我自己维护引擎的github地址在这里,里面加了不少注释,有需要的可以看看
Hazel引擎是dll还是lib?
引擎作为dll的优点:
- hotswapping code
- Easy to Link
引擎作为dll的缺点:
- 没有static linking快,因为Linker可以对static link的东西做优化,比如inline操作
- lib只会产生一个exe,比dll方便
- 不用担心dll的版本与使用引擎的代码不匹配的问题
- 使用dll,有一些因为使用template或者其他内容的警告很难处理,比如说下面这个警告:
// 因为使用了智能指针,而没有把unique_ptr作为dll接口导出(dll boundary issues)
warning C4251: 'Hazel::Application::m_Window': class 'std::unique_ptr<Hazel::Window,std::default_delete<_Ty>>' needs to have dll-interface to be used by clients of class 'Hazel::Application
也可以维护两个版本,一个dll版本一个lib版本,但是工作量太大,就算了。
其实,一个Game Engine没有太大必要去做成hot swappable的,Game Engine做出来的游戏很有必要支持热更,但是游戏引擎本身就没必要了,比如说Doom这个游戏,他们就是把游戏的内容做成dll,然后用Engine去启动这个dll作为游戏,这样用户可以直接热更dll更新游戏,但是引擎本身是不会更新的,所以说具体使用Engine的时候,Engine改动的频率不会很高,所以最终还是决定把Hazel从dynamic library改为static library,热更可以交给编写游戏程序的脚本语言来做,而不一定非得用C++支持热更
如何将引擎从dll改为lib
这里是用premake构建的工程,直接在premake5.lua文件里进行修改Hazel工程的类型就可以了。
原来的Hazel的premake部分内容如下:
project "Hazel"
location "%{prj.name}" -- 这里的location是生成的vcproj的位置
kind "SharedLib"-- 类型为dll
staticruntime "on"
...
修改之后变为:
project "Hazel"
location "%{prj.name}" -- 这里的location是生成的vcproj的位置
kind "StaticLib"-- 类型为.lib
staticruntime "off"
...
同时,记得把之前的dllexport和dllimport的宏干掉就行了,如下所示:
#ifdef HZ_PLATFORM_WINDOWS
#ifdef HZ_BUILD_DLL
#define HAZEL_API //_declspec (dllexport)
//#define IMGUI_API _declspec (dllexport)
#else
#define HAZEL_API //_declspec (dllimport)
#define IMGUI_API //_declspec (dllimport)
#endif // HZ_BUILD_DLL
#endif
解决所有Warnings
这里把Hazel游戏引擎,从dll改成lib文件,有个重要目的:为了消除一些原本不可以解决的警告。
之前存在的所有的警告
先来看一下之前有哪几种Warning:
// 第一种警告
warning C4172: returning address of local variable or temporary
// 第二种警告,函数声明参数是int,但代码传入的参数是float,发生了隐式转换
warning C4244: 'initializing': conversion from 'float' to 'int', possible loss of data
// 第三种警告,使用的别人的库里用的是老的string的操作方式,
warning C4996: 'strcpy': This function or variable may be unsafe. Consider using strcpy_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.
// 第四种警告,后面会说怎么解决
Command line warning D9025: overriding '/MTd' with '/MDd'
// 第五种警告,这种needs to have dll-interface的Warning有很多,这里只拿一个举例
warning C4251: 'Hazel::Application::m_Window': class 'std::unique_ptr<Hazel::Window,std::default_delete<_Ty>>' needs to have dll-interface to be used by clients of class 'Hazel::Application
// 第六种警告
Command line warning D9002: ignoring unknown option '-std=c11'
Command line warning D9002: ignoring unknown option '-lgdi32'
// 第七种警告
LINK : warning LNK4098: defaultlib 'LIBCMTD' conflicts with use of other libs; use /NODEFAULTLIB:library
前面两种都很简单,下面说后面五种警告:
第三种警告:也算简单,因为使用的submodule里用到了不安全的string相关函数,没有必要去改它们的代码,在对应的premake的文件里添加_CRT_SECURE_NO_WARNINGS宏定义即可
第四种警告:Command line warning D9025: overriding ‘/MTd’ with ‘/MDd’
其实这个警告是因为之前写在Premake5.lua里的这一行代码:
filter { "configurations:Debug" }
defines { "DEBUG", "HZ_BUILD_DLL"}
buildoptions {"/MDd"} --其实这一行代码可以用staticruntime的命令来代替
symbols "On"
runtime "Debug" -- 运行时链接的dll是debug类型的
premake5.lua文件里可以设置是用/MT还是/MD:
staticruntime "on" --用/MT
staticruntime "off" --用/MD
现在问题就来了,现在Hazel整个是作为一个.lib的,然后Sandbox是作为一个.exe的,Sandbox要Link这个lib,然后整个打出一个exe来使用,这个时候,Hazel是用/MT或者/MD,到底哪个好呢?
首先我做了个测试,得到的结论是,Hazel工程和Sandbox工程都必须是相同的staticruntime设置,要么都是/MT,要么都是/MD,否则会Link失败,然后Cherno在视频里说,都用/MT的方式,也就是staticruntime "on",至于为什么不能用/MD,没太懂为啥原因,其实我觉得是可以用的,总之就先按照/MT来弄吧
如果忘了/MT和/MD这俩参数的作用,可以回顾一下我之前写的文章Visual Studio 设置里的Runtime Library
第五种警告
当一个类导出作为dll的接口类,而该类里使用到了std里的模板,就容易出现这个警告。
警告出现的原因是,dll使用的编译器与实际上使用dll的application的编译器是不保证相同的,使用dll的Application,如果有权限直接访问到对应的数据成员,就会报错。
举个例子:
// 这是我的dll类
// dll header
class FrameworkImpl;
class EXPORT_API Framework
{
Framework(const Framework&) = delete;
Framework& operator=(const Framework&) = delete;
Framework(Framework&&) = delete;
Framework& operator=(Framework&&) = delete;
public:
Framework();
~Framework();
private:
std::unique_ptr<FrameworkImpl> impl_;// 这里会引起Warning
};
// 这是我的Application,它使用了dll
// application implementation
int main()
{
std::unique_ptr<Framework> test = std::make_unique<Framework>();
}
这里就会警告:
warning C4251: 'Framework::impl_': class 'std::unique_ptr<FrameworkImpl,std::default_delete<_Ty>>' needs to have dll-interface to be used by clients of class 'Framework'
因为用declspec(dllexport)会把整个类暴露出来,而实际上Application类,不会直接用到私有成员impl_,所以没有必要暴露它,代码改成下面这个样子,就不会警告了:
class Framework
{
Framework(const Framework&) = delete;
Framework& operator=(const Framework&) = delete;
Framework(Framework&&) = delete;
Framework& operator=(Framework&&) = delete;
public:
EXPORT_API Framework();
EXPORT_API ~Framework();
private:
std::unique_ptr<FrameworkImpl> impl_;
};
总体来说,消除这些警告主要是这么做:
- 如果Application用不到这个数据,那么没有必要把它暴露出来,如果心里有数,确实用不到的话,可以禁用掉警告
- 可以创建Wrapper,然后把它export出去(If you have members, that are intended to use by client code, create wrapper, that is dllexported or use additional indirection with dllexported methods. )
- 如果实在要暴露,那么要把对应的东西暴露出来,比如上面这个接口,应该要去把std::unique_ptr这个类给export出去(这一种方法是我想的,我不确定是不是可行)
至于为什么这个问题跟模板有关,我还不是特别清楚,相关的链接都放这里,以后需要再仔细研究:
https://stackoverflow.com/questions/32098001/stdunique-ptr-pimpl-in-dll-generates-c4251-with-visual-studio
https://stackoverflow.com/questions/4145605/stdvector-needs-to-have-dll-interface-to-be-used-by-clients-of-class-xt-war/6869033
第六种警告
这个问题是在Cherno视频里,实际上我并没有遇到,但是知道原理就可以了:
-std=c11,这句话是为了指定GCC/CLang的编译器,而Visual Studio不是用的这个编译器,所以自动忽略了这段代码,至于Cherno怎么搞出这个警告的,就是具体怎么写的Premake,我还不清楚,不过这么写应该没问题:
cppdialect "C++17"
这种情况在CMakeLists也会出现,注意一下就行了,可以参考:Command line warning D9002: ignoring unknown option ‘-std=c++11’
第七种警告
这个警告之前好像没看到过:
warning LNK4221: This object file does not define any previously undefined public symbols, so it will not be used by any link operation that consumes this library
这个警告发生在,当一个.obj文件要被Linker链接到一起的时候,如果这个.obj里的东西,其他的.obj都有,那么这个.obj就会被忽略。
举个例子,有两个CPP:
// a.cpp
#include <iostream>
// b.cpp
#include <iostream>
int func1()
{
return 0;
}
然后在Command Line执行以下命令,就会出现这样的Warning:
1. cl /c a.cpp b.cpp
2. link /lib /out:test.lib a.obj b.obj
这种问题,一般出现在precompiled header里,如下图所示,就是我这次报错的原因,这个Event.cpp完全没用,里面的Event.h其他的cpp也有引用,所以这个cpp完全没有必要,就给了这么个警告,我把cpp删掉,就好了
更多的关于LNK4221的可以参考这里
最后再做一些小的premake文件的修改就行了,主要是:
- system 应该都设置为latest
- GLFW 的Configuration应该就两种,Debug和Release
- C++ Dialect和Staticruntime都不应该与平台或Configuration相关
- 然后整个格式整理,要么都用空格,要么都用tab
- 把/MT这些build options去掉
- 确保Glad库和GLFW库都有Debug和Release两个平台的配置
- 有的改动要到submodule里去改,然后提交更改
Rendering
在视频的第23课,开始讲到了游戏引擎最核心的部分——Rendering
Introduction
Renderging负责在屏幕上的绘制工作,同时接受与外部Input的交互,为了表现更好的画面效果,需要使用Graphics Processing Unit(GPU),GPU的主要优点是:能并行处理、能很快的进行数学运算(比如矩阵的运算)
Design Architecture
如何Draw API Line,举个例子,不同的平台上渲染的方式都不同,那么如何设计出那些通用的API方法,也就是找到一个普适的由Hazel的Drawing API Line组成的程序,根据平台的不同,去使用对应的override的方法。举个例子,Vulkan和OpenGL完全不一样,在OpenGL里,绘制一个三角形需要创建对应的Contex,而Vulkan里面需要调用Command Queue、rendering devices等等,但是二者肯定是有通用的地方的,比如都需要上传对应的vertices数据、上传对应的顶点数据、上传一个shader、调用drawcall等等,那么设计游戏引擎的时候,能不能设计出来通用的API框架呢?
如何设计Graphics API Abstraction
下面给出了一个架构图,右边的都是具体与各个platform绑定的API,所以右边的API,需要对每一个平台,完成该平台对应的具体API的实现,简单的说,就是右边的东西都是与Platform相关的,这些东西属于Render API Primitives,而左边的渲染概念是所有平台通用的,举个例子,如果现在多了一个平台,叫Toby平台,那么右边所有的内容,都需要加一个分支,也就是增加对应的Toby平台的API的相关内容,而左边的内容是完全不会改变的:
关于渲染,如何画出上面这条线,也就是如何决定哪些类的平台无关的,哪些类是平台通用的,其实挺难的。即使做出了上面的这个划分,实际执行起来也没有那么简单,因为不同的平台使用的primitive(图右边的内容)可能也不是一样的,比如在OpenGL和Vulkan实现Deffered Renderer,在OpenGL上只需要创建一些frame buffers就可以了,而Vulkan需要额外的内容,比如pipelines、descriptive sets等,两个平台上相同内容的执行逻辑本身就是不一样的

关于左边的内容,这里再进一步解释一下
- Scene Graph:场景里物体的Hierarchy,相当于Unity的Scene Hierarchy,UE4的World Outliner
- Sorting:用于决定物体的渲染顺序,可以用于透明颜色的Blending,还可以把相同Material的物体sort到一起,然后一起渲染
- Culling:决定哪些在Frustum里面,比如Occlusion Culling
- Material:Material其实就是Shader和Uniform Data的集合(或者再加一个Texture)
- LOD
- Animation
- Camera:Camera can be tied to a framebuffer or a camera may be redering to a render target
- VFX:Visual Effects,比如粒子系统
- postVFX:后处理效果,比如说颜色矫正,实现眩晕、酒醉效果或Screen Space Occlusion等
还有些内容,比如Render Command Queue,这个Queue用来存储所有渲染的指令,这样就可以开一个单独的线程用于执行这个Queue,Command Queue在Vulkan里是本身就有的,而OpenGL就没有这个功能,所以需要单独为OpenGL添加这一块的功能
如何开始渲染部分的工作
- 首先,选择使用OpenGL来开始工作,因为它是最简单和容易的图形库
- 然后,需要build Render API,这里就是使用OpenGL渲染出一个三角形即可,这一步我以前做过,没啥难度,注意这里并不是一次性build所有的Render API
- 接着,需要build Renderer,这个Renderer可以绘制一个三角形
总体流程如下图所示:

Rendering: Render Context
开始搭建渲染引擎的第一件事,就是创建对应的Render Context,这个Context是与平台相关的,不同的平台对应的Render Context也是不同的,现阶段不会像之前设计EventSystem那样先搭建好大多数的代码框架,而是会先从Render Context开始搭建
PS:GLFW支持OpenGL和Vulkan
现在要做的就是创建一个Context类,经过反复考虑谁应该拥有Context后,决定,Context需要作为一个Static对象放到Window类里,这样就是一个Window里绘制一个平台的渲染图像,有的引擎可以在一个Window里实现左半边用DirectX绘制,右半边用OpenGL绘制,Hazel引擎暂时不打算支持这种功能。
其实具体的做法,就是创建一个Context类,然后把OpenGL的相关操作再封装一层,Context的基类如下所示:
class GraphicsContext{
public:
virtual void Init() = 0; // 创建context,相当于把glfwSetCurrentContext封装到这里
virtual void SwapBuffer() = 0; //
};
然后实现一个OpenGL平台的Context类:
具体使用的时候,希望实现这样的效果:
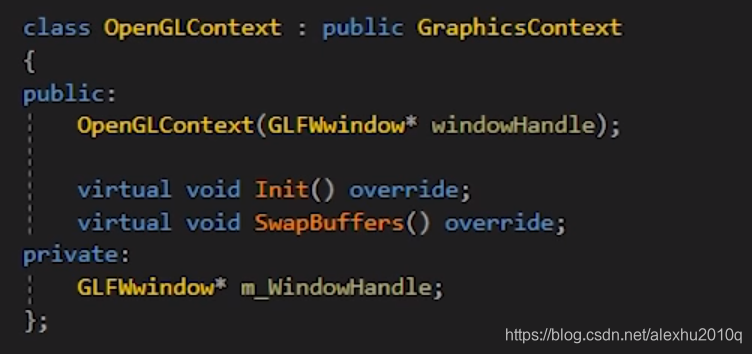
// OpenGL Context
Window::Init(){
m_Context = new OpenGLContext(m_Window);
m_Context.Init();
}
Window::OnUpdate(){
m_Context.SwapBuffer();
}
// DX Context
Window::Init(){
m_Context = new DXContext(m_Window);
m_Context.Init();
}
Window::OnUpdate(){
m_Context.SwapBuffer();
}
Our First Triangle
由于之前学过OpenGL,这一课应该是有史以来最简单的,本课重点是:
- 温习怎么使用VAO、VBO和EBO
- 想想绘制三角形的代码应该放哪
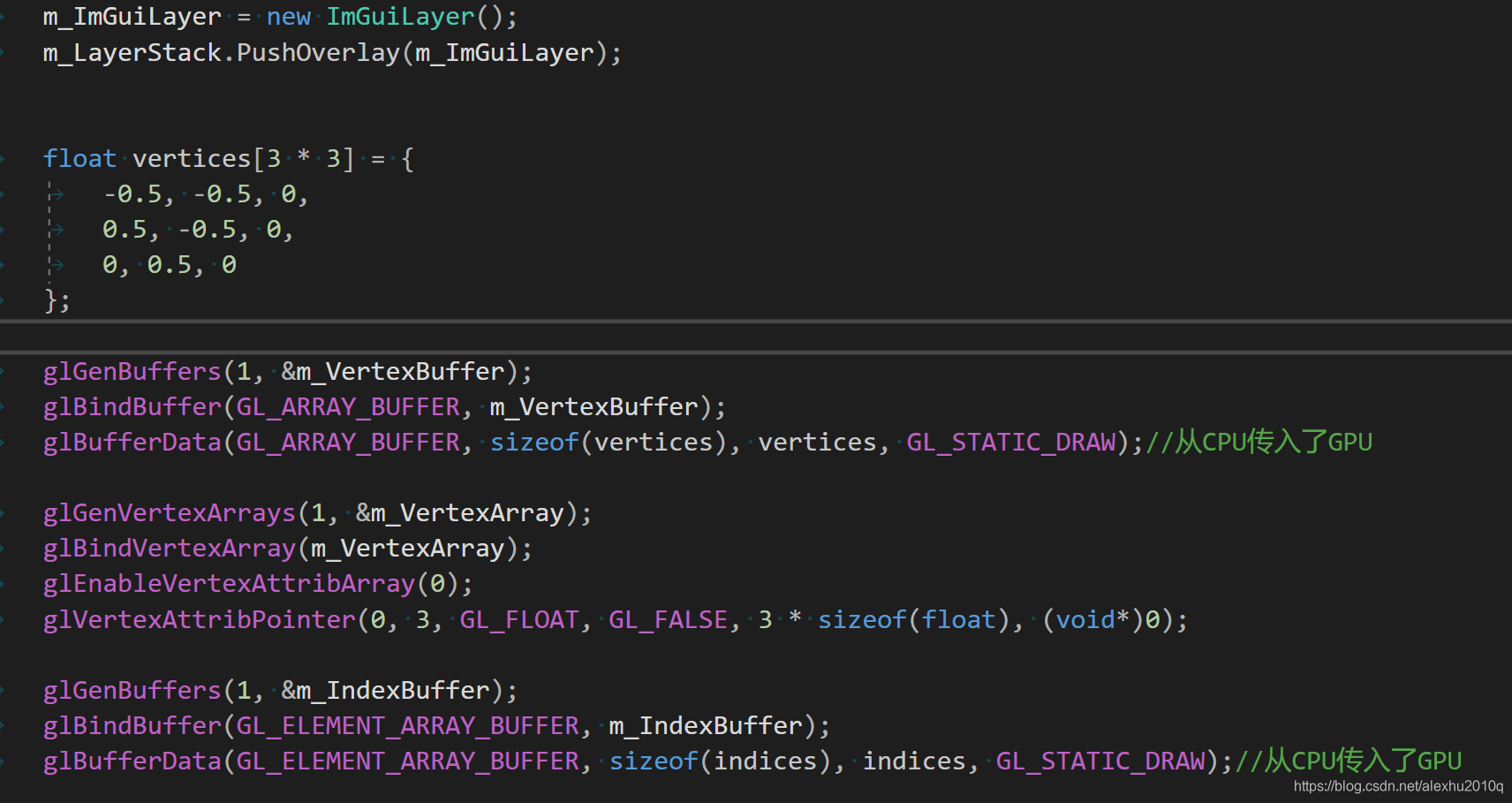
根据课程,绘制三角形的代码放到了Application里,应该也只是暂时的,一开始我打算放在WindowsWindow.cpp里,感觉放Application好一点,毕竟绘制三角形的操作不应该在Window代码里执行。
就这么点代码:
int indices[3] = { 0,1,2 };
Application::Application()
{
HAZEL_ASSERT(!s_Instance, "Already Exists an application instance");
s_Instance = this;
m_Window = std::unique_ptr<Window>(Window::Create());
m_Window->SetEventCallback(std::bind(&Application::OnEvent, this, std::placeholders::_1));
m_ImGuiLayer = new ImGuiLayer();
m_LayerStack.PushOverlay(m_ImGuiLayer);
// 创建VAO,VBO,EBO
float vertices[3 * 3] = {
-0.5, -0.5, 0,
0.5, -0.5, 0,
0, 0.5, 0
};
glGenBuffers(1, &m_VertexBuffer);
glBindBuffer(GL_ARRAY_BUFFER, m_VertexBuffer);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);//从CPU传入了GPU
glGenVertexArrays(1, &m_VertexArray);
glBindVertexArray(m_VertexArray);
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
glGenBuffers(1, &m_IndexBuffer);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, m_IndexBuffer);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);//从CPU传入了GPU
}
void Application::Run()
{
std::cout << "Run Application" << std::endl;
while (m_Running)
{
// 每帧开始Clear
glClearColor(0.1f, 0.1f, 0.1f, 1);
glClear(GL_COLOR_BUFFER_BIT);
glBindVertexArray(m_VertexArray);
// 注意最后一个参数是nullptr
glDrawElements(GL_TRIANGLES, 3, GL_UNSIGNED_INT, nullptr);
// Application并不应该知道调用的是哪个平台的window,Window的init操作放在Window::Create里面
// 所以创建完window后,可以直接调用其loop开始渲染
for (Layer* layer : m_LayerStack)
{
layer->OnUpdate();
}
m_ImGuiLayer->Begin();
for (Layer* layer : m_LayerStack)
{
// 每一个Layer都在调用ImGuiRender函数
// 目前有两个Layer, Sandbox定义的ExampleLayer和构造函数添加的ImGuiLayer
layer->OnImGuiRender();
}
m_ImGuiLayer->End();
// 每帧结束调用glSwapBuffer
m_Window->OnUpdate();
}
}
通过OpenGL获取设备的显卡信息
如下代码所示:
void OpenGLContext::Init() {
glfwMakeContextCurrent(m_Window);
int status = gladLoadGLLoader((GLADloadproc)glfwGetProcAddress);
HAZEL_ASSERT(status, "Failed to init glad");
LOG("OpenGL Info:");
LOG(" Vendor: {0}", glGetString(GL_VENDOR));//打印厂商
LOG(" Renderer: {0}", glGetString(GL_RENDERER));
LOG(" Version: {0}", glGetString(GL_VERSION));
}
如下图所示是我的机器的型号:
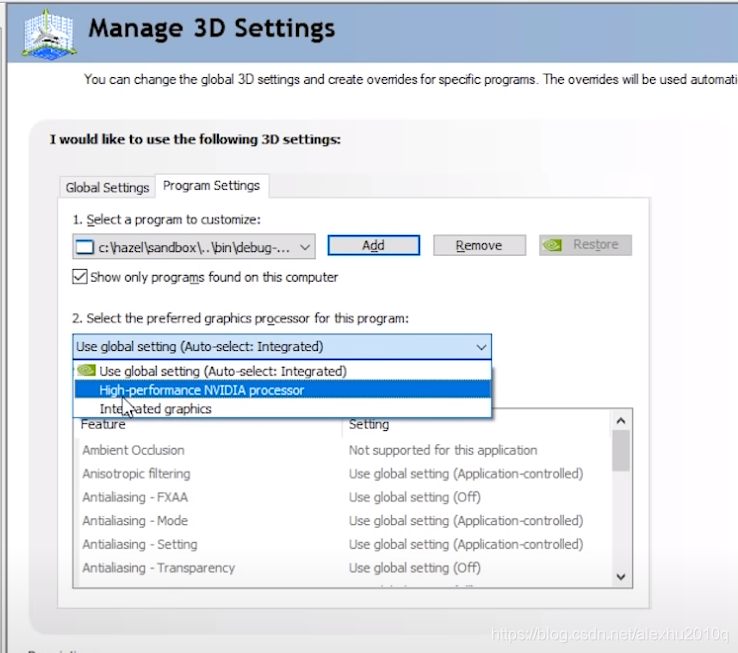
对于一些电脑,可能这里不会默认使用最新的显卡,比如N卡可以在NVDIA ControlPanel里对这个exe使用高质量的GPU处理器,如下图所示

OpenGL Shaders
接下来就是先创建OpenGL的Shader了,需要在Hazel项目的Renderer目录下创建Shader.h和Shader.cpp类,大概是这么写:
class Shader{
public:
Shader(const string& vertSource, const string& fragSource);
~Shader();//未来会有OpenGLShader、DirectXShader,所以未来虚函数可能是virtual的
void Bind();
void Unbind();
private:
unsigned int m_RendererID;//其实就是program对应的id,program里存放了一套渲染管线的shader
}
接下来就是从OpenGL的官方Shader编译代码里获取代码,放到Shader的构造函数里,然后把里面的报错Log信息转换成Hazel内置的Spdlog就行。
另外,在使用OpenGL的shader的时候,需要创建program,然后把shader绑定到program上,这个program之前我用过,但是没理解他具体是什么东西,这里的Program相当于当前渲染管线所使用的程序,是Shader的容器。
在Shader的Compile或Link阶段执行__debugbreak()
这里在报错的时候,需要调用spdlog来打印错误讯息,同时利用Assert宏提前终止Debug过程,代码如下所示:
// Use the infoLog as you see fit.
CORE_LOG_ERROR("Compile Vertex Shader Failed!:{0}", &infoLog[0]);
HAZEL_ASSERT(false, "Compile Vertex Shader Error Stopped Debugging!");
在C++里写多行的字符串
以前用过一种方案,是这么写的:
std::string vertexSource = "#version 330 core/n"
"layout(location = 0) in vec3 a_Position;/n"
"void main(){...}"
大概是这样,总之就是换行的地方要用/n,然后每一行用双引号括起来就行了,写起来有点麻烦。
现在介绍一个更容易写的语法,用R"()",括号里的内容放多行字符串就可以了:
std::string vertexSource = R"(
#version 330 core
layout(location = 0) in vec3 a_Position;
void main(){
...
}
)";
在Application.cpp里实现Shader的创建
Application类负责进行实际的绘制,实际的Sandbox会继承于Application类,所以在Application里需要创建一个Shader,这里用一个unique_ptr来记录,如下所示:
// Application类里声明:
class HAZEL_API Application
{
public:
Application();
virtual ~Application();
inline static Application& Get() { return *s_Instance; }
void OnEvent(Event& e);
void Run();
bool OnWindowClose(WindowCloseEvent& e);
void PushLayer(Layer* layer);
Layer* PopLayer();
Window& GetWindow()const { return *m_Window; }
private:
static Application* s_Instance;
unsigned int m_VertexArray = 0;
unsigned int m_VertexBuffer = 0;
unsigned int m_IndexBuffer = 0;
protected:
std::unique_ptr<Window>m_Window;
std::unique_ptr<Shader>m_Shader;//添加Shader, 其实我感觉叫m_Renderer是不是更合适
};
=========================================
// 实际的cpp里
glGenBuffers(1, &m_VertexBuffer);
glBindBuffer(GL_ARRAY_BUFFER, m_VertexBuffer);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);//从CPU传入了GPU
glGenVertexArrays(1, &m_VertexArray);
glBindVertexArray(m_VertexArray);
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
glGenBuffers(1, &m_IndexBuffer);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, m_IndexBuffer);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);//从CPU传入了GPU
// 这个排版还是挺难看的
std::string vertexSource = R"(
#version 330 core
layout(location = 0) in vec3 aPos;
void main()
{
gl_Position = vec4(aPos, 1.0);
}
)";
std::string fragmentSource = R"(
#version 330 core
out vec4 color;
void main()
{
color = vec4(0.8,0.2,0.3,1.0);
}
)";
// 注意这里直接用了reset,没有make_unique,二者效果是一样的,只是reset更好写
// 可以直接用reset是因为unique_ptr没有引用计数这种东西
m_Shader.reset(new Shader(vertexSource, fragmentSource));
}
============================================
// 最后在Loop里先Bind,再Bind VAO,就可以了
while (m_Running)
{
// 每帧开始Clear
glClearColor(0.1f, 0.1f, 0.1f, 1);
glClear(GL_COLOR_BUFFER_BIT);
m_Shader->Bind();
glBindVertexArray(m_VertexArray);
glDrawElements(GL_TRIANGLES, 3, GL_UNSIGNED_INT, nullptr);
...
Renderer API Abstraction
这一课的目的,是判断Hazel引擎具体该怎么设计渲染相关的API,让它可以支持多个平台的渲染工作。
Compile Time Or Runtime
关于游戏引擎Hazel,它需要可以根据不同的平台使用不同的渲染接口,比如DirectX、OpenGL、Metal或者Vulkan等。目前有两种做法。
第一种是在Compile Time决定Hazel引擎使用哪种渲染API,具体是通过不同的宏来实现的,比如USE_OPENGL_RENDERER这些宏,然后根据这些宏的设定,对引擎代码进行编译,就只会编译OpenGL相关的渲染代码,如果我想要OpenGL来实现绘制,就使用对应的宏build OpenGL的代码,如果想用Vulkan就用Vulkan对应的宏来build Vulkan的代码,总之最后的build出来的引擎就只是支持一个平台的渲染API。
这样做的坏处时,一次build只能用一个平台的渲染API,而且每次切换渲染的API时,都需要rebuild相关代码,这对开发者来说是很不友好的,比如说同样的技术实现的画面效果,用DX或OpenGL应该是一样的,如果不一样就说明出了什么问题,如果开发者要对比两个平台的画面效果,那么要反复切换宏,然后rebuild,这很麻烦。虽然可以把各个渲染平台对应的组件,设置为各自的dll,但仍然需要在Compile Time重新编译代码,生成新的引擎build(应该最终是exe文件)。而好处就是,引擎在runtime不必花时间去判断到底用哪个平台的渲染API,所以runtime下效率会更快
第二种是在Runtime决定使用哪种渲染API,既然是Runtime那么肯定是不能用宏了,有人之前用if条件去为每一个渲染的API做一个条件判断,这样做工程量很大,也有点傻,这里建议的做法是利用多态(虚函数)来做,比如说有Shader类,那么就有OpenGLShader和DirectXShader这样各平台的派生类,这样在build时会编译所有可用平台的相关渲染api,比如ios平台就会编译OpenGL和metal的渲染API。
抽象具体的API------抽象RendererAPI的类型
首先,必须有一个全局的参数,来表示当前位于什么平台,这个很容易理解,这个参数可以用枚举来表示,如下所示:
enum class RendererAPI
{
None = 0, OpenGL = 1//后续还会再加,目前只有两种
};
然后设计一个GetAPI函数,用于得到当前运行的渲染API类型,同时还要创建一个static变量,代表当前平台的具体值,可以把这些内容放到一个类里,类就叫RenderAPI:
class Renderer
{
public:
static inline RendererAPI GetAPI const { return m_RendererAPI; }
private:
static m_RendererAPI;
};
Renderer::m_RendererAPI = RendererAPI::OpenGL;//这个参数可以在Runtime更改的,只要提供SetAPI函数就可以了
在之前的Application.cpp里,我实现了绘制有色三角形的过程,但是这段代码明显是基于OpenGL平台的,如下图所示:
现在的目的,就是把这些创建VBO、VAO和EBO的操作,抽象化,把上面的这一段代码改成如下代码所示的样子:
float vertices[3 * 3] = {
-0.5, -0.5, 0,
0.5, -0.5, 0,
0, 0.5, 0
};
VertexBuffer buffer = VertexBufer::Create(sizeof(vertices), vertices);
buffer.Bind();
注意这里的VertexBuffer是一个抽象类,实际上在Runtime它会根据具体的对象的类型执行对应的Create函数,一个VertexBuffer应该具有创建Buffer、BindBuffer和UnbindBuffer的操作,基类接口设计如下:
class VertexBuffer
{
public:
virtual ~VertexBuffer() = 0;
virtual void Bind() const = 0;// 别忘了加const
virtual void Unbind() const = 0;
static VertexBuffer* Create(float* vertices, uint32_t size);
};
同理还有EBO,也就是IndexBuffer,跟VertexBuffer接口类差不多:
class IndexBuffer
{
public:
virtual ~IndexBuffer() = 0;
virtual void Bind() const = 0;// 别忘了加const
virtual void Unbind() const = 0;
static IndexBuffer* Create(int* indices, uint32_t size);
};
Vertex Buffer Layouts
其实这一块就是VAO的内容,Vertex Array Buffer,VAO负责定义从Vertex Buffer中挖取数据的方式,所以我理解的是,VBO本身会分配内存,而VAO应该只是记录从VBO中挖取内存的方式,本身并不分配内存,参考Vertex Buffer Layout,从这个角度理解,可以把VAO、或者说VBO中顶点分割的情况,记录在VertexBuffer里面,代码如下:
m_VertexBuffer = std::unique_ptr<VertexBuffer>(VertexBuffer::Create(vertices, sizeof(vertices)));
m_VertexBuffer->Bind();
// 原本是这么写的
glGenVertexArrays(1, &m_VertexArray);
glBindVertexArray(m_VertexArray);
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
// 现在想改成这么写,核心就是创建一个layout, 然后设置给顶点Buffer
BufferLayout layout = {
// vertexBuffer里每七个浮点数是一组,前面三个数是Position,后面四个是Color
{ ShaderDataType::Float3, "a_Position" },// 这里的a_Position就是Shader里输入的参数名字
{ ShaderDataType::Float4, "a_Color" }
};
m_VertexBuffer->SetLayout(layout);
总体思路就是这样,把这一层封装起来。
PS1:在OpenGL里,对VertexArray和VertexBuffer的理解:VertexArray有点像是VertexBuffer的parent容器,一个OpenGL里的VertexArray应该是有16个顶点属性的槽位,可以存放多个VertexBuffer的数据(这里应该存的是地址,不是真实复制了数据吧)。比如说,我可以有三个VBO,一个放顶点坐标,一个放normal,一个放纹理,最后都加入到VAO里,也是可以的。
PS2:提两个OpenGL与DX不同的点:
- 在OpenGL里,描述顶点缓存的布局,与顶点着色器的关系不大,而DX里,只有绑定了顶点着色器后,才可以描述Buffer Layout。
- 在DX里,只有Vertex Buffer和Buffer Layout这种东西,没有像OpenGL这样专门搞一个VAO来描述最终使用的顶点数据,所以这里就按照DX的来,每一个Vertex Buffer,都有他自己对应的BufferLayout(所以要定义一个BufferLayout的类)
如何设计BufferLayout
前面也提过了,这里再重复一次,OpenGL里其实就是以下代码组合就得到了Layout:
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
为了尽可能的泛化和抽象化,这样写应该是最简单的:
// 注意,OpenGL里应该连名字都不需要,写Float3 Float2就行了,但是DX里需要先绑定Vertex Shader才可以描述
// BufferLayout,所以设置了传入属性的名字, 同时这样可以用一个string来描述,这一块变量代表属性是什么意思
BufferLayout layout = {
{ ShaderDataType::Float3, "a_Position"},
{ ShaderDataType::Float2, "a_TexCoord"} };
开始写代码
首要的任务是构建BufferLayout类,前面说了,它是属于VertexBuffer的,那么就把它定义在Buffer.h文件里好了,在概念上,BufferLayout是由基本的元素构成的,比如上面的{ ShaderDataType::Float3, "a_Position"}就是一个BufferElement,所以这里也需要构建一个BufferElement类,代码如下所示:
struct BufferElement
{
std::string Name;
ShaderDataType Type;
// 其实Size和Offset都是可以算出来的,这些数据主要是为了方便后面进行计算
uint32_t Size; // Size可以根据ShaderDataType的类型算出来,比如Float3就是12个字节
uint32_t Offset; // 而Offset则要根据BufferLayout的vector的前面的BufferElement的size加起来求和得到
BufferElement(ShaderDataType type, const std::string& name)
: Name(name), Type(type), Size(0), Offset(0)
{}
};
// 最简单的BufferLayout类,连构造函数都还没写
class BufferLayout
{
public:
inline const std::vector<BufferElement>& GetElements() const { return m_Elements; }
private:
std::vector<BufferElement> m_Elements;
};
接下来就是实现ShaderDataType类了,其实就是一个枚举,然后在写一个ShaderDataTypeSize函数,用于返回每种类型占的内存大小,也是为了方面后面使用:
// 一个枚举
enum class ShaderDataType
{
None = 0, Float, Float2, Float3, Float4, Mat3, Mat4, Int, Int2, Int3, Int4, Bool
};
// 一个static函数
static uint32_t ShaderDataTypeSize(ShaderDataType type)
{
switch (type)
{
case ShaderDataType::Float: return 4;
case ShaderDataType::Float2: return 4 * 2;
case ShaderDataType::Float3: return 4 * 3;
case ShaderDataType::Float4: return 4 * 4;
case ShaderDataType::Mat3: return 4 * 3 * 3;
case ShaderDataType::Mat4: return 4 * 4 * 4;
case ShaderDataType::Int: return 4;
case ShaderDataType::Int2: return 4 * 2;
case ShaderDataType::Int3: return 4 * 3;
case ShaderDataType::Int4: return 4 * 4;
case ShaderDataType::Bool: return 1;
}
HZ_CORE_ASSERT(false, "Unknown ShaderDataType!");
return 0;
}
再根据ShaderDataTypeSize函数,可以把之前BufferElement的构造函数修改一下了:
BufferElement(ShaderDataType type, const std::string& name, bool normalized = false)
: Name(name), Type(type), Size(ShaderDataTypeSize(type)), Offset(0)
之后就可以处理BufferElement里的Offset属性了,它是不可能在BufferElement的构造函数里算的,只能在BufferLayout里的构造函数结合其他的BufferElement算出来,代码如下:
BufferLayout(const std::initializer_list<BufferElement>& elements)
: m_Elements(elements)
{
CalculateOffsetsAndStride();
}
void CalculateOffsetsAndStride()
{
m_Stride = 0;// m_Stride是成员变量,用于描述VertexBuffer里的步长
// 遍历元素,根据其Size进行累加算出offset,比较简单
for (auto & element : m_Elements)
{
element.Offset = offset;
m_Stride += element.Size;
}
}
这就差不多了,可以完成对BufferLayout的创建了,下面就是把它放到VertexBuffer类里了,可以把它放基类里,代码如下:
class VertexBuffer
{
public:
virtual void Bind() const = 0;
virtual void Unbind() const = 0;
// 添加两个虚接口
virtual const BufferLayout& GetLayout() const = 0;
virtual void SetLayout(const BufferLayout& layout) = 0;
static VertexBuffer* Create(float* vertices, uint32_t size);
};
class OpenGLVertexBuffer : public VertexBuffer
{
public:
OpenGLVertexBuffer(float* vertices, uint32_t size);
virtual ~OpenGLVertexBuffer();
virtual void Bind() const override;
virtual void Unbind() const override;
virtual const BufferLayout& GetLayout() const override { return m_Layout; }
virtual void SetLayout(const BufferLayout& layout) override { m_Layout = layout; }
private:
uint32_t m_RendererID;
BufferLayout m_Layout;// BufferLayout放在这里
};
最后一步,就是把前面写的代码应用上,替换掉下面这两句了:
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
注意,这里的0代表一个index,代表一个BufferElement,3代表BufferElement里的data的个数,而data的类型就是接下来的GL_FLOAT,所以float和3组合就是Float3了,但是前面设计的Type是Float3(这也是DX里的数据类型),他们的count和type是放在一起的,所以对于OpenGL而言,不适用,所以需要再在BufferElement里定义一个接口:
uint32_t GetComponentCount() const
{ // 根据Type,拆出来数据的个数
switch (Type)
{
case ShaderDataType::Float: return 1;
case ShaderDataType::Float2: return 2;
case ShaderDataType::Float3: return 3;
case ShaderDataType::Float4: return 4;
case ShaderDataType::Mat3: return 3 * 3;
case ShaderDataType::Mat4: return 4 * 4;
case ShaderDataType::Int: return 1;
case ShaderDataType::Int2: return 2;
case ShaderDataType::Int3: return 3;
case ShaderDataType::Int4: return 4;
case ShaderDataType::Bool: return 1;
}
HZ_CORE_ASSERT(false, "Unknown ShaderDataType!");
return 0;
}
对于glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);,还要GL_FLOAT也需要拆分,这里临时做一个函数,进行拆分好了,后面会修正的,后面也会把glVertexAttribPointer这个函数封装到OpenGL对应的cpp里,不会再是Context Sensitive:
// 在Application.cpp里写一个临时转换的static函数
static GLenum ShaderDataTypeToOpenGLBaseType(ShaderDataType type)
{
switch (type)
{
case Hazel::ShaderDataType::Float: return GL_FLOAT;
case Hazel::ShaderDataType::Float2: return GL_FLOAT;
case Hazel::ShaderDataType::Float3: return GL_FLOAT;
case Hazel::ShaderDataType::Float4: return GL_FLOAT;
case Hazel::ShaderDataType::Mat3: return GL_FLOAT;
case Hazel::ShaderDataType::Mat4: return GL_FLOAT;
case Hazel::ShaderDataType::Int: return GL_INT;
case Hazel::ShaderDataType::Int2: return GL_INT;
case Hazel::ShaderDataType::Int3: return GL_INT;
case Hazel::ShaderDataType::Int4: return GL_INT;
case Hazel::ShaderDataType::Bool: return GL_BOOL;
}
HZ_CORE_ASSERT(false, "Unknown ShaderDataType!");
return 0;
}
关于glVertexAttribPointer函数,还剩三个参数,其中一个是normalized的布尔值,(normalized用于处理当输入为uint但是当作float用的时候的这些情况,表示输入的数据是否需要格式化),这个需要加到前面的BufferElement的属性里,很简单就不多说,第二个是stride,这个也算出来的,最后一个是offset,这个也有,转成(void*)就行了,所以最后的代码是:
uint32_t index = 0;
const auto& layout = m_VertexBuffer->GetLayout();
// 这里的for需要在layout的vector里写iterator begin和end,文章里省略了
for (const auto& element : layout)
{
glEnableVertexAttribArray(index);
glVertexAttribPointer(index,
element.GetComponentCount(),
ShaderDataTypeToOpenGLBaseType(element.Type),
element.Normalized? GL_TRUE : GL_FALSE,
layout.GetStride(),
(const void*)element.Offset);
index++;
}
Vertex Arrays
OpenGL里的VAO,其实本身不包含任何Buffer的数据,它只是记录了Vertex Buffer和IndexBuffer的引用,并且使用glVertexAttribPointer函数来决定VAO通过哪种方式来挖取 VBO中的数据。
这一节课的目的是创建Vertex Array类,由于OpenGL有VAO这个东西,而DX里完全没有这个概念,但是前期的Hazel引擎是极大程度依赖OpenGL的,所以目前是先创建VertexArray类,至于Dx这种的,里面可能会有对应VertexArray的API,但里面的执行代码弄成空的就行了。
同之前的几节课一样,这里仍然是有一些关于Vertex Array的代码要把它抽象化:
// 1. 创建VertexArray,这一段还没抽象化
glGenVertexArrays(1, &m_VertexArray);
glBindVertexArray(m_VertexArray);
// 这一段已经成功抽象化了
{
BufferLayout layout = {
{ShaderDataType::FLOAT3, "a_Pos" },
{ShaderDataType::FLOAT4, "a_Color" }
};
m_VertexBuffer->SetBufferLayout(layout);
}
BufferLayout layout = m_VertexBuffer->GetBufferLayout();
int index = 0;
// 2. 指定VAO挖数据的方法,这一段也没抽象化
for (const BufferElement& element : layout)
{
glEnableVertexAttribArray(index);
glVertexAttribPointer(index,
GetShaderTypeDataCount(element.GetType()),
GetShaderDataTypeToOpenGL(element.GetType()),
element.IsNormalized()? GL_TRUE : GL_FALSE,
layout.GetStride(),
(const void*)(element.GetOffset()));
index++;
}
接下来就是正式开始写代码了。
前面两句代码要把它抽象化,也就是把它变成跟平台无关的东西,跟之前创建的VertexBuffer和IndexBuffer都差不多
glGenVertexArrays(1, &m_VertexArray);
glBindVertexArray(m_VertexArray);
这里单独建一个VertexArray的cpp和h文件,之所以单独建立cpp和h文件,是因为Cherno还不确定相关的VertexArray的内容以后还会不会会保留,毕竟DX里是没有这个概念的
// 直接复制VertexBuffer的相关内容就行:
class VertexArray
{
public:
// 这些都是跟VertexBuffer和IndexBuffer的接口一样的
virtual ~VertexArray() {};
virtual void Bind() const = 0;
virtual void Unbind() const = 0;//Unbind函数一般用于debuging purposes
// 注意这个Create函数与VertexBuffer的Create函数一样,为static的函数,在定义的时候不需要写static关键字
// 而且这个Create函数是在基类定义的,因为创建的窗口对象应该包含多种平台的派生类对象,所以放到了基类里
// 而且这个基类的cpp引用了相关的派生类的头文件,相关的Create函数定义在VertexArray.cpp里完成
static VertexArray* Create(float* vertices, uint32_t size);
// 原本VertexBuffer的接口SetLayout的函数就不需要了
// 由于一个VAO可以挖取多个VBO的数据,所以需要添加记录相关VBO引用的接口
virtual void AddVertexBuffer(std::shared_ptr<VertexBuffer>& ) = 0;
virtual void AddIndexBuffer(std::shared_ptr<IndexBuffer>& ) = 0;
};
接下来就是创建OpenGLVertexArray的头文件和cpp文件了,放到Platform的文件夹里,实现过程跟OpenGLVertexBuffer差不多,不多说了,唯一需要注意的就是这里的AddVertexBuffer函数和AddIndexBuffer函数,在之前的Application.cpp里,有一段是OpenGL相关的代码,调用了glVertexAttribPointer函数,具体作用是把VertexBuffer的数据挖到VAO里(其实是记录的引用),这一段代码会转移到AddVertexBuffer函数里,代码如下所示:
void OpenGLVertexArray::AddVertexBuffer(std::shared_ptr<VertexBuffer>& vertexBuffer)
{
HAZEL_CORE_ASSERT(vertexBuffer->GetBufferLayout().GetCount(), "Empty Layout in VertexBuffer!");
BufferLayout layout = vertexBuffer->GetBufferLayout();
int index = 0;
for (const BufferElement& element : layout)
{
glEnableVertexAttribArray(index);
glVertexAttribPointer(index,
GetShaderTypeDataCount(element.GetType()),
GetShaderDataTypeToOpenGL(element.GetType()),
element.IsNormalized() ? GL_TRUE : GL_FALSE,
layout.GetStride(),
(const void*)(element.GetOffset()));
index++;
}
}
多个VBO来验证
做到这里其实就差不多了,但是Cherno为了验证之前做的是正确的,创建了一个应用场景,就是通过使用两个Shader,一个VAO,两个VBO,一个EBO来绘制出来
1. 保留VertexArray里的VertexBuffer数组和IndexBuffer
这里在VertexArray的类里,添加了两个接口:
class VertexArray
{
public:
...
// 注意前后两个const
virtual const std::vector<std::shared_ptr<VertexBuffer>>& GetVertexBuffers() const = 0;
virtual const std::shared_ptr<IndexBuffer>& GetIndexBuffer() const = 0;
};
2. 创建第二个VertexArray
前面画了个三角形,下面再画一个Quad,在Application类里创建:
std::shared_ptr<VertexArray> m_QuadVertexArray;
然后按照同样的方式,创建VAO、VBO和顶点数据,再创建一个Shader,这里做一个只输出蓝色的Shader,就可以了,最后在Loop里分别绑定VBO和Shader就可以了:
m_BlueShader->Bind();
m_QuadVertexArray->Bind();
glDrawElements(GL_TRIANGLES, m_QuadVertexArray->GetIndexBuffer()->GetCount(), GL_UNSIGNED_INT, nullptr);
m_Shader->Bind();
m_VertexArray->Bind();
glDrawElements(GL_TRIANGLES, m_VertexArray->GetIndexBuffer()->GetCount(), GL_UNSIGNED_INT, nullptr);
附录
一个关于static变量的报错
我的window类是这样的
// 头文件里
class HAZEL_API Window
{
public:
...
static GraphicsContext* m_Contex;
};
使用Window的类是这样的:
// cpp文件里,WindowsWindow继承于Windows类
void Hazel::WindowsWindow::Init(const WindowProps& props)
{
...
// 在这里为static变量进行了初始化
m_Contex = new OpenGLContext(m_Window);
m_Contex->Init();
这样Link阶段会报错:
2>Hazel.lib(WindowsWindow.obj) : error LNK2001: unresolved external symbol "public: static class Hazel::GraphicsContext * Hazel::Window::m_Contex" (?m_Contex@Window@Hazel@@2PEAVGraphicsContext@2@EA)
2>..\bin\Debug-windows-x86_64\Sandbox\Sandbox.exe : fatal error LNK1120: 1 unresolved externals
然后我加了个初始化:
class HAZEL_API Window
{
public:
...
static GraphicsContext* m_Context;
};
GraphicsContext* Window::m_Context = nullptr;
继续编译,则会有新的报错,表示m_Context被定义了两次:
1>Hazel.lib(WindowsWindow.obj) : error LNK2005: "public: static class Hazel::GraphicsContext * Hazel::Window::m_Contex" (?m_Contex@Window@Hazel@@2PEAVGraphicsContext@2@EA) already defined in SandboxApp.obj
这个报错说是定义了两次,我就很疑惑,直到我查了一下Stack Overflow:link-error-when-declaring-public-static-variables-in-c,才知道,我把static变量的定义放到了头文件里,这样同个Translation Unit里的多个cpp,同时引用这个头文件就会出现重定义的问题。
后来发现一个Window应该对应一个Context,所以不应该把m_Context设置为static变量,把Static去掉就可以了
关于std::intializer_list
C++11提供了std::initializer_list,它可以代表一组同一类型组成的List,注意这里说的intializer_list与类成员列初始化(member initializer list)不是一个东西。
An object of type std::initializer_list is a lightweight proxy object that provides access to an array of objects of type const T.
话不多说,直接看一个例子,这个例子实现了一个累加函数,计算传入的参数的总和:
#include <iostream>
#include <initializer_list>
int calcSum(std::initializer_list<int> list)
{
int total= 0;
for(auto i : list)
{
total += i;
}
return total;
}
int main()
{
// 一定不要忘了花括号
std::cout << calcSum({1,2,3}) << std::endl;
std::cout << calcSum({1,43,21,2,3}) << std::endl;
std::cin.get();
return 0;
}
打印:
6
70
再结合上模板,就更好用了:
// 做一个万能的打印输入元素的函数
template<typename T>
void print(std::initializer_list<T> list)
{
for(auto i : list)
std::cout << i << std::endl;
}
结合上面的例子,可以看出来,当参数个数不确定、但参数类型是统一的时候,很适合使用initializer_list(不过感觉直接输入对应的vector也也是可以的),下面是Cherno使用的时候涉及到的代码:
// 使用Initializer作为参数创建layout的构造函数
// std::vector<BufferElement> m_Elements
BufferLayout(const std::initializer_list<BufferElement>& elements)
: m_Elements(elements)
{
CalculateOffsetsAndStride();
}
void CalculateOffsetsAndStride()
{
uint32_t offset = 0;
m_Stride = 0;
for (auto& element : m_Elements)
{
element.Offset = offset;
offset += element.Size;
m_Stride += element.Size;
}
}
// 在创建layout的时候
BufferLayout layout = {
// 这里不创建vector而是用initializer_list是为了什么?方便写入或者避免拷贝吗
{ ShaderDataType::Float3, "a_Position" },
{ ShaderDataType::Float4, "a_Color" }
};
m_VertexBuffer->SetLayout(layout);
额外提一下为什么这里用了initializer_list,而没有直接用vector,可以看一下,如果用vector传入会发生什么:
// 代码会变成这么写
// 构造函数参数变为vector
BufferLayout(const std::vector<BufferElement>& elements)
: m_Elements(elements)
{
...
}
// 在创建layout的时候
std::vector<BufferElement> vec = {
{ ShaderDataType::Float3, "a_Position" },
{ ShaderDataType::Float4, "a_Color" }
};
BufferLayout layout(vec);
可以看到,使用vector这么写也可以,但是写起来会更麻烦一些。另外,由于这段代码在创建vec的时候,仍然是用了initializer_list,所以它本质上是差不多的。注意两点,第一点,这里的vec是由intializer_list发生隐式转换得到的,第二点,这里的m_Elements会去拷贝elements,所以如果输入的elements是左值,可能还会做一次深拷贝,所以这么写应该才能达到initializer_list的相同性能水平:
// 在创建layout的时候
std::vector<BufferElement> vec = {
{ ShaderDataType::Float3, "a_Position" },
{ ShaderDataType::Float4, "a_Color" }
};
BufferLayout layout(std::move(vec));
不知道隐式转换会不会造成性能消耗,initializer_list还是不够熟悉,上面的结论有时间可以再验证一下
为什么VertexArray里只有一个EBO,但是多个VBO
他这里一个VertexArray里,记录了多个VBO和一个EBO,他这里一个VAO有多个VBO,这个我可以理解,但是为什么只有一个EBO呢?
这里我回想了一下我之前写OpenGL的代码,里面是一个物体对应一个单独的VAO和VBO,然后实际绘制的时候切换VAO就行了,代码如下所示:
// 在渲染的Loop里
// 绘制1号三角形
glBindVertexArray(VAO[0]);
glDrawArrays(GL_TRIANGLES, 0, 3);
// 绘制2号三角形
glBindVertexArray(VAO[1]);
glDrawArrays(GL_TRIANGLES, 0, 3);
而且这里面绘制的物体,他的Vertex Buffer里面都自带了顶点的组合顺序,比如Cube,他不是8个顶点,而是36个顶点,顺序绘制就行了,所以没有使用EBO:
// 里面的vertex buffer 自带顺序,调用的函数是,glDrawArrays不是glDrawElements,没有用到EBO
float vertices[] = {
-0.5f, -0.5f, -0.5f,
0.5f, -0.5f, -0.5f,
0.5f, 0.5f, -0.5f,
0.5f, 0.5f, -0.5f,
-0.5f, 0.5f, -0.5f,
-0.5f, -0.5f, -0.5f,
-0.5f, -0.5f, 0.5f,
0.5f, -0.5f, 0.5f,
0.5f, 0.5f, 0.5f,
0.5f, 0.5f, 0.5f,
-0.5f, 0.5f, 0.5f,
-0.5f, -0.5f, 0.5f,
-0.5f, 0.5f, 0.5f,
-0.5f, 0.5f, -0.5f,
-0.5f, -0.5f, -0.5f,
-0.5f, -0.5f, -0.5f,
-0.5f, -0.5f, 0.5f,
-0.5f, 0.5f, 0.5f,
0.5f, 0.5f, 0.5f,
0.5f, 0.5f, -0.5f,
0.5f, -0.5f, -0.5f,
0.5f, -0.5f, -0.5f,
0.5f, -0.5f, 0.5f,
0.5f, 0.5f, 0.5f,
-0.5f, -0.5f, -0.5f,
0.5f, -0.5f, -0.5f,
0.5f, -0.5f, 0.5f,
0.5f, -0.5f, 0.5f,
-0.5f, -0.5f, 0.5f,
-0.5f, -0.5f, -0.5f,
-0.5f, 0.5f, -0.5f,
0.5f, 0.5f, -0.5f,
0.5f, 0.5f, 0.5f,
0.5f, 0.5f, 0.5f,
-0.5f, 0.5f, 0.5f,
-0.5f, 0.5f, -0.5f,
};
所以他说的一个VAO,一般只需要一个EBO(而且我搜的是OpenGL一次只支持一个EBO),我看了一下glDrawElements的函数接口大概就知道了,如果说VAO是顶点数据按分类的不同挖取出来的,那么EBO就可以是顶点数据对应的索引数据组成的一个buffer,它可以存储多块顶点数据对应的索引顺序:
// 这个indices应该包含很多VertexBuffer的顶点顺序
std::vector indices;
// fill "indices" as needed
// Generate a buffer for the indices
GLuint elementbuffer;
glGenBuffers(1, &elementbuffer);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, elementbuffer);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, indices.size() * sizeof(unsigned int), &indices[0], GL_STATIC_DRAW);
// Index buffer
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, elementbuffer);
// Draw the triangles !
glDrawElements(
GL_TRIANGLES, // mode
indices.size(), // count
GL_UNSIGNED_INT, // type
(void*)0 // element array buffer offset
);
相关内容可以参考:第九课:VBO索引
uint32_t和unsinged int
额外提一下,IndexBuffer的Create函数里的indices数组,Cherno用的是uint32_t* indices,我在C++里输入uint32_t,F12点进去发现在C++ runtime的头文件stdint.h里有typedef unsigned int uint32_t;,所以二者有啥区别,为啥不直接写unsigned int呢。uint32_t保证了该变量一定是32位无符号的2,也就是说,在别的平台上可能uint32_t不等同于unsigned int
一个因为返回指针引发的bug
下面是我写的函数,这个函数返回的指针
VertexBuffer* VertexBuffer::Create(float* vertices, uint32_t size)
{
std::unique_ptr< VertexBuffer> buffer;
switch (Renderer::GetAPI())
{
case RendererAPI::None:
{
CORE_LOG_ERROR("No RendererAPI selected");
HAZEL_ASSERT(false, "Error, please choose a Renderer API");
break;
}
case RendererAPI::OpenGL:
{
buffer.reset(new OpenGLVertexBuffer());
glGenBuffers(1, &buffer->m_VertexBuffer);
glBindBuffer(GL_ARRAY_BUFFER, buffer->m_VertexBuffer);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);//从CPU传入了GPU
break;
}
default:
break;
}
// buffer指针被销毁,调用OpenGLVertexBuffer的析构函数,销毁该对象,所以返回的是一个野指针
return &(*buffer);
}
上面这段代码有两个错误:
- 不应该用智能指针,由于智能指针的范围只在这个Scope范围内,它出了这个范围会调用所指向对象的析构函数,同时销毁对象
- 这个函数接受的第一个参数是float* vertices,所以在glBufferData里应该填,
(GL_ARRAY_BUFFER, size, vertices,GL_STATIC_DRAW)而不是
因为这里的vertices会退化成指针,所以在sizeof下,64位平台是8,而不是9个float应该对应的字节数36,如下图所示:

被初始化为nullptr的unique_ptr A,可以通过等号,用B给A赋值?
在搞清楚这个问题之前,先搞清楚另一个我遇到的问题,我看了一下我之前写的关于智能指针的博客这里,里面提到了,unique_ptr类的Copy Constructor和Copy Assignment Operator都会被声明为Delete,如下图所示:
注意上面两行代码虽然有const,也不意味着Move Constructor和Move Assignment Operator是被禁用的,实际上一个unique_ptr应该是uncopyable but movable的,可以参考如下代码:

class E {
public:
E() { a = 0; }
E(const E&) = delete;
E(E&& c) {}
int a = 3;
};
int main()
{
E a;
E b(a); // 编译错误,it's a deleted funtion
E b((E&&)a);//编译正确,当E定义了move constructor的时候,就不会再去const E&里找了
}
问题在于,为什么已经定义过的unique_ptr(虽然是定义为nullptr),可以再去指向别的内容,后来我发现我搞混淆了,unique_ptr本身是一个指针的wrapper,指针本身是一个地址,也就是说unique_ptr不允许别的unique_ptr指向相同的位置,但是如果让原本的指针指向新的内容,是完全没问题的,比如下面的代码应该是没问题的:
#include <memory>
class A
{
public:
A(){}
};
int main()
{
std::unique_ptr<A> a1 = nullptr;
std::unique_ptr<A> a2 (new A());
a1 = std::unique_ptr<A>(new A());
a2 = std::unique_ptr<A>(new A());
A* p = new A();
a2 = std::unique_ptr<A>(p);
}
unique_ptr配合抽象类对象使用
原来写的是VertexBuffer* m_VertexBuffer,然后想改成智能指针,我这么做,结果报错了,如下图所示:
然后我发现我是这么写的:
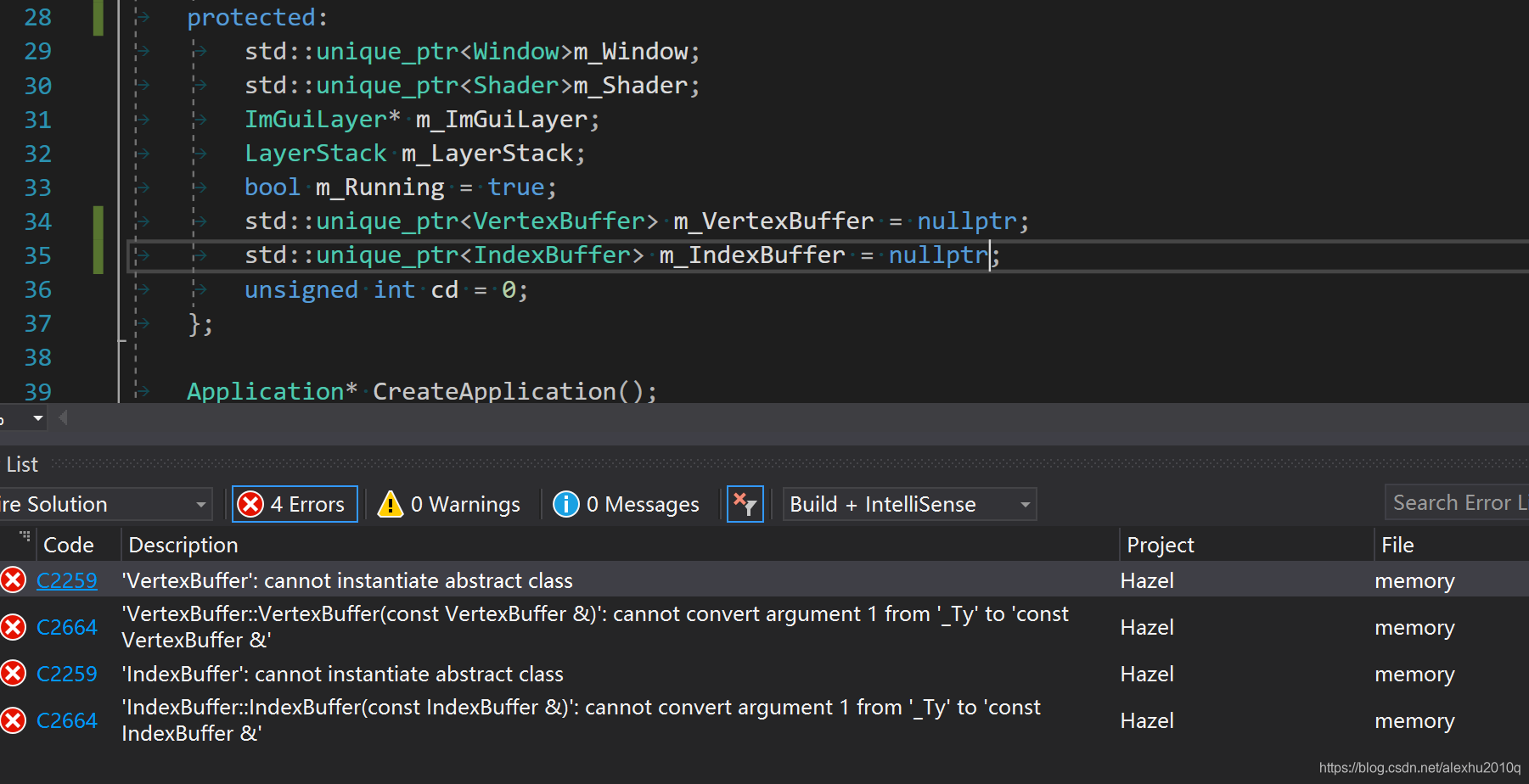
// 写法一,这样写会报上图的错
m_VertexBuffer = std::make_unique<VertexBuffer>(VertexBuffer::Create(vertices, sizeof(vertices)));
// 写法二,这样写是正常的
m_VertexBuffer.reset(VertexBuffer::Create(vertices, sizeof(vertices)));
查了一下发现,我好像是理解错了std::make_unique的用法,因为写法一改成下面这行代码就可以跑通了:
m_VertexBuffer = std::unique_ptr<VertexBuffer>(VertexBuffer::Create(vertices, sizeof(vertices)));
所以std::make_unique和std::unique_ptr的区别在哪呢?可以参考这里,这里还有个std::make_shared,这个问题以后再说吧
OpenGL糟糕的API设计
这里Chernot提到了OpenGL糟糕的API设计,比如说,OpenGL里,我要绑定一个IndexBuffer到VertexArray,那么需要这么写代码
// 先要保证想要绑定的VAO处于OpenGL的Context里
// 这两行代码感觉可读性很弱
glBindVertexArray(m_Index);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, m_IndexBuffer);
不过OpenGL新版本,好像是4.5的版本,推出了更可读的API,有机会可以学习一下
总而言之,就是Bind一个VertexArray,再Bind一个VertexBuffer,这两个就会自动关联起来,这就可能会造成bug,所以说这里的API设计的不好,所以代码里设计了Unbind函数,就是为了方便Debug用的
const成员调用const函数
在写这两个接口时遇到了问题:
class VertexArray
{
public:
...
// 如果我这么写
virtual const std::vector<std::shared_ptr<VertexBuffer>>& GetVertexBuffers() const = 0;
};
class OpenGLVertexArray : public VertexArray
{
public:
std::vector<std::shared_ptr<VertexBuffer>>& GetVertexBuffers() const override;
private:
std::vector<std::shared_ptr<VertexBuffer>>m_VertexBuffers;
};
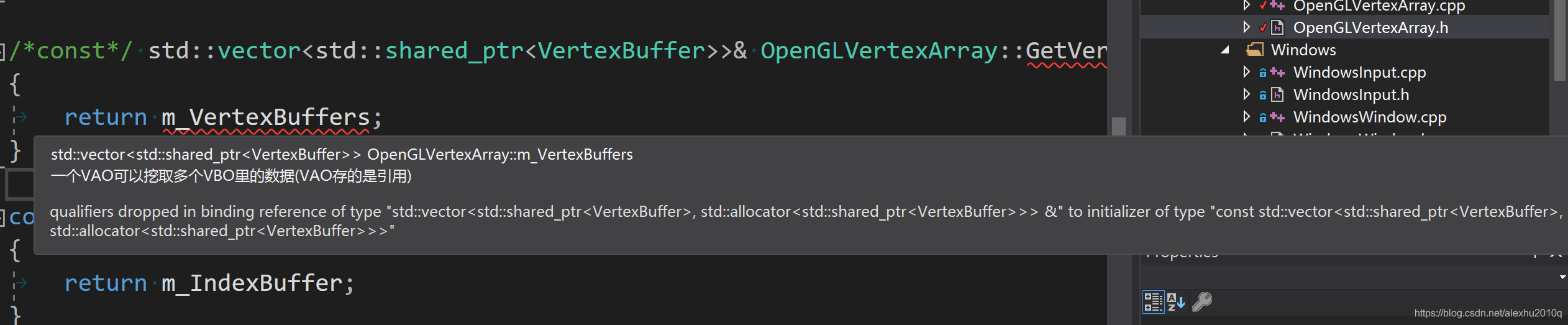
std::vector<std::shared_ptr<VertexBuffer>>& OpenGLVertexArray::GetVertexBuffers() const
{
return m_VertexBuffers;// 编译报错,qualifiers dropped in binding reference of type
}
如下图所示:
只要在函数前面加上const,就可以了,好像侯捷讲过,const成员调用const函数,具体原因Remain