一、对象销毁
纯C++类销毁
尽量不要使用new、delete方案,可以使用智能指针。智能指针会使用引用计数来完成自动的内存释放。
使用MakeShareable函数可以来转化普通指针为智能指针。
TSharedPtr<YourClass> YourClassPtr = MakeShareable(new YourClass());
UObject类
无法使用智能指针来管理UObject对象。
UObject类采用自动垃圾回收机制。当一个类的成员变量包含指向UObject的对象,同时又带有UPROPERTY宏定义,那么这个成员变量将会触发引用计数机制。
垃圾回收器会定期从根节点Root开始检查,当一个UObject没有被别的任何UObject引用,就会被垃圾回收。可以通过AddToRoot函数来让一个UObject一直不被回收。
;
Actor类
Actor类对象可以通过调用Destroy函数来请求销毁。
二、从C++到蓝图
UPROPERTY
当需要将一个UObject类的子类的成员变量注册到蓝图中时,只需要借助UPROPERTY宏即可。
UPROPERTY(BlueprintReadWrite, VisibleAnywhere,Category="Object")
BlueprintReadWrite 可从蓝图读取或写入此属性。此说明符与 BlueprintReadOnly 说明符不兼容。
VisibleAnywhere 说明此属性在所有属性窗口中可见,但无法被编辑。此说明符与“Edit”说明符不兼容。
Blueprintable - 该类可以由蓝图扩展。
BlueprintReadOnly - 该属性可以从蓝图读取,但不能写入蓝图。
EditAnywhere - 该属性可以在原型和实例上的属性窗口中编辑。
Category - 定义该属性将出现在编辑器“细节(Details)”视图下面的哪个部分。这对于整理结构而言十分有用。
BlueprintCallable - 该函数可以从蓝图调用。仅用于组播委托。应公开属性在蓝图代码中调用。
UFUNCTION
UFUNCTION(BlueprintCallable, Category="Object")
可选的还有:
BlueprintImplementEvent:表示这个成员函数有其蓝图的子类实现,不应该尝试在C++中给出函数的实现,这会导致错误。
BlueprintNativeEvent:表示这个成员函数提供一个“C++的默认实现”,同时也可以被蓝图重载。需要提供一个“函数名_Implement”的函数实现,放置于.cpp中。
说明符众多,不便在此一一列出,但可以参考下面的链接:
UCLASS说明符列表
UPROPERTY说明符列表
UFUNCTION说明符列表
USTRUCT说明符列表
三、引擎相关的类
1. FPaths类
FPaths::GameDir() 游戏根目录
FPaths::FileExists() 文件是否存在
FPaths::ConvertRelativePathToFull() 转变相对路径为绝对路径
2.使用Log类
FString dir = FPaths::ProjectPluginsDir(); UE_LOG(LogTemp, Log, TEXT("%s"), *dir);
第一个参数是Log的分类,第二个参数是Log的类型,分为Log,Warning,Error。Log灰色,Warning黄色,Error红色。具体输出内容为TEXT宏,有三种常用符号:
1.%s字符串(Fstring)
2.%d整形数据(int32)
3.%f浮点型(float)
3.文件的读写与访问
FString str = FPaths::ProjectDir() + TEXT("Setting.xml"); if (FPlatformFileManager::Get().GetPlatformFile().FileExists(*str)) { }
FPlatformFileManager::Get().GetPlatformFile()获得一个IPlatformFile类型的引用,这个接口提供了通用的文件访问接口。
4.字符串处理
FName 是无法被修改的字符串,不管出现多少次,在字符串表中只被存储一次。
FText 提供本地化支持。
FString 是唯一提供修改操作的字符串类。
5.ImageWrapper
转换图片类型;从硬盘导入图片作为贴图。
图片文件自身的数据是压缩后的数据,称为CompressedData
图片对应的真正的RGBA数据,是没有压缩的,与格式无关,称为RawData
所有的图片格式,都可以抽象为一个CompressedData和RawData的组合。
读取JPG图片:
从文件中读取为TArray的二进制数据
使用SetCompressData填充为压缩数据
将压缩后的数据借助ImageWrapper的GetRaw转换为RGB数据
填充RGB数据到UTexture的数据中
转换PNG图片到JPG:
从文件中读取为TArray的二进制数据
使用SetCompressData填充为压缩数据
将压缩后的数据借助ImageWrapper的GetRaw转换为RGB数据
SetRaw将RGB数据填充到JPG类型的ImageWrapper中
使用GetCompressData获得压缩后的JPG数据
最后用FFileHelper写入到文件中
6.模块机制
虚幻源码目录包含四大部分:Runtime,Development,Editor,Plugin
每个部分有包含了很多个模块。
一个模块文件夹包含:Public文件夹,Private文件夹,模块构建文件.build.cs
只有通过XXX_API宏暴露的类和成员函数才能被其他模块访问。
1. 模块包含文件结构:
模块名.build.cs (模块构建文件,告知UBT如何配置自己的编译和构建环境)
public文件夹:
模块名.h
private文件夹:
模块名.cpp
模块名PrivatePCH.h (模块预编译头文件,加速代码的编译,当前模块公用的头文件可以放置于这个头文件中,当前模块所有的.cpp文件,都需要包含预编译头文件)
2. 引入模块
对于游戏模块,引入当前模块的方式是在游戏工程目录下的Source文件夹中,找到工程名.Target.cs文件。修改SetupBinaries函数,添加引入的模块。
对于插件模块,修改当前插件的.uplugin文件,在Modules数组中引入新的模块。
3. 虚幻引擎初始化
初始化分为预初始化和初始化。
首先加载的是FPlatformFileModule,读取文件
调用FEngineLoop::PreInit,预初始化PreInit:
设置路径:当前程序路径,当前工作目录路径,游戏工程路径
设置标准输出:GLog系统输出
初始化游戏主线程GameThread,把当前线程设置为主线程
初始化随机数系统
初始化TaskGraph任务系统,并按照当前平台核心数量设置TaskGraph的工作线程数量
加载核心模块,FEngineLoop::LoadCoreModules,加载CoreUObject
在初始化引擎之前,加载模块,FEngineLoop::LoadPreInitModules,包括:引擎模块、渲染模块、动画蓝图、Slate渲染模块、Slate核心模块、贴图压缩模块和地形模块。
加载这些模块后,AppInit函数会被调用,进入引擎正式的初始化阶段。
所有被加载到内存中的模块,如果有PostEngineInit函数,都会被调用从而初始化。借助IProjectManager完成。
游戏主循环
GEngine->Tick:最重要的任务是更新当前的World。无论是编辑器中正在编辑的World,还是游戏模式下只有一个的World。此时所有World中持有的Actor都会被得到更新。
很多任务无法在一次Tick中完成,就会分在多次Tick函数中完成。
8.虚幻内存分配
《游戏引擎架构》书中,对内存分配方案重点提到两个方面:
1. 通过内存池降低malloc消耗
2. 通过对齐降低缓存命中失败消耗。
在虚幻引擎中,主要使用还是Intel TBB内存分配器提供的scalable_allocator:不在同一个内存池中分配内存,解决多线程竞争带来的无谓消耗;cache_aligned_allocator:通过缓存对齐,避免假共享。
9.多线程
FRunnable
1. 声明一个继承自FRunnable的类FRunnableTestThread,并实现三个函数:Init、Run和Exit。
2. 借助FRunnableThread的Create方法,第一个参数传入FRunnable对象,第二个参数传入线程的名字。
FRunnableThread::Create(new FRunnableTestThread(0), TEXT("TestThread"));
Task Graph任务系统
由于采用的是模板匹配,不需要每个Task继承自一个指定的类FTestTask,只要具有指定的几个函数,就能够让模板编译通过。
GetTaskName:静态函数,返回当前Task的名字
GetStatId:静态函数,返回当前Task的ID记录类型,可以借助RETURN_QUICK_DECLARE_CYCLE_STAT宏快速定义一个并返回。
GetDesiredThread:指定Task在哪个线程执行
GetSubsequentsMode:用来进行依赖检查的前置标记
DoTask:最重要的函数,Task的执行代码
TGraphTask<FTestTask>::CreateTask(NULL, ENamedThreads::GameThread). ConstructAndDispatchWhenReady(0);
Std::Thread
C++11的特性
10.UObject
对象初始化分为:内存分配和对象构造阶段。
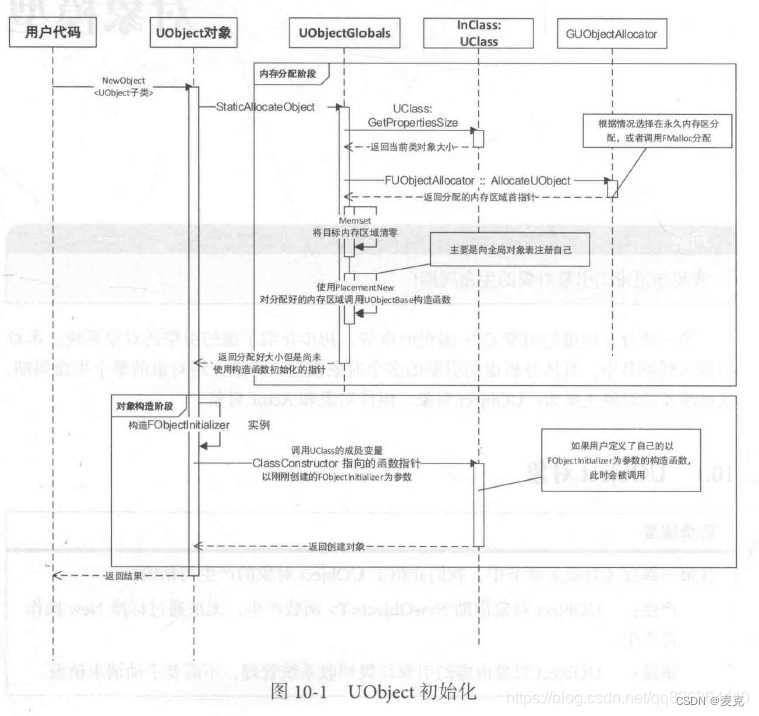
内存分配阶段:
获取当前UObject对象对应的UClass类的信息,根据类成员变量的总大小,加上内存对齐,然后在内存中分配一块合适的区域存放。
对象构造阶段:
获取FObjectInitializer对象持有的、指向刚刚构造出来的UObject指针,调用以FObjectInitializer为参数的构造函数(ClassConstructor),完成对象构造。
序列化
虚幻引擎序列化每个继承自UClass类的默认值,然后序列化对象与类默认对象的差异。节约了大量子类对象序列化后的存储空间。
反序列化:先实例化对应类的对象,然后还原原始对象数据
如果成员变量没有被UPROPERTY标记,不会被序列化。
如果成员变量与默认值一致,也不会进行序列化。
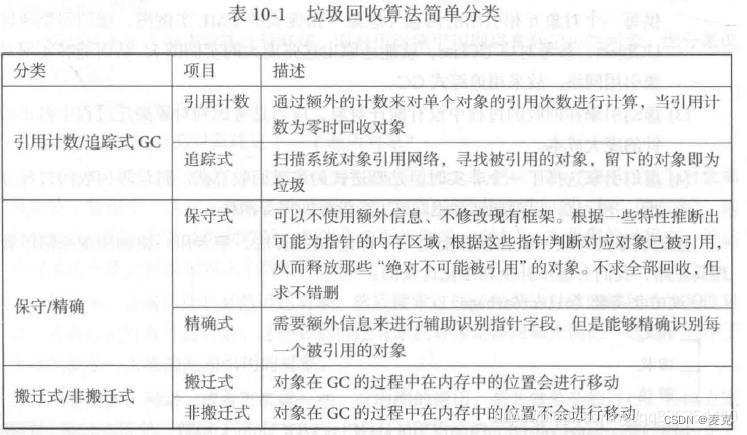
11.垃圾回收
垃圾回收算法
引用计数法
给每个东西保持一个引用计数。用时加1,不用减1。一旦减为0,进行回收。
优点:
引用计数不用暂停,是逐渐完成的。将垃圾回收的过程分配到运行的过程中。
缺点:
指针操作开销,每次使用都要调整引用计数,频繁使用的物品,频繁修改计数是很大的一笔开销。
环形引用,互相引用的对象,锅与锅盖配套,互相引用,导致两者引用计数都是1。但是实际上需要把锅和锅盖一起垃圾回收。
标记-清扫算法
是追踪式GC的一种。追踪式引用计数算法会寻找整个对象引用网络,从应用程序的root出发,利用相互引用关系,遍历其在Heap(堆)上动态分配的所有对象,没有被引用的对象不被标记,即成为垃圾;存活的对象被标记,即维护成了一张“根-对象可达图”。
优点:
没有环形引用问题,即使锅盖和锅互相引用,也可以垃圾回收。
缺点:
必须暂停,执行完垃圾回收算法后,才能继续做其他事情,导致系统有延迟。
如果只是丢掉垃圾而不整理,就会导致可用空间越来越细碎,最终导致大对象无法被分配。
整理内存:
C#中,启用Compact算法,对内存中存活的对象进行移动,修改它们的指针,使之在内存中连续,这样空闲的内存也就连续了,这就解决了内存碎片问题,当再次为新对象分配内存时,CLR不必在充满碎片的内存中寻找适合新对象的内存空间,所以分配速度会大大提高。但是大对象(large object heap)除外,GC不会移动一个内存中巨无霸,因为它知道现在的CPU不便宜。通常,大对象具有很长的生存期,当一个大对象在.NET托管堆中产生时,它被分配在堆的一个特殊部分中,移动大对象所带来的开销超过了整理这部分堆所能提高的性能。
Compact算法除了会提高再次分配内存的速度,如果新分配的对象在堆中位置很紧凑的话,高速缓存的性能将会得到提高,因为一起分配的对象经常被一起使用(程序的局部性原理),所以为程序提供一段连续空白的内存空间是很重要的。
虚幻引擎的智能指针系统
采用引用计数算法,使用弱指针方案来(部分)解决环形引用问题。
问题:往往忘记去判断哪些是强指针,哪些是弱指针,从而导致内存释放的问题。
智能指针系统管理非UObject对象。

UObject的标记清扫算法
UClass包含了类的成员变量信息,类的成员变量包含了“是否是指向对象的指针”,因此具备选择精确式GC的客观条件。利用反射系统,完成对每一个被引用的对象的定位。故采用追踪式GC。
虚幻在回收过程中,没有搬迁对象,应该是考虑到对象搬迁过程中修正指针的庞大成本。
选择了一个非实时但是渐进式的垃圾回收算法,将垃圾回收的过程分步、并行化,以削弱选择追踪式GC带来的暂停等消耗。
虚幻引擎的GC
是追踪式、非实时、精确式,非渐近、增量回收(时间片)。
垃圾回收函数 CollectGarbage
锁定
回收:标记和清除
解锁
虚幻的GC入口是CollectGarbage()
COREUOBJECT_API void CollectGarbage(EObjectFlags KeepFlags, bool bPerformFullPurge = true);
void CollectGarbage(EObjectFlags KeepFlags, bool bPerformFullPurge)
{
// No other thread may be performing UOBject operations while we're running
GGarbageCollectionGuardCritical.GCLock();
// Perform actual garbage collection
CollectGarbageInternal(KeepFlags, bPerformFullPurge);
// Other threads are free to use UObjects
GGarbageCollectionGuardCritical.GCUnlock();
}
锁定/解锁
借助GGarbageCollectionGuardCritical.GCLock/GCUnLock函数,在垃圾回收期间,其他线程的任何UObject操作都不会工作,从而避免出现一边回收一边操作导致各种问题。
回收
回收过程对应函数CollectGarbageInternal中的FRealtimeGC::PerfomReachablilityAnanlysis函数,可以看做两个步骤:标记和清除。不过,增加了簇和增量清除,簇是为了提高回收效率,增量清除是为了避免垃圾回收时导致的卡顿。
标记过程:全部标记为不可达,然后遍历对象引用网络来标记可达对象。
清除过程:直接检查标记,对没有被标记可达的对象调用ConditionalBeginDestroy函数来请求删除。
标记过程的实现原理:
全部标记为不可达:虚幻引擎的MarkObjectsAsUnreachable函数就是用来标记不可达的。借助FRawObjectIterator遍历所有的Object,然后设置标记为Unreachable即可。
MarkObjectsAsUnreachable(ObjectsToSerialize, KeepFlags);
遍历对象引用网络来标记可达对象:
FGCReferenceProcessor ReferenceProcessor;
TFastReferenceCollector<FGCReferenceProcessor, FGCCollector, FGCArrayPool>
ReferenceCollector(ReferenceProcessor, FGCArrayPool::Get());
ReferenceCollector.CollectReferences(ObjectsToSerialize, bForceSingleThreaded);
这里有几个重要的对象TFastReferenceCollector、FGCReferenceProcessor、以及FGCCollector,分别介绍一下。
TFastReferenceCollector:用于可达性分析。
如果是单线程就调用ProcessObjectArray()函数,遍历UObject的记号流(token stream)来查找存在的引用,如果没有记号流,调用UClass::AssembleReferenceTokenStream()函数就是用生成记号流(token steam,其实就是记录了什么地方有UObject引用),用CLASS_TokenStreamAssembled来保存。
如果是多线程,创建几个FCollectorTask来处理,最终还是调用ProcessObjectArray()函数来处理。
UClass::AssembleReferenceTokenStream()函数
如果没有创建token stream,那么就会遍历当前UClass的所有UProperty,对每个UProperty调用EmitReferenceInfo()函数,这是一个虚函数,如果它有父类,那么就会调用父类的AssembleReferenceTokenStream()函数,并把父类添加到数组的前面,最后加上GCRT_EndOfStream到记号流中,并设置CLASS_TokenStreamAssembled来保存。
FGCReferenceProcessor
处理由TFastReferenceCollector查找得到的UObject引用。
如果Object->IsPendingKill()的返回值为true且允许引用消除,那么把Object的引用设置为NULL
否则,调用ThisThreadAtomicallyClearedRFUnreachable()清除不可达标记,标记为可达,如果这个UObject是簇的根,调用MarkReferencedClustersAsReachable函数,把当前簇引用的其他簇标记为可达,当这个UObject簇根不可达,整个簇都会被回收。
基于簇的垃圾回收
其中跟Cluster相关的几个函数在UObjectBaseUtility中,如下图所示:
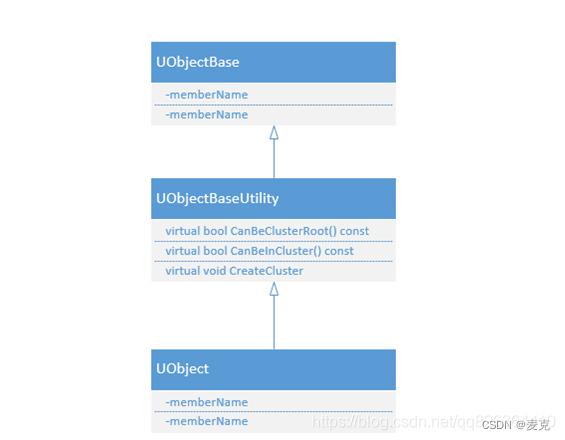
用于加速Cook后的对象的回收,所以编辑器下不会使用簇来GC。能够作为簇根的为UMaterial和UParticleSystem,基本上所有的类都可以在簇中。当垃圾回收阶段检查到一个簇根不可达,整个簇都会被回收,加速回收的效率,节省了再去处理簇的子对象的时间。
FGCCollector
继承自FReferenceCollector,HandleObjectReference()和HandleObjectReferences()都调用了FGCReferenceProcessor的HandleObjectReference()方法来进行UObject的可达性分析。
清除过程的实现原理:
为了减少卡顿,虚幻增加了增量清除的概念(IncrementalPurgeGarbage()函数),就是一次删除只占用固定的时间片,一段段进行销毁的触发。
需要注意的是,由于会在两次清除时间内产生新的UObject,故在每次进入清除时,需要检查GObjCurrentPurgeObjectIndexNeedsReset,如果为true,那么重新创建一个FRawObjectIterator用于遍历所有的UObject。
通过GObjCurrentPurgeObjectIndex来循环遍历所有的FUObjectItem(记录了UObject相关的信息,比如ClusterIndex,Flags等),如果对象不可达且IsReadyForFinishDestroy()为true,那么我们就调用ConditionalFinishDestroy();
而如果IsReadyForFinishDestroy()为false,那么把它添加到GGCObjectPendingDestruction中去。待到下一次增量清除时,如果GGCObjectPendingDestructionCount不为0且IsReadyForFinishDestroy()为true,那么我们就调用ConditionalFinishDestroy()。
当然如果有时间限制,到了时间限制,也会退出。
虚幻的渲染流程
虚幻引擎在FEngineLoop::PreInit中对渲染线程进行初始化。
渲染线程的启动位于StartRenderingThread全局函数中。
创建渲染线程类实例
通过FRunnableThread::Create函数创建渲染线程
等待渲染线程准备好,从TaskGraph取出任务并执行
注册渲染线程
创建渲染线程心跳更新线程
渲染线程的主要执行在全局函数RenderingThreadMain中,游戏线程会借助EQUEUE_Render_COMMAND宏,向渲染线程的TaskMap中添加渲染任务。渲染线程则不断的提取这些任务去执行。
这里需要注意,渲染线程并非直接向GPU发送指令,而是将渲染命令添加到RHICommandList,也就是RHI命令列表中。由RHI线程不断取出指令,向GPU发送。并阻塞等待结果。此时,RHI线程虽然阻塞,但是渲染线程依然正常工作,可以继续处理向RHI命令列表填充指令,从而增加CPU时间的利用率,避免渲染线程凭空等待GPU的处理。
渲染架构
虚幻引擎对于场景中所有不透明物体的渲染方式,是延迟渲染
对于半透明物体的渲染方式,是前向渲染
在虚幻引擎中,先进行延迟光照计算不透明物体,然后借助深度排序,计算半透明物体。
FDeferedSceneRender::Render函数
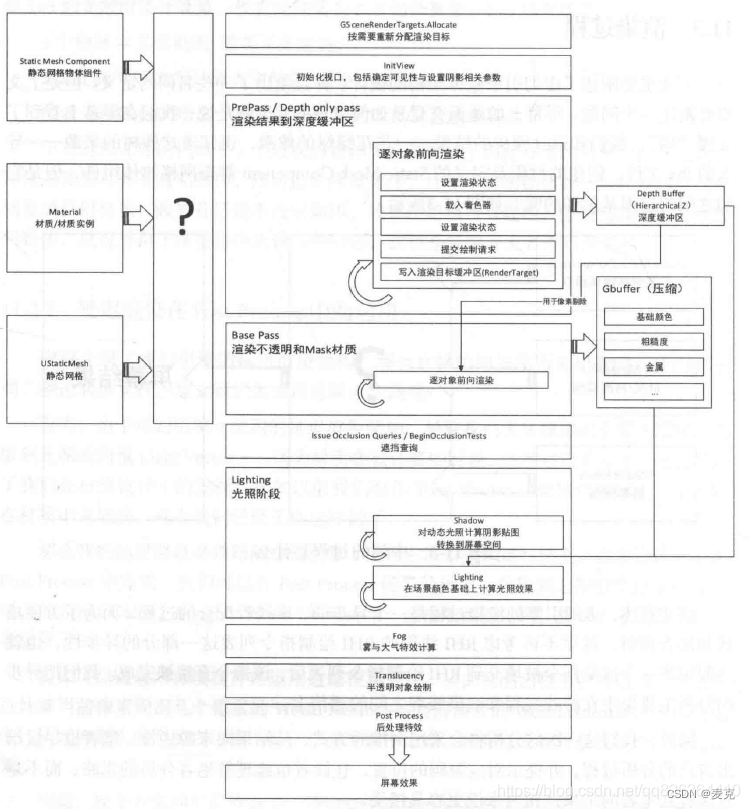
1、初始化视口 InitViews
进行必要的可见性剔除。分为三步:预设置可见性,可见性计算,完成可见性计算。
预设置可见性 PreVisibilityFrameSetup
1.根据当前画质,设置TemporalAA的采样方式,同时确定采样位置。采样位置用来微调视口矩阵。TemporalAA采样,每一帧渲染的时候,让这个像素覆盖的位置进行微弱的偏移,然后混合前面几帧的渲染结果。
2.设置视口矩阵,包括视口投影矩阵和转换矩阵。
可见性计算 ComputeViewVisibility
1.初始化用于可视化检测的缓冲区,位数组,用0和1表示是否可见。翻译为位图BitMap
2.视椎体剔除,对应函数FrustumCull,该函数内部使用ParallelFor函数的线性剔除,进行并行化的异步剔除。
3.遮挡剔除
4.根据可见性位图,设置每个需要渲染对象的可见性,即Hidden flags
5.开发者控制对象可见
6.获取所有对象的渲染信息,对应函数是每个RenderProxy的GetDynamicMeshElements函数。
网格物体组件对应的容器是RenderProxy,材质对象的容器是MaterialRenderProxy
完成可见性计算 PostVisibilityFrameSetup
1.对半透明的对象进行排序。半透明对象的渲染由于涉及互相遮挡,必须按照从后往前的顺序来渲染。
2.对每个光照确定当前光照可见的对象列表
3.初始化雾与大气的常量值。
4.完成对阴影的计算。包括对覆盖整个世界的阴影,对固定光照的级联阴影贴图和对逐对象的阴影贴图的计算。
虚幻引擎的剔除方式是借助ParallelFor的线性剔除,并行化的线性结构剔除在性能上优于基于树的剔除。
2、PrePass 预处理阶段
降低Base Pass的渲染工作量。通过渲染一次深度信息,如果某个像素点的深度不符合要求,这个像素点就不会进行工作量最大的像素渲染器计算。
不是基于分块的GPU,渲染器的EarlyZPassMode参数不为DDM_None,或GEarlyZPassMovable不为0,才会进行PrePass计算。
对象的渲染按照设置渲染状态,载入着色器,设置渲染参数,提交渲染请求,写入渲染目标缓冲区的步骤进行。
设置渲染状态 SetupPrePassView
关闭颜色写入,打开深度测试与深度写入。PrePass不需要计算颜色,只需要计算每个不透明物体像素的深度。
渲染静态数据
三个绘制列表由静态模型组成,通过可见性位图控制是否可见。
只绘制深度的PositionOnlyDepthDrawList
主要绘制不透明物体的DepthDrawList
带蒙版的深度绘制列表MaskedDepthDrawList,蒙版对应材质系统中的Mask类型
渲染动态数据
通过ShouldUseAsOccluder函数询问Render Proxy是否被当做一个遮挡物体,是否为可移动,决定是否需要在这个阶段绘制。
写入渲染目标缓冲区
通过RHI的SetRenderTarget设置。
TStaticMeshDrawList::DrawVisible函数
绘制可见对象
绘制可见对象的基础是可见对象列表,在绘制之前,每个绘制列表已经进行了排序,尽可能共用同样的绘制状态。
每个绘制列表都共用以下着色器状态,区别只是在于具体参数不同:
顶点描述 Vertex Declaration
顶点着色器 Vertex Shader
壳着色器 Hull Shader
域着色器 Domain Shader
像素着色器 Pixel Shader
几何着色器 Geometry Shader
载入公共着色器的信息 SetBoundShaderState 和SetSharedState
SetBoundShaderState 载入需要的着色器
SetSharedState 对于TBasePass,设置顶点着色器和像素着色器的参数。
逐元素渲染
1.对于每个DrawingPolicy调用SetMeshRenderState函数,设置渲染状态。包括调用每个着色器的SetMesh函数,以设置与当前Mesh相关的参数
2.调用Batch Element的DrawMesh函数,完成绘制。调用RHICmdList的DrawIndexedPrimitive函数,指定顶点缓冲区和索引缓冲区的位置。
3、BasePass
极为重要的阶段,通过对逐对象的绘制,将每个对象和光照相关的信息都写入到缓冲区中。
BasePass和PrePass的过程非常接近,分为设置渲染状态,渲染静态数据和渲染动态数据。
设置渲染状态
1.如果PrePass已经写入深度,则深度写入被关闭,直接使用已经写入的深度结果。
2.通过RHICmdList.SetBlendState,打开前4个渲染目标的RGBA写入。TStaticBlendStateWriteMask用模板参数定义渲染目标是否可写入,最高支持8个渲染目标。
RHICmdList.SetBlendState(TStaticBlendStateWriteMask<CW_RGBA, CW_RGBA, CW_RGBA, CW_RGBA>::GetRHI());
RHICmdList.SetBlendState(TStaticBlendStateWriteMask<CW_RGBA, CW_RGBA, CW_RGBA, CW_RGBA>::GetRHI());
3.设置视口区域大小。这个大小会因为是否开启InstancedStereoPass而有所变化。
渲染静态数据
如果PrePass已经进行深度渲染,那么会先渲染Masked蒙版对象,然后渲染普通不透明对象。否则,先渲染不透明对象,再渲染蒙版对象。
渲染动态数据
与PrePass基本相同
BasePass采用MRT(Multi_Render Target)多渲染目标技术,从而允许Shader在渲染过程中向多个渲染目标进行输出。
渲染目标来自哪里?
渲染目标由当前请求渲染的视口(Viewport)分配,对应FSceneViewport::BeginRenderFramw函数。
如何写入?输出到何处?
并没有在C++代码中,而是在Shader着色器代码中。打开Engine/Shader/BasePassPixelShader.usf文件,大体过程:
通过GetMaterialXXX函数,获取材质的各个参数,比如BaseColor基本颜色,Metallic金属等。
然后,填充到GBuffer结构体中
最后,通过EncodeGBuffer函数,把GBuffer结构体压缩、编码后,输出到SV_Target。
RenderOccusion渲染遮挡
虚幻引擎的遮挡计算,实质上是在PrePass中直接进行基于并行队列的硬件遮挡查询。除非在r.HZBOcclusion这个控制台变量被设置为1的情况下,或者有些特效需要的情况下,才会开启Hierarchical Z-Buffer Occlusion Culling 作用遮档查询。
全平台默认关闭
总体来说,这个步骤是为了尽可能剔除处于屏幕内但是被其他对象遮挡的对象。在视口初始化阶段,剔除了处于视锥体之外的对象。但是依然有大量对象处于视锥体内,却被其他对象遮挡。比如一座山背面的一大堆石头,这些石头能够正常通过我们的视锥体遮挡测试,却并不需要渲染。
因此, HZB渲染遮挡技术被用于解决这个问题,通常的HZB步骤如下:
(1)预先准备屏幕的深度缓冲区,这个缓冲区将会作为深度测试的基础数据。因此,这个步骤必须在PrePass之后,如果没有PrePass,则必须在BasePass 之后。
(2)逐层创建缓冲区的Mipmap级联贴图。层级越高,贴图分辨率越低,对应的区域越大。而每个层级对应这个区域“最远”元素到屏幕的距离(深度最大值)。
(3)计算所有需要进行测试的对象的包围球半径,根据这个半径,选择对应的深度缓冲区层级进行深度测试,判断是否被遮挡。这个的用意在于,如果对象较大,我们可以直接用更高的层级进行测试,这个对象的深度若比这个层级对应的距离还远,那么该对象一定被遮挡,因为层级对应的是这一片区域中可见元素的最远距离。
需要注意的是, OpenGL平台下不会进行这个测试。这个步骤中的第二步可以使用像素着色器多次绘制完成级联贴图层级,第三步则可以使用计算着色器ComputeShader,或者使用顶点着色器进行计算,将结果写入到一个渲染目标中。从而借助GPU的高度并行化来加速这个遮挡剔除过程。
这个步骤输出的结果会被用于下一帧计算,而不是在本帧。
光照渲染
对应函数RenderLights,光照渲染与阴影渲染是分离的,阴影渲染是在视口初始化阶段完成的,光照渲染大体步骤如下:
收集可见光源。对可见性的判断,利用视口初始化阶段保存的VisibleLightInfos信息,以当前Id查询即可获得结果。对每个光源构建FLightSceneInfo结构,然后通过ShouldRenderLights对光源是否需要渲染进行计算。
对收集好的光源进行排序。将不需要投射阴影、无光照函数的光源排在前面。
如果是TiledDeferredLighting,则通过RenderTiledDeferredLighting对光照进行计算。如果是PC平台,使用RenderLight函数进行光照计算。
如果平台支持Shader Model 5,则会计算反射阴影贴图与PLV信息。
核心光照渲染RenderLight函数
每个光源都会调用这个函数,遍历所有视口,计算光照强度,并叠加到屏幕颜色上。
1. 设置混合模式为叠加
2. 判断光源类型
平行光源
载入延迟渲染光照对应的顶点着色器(TDeferredLightVS)和像素着色器(TDeferredLightPS)
设置光照参数
绘制一个覆盖全屏幕的矩阵,调用着色器。
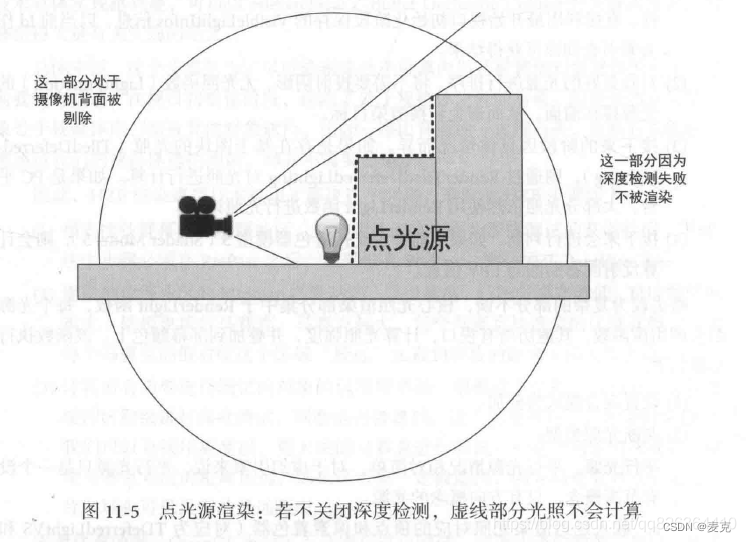
非平行光源
判断摄像机是否在光源范围内
如果是,关闭深度测试,从而避免背面被遮盖部分不进行光照渲染
否则,打开深度测试,以加速渲染
载入着色器
设置光照参数
根据是点光源还是聚光灯,绘制一个对应的几何体,从而排除几何体外对象的渲染,加速光照计算。
ShaderMap
顶点工厂:负责抽象顶点数据以供后面的着色器获取,从而让着色器忽略由于顶点类型造成的差异。
当前着色器继承自FMaterialShader,则对每个材质类型编译出一组对应渲染管线的着色器
当前着色器继承自FMeshMaterialShader,则对每个材质类型的每个顶点工厂类型编译出一组顶点着色器和像素着色器。
通过GetMaterialXXX,可以获取材质的参数。
————————————————
版权声明:本文为CSDN博主「鹅厂程序小哥」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq826364410/article/details/102717636