Python爬虫技术与应用:Python基本知识介绍
2.1 Python编程
2.1.1 Python的安装与环境配置
Python是一门计算机编程语言。相比于C语言及Java来说,Python更容易上手,同时也十分简单,易懂易用。很多大型网站,例如YouTube、Google等都在大量使用Python,各种常用的脚本任务用Python实现也十分容易,无须担心学非所用。
1.计算机编程语言这么多,为什么用Python来写网络爬虫呢?
(1)对比其他静态编程语言来说,如Java、C#、C++,Python抓取网页文档接口更加简洁;对比其他动态语言Perl、Shell,Python的urllib2包提供非常完整的访问网页文档API。抓住网页有时候需要模拟浏览器的行为,而Python具有很多第三方包,如requests、XPath等均提供此类支持。
(2)对于抓取之后的网页需要进行处理,如过滤标签、提取文本等。Python提供简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
(3)具有各种网络爬虫框架,可方便高效地下载网页。
(4)多线程、进程模型成熟稳定,网络爬虫是一个典型的多任务处理场景,请求页面时会有较长的延迟,总体来说更多的是等待。多线程或进程会更优化程序效率,提升整个系统的下载和分析能力。
2.Python的概念
百度百科解释Python是一种计算机程序设计语言,是一种面向对象的动态类型语言,最初被设计用于编辑自动化脚本(Shell),随着版本的不断更新和语言新功能的添加,Python被越来越多地用于独立的、大型项目的开发。
Python是有名的“龟叔”Guido van Rossum在1989年圣诞节期间,为打发无聊的圣诞节而编辑的一个编程语言。
Python能够提供十分完善的基础代码库,涵盖网络、文件、GUI、数据库、文本等大量内容,被形象地称作“内置电池”。用Python开发,很多功能没必要从零编辑,直接利用现有的即可。
除内置的库外,Python还有大量的第三方库,也就是别人开发的、供直接运用的工具。当然,假如开发的代码经由很好的封装,也能够作为第三方库给别人使用。
很多大型网站都是用Python开发的,例如YouTube、Instagram,还有国内的豆瓣网。很多大公司,包括Google、Yahoo等,乃至NASA(美国航空航天局)都大量地应用Python。
“龟叔”赋予Python的定位是“优雅”“明确”“简短易懂”,所以Python程序看上去总是简短易懂。初学者学习Python,不但初学容易,而且来日深入下去,能够编辑那些十分复杂的程序。
总的来说,Python的哲学便是简短、易懂、优雅,尽可能写出容易看明白的代码,尽可能写少的代码。
3.Python的应用领域
Python拥有很多免费数据函数库、免费Web网页模板系统和与Web服务器进行交互的库,能够实现Web开发,搭建Web框架,目前比较有名气的Python Web框架为Django。同样是解释型语言的JavaScript,在Web开发中的应用已经较为广泛,原因是其有一套完善的框架。但Python也有着特有的优势。例如,Python相比于JS、PHP在语言层面较为完好并且关于同一个开发需求能够提供多种方案,库的内容丰富,使用方便。从事该领域应从数据、组件、安全等多领域进行学习,从底层了解其工作原理并可支配任何业内主流的Web框架。
下面来介绍一下基于Python语言的Web开发中几种常见的Web开发框架。
1)Django
Django是一个常见的Python Web应用框架。它是开源的Web开发框架,包括多种组件,能够实现关系映射、动态内存管理、界面管理等功能。Django开发采用DRY原则,同时拥有独立的轻量级Web服务器,能快速开发Web应用。Django开发遵循MVC模式,包括模型、视图、控制三部分。模型层是应用程序底层,主要用于处理与数据有关的事件,如数据存取验证等。由于Django中用户输入控制模块是由框架处理的,因此也能够称为模板层。模板层用于展现数据,负责模板的存取和正确调用模板等业务。程序员使用模板语言来渲染HTML页面,给模板所需显示的信息,使用既定的模板来渲染结果。视图层组成应用程序的业务逻辑,负责在网页或类似类型的文档中展示数据。
2)CherryPy
CherryPy是基于Python的面向对象的HTTP框架,适合Python开发者。CherryPy本身内置Web服务器。CherryPy的用户无须搭设别的Web服务器,能直接在内置的服务器上运行应用程序。服务器一方面把底层TCP套接字传输的信息转换成HTTP请求,并传递给相应的处理程序;另一方面把上层软件传来的信息打包成HTTP响应,向下传递给底层的TCP套接字。
3)Flask
Flask适合开发轻量级的Web应用。它的服务器网关接口工具箱采用Werkzeug,模板引擎使用Jinja2。Flask使用BSD授权。Flask自身没有如表单验证和数据库抽象层等一些基本功能,而是依附第三方库来完成这些工作。Flask的结构是可扩展的,能够比较容易地为它添加一些需要的功能。
4)Pyramid
Pyramid是开源框架,执行效率高,开发周期短。Pyramid包含Python、Perl、Ruby的特性,拥有不依赖于平台的MVC架构,以及最快的启动开发的能力。
5)TurboGear
TurboGear创建在其框架基础上,它尝试把其框架优秀的部分集成到一起。它允许开发者从一个单文件服务开始开发,慢慢扩大为一个全栈服务。
4.数据分析与处理
通常情况下,Python被用来做数据分析。用C设计一些底层的算法进行封装,而后用Python进行调用。由于算法模块较为固定,所以用Python直接进行调用,方便且灵活,能够根据数据分析与统计的需要灵活使用。Python也是一个比较完善的数据分析生态系统,其中,matplotlib常常会被用来绘制数据图表,它是一个2D绘图工具,有着杰出的跨平台交互特性,日常做描述统计用到的直方图、散点图、条形图等都会用到它,几行代码便可出图。平常看到的K线图、月线图也可用matplotlib绘制。假如在证券行业做数据分析,Python是必不可少的。
随着大数据和人工智能时代的到来,网络和信息技术开始渗透到人类日常生活的方方面面,产生的数据量也呈现指数级增长的态势,同时现有数据的量级已经远远超过目前人力所能处理的范畴。在此背景下,数据分析成为数据科学领域中一个全新的研究课题。在数据分析的程序语言选择上,由于Python语言在数据分析和处理方面的优势,大量的数据科学领域的从业者使用Python来进行数据科学相关的研究工作。
数据分析是指用合适的分析方法对收集来的大量数据进行分析,提取实用信息和构成结论,对数据加以具体钻研和归纳总结的过程。随着信息技术的高速发展,企业的生产、收集、存储数据的能力大大提升,同时数据量也与日俱增。把这些繁杂的数据经由数据分析方法进行提炼,以此研究出数据的发展规律和展望趋向走向,进而帮助企业管理层做出决策。
数据分析是一种解决问题的过程和方法,主要的步骤有需求分析、数据获得、数据预处理、分析建模、模型评价与优化、部署。下面分别介绍每个步骤。
1)需求分析
数据分析中的需求分析是数据分析环节中的第一步,也是十分重要的一步,决定后续的分析方法和方向。主要内容是根据业务、生产和财务等部门的需要,结合现有的数据情况,提出数据分析需求的整体分析方向、分析内容,最终和需求方达成一致。
2)数据获得
数据获得是数据分析工作的基础,是指按照需求分析的结果提取、收集数据。数据获得主要有两种方式:网络爬虫获得和本地获得。网络爬虫获得是指经由网络爬虫程序合法获得互联网中的各种文字、语音、图片和视频等信息;本地获得是指经由计算机工具获得存储在本地数据库中的生产、营销和财务等系统的历史数据和实时数据。
3)数据预处理
数据预处理是指对数据进行数据合并、数据清洗、数据标准化和数据变换,并直接用于分析建模的这一过程的总称。其中,数据合并能够把多张互相关联的表格合并为一张;数据清洗能够去掉重复、缺失、异常、不一致的数据;数据标准化能够去除特征间的量纲差异;数据交换则能够经由离散化、哑变量处理等技术满足后期分析与建模的数据要求。在数据分析过程中,数据预处理的各个过程互相交叉,并没有固定的先后顺序。
4)分析建模
分析建模是指经由对比分析、分组分析、交叉分析、回归分析等分析方法,以及聚类模型、分类模型、关联规则、智能推荐等模型和算法,发现数据中的有价值信息,并得出结论的过程。
5)模型评价与优化
模型评价是指对于已经创建的一个或多个模型,根据其模型的类型,使用不同的指标评价其性能好坏的过程。模型的优化则是指模型性能在经由模型评价后已经达到要求,但在实际生产环境应用过程中,发现模型的性能并不理想,继而对模型进行重构与优化的过程。
6)部署
部署是指把数据分析结果与结论应用至实际生产系统的过程。根据需求的不同,部署阶段可以是一份包含现状具体整改措施的数据分析报告,也可以是把模型部署在整个生产系统的解决方案。在多数项目中,数据分析员提供的是一份数据分析报告或者一套解决方案,实际执行与部署的是需求方。
Python是一门应用十分广泛的计算机语言,在数据科学领域具有无可比拟的优势。Python正在逐步成为数据科学领域的主流语言。Python数据分析具备以下几方面优势:
(1)语法简短、易懂、精练。对于初学者来说,比起其他编程语言,Python更容易上手。
(2)有很多功能强大的库。结合在编程方面的强大实力,只使用Python这一种语言就能够去构建以数据为中心的应用程序。
(3)不单适用于研究和构建原型,同时也适用于构建生产系统。研究人员和工程技术人员使用同一种编程工具,能给企业带来明显的组织效益,并降低企业的运营成本。
(4)Python程序能够以多种方式轻易地与其语言的组件“粘接”在一起。例如,Python的C语言API能够帮助Python程序灵活地调用C程序,这意味着用户能够根据需要给Python程序添加功能,或者直接使用Python语言,不要调用API接口。
(5)Python是一个混合体,丰富的工具集使它介于系统的脚本语言和系统语言之间。Python不但具备全部脚本语言简短易懂和易用的特点,还拥有编译语言所具有的高级软件工程工具。
Python具有IPython、NumPy、SciPy、Pandas、Matplotlib、Scikit-learn和Spyder等功能齐全、接口统一的库,能为数据分析工作提供极大的便利。
5.人工智能应用
人工智能的核心算法是完全依赖于C/C++的,由于是计算密集型,因此需要十分致密的优化,还需要GPU、专用硬件之类的接口,这些都只有C/C++能做到。所以在某种意义上,其实C/C++才是人工智能领域最主要的语言。Python是这些库的API Binding,使用Python是因为C-Python的胶水语言特性,要开发一个其语言到C/C++的跨语言接口用Python是最容易的,比其语言门槛要低不少,尤其是使用C-Python的时候。
说到AI,Python已经逐步成为一些AI算法的一部分,从最开始的简短易懂的双人游戏到后来复杂的数据工程任务。Python的AI库在现今的软件中充当着不可取代的角色,包括NLYK、PyBrain、OpenCV和AIMA,一些AI软件功能,短短的一个代码块就足够。再看人脸识别技术、会话接口等领域,Python正在一步步覆盖更多新领域。可以说,Python未来的潜力是不可估量的。
在人工智能的应用方面,例如在神经网络、深度学习方面,Python都能够找到比较成熟的包来加以调用。并且Python是面向对象的动态语言,且适用于科学计算,这就使得Python在人工智能方面颇受喜爱。虽然人工智能程序不限于Python,但仍然为Python提供大量的API,这也正是由于Python当中包含着较多的适用于人工智能的模块,如sklearn模块等。调用方便、科学计算功能强大依旧是Python在AI领域最强大的竞争力。
2.1.2 PyCharm的安装与使用
PyCharm是一种Python IDE,带有一整套能够帮助用户在使用Python语言开发时提高效率的工具,如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。另外,该IDE能够提供一些高级功能,以用于支持Django框架下的专业Web开发。
1.下载PyCharm安装包
首先要下载PyCharm的安装包,下载地址为https://www.jetbrains.com/pycharm/download/#section=linux,PyCharm官网如图2-9所示。
2.把该文件移动到python文件夹中解压并赋予权限
#进入安装目录
cd /usr/local/python3
#解压安装文件
tar -zxvf pycharm-professional-2021.3.1.tar.gz
#权限设置
chmod -R 777 /usr/local/python3/pycharm-2021.3.1
3.安装前修改hosts文件
#在终端设备中输入命令
vi /etc/hosts
#在打开的文件中加入下面的代码
0.0.0.0 account.jetbrains.com
配置hosts如图2-10所示。
4.进入PyCharm下的bin目录中,执行sh命令开始安装
#安装命令
cd /usr/local/python3/pycharm-2021.3.1/bin
export DISPLAY=localhost:0.0
sh ./pycharm.sh
在弹出的窗口中单击OK按钮。之后弹出PyCharm Privary Policy Agreement对话框,即隐私政策协议,直接单击Continue按钮同意。在弹出的发送请求中,单击发送统计信息。选择风格,单击Next:Featuredplugins,再单击StartusingPyCharm。
5.搭建Python解释器
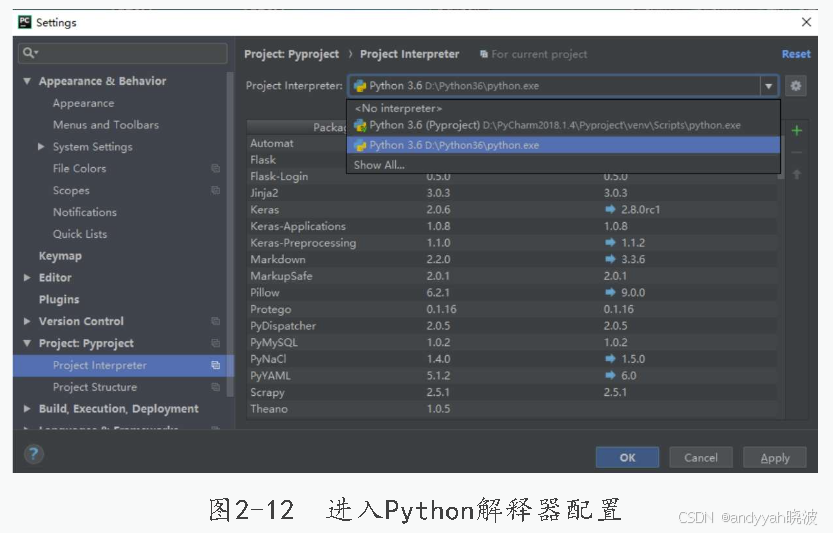
打开设置界面,配置PyCharm如图2-11所示。
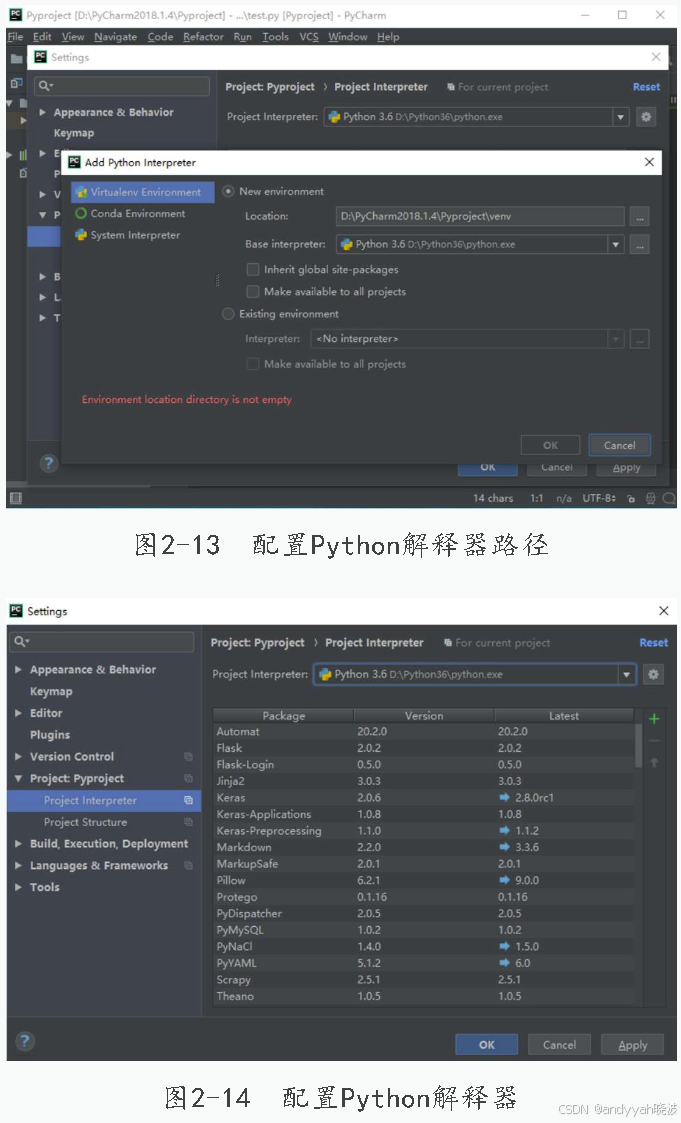
搭建Python解释器,选择Python的安装路径后单击OK按钮确定,进入Python解释器配置,如图2-12所示,配置Python解释器路径如图2-13所示。
6.创建项目与文件
打开PyCharm软件,单击创建新项目,选择存放的项目路径及名称后,选择建好的Python环境,配置Python解释器如图2-14所示。
新建Python文件,右击项目名,选择New→Python-File,输入代码。第一次运行右击编辑区域,单击Run命令,以后可直接单击右上角或者左下角的绿三角按钮,在PyCharm软件中运行Python如图2-15所示。
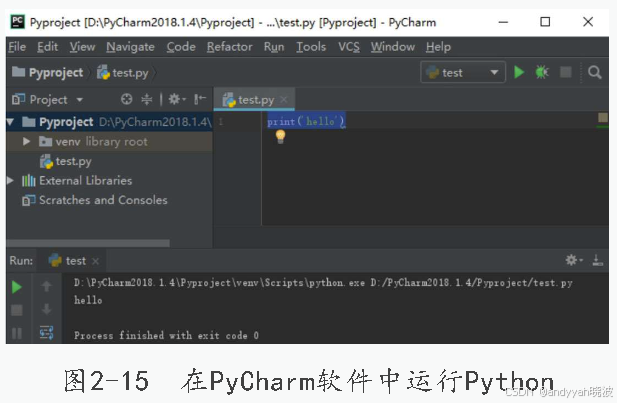
到这里,Linux系统的PyCharm就已经安装完成,Windows系统下的PyCharm安装方法与此类似,不同是路径的选择及host文件部分。
2.2 HTML基本原理
2.2.1 HTML简介
1.HTML解释
(1)HTML是指超文本标记语言(Hyper Text Markup Language)。
(2)HTML不是一种编程语言,而是一种标记语言(Markup Language)。(3)标记语言是一套标记标签(Markup Tag)。
(4)HTML使用标记标签来描述网页。
2.HTML标签
(1)HTML标签是由尖括号包围的关键词,如。
(2)HTML标签通常是成对出现的,如和。
(3)标签对中的第一个标签是开始标签,第二个标签是结束标签。
(4)开始标签和结束标签也被称为开放标签和闭合标签。
3.HTML文档=网页
(1)HTML的基本原理是HTML文档描述网页。
(2)HTML文档包含HTML标签和纯文本。
(3)HTML文档也被称为网页。
2.2.2 HTML的基本原理
1.HTML
HTML是超文本标记语言,不需要编译,直接经由浏览器执行,例如如下代码:
<input type= "text" name= "jake" />
2.基本作用
(1)能够编辑静态网页,在网页显示图片、文字、声音、表格、链接。
(2)静态网页html只能够写成静态网页html。
(3)动态网页是能够交互的,而不是动画。
HTML发展史如图2-16所示。
2.3 基本库的使用
2.3.1 urllib库
在Python 3中,urllib和urllib2进行归并,目前只有一个urllib模块,urllib和urllib2中的内容整合进urllib.request,urlparse整合进urllib.parse。
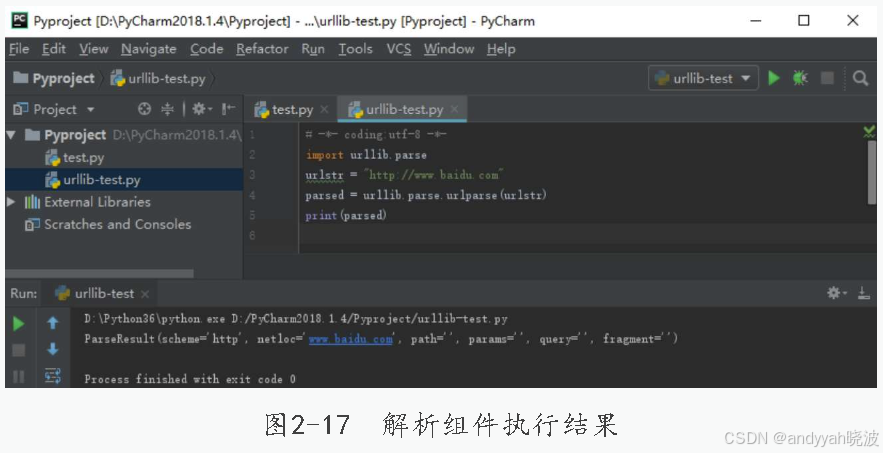
(1)urlparse把urlstr解析成各个组件,代码如下:
#-*- coding:utf-8 -*-
import urllib.request
import urllib.parse
urlstr = "http://www.baidu.com"
parsed = urllib.parse.urlparse(urlstr)
print(parsed)
解析组件执行结果如图2-17所示。
(2)urljoin把URL的根域名和新URL拼合成一个完整的URL,代码如下:
import urllib.parse
url = "http://www.baidu.com"
new_path = urllib.parse.urljoin(url,"index.html")
print(new_path)
(3)urlopen打开一个URL的方法,返回一个文件对象,而后能够进行类似文件对象的操作,代码如下:
import urllib.request
req = urllib.request.urlopen('http://www.baidu.com')
print(req.read())
2.3.2 requests库
requests库基于urllib,且比urllib更加方便,是Python更加简短易懂的http库。以下是使用requests库的一个例子:
import requests
response = requests.get('http://www.baidu.com')
print(type(response)) #返回值的类型
print(response.status_code) #当前网站返回的状态码
print(type(response.text)) #网页内容的类型
print(response.text) #网页的具体内容(html代码)
print(response.cookies) #网页的Cookie
requests中输出网页的HTML代码的方法是response方法,它相当于urllib库的response.read方法,只不过不需要进行decode操作。打印Cookie的操作也比urllib简短易懂,只需要使用Cookie方法便可,各种请求方式代码如下:
import requests
requests.post('http://httpbin.org/post')
requests.delete('http://httpbin.org/delete')
requests.put('http://httpbin.org/put')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.org/get')
2.3.3 re库
1.match()方法
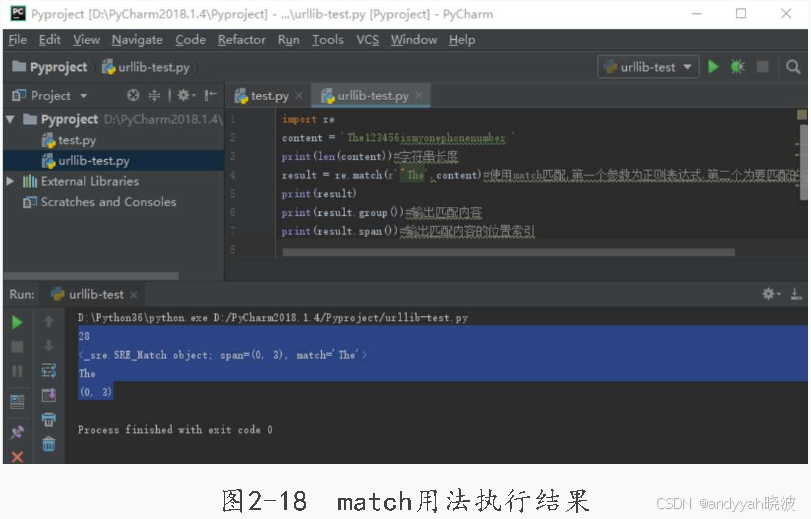
从字符串头部开始匹配,代码如下:
import re
content = 'The123456ismyonephonenumber.'
print(len(content)) #字符串长度
result = re.match(r'^The',content)
#使用match匹配,第一个参数为正则表达式,第二个为要匹配的字符串
print(result)
print(result.group()) #输出匹配内容
print(result.span()) #输出匹配内容的位置索引
match用法执行结果如图2-18所示。
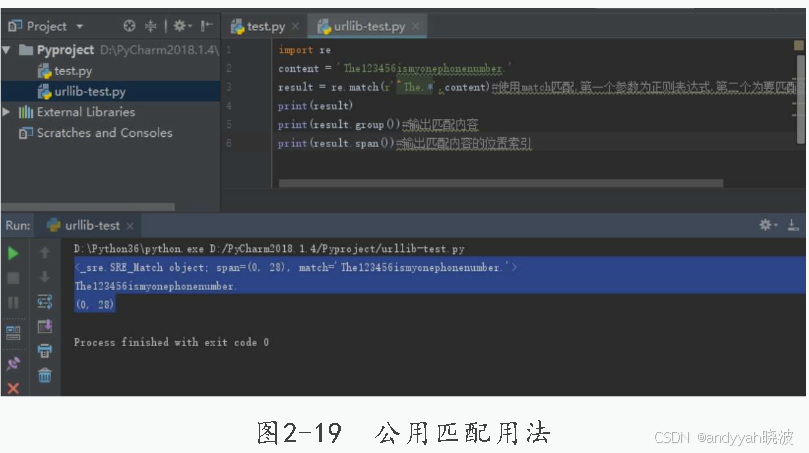
2.公用匹配
import re
content = 'The123456ismyonephonenumber.'
result = re.match(r'^The.*',content)
print(result)
print(result.group()) #输出匹配内容
print(result.span()) #输出匹配内容的位置索引
公用匹配用法如图2-19所示。
3.search()方法
与match()方法不同,search()方法不需要从头部开始匹配,代码如下:
import re
content = 'OtherThe123456ismyonephonenumber.'
result = re.search('The.*?(\d+).*?number.',content)
print(result.group())
4.findall()方法
match()方法和search()方法都是返回匹配到的第一个内容就结束匹配,findall()方法是返回全部符合匹配规则的内容,返回的是一个列表,代码如下:
import re
text = 'pyypppyyyypppp'
pattern = 'py'
for match in re.findall(pattern, text):
print('Found {!r}'.format(match))
5.sub()方法
去除或替换匹配的字符。假如写sub(‘\d+’,‘-’),则把匹配的内容替换成’-',例子如下:
import re
content='54abc59de335f7778888g'
content=re.sub('\d+','',content)
print(content)
2.4 实战案例:百度新闻的抓取
1.获得URL
打开百度,单击左上角的新闻,百度新闻如图2-20所示。
2.元素审查
在打开的界面按下F12键或右击选择“检查”选项,选择所要抓取的新闻,能够看到的URL地址为:http://news.baidu.com/,百度新闻域名如图2-21所示。

3.导入模块
导入urllib和re两个模块,代码如下
import urllib.request
import re
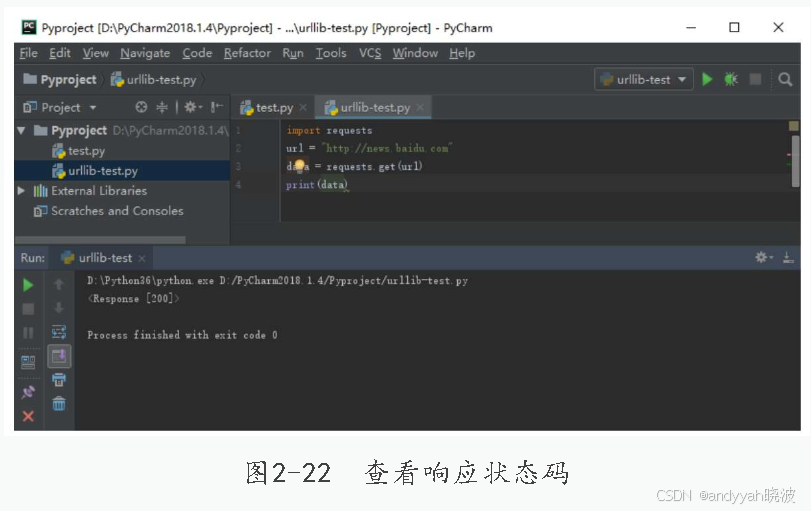
4.请求http页面,响应状态
首先确认URL地址后向网站发送请求,查看响应状态码如图2-22所示。
import requests
url = "http://news.baidu.com"
data = requests.get(url)
print(data)
requests.get发送地址,尝试获得URL地址的响应状态后输出响应状态码,返回的值为200,该类型状态码表示动作被成功接收、理解和接受。
5.抓取百度新闻
在进行模块与库的添加时,要注意Python库及模块是否已存在,模块分别是re、urllib.request及datetime。
6.寻找数据特征
打开百度新闻,网址URL为http://news.baidu.com/,打开网页,按住F12键显示开发者工具,浏览器开发者工具如图2-23所示。

7.查看HTML信息
需要抓取的是这个页面每一条新闻的标题,右击一条新闻的标题,选择“查看”选项,出现图2-24所示的窗口,则图片中红框的位置便是那一条新闻标题在HTML中的结构、位置和表现。
8.分析网页源代码
从上一步骤中,经由对网页的源代码来进行分析,小标题都位于
的标签下面,这时候就可以使用正则的惰性匹配(.*?)来进行对标题的匹配,抓取标题的正则写法如图2-25所示。

9.准备抓取数据
在把准备工作完成后,开始抓取页面中的数据,整体代码展示如图2-26所示。
10.抓取结果展示如图2-27所示。
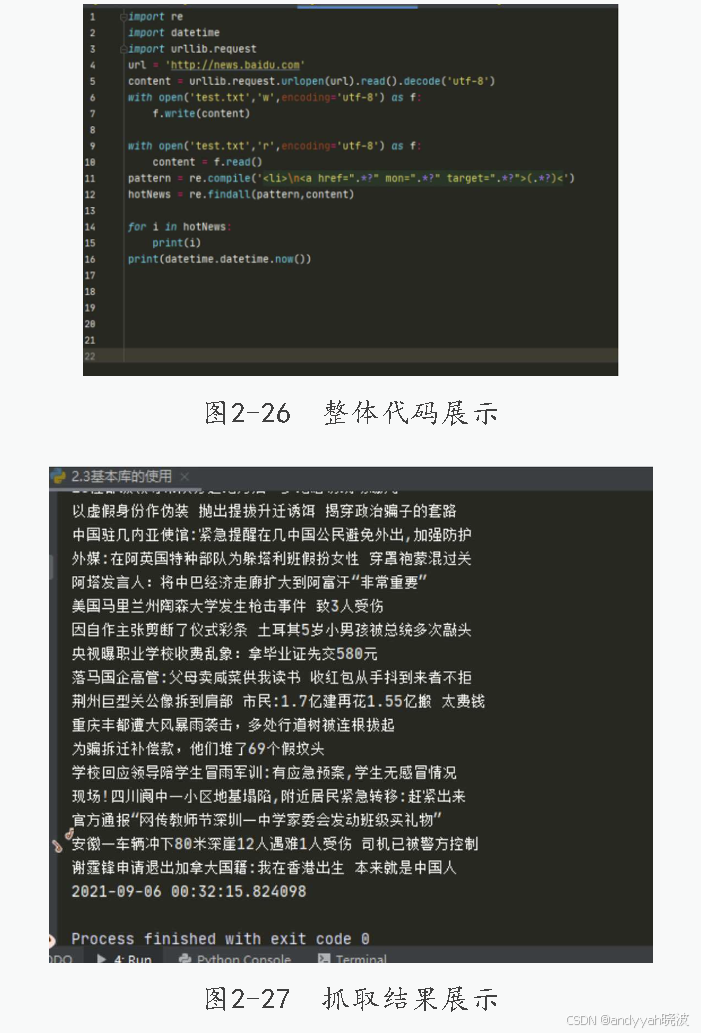
11.设置时间点
在图2-27中能够看到抓取的内容,在最后一行显示着当前系统的时间,在实际环境中进行抓取的内容可能不止图2-27中的这一小部分,而数据内容过多会导致在处理数据时遇到一些问题,所以需要(或可以)在代码中添加一个时间戳。代码如下:
#使用到先前所添加的一个模块
import datetime
在代码的最后一行添加如下代码,这样在每次抓取完后,当前的系统时间会自动标记在后方。
print(datetine.datetime.now())
