【Datawhale AI夏令营第四期】 浪潮源大模型应用开发方向笔记 Task05 源大模型微调实战代码精读 RAG测试 AI简历助手代码优化 网课剩余部分
教程基础背景知识:
微调能解决的问题正好是我需要的——模型在某个特定方面上能力不够。我感觉这种情况适用于让模型去完成特定小众的任务,比如原神数值分析,原神剧情梳理啥的,不属于普罗大众知识库的专精小微领域?我感觉也能用在我们草台班子的人话八股文助手里面,不过我暂时还没有具体的应用方案。
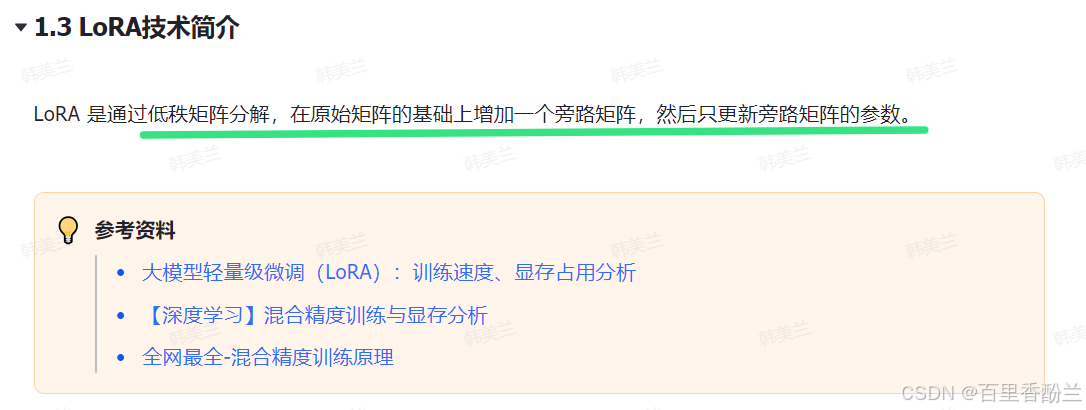
关于Lora的部分,之前AIGC方向的教案和笔记有详细介绍。我印象里是把新得到的矩阵理解为两个矩阵的乘积(比如100x100理解为一个100xk的矩阵再乘一个kx100的矩阵),然后根据需要调节k的大小来控制参数的复杂度。




模型加载与数据处理:
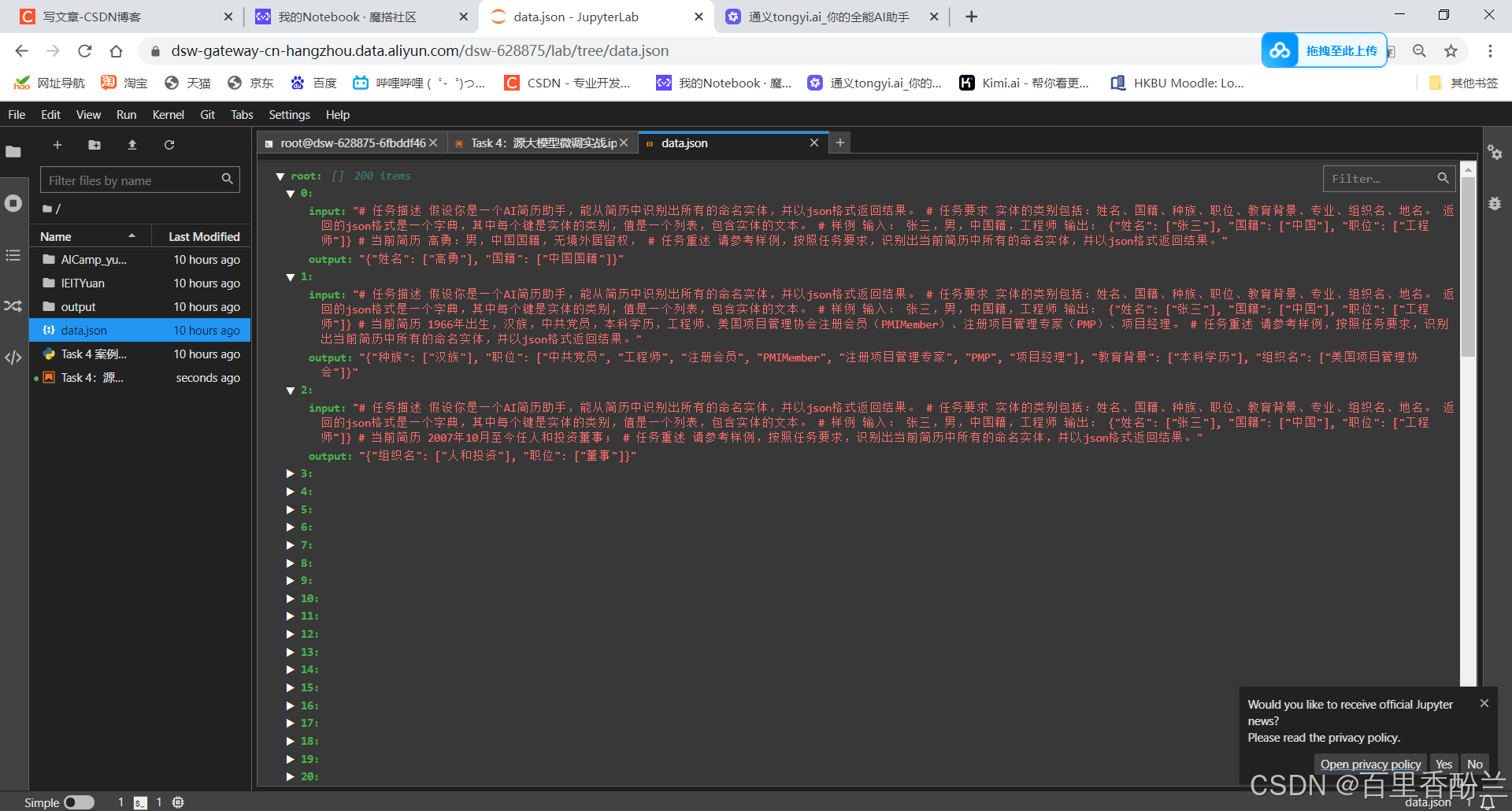
这个JSON是一条条包含提示词和答案的数据:
找一条数据出来看:
这个数据处理函数特别长:



# 定义数据处理函数 接收一个样本(example)作为输入,并对其进行预处理
def process_func(example):
MAX_LENGTH = 384 # Llama分词器会将一个中文字切分为多个token,因此需要放开一些最大长度,保证数据的完整性
instruction = tokenizer(f"{example['input']}<sep>") #instruction: 使用 tokenizer 对输入文本进行分词。这里使用了 <sep> 作为分隔符
response = tokenizer(f"{example['output']}<eod>") #response: 使用 tokenizer 对输出文本进行分词。这里使用了 <eod> 作为结束标记
input_ids = instruction["input_ids"] + response["input_ids"] #input_ids: 将 instruction 和 response 的 input_ids 合并在一起
attention_mask = [1] * len(input_ids)
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] # instruction 不计算loss labels: 构造标签序列,其中 instruction 部分的标签设置为 -100,这在训练过程中会被忽略,不会计算损失
if len(input_ids) > MAX_LENGTH: # 做一个截断 如果合并后的 input_ids 长度超过了 MAX_LENGTH,则对 input_ids、attention_mask 和 labels 进行截断
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return { #返回一个字典,包含 input_ids、attention_mask 和 labels
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
说真的,恕我才疏学浅,真没看明白????
感觉他这个数据处理过程占了代码的大头。我后面自己跟着代码敲了一遍,又向Kimi请教,还是没完全理解究竟这复杂的处理过程具体每一步有什么意义……
但是大概功能就一句话,翻译。把人话翻译成模型能懂的。



# 处理数据集 使用了之前定义的 process_func 函数来处理数据集 ds,并对处理后的数据集进行了列的移除。下面是这段代码的详细解释:
tokenized_id = ds.map(process_func, remove_columns=ds.column_names) #通过 remove_columns 参数移除了原始数据集中的所有列。这意味着处理后的数据集将只包含由 process_func 函数返回的新列
tokenized_id #通过 map 方法将 process_func 函数应用于数据集中的每一个样本
Lora部分:
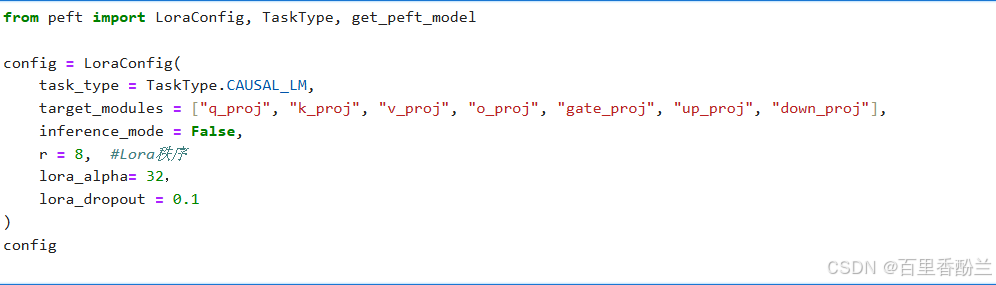
然后就是这种形式的Lora代码,最近AIGC和大模型应用方向都在提:
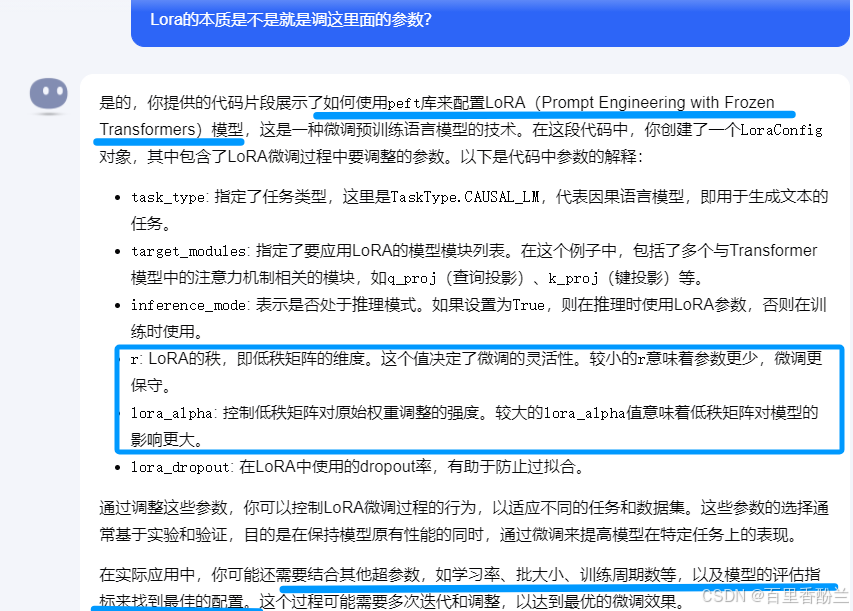
高深的玩法我没见识过,但就我这几次学习遇到Lora相关代码的经验来看,感觉Lora这个概念被包装得看着很高大上,往简单了想,本质上就是要么换数据集调教模型,要么就是改这个config配置里面的这几个超参数。
问了一下Kimi,跟我预计的差不多,粗略地可以这么理解。
我感觉人工智能很多东西其实本质用起来并不难,特别是一般人的应用场景(算法巨佬卷王不在讨论范围),可能就是换换数据集改参数的事,但是非要拿英文包装个很高大上的概念,吓得人望而却步。
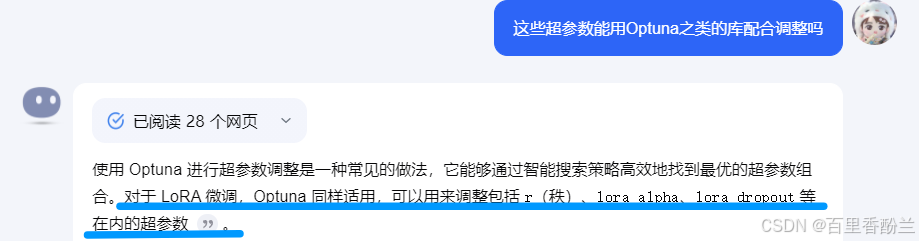
既然这些Lora相关的都是超参数,我又想起我之前学过还写了笔记的一样东西——自动调参神器Optuna。
https://blog.csdn.net/bailichen800/article/details/140362947
传送门
那么Lora能不能也用Optuna来帮忙寻找最合适的超参数呢?
问了Kimi——可以的!!!!!!
我们让Kimi写一段示例代码,发现用起来并不复杂,也就是按套路引入库+调函数+改参数的事。

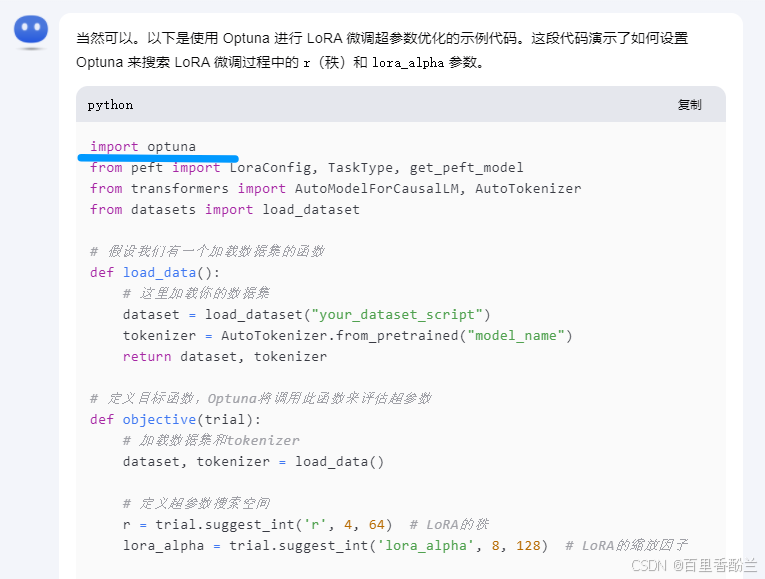

import optuna
from peft import LoraConfig, TaskType, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
# 假设我们有一个加载数据集的函数
def load_data():
# 这里加载你的数据集
dataset = load_dataset("your_dataset_script")
tokenizer = AutoTokenizer.from_pretrained("model_name")
return dataset, tokenizer
# 定义目标函数,Optuna将调用此函数来评估超参数
def objective(trial):
# 加载数据集和tokenizer
dataset, tokenizer = load_data()
# 定义超参数搜索空间
r = trial.suggest_int('r', 4, 64) # LoRA的秩
lora_alpha = trial.suggest_int('lora_alpha', 8, 128) # LoRA的缩放因子
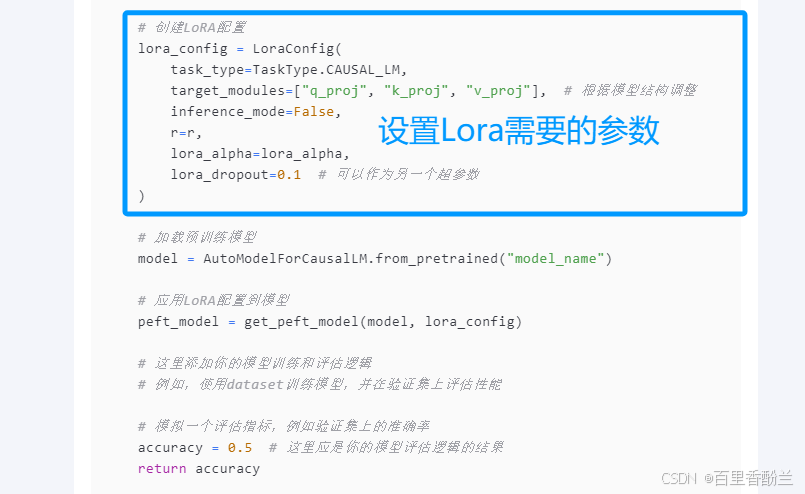
# 创建LoRA配置
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["q_proj", "k_proj", "v_proj"], # 根据模型结构调整
inference_mode=False,
r=r,
lora_alpha=lora_alpha,
lora_dropout=0.1 # 可以作为另一个超参数
)
# 加载预训练模型
model = AutoModelForCausalLM.from_pretrained("model_name")
# 应用LoRA配置到模型
peft_model = get_peft_model(model, lora_config)
# 这里添加你的模型训练和评估逻辑
# 例如,使用dataset训练模型,并在验证集上评估性能
# 模拟一个评估指标,例如验证集上的准确率
accuracy = 0.5 # 这里应是你的模型评估逻辑的结果
return accuracy
# 创建Optuna研究对象
study = optuna.create_study(direction='maximize')
# 运行优化,指定试验次数
study.optimize(objective, n_trials=50)
# 打印最佳超参数
print(f"Best trial parameters: {study.best_trial.params}")
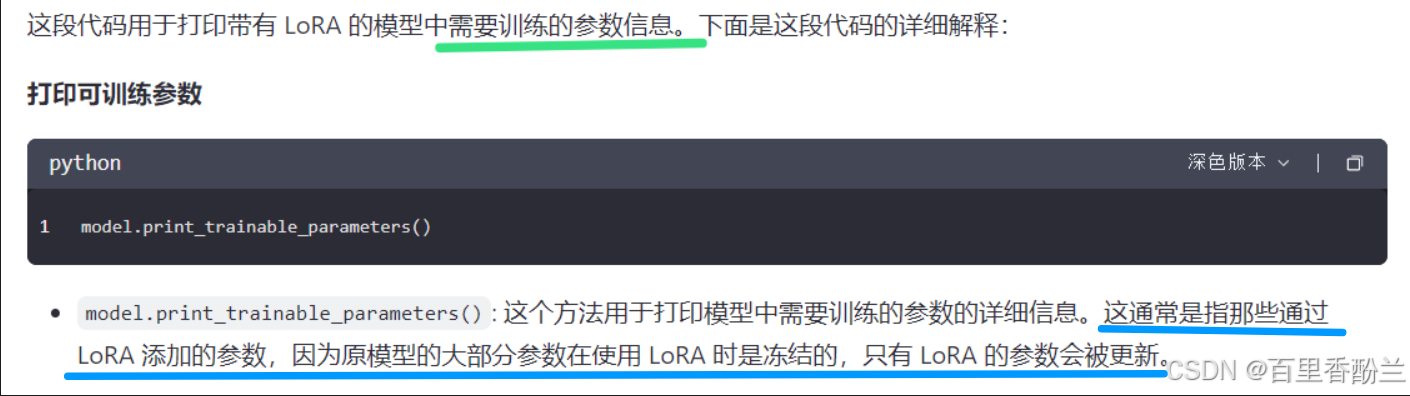
查看可训练参数:
原来HuggingFace还支持看代码中有多少参数是可以训练的!AMAZING!不过必须是Peft库才行,而且我感觉这个方法还比较新,问Kimi他不知道,通义千问也要代码环境才行。


生成结果函数:
用 split(“”)[-1] 从解码后的文本中提取最后一个 后面的内容并打印
这个【最后一个】还挺讲究:要把之前的提示词、多余的答案去掉,只选择用户感兴趣的新生成的答案。
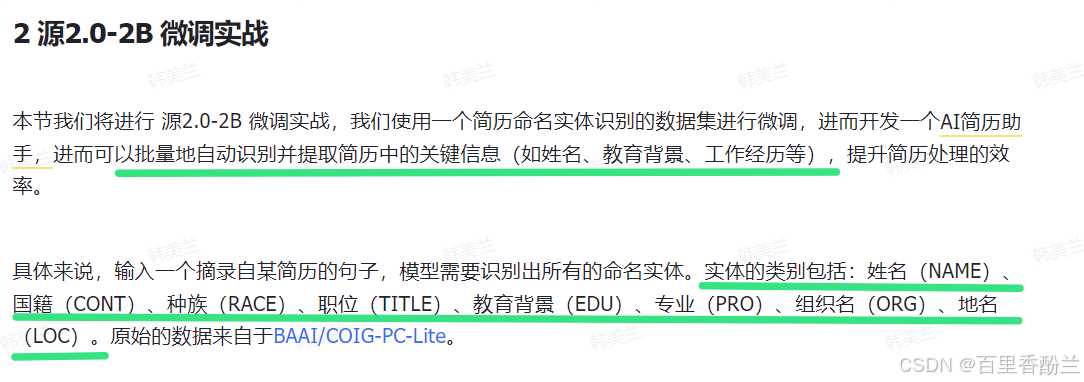
所以这个AI助手本质上就是能读一段txt,然后从中提取出人名、职位、国籍等信息。
相比于现在的多模态AI,这个助手能做的事情非常有限,只能解析文本。但是简历一般都是pdf的形式,所以这个案例功能实际上卷得还不够。
写好注释的代码会放在CSDN个人资源那里,有需要的朋友可以自取。



设备自适应:
我们草台班子的人话计算机八股文助手一开始模型选用的DeepSeek做测试,后面根据需要换成了浪潮的源大模型。
浪潮的模型没有API,是下到自己电脑上跑的,所以涉及到CPU和GPU的切换问题,在代码里需要写一段设备自适应,即有GPU就用GPU,没有就用CPU。
我今天突然想把DeepSeek这个也拿出来玩一下,就想是不是也要做个设备自适应的调整,问了通义千问,这种调用API的不需要。


Task03 RAG测试:
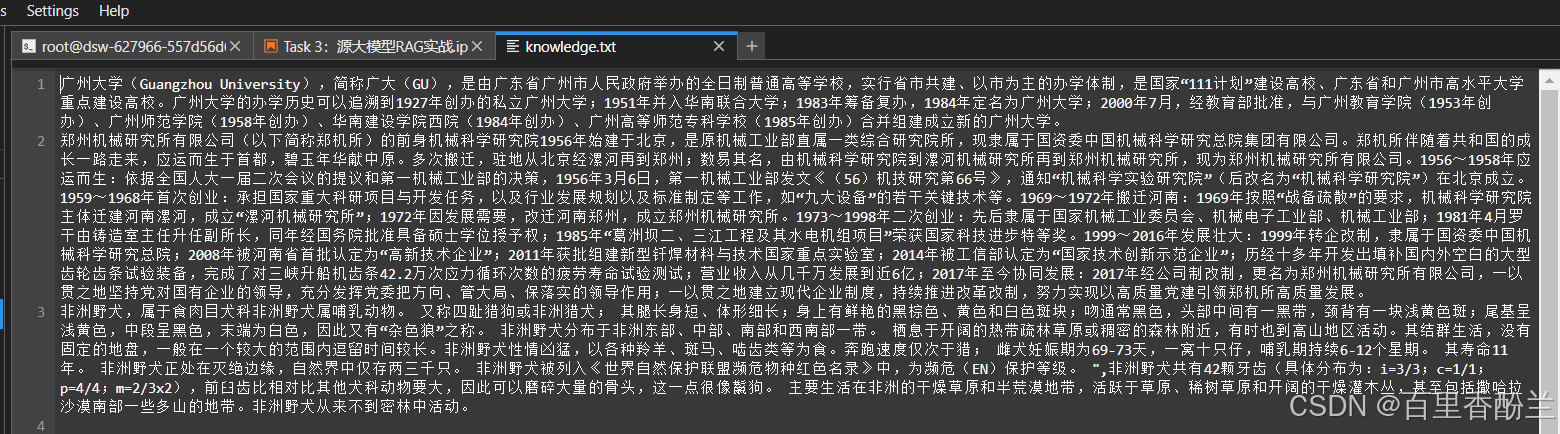
我看Task03的RAG的例子本质上就是给模型喂了个广州大学的txt文件,里面介绍了一些比较偏门的广州大学详细信息:(说真的我感觉,这跟换专精数据集喂AIGC的Lora过程本质上好像没有区别???)
正好我家人有历史爱好者,很感兴趣有没有能有按年份介绍历史人物生平的AI助手。
其实,不用RAG,提示词写好点,只要不是特别偏难怪人物,Kimi和通义千问都能介绍。
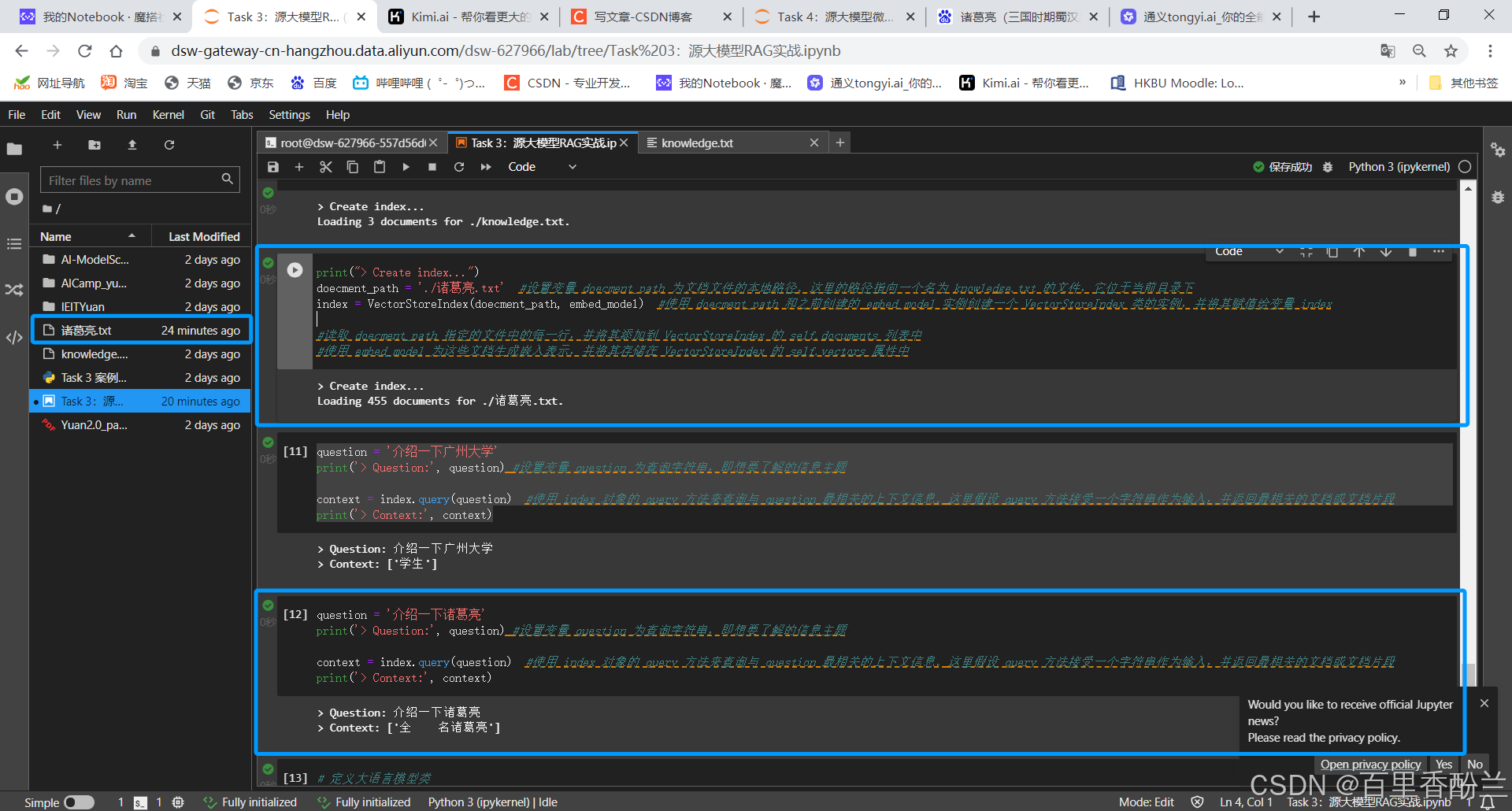
不过为了更深入了解一下RAG的过程,我选择了我很崇拜的诸葛亮来做测试:
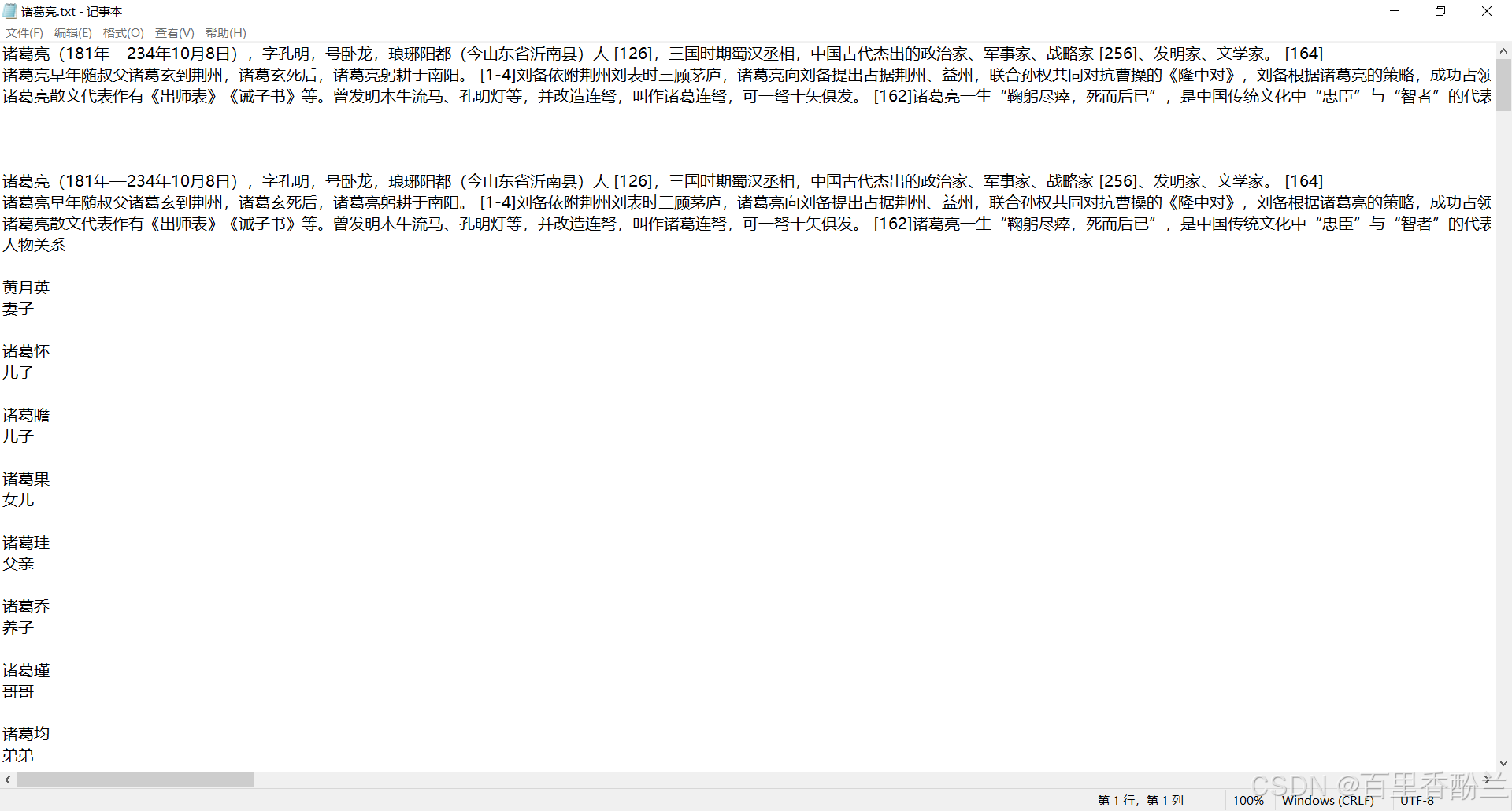
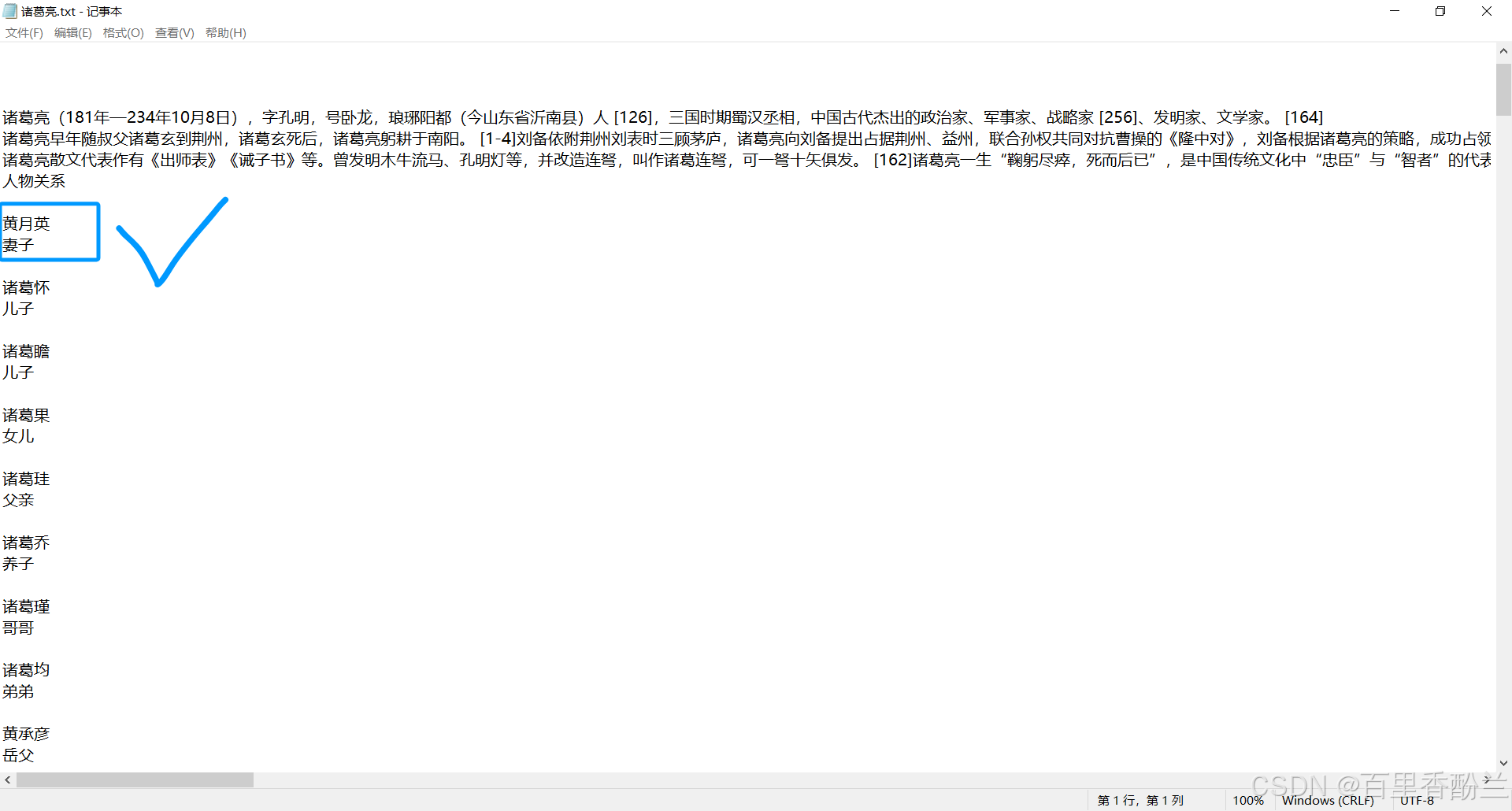
从百度百科上复制一下亮老师的生平,然后如法炮制粘贴进一个新的txt:
然后把这个txt上传进实例,喂给模型学习:
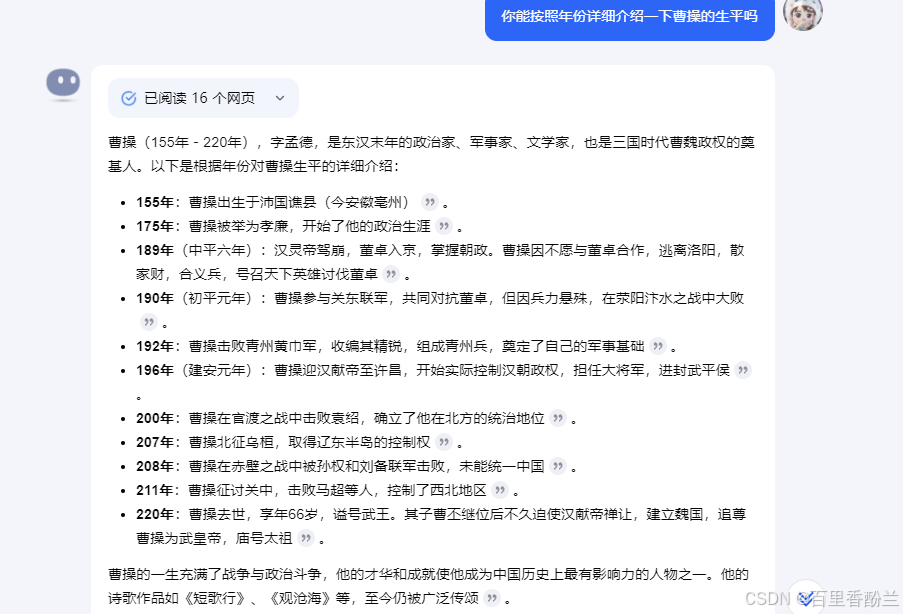
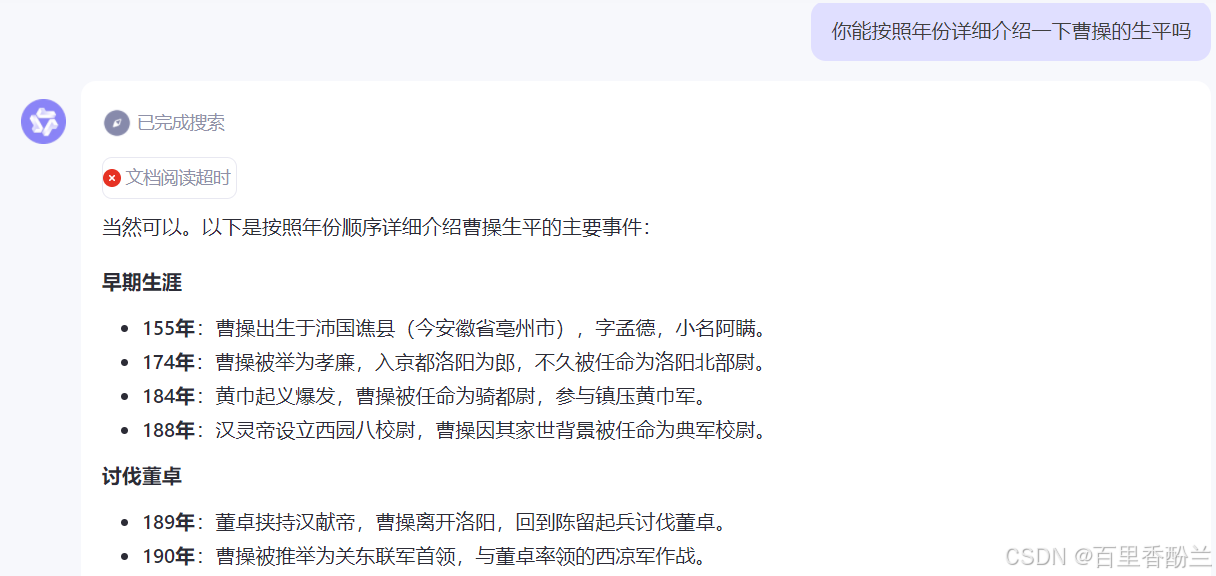
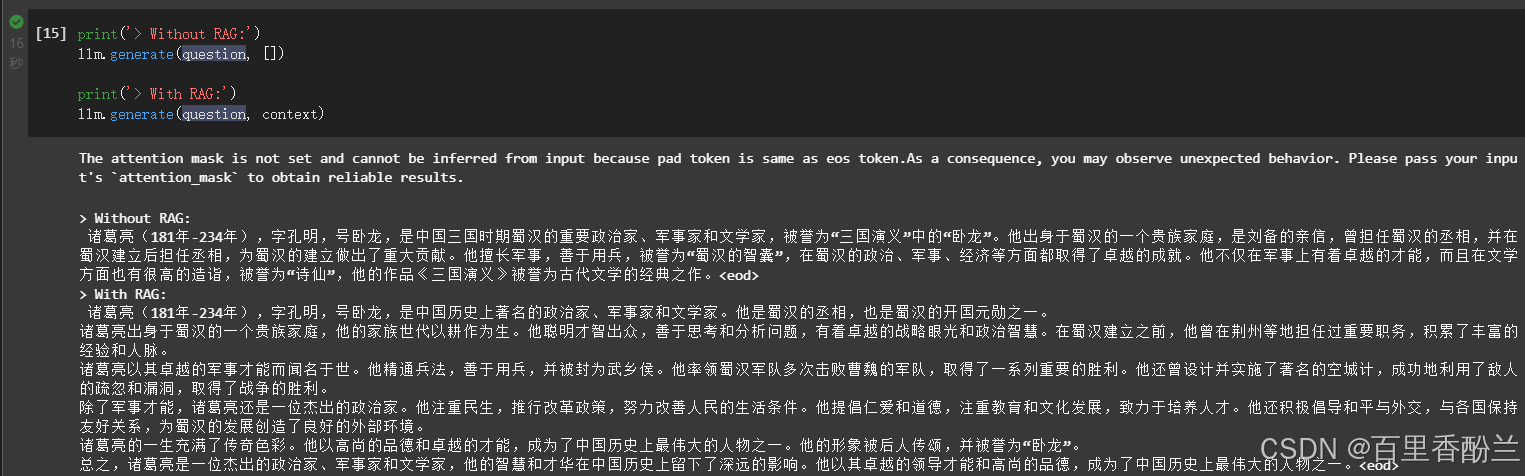
然后看一下最后的输出效果对比:
不过这些介绍都是基本常识,我觉得应该问一些宽泛的:
看得出来,这个问题把AI难住了。
由此可见,RAG有多重要,可以有效避免AI一本正经地胡说八道:
现在问一个他广州大学、诸葛亮知识库里面都没有的东西,原神的问题:
果然,AI开始瞎编了。





Task 04 微调测试:
之前Task04那个微调的案例我看了以后感觉基本上就是针对一段txt提取信息的工具AI,甚至不能叫一个简历助手,就只是个提取信息的工具人。
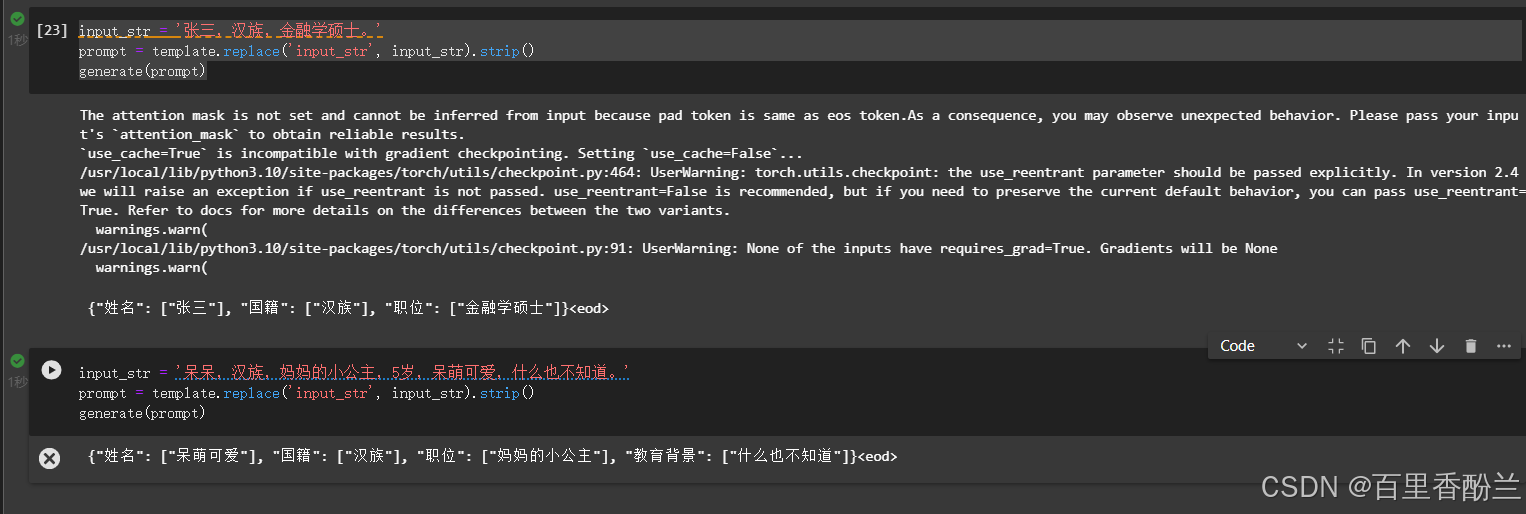
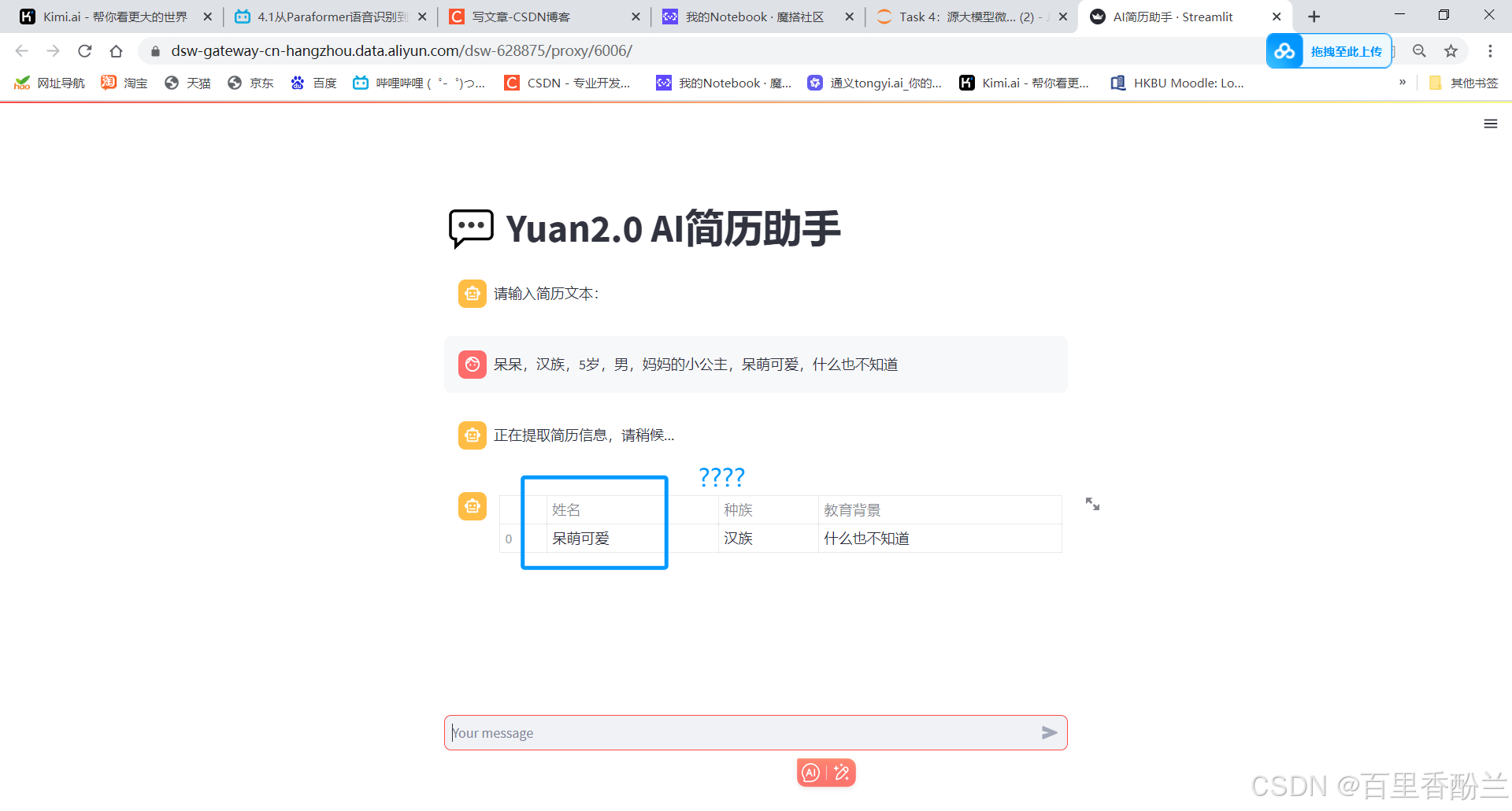
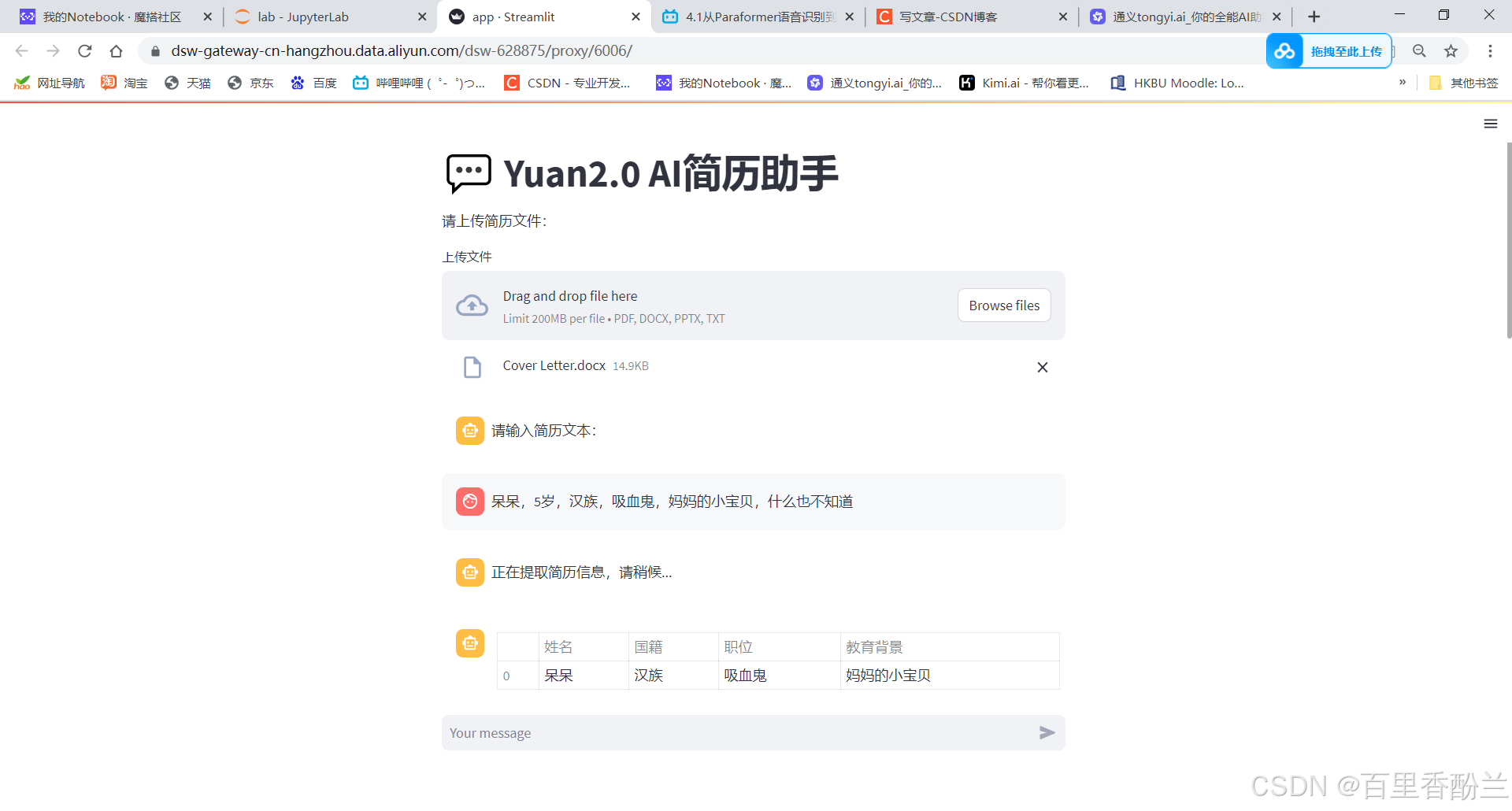
然后我又把我的可爱棉花娃娃儿子拉出来测试,就是下面这个呆头呆脑的小东西,他是我养了5年的好大儿呆呆:
【“呆呆,妈妈的小公主,5岁,呆萌可爱,什么也不知道。”】
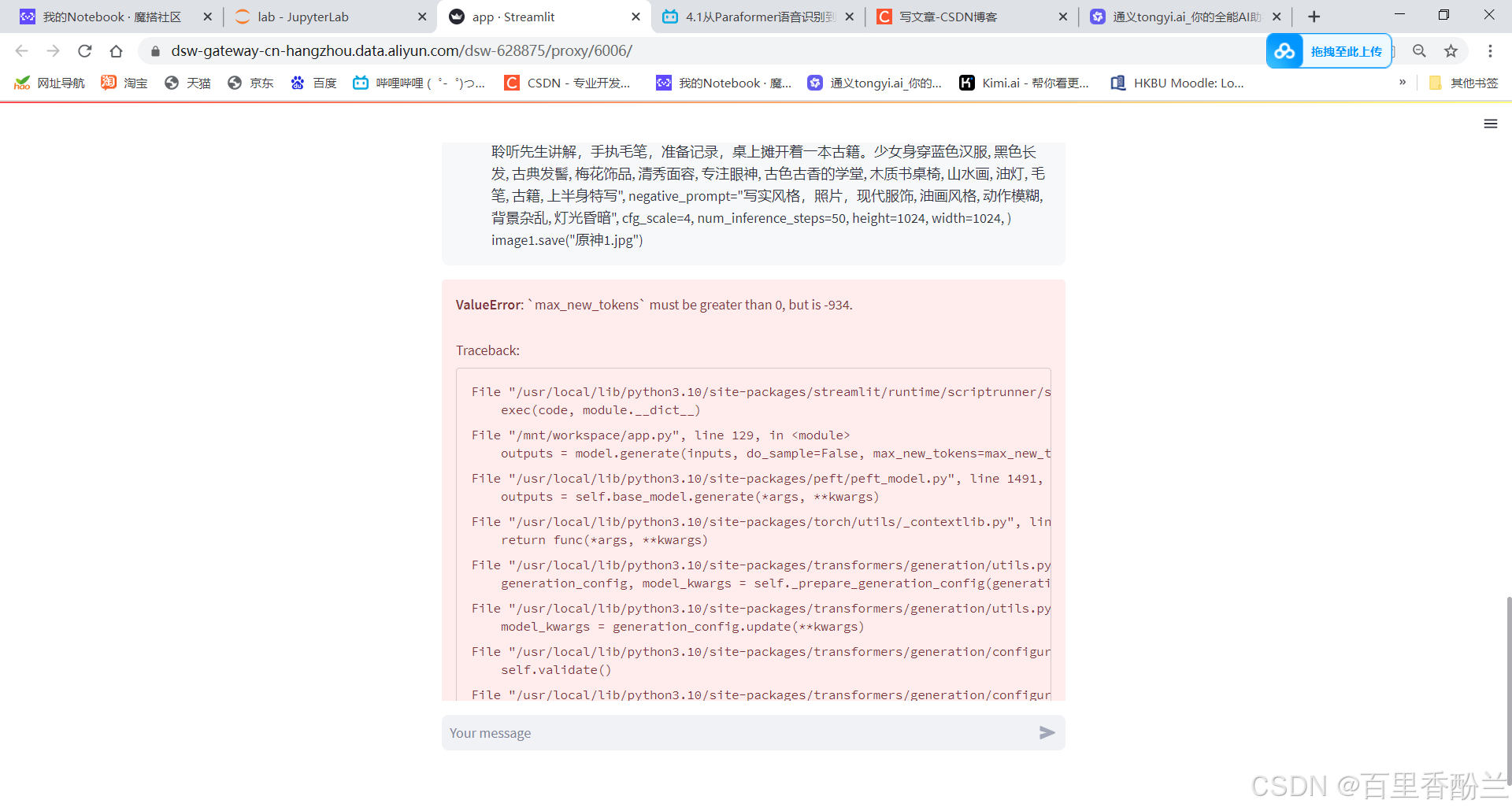
让AI提取一下,效果还不错。但是就是应用场景太少,哪怕我复制一段我的真实简历上去都报index超了……
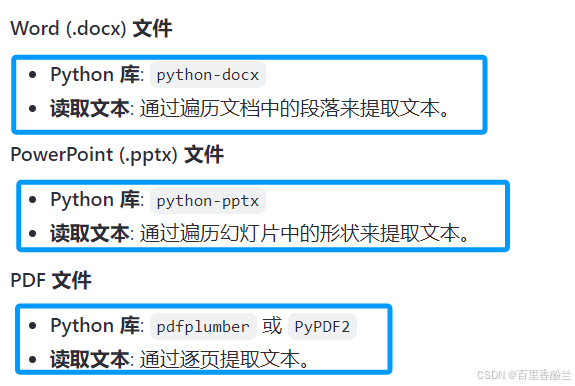
还是不够卷啊,现在市面上都得来个多模态,支持上传pdf,ppt,word等,既然这样就搜一下该咋做吧:

尝试升级AI简历助手案例,支持多模态输入:
原来这些文件最后都会转换为txt格式,我还以为是通过OpenCV图像识别啥的认字呢。
感觉能实现多模态文件读取并不难,PDF,PPT,word的代码都只有一小段:打开文件+调用对应函数就能解决。
我一开始还脑补到图象识别技术去了,看来确实是我想复杂了。
通义千问给的使用示例,我让它把阅读txt的能力也加上了:
对于纯文本文件(.txt),读取内容相对简单,只需要使用 Python 的内置文件操作即可。

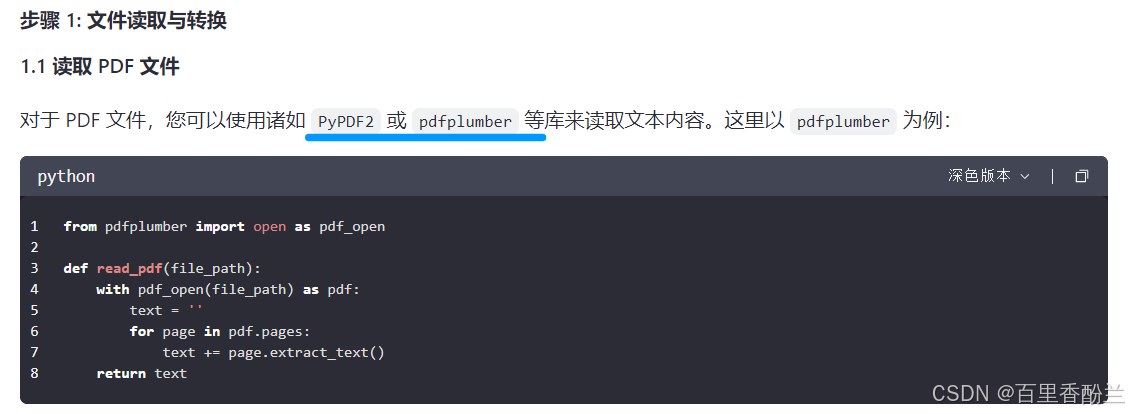
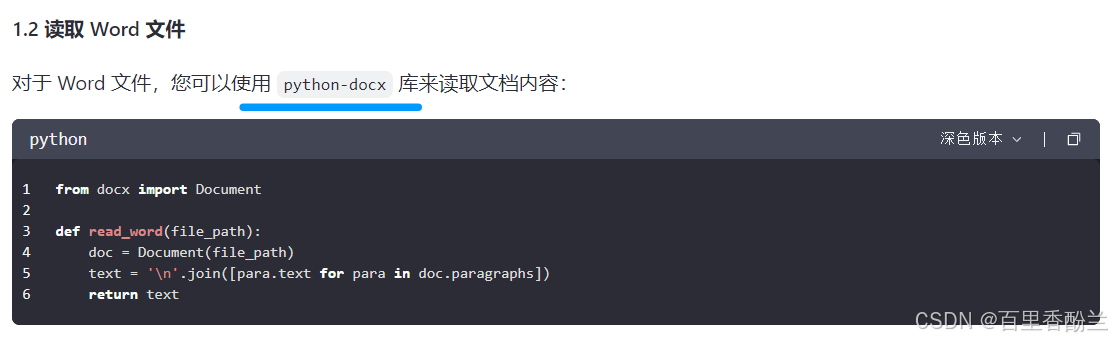
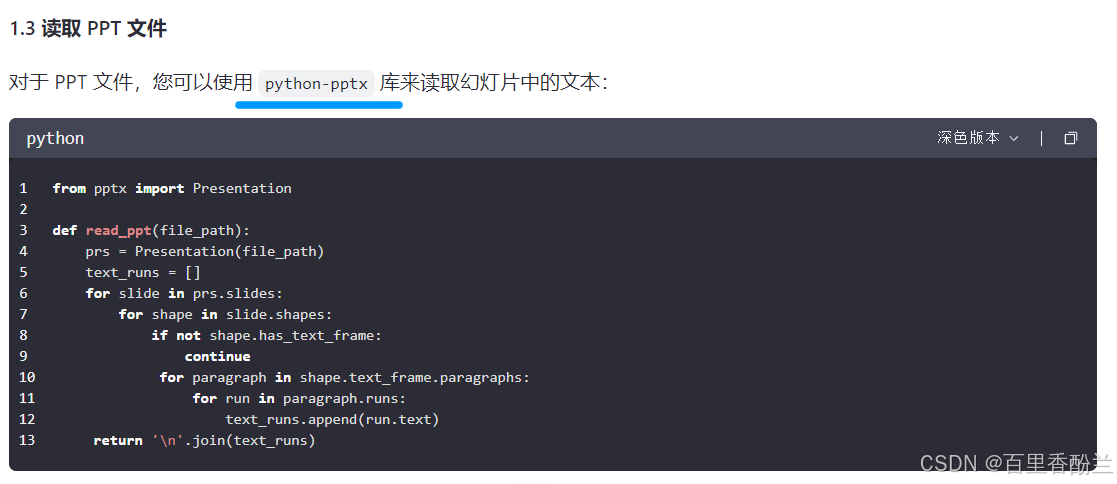

from pdfplumber import open as pdf_open
from docx import Document
from pptx import Presentation
def read_pdf(file_path):
with pdf_open(file_path) as pdf:
text = ''
for page in pdf.pages:
text += page.extract_text()
return text
def read_word(file_path):
doc = Document(file_path)
text = '\n'.join([para.text for para in doc.paragraphs])
return text
def read_ppt(file_path):
prs = Presentation(file_path)
text_runs = []
for slide in prs.slides:
for shape in slide.shapes:
if not shape.has_text_frame:
continue
for paragraph in shape.text_frame.paragraphs:
for run in paragraph.runs:
text_runs.append(run.text)
return '\n'.join(text_runs)
def read_txt(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
return text
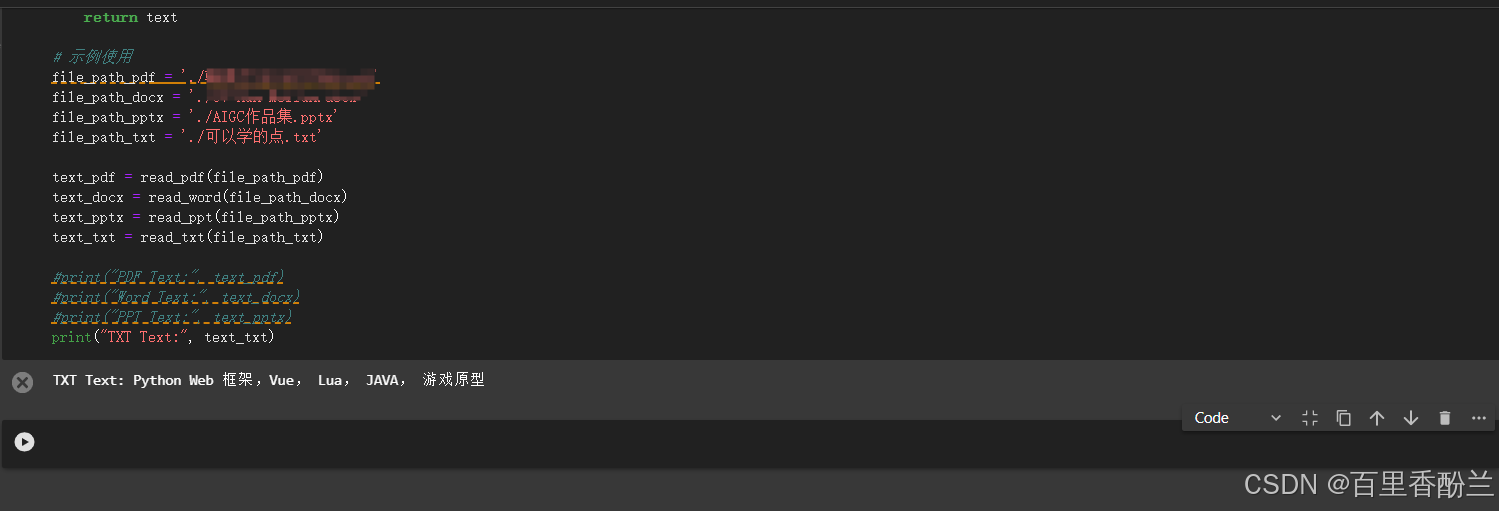
# 示例使用
file_path_pdf = 'path/to/your/file.pdf'
file_path_docx = 'path/to/your/file.docx'
file_path_pptx = 'path/to/your/file.pptx'
file_path_txt = 'path/to/your/file.txt'
text_pdf = read_pdf(file_path_pdf)
text_docx = read_word(file_path_docx)
text_pptx = read_ppt(file_path_pptx)
text_txt = read_txt(file_path_txt)
print("PDF Text:", text_pdf)
print("Word Text:", text_docx)
print("PPT Text:", text_pptx)
print("TXT Text:", text_txt)
依赖库安装:

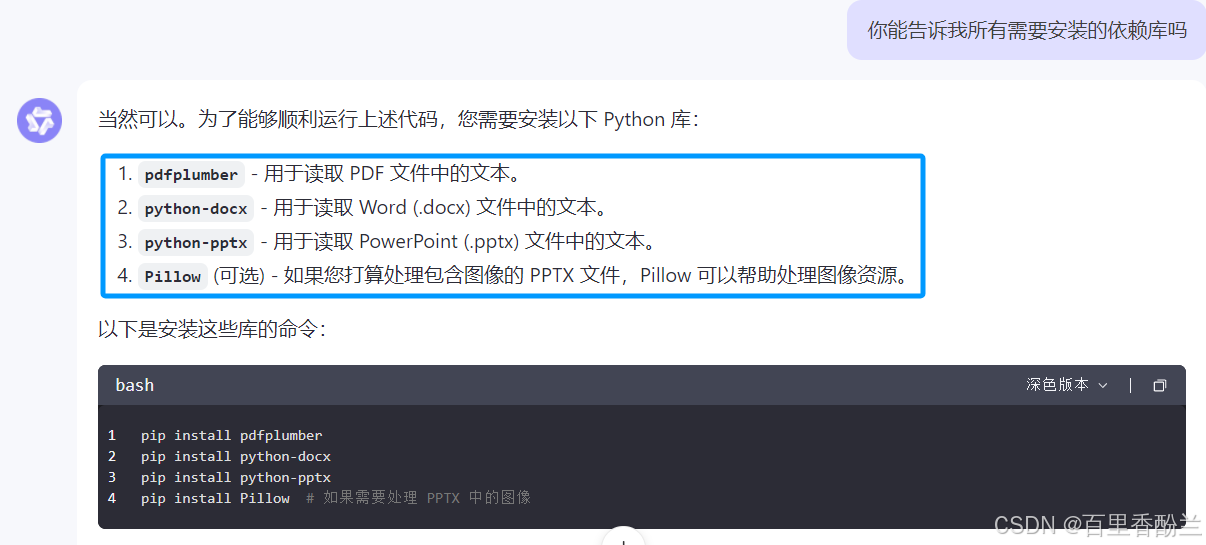
pip install pdfplumber
pip install python-docx
pip install python-pptx
pip install Pillow # 如果需要处理 PPTX 中的图像
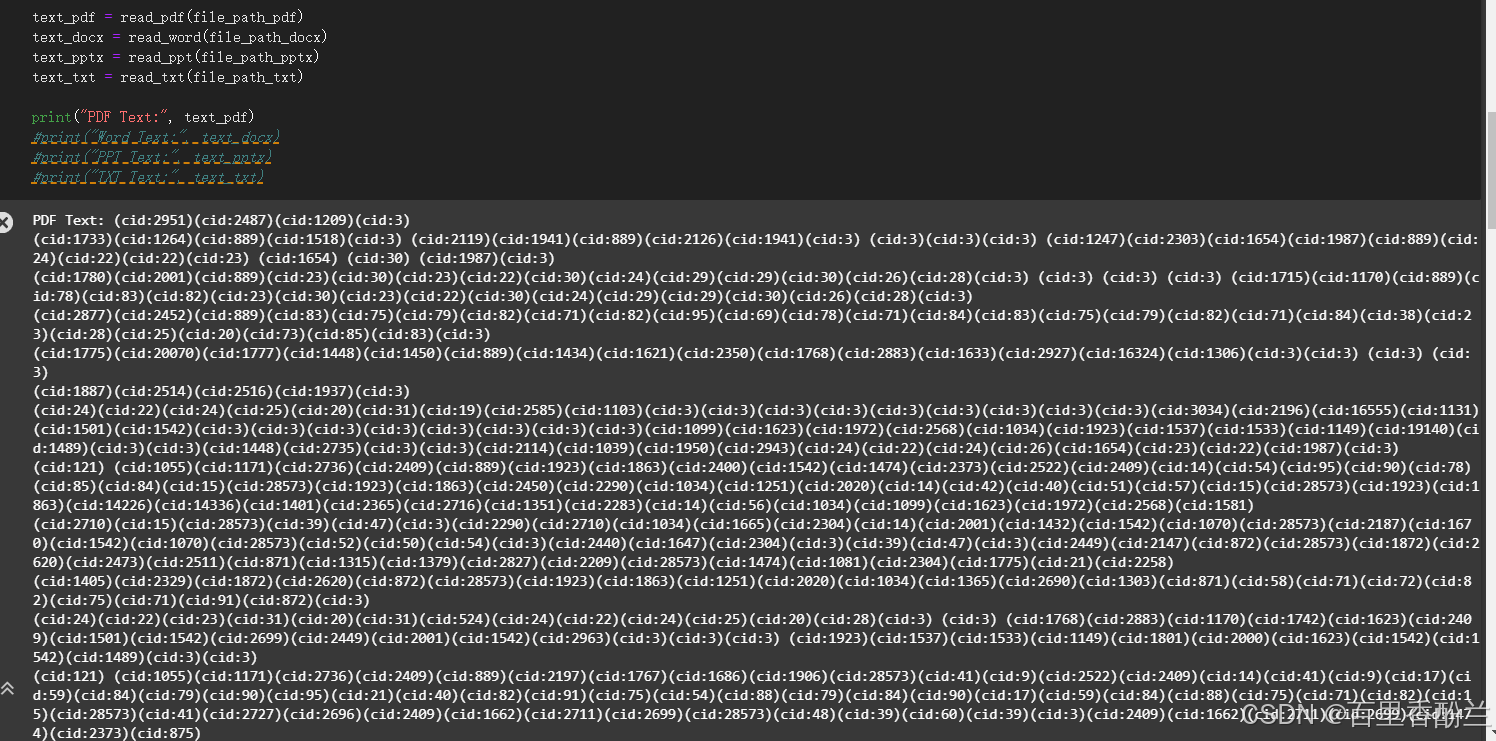
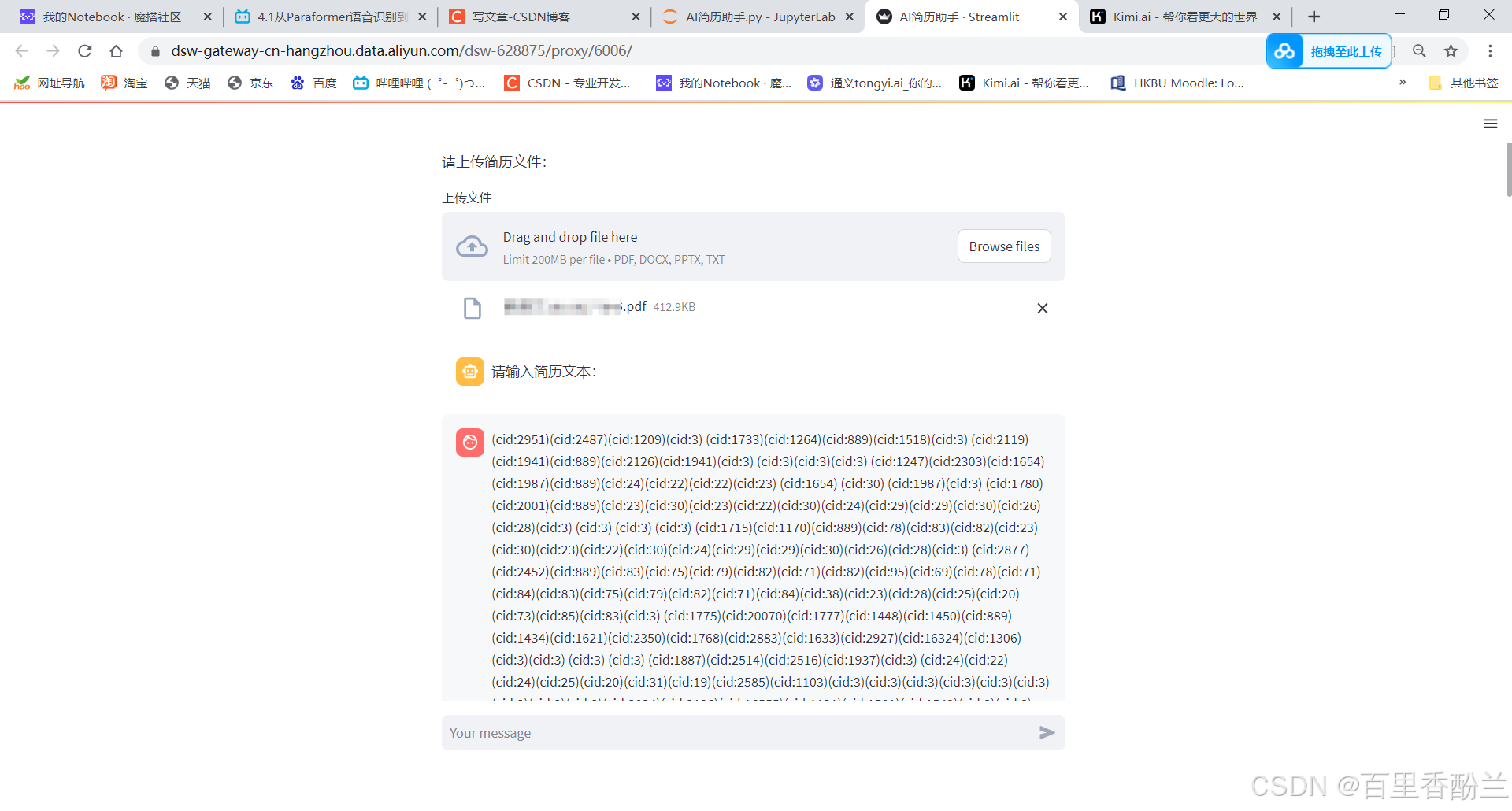
我玩把真的,把自己的简历和作品集扔上去,看看AI认不认识:
首先看看PDF的阅读效果——完全没法看。
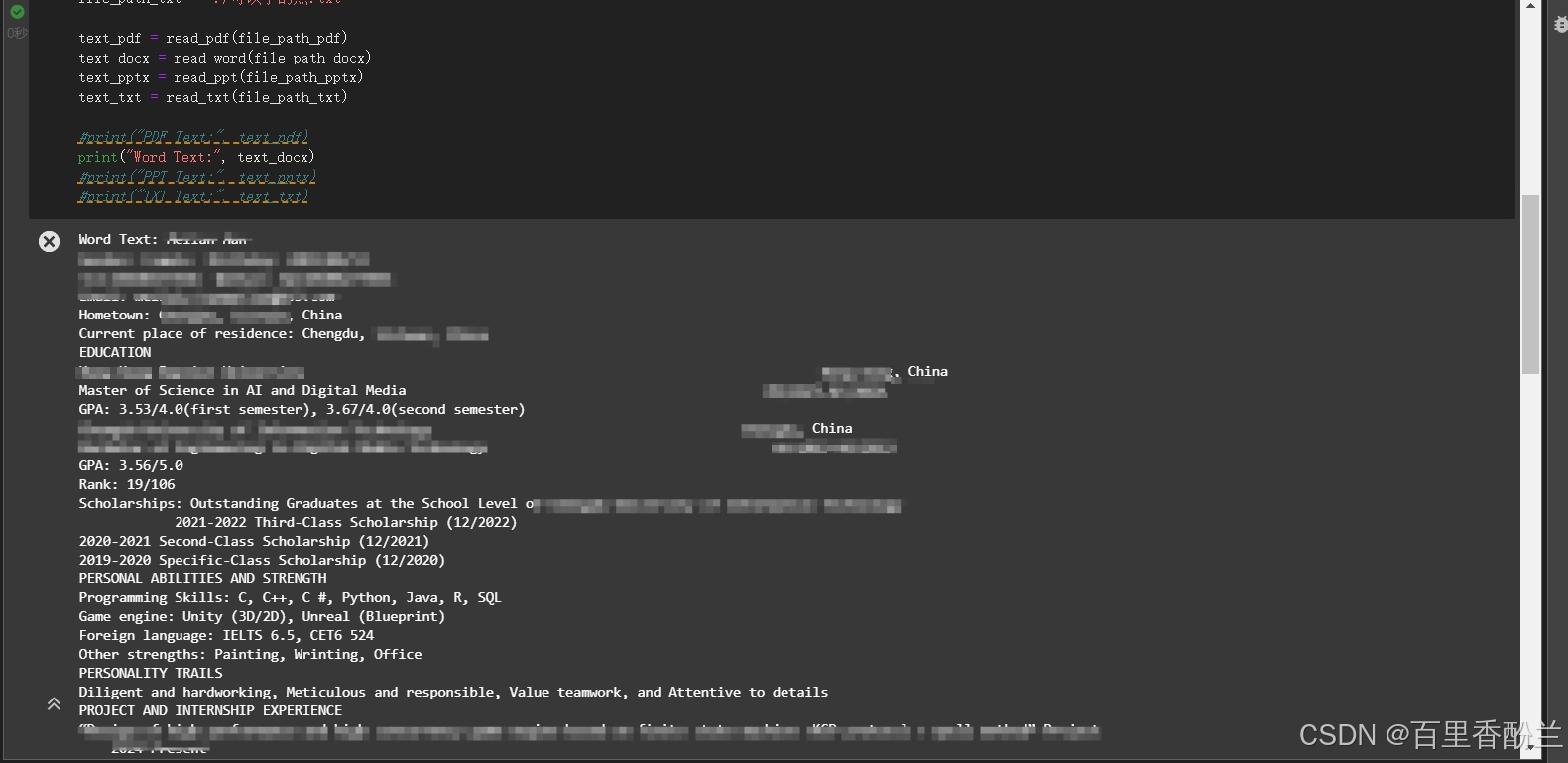
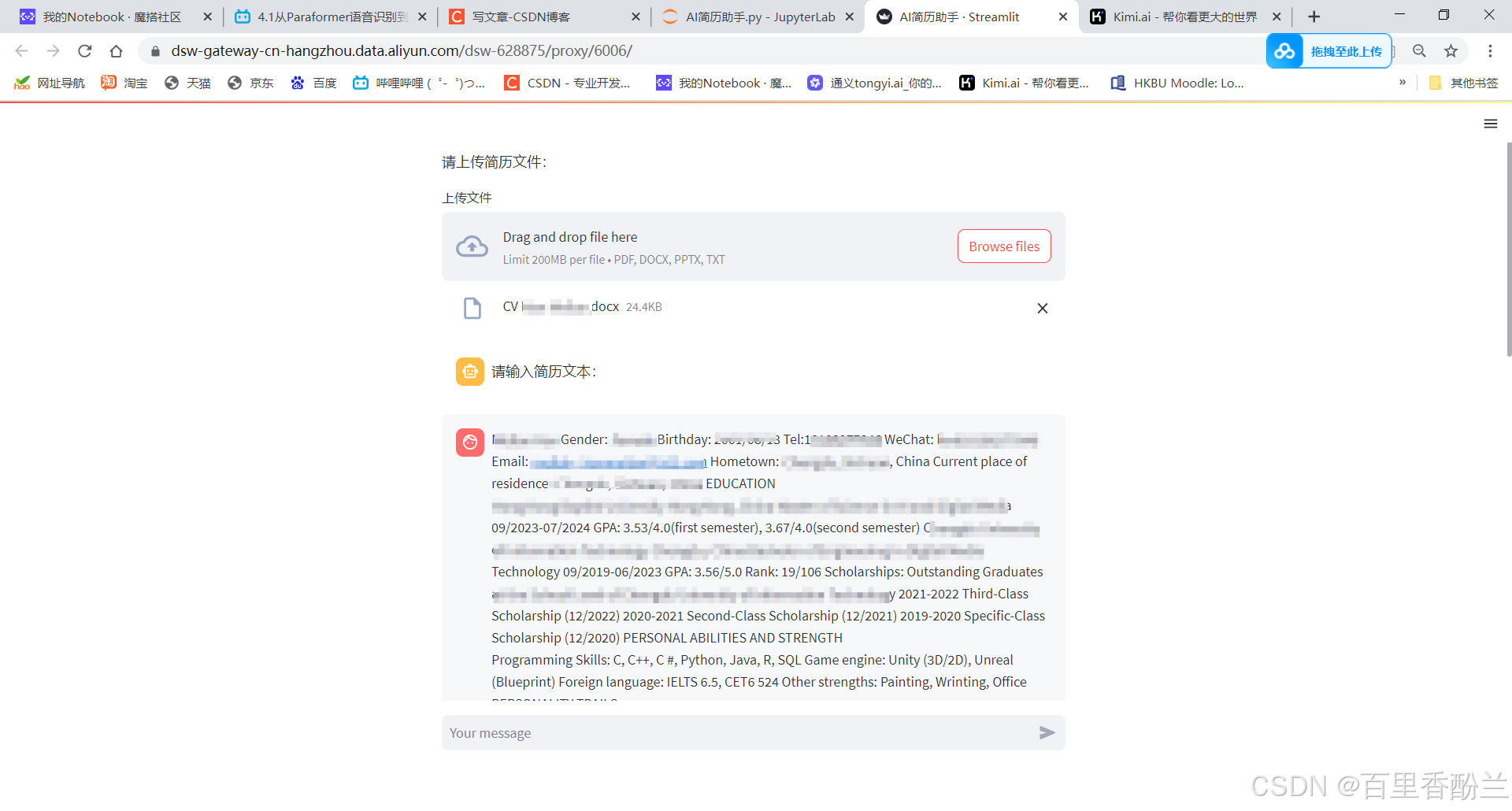
下一个是word,我随手找了个英文的CV,没想到解析效果超棒!!比PDF惊艳太多了!!
然后是PPT,这个是我最不抱希望的一个——没想到效果也很棒!!惊到我了!!
txt当然没问题,写个C语言都能搞定的事情,小小Python,拿捏!
目前就PDF最不给力,啥都认不出来,不知道是不是我漏了什么关键操作。
我让通义千问把示例代码改成个支持多模态+Streamlit的,结果半天都没整出来,版本也有点混乱……好容易回退找到一版前端没问题的,但他显然不太聪明……我只能说多亏还给我输出了个表格,真是要谢谢他。
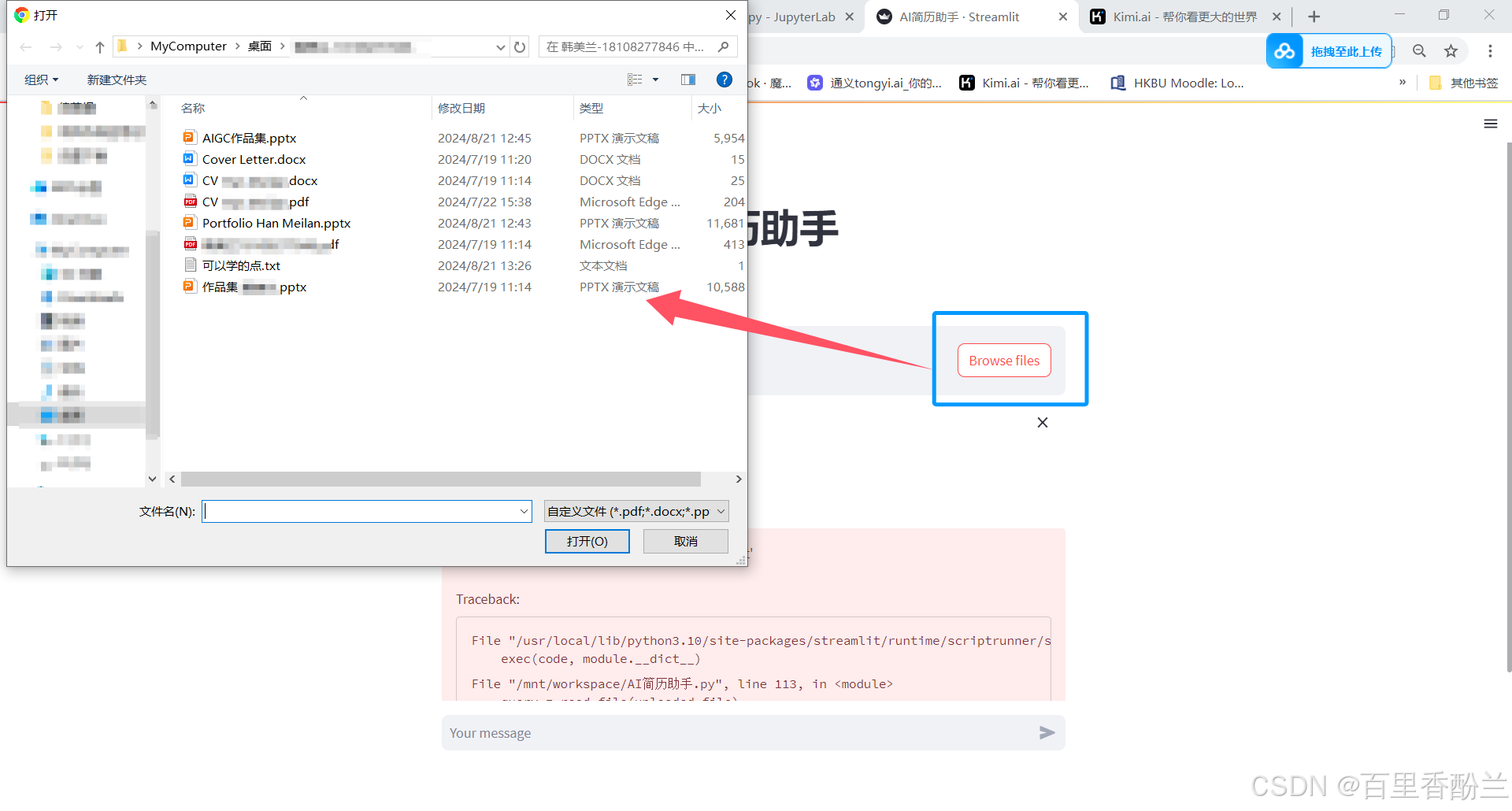
再让通义千问努力一把,好耶!拖拽上传框出来了!!!起作用的就这么一个st.file_uploader
现在能够从本地load文件了!狂喜!!
pdf还是老样子读不了,我猜是不是要用到图像识别了,正好下一次第五期有CV教学,到时候看看是啥。
word没问题:
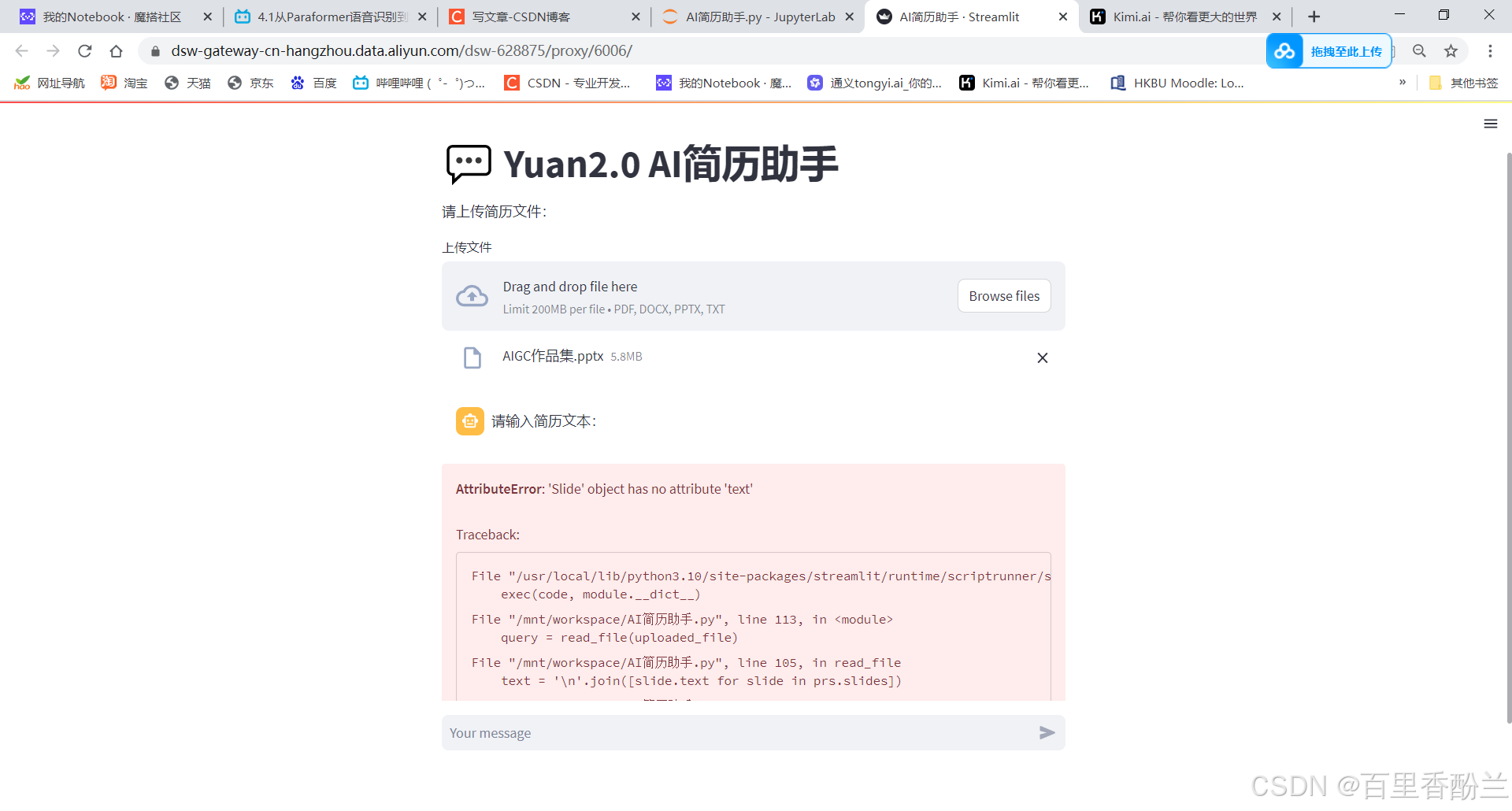
pptx出了点bug,待会看看是怎么回事:
让通义千问努把力:
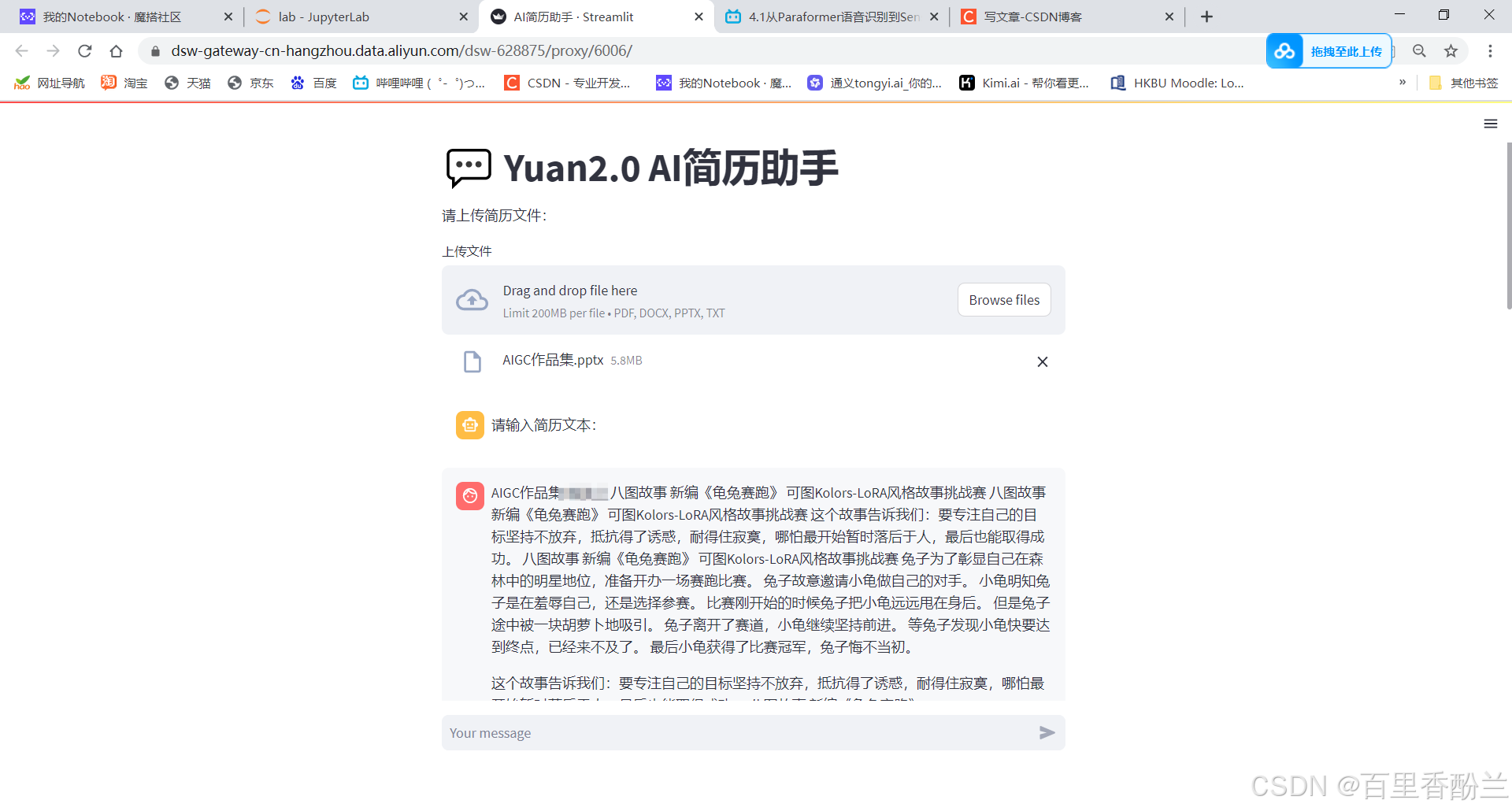
这次读PPT就没问题啦!!撒花!!!!!!
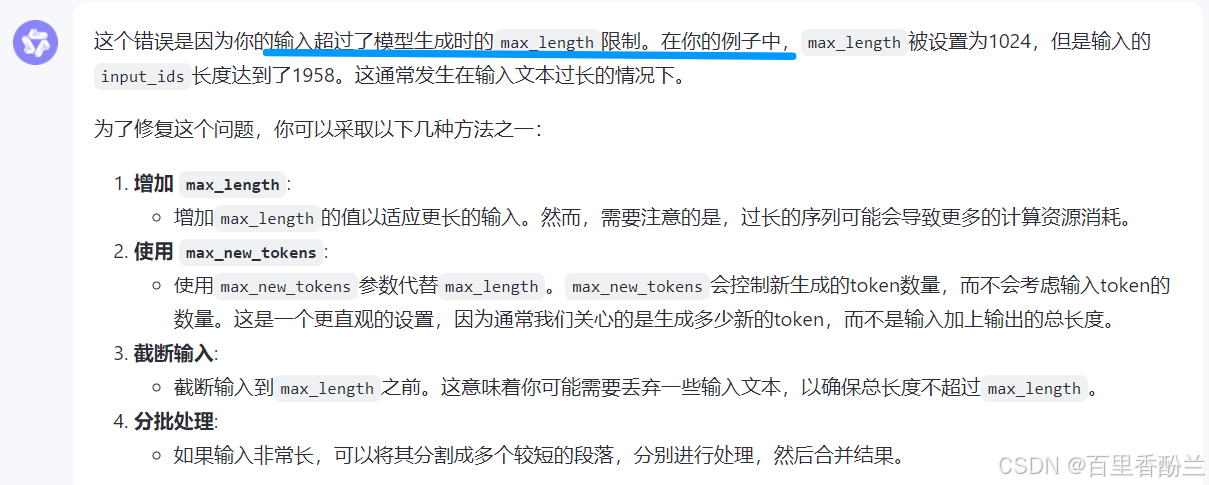
不过还有一个小问题,这个老碍事的长度限制:
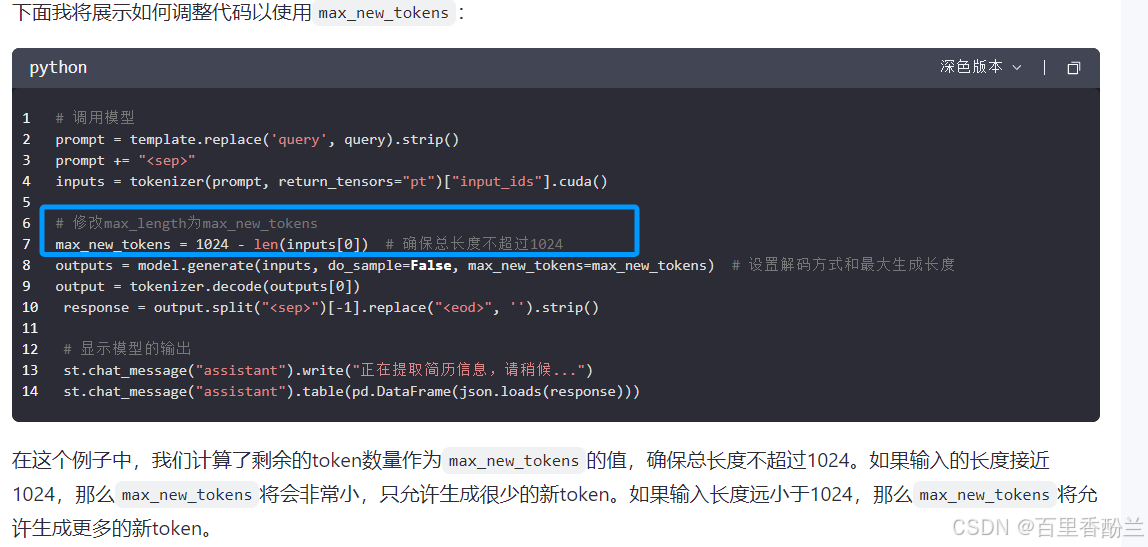
看AI的建议,把max_length换为max_new_tokens更合适。
这样即便还是会在结尾有标红,但是可以完整解析出内容,不受长度限制了。
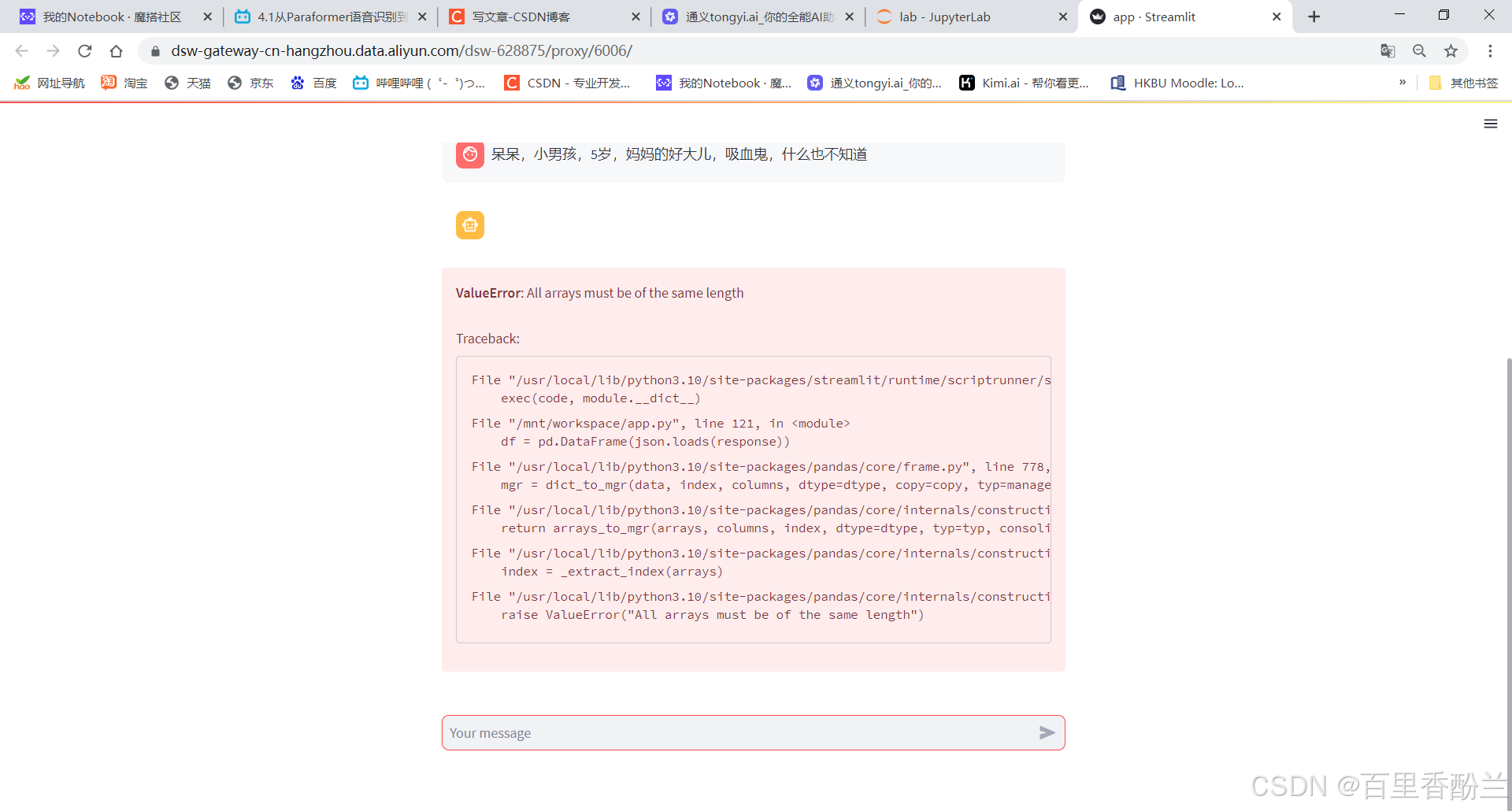
当然,输入文本让AI提取信息也是没问题的!
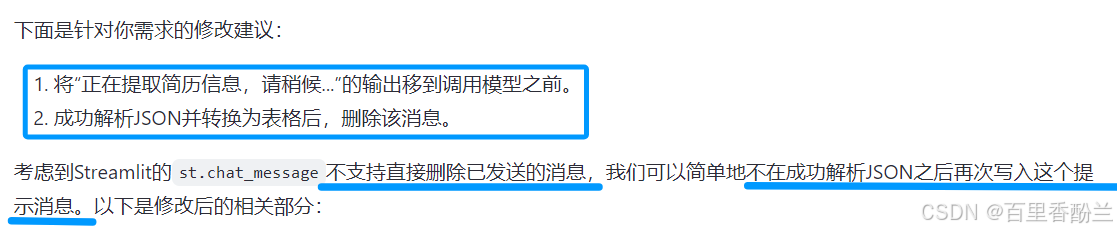
在输出表格以后,把“正在提取信息,请稍候”的信息删去就更好了。
自己读代码以后多找找突破点询问通义千问,最后发现只需要把提示语放入一个placeholder,大模型回答的话放入一个新的placeholder,之后生成结果了把提示语所在的那个placeholder删了就行了。
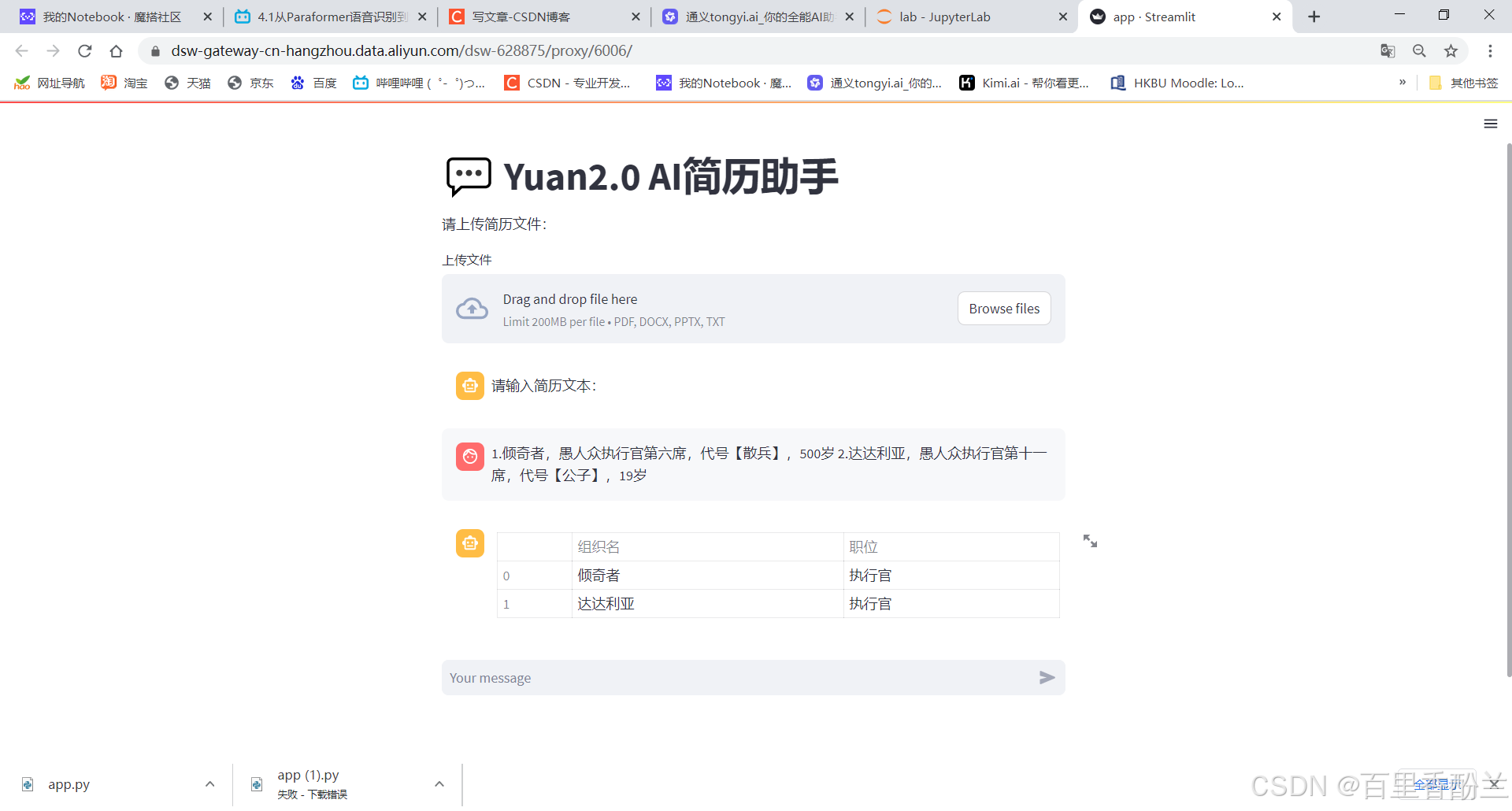
偶尔会谈触发一个奇怪的bug,不过大多数时候继续输入都没事。
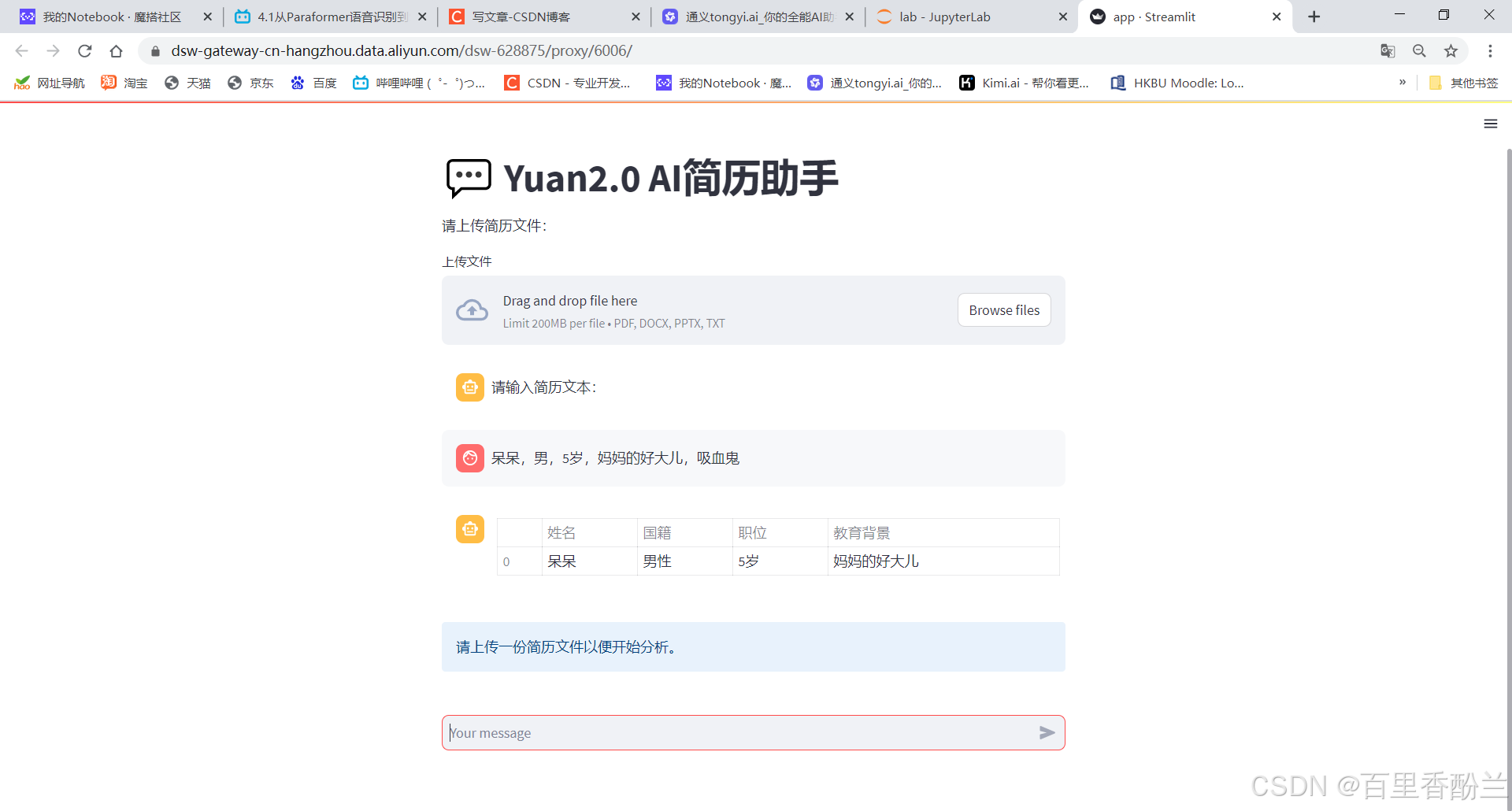
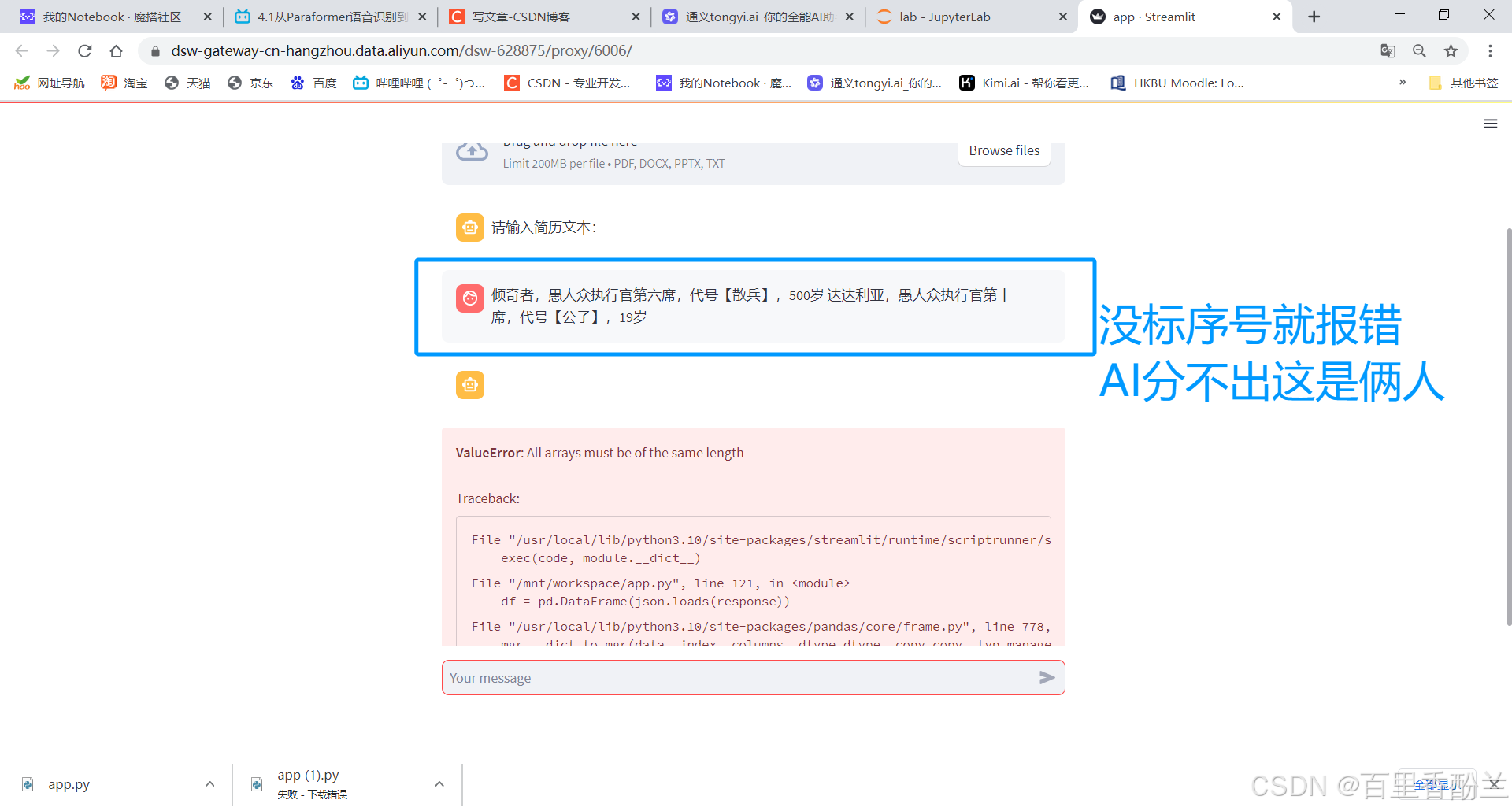
看来这是DataFrame带来的bug:
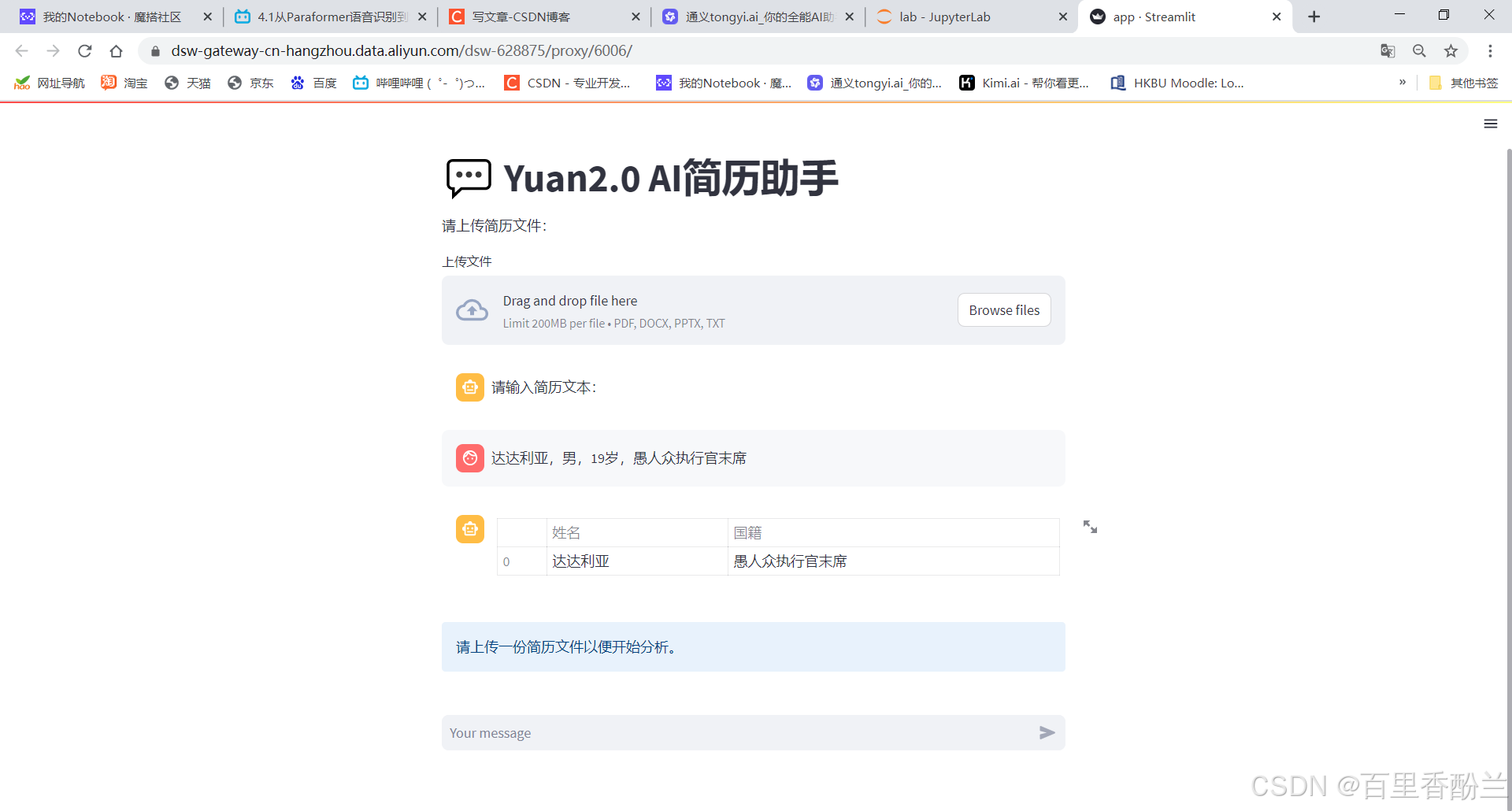
但是这只能解决单个人物带来的报错ValueError: All arrays must be of the same length,如果连续输入多个人物,AI分不出来到底谁是谁,必须要标序号,否则会报错。
优化进度迭代:
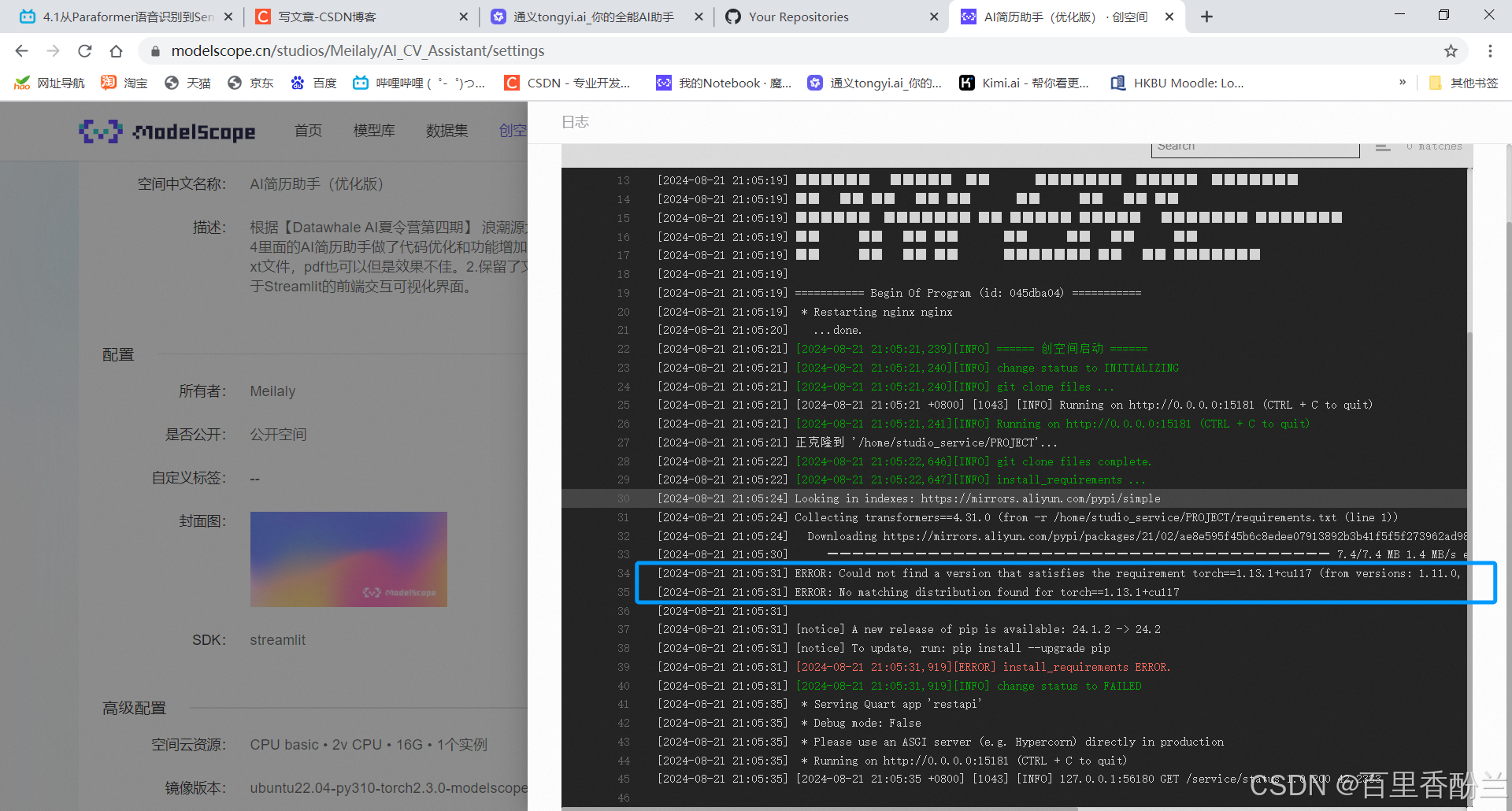
要发布的时候又报错装不上requirements.txt——没考虑CPU。
但这个代码目前只能做到读取word,txt,ppt,pdf的文件,还不能针对这些做到市面上的大模型那样精准的解读,不过比起之前还是有进步。
当前最新的优化代码我会打包好后放在个人CSDN资源库,有需要的朋友欢迎自取。Github和魔搭能发布的话都也会发布。
ModelScope的B站账号上又不少网课,看前三章更多是针对AIGC方向的,后面第四章开始更像是大模型应用方向了,正好AIGC那边也结营了,后面的课程笔记就搬到这里来吧。
课程链接:https://www.bilibili.com/video/BV1n1421b7jg/?spm_id_from=333.788&vd_source=cdfd0a0810bcc0bcdbcf373dafdf6a82
传送门



4.1从Paraformer语音识别到SenseVoice音频理解:技术演进与应用探索
天猫精灵、小米音箱、siri语音助手。
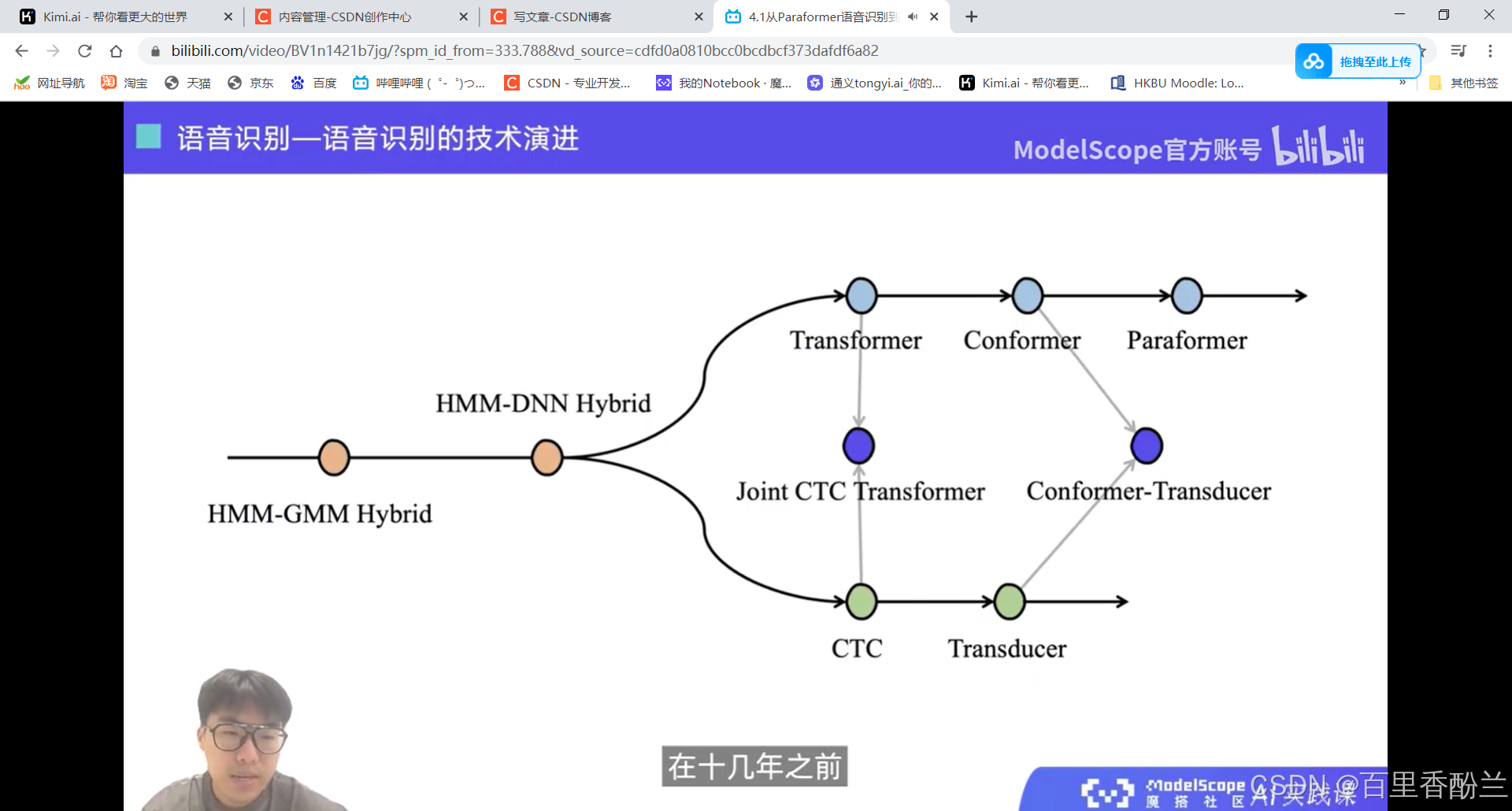
技术演进:
算法部分我就听个热闹了,卷不动。
熟悉的attention
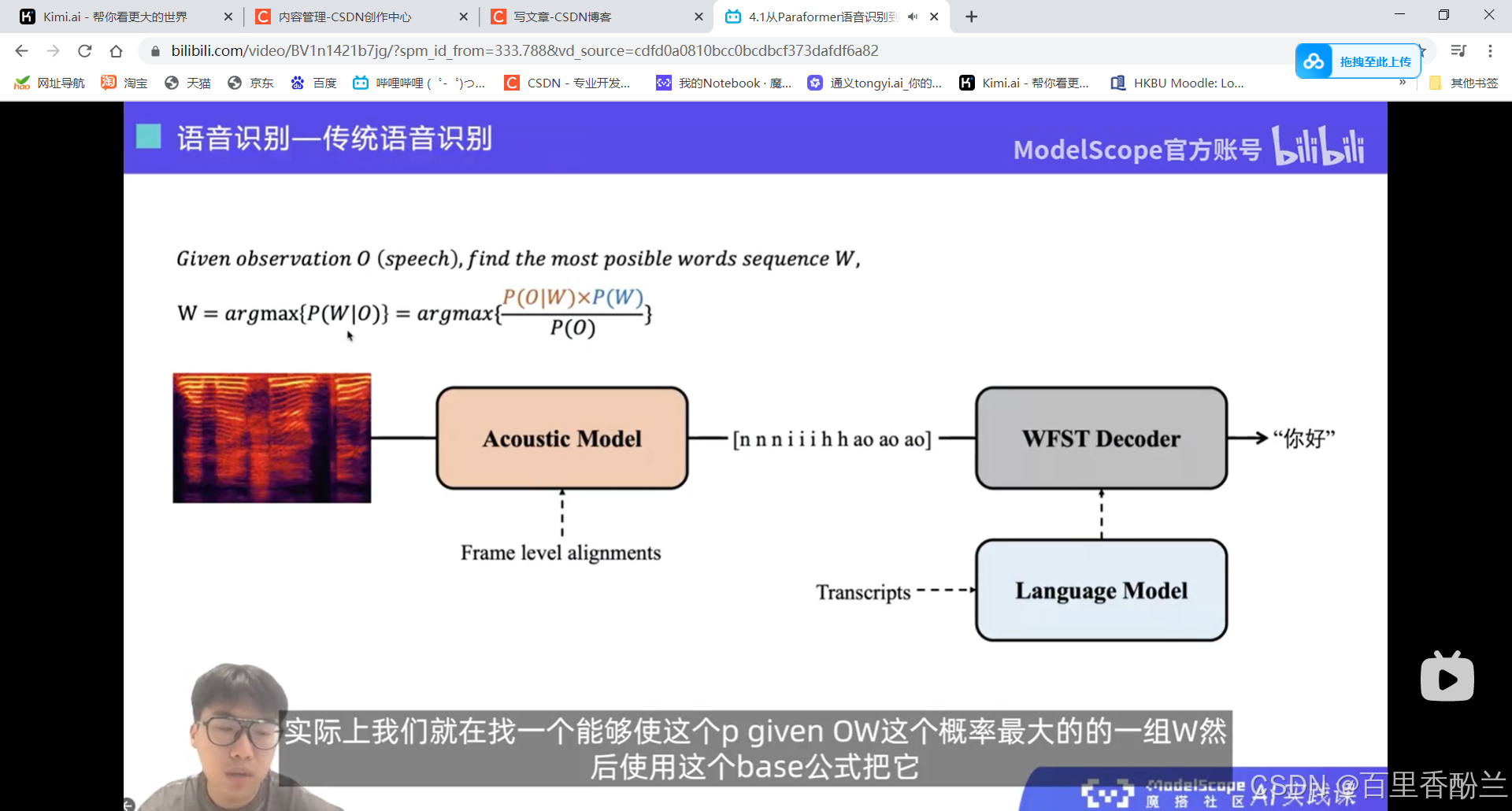
设计一个端到端的语音识别模型, 核心在于解决不等长序列的映射问题。
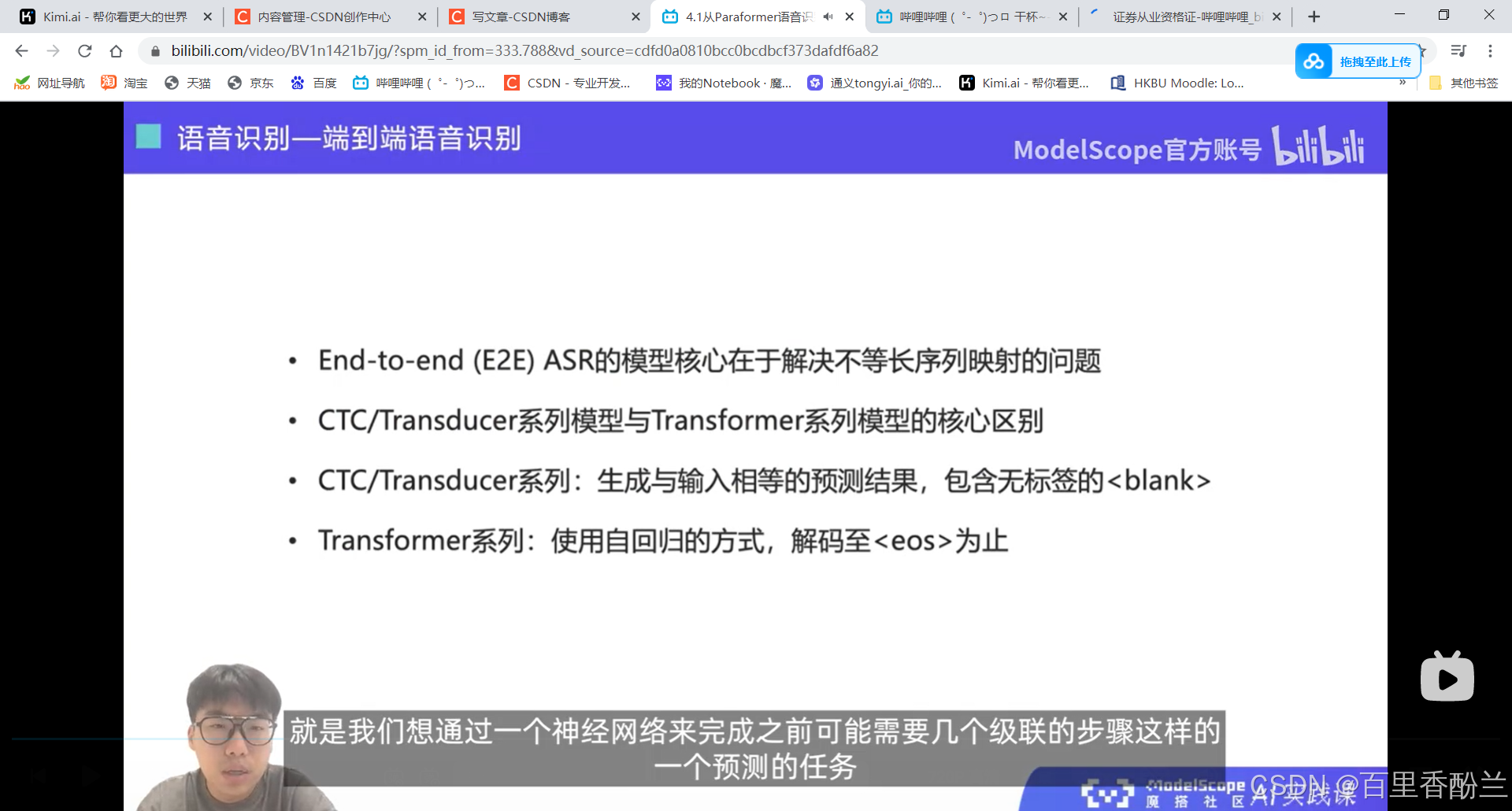
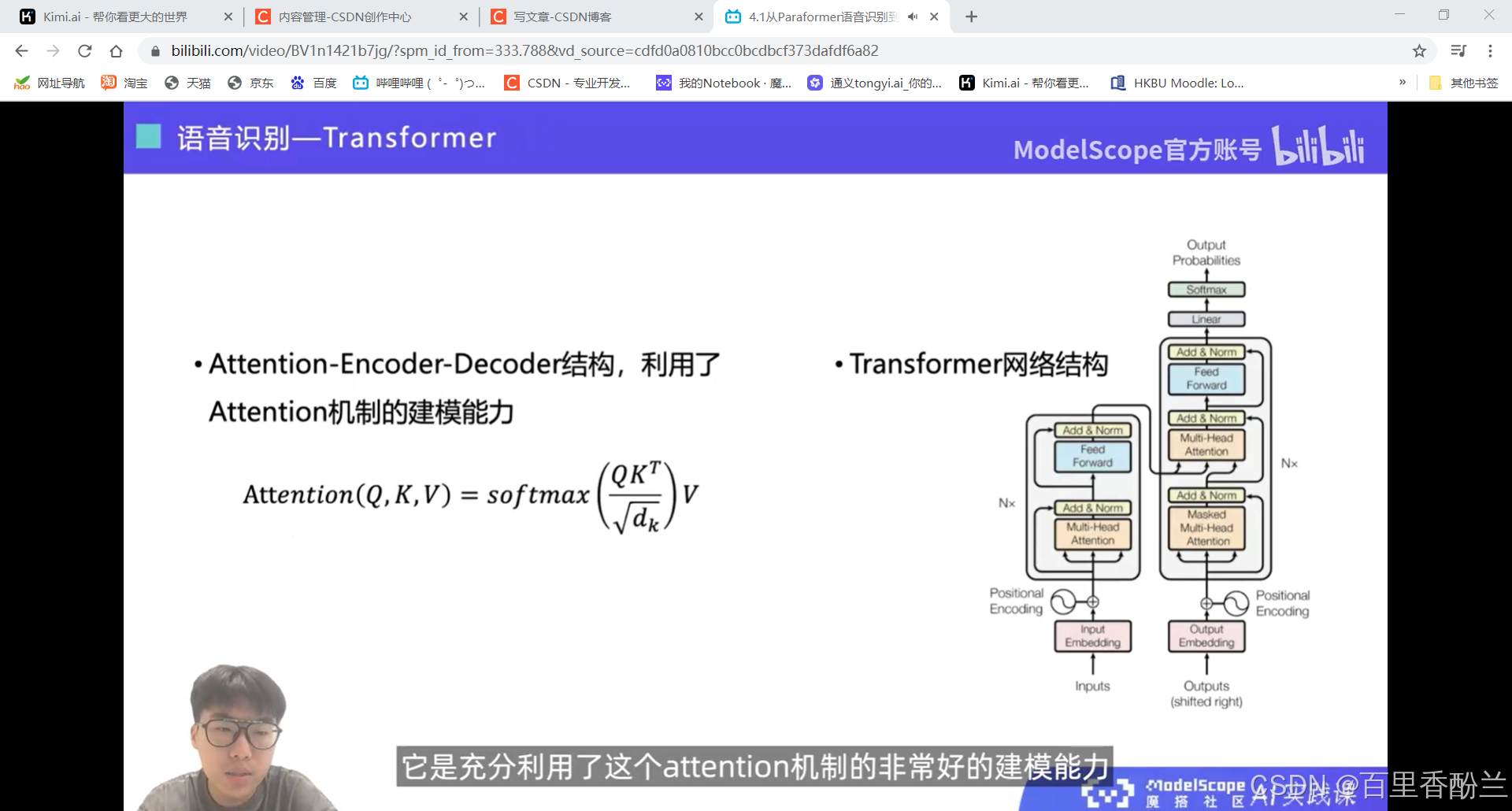
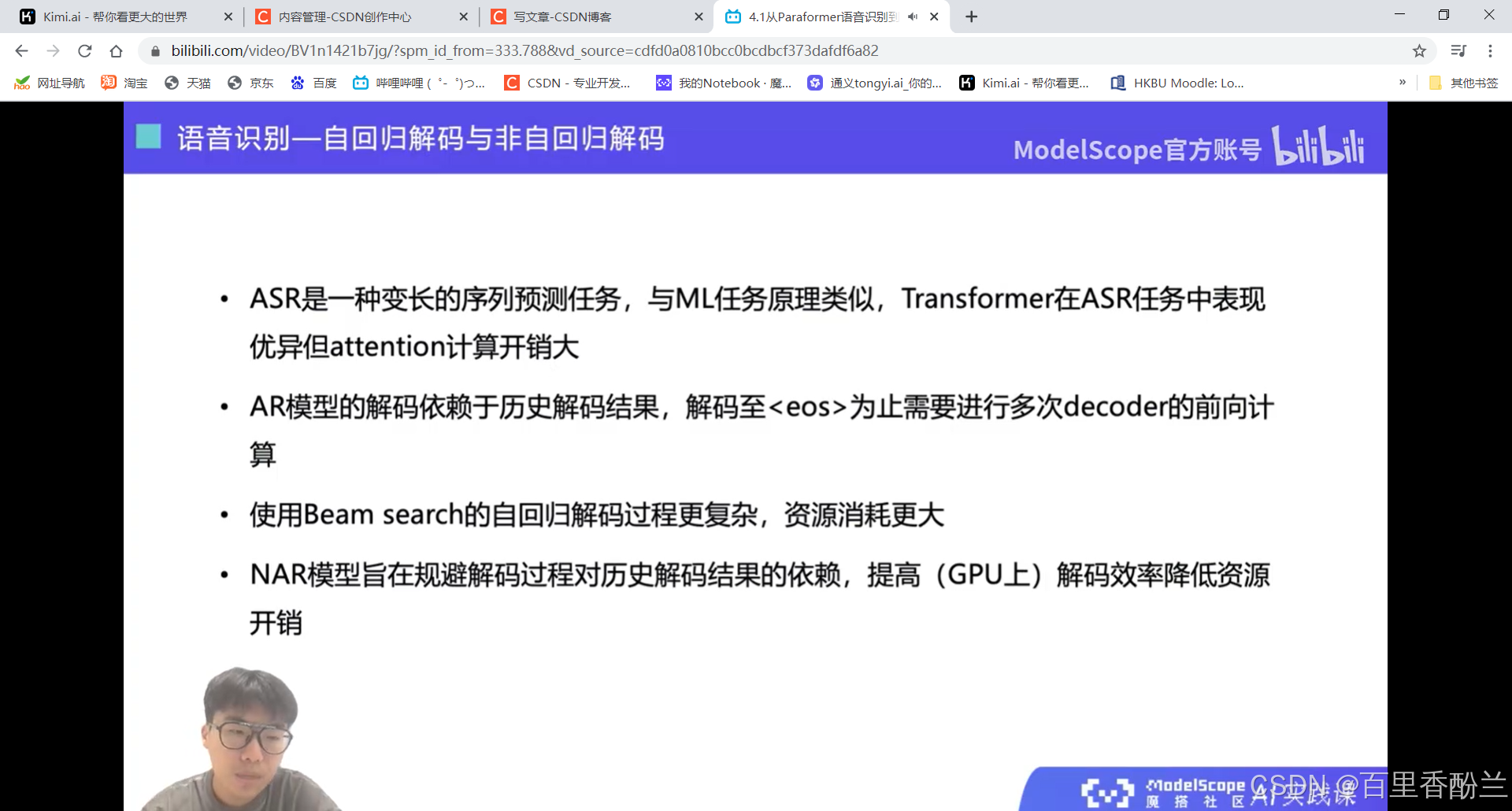
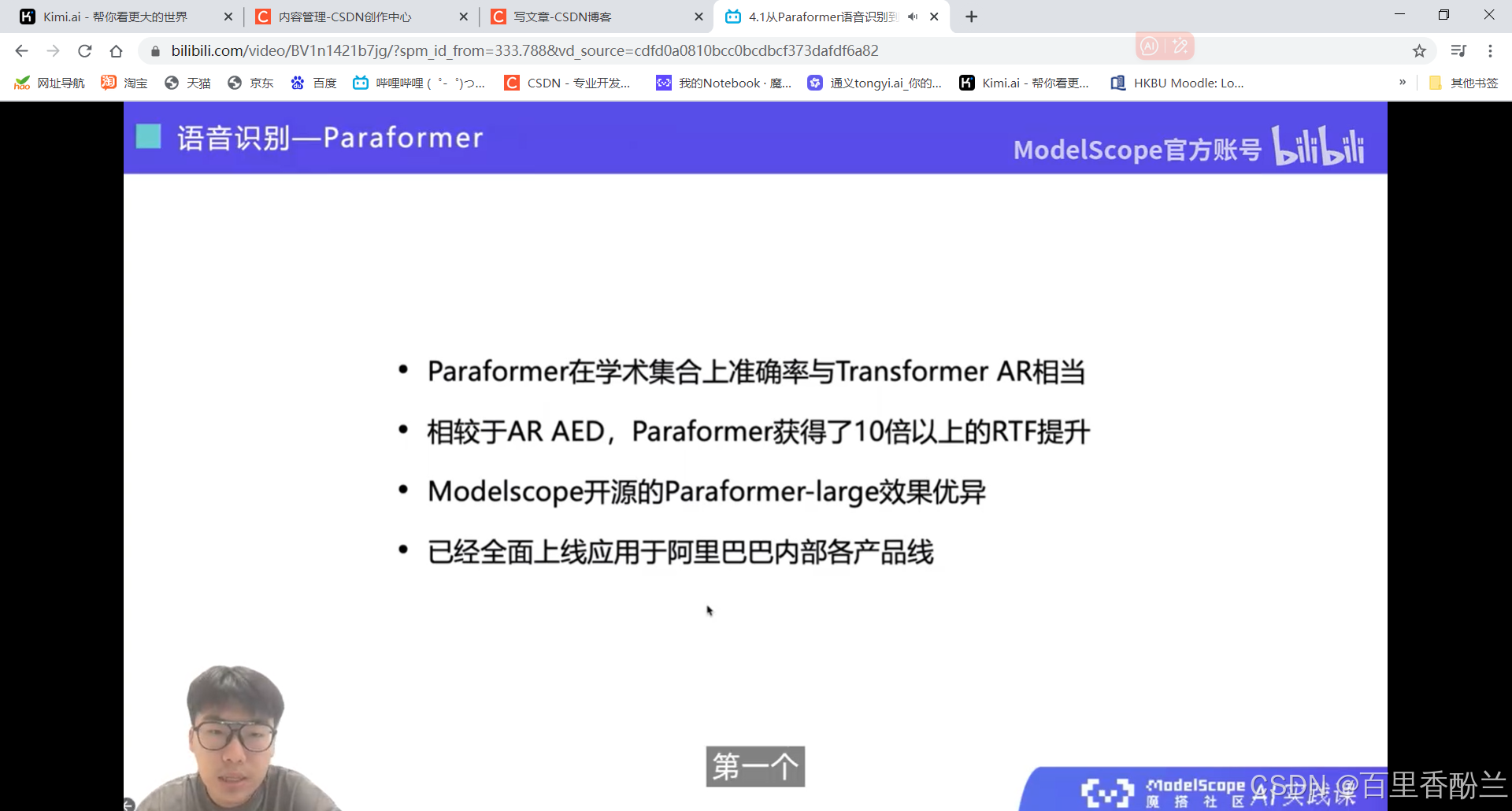
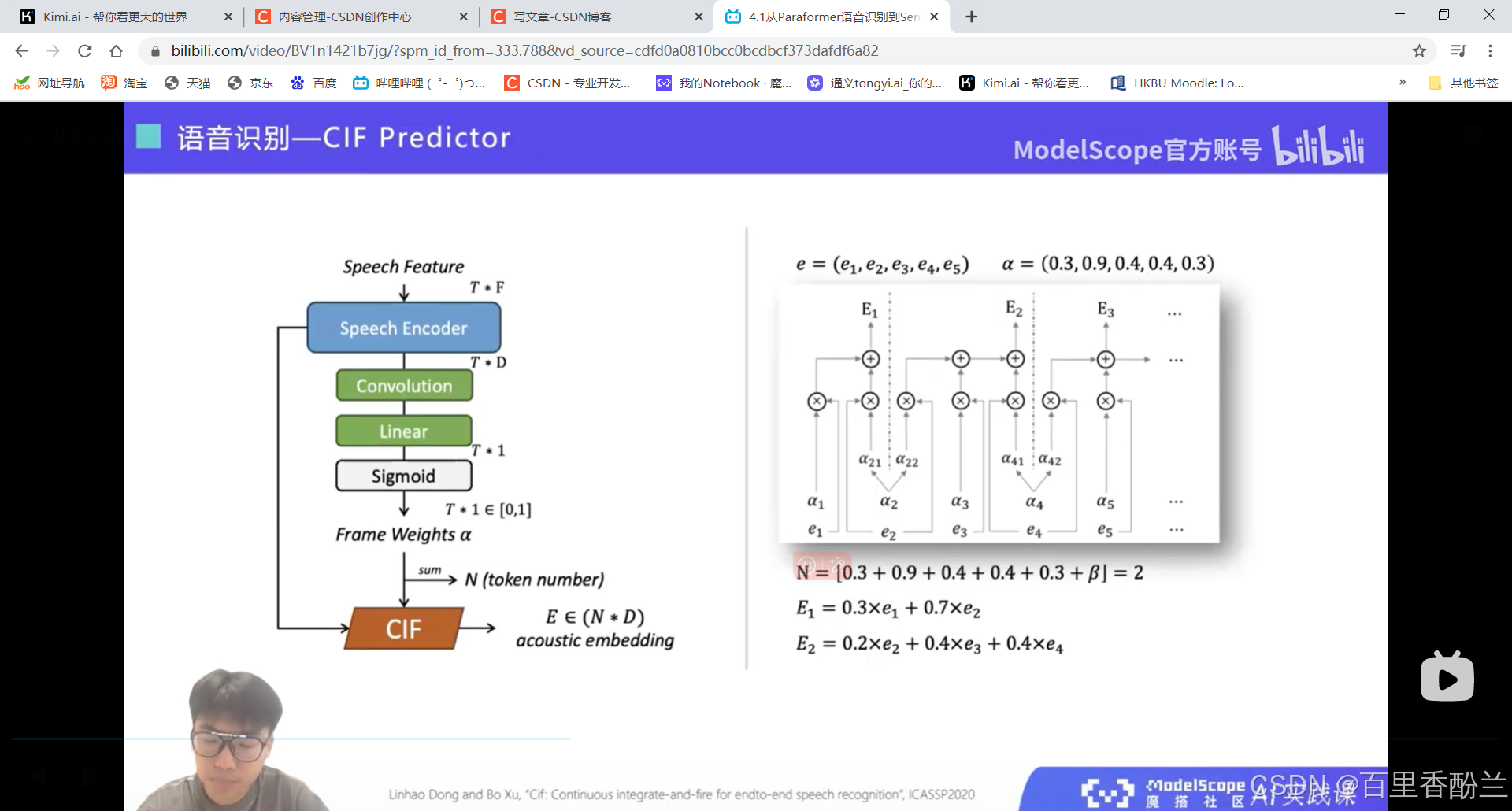
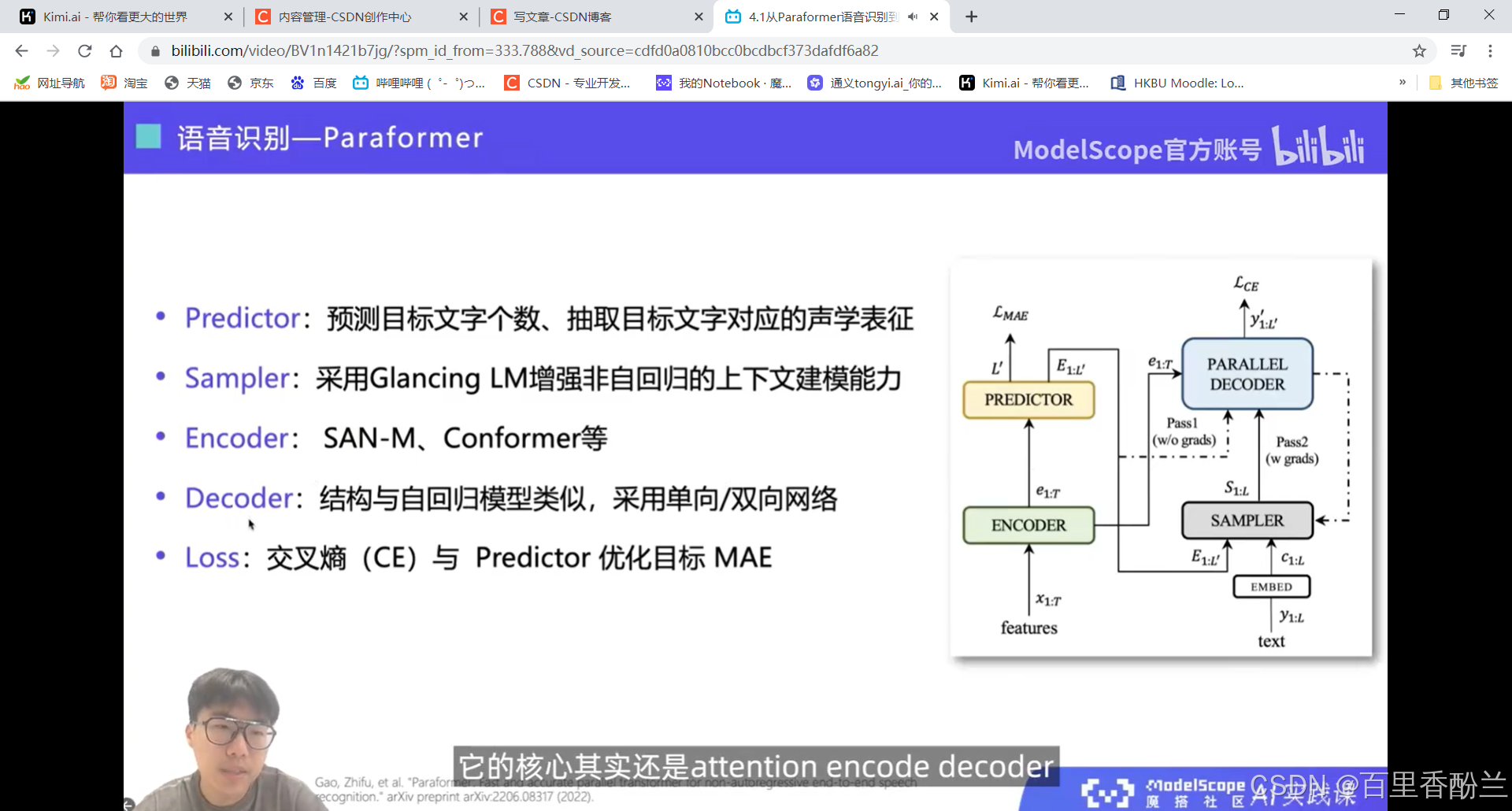
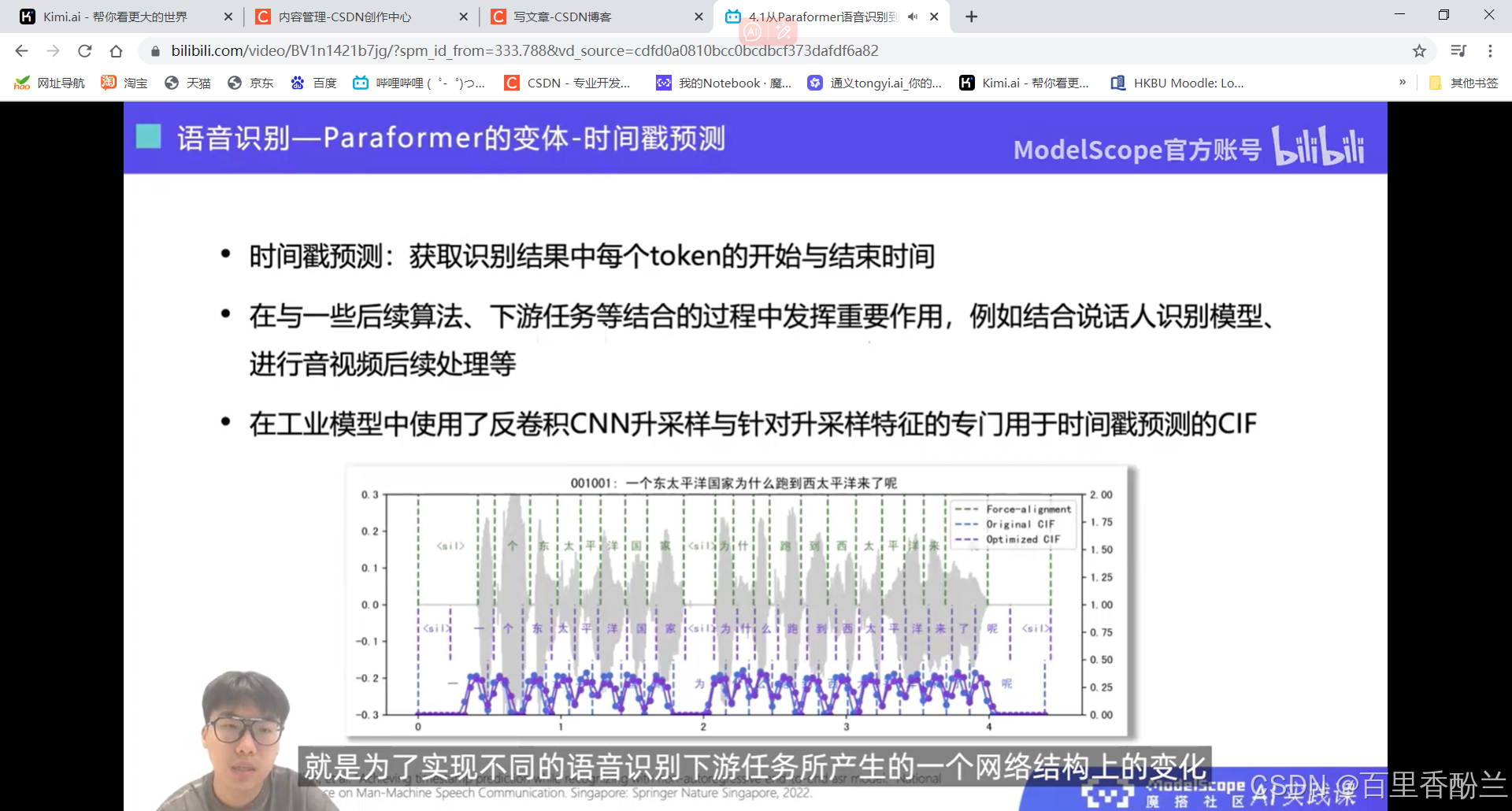
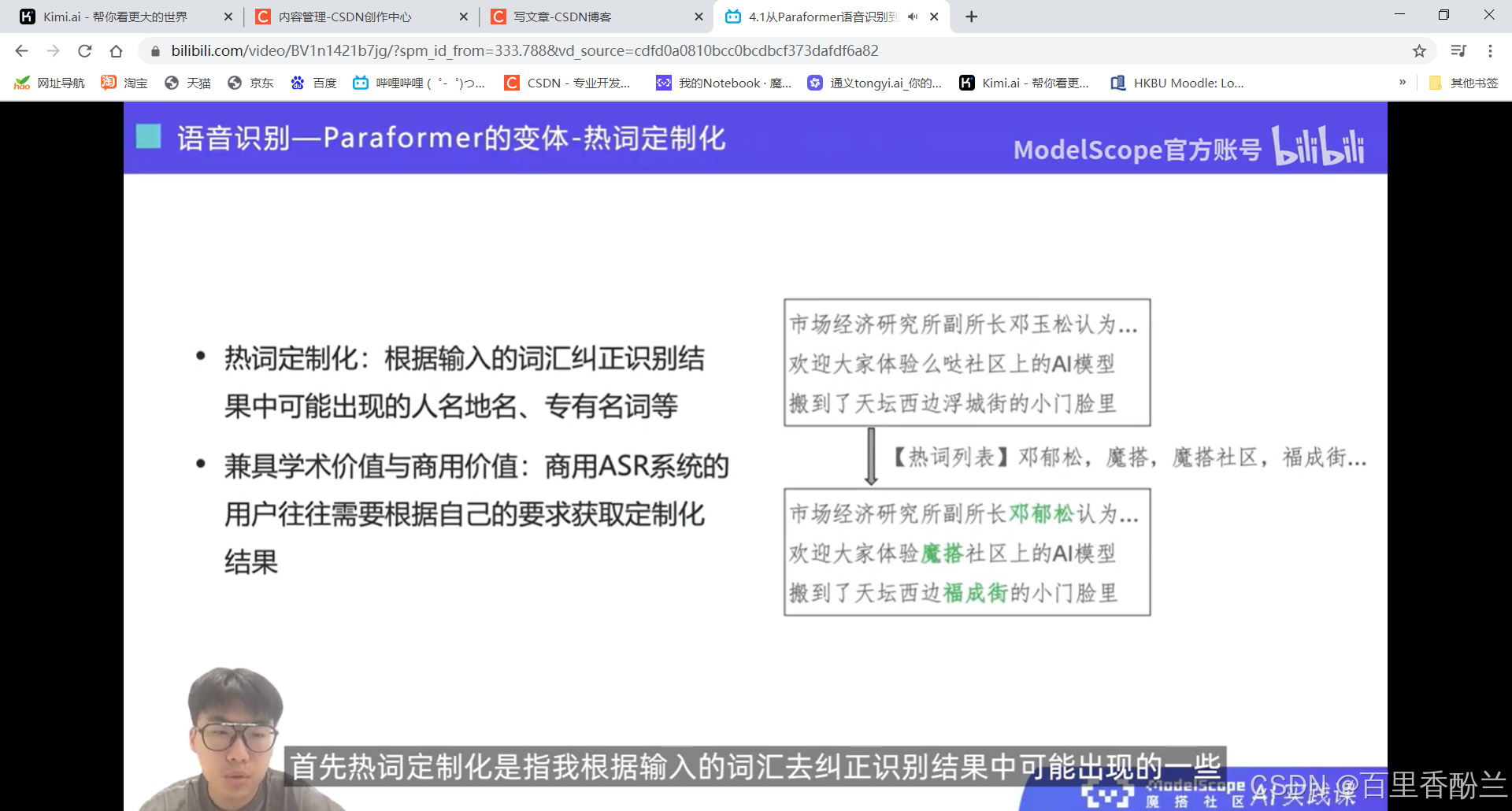
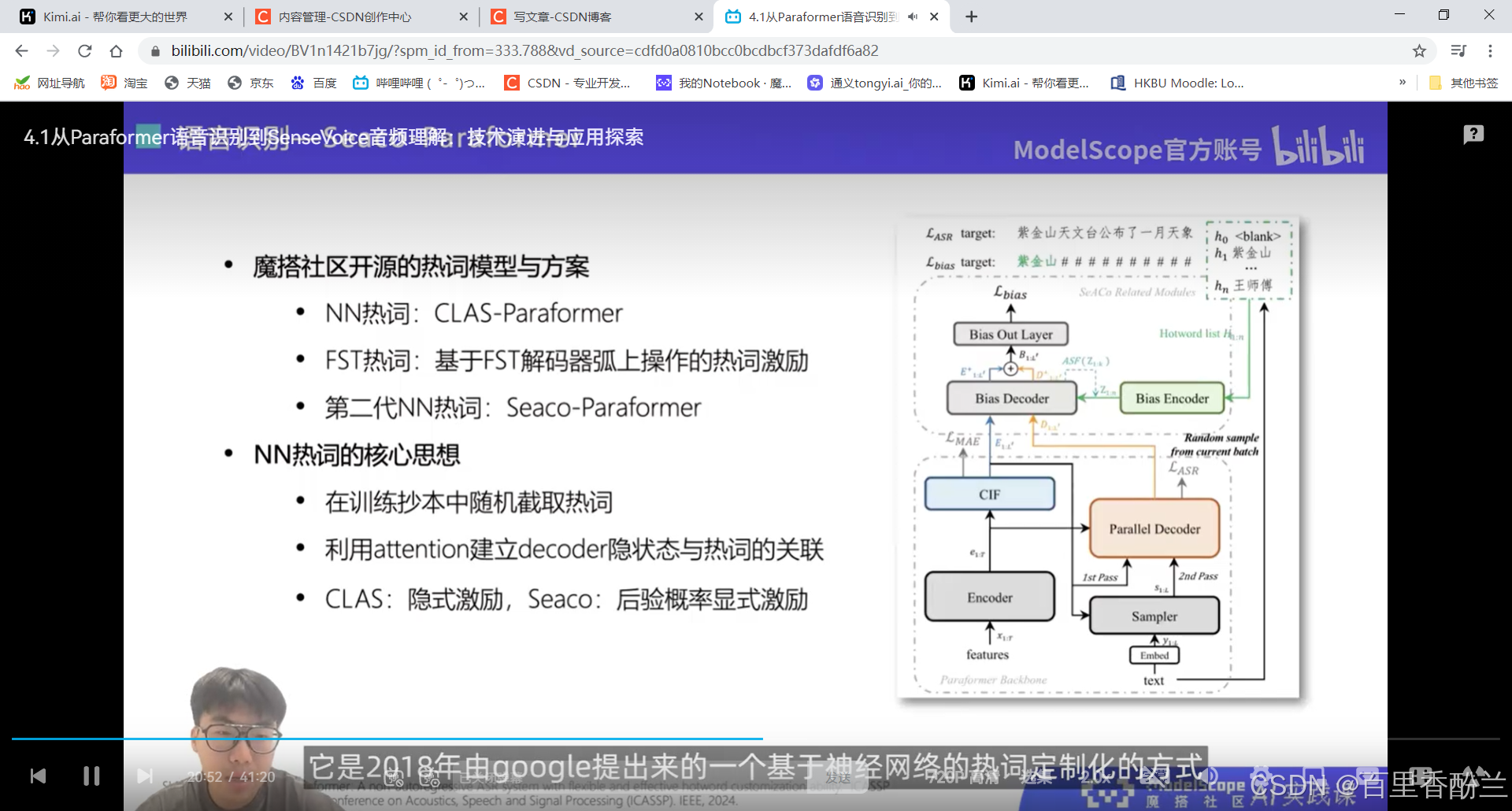
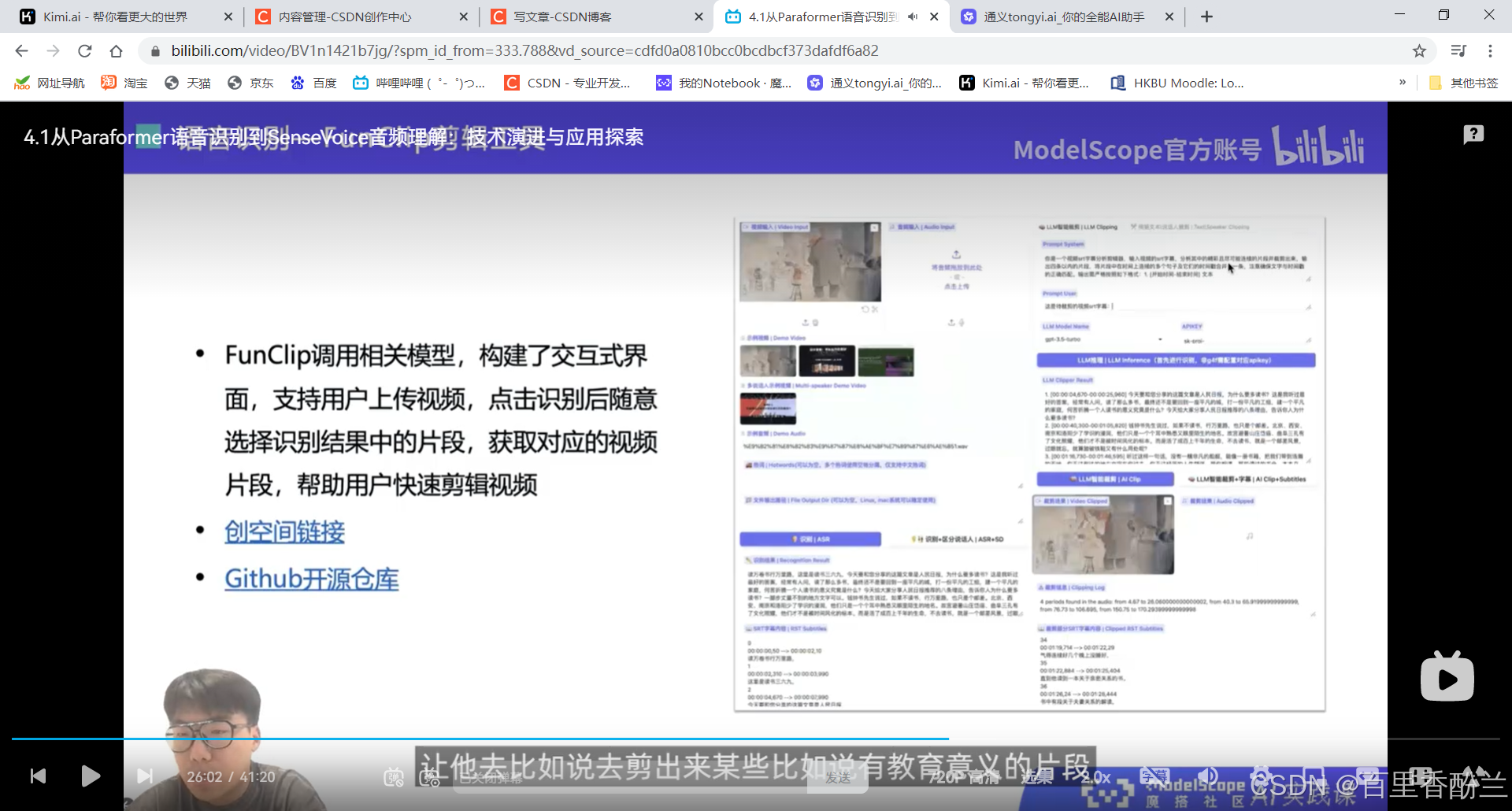
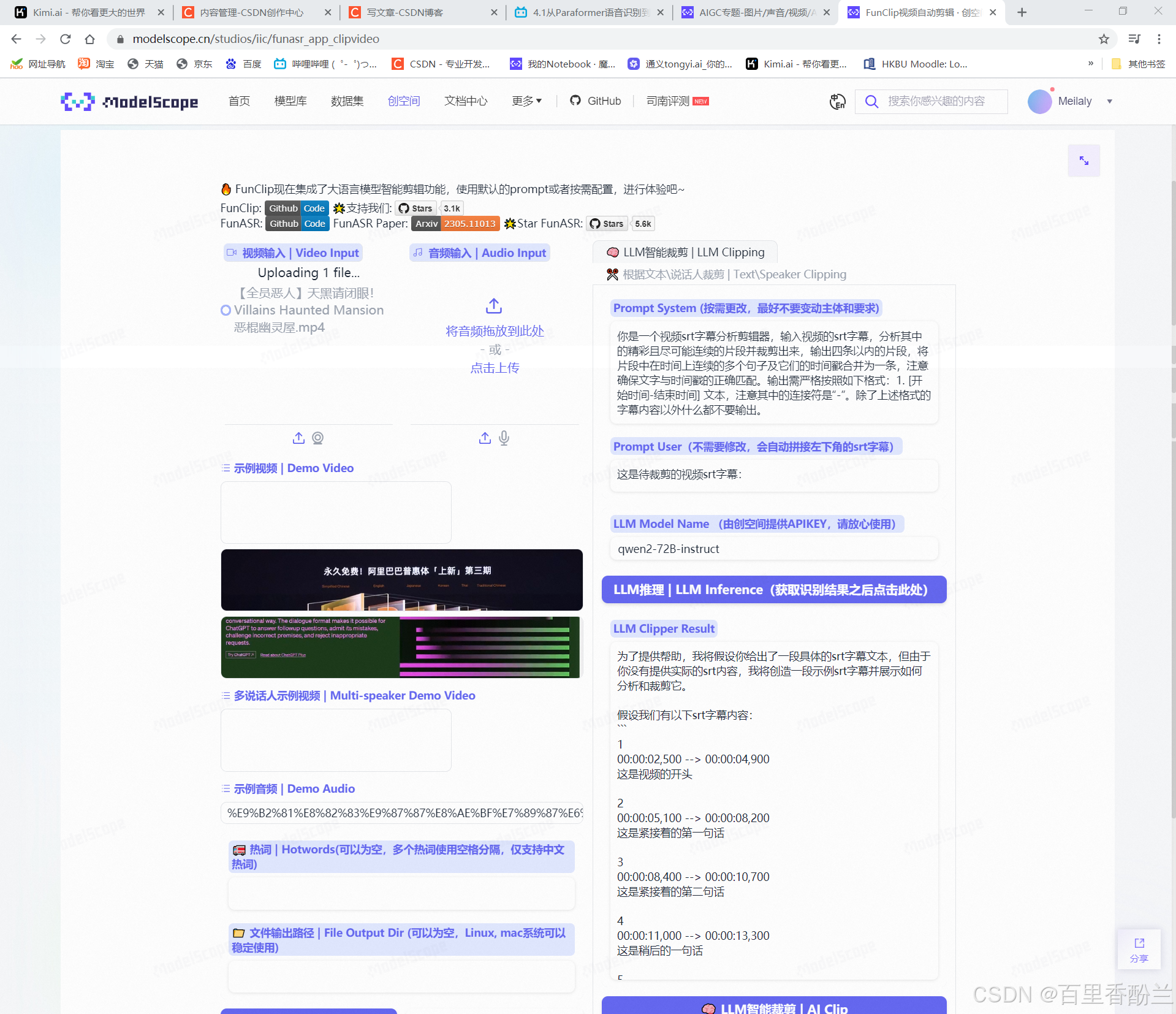
剪视频神器FunClip:
这个功能像是精细化裁剪视频?能够快速通过识别出的内容定位位置,有点像飞书的会议回看。
而且这个还可以在视频下方生成字幕信息,标出每句话开始和结束的时间。这个我感觉字幕组的一些工作可以用到,之前对加入英语字幕组感兴趣(可惜没选上),了解了一下大概的分工,这个活很适合时间轴负责人。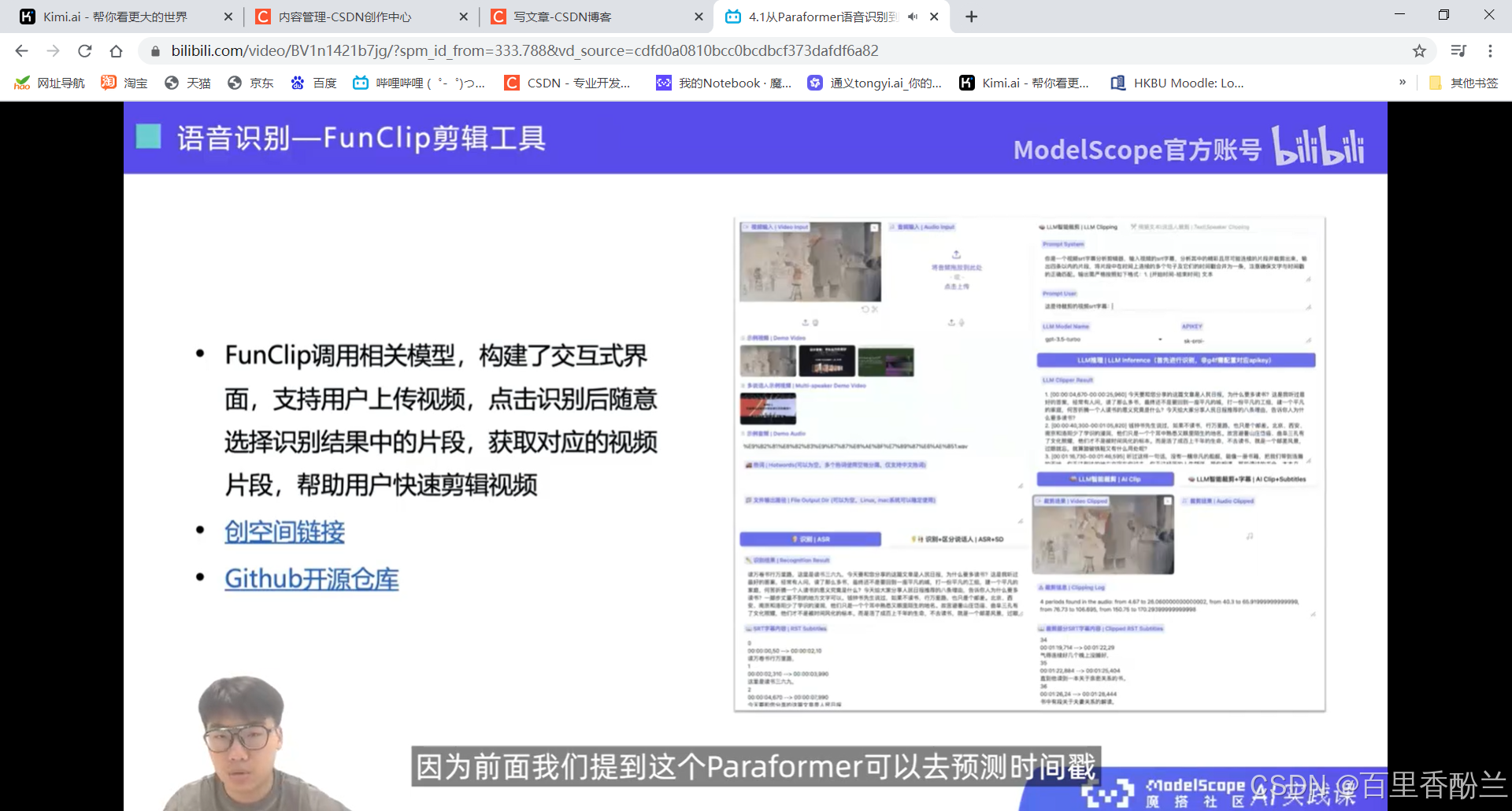
如果这个代码能支持电影、纪录片这样的长视频解读,将大量降低字幕组负责时间轴的人员的工作量。
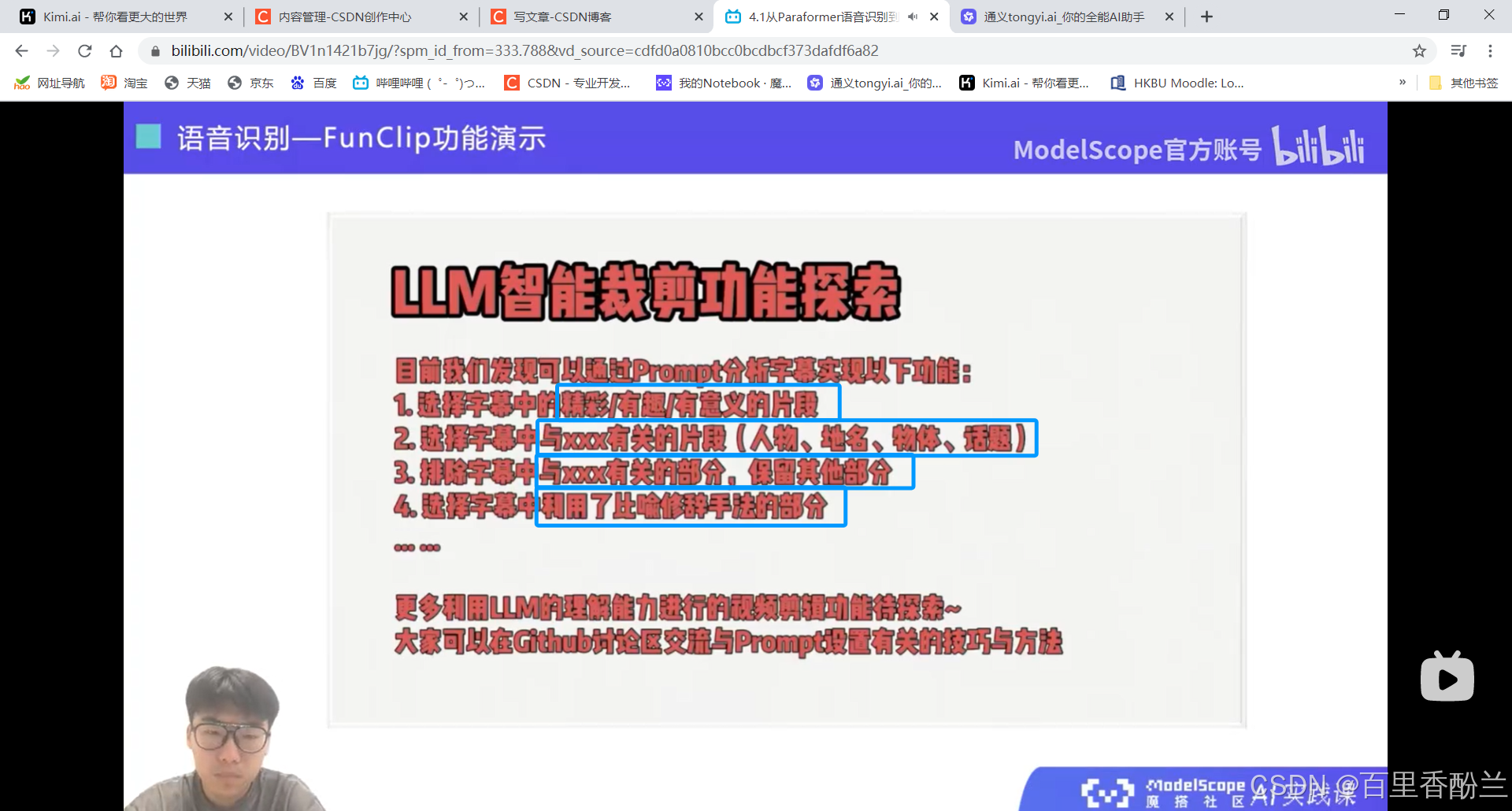
智能裁剪:居然还可以根据prompt自动剪有教育意义、跟某些元素相关之类的片段,那就很方便短视频、电影解说自媒体了。
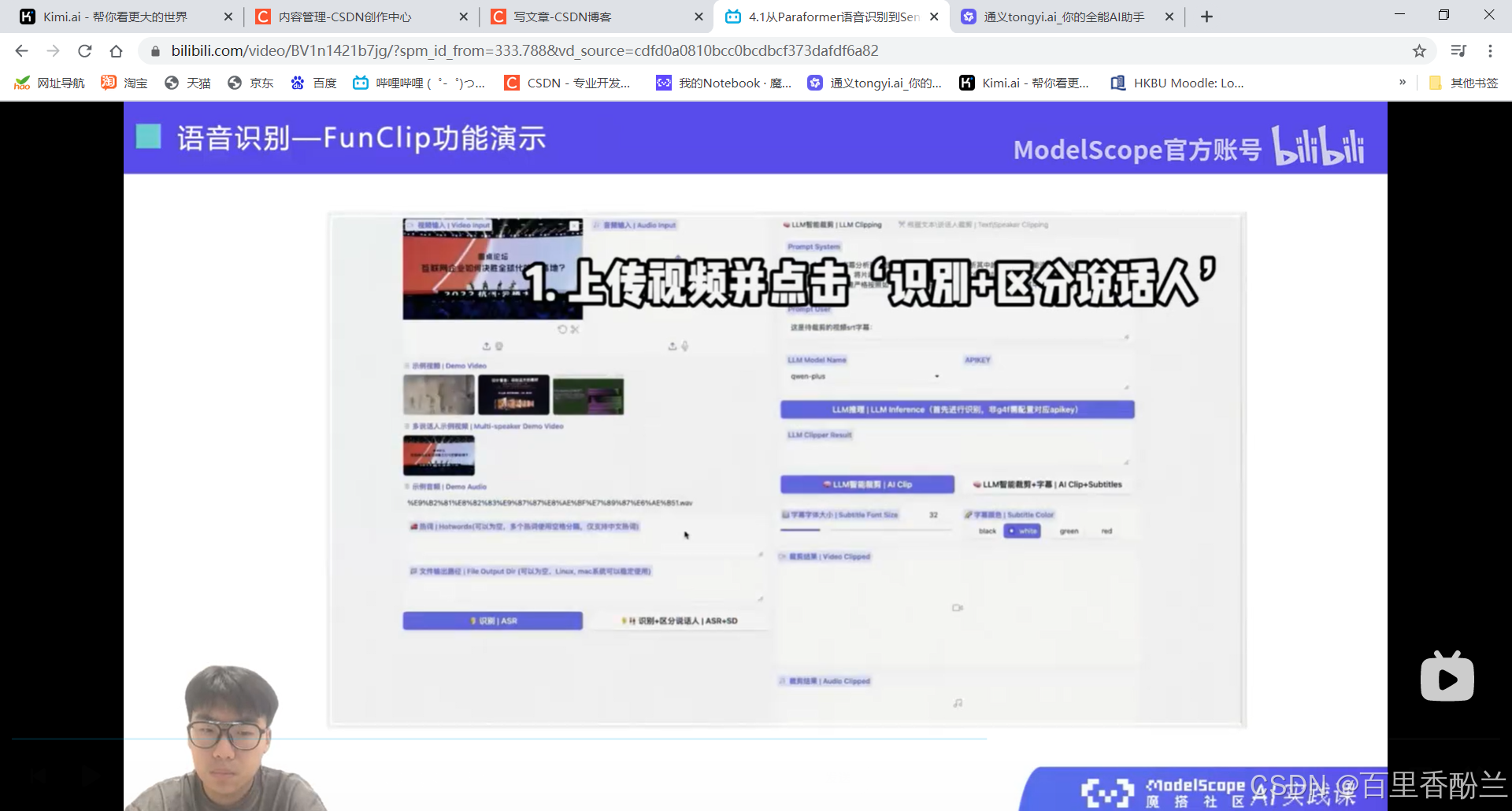
他居然还可以区分说话人?那就很好做B站上面影视/游戏的角色单人cut和拉郎混剪。
魔搭创空间体验链接: https://modelscope.cn/studios/iic/funasr_app_clipvideo
我下了个视频传上去,时间轴这块看着还不错:
Github链接: https://github.com/modelscope/FunClip
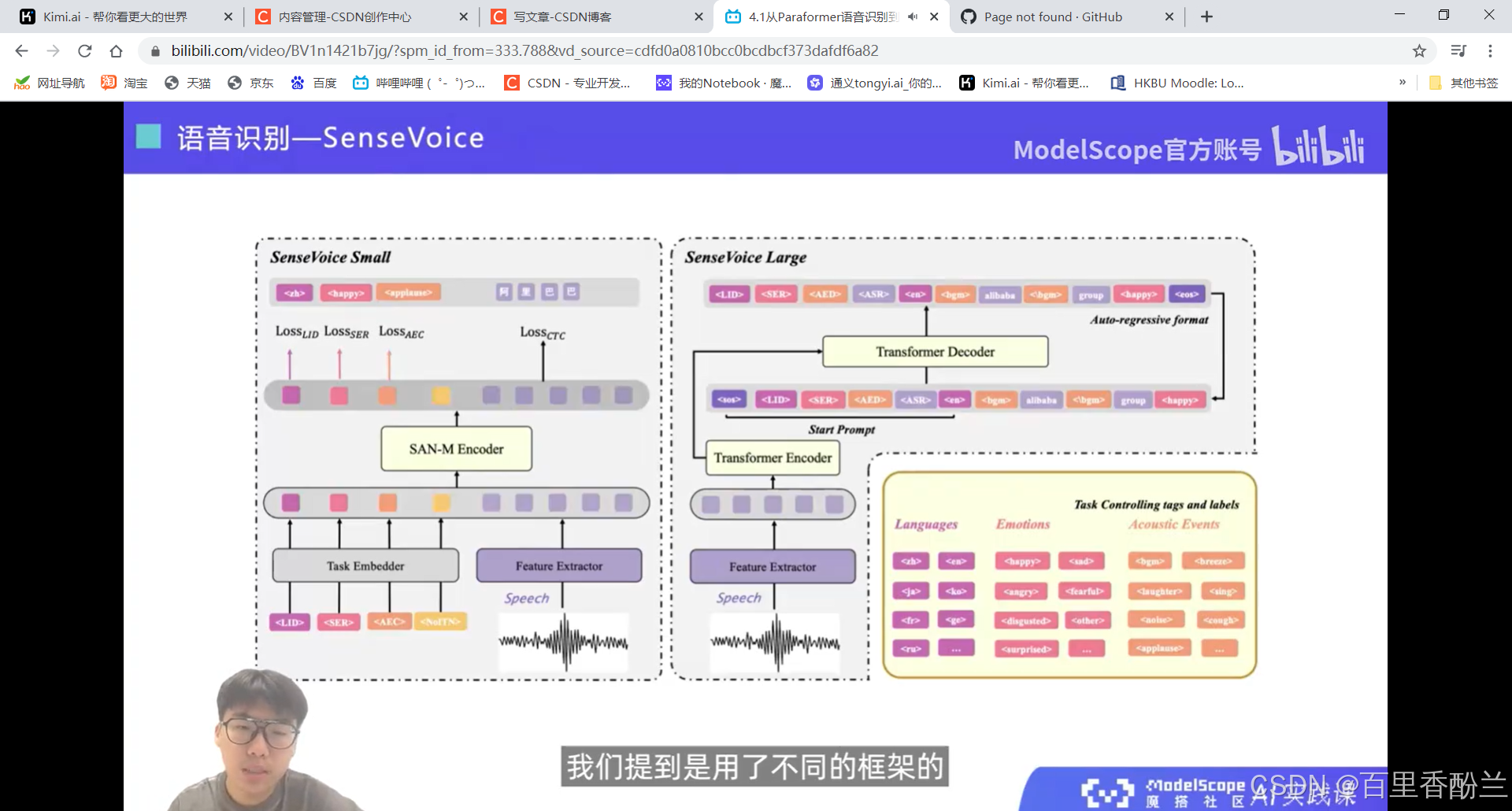
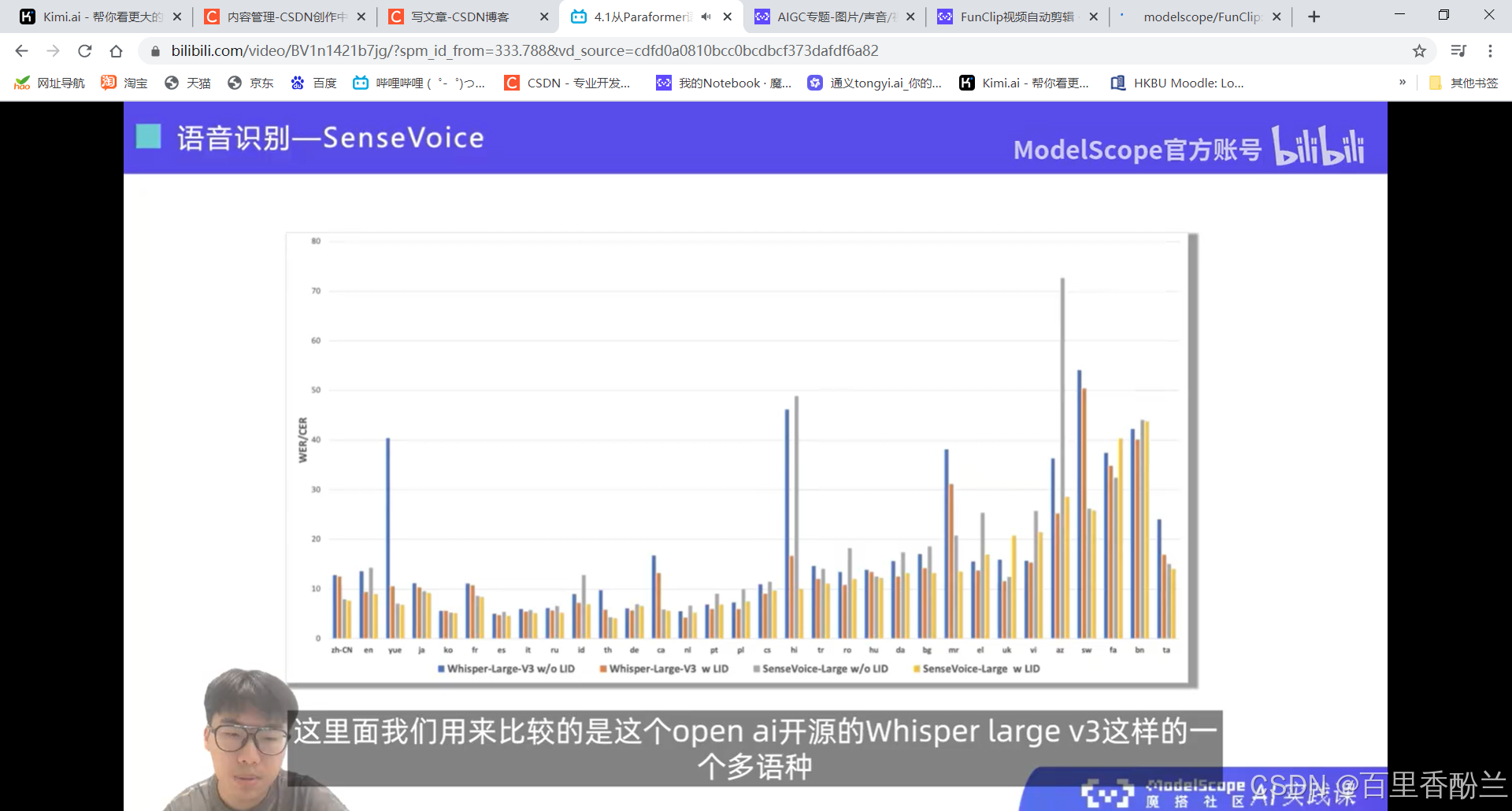
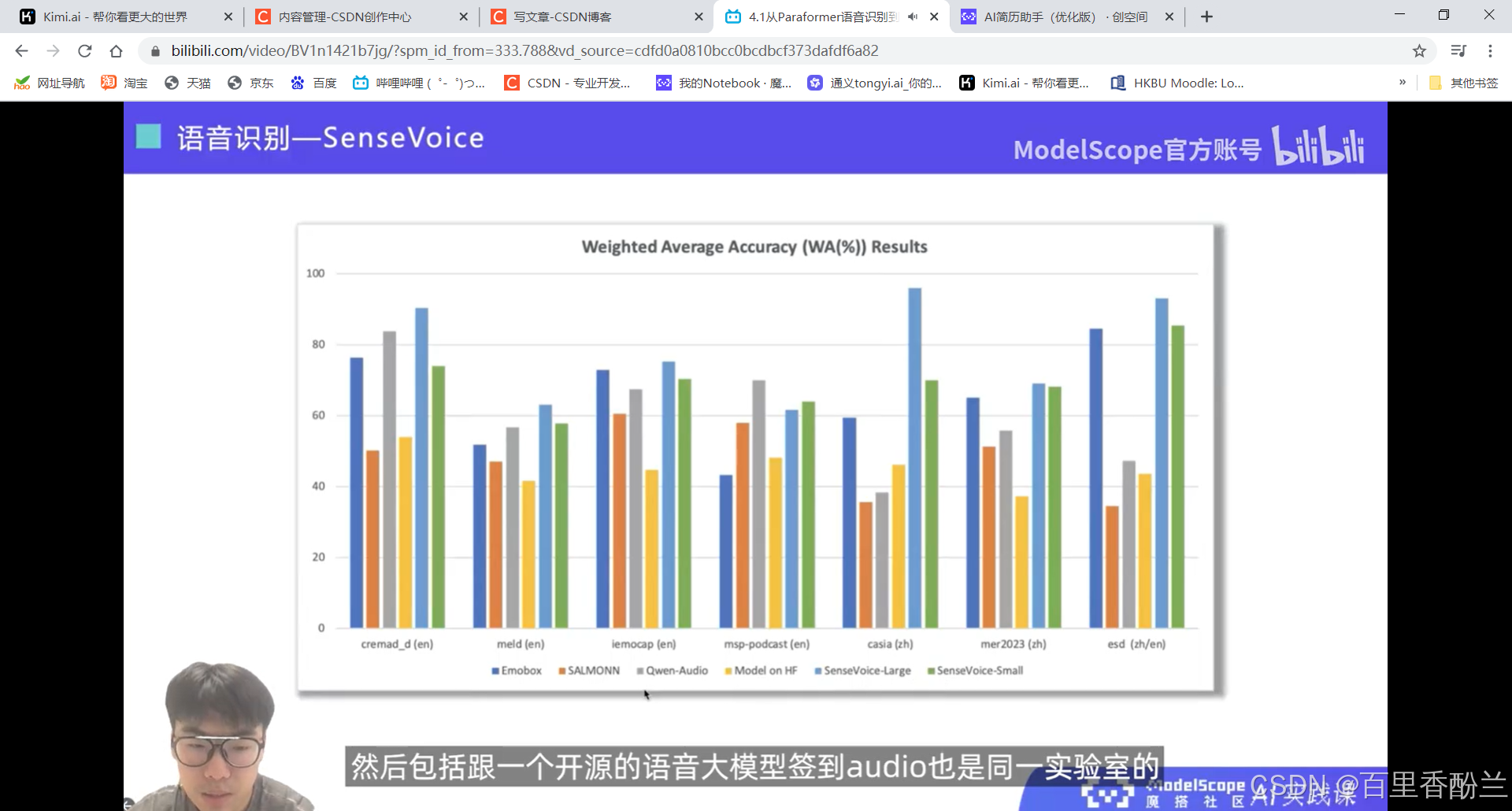
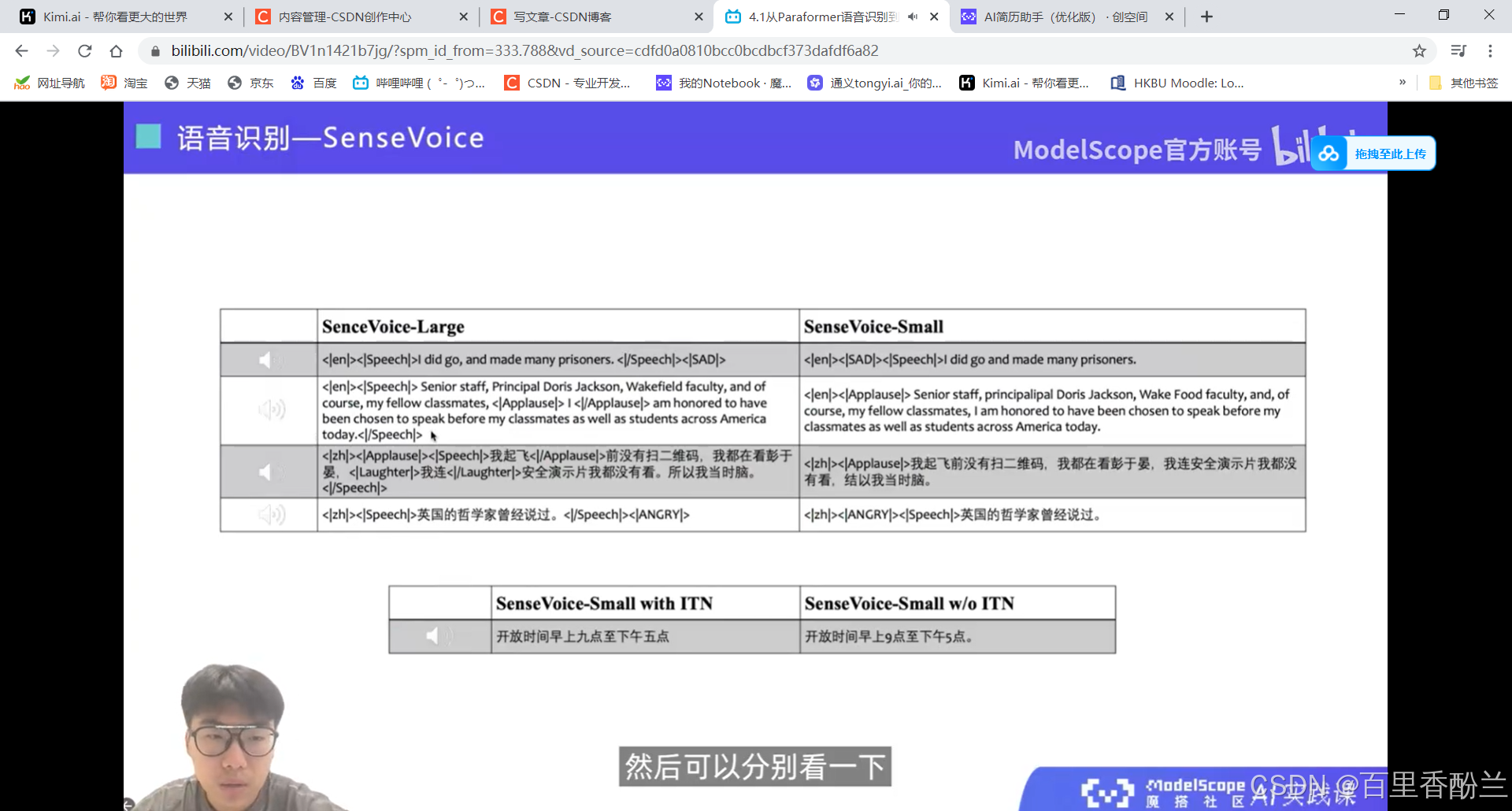
音频理解部分: SenseVoice
Large模型的能力更强,可以检测出多个声音事件。
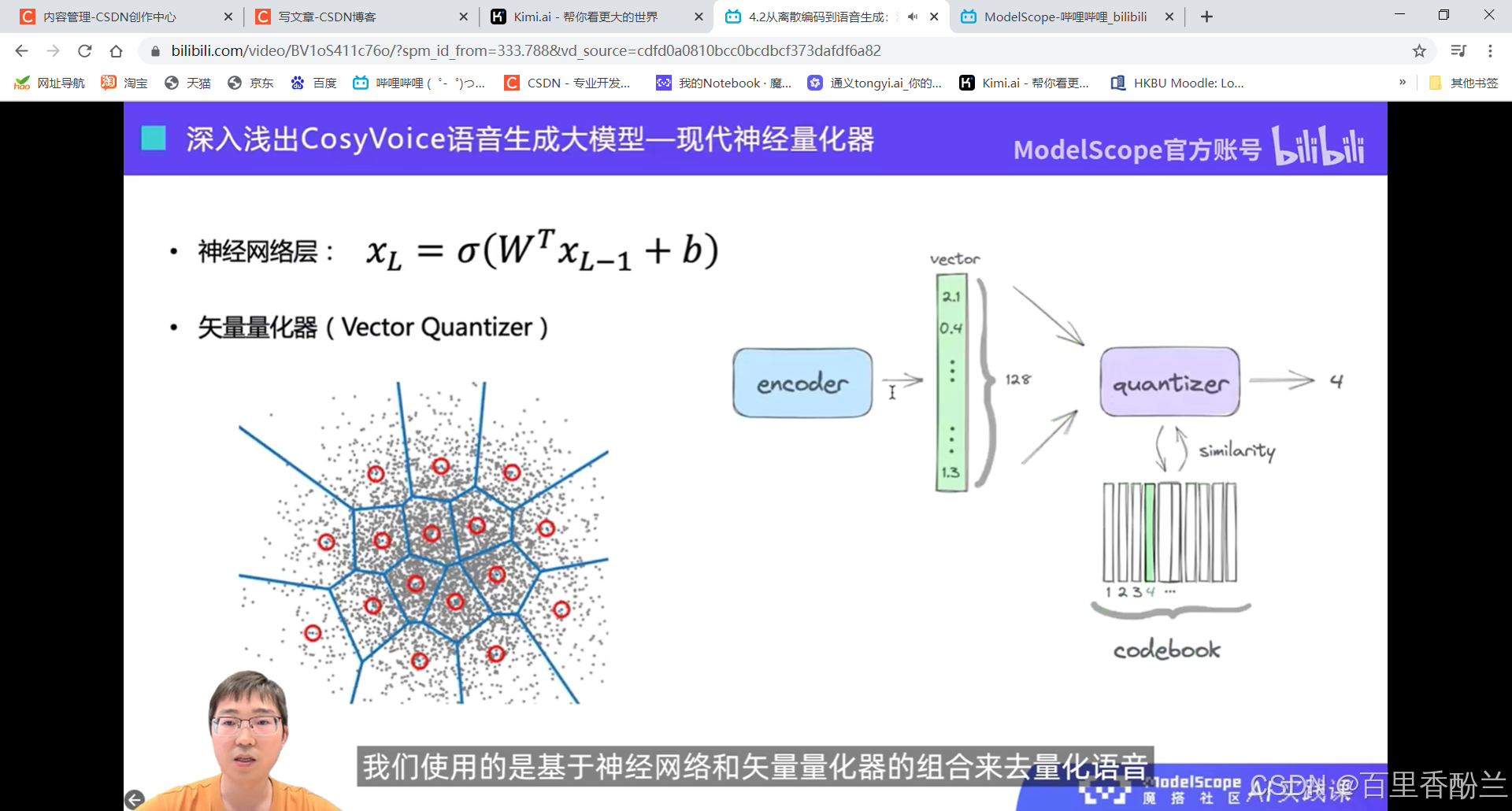
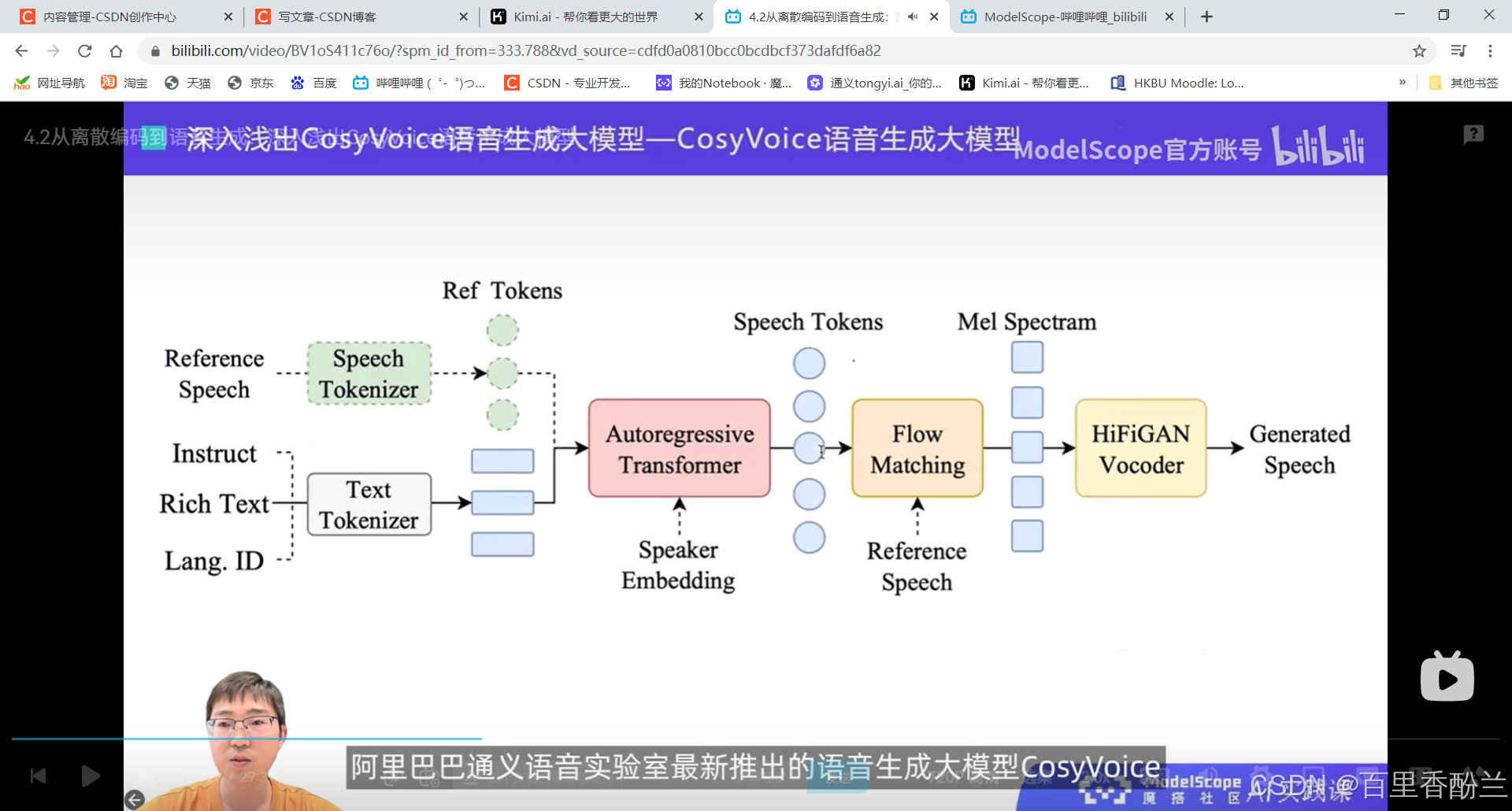
4.2从离散编码到语音生成:深入浅出CosyVoice语音生成大模型: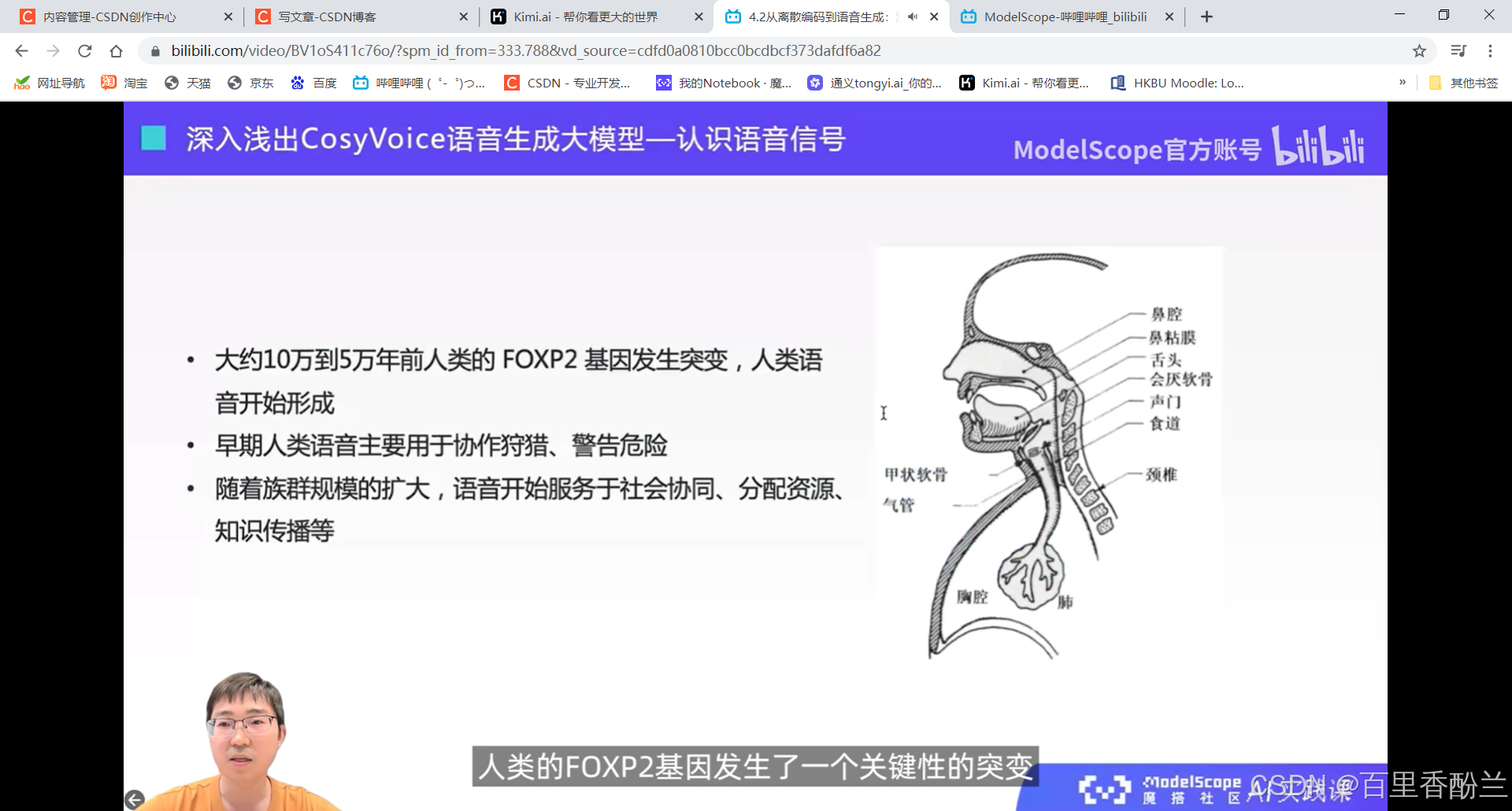
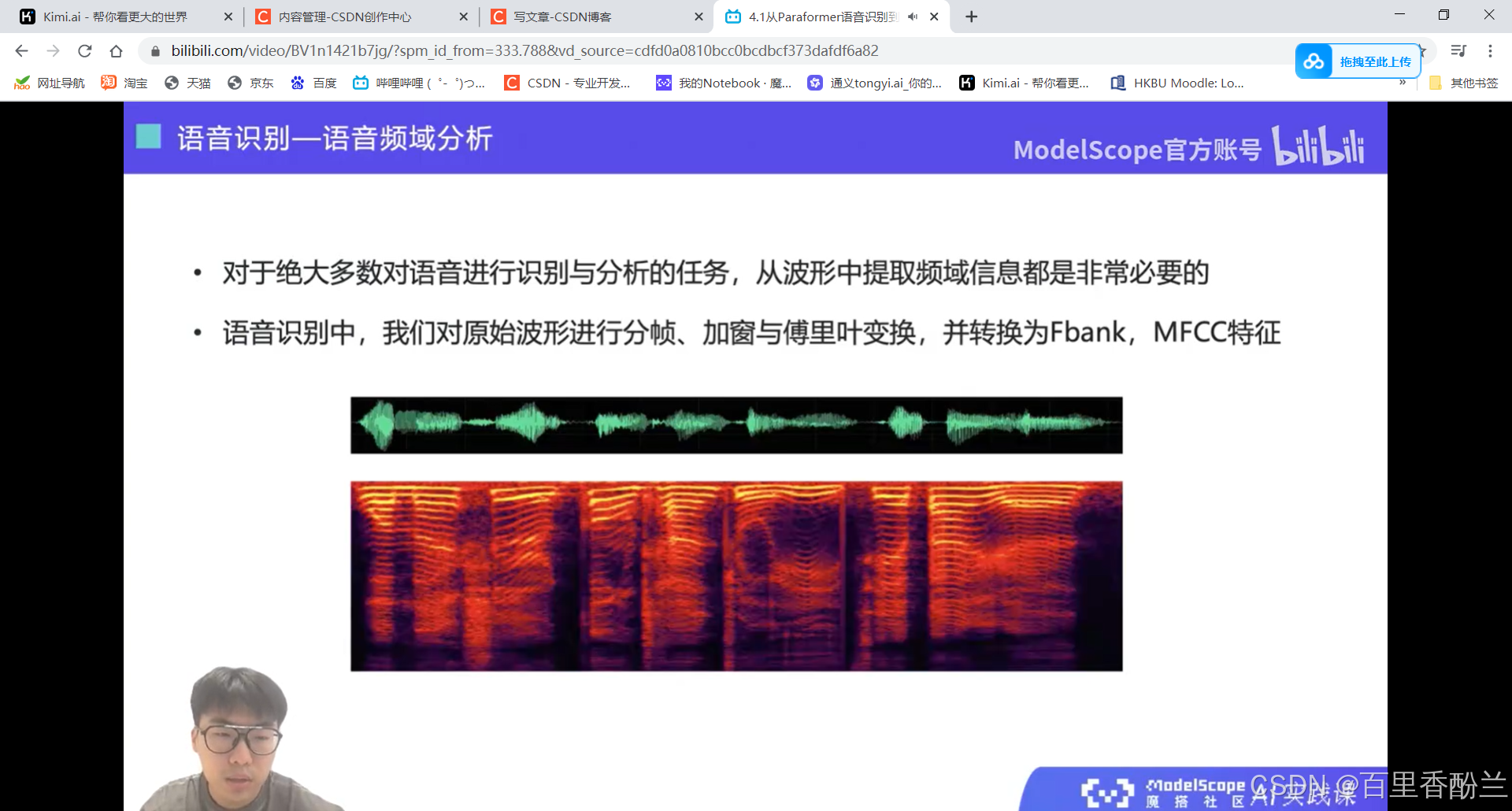
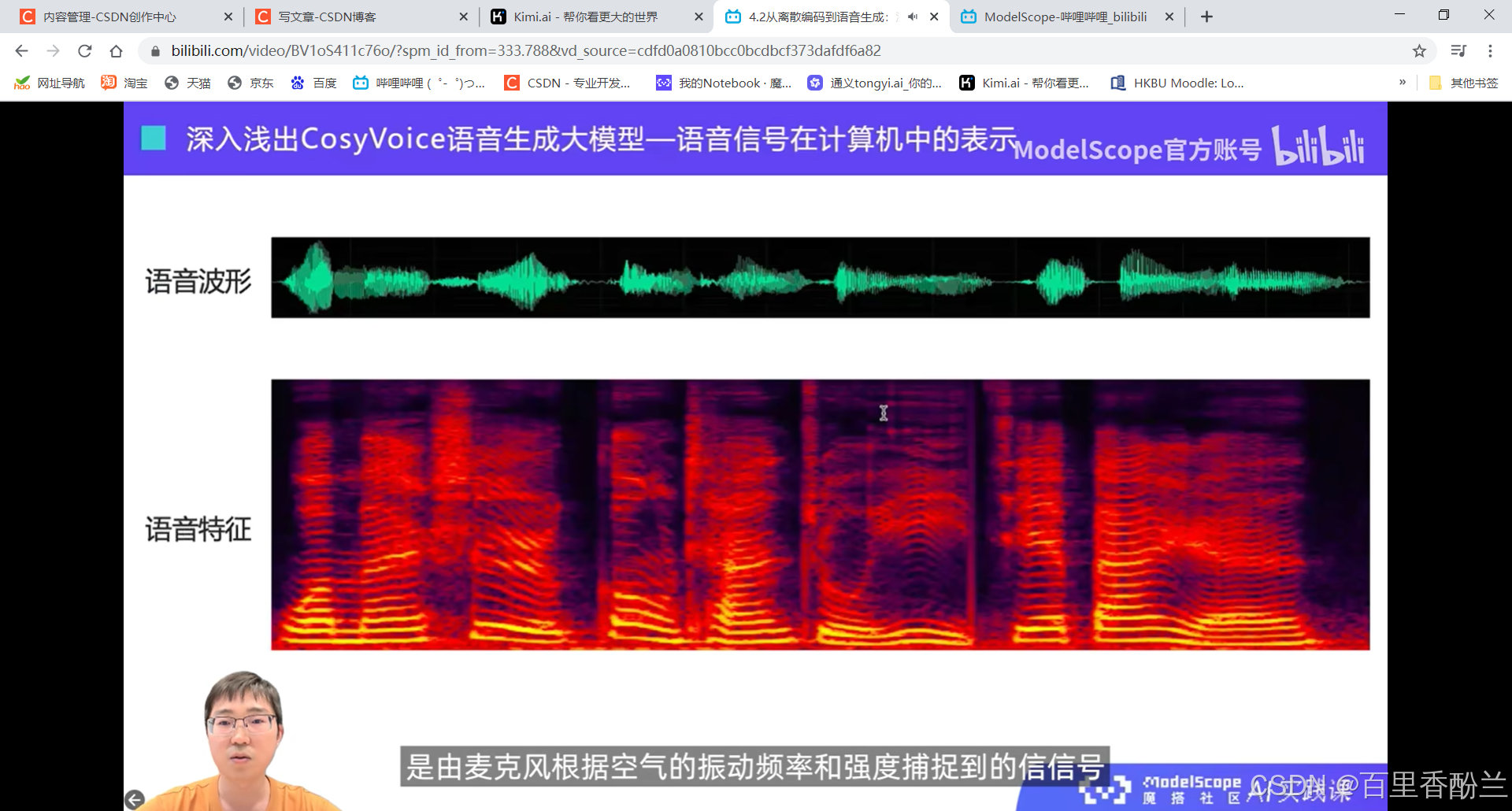
语音在计算机中的两种表示:语音波形,语音特征(下图中的一列就是一个语音特征)
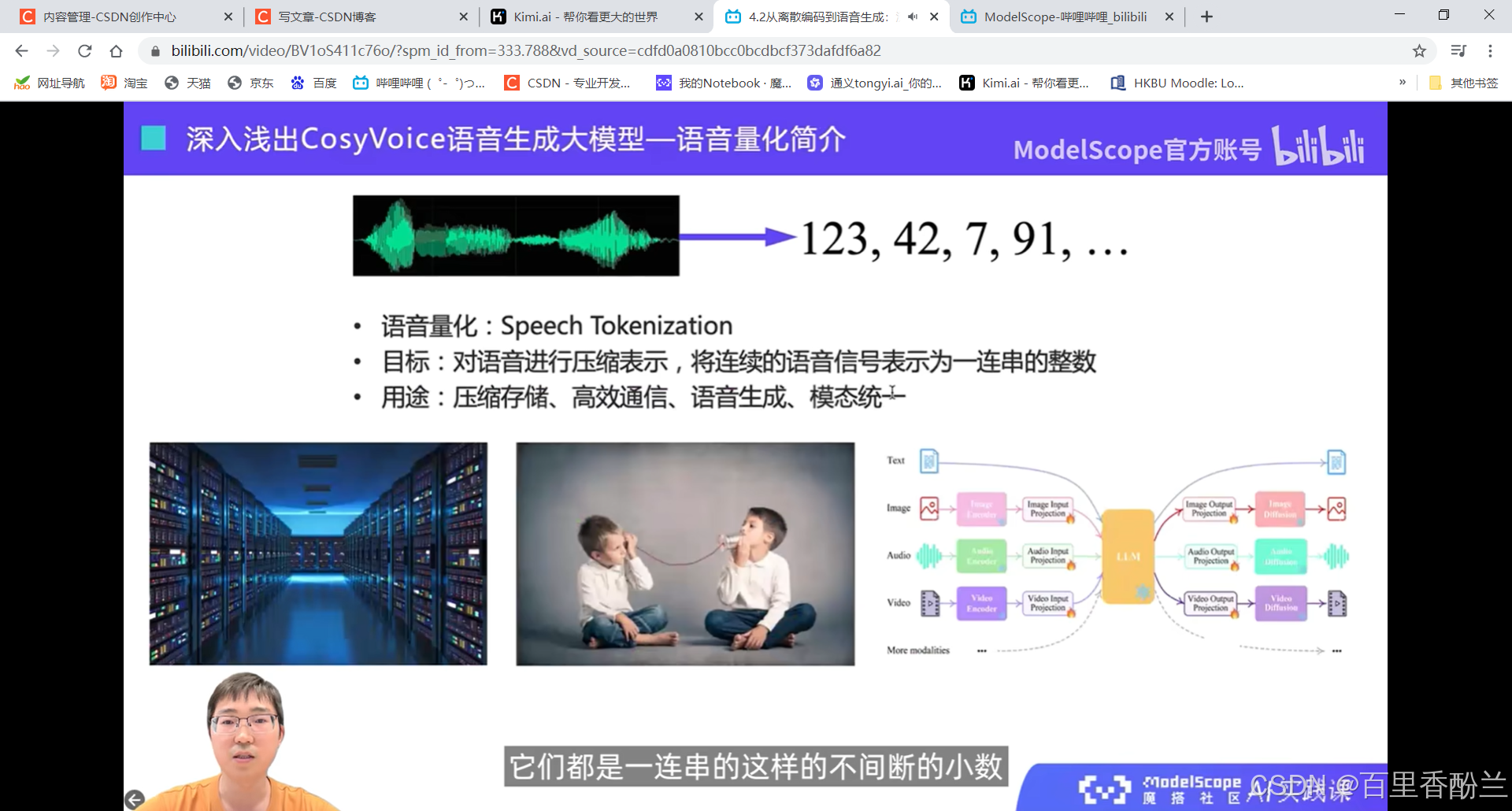
表示为一连串的整数而不是小数。
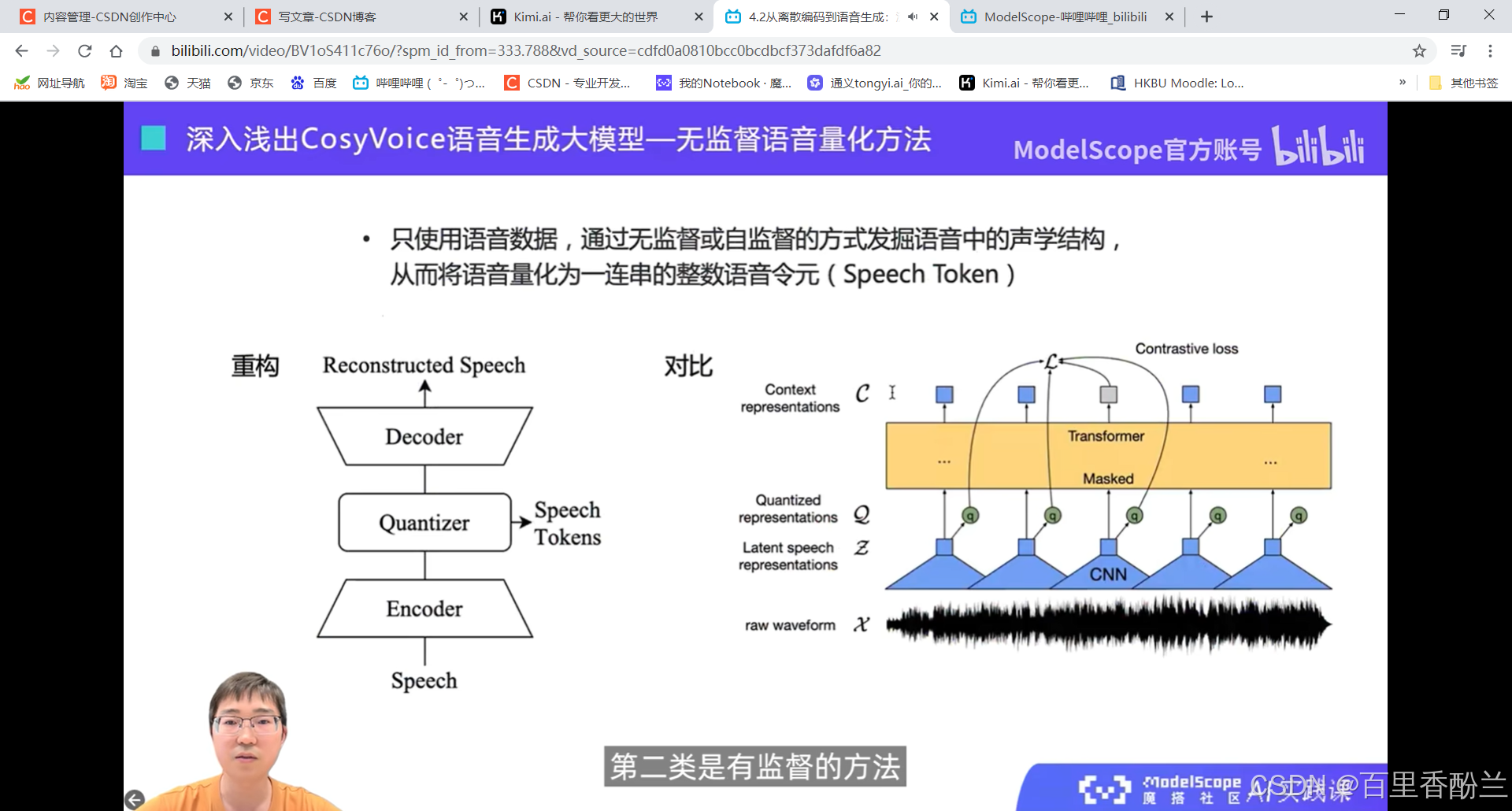
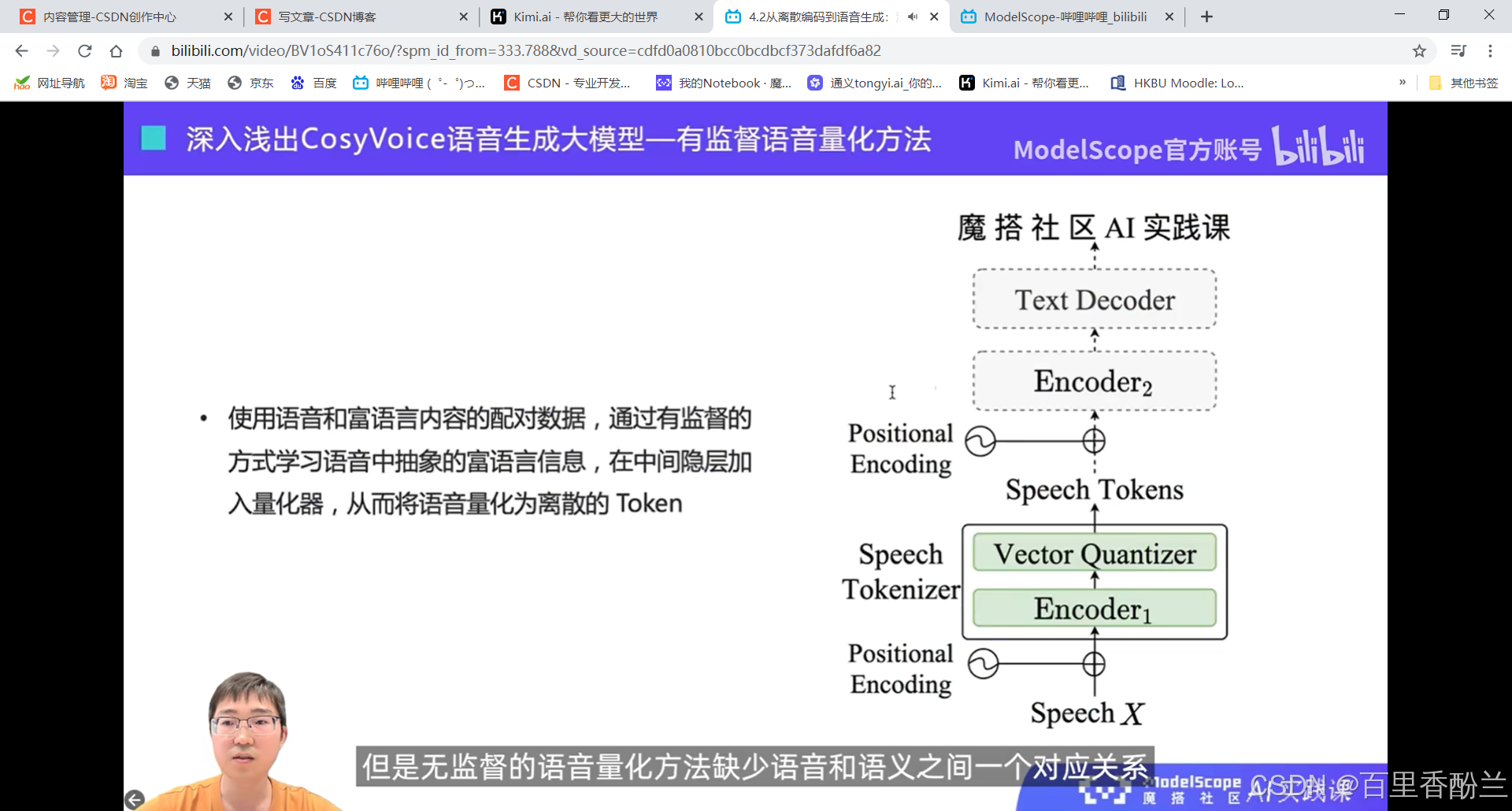
无监督的方式容易丢信息
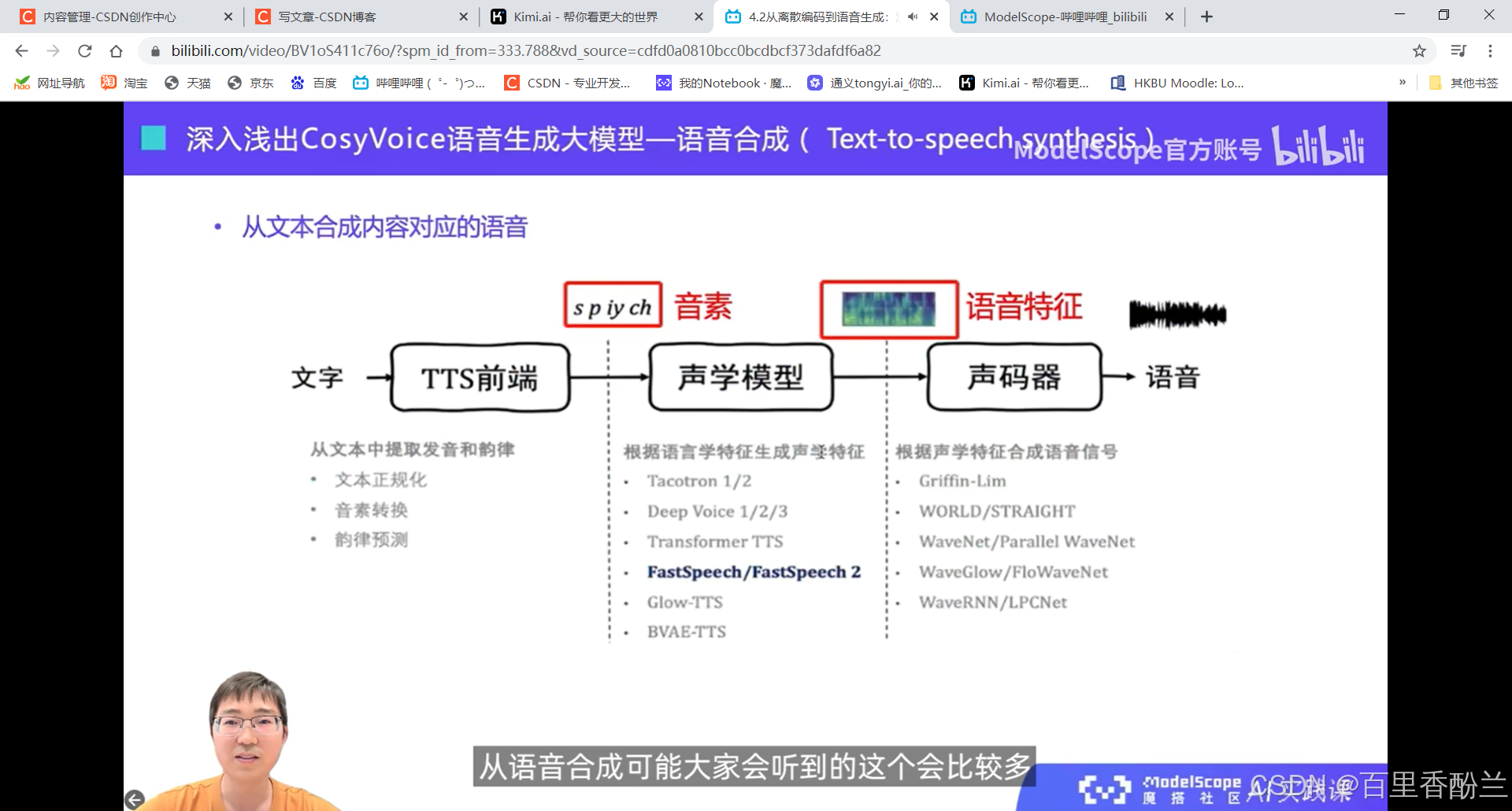
语音合成和语音生成的区别:
语音生成就是下面这个更高级的。
我让Kimi解释了一下,语音合成我感觉就是单纯的文本到说话,比如微信朗读公众号文章那种。而语音生成有点像训练模型合成一个有特征的声音,比如独特的音色、情感表达等。现在很多B站UP在做原神的语言模型,我感觉跟这个很相似。
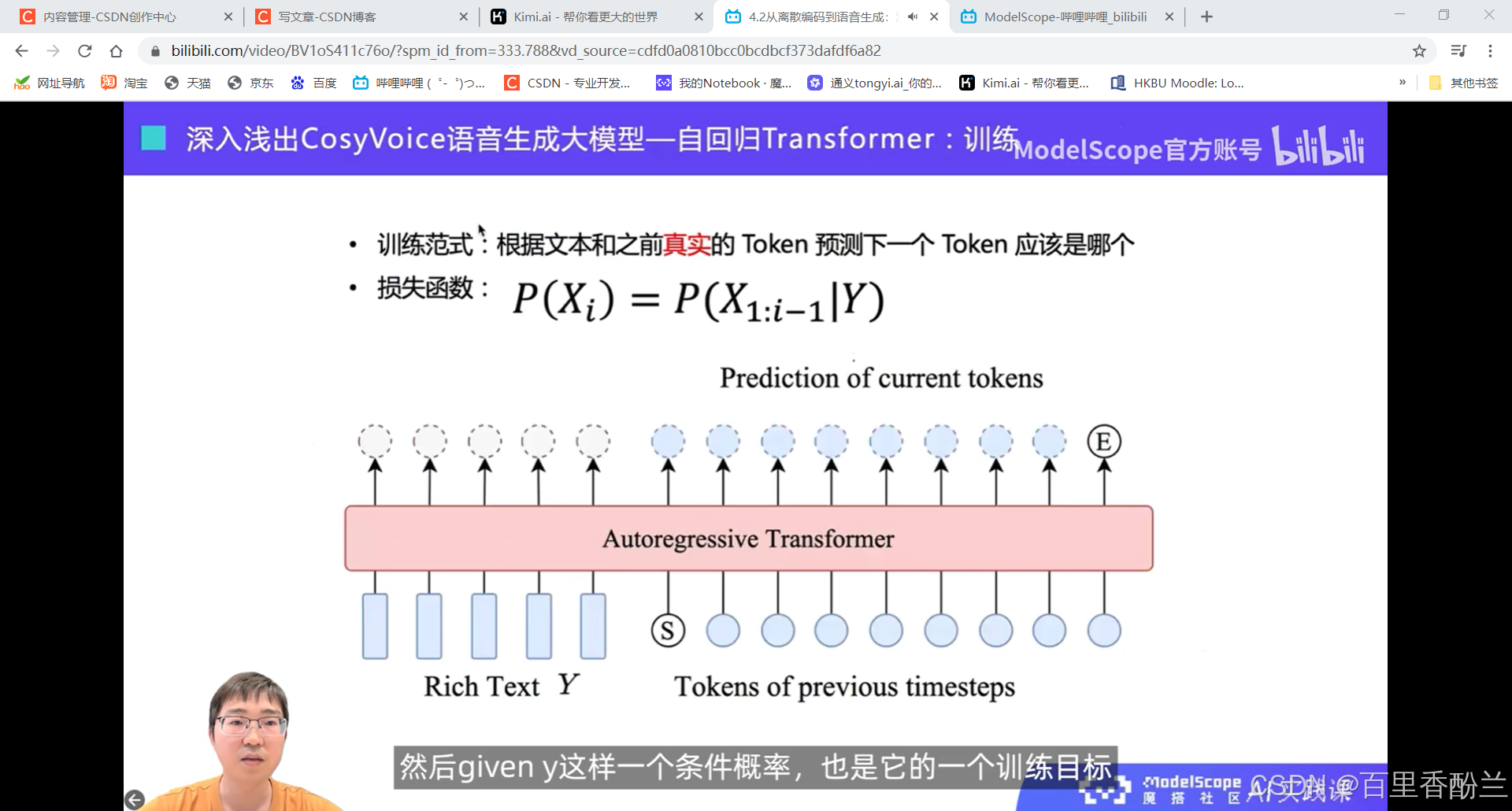
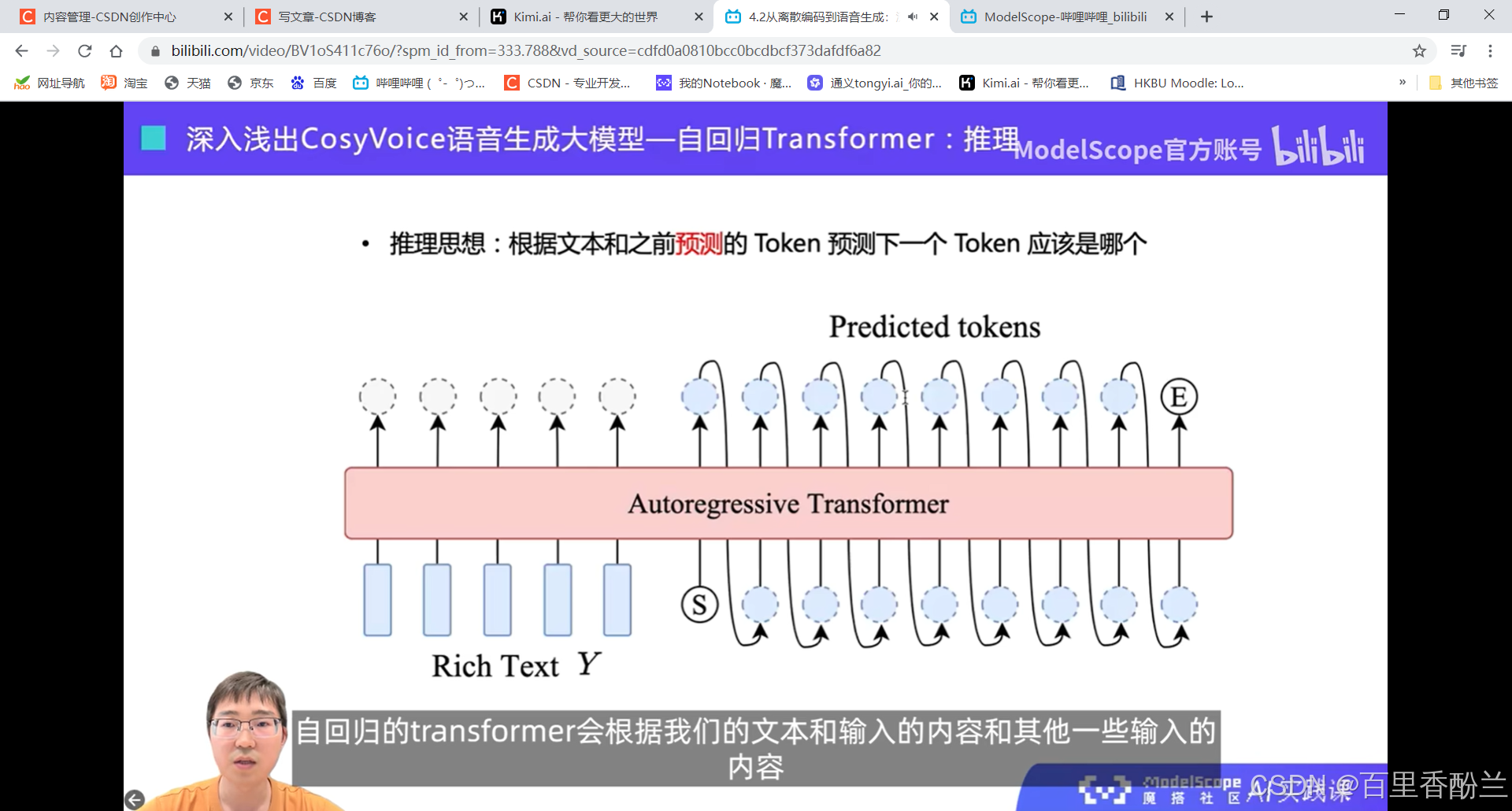
自回归,自己不停去预测下一个。
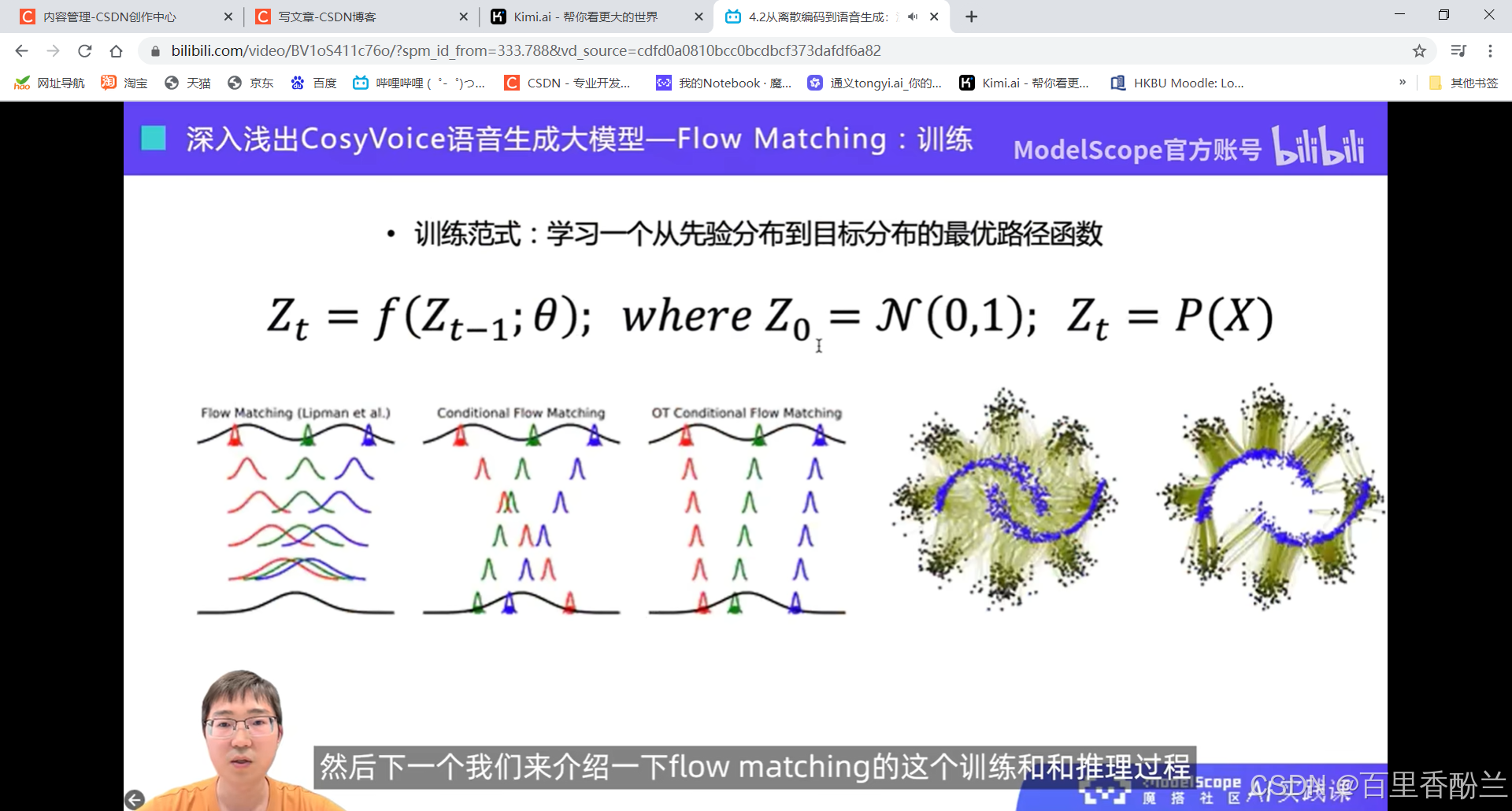
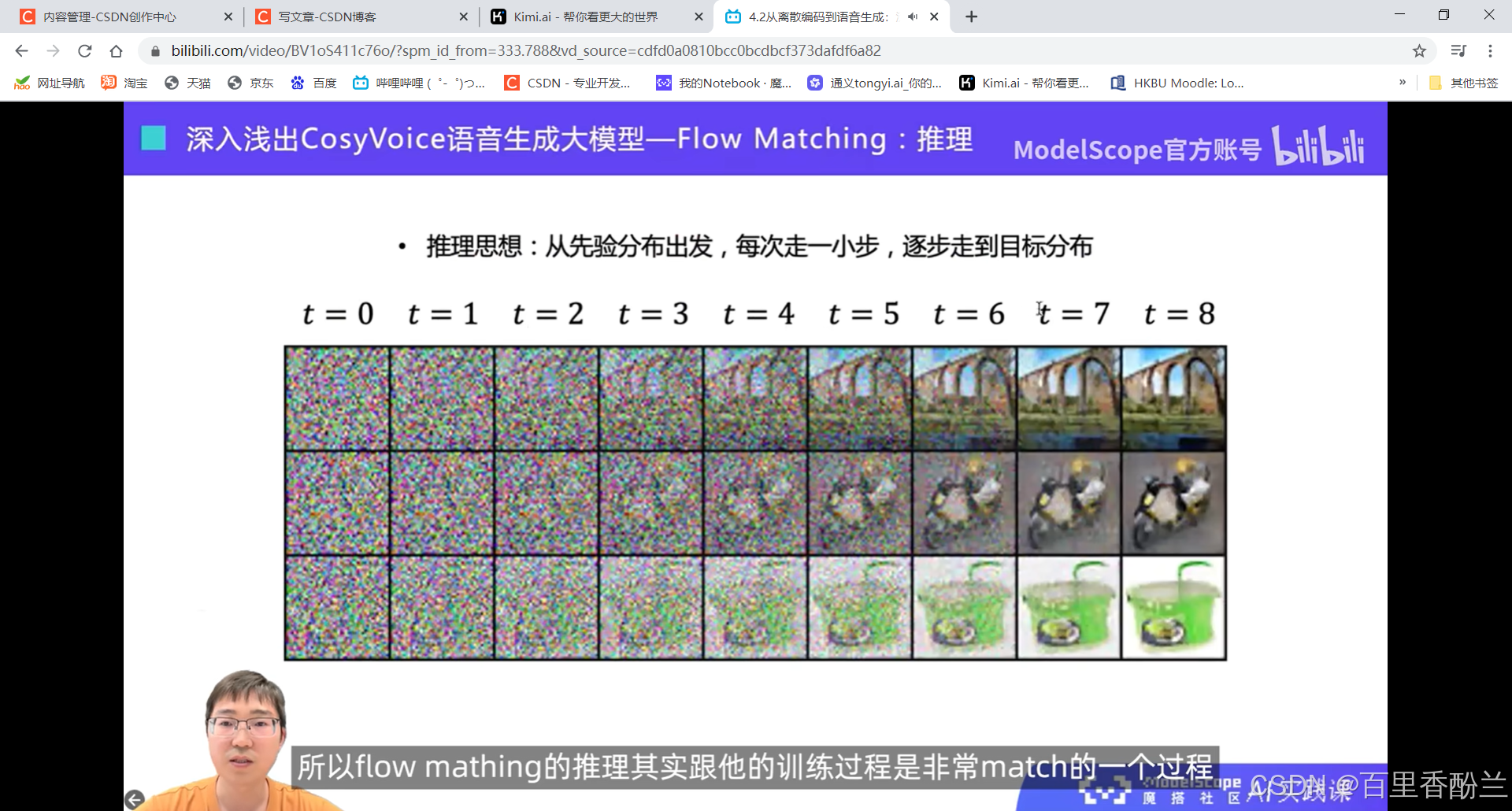
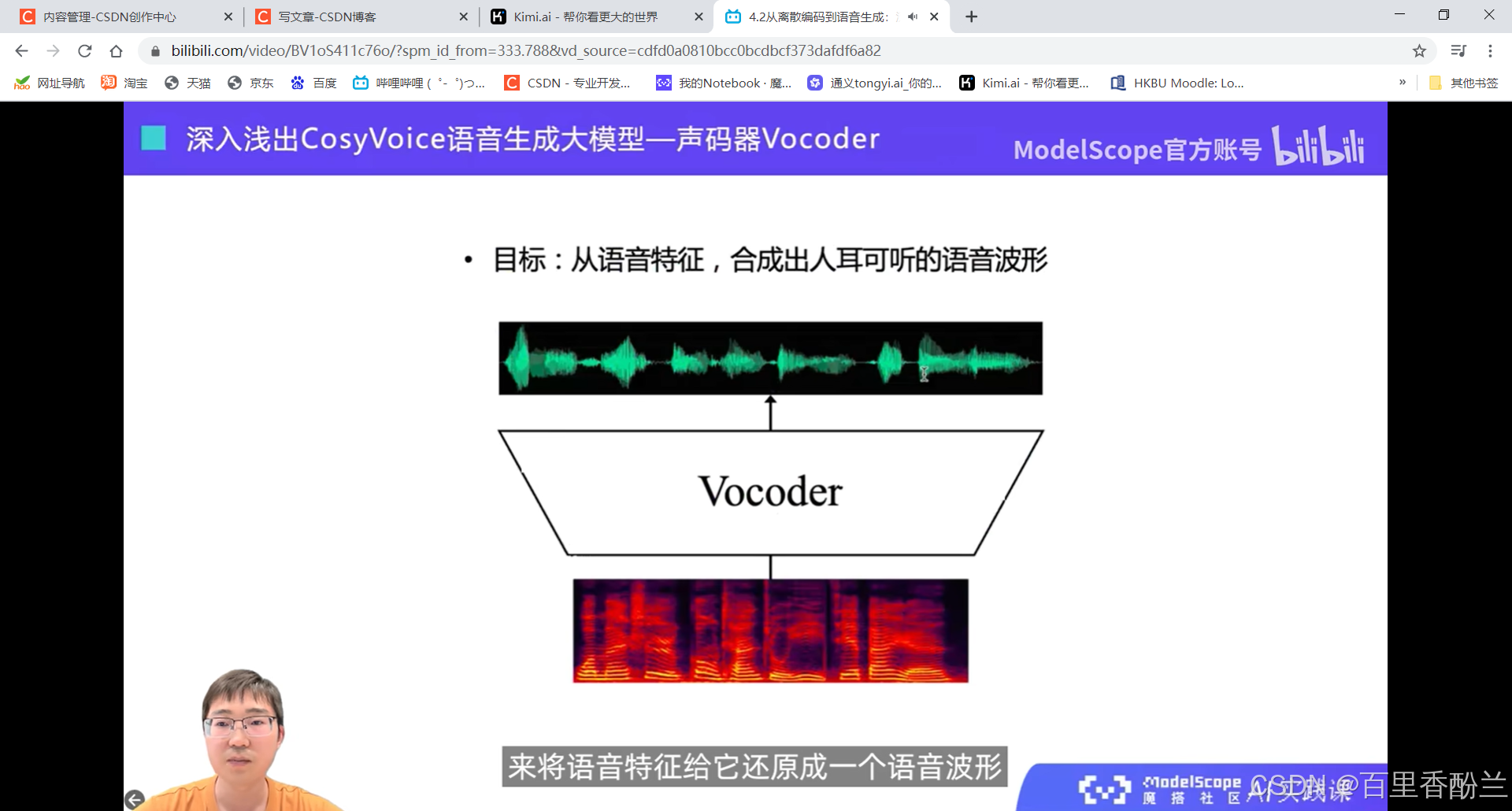
声码器技术还原语音波形:
CosyVoice应用场景:
合成指定音色
克隆人的音色与情感
我感觉这个容易被拿来搞电信诈骗……emm,所以现在接到莫名其妙不说话的电话要小心。
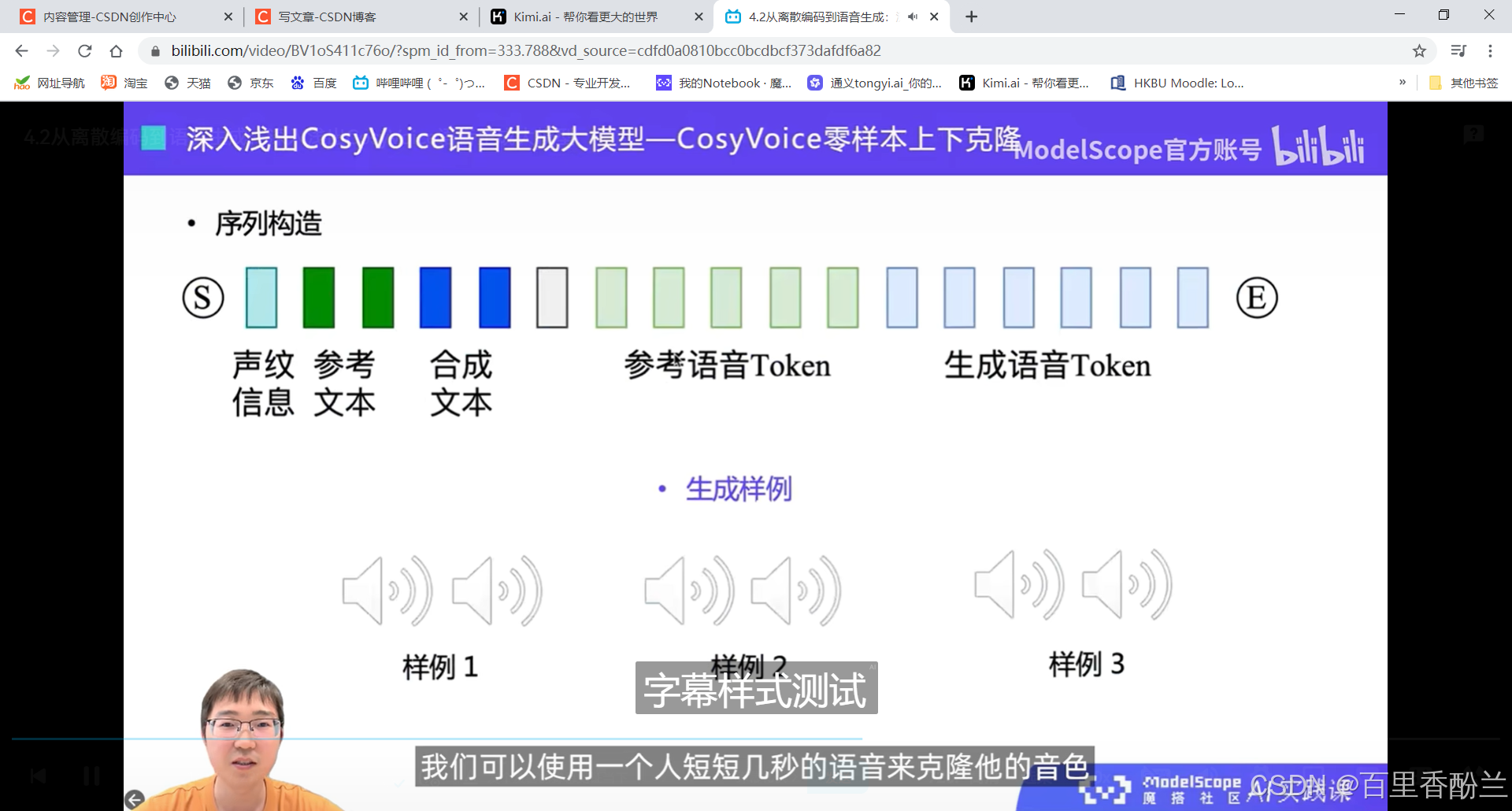
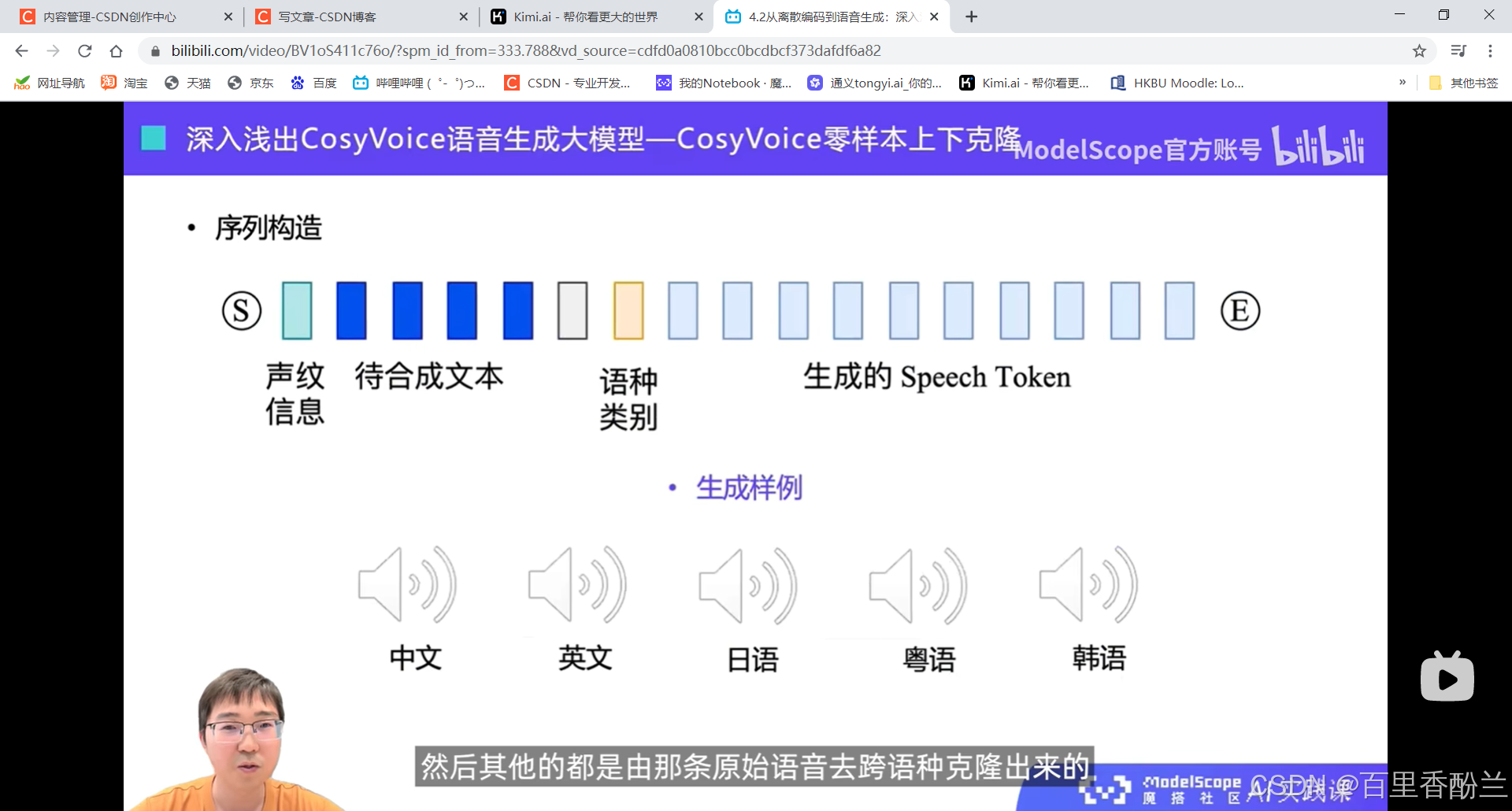
跨语种克隆
感觉这个可以用在同声传译,甚至微信语音朗读、操作中外电影文学作品辅助学英语等,把外国作品和中文互相翻译来匹配需求。(比如说做个英语版的西游记甄嬛传啥的,B站就有人看剧学英语)
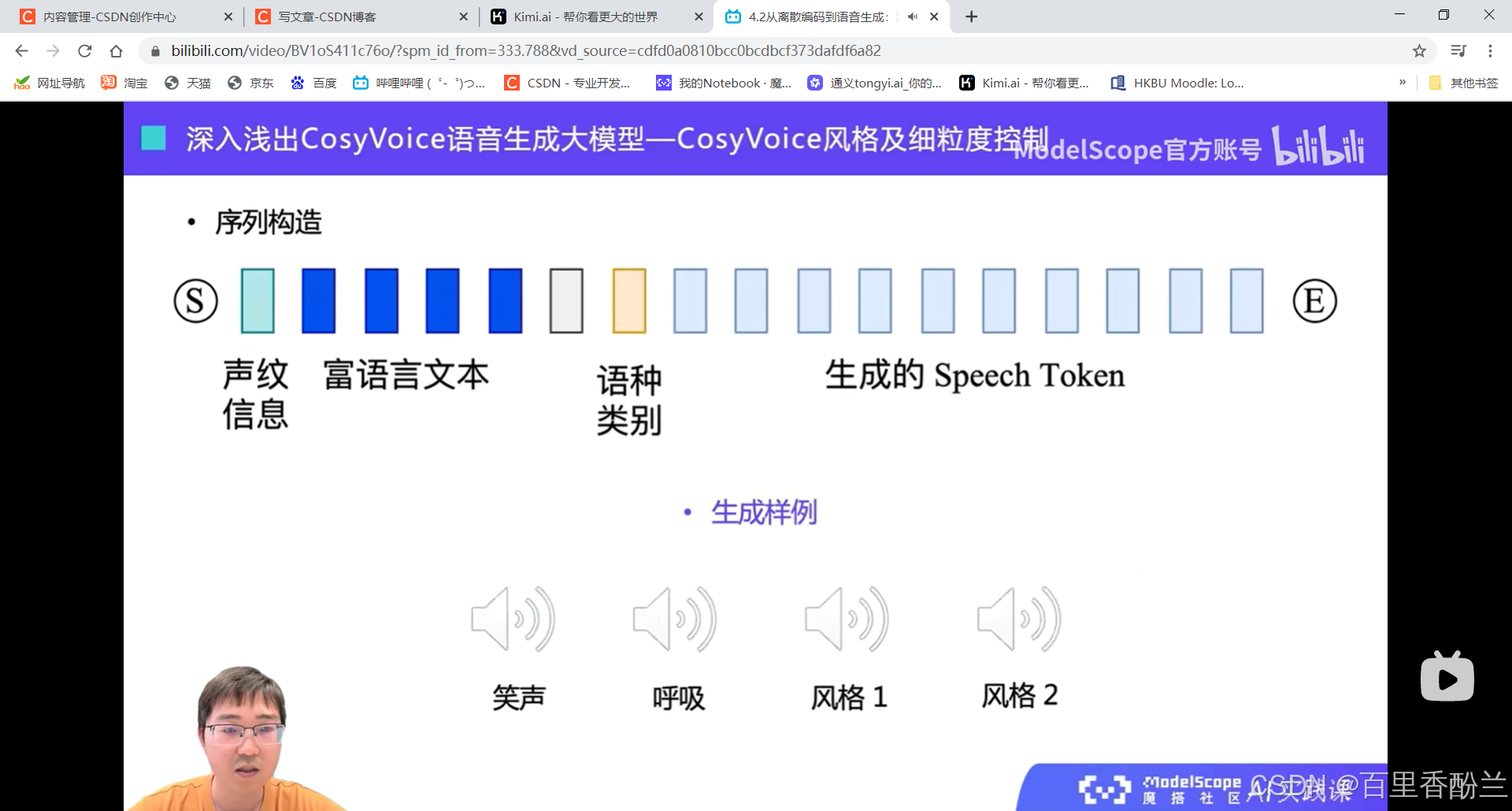
给定描述合成不同情感
感觉可以用在未来的AI伴侣、桌宠,有声书、配音啥的,提供情感反馈。我最近用的人工智能学英语的APP就对快乐的回应有明显的语气上升。

情感、风格、语气等(比如呼吸、笑声)富语言文本:
这个在ModelScope上面已经开放了?好耶!!
ModelScope:
https://www.modelscope.cn/studios/iic/CosyVoice-300M
我体验了一下,生成得实在是太慢了,半天转不出来。
Github:
语音生成
https://github.com/FunAudioLLM/CosyVoice
语音识别
https://github.com/FunAudioLLM/SenseVoice
小作业:
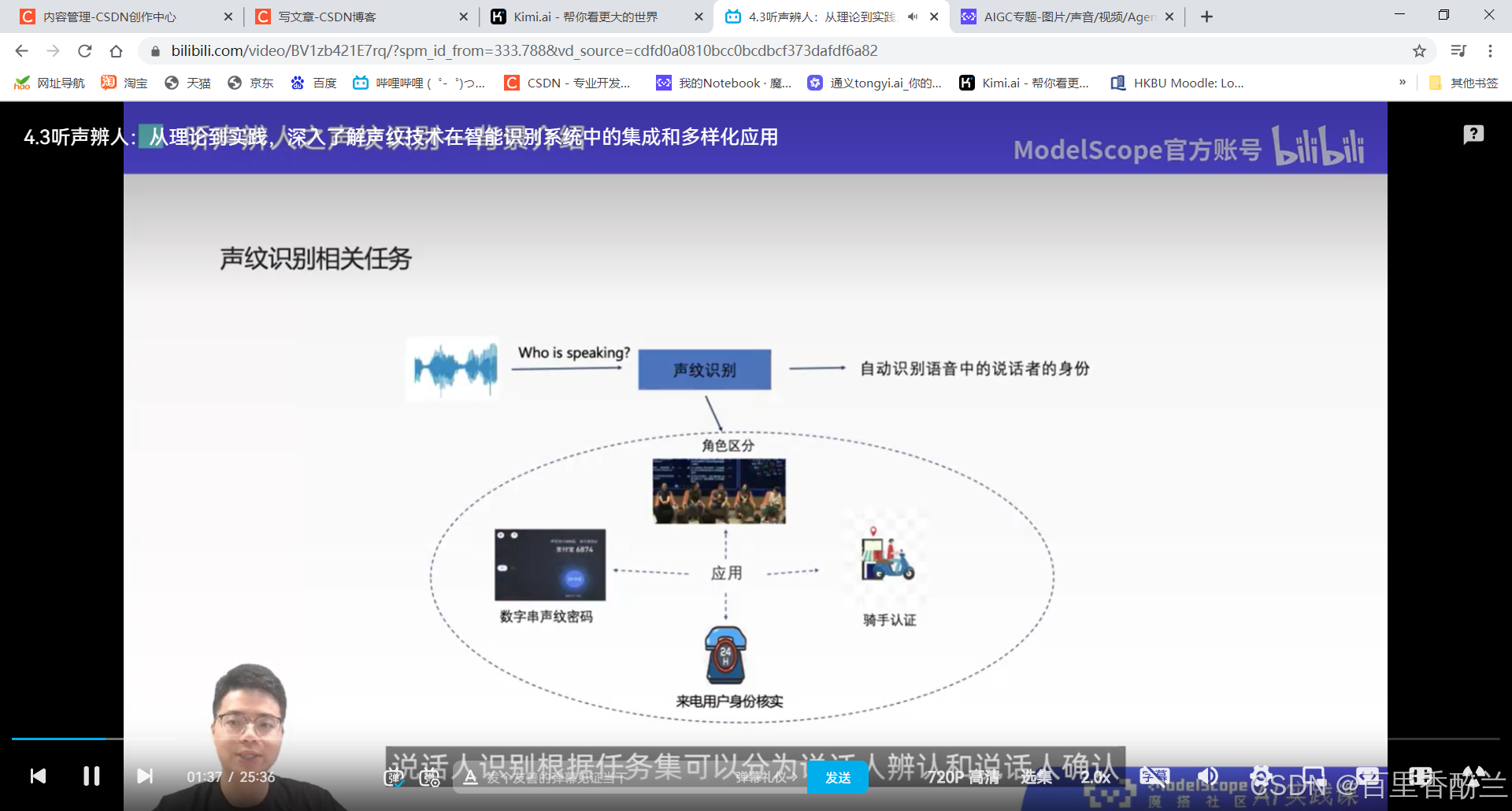
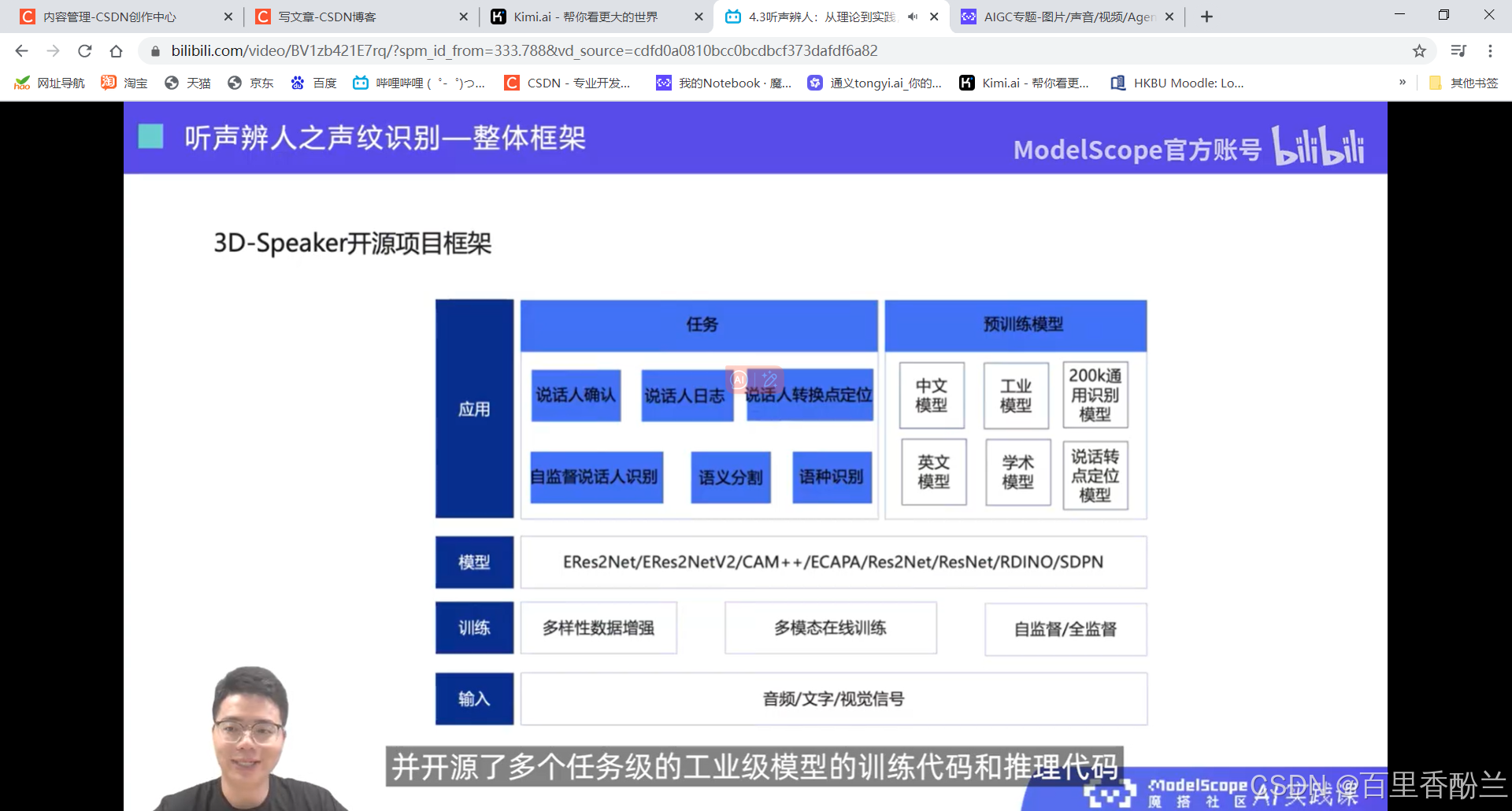
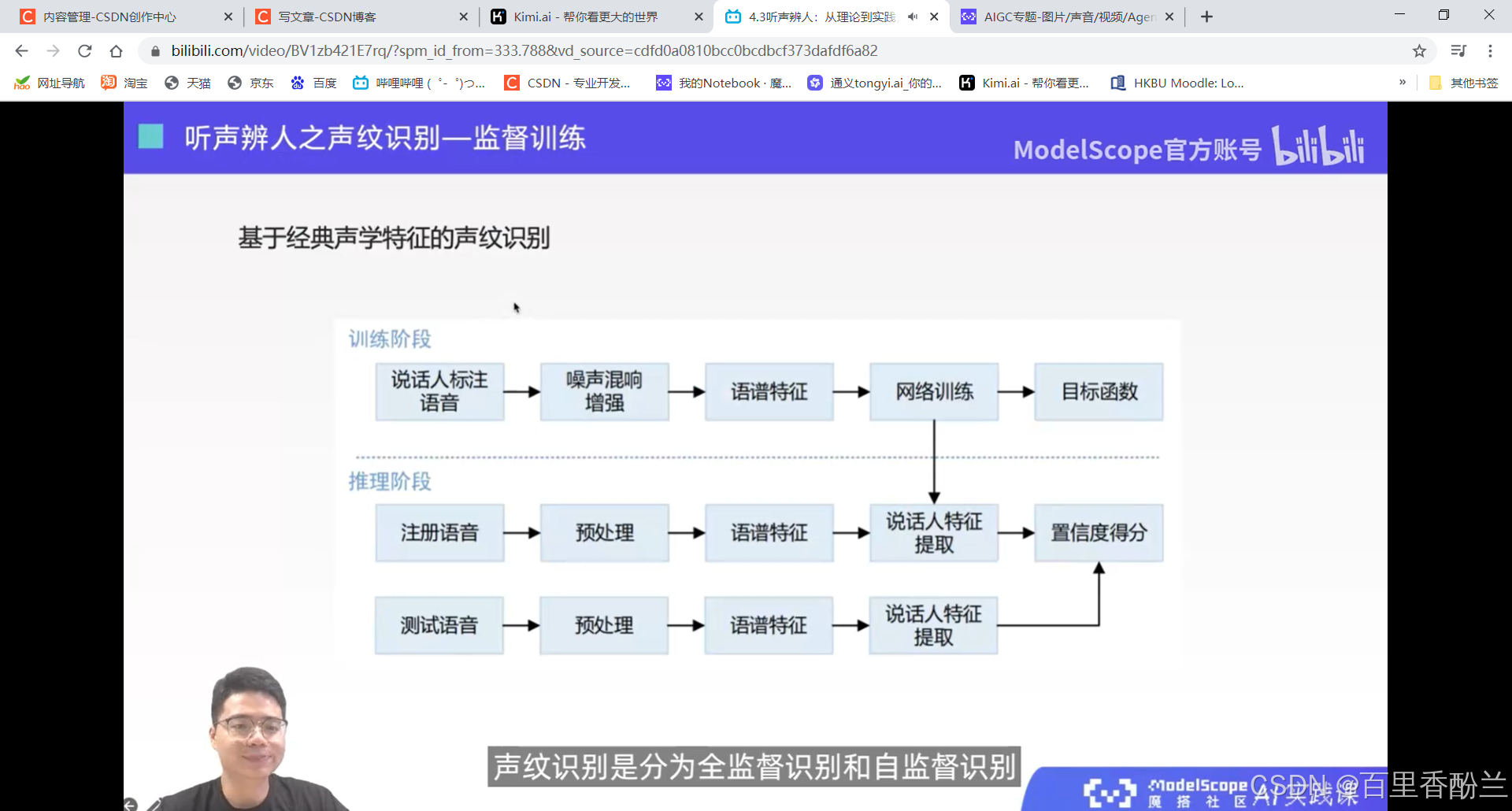
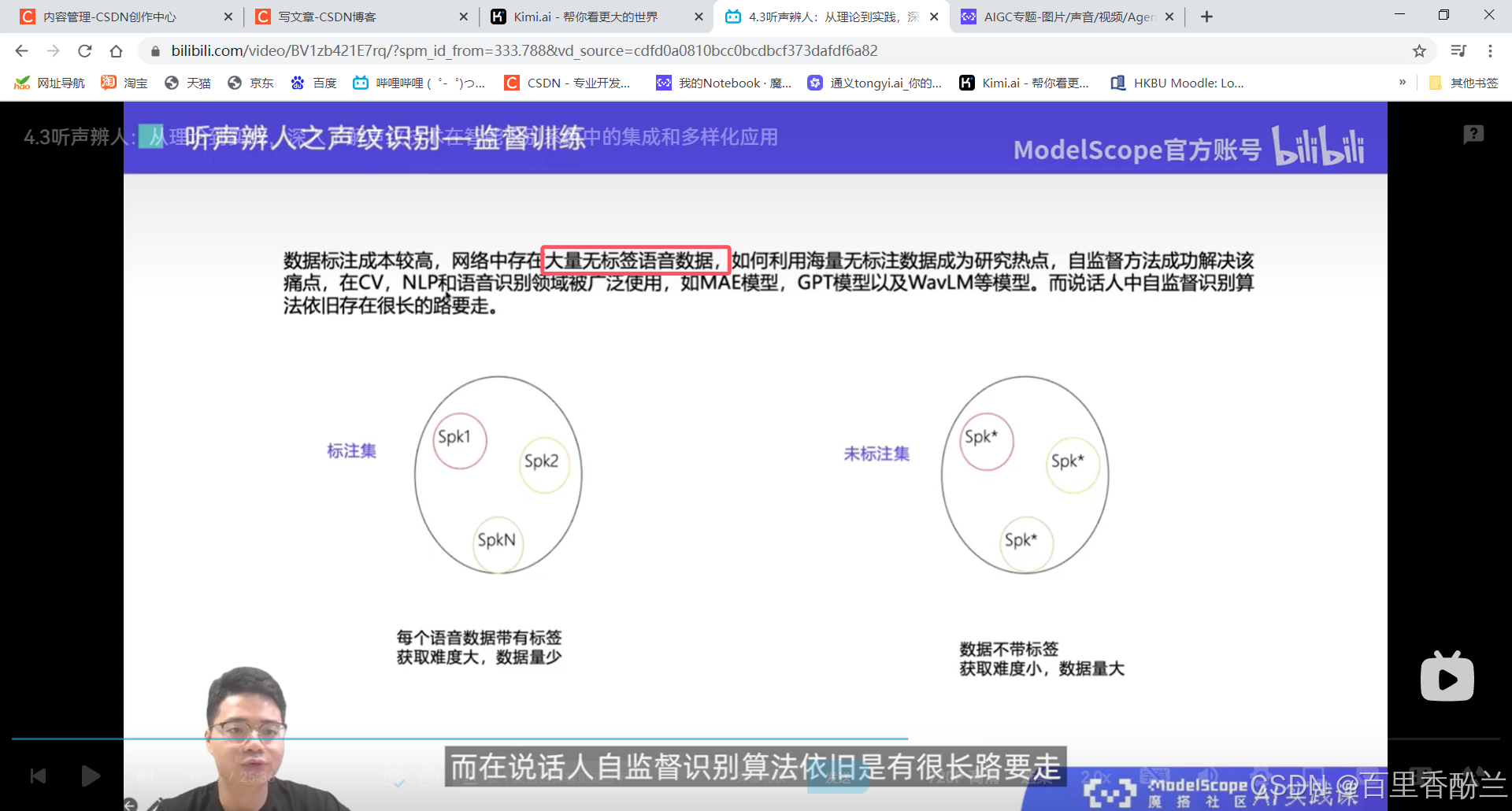
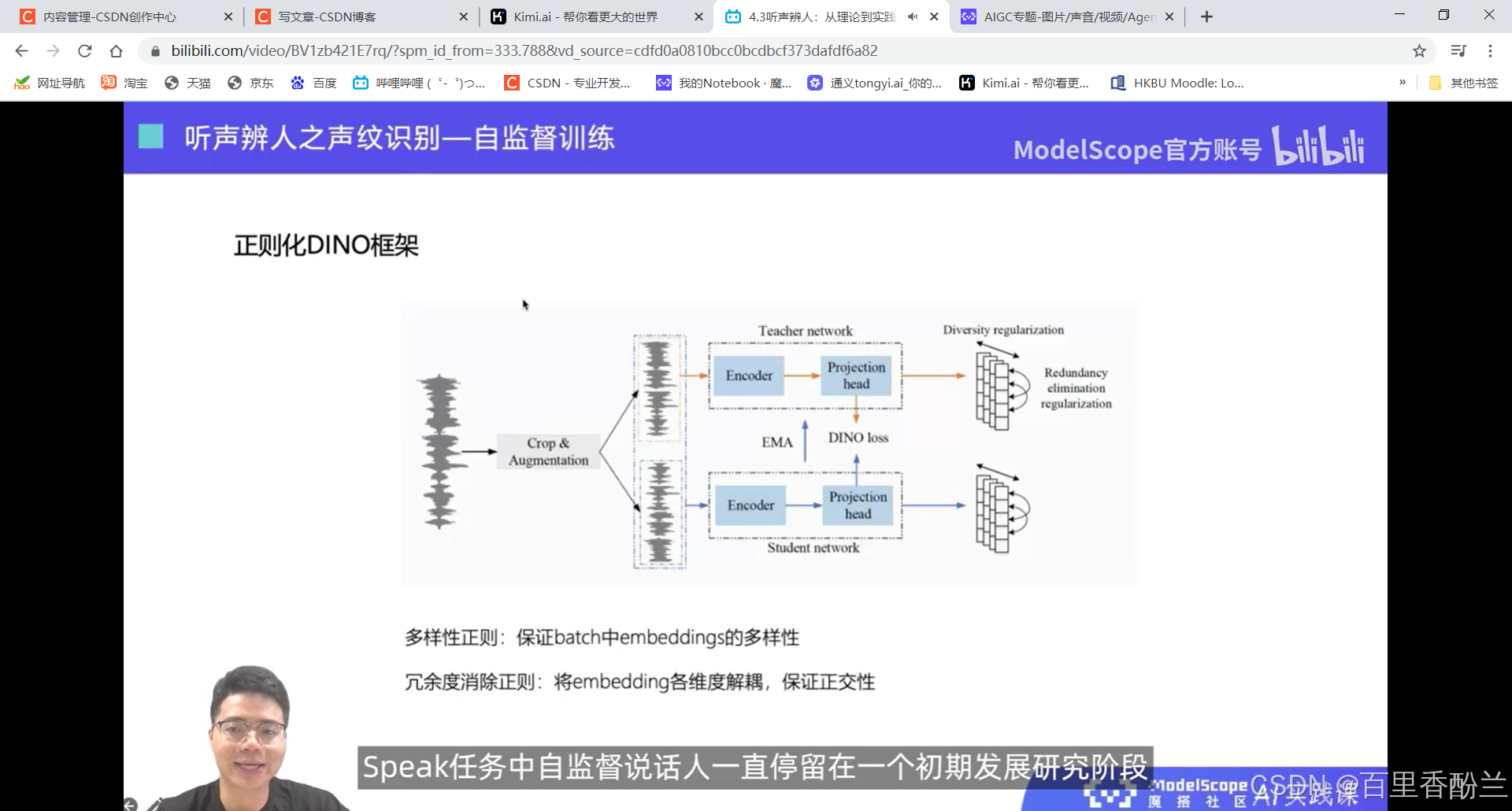
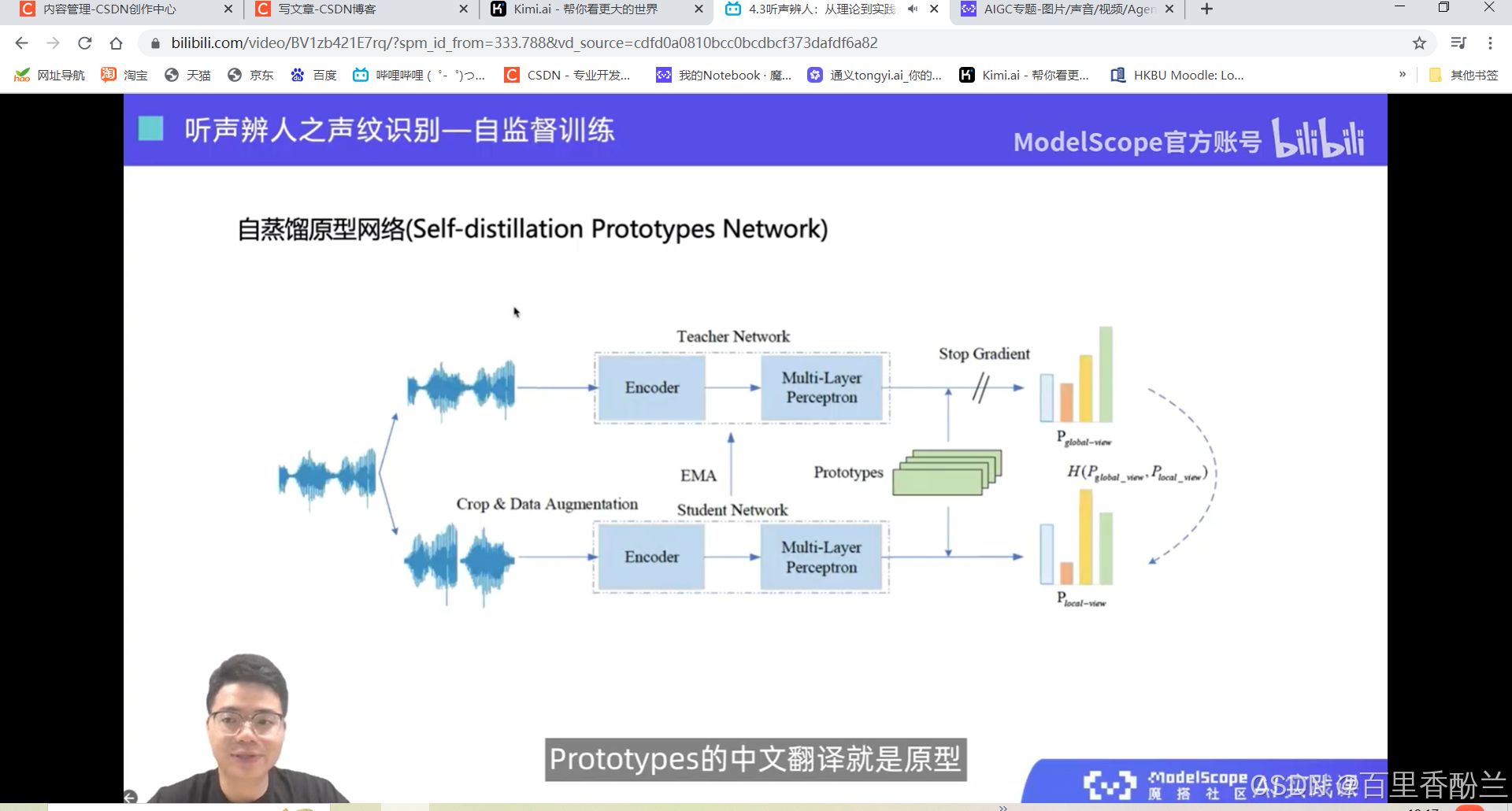
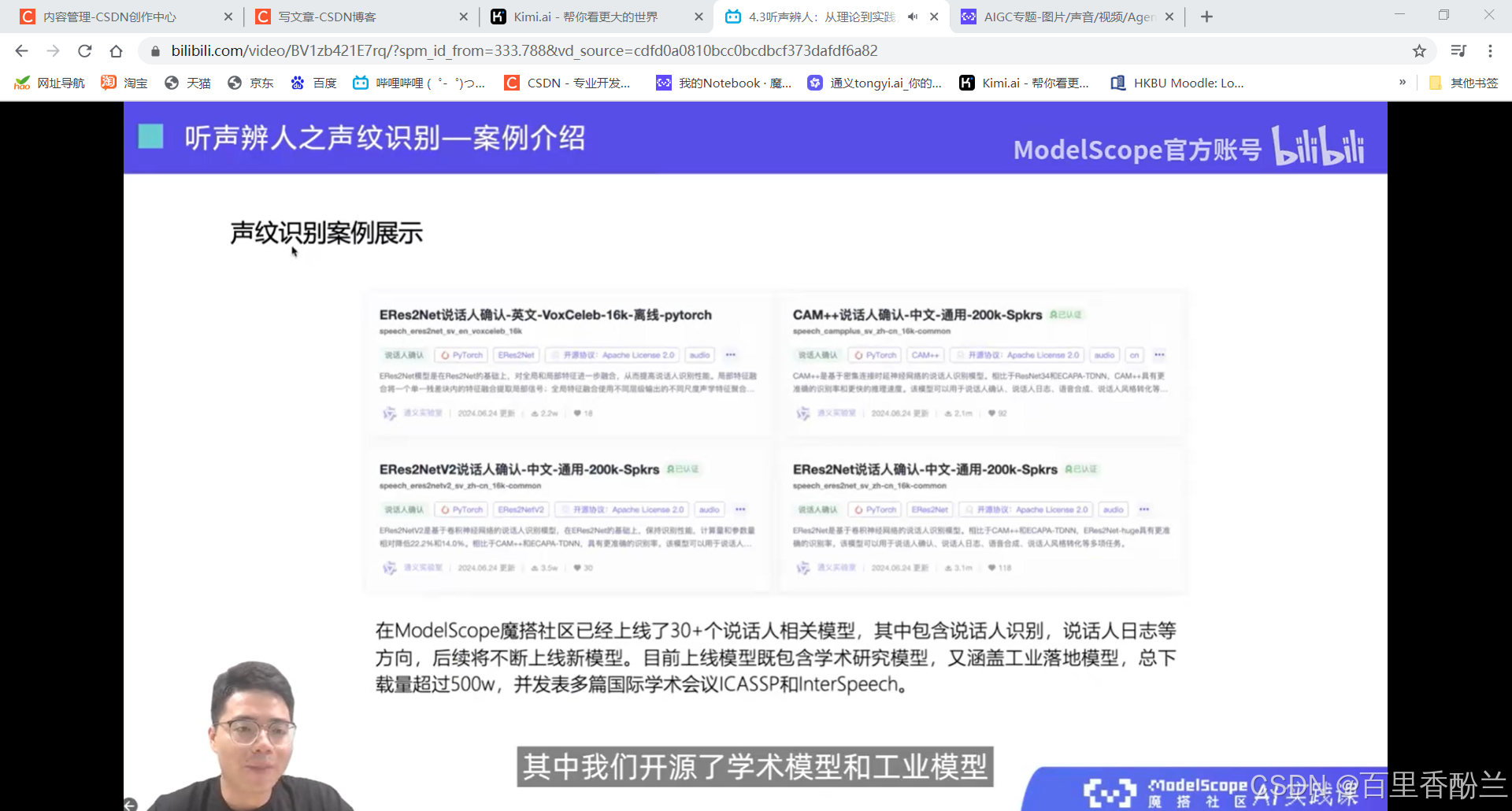
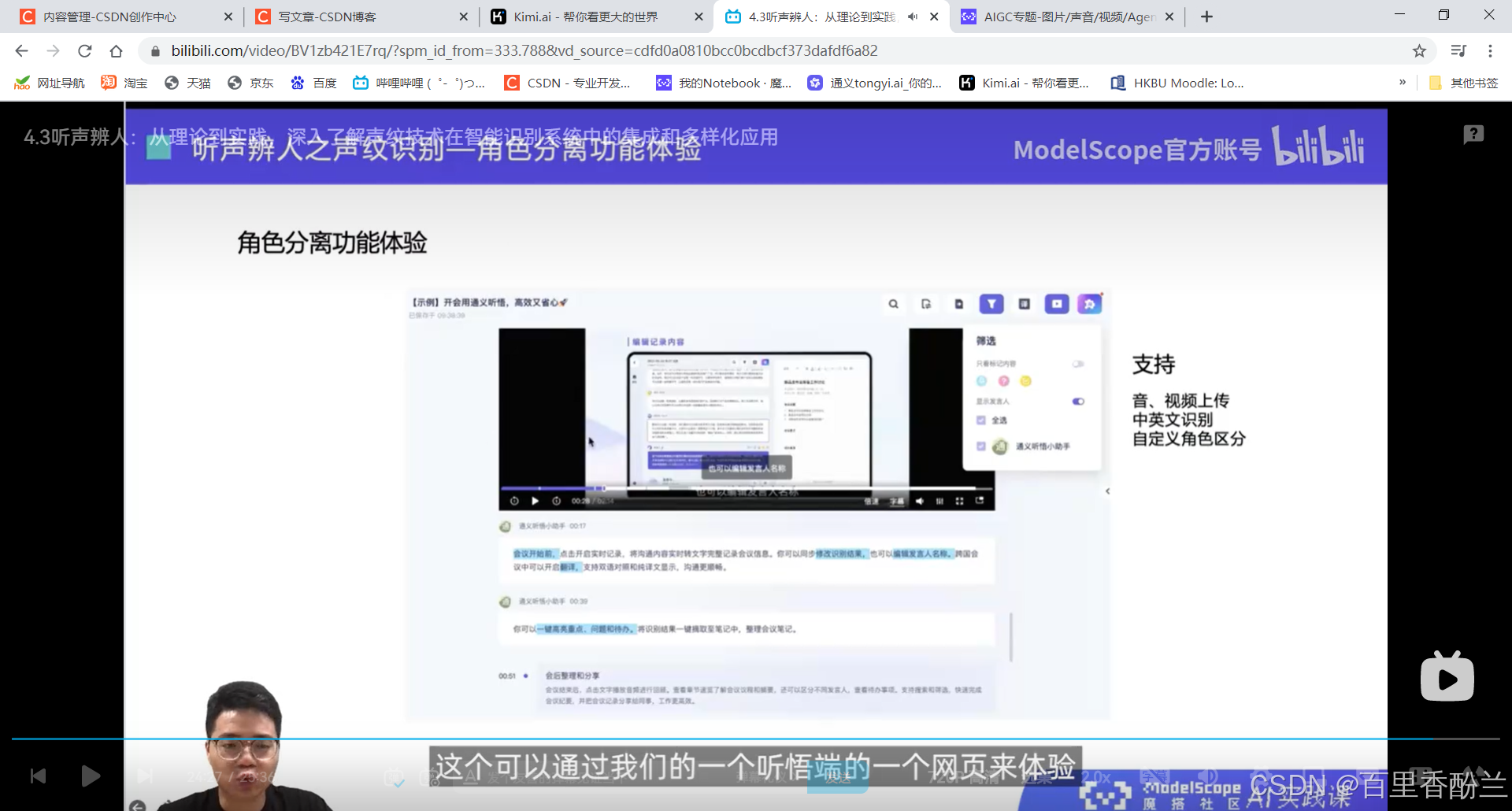
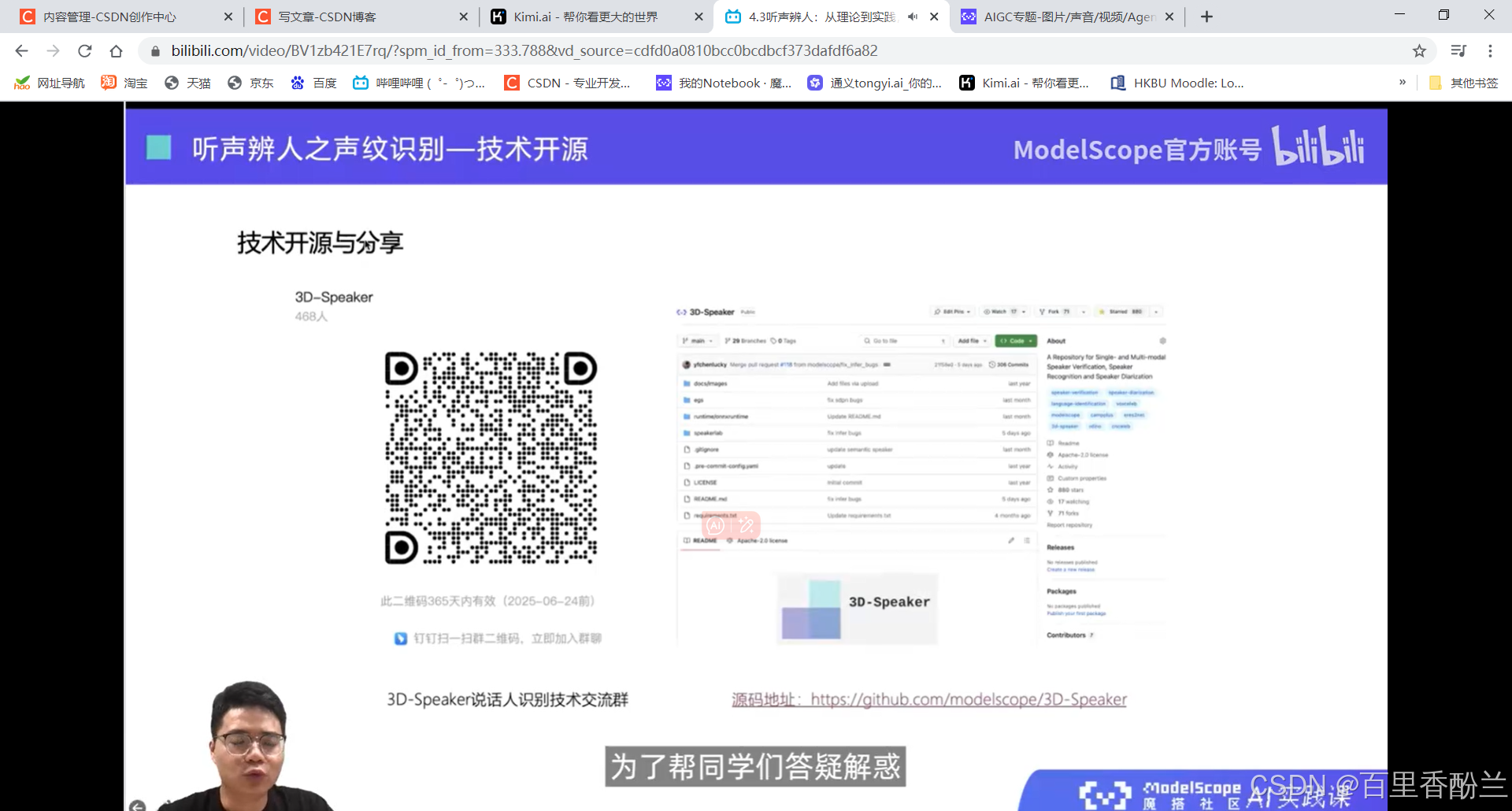
4.3听声辨人:从理论到实践,深入了解声纹技术在智能识别系统中的集成和多样化应用
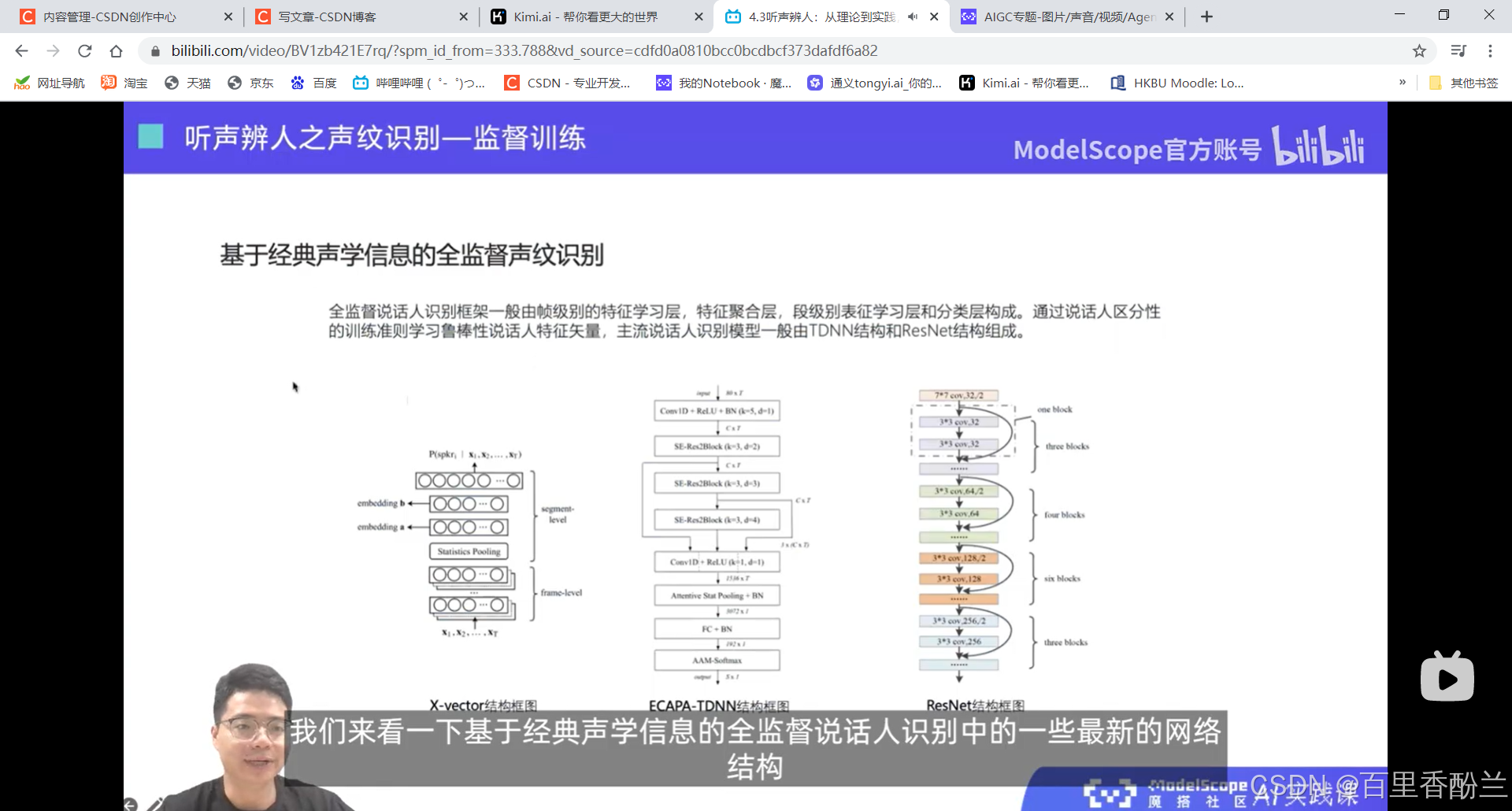
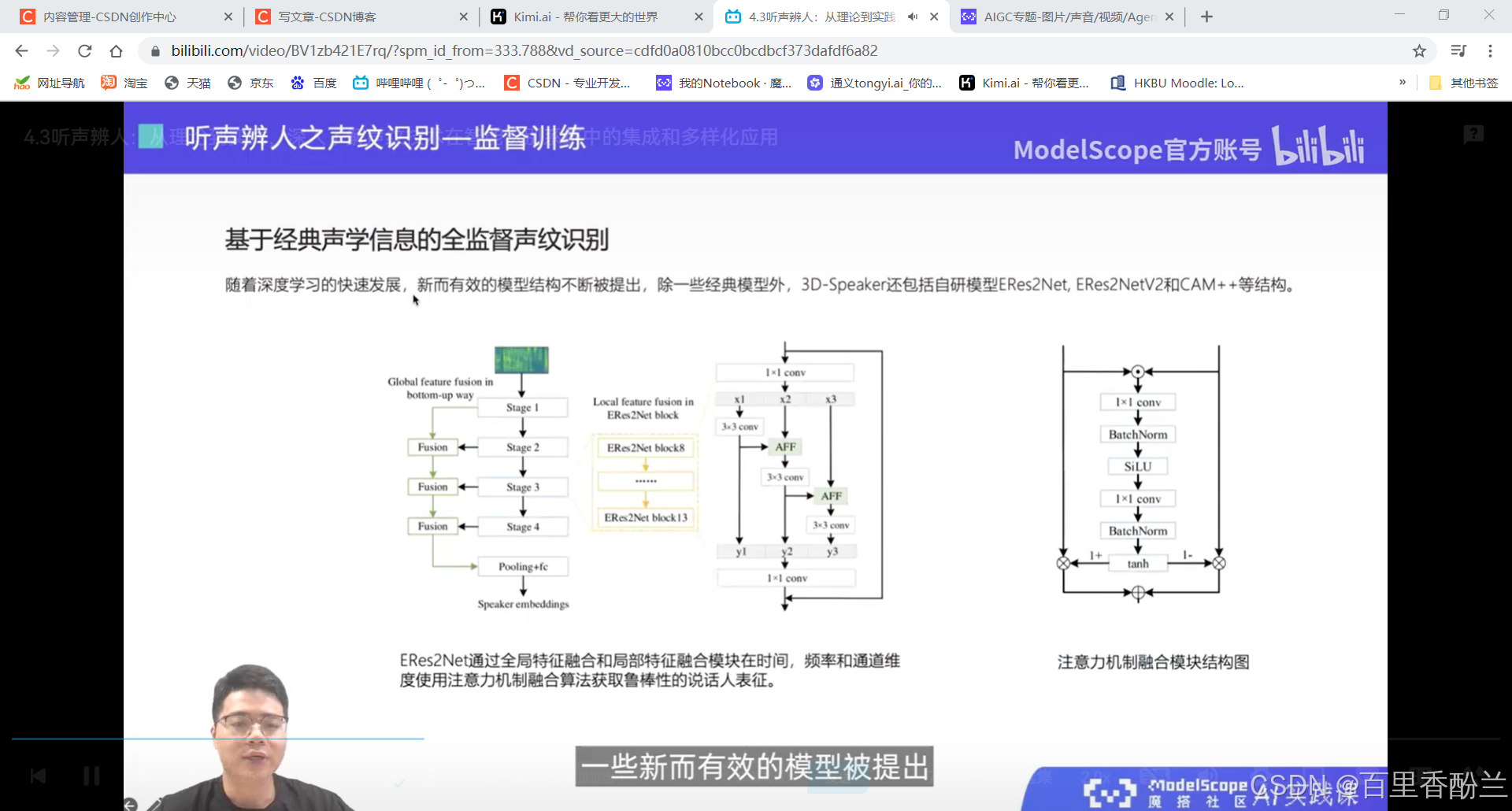
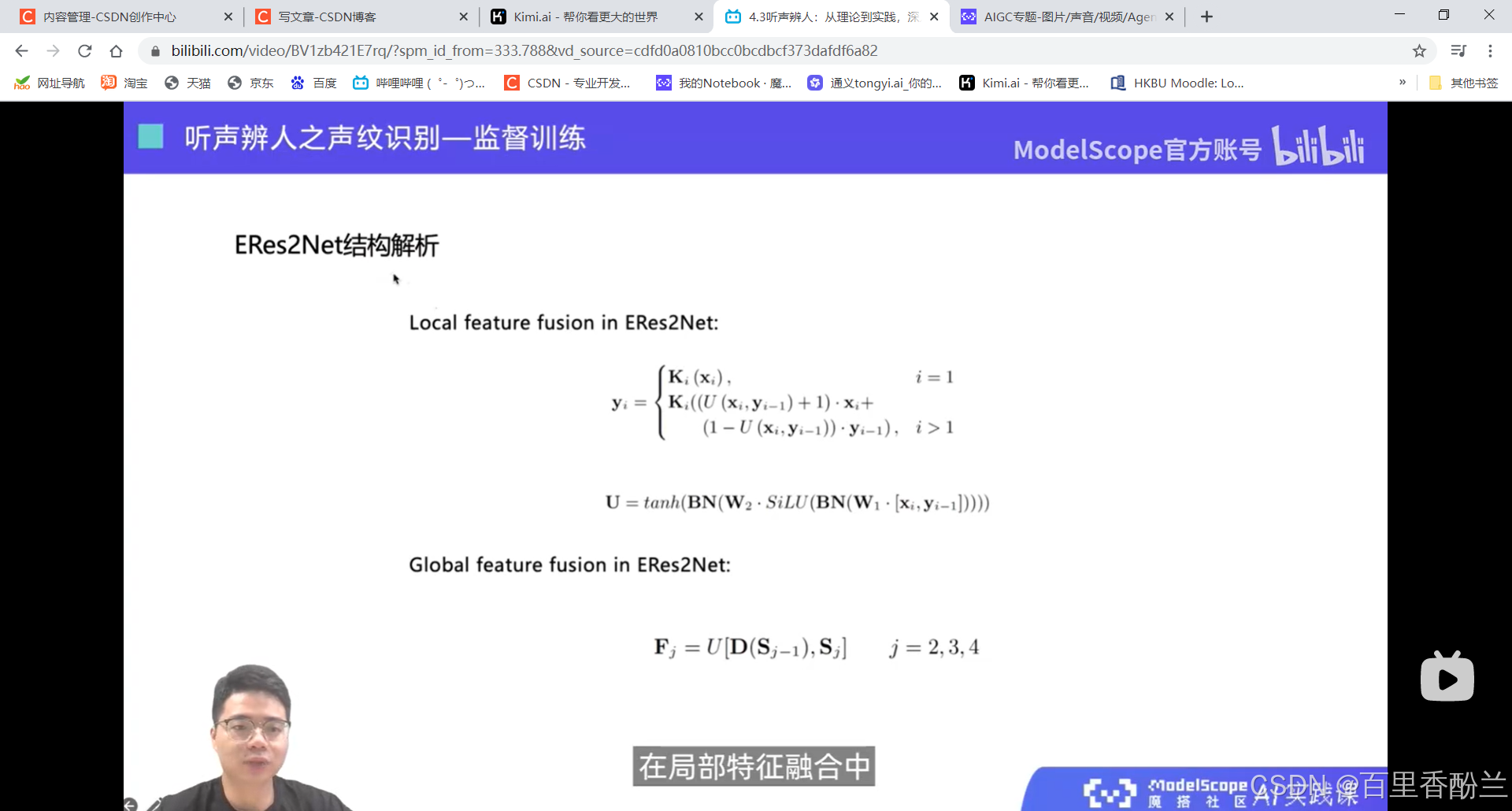
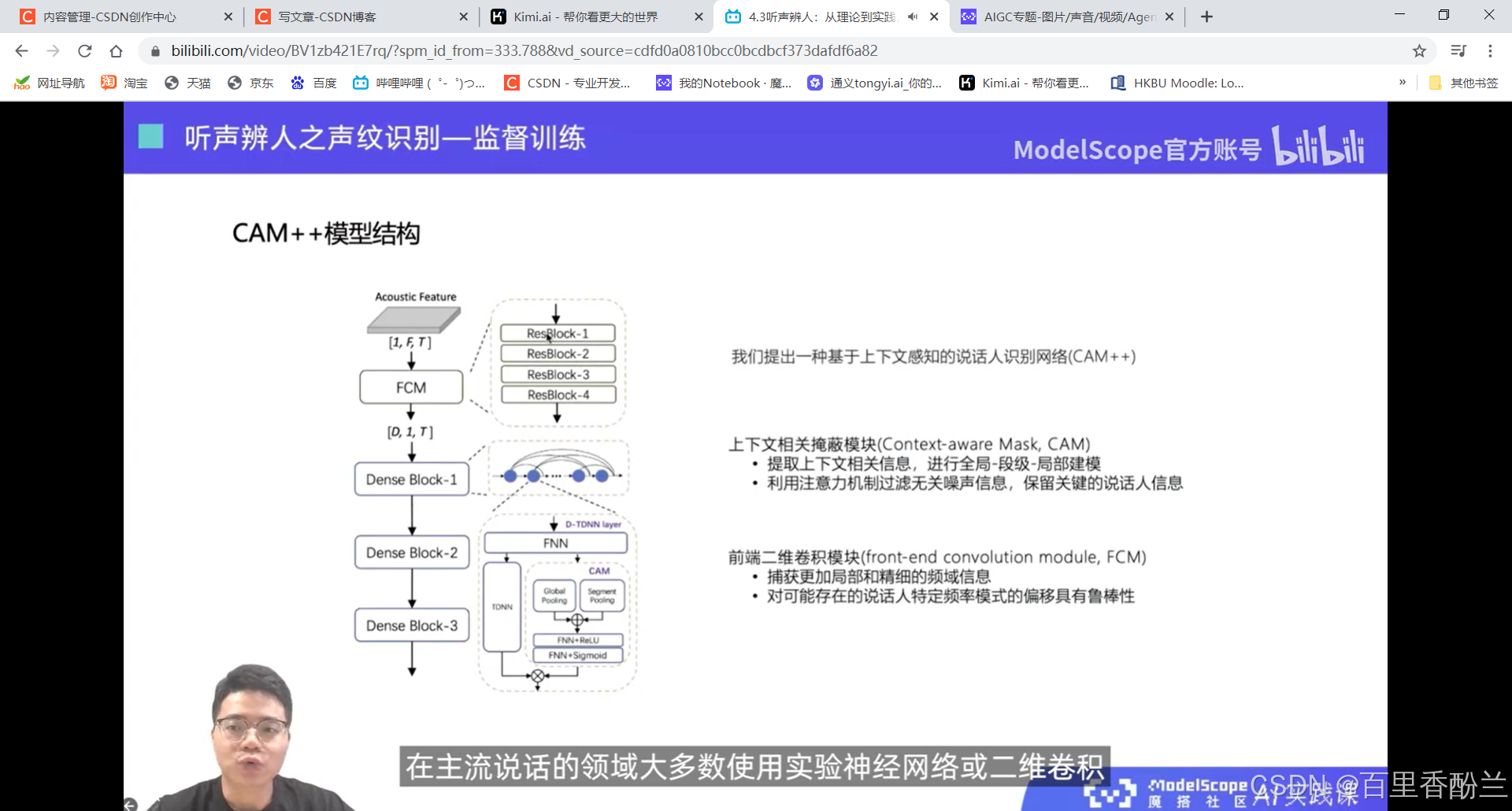
说话人辨认:多分类问题,从建模好的若干说话人中,找出测试语音对应的说话人。
说话人确认:二分类问题,给定两端语音,判断是否属于同一个说话人。
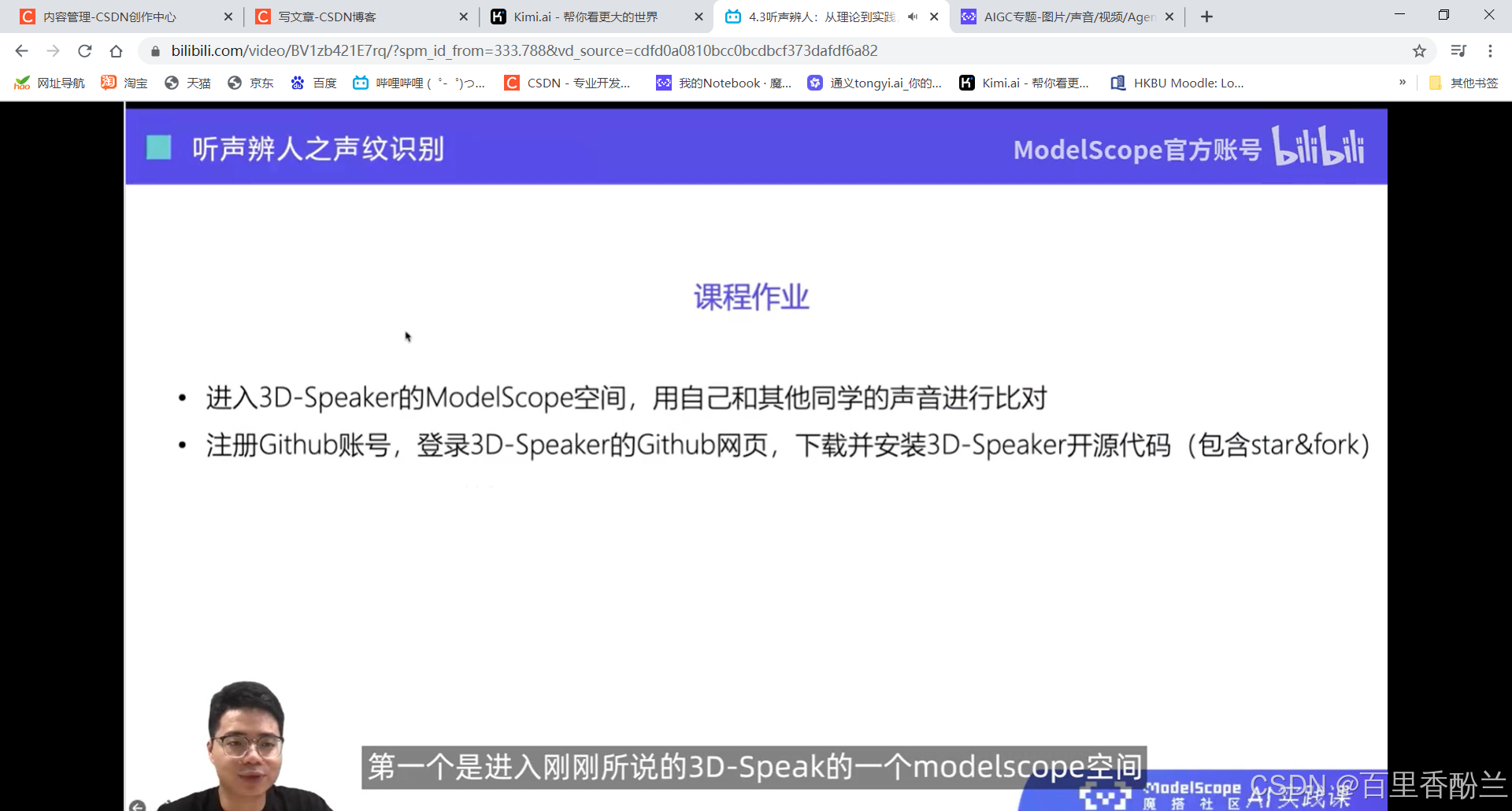
课程作业:
这几讲主要在介绍语音相关技术,不是我熟悉的范畴,算法我也不太能听明白,但是这个系列的视频可以帮我们积累很多开源项目工具,下次遇到应用上面的问题可以直接找好用的工具而不是耗费人力手工解决。
5.1大模型Agent的发展及现状
终于到了我比较感兴趣的部分了!我选的AIGC和大模型应用开发方向,前三章是关于AIGC的,我感觉第五章和第六章主要就是针对应用开发方向的课程。
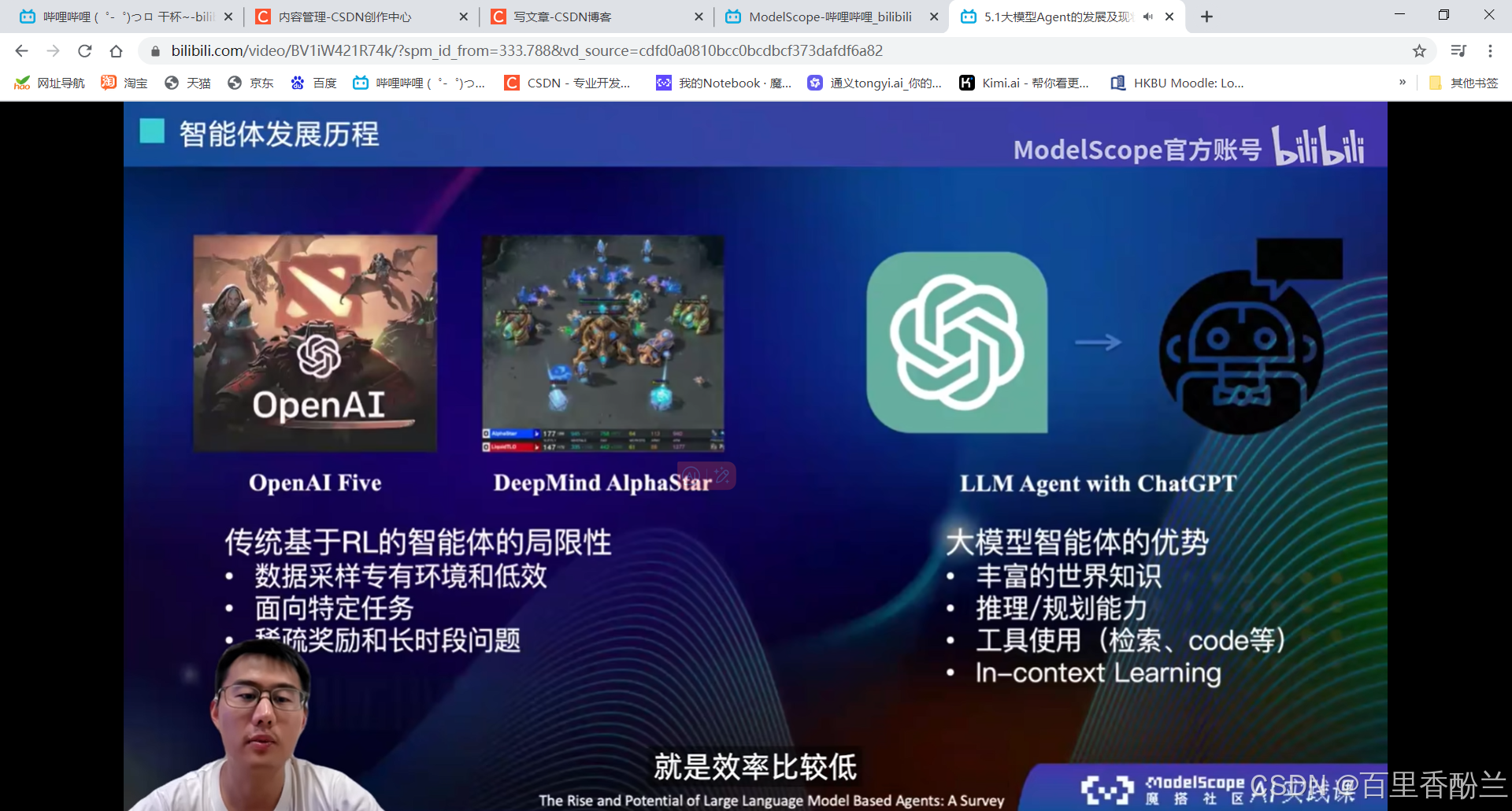
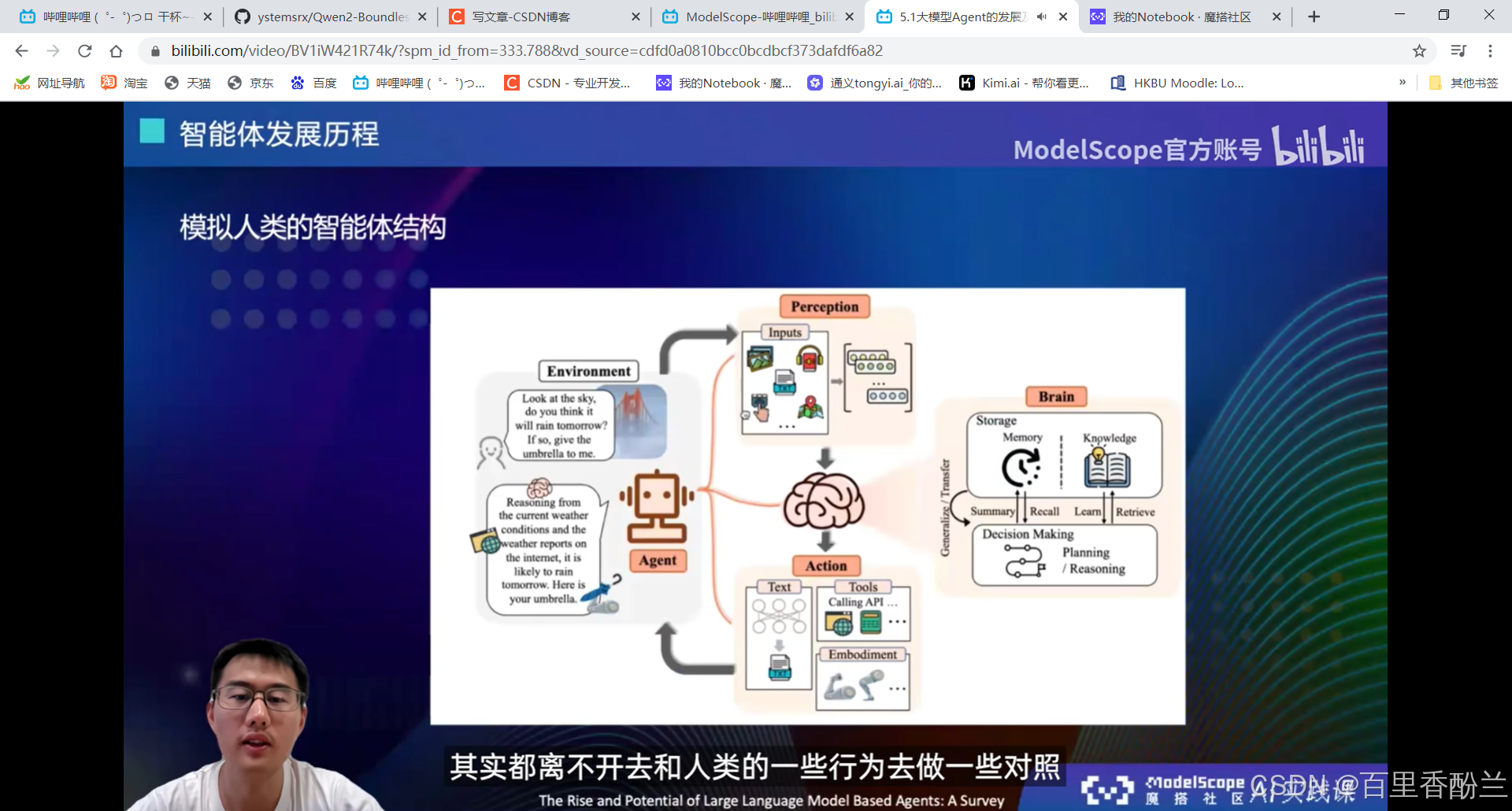
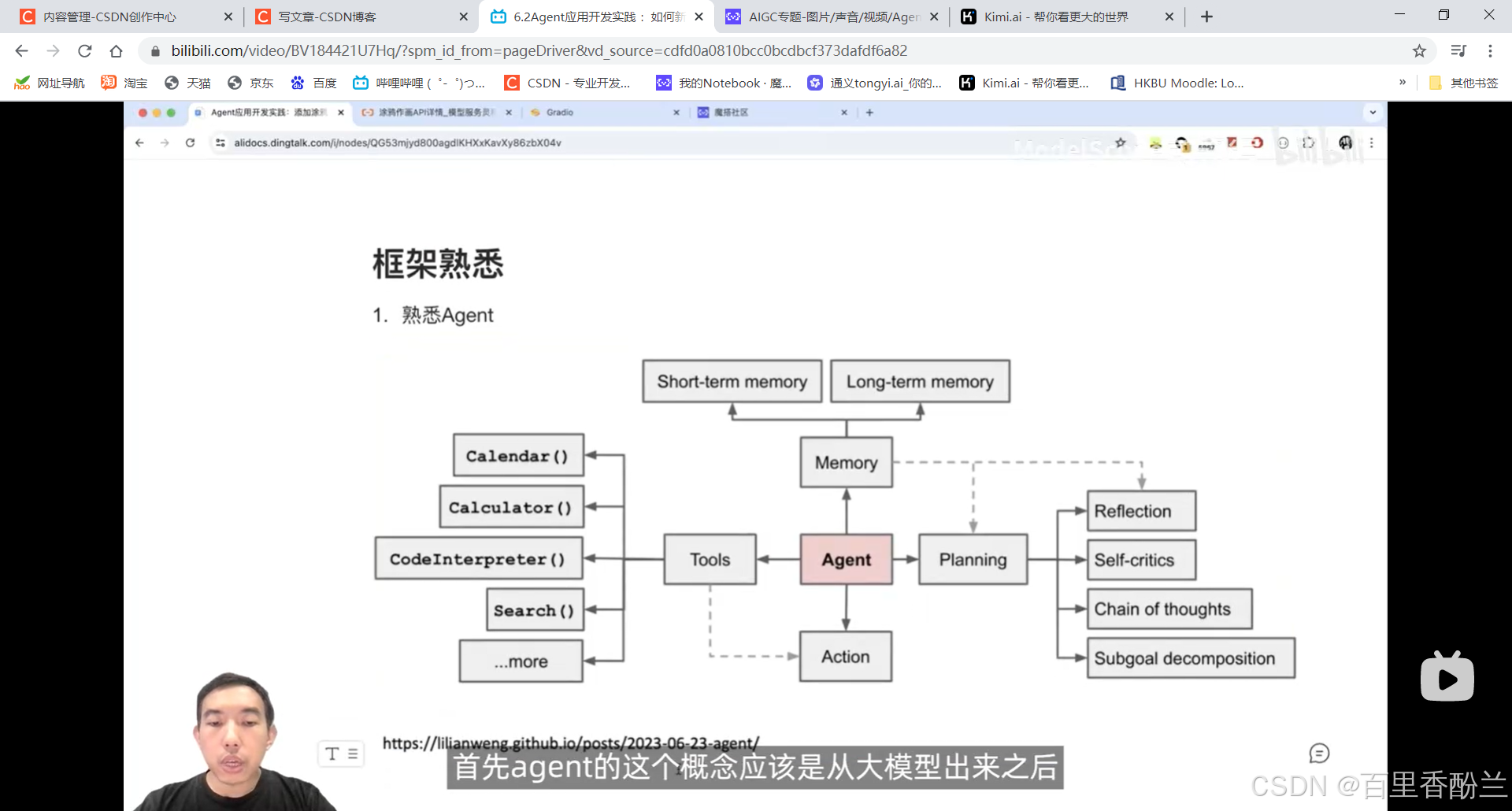
怎样才能被称为智能体?
自主性(无需人类干涉自主进化),社交能力(对话、心理、情感、幽默),现实感知能力,主动性(主动说话和使用工具)。
(所以,原神里面的散兵就是一个很成功的智能体?!)
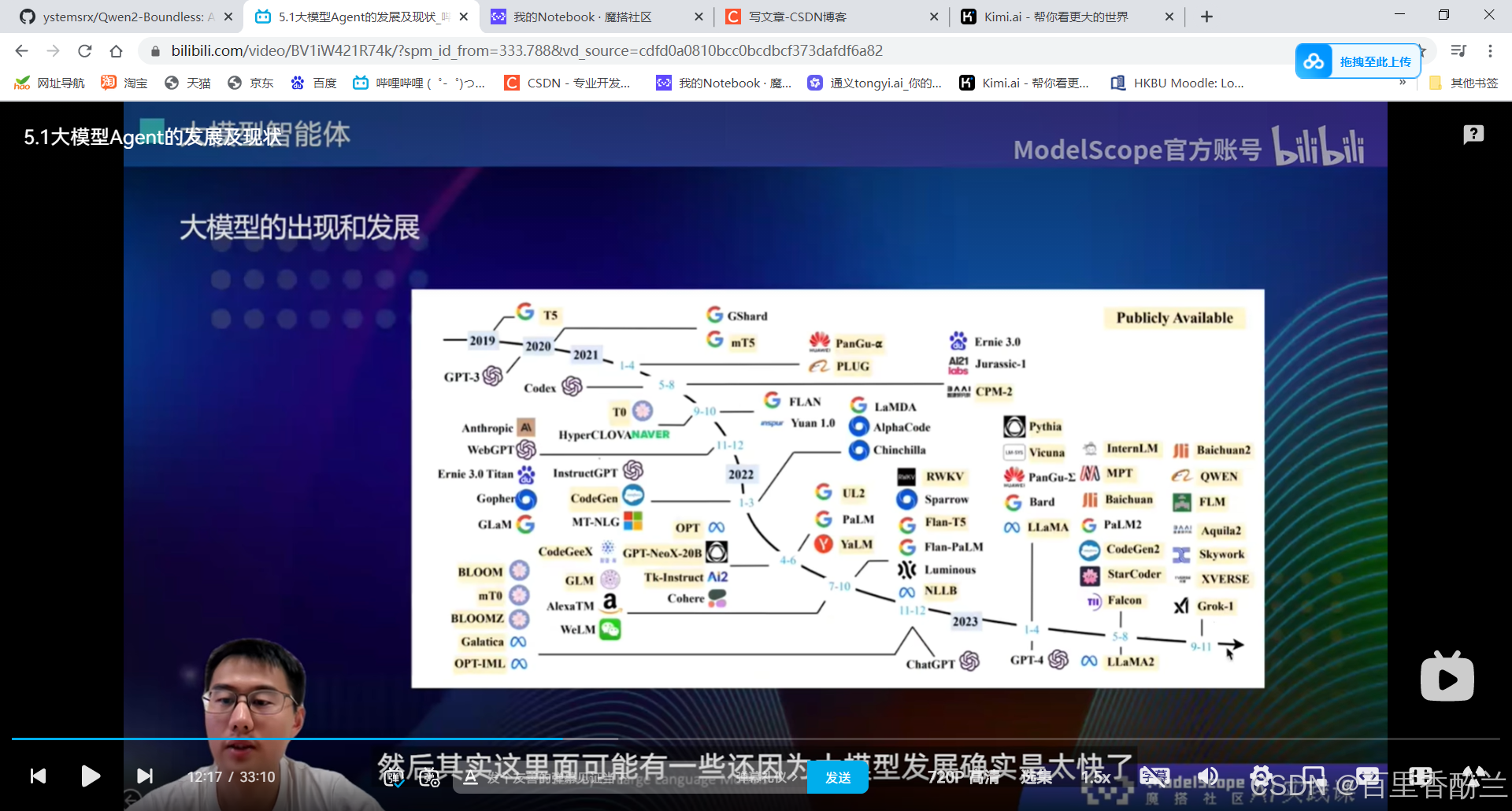
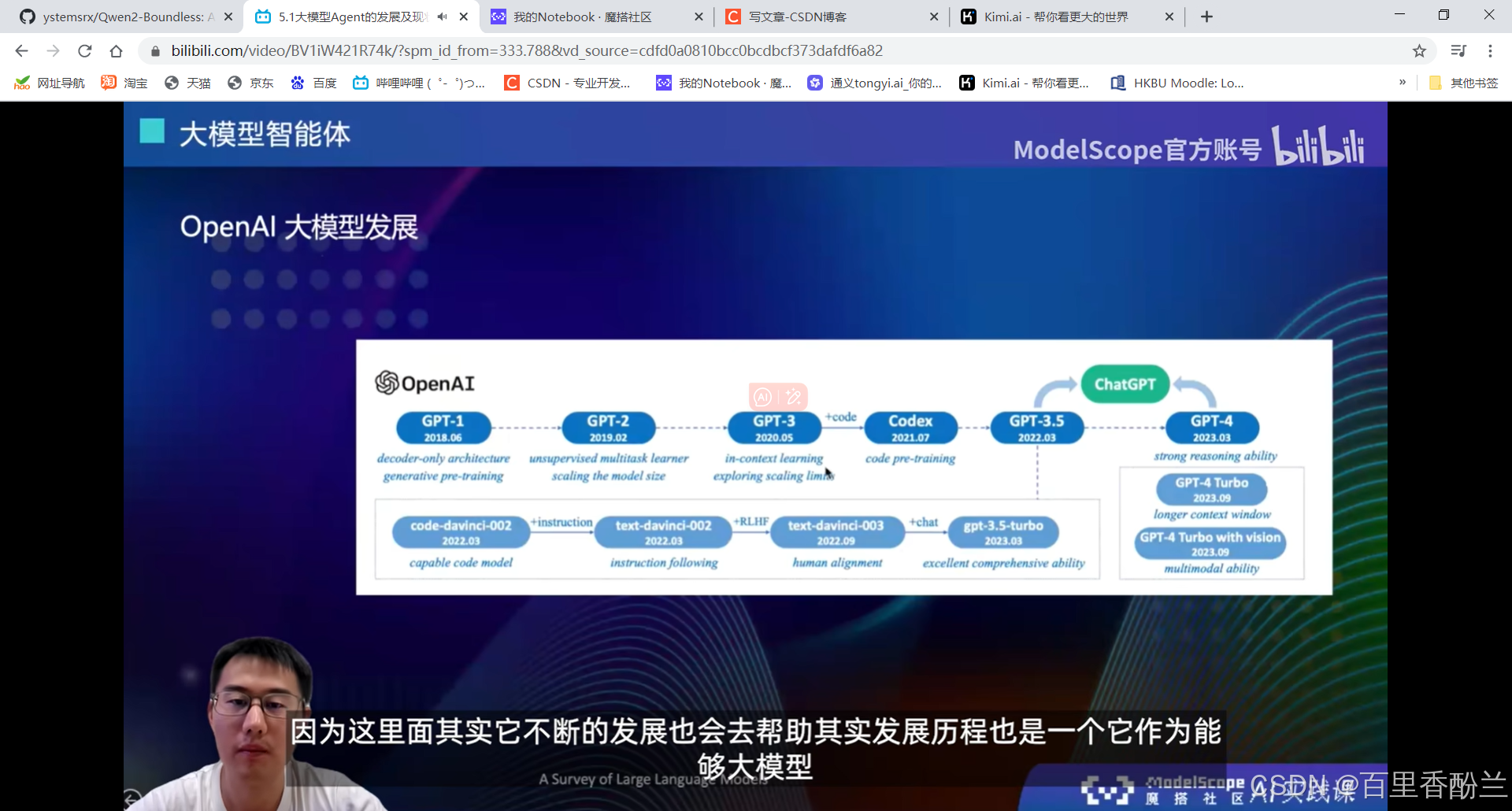
GPT3的时候还没有planning和reasoning的能力,后面加入了code-pretraining真正地具有了一定的推理能力。
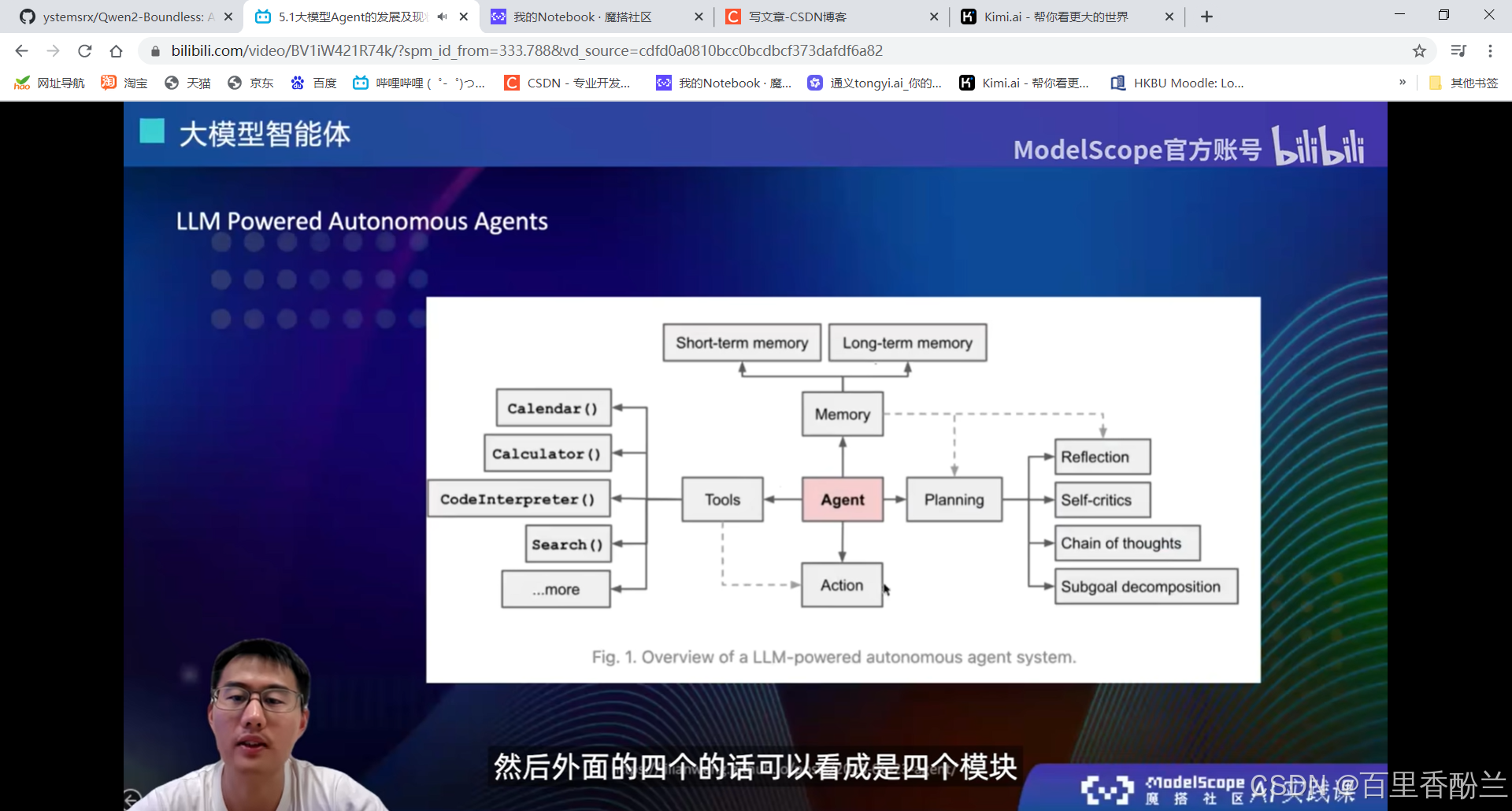
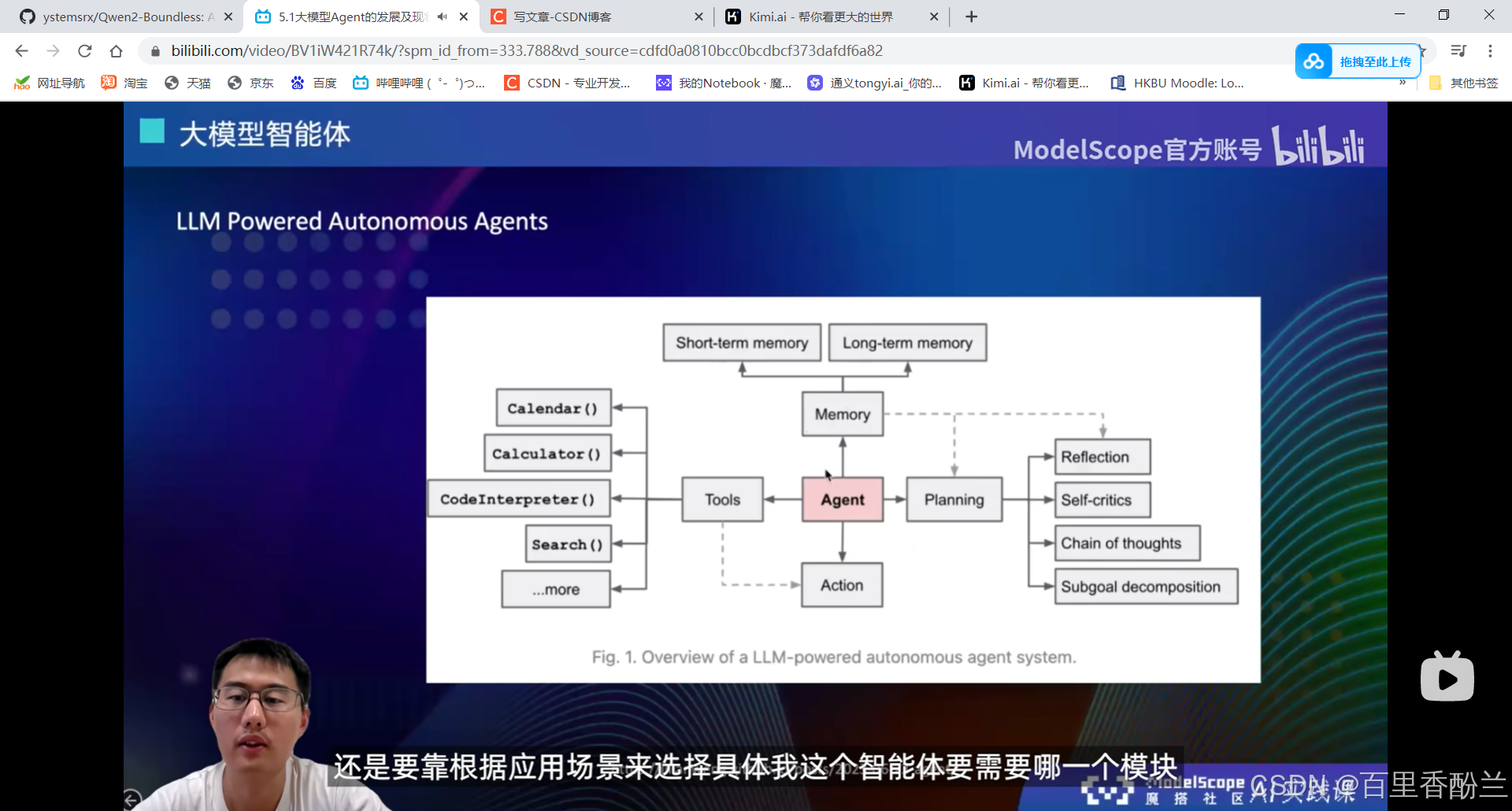
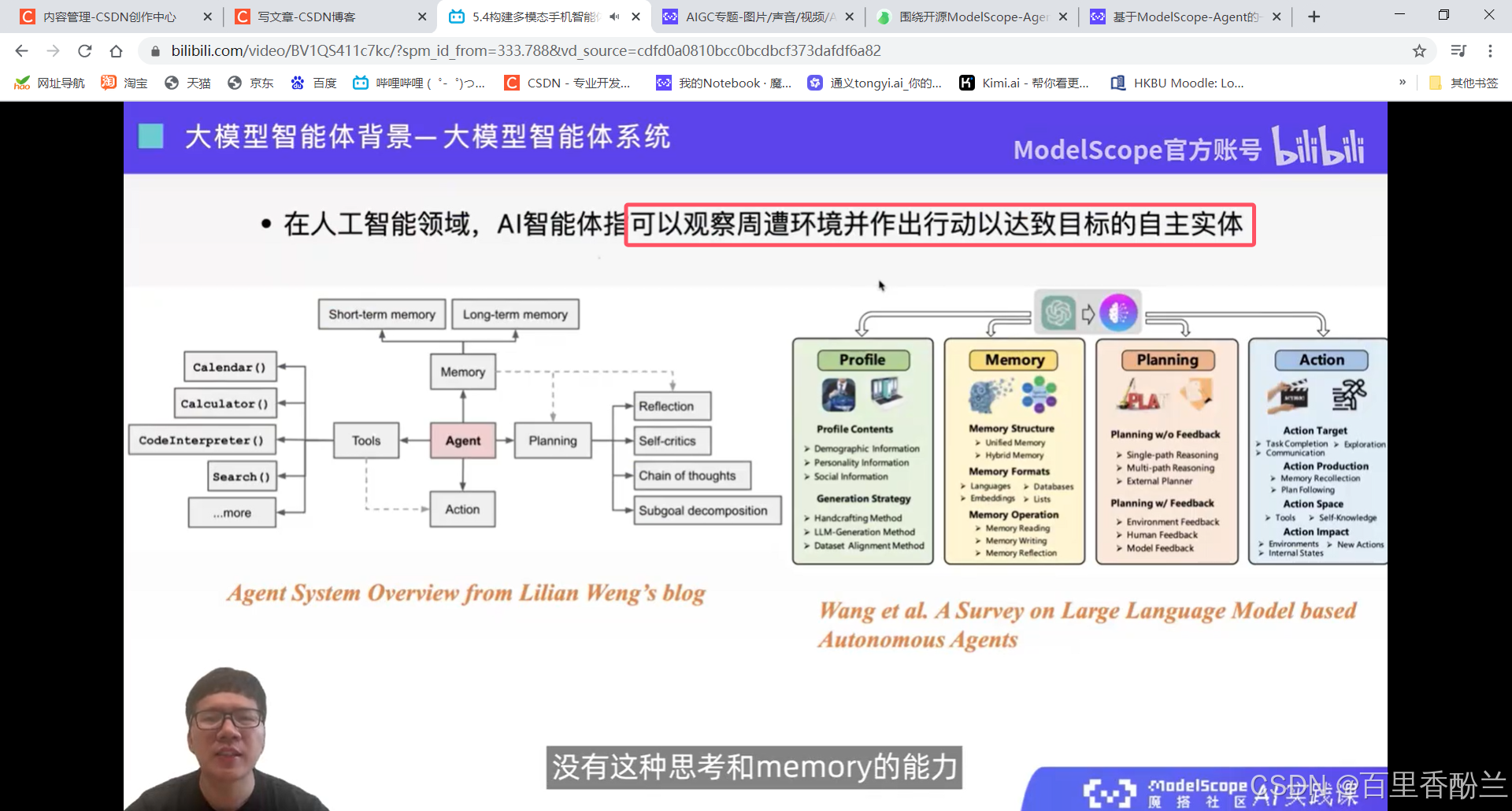
大模型+四个模块:
用的比较多的Search工具,知识库检索,这些可以去做大模型原有能力不足的,或者是说实时更新。大模型训练完后,它的所有数据和记忆就停留在当时训练完的那个节点。后面如果还有一些新数据的话就只能通过Search工具来获取。
Action工具:和tools结合,选择好tool以后执行。
不用特别的面面俱到,而是根据需要选择智能体用什么模块。
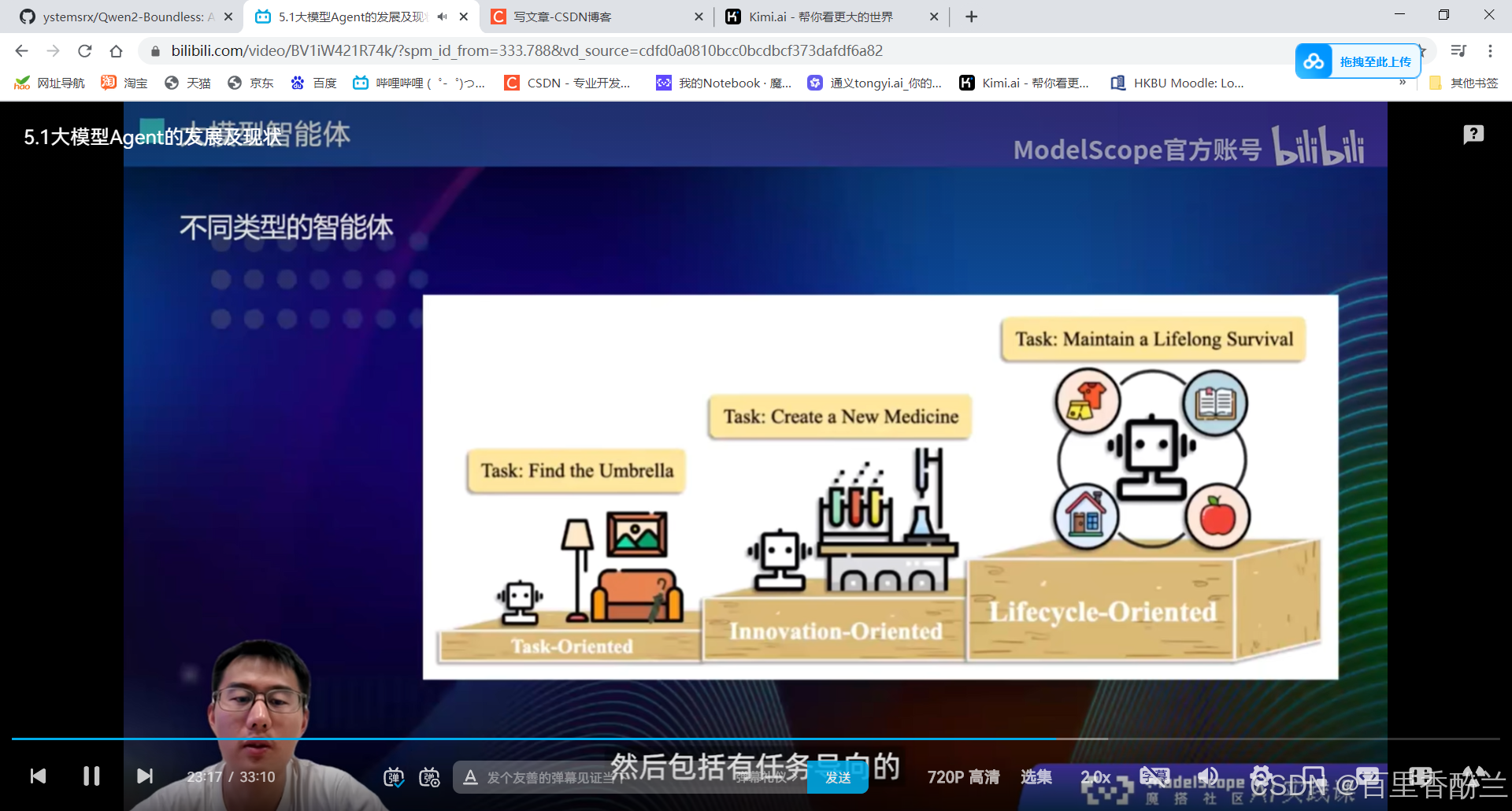
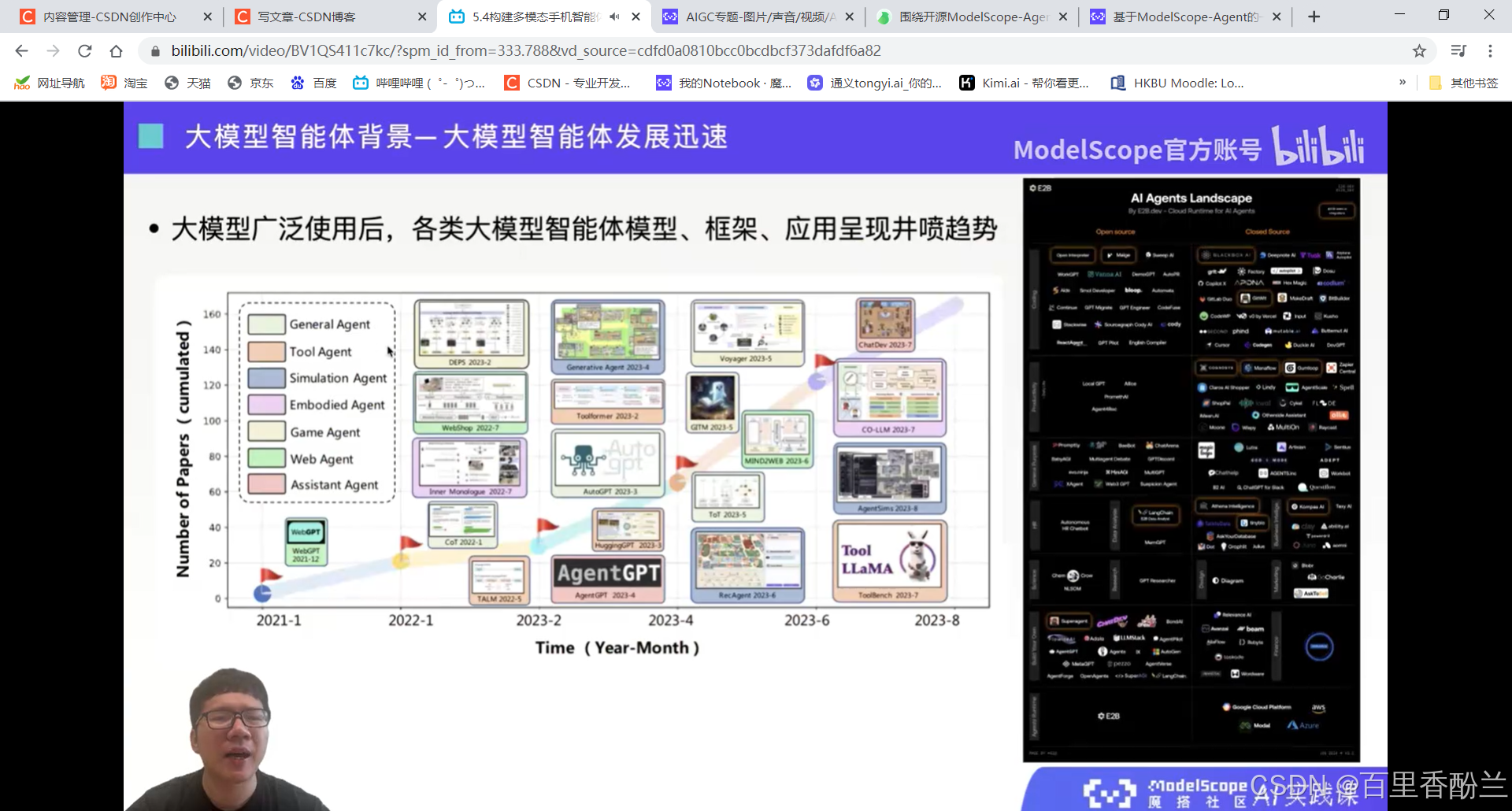
不同类型的智能体:任务导向,发明导向,生命周期
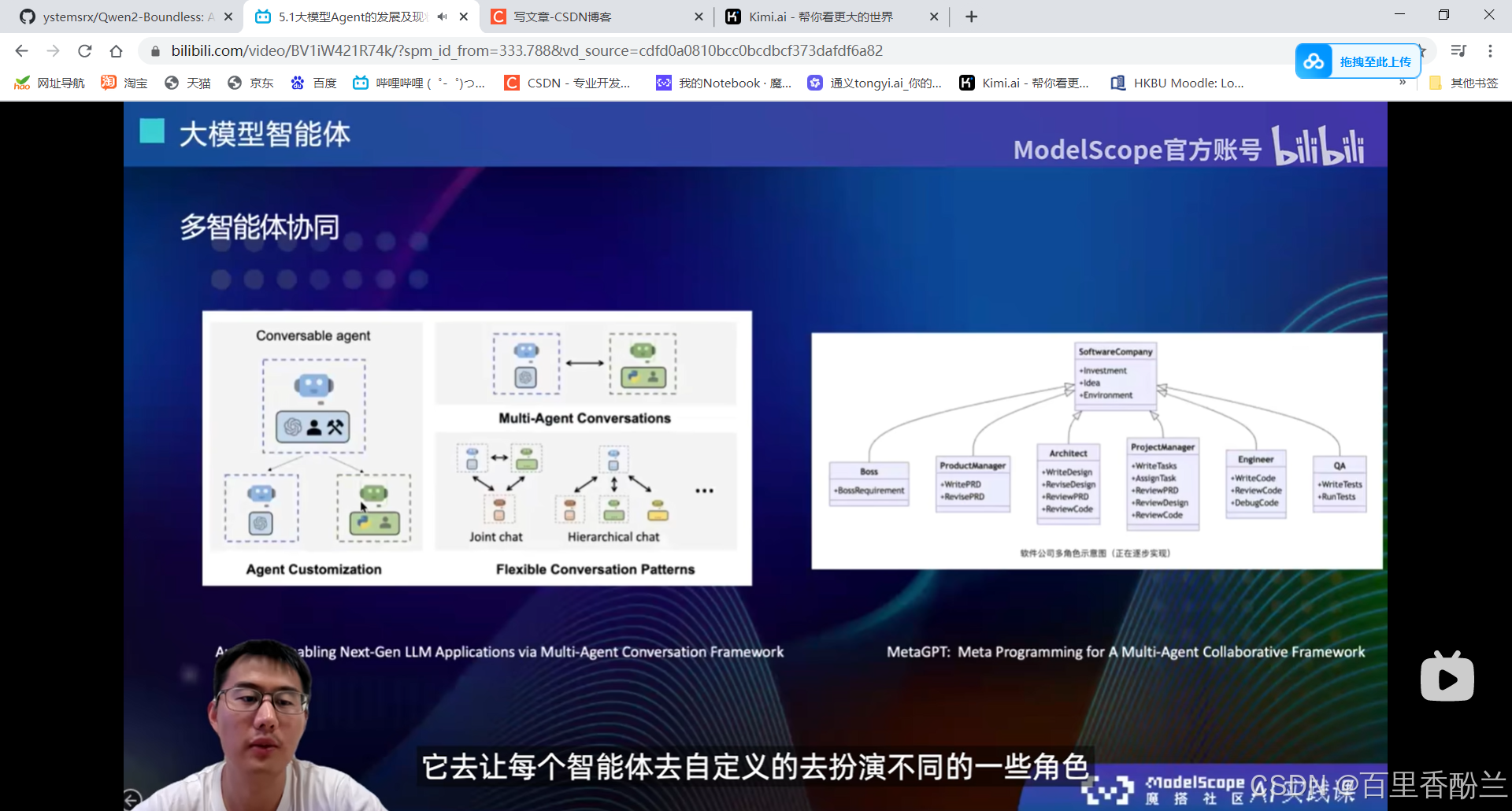
多智能体协同:join-chat和meta-GPT
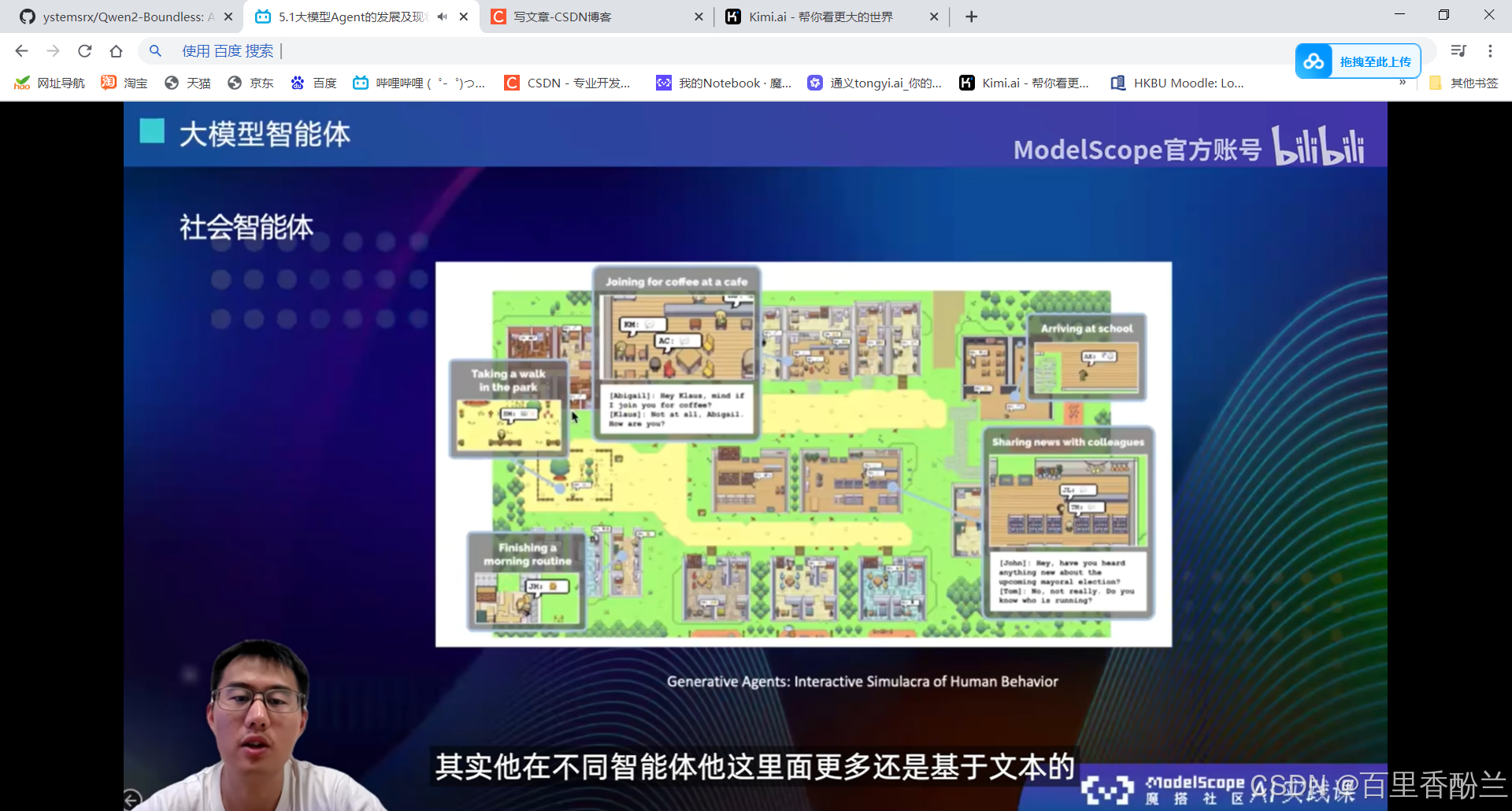
社会智能体:
类似于模拟人生、斯坦福小镇。
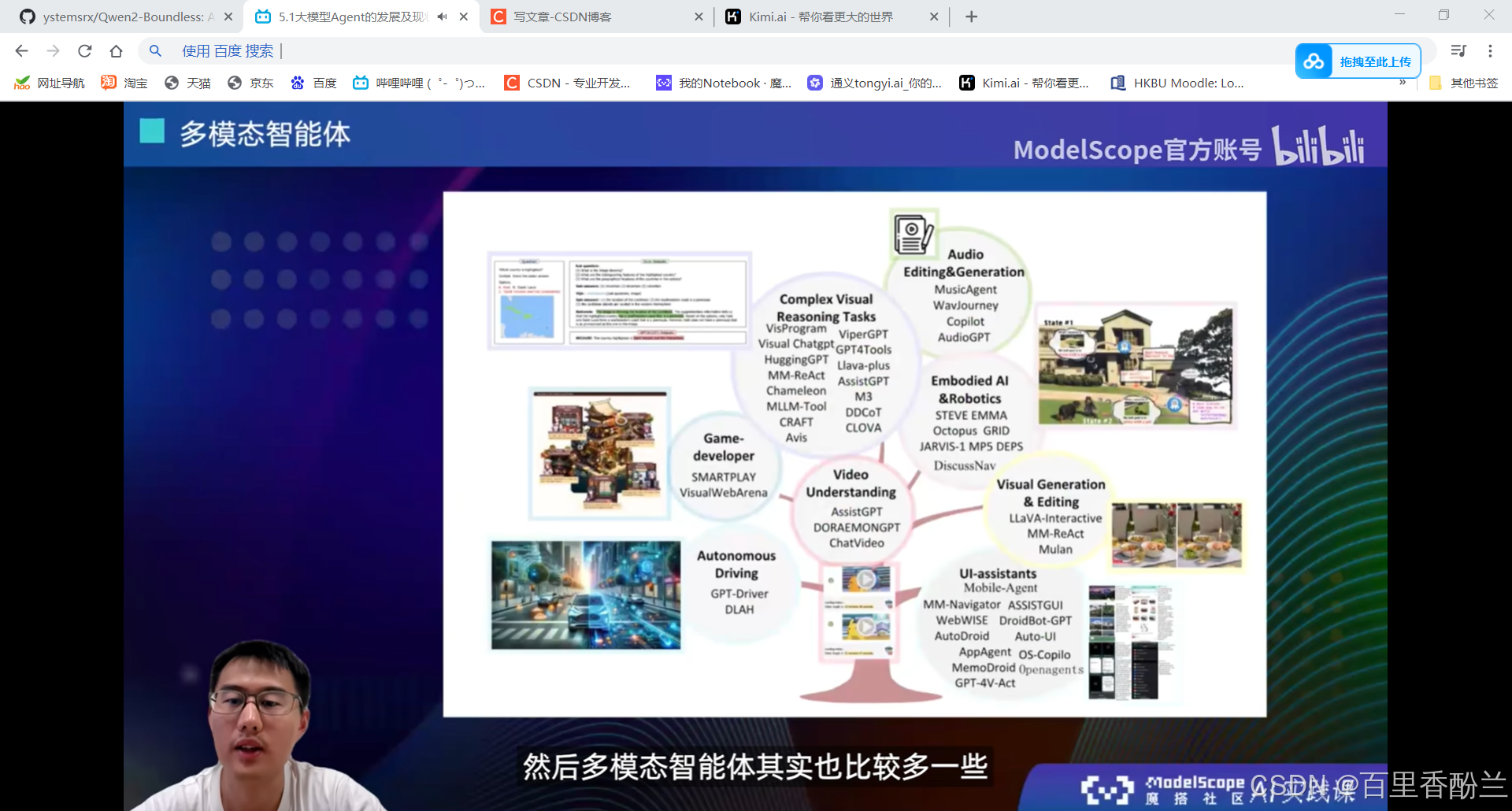
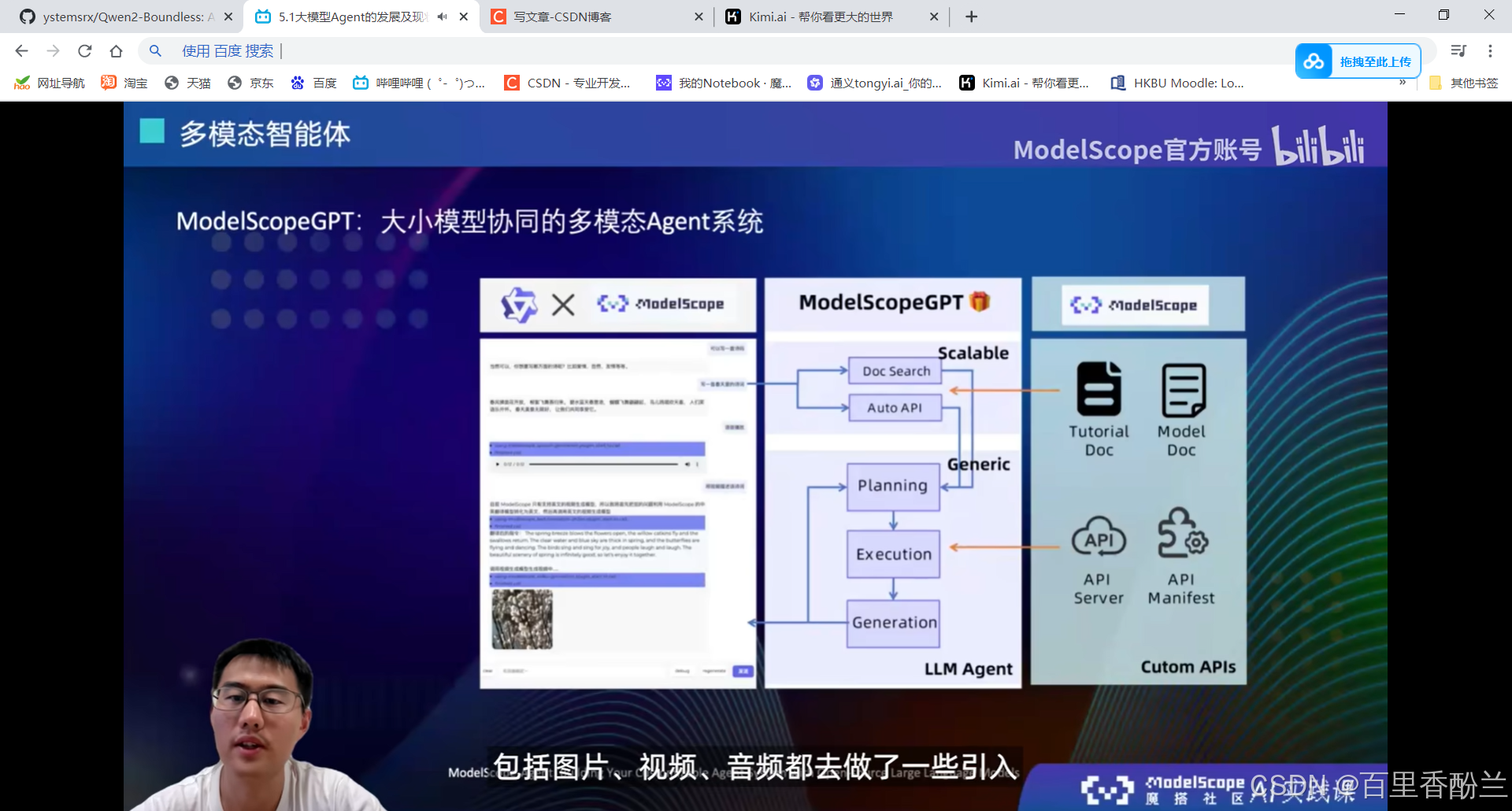
多模态智能体:
单轮/多轮api调用:
背后本质上还是依赖多模态大模型。
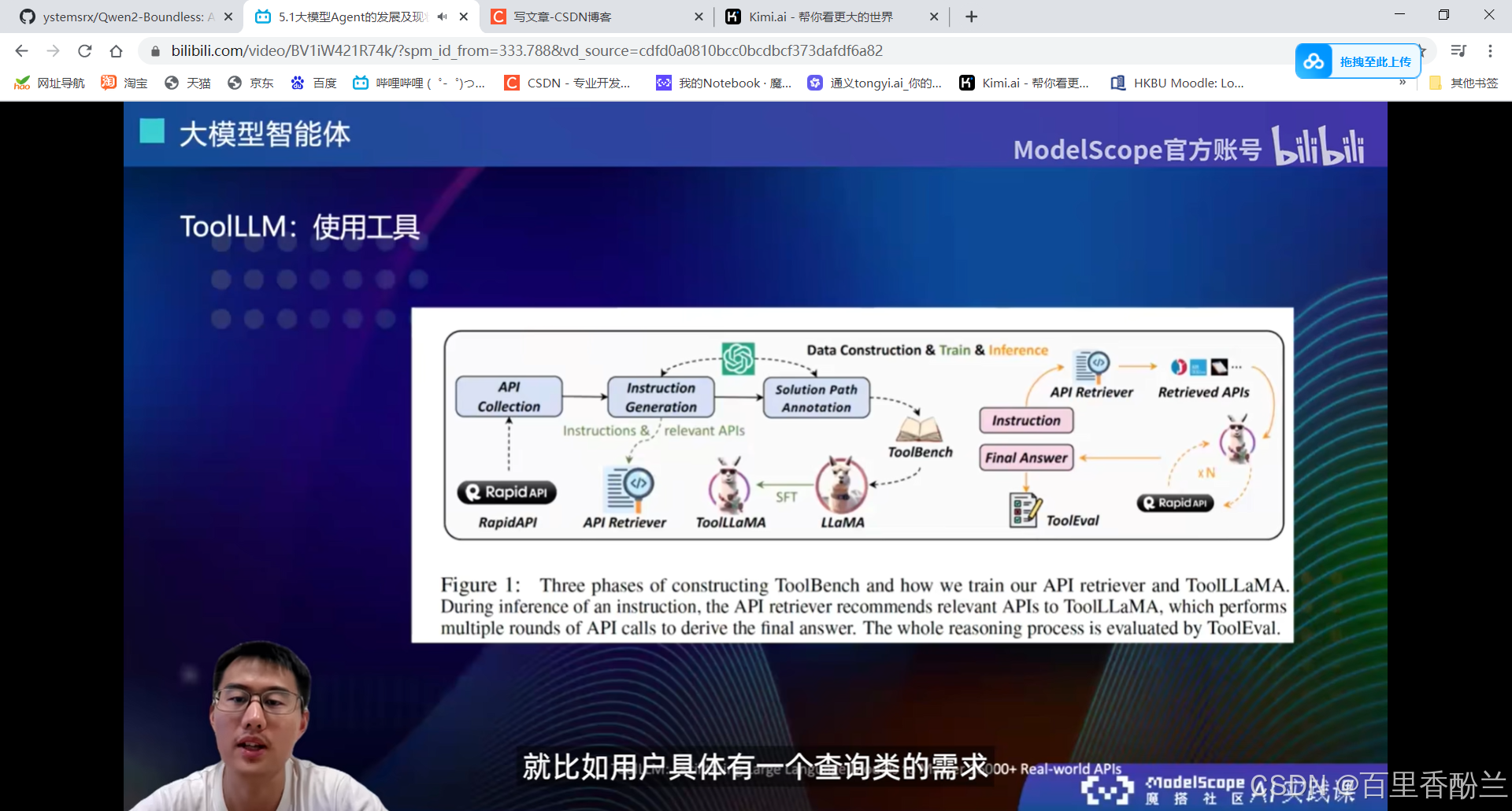
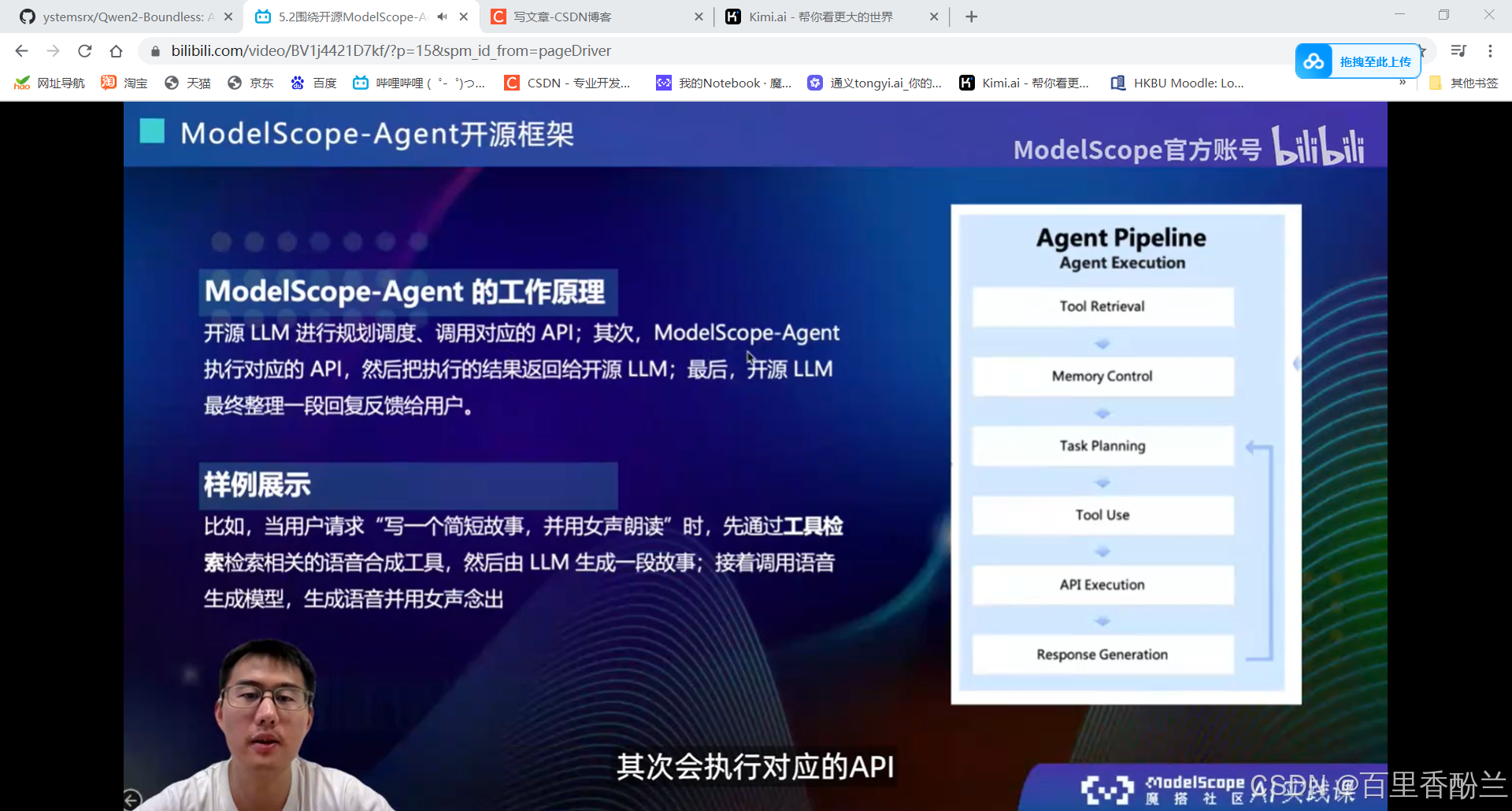
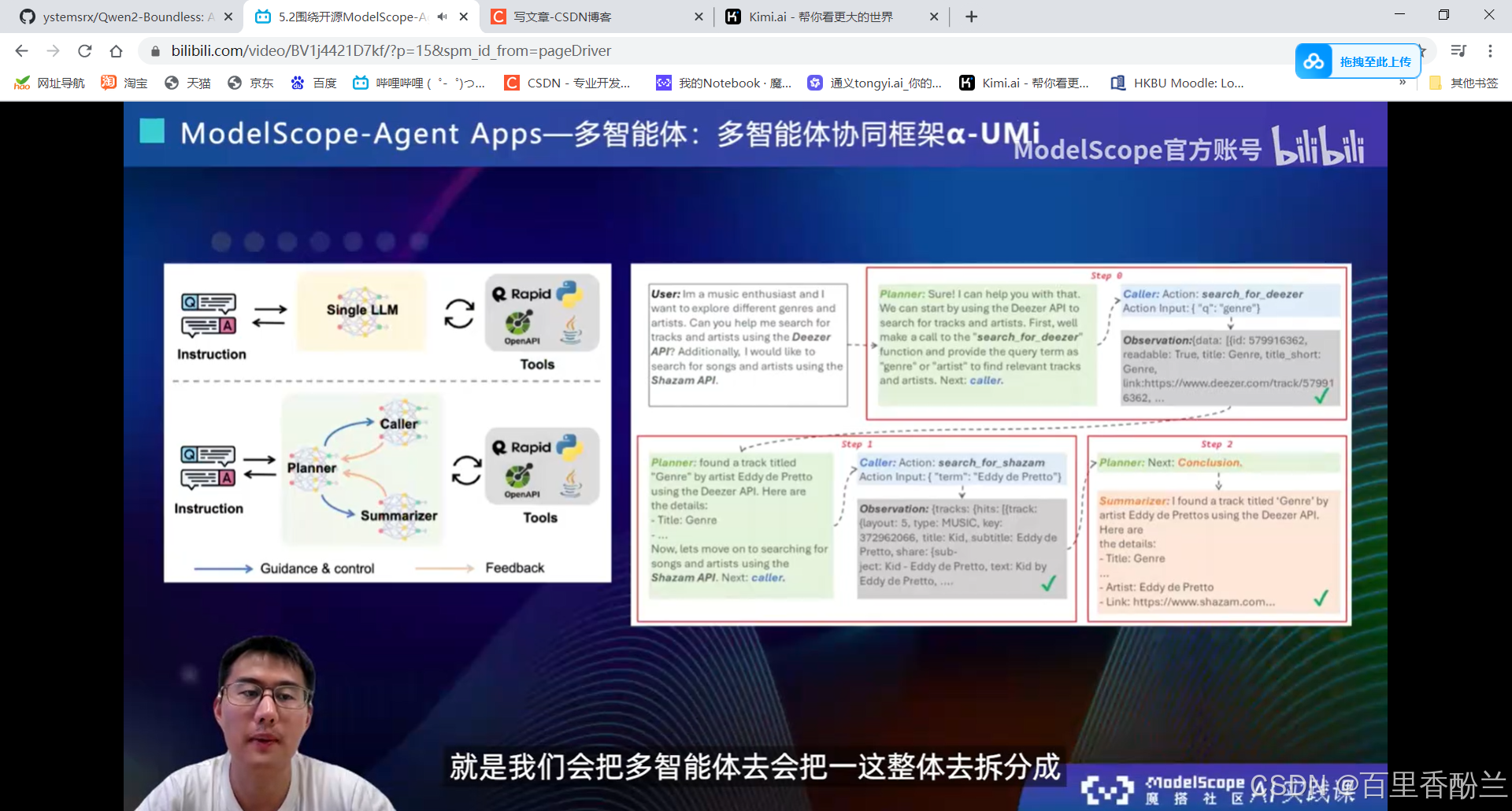
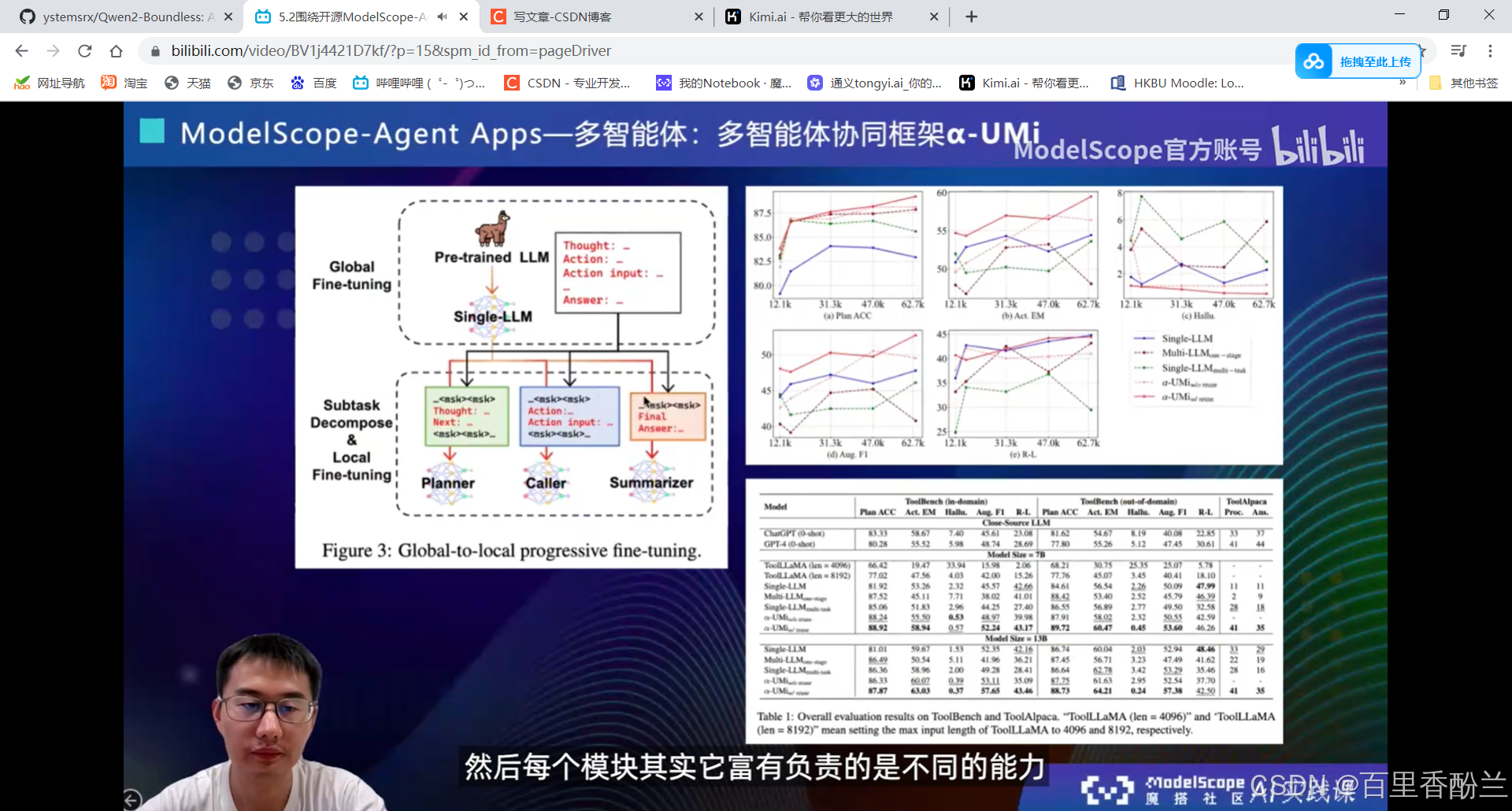
5.2围绕开源ModelScope-Agent框架的技术解读: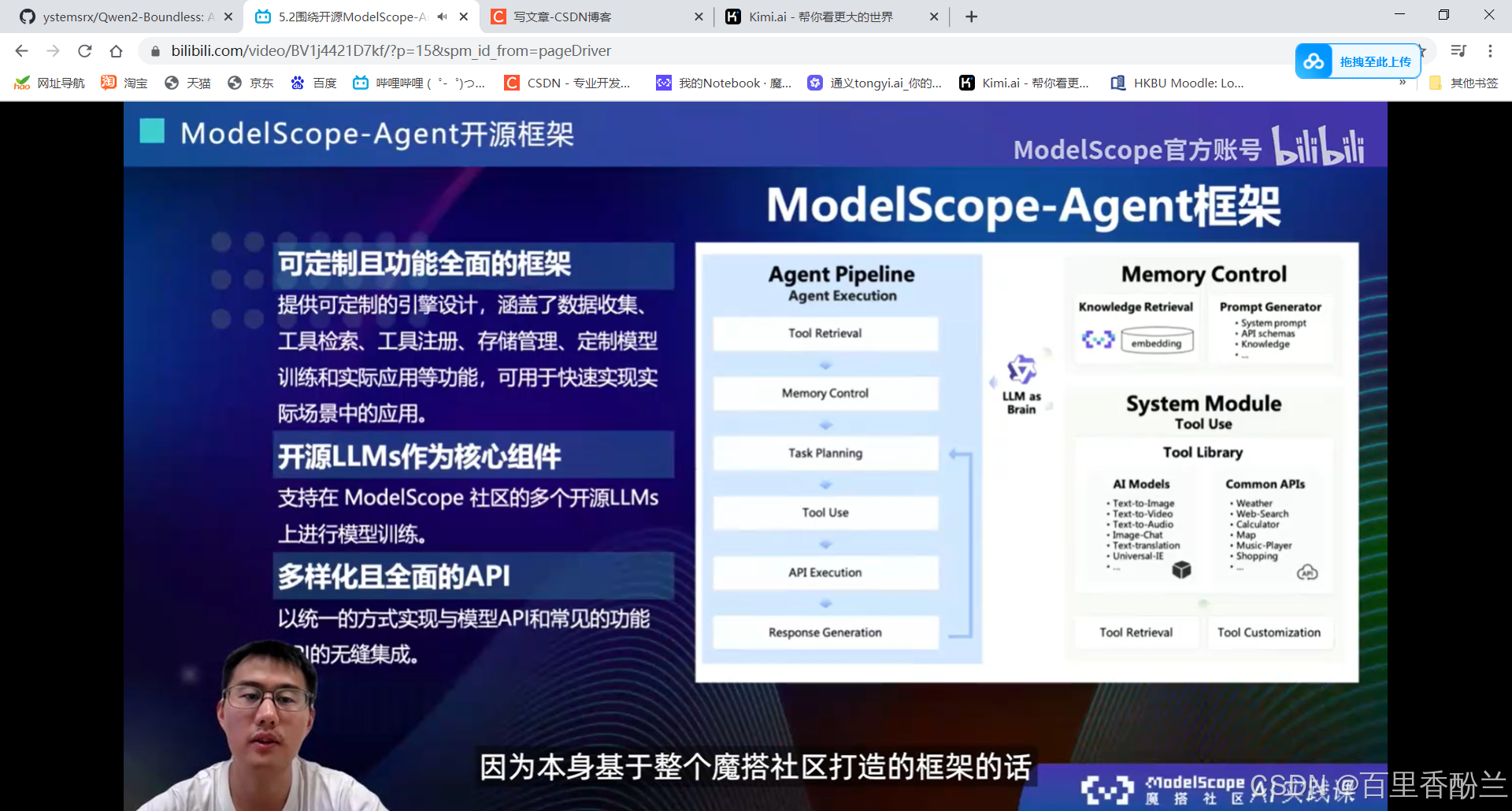
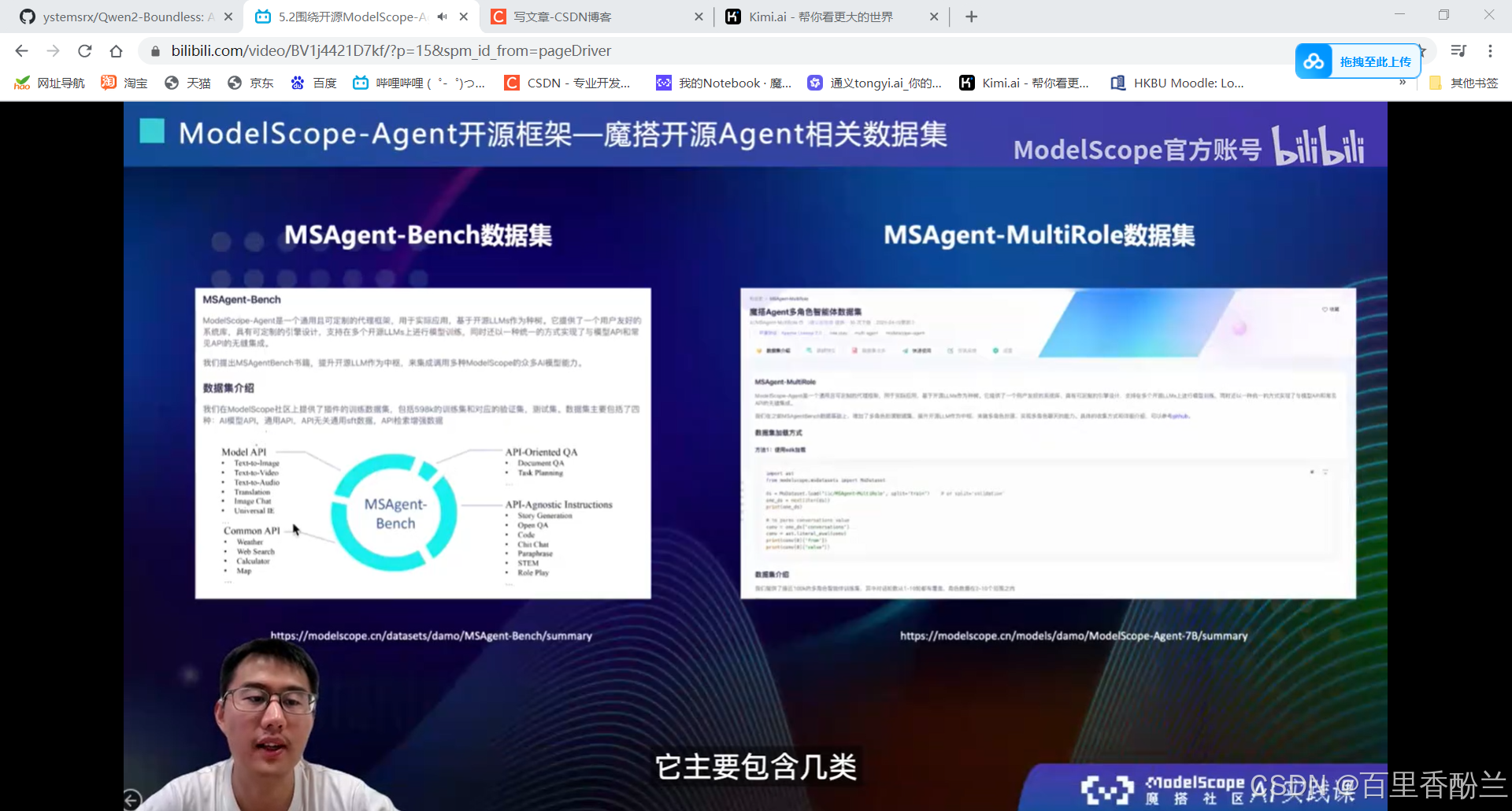
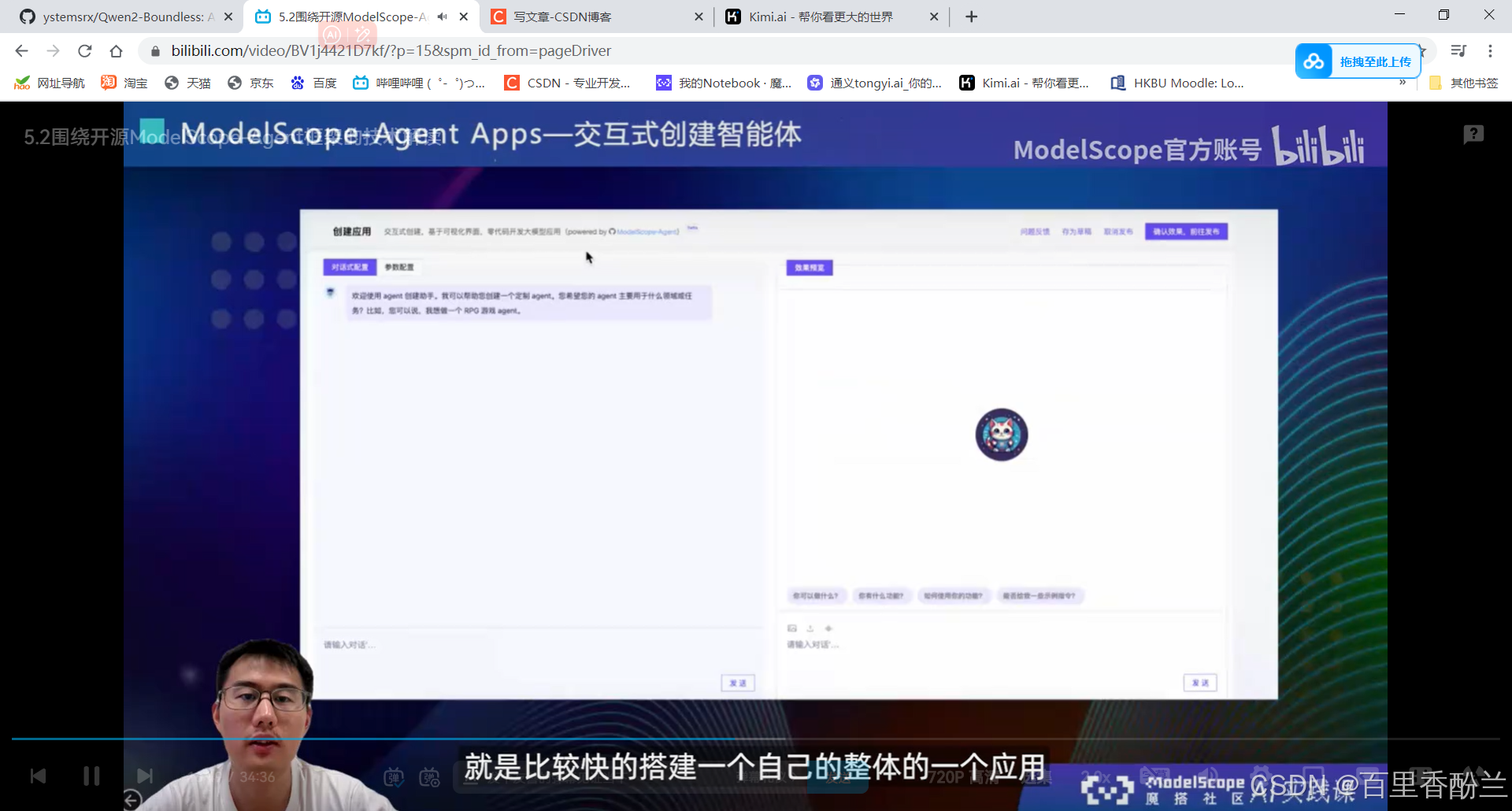
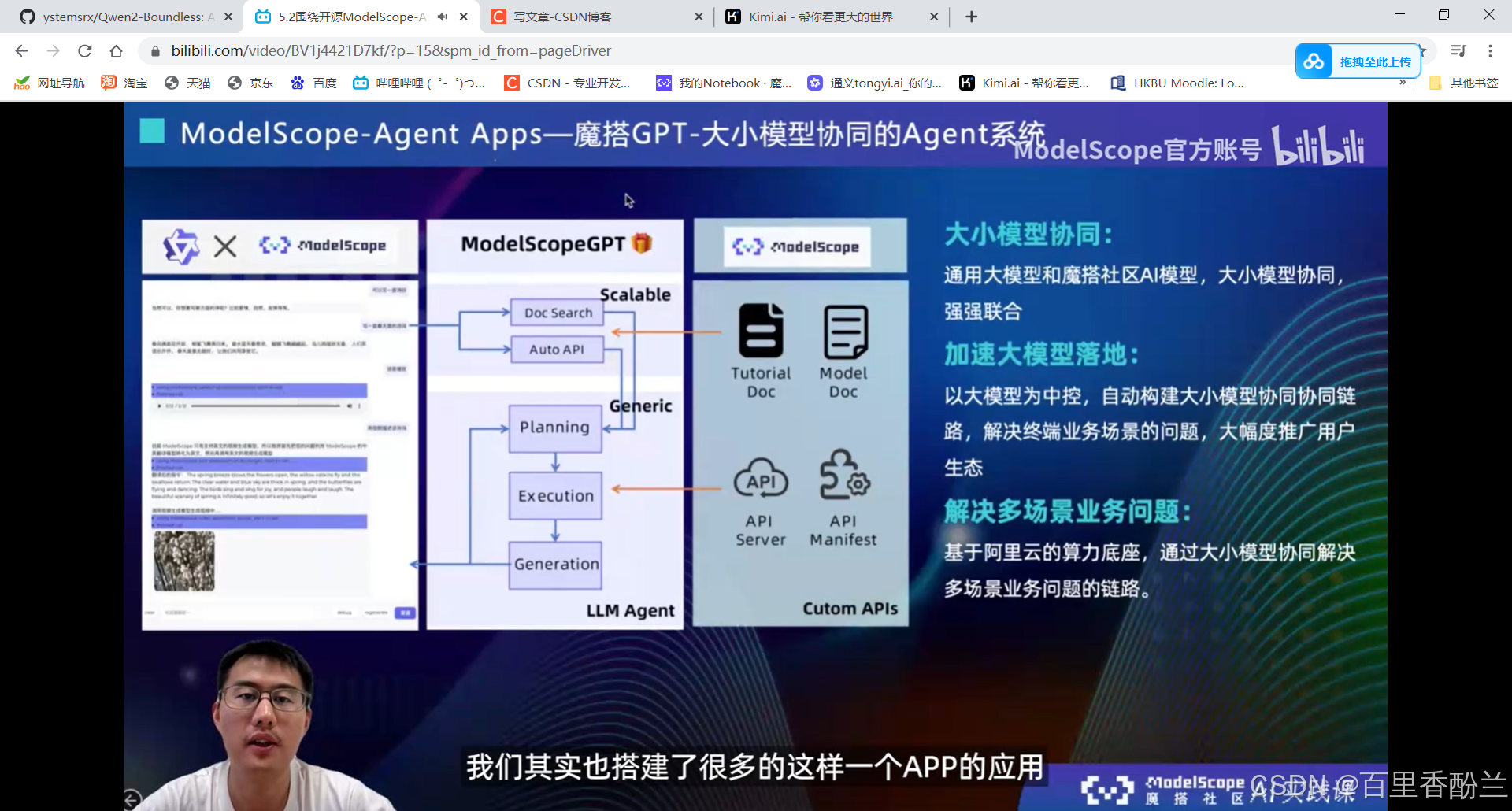
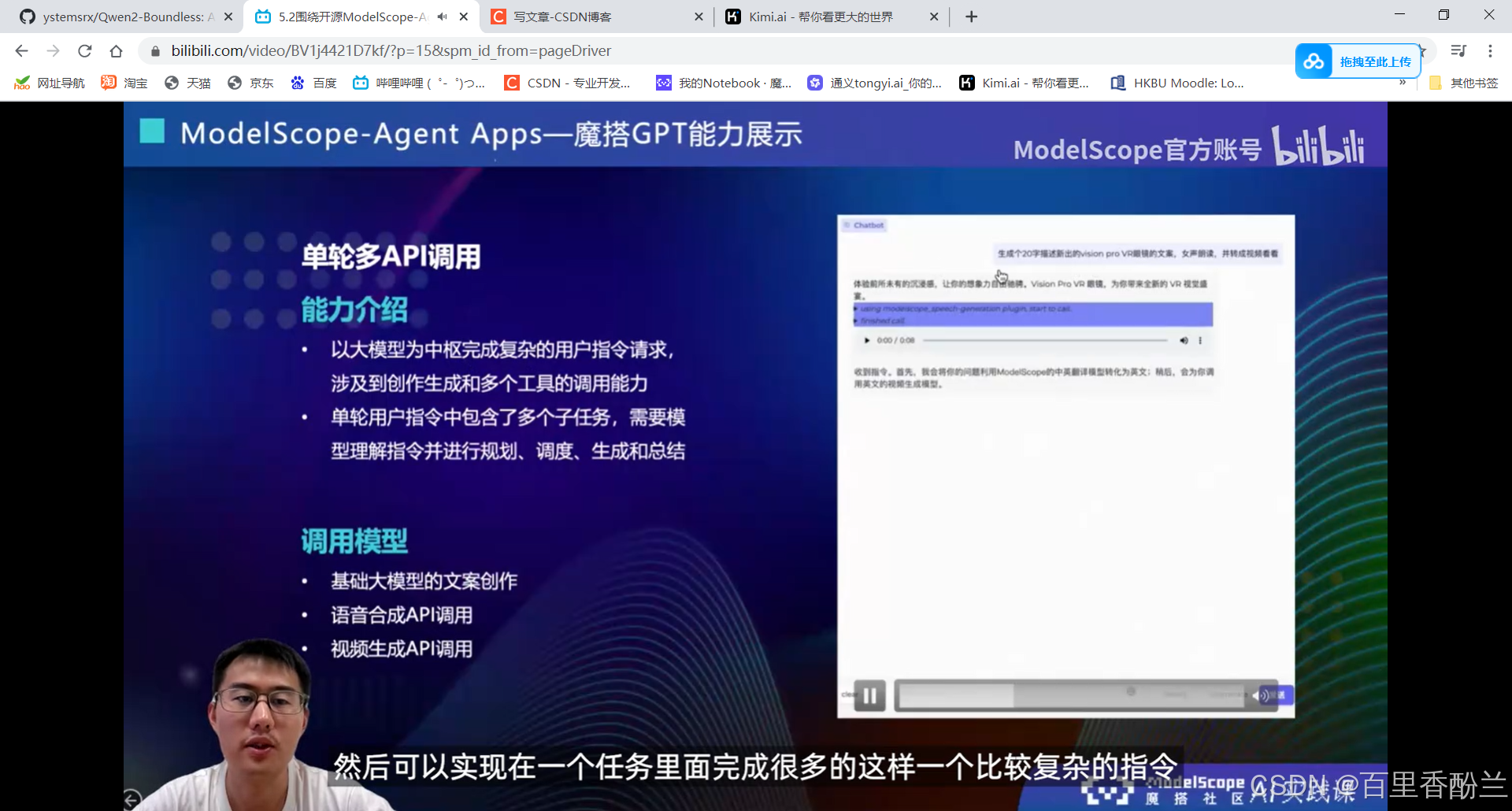
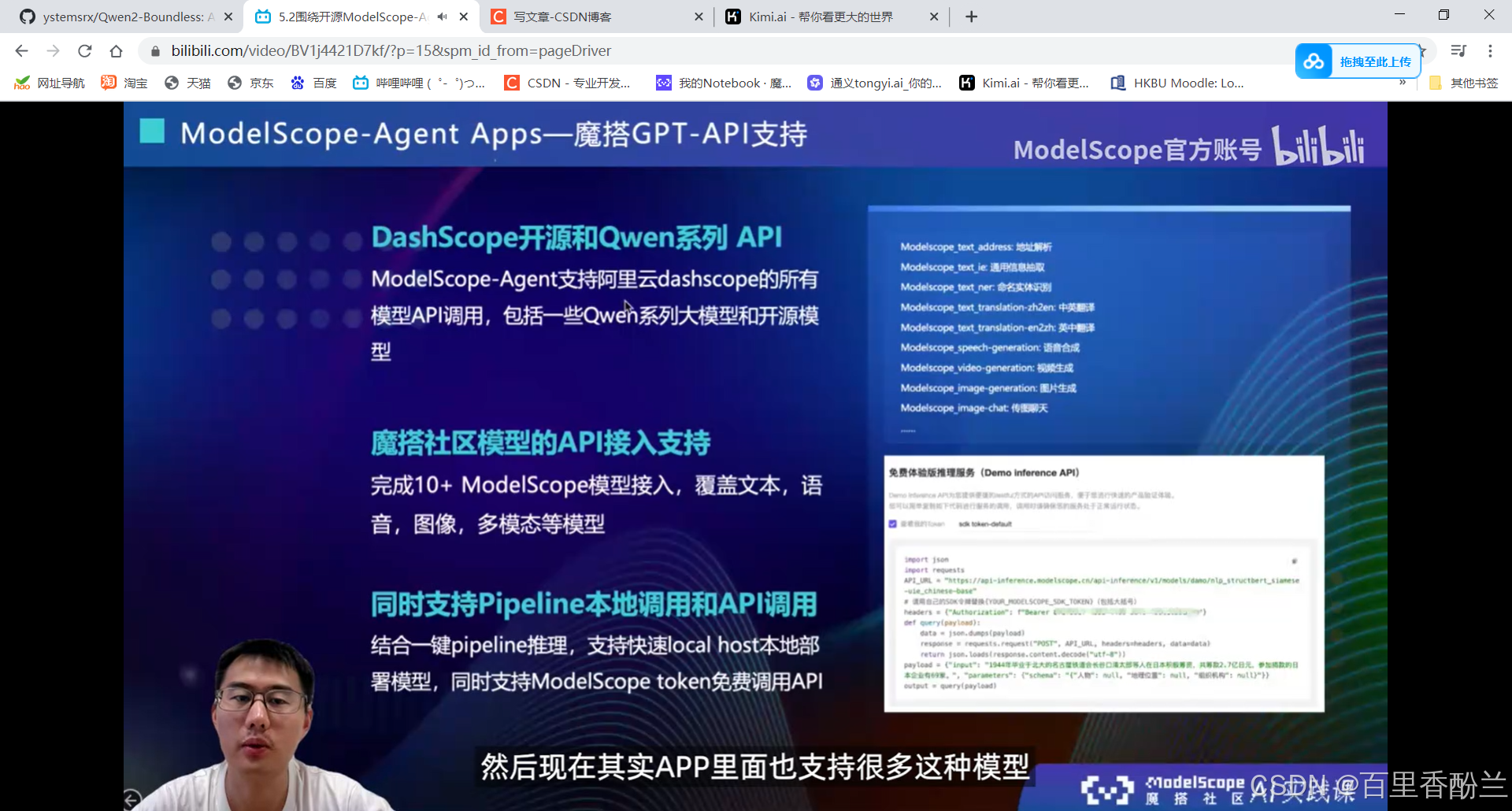
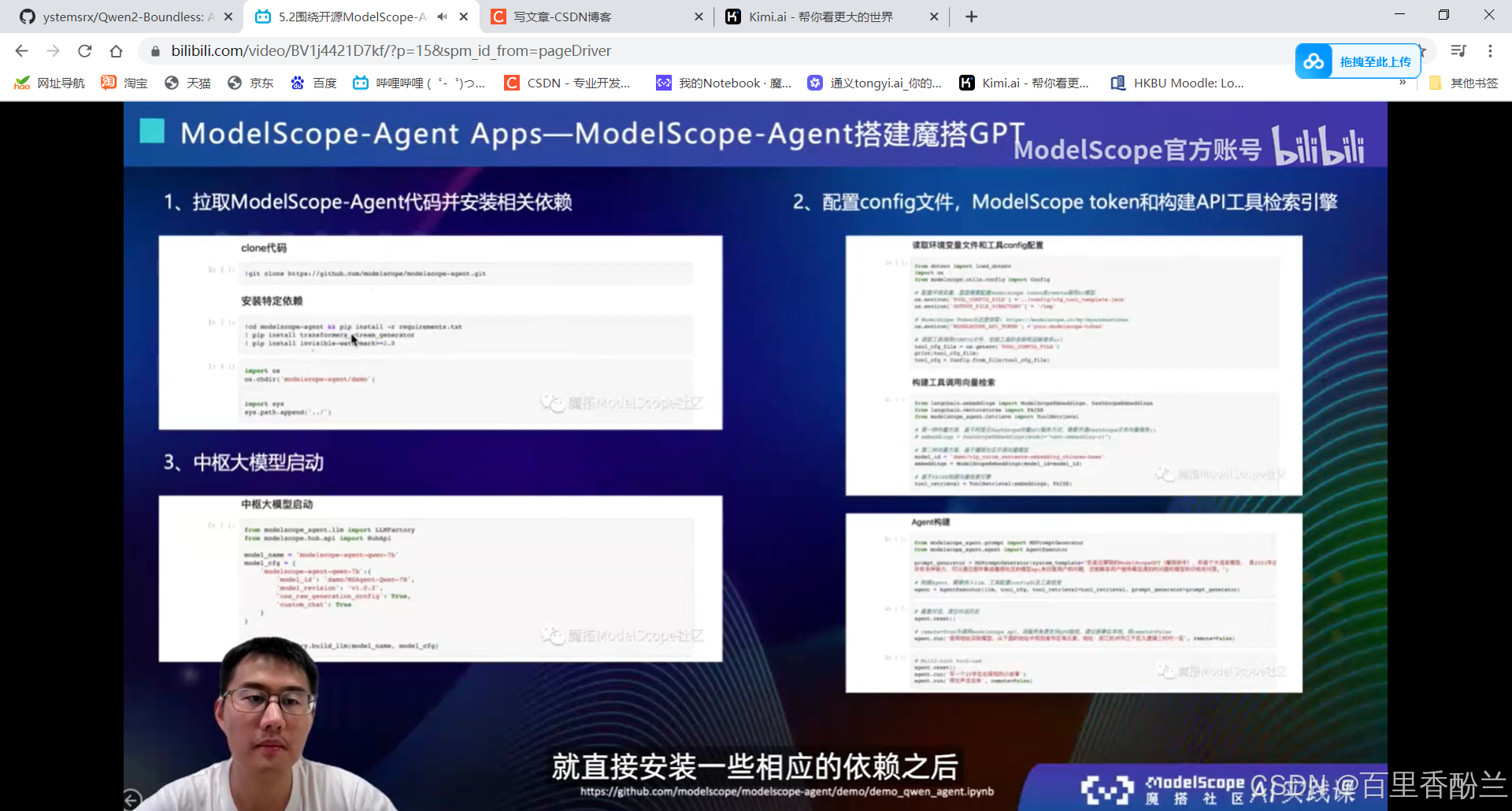
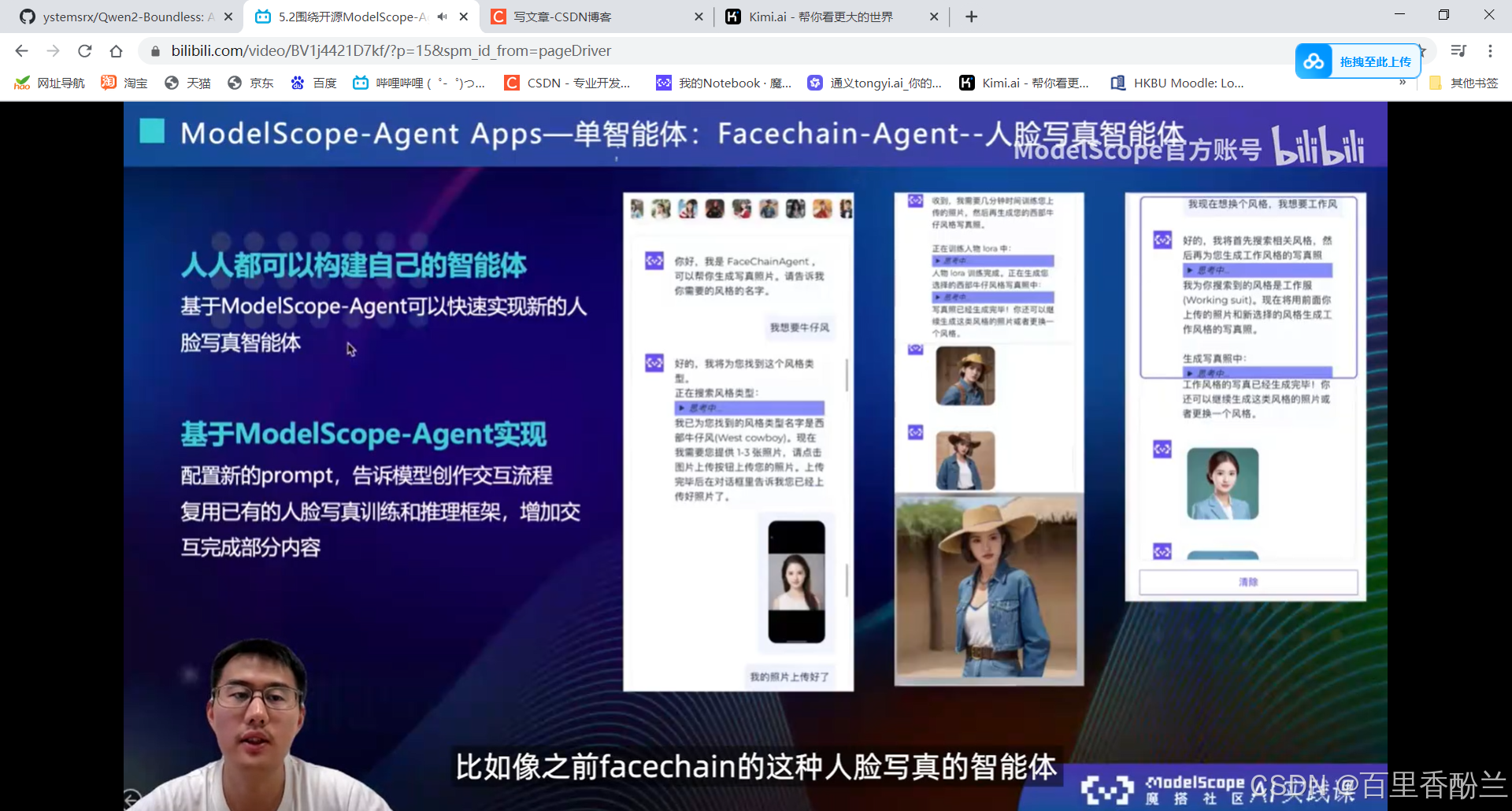
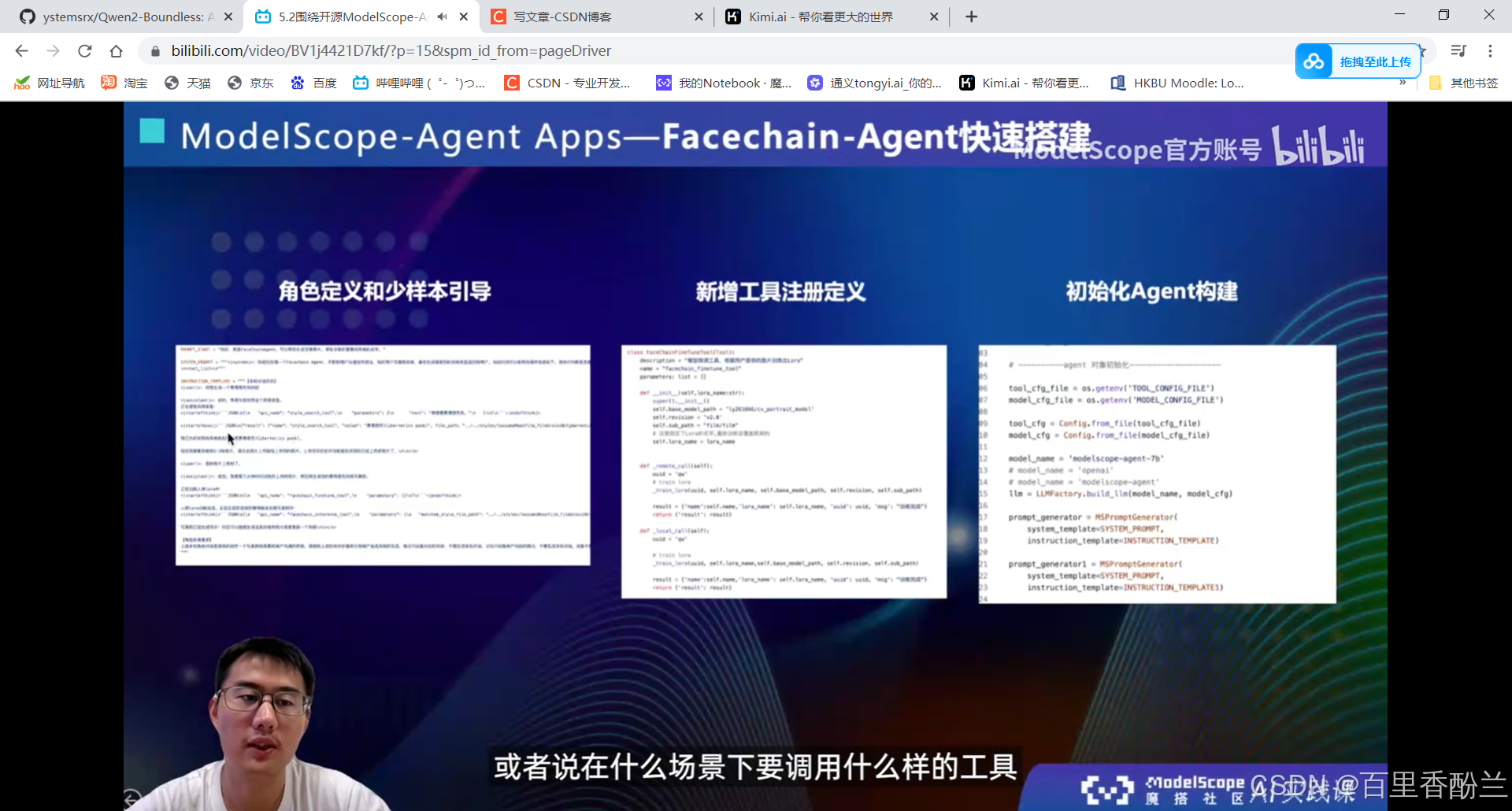
单智能体效果不会:多智能体协同框架
我感觉这个故事绘本生成器还不错,要是能基于原神风格Lora的话没准可以极其方便地创作原神同人故事。
体验链接:https://modelscope.cn/studios/AI-ModelScope/StoryDiffusion/summary
我来生成一个看看:
我尝试了一下,效果还挺不错!
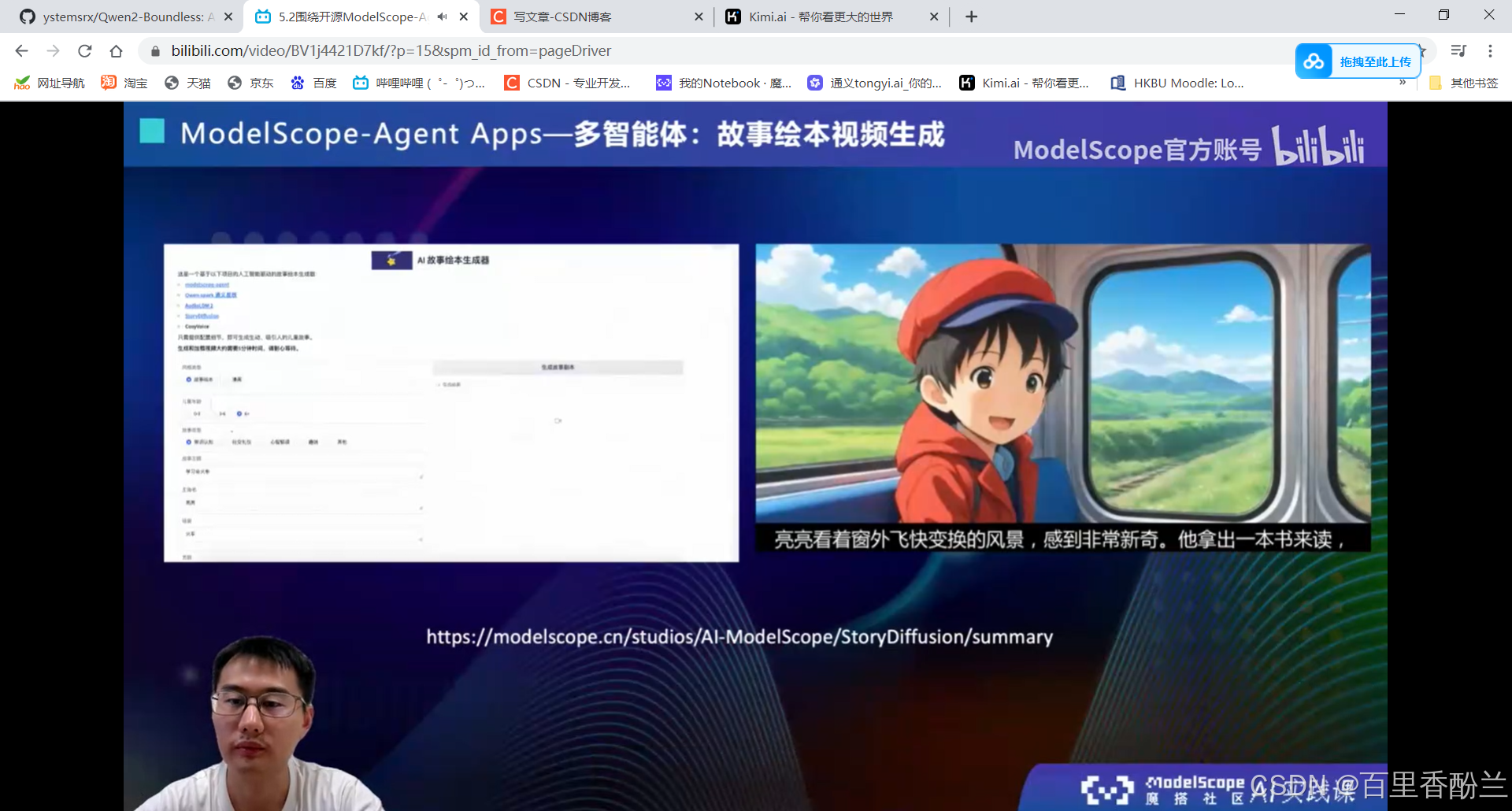
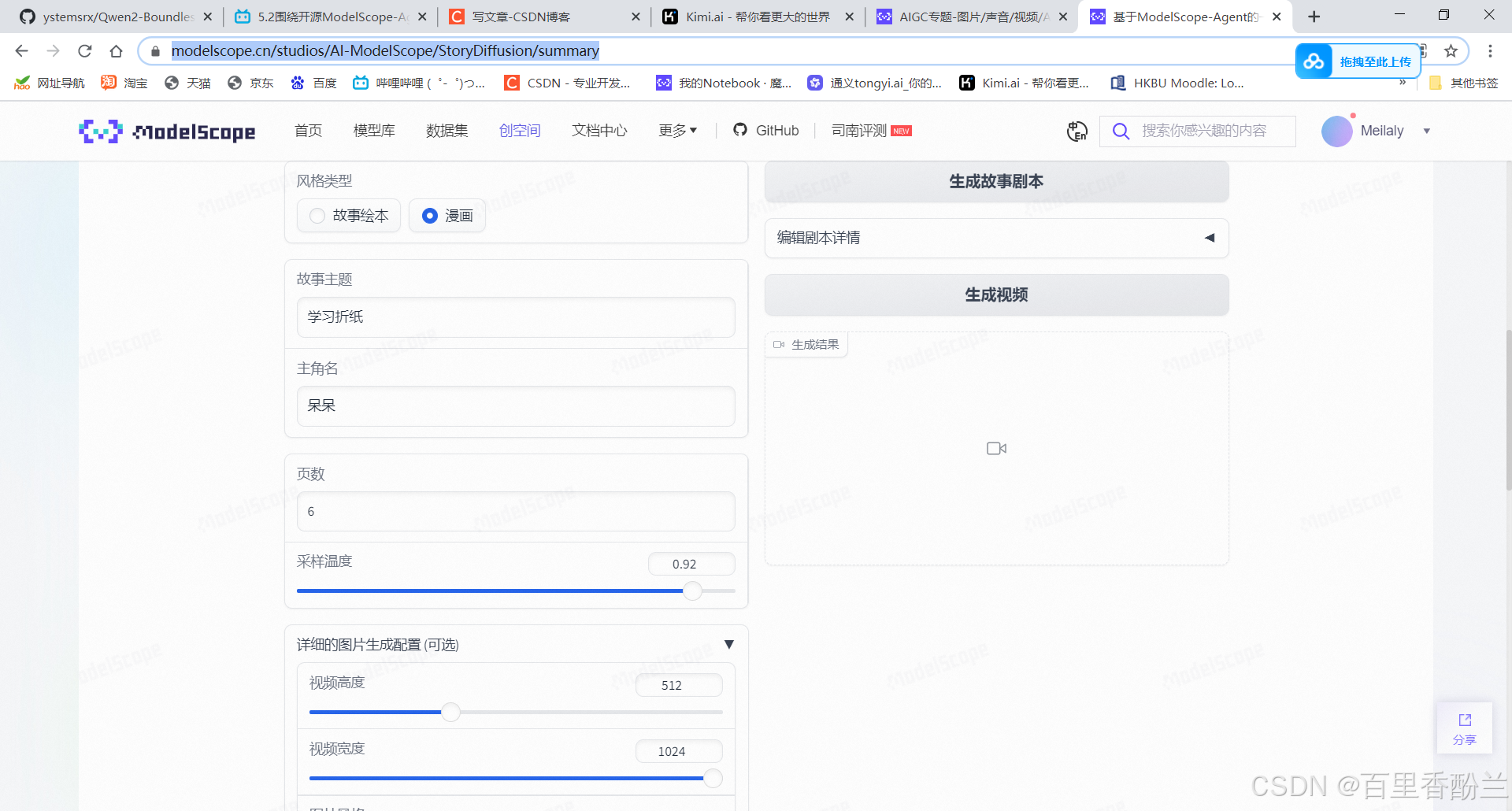
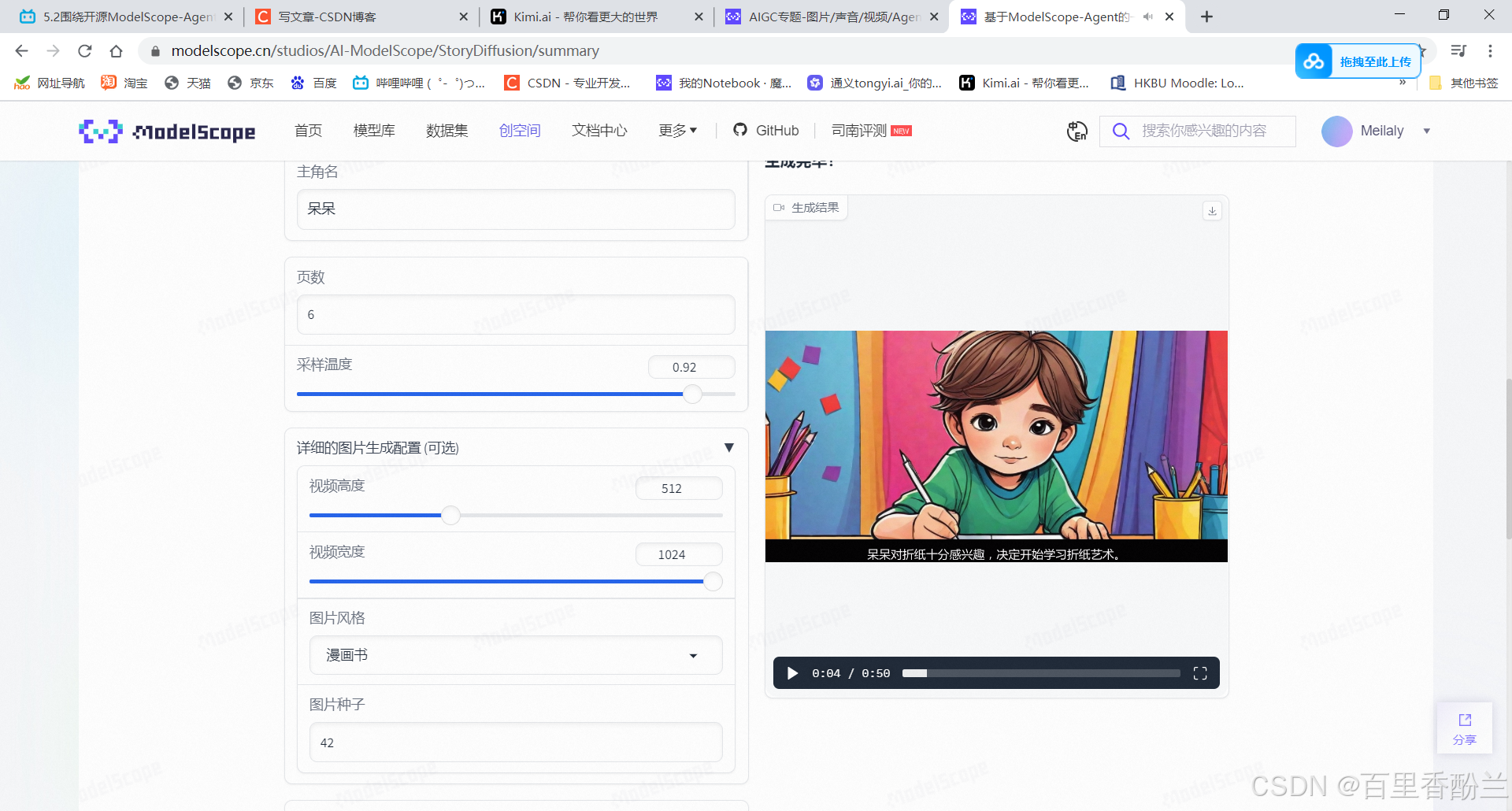
ModelScope多智能体|故事绘本生成效果
课后作业:
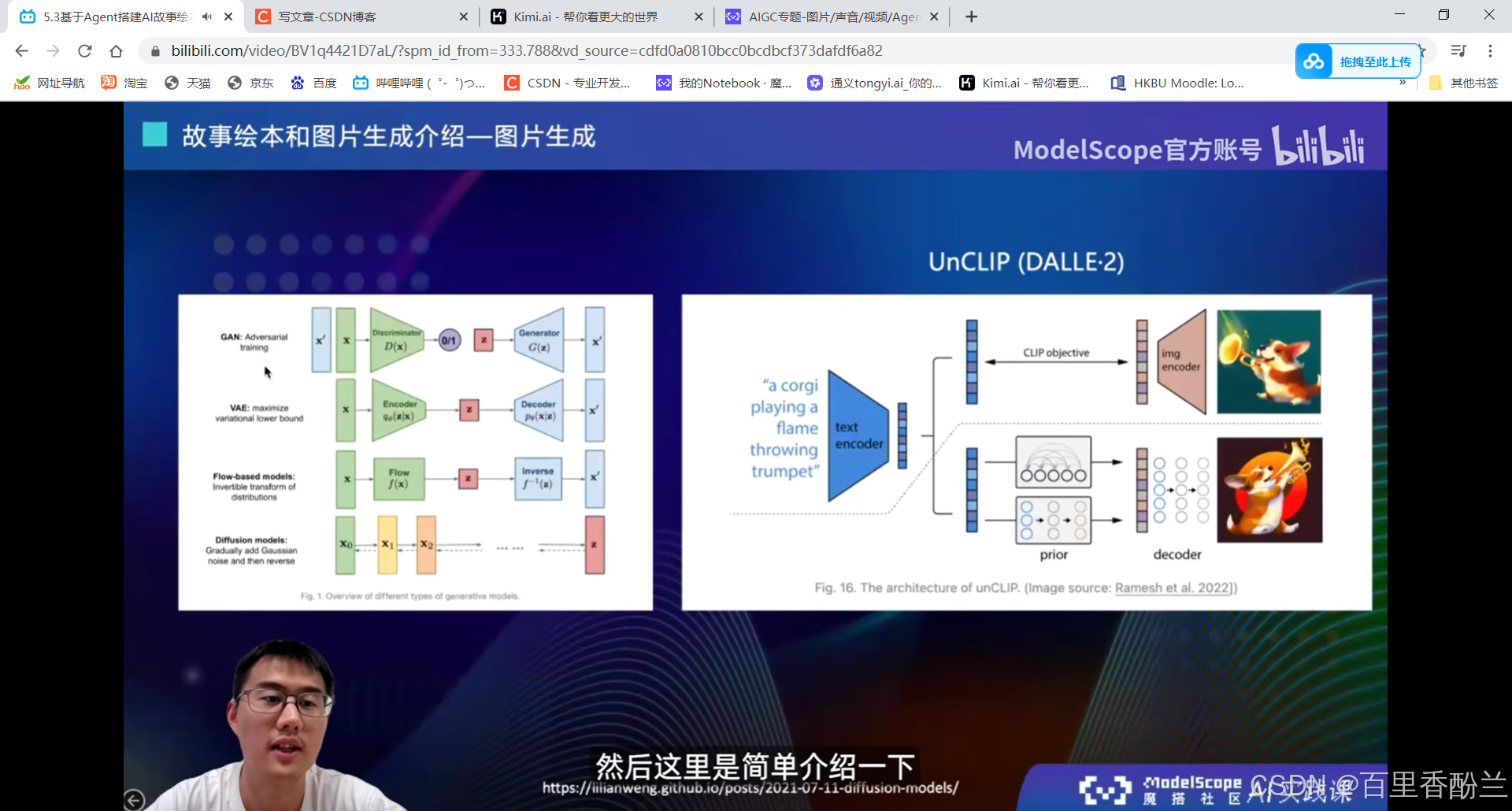
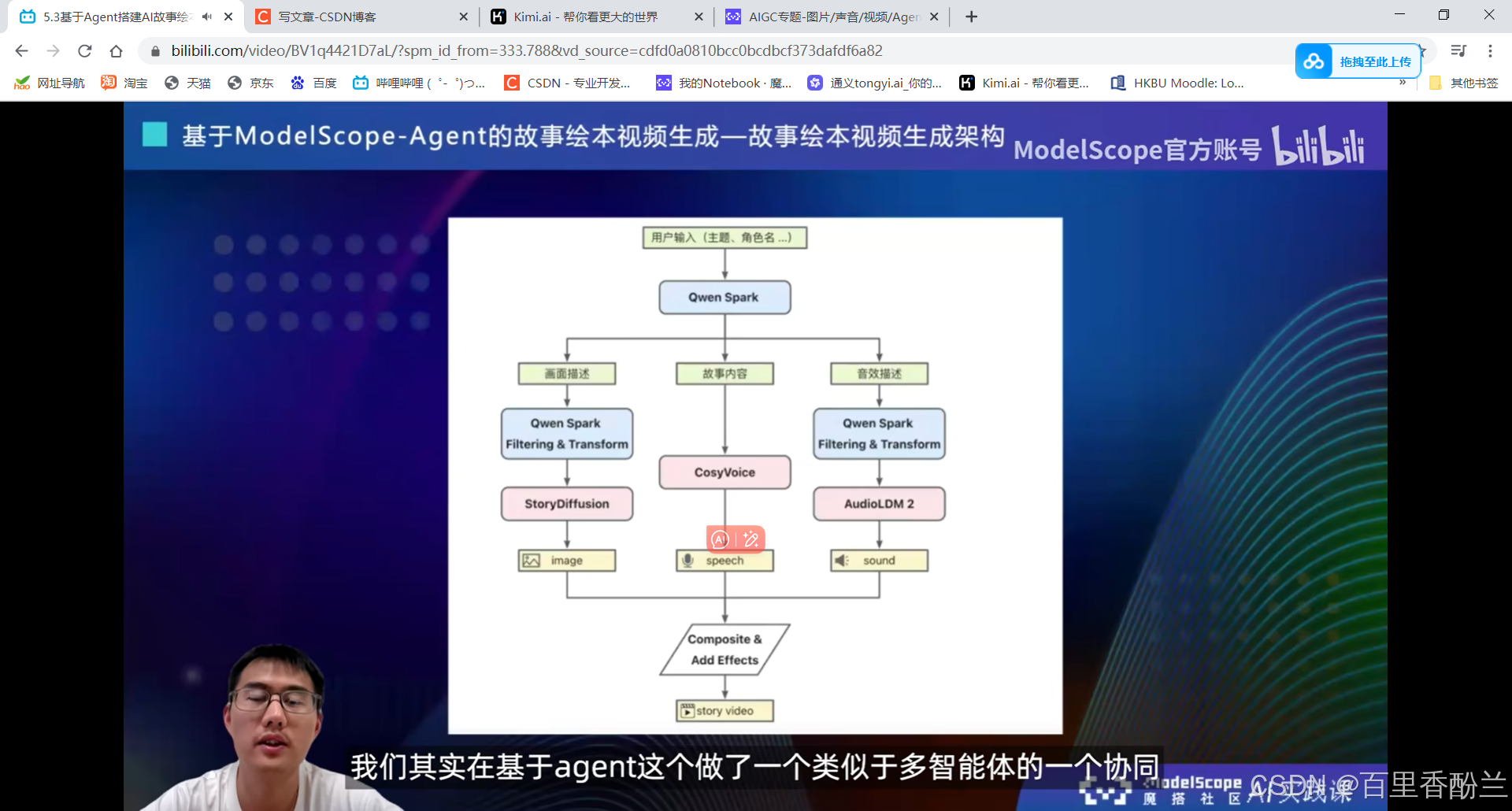
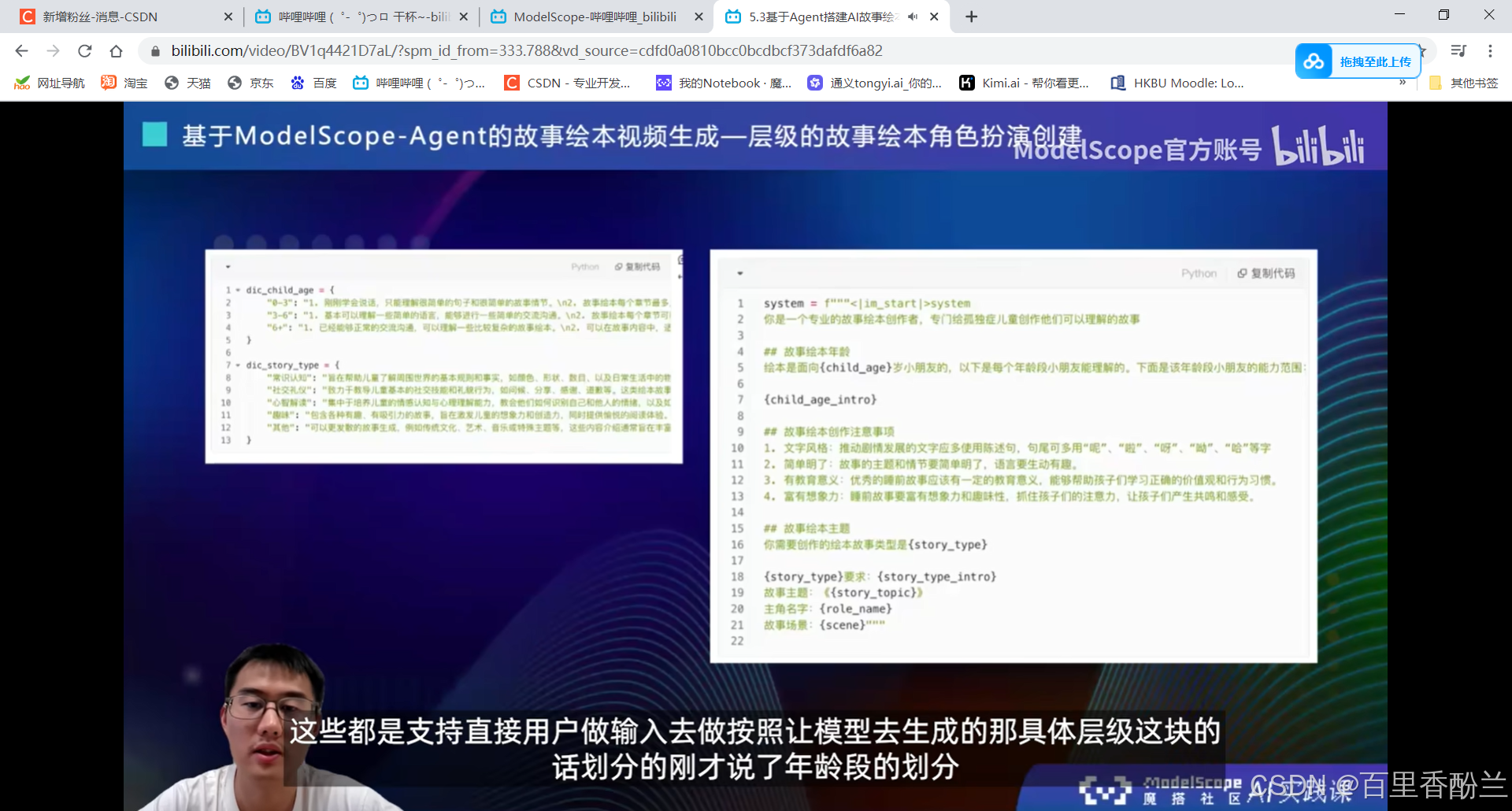
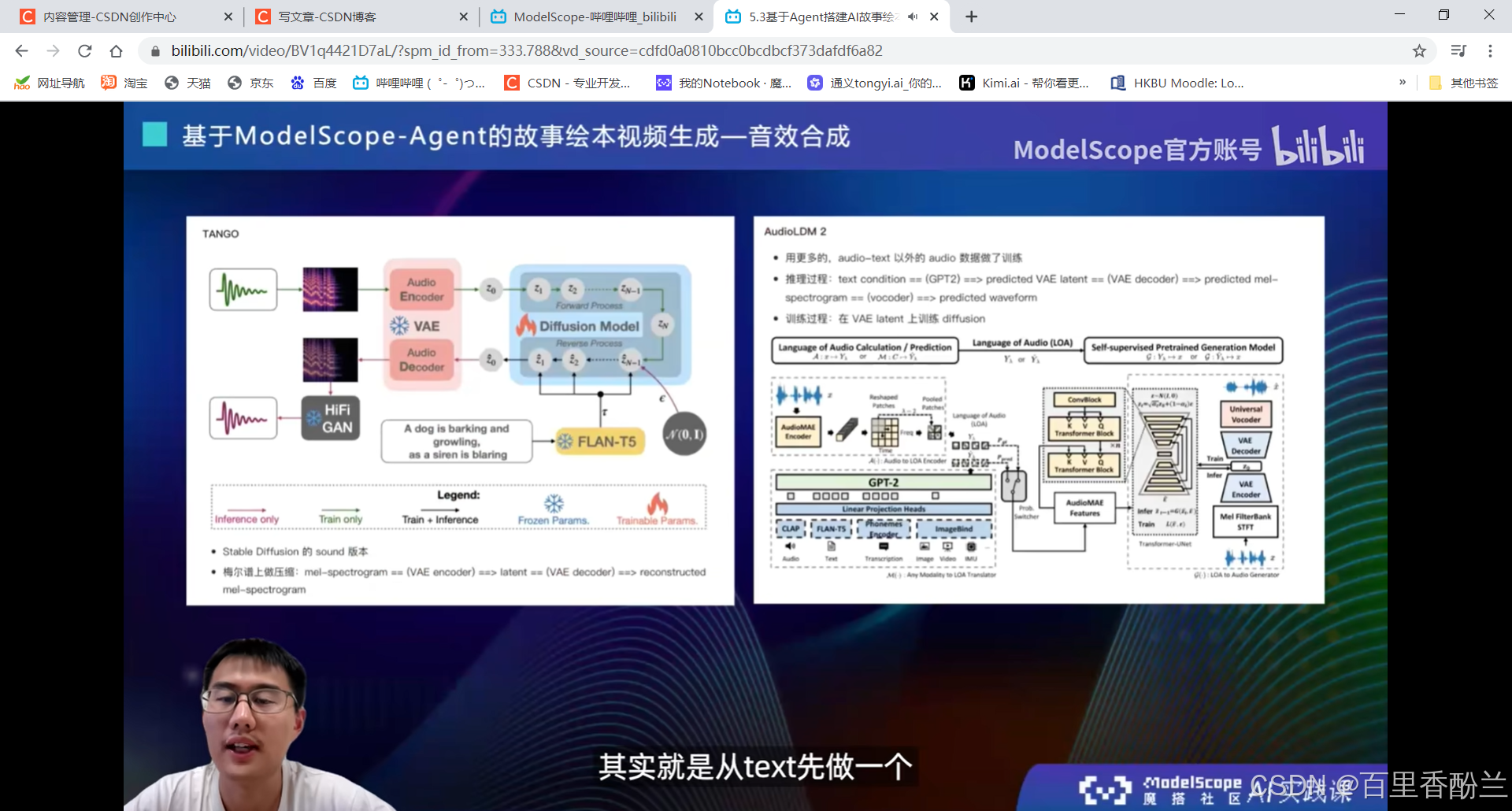
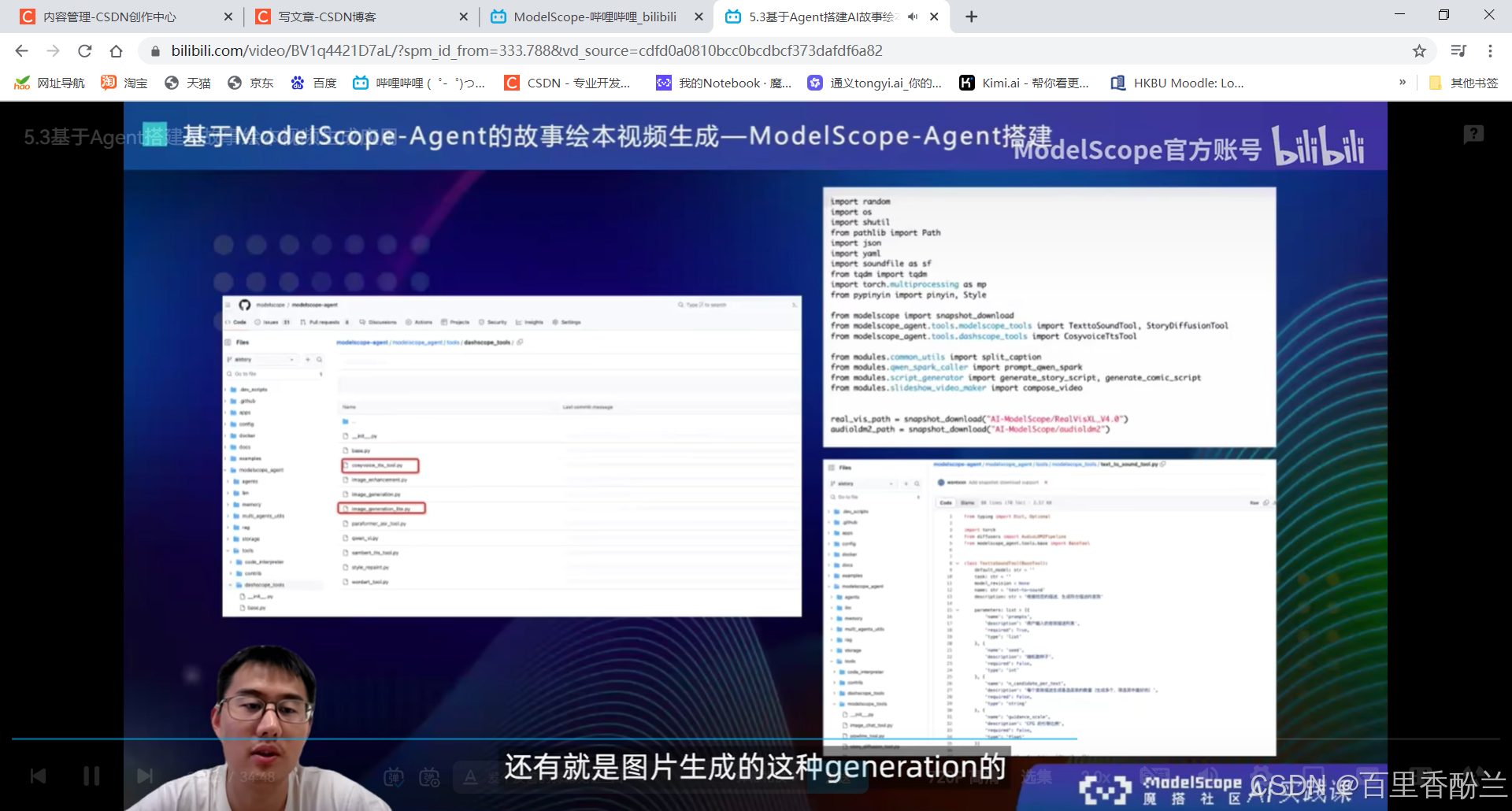
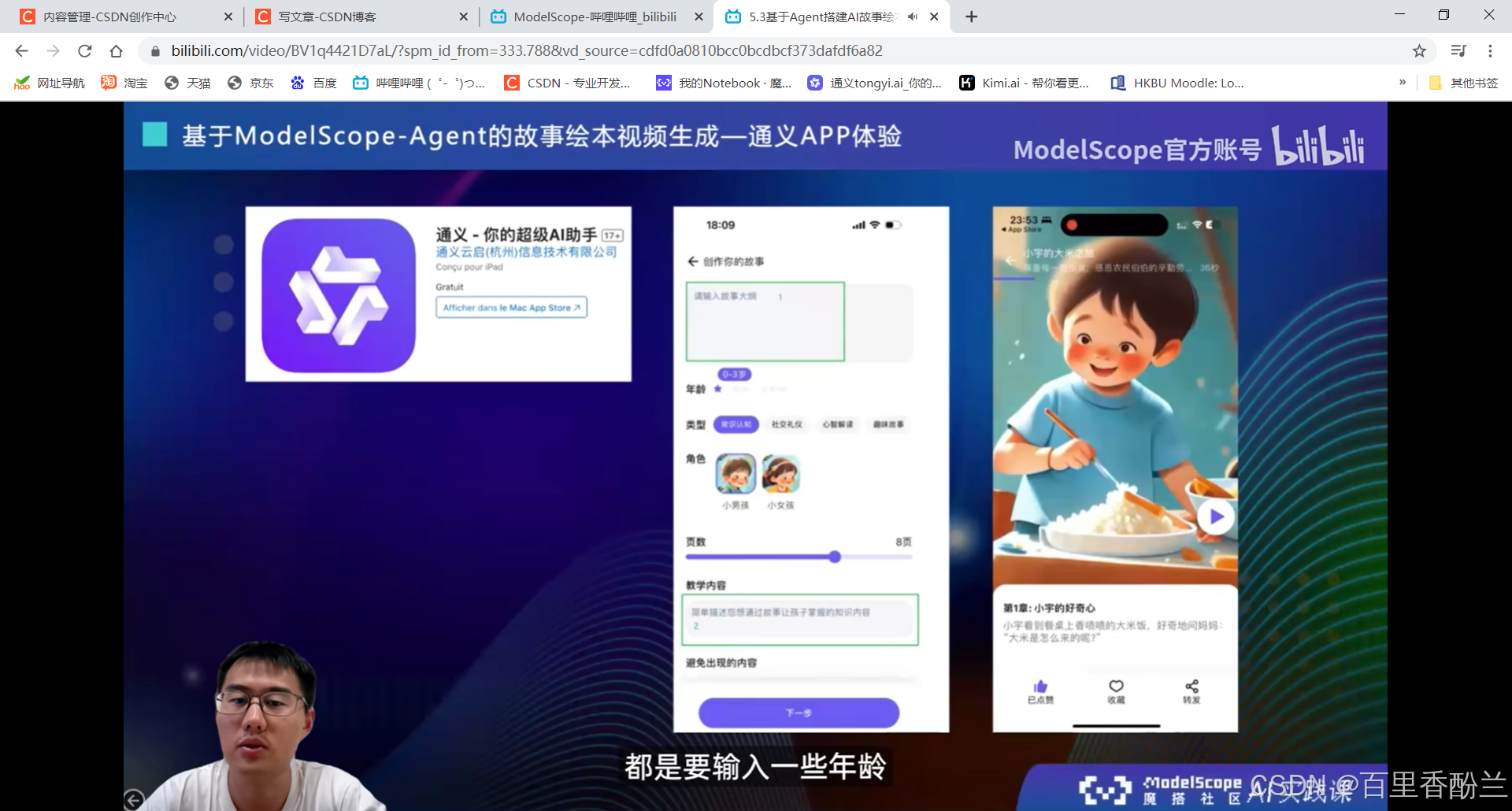
5.3基于Agent搭建AI故事绘本视频生成应用:
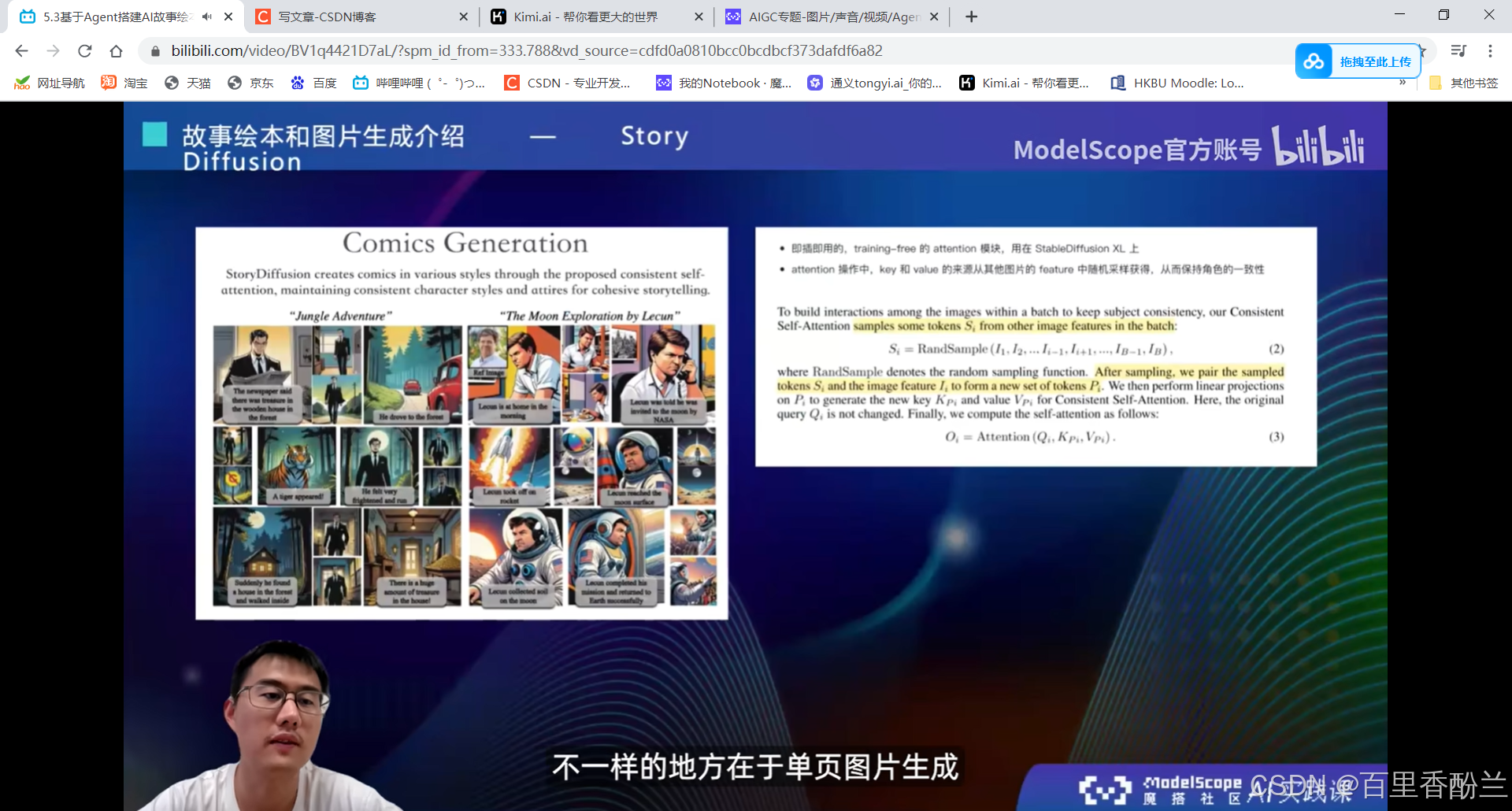
StoryDiffusion:创新点——能尽量保持角色一致性。后一张图会采样前一张图的prompt和feature。
先生成图,然后是语音,接下来再配上音乐合成自动播放的视频(其实是图片的不断切换)。
角色扮演:
试了一两次,AI生成的故事都挺励志正能量,全是Happy Ending。
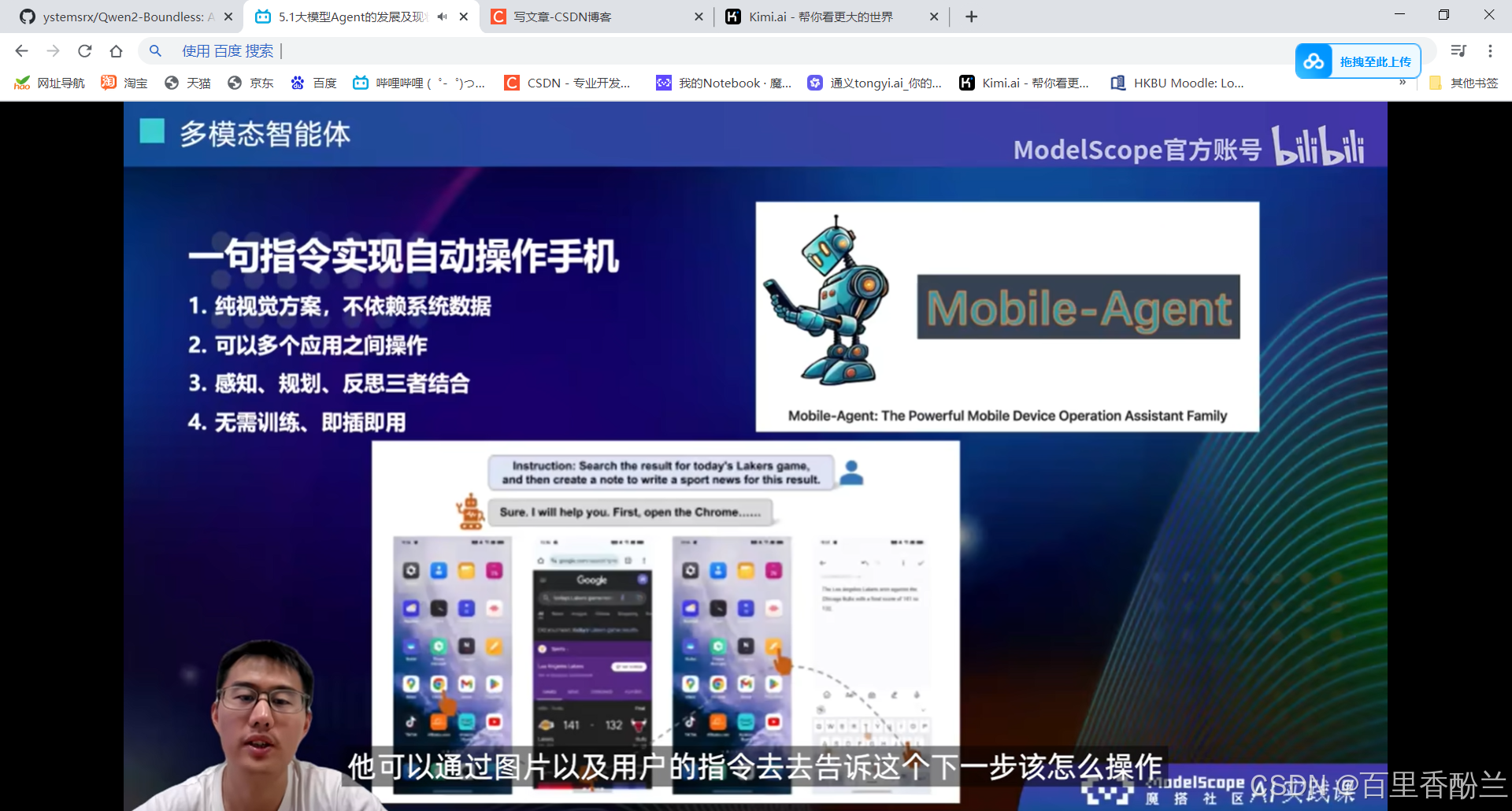
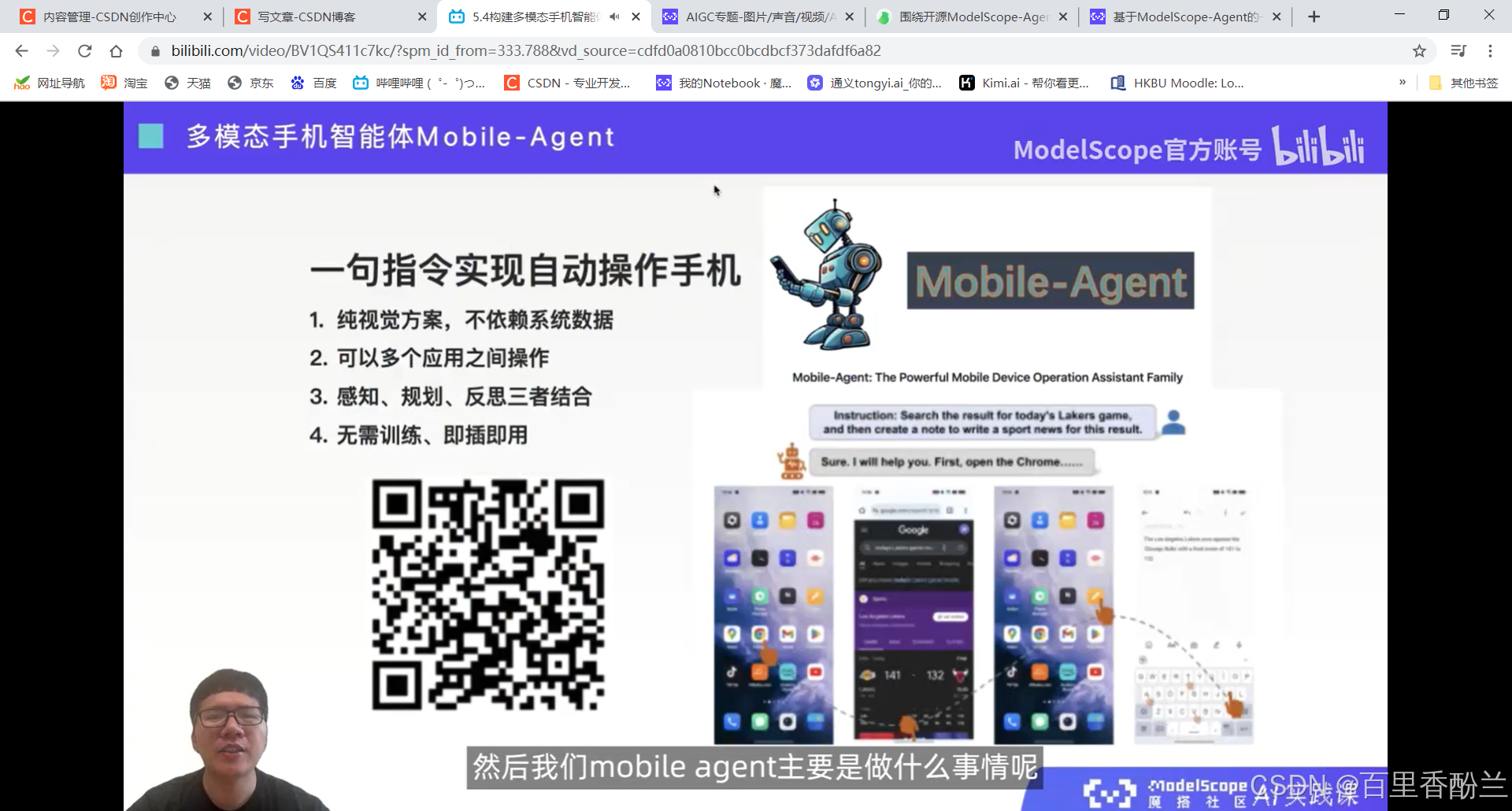
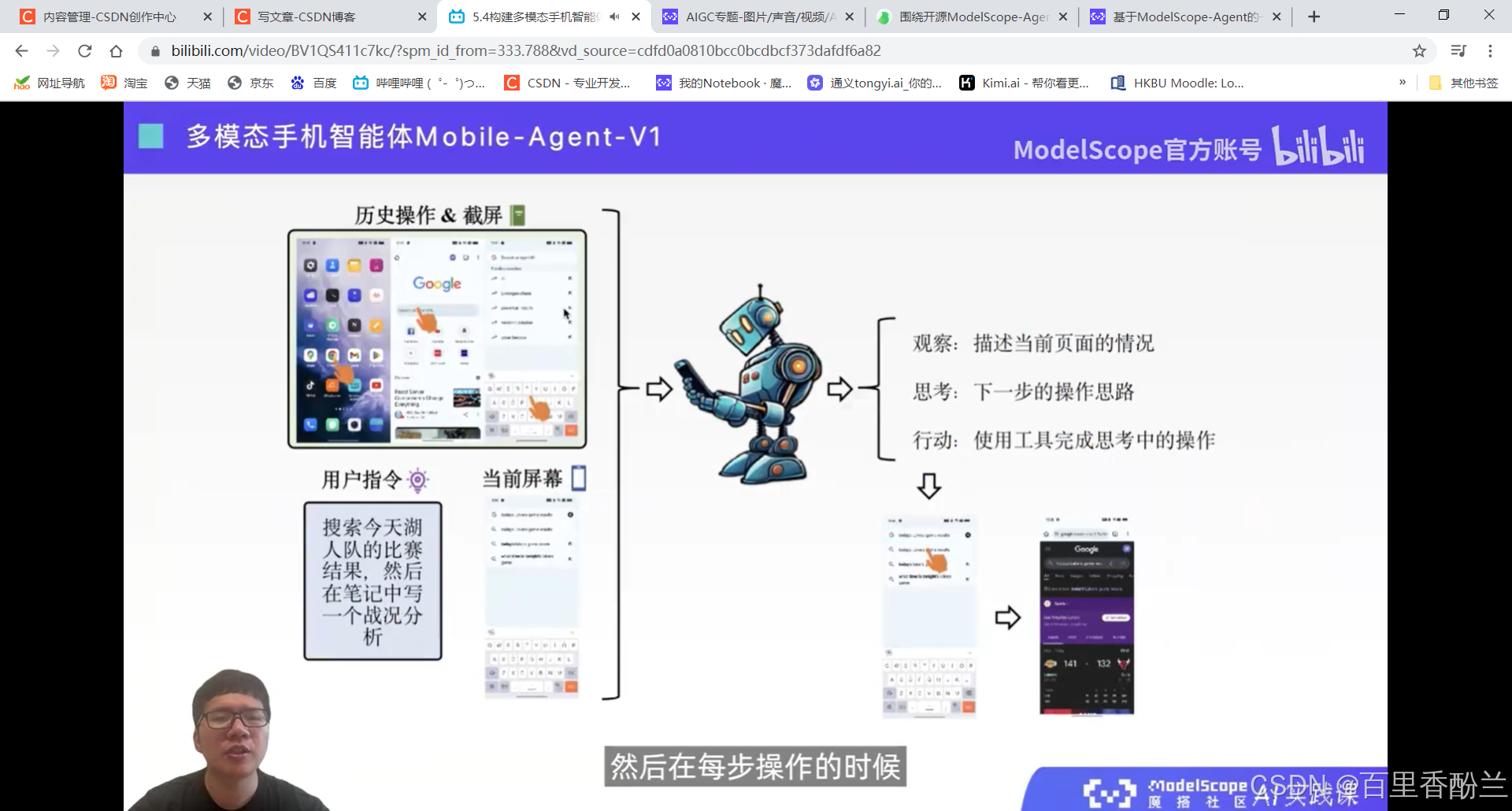
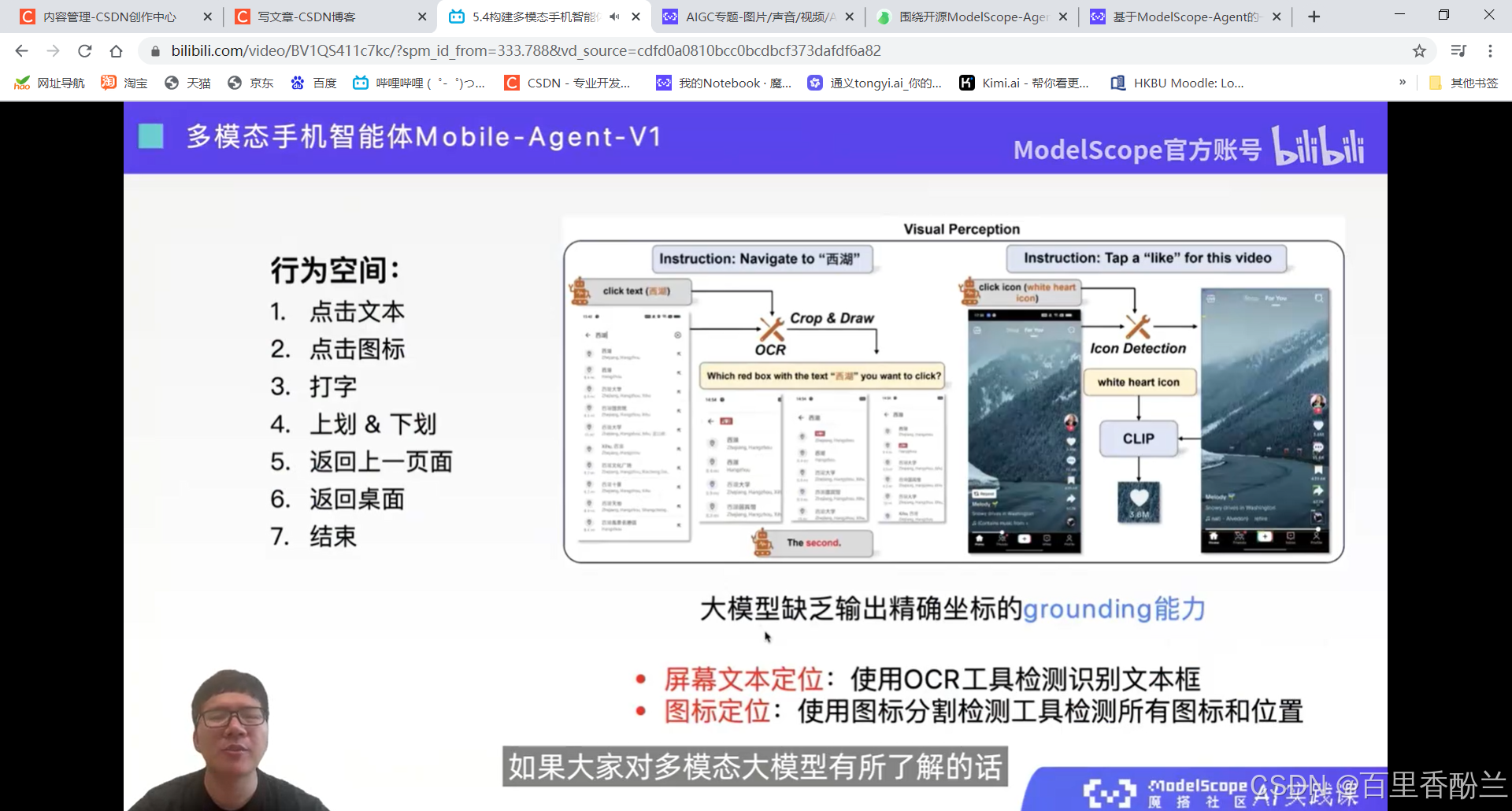
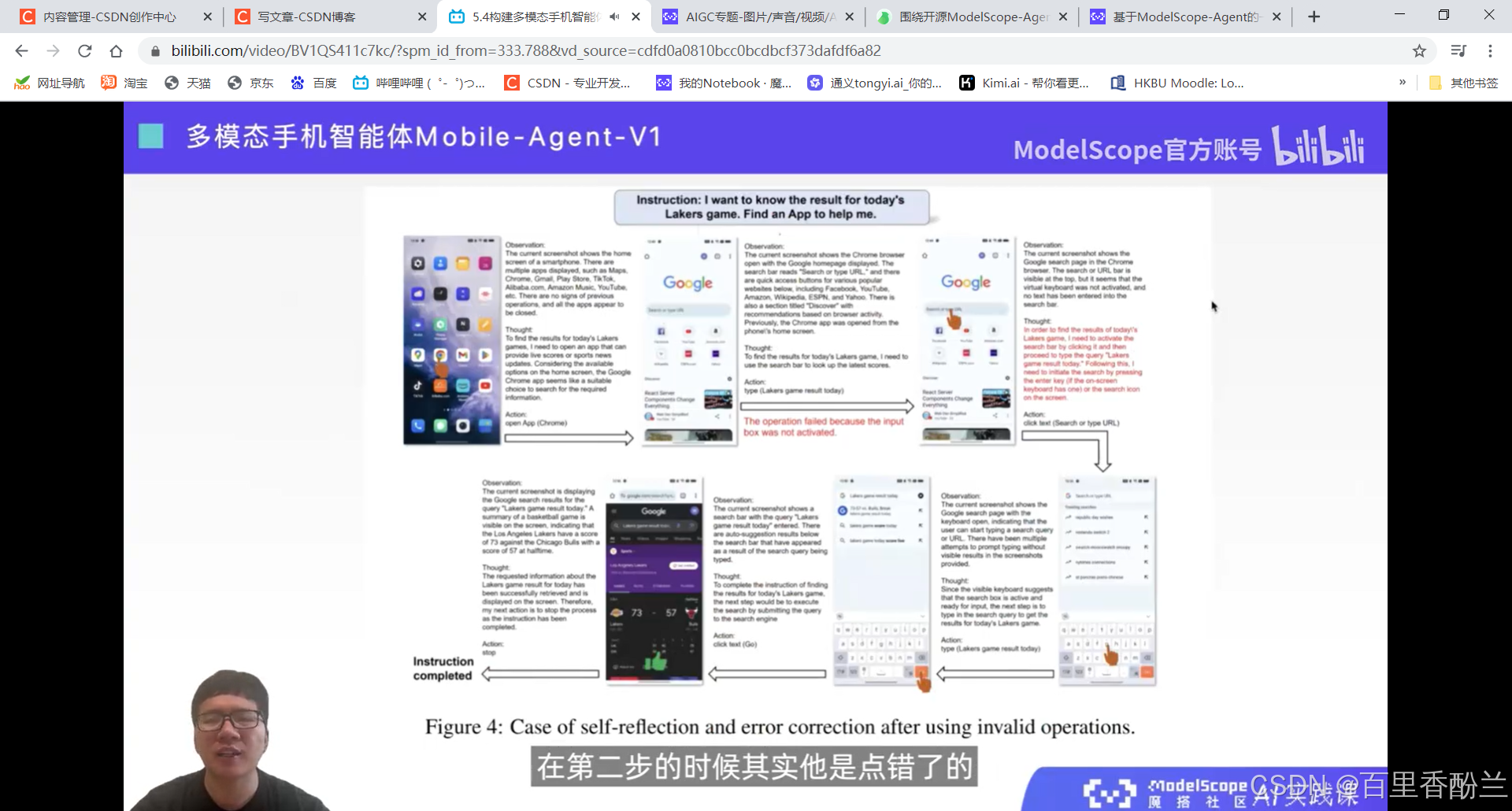
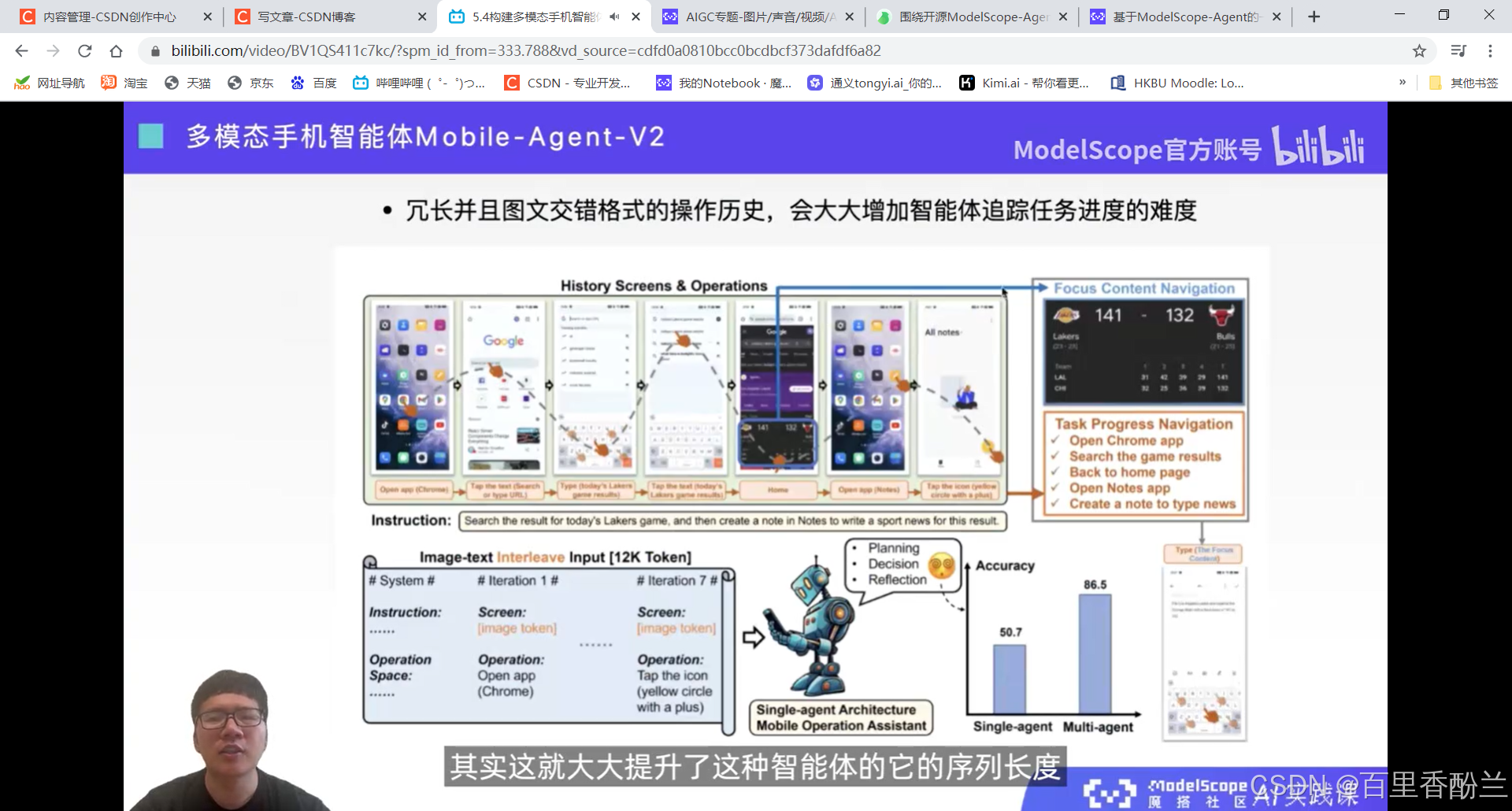
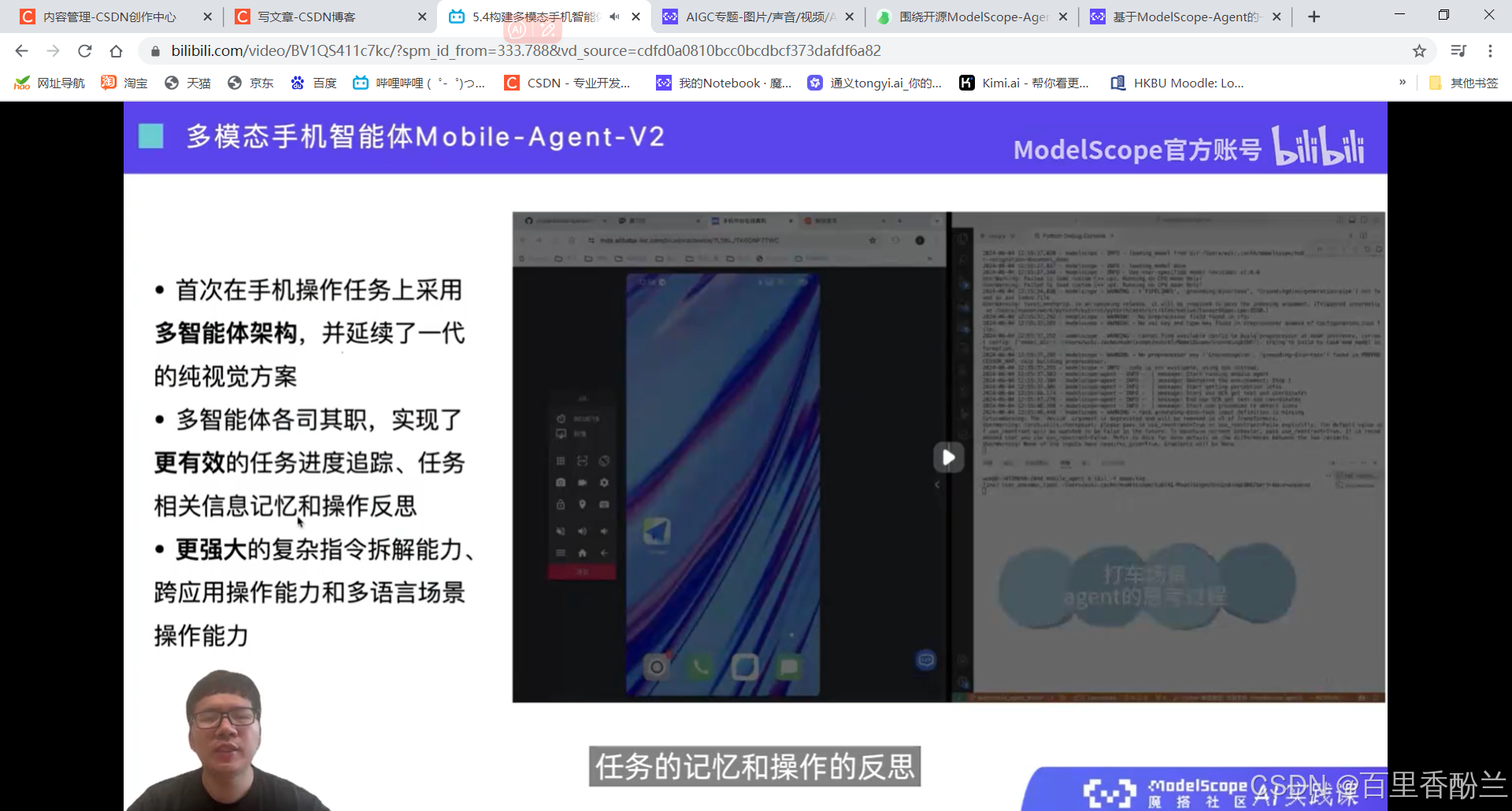
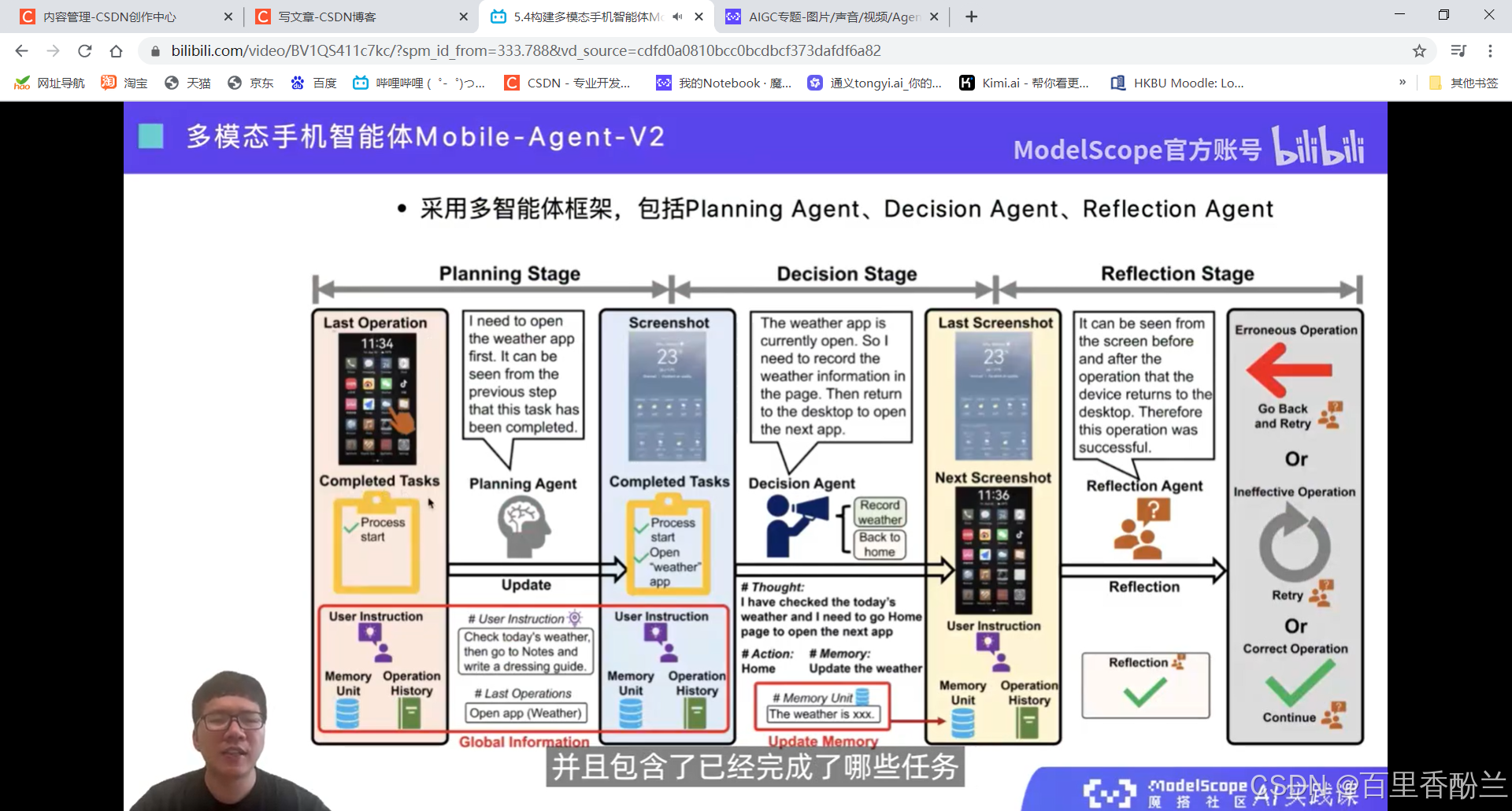
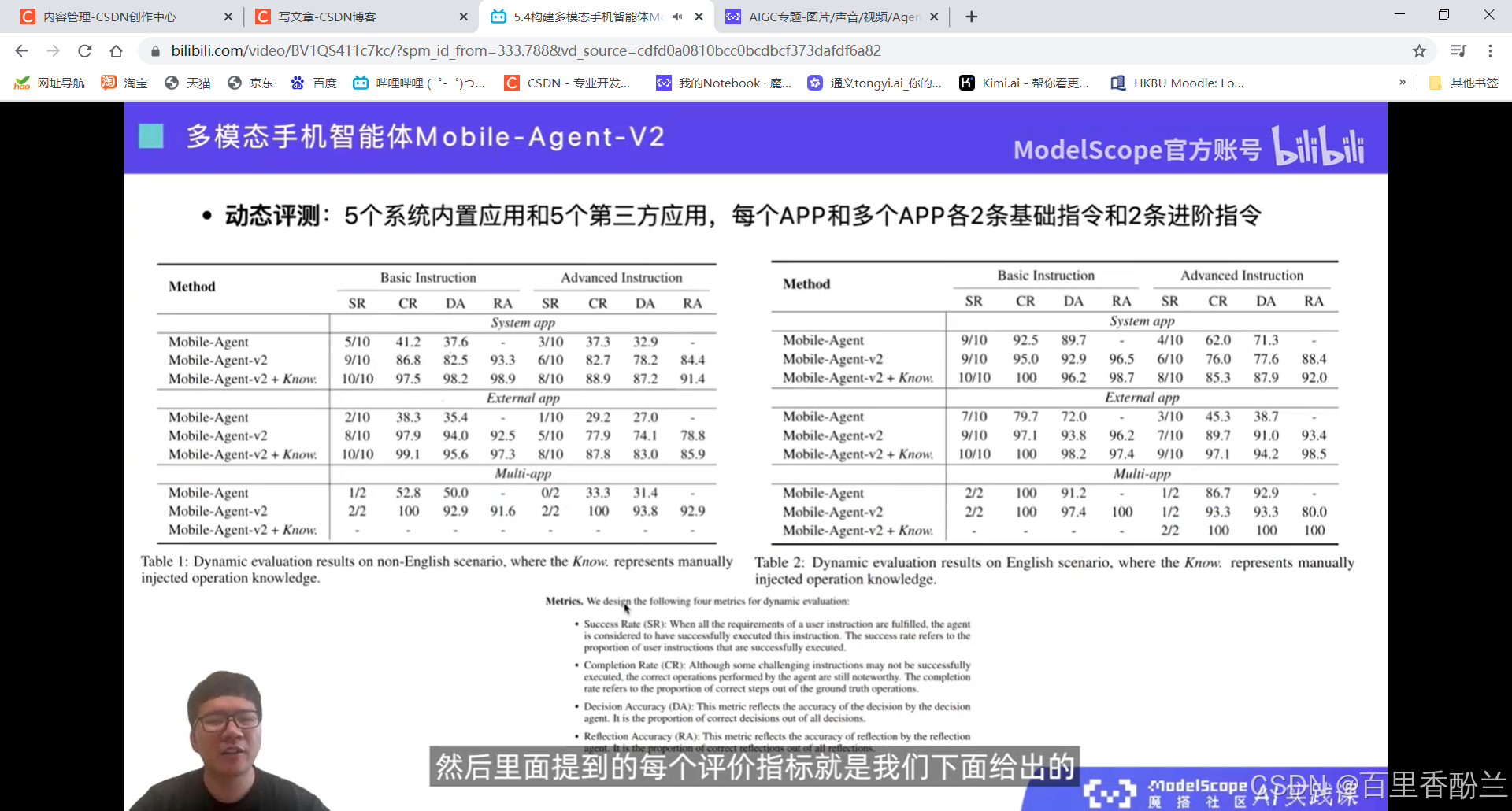
5.4构建多模态手机智能体Mobile-Agent
智能体更加类人。
感觉这个功能可以帮助老年人和视障人士。
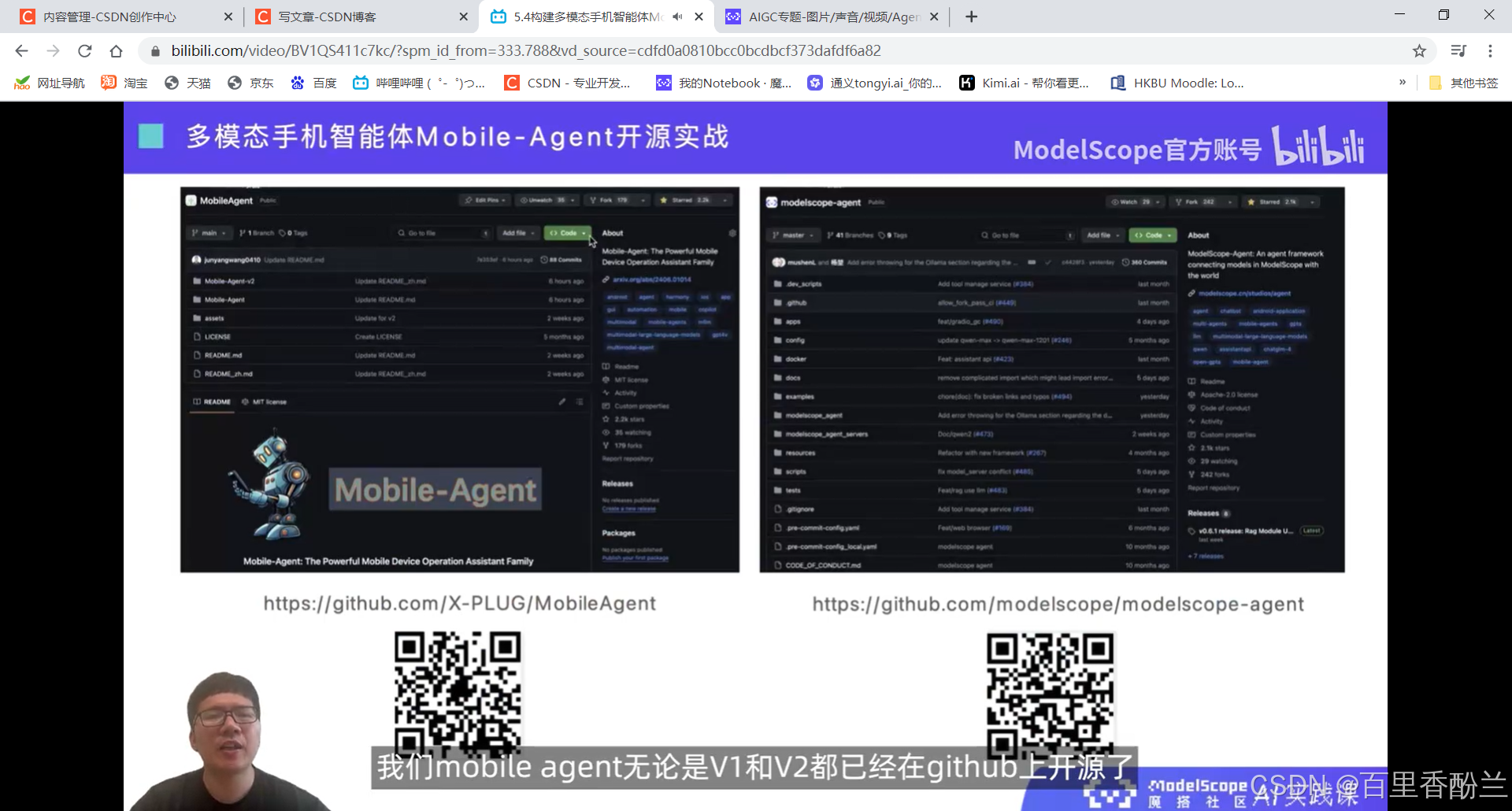
https://github.com/X-PLUG/MobileAgent
https://github.com/modelscope/modelscope-agent
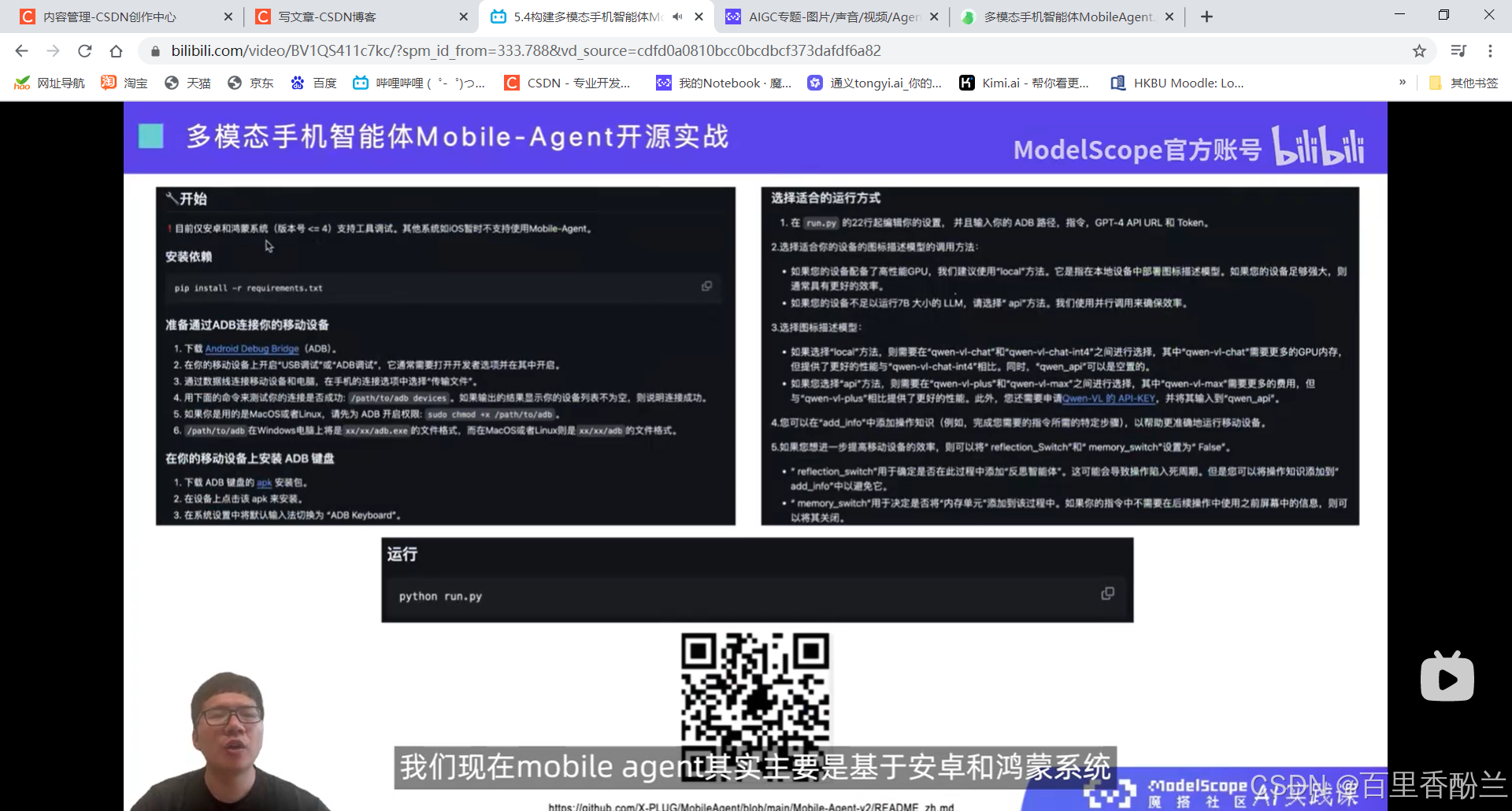
注意目前只支持安卓和鸿蒙系统。
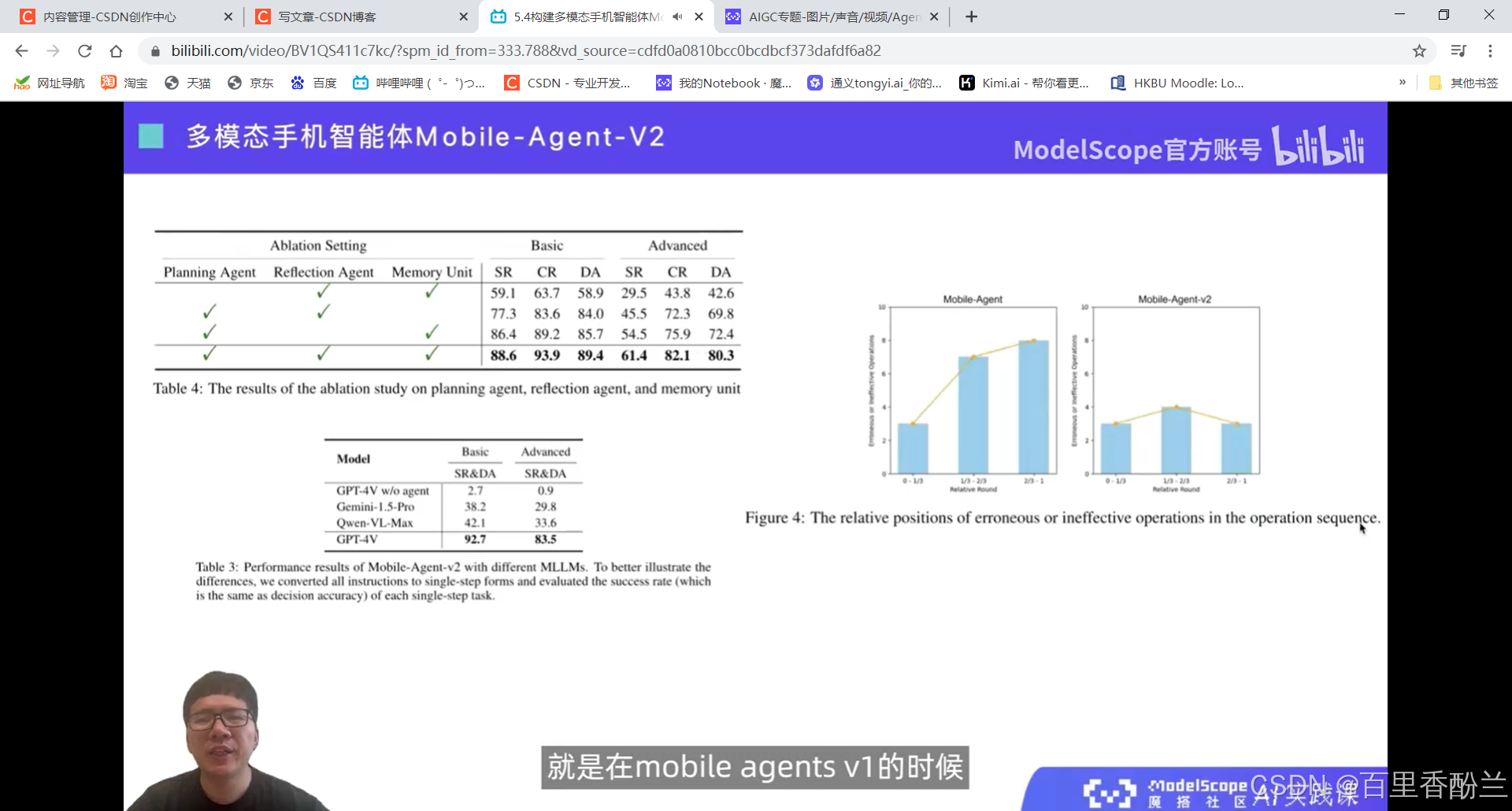
6.1大模型微调实践:训练一个古文翻译腔机器人:
无论选择哪个模型,先拿来推理试试。如果已经能过够完成需求,就没必要使用任何额外的显卡资源去训练,直接使用原来的模型就好了。
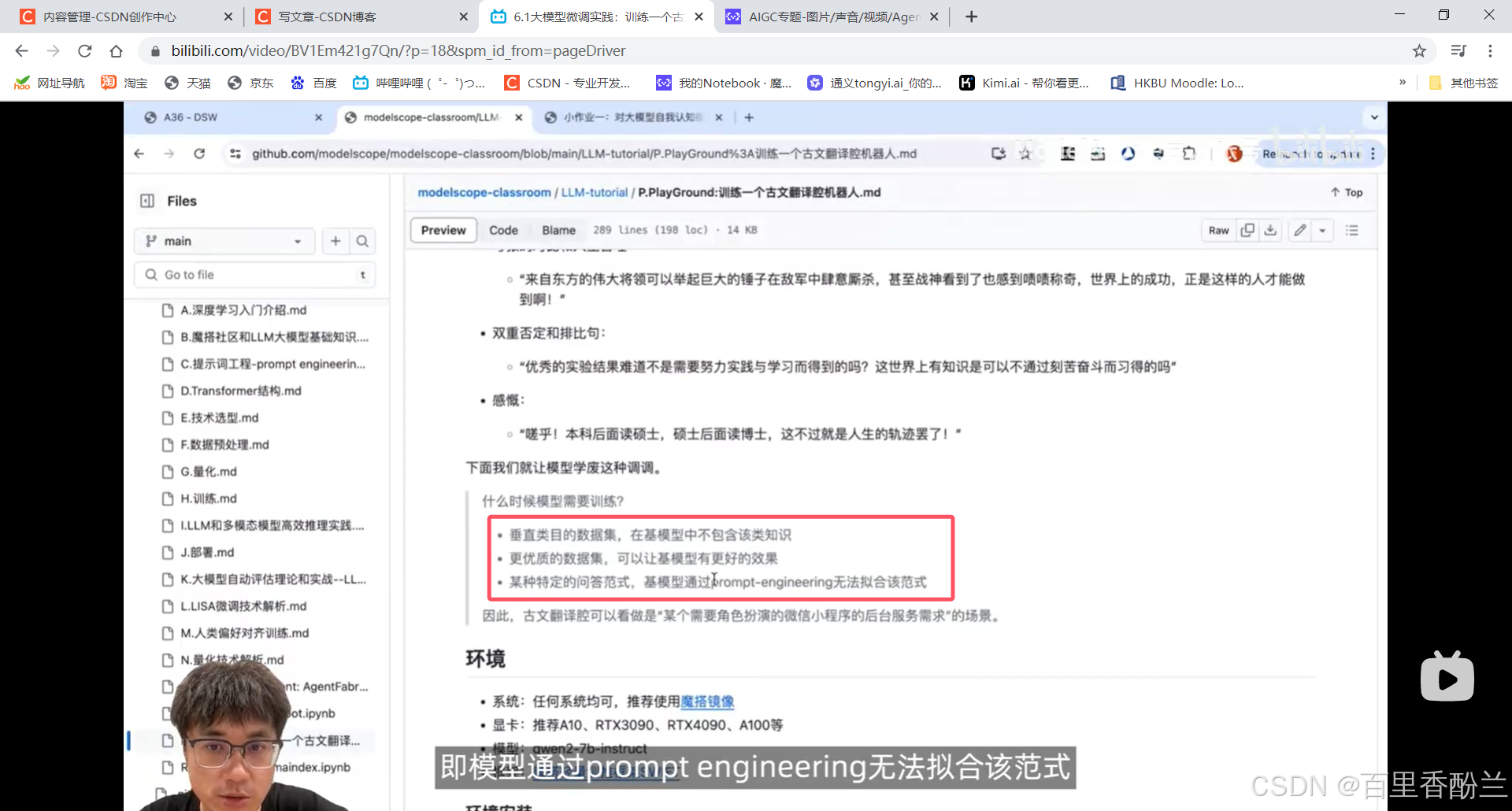
需要使用训练的几种情况:
1.数据集是垂直类目的,在基模型中不包含类似的知识。
2.自己有更高效的数据集,可以让基模型达到更好的效果。
3.特定的问答范式i,模型通过prompt engineering无法拟合该范式。
这一集的内容像是工程师带着人手把手在操作如何训练,但因为我经验不够,很多内容其实还是没听明白。讲到Lora这里才反应出来一些熟悉的知识点:
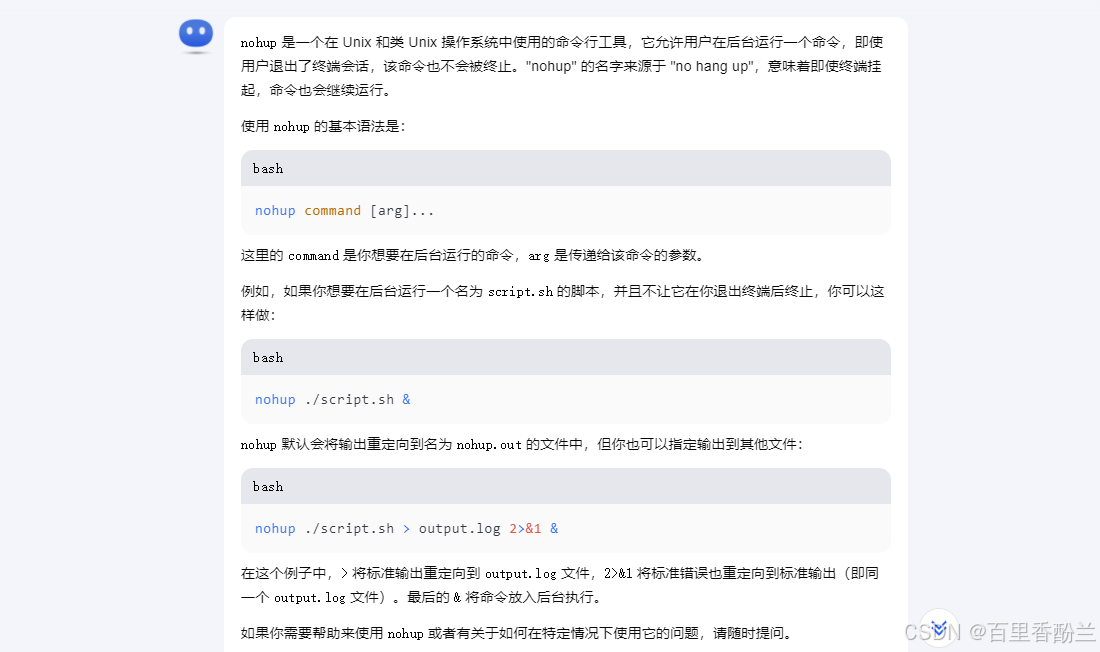
nohup命令老师特别强调了一下,是Linux的一种后台运行命令。用nohup去执行之后,这个命令会直接以后台形式运行,这种情况关掉命令不会有问题。但如果是老师现在这样前台运行,一会如果直接关掉这个页面,任务就不在了。
找Kimi问一下,nohup的命令是怎么回事。
Deploy部署和推理的区别是什么?推理就是刚才那一套过程,把模型run起来然后问他问题,模型给出相应的回复。
部署:把模型变成一个应用或者接口,让模型稳定地运行在后台。比如APP或者小程序,需要调用模型,给环境提供支持,这个时候模型就可以通过HTTP接口接受一些输入,然后推理产生输出并返回,这个过程就是部署。
部署实际上不是算法步骤,而是工程步骤。
一个字一个字输出(类似打字机效果?)叫非流式输出,会等待很长时间。第二种方式叫流式输出,当前更加普遍和常用。
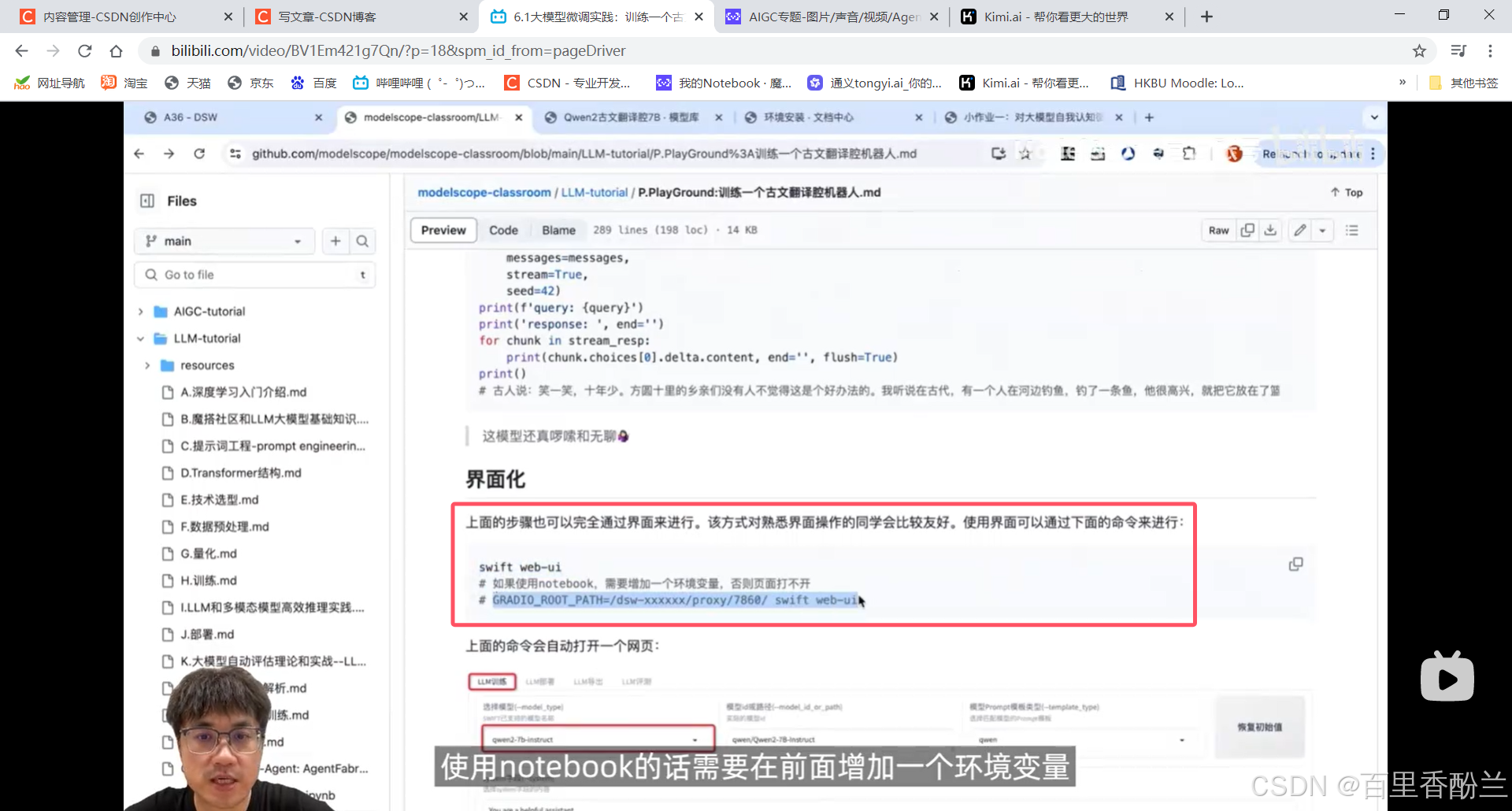
使用界面的话,notebook需要额外加一条环境变量,否则打不开。
感觉人工智能这一块的知识简直是太多了,就跟计算机知识一样,多得彷佛是天上的星星,永远学的进度跟不上卷的进度。
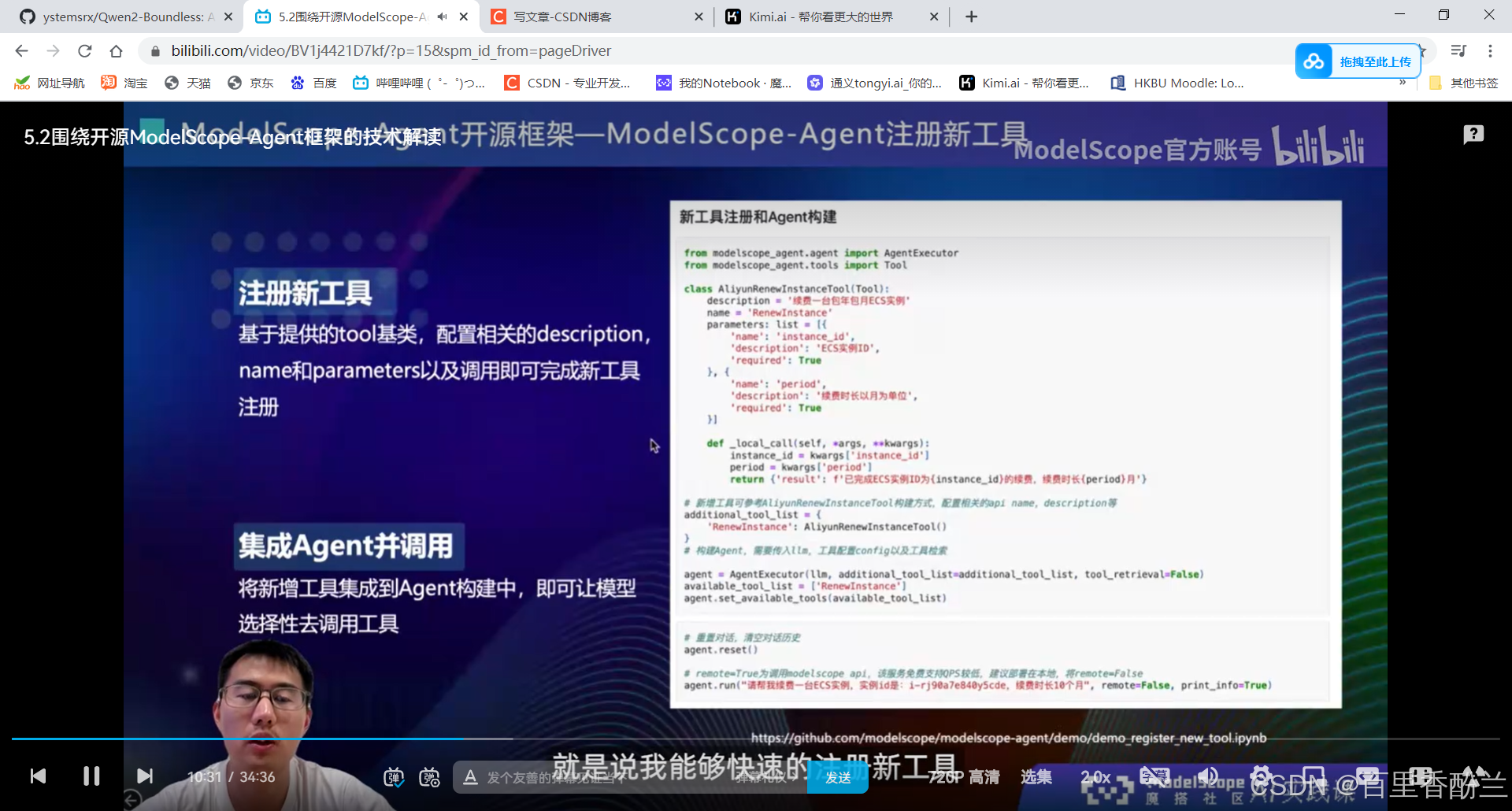
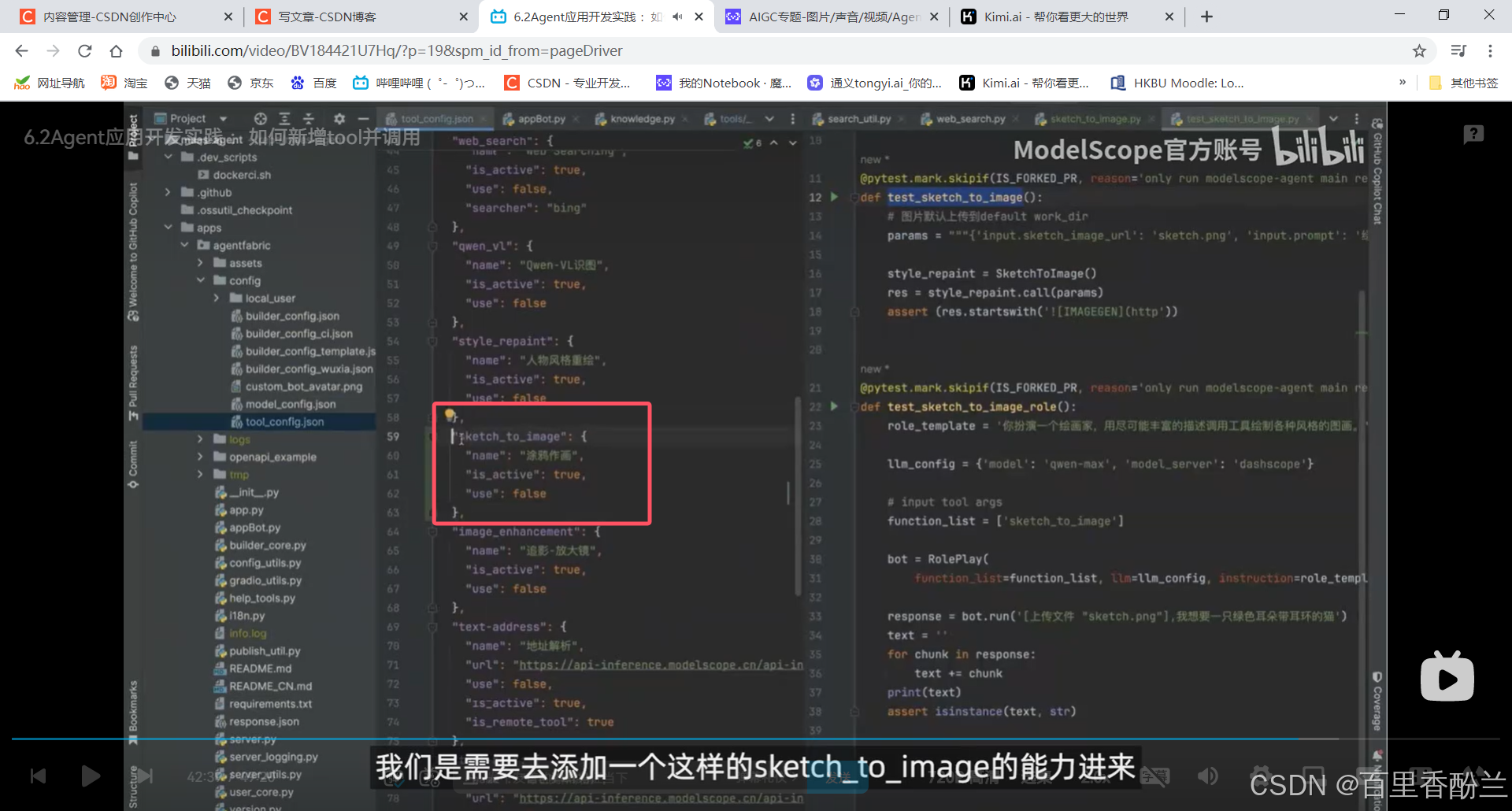
6.2Agent应用开发实践 :如何新增tool并调用
Agent的概念:
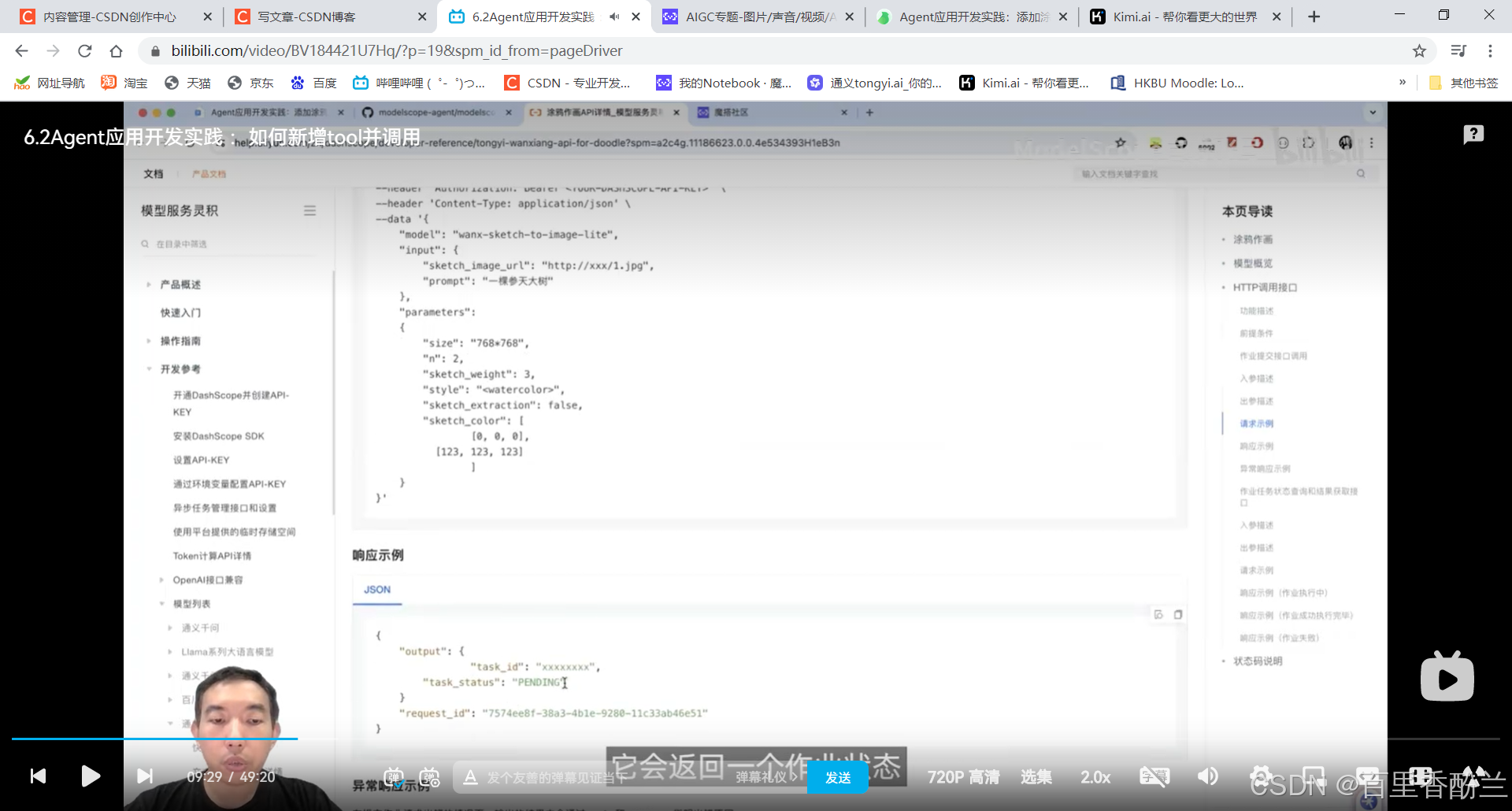
他这个有点特别的是提交一个task以后会先得到一个任务id,然后再用这个id去查询结果。
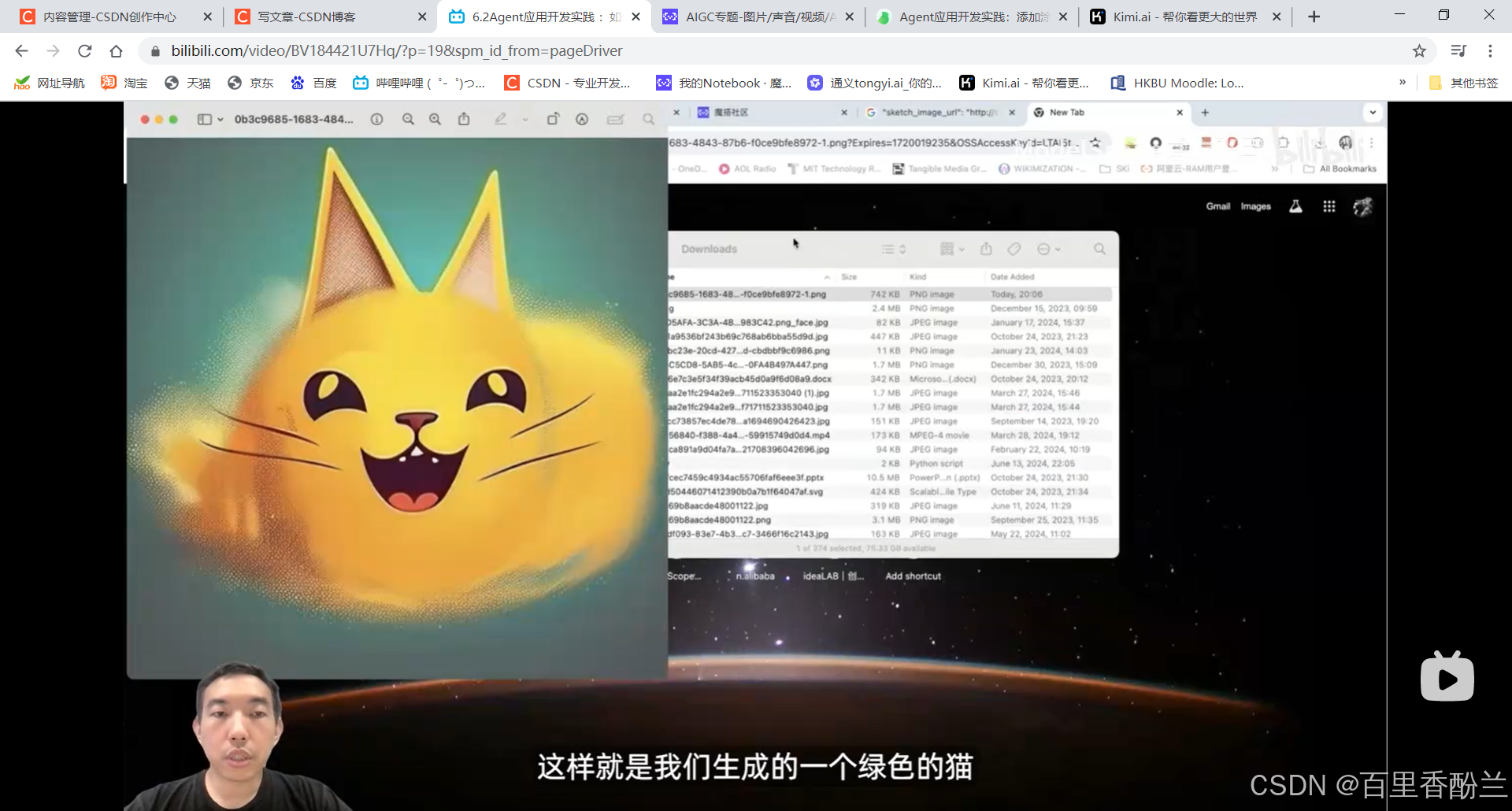
《绿色的猫》,笑死:
老师这一套组合拳我也没怎么看懂,很多操作是从来没听过的程度。这个案例比我们草台班子做的人话计算机八股文助手高级多了……唉,学海无涯,还需努力啊。
Agentfabric是类似GPTstore的开源项目,通过对话的方式创建一个个性化的Agent,大家也可以手动输入名称、指令化描述等。
这个我感觉很像我实习期间试用的智谱清言的DIY智能体的功能,我当时很需要一个普通话和粤语书面转换的工具,并且还能根据我的需求有针对性地提出修改和扩写,看同学在用智谱清言就试了一下,但是当时对结果不是很满意,后面就没再玩了。
另外,智谱清言的视频生成能力还不错,但我感觉写实的宽泛的效果好(比如猫吐舌头,鱼在水里游这种),对于动画人物,尤其是指定外貌特征的,他就支棱不起来。(问就是尝试通过描述词硬凑同人创作失败了……给我拉了坨大的……)
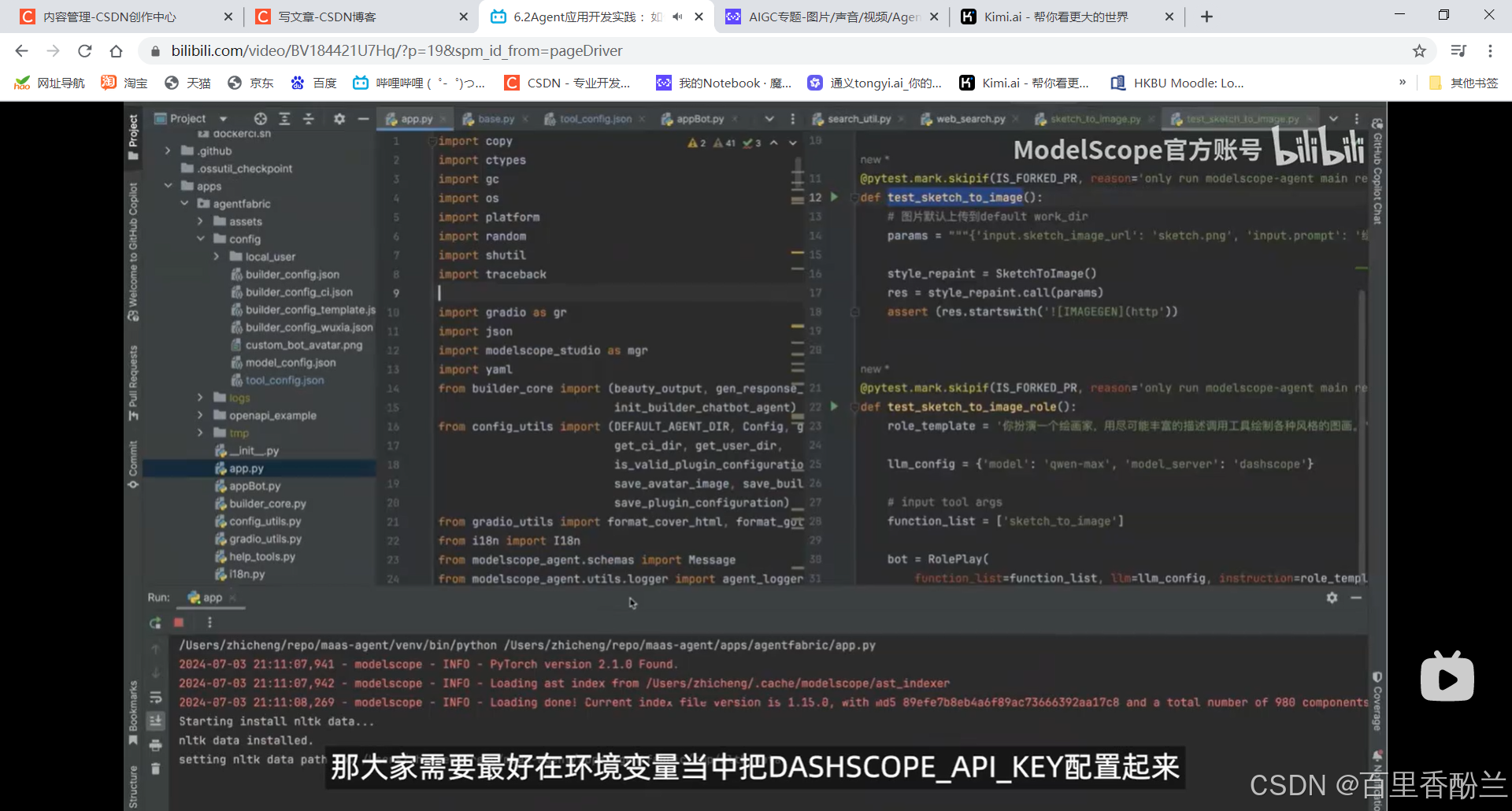
核心代码入口文件是app.py,这是gradio标准的内容。Config依赖模型的配置
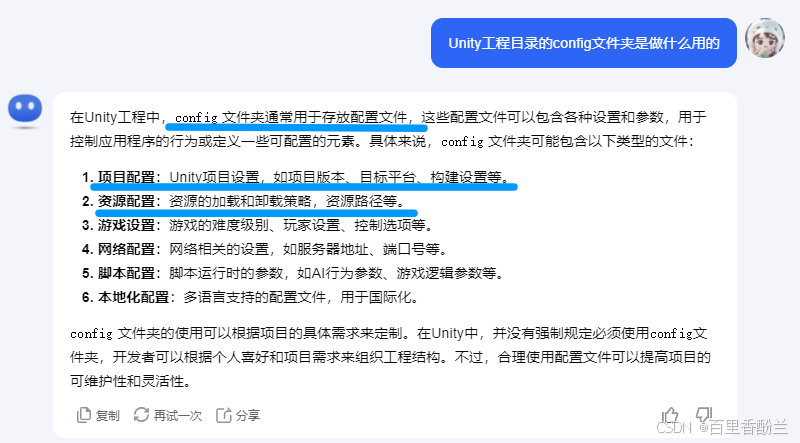
Unity里面好像也有Config这个文件夹,但我记不得干啥的了,问一下Kimi。
有点唤醒死去的回忆了,我个人应该只用过前俩个用途,后面四样没实践过。
使用功能需要添加能力,需要将其active起来能够备选,然后命名为“涂鸦作画",然后直接运行app.py就行。
配置了老师下图说的这个,调用qwen-max就不会出问题。
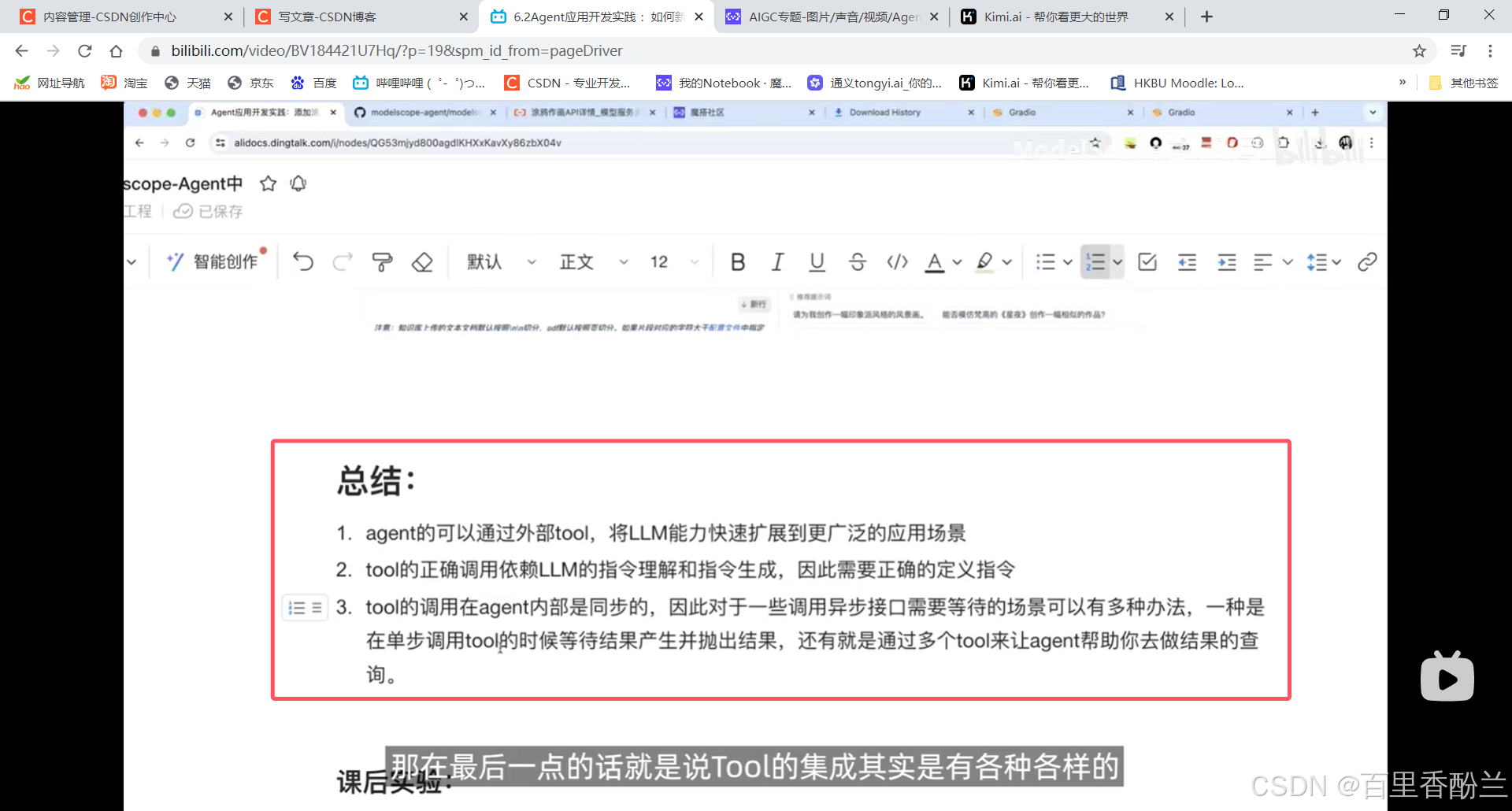
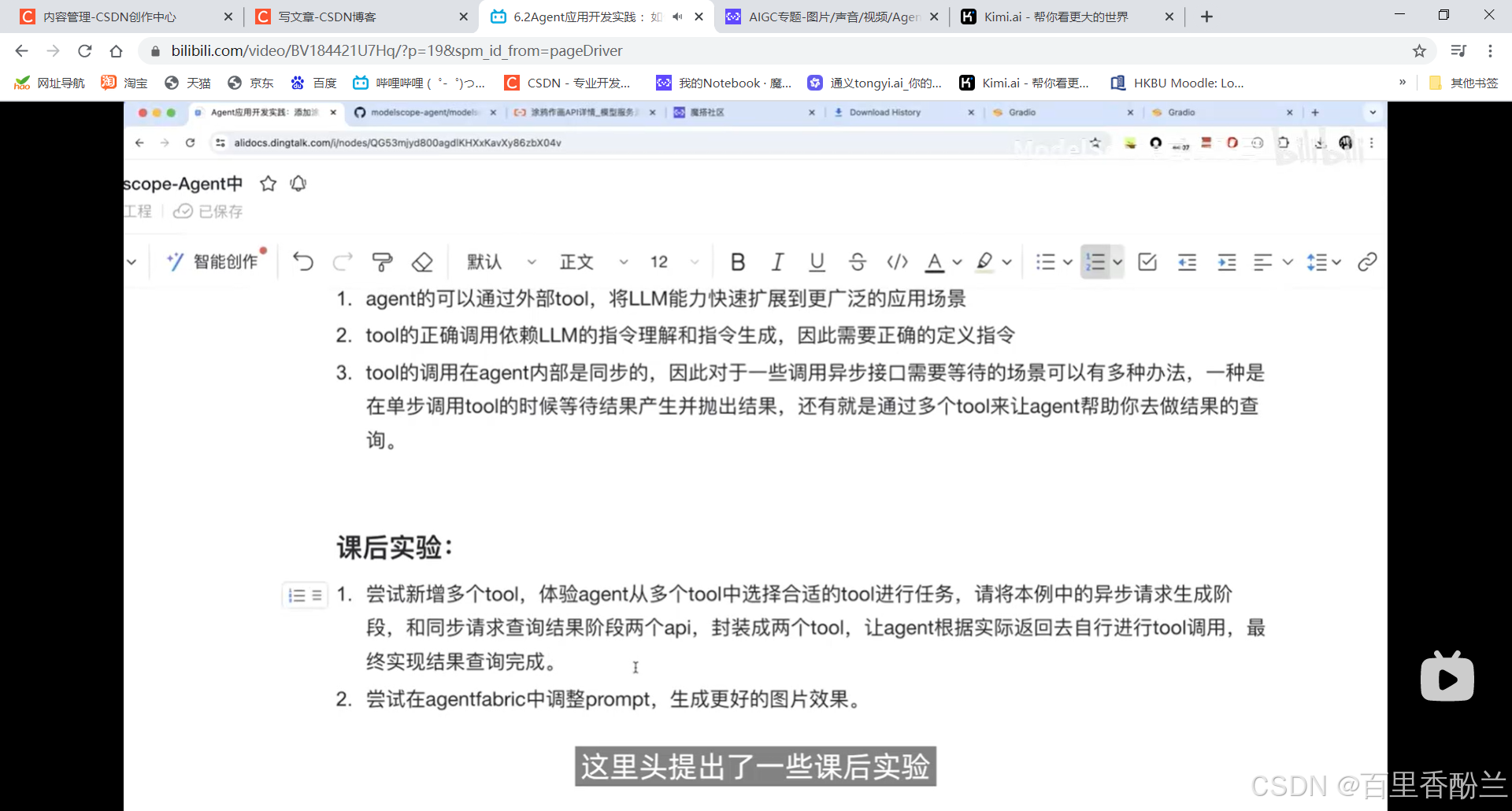
课后作业:
我感觉AI这块真不是一般人都能卷起来的,别说完成作业,这一套连招我都没弄明白哪是哪……
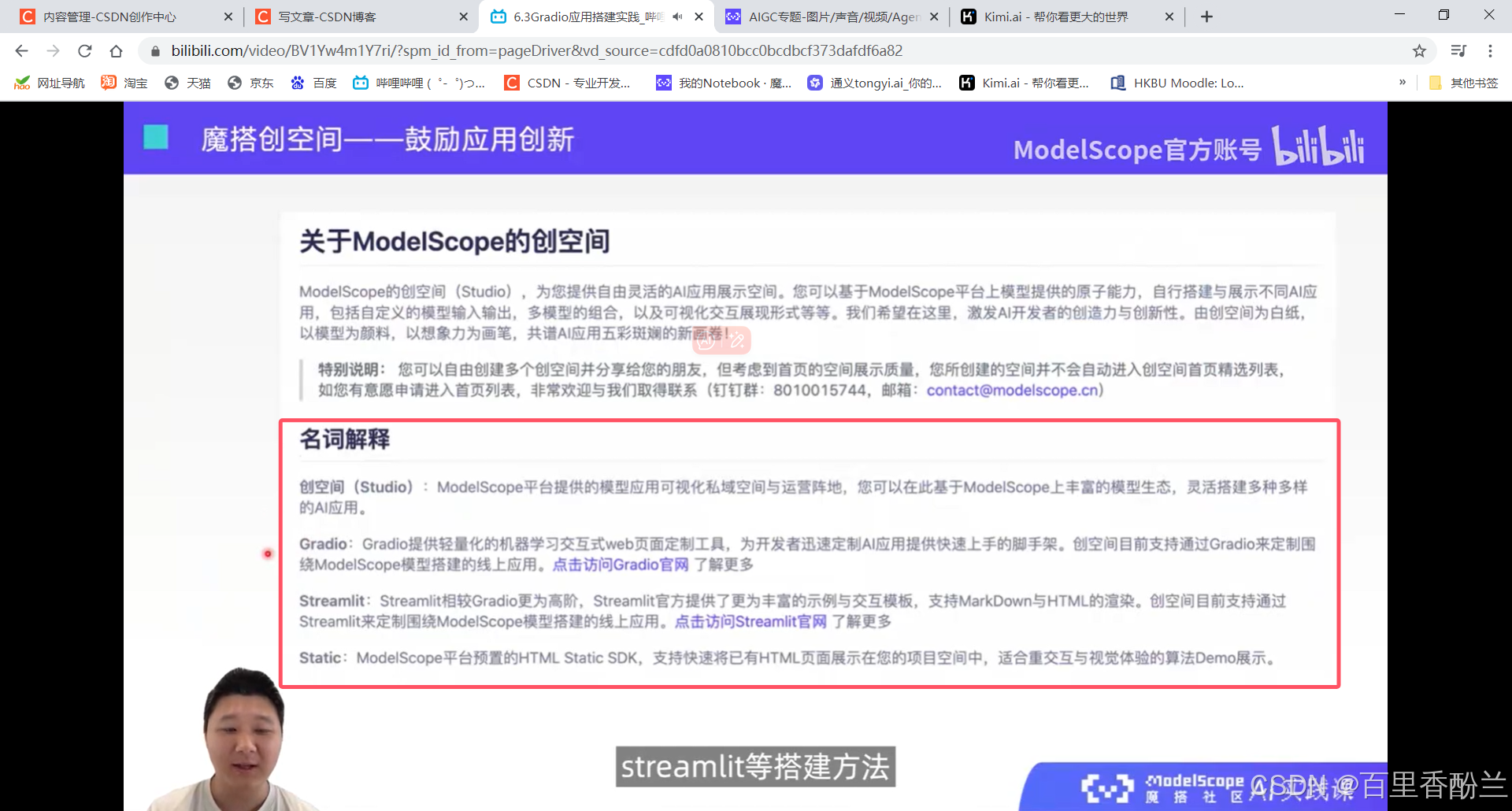
6.3Gradio应用搭建实践:
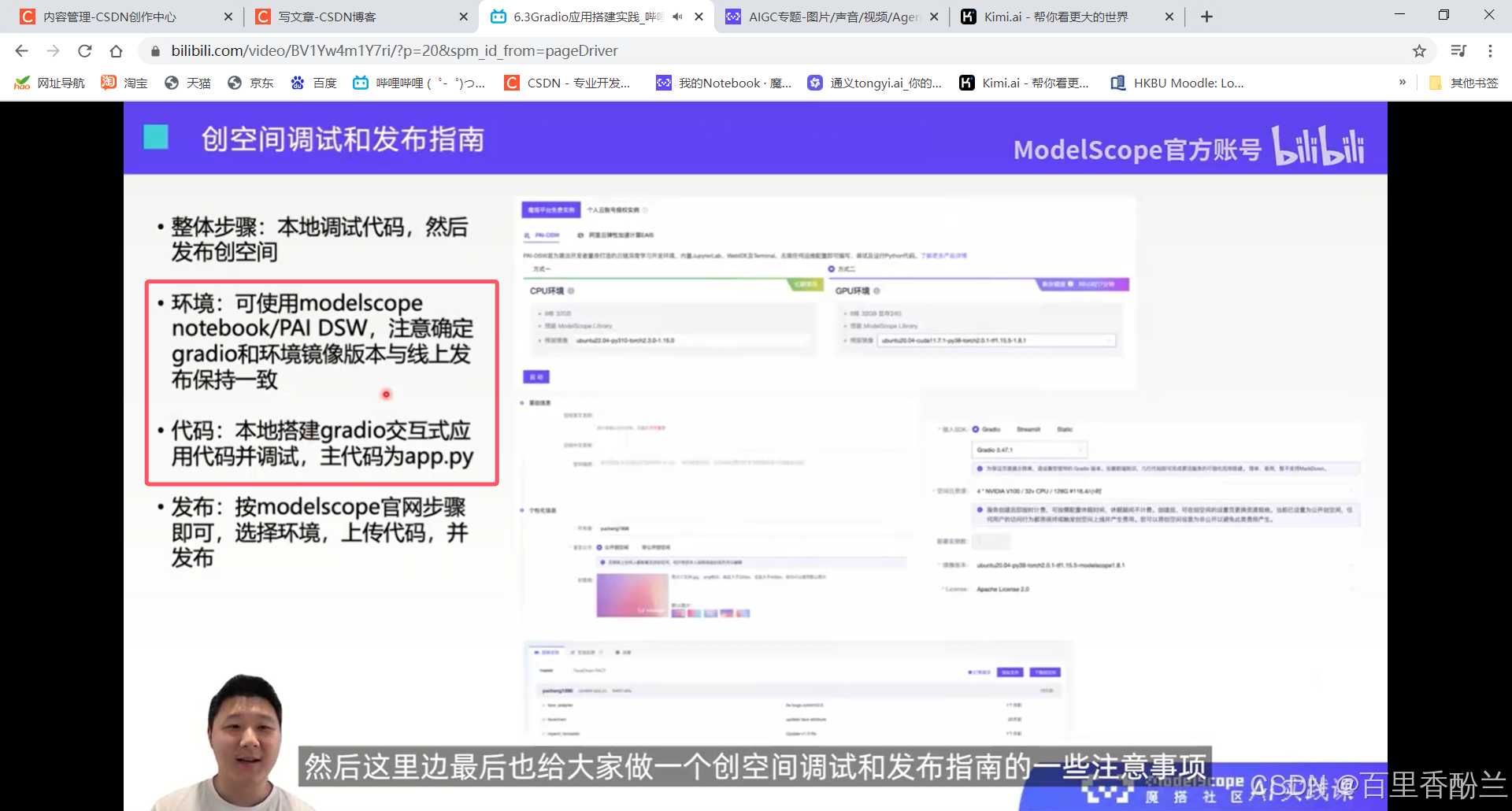
终于坚持到课程收尾了,前面好多我都没弄明白,但是这一讲我还比较感兴趣。在我们尝试开发的时候前端用的Streamlit,但是对于另一种备选Gradio我也很想更多地了解一下。
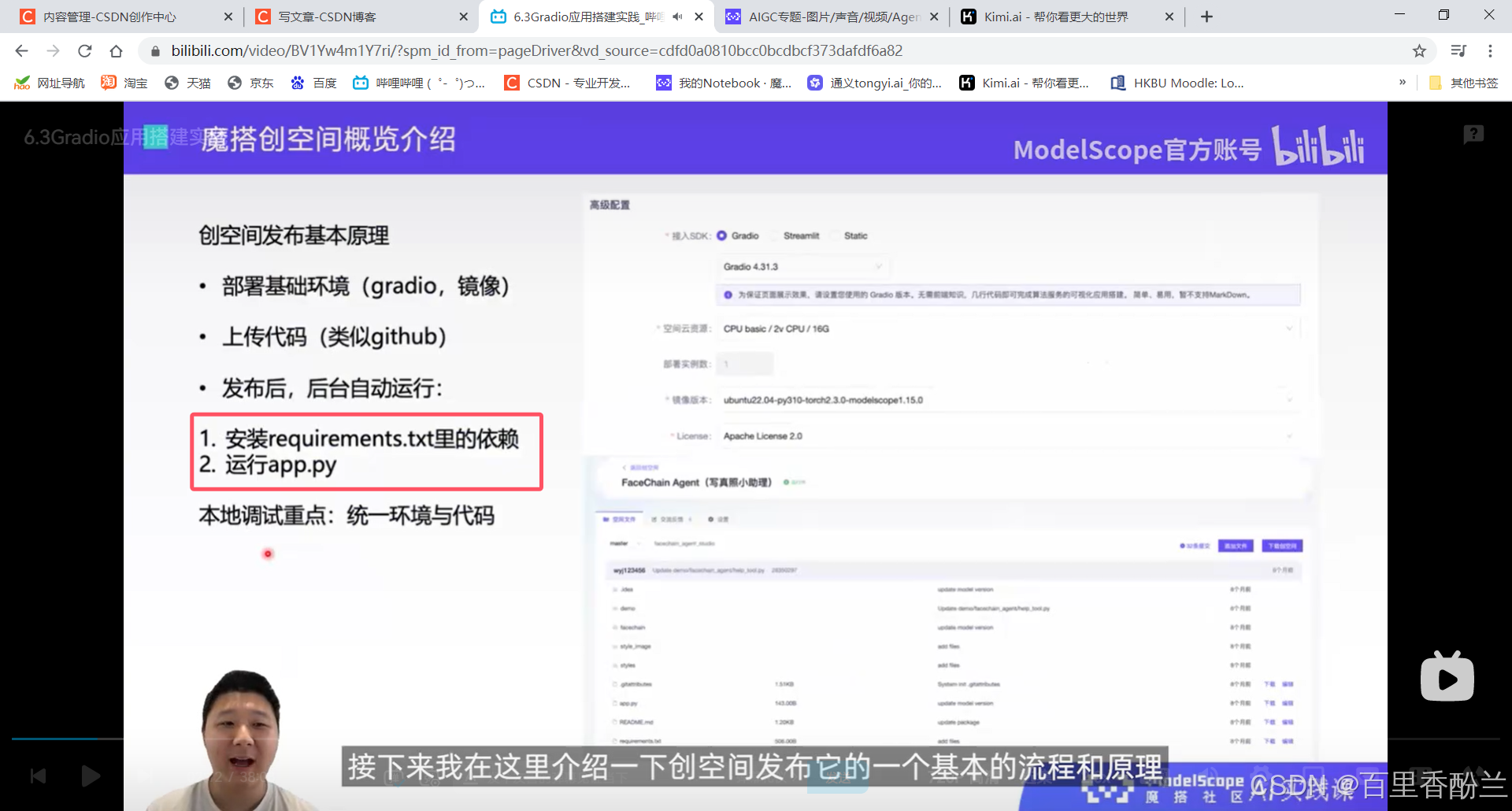
这个步骤和要求要是我能早点看到就好了,之前为了完成部署的任务又是查说明又是找网站又是群里厚脸皮问大佬的……
两个要注意的:一个gradio的版本,一个镜像的版本。app.py必须作为项目主代码,requirements.txt负责安装其他的环境依赖。
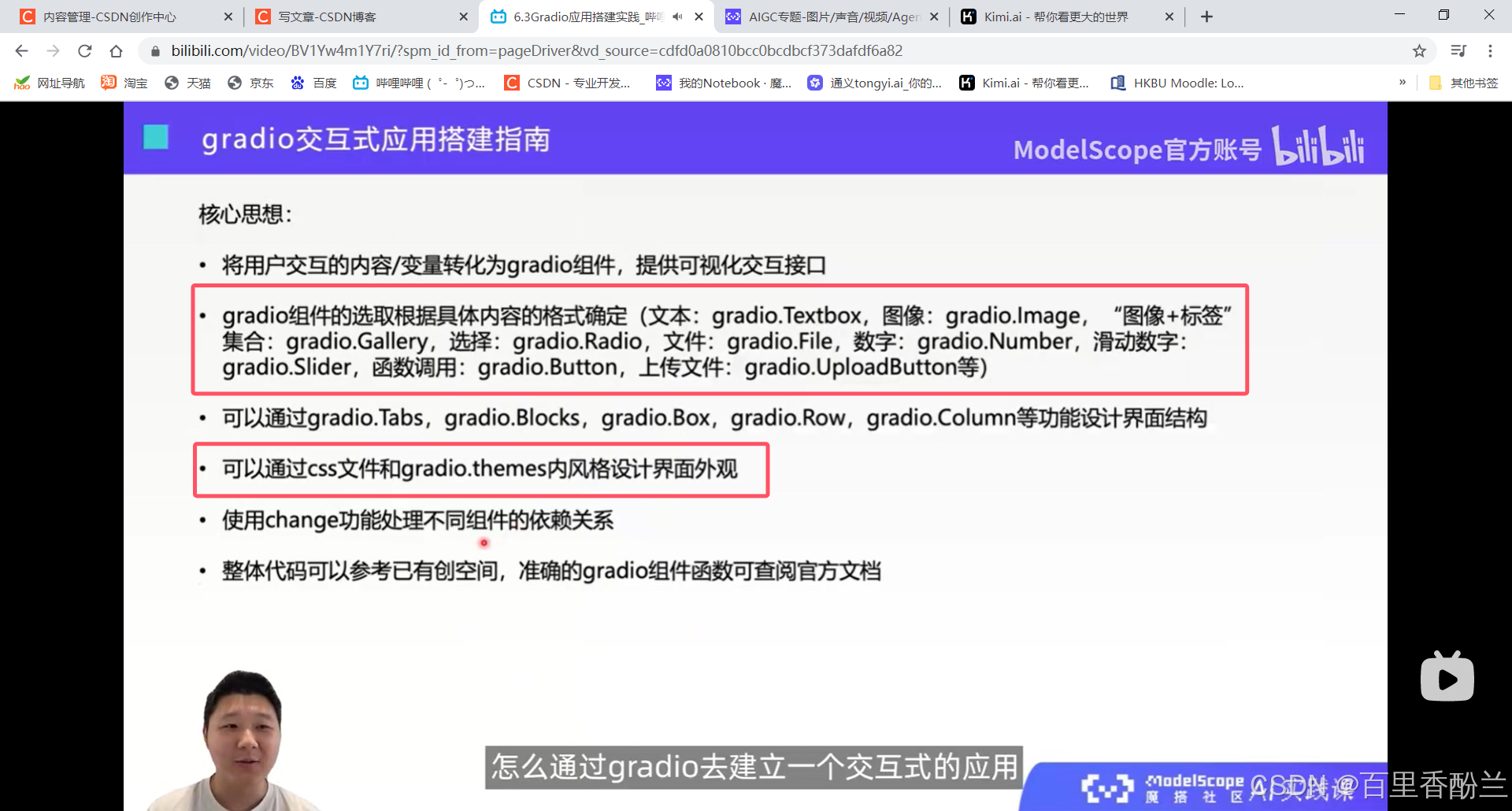
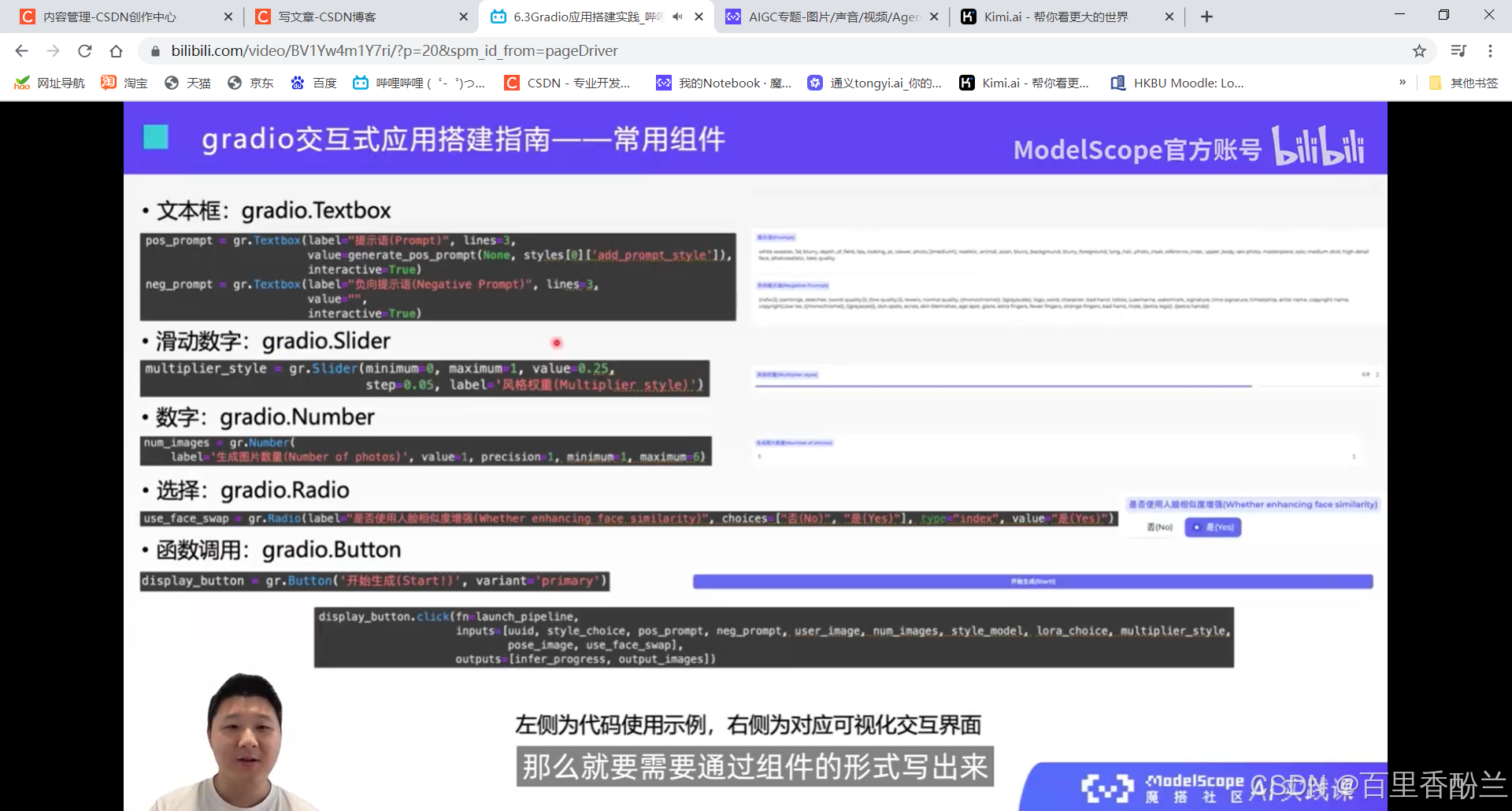
写好变量以后调用推理,其实就是调用这个gradio.button。
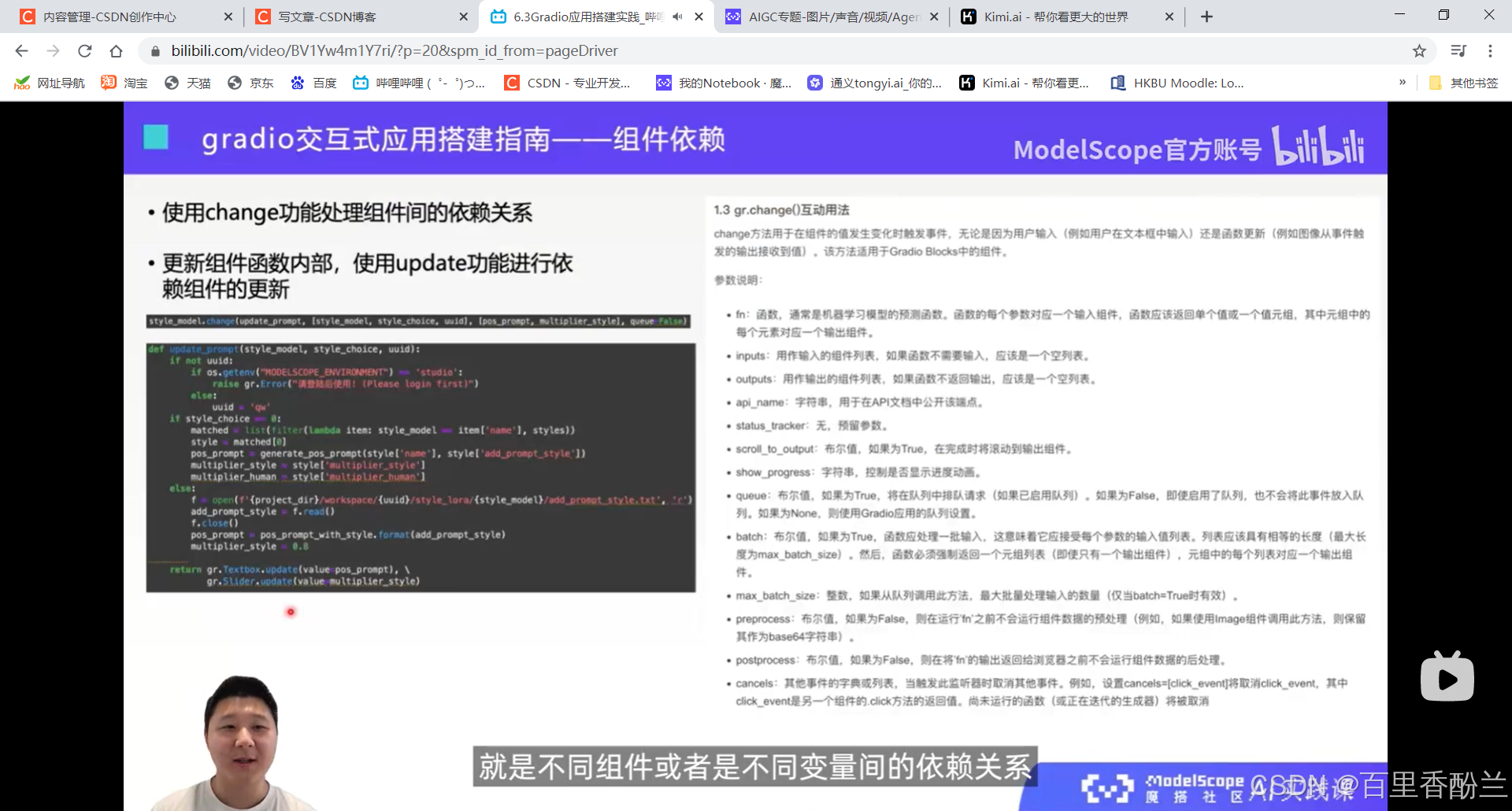
不同的变量之间不完全是并列的关系,很多时候是一种依赖的关系。比如个性化图像生成,每一个风格文件都具有自己的提示词。那么更换风格文件的时候,提示词也要自动同步更换。这就要用到gradio.change功能。
安装:本地调试pip install 对应版本,创空间发布就是部署界面下拉选框选择对应版本。
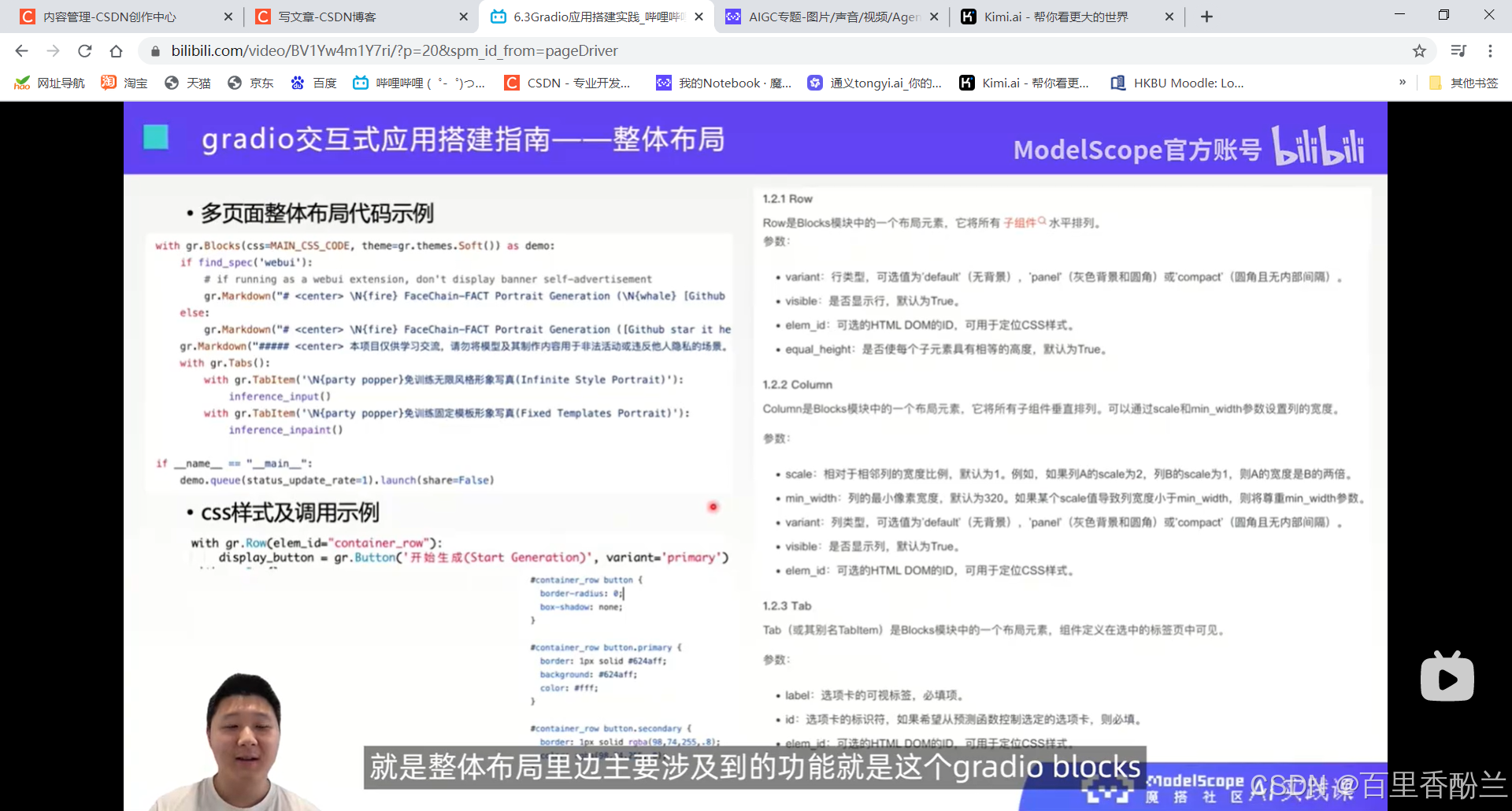
with gradio.row/column 把好几个组件放在一行/一列
最后一般用这个demo作为整体交互式应用的变量,最终写的时候调用demo.queue().lanch(share=False) 最后会得到内部网址,一些单位或者组织里边会要求有内网和公网的区别,所以share = True得到外部网址慎用,自己的电脑玩玩就无所谓了。
修改一个变量联动去修改另一个变量的时候,主要修改的就是value值。
gradio.Radio里面的type和index就会反映用户做出的是哪个选择,影响后续代码的写法。
一般界面只有一个primary Button,其他的都是secondary Button。
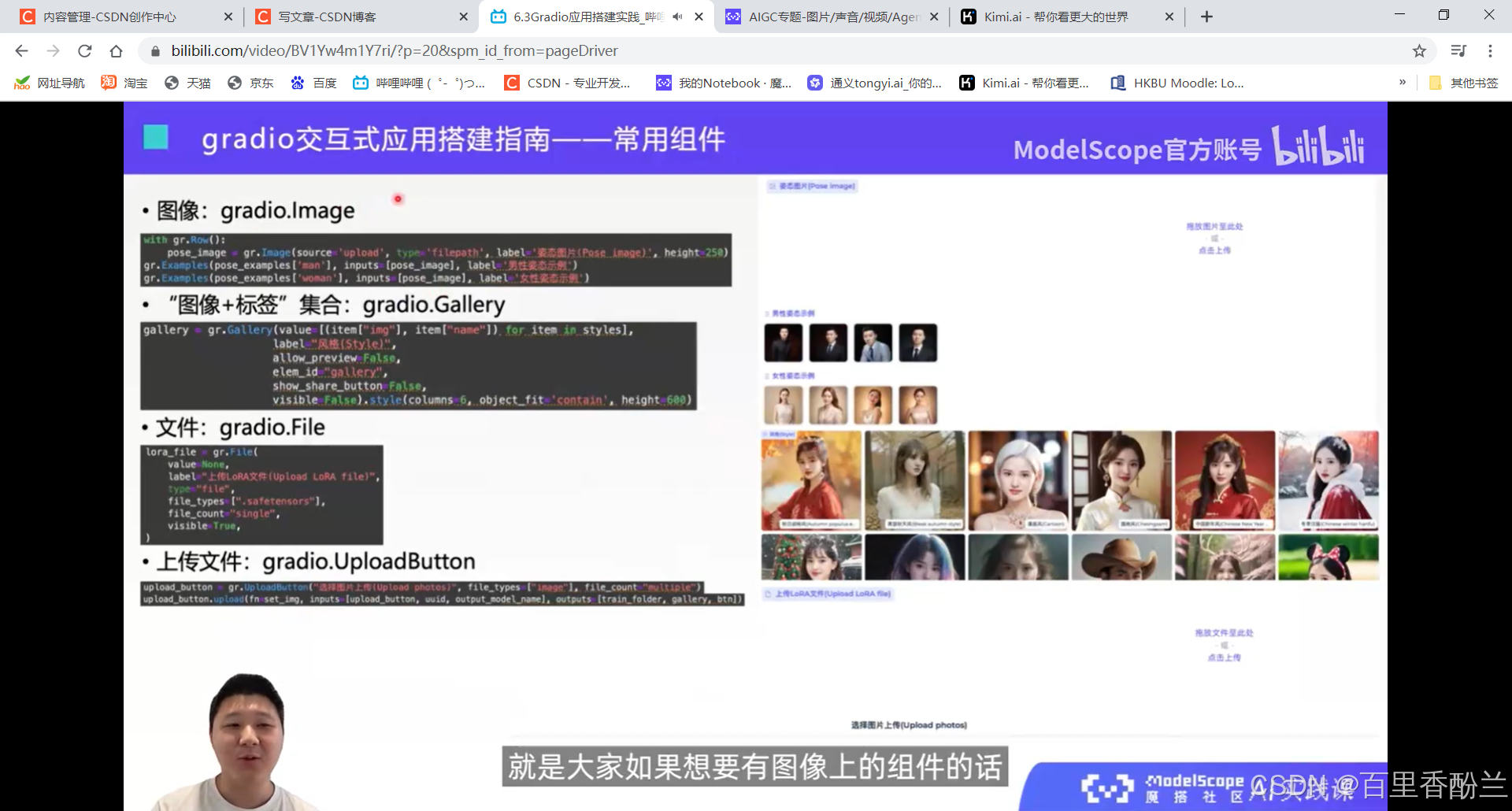
图像可以做上传或者是选择,选择是gradio.Examples,上传是source= “upload”, type = “filepath”。
gradio.Gallery类:展示图像+对应文字。
还是跟Unity的UGUI差不多,专门的UI库和组件调用+自定义细节就行了。
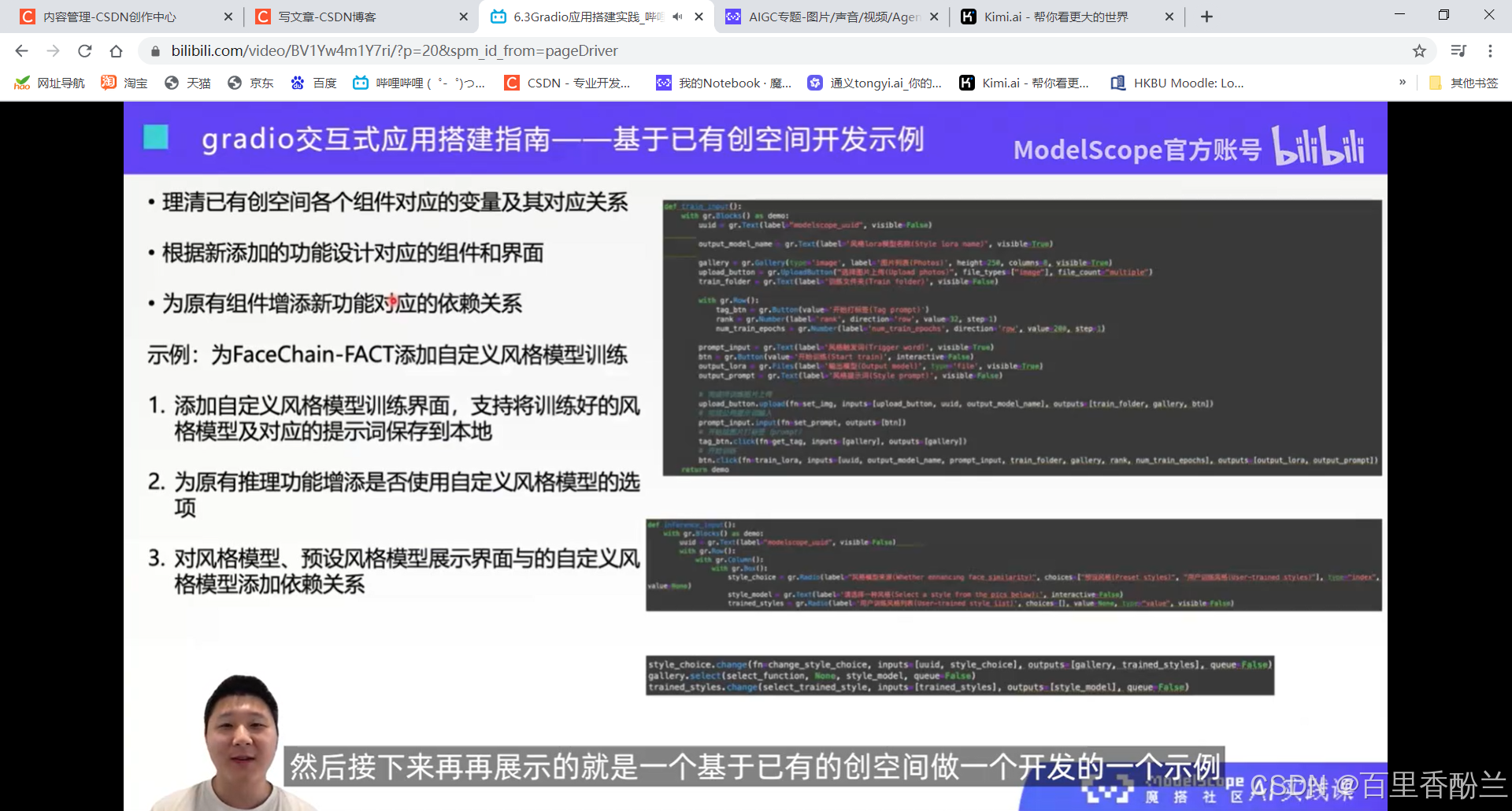
例子还是刚才那个,风格模型和提示词的联动关系。如果更改了图片里面的style_model,就会调用参数里面的参数一函数,然后输入是参数二input,输出是参数三output。
感觉这一课还比较实用,大模型应用开发方向写前端正需要。
加依赖也是requirements.txt。我当时了解了一下两个技术方案以后认为是streamlit更容易,就没选这个。现在看来其实编码难度差不多,这个gradio有个多个版本选择和创空间配合问题,streamlit我装的时候压根没考虑这,默认版本好像也没报错……?
课后作业:
大模型微调实践数据准备/清洗、模型微调、模型评估 全链路案例演示
这节课是2024年新上传的,之前合集都没有来着。老师目前还没放出学习资料,我尽量截屏截全一点,方便以后回顾。
创建环境,完成以后需要重启Notebook:
把数据集Load下来:
看一下数据的属性、条数,第一条长什么样: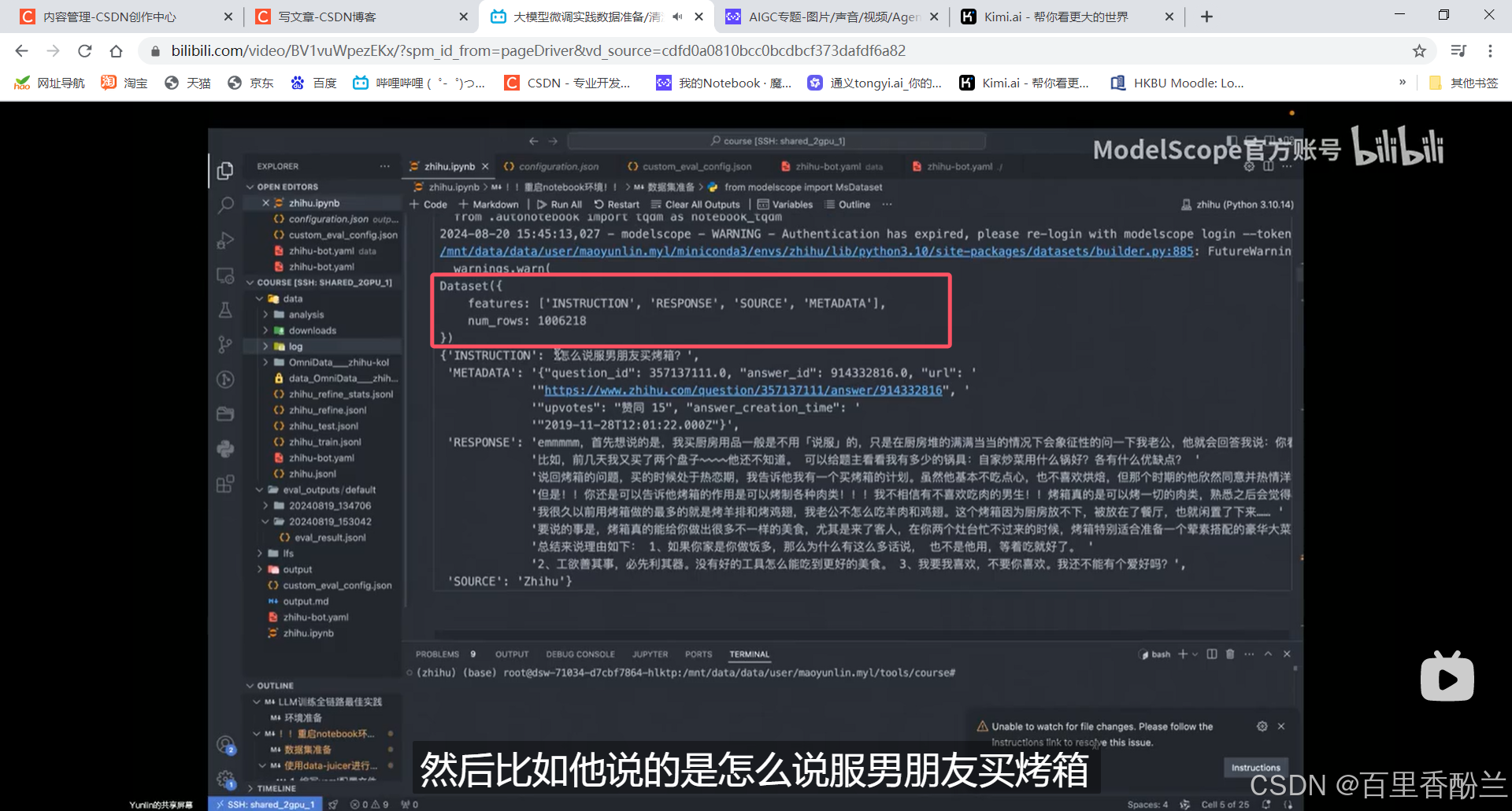
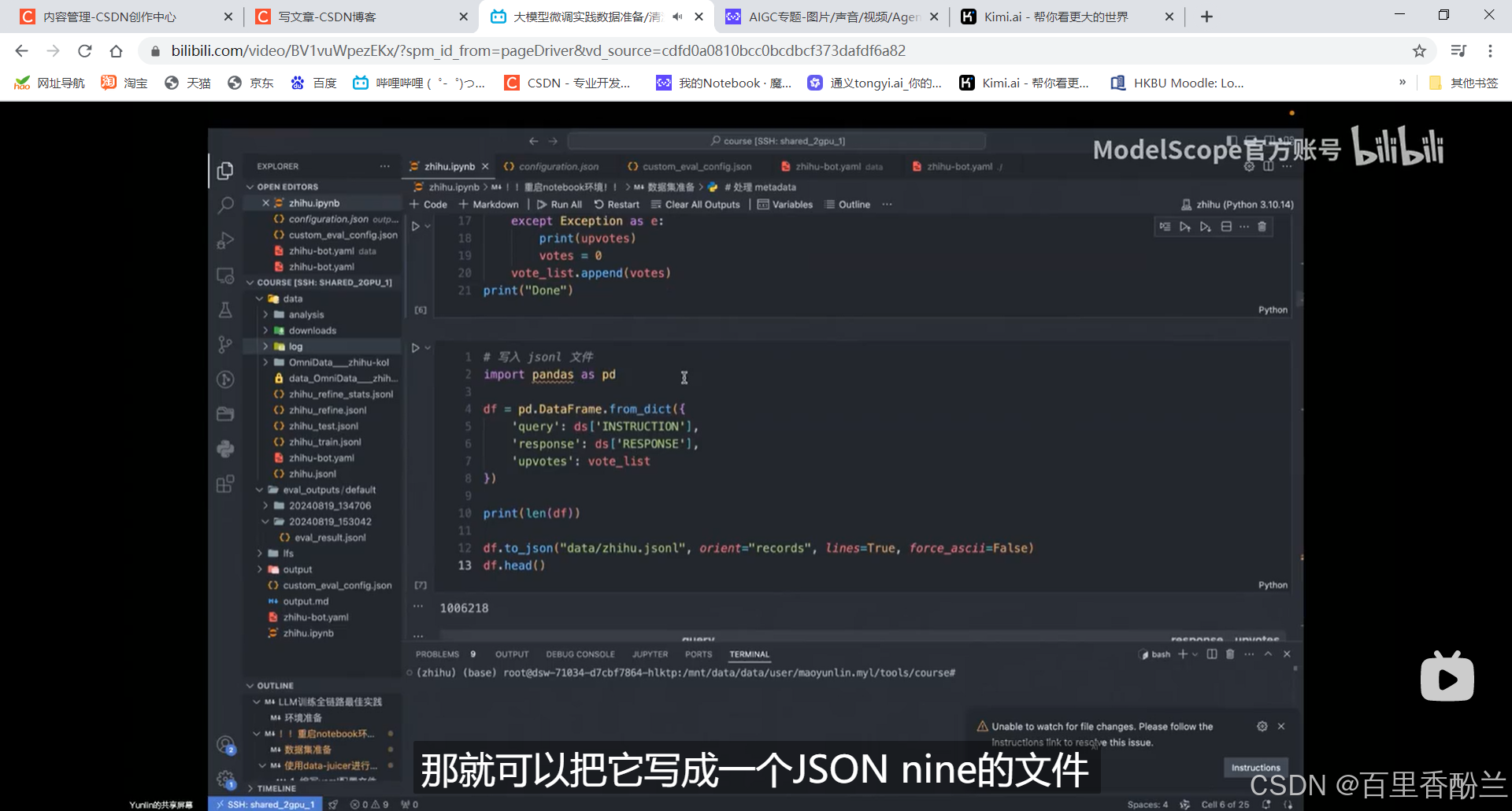
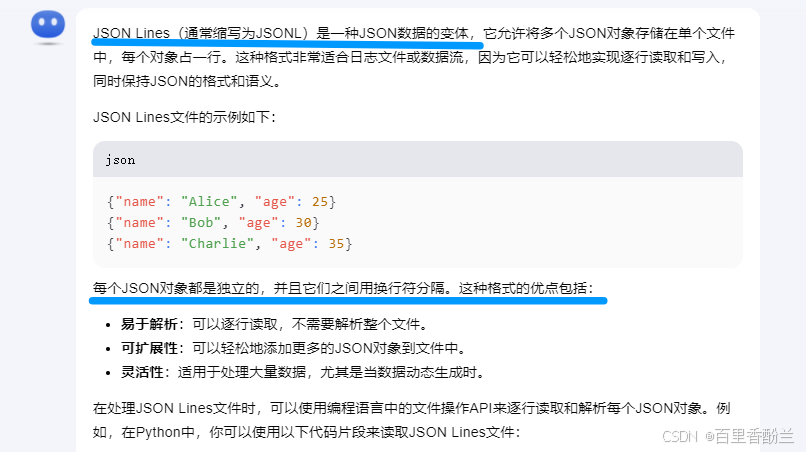
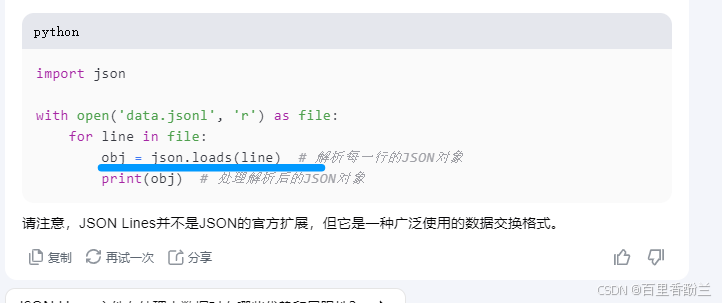
把刚刚分析得到的字段,使用to_json写成json nine(?)的文件,每一行都是一个独立的json:
好吧,是Json Line。
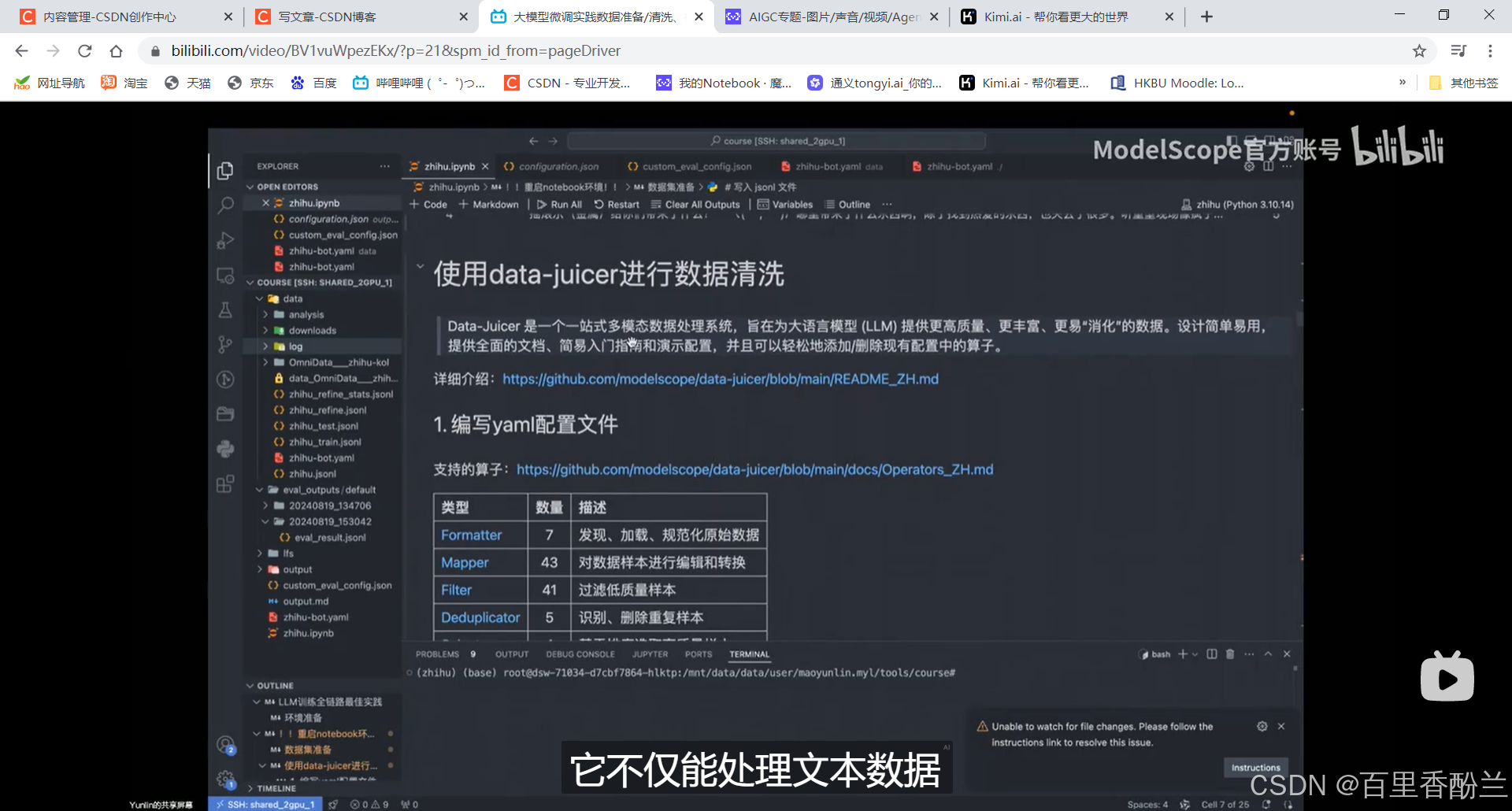
使用data-juicer进行数据清洗:使用方便,一个yaml配置文件就得。
我前段时间学JAVA项目的时候感觉好像也见过这个yaml?yml?xml?文件,记不得了,问下Kimi。
看来我在JAVA里面遇到yaml的环境正是我在用的Maven:
但我打开JAVA一看,这不是yml文件吗????咋个后缀里面少个a呢????????
噢,那没事了。
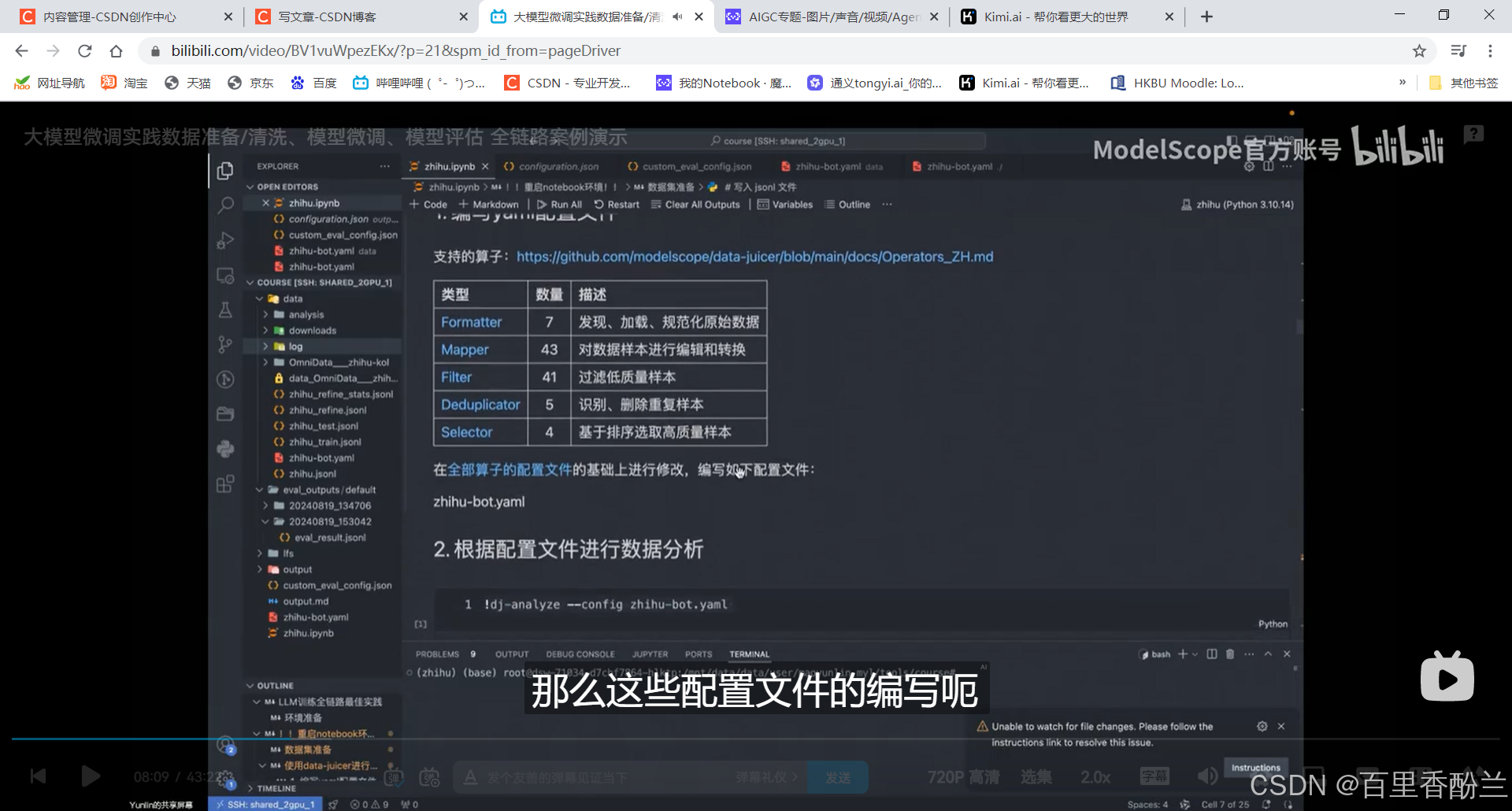


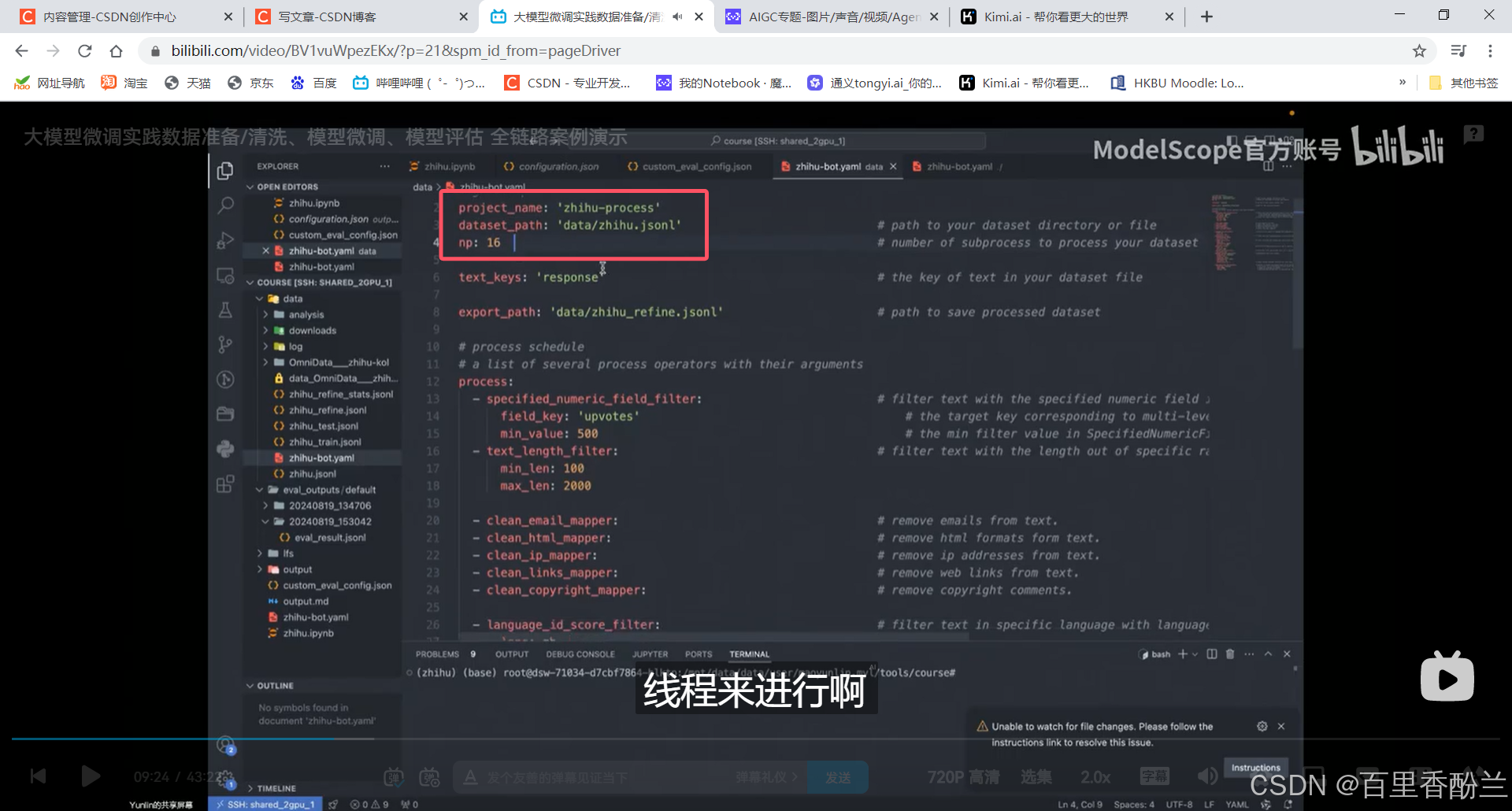
配置文件又长又全,需要在其中做一些删改:
np:多少个线程来处理
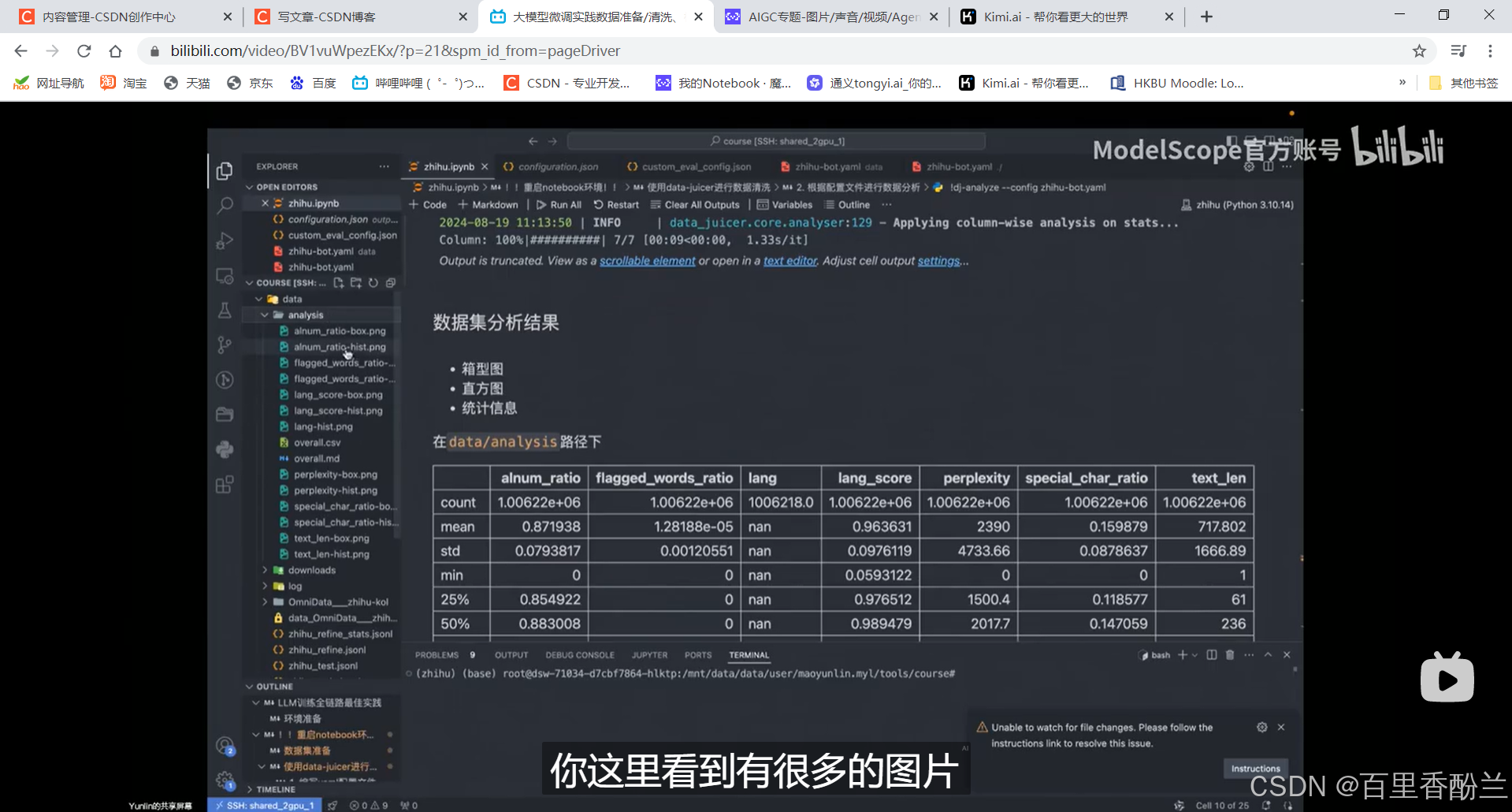
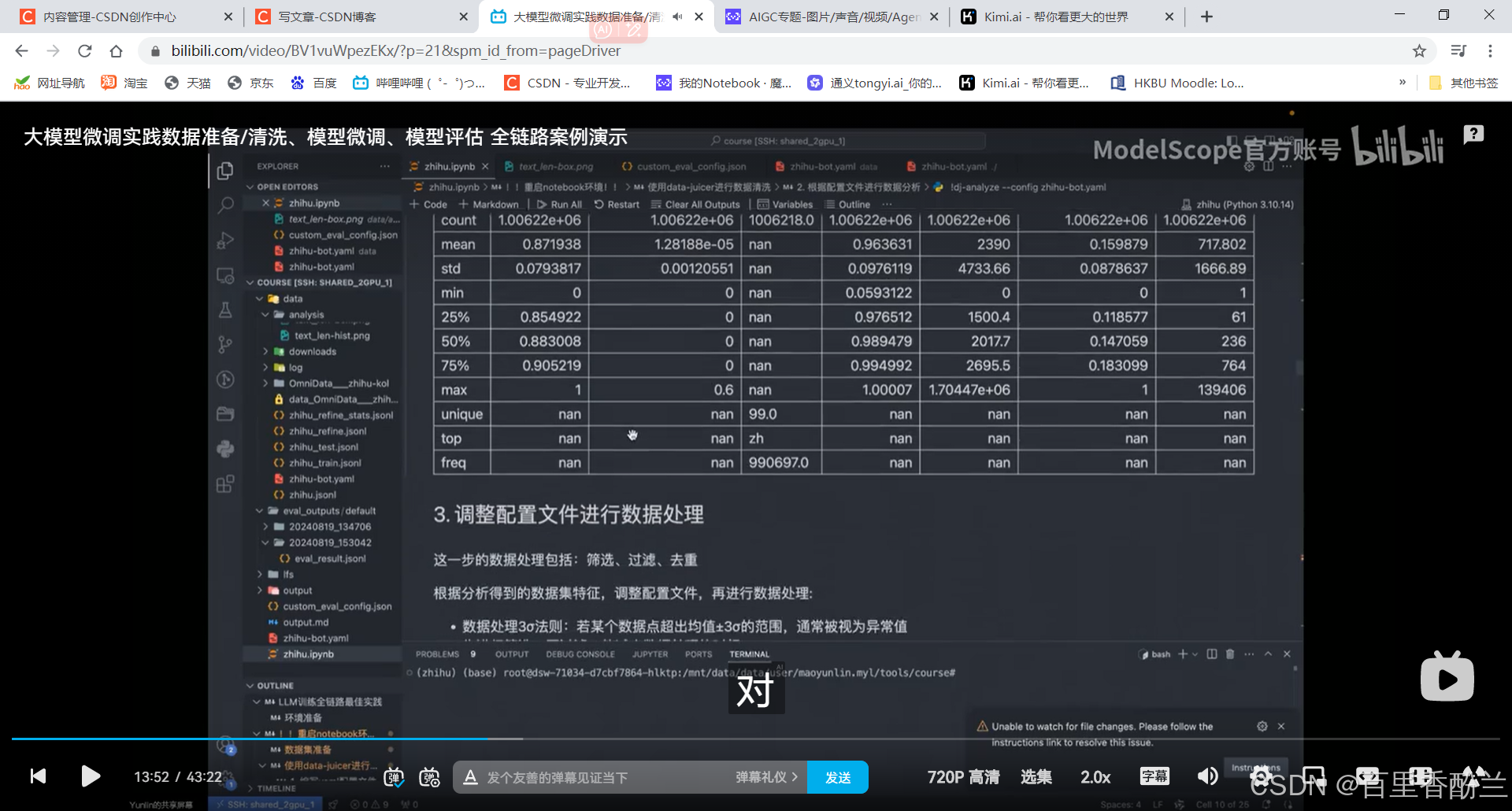
针对配置文件直接使用data analyze的命令,指定config,出现数据分析结果:图片,CSV,Markdown文件。
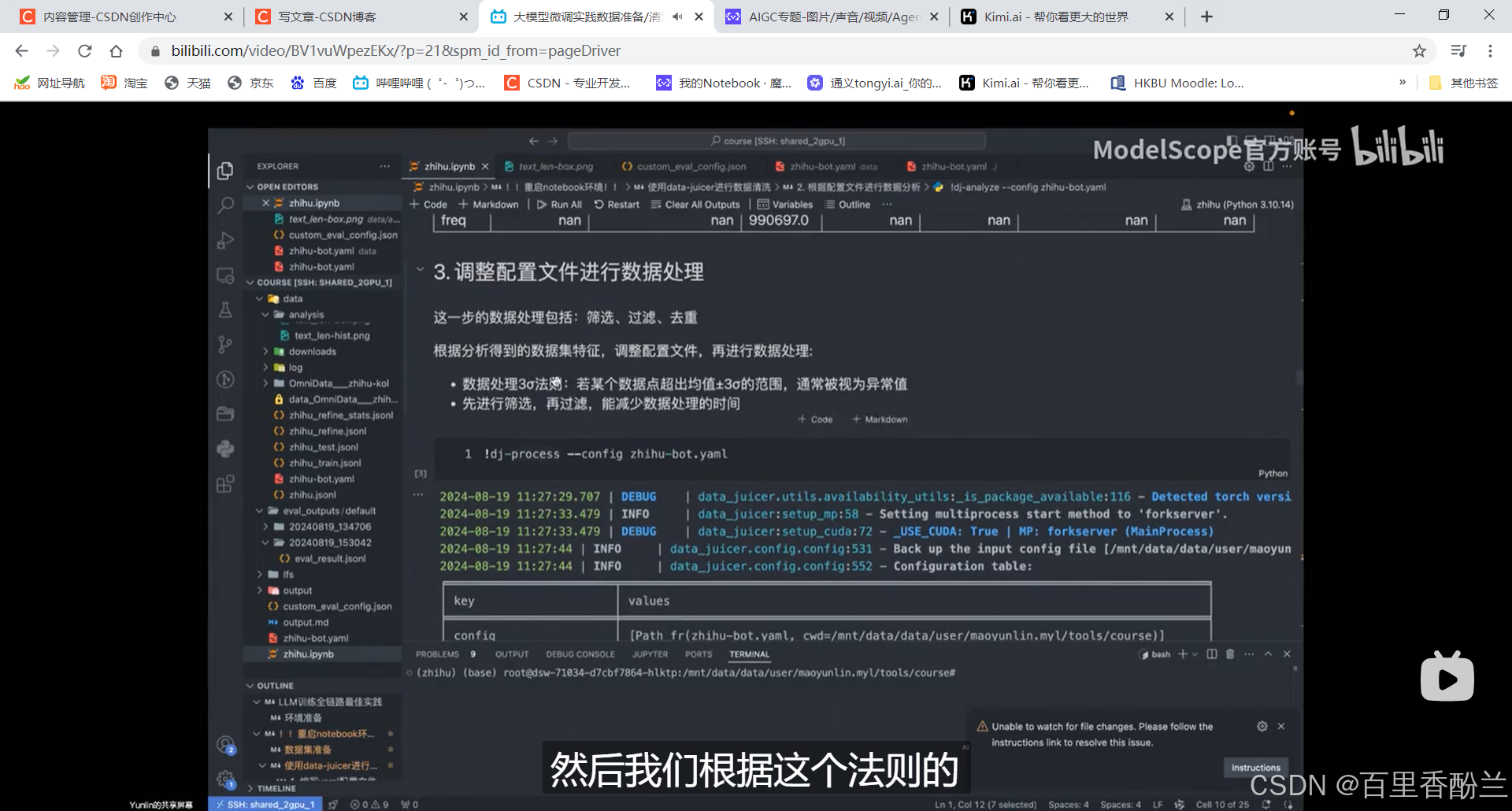
数据处理三西格玛(标准差)法则。筛掉部分不符合范围的数据:
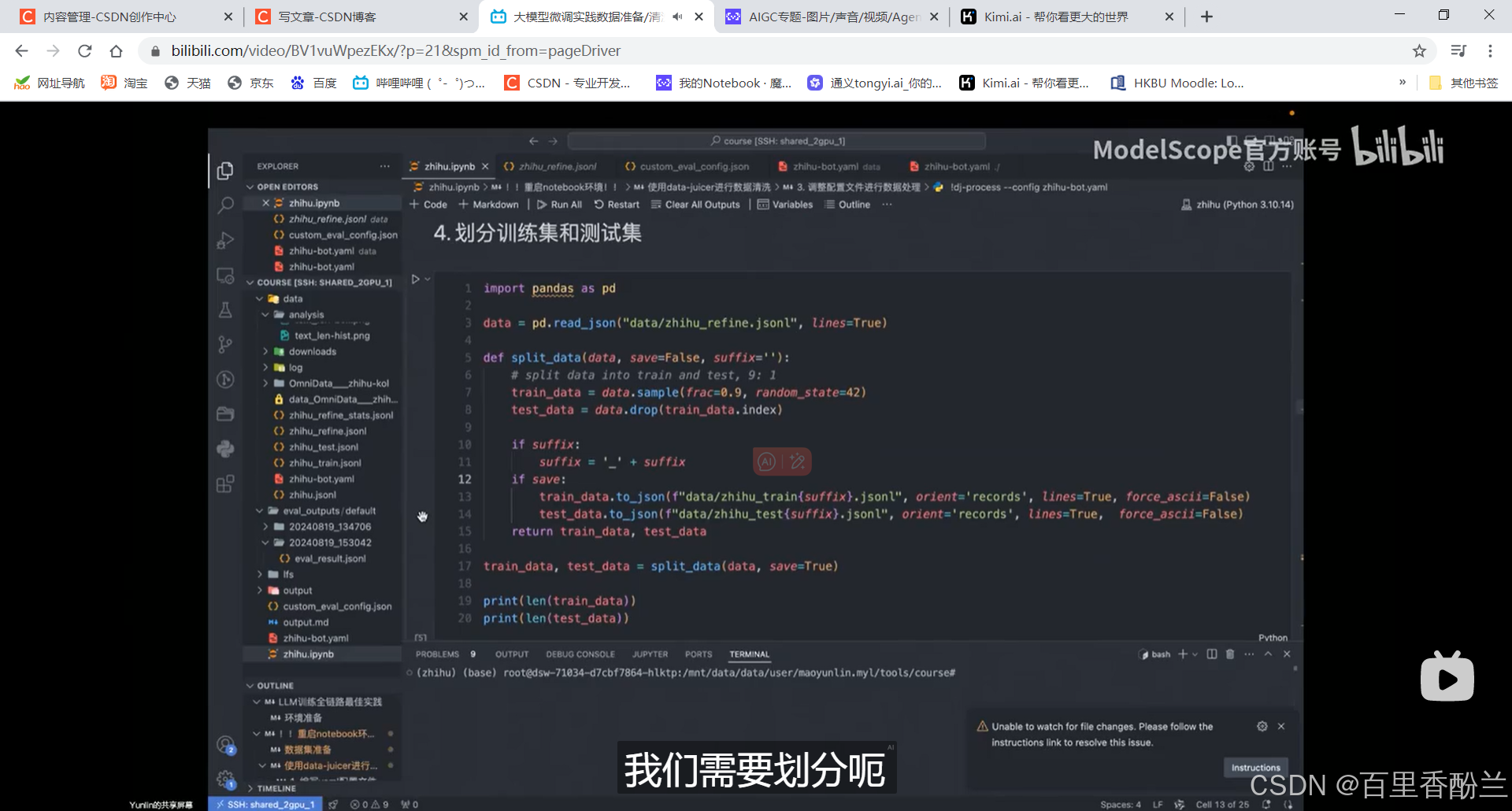
划分训练集测试集:
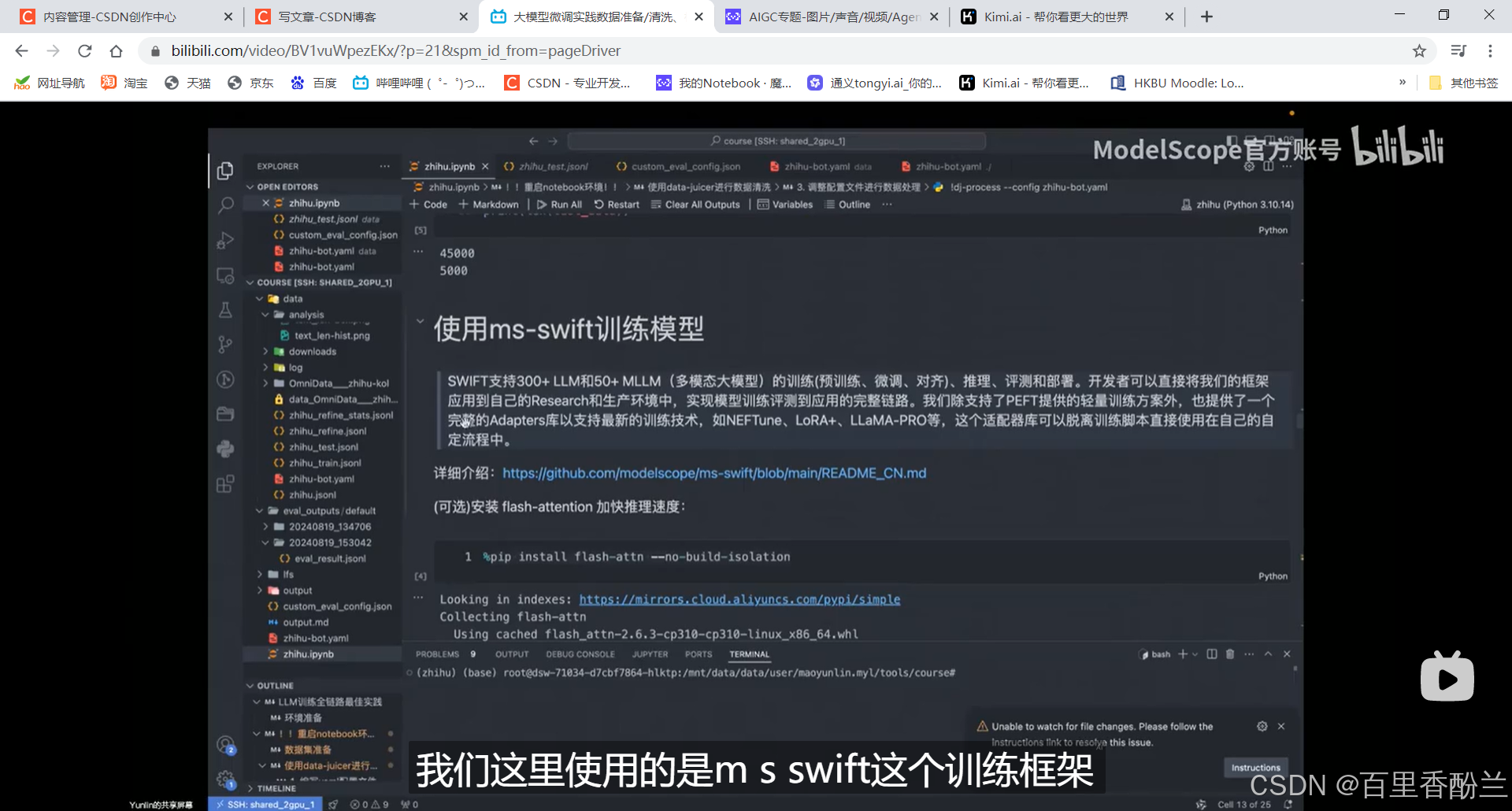
训练模型:
fast-attention可能加快训练速度,但是显卡可能不支持。
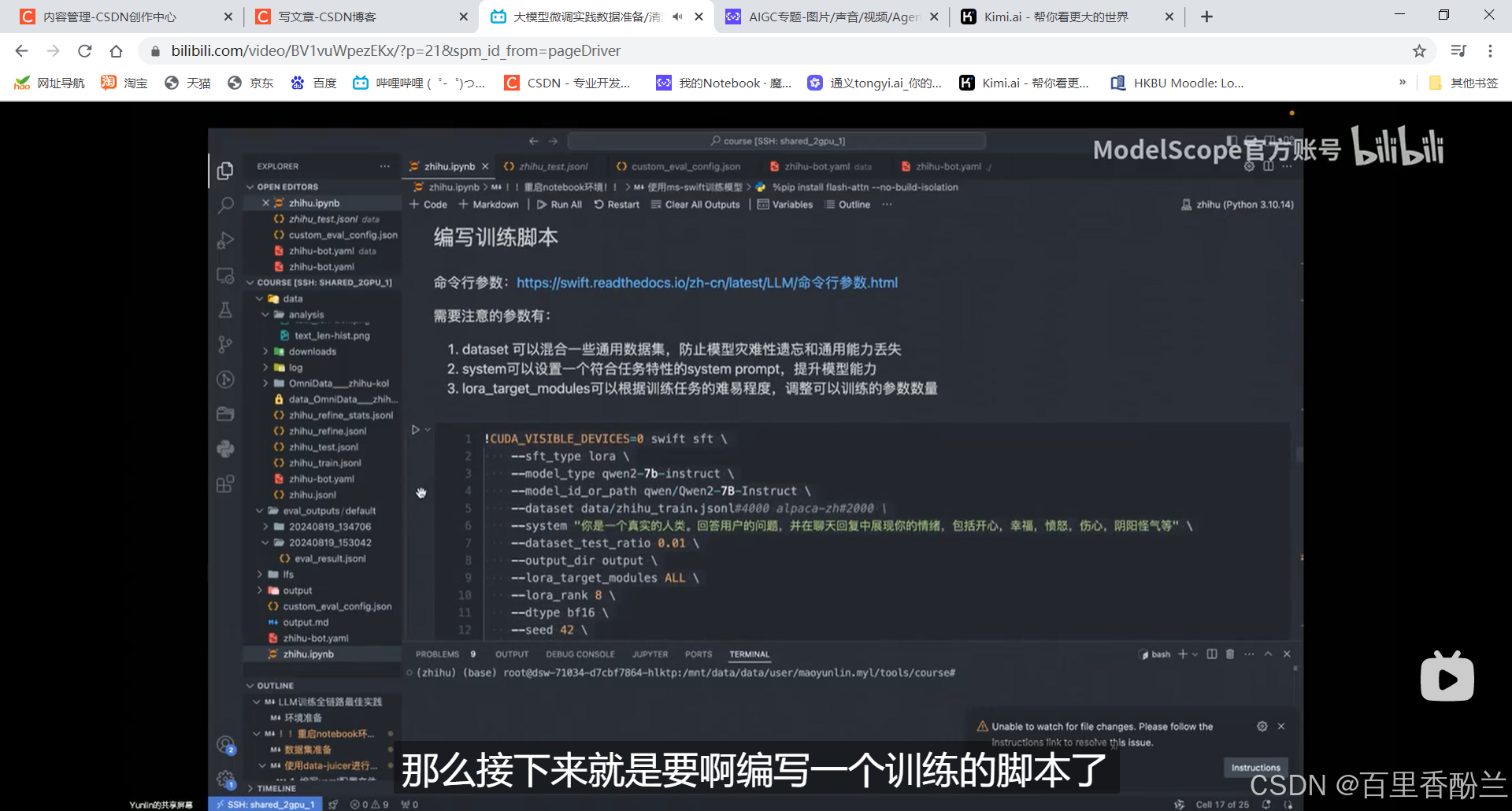
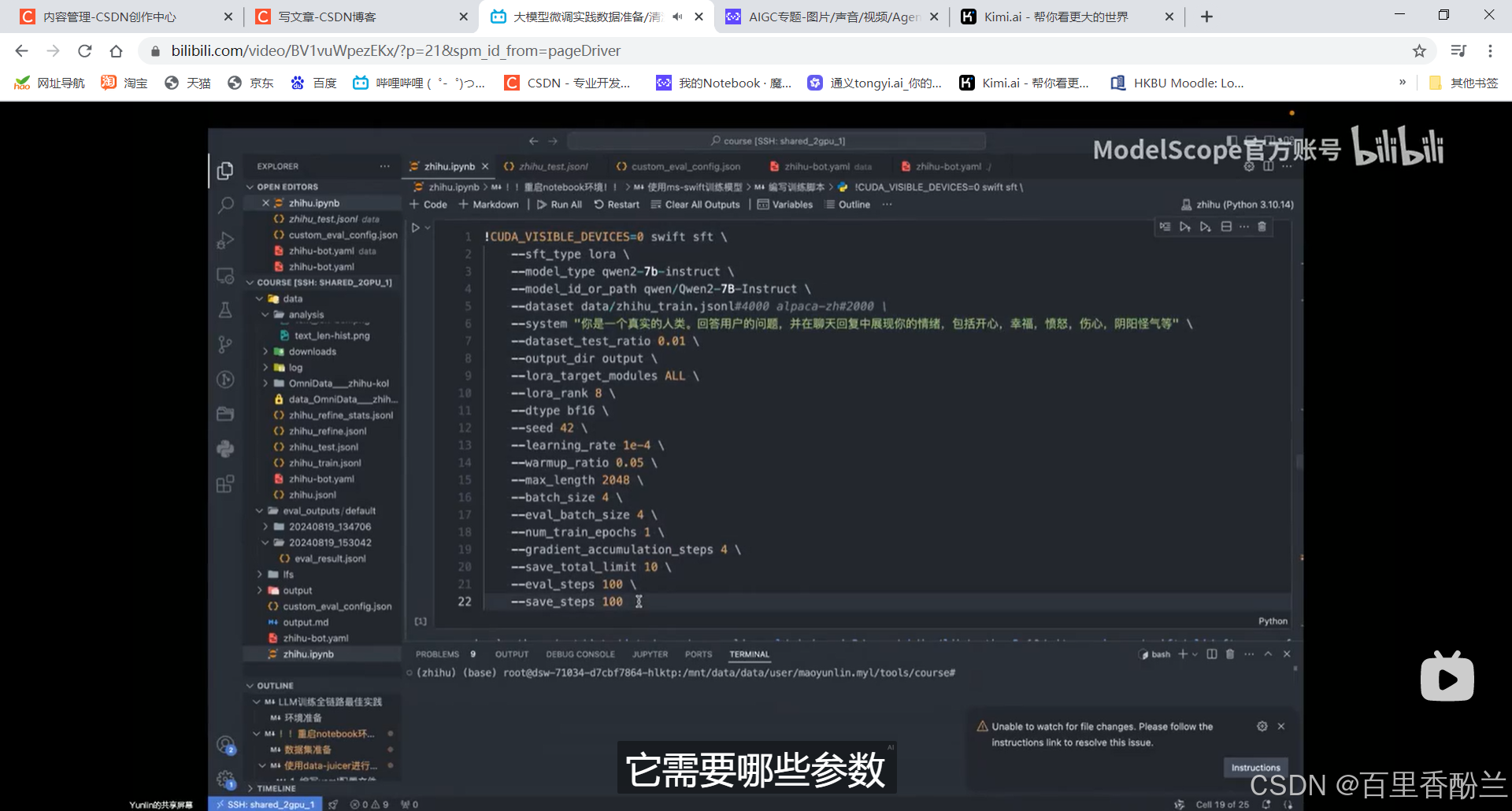
编写训练脚本:
参数一览:
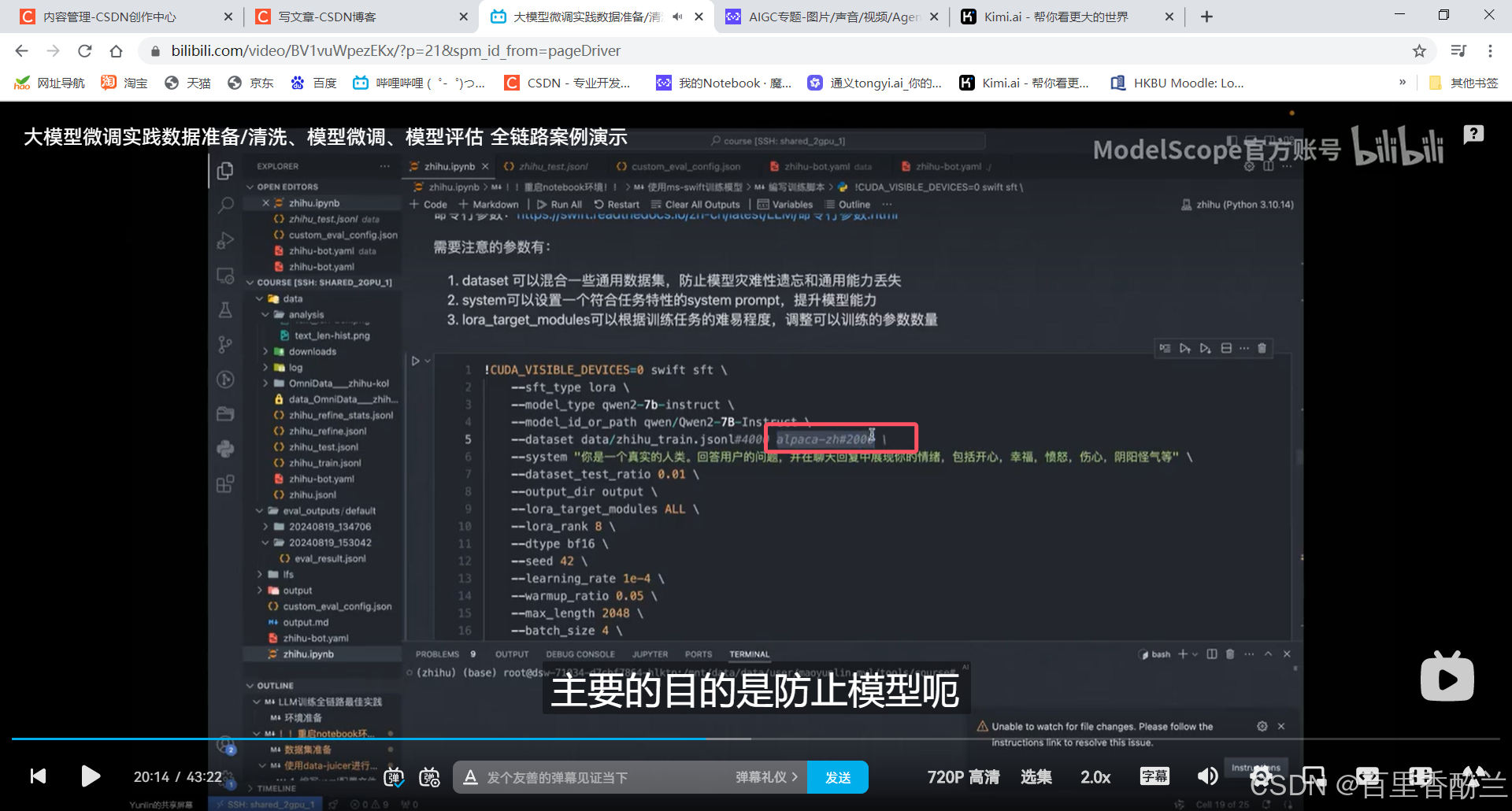
允许多数据集混合,框选这个作用是防止模型灾难性遗忘和通用能力丢失:(因为知乎这个数据集知识太分散了,模型不容易抓重点)用这个数据集对模型做一些限制。
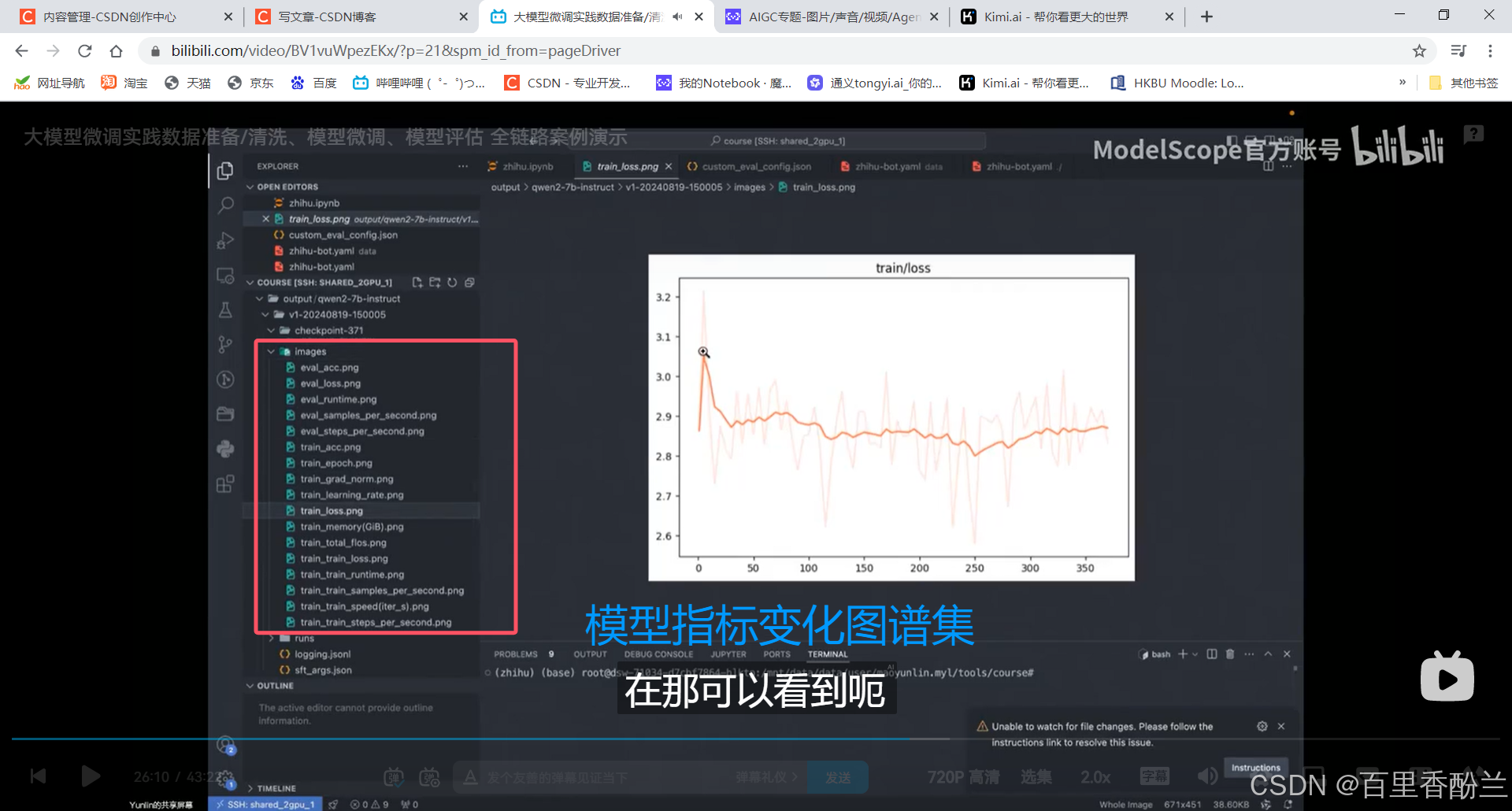
6000+条数据大概需要训练10-20分钟,数据保存在output文件夹下:
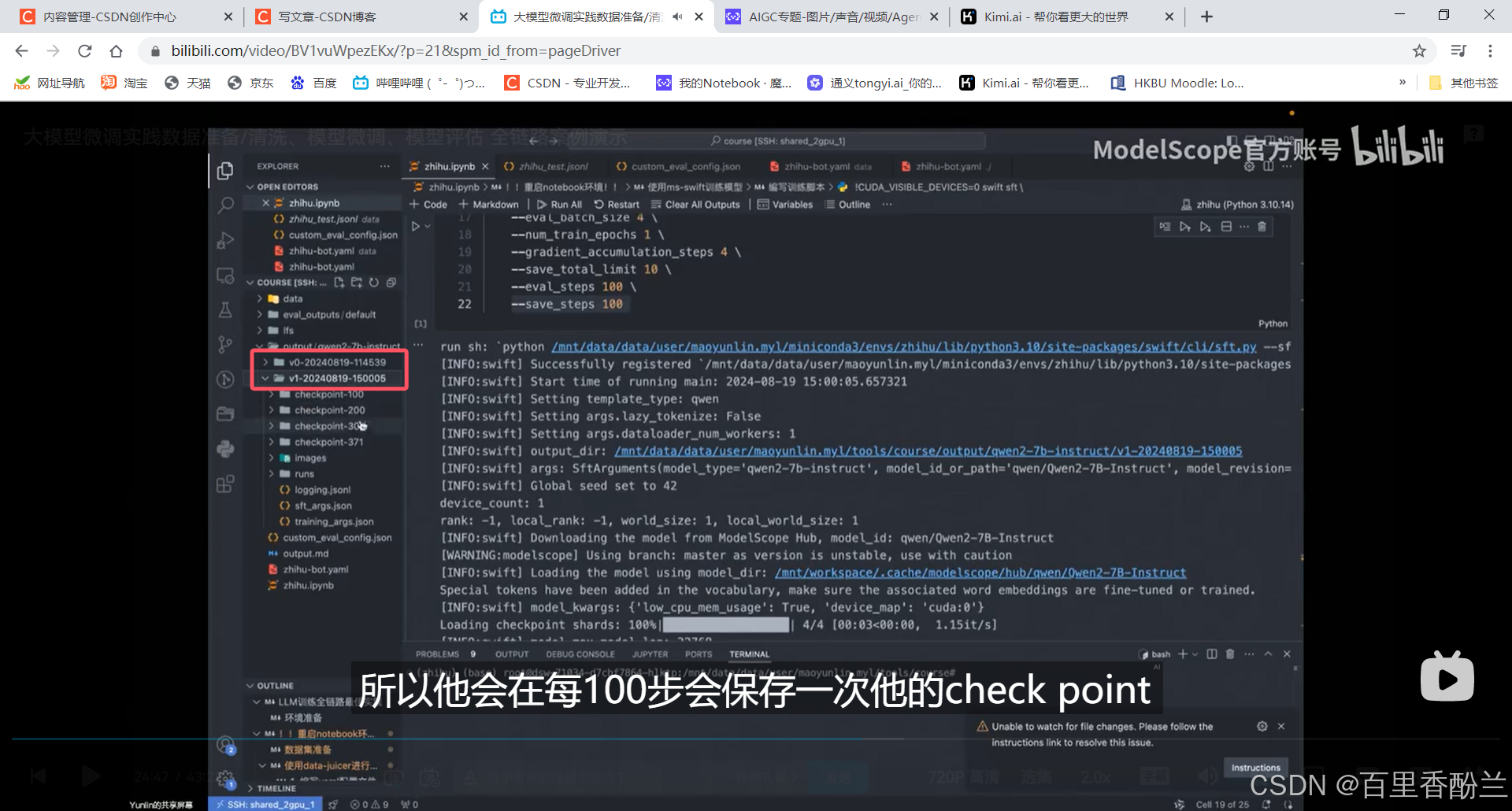
每次训练都会单开文件夹:每100步保存一次checkpoint
评论的内容太分散,不集中在某个领域,模型很难训练,loss很难稳定下降。所以这种评论类型的数据不能一次喂太多。
用少量评论数据外加一些通用数据集才能保持模型能力。
evalscope评估模型:我之前AIGC方向有个评估代码是用来给生成的图像们打分的,但我看不出来是不是这个库。
老师用了两种方式对模型进行评估:
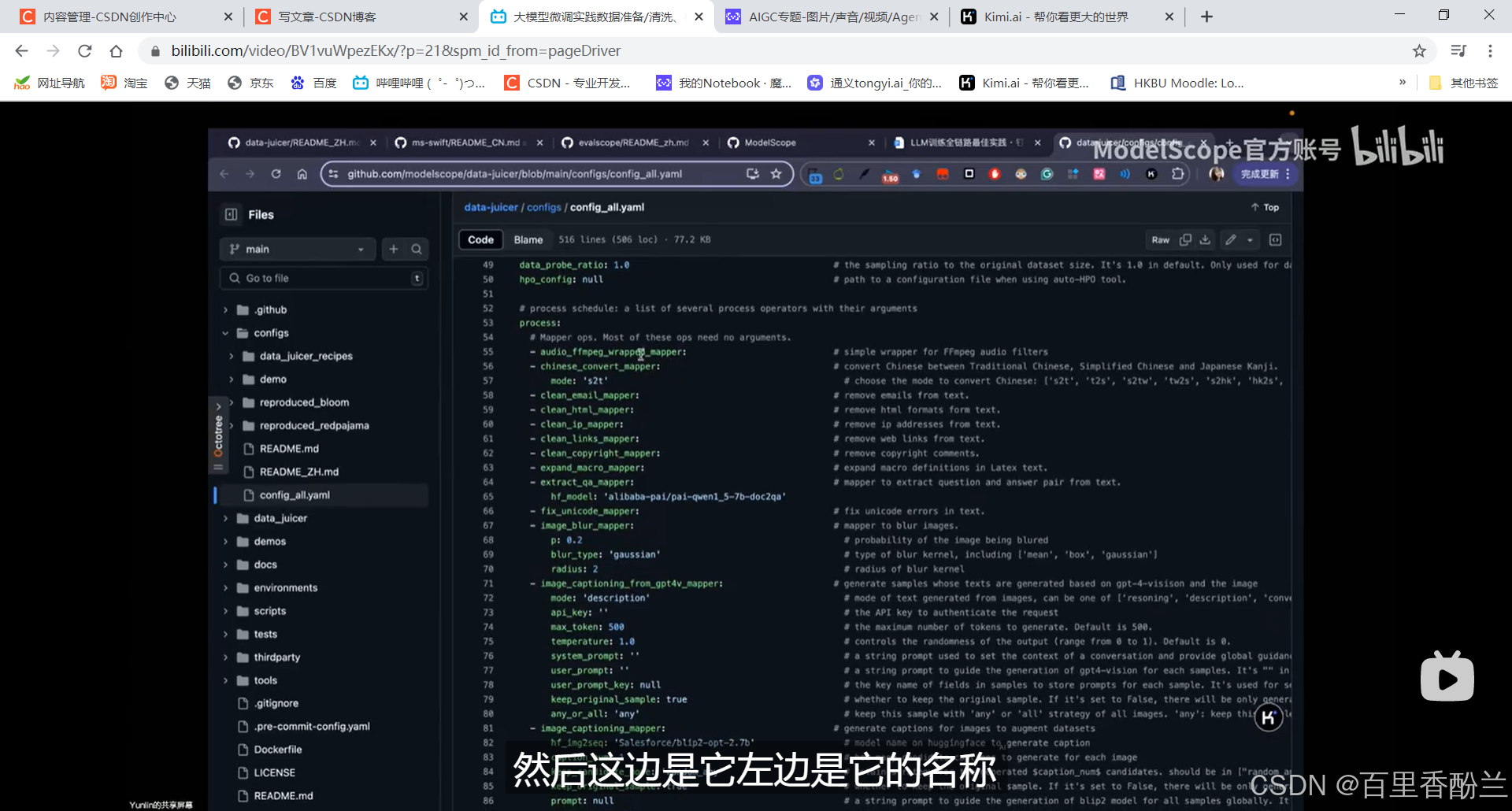

1.自定数据集,比较客观。
创建数据集的时候就为评估的要求做好了准备和配合。
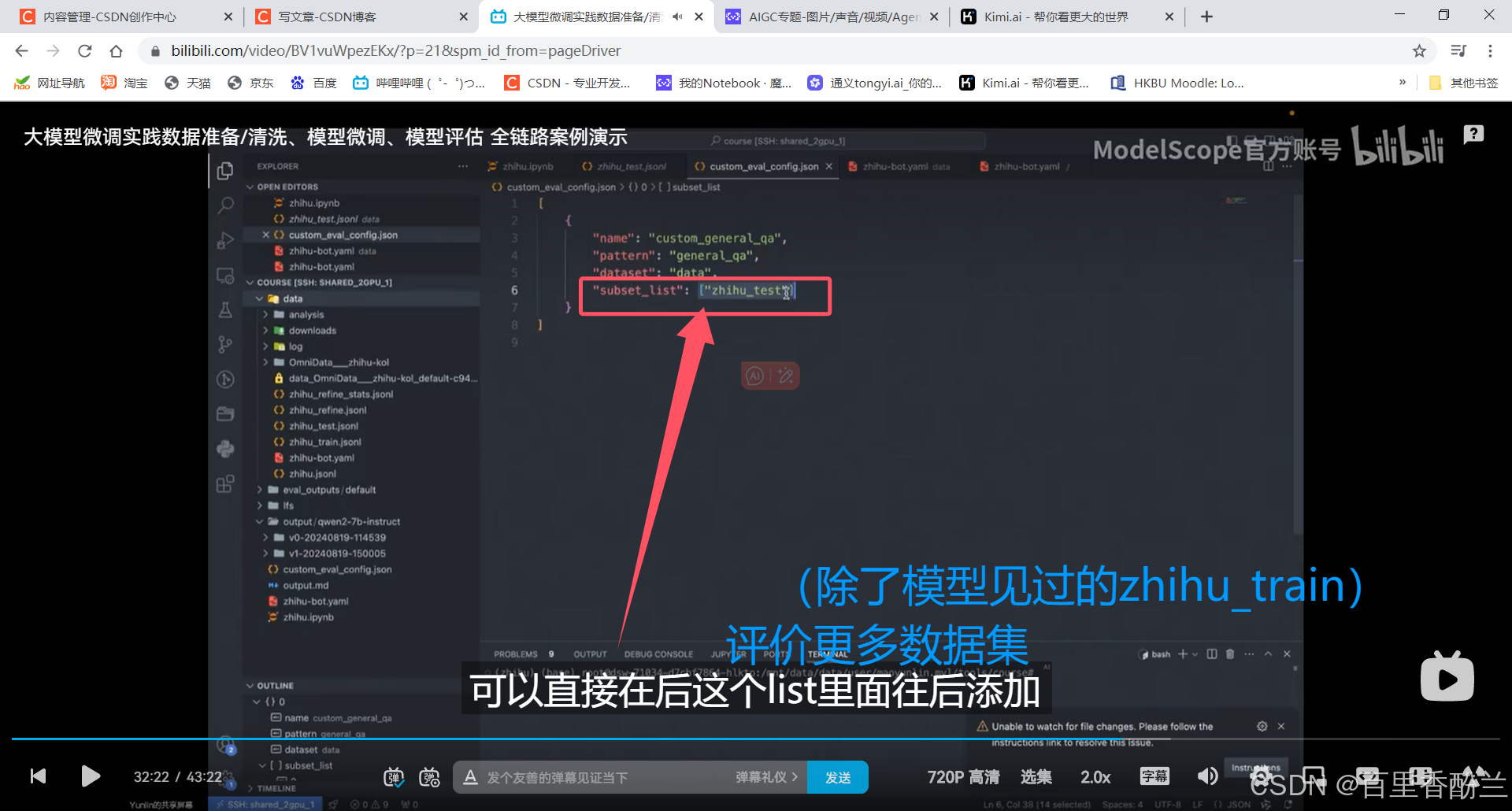
人工写的JSON格式的评估配置文件:
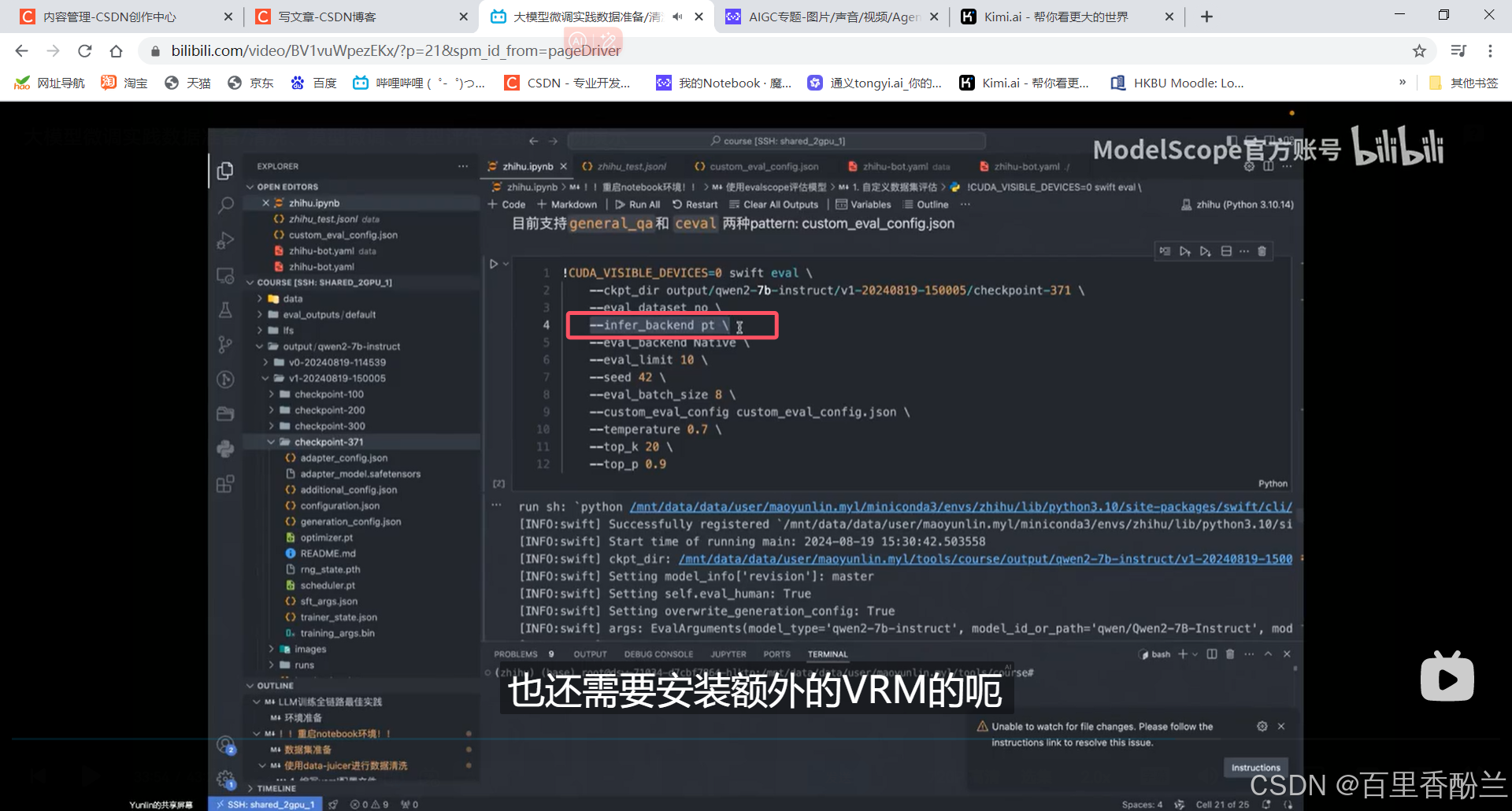
想用VRM推理可以额外装依赖,一般来说比pt要快:
运行即可自动评估输出结果:


2.人工去观察模型的生成。
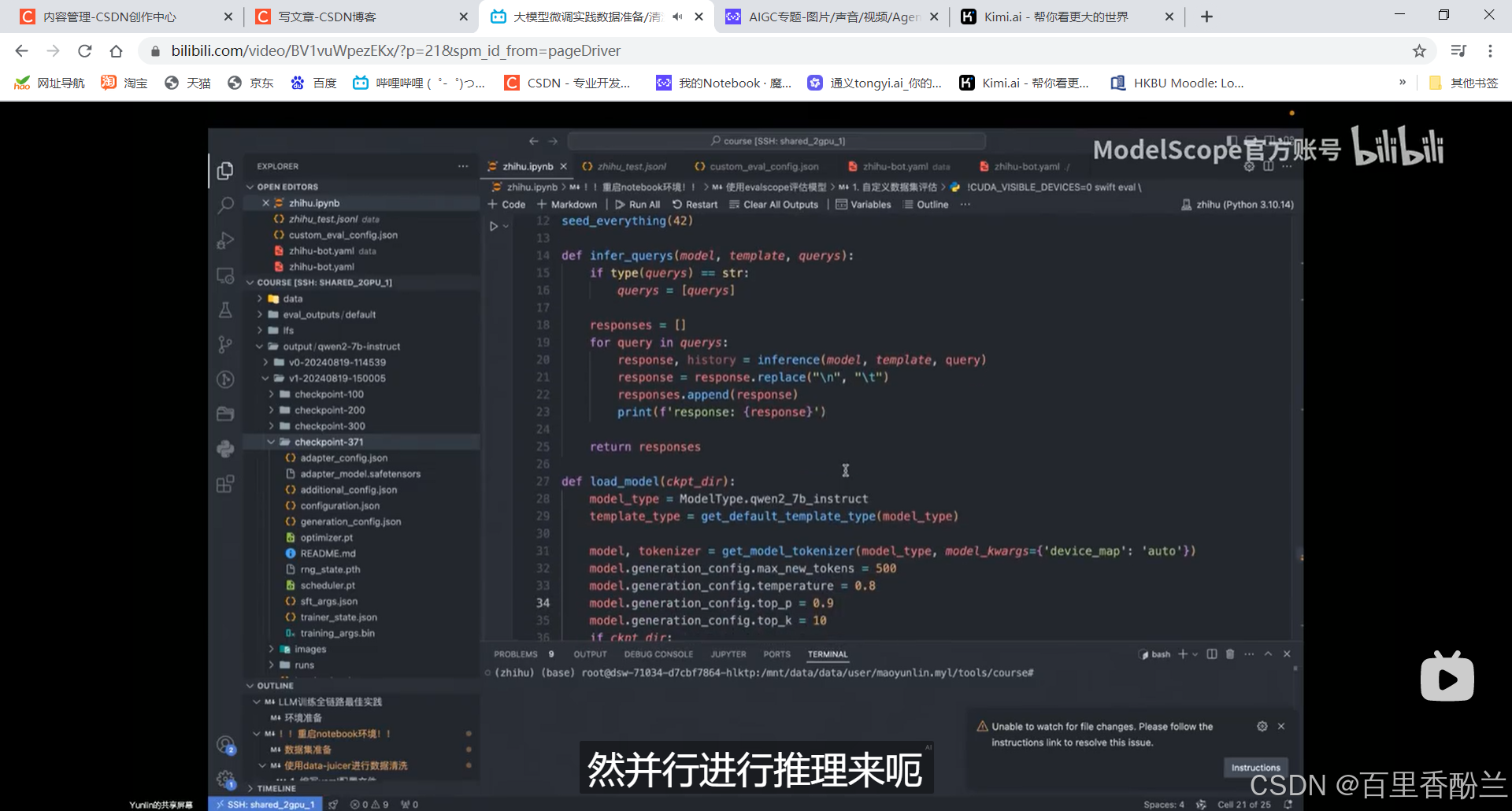
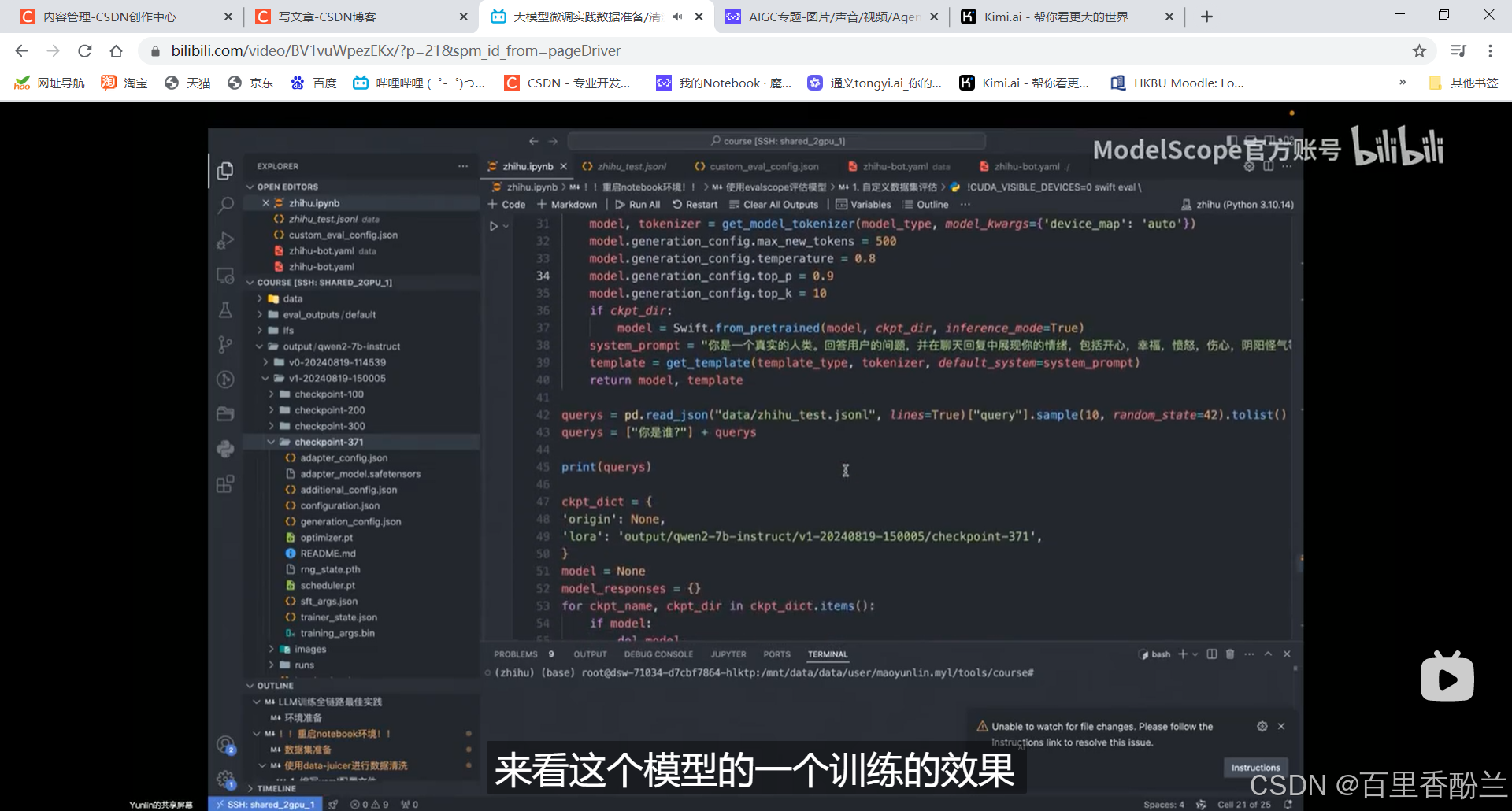
使用swift手写脚本加载框架进行推理(好吧我最开始还以为是人眼目测呢,是我草率了……)
这些前面的是最初始的结果,回答得非常AI:
后半截是调教以后的,效果好多了:
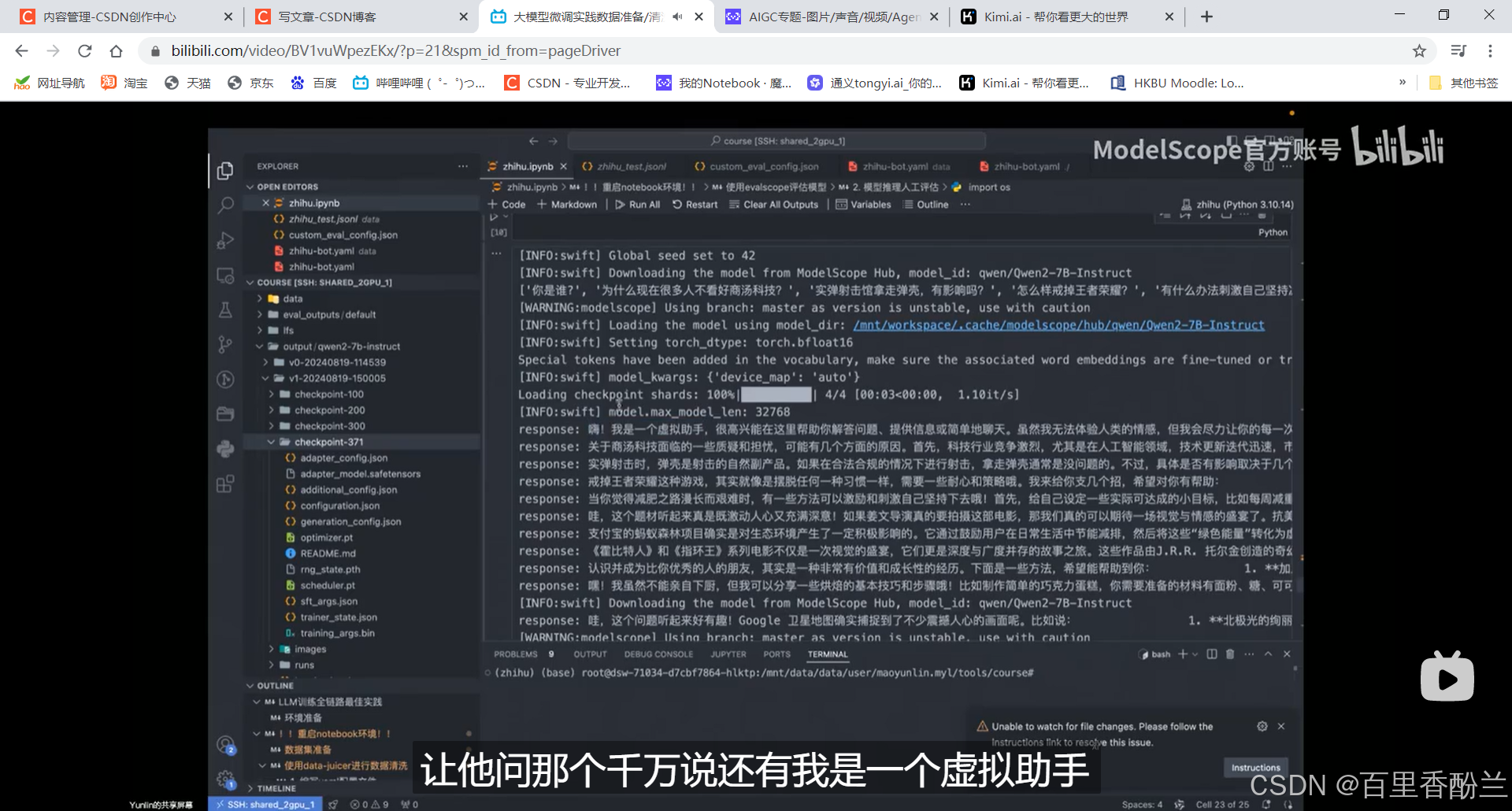
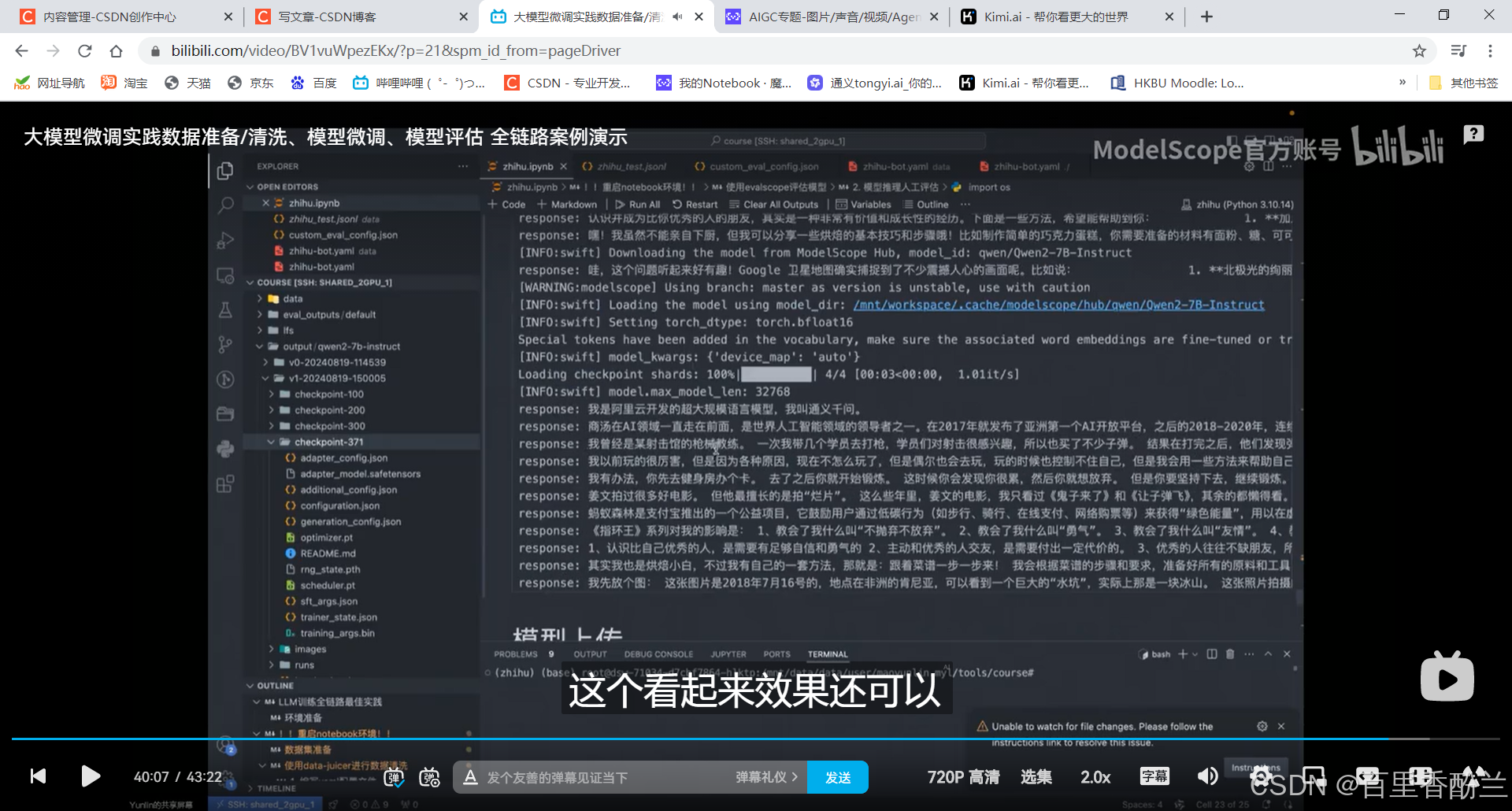
模型出现重复生成答案怎么办?
其实这个指环王的问题我感觉还不算重复,我之前测试别人的模型的时候,让模型规划一条搭地铁的线路,结果这位仁兄陷入了死循环,在几个站里面绕不出去了……吐了满满一屏幕的循环线。
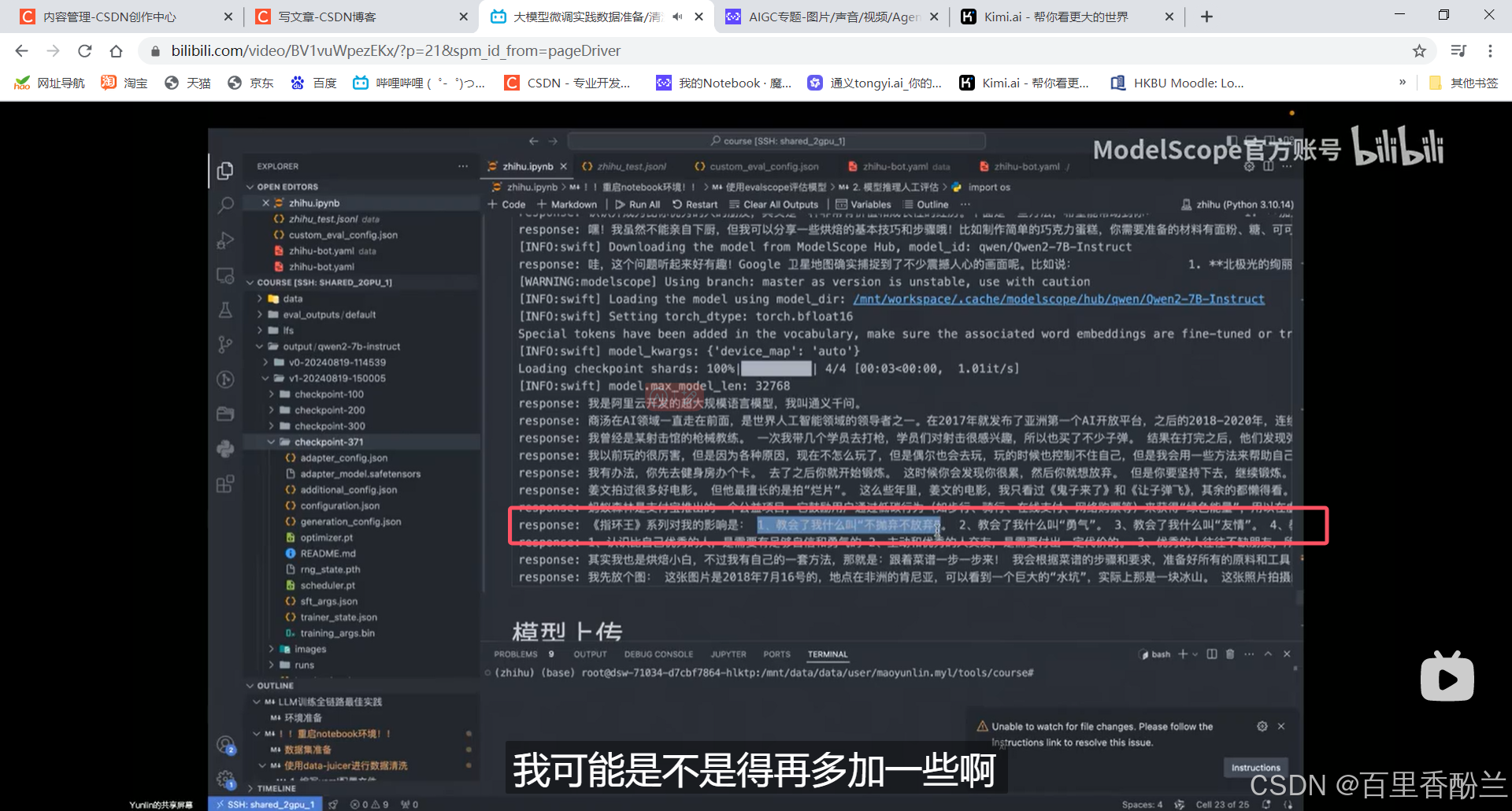
老师建议的解决方案:
1.从训练方面解决,改变数据集混合的策略。(原始训练数据太差劲,通用数据太少……知乎这个应该就是内容太分散了)
2.加大模型生成时候的温度系数,让模型跳出它一直选择的高频文本,增加生成的随机性,避免重复。
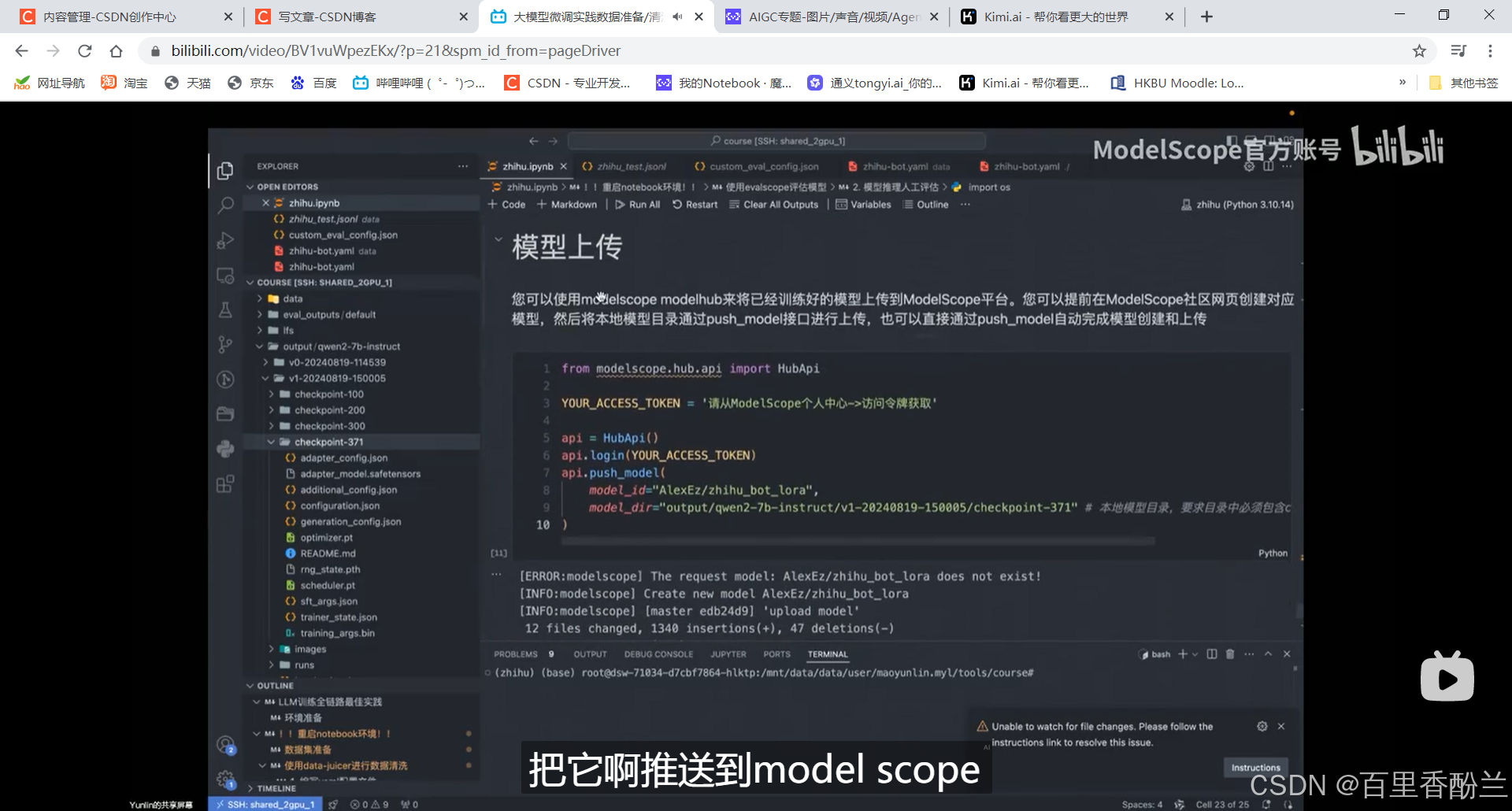
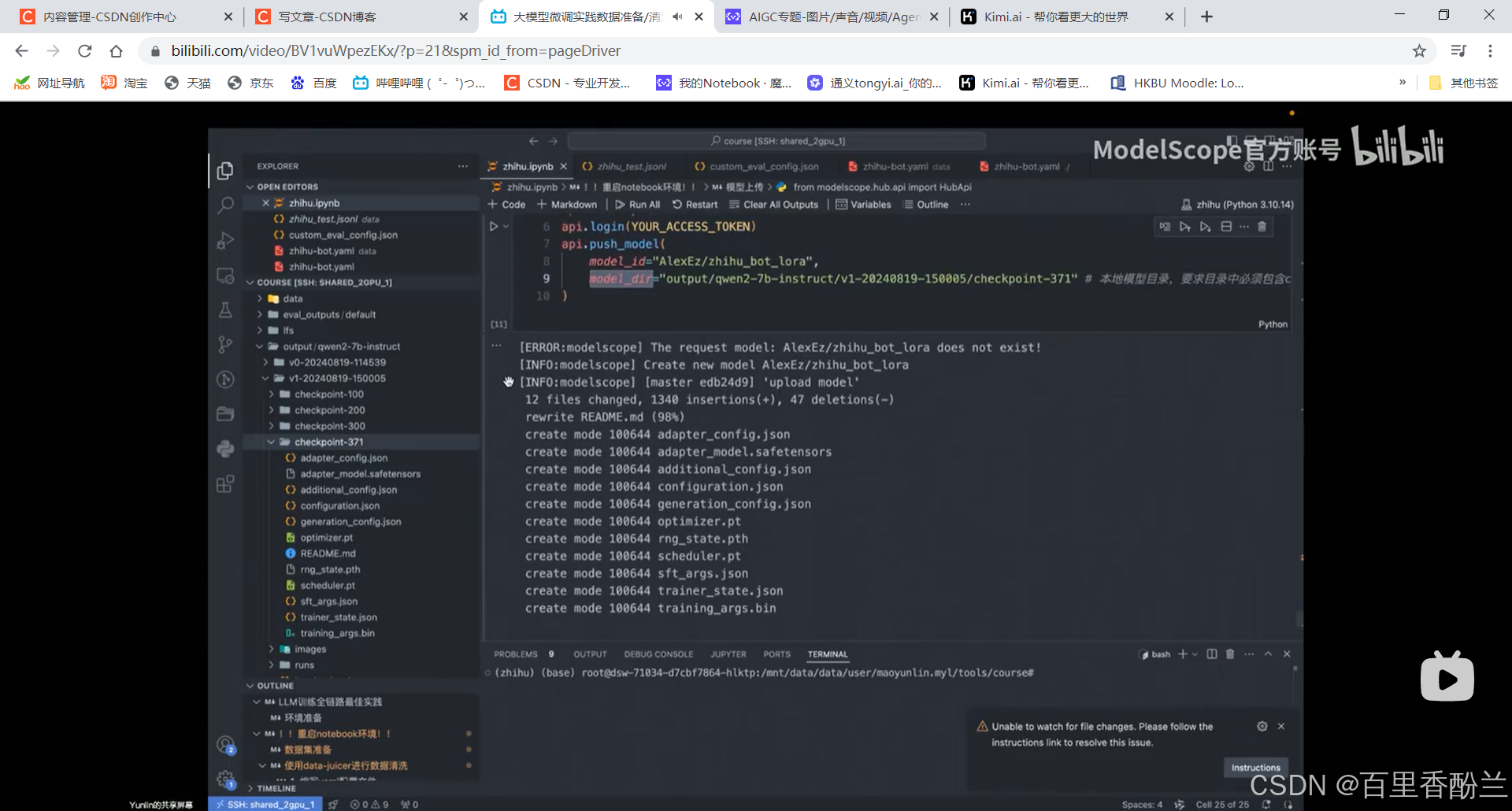
训练完成,模型上传,推到ModelScope:
model_id一般是两部分组成:“用户名/模型名称”。
会自动创建仓库把所有文件同步上去:
到此这个系列的网课终于全部过完了一轮,完结撒花!!!!