本文参考以下链接,如有侵权,联系删除
参考链接
Objects as Points
CenterNet (CVPR2019)
概要
这篇CenterNet算法也是anchor-free类型的目标检测算法,基于点的思想和CornerNet(参考博客:CornerNet笔记)是相似的,方法上做了较大的调整,整体上给人一种非常清爽的感觉,算法思想很朴素、直接,而且重点是在效果和效率之间能取得很好的平衡,提供的几个模型基本上能满足大部分人对效果和效率的需求.
CenterNet和CornerNet的对比
预测目标的中心点
CenterNet,从算法名也可以看出这个算法要预测的是目标的中心点,而不再是CornerNet中的2个角点;
- 相同点是都采用热力图(heatmap)来实现,都引入了预测点的高斯分布区域计算真实预测值,同时损失函数一样(修改版focal loss,网络输出的热力图也将先经过sigmod函数归一化成0到1后再传给损失函数)。
- 另外CenterNet也不包含corner pooling等操作,因为一般目标框的中心点落在目标上的概率还是比较大的,因此常规的池化操作能够提取到有效的特征,这是其一。
偏置(offset)预测
CerterNet中也采用了和CornerNet一样的偏置(offset)预测,表示的是标注信息从输入图像映射到输出特征图时由于取整操作带来的坐标误差
- 只不过在CornerNet中计算的是2个角点的offset,而CenterNet计算的是中心点的offset。
- 这部分还有一个不同点:损失函数,在CornerNet中采用SmoothL1损失函数来监督回归值的计算,但是在CenterNet中发现用L1损失函数的效果要更好,实验如下表所示,差异这么大是有点意外的。

直接回归目标框尺寸
CenterNet直接回归目标框尺寸,最后基于目标框尺寸和目标框的中心点位置就能得到预测框,
这部分和CornerNet是不一样的,
- 因为CornerNet是预测2个角点,所以需要判断哪些角点是属于同一个目标的过程,在CornerNet中通过增加一个corner group任务预测embedding vector,最后基于embedding vector判断哪些角点是属于同一个框。
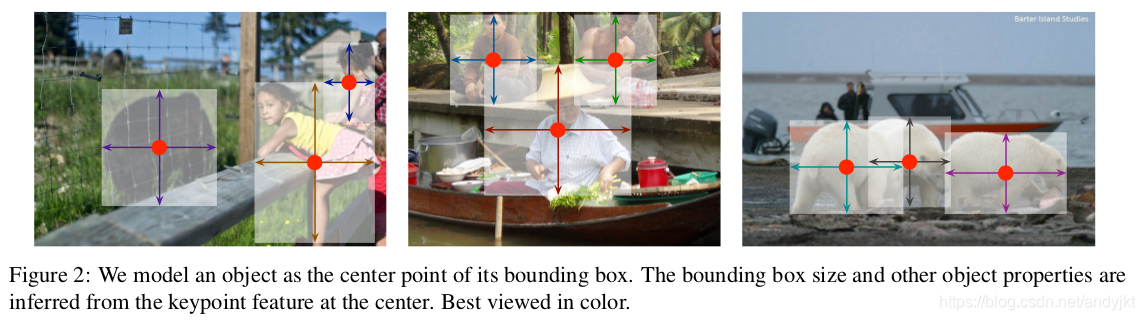
- 而CenterNet是预测目标的中心点,所以将CornerNet中的corner group操作替换成预测目标框的size(宽和高),这样一来结合中心点位置就能确定目标框的位置和大小了,如Figure2所示,这部分的损失函数依然采用L1损失.
以上这3者组成了CenterNet,可以分别用下面这3个图来描述
第一个图中粉色区域大致表示了以预测点为中心点的高斯分布区域

网络结构
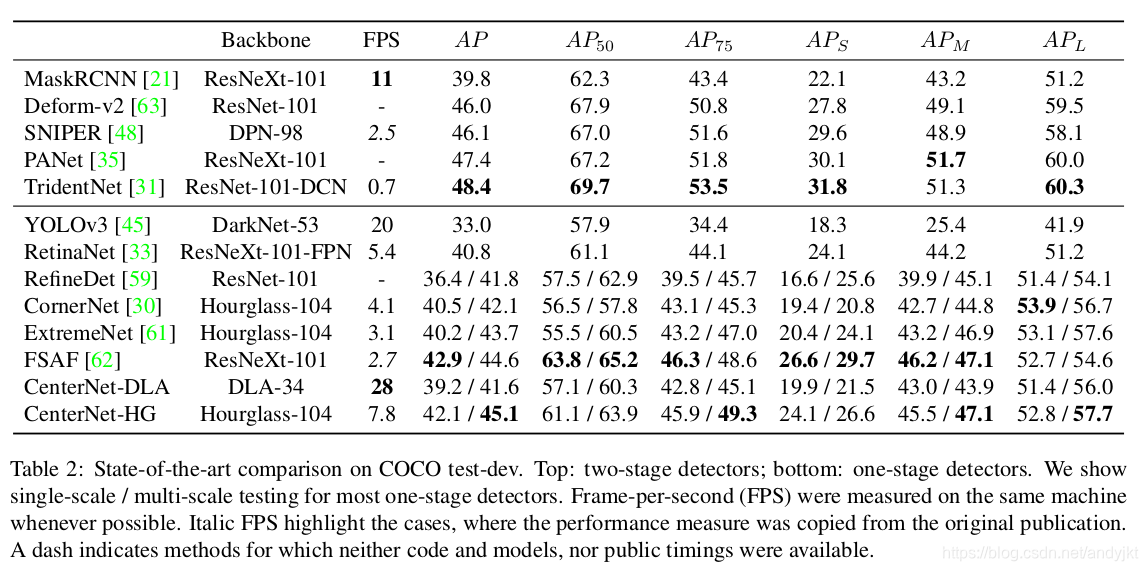
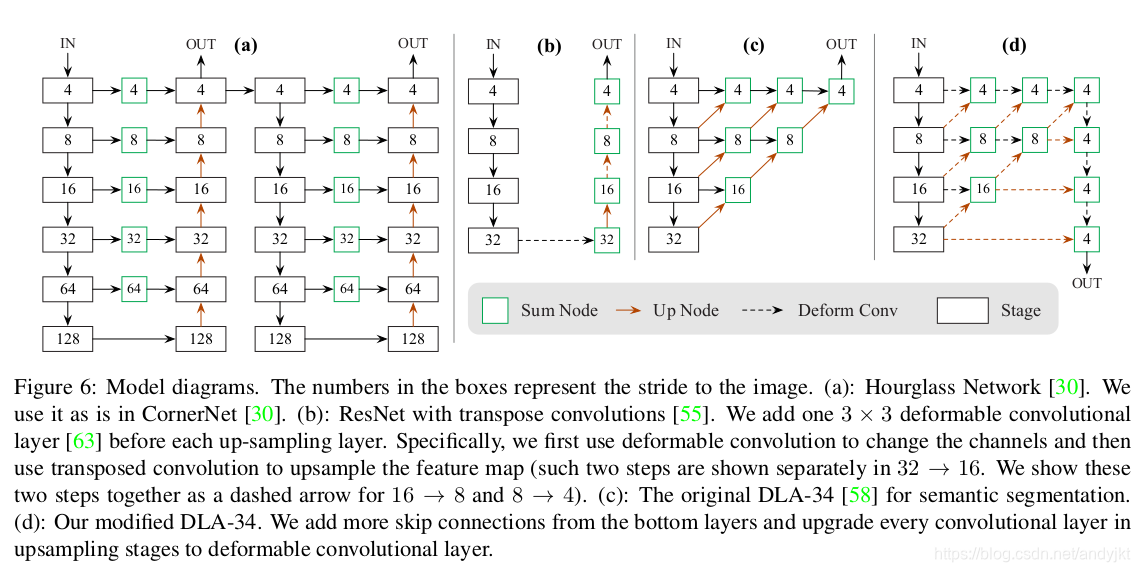
这篇论文的一大特点是提供了多种不同效果和效率的模型,主要提到的有4个网络,效果见下表
其中DLA和ResNet网络均引入了deformable卷积,另外ResNet部分并非采用原ResNet网络的实现,而是增加了上采样、减少通道数等操作,前者是为了增大输出特征图尺寸(原来stride=32,现在是4),后者则是为了减少计算量。
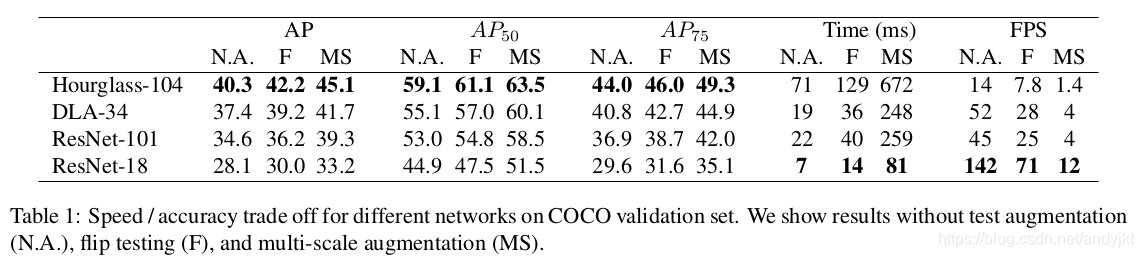
网络详细结构见下表
ResNet部分主要增加了上采样操作,保证输出特征图和输入图像之间的stride为4;DLA网络主要是增加了更多的特征融合操作,这部分没有对比实验。
中心点重合,如何预测
当不同目标框的中心点重合时,这种情况下怎么预测?
这个问题和FCOS算法(参考博客:FCOS详解)中遇到的问题类似,在FCOS中当多个目标框区域重叠时,重叠部分的点的监督信息就有多个,但模型训练时监督信息肯定只能有一个,因为这种情况占比23%,影响较大,因此通过引入FPN网络解决。
CenterNet中的冲突是目标框的中心点重合(基于输出特征层计算的中心点),作者从COCO数据集的统计信息来看,这种重合框的比例非常少,不到0.1%,基本上不会对训练稳定产生太大影响,因此没有针对这个进行解决。
推理细节
论文中强调了在inference阶段不需要NMS操作做重复框去除的操作
- 假设测试输入是一张图像,默认配置下会先对图像做仿射变换,这一步重点在于将图像尺寸处理成512*512大小后作为网络的输入。
- 执行网络的前向计算将得到3个输出:1、[1,80,128,128]大小的heatmap,2、[1,2,128,128]大小的尺寸预测,3、[1,2,128,128]大小的offset预测。heatmap会经过一个sigmoid函数使得范围为0到1,符合heatmap的定义
- 接下来对heatmap执行一个最大池化操作,kernel设置为3,stride设置为1,pad设置为1,这一步其实是在做重复框过滤,这也是为什么后续不再需要NMS操作的一个重要原因,毕竟这里3✖️3大小的kernel加上特征图和输入图像之间的stride=4,相当于输入图像中每12✖️12大小的区域都不会有重复的中心点,想法非常简单有效!
- 然后再基于heatmap选择top K个得分最高的点(默认K=100),这样就确定了100个置信度最高的预测框的中心点位置了,这一步也会去掉一定的重复框。接下来就要确定预测框的大小了,通过输出的尺寸预测值和offset就可以得到。到目前位置,得到的预测框信息都是在128✖️128大小的特征图上,因此最后将预测框信息再映射到输入图像上就得到最终的预测结果了,显示预测结果时可以设定一个置信度阈值,高于阈值的才显示。