诗经史哲志风流,回首应觉少年柔
使用 & 代码解析
总结
微调是 AI 模型绕不开的一个话题,它是迁移学习的一种(最常用的)实现方法。在“小模型”时代,参数量不过几百万,全参数微调(full fine tuning)毫无压力。GPT 系列的 NLP 模型引领潮流后,大家在把模型做大这条路上越走越远,几亿参数量的语言模型早已成为弟中之弟。
这种背景下,全参数微调既占显存,速度又慢,相比之下,PEFT (Parameter-Efficient Fine-Tuning) 就显得很重要了。目前用得最多的 PEFT 方法就是 LoRA(低秩自适应方法) 了,但其他诸如 Prefix-tuning, Prompt-tuning, P-tuning 也是比较常见的方法。
我将按照对论文的理解,对 NLP 领域常见的 PEFT 方法做个总结,意在拓宽视野,说不定可以在其中汲取些许灵感。若有理解偏差之处,欢迎斧正。
In-context learning
In-context learning(上下文学习)其实不算是微调,它没有变动模型结构,也没有更新任何参数。把它放在这里,是因为后面一系列基于 Continuous prefix (soft) prompt 的工作都受到了它的启发。
In-context learning 也叫 few-shot learning(少样本学习)。在推理阶段,给出下游任务的几个示例,就可以“激发”模型在这类任务上的能力。它的本质就是给予模型一些先验知识(prompt),模型输出 token 的概率分布就会改变(条件概率),进而得到合适的输出。
查资料的时候我看到了一篇论文 Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers
从标题看出,它认为 In-context learning 在 prompt 给出的示例上隐式地做了梯度下降,如下图所示。论文我还没有详细读,细节之后再来补充。

Prefix-tuning
In-context learning 中的 prompt 是一些自然语言,并且是人们手动设计的,目的是改变条件概率,“激发”模型潜能。prompt 的设计对输出有很大影响;并且针对不同的下游任务,需要精心设计不同的 prompt
那么有没有一种方法可以自动确定 prompt 呢?Prefix-tuning 说:“有,而且不一定是自然语言”。它把下游任务的示例替换成一些虚拟 token(下图中的 prefix)。这些虚拟 token 并不对应任何自然语言中的 subword,它们仅仅是一些连续的向量
原先人工设计的 prompt 中那些对应自然语言的真实 token 也要经过嵌入层,被向量化。由于 token 是离散的,得到的结果大概率是次优的。相较而言,连续化的 prefix prompt 搜索更具优势。
Recent works have focused on automatically searching discrete prompts and demonstrated their effectiveness. However, since neural networks are inherently continuous, discrete prompts can be sub-optimal. —— GPT Understands, Too
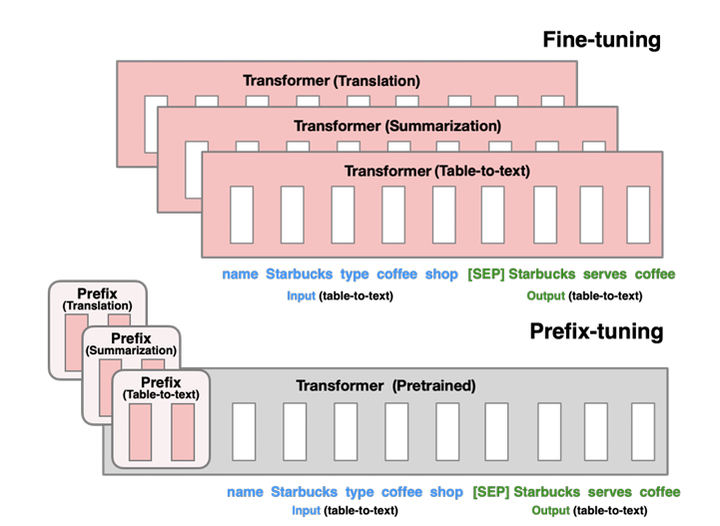
Prefix-tuning 时,原本模型的参数被冻结,这些虚拟 token 对应的向量就是可学习参数。有一点需要注意:如下图所示,为了增强表达力,不只是嵌入层后的第一个 Transformer block,Prefix-tuning 对模型的每个 Transformer block 的输入都加入了 Prefix vector。
这些 Prefix vector 对应着自注意力中的 key-value 对. 下图是单个 Transformer block 内的示意图。
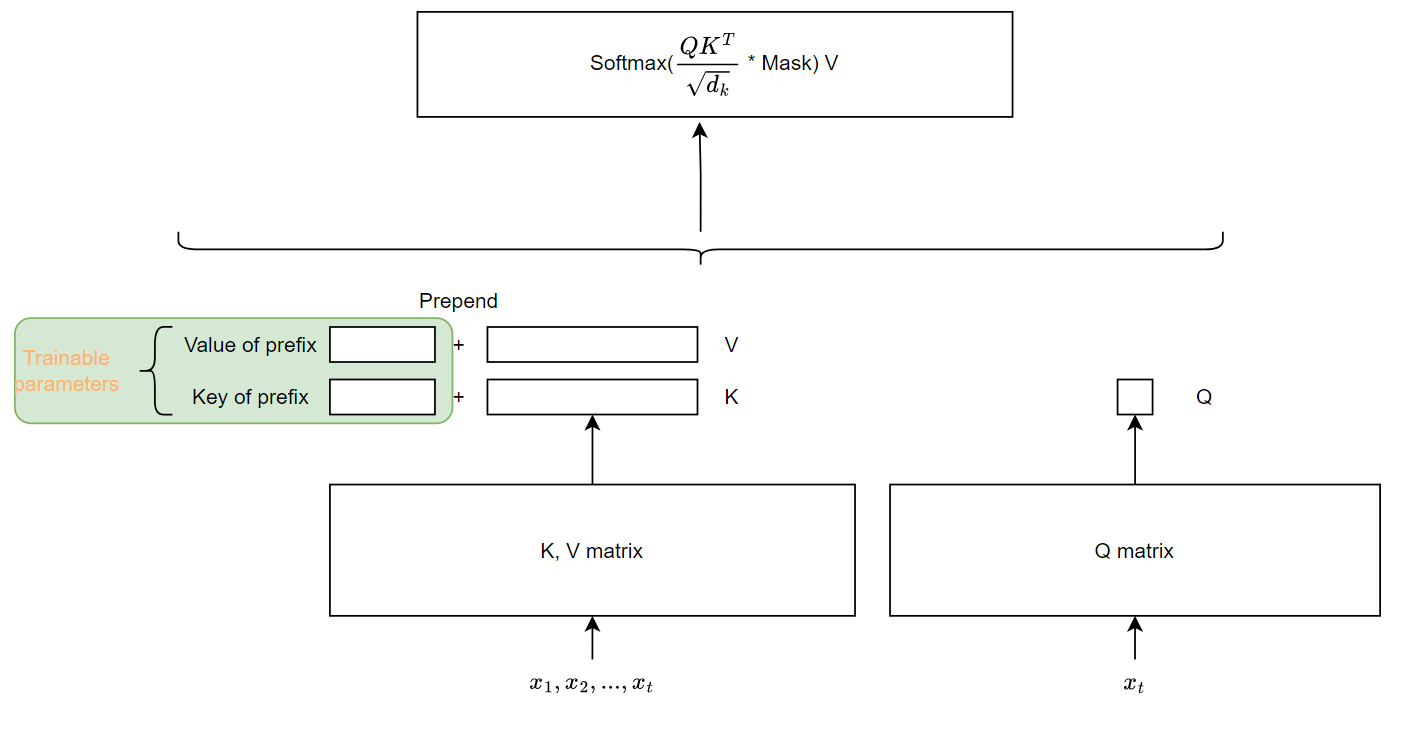
另外论文提到,直接更新这些 Prefix vector 会导致训练的不稳定以及些许性能掉点。因此作者用 MLP 重构参数。原本参数矩阵形状是 |����|×���(ℎ�) ,其中 |����| 是 prefix 的长度。现在把它分解成形状为 |����|×� 的参数矩阵和一个形状为 �×���(ℎ�) 的 MLP
总的来说,Prefix-tuning 通过在更大的向量空间内搜索、优化 Prefix vector,有点像自动化的 prompt engineering. 只不过它对每个 Transformer block 的输入都加了一个 prompt
Prefix-tuning 论文中关注了两个下游任务:Table-to-text Generation 以及 Summarization,都属于自然语言生成任务(NLG)。prefix 的长度是一个重要的超参数。论文提到,在到达阈值之前(对于 Table-to-text 任务大约是 10;对于 Summarization 任务大约是 100),prefix 越长效果越好;超过阈值后效果会有轻微下降。

XSUM 为 Summarization 数据集,其余为 Table-to-text 数据集
Prefix-tuning 是一种“即插即用”的方法:针对每个下游任务,只需要保存一份 prefix vector 就好了。
Prompt-Tuning
Prompt-Tuning 在论文摘要里提到,这是 Prefix-tuning 的一个简化版本。
Prompt-Tuning 也有一些 prefix vector,但它们只拼接在嵌入层的输出(第一个 Transformer block 的输入):如下图所示

关于 prefix 长度:长度为 100 时,几乎在各个模型尺度上效果都是最好。需要注意的是,由于 Prompt-Tuning 只在第一个 block 拼接,同等 prefix 长度下可训练参数量比 Prefix-tuning 少很多。

Prompt-Tuning 针对的是自然语言理解任务(NLU),实验数据集是 SuperGLUE。注意到,模型规模到达 10B 时,Prompt-Tuning 与全参数微调在 SuperGLUE 下游任务上打成平手。但是在小模型上,仍有不小的差距。

P-Tuning
和前面两个方法一样,P-Tuning 的思路也是基于 Continuous prefix (soft) prompt。和 Prompt-Tuning 类似,P-Tuning 也是只对模型的输入 embedding 做了拼接。
Similar to discrete prompts, the P-tuning only applies non-invasive modification to the input.

对于 context information � 的 embedding �(�) —— 上图中蓝色部分,以及 target tokens � 的 embedding �(�) —— 上图中红色部分,我们都可以在前面拼接 pseudo prompts 的 embedding,即 ℎ0,...,ℎ� 以及 ℎ�+1,...,ℎ�
最终 Transformer 的输入形式是 [ℎ0,...,ℎ�,�(�),ℎ�+1,...,ℎ�,�(�)]
P-Tuning 提出了一个很有价值的点:prompt embeddings ℎ� 们应该是相关联的。于是论文提出用双向 LSTM 建立 prompt embeddings 之间的联系。

通过公式 (4),最终与 �(�),�(�) 拼接的 prompt embeddings 就与前后的 prompt (virtual) tokens 建立了关联。这也可以算作一种参数重构:Prefix-tuning 用 MLP 重构参数,这里用 LSTM。
和 Prompt-Tuning 一样,P-Tuning 也是关注 NLU 任务,选取的 benchmark 也是 SuperGLUE. 除此之外,P-Tuning 还对知识探测(也叫事实抽取)做了实验,数据集是 LAMA。

数据集 LAMA。MP: Manual prompt; FT: Fine-tuning;
上图是在知识探测数据集 LAMA 上的实验结果。结论:
- 在 encoder-only 的模型上(BERT 系列),P-tuning 基本可以与人工构建模板+直接微调打成平手;
- 在 decoder-only 的模型上(GPT 系列),P-tuning 提升显著,明显优于人工构建模板+直接微调。
- P-tuning 可以让原本不擅长知识探测的 GPT 可以与 BERT 战成平手(所以论文标题是 GPT understands, too,这是文章的主要卖点)

数据集 SuperGLUE。MP: Manual prompt
在 SuperGLUE 上的结论类似。虽然相对于人工构建模板+直接微调的提升不如 LAMA 上明显,但略占优势已经不错了。
P-Tuning v2
P-Tuning 的作者在 2022 年 3 月发布了 P-Tuning v2,提到了之前一些 soft prompt 方法的不足:缺乏泛化性。譬如 Prompt-Tuning 在小规模模型上(<10B)的表现不佳;Prompt-Tuning 和 P-tuning 虽然在 SuperGLUE 的一些 NLU 数据集上表现很好,但在其他一些譬如序列标注这种比较困难的任务上表现不佳。
所以 P-Tuning v2 的一大卖点,就是模型规模、下游任务这两方面的泛化性。
还是拿 Prompt-Tuning 和 P-tuning 举例,这两种方法都仅仅在输入序列前端拼接 prefix prompt,这样做有两个弊端:一、可学习参数量较少,并且受限于输入序列的长度限制;二、很难直接影响最终的预测结果。想来想去,P-Tuning v2 说:还是 Prefix-tuning 的方法好啊!咱们还是在每个 Transformer block 的输入端都拼接 prefix (virtual) tokens 吧!【主打一个返璞归真】
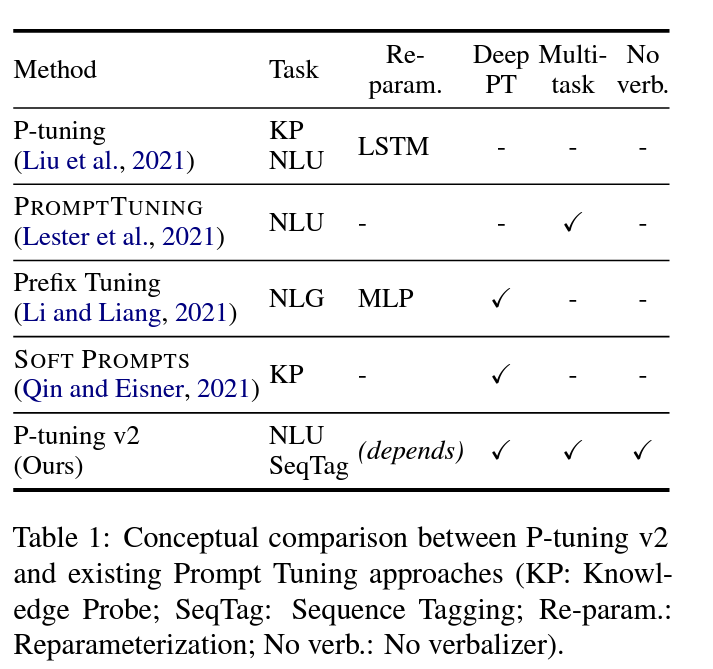
几种方法的对比总结。P-Tuning v2 发现:
- 用 MLP 重构参数并不能保证在所有下游数据集上有效;
- 比较难的任务需要更长的 prefix prompt;
- 可以采用多任务学习:在多个任务上一起训练共同的 prefix prompt vectors,然后在各个任务上分别微调。
其实 P-Tuning v2 在概念上并没有太多创新点,基本上沿用了 Prefix-tuning 的思路(除了对 MLP 参数重构做了一些分析)
Adapter
Adapter 的思路非常简单,一张图就可以讲清:

图源:[PPT]浅析大语言模型从预训练到微调的技术原理;作者:回旋托马斯x
LLaMA-Adapter
LLaMA-Adapter 虽然名字里有 Adapter,但它更像是基于 Continuous prefix (soft) prompt 的工作。它同样是 prepend 一些 prompt vectors,但有几点不同:
- 只在模型的最后 L 个 Transformer block 中添加;
- 采用 zero-initialized attention 机制
论文主要的创新点就在这个 zero-initialized attention 机制,它是为了解决 prefix (soft) prompt 微调的通病:训练不稳定。由于添加了一些随机初始化的参数,在微调的初始阶段,loss 很有可能会飞掉。譬如说在生成某个 token 的时候,模型施加了很多注意力在 prefix prompt 上面,但此时这部分参数仍处于欠拟合状态,很有可能导致生成效果变得很差。
我们把 prefix prompt 部分未经过 softmax 的 attention score 记作 ��� ;还有一部分是原本的 instruction 以及已经有的输入,把这部分未经过 softmax 的 attention score 记作 ���+1
原本的计算方法是: ���=softmax([���;���+1])
zero-initialized attention 的做法是,对 ��� 和 ���+1 独立计算 softmax,并且对 prefix prompt 部分施加门控:
���=[softmax(���)⋅��; softmax(���+1)]
上式中的 �� 可以控制 ��� 对输出的影响力。微调的初始阶段, �� 接近于零,随后可以自适应性地调整。并且对于不同的 heads, �� 是不同的,保证一定的多样性。注意: ��� 在相应维度上的和不再是 1

LoRA
LoRA (Low rank adaptation) 是现在最常用的 PEFT 方法。它也是一种“即插即用” 的方案。
思路很简单:既然微调就是更新参数,那么不如直接模拟参数的更新量 Δ� —— 用两个 MLP 去近似 Δ� 。一图以蔽之:
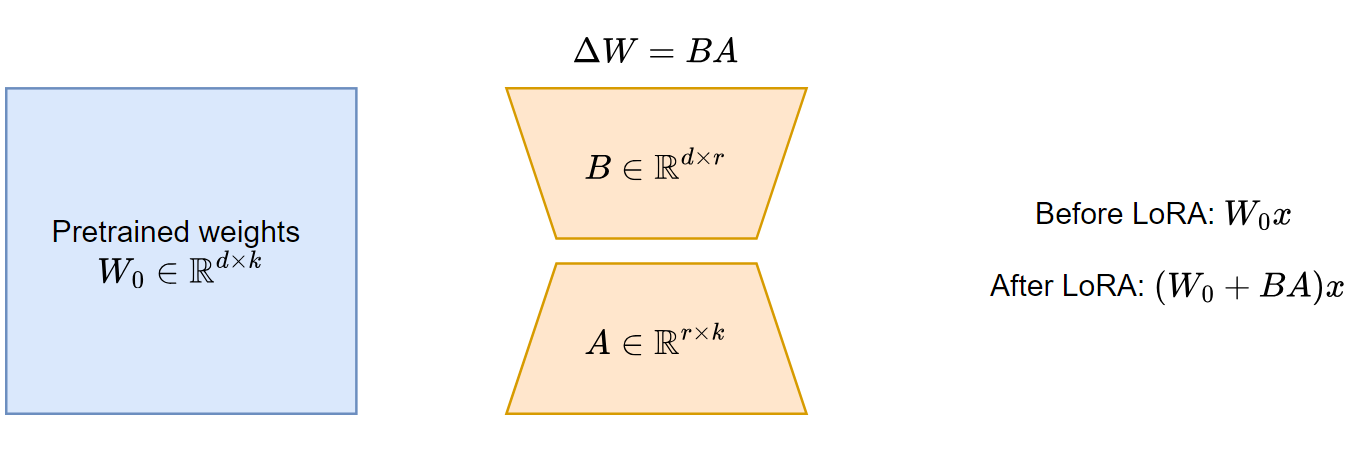
用两个低秩矩阵替代某个大矩阵的思路,在 ALBERT 这篇论文中就有所体现。它提出了一些对 BERT 的改进,其中包括 Factorized embedding parameterization:就是利用一个 �×� 和一个 �×� 的矩阵替代原本 �×� 的嵌入层。其中 �≪�
LoRA 微调时,原来模型参数冻结,只更新 A 和 B 的参数。其中 � 称为 rank,是一个重要的超参数。 � 越大,可训练参数越多,表达力越强,不过一般也不需要太大, �=4,8,16 是常见的设置。
另外,在 Transformer block 中,对哪些参数矩阵的更新量进行模拟?一般是选择自注意力层的 Q, V 矩阵;或者范围更大一些:Q, K, V, O(输出矩阵)。

底座模型是 GPT-3 175B
QLoRA
顾名思义,QLoRA 就是 LoRA 的量化版本。由于 LoRA 微调时不需要更新原本的模型参数,可以对它们进行 8bit 甚至 4bit 量化存储,节省显存、加速训练。
现阶段,QLoRA 是重要的节省显存的 PEFT 方法。论文声称,微调 65B 的模型只需要 48 GB 显存,并且效果不输 16bit 全参数微调。
具体来说,QLoRA 的两个主要技术:
- 提出了一种新的 4bit 数据类型—— 4-bit NormalFloat (NF4) —— 更适合对正态分布的权重做量化;
- 使用双量化技术(Double Quantization),进一步节省量化常数的空间占用;
QLoRA 中,模型的权重有两种格式:用 NF4 存储;用 BF16 计算。需要用相应权重计算前向传播时,对 NF4 的权重反量化为 BF16(下图公式 5);计算结束后,再量化为 NF4( �NF4 ).

使用 & 代码解析
利用 HuggingFace peft 库,可以快速地使用 QLoRA。我们逐行看一下代码:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
from peft import prepare_model_for_kbit_training, LoraConfig, get_peft_model
model_name = "EleutherAI/gpt-neox-20b"
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config, device_map={"":0})
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["query_key_value"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
model.config.use_cache = FalseBitsAndBytesConfig 中,load_in_4bit参数是 bitsandbytes 库提供的功能:先把高精度的模型下载到磁盘,在加载的时候,转化成混合 4bit 的量化模型。注:也有一些模型提供了量化后的版本,可以直接下载。
Remark 1:这里的量化模型只用于模型推理,不要和 bitsandbytes 提供的 optimizer 量化搞混了。后者可以对优化器状态用 8bit 量化,可以用在训练中。如
bitsandbytes.optim.Adam8bit(....)
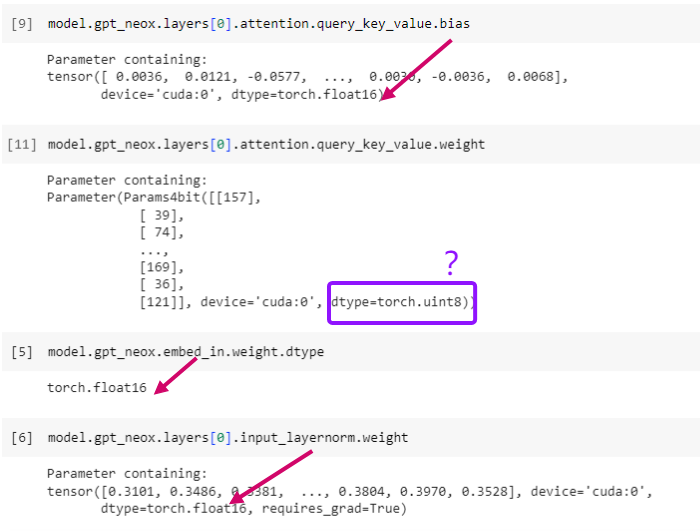
Remark 2:这个时候大多数层的参数变成 uint8,但也有一部分层保持 FP16;bias 的精度也保持 FP16
疑问:文档中明明写 load_in_4bit,为什么这里的参数精度是 uint8?
bitsandbytes 的 Github issues 里有人有同样的疑问 https://github.com/TimDettmers/bitsandbytes/issues/691,后续跟进一下。
prepare_model_for_kbit_training 用来在微调中提高训练的稳定性,主要包括
- layer norm 层保留 FP32 精度
- 嵌入层以及 LM head 输出层保留 FP32 精度

get_peft_model 在模型中添加 LoRA 层(参数使用 FP32)
use_cache 是对解码速度的优化,它会使用 KV cache,默认开启;如果同时使用 gradient checkpoint,中间激活值不会存储,二者存在冲突。因此这里设置 use_cahe=False。其实#21737已经加入了参数检查,这里设置只是为了不输出 warning。
总结
以上这些 PEFT 方法,都是在原来模型参数之外,添加不到原参数量 1% 的参数。在这些新添加的参数上做微调,很多时候就可以媲美全参数微调了。
以我个人经验来说,LoRA 和 QLoRA 是现在比较常用的,bitsandbytes 库也很好地支持了这两种方法。 像是 Adapter 以及基于 pseudo soft prompt 的一些方法比较少会用到。【一家之言,欢迎评论区交流】
参考:
一些论文:
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Prompt tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
P-tuning: GPT Understands, Too
P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
Adapter: Parameter-Efficient Transfer Learning for NLP
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
LoRA: Low-Rank Adaptation of Large Language Models
QLoRA: Efficient Finetuning of Quantized LLMs
Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers
几篇博文:
解密Prompt系列3. 冻结LM微调Prompt: Prefix-Tuning & Prompt-Tuning & P-Tuning