前言
笔者有一定的机器学习和深度学习理论基础,对 Pytorch 的实战还不够熟悉,打算入职前专项突击一下
本文内容为笔者学习《动手学深度学习》一书的学习笔记
主要记录了代码的实现和实现过程遇到的问题,不完全包括其理论知识
引用:
一、预备知识
1. 数据操作
1.1 入门
创建行向量
# 创建行向量
x = torch.arange(12)
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
报错:module ‘numpy’ has no attribute ‘array’
解决方案:
numpy 版本过高,原版本为 1.21.5,使用以下命令安装 1.21.0 的 numpy
pip uninstall numpy
pip install numpy==1.21
张量的基本操作
# 元素的数量
print(x.numel())
# 张量的形状
print(x.shape)
# 更改形状
print(x.reshape(3, 4))
12
torch.Size([12])
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
创建张量
# 全零张量
print(torch.zeros((2, 3, 4)))
# 全一张量
print(torch.ones((2, 3, 4)))
# 随机数张量
print(torch.rand((2, 3, 4)))
# 创建时初始化
print(torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]]))
tensor([[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]])
tensor([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
tensor([[[0.2715, 0.4234, 0.4764, 0.5638],
[0.0958, 0.8449, 0.0129, 0.3975],
[0.4510, 0.2093, 0.6003, 0.6838]],
[[0.7996, 0.2331, 0.8481, 0.6440],
[0.6056, 0.7846, 0.6360, 0.6849],
[0.0169, 0.4028, 0.7457, 0.1688]]])
tensor([[2, 1, 4, 3],
[1, 2, 3, 4],
[4, 3, 2, 1]])
1.2 运算符
基本运算
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
# 四则运算
print(x + y, x - y, x * y, x / y, x ** y)
# 自然指数
print(torch.exp(x))
# 求和
print(torch.sum(x))
# 逻辑运算
print(x == y)
tensor([ 3., 4., 6., 10.]) tensor([-1., 0., 2., 6.]) tensor([ 2., 4., 8., 16.]) tensor([0.5000, 1.0000, 2.0000, 4.0000]) tensor([ 1., 4., 16., 64.])
tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03])
tensor(15.)
tensor([False, True, False, False])
连接运算
# 张量连接
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
# 按行 (3, 4) 和 (3, 4) 连接成 (6, 4)
print(torch.cat((X, Y), dim=0))
# 按列 (3, 4) 和 (3, 4) 连接成 (3, 8)
print(torch.cat((X, Y), dim=1))
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[ 2., 1., 4., 3.],
[ 1., 2., 3., 4.],
[ 4., 3., 2., 1.]])
tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],
[ 4., 5., 6., 7., 1., 2., 3., 4.],
[ 8., 9., 10., 11., 4., 3., 2., 1.]])
1.3 广播机制
pytorch 允许不同维度的张量做运算
当两个张量满足以下规则时,允许将维度较小的张量广播至维度较大的张量:
从尾部的维度起,两个张量的维度:
- 相等
- 或 其中一个维度为1
- 或 其中一个维度不存在
# 广播机制
# 简单版
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
print(a)
print(b)
print(a + b, '\n')
# 复杂版
# 从尾部维度数起,d最后一个维度为1,c与d倒数第二个维度相等,d倒数第三个维度不存在。故可广播
c = torch.arange(12).reshape((2, 3, 2))
d = torch.arange(3).reshape((3, 1))
print(c)
print(d)
print(c + d)
tensor([[0],
[1],
[2]])
tensor([[0, 1]])
tensor([[0, 1],
[1, 2],
[2, 3]])
tensor([[[ 0, 1],
[ 2, 3],
[ 4, 5]],
[[ 6, 7],
[ 8, 9],
[10, 11]]])
tensor([[0],
[1],
[2]])
tensor([[[ 0, 1],
[ 3, 4],
[ 6, 7]],
[[ 6, 7],
[ 9, 10],
[12, 13]]])
1.4 索引和切片
用法同 numpy
# 索引和切片,同 numpy
X = torch.arange(12, dtype=torch.float32).reshape((3, 4))
print(X)
# 利用切片取值
print(X[-1]) # 相当于 X[X.shape[0] - 1]
print(X[1: 3]) # 左闭右开 X[a, b] 相当于 [a, b)
# 利用切片赋值
X[1, 2] = 9
print(X)
X[0:2, :] = 12
print(X)
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
tensor([ 8., 9., 10., 11.])
tensor([[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 9., 7.],
[ 8., 9., 10., 11.]])
tensor([[12., 12., 12., 12.],
[12., 12., 12., 12.],
[ 8., 9., 10., 11.]])
1.5 节省内存
# 浪费内存的写法
X = X + Y
# 节省内存的写法
X += Y
X[:] = X + Y
1.6 转换为其它 Python 对象
使用 .numpy() 将 ndarray 转 tensor
使用 .item() 取单个元素为 Python 基本类型元素
A = X.numpy()
# ndarray 转 tensor
B = torch.tensor(A)
print(type(A), type(B))
# 使用 .item() 取单个元素为 Python 基本类型元素
a = torch.tensor([3.5])
print(a, a.item(), float(a), int(a))
<class 'numpy.ndarray'> <class 'torch.Tensor'>
tensor([3.5000]) 3.5 3.5 3
2. 数据预处理
2.1 读取数据集
利用 pandas 读取数据集
import os.path
import pandas as pd
data_file = os.path.join('..', 'datas', 'heart', 'heart.csv')
data = pd.read_csv(data_file)
print(data.head())
age sex cp trestbps chol ... oldpeak slope ca thal target
0 63 1 1 145 233 ... 2.3 3 0 fixed 0
1 67 1 4 160 286 ... 1.5 2 3 normal 1
2 67 1 4 120 229 ... 2.6 2 2 reversible 0
3 37 1 3 130 250 ... 3.5 3 0 normal 0
4 41 0 2 130 204 ... 1.4 1 0 normal 0
[5 rows x 14 columns]
2.2 处理缺失值
详见:Pandas数据分析学习笔记- 掘金 (juejin.cn)
2.3 转换为张量
x, y = data.iloc[:, :-2], data.iloc[:, -1]
print(x.head())
print(y.head())
# 需要先转换为 ndarray 再转换为 tensor
X = torch.tensor(x.to_numpy(dtype=float))
Y = torch.tensor(y.to_numpy(dtype=float))
print(type(X), X.shape)
print(type(Y), Y.shape)
[5 rows x 14 columns]
age sex cp trestbps chol ... thalach exang oldpeak slope ca
0 63 1 1 145 233 ... 150 0 2.3 3 0
1 67 1 4 160 286 ... 108 1 1.5 2 3
2 67 1 4 120 229 ... 129 1 2.6 2 2
3 37 1 3 130 250 ... 187 0 3.5 3 0
4 41 0 2 130 204 ... 172 0 1.4 1 0
[5 rows x 12 columns]
0 0
1 1
2 0
3 0
4 0
Name: target, dtype: int64
<class 'torch.Tensor'> torch.Size([303, 12])
<class 'torch.Tensor'> torch.Size([303])
3. 线性代数
标量、向量、矩阵、张量、张量运算性质、降维部分与 numpy 相似,故略过
求和操作及其应用
x = torch.arange(4, dtype=torch.float32)
# 求和
print(x, x.sum())
# 非降维求和
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
print(A)
print(A.sum(axis=0))
print(A / A.sum(axis=0)) # 利用广播归一化
tensor([0., 1., 2., 3.]) tensor(6.)
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.],
[16., 17., 18., 19.]])
tensor([40., 45., 50., 55.])
tensor([[0.0000, 0.0222, 0.0400, 0.0545],
[0.1000, 0.1111, 0.1200, 0.1273],
[0.2000, 0.2000, 0.2000, 0.2000],
[0.3000, 0.2889, 0.2800, 0.2727],
[0.4000, 0.3778, 0.3600, 0.3455]])
矩阵、向量相关运算
x = torch.arange(4, dtype=torch.float32)
y = torch.ones(4, dtype = torch.float32)
# 点积
print(x, y, torch.dot(x, y))
# 矩阵-向量积
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
print(torch.mv(A, x))
# 矩阵乘法
B = torch.ones(4, 3)
print(torch.mm(A, B))
tensor([0., 1., 2., 3.]) tensor([1., 1., 1., 1.]) tensor(6.)
tensor([ 14., 38., 62., 86., 110.])
tensor([[ 6., 6., 6.],
[22., 22., 22.],
[38., 38., 38.],
[54., 54., 54.],
[70., 70., 70.]])
范数
# 向量的 L2-范数 及 矩阵的 F-范数
u = torch.tensor([3.0, -4.0])
print(torch.norm(u))
A = torch.ones((4, 9))
print(torch.norm(A))
# L1-范数
print(torch.abs(u).sum())
tensor(5.)
tensor(6.)
tensor(7.)
4. 微积分
绘制图线
参考资料:
xscale 和 yscale 的使用:坐标轴刻度 — Matplotlib 3.9.0 文档 - Matplotlib 中文
ptl.gca 的含义:matplotlib plt.gca()学习-CSDN博客
fmts 详解:matplotlib.pyplot中的plot函数
fig、axes 等的含义:plt、fig、axes、axis的含义_fig, axes-CSDN博客
绘制图线的函数:
from matplotlib import pyplot as plt
import numpy as np
def plot(X, Y=None, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), figsize=(3.5, 2.5)):
"""
:param X: 自变量
:param Y: 因变量
:param xlabel: 自变量的名称
:param ylabel: 因变量的名称
:param legend: 图例
:param xlim: X轴的取值范围
:param ylim: Y轴的取值范围
:param xscale: X轴的缩放方式,默认为 linear
:param yscale: Y轴的缩放方式,默认为 linear
:param fmts: 图线的类型,默认 '-'为实线, 'm--'为红色虚线, 'g-.'为绿色点划线, 'r:'为红色点线
:param figsize: 整张图像的大小
:param axes: 已有的图像,默认为 None
:return:
"""
# 确定图像大小
plt.figure(figsize=figsize)
# 确定坐标轴
if xlim is not None:
plt.xlim(xlim)
if ylim is not None:
plt.ylim(ylim)
# label为标记
plt.xlabel(xlabel)
plt.ylabel(ylabel)
# scale为缩放方式
plt.xscale(xscale)
plt.yscale(yscale)
# plot为绘制图像的函数,,scale为缩放方式
for x, y, fmt in zip(X, Y, fmts):
plt.plot(x, y, fmt)
# 将标记绘制图例
plt.legend(legend)
plt.show()
plt.close()
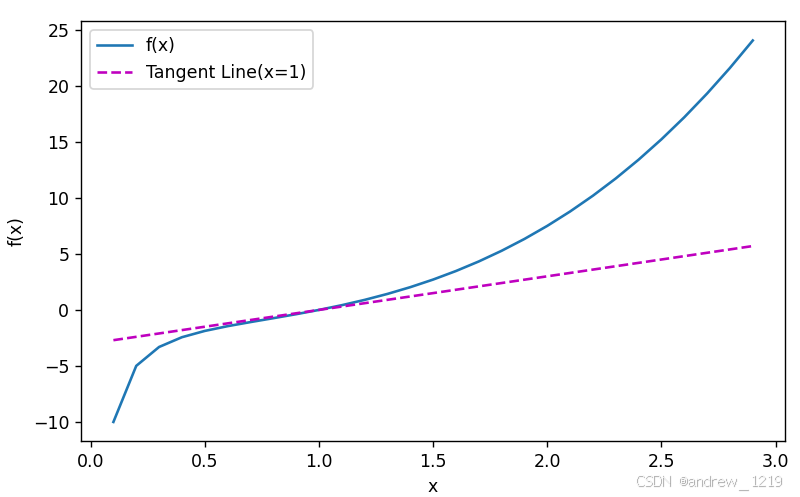
练习一:绘制函数 y = f(x) = x^3 - 1/x 及其在 x = 1 处切线的图像
"""
练习一
绘制函数 y = f(x) = x^3 - 1/x 及其在 x = 1 处切线的图像
f(1) = 0
f'(x) = 3x^2 + 1/x^2 f'(1) = 3
那么,x = 1 处切线方程为 y = 3x - 3
"""
def f(x):
return x**3 - 1/x
x = np.arange(0.1, 3, 0.1)
plot(X=[x, x], Y=[f(x), 3 * x - 3],
xlabel='x', ylabel='f(x)',
legend=['f(x)', 'Tangent Line(x=1)'])
5. 自动微分
5.1 基本用法
import torch
# 设置自动微分
# 方式一:定义时设置
x = torch.arange(4.0, requires_grad=True)
# 方式二:.requeres_grad(True)
# x = torch.arange(4.0)
# x.requires_grad(True)
y = 2 * torch.dot(x, x)
print(y) # 此时,y 是一个计算图
# 可对 y 求导
y.backward()
print(x.grad)
# 默认梯度会积累,一般需要将梯度清空
x.grad.zero_()
print(x.grad)
tensor(28., grad_fn=<MulBackward0>)
tensor([ 0., 4., 8., 12.])
tensor([0., 0., 0., 0.])
5.2 非标量的反向传播
y = x ⊙ x y = x \odot x y=x⊙x
得
∂ y ∂ x i = 2 x i \frac{\partial y}{\partial x_i} = 2 x_i ∂xi∂y=2xi
# 非标量的反向传播 需要 .sum() 求和
x = torch.arange(4.0, requires_grad=True)
y = x * x
y.sum().backward()
print(x.grad)
x.grad.zero_()
tensor([0., 2., 4., 6.])
5.3 分离计算
当 z = y * x ,y = x * x 时,并且我们希望将 y 视为常数,只考虑到 x 在 y 被计算后发挥的作用
需要分离 y 获得一个新变量 u,丢弃计算图中如何计算 y 的信息
# 分离计算
# 没有使用分离计算
x = torch.arange(4.0, requires_grad=True)
y = x * x
z = y * x
z.sum().backward()
print(x.grad, x.grad == y)
# 使用分离计算
x = torch.arange(4.0, requires_grad=True)
y = x * x
u = y.detach()
z = u * x
z.sum().backward()
print(x.grad, x.grad == u)
tensor([ 0., 3., 12., 27.]) tensor([ True, False, False, False])
tensor([0., 1., 4., 9.]) tensor([True, True, True, True])
5.4 Python 控制流得梯度计算
# f(a) 是关于 a 得分段线性函数
def f(a):
b = a * 2
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
a = torch.randn(size=(), requires_grad=True)
d = f(a)
d.backward()
print(a.grad == d / a)
tensor(True)
6. 概率
参考资料:Pytorch中的多项分布multinomial.Multinomial().sample()解析 - 知乎 (zhihu.com)
probs = torch.ones(6)
# total_count 为抽样次数,probs为样本,是一个tensor
multinomial_distribution = multinomial.Multinomial(total_count=1, probs=probs)
# 采样
print(multinomial_distribution.sample())
# 对数概率分布
print(multinomial_distribution.logits)
tensor([0., 0., 1., 0., 0., 0.])
tensor([-1.7918, -1.7918, -1.7918, -1.7918, -1.7918, -1.7918])
二、线性神经网络
1. 线性回归从零开始实现
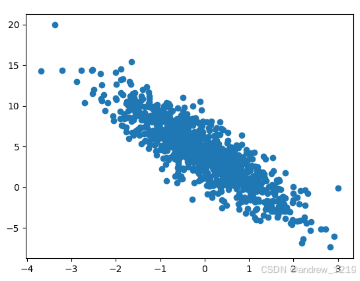
1.1 生成数据集
import torch
from matplotlib import pyplot as plt
def synthetic_data(w, b, num_examples): #@save
"""生成y=Xw+b+噪声"""
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
# 观察第二个维度与标签的关系
plt.scatter(features[:, 1].detach().numpy(), labels.detach().numpy())
plt.show()
1.2 读取数据集
# 小批量读取数据集
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples)) # 样本下标
random.shuffle(indices) # 打乱顺序
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
batch_size = 5
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break
tensor([[ 1.0637, 0.3883],
[ 1.3318, 0.7545],
[ 1.0563, 1.2710],
[-0.6162, -0.2641],
[ 0.2506, 1.1129]])
tensor([[5.0095],
[4.3107],
[1.9846],
[3.8708],
[0.9319]])
1.3 模型定义和训练
参考资料:
with torch.no_grad() 的作用:【pytorch】 with torch.no_grad():用法详解_pytorch with no grad-CSDN博客
# 初始化模型参数
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# 定义模型
def linear_reg(w, b, X):
return torch.matmul(X, w) + b
# 定义损失函数
def squared_loss(y_hat, y):
return (y - y_hat.reshape(y.shape)) ** 2 / 2
# 定义优化算法
def sgd(params, lr, batch_size):
"""
小批量梯度下降
:param params: 参数
:param lr: 学习率
"""
with torch.no_grad():
# with torch.no_grad(): 以内的空间计算结果得 requires_grad 为 False
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
# 训练
lr = 0.01
num_epochs = 3
net = linear_reg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(w, b, X), y) # X和y的小批量损失
l.sum().backward()
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(w, b, features), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
epoch 1, loss 0.292531
epoch 2, loss 0.005235
epoch 3, loss 0.000142
2. 线性回归简洁实现
参考资料:
Python 星号的作用:Python中的*(星号)和**(双星号)完全详解_python *-CSDN博客
TensorDataset 和 DataLoader:PyTorch中 DataLoader 和 TensorDataset 的详细解析_tensordataset会打乱顺序吗-CSDN博客
torch 中实现了更方便地读取数据的方法,只需要我们将 tensor 封装到 TensorDataset 中,再与 DataLoader 结合使用,即可实现前面 data_iter 的效果
DataLoader 的核心功能有:批量加载、打乱顺序、并行处理
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
def load_array(data_arrays, batch_size, is_train=True):
"""构造一个PyTorch数据迭代器"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
仍然按照步骤:定义模型 -> 初始化模型参数 -> 定义损失函数 -> 定义优化算法 -> 训练
from torch import nn
# 定义模型
net = nn.Sequential(nn.Linear(2, 1))
# 初始化模型参数
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
# 定义损失函数
loss = nn.MSELoss()
# 定义优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.01)
# 训练
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X), y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')
epoch 1, loss 0.552002
epoch 2, loss 0.009066
epoch 3, loss 0.000246
3. softmax
由交叉熵损失
l o s s ( y , y ^ ) = − ∑ j = 1 q y j l o g y j ^ loss(y, \widehat{y}) = - \sum_{j=1}^{q} y_j log \hat{y_j} loss(y,y )=−∑j=1qyjlogyj^
以及使用 softmax 函数时
y ^ = s o f t m a x ( o ) = e o j ∑ k = 1 q e o k \hat{y} = softmax(o) = \frac{e^{o_j}}{\sum_{k=1}^q e^{o_k}} y^=softmax(o)=∑k=1qeokeoj
得
l o s s ( y , y ^ ) = − ∑ j = 1 q y j l o g e o j ∑ k = 1 q e o k = ∑ j = 1 q y j l o g ∑ k = 1 q e o k − ∑ j = 1 q y j o j = l o g ∑ k = 1 q e o k − ∑ j = 1 q y j o j \begin{align} loss(y, \widehat{y}) =& - \sum_{j=1}^{q} y_j log \frac{e^{o_j}}{\sum_{k=1}^q e^{o_k}} \\ =& \sum_{j=1}^{q} y_j log \sum_{k=1}^q e^{o_k} - \sum_{j=1}^{q} y_j o_j \\ =& log \sum_{k=1}^q e^{o_k} - \sum_{j=1}^{q} y_j o_j \\ \end{align} loss(y,y )===−j=1∑qyjlog∑k=1qeokeojj=1∑qyjlogk=1∑qeok−j=1∑qyjojlogk=1∑qeok−j=1∑qyjoj
那么
∂ o j l o s s ( y , y ^ ) = e o j ∑ k = 1 q e o k − y j = s o f t m a x ( o ) j − y j \begin{align} \partial_{o_j} loss(y, \widehat{y}) =& \frac{e^{o_j}}{\sum_{k=1}^q e^{o_k}} - y_j \\ =& softmax(o)_j - y_j \end{align} ∂ojloss(y,y )==∑k=1qeokeoj−yjsoftmax(o)j−yj
4. softmax 回归从零开始实现
torchvision 的 transforms详解: pytorch中数据预处理模块:transforms详解
读取 Fashion-MINST 数据集
def load_data_fashion_mnist(batch_size, resize=None):
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True),
data.DataLoader(mnist_test, batch_size, shuffle=False))
batch_size = 18
train_iter, test_iter = load_data_fashion_mnist(batch_size, resize=64a)
for X, y in train_iter:
print(X.shape)
print(y.shape)
break
torch.Size([18, 1, 64, 64])
torch.Size([18])
定义模型 + 初始化模型参数
# 初始化模型参数
num_inputs = 28 * 28
num_outputs = 10
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
# 定义模型
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True) # 求和后保留被求和的维度
return X_exp / partition
def net(W, b, X):
return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
定义损失函数 以及 预测准确率的函数
由于数据集的 y 不是独热编码,在得到 y_hat 时利用 argmax 得到最大数的下标
# 定义损失函数
def cross_entropy(y, y_hat):
return -torch.log(y_hat[range(len(y_hat)), y])
def accuracy(y_hat, y):
"""计算预测正确的数量"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1) # 得到每一行最大的下标
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum()) # 预测正确返回1,否则返回0
class Accumulator: #@save
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def evaluate_accuracy(net, data_iter):
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(W, b, X), y), y.numel())
return metric[0] / metric[1]
训练,同线性回归
# 训练
lr = 0.01
num_epochs = 3
loss = cross_entropy
for epoch in range(num_epochs):
for X, y in train_iter:
l = loss(net(W, b, X), y) # X和y的小批量损失
l.sum().backward()
sgd([W, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
acc = evaluate_accuracy(net, test_iter)
print(f'epoch {epoch + 1}, loss {acc:f}')
epoch 1, acc 0.801700
epoch 2, acc 0.818800
epoch 3, acc 0.822200
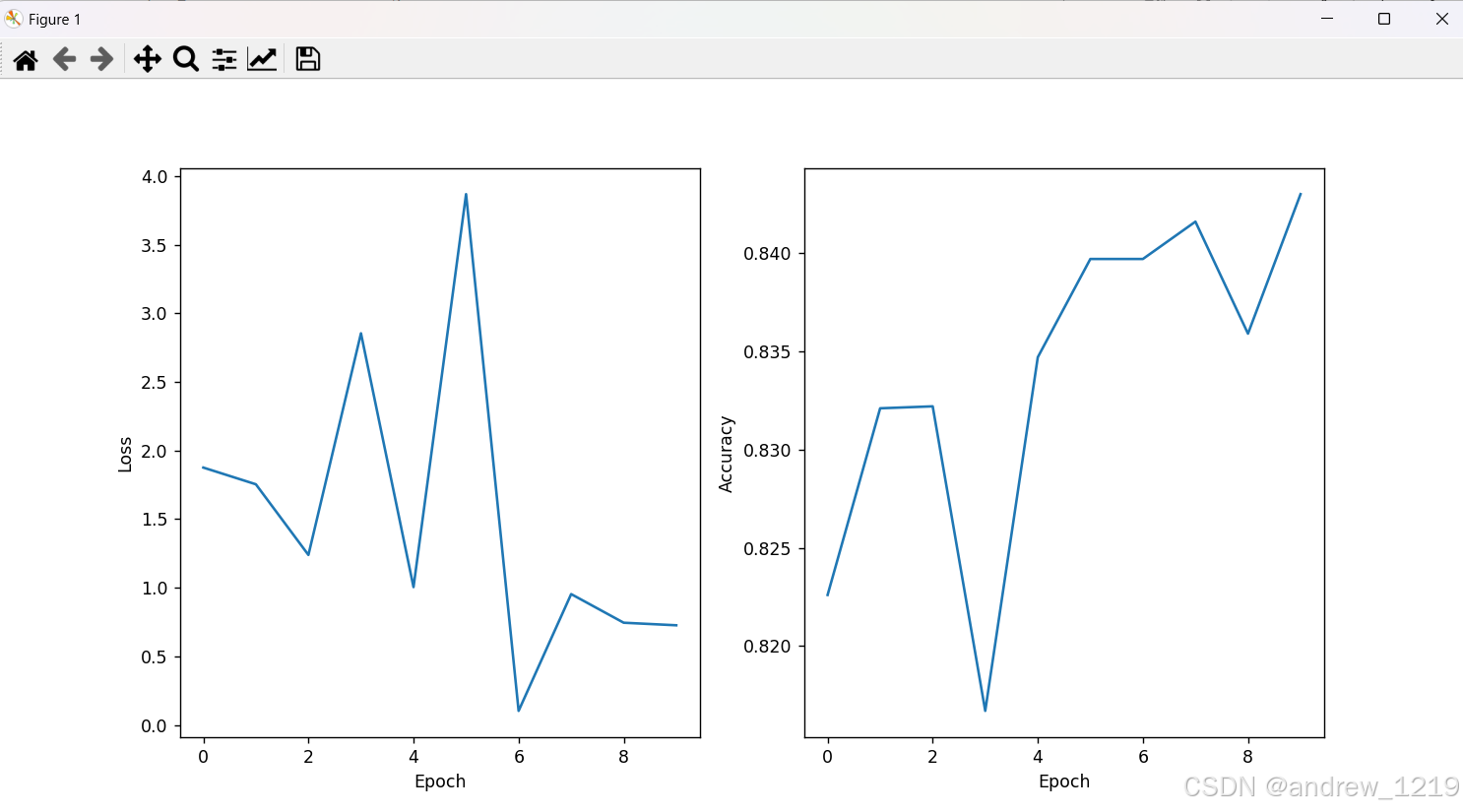
动态展示 loss 和 acc
# 实时追踪 loss 和 acc
# 初始化绘图
plt.ion() # 开启交互模式
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 6))
loss_list = []
acc_list = []
for epoch in range(num_epochs):
for X, y in train_iter:
l = loss(net(W, b, X), y) # X和y的小批量损失
l.sum().backward()
sgd([W, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
acc = evaluate_accuracy(net, test_iter)
print(f'epoch {epoch + 1}, acc {acc:f}')
loss_list.append(l.sum().item())
acc_list.append(acc)
# 更新绘图
ax1.clear()
ax1.plot(loss_list, label='Training Loss')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Loss')
ax2.clear()
ax2.plot(acc_list, label='Training Accuracy')
ax2.set_xlabel('Epoch')
ax2.set_ylabel('Accuracy')
plt.pause(0.1) # 暂停一小段时间以更新图形
plt.ioff() # 关闭交互模式
plt.show()
5. softmax 回归简洁实现
nn.Linear 于 nn.Dense 等价
model.apply(fn) 会递归地将函数 fn 应用到父模块的每个子模块 submodule
nn.CrossEntropyLoss() 的参数 reduction 可以指定输出的归约方式。默认为’mean’,详见:PyTorch nn.CrossEntropyLoss() 交叉熵损失函数详解和要点提醒
from torch import nn
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
# 初始化模型参数
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
# 定义损失函数
loss = nn.CrossEntropyLoss(reduction='none')
# 定义优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.01)
# 训练
num_epochs = 10
for epoch in range(num_epochs):
for X, y in train_iter:
l = loss(net(X), y) # X和y的小批量损失
trainer.zero_grad()
l.mean().backward()
trainer.step()
with torch.no_grad():
acc = evaluate_accuracy(net, test_iter)
print(f'epoch {epoch + 1}, acc {acc:f}')
epoch 1, acc 0.800500
epoch 2, acc 0.818300
epoch 3, acc 0.825700
epoch 4, acc 0.824500
epoch 5, acc 0.828200
epoch 6, acc 0.825700
epoch 7, acc 0.834300
epoch 8, acc 0.836000
epoch 9, acc 0.833700
epoch 10, acc 0.831000
三、多层感知机
1. 多层感知机
1.1 多层感知机引入
多层感知机在每层输出利用激活函数,使之得到非线性的结果,不至于退化为线性
不使用激活函数:
H = X W ( 1 ) + b ( 1 ) O = H W ( 2 ) + b ( 2 ) \begin{align} H =& XW^{(1)} + b^{(1)} \\ O =& HW^{(2)} + b^{(2)} \end{align} H=O=XW(1)+b(1)HW(2)+b(2)
则有
O = H W ( 2 ) + b ( 2 ) = ( X W ( 1 ) + b ( 1 ) ) W ( 2 ) + b ( 2 ) = X W ( 1 ) W ( 2 ) + b ( 1 ) W ( 2 ) + b ( 2 ) = X W + b \begin{align} O =& HW^{(2)} + b^{(2)} \\ =& (XW^{(1)} + b^{(1)}) W^{(2)} + b^{(2)} \\ =& XW^{(1)}W^{(2)} + b^{(1)}W^{(2)} + b^{(2)} \\ =& XW + b \end{align} O====HW(2)+b(2)(XW(1)+b(1))W(2)+b(2)XW(1)W(2)+b(1)W(2)+b(2)XW+b
使用激活函数:
H = σ 1 ( X W ( 1 ) + b ( 1 ) ) O = σ 2 ( H W ( 2 ) + b ( 2 ) ) \begin{align} H =& \sigma_1(XW^{(1)} + b^{(1)}) \\ O =& \sigma_2(HW^{(2)} + b^{(2)}) \end{align} H=O=σ1(XW(1)+b(1))σ2(HW(2)+b(2))
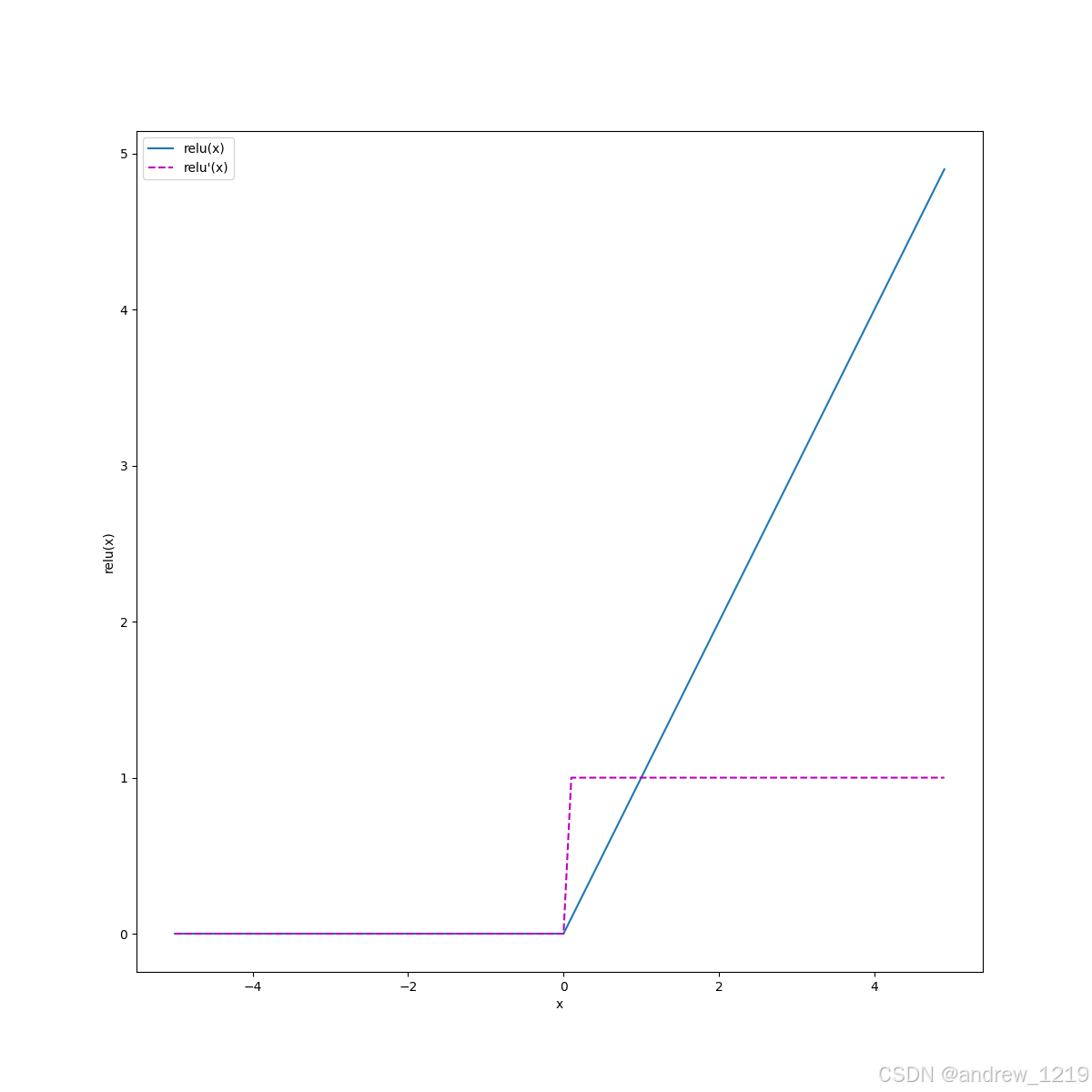
1.2 常用激活函数
relu(x)
y = r e l u ( x ) = m a x ( 0 , x ) y = relu(x) = max(0, x) y=relu(x)=max(0,x)
y ′ ( x ) = { 1 , x > 0 0 , x ≤ 0 y'(x) = \begin{cases} 1,\,\,x>0\\ 0,\,\,x\le0\\ \end{cases} y′(x)={1,x>00,x≤0
# 常用激活函数
x = torch.arange(-5., 5., 0.1, requires_grad=True)
# relu
y = torch.relu(x)
y.sum().backward()
x_np = x.detach().numpy()
plot([x_np, x_np], [y.detach().numpy(), x.grad.numpy()],
xlabel='x', ylabel='relu(x)',
figsize=(12, 12), legend=['relu(x)', 'relu'(x)'])
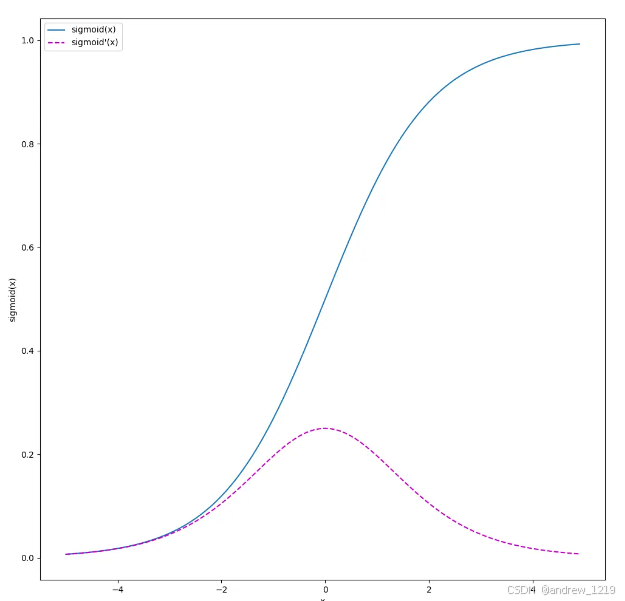
sigmoid(x)
y = s i g m o i d ( x ) = 1 1 + e − x y = sigmoid(x) = \frac{1}{1 + e^{-x}} y=sigmoid(x)=1+e−x1
y ′ ( x ) = y ( 1 − y ) y'(x) = y(1 - y) y′(x)=y(1−y)
# sigmoid
y = torch.sigmoid(x)
x.grad.zero_()
y.sum().backward()
plot([x_np, x_np], [y.detach().numpy(), x.grad.numpy()],
xlabel='x', ylabel='sigmoid(x)',
figsize=(12, 12), legend=['sigmoid(x)', 'sigmoid'(x)'])
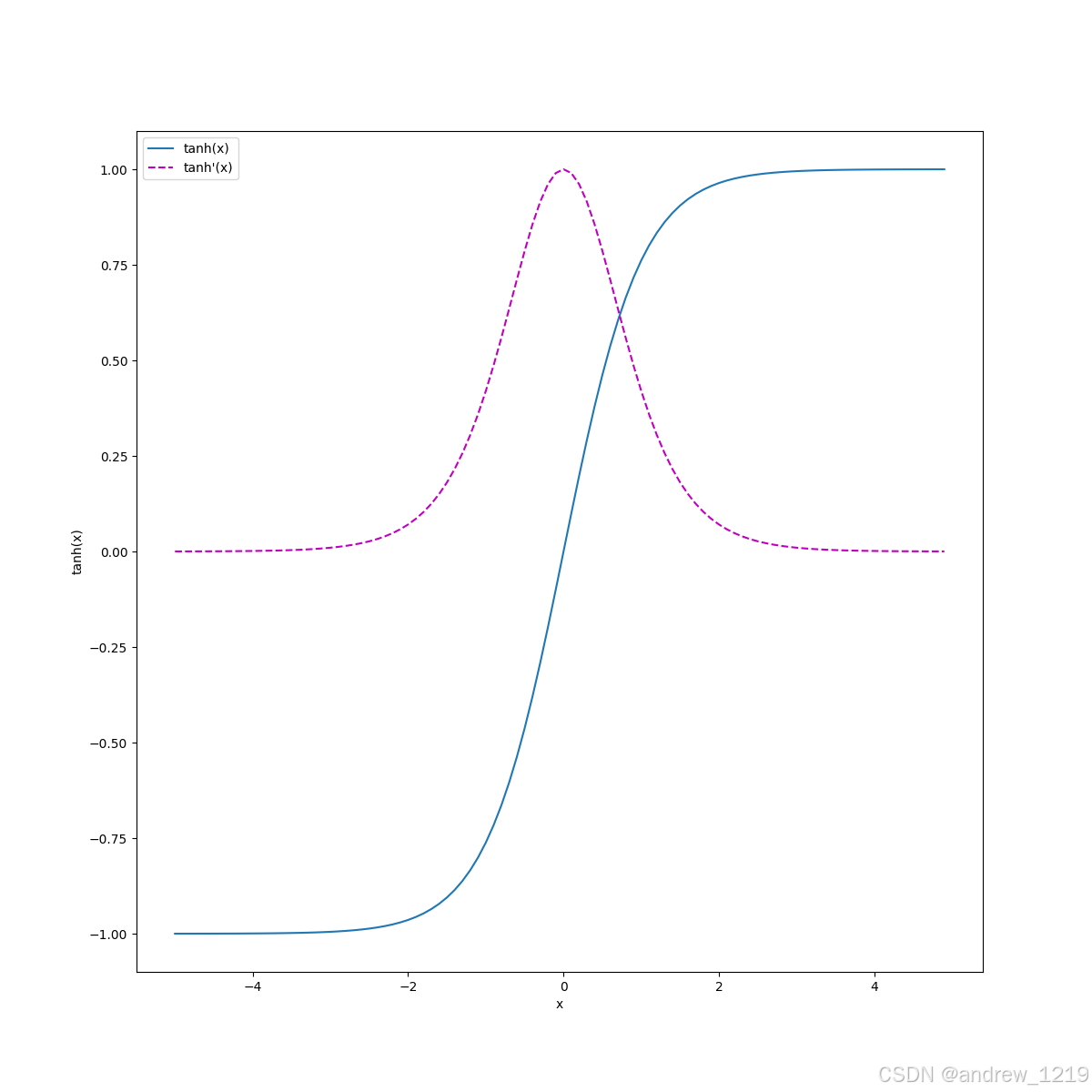
tanh(x)
y = t a n h ( x ) = 1 − e − 2 x 1 + e − 2 x y = tanh(x) = \frac{1 - e^{-2x}}{1 + e^{-2x}} y=tanh(x)=1+e−2x1−e−2x
y ′ ( x ) = 4 e − 2 x ( 1 + e − 2 x ) 2 = 1 − y 2 y'(x) = \frac{4 e^{-2x}}{(1 + e^{-2x})^2} = 1 - y^2 y′(x)=(1+e−2x)24e−2x=1−y2
# tanh
y = torch.tanh(x)
x.grad.zero_()
y.sum().backward()
plot([x_np, x_np], [y.detach().numpy(), x.grad.numpy()],
xlabel='x', ylabel='tanh(x)',
figsize=(12, 12), legend=['tanh(x)', 'tanh'(x)'])
2. 多层感知机从零实现
初始化模型参数
nn.Parameter 的对象的 requires_grad 属性的默认值是 True
# 初始化模型参数
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
定义模型,结果记得要加 softmax
# 定义模型
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X @ W1 + b1)
return softmax(H @ W2 + b2)
定义损失函数和优化算法及训练同上一章 softmax 回归
3. 多层感知机简洁实现
# 定义模型,初始化模型参数
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
# 定义损失函数
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
for epoch in range(num_epochs):
for X, y in train_iter:
l = loss(net(X), y) # X和y的小批量损失
trainer.zero_grad()
l.mean().backward()
trainer.step()
with torch.no_grad():
acc = evaluate_accuracy(net, test_iter)
print(f'epoch {epoch + 1}, acc {acc:f}')
4. 正则化技术
4.1 添加正则化项
从零实现
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2
# 增加了L2范数惩罚项,
# 广播机制使l2_penalty(w)成为一个长度为batch_size的向量
l = loss(net(X), y) + lambd * l2_penalty(w)
简洁实现
定义优化算法时,设置参数的 weight_decay,表示正则化项的系数。
pytorch 默认只提供 L2 范数,如果需要 L1 范数,需要自行在损失函数上添加
trainer = torch.optim.SGD([
{"params":net[0].weight,'weight_decay': wd},
{"params":net[0].bias}], lr=lr)
4.2 Dropout
Dropout 一般仅在训练过程中使用
按 dropout 比例丢弃元素,并进行缩放(除以 1 - dropout)
torch.rand 生成 [0, 1)的均匀分布的随机数
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
if dropout == 1:
return torch.zeros_like(X)
if dropout == 0:
return X
mask = torch.rand(X.shape) > dropout
return mask.float() * X / (1 - dropout)
X= torch.arange(16, dtype = torch.float32).reshape((2, 8))
print(X)
print(dropout_layer(X, 0.))
print(dropout_layer(X, 0.5))
print(dropout_layer(X, 1.))
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 2., 4., 0., 0., 0., 12., 14.],
[ 0., 0., 0., 0., 0., 26., 28., 30.]])
tensor([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])
定义模型时,前向传播使用 Dropout
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
is_training = True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用dropout
if self.training == True:
# 在第一个全连接层之后添加一个dropout层
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
# 在第二个全连接层之后添加一个dropout层
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return softmax(out)
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
简洁实现:
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
5. 模型初始化
参考文章:深度前馈网络与Xavier初始化原理 - 知乎 (zhihu.com)
默认初始化为 U [ 0 , 1 ] U[0, 1] U[0,1] 可以满足中等难度的问题
但是问题的规模增大时,后续层的输出的方差可能接近 0
为了尽可能让样本空间和类别空间的方差相近,可使用 Xavier 初始化:
w ∼ U [ − 6 n i n + n o u t , 6 n i n + n o u t ] w \sim U[-\sqrt{\frac{6}{n_{in} + n_{out}}}, \sqrt{\frac{6}{n_{in} + n_{out}}} ] w∼U[−nin+nout6,nin+nout6]
def init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight) # 均匀分布的 Xavier 初始化
# nn.init.xavier_normal_(m.weight) # 正态分布的 Xavier 初始化
if m.bias is not None:
nn.init.constant_(m.bias, 0) # 偏置项初始化为 0
6. 环境和分布偏移
6.1 分布偏移
训练集和测试集的分布不一致叫做分布偏移
分布偏移包含三种类型:
- 协变量偏移:输入的分布 q ( x , y ) q(x, y) q(x,y) 发生变化
- 标签偏移:标签的边缘概率 P ( y ) P(y) P(y) 发生变化
- 概念偏移:标签的定义发生变化
6.2 经验风险和实际风险
我们在最小化损失函数时使用的损失函数叫经验风险,例如:
m i n f 1 n ∑ i = 1 n l ( f ( x i ) , y i ) min_f \frac{1}{n} \sum_{i=1}^n l(f(x_i), y_i) minfn1i=1∑nl(f(xi),yi)
经验风险实际上是为了去近似实际风险,即从实际分布 p ( x , y ) p(x, y) p(x,y) 去抽取数据进行预测的总损失的期望值:
E p ( x , y ) [ l ( f ( x ) , y ) ] = ∫ ∫ l ( f ( x ) , y ) p ( x , y ) d x d y E_{p(x, y)}[l(f(x), y)] = \int \int l(f(x), y) p(x, y) dxdy Ep(x,y)[l(f(x),y)]=∫∫l(f(x),y)p(x,y)dxdy
6.3 纠正协变量偏移
由 p ( y ∣ x ) = q ( y ∣ x ) p(y| x) = q(y| x) p(y∣x)=q(y∣x),利用以下等式进行纠正
∫ ∫ l ( f ( x ) , y ) p ( y ∣ x ) p ( x ) d x d y = ∫ ∫ l ( f ( x ) , y ) q ( y ∣ x ) p ( x ) q ( x ) d x d y \int \int l(f(x), y) p(y| x) p(x) dxdy = \int \int l(f(x), y) q(y| x) \frac{p(x)}{q(x)} dxdy ∫∫l(f(x),y)p(y∣x)p(x)dxdy=∫∫l(f(x),y)q(y∣x)q(x)p(x)dxdy
定义
β i = p ( x i ) q ( x i ) \beta_i = \frac{p(x_i)}{q(x_i)} βi=q(xi)p(xi)
令损失函数为
m i n f 1 n ∑ i = 1 n β i l ( f ( x i ) , y i ) min_f \frac{1}{n} \sum_{i=1}^n \beta_i l(f(x_i), y_i) minfn1i=1∑nβil(f(xi),yi)
再进行训练
实际操作中,会利用 p ( x ) p(x) p(x) 和 q ( x ) q(x) q(x)训练一个分类器:
p ( x ) q ( x ) = 1 / ( 1 + e − h ( x i ) ) 1 − 1 / ( 1 + e − h ( x i ) ) = e − h ( x i ) \frac{p(x)}{q(x)} = \frac{ 1 / (1 + e^{-h(x_i)}) }{ 1 - 1 / (1 + e^{-h(x_i)}) } = e^{-h(x_i)} q(x)p(x)=1−1/(1+e−h(xi))1/(1+e−h(xi))=e−h(xi)
即 β i = e − h ( x i ) \beta_i = e^{-h(x_i)} βi=e−h(xi)
6.4 纠正标签偏移
同理有
∫ ∫ l ( f ( x ) , y ) p ( x ∣ y ) p ( y ) d x d y = ∫ ∫ l ( f ( x ) , y ) q ( x ∣ y ) p ( y ) q ( y ) d x d y \int \int l(f(x), y) p(x | y) p(y) dxdy = \int \int l(f(x), y) q(x | y) \frac{p(y)}{q(y)} dxdy ∫∫l(f(x),y)p(x∣y)p(y)dxdy=∫∫l(f(x),y)q(x∣y)q(y)p(y)dxdy
β i = p ( y i ) q ( y i ) \beta_i = \frac{p(y_i)}{q(y_i)} βi=q(yi)p(yi)
定义混淆矩阵 C C C
C i , j C_{i, j} Ci,j 为 模型预测为标签 i i i 但是真实标签为 j j j 的数据所占比例
记 μ ( y ) \mu(y) μ(y) 是模型在测试时的预测的平均输出,则有
C p ( y ) = μ ( y ) C p(y) = \mu(y) Cp(y)=μ(y)
那么
p ( y ) = C − 1 μ ( y ) p(y) = C^{-1} \mu(y) p(y)=C−1μ(y)
又易得 q ( y ) q(y) q(y),故可求得 p ( y ) q ( y ) \frac{p(y)}{q(y)} q(y)p(y)
四、深度学习计算
1. 层和块
一个层可以由多个层或多个块组成
class MySequential(nn.Module):
def __init__(self, *args):
super().__init__()
for idx, module in enumerate(args):
self._modules[str(idx)] = module
def forward(self, X):
for block in self._modules.values():
X = block(X)
return X
块中可以编写任意的计算,包括 Python 代码
2. 参数操作
2.1 参数访问
net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))
# 参数访问
print(net[2].weight)
print(net[2].bias)
# 只访问参数的值,即 requires_grad = False
print(net[2].bias.data)
# 访问包含所有参数的字典
print(net[2].state_dict())
Parameter containing:
tensor([[-0.1868, -0.2378, -0.1849, 0.1916, -0.0438, 0.0436, 0.0416, 0.2273]],
requires_grad=True)
Parameter containing:
tensor([0.2626], requires_grad=True)
tensor([0.2626])
OrderedDict([('weight', tensor([[-0.1868, -0.2378, -0.1849, 0.1916, -0.0438, 0.0436, 0.0416, 0.2273]])), ('bias', tensor([0.2626]))])
named_parameters 返回的是 (name, param) 元组的列表
parameters 仅返回参数
print([(name, param.shape) for name, param in net[0].named_parameters()])
print([(name, param.shape) for name, param in net.named_parameters()])
print([param.shape for param in net.parameters()])
[('weight', torch.Size([8, 4])), ('bias', torch.Size([8]))]
[('0.weight', torch.Size([8, 4])), ('0.bias', torch.Size([8])), ('2.weight', torch.Size([1, 8])), ('2.bias', torch.Size([1]))]
[torch.Size([8, 4]), torch.Size([8]), torch.Size([1, 8]), torch.Size([1])]
嵌套块的参数
# 嵌套块
def block1():
return nn.Sequential(nn.Linear(4, 8), nn.ReLU(),
nn.Linear(8, 4), nn.ReLU())
def block2():
net = nn.Sequential()
for i in range(4):
# 在这里嵌套
net.add_module(f'block {i}', block1())
return net
rgnet = nn.Sequential(block2(), nn.Linear(4, 1))
print(rgnet)
print([(name, param.shape) for name, param in rgnet[0][1][0].named_parameters()])
Sequential(
(0): Sequential(
(block 0): Sequential(
(0): Linear(in_features=4, out_features=8, bias=True)
(1): ReLU()
(2): Linear(in_features=8, out_features=4, bias=True)
(3): ReLU()
)
(block 1): Sequential(
(0): Linear(in_features=4, out_features=8, bias=True)
(1): ReLU()
(2): Linear(in_features=8, out_features=4, bias=True)
(3): ReLU()
)
(block 2): Sequential(
(0): Linear(in_features=4, out_features=8, bias=True)
(1): ReLU()
(2): Linear(in_features=8, out_features=4, bias=True)
(3): ReLU()
)
(block 3): Sequential(
(0): Linear(in_features=4, out_features=8, bias=True)
(1): ReLU()
(2): Linear(in_features=8, out_features=4, bias=True)
(3): ReLU()
)
)
(1): Linear(in_features=4, out_features=1, bias=True)
)
[('weight', torch.Size([8, 4])), ('bias', torch.Size([8]))]
2.2 参数初始化
w ∼ { U ( 5 , 10 ) , 概率为 1 4 0 , 概率为 1 2 U ( − 5 , − 10 ) , 概率为 1 4 w \sim \begin{cases} U(5, 10), \,\, 概率为 \frac{1}{4} \\ 0, \,\, 概率为\frac{1}{2} \\ U(-5, -10), \,\, 概率为 \frac{1}{4} \\ \end{cases} w∼⎩ ⎨ ⎧U(5,10),概率为410,概率为21U(−5,−10),概率为41
# 初始化
def init_weights(m):
if type(m) == nn.Linear:
nn.init.uniform_(m.weight, -10, 10)
m.weight.data *= m.weight.data.abs() >= 5
net.apply(init_weights)
print(net[0].weight[:2])
tensor([[ 7.5637, -9.7594, -0.0000, -6.0625],
[ 0.0000, 0.0000, 0.0000, -5.8875]], grad_fn=<SliceBackward0>)
2.3 参数共享
多次指定同一个 Module 对象
# 参数共享
# 我们需要给共享层一个名称,以便可以引用它的参数
shared = nn.Linear(8, 8)
net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(),
shared, nn.ReLU(),
shared, nn.ReLU(),
nn.Linear(8, 1))
# 检查参数是否相同
print(net[2].weight.data[0] == net[4].weight.data[0])
net[2].weight.data[0, 0] = 100
# 确保它们实际上是同一个对象,而不只是有相同的值
print(net[2].weight.data[0] == net[4].weight.data[0])
tensor([True, True, True, True, True, True, True, True])
tensor([True, True, True, True, True, True, True, True])
2.4 延后初始化
允许只指定输出维度
# 延后初始化
net = nn.Sequential(
nn.LazyLinear(256),
nn.ReLU(),
nn.LazyLinear(10)
)
X = torch.rand((5, 20))
print(net(X).shape)
torch.Size([5, 10])
3. 自定义层
# 自定义层
class MeanLayer(nn.Module):
def __init__(self):
super().__init__()
def forward(self, X):
return X - X.mean(axis=1)
X = torch.rand((1, 5))
print(X)
layer = MeanLayer()
print(layer(X))
tensor([[0.0670, 0.8884, 0.4443, 0.3047, 0.5332]])
tensor([[-0.3805, 0.4409, -0.0032, -0.1429, 0.0857]])
4. 保存模型
保存/读取张量
# 保存/读取张量
x = torch.arange(4)
torch.save(x, 'x-file')
y = torch.load('x-file')
print(x, y)
tensor([0, 1, 2, 3]) tensor([0, 1, 2, 3])
保存/读取字典
# 保存/读取字典
mydict = {'x': x, 'y': y}
torch.save(mydict, 'mydict')
mydict2 = torch.load('mydict')
print(mydict, mydict2)
tensor([0, 1, 2, 3]) tensor([0, 1, 2, 3])
{'x': tensor([0, 1, 2, 3]), 'y': tensor([0, 1, 2, 3])} {'x': tensor([0, 1, 2, 3]), 'y': tensor([0, 1, 2, 3])}
保存/读取模型参数
# 保存/读取模型参数
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.Linear(20, 256)
self.output = nn.Linear(256, 10)
def forward(self, x):
return self.output(F.relu(self.hidden(x)))
net = MLP()
torch.save(net.state_dict(), 'mlp_state_dict')
clone = MLP()
clone.load_state_dict(torch.load('mlp_state_dict'))
X = torch.rand((1, 20))
print(net(X) == clone(X))
tensor([[True, True, True, True, True, True, True, True, True, True]])
5. GPU
查看设备的 GPU 运行状况
root@Andrew:~# watch -n 2 nvidia-smi
查看 Pytorch 中 GPU的可用情况
# GPU 使用情况
print(torch.cuda.is_available())
print(torch.cuda.device_count())
True
1
指定张量的存储设备
# 指定张量的环境
x = torch.tensor([1, 2, 3])
print(x.device)
def try_gpu(i=0):
if i < torch.cuda.device_count():
return torch.device(f'cuda:{i}')
return torch.device('cpu')
X = torch.ones(2, 3, device=try_gpu())
print(X.device)
cpu
cuda:0
张量需在同一个设备中才能进行运算,需复制张量到不同设备
# 复制张量到不同设备
X = torch.ones(2, 3, device=try_gpu())
Y = torch.rand(2, 3, device=try_gpu(1))
Z = X.cuda(1) # 之后才能将 Y 和 Z 做运算
将神经网络保存在同一设备
# 神经网络与 GPU
net = nn.Sequential(nn.Linear(3, 1))
net = net.to(device=try_gpu())
print(net(X))
print(net[0].weight.device)
tensor([[-1.1118],
[-1.1118]], device='cuda:0', grad_fn=<AddmmBackward0>)
cuda:0
五、卷积神经网络
1. 从全连接层到卷积
如何从“全连接”引入到卷积?
需要看在图像处理中,有什么需求
在多层感知机中:
H i , j = U i , j + ∑ k ∑ j W i , j , k , l X k , l = U i , j + ∑ a ∑ b V i , j , a , b X i + a , j + b \begin{align} H_{i, j} =& U_{i, j} + \sum_k \sum_j W_{i, j, k, l} X_{k, l} \\ =& U_{i, j} + \sum_a \sum_b V_{i, j, a, b} X_{i + a, j + b} \end{align} Hi,j==Ui,j+k∑j∑Wi,j,k,lXk,lUi,j+a∑b∑Vi,j,a,bXi+a,j+b
其中, k = i + a , l = j + b , V i , j , a , b = W i , j , i + a , j + b k = i + a, l = j + b, V_{i, j, a, b} = W_{i, j, i + a, j + b} k=i+a,l=j+b,Vi,j,a,b=Wi,j,i+a,j+b
图像处理中,我们希望识别对象 X 的平移,仅导致其隐藏含义的平移 H(位置的改变而非值),即 平移不变性,数学表示如下:
引入平移不变性,那么令 V i , j , a , b = V a , b V_{i, j, a, b} = V_{a, b} Vi,j,a,b=Va,b, U i , j = u U_{i, j} = u Ui,j=u,得
H i , j = u + ∑ a ∑ b V a , b X i + a , j + b H_{i, j} = u + \sum_a \sum_b V_{a, b} X_{i + a, j + b} Hi,j=u+a∑b∑Va,bXi+a,j+b
另外,我们希望神经网络的前几层只探索图像的局部信息,不希望 H i , j H_{i, j} Hi,j 的值被偏离的很远的像素影响,即局部性,数学表示为:
H i , j = u + ∑ a = − Δ Δ ∑ b = − Δ Δ V a , b X i + a , j + b H_{i, j} = u + \sum_{a=-\Delta}^\Delta \sum_{b=-\Delta}^\Delta V_{a, b} X_{i + a, j + b} Hi,j=u+a=−Δ∑Δb=−Δ∑ΔVa,bXi+a,j+b
多通道情况下,令输入通道为 c c c,输出通道为 d d d,则有:
H i , j , d = u + ∑ a = − Δ Δ ∑ b = − Δ Δ ∑ c V a , b , c , d X i + a , j + b , c H_{i, j, d} = u + \sum_{a=-\Delta}^\Delta \sum_{b=-\Delta}^\Delta \sum_c V_{a, b, c, d} X_{i + a, j + b, c} Hi,j,d=u+a=−Δ∑Δb=−Δ∑Δc∑Va,b,c,dXi+a,j+b,c
2. 图像卷积
手撕卷积层
# 卷积操作定义
def conv2d(X, K):
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i+h, j:j+w] * K).sum()
return Y
# 卷积层定义
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super().__init__()
self.kernel = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, X):
return conv2d(X, self.kernel) + self.bias
X = torch.arange(16).reshape(4, 4)
conv2dLayer = Conv2D(kernel_size=(2, 2))
print(X)
print(conv2dLayer.kernel)
print(conv2dLayer(X))
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
Parameter containing:
tensor([[0.2574, 0.7522],
[0.7505, 0.0085]], requires_grad=True)
tensor([[ 3.7968, 5.5654, 7.3340],
[10.8712, 12.6398, 14.4084],
[17.9456, 19.7142, 21.4828]], grad_fn=<AddBackward0>)
卷积层用于边缘检测
# 边缘检测
X = torch.zeros((4, 8))
X[:, 2:6] = 1
K = torch.tensor([[1, -1]])
print(X, '\n', K)
print(conv2d(X, K))
tensor([[0., 0., 1., 1., 1., 1., 0., 0.],
[0., 0., 1., 1., 1., 1., 0., 0.],
[0., 0., 1., 1., 1., 1., 0., 0.],
[0., 0., 1., 1., 1., 1., 0., 0.]])
tensor([[ 1, -1]])
tensor([[ 0., -1., 0., 0., 0., 1., 0.],
[ 0., -1., 0., 0., 0., 1., 0.],
[ 0., -1., 0., 0., 0., 1., 0.],
[ 0., -1., 0., 0., 0., 1., 0.]])
卷积层的输出又叫做特征映射(feature map),其覆盖的输入又称之感受野(receptive field)
3. 填充和步幅
由于 nn.Conv2D 只能接收 3D or 4D 的张量,即前两个维度为 批大小、通道大小。故编写函数先将输入 X reshape,再作卷积操作
def comp_conv2d(conv2d, X):
# 这里的(1,1)表示批量大小和通道数都是1
X = X.reshape((1, 1) + X.shape)
Y = conv2d(X)
# 省略前两个维度:批量大小和通道
return Y.reshape(Y.shape[2:])
填充和步幅示例:
# 填充
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)
X = torch.rand(size=(8, 8))
print(comp_conv2d(conv2d, X).shape)
# 步幅
conv2d = nn.Conv2d(1, 1, kernel_size=3, stride=2)
X = torch.rand(size=(8, 8))
print(comp_conv2d(conv2d, X).shape)
torch.Size([8, 8])
torch.Size([3, 3])
复杂示例:
H o u t = H i n + 2 P − K S + 1 H_{out} = \frac{H_{in} + 2P - K}{S} + 1 Hout=SHin+2P−K+1
其中, H i n H_in Hin 为输入维度, H o u t H_out Hout为输出维度, P P P为填充, K K K为卷积核维度, S S S为步幅
# 复杂示例
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
# X.shape = (8, 8)
# 正常经过 conv2d 输出的 shape 为 (6, 4)
# 由于 padding 是 (0, 1) 那么输入的 shape 变为 (8, 10)
# 那么 stride 为 1 时输出 (6, 6)
# stride 为 (3, 4) 时,输出为 (2, 2)
print(comp_conv2d(conv2d, X).shape)
torch.Size([8, 8])
torch.Size([3, 3])
torch.Size([2, 2])
4. 多输入多输出通道
多输入通道,图像 X 和卷积核都是 3D
# 多输入
def conv2d_multi_in(X, K):
return sum(conv2d(x, k) for x, k in zip(X, K))
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
print(conv2d_multi_in(X, K))
tensor([[ 56., 72.],
[104., 120.]])
多输入 + 多输出通道,卷积核是 4D
torch.stack 会将列表沿指定的新维度进行堆叠
# 多输入 + 多输出
def conv2d_multi_in_out(X, K):
return torch.stack([conv2d_multi_in(X, k) for k in K], 0)
K = torch.stack((K, K + 1, K + 2), 0)
print(K.shape)
print(conv2d_multi_in_out(X, K))
torch.Size([3, 2, 2, 2])
tensor([[[ 56., 72.],
[104., 120.]],
[[ 76., 100.],
[148., 172.]],
[[ 96., 128.],
[192., 224.]]])
1 × 1 1 \times 1 1×1 的卷积核常用于调整通道数、控制模型复杂性
1 × 1 1 \times 1 1×1 的卷积核的计算可以使用类似全连接层的方式实现
# 1 * 1 卷积
def conv2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape
c_o = K.shape[0]
X = X.reshape((c_i, h * w))
K = K.reshape((c_o, c_i))
# 全连接层中的矩阵乘法
Y = torch.matmul(K, X)
return Y.reshape((c_o, h, w))
X = torch.normal(0, 1, (3, 3, 3))
K = torch.normal(0, 1, (2, 3, 1, 1))
Y1 = conv2d_multi_in_out_1x1(X, K)
Y2 = conv2d_multi_in_out(X, K)
print(float(torch.abs(Y1 - Y2).sum()) < 1e-6)
5. 汇聚层
其实就是池化层啦
def pool2d(X, pool_size, mode='max'):
h, w = pool_size
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + h, j: j + w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + h, j: j + w].mean()
return Y
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
# 最大池化
print(pool2d(X, (2, 2)))
# 平均池化
print(pool2d(X, (2, 2), mode='avg'))
tensor([[4., 5.],
[7., 8.]])
tensor([[2., 3.],
[5., 6.]])
同卷积层,池化层也可指定填充、步幅
输入输出维度及填充步幅之间的关系式同卷积层
# 填充和步幅
X = torch.arange(9.).reshape(1, 1, 3, 3)
pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1))
# ((3, 3) + 2 * (0, 1) - (2, 3)) / (2, 3) + (1, 1) = (1, 1)
print(pool2d(X))
tensor([[[[4.]]]])
池化层使用多个通道的输入时,只会分别对每个通道做池化
# 多个通道
X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4))
X = torch.cat((X, X + 1), 1)
print(X.shape)
print(pool2d(X).shape)
torch.Size([1, 2, 4, 4])
torch.Size([1, 2, 2, 2])
6. LeNet
模型定义
# 模型定义
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
或者
class LeNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5, padding=2)
self.conv2 = nn.Conv2d(6, 16, kernel_size=5)
self.pool = nn.AvgPool2d(kernel_size=2, stride=2)
self.sigmoid = nn.Sigmoid()
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, X):
X = self.sigmoid(self.conv1(X))
X = self.pool(X)
X = self.sigmoid(self.conv2(X))
X = self.pool(X)
X = self.flatten(X)
X = self.sigmoid(self.fc1(X))
X = self.sigmoid(self.fc2(X))
return self.fc3(X)
net = LeNet()
评估函数将测试集移动到 gpu
def evaluate_accuracy_gpu(net, data_iter, device=None):
if isinstance(net, torch.nn.Module):
net.eval()
if not device:
device = next(iter(net.parameters())).device # 未指定设备时,自动寻找设备
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
# 将数据复制到网络所在的设备
if isinstance(X, list):
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
在 gpu 中进行训练,并使用 xavier 初始化
# 训练
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)"""
# 初始化参数
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
# 定义损失函数和优化算法
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
# 训练
for epoch in range(num_epochs):
net.train()
for i, (X, y) in enumerate(train_iter):
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
acc = evaluate_accuracy_gpu(net, test_iter)
print(f'epoch {epoch + 1}, acc {acc:f}')
# 保存模型
torch.save(net.state_dict(), 'lenet_state_dict')
batch_size, lr, num_epochs = 256, 0.9, 10
train_iter, test_iter = load_data_fashion_mnist(batch_size)
train_ch6(net, train_iter, test_iter, num_epochs, lr, 'cuda')
六、现代卷积神经网络
1. AlexNet
net = nn.Sequential(
# 这里使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10))
X = torch.randn(1, 1, 224, 224)
for layer in net:
X=layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape)
Conv2d output shape: torch.Size([1, 96, 54, 54])
ReLU output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Conv2d output shape: torch.Size([1, 256, 26, 26])
ReLU output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 256, 12, 12])
ReLU output shape: torch.Size([1, 256, 12, 12])
MaxPool2d output shape: torch.Size([1, 256, 5, 5])
Flatten output shape: torch.Size([1, 6400])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
2. VGG
VGG 引入了使用块去构建网络
# 卷积和池化层组成的块
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
# 每一块的 卷积层数/输出通道数
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
# 构建 VGG 网络
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
net = vgg(conv_arch)
3. NiN
NiN 将通道维度视作不同特征,NiN 块在每个卷积层后使用两个 1 × 1 1 \times 1 1×1卷积核,作为在每个像素上独立作用的全连接层
# NiN 块
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
# NiN 网络
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
nn.Flatten())
4. GoogLeNet
GoogLeNet 的 Inception 将一个输入经过多个不同的卷积层得到多个输出,再通过通道堆叠
定义 Inception
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
# 7x7卷积 + 3x3池化
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 1x1卷积 + 3x3卷积 + 3x3池化
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 两个Inception + 3x3池化
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 五个Inception + 3x3池化
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 两个Inception + 全局平均池化
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten())
# 增加全连接层
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
5. Batch Normalization
BatchNorm 层计算每个小批量数据集的均值和方差,并利用两个参数 γ \gamma γ 和 β \beta β 对其做缩放和平移
B N ( x ) = γ ⊙ x − μ ^ B σ ^ B 2 + β BN(x) = \gamma \odot \frac{x - \hat\mu_B}{\hat\sigma_B^2} + \beta BN(x)=γ⊙σ^B2x−μ^B+β
其中, x ∈ B x \in B x∈B 表示 x x x 来自一个小批量的输入 B B B
BatchNorm 层在训练过程中利用指数移动平均的方式去近似整个数据集的均值和方差,并在推理过程中利用累计的结果直接作为数据集的均值和方差
移动平均可参考:移动平均(Moving Average) - 知乎 (zhihu.com)
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 通过is_grad_enabled来判断当前模式是训练模式还是预测模式
if not torch.is_grad_enabled():
# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# 使用全连接层的情况,计算特征维上的均值和方差
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。
# 这里我们需要保持X的形状以便后面可以做广播运算
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
# 训练模式下,用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 缩放和移位
return Y, moving_mean.data, moving_var.data
class BatchNorm(nn.Module):
# num_features:完全连接层的输出数量或卷积层的输出通道数。
# num_dims:2表示完全连接层,4表示卷积层
def __init__(self, num_features, num_dims):
super().__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# 非模型参数的变量初始化为0和1
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
# 如果X不在内存上,将moving_mean和moving_var
# 复制到X所在显存上
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var
Y, self.moving_mean, self.moving_var = batch_norm(
X, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.9)
return Y
6. ResNet
残差块使得每一块更容易包含上一块的输出
设上一块的输出为 x x x,当前块期望的输出为 f ( x ) f(x) f(x),假设 f ( x ) = x f(x) = x f(x)=x(可以是任意函数)
那么当前块需要拟合一个 f ( x ) = x f(x) = x f(x)=x 就比拟合一个 h ( x ) = f ( x ) − x h(x) = f(x) - x h(x)=f(x)−x 要困难
因为 h ( x ) = f ( x ) − x = 0 h(x) = f(x) - x = 0 h(x)=f(x)−x=0,只需要让参数都为 0
实际上,如果希望这一块的输出能够更容易包含上一块的输出,那么只让这一块去拟合一个残差函数 h ( x ) h(x) h(x),再与原始输入 x x x 相加会更高效
class Residual(nn.Module): #@save
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
7. DenseNet
DenseNet 定义了一种稠密块,包含多个卷积块,每个卷积块的输入是前面所有卷积块的输出的堆叠
DenseNet 的卷积块中包含 Batch Normalization 操作
def conv_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1))
class DenseBlock(nn.Module):
def __init__(self, num_convs, input_channels, num_channels):
super(DenseBlock, self).__init__()
layer = []
for i in range(num_convs):
layer.append(conv_block(
num_channels * i + input_channels, num_channels))
self.net = nn.Sequential(*layer)
def forward(self, X):
for blk in self.net:
Y = blk(X)
# 连接通道维度上每个块的输入和输出
X = torch.cat((X, Y), dim=1)
return X
输入通道为3,带 2 个输出通道为 10 的卷积块的稠密块的输出通道为 3 + 2 * 10 = 23。卷积块的输出通道又叫增长率
由于稠密块会带来通道数的增加,所以需要过渡层利用 1 × 1 1 \times 1 1×1 的卷积核降低模型的复杂度
def transition_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=1),
nn.AvgPool2d(kernel_size=2, stride=2))