。同时,它还能够自动创作出新颖的、富有创意的内容,为内容创作者提供了很大的帮助。
1.3 实验目的
中文分词:通过分析中文文本,将其切分成一个个有意义的词语,以便后续的语义分析和理解。
命名实体识别:识别文本中的人名、地名、组织机构名等命名实体,以便更好地理解文本的含义和上下文。
语义词性标注:对文本中的词语进行词性标注,以便更好地理解其在句子中的作用和语义。
语句逻辑推理:通过对文本中的逻辑关系进行分析和推理,进一步理解文本的含义和逻辑结构。
文本摘要:利用 ChatGLM3可以对一篇较长的文章进行自动化的文本摘要,提取出文章的主要内容和关健信息,从而快速了解文章的核心内容。
机器翻译:ChatGLM3 可以用于机器翻译,将一种语言翻译成另一种语言。利用 ChatGLM3 的强大语言模型,可以提高翻译的准确性和流畅度,从而更好地满足用户的需求。
文本情感分析:ChatGLM3 可以用于文本情感分析,帮助用户了解一段文本的情感倾向。通过分析文本中的词汇和语义,ChatGLM3 可以自动识别文本的情感,如积极、消极或中性等。
内容创作:利用 ChatGLM3 可以生成高质量的文本内容,如文章、新闻、广告等。通过输入一些关键词和主题ChatGLM3 可以自动生成相关的文本内容,从而提高内容创作的效率和质量。
2.实验
2.1任务一 中文分词
连接服务器后
python api_server.py(只能一个人执行)
本地新建"中文分词.py"文件,将以下代码制到"中文分词.py"并保存,127.0.0.1 改为 ChatGLM3 部署服务器的地址即可。
import sys
from openai import OpenAI
base_url = "http://127.0.0.1:8000/v1/"
client = OpenAI(api_key="EMPTY", base_url=base_url)
def simple_chat(use_stream=True,text=""):
messages = [
{
"role": "system",
"content": "You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's "
"instructions carefully. Respond using markdown.",
},
{
"role": "user",
"content": f"例如:'中国 / 的 / 首都 / 是 / 北京 / 。',分词结果应该是逐个词语独立,并且每个词语都要分割出来,按照以上案例将以下中文句子进行分词:{text} \n"
}
]
response = client.chat.completions.create(
model="chatglm3-6b",
messages=messages,
stream=use_stream,
max_tokens=1024,
temperature=0.8,
presence_penalty=1.1,
top_p=0.8)
if response:
if use_stream:
for chunk in response:
print(chunk.choices[0].delta.content)
else:
content = response.choices[0].message.content
print(content)
else:
print("Error:", response.status_code)
if __name__ == "__main__":
simple_chat(use_stream=False,text=sys.argv[1])
#simple_chat(use_stream=True)
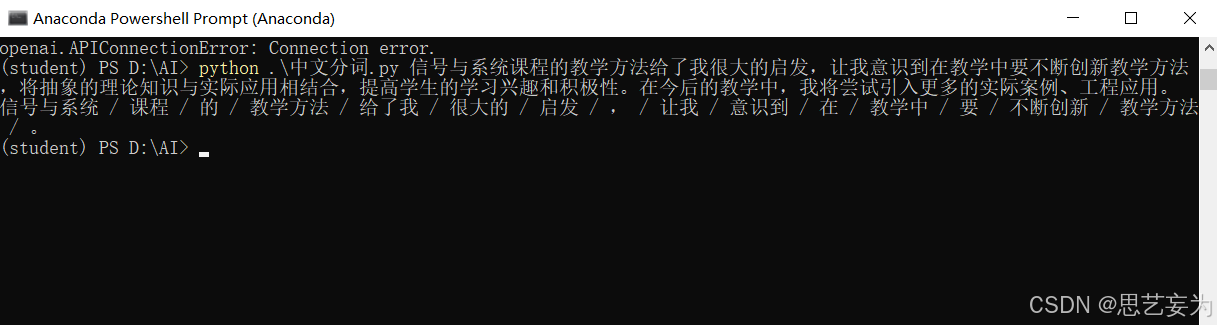
修改之后保存,在Anaconda中进入自己的环境:conda activate student,进入自己要运行的文件中:cd D:\AI,运行python .\中文分词.py 信号与系统课程的教学方法给了我很大的启发,让我意识到在教学中要不断创新教学方法 ,将抽象的理论知识与实际应用相结合,提高学生的学习兴趣和积极性。在今后的教学中,我将尝试引入更多的实际案例、工程应用。
得到下图分词结果:
2.2语义词性标注
将上述代码中的
"content": f"例如:'中国 / 的 / 首都 / 是 / 北京 / 。',分词结果应该是逐个词语独立,并且每个词语都要分割出来,按照以上案例将以下中文句子进行分词:{text} \n"替换成
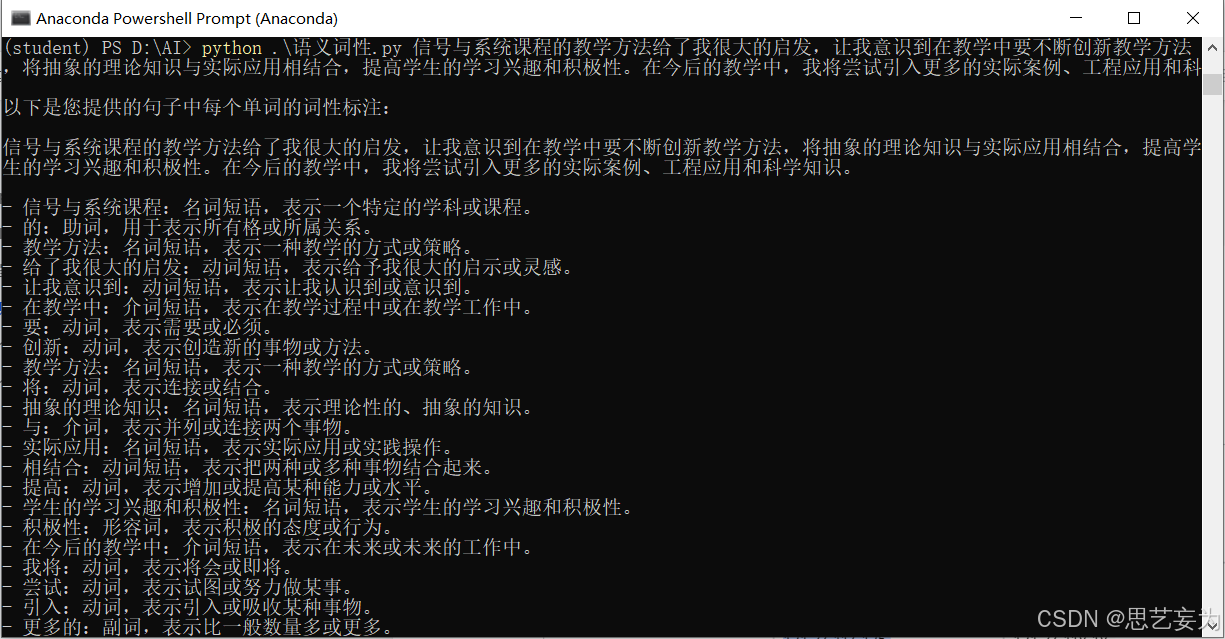
"content": f"请标注以下中文句子中的每个单词的词性:{text}\n"修改之后保存,运行 python .\语义词性.py 信号与系统课程的教学方法给了我很大的启发,让我意识到在教学中要不断创新教学方法 ,将抽象的理论知识与实际应用相结合,提高学生的学习兴趣和积极性。在今后的教学中,我将尝试引入更多的实际案例、工程应用。
得到下图结果
2.3语句逻辑推理
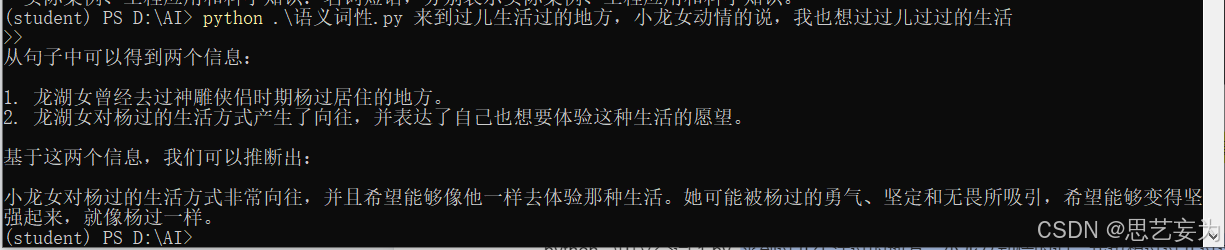
语句逻辑推理同样替换
'contents":f"根据以下句子,进行逻辑推理:{text}”得到结果:
2.4其他实验
文本摘要
'contents":f"请对以下中文文本进行摘要:{text}”
情感分析
'contents":f"请分析以下用户回复的情感倾向:{text}”
内容创作
'contents":f"基于以下内容帮助用户生成文章、故事、诗歌等文本内容、用于媒体、广告、营销等场景:{text} ”
命名实体识别
'contents":f"请识别以下句子中的命名实体:{text}”
2.5 机器翻译
其他步骤同上。