
在 Java 并发编程中,锁是确保线程安全、协调多线程访问共享资源的关键机制。从基本的 synchronized 同步关键字到高级的 ReentrantLock、读写锁 ReadWriteLock、无锁设计如 AtomicInteger,再到复杂的同步辅助工具如 CountDownLatch、CyclicBarrier 和 Semaphore,每种锁都针对特定的并发场景设计,以解决多线程环境下的同步问题。StampedLock 提供了乐观读锁和悲观写锁的选项,而 ConcurrentHashMap 和 ConcurrentLinkedQueue 等并发集合则通过内部机制优化了并发访问。了解不同锁的特点和适用场景,对于构建高效、稳定的并发应用程序至关重要。
肖哥弹架构 跟大家“弹弹” 高并发锁, 关注公号回复 ‘mvcc’ 获得手写数据库事务代码
欢迎 点赞,关注,评论。
关注公号Solomon肖哥弹架构获取更多精彩内容
历史热点文章
- 解锁大语言模型参数:零基础掌握大型语言模型参数奥秘与实践指南
- 高性能连接池之HikariCP框架分析:高性能逐条分解(架构师篇)
- 缓存雪崩/穿透/击穿/失效原理图/14种缓存数据特征+10种数据一致性方案
- Java 8函数式编程全攻略:43种函数式业务代码实战案例解析(收藏版)
- 一个项目代码讲清楚DO/PO/BO/AO/E/DTO/DAO/ POJO/VO
- 17个Mybatis Plugs注解:Mybatis Plugs插件架构设计与注解案例(必须收藏)
1、锁选择维度
选择适合的锁通常依赖于特定的应用场景和并发需求。以下是一个表格,概述了不同锁类型的关键特性和选择它们的考量维度:
| 锁类型 | 适用场景 | 锁模式 | 性能特点 | 公平性 | 锁的粗细 | 条件支持 | 阻塞策略 | 用途举例 |
|---|---|---|---|---|---|---|---|---|
synchronized | 简单的同步需求,无需复杂控制 | 独占式 | 适中,偏向锁、轻量级锁优化 | 无公平策略 | 粗粒度锁 | 不支持 | 阻塞等待 | 单例模式、简单的计数器 |
ReentrantLock | 需要灵活的锁控制,如可中断、超时、尝试锁定等 | 独占式 | 高,支持多种锁定方式 | 可配置公平性 | 细粒度锁 | 支持 | 可中断、超时、尝试 | 同步代码块或方法、复杂同步控制 |
ReadWriteLock | 读多写少的场景 | 共享-独占式 | 高,提高读操作并发性 | 不支持公平性 | 细粒度锁 | 不支持 | 阻塞等待 | 缓存系统、文件系统 |
StampedLock | 读多写多,需要乐观读和悲观写的场景 | 乐观读-悲观写 | 高,提供读写锁的扩展 | 可配置公平性 | 细粒度锁 | 支持 | 可中断、超时、尝试 | 高性能计数器、数据缓存 |
CountDownLatch | 需要等待一组操作完成的场景 | 无 | 低,一次性 | 不支持公平性 | 粗粒度锁 | 不支持 | 阻塞等待 | 任务协调、初始化操作 |
Semaphore | 需要控制资源访问数量的场景 | 信号量 | 高,控制并发数量 | 不支持公平性 | 细粒度锁 | 支持 | 阻塞等待 | 限流、资源池管理 |
CyclicBarrier | 需要周期性执行一组操作的场景 | 无 | 低,重用性 | 支持公平性 | 粗粒度锁 | 支持 | 阻塞等待 | 并行计算、批处理 |
2、锁详细分析
2.3. ReadWriteLock
ReadWriteLock 是 Java 中用于提供对共享资源进行并发访问的锁,它允许多个读操作并行执行,但写操作是独占的。
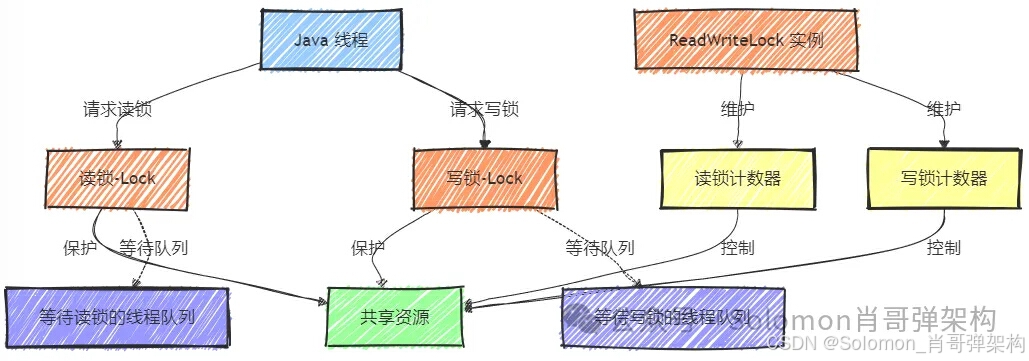
图解说明:
- Java 线程:表示运行中的线程,它们可能需要访问共享资源。
- ReadWriteLock 实例:是
ReadWriteLock类的实例,用于控制对共享资源的读写访问。 - 读锁(Lock) :用于同步读操作的锁,允许多个线程同时获取读锁。
- 写锁(Lock) :用于同步写操作的锁,一次只允许一个线程获取写锁。
- 共享资源:表示被多个线程共享的数据,需要通过锁来保护以确保线程安全。
- 读锁计数器:记录当前持有读锁的线程数量。
- 写锁计数器:记录当前持有写锁的线程数量。
- 等待写锁的线程队列:当写锁被占用时,请求写锁的线程可能会被放入等待队列。
- 等待读锁的线程队列:在特定情况下,如果写锁经常被频繁请求,读锁请求的线程也可能会被放入等待队列。
综合说明:
- 作用:
ReadWriteLock是一种允许多个读操作并行执行,但写操作会阻塞所有其他读写操作的锁。它通常用于读多写少的场景,可以提高系统的并发性能。 - 背景:在许多应用中,读操作远多于写操作,如数据库读取、缓存访问等。为了提高这类场景的并发性能,
ReadWriteLock被设计出来,允许多个线程同时进行读操作,而写操作则需要独占锁。 - 优点:
- 提高并发性:在读多写少的场景下,允许多个线程同时进行读操作,提高了系统的并发性能。
- 读写分离:将读操作和写操作分离,减少了读写操作之间的冲突。
- 缺点:
- 写操作独占:写操作会阻塞所有其他读写操作,可能导致写操作的响应时间较长。
- 可能导致写饥饿:在高并发的读操作下,写操作可能长时间得不到执行。
- 场景:适用于读操作远多于写操作的场景,如缓存系统、数据库读取等。
- 业务举例:在内容管理系统中,
ReadWriteLock可以用来同步对文章内容的访问。由于文章的读取操作远多于更新操作,使用ReadWriteLock可以显著提高读取文章的并发性能。例如,当多个用户同时阅读同一篇文章,而偶尔有编辑更新文章内容时,ReadWriteLock可以确保在编辑更新文章时,读者的阅读体验不受影响。
使用方式:
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
import java.util.HashMap;
public class Cache {
// 定义一个 ReadWriteLock 对象
private final ReadWriteLock lock = new ReentrantReadWriteLock();
// 使用 HashMap 来存储缓存数据
private final HashMap<String, String> cache = new HashMap<>();
// 读操作:获取缓存中的数据
public String getValue(String key) {
// 获取读锁
lock.readLock().lock();
try {
// 有读锁时,可以读取缓存中的值
return cache.get(key);
} finally {
// 释放读锁
lock.readLock().unlock();
}
}
// 写操作:向缓存中添加或更新数据
public void setValue(String key, String value) {
// 获取写锁
lock.writeLock().lock();
try {
// 有写锁时,可以修改缓存中的值
cache.put(key, value);
} finally {
// 释放写锁
lock.writeLock().unlock();
}
}
// 清除缓存
public void clearCache() {
// 获取写锁
lock.writeLock().lock();
try {
// 有写锁时,可以清空缓存
cache.clear();
} finally {
// 释放写锁
lock.writeLock().unlock();
}
}
}
// 测试类
public class ReadWriteLockDemo {
public static void main(String[] args) {
final Cache cache = new Cache();
// 读线程:从缓存中获取数据
Thread readerThread = new Thread(() -> {
String value = cache.getValue("key1");
System.out.println("Read Thread: key1 has value: " + value);
});
// 写线程:向缓存中添加数据
Thread writerThread = new Thread(() -> {
cache.setValue("key1", "value1");
System.out.println("Write Thread: Set key1 to value1");
});
// 启动读线程
readerThread.start();
// 启动写线程
writerThread.start();
}
}
业务代码案例:
业务说明: 在一个多用户实时数据访问系统中,比如在线教育平台,每个用户可能在同一时间查询课程信息、学生信息或教师评分。同时,后台管理员可能需要更新这些信息。系统需要保证数据的实时性和一致性,同时允许高并发的读取操作和较少发生的写入操作。
为什么需要 ReadWriteLock 技术: 在这种场景中,读操作远多于写操作。如果使用传统的互斥锁(例如 ReentrantLock),每次读操作都需要独占锁,会大大减少系统的并发能力。而 ReadWriteLock 允许多个读操作并行执行,只有写操作需要独占锁。这样可以显著提高系统的并发读取能力,同时保证了写操作的安全性。
没有 ReadWriteLock 技术会带来什么后果:
如果没有使用 ReadWriteLock 或类似的并发控制技术,可能会导致以下问题:
- 性能瓶颈:读操作等待写操作完成,写操作等待读操作完成,造成大量线程阻塞和等待,降低了系统的整体性能。
- 用户体验下降:用户查询数据时可能会遇到延迟,尤其是在高并发时段,如课程报名开始时。
- 数据竞争和一致性问题:在没有适当同步控制的情况下,写操作可能会干扰或覆盖彼此,导致数据不一致。
代码实现:
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
import java.util.concurrent.ConcurrentHashMap;
public class RealTimeDataAccessSystem {
private final ReadWriteLock lock = new ReentrantReadWriteLock();
private final ConcurrentHashMap<String, Object> dataStore = new ConcurrentHashMap<>();
public Object readData(String key) {
lock.readLock().lock();
try {
return dataStore.get(key);
} finally {
lock.readLock().unlock();
}
}
public void writeData(String key, Object value) {
lock.writeLock().lock();
try {
dataStore.put(key, value);
} finally {
lock.writeLock().unlock();
}
}
}
// 测试类
public class Main {
public static void main(String[] args) {
RealTimeDataAccessSystem system = new RealTimeDataAccessSystem();
// 多个用户同时读取数据
for (int i = 0; i < 10; i++) {
int finalI = i;
new Thread(() -> {
System.out.println("Thread " + finalI + " read: " + system.readData("student" + finalI));
}).start();
}
// 管理员更新数据
new Thread(() -> {
system.writeData("student1", "New Data");
}).start();
}
}
4. StampedLock
StampedLock 是 Java 中一种较新的锁机制,它提供了乐观读锁和悲观写锁的概念,同时支持锁的降级,但不支持升级。
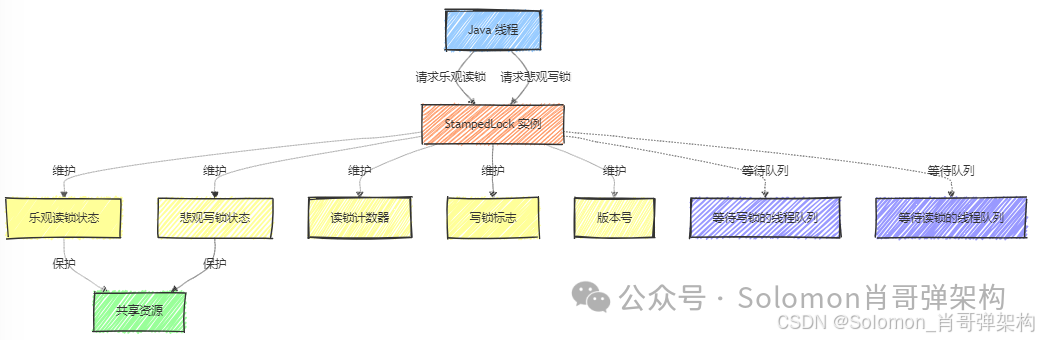
图解说明:
- Java 线程:表示运行中的线程,它们可能需要访问共享资源。
- StampedLock 实例:是
StampedLock类的实例,用于控制对共享资源的访问。 - 乐观读锁状态:用于同步乐观读操作的状态,允许多个线程同时进行读操作,除非有写操作发生。
- 悲观写锁状态:用于同步写操作的状态,一次只允许一个线程获取写锁。
- 共享资源:表示被多个线程共享的数据,需要通过锁来保护以确保线程安全。
- 读锁计数器:记录当前持有乐观读锁的线程数量。
- 写锁标志:标记当前是否有线程持有悲观写锁。
- 版本号:用于检测在读操作期间是否有写操作发生,以避免乐观读锁下的ABA问题。
- 等待写锁的线程队列:当写锁被占用时,请求写锁的线程可能会被放入等待队列。
- 等待读锁的线程队列:在特定情况下,如果写锁频繁被请求,读锁请求的线程也可能会被放入等待队列。
综合说明:
- 作用:
StampedLock是一种新颖的锁机制,它提供了乐观读模式、悲观写模式和允许锁的降级。它通过版本号来避免ABA问题,适用于读多写多的场景。 - 背景:为了解决
ReadWriteLock在高并发写操作下可能出现的写饥饿问题,同时提供更细粒度的锁控制,StampedLock被引入。它通过引入版本号和乐观读模式,提高了锁操作的灵活性和并发性能。 - 优点:
- 乐观读模式:在读操作远多于写操作的场景下,可以提高读操作的性能。
- 避免ABA问题:通过版本号来确保数据的一致性。
- 锁的降级:允许从写锁模式降级到读锁模式,提高了灵活性。
- 缺点:
- 使用复杂:需要正确管理版本号和锁模式,增加了编码复杂度。
- 可能导致写饥饿:在高并发的读操作下,写操作可能长时间得不到执行。
- 场景:适用于读多写多,且对性能有高要求的场景。
- 业务举例:在实时数据处理系统中,
StampedLock可以用于同步对实时数据的访问。由于实时数据需要频繁的读取和更新,StampedLock的乐观读模式和锁的降级特性可以提高系统的响应速度和并发性能。例如,在一个金融交易平台中,交易数据需要被频繁读取以供监控和分析,同时交易操作需要更新这些数据,StampedLock可以确保在高并发环境下,数据的一致性和系统的响应速度。
使用方式:
import java.util.concurrent.locks.StampedLock;
public class Cache {
private static class Data {
String value;
long version;
}
private final Data data = new Data();
private final StampedLock stampedLock = new StampedLock();
// 乐观读
public String get() {
long stamp = stampedLock.tryOptimisticRead(); // 尝试乐观读锁
String value;
if (stamp == 0) { // 获得锁失败,尝试悲观锁
stamp = stampedLock.readLock();
try {
value = data.value;
} finally {
stampedLock.unlock(stamp); // 释放读锁
}
} else {
value = data.value;
if (data.version != stampedLock.getReadLockCount(stamp)) { // 验证版本号
stamp = stampedLock.readLock(stamp); // 版本号不匹配,转换为悲观锁
try {
value = data.value;
} finally {
stampedLock.unlock(stamp); // 释放锁
}
}
}
return value;
}
// 写入
public void put(String value) {
long stamp = stampedLock.writeLock(); // 获取写锁
try {
data.value = value;
data.version = data.version + 1; // 更新版本号
} finally {
stampedLock.unlock(stamp); // 释放写锁
}
}
}
// 测试类
public class StampedLockDemo {
public static void main(String[] args) {
final Cache cache = new Cache();
// 写线程
Thread writerThread = new Thread(() -> {
cache.put("New Value");
});
// 读线程
Thread readerThread = new Thread(() -> {
String value = cache.get();
System.out.println("Read value: " + value);
});
writerThread.start();
readerThread.start();
}
}
业务代码案例:
业务说明: 高频交易系统需要处理大量的买入和卖出请求,每个交易操作都需要实时更新账户余额和持仓信息。由于交易请求非常频繁,系统必须能够支持高并发的读写操作,同时保证数据的一致性和准确性。
为什么需要 StampedLock 技术: 在高频交易系统中,读操作(如检查账户余额和持仓信息)远多于写操作(如更新交易记录和账户状态)。StampedLock 提供了乐观读锁模式,允许多个线程同时进行读操作而不会相互阻塞,提高了系统的并发读取能力。同时,它也支持悲观写锁模式,确保写操作的安全性和数据一致性。
没有 StampedLock 技术会带来什么后果:
如果没有使用 StampedLock 或其他适合高并发读写的同步机制,可能会导致以下问题:
- 性能瓶颈:使用传统的互斥锁可能导致大量的线程阻塞和等待,特别是在高并发读取时,会显著降低系统的性能。
- 数据不一致:在高并发写入时,如果没有适当的同步控制,可能会导致数据不一致的问题,如账户余额更新错误。
- 交易失败:由于锁竞争导致的延迟可能会错过交易时机,造成交易失败,给公司带来经济损失。
代码实现:
import java.util.concurrent.locks.StampedLock;
public class TradingAccount {
private double balance;
private int shareCount;
private final StampedLock lock = new StampedLock();
public double getBalance() {
long stamp = lock.tryOptimisticRead(); // 尝试乐观读锁
double currentBalance = balance;
// 验证是否读过程中有写操作
if (lock.validate(stamp)) {
return currentBalance;
} else {
stamp = lock.readLock(); // 转换为悲观读锁
try {
return balance;
} finally {
lock.unlock(stamp);
}
}
}
public void deposit(double amount) {
long stamp = lock.writeLock(); // 获取写锁
try {
balance += amount;
} finally {
lock.unlock(stamp);
}
}
public void buyShares(int shares) {
long stamp = lock.writeLock(); // 获取写锁
try {
balance -= shares * 10; // 假设每股10元
shareCount += shares;
} finally {
lock.unlock(stamp);
}
}
public int getShareCount() {
long stamp = lock.tryOptimisticRead(); // 尝试乐观读锁
int currentShareCount = shareCount;
// 验证是否读过程中有写操作
if (lock.validate(stamp)) {
return currentShareCount;
} else {
stamp = lock.readLock(); // 转换为悲观读锁
try {
return shareCount;
} finally {
lock.unlock(stamp);
}
}
}
}
// 测试类
public class HighFrequencyTradingSystem {
public static void main(String[] args) {
TradingAccount account = new TradingAccount();
account.deposit(1000);
System.out.println("Balance: " + account.getBalance());
account.buyShares(100);
System.out.println("Share Count: " + account.getShareCount());
}
}
5. Semaphore
Semaphore 是 Java 中用于控制对有限资源的访问的同步辅助类,它通过维护一组许可来实现对资源的并发访问控制。
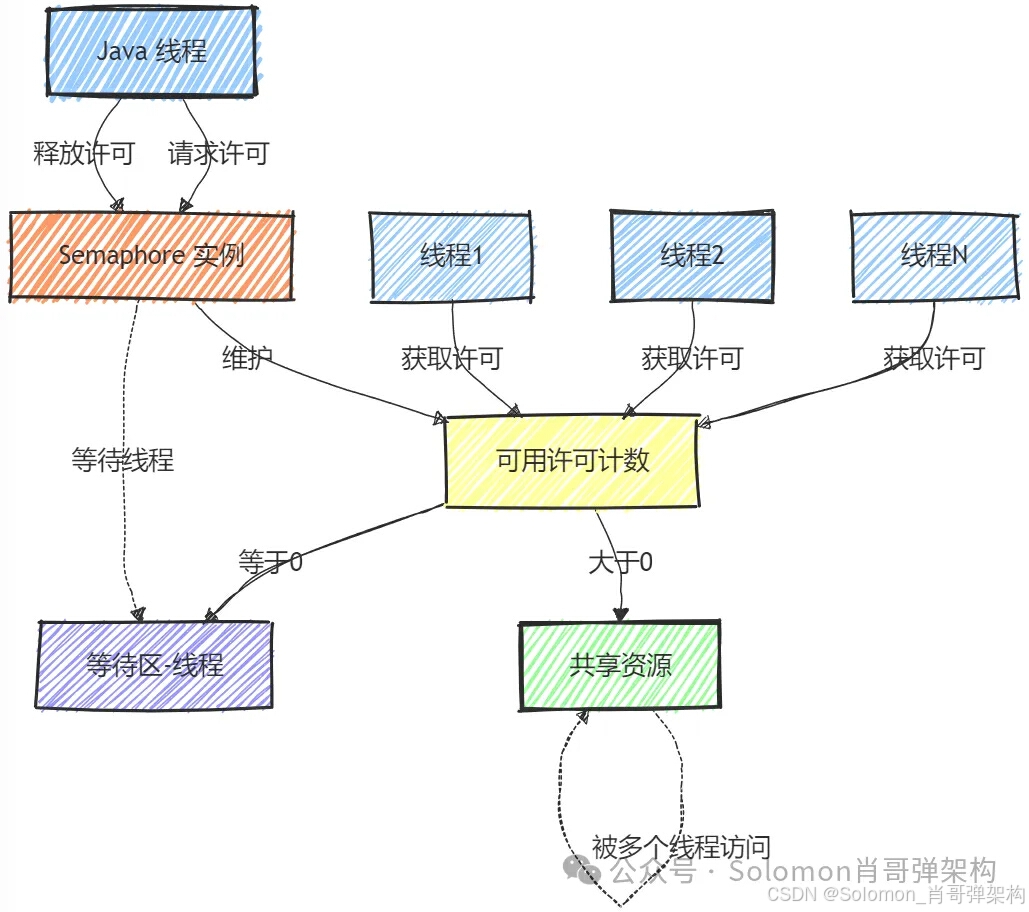
图解说明:
- Java 线程:表示运行中的线程,它们可能需要访问有限的共享资源。
- Semaphore 实例:是
Semaphore类的实例,用于控制对共享资源的访问。 - 可用许可计数:
Semaphore内部维护一个可用许可的计数器,表示当前可用的资源数量。 - 等待区(线程) :当没有可用许可时,请求资源的线程可能会被放入等待区。
- 共享资源:表示有限的共享资源,如数据库连接、线程池中的线程等。
综合说明:
- 作用:
Semaphore是一种计数信号量,用于控制对有限资源的访问,允许多个线程同时访问资源,但是不超过某个特定的最大值。 - 背景:在多线程环境中,经常需要控制对共享资源的访问数量,以避免资源过载或数据不一致。
Semaphore提供了一种方式来限制对资源的并发访问。 - 优点:
- 灵活控制并发数:可以设定最大并发数,有效控制资源使用。
- 支持公平性:可以选择公平或非公平的调度策略。
- 缺点:
- 可能导致线程饥饿:在非公平模式下,新请求的线程可能会抢占资源,导致长时间等待的线程饥饿。
- 复杂性:需要合理设计以避免死锁和资源泄露。
- 场景:适用于需要限制对资源并发访问数量的场景,如数据库连接池、线程池等。
- 业务举例:在云服务环境中,对某个API的调用频率进行限制,以防止API过载。使用
Semaphore可以控制同时访问API的线程数量。
使用方式:
import java.util.concurrent.Semaphore;
public class LimitedResource {
// 初始化一个计数信号量,计数值为可用资源的数量
private final Semaphore semaphore;
public LimitedResource(int permits) {
// permits 表示可用的资源数量
this.semaphore = new Semaphore(permits);
}
// 访问资源的方法
public void useResource() throws InterruptedException {
semaphore.acquire(); // 从信号量中获取一个许可
try {
// 执行业务逻辑,访问资源
System.out.println("Using resource.");
// 资源使用时间
Thread.sleep(1000);
} finally {
semaphore.release(); // 使用完毕后释放许可
System.out.println("Released resource.");
}
}
// 测试类
public static void main(String[] args) {
final LimitedResource resource = new LimitedResource(2);
// 创建线程任务
Runnable task = () -> {
try {
resource.useResource();
} catch (InterruptedException e) {
e.printStackTrace();
}
};
// 创建并启动 4 个线程,同时访问有限资源的场景
for (int i = 0; i < 4; i++) {
new Thread(task).start();
}
}
}
业务代码案例:
业务说明: 数据库连接池用于管理和复用数据库连接,以提高性能并减少建立连接的开销。在多线程应用中,多个线程可能会同时请求数据库连接,因此需要一种机制来控制对数据库连接这一有限资源的访问。
为什么需要 Semaphore 技术: Semaphore 能够限制同时访问资源的线程数量。在数据库连接池中,它可以用来限制同时打开的数据库连接数,以避免系统过载和数据库服务器的压力过大。通过 Semaphore,我们可以确保不超过最大连接数限制的线程能够同时持有数据库连接。
没有 Semaphore 技术会带来什么后果:
没有使用 Semaphore 或其他限流技术可能会导致以下问题:
- 资源耗尽:过多的线程尝试同时获取数据库连接,可能会导致数据库服务器资源耗尽,无法处理更多的请求。
- 性能瓶颈:数据库连接如果无限制地被创建,可能会占用大量内存和网络资源,导致系统整体性能下降。
- 系统崩溃:在极端情况下,过高的并发请求可能会导致数据库服务器崩溃,影响服务的可用性。
代码实现:
import java.util.concurrent.Semaphore;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class DatabaseConnectionPool {
private static final Semaphore semaphore = new Semaphore(10); // 允许最大10个并发连接
private static final String URL = "jdbc:mysql://localhost:3306/yourdb";
private static final String USER = "username";
private static final String PASSWORD = "password";
public static Connection getConnection() throws SQLException {
semaphore.acquire(); // 请求一个许可
try {
// 建立数据库连接
return DriverManager.getConnection(URL, USER, PASSWORD);
} catch (SQLException e) {
semaphore.release(); // 如果连接失败,释放许可
throw e;
}
}
public static void releaseConnection(Connection connection) {
if (connection != null) {
try {
connection.close(); // 关闭数据库连接
} catch (SQLException e) {
e.printStackTrace();
} finally {
semaphore.release(); // 释放许可,返回连接池
}
}
}
}
// 测试类
public class SemaphoreDemo {
public static void main(String[] args) {
for (int i = 0; i < 15; i++) { // 请求15个连接,超过最大限制
int finalI = i;
new Thread(() -> {
try {
Connection connection = DatabaseConnectionPool.getConnection();
System.out.println("Thread " + finalI + " got connection: " + connection);
// 数据库操作
Thread.sleep(1000);
DatabaseConnectionPool.releaseConnection(connection);
} catch (SQLException | InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
}
6. CountDownLatch
CountDownLatch 是 Java 中用于线程间同步的一种工具,它允许一个或多个线程等待一组操作完成
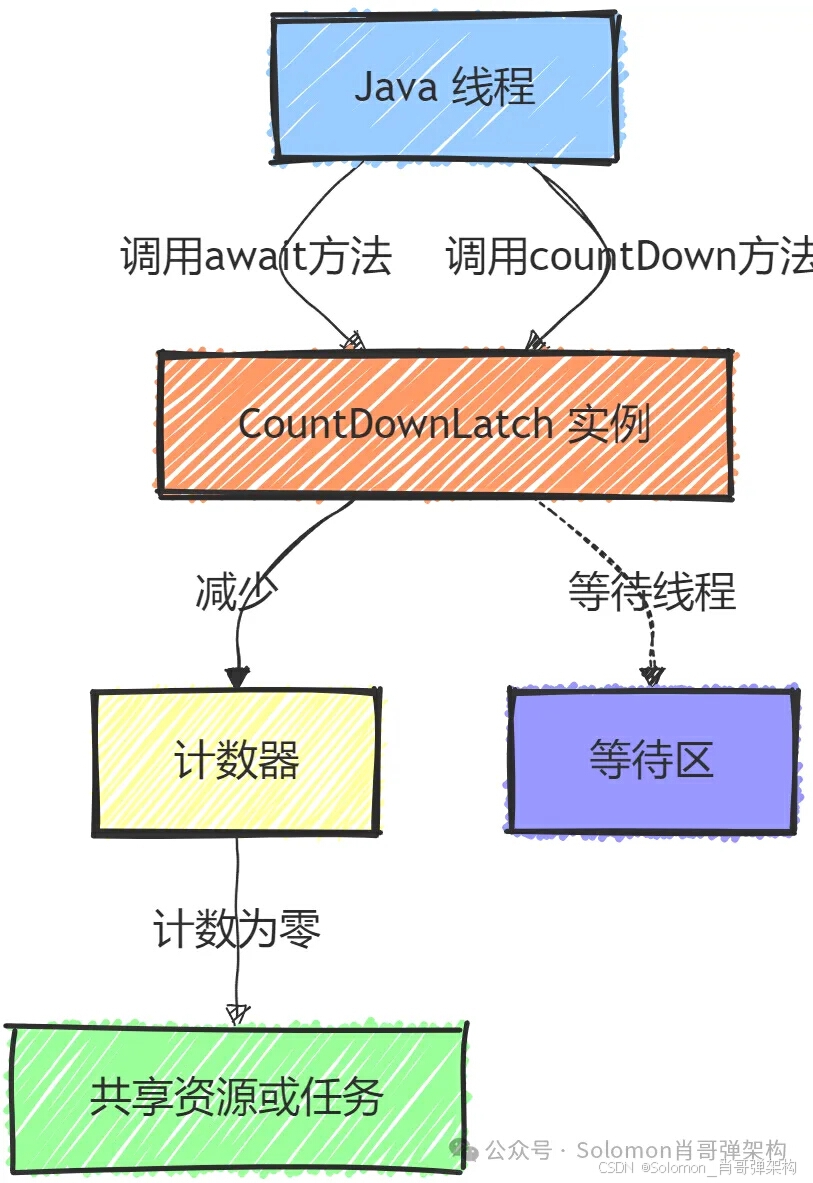
图解说明:
- Java 线程:表示运行中的线程,它们可能需要等待特定的事件或条件发生。
- CountDownLatch 实例:是
CountDownLatch类的实例,用于协调一个或多个线程等待一组操作完成。 - 计数器:
CountDownLatch内部维护一个计数器,用于跟踪尚未完成的操作数量。 - 共享资源或任务:表示需要等待的共享资源或任务,只有当计数器归零时,等待的线程才会继续执行。
- 等待区:表示等待
CountDownLatch计数器归零的线程集合。
综合说明:
- 作用:
CountDownLatch是一种同步帮助工具,允许一个或多个线程等待一组操作完成。 - 背景:在复杂的业务逻辑中,经常需要某个线程等待其他线程执行完特定的任务后再继续执行。
CountDownLatch通过计数器来实现这种同步。 - 优点:
- 简单易用:通过简单的计数机制实现线程间的同步。
- 一次性:计数器只能减到零,适用于完成一次任务的同步。
- 缺点:
- 计数器不可重置:一旦计数器到达零,不能再重新使用。
- 灵活性有限:只能用于单次的同步任务。
- 场景:适用于需要等待一组特定任务完成后再继续的场景。
- 业务举例:在批量数据处理系统中,主控线程需要等待所有数据加载线程完成后,才能进行数据处理。使用
CountDownLatch可以确保主控线程正确同步所有数据加载线程。
使用方式:
import java.util.concurrent.CountDownLatch;
public class TaskExecutor {
// 定义一个 CountDownLatch 对象,传入一个计数器初始化参数
private final CountDownLatch latch;
public TaskExecutor(int count) {
this.latch = new CountDownLatch(count); // 设置等待的事件数量
}
// 执行任务的方法
public void executeTask(Runnable task) {
// 执行任务的线程
Thread thread = new Thread(() -> {
try {
task.run(); // 执行传入的任务
} finally {
latch.countDown(); // 任务执行完毕后,计数器减1
}
});
thread.start();
}
// 等待所有任务完成的方法
public void awaitTasks() throws InterruptedException {
latch.await(); // 等待计数器减到0
System.out.println("All tasks completed");
}
// 测试类
public static void main(String[] args) throws InterruptedException {
final int taskCount = 3; // 需要执行的任务数量
TaskExecutor executor = new TaskExecutor(taskCount);
// 提交任务
for (int i = 0; i < taskCount; i++) {
int finalI = i;
executor.executeTask(() -> {
// 任务执行时间
System.out.println("Task " + finalI + " is running.");
try {
Thread.sleep(1000); // 耗时操作
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
// 等待所有任务完成
executor.awaitTasks();
}
}
业务代码案例:
业务说明: 在一个分布式文件上传系统中,用户上传的大文件首先被分割成多个小块,然后并行上传这些文件块。只有当所有文件块都上传成功后,系统才将这些块重新组合成原始文件。这种场景下,需要等待所有上传任务完成后才能进行下一步操作。
为什么需要 CountDownLatch 技术: CountDownLatch 允许主线程等待直到所有文件块上传任务完成。通过初始化 CountDownLatch 的计数与文件块的数量相同,每上传完成一个文件块,计数减一。这样,可以确保在所有文件块上传完成之前,主线程不会进行文件块的合并操作。
没有 CountDownLatch 技术会带来什么后果: 没有使用 CountDownLatch 或其他同步协调机制可能会导致以下问题:
- 数据不一致:如果合并操作在所有文件块上传完成之前开始执行,那么可能会得到一个不完整的文件,导致数据不一致。
- 资源浪费:在文件块未全部上传完成的情况下进行合并操作,可能会需要额外的存储空间和处理时间,造成资源浪费。
- 用户体验差:用户可能会遇到文件上传失败或损坏的情况,影响用户体验。
代码实现:
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class FileUploader {
private final CountDownLatch latch;
private final int numberOfChunks;
private final ExecutorService executor = Executors.newFixedThreadPool(4); // 文件上传线程池
public FileUploader(int numberOfChunks) {
this.numberOfChunks = numberOfChunks;
this.latch = new CountDownLatch(numberOfChunks);
}
public void uploadFile(String fileContent) {
String[] chunks = fileContent.split(" "); // 假设文件内容按空格分割成多个块
for (String chunk : chunks) {
final String finalChunk = chunk;
executor.submit(() -> {
boolean uploadSuccess = uploadChunk(finalChunk); // 上传操作
if (uploadSuccess) {
System.out.println("Uploaded: " + finalChunk);
latch.countDown(); // 上传成功后计数减1
} else {
System.out.println("Upload failed: " + finalChunk);
}
});
}
waitForAllChunks();
}
private boolean uploadChunk(String chunk) {
//上传操作,随机失败的可能性
try {
Thread.sleep(100); // 耗时操作
return Math.random() > 0.2;
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return false;
}
}
private void waitForAllChunks() {
try {
latch.await(); // 等待所有文件块上传完成
System.out.println("All chunks have been uploaded.");
mergeFile(); // 合并文件块
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
private void mergeFile() {
// 执行文件块合并操作
System.out.println("Merging file...");
}
public static void main(String[] args) {
FileUploader uploader = new FileUploader(10); // 假设文件被分割成10块
uploader.uploadFile("The quick brown fox jumps over the lazy dog");
}
}
其他内容在第二篇文章《精通Java并发锁机制:24种锁技巧+业务锁匹配方案(第三部分)》中。。。