三维重建介绍
三维重建是指根据基于一个视图或者多个视图所获得的物体或者场景的图像重建三维模型的过程。由于单视图的信息很单一,因此三维重建需要更复杂的算法和过程。相比之下,多视图的三维重建(模仿人类观察世界的方式)就比较容易实现,其方法是先对摄像机进行标定,即计算出摄像机的图像坐标系与世界坐标系的关系.然后利用多个二维图像中的信息重建出三维信息
1.根据摄像机(图片)数目划分:
对于基于图像的三维重建,主要有单目视觉法、双目视觉法、多目视觉法。
基于图像的三维重建是从若干幅图片计算提取出场景和物体的三维深度信息,根据获取的三维深度信息,重构出具备很强真实感的物体或者场景的三维模型的方法。
2.单幅图像的三维重建
目前,基于单幅图像三维重建最广泛和最实用的方法利用几何投影的原理进行重建。每一幅图像中含有的大量平行线、平行面、垂直线、垂直面、消失点、消失线等多种几何属性的约束,利用图像的这些几何约束进行摄像机标定或平面标定。进而估算出摄像机的内部各种参数、摄像机的焦距; 然后通过测量目标的几何形状或计算目标高度来估算出必需的深度信息; 最后利用几何投影知识等对图像进行数字化的表述,构建数字化的三维模型,将得到的模型绘制出来,这就是整个的基于单幅图像的三维重建过程。
3.立体视觉的三维重建
立体视觉的基本原理是从两个或者多个视点观察同一景物,已获得在多个不同的视角下对景物的多张感知图像,运用三角测量的基本原理计算图像像素间位置偏差,获得景物的三维深度信息,这一个过程与人类观察外面的世界的过程是一样的。要建立完整的一个双目立体视觉系统通常大致需要经过6个步骤,分别是获得图像、标定摄像机、提取特征、立体匹配、模型重建等
4.深度图像三维重建
一般的通过激光扫描仪进行一次扫描得到的是一组二维有序的点阵,其中每一点包含了相应的场景上被扫描点的距离信息,这个点阵被称为深度图像。为了获得完整的场景,往往需要从几个不同的位置对目标场景进行扫描而得到的不同的深度图像则需要匹配到一个坐标系下。通过深度图像获得场景的数据,对点云数据进行基于平面的分割,提取平面特征实现三维场景的重
本文主要学习基于双目的立体视觉三维重建。
SfM介绍
SfM的全称为Structure from Motion,即通过相机的移动来确定目标的空间和几何关系,是三维重建的一种常见方法。它与Kinect这种3D摄像头最大的不同在于,它只需要普通的RGB摄像头即可,因此成本更低廉,且受环境约束较小,在室内和室外均能使用。但是,SfM背后需要复杂的理论和算法做支持,在精度和速度上都还有待提高,所以目前成熟的商业应用并不多。
本系列介绍SfM中的基本原理与算法,借助OpenCV实现一个简易的SfM系统。
极线约束与本征矩阵
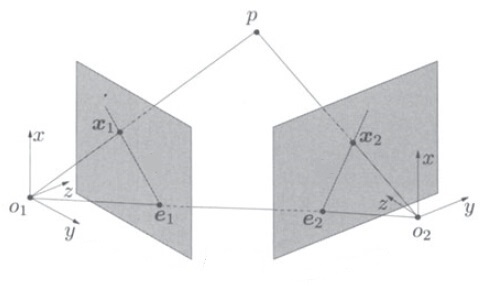
在三维重建前,我们先研究一下同一点在两个相机中的像的关系。假设在世界坐标系中有一点
p
,坐标为
X
,它在1相机中的像为
x1
,在2相机中的像为
x2
(注意
x1
和
x2
为齐次坐标,最后一个元素是1),如下图。
设
X
到两个相机像面的垂直距离分别为
s1
和
s2
,且这两个相机具有相同的内参矩阵
K
,与世界坐标系之间的变换关系分别为
[R1 T1]
和
[R2 T2]
,那么我们可以得到下面两个等式
由于K是可逆矩阵,两式坐乘K的逆,有
设 K−1x1=x′1 , K−1x2=x′2 ,则有
我们一般称 x′1 和 x′2 为归一化后的像坐标,它们和图像的大小没有关系,且原点位于图像中心。
由于世界坐标系可以任意选择,我们将世界坐标系选为第一个相机的相机坐标系,这时 R1=I, T1=0 。上式则变为
将第一式带入第二式,有
x′2 和 T2 都是三维向量,它们做外积(叉积)之后得到另外一个三维向量 T2ˆx′2 (其中 T2ˆ 为外积的矩阵形式, T2ˆx′2 代表 T2×x′2 ),且该向量垂直于 x′2 和 T2 ,再用该向量对等式两边做内积,有
即
令 E=T2ˆR2 有
可以看出,上式是同一点在两个相机中的像所满足的关系,它和点的空间坐标、点到相机的距离均没有关系,我们称之为极线约束,而矩阵 E 则称为关于这两个相机的本征矩阵。如果我们知道两幅图像中的多个对应点(至少5对),则可以通过上式解出矩阵 E ,又由于 E 是由 T2 和 R2 构成的,可以从E中分解出 T2 和 R2 。
如何从 E 中分解出两个相机的相对变换关系(即 T2 和 R2 ),背后的数学原理比较复杂,好在OpenCV为我们提供了这样的方法,在此就不谈原理了。
特征点提取与匹配
从上面的分析可知,要求取两个相机的相对关系,需要两幅图像中的对应点,这就变成的特征点的提取和匹配问题。对于图像差别较大的情况,推荐使用SIFT特征,因为SIFT对旋转、尺度、透视都有较好的鲁棒性。如果差别不大,可以考虑其他更快速的特征,比如SURF、ORB等。
本文中使用SIFT特征,由于OpenCV3.0将SIFT包含在了扩展部分中,所以官网上下载的版本是没有SIFT的,为此需要到https://github.com/itseez/opencv_contrib/下载扩展包opencv_contrib,并按照里面的说明重新编译OpenCV。如果使用其他特征,就不必做这一步。
编译opencv的时候要通过cmake -DOPENCV_EXTRA_MODULES_PATH将opencv_contrib的module编译进来,一定要保持两者的版本一致,opencv链接:https://github.com/opencv/opencv.git pull到最近即可成功cmake
下面的代码负责提取图像特征,并进行匹配。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
需要重点说明的是,匹配结果往往有很多误匹配,为了排除这些错误,这里使用了Ratio Test方法,即使用KNN算法寻找与该特征最匹配的2个特征,若第一个特征的匹配距离与第二个特征的匹配距离之比小于某一阈值,就接受该匹配,否则视为误匹配。当然,也可以使用Cross Test(交叉验证)方法来排除错误。
得到匹配点后,就可以使用OpenCV3.0中新加入的函数findEssentialMat()来求取本征矩阵了。得到本征矩阵后,再使用另一个函数对本征矩阵进行分解,并返回两相机之间的相对变换R和T。注意这里的T是在第二个相机的坐标系下表示的,也就是说,其方向从第二个相机指向第一个相机(即世界坐标系所在的相机),且它的长度等于1。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
三维重建
现在已经知道了两个相机之间的变换矩阵,还有每一对匹配点的坐标。三维重建就是通过这些已知信息还原匹配点在空间当中的坐标。在前面的推导中,我们有
这个等式中有两个未知量,分别是 s2 和 X 。用 x2 对等式两边做外积,可以消去 s2 ,得
整理一下可以得到一个关于空间坐标X的线性方程
上面的方程不能直接取逆求解,因此化为其次方程
用SVD求X左边矩阵的零空间,再将最后一个元素归一化到1,即可求得X。其几何意义相当于分别从两个相机的光心作过 x1 和 x2 的延长线,延长线的焦点即为方程的解,如文章最上方的图所示。由于这种方法和三角测距类似,因此这种重建方式也被称为 三角法(triangulate)。OpenCV提供了该方法,可以直接使用。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
测试
我用了下面两幅图像进行测试

得到了着色后的稀疏点云,是否能看出一点轮廓呢?!


图片中的两个彩色坐标系分别代表两个相机的位置。
在接下来的文章中,会将相机的个数推广到任意多个,成为一个真正的SfM系统