文章目录
一、MICS
1、MISC-LSB
解题思路
下载附件得到一个压缩包,解压得到一张“中国矿业大学的校标”;

根据题目的名字:LSB
我们可知这是一题“LSB”隐写,那什么是“LSB”隐写呢,我们简单来说一下;
LSB隐写术(Least Significant Bit Steganography) 是一种在数字媒体中隐藏信息的技术。它通过将数据隐藏在文件的最不重要的位(即最低有效位)中,使得嵌入的秘密信息不会明显改变文件的外观或行为。
LSB隐写的主要原理:
-
数字图像:图像中的每个像素通常由红色、绿色、蓝色(RGB)三种颜色的值来表示,每种颜色值用8位二进制表示。LSB隐写术会将秘密信息嵌入到这些颜色值的最后一位(最低有效位)中。例如,如果某个颜色值是
10010010,将其最后一位替换为秘密信息中的一位,就可能变成10010011。这种微小的变化人眼几乎察觉不到。 -
音频或视频文件:同样可以使用LSB隐写术,将信息隐藏在音频或视频文件的每个采样值的最低有效位中。
LSB隐写的优点:
-
隐蔽性强:因为最低有效位的变化非常细微,通常不会影响文件的整体质量,人眼或耳无法察觉。
-
适用范围广:可以应用于图片、音频、视频等多种类型的媒体文件。
LSB隐写的缺点:
-
容易被检测和破坏:由于嵌入的信息只改变了最低有效位,文件经过压缩或编辑时,隐藏的信息很容易被破坏。
-
信息容量有限:LSB隐写能隐藏的信息量通常有限,取决于文件的大小和数据的位深度。
总的来说就是LSB隐写术常用于CTF比赛中的隐写题目,通过提取图像或音频文件中的最低有效位来获取隐藏的信息。
那这里我们直接丢进常用的工具“Stegsolve.jar”,那有的师傅可能就疑问了,这是一个什么样的工具呢?
Stegsolve.jar 是一款常用的隐写分析工具,主要用于提取图像中的隐藏信息。它在CTF(Capture The Flag)比赛中的隐写题目中广泛应用,帮助参赛者通过图像的各种操作和分析来发现嵌入的秘密数据。
Stegsolve.jar的主要功能:
-
图像通道分离:
- Stegsolve 可以分离出图像的各个颜色通道(如红、绿、蓝、Alpha等),以便分析隐藏信息。某些隐写信息可能隐藏在特定的颜色通道中,通过通道分离,可以轻松找到这些信息。
-
二进制位平面分析(Bit Plane):
- 该工具可以分离和查看图像的每个位平面,尤其是最低有效位(LSB)。一些隐写信息可能嵌入在图像的最低位平面中,而Stegsolve 可以通过位平面查看这些隐藏数据。
-
图像格式转换和查看:
- Stegsolve 支持多种图像格式,并可以对图像进行多种查看模式的切换,包括灰度模式、颜色反转、对比增强等,以帮助分析。
-
逐帧分析:
- 对于多帧图像(如GIF),Stegsolve 能够逐帧查看每一帧的内容,帮助查找在不同帧中隐藏的信息。
-
其他图像处理功能:
- Stegsolve 还提供了图像的 XOR、AND、OR 操作,常用于比较不同图片的差异,查找隐藏内容。
Stegsolve.jar的使用步骤:
- 下载并运行
Stegsolve.jar(需要安装 Java 环境)。 - 打开目标图像文件。
- 使用不同的分析模式(如通道分离、位平面等)查看图像。
- 根据题目的提示或观察的变化,提取隐藏的信息。
Stegsolve的优点:
- 界面直观:操作简单,图像切换方便。
- 分析强大:多种模式分析图像中的隐写信息,尤其擅长处理 LSB 隐写。
那我们直接把图片导入到“Stegsolve.jar”中,那我这里已经是成功导入;

那既然已经打开了,我们就可以点击下方的两个箭头,向左向右翻动;
哎,也是惊奇的发现在“Red plane 0”这个通道最上方发现了一抹说不清是什么的东西;(我们暂且先不管,记住这个通道就行——Red plane 0)

那我们接着往右进行翻找,也是很快在“Green plane 0”发现了同样的;(也是同样的无需理会,记住即可——Green plane 0)
那我们接着往右进行翻找,又在“Blue plane 0”发现了同样的;(同样需要理会——Blue plane 0)
那往后翻找就没有在发现类似的了,那我们继续进行下一步;
首先点击最上方的Analyse---->接着选中Data Extract
我们就能看到;
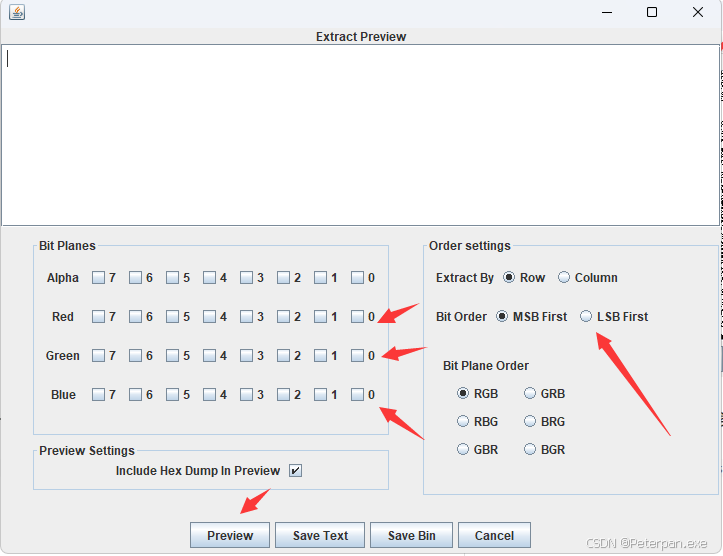
这时候勾选之前我们看见的:Red plane 0、Grenn plane 0、Blue plane0
接着再根据题目的提示:LSB
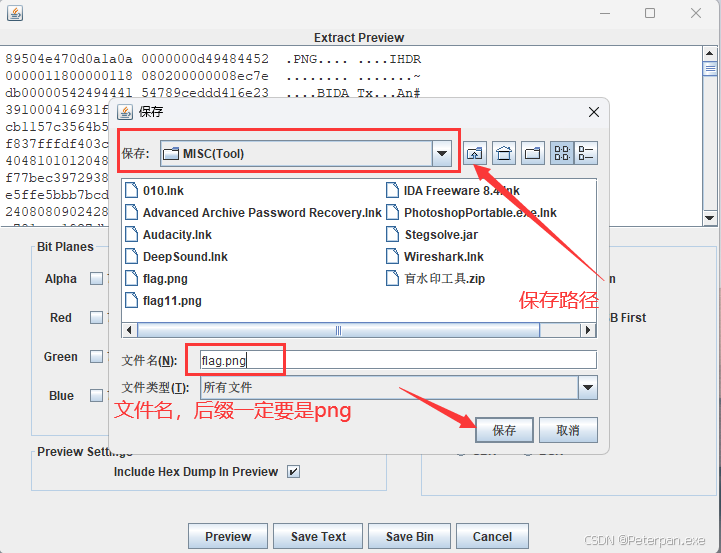
最后勾选完整并且点击:Preview
如图下;
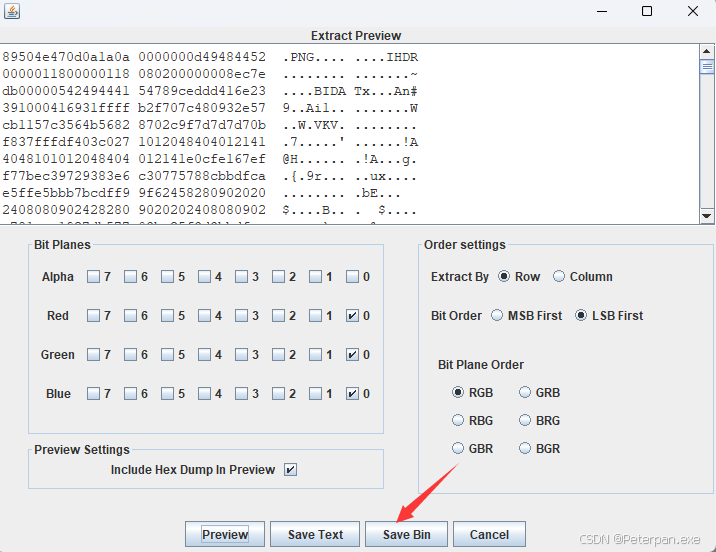
最后的最后,再点击Save Bin,保存为——flag.png;
最后打开我们保存下来的图片,会得到一个二维码,这时候我们不管使用什么扫描都是可以扫出二维码的,不过要说更为便捷一些,那也还得是我们“MICS”常用到的扫描工具——QR_Research
简单介绍一下“QR_Research”;
“QR_Research” 是一个专注于二维码分析和研究的工具。该工具主要用于帮助用户深入分析和探索二维码的内容和结构,尤其在安全领域,如二维码中的隐写、恶意二维码检测等。它的功能包括:
- 二维码解析:解码二维码中存储的信息,如文本、链接、网址等。
- 结构分析:深入分析二维码的编码方式、版本、纠错级别和其他相关参数。
- 安全检测:检测二维码中是否包含潜在的恶意代码或隐写信息,防止二维码被用于恶意目的。
- 生成与篡改:可以生成自定义二维码,甚至篡改现有二维码中的部分信息,便于研究二维码的脆弱性。
最后的最后也是成功扫出flag;
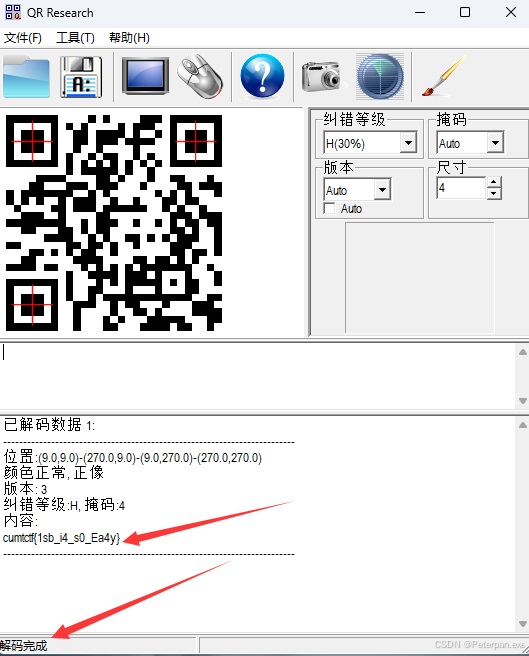
至此;
flag{1sb_i4_s0_Ea4y}
2、MISC-循环解压
解题思路
下载附件得到一个压缩包,解压得到一个空白无后缀文件——circle;
那我们选中右键——打开方式——使用“010”编辑器打开得到;(当然有“winhex”就不一定需要使用“010”,看自己喜欢即可)
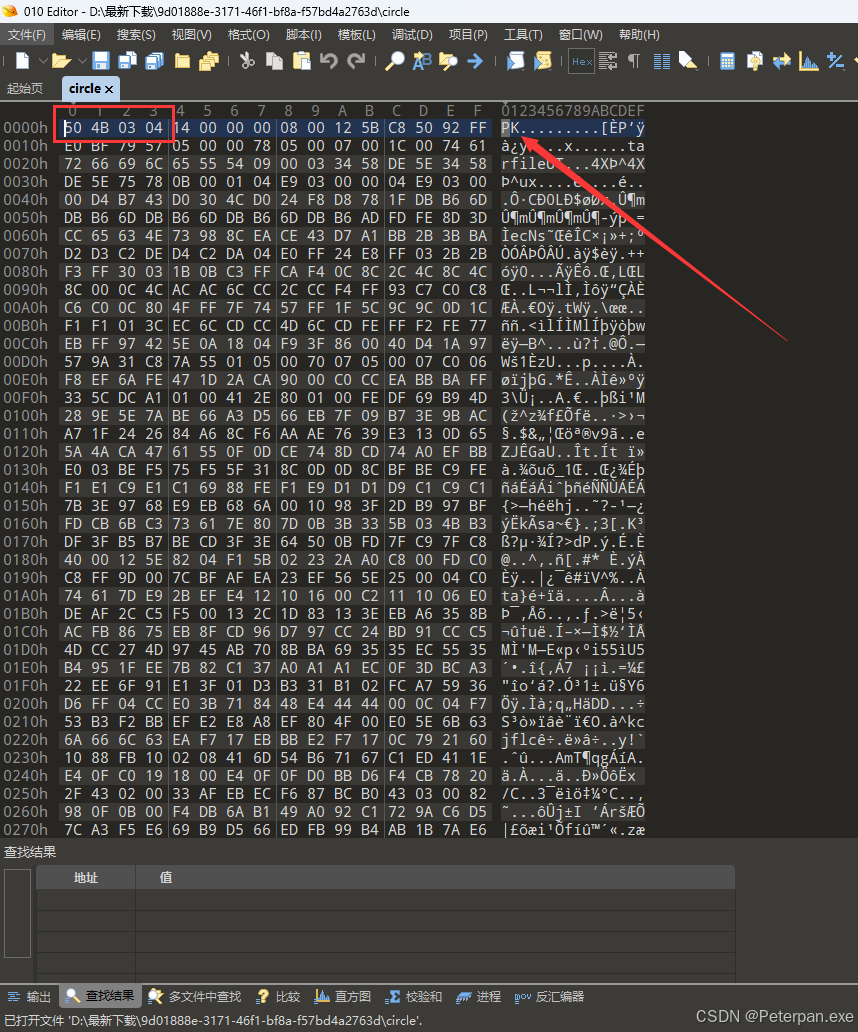
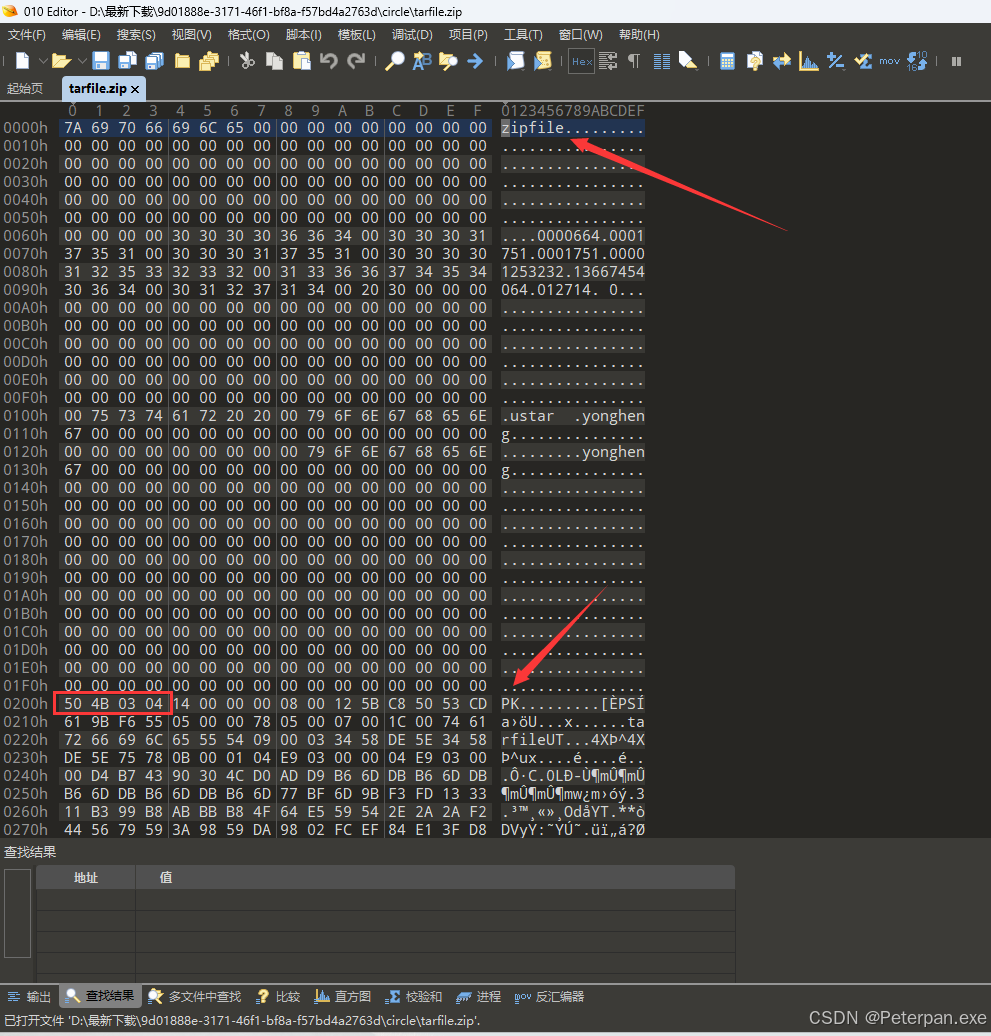
一眼望过去就发现这是一个以ASCll码头部PK为首的文件,接着又看见十六进制头部为:50 4B 03 04,那这里我们就不需要再看了直接退出,选中文件将后缀修改为“circle.zip”接着继续打开即可!
接着继续打开压缩包,会发现里面还有一个空白后缀文件;
那我们解压完成继续使用“010十六进制编辑器”进行查看分析,然后发现这次的文件头部还是"PK"、50 4B 03 04;
那没办法了继续退出文件改为——tarfile.zip,改完之后继续打开压缩包,发现里面又有一个一模一样文件名的文件
那我们解压继续丢进“010”分析;
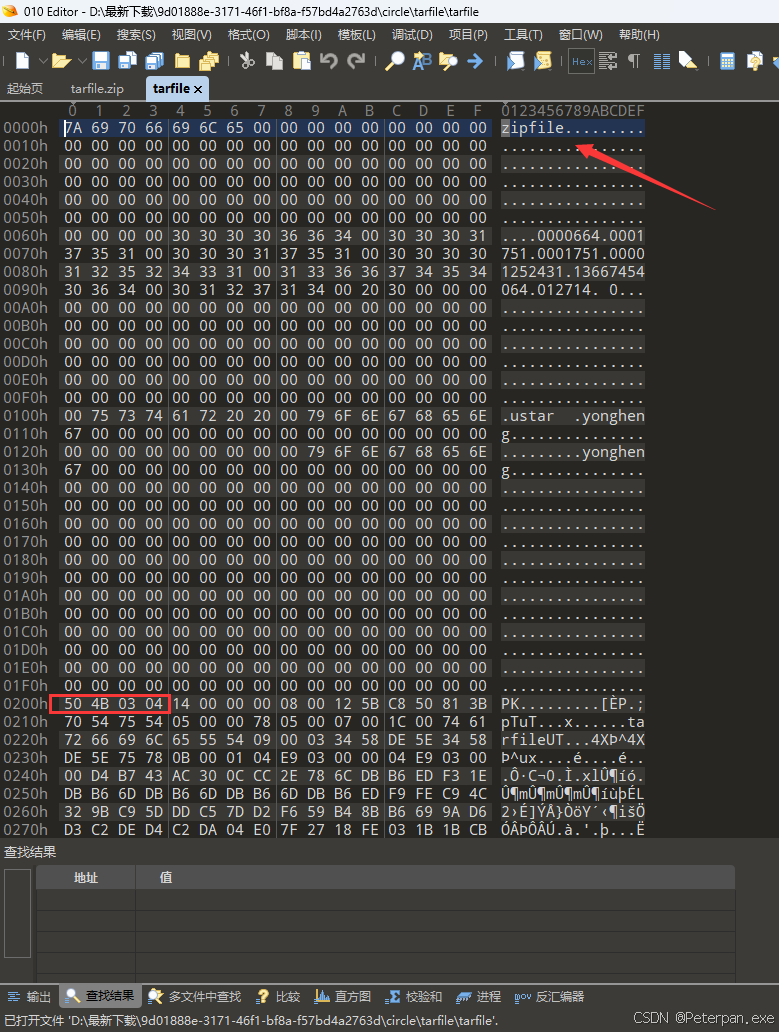
发现也还是跟前面基本一模一样的场景,那到这里就没必要继续进行手动解压改后缀了,因为这里我们遇到压缩包套娃了,那什么是所谓的压缩包套娃呢?
简单解释一下什么是压缩包套娃
在MISC (Miscellaneous) 题目中,压缩包套娃 是一种常见的挑战形式。压缩包套娃的核心思想是将多个压缩文件嵌套在一起,选手需要逐层解压,最终找到目标文件或信息(如 flag)。
以下是压缩包套娃的具体描述:
- 嵌套压缩文件
- 题目提供的文件通常是一个压缩包(如
.zip、.rar、.tar等格式),选手在解压缩后,会发现另一个压缩包,依次类推,直到解压到最终的文件。 - 每一层压缩包可能使用不同的压缩格式,以增加难度。
- 密码保护
- 某些压缩包可能会设置密码,选手需要破解密码或从其他提示中获取密码才能继续解压。
- 密码可能隐藏在文件名、解压文件的内容、或者题目描述中。
- 多种解压工具的使用
- 由于每层的压缩包可能使用不同的格式(如
.zip、.7z、.tar.gz等),选手需要使用相应的工具(如unzip、7z、tar等)解压。
- 隐藏信息
- 除了解压过程外,某些题目会在某个压缩包层中隐藏信息,比如通过修改压缩包的结构或在解压后的文件中埋藏 flag。
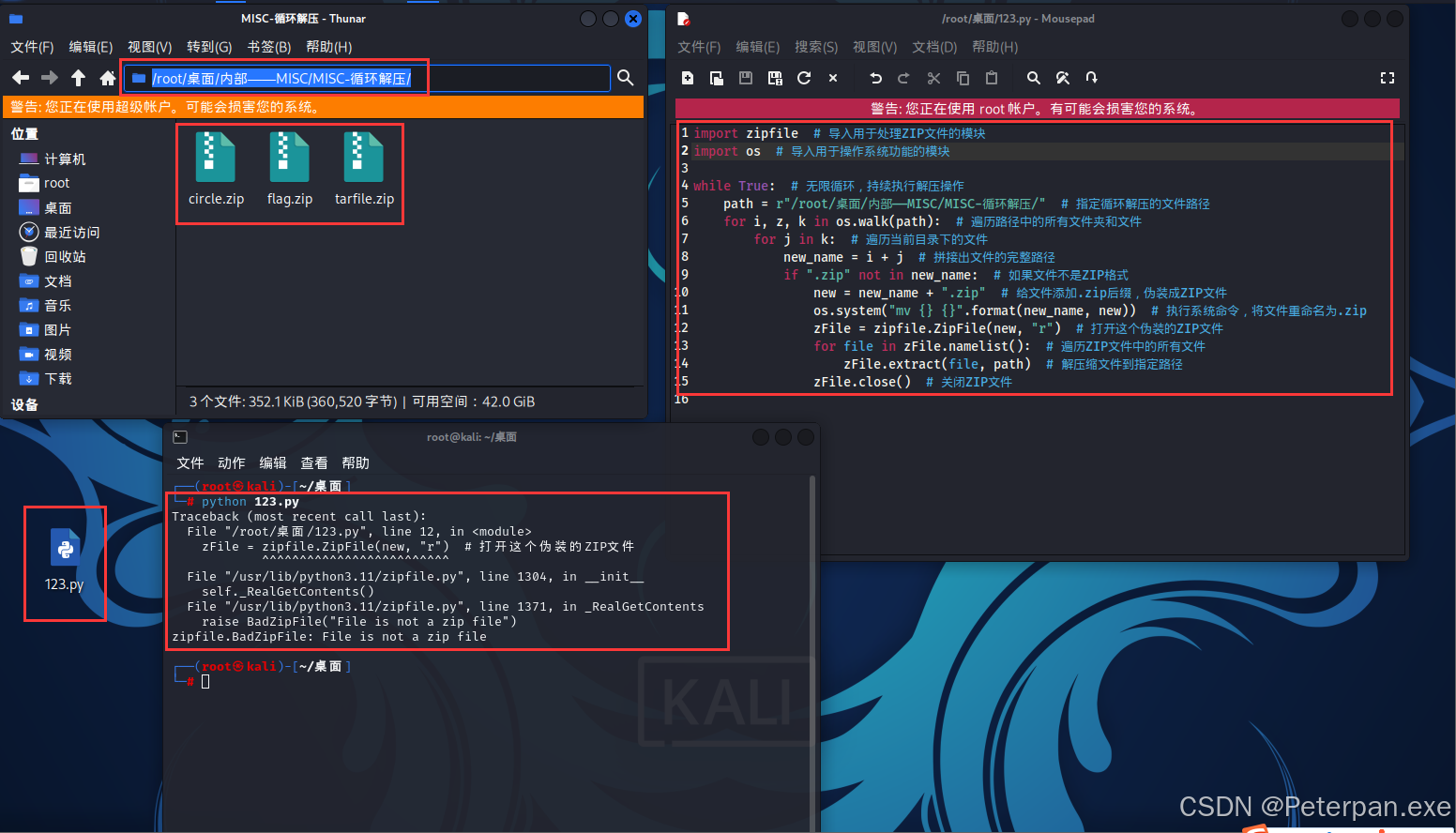
那这里我们直接丢给GPT帮我写一个自动修改文件后缀并解压的脚本;
脚本如下(Python);
import zipfile # 导入用于处理ZIP文件的模块
import os # 导入用于操作系统功能的模块
while True: # 无限循环,持续执行解压操作
path = r"/root/桌面/内部——MISC/MISC-循环解压/" # 指定循环解压的文件路径
for i, z, k in os.walk(path): # 遍历路径中的所有文件夹和文件
for j in k: # 遍历当前目录下的文件
new_name = i + j # 拼接出文件的完整路径
if ".zip" not in new_name: # 如果文件不是ZIP格式
new = new_name + ".zip" # 给文件添加.zip后缀,伪装成ZIP文件
os.system("mv {} {}".format(new_name, new)) # 执行系统命令,将文件重命名为.zip
zFile = zipfile.ZipFile(new, "r") # 打开这个伪装的ZIP文件
for file in zFile.namelist(): # 遍历ZIP文件中的所有文件
zFile.extract(file, path) # 解压缩文件到指定路径
zFile.close() # 关闭ZIP文件
脚本分析;
这个脚本的功能是循环遍历指定文件夹中的文件,将不是
.zip后缀的文件重命名为.zip,然后尝试解压这些文件。解压过程会无限进行,直到手动停止。这种方法可以用于解压套娃式的文件,即多个嵌套的压缩包。
脚本深入分析:
-
模块导入:
zipfile:用于处理 ZIP 压缩文件的模块。os:用于操作系统级的文件操作,如遍历目录和重命名文件。
-
无限循环:
while True::脚本在无限循环中执行,除非手动终止。它会不断地遍历目标目录并处理文件。
-
遍历文件夹:
os.walk(path):遍历指定目录及其子目录,返回当前路径、子目录列表、文件列表。i是当前目录路径,z是子目录,k是文件列表。
-
处理文件:
for j in k::遍历当前文件夹中的每个文件。new_name = i + j:拼接出文件的完整路径(i是文件路径,j是文件名),例如:/root/桌面/内部——MISC/MISC-循环解压/file.txt。
-
检查是否是
.zip文件:if ".zip" not in new_name::如果文件名中不包含.zip,则将该文件视为非 ZIP 文件。new = new_name + ".zip":将文件名加上.zip扩展名,伪装成 ZIP 文件。os.system("mv {} {}".format(new_name, new)):通过系统命令mv将文件重命名为 ZIP 文件(在 Linux 环境中有效)。
-
解压 ZIP 文件:
zFile = zipfile.ZipFile(new, "r"):将重命名后的文件尝试作为 ZIP 文件打开。for file in zFile.namelist()::遍历 ZIP 文件中的所有文件。zFile.extract(file, path):解压文件到指定路径(原文件夹路径)。zFile.close():解压完成后关闭 ZIP 文件。
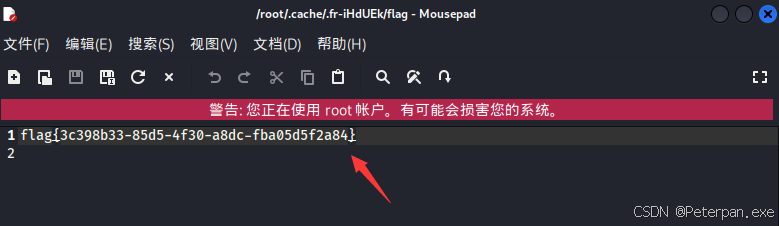
运行也是成功得到了“flag.zip”,最后解压即可得到flag;
这里需要注意的是读取文件的具体路径;
至此;
flag{3c398b33-85d5-4f30-a8dc-fba05d5f2a84}
3、MISC-一个不同的压缩包
解题思路
下载附件得到一个压缩包,打开说损坏的,接着使用“010”打开分析,发现存在——伪加密;
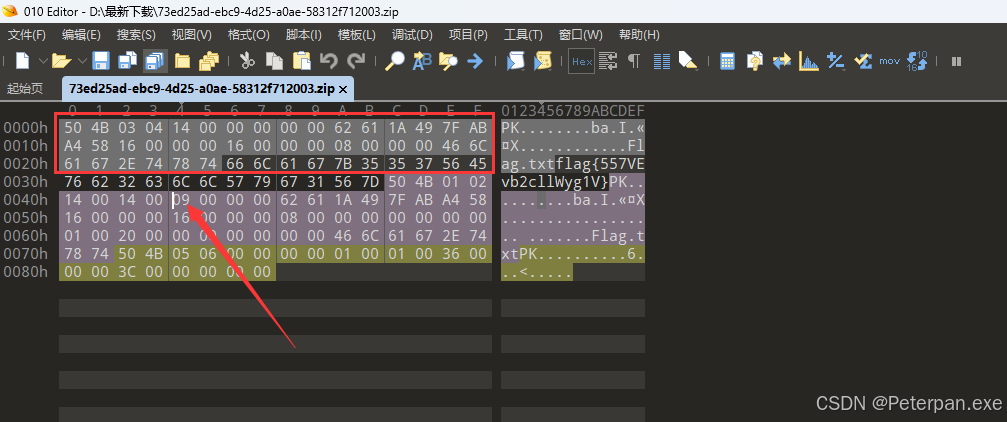
那有的师傅可能就有疑问了,那什么是“伪加密”呢?
简单来说ZIP 伪加密 中一个非常经典的破解方式,也叫做“ZIP 伪加密破解”,这是利用 ZIP 加密文件中的漏洞进行破解,而不需要知道密码的情况。
在早期的 ZIP 加密算法(尤其是弱加密算法)的实现中,文件的第 9 和第 15 字节的值被设置为 0,会让 ZIP 文件看起来像是加密的,但实际上它并没有进行有效加密。这是一种非常常见的漏洞,它可以被利用来绕过加密,直接访问压缩包内容。
破解这种伪加密 ZIP 文件的方法通常是通过手动修改文件的这些特定字节,或者使用专门的工具进行自动化操作。具体步骤如下:
-
识别 ZIP 文件的加密标志: ZIP 文件格式有一个固定的结构,其中包含头部信息。如果发现 ZIP 文件的第 9 和第 15 字节是
0,可以推测该文件可能使用了伪加密。 -
手动修改 ZIP 文件: 使用二进制编辑器(如
HexEditor)直接修改文件中的加密标志,删除这两个字节的加密标志,重新保存文件。此时,文件即使有加密提示,也可以被打开。 -
工具破解: 一些破解工具可以自动检测并绕过这种伪加密,常见的工具包括
pkcrack或者fcrackzip等,这些工具通过字节分析找到文件中的加密弱点,并自动破解。
总结来说,这种第九、第十五字节的设置为 0 的现象是 ZIP 文件格式中一种特定的加密漏洞,属于 ZIP 弱加密破解中的一种技巧,也属于 CTF 中 MISC 类题目可能会考察的知识点。
但其实现在也不需要那么麻烦了,现在的MISC很少会出现这种所谓的“送分题”,因为现在很多的解压工具能直接识别并且直接解压出来,刚刚我的其实就自动识别并且解压的,要不是看题目“wp”我甚至都以为这题白送呢;
那如今许多解压工具已经能够自动识别并处理 ZIP 文件中的这种“伪加密”情况。这是因为现代的解压缩工具更加智能化,能够检测并绕过早期 ZIP 文件加密算法中的漏洞。
以下是几种可以自动识别并直接解压伪加密 ZIP 文件的常用解压工具:
-
WinRAR
WinRAR 是一种非常流行的压缩和解压缩工具,支持多种压缩格式。它能够自动识别并绕过伪加密 ZIP 文件,不需要手动破解。 -
7-Zip
7-Zip 是一款开源的解压缩工具,它同样可以自动识别并解压伪加密 ZIP 文件,省去了手动修改的麻烦。它支持多种格式,尤其以对压缩比和性能的支持而闻名。 -
Bandizip
Bandizip 是另一款支持多种压缩格式的工具,它也具备处理伪加密 ZIP 文件的功能,用户可以直接解压而不会受到加密标志的限制。
这些现代工具通过智能分析 ZIP 文件头部信息,可以识别出伪加密标志,直接解压文件而无需手动破解。这使得伪加密漏洞的破解变得不再是一个复杂的过程,因此这个考点在 CTF 中确实不再常见。
不过这里我用的“360解压”,也是成功直接解压出来;
当然如果还是打不开的,就可以尝试在“010”中修改一下;
修改如下;
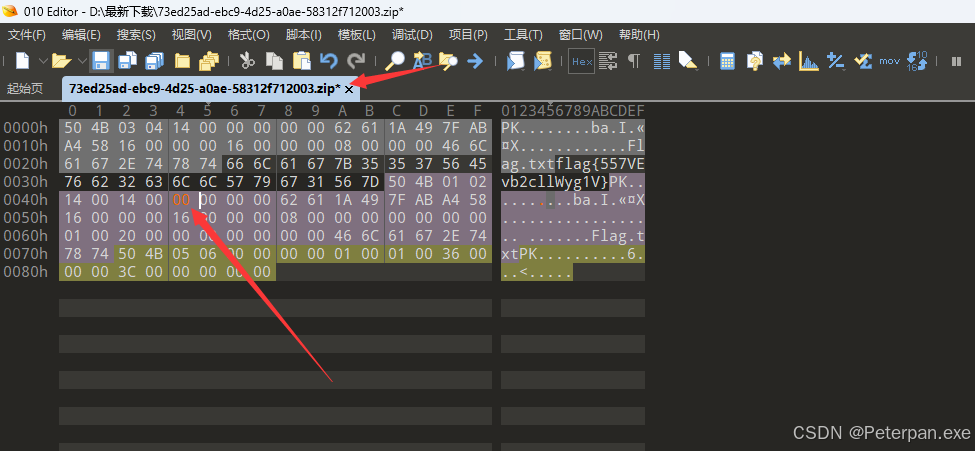
接着“Ctrl+s”保存并退出,这时候在打开压缩包就会发现是可以打开了;
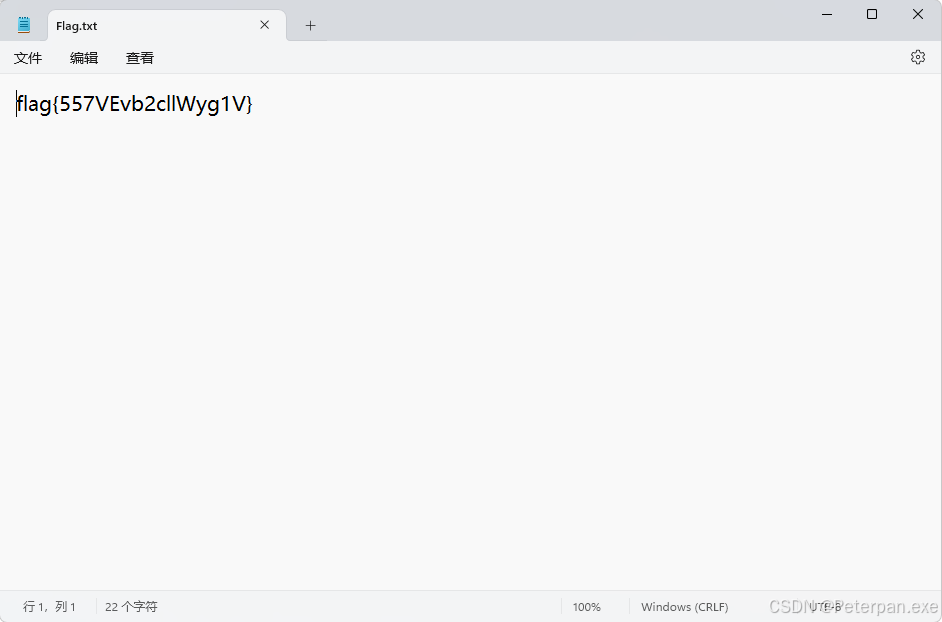
至此;
flag{557VEvb2cllWyg1V}
4、MISC-异性相吸
解题思路
下载附件得到一个“提示.txt”以及一个“MISC-yxx.zip”,那我们接着继续打开“MISC-yxx.zip”,发现里面有一个“密文.txt”和一个“明文.txt”,那我们接着先打开“提示.txt”进行分析;
“提示.txt”
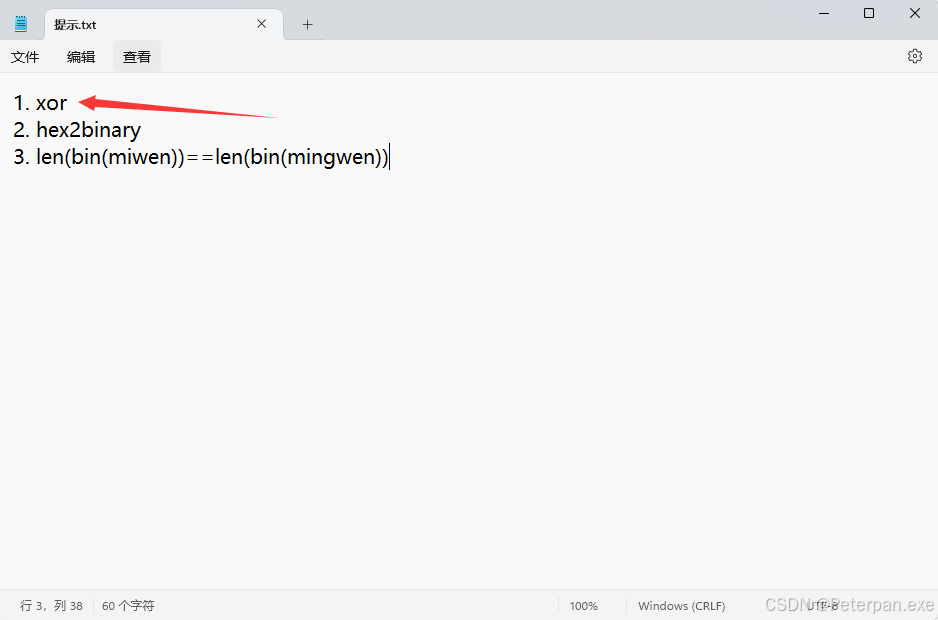
一眼就发现了关键的——xor,那这里面可能有的师傅是第一次接触“xor”这个东西,不过那也没关系,我们一起来简单介绍一下什么是“xor”;
什么是“xor”?
其实简单来说,XOR(异或)是一种逻辑运算,常用于计算机科学、密码学和数字电路中。它的全称是“exclusive OR”(排他或),是一种二进制运算,其运算规则如下:
- 当两个输入相同时,输出为 0。
- 当两个输入不同时,输出为 1。
用符号来表示:
- 0 ⊕ 0 = 0
- 0 ⊕ 1 = 1
- 1 ⊕ 0 = 1
- 1 ⊕ 1 = 0
XOR 的性质:
- 自反性:
A ⊕ A = 0,任何数与自身异或的结果为 0。 - 交换性:
A ⊕ B = B ⊕ A,异或运算是交换律的。 - 结合性:
(A ⊕ B) ⊕ C = A ⊕ (B ⊕ C),异或运算满足结合律。 - 单位元:
A ⊕ 0 = A,任何数与 0 异或的结果是其本身。
XOR 的应用:
- 密码学:XOR 常用于加密和解密算法。因为 XOR 的自反性,常用于简单的加密场景。例如,将明文和密钥异或得到密文,而再次异或密文和相同密钥又能还原明文。
- 数据校验:XOR 可以用于快速计算校验值或实现简单的错误检测算法。
- 位操作:在位运算中,XOR 常用于翻转特定位的值。比如,可以通过异或运算来交换两个变量而不使用临时变量。
那我们再结合“提示.txt”里面的提示,简单分析一下;
1. xor
2. hex2binary
3. len(bin(miwen))==len(bin(mingwen))
初步来看这三个点结合在一起,大致可以解释为一种基于 XOR 运算的加密过程,并且通过十六进制转换为二进制来确保明文和密文的长度一致。下面是每个点的简单分析:
- XOR(异或)
XOR 是一种加密算法的核心运算。它的性质使得 XOR 可以用于对称加密:
- 加密时,
密文 = 明文 ⊕ 密钥 - 解密时,
明文 = 密文 ⊕ 密钥
由于 XOR 的自反性,使用同一个密钥再次 XOR 密文,就可以还原出明文。
- hex2binary(十六进制转二进制)
这一步涉及数据表示格式的转换。在加密或解密过程中,数据可能会以十六进制表示。为了使用 XOR 进行运算,通常需要将十六进制数据转换成二进制格式进行位级别的操作。
hex2binary 就是将一个用十六进制表示的数转换成其对应的二进制数。例如:
- 十六进制
A转换成二进制是1010 - 十六进制
3F转换成二进制是111111
这样可以使数据适应位操作(如 XOR 运算)。
- len(bin(miwen)) == len(bin(mingwen))
这一点强调了加密后的密文和明文的二进制表示长度是相等的。因为 XOR 是位操作,在加密和解密过程中,密文和明文的二进制位数需要相同。否则,位级别的 XOR 运算将无法正确执行。这意味着:
- 明文的二进制长度与密文的二进制长度必须一致,通常会对数据进行一定的填充或规范化,使两者长度匹配。
总结
这三个步骤描述了一个加密流程:
- 明文和密钥通过 XOR 运算加密。
- 数据以十六进制格式表示,并通过
hex2binary转换成二进制进行位操作。 - 明文和密文在加密或解密过程中,二进制表示的长度需要保持一致,以确保 XOR 运算能够顺利完成。
那这里我们打开所给出的“密文.txt”以及“明文.txt”来看一下;
“密文.txt”
“明文.txt”
那既然都已经了解成这样了,我们也话不多说直接上脚本吧!
脚本如下;(Python)
#coding:utf-8
# 打开密文文件和明文文件,使用二进制模式读取
file_a = open('密文.txt', 'rb')
file_b = open('明文.txt', 'rb')
# 将字节解码为字符串
str_a = ''.join([line.decode('utf-8') for line in file_a.readlines()])
str_b = ''.join([line.decode('utf-8') for line in file_b.readlines()])
# 初始化一个空字符串用于保存异或后的结果
ans = ''
# 使用zip函数将两个字符串中的字符逐个配对,进行异或运算
for i, j in zip(str_a, str_b):
ans += chr(ord(i) ^ ord(j)) # 将字符i和j的ASCII码进行异或运算,并将结果转为字符
# 打印异或后的结果
print(ans)
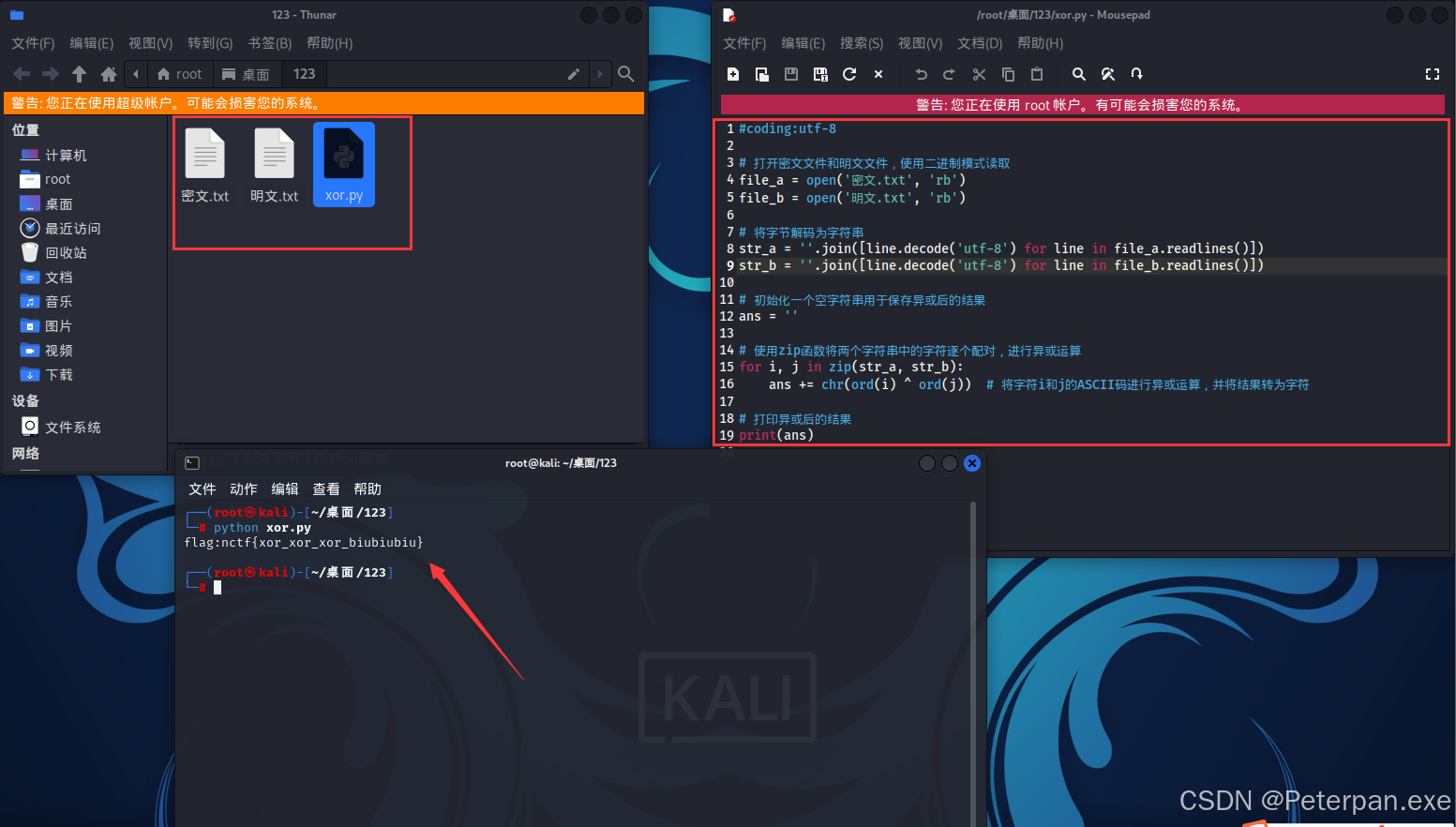
运行得到;
至此;
flag{xor_xor_xor_biubiubiu}
5、MISC-仔细找找
题目描述:
南梦最近天天看冬奥会,这时他突然想到一个思路,出了这道题,大家可以仔细看看图片有啥端倪?请下载附件答题获取到flag进行提交
解题思路
下载附件得到一个压缩包,解压出来得到一张图片如下;
那这里我们对这张图片进行分析的时候,对这张图放发现一个一个的像素点;
如图下;
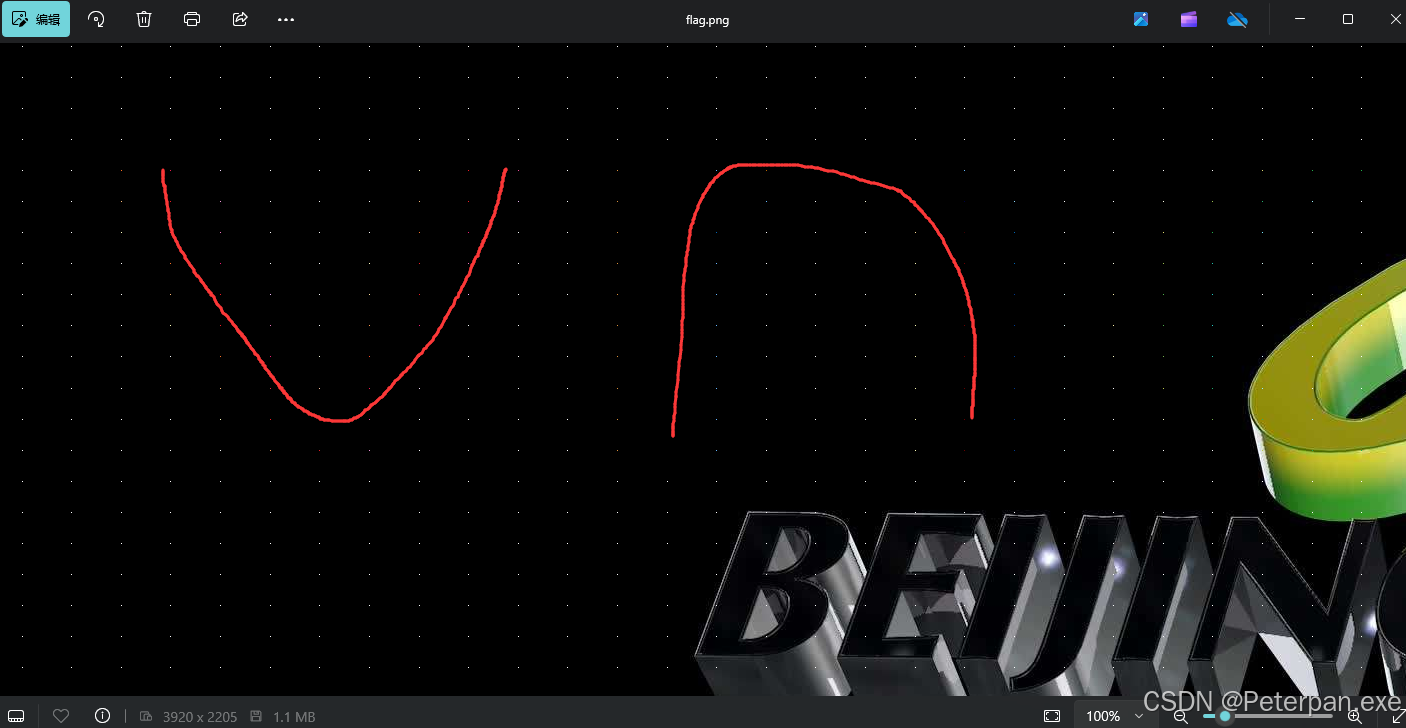
这样看大家可能就明细一些,那这题是的没错,就是把这些带有颜色的像素点,每一个都可以手动用笔画出来,最后也是可以得出flag,当然这样肯定是费眼睛的,因为后面的背景是黑色的,所以这里我们就可以观察一下这些像素点的规律写一个脚本直接提取出最后的flag;
如果是用笔画的,那可能看这张图会更明细一些;
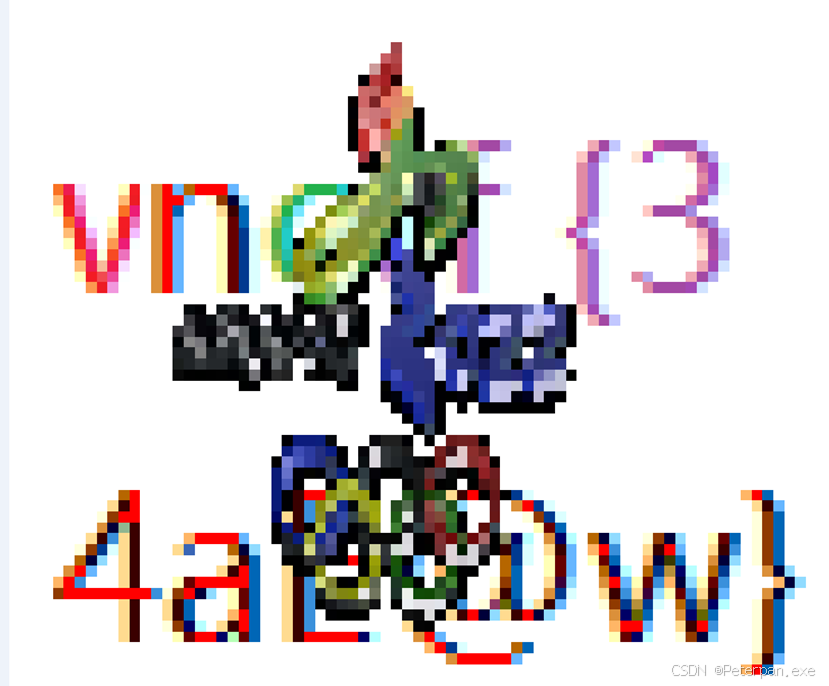
那这里我们也可以写脚本进行像素提取;
脚本如下;(Python)
from PIL import Image
# 打开图片文件
pic = Image.open('./flag.png')
w, h = [], [] # 用于存放满足条件的像素坐标
# 遍历图片的宽度,检查第15行是否有像素点为白色(255,255,255)
for i in range(pic.size[0]):
if pic.getpixel((i, 15)) == (255, 255, 255):
w.append(i)
# 遍历图片的高度,检查第24列是否有像素点为白色(255,255,255)
for j in range(pic.size[1]):
if pic.getpixel((24, j)) == (255, 255, 255):
h.append(j)
# 创建一个新的空白图片,大小为符合条件的像素点数
flag = Image.new('RGB', (len(w), len(h)), (255, 255, 255))
# 将满足条件的像素点从原图中复制到新图
for i in range(len(w)):
for j in range(len(h)):
flag.putpixel((i, j), pic.getpixel((w[i], h[j])))
# 显示新生成的图片
flag.show()
运行得到;
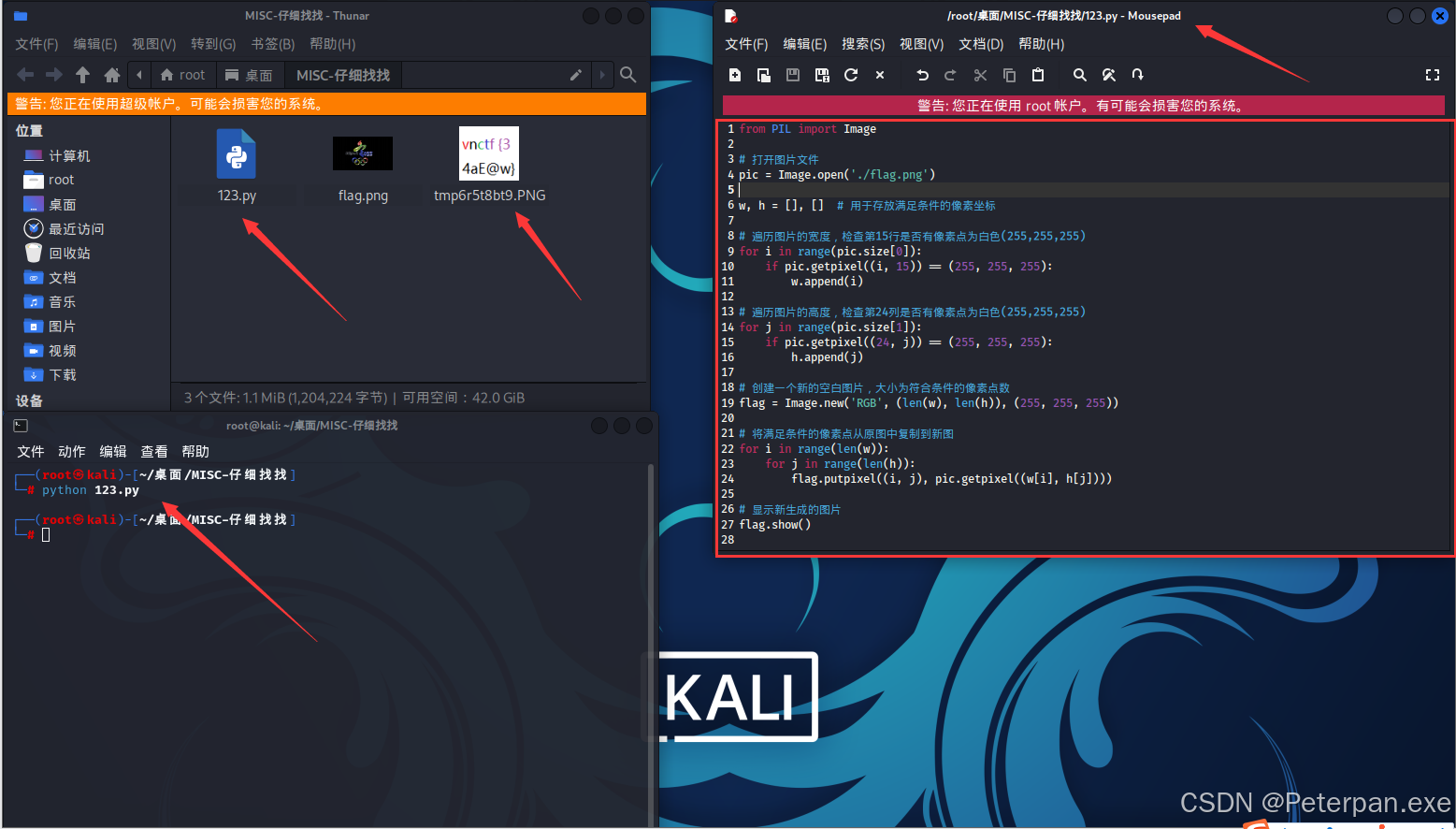
flag如图下;

至此;
flag{34aE@w}
6、MISC-再来一题隐写
解题思路
下载附件得到一个压缩包,打开来里面还是一张图片,不过这个图片看起来只有半边身子,别问我为什么看起来只有半边身子,因为这题很“BUU”,那这里我们话不多说直接上实操;
“dabai.png”
其实这种题一眼就是宽高有问题,要不知道是宽高的话,我们可以直接丢进“Kali”中看看图片是否能正常显示,如不能正常显示出来,说明就是图片的宽高有问题,因为“Kali”对图片的宽高有严格的CRC值效验;
其实严格一些来解释就是;
在Kali Linux(或其他操作系统)中,如果图片显示不出来,可能是因为图片的宽高存在以下问题:
- 损坏的图片文件
图片文件可能在传输、保存、或处理过程中损坏,导致其宽高等元数据无法正确读取。某些图片查看器无法解析受损的图片,从而无法显示图片。
- 不正确的宽高比
图片的宽高信息在图片文件头中存储。如果图片的宽高信息不正确(例如宽高为零或负数),图片查看器将无法正常渲染图像,导致显示错误。
主要其实就是这两点,其它的到无所谓了,因为平时也遇不到;
图片在kali中;

所以这里我们直接使用“010”打开图片修改一下图片的宽高即可;
那这里我们使用“010”来修稿图片的宽高时需要注意一下几点;
- 了解图片格式
不同的图片格式(如 PNG、JPEG、BMP 等)有不同的文件结构,宽高信息存储的位置不同。因此,首先要了解你所使用的图片格式的规范。
- 图片格式常见的宽高位置
- PNG 文件:宽高信息存储在 IHDR 块中,通常在文件的开头部分。
- 宽度:IHDR 块的第 16 到 19 字节。
- 高度:IHDR 块的第 20 到 23 字节。
- JPEG 文件:宽高信息存储在 SOF0(Start of Frame 0)段中,该段通常出现在文件头后面的 0xFFC0 处。
- 宽度和高度紧跟在 SOF0 标识符后,通常在 5-9 字节处。
- BMP 文件:宽高信息位于文件头的 BITMAPINFOHEADER 中,通常在文件开头的 18-21 字节(宽度)和 22-25 字节(高度)。
. 用 010 Editor 修改宽高
- 打开图片文件:使用 010 Editor 打开图片文件,你会看到二进制格式的数据。
- 查找宽高信息:根据图片格式的规范,找到宽度和高度的字节位置。
- 修改宽高:宽高信息通常存储为 4 字节整数(Big-Endian 或 Little-Endian),你可以将其转换为十六进制并编辑。如果你要将宽度设置为 1024,十六进制值为
00 04 00 00(Big-Endian)。 - 保存文件:编辑完后,保存文件并尝试打开图片查看修改是否成功。
- Endianness(字节序):不同格式可能使用不同的字节序(Big-Endian 或 Little-Endian)。确保你理解图片格式使用的字节顺序。
- 修改后图片是否显示正常:直接修改宽高可能导致图片数据与其结构不一致,尤其是 JPEG 格式,如果修改后宽高与实际图像数据不匹配,图片可能无法正常显示或被损坏。
- 备份原始文件:为了防止修改导致图片不可恢复,建议在修改前备份原始文件。
通过正确识别和编辑宽高信息,可以成功修改图片的尺寸,不过修改后图片质量和显示效果可能会受到影响。
那这里我们的图片格式是“png”,而且也只是需要修改图片的高度,所以只需要修改 “IHDR”块的第 20 到 23 字节;
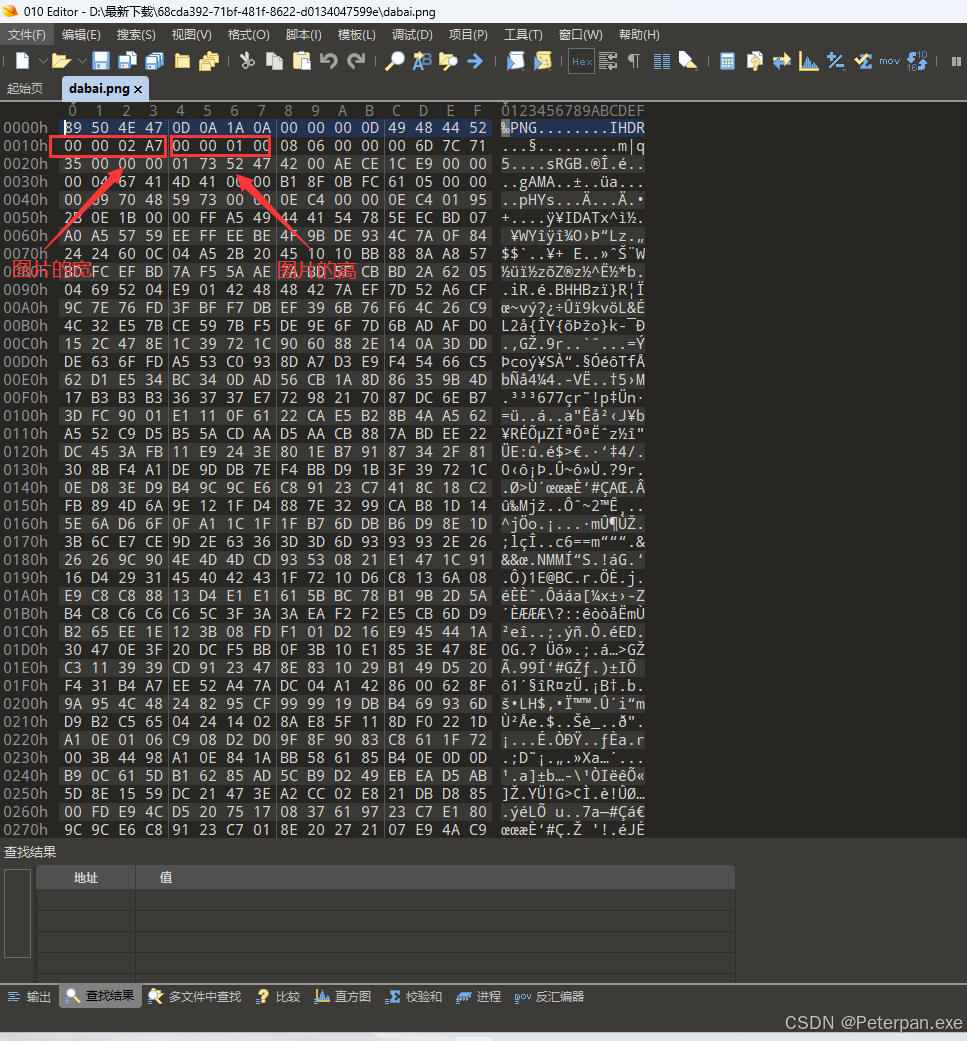
那这里你像我就直接喜欢把图片改到最高,这样不管它藏的在深都能找出来;
修改高:00 03 01 4c
如图下;
修改完之后,注意文件上方的星号,“Ctrl+s”进行保存;
最后选择打开方式为“画图”即可看见flag;
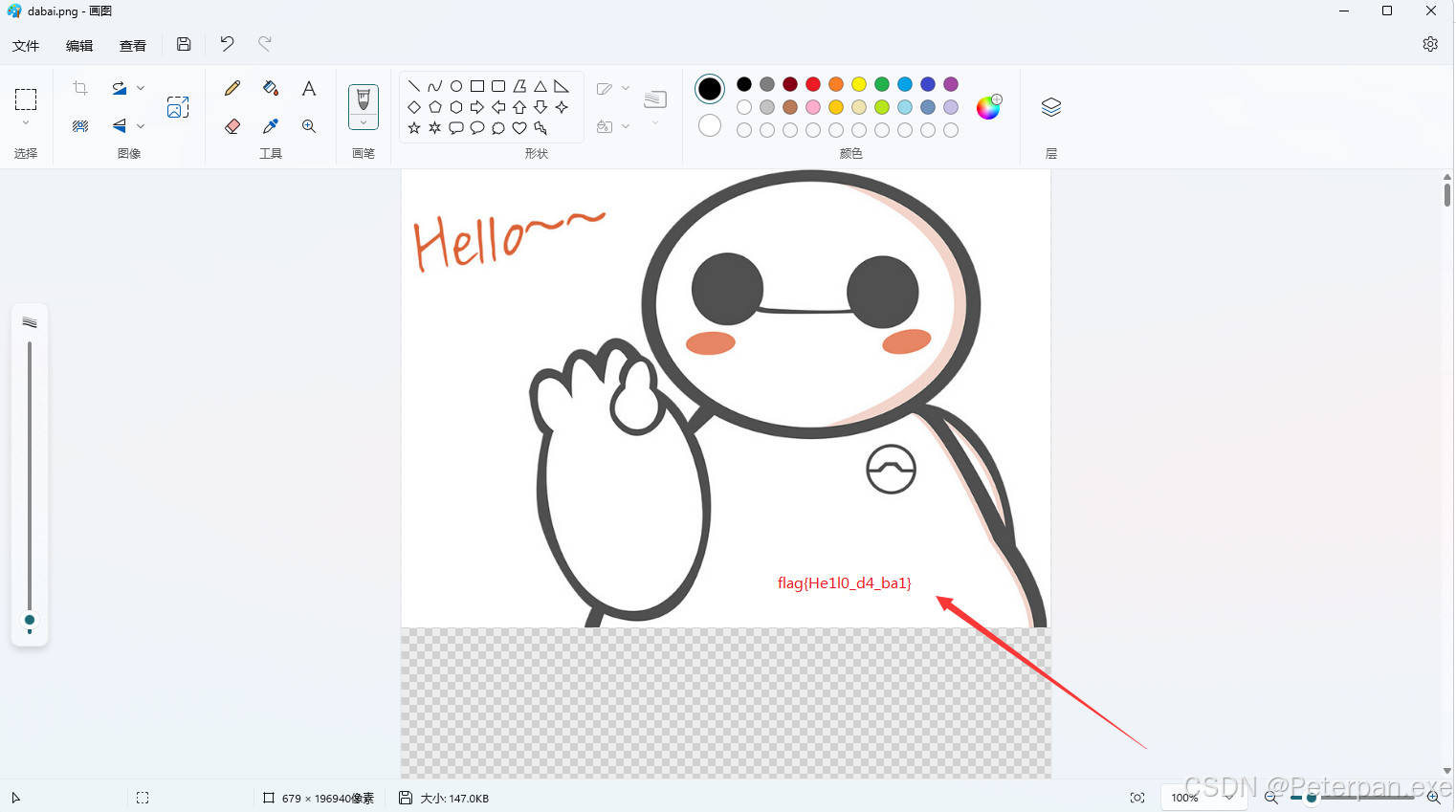
至此;
flag{He1l0_d4_ba1}
7、MISC-找找吧
题目描述:
我猜你找不到我
请下载附件答题获取到flag进行提交
解题思路
下载附件得到一个带锁的压缩包,那没办法我们先丢进“010”简单分析一下;
“压缩包需要密码”
使用“010”打开压缩包,翻到最底下疑似发现密码,尝试输入发现密码正确;
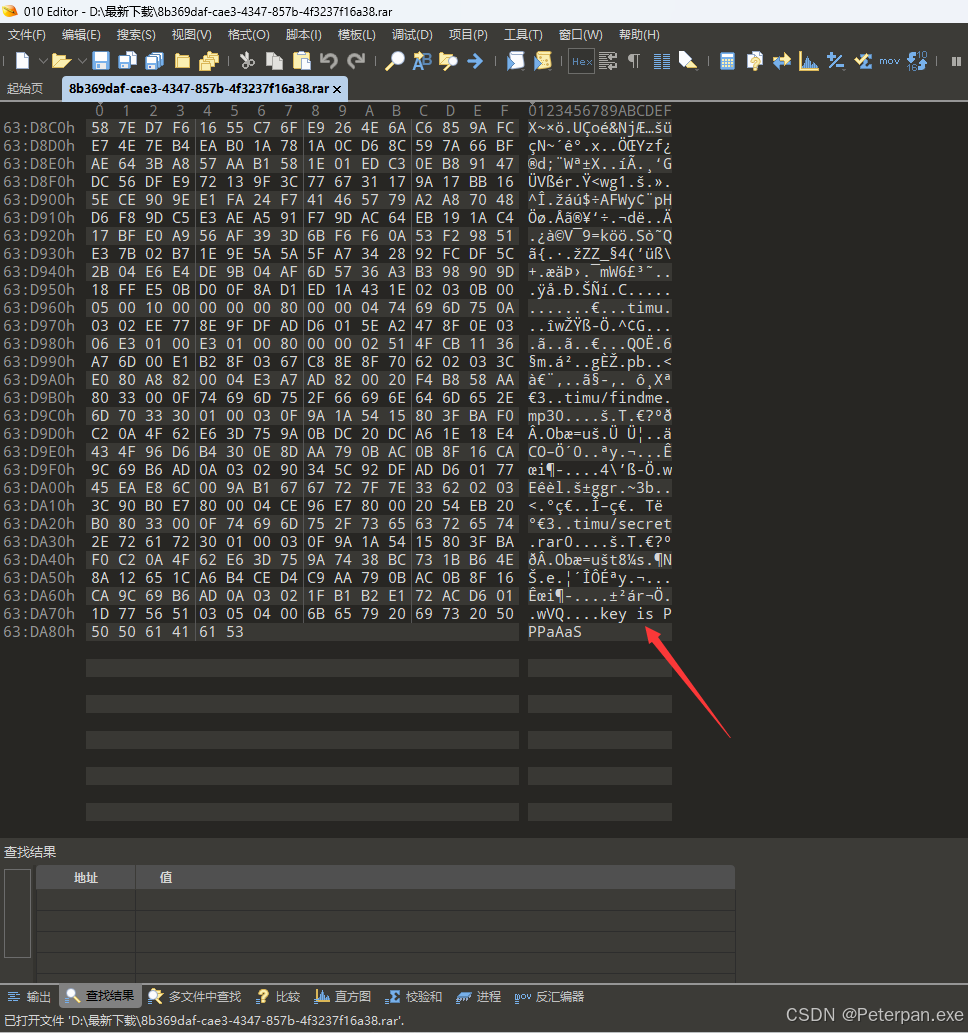
尝试解压发现密码正确——key is PPPaAaS;
解压出来得到两个文件“findme.mp3”以及“secret.rar”;

这时候我们想打开压缩包简单看一下发现也还是需要密码;
那就没办法了,我们先去简单分析一下“findme.mp3”,首先MP3格式的首先我就想到一个常用的分析工具——Audacity
那我们简单来介绍一下“Audacity”这个工具的具体使用方法;
Audacity 是一个免费的开源音频编辑软件,广泛用于录制、编辑和处理音频文件。在 CTF(Capture The Flag)比赛中,Audacity 是一个分析和提取音频文件中隐藏信息的有力工具,通常用于“取证”或“隐写术”类的挑战。
使用方法:
- 音频编辑:你可以将音频文件导入 Audacity,进行剪辑、添加效果或调整音频波形。
- 频谱图分析:Audacity 提供频谱图视图,可以让你从视觉上分析音频文件的频率组成。这在识别隐藏信息时非常有用,因为 CTF 挑战可能会在频率域中隐藏文本或图案。
- 音频反转:Audacity 可以反转音频轨道,用于揭示一些被倒放录制的隐藏消息或线索。
- 速度调整:有些挑战可能通过改变音频速度隐藏信息,Audacity 能将音频调整为正常速度,便于发现线索。
常见的 CTF 场景:
- 音频隐写术:信息可能隐藏在音频文件的频率频谱中。
- 摩尔斯电码:音频文件可能包含摩尔斯电码信号,需通过 Audacity 解析。
- 频谱图中的图像或文本:一些挑战会将图像或文字隐藏在音频文件的频谱图中,可以通过 Audacity 的频谱功能检测到。
那这里我们直接把文件“findme.mp3”丢进去看一下音频的“频谱图视图”;简单分析一下;
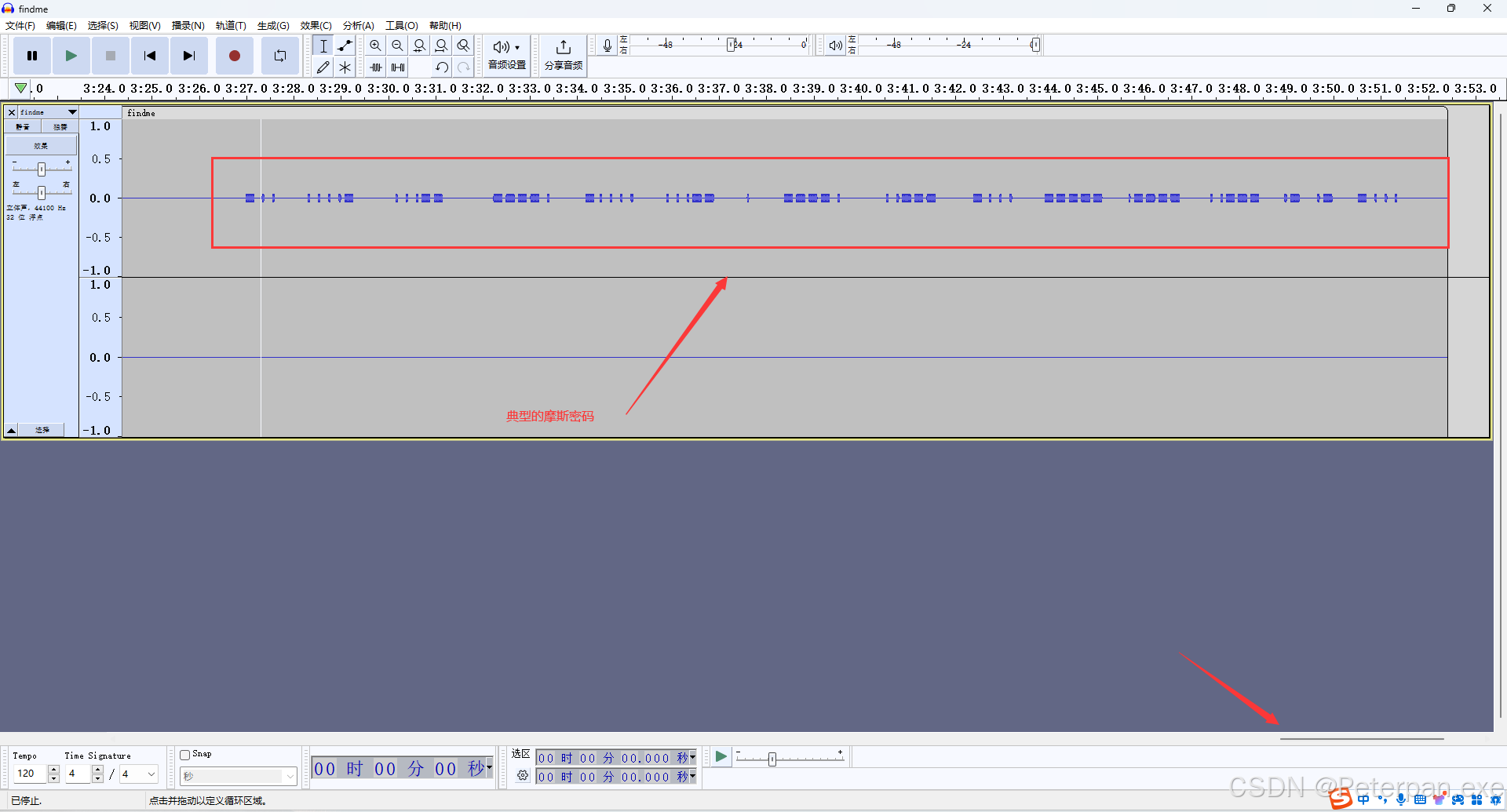
也是根本不需要费什么劲,直接移动到最后也是成功发现音频中的“摩斯密码”,那这里我们直接上“记事本”手敲一下,其实也很简单,”摩斯密码“无非就是长和短的区别;
成功得到;
-.. ....- ...-- ----. -.... ...-- . ----. ..--- -... ----- .---- ..--- .- .- -...
那既然都得出“摩斯密码”了,我们就直接找一个在线的网站给它解码一下;
得到;
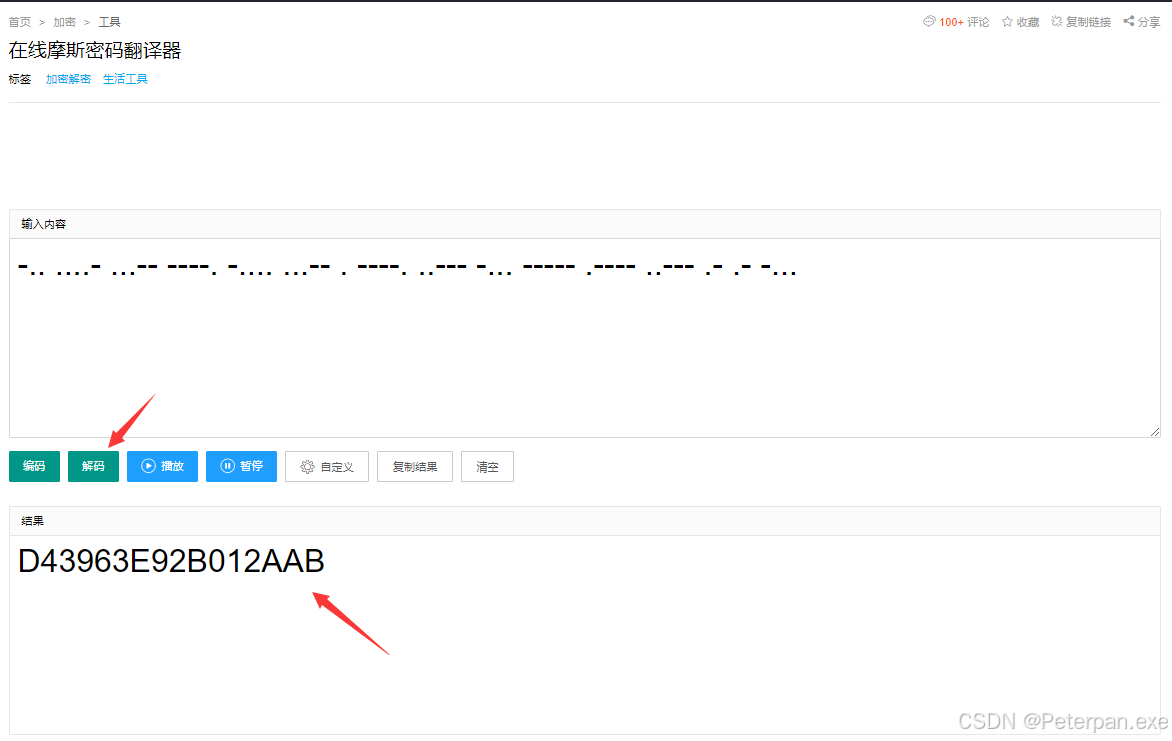
得到:D43963E92B012AAB
尝试去解压缩包,但是发现密码不对;
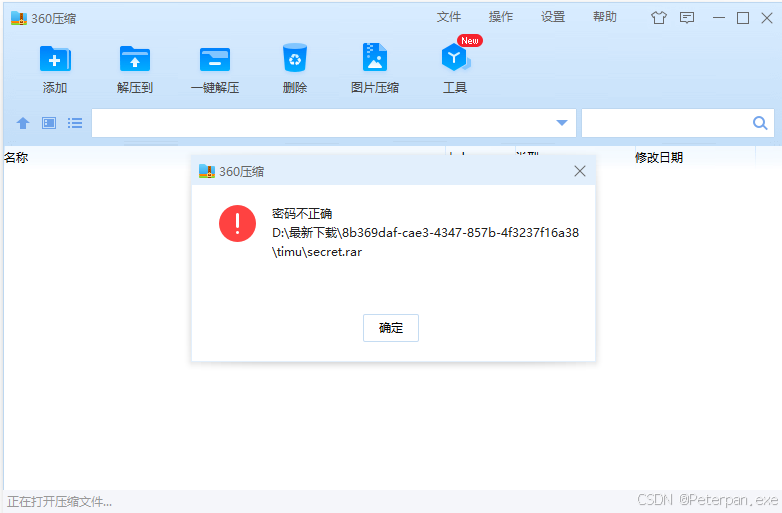
那就暂时没办法了,不过也没有关系,可能是我们刚刚的“findme.mp3”误导了我们(因为一看到MP3格式结尾的文件,可能一些老师傅就率先想到了“Audacity”),那这次我们直接丢进"010"简单分析一下,看它还藏着什么;
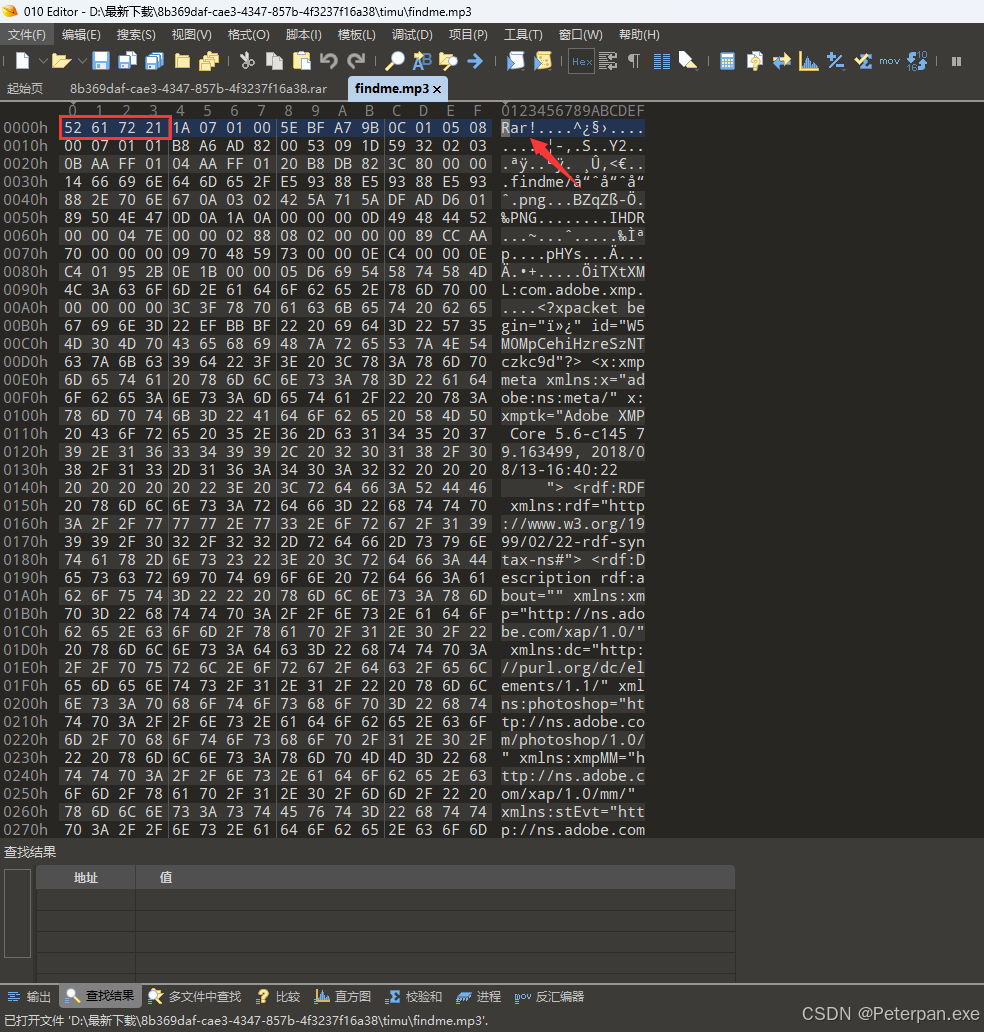
哎,直接打开就发现了“Rar!”,这里不需要我多说就明白了吧?那我们直接退出把后缀改为“findme.rar”那这里我们直接解压打开即可;
也是成功又得到两个新的文件“采茶纪.mp3”及“哈哈哈.png”

“哈哈哈.png”
图片暂时没发现有什么用,我们直接来分析"采茶纪.mp3",那就是老规矩嘛,直接“Audacity”里面走一走;
得到;
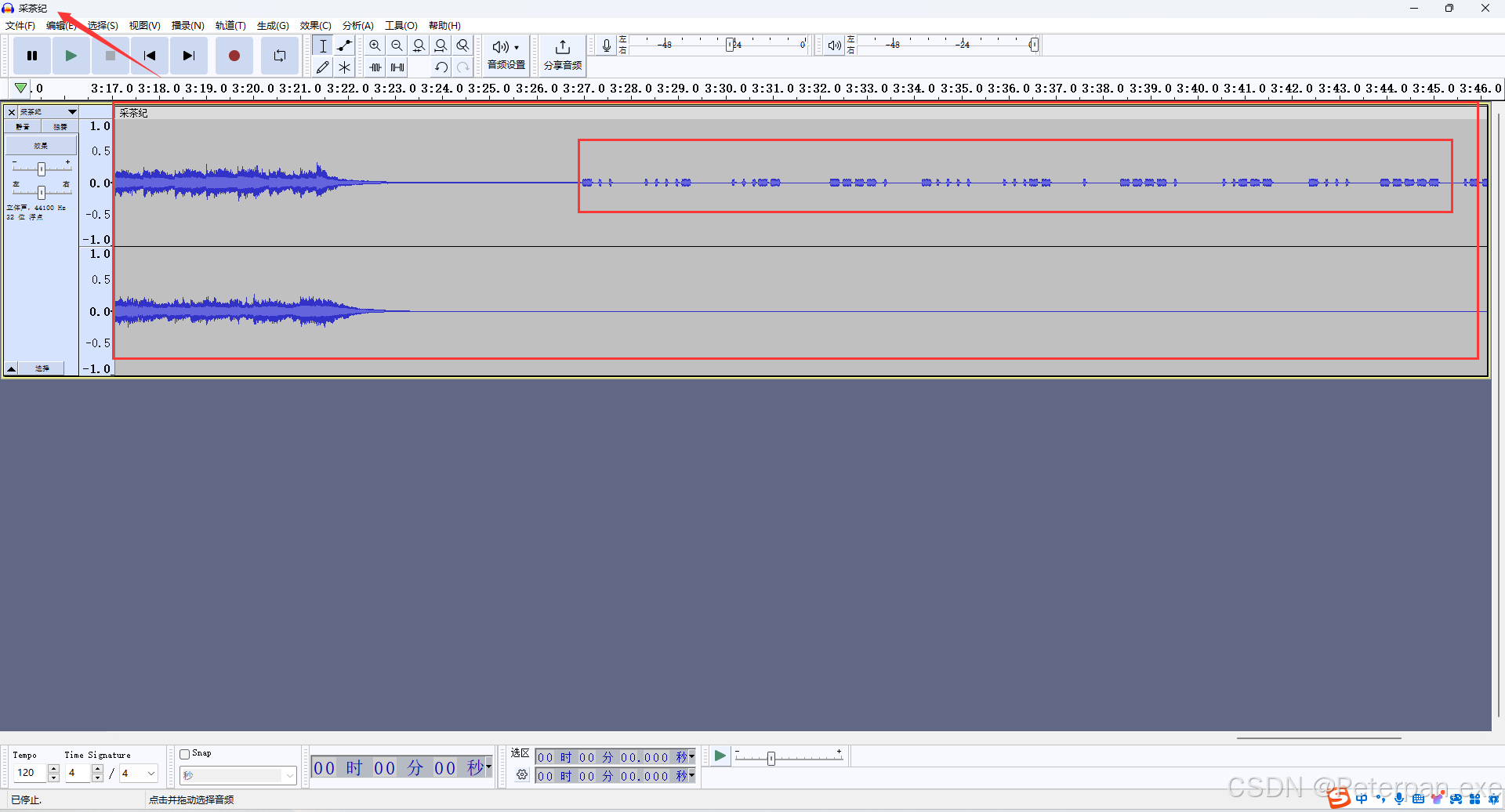
最后也还是得出“摩斯密码”,解出来和之前的密码一样,那这里没办法了,去看了一眼别的师傅的wp,然后发现这里是把解出来的密码进行“MD5”加密,感觉奇奇怪怪的,题目中也我也暂时没有发现任何关于MD5加密的提示,那这里为了节省些时间,这里我们就不深究下去了,那我们也把解出来的“摩斯密码”进行“MD5”加密;
得到;
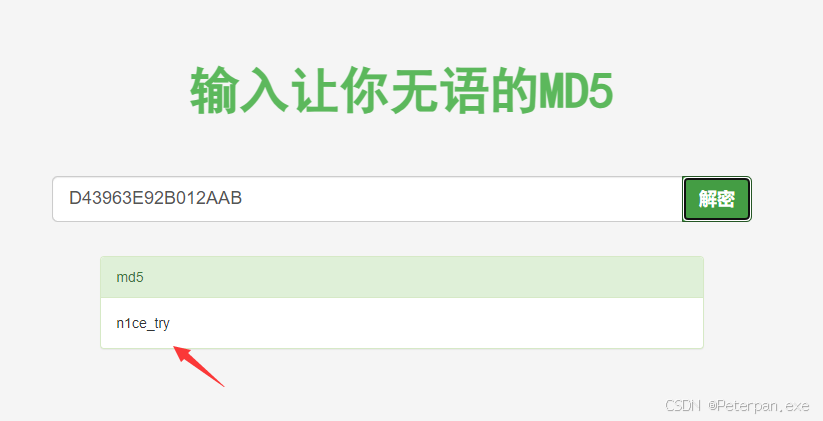
那这个应该就是最开始我们打不开的压缩包密码了:n1ce_try
那这里输入之后也是成功打开,打开之后得到;
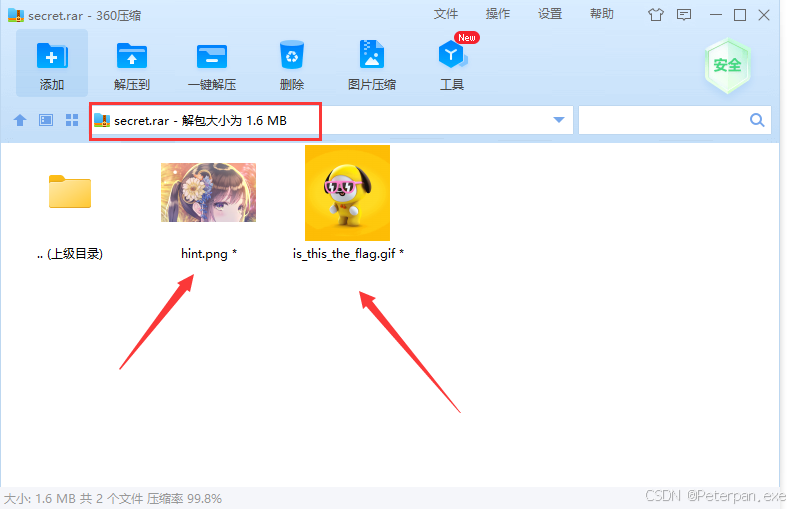
哎哎哎,一看见这两个文件,我相信常用做MISC的老师傅肯定就饥渴难耐了,是的没错,也正如我们所想,一张半个头的图片,谁家图片没事喜欢漏半个头?要在不确认待会直接丢“Kali”里面分析一番,还有这个“GIF”的图片,经常做MICS做多了,现在一看见关于“GIF”后缀就想给它逐帧给它分解咯!什么你问我用什么分解?笨一点的直接百度“GIF在线分解”,机灵些的师傅则默默打开“Stegsolve.jar”,当这里方法不唯一哈,我也只是开个玩笑,方法不一,不轮笨与机灵如有冒犯纯属意外哈~
window正常显示,kali直接加载不出,石锤宽高!

那宽高我们待会再改,我们先来确认一下这个“GIF”图片,那这里我们直接打开“Stegsolve”这个工具;
接着选择——>Analyse——>Frame Browser

最后也是在“9 of 40”看见了关键,但是这个我们看不明白是什么的编码或者密码啊,那就没办法了,那我们转个方向,去把图片的宽高改一下;

得到:bFyd_W1l3_Cah
直接把“hint.png”丢进“010”里面进行宽高修改,最后保存退出也是成功发现了“hint!”
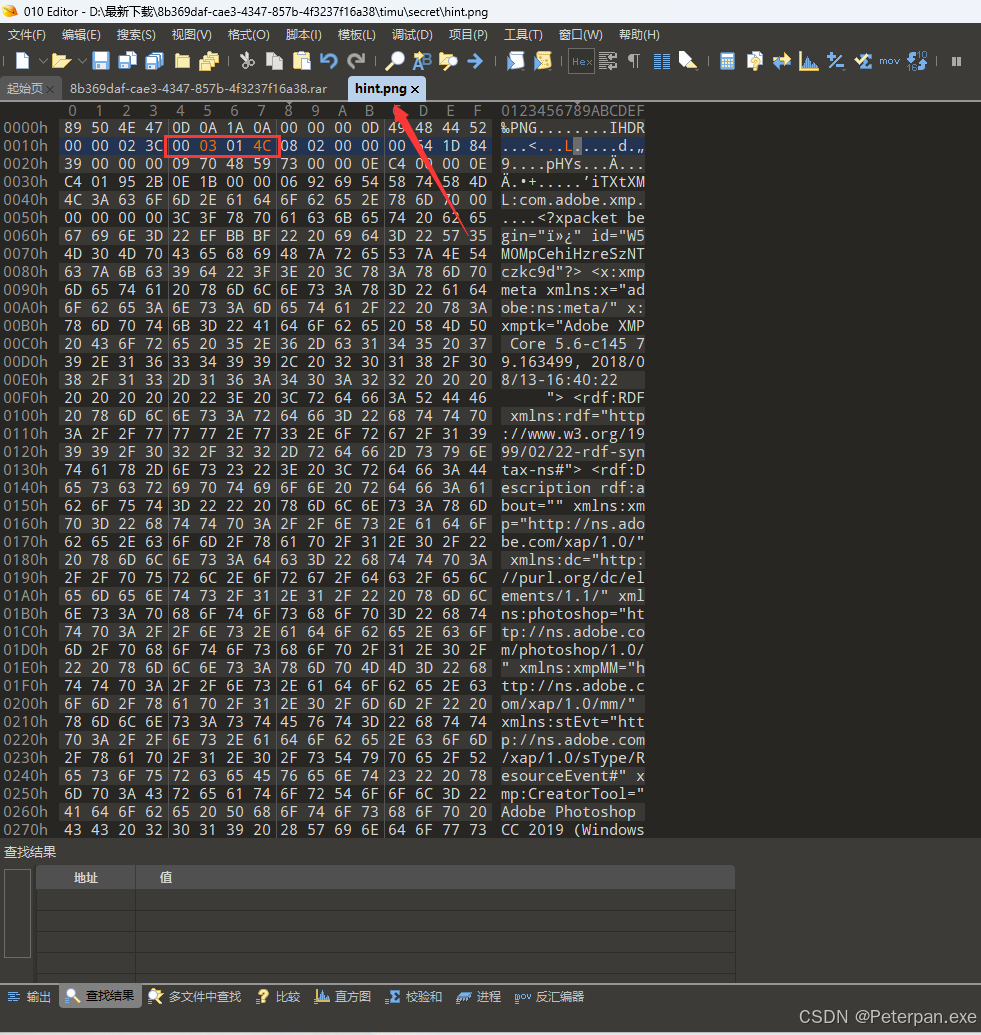
右键打开方式选择“画图“;
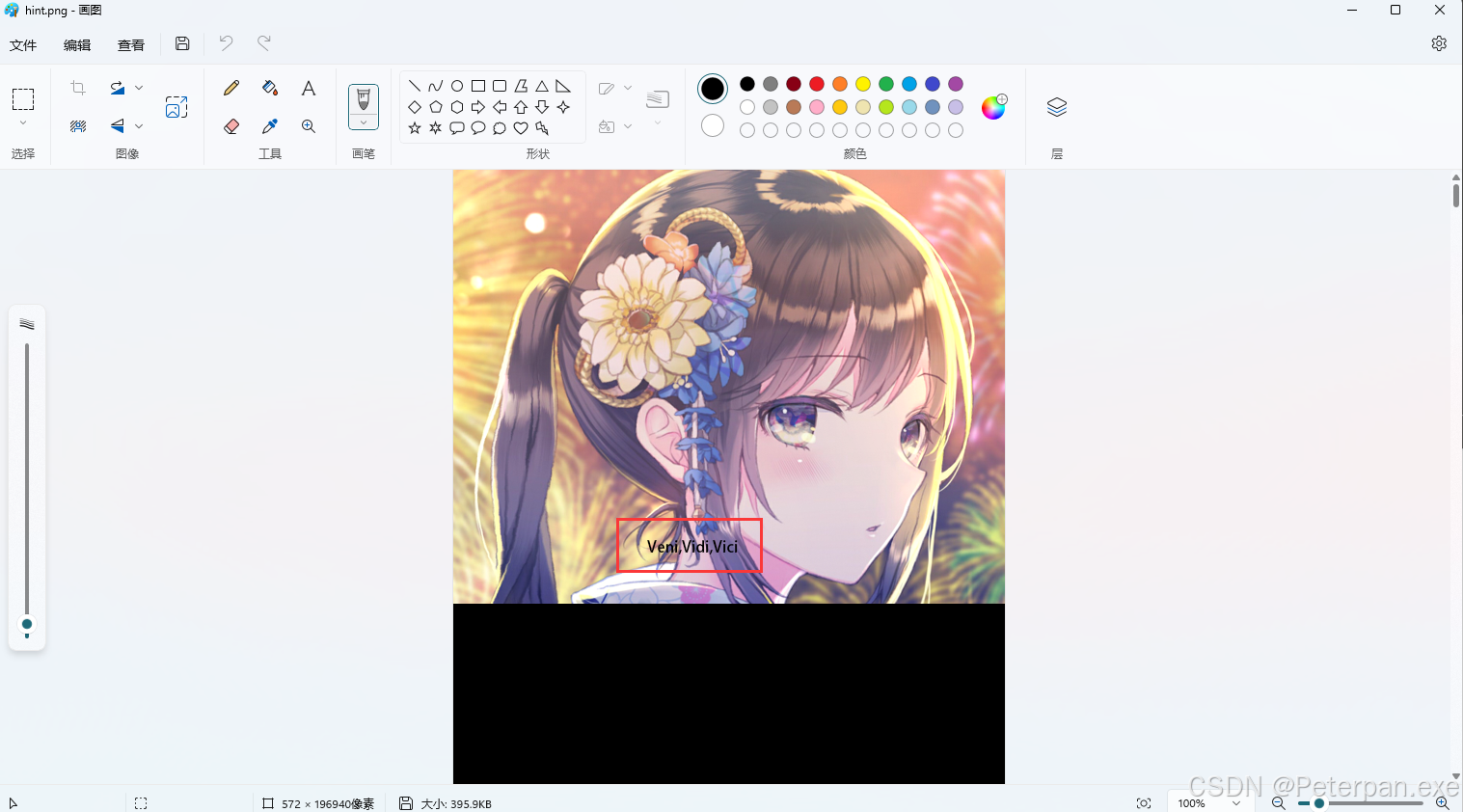
哎哎哎,看见这个又让我想起来凯撒密码,那为什么看见这个:Veni,Vidi,Vici,就能想起来凯撒密码呢?那我们来一起简单说一下;
其实简单来说就是;
看到“Veni, Vidi, Vici”这句拉丁语短语(意思是“我来,我见,我征服”),让人联想到凯撒密码,主要是因为这句话与凯撒(Julius Caesar)的历史关联。凯撒密码是由古罗马将领尤利乌斯·凯撒发明的一种简单的替换加密方式,因此看到凯撒的名言就容易联想到他发明的加密技术。
凯撒密码(Caesar cipher)是一种经典的加密方式,它通过将字母表中的每个字母按固定位数进行偏移来加密消息。比如将字母表每个字母向右偏移3位,A变成D,B变成E,依此类推。
总的来说,看到这句历史上著名的凯撒名言,自然会联想到凯撒密码,因为凯撒本身是这种密码加密方法的发明者。
那这里再结合之前我们得到的神奇编码:bFyd_W1l3_Cah,直接找一个在线凯撒解码的网站进行解码:
但是这里我们值得注意的是,因为凯撒密码是需要知道具体的一个“偏移量”才能进行正确的解码,但是这里并没有对我们说明,而且也没有任何的“hint”,所以这里我就不得不提一下一个专门解凯撒密码的在线网站的一个“枚举”功能!

至此;
flag{sWpu_N1c3_Try}
8、MISC-这是一张单纯的图片
解题思路
这里我们直接下载附件得到一个压缩包,解压得到一张图片“file.jpg”;
“file.jpg”

kali中宽高某问题

那我们直接丢进“010”简单分析一下;
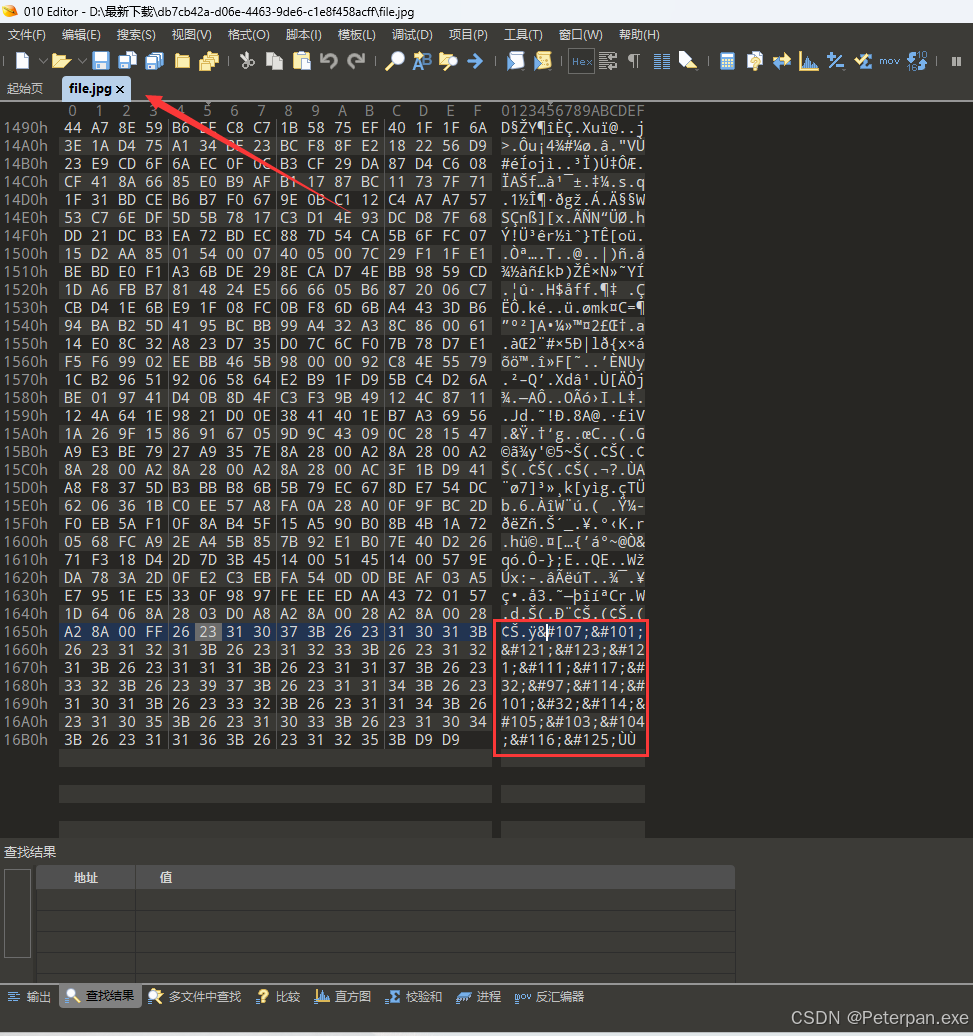
也是在最后发现了很可疑的地方,通过简单的观察,发现这是“Unicode”编码;
key{you are right}ÙÙ
那这里既然提到了“Unicode”编码,那我们就简单说一下“Unicode”编码的特征以及规律;
Unicode编码是一种用于处理不同语言和字符集的国际标准字符编码方案,目的是统一全球各种文字、符号和控制字符。它的主要特征和规律包括:
特征:
-
全球通用:Unicode 包含了世界上几乎所有的书写系统字符,包括拉丁字母、汉字、阿拉伯字母、希腊字母等。它为不同的语言提供统一的字符表示。
-
兼容性强:Unicode 支持多种现有的字符集,并可以与其他编码标准(如ASCII、ISO-8859-1等)兼容,扩展性好。
-
多种编码形式:Unicode有多种实现方式,包括UTF-8、UTF-16和UTF-32,它们之间的主要区别在于存储一个字符所需的字节数:
- UTF-8:使用1至4个字节编码字符,向后兼容ASCII编码,是互联网和文件系统中最常用的Unicode实现。
- UTF-16:使用2个或4个字节编码字符,适用于字符较多的场景(如东亚语言)。
- UTF-32:使用固定的4个字节编码每个字符,但较浪费空间。
-
唯一性:每个字符在Unicode中都有一个唯一的编码点(码位),如汉字“中”的Unicode码是U+4E2D。
规律:
-
基本多文种平面(BMP):Unicode的前65536个码点(从U+0000到U+FFFF)称为BMP,包含常见的字符。超出BMP范围的字符称为增补字符,需要用4字节(在UTF-16中需要两个“代理对”)来编码。
-
字符的分类与区间:Unicode将字符按类型划分,比如数字、字母、符号、标点等,并在特定范围内编码。例如,拉丁字母在U+0000到U+007F之间,汉字从U+4E00到U+9FFF。
-
可扩展性:Unicode最多可以表示超过100万个字符,通过编码范围(U+000000至U+10FFFF)确保未来新的字符可以被添加。
那话不多说,我们直接找一个“Unicode”编码转“ASCll”在线网站即可;
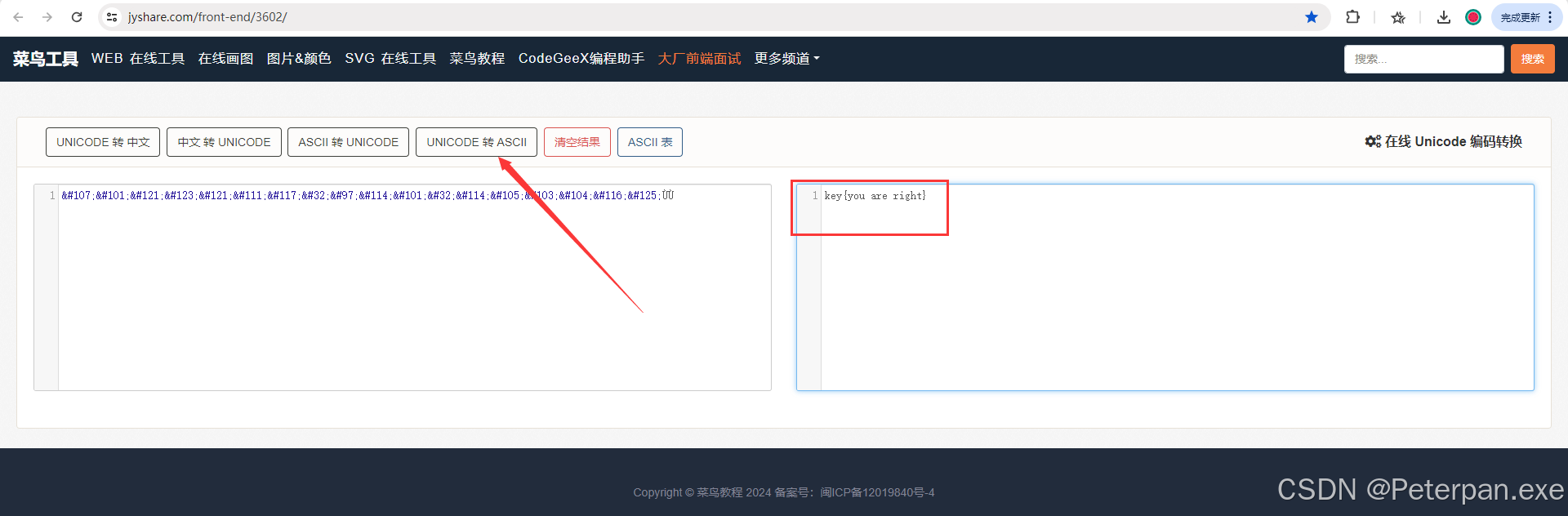
至此;
flag{you are right}
9、MISC-真假flag
解题思路
下载附件得到一个压缩包,解压得到一个空白的文件“真假flag”;
暂时不知道是什么文件,我们直接右键选择打开方式“010”,简单分析一下;
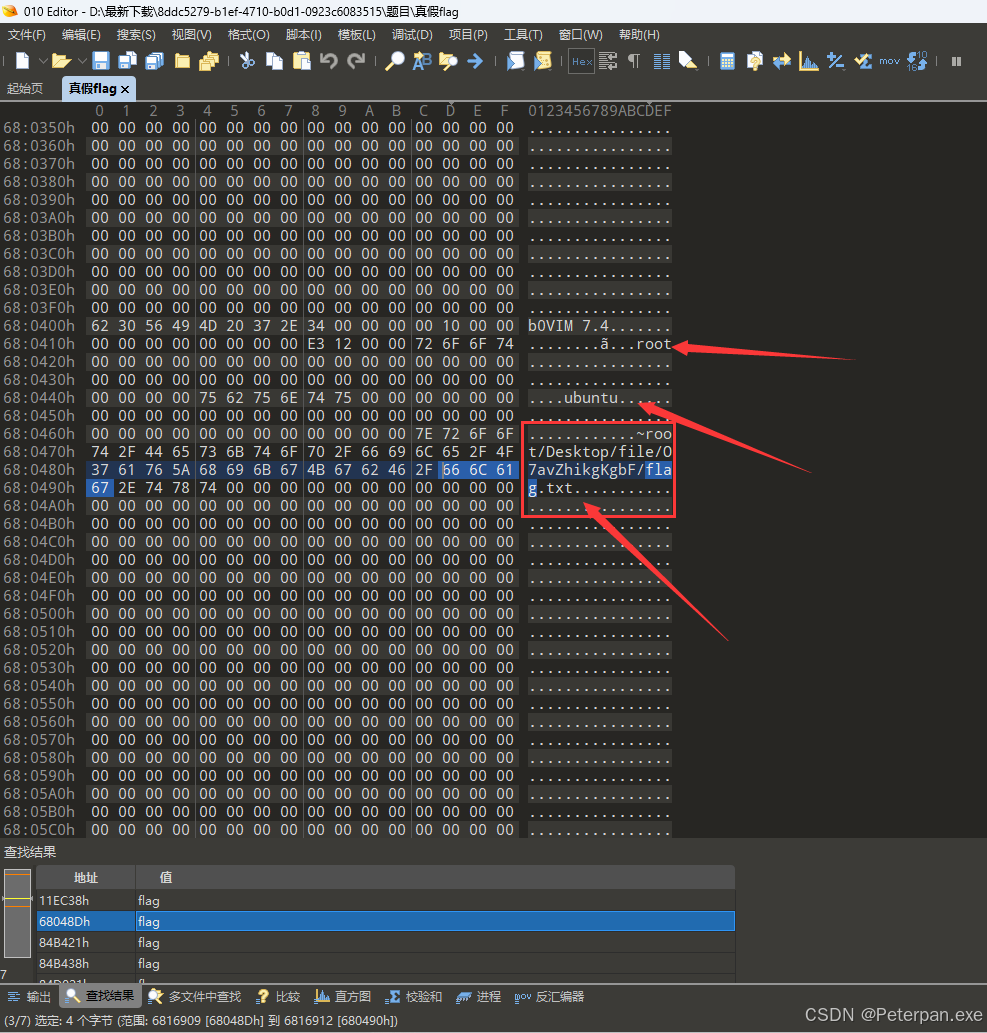
这里我们直接查找“ASCll”的“flag”,也是成功发现了几个关键点,首先就是发现这个文件系统中出现“ubuntu”,以及“root”,所以有理由怀疑这个空白文件是需要通过“Liunx”进行文件读取的,需要类似于“cat”的这种命令,不过现在我们可以尝试一下;
~root/Desktop/file/:通常表示一个文件路径,特别是在 Linux 系统中。~root 代表的是超级用户(root)的家目录,路径下的 Desktop/file/ 则指向桌面上的某个文件夹。
所以我们直接将“真假flag”丢进“Liunx”中进行文件读取;
但是直接读取之后发现全部是乱码而且内容太多也看不过来,所以这里决定换一种方式对文件进行读取;
在 Linux 中,读取文件的常见方式包括:
cat:直接输出文件内容。strings:从二进制文件中提取可打印字符串。more、less:用于分页查看文件内容。head、tail:分别查看文件的开头或结尾部分。od:用于查看二进制文件的八进制或十六进制格式。grep:搜索文件中特定的内容。
那这里我们换一个“strings”试试看,没关系嘛,一个一个尝试;
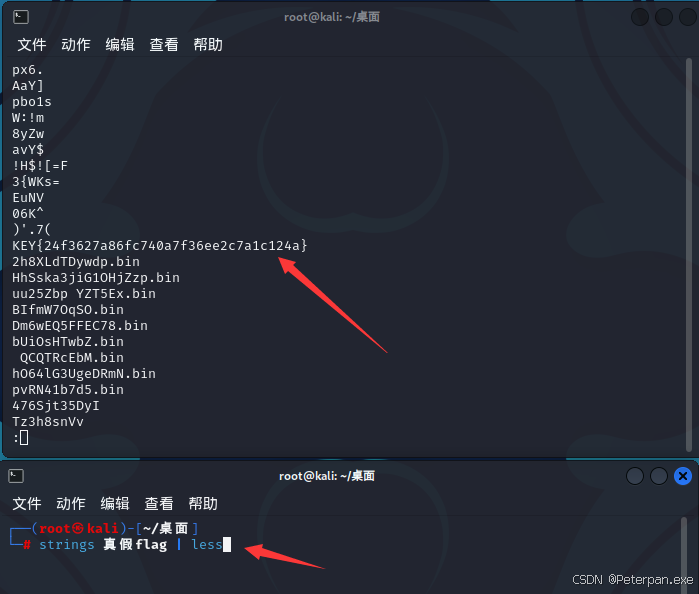
哎,往下翻的时候惊喜的就发现了一个“KEY”,尝试提交发现正确;
至此;
flag{24f3627a86fc740a7f36ee2c7a1c124a}
10、MISC-真正的黑客才可以看到本质
解题思路
下载得到一个压缩包解压得到一个文件夹,文件夹中有几张图片;
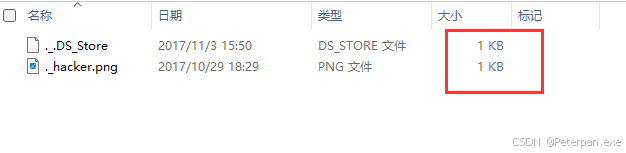
从文件的大小不难看出谁是真正的有关信息的“文件”,那我们直接话不多说,直接“MISC”基本操作一套带走,最后也是在“Stegsolve”的“Blue plane 0”的通道发现一个二维码,扫描直接得出“flag”;
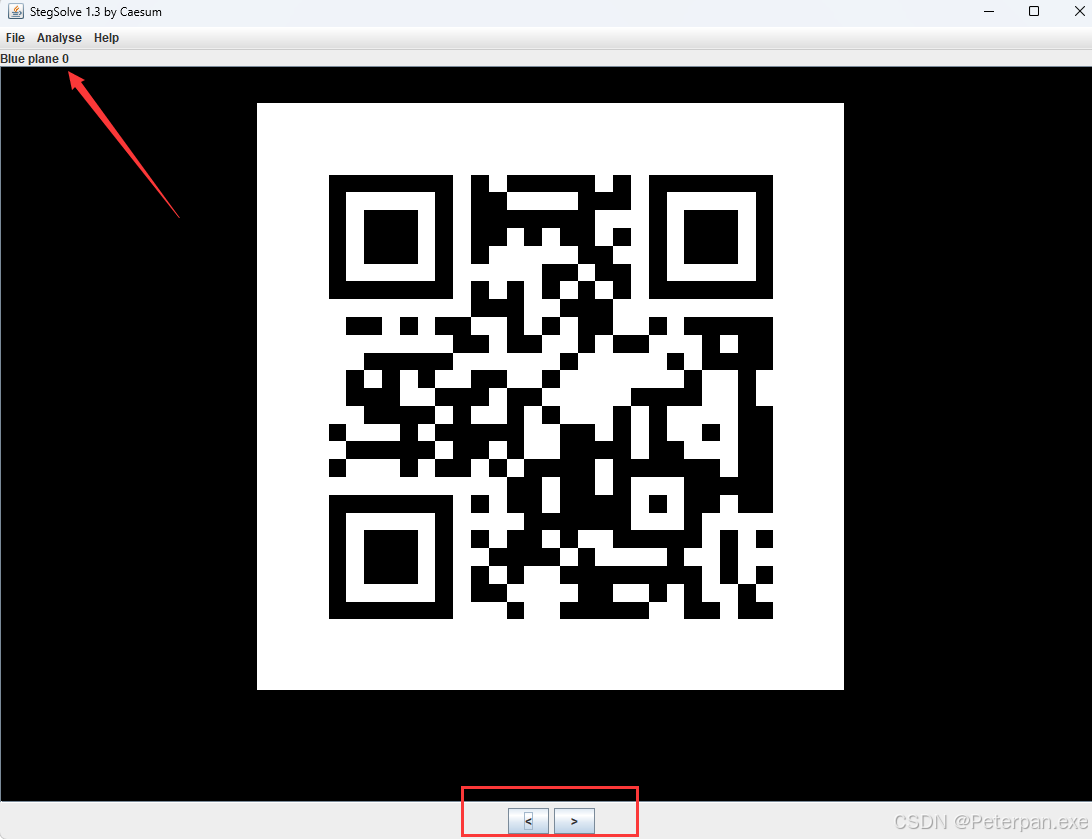
这里扫描我直接上的“QR_Research”;
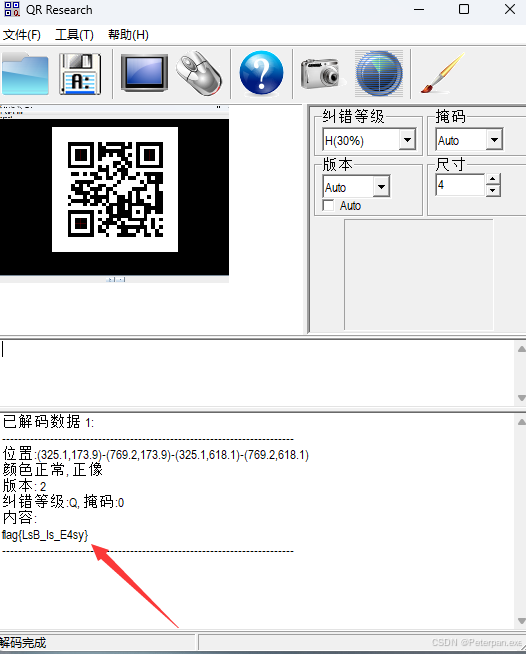
至此;
flag{LsB_Is_E4sy}
11、MISC-追象者
解题思路
下载附件得到一个压缩包,解压出来一个“2.png”;
暂时没发现什么特别的地方,那这里还是老规矩,直接上“MISC”基础操作一套;
最后也是在把图片丢进“Kali”中发现图片既然显示不出来,那多半宽高有一些问题,于是就改了宽高,但是没想到答案一下子就出来了;
“宽高无法正常显示”

“尝试修改图片的高”在“010”中
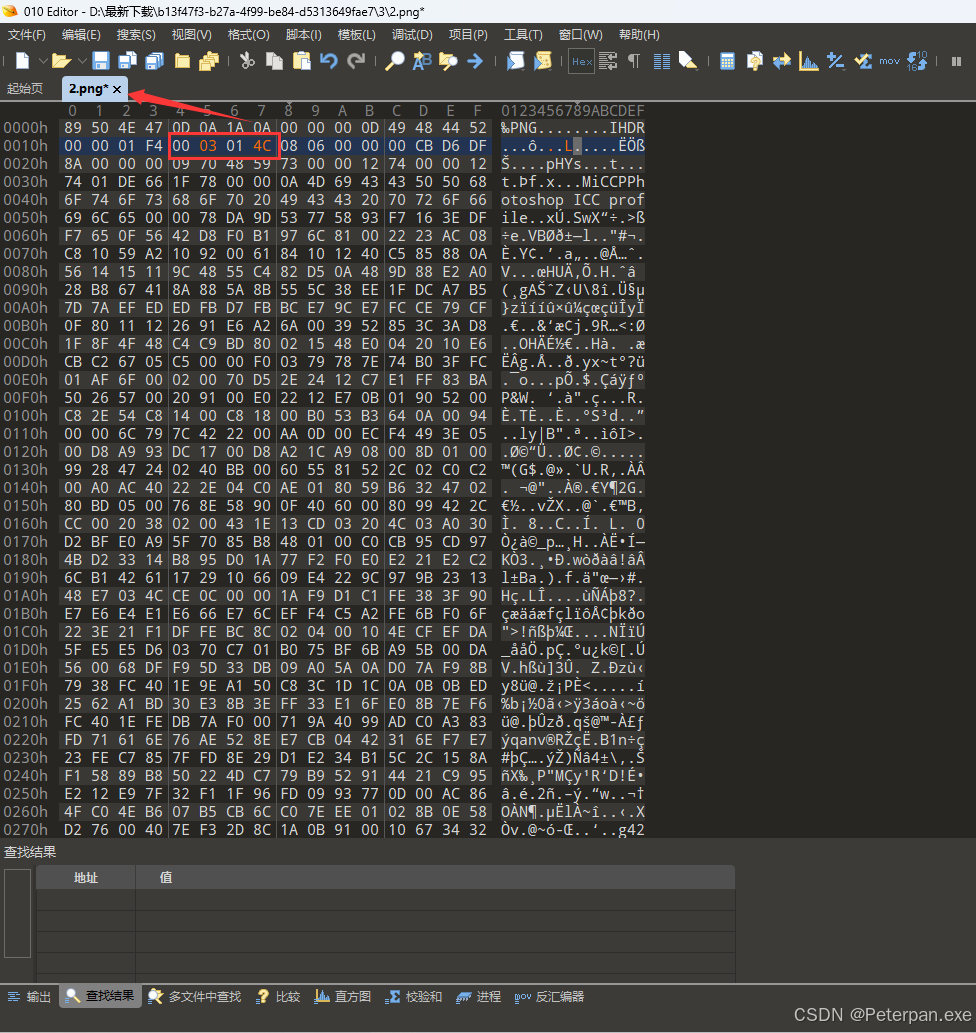
“Ctrl+s”保存退出,图片打开方式选择“画图”;
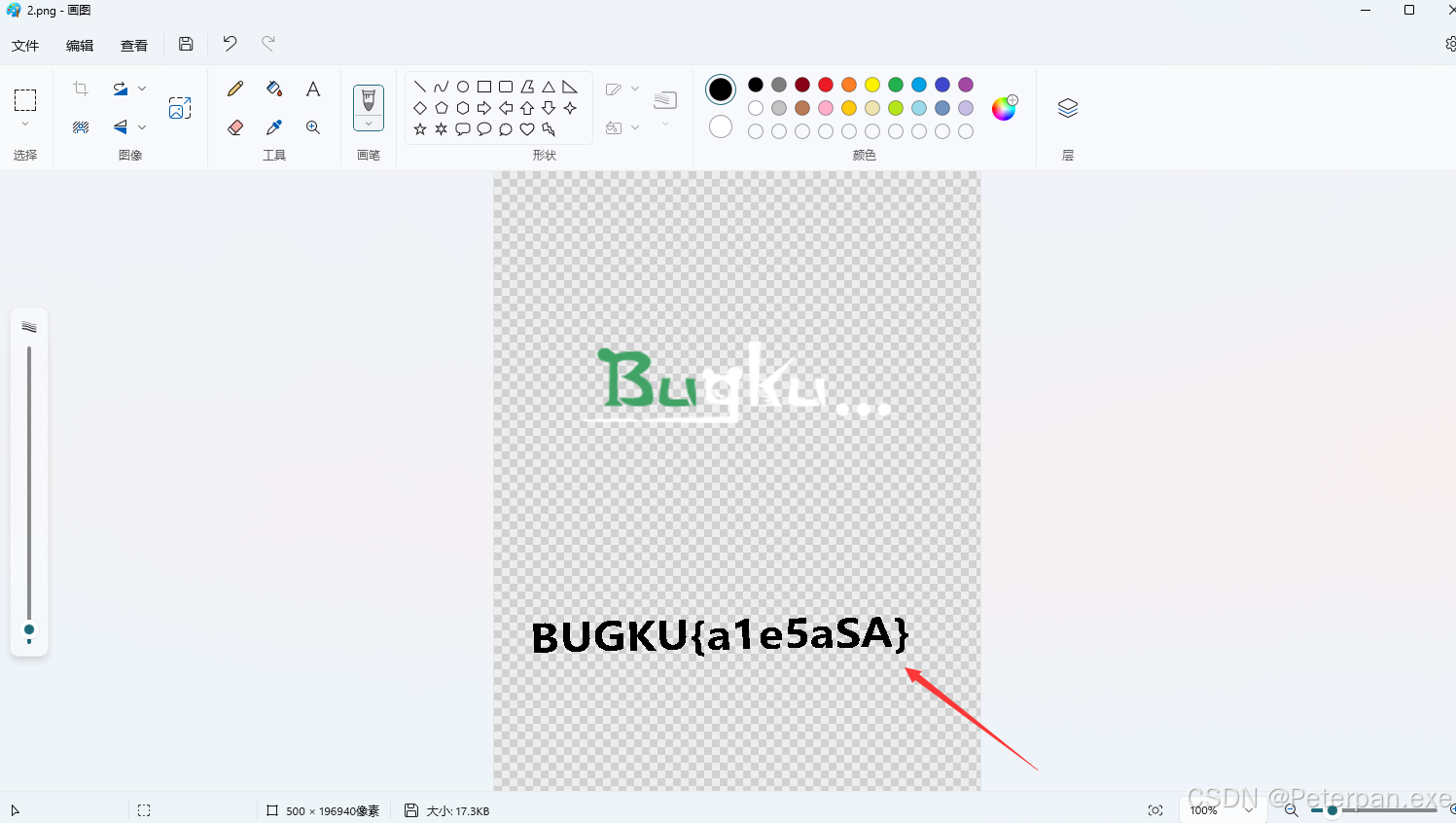
至此;
flag{a1e5aSA}
12、MICS-鸡蛋别放在一起
题目描述:
我藏起了一条重要信息,真是应了一句古语:“鸡蛋不能放在一个篮子里”。所以,额……篮子是不是略多了一点。
解题思路
下载附件得到一个压缩包,解压发现里面一共有“5141”个“txt“文档且每个”txt“文档都有是内容的,而且还发现是都是”base64“加密的字符内容;
“5141个txt文档”
都是“bae64”加密的字符内容
而且我们通过观察文件,偶然发现给个txt文档名字前面都是又26个英文字母的,那我们就尝试把所有的“base64”全部结合在一个txt文档里面会发现什么呢?其实也是没有办法的办法总不能一个一个去文档去解“base64”编码对吧?很显然不切实际;
“发现文档排序是有规律的,尝试讲所文档内容结合在一起”
但是正要准备些脚本的时候,突然发现这个文件名称有点古怪,而且这个排序也并不是我们想的那样,感觉直接使用“26个英文字母”还是会出现很多的“a”、很多“b”,而且最后也不知道能拼出个啥样的来,所以我决定对文件名称研究一下,看看有没有什么规律!
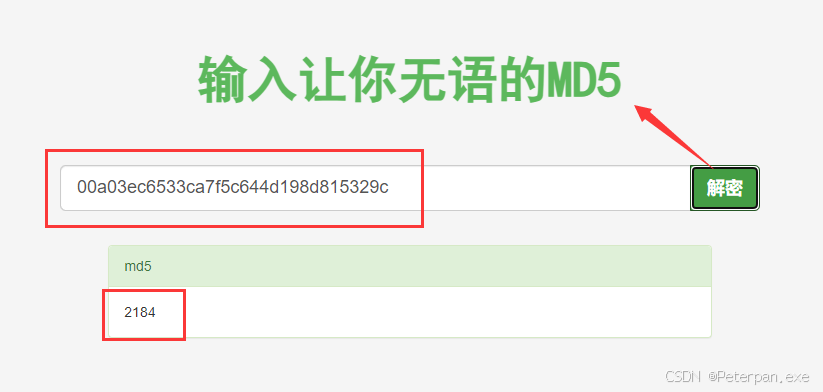
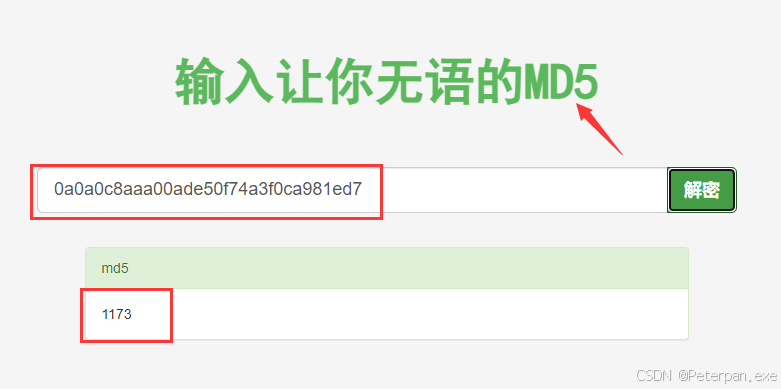
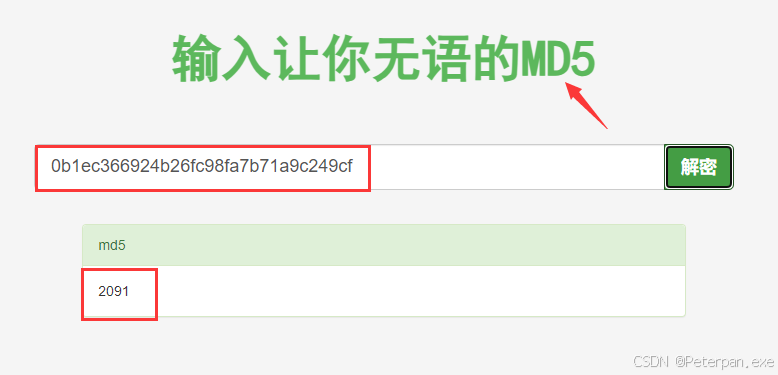
哎,拿去进行“MD5”解密的时候发现既然可以解出来,而且还是个数字,那这时候就正式了我们前面的猜想,这个文件的排序并不是简单的文件名“26个字母”排序,还可以进行“MD5解密”得出其中文件的具体数字,那这时候我们就可以根据文件MD5数值把每个文件的内容进行排序拼接试试看!
那这里我们直接上脚本,手动是不可能手动呢那么文件呢!
脚本如下;(Python)
import base64 # 导入 base64 编码库,用于对 base64 编码的字符串进行解码
import zipfile # 导入 zipfile 库,用于处理 ZIP 文件
import hashlib # 导入 hashlib 库,用于生成 MD5 哈希值
# 创建一个字典,键是从 0 到 5140 的数字的 MD5 哈希值,值是对应的数字
dic = {hashlib.md5(str(i).encode()).hexdigest(): i for i in range(5141)}
# 打开 ZIP 文件
zf = zipfile.ZipFile("./1111.zip")
# 创建一个长度为 5141 的空字符列表,代表解压后的 base64 编码数据
baseStr = list(5141 * " ")
# 遍历 ZIP 文件中的所有文件名
for fileName in zf.namelist():
# 去掉文件名中的 .txt 后缀,得到文件名的 MD5 值
md5 = fileName.replace(".txt", "")
# 使用字典查找文件名对应的数字,将对应文件的内容(base64 编码)放到 baseStr 中正确的位置
baseStr[dic[md5]] = zf.read(fileName)
# 将 base64 编码的字符列表连接成一个字符串,并解码成原始数据
with open("flag.out", "wb") as f:
f.write(base64.b64decode(b''.join(baseStr))) # 将解码后的数据写入 flag.out 文件
脚本简单分析;
-
哈希字典生成:
dic = {hashlib.md5(str(i).encode()).hexdigest(): i for i in range(5141)}:首先,创建一个字典dic,其中键是从 0 到 5140 的数字的 MD5 哈希值,值是对应的数字。这样可以通过文件名中的 MD5 值,找到相应的数字位置。
-
打开 ZIP 文件:
zf = zipfile.ZipFile("1a8158054c76602e19ee7face3c3aaef.zip"):这行代码打开名为1a8158054c76602e19ee7face3c3aaef.zip的 ZIP 文件,准备对其中的文件进行读取。
-
处理文件并重建 base64 字符串:
-
baseStr = list(5141 * " "):创建一个长度为 5141 的空字符串列表baseStr,用于存储文件内容。每个文件名对应 ZIP 文件中的一个文件,文件名是经过哈希处理的数字。 -
for fileName in zf.namelist()::遍历 ZIP 文件中所有文件的名字。 -
md5 = fileName.replace(".txt", ""):去除.txt扩展名,获取文件名中包含的 MD5 哈希值。 -
baseStr[dic[md5]] = zf.read(fileName):通过文件名的 MD5 值查找其对应的数字索引,读取文件内容并存入baseStr的正确位置。每个文件的内容应该是 base64 编码的数据片段。
-
-
解码 base64 并写入文件:
-
with open("flag.out", "wb") as f::打开或创建一个名为flag.out的文件,准备将解码后的数据写入其中。 -
f.write(base64.b64decode(b''.join(baseStr))):将baseStr列表中的所有字符串连接起来,然后使用base64.b64decode()进行解码,得到原始数据并写入flag.out文件。
-
总结:
- 这个脚本的功能是从一个 ZIP 文件中提取经过 MD5 哈希处理的文件名,按照文件名对应的顺序拼接文件内容(base64 编码),然后解码成原始数据并保存到
flag.out文件中。
运行得到;
打开文件“flag.out”里面有两个文件“flag.jpg”及“hint.txt”;
那我们打开“hint.txt”
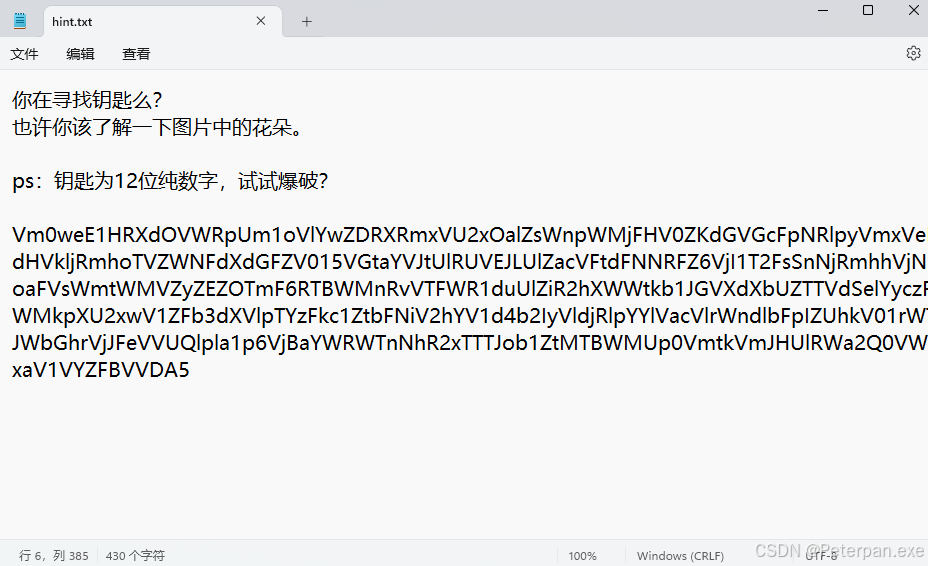
这时候观察里面的内容,会发现让我去了解一下图片中的花朵,花朵我们暂且不说,我们现在可以先把下面这窜“base64”解码一下看看是啥;
ps:我也是真服了,套那么多层base64,真好!
最终也是经过“9次”解码得出了:劝你还是多看看花吧
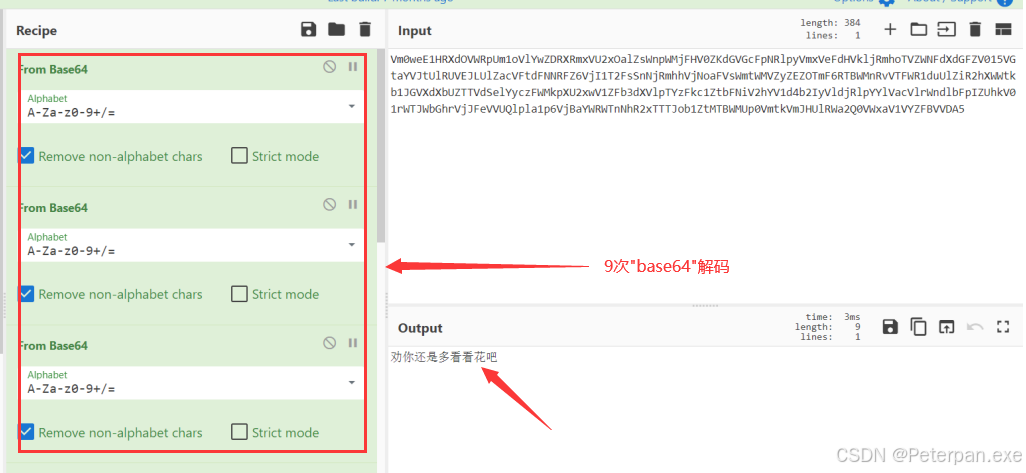
那图片中的花也不知道是什么呀,那没办法毕竟是联网的,我们直接上百度识图看看这是什么花,或者看看还有什么提示吧!
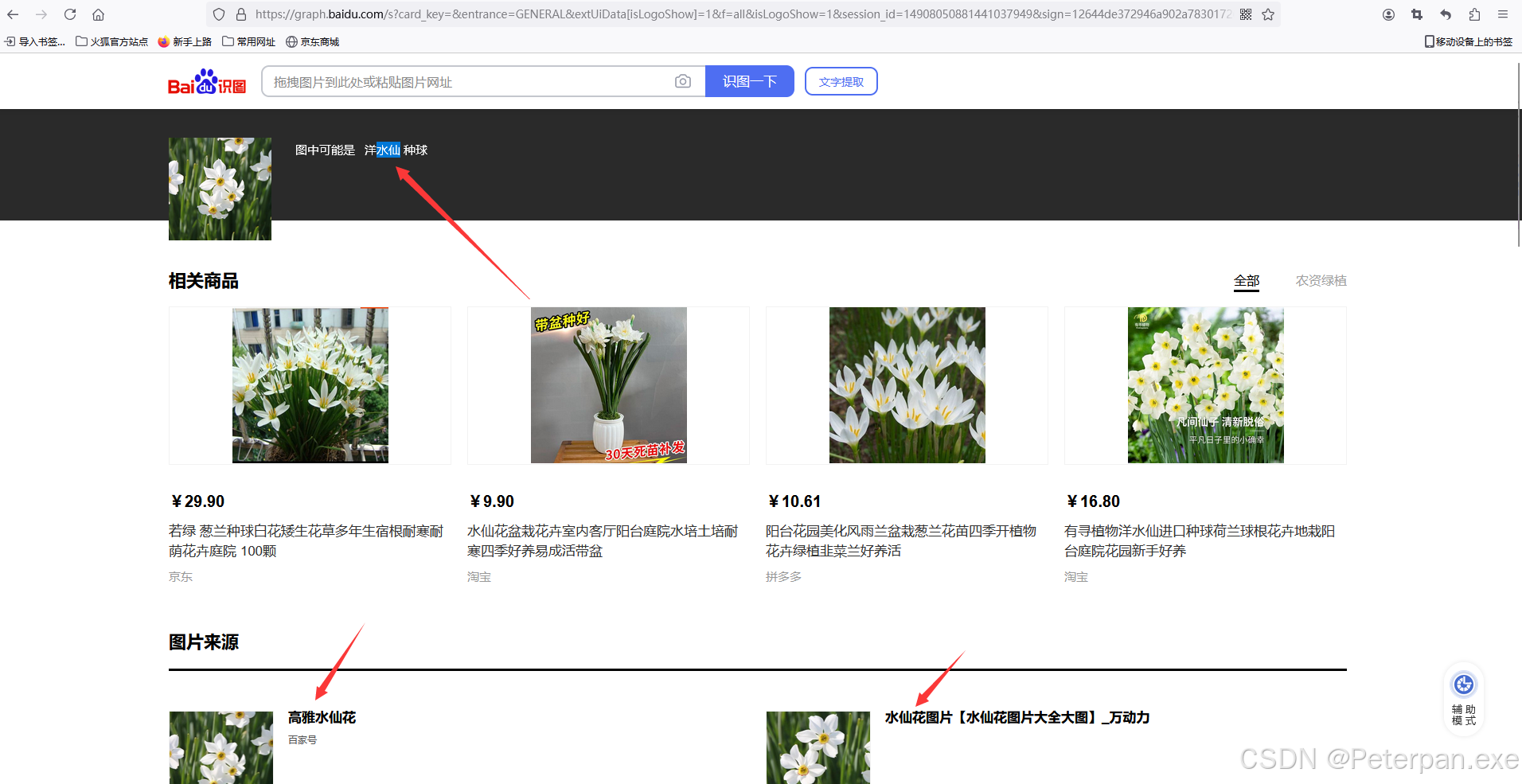
得出的说明中,无不透露着这是“水仙花”,那水仙花又关这个什么事呢?于是也是抱着尝试去百度直接搜索“水仙花”这三个字也是有了惊奇的发现!
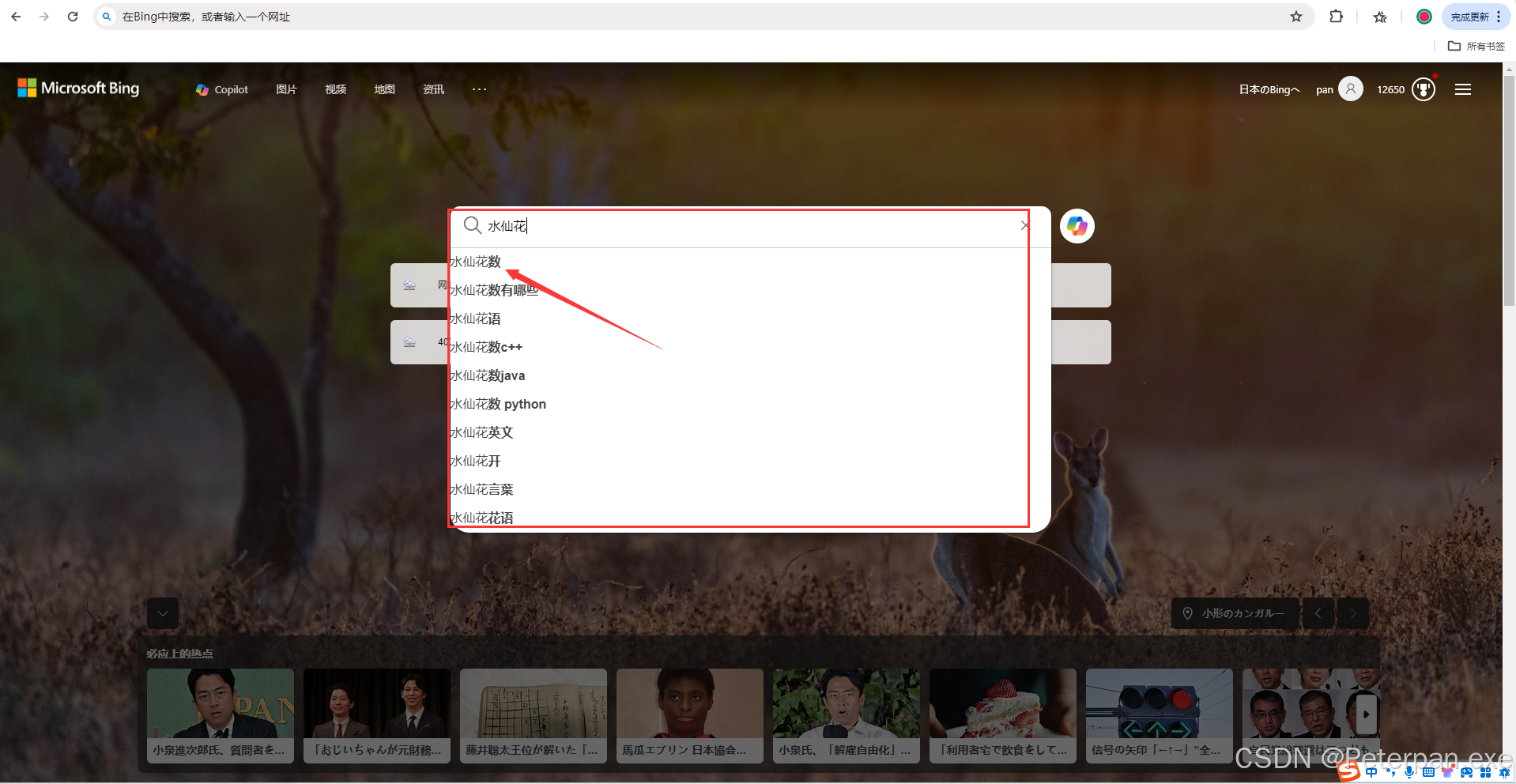
这边我用的是“bing”的搜索引擎,这不查不知道一查吓一跳啊,水仙花数兜出来了!那有什么办法,我们只能简单先了解一下什么是“水仙花数吧!”
什么是水仙花数?
水仙花束(Narcissistic Numbers,或称为自恋数)是一种特殊的数字类型。它是指一个n位的正整数,其各个位上的数字的n次方的和等于该整数本身。
水仙花数的特点:
- 只有在满足“某个数的每一位数字的n次幂的和等于该数本身”时,才能称为水仙花数。
- n位数的水仙花数一般是稀有的,随着位数的增加,符合条件的数目会减少。
当然水仙花数也可以是指一个 n 位数,它等于其每个位上的数字的 n 次方之和。简单来说,如果一个数满足以下条件:
x=d1n+d2n+⋯+dnnx = d_1^n + d_2^n + \dots + d_n^nx=d1n+d2n+⋯+dnn
其中,xxx 是这个数,d1,d2,…,dnd_1, d_2, \dots, d_nd1,d2,…,dn 是它的每一位数字,nnn 是数字的位数,那么这个数就是水仙花数。
那这边我们举例最常见的 3位水仙花数有 4个:
-
153:
13+53+33=1+125+27=1531^3 + 5^3 + 3^3 = 1 + 125 + 27 = 15313+53+33=1+125+27=153 -
370:
33+73+03=27+343+0=3703^3 + 7^3 + 0^3 = 27 + 343 + 0 = 37033+73+03=27+343+0=370 -
371:
33+73+13=27+343+1=3713^3 + 7^3 + 1^3 = 27 + 343 + 1 = 37133+73+13=27+343+1=371 -
407:
43+03+73=64+0+343=4074^3 + 0^3 + 7^3 = 64 + 0 + 343 = 40743+03+73=64+0+343=407
简单分析:
- 这些数的共同点是它们都可以通过计算每个数字的立方和得到自身。
- 它们是三位数水仙花数,并且不多,只有这4个。
所以常用且常见的也仅仅只有这四个:153、370、371、407
正当又准备没思路的时候,哎!突然又发现水仙花的图片中丢进“010”分析翻到最底下“十六进制”,既然惊奇的发现了“RC4”!,那这时候可能新来的师傅又懵了,什么是“RC4”啊?没关系我们不嫌麻烦这边也简单介绍一下!
水仙花图片在“010”最底部发现“RC4”!
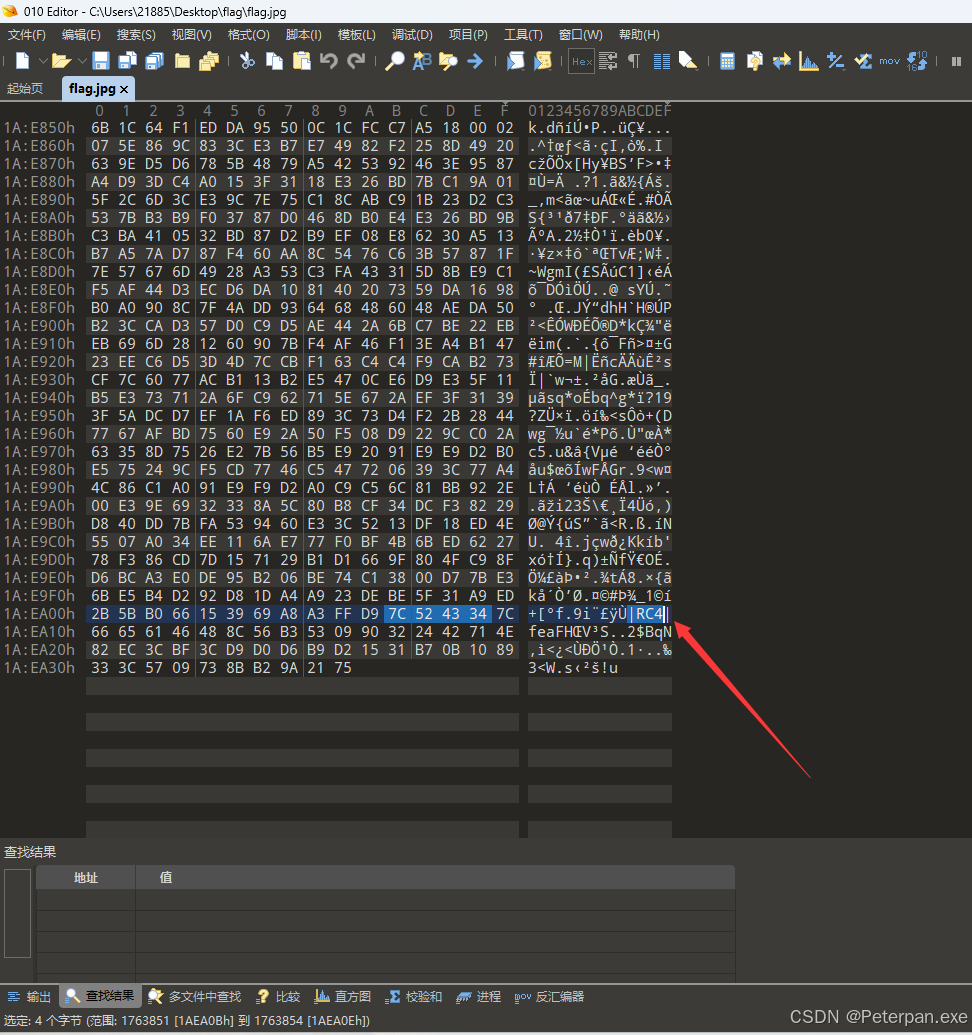
什么是“RC4”?
简单来说就是RC4 是一种流加密算法,由 Ron Rivest 于 1987 年设计,RC4 代表 “Rivest Cipher 4”。它曾广泛应用于多种加密协议(如 SSL/TLS 和 WEP/WPA 等),但由于其弱点,现已被逐步淘汰。
RC4 的工作原理
-
密钥调度算法 (KSA):
- 生成初始的状态向量 SSS,大小为 256 字节(从 0 到 255),并通过密钥来混淆该状态。
- 使用用户提供的密钥来初始化并打乱状态向量。
-
伪随机数生成算法 (PRGA):
- 根据状态向量 SSS 生成伪随机的字节流(密钥流)。
- 将明文与密钥流进行按位异或 (XOR) 操作,生成密文。
RC4 算法步骤:
- 初始化:将一个长度为 256 字节的状态向量 SSS 初始化为 0 到 255 的整数序列。
- 密钥调度:使用密钥打乱状态向量 SSS。
- 生成密钥流:通过 PRGA 生成密钥流,然后将密钥流与明文异或,生成密文。
那这里既然知道是"RC4"加密,我们就去“Cyber”里面简单解码一下;
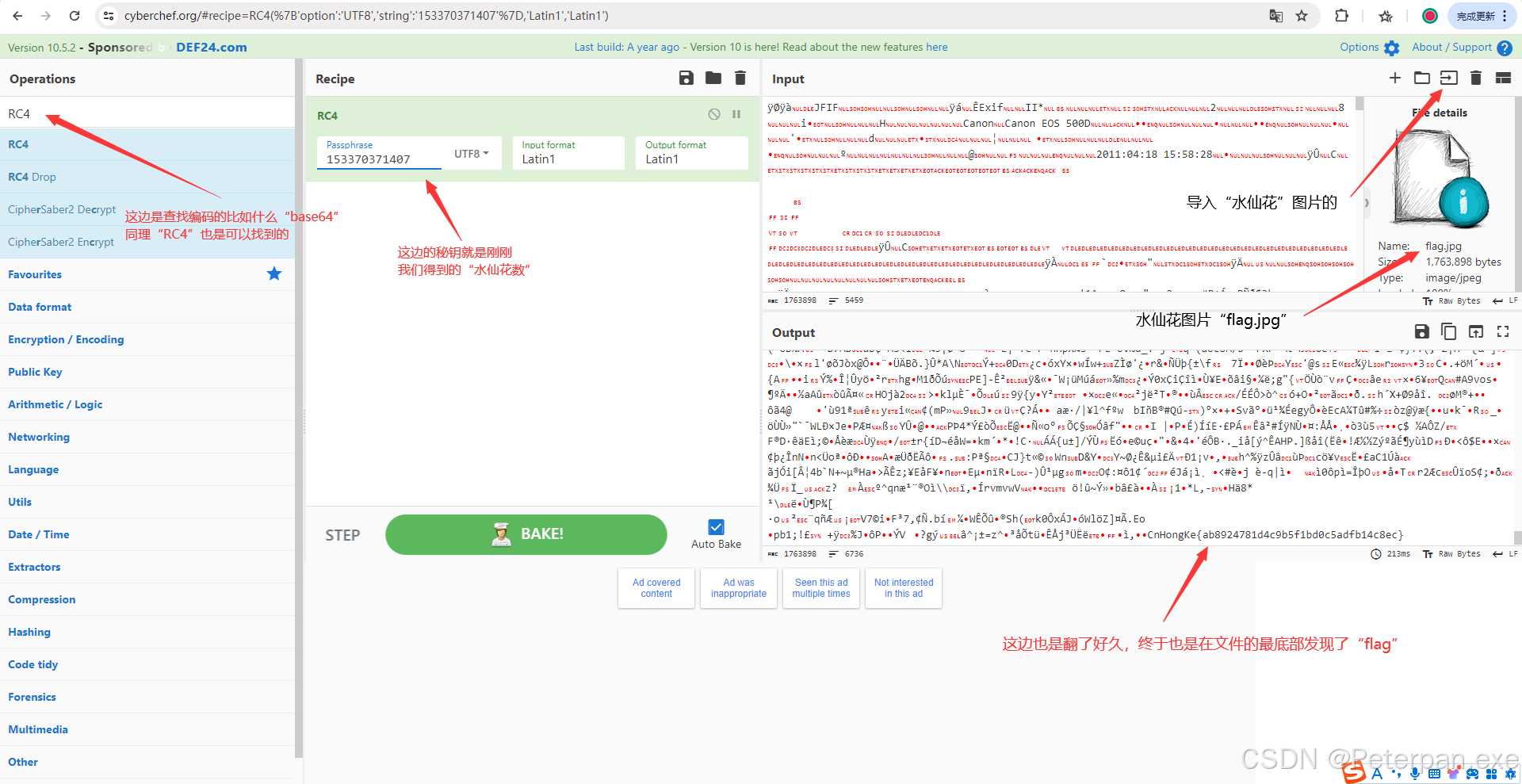
最后我们也是直接“导入flag.jpg”的图片,至于“RC4”的秘钥就是前面得到的“水先花数”,最后的最后也是翻了很久,终于在文件的最底部发现了flag!
至此;
CnHongKe{ab8924781d4c9b5f1bd0c5adfb14c8ec}