《昇思25天学习打卡营第1天|LXS》
前言
首先先对昇思大模型平台表示感谢,作为有一定经验的炼丹师,一直使用的是AutoDL算力云租用算力做语音模型,如GPT-sovits,此类模型推理需要用到4090芯片,而且租用往往困难,操作也没有提供jupyter编程。
昇思充分考虑初学者的入门困难问题,为初学者降低机器学习入门门槛,只需专注模型训练流程和模型关键参数,机器学习代码往往需要真正理解,而非记忆代码,所以跟敲对于机器学习的代码学习来说是事倍功半的。
此外,昇思提供了免费的本地CPU模式,与云上算力使用模式,应对多样的开发学习环境,免费的算力什么的对于初学者来说是最大的福利,所以请大家坚持学下来,不要辜负主办方的一片好意,也多为昇思打call。好了闲话少叙,进入正题。
重点内容与大纲
此大纲仅为参考(持续更新):
- 掌握模型训练流程与理解参数意义(理解参数,超参数);
- 参数调优的方法与原理;
- 数据集加载与数据预处理;
- 模型训练与保存;
- 手写字母识别流程实操(属于经典的机器学习入门项目);
- 量子计算流程(后续更新);
- 实操项目(NLP自然语言处理,计算机视觉如人脸识别水质分析,语音处理如sovits,图像处理如图片生成);
今日内容:手写数字识别实操
-
首先是加载数据集,注意使用过飞桨的同志,此次数据集dataset的来源是mindspore,导包时导入的是mindspore的dataset与transforms。
-
分别得到train训练集60000张图片,是带Label标签的,test测试集10000张图片,核心思想就是通过训练集得到泛化和拟合能力较为平衡的参数,然后保存模型,通过该模型进行predict对测试集输出结果。
-
训练集与测试集数据格式必须一致,分为两列非结构化数据(一列为图片,一列为标签),如下图
-
接下来是transform,数据预处理,处理的内容有三部分,rescale,英文翻译是重新权重,就是归一化处理,图片是黑白的,根据图像处理知识黑白图只有灰度值[0,255],除以255得到[0,1]之间的小数,如下图公式分母为(255-0),分子则为(灰度值xi-0)

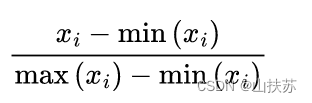
-
跟归一化类似的是标准化,Normalize标准化比归一化要更复杂,标准化可以保持样本间距,可以将间距理解为样本分类的依据,标准化能加快收敛的速度,收敛是机器学习核心关注的内容。
-
对数据进行归一化或者标准化之后,就需要构建模型了,我们通过网络构建的方式构建一个通用的model模板,还没有填入具体的训练步骤,什么叫网络构建?可以搜索神经网络模型,此处粗略讲神经网络,就像神经信号从一个节点传到另一个节点,中间传递过程则是激活函数Relu(),激活函数是用来确定输出值的,机器学习一定要严谨的确定每一步的 输入->>输出,我们把一根神经看成一次运算,那么神经网络就是多次这样的运算,经过多次输入->输出,最终得到结果。注意上一次的输出一定是这一次的输入,请看下图,只有第一行的nn.dense(28*28,)是可控的,其余层级的输入都要严格按照上一次的输出设置大小
-
模型构建考虑参数,梯度,loss(损失),价值函数(目标函数)四个方向。首先是价值函数,针对手写数字识别模型,正确就是有价值的反之就是损失,我们的目标是找出准确率最高的模型。最高是一种求极值的行为,计算机判断极值需要迭代,也就是导数为零的点,而在机器学习中我们将其叫为梯度,梯度是唯一决定收敛位置的指标,因此在正向计算准确率与损失率后需要反向计算梯度,以找寻收敛的方向判断是否收敛。前三个都是最终为参数服务的,我们需要找到梯度为零处的参数,这就是最优参数了。
-
训练的过程,提到了是迭代的过程,因此可以设置训练的轮次(epoch),轮次越多,收敛的可能性越大,模型准确率越高,loss越小,模型拟合能力越强,但同时导致泛化能力下降。
-
最后的最后,是save模型,保存了模型就是保存了参数,参数比模型重要的多,部分同志可能刚接触机器学习,真正在单个云机里跑模型可能要跑一天,稍有不慎跑过的数据就没了,参数没了等于白跑,所以训练完一个大轮请一定save模型。
-
需要使用模型做预测时,load出来将测试集放进去即可。