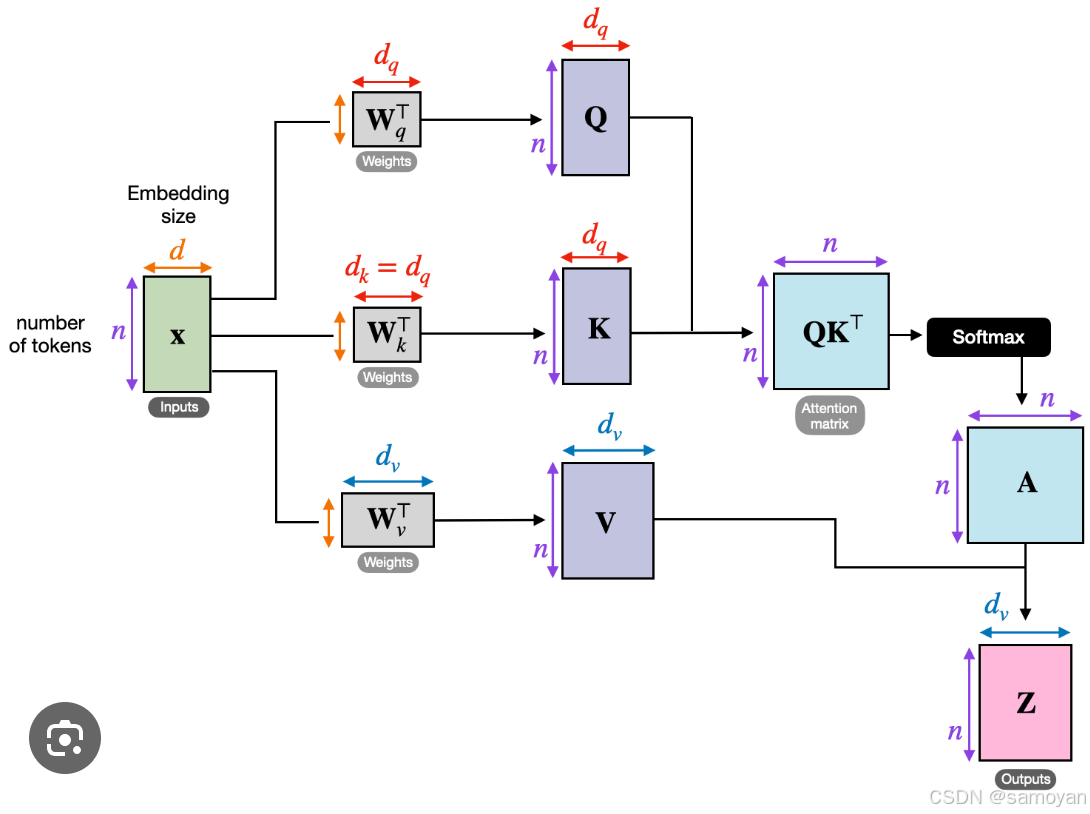
Self-Attention机制的原理
Self-Attention机制的核心思想是通过计算输入序列中每个元素与其他元素的相关性来生成一个加权和。这个过程通常分为以下几个步骤:
-
输入表示
假设输入序列为 X = [ x 1 , x 2 , . . . , x n ] X = [x_1, x_2, ..., x_n] X=[x1,x2,...,xn],其中 x i x_i xi是输入序列中的第 i i i个元素,通常是一个向量。 -
线性变换
对于每个输入元素$x_i $,通过三个不同的线性变换得到查询(Query)、键(Key)和值(Value)向量:Q i = W Q x i , K i = W K x i , V i = W V x i Q_i = W_Q x_i, \quad K_i = W_K x_i, \quad V_i = W_V x_i Qi=WQxi,Ki=WKxi,Vi=WVxi
其中 W Q W_Q WQ、 W K W_K WK、 W V W_V WV是可训练的权重矩阵。
-
计算注意力得分
注意力得分 e i j e_{ij} eij是通过查询向量 Q i Q_i Qi和键向量 K j K_j Kj的点积来计算的:e i j = Q i ⋅ K j T e_{ij} = Q_i \cdot K_j^T eij=Qi⋅KjT
-
归一化注意力得分
使用Softmax函数将注意力得分归一化,得到权重系数:α i j = exp ( e i j ) ∑ k = 1 n exp ( e i k ) \alpha_{ij} = \frac{\exp(e_{ij})}{\sum_{k=1}^{n} \exp(e_{ik})} αij=∑k=1nexp(eik)exp(eij)
-
加权求和
使用归一化的注意力权重对值向量进行加权求和,得到输出向量:z i = ∑ j = 1 n α i j V j z_i = \sum_{j=1}^{n} \alpha_{ij} V_j zi=j=1∑nαijVj
维度变化解释
- 输入
values,keys,query的形状为(N, seq_len, embed_size),其中N是批次大小,seq_len是序列长度,embed_size是嵌入维度。 - 线性变换后,
values,keys,queries的形状变为(N, seq_len, heads, head_dim),其中head_dim = embed_size // heads。 energy的形状为(N, heads, query_len, key_len),通过queries和keys的点积计算得到。attention的形状为(N, heads, query_len, key_len),通过Softmax归一化注意力得分。out的形状为(N, query_len, heads * head_dim),通过对values和attention的加权求和并重新排列维度得到。- 最终输出
out的形状为(N, query_len, embed_size),通过一个线性变换恢复到原始的嵌入维度。
代码示例
import torch
import numpy as np
from torch.nn.functional import softmax
def preData():
# 输入数据
x = [[1, 0, 1, 0], # 输入1
[0, 2, 0, 2], # 输入2
[1, 1, 1, 1]] # 输入3
x = torch.tensor(x, dtype=torch.float32) # (3, 4)
# 定义权重矩阵
w_key = [[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0]]
w_query = [[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1]]
w_value = [[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0]]
w_key = torch.tensor(w_key, dtype=torch.float32) # (4, 3)
w_query = torch.tensor(w_query, dtype=torch.float32) # (4, 3)
w_value = torch.tensor(w_value, dtype=torch.float32) # (4, 3)
# 计算 Key, Query, Value
k = torch.tensor(np.dot(x, w_key), dtype=torch.float32) # (3, 3)
q = torch.tensor(np.dot(x, w_query), dtype=torch.float32) # (3, 3)
v = torch.tensor(np.dot(x, w_value), dtype=torch.float32) # (3, 3)
# 计算注意力得分
att_score = torch.tensor(np.dot(q, k.T)) # (3, 3)
print("Attention Scores:\n", att_score)
# 计算Softmax后的注意力得分
att_score_softmax = softmax(att_score, dim=-1) # (3, 3)
print("Softmax Attention Scores:\n", att_score_softmax)
print("Shapes - att_score_softmax:", att_score_softmax.shape, "v:", v.shape)
# 计算加权值
weight_values = v[:, None] * att_score_softmax[:, :, None] # (3, 3, 3)
outputs = weight_values.sum(dim=0) # (3, 3)
return outputs
print(preData())