温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目简介
心脏病是全球范围内导致死亡的主要原因之一。早期识别和预防心脏病对于减少发病率和死亡率至关重要。传统的风险评估方法通常依赖于医生的经验和简单的风险因子计算,这种方法存在一定的局限性。近年来,机器学习技术在医学领域取得了显著进展,能够从大量的医疗数据中自动学习和提取特征,从而实现高效、准确的风险预测。
本项目利用pandas工具,计算特征与患心脏病的斯皮尔曼相关性,并利用 Matplotlib 绘制绘制相关性热力图,同时对各特征统计量进行可视化,对性别、年龄、血压、胆固醇、血糖、心率、心绞痛等特征进行统计分布的可视化,分析与患病的潜在相关性。利用scikit-learn、xgboost等工具包构建不同机器学习模型,对患心脏病的预测性能进行对比分析,测试集预测准确率达到92.2%。后端利用Flask框架搭建 web 服务接口,前端采用 Bootstrap 和 echarts 等框架,构建可视化交互平台,方便对心脏病的在线评估预测。
基于机器学习的心脏病风险评估预测系统
2. 心脏病数据集预处理
该数据集包含用于预测心脏病的医学数据。这些数据包括各种属性,如年龄、性别、胸痛类型(cp)、静息血压(trestbps)、胆固醇(chol)、空腹血糖(fbs)、静息心电图结果(restecg)、达到的最大心率(丘脑)、运动性心绞痛(exang)和运动相对于休息引起的ST段压低(oldpeak)。
df = pd.read_csv("./heart-disease.csv")
## 列名汉化
df.rename(columns={
"age":"年龄",
"sex":"性别",
"cp":"胸痛类型",
"chol":"胆固醇",
"fbs":"空腹血糖",
"restecg":"静息心电图结果",
"thalach":"达到的最大心率",
"exang":"运动性心绞痛",
"oldpeak":"ST段压低",
"slope":"最高运动ST段的斜率",
"trestbps": "静息血压",
"ca":"萤光显色主要血管数目",
"thal":"地中海贫血",
"target":"患病"
},inplace=True)
df.sample(10)
df.info()
3. 数据探索式可视化分析
3.1 类别标签数量分布
tmp = df["患病"].value_counts().to_frame().reset_index().rename(columns={"count":"数量"})
tmp["患病"] = tmp["患病"].map(lambda x:"心脏病" if x == 1 else "正常")
tmp["百分比"] = tmp["数量"].map(lambda x:round(x/tmp["数量"].sum()*100,2))
labels,values,percent = tmp["患病"].tolist(),tmp["数量"].tolist(),tmp["百分比"].tolist()
fig = plt.figure(figsize=(6,6))
wedges,texts=plt.pie(values,wedgeprops={"width": 0.4, 'edgecolor': '#000', 'linewidth': 2})
kw = dict(arrowprops=dict(arrowstyle="-"), zorder=0, va="center")
for i, p in enumerate(wedges):
ang = (p.theta2 - p.theta1) / 1.8 + p.theta1
y = np.sin(np.deg2rad(ang))
x = np.cos(np.deg2rad(ang))
horizontalalignment = {-1: "right", 1: "left"}[int(np.sign(x))]
connectionstyle = "angle,angleA=0,angleB={}".format(ang)
kw["arrowprops"].update({"connectionstyle": connectionstyle})
plt.annotate(
labels[i]+"\n"+str(percent[i])+"%",
xy=(x, y),
xytext=(1.35 * np.sign(x), 1.4 * y),
horizontalalignment=horizontalalignment,
fontsize=12,
**kw
)
plt.title("是否患有心脏病的样本数量分布占比", fontsize=18, pad=20)
plt.show()
3.2 特征与目标的相关性分析

可以看出:与心脏病是否患病的相关性较高的特征有:胸痛类型、达到的最大心率、最高运动ST段的斜率等。
- cp(胸痛类型):与目标值呈强正相关(0.43)。这表明某些类型的胸痛与心脏病的存在显著相关。
- 丘脑(达到的最大心率):与目标值(0.42)呈正相关,表明心率较高的患者更有可能患心脏病。
- exang(运动诱导型心绞痛):与目标值呈强负相关(-0.44),表明运动诱导性心绞痛在没有心脏病的患者中更常见。
- oldpeak(ST段压低):与目标呈负相关(-0.43),表明ST段压低水平越高,患心脏病的可能性越低。
- 斜率(峰值运动ST段斜率):也与目标值呈负相关(-0.34),表明ST段斜率可能是一个重要因素。
- 性别:呈负相关(-0.28),表明在此数据集中,男性(编码为1)患心脏病的可能性较小。
- ca(荧光镜检查着色的主要血管数量):与目标呈中度负相关(-0.41),这意味着与心脏病相关的着色血管较少。
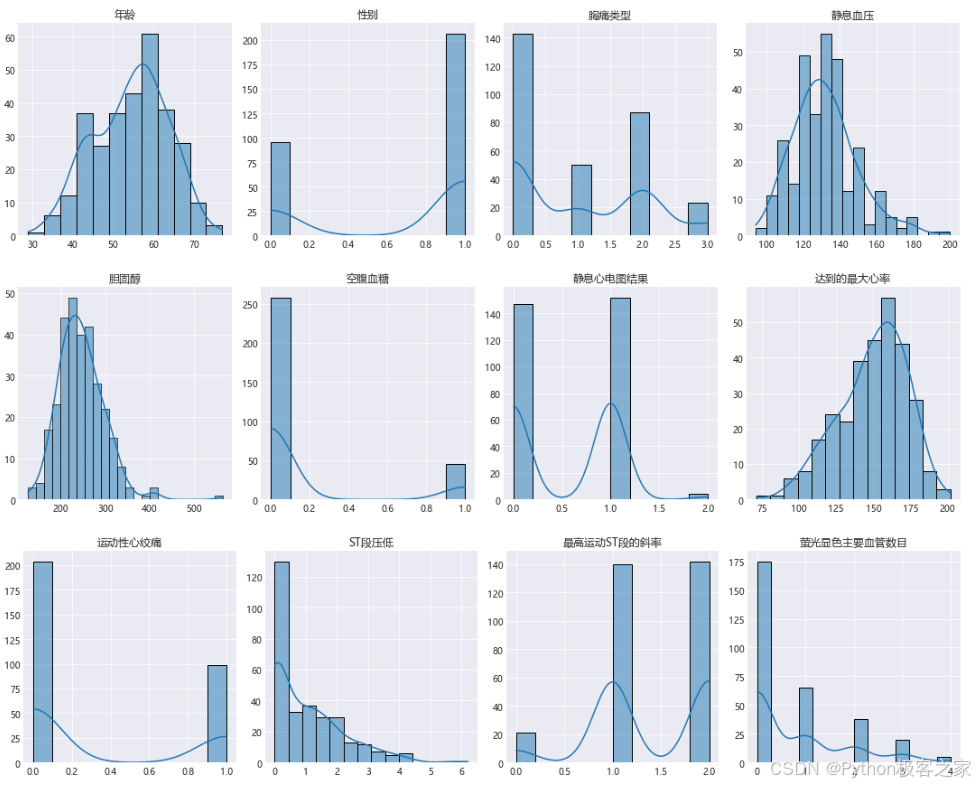
3.3 直方图和密度图上的数据分布
3.4 性别与心脏病患病相关性分析

3.5 胸痛类型与心脏病相关性分析
type_count = df.groupby('胸痛类型')['患病'].value_counts().unstack()
chest_pain_type_dict = {
0: '典型心绞痛', 1: '非典型性心绞痛', 2: '非心绞痛', 3: '无症状'
}
type_count.index = type_count.index.map(chest_pain_type_dict)
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(20, 6))
sns.countplot(df, x="胸痛类型", ax=axes[0])
axes[0].tick_params(axis='x', rotation=0)
axes[0].set_ylabel('胸痛类型')
axes[0].set_title('不同胸痛类型的样本数量分布', fontsize=16)
axes[0].set_xticklabels(labels=chest_pain_type_dict.values(), fontsize=12)
type_count.plot(kind='bar' , stacked=True, ax=axes[1], fontsize=12)
axes[1].tick_params(axis='x', rotation=0)
axes[1].set_ylabel('客户类型')
axes[1].set_title('不同胸痛类型的满患病占比分布', fontsize=16)
plt.show()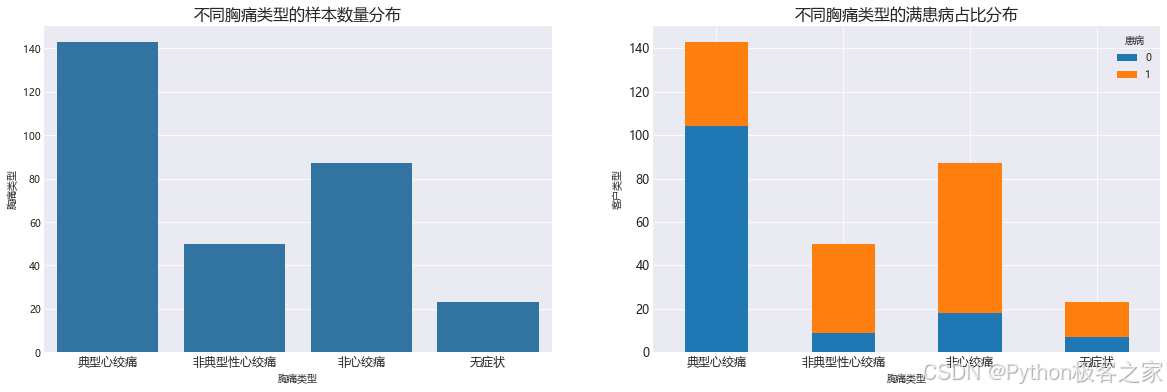
3.6 心脏病的胆固醇与达到的最大心率的联合分布

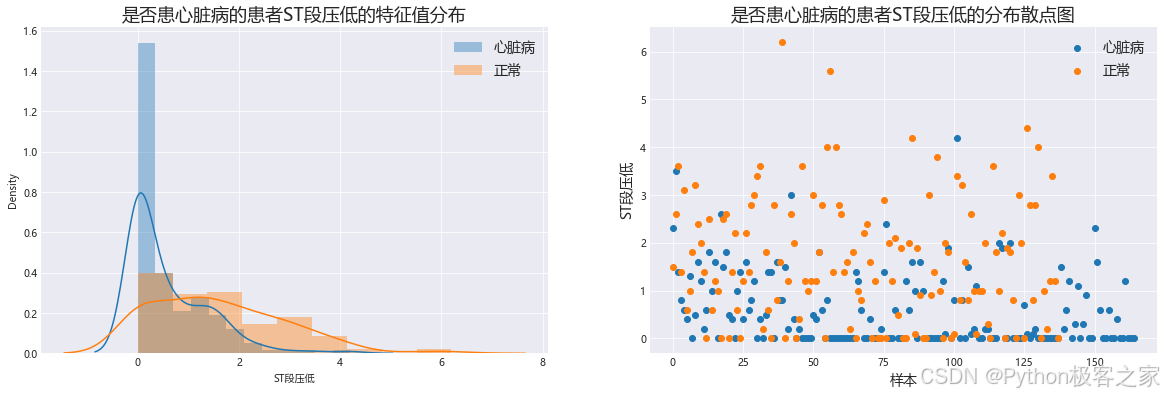
3.7 ST段压特征与是否患心脏病的相关性分析
3.8 萤光显色主要血管数目与是否患心脏病的相关性分析
plt.figure(figsize=(20, 6))
plt.subplot(121)
xg_counts = pos_df['萤光显色主要血管数目'].value_counts().reset_index()
labels = xg_counts['萤光显色主要血管数目'].values.tolist()
sizes = xg_counts['count']
# colors = ['gold', 'yellowgreen', 'lightcoral'] # 扇区颜色
explode = (0.1, 0, 0, 0, 0) # 将第一块扇区突出显示
# 创建饼状图
plt.pie(sizes, labels=labels, explode=explode,
......
# colors = ['gold', 'yellowgreen', 'lightcoral'] # 扇区颜色
explode = (0.1, 0, 0, 0, 0) # 将第一块扇区突出显示
# 创建饼状图
plt.pie(sizes, labels=labels, explode=explode,
autopct='%1.1f%%', shadow=True, startangle=140)
plt.axis('equal')
plt.title('未患有心脏病患者的萤光显色主要血管数目分布', fontsize=16)
# 显示图表
plt.show()
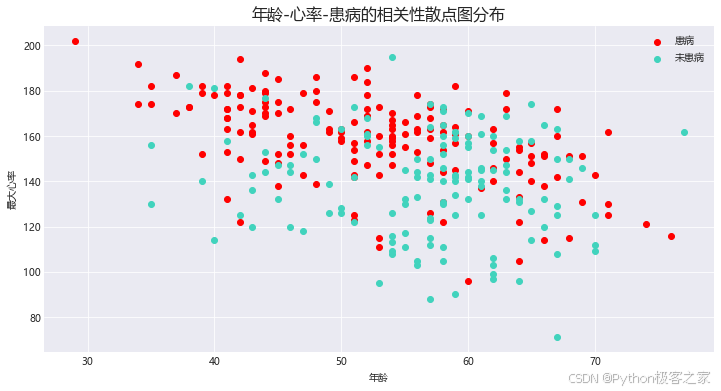
3.9 年龄-心率-患病的相关性分析
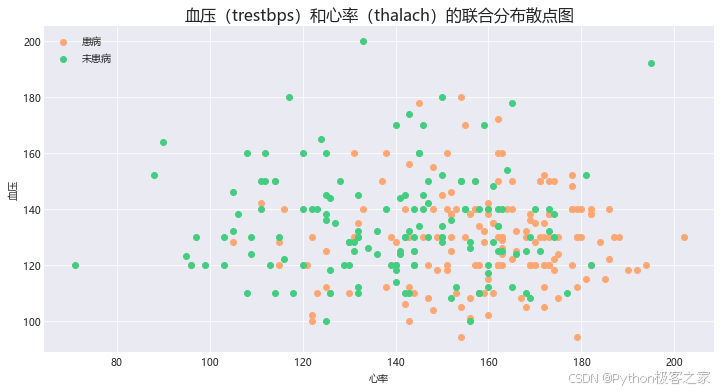
3.10 血压(trestbps)和心率(thalach)关系
3.11 大血管数量(ca)和血压(trestbps)、患病关系
plt.figure(figsize=(12, 6))
sns.swarmplot(y='静息血压',data=df, x='萤光显色主要血管数目',hue='患病', size=7)
plt.xlabel('大血管数量')
plt.ylabel('静息血压')
plt.title('大血管数量(ca)和血压(trestbps)、患病的联合分布散点图', fontsize=16)
plt.show()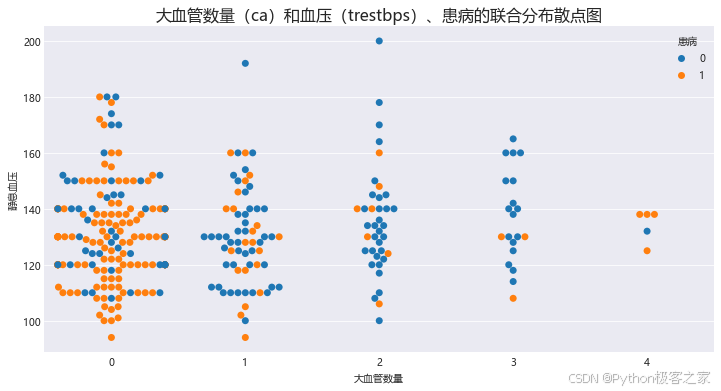
4. 基于机器学习的心脏病风险预测算法建模
4.1 多模型预测性能对比初探
利用 scikit-learn、xgboost等工具包,构建AdaBoostClassifier、GradientBoostingClassifier、LogisticRegression、SVC、XGBClassifier等模型,利用切分出的训练集、验证集进行模型的训练:
abc = AdaBoostClassifier()
gbc = GradientBoostingClassifier()
lgr = LogisticRegression()
svc = SVC()
xgb_clf = XGBClassifier()
models = [abc, gbc, lgr, svc, xgb_clf]
names = ["Ada Boost", "Gradient Boosting",
"Logistic Regression", "Support Vector Machine", "XGBoost"]
def training(model):
model.fit(X_train, y_train)
pred = model.predict(X_test)
score = accuracy_score(pred, y_test)
report = classification_report(pred, y_test)
cm = confusion_matrix(pred, y_test)
return score*100, report, cm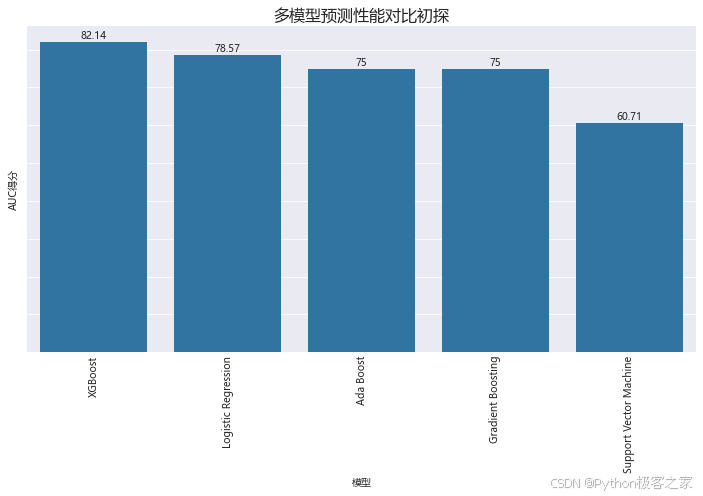
可以看出,默认参数下XGBoost模型的预测准确率达到82.14%,下面对xgboost模型进行参数优化,以提升性能。
4.2 Xgboost 模型优化与模型训练
df_columns = X_train.columns.values
print('===> feature count: {}'.format(len(df_columns)))
xgb_params = {
'eta': 0.01,
'colsample_bytree': 0.4,
'max_depth': 10,
# 'lambda': 2.0,
'eval_metric': 'auc',
'objective': 'binary:logistic',
'nthread': -1,
'silent': 1,
'booster': 'gbtree'
}
dtrain = xgb.DMatrix(X_train, y_train, feature_names=df_columns)
dvalid = xgb.DMatrix(X_valid, y_valid, feature_names=df_columns)
watchlist = [(dtrain, 'train'), (dvalid, 'valid')]
model = xgb.train(dict(xgb_params),
dtrain,
evals=watchlist,
verbose_eval=10,
early_stopping_rounds=100,
num_boost_round=4000)
4.3 特征重要程度情况
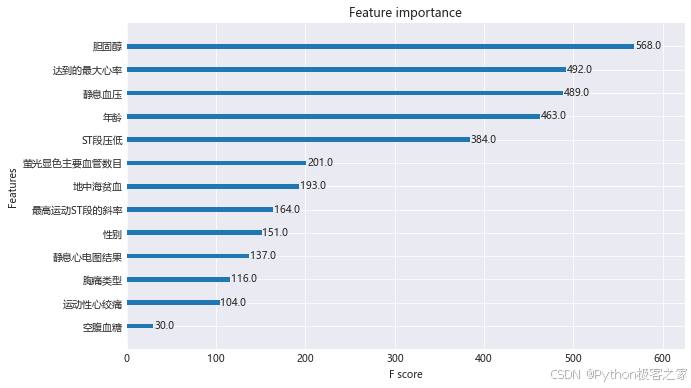
可以看出,胆固醇、达到的最大心率对于预测是否存在缺陷的重要程度最高.
4.4 模型性能评估
(1)AUC评估
# predict train
predict_train = model.predict(dtrain)
train_auc = evaluate_score(predict_train, y_train)
# predict validate
predict_valid = model.predict(dvalid)
valid_auc = evaluate_score(predict_valid, y_valid)
# predict test
dtest = xgb.DMatrix(X_test, feature_names=df_columns)
predict_test = model.predict(dtest)
test_auc = evaluate_score(predict_test, y_test)
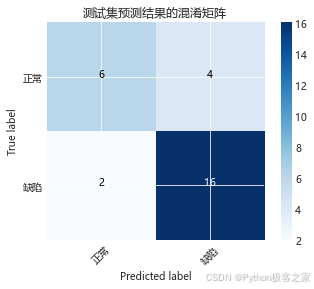
print('训练集 auc = {:.7f} , 验证集 auc = {:.7f} , 测试集 auc = {:.7f}\n'.format(train_auc, valid_auc, test_auc))训练集 auc = 0.9975709 , 验证集 auc = 0.8781513 , 测试集 auc = 0.9222222
(2)测试集预测 ROC 曲线

(3)测试集预测结果混淆矩阵计算
5. 心脏病风险评估预测系统
5.1 系统首页
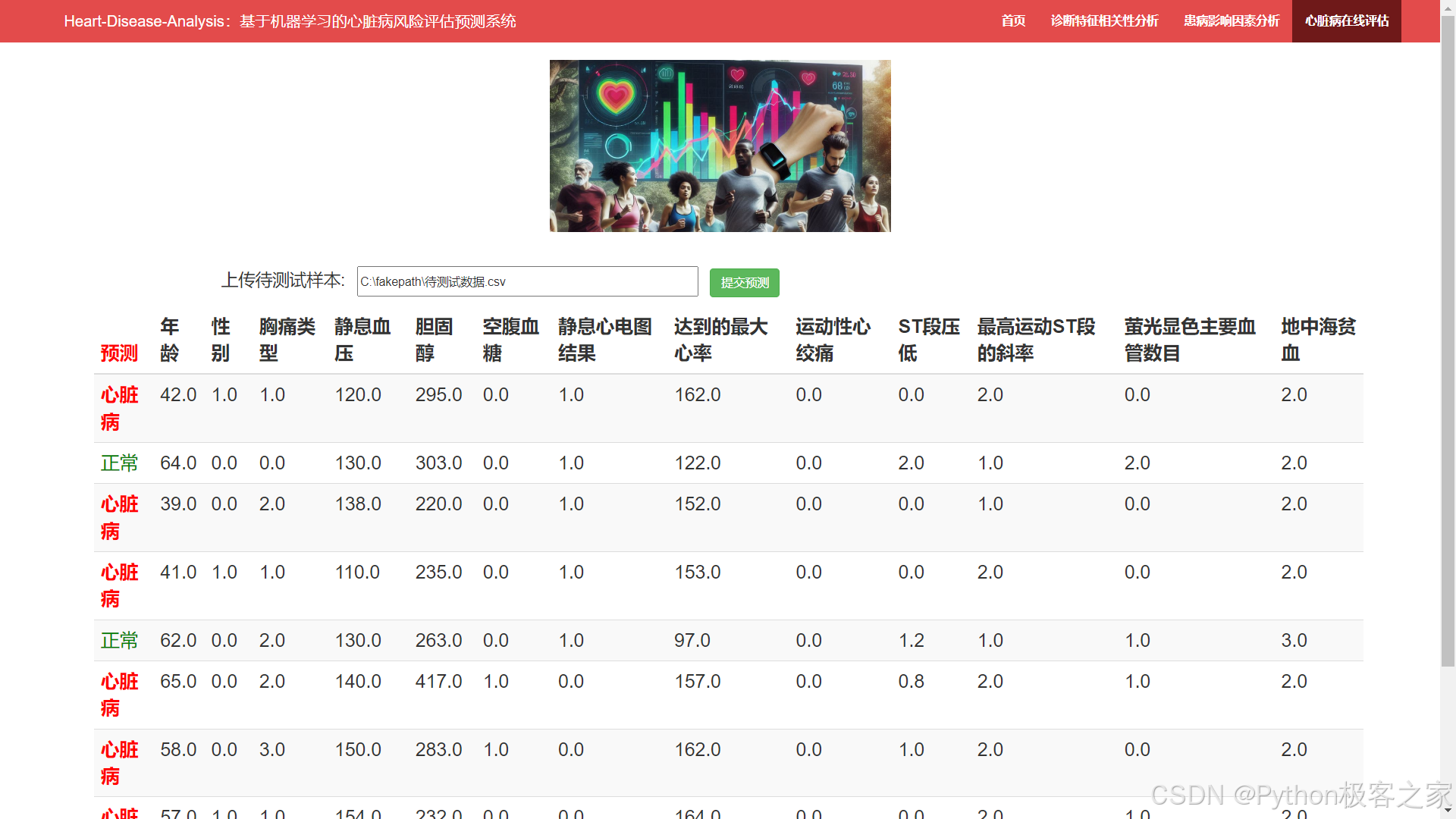
系统首页提供简洁明了的界面设计,包括系统名称、主要功能简介以及使用指南等内容。用户可以通过主页快速了解系统的基本操作流程及注意事项。首页上还会展示一些示例数据和预测结果,让用户直观地感受到系统的实际效果。
- Web应用框架:使用Flask构建Web应用程序。
- 前端框架:使用Bootstrap构建响应式前端界面。

5.2 诊断特征相关性分析
 5.3 患病影响因素分析
5.3 患病影响因素分析

5.4 心脏病在线评估
6. 总结
本项目利用pandas工具,计算特征与患心脏病的斯皮尔曼相关性,并利用 Matplotlib 绘制绘制相关性热力图,同时对各特征统计量进行可视化,对性别、年龄、血压、胆固醇、血糖、心率、心绞痛等特征进行统计分布的可视化,分析与患病的潜在相关性。利用scikit-learn、xgboost等工具包构建不同机器学习模型,对患心脏病的预测性能进行对比分析,测试集预测准确率达到92.2%。后端利用Flask框架搭建 web 服务接口,前端采用 Bootstrap 和 echarts 等框架,构建可视化交互平台,方便对心脏病的在线评估预测。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
