视频链接 https://www.bilibili.com/video/BV1tr421x75B/?vd_source=a1ce254b4a97f9f687a83e661793cb2c
什么是模型部署
部署指的是已经开发好的大模型投入使用,要把模型部署到服务器或者移动端里,如何在有限的资源里加载大模型?
比如你好不容易训好了一个大模型,想在手机上跑,可是模型参数那么大,一次推理需要的显存也不小,手机上怎么访问?
计算量问题:
模型前向推理所需要的计算量(最终结果以flot 浮点运算次数来表示)
forward = 2*模型参数量+ 2层数 *上下文长度(默认1024)*模型层数 *注意力输出的维度(2048/4096等)
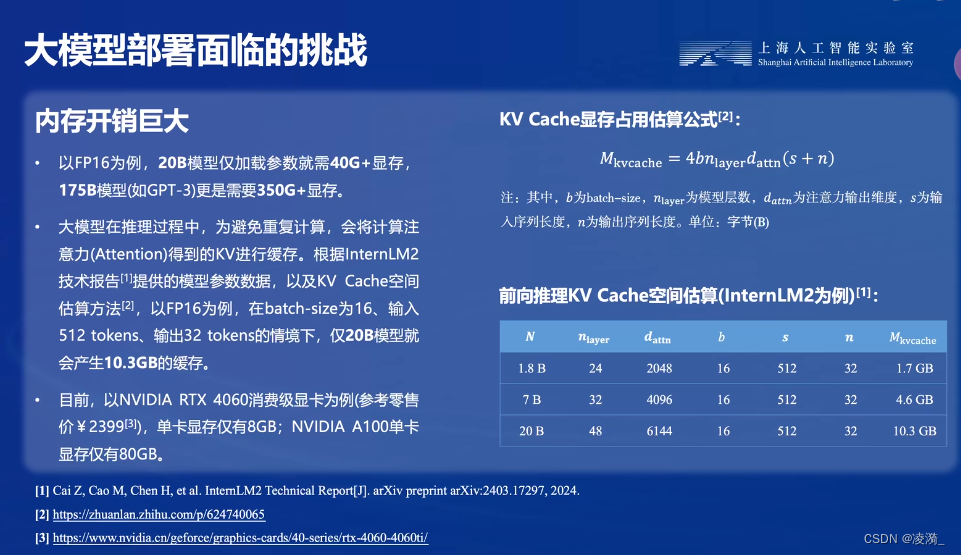
内存开销问题:
访存瓶颈
前面提到计算量和内存开销两个问题

可以通过三种方式来进行部署:
剪枝(主动减少一些的参数)、蒸馏(大模型训练小模型)、量化