这篇博客将会记录Structured Streaming + Kafka的一些基本使用(Java 版)
spark 2.3.0
1. 概述
Structured Streaming (结构化流)是一种基于 Spark SQL 引擎构建的可扩展且容错的 stream processing engine (流处理引擎)。可以使用Dataset/DataFrame API 来表示 streaming aggregations (流聚合), event-time windows (事件时间窗口), stream-to-batch joins (流到批处理连接) 等。
Dataset/DataFrame在同一个 optimized Spark SQL engine (优化的 Spark SQL 引擎)上执行计算后,系统通过 checkpointing (检查点) 和 Write Ahead Logs (预写日志)来确保 end-to-end exactly-once (端到端的完全一次性) 容错保证。
简而言之,Structured Streaming 提供快速,可扩展,容错,end-to-end exactly-once stream processing (端到端的完全一次性流处理),且无需用户理解 streaming 。
具体原理可以看之前的这篇博客
2. 数据源
对于Kafka数据源我们需要在Maven/SBT项目中引入:
groupId = org.apache.spark
artifactId = spark-sql-kafka-0-10_2.11
version = 2.3.2
首先我们需要创建SparkSession及开始接收数据,这里以Kafka数据为例
SparkSession spark = SparkSession
.builder()
.appName("appName")
.getOrCreate();
Dataset<Row> df = spark.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic.*")
.load();
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
这里我们创建了SparkSession并订阅了几个host的Kafka。
这里我们不需要自己设置group.id参数, Kafka Source 会将自动为每个查询创建一个唯一的 group id
Kafka源数据中的schema如下:
| Column | Type |
|---|---|
| key | binary |
| value | binary |
| topic | string |
| partition | int |
| offset | long |
| timestamp | long |
| timestampType | int |
对于批处理和流查询,须为 Kafka source 设置以下选项。
| Option | value | meaning |
|---|---|---|
| assign | json string {“topicA”:[0,1],“topicB”:[2,4]} | 指定 TopicPartitions 来消费。针对 Kafka Source 只能指定 “assign”, “subscribe” 或 “subscribePattern” 其中的一个选项。 |
| subscribe | 逗号分隔的 topics 列表 | 要订阅的 topic 列表。针对 Kafka Source 只能指定 “assign”, “subscribe” 或 “subscribePattern” 其中的一个选项 |
| subscribePattern | Java regex string | 用于订阅 topic(s) 的 pattern(模式)。针对 Kafka Source 只能指定 “assign”, “subscribe” 或 “subscribePattern” 其中的一个选项。 |
| kafka.bootstrap.servers | 逗号分隔的 host:port 列表 | Kafka 中的 “bootstrap.servers” 配置。 |
以下配置是可选的:
| Option | value | default | query type | meaning |
|---|---|---|---|---|
| startingOffsets | “earliest”, “latest” (streaming only), or json string “”" {“topicA”:{“0”:23,“1”:-1},“topicB”:{“0”:-2}} “”" | “latest” 用于 streaming, “earliest” 用于 batch(批处理) | streaming 和 batch | 当一个查询开始的时候, 或者从最早的偏移量:“earliest”,或者从最新的偏移量:“latest”,或JSON字符串指定为每个topicpartition起始偏移。在json中,-2作为偏移量可以用来表示最早的,-1到最新的。注意:对于批处理查询,不允许使用最新的查询(隐式或在json中使用-1)。对于流查询,这只适用于启动一个新查询时,并且恢复总是从查询的位置开始,在查询期间新发现的分区将会尽早开始。 |
| endingOffsets | latest or json string {“topicA”:{“0”:23,“1”:-1},“topicB”:{“0”:-1}} | latest | batch query | 当一个批处理查询结束时,或者从最新的偏移量:“latest”, 或者为每个topic分区指定一个结束偏移的json字符串。在json中,-1作为偏移量可以用于引用最新的,而-2(最早)是不允许的偏移量。 |
| failOnDataLoss | true or false | true | streaming query | 当数据丢失的时候,这是一个失败的查询。(如:主题被删除,或偏移量超出范围。)这可能是一个错误的警报。当它不像你预期的那样工作时,你可以禁用它。如果由于数据丢失而不能从提供的偏移量中读取任何数据,批处理查询总是会失败。 |
| kafkaConsumer.pollTimeoutMs | long | 512 | streaming and batch | 在执行器中从卡夫卡轮询执行数据,以毫秒为超时间隔单位。 |
| fetchOffset.numRetries | int | 3 | streaming and batch | 放弃获取卡夫卡偏移值之前重试的次数。 |
| fetchOffset.retryIntervalMs | long | 10 | streaming and batch | 在重新尝试取回Kafka偏移量之前等待毫秒值。 |
| maxOffsetsPerTrigger | long | none | streaming and batch | 对每个触发器间隔处理的偏移量的最大数量的速率限制。偏移量的指定总数将按比例在不同卷的topic分区上进行分割。 |
注意下面的参数是不能被设置的,否则kafka会抛出异常:
group.idkafka的source会在每次query的时候自定创建唯一的group idauto.offset.reset为了避免每次手动设置startingoffsets的值,structured streaming在内部消费时会自动管理offset。这样就能保证订阅动态的topic时不会丢失数据。startingOffsets在流处理时,只会作用于第一次启动时,之后的处理都会自定的读取保存的offset。key.deserializer,value.deserializer,key.serializer,value.serializer 序列化与反序列化,都是ByteArraySerializerenable.auto.commitkafka的source不会提交任何的offsetinterceptor.classes由于kafka source读取数据都是二进制的数组,因此不能使用任何拦截器进行处理。
3. 解析数据
对于Kafka发送过来的是JSON格式的数据,我们可以使用functions里面的from_json()函数解析,并选择我们所需要的列,并做相对的transformation处理。
注意在这里不能有Action操作,如foreach(),这些操作需在后面StreamingQuery中使用
Dataset<Row> tboxDataSet = rawDataset
.where("topic = my_topic")
.select(functions.from_json(functions.col("value").cast("string"), tboxScheme).alias("parsed_value"))
.select("parsed_value.columnA",
"parsed_value.columnB",
"parsed_value.columnC",
"timestamp");
最后一行我们选择了timestamp时间戳,以供后面时间窗口聚合使用。
4. 时间窗口
如果我们要使用groupby()函数对某个时间段所有的数据进行处理,我们则需要使用时间窗口函数如下:
Dataset<Row> windowtboxDataSet = tboxDataSet
.withWatermark("timestamp", "5 seconds")
.groupBy(functions.window(functions.col("timestamp"), "10 minutes", "5 minutes"),
functions.col("columnA"))
.count();
这里对columnA列进行groupby()+count()计数,详解如下:
4.1 简易例子
为了理解时间窗口,举一个官方例子:
ataset<Row> words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
Dataset<Row> windowedCounts = words
.withWatermark("timestamp", "10 minutes")
.groupBy(
functions.window(words.col("timestamp"), "10 minutes", "5 minutes"),
words.col("word"))
.count();
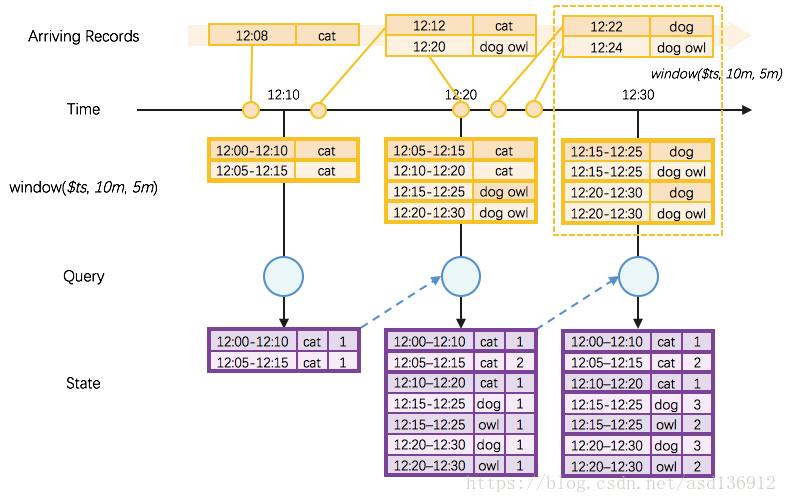
- 我们有一系列 arriving 的 records
- 首先是一个对着时间列timestamp做长度为10m,滑动为5m的window()操作
- 例如上图右上角的虚框部分,当达到一条记录
12:22|dog时,会将12:22归入两个窗口12:15-12:25、12:20-12:30,所以产生两条记录:12:15-12:25|dog、12:20-12:30|dog,对于记录12:24|dog owl同理产生两条记录:12:15-12:25|dog owl、12:20-12:30|dog owl - 所以这里 window() 操作的本质是 explode(),可由一条数据产生多条数据
- 例如上图右上角的虚框部分,当达到一条记录
- 然后对window()操作的结果,以window列和 word列为 key,做groupBy().count()操作
- 这个操作的聚合过程是增量的(借助 StateStore)
- 最后得到一个有
window,word,count三列的状态集
4.2 OutputModes
我们继续来看前面 window() + groupBy().count() 的例子,现在我们考虑将结果输出,即考虑 OutputModes:
4.2.1 Complete
Complete 的输出是和 State 是完全一致的:

4.2.2 Append
Append 的语义将保证,一旦输出了某条 key,未来就不会再输出同一个 key。

所以,在上图 12:10 这个批次直接输出 12:00-12:10|cat|1, 12:05-12:15|cat|1 将是错误的,因为在 12:20 将结果更新为了 12:00-12:10|cat|2,但是 Append 模式下却不会再次输出 12:00-12:10|cat|2,因为前面输出过了同一条 key 12:00-12:10|cat 的结果12:00-12:10|cat|1。
为了解决这个问题,在 Append 模式下,Structured Streaming 需要知道,某一条 key 的结果什么时候不会再更新了。当确认结果不会再更新的时候(下一篇文章专门详解依靠 watermark 确认结果不再更新),就可以将结果进行输出。

如上图所示,如果我们确定 12:30 这个批次以后不会再有对 12:00-12:10 这个 window 的更新,那么我们就可以把 12:00-12:10 的结果在 12:30 这个批次输出,并且也会保证后面的批次不会再输出 12:00-12:10 的 window 的结果,维护了 Append 模式的语义。
4.2.3 Update
Update 模式已在 Spark 2.1.1 及以后版本获得正式支持。

如上图所示,在 Update 模式中,只有本执行批次 State 中被更新了的条目会被输出:
- 在 12:10 这个执行批次,State 中全部 2 条都是新增的(因而也都是被更新了的),所以输出全部 2 条;
- 在 12:20 这个执行批次,State 中 2 条是被更新了的、 4 条都是新增的(因而也都是被更新了的),所以输出全部 6 条;
- 在 12:30 这个执行批次,State 中 4 条是被更新了的,所以输出 4 条。这些需要特别注意的一点是,如 Append 模式一样,本执行批次中由于(通过 watermark 机制)确认
12:00-12:10这个 window 不会再被更新,因而将其从 State 中去除,但没有因此产生输出。
4.3 Watermark 机制
对上面这个例子泛化一点,是:
- (a+) 在对 event time 做 window() + groupBy().aggregation() 即利用状态做跨执行批次的聚合,并且
- (b+) 输出模式为 Append 模式或 Update 模式
时,Structured Streaming 将依靠 watermark 机制来限制状态存储的无限增长、并(对 Append 模式)尽早输出不再变更的结果。
换一个角度,如果既不是 Append 也不是 Update 模式,或者是 Append 或 Update 模式、但不需状态做跨执行批次的聚合时,则不需要启用 watermark 机制。
具体的,我们启用 watermark 机制的方式是:
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words
.withWatermark("timestamp", "10 minutes") // 注意这里的 watermark 设置!
.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word")
.count()
这样即告诉 Structured Streaming,以 timestamp 列的最大值为锚点,往前推 10min 以前的数据不会再收到。这个值 —— 当前的最大 timestamp 再减掉 10min —— 这个随着 timestamp 不断更新的 Long 值,就是 watermark。
所以,在之前的这里图示中:
- 在
12:20这个批次结束后,锚点变成了12:20|dog owl这条记录的 event time12:20,watermark 变成了12:20 - 10min = 12:10; - 所以,在
12:30批次结束时,即知道 event time12:10以前的数据不再收到了,因而 window12:00-12:10的结果也不会再被更新,即可以安全地输出结果12:00-12:10|cat|2; - 在结果
12:00-12:10|cat|2输出以后,State 中也不再保存 window12:00-12:10的相关信息 —— 也即 State Store 中的此条状态得到了清理。
5. 输出
5.1 StreamingQuery定义
定义完 final result DataFrame/Dataset ,剩下的就是开始 streaming computation 。 为此,我们须使用 DataStreamWriter 通过 Dataset.writeStream() 返回。
-
Output mode (输出模式): 指定写入 output sink 的内容,即上文提到的complete, append, update模式
-
Query name (查询名称): 可选,指定用于标识的查询的唯一名称。
-
Trigger interval (触发间隔): 可选,指定触发间隔。 如果未指定,则系统将在上一次处理完成后立即检查新数据的可用性。 如果由于先前的处理尚未完成而导致触发时间错误,则系统将尝试在下一个触发点触发,而不是在处理完成后立即触发。
-
Checkpoint location (检查点位置): 对于可以保证 end-to-end fault-tolerance (端对端容错)能力的某些 output sinks ,请指定系统将写入所有 checkpoint (检查点)信息的位置。 这是与 HDFS 兼容的容错文件系统中的目录。
如果实时计算作业遇到了某个错误挂掉了,那么我们可以配置容错机制让它自动重启,同时继续之前的进度运行下去。这是通过checkpoint和wal机制完成的。可以给query配置一个checkpoint location,接着query会将所有的元信息(比如每个trigger消费的offset范围、至今为止的聚合结果数据),写入checkpoint目录。
aggDF .writeStream .outputMode("complete") .option(“checkpointLocation”, “path/to/HDFS/dir”) .format("memory") .start()
不同的输出模式有不同的兼容性:
- Append mode (default) - 这是默认模式,其中只有 自从上一次触发以来,添加到 Result Table 的新行将会是 outputted to the sink 。 只有添加到 Result Table 的行将永远不会改变那些查询才支持这一点。即上文提到的一旦输出了某条 key,未来就不会再输出同一个 key。 因此,这种模式 保证每行只能输出一次(假设 fault-tolerant sink )。例如,只有 select, where, map, flatMap, filter, join 等查询支持 Append mode 。
- Complete mode - 每次触发后,整个 Result Table 将被输出到 sink 。 aggregation queries (聚合查询)支持这一点。
- Update mode - (自 Spark 2.1.1 可用) 只有 Result Table rows 自上次触发后更新将被输出到 sink 。
5.2 Output Sinks
Spark有几种类型的内置输出接收器。
- **File sink ** - 将输出存储到目录中。
writeStream
.format("parquet") // can be "orc", "json", "csv", etc.
.option("path", "path/to/destination/dir")
.start()
- Foreach sink - 对 output 中的记录运行 arbitrary computation ,一般很常用,可以将流数据保存到数据库等,详细用法后面会提到
writeStream
.foreach(...)
.start()
- **Console sink (for debugging) ** - 每次触发时,将输出打印到 console/stdout 。 都支持 Append 和 Complete 输出模式。 这应该用于低数据量的调试目的,因为在每次触发后,整个输出被收集并存储在驱动程序的内存中。
writeStream
.format("console")
.start()
- **Memory sink (for debugging) ** - 输出作为 in-memory table (内存表)存储在内存中。都支持 Append 和 Complete 输出模式。 这应该用于调试目的在低数据量下,整个输出被收集并存储在驱动程序的存储器中。因此,请谨慎使用。
writeStream
.format("memory")
.queryName("tableName")
.start()
- Kafka sink将数据输出至Kafka
// Write key-value data from a DataFrame to Kafka using a topic specified in the data
StreamingQuery ds = df
.selectExpr("topic", "CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream()
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.start()
Dataframe 写入 Kafka 应该在 schema(模式)中有以下列:
| Column | Type |
|---|---|
| key (optional) | string or binary |
| value (required) | string or binary |
| topic (*optional) | string |
某些 sinks 是不容错的,因为它们不能保证输出的持久性并且仅用于调试目的。参见前面的部分 容错语义 。以下是 Spark 中所有接收器的详细信息。
| Sink (接收器) | Supported Output Modes (支持的输出模式) | Options (选项) | Fault-tolerant (容错) | Notes (说明) |
|---|---|---|---|---|
| File Sink (文件接收器) | Append (附加) | path: 必须指定输出目录的路径。 有关特定于文件格式的选项,请参阅 DataFrameWriter (Scala/Java/Python/R) 中的相关方法。 例如,对于 “parquet” 格式选项,请参阅 DataFrameWriter.parquet() | Yes | 支持对 partitioned tables (分区表)的写入。按时间 Partitioning (划分)可能是有用的。 |
| Foreach Sink | Append, Update, Compelete (附加,更新,完全) | None | 取决于 ForeachWriter 的实现。 | 更多详细信息在 下一节 |
| Console Sink (控制台接收器) | Append, Update, Complete (附加,更新,完全) | numRows: 每个触发器需要打印的行数(默认:20) truncate: 如果输出太长是否截断(默认: true) | No | |
| Memory Sink (内存接收器) | Append, Complete (附加,完全) | None | 否。但是在 Complete Mode 模式下,重新启动的查询将重新创建完整的表。 | Table name is the query name.(表名是查询的名称) |
5.3 Foreach
foreach 操作允许在输出数据上计算 arbitrary operations 。从 Spark 2.1 开始,这只适用于 Scala 和 Java 。为了使用这个,你必须实现接口 ForeachWriter 其具有在 trigger (触发器)之后生成 sequence of rows generated as output (作为输出的行的序列)时被调用的方法。
举个例子:
// storage result into mongodb
dataset.writeStream()
.queryName("mongodb" + collectionName)
.foreach(new ForeachWriter<Row>() {
Map<String, String> writeOverrides = new HashMap<String, String>() {{
put("uri", MongoDbConfig.MONGO_DB_URI);
put("database", MongoDbConfig.MONGO_MOFANG_TSP_DATA_DB);
put("collection", collectionName);
}};
WriteConfig writeConfig = WriteConfig.create(jsc).withOptions(writeOverrides);
MongoConnector mongoConnector = null;
ArrayList<Row> list = null;
@Override
public void process(Row value) {
list.add(value);
}
@Override
public void close(Throwable errorOrNull) {
if (!list.isEmpty()) {
mongoConnector.withCollectionDo(writeConfig, Document.class, (MongoCollection<Document> mongoCollection) -> {
for (Row row : list) {
Map<String, Object> map = new HashMap<>();
String[] fieldNames = row.schema().fieldNames();
for (String s : fieldNames) {
map.put(s, row.getAs(s));
}
Document document = new Document(map);
mongoCollection.insertOne(document);
}
return null;
});
}
}
@Override
public boolean open(long partitionId, long version) {
mongoConnector = MongoConnector.apply(writeConfig.asOptions());
list = new ArrayList<>();
return true;
}
})
.start();
}
以上代码将Dataset的所有列存入MongoDB的指定DB与Collection
注意以下要点。
-
writer 必须是 serializable (可序列化)的,因为它将被序列化并发送给 executors 执行。
-
open ,process 和 close 三个方法都会在executor上被调用。
-
只有当调用 open 方法时,writer 才能执行所有的初始化(例如打开连接,启动事务等)。请注意,如果在创建对象时立即在类中进行任何初始化,那么该初始化将在 driver 中发生(因为这是正在创建的实例)。
-
version 和 partition 是 open 中的两个参数,它们独特地表示一组需要被 pushed out 的行。 version 是每个触发器增加的单调递增的 id 。 partition 是一个表示输出分区的 id ,因为输出是分布式的,将在多个执行器上处理。
-
open 可以使用 version 和 partition 来选择是否需要写入行的顺序。因此,它可以返回 true (继续写入)或 false ( 不需要写入 )。如果返回 false ,那么 process 不会在任何行上被调用。例如,在 partial failure (部分失败)之后,失败的触发器的一些输出分区可能已经被提交到数据库。基于存储在数据库中的 metadata (元数据), writer 可以识别已经提交的分区,因此返回 false 以跳过再次提交它们。
-
当 open 被调用时, close 也将被调用(除非 JVM 由于某些错误而退出)。即使 open 返回 false 也是如此。如果在处理和写入数据时出现任何错误,那么 close 将被错误地调用。我们有责任清理以 open 创建的状态(例如,连接,事务等),以免资源泄漏。
6. 最后
最后等待所有流查询完成:
// await for termination
try {
sparkSession.streams().awaitAnyTermination();
} catch (StreamingQueryException e) {
e.printStackTrace();
}
管理StreamingQuery对象的全部操作如下:
StreamingQuery query = df.writeStream().format("console").start(); // get the query object
query.id(); // get the unique identifier of the running query that persists across restarts from checkpoint data
query.runId(); // get the unique id of this run of the query, which will be generated at every start/restart
query.name(); // get the name of the auto-generated or user-specified name
query.explain(); // print detailed explanations of the query
query.stop(); // stop the query
query.awaitTermination(); // block until query is terminated, with stop() or with error
query.exception(); // the exception if the query has been terminated with error
query.recentProgress(); // an array of the most recent progress updates for this query
query.lastProgress(); // the most recent progress update of this streaming query
SparkSession spark = ...
spark.streams().active(); // get the list of currently active streaming queries
spark.streams().get(id); // get a query object by its unique id
spark.streams().awaitAnyTermination(); // block until any one of them terminates
7. Reference
- https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
- https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
- https://github.com/lw-lin/CoolplaySpark/blob/master/Structured Streaming 源码解析系列/1.1 Structured Streaming 实现思路与实现概述.md
- https://blog.csdn.net/asd136912/article/details/82147657
- https://docs.databricks.com/spark/latest/structured-streaming/kafka.html