本文记录自己在自学C++过程中不同于C的一些知识点,适合于有C语言基础的同学阅读。如果纰漏,欢迎回复指正
目录
第一部分 基础知识
一、HelloWorld与命名空间
#include <iostream>
using namespace::std;
cout << "Hello World!" << endl;
namespace One {
int M = 200;
int inf = 10;
}
namespace Two {
int x;
int inf = 100;
}
int main(int argc, char *argv[])
{
using Two::x;
cout << x << endl;
cout << One:inf << endl;
}
二、引用和引用参数
引用是别名,声明时必须初始化。实际代码中多用作函数的形参,通过将引用变量用作参数,函数将使用原始数据,而不是其副本。
2.1引用的定义
int intOne;
int& rInt = intOne;
intOne = 5;
cout << rInt << endl; // 5
rInt = 7; //修改引用的值,也就是修改intOne
cout << intOne << endl; // 7
2.2 将引用用作函数参数
void swap(int &x, int &y) {
int tmp;
tmp = x;
x = y;
y = tmp;
}
//调用:
int a = 10;
int b = 2;
swap(a, b);
2.3 将引用用于类对象
double price_count(const Pen &p1, const Pen &p2); //形参使用指向类对象的引用
result = price_count(pen1, pen2); //调用函数时传入类对象即可,而不是指向类对象的引用
price_count函数的两个形参都是const引用,可以接受const和非const Pen,函数内不能对实参进行修改,只能读取。
2.4 引用和继承
基类引用可以指向派生类对象,而无需进行强制类型转换。实际结果是:可以定义一个接受基类引用作为参数的函数,调用该函数时,可以将基类对象作为参数,也可以将派生类对象作为参数。
2.5 何时使用引用参数
一般而言,传递类对象参数的标准方式就是按引用传递。
数组-------->只能使用指针
结构-------->可以使用指针、引用
类对象------>使用引用
2.6 引用和指针的区别
- 指针是变量,可以重新赋值指向别的变量(地址)
- 引用在定义时必须进行初始化,并且不能再关联其它变量。
- 有空的指针,没有空的引用:(void引用是不合法的)
void &a = 3; //void本质上不是类型,没有void的引用。
三、内联函数
在定义和声明一个函数时加上inline,inline函数应该尽可能简短,且不要做复杂的操作,如浮点运算等。
四、默认参数的函数
4.1 默认参数的使用形式
只需在声明函数时使用如下的形式来指定默认值(定义时不用指定)。
int add(int x = 5, int y = 6, int z = 3);
int main()
{
add(); //三个参数都使用默认值,结果是14
add(1,5); //第三个参数使用默认值
add(1,2,3); //不适用默认值
}
4.2 默认参数的顺序规定
默认参数从右到左逐渐定义;调用函数时,也只能从右到左匹配默认参数(即从左到右使用自定义的值):
void func(int a=1, int b, int c=3, int d=4); //error
void func(int a, int b=2, int c=3, int d=4); //ok
对于第二个函数声明,其调用的方法规定为:
func(10,20); //ok: c、d使用默认值
func(10,20,30,40); //ok: 不适用默认值
func(); //error: a没有默认值,必须给定一个值
func(10,20,,40); //error: 只能从右到左匹配默认参数
五、函数重载(多态)
5.1 函数重载的定义
两个及以上的函数,函数名相同,形参的数目或类型不同,编译器根据参数的类型和个数自动匹配并调用,即函数重载。
int abs(int);
long abs(long);
double abs(double);
注意:
- 编译器将类型引用和类型本身是为同一特征标,所以下面两个函数原型不能重载:
double cube(double x);
double cube(double &x);
- 形参数目和类型相同,只有函数类型不同时,则不可以对函数进行重载。
5.2 extern "C"
extern "C"的主要作用就是为了能够正确实现C++代码调用其他C语言代码。加上extern "C"后,会指示编译器这部分代码按C语言的进行编译,而不是C++的。
由于C++支持函数重载,因此编译器编译函数的过程中会将函数的参数类型也加到编译后的代码中,而不仅仅是函数名;而C语言并不支持函数重载,因此编译C语言代码的函数时不会带上函数的参数类型,一般只包括函数名。
#ifdef __cplusplus
extern "C" {
#endif
int foo(char, int);
#ifdef __cplusplus
}
#endif
六、函数模板和类模板
在 C++ 中,模板分为函数模板和类模板两种。函数模板是用于生成函数的,类模板则是用于生成类的。
6.1 函数模板
函数模板使用泛型来定义函数,其中的泛型可以用具体的类型(如int或double)替换,因此有时也称为通用编程。


6.1.1 一个类型参数的函数模板
template<typename T>
void Swap(T &x, T &y)
{
T tmp = x;
x = y;
y = tmp;
}
typename可以用class替换。
int main(int argc, char *argv[])
{
//函数模板
int a = -10;
int b = 23;
double c = -12.34;
double d = 56.789;
cout << "Swap(a, b) = " << Swap(a, b) << endl;
cout << "Swap(c, d) = " << Swap(c, d) << endl;
}
编译器在编译到Swap(a, b);时找不到函数 Swap 的定义,但是发现实参a、b都是int类型的,用int类型替换Swap模板中的T能得到下面的模板函数:
void Swap(int &x, int &y)
{
int tmp = x;
x = y;
y = tmp;
}
同理,编译器在编译到Swap(c, d)时会生成模板函数:
void Swap(double &x, double &y)
{
double tmp = x;
x = y;
y = tmp;
}
6.1.2 多个类型参数的函数模板
函数模板也可以有多个类型的参数:
template<typename T1, typename T2>
T2 print(T1 arg1, T2 arg2)
{
cout << arg1 << “ ” << arg2 << endl;
return arg1;
}
6.1.3 函数模板进阶
当函数模板遇上重载和普通函数:
函数模板不允许自动类型转换,普通函数则可以;
编译器会优先选择普通函数,如果函数模板能产生更好的参数类型匹配,则选择函数模板;函数模板也可以重载。
可以通过空模板实参列表的语法限定编译器只通过模板匹配:Swap<>(a, b);
6.2 类模板

6.2.1 单个类模板
template<typename T>
class ClassModule {
public:
ClassModule(T n) {
this->num = n;
}
T getnum() {
return num;
}
private:
T num;
}
void main()
{
ClassModule<int> myclass(100); //使用类模板需要用参数列表指定具体的参数类型
cout << myclass.getnum() << endl;
return;
}
6.2.2 继承中的类模板

当子类从模板类继承时,需要让编译器指定基类的具体数据类型,即需要指定基类的参数类型:class B: public A<int>
//继承中的类模板
template<typename T>
class A {
public:
A(T n) {
this->t = n;
}
void printA() {
cout << "A:" << t << endl;
}
public:
T t;
};
class B : public A<int> {
public:
B(int m) : A(m){}; //使用基类的构造函数
void printB() {
cout << "B:" << t << endl;
}
};
int main(int argc, char *argv[])
{
B b(88);
b.printA(); //88
b.printB(); //88
return 0;
}
七、类、对象、封装
7.1 概念
类是创建对象的模板
类是对象的定义,对象是类的实例化,对象的产生离不开类这个模板
对象的三大特性:行为、状态、标识
7.2 定义一个类
class Car {
public:
void run() { //公有函数
...
}
void stop() {
...
}
protected:
private:
int price; //私有数据成员
int carNum;
};
在类中定义成员函数:
类中定义的成员函数一般为内联函数,即使没有明确用inline标识
类定义通常放在头文件中
在类之后定义成员函数:
将类定义和其成员函数定义分开
类定义(头文件)是类的外部接口,类的成员函数定义是类的内部实现
7.3 成员函数
7.3.1 成员函数的定义和使用:
类成员函数的重载:
类成员函数可以像普通函数一样重载,但不同类的同名函数不算重载
类成员函数的默认参数:
类成员函数可以像普通函数一样使用默认参数
成员函数一般在.cpp中实现,在对象定义时只提供一个接口供外部使用:
car.h:
class Car {
public:
void run();
private:
int price;
int carnum;
}
-------------------------------------------------------------------------
car.cpp:
void Car::run() {
cout << "Car run..." << endl;
}
-------------------------------------------------------------------------
main.cpp:
int main() {
Car a;
a.run();
}
7.3.2 this指针
等于对象的地址
7.3.3 对象做参数
7.4 封装
OOP三大特性:封装、继承、多台
定义类,定义其数据成员、成员函数的过程陈为封装。
类的访问修饰符:
public: 类本身(即成员函数)、子类、对象
protected: 类本身(即成员函数)、子类
private: 类本身(即成员函数)
八、构造函数
完成对象初始化的函数,是特殊的成员函数。
构造函数名和类名相同,且无返回类型(不是void型)。
class Car {
public:
Car(int pri=100000, int num=0);
int setProperty(int pri, int num);
private:
int price;
int carnum;
}
Car::Car() {
setProperty(int pri, int num);
}
对于一个类,如果定义了带参数的构造函数,并且不是所有的形参都有默认值,那么就必须定义一个不带参数的构造函数,否则当调用不带参数的构造函数时会报错。例如:
class Person {
public:
Person(const string & name, const int age) : m_name(name), m_age(age);
private:
string m_name;
int m_age;
}
类定义如上,
1、如果则使用Person person01;创建对象时会报错,必须定义一个不带参数的构造函数:Person(){ };
2、如果构造函数第一个形参name有默认值,则使用Person person01;创建对象时不会报错,此时会调用带参数的构造函数。并且,此时也不能再定义一个不带参数的构造函数,否则当使用Person person01;创建对象时,编译器会同时匹配上两个构造函数,会报类似“warning C4520: “Person”: 指定了多个默认构造函数”这样的错误。
九、析构函数
完成释放对象空间的函数,是特殊的成员函数。
析构函数名为类名前加“~”,且无形参、无返回类型(不是void型)。
析构函数不能随意调用,也不能重载,只是在类对象生命周期结束的时候,由系统自动调用。
析构函数都是虚函数,基类的析构器应写成虚函数,否则析构器只会调用基类的析构器。
十、标准库类型string
10.1 字符串对象的初始化
| 初始化方法 | 说明 |
| string s1; | 默认构造函数,s1为空字符串 |
| string s2(s1); | 将s2初始化为s1的一个副本 |
| string s3("value"); | 将s3初始化为字符串的副本 |
| string s4(n, 'c'); | 将s4初始化为n个c的字符串 |
| string s5 = "abcd"; |
|
| string s6 = {"abcd"}; |
|
10.2 字符串操作
| string操作 | 说明 |
| s.empty() | 字符串为空则返回true,否则返回false |
| s.size() | 返回长度 |
| s[n] | 返回第n个字符 |
| s1+s2 | 两个字符串连接 |
| s1=s2 | s1的内容替换为s2 |
| s1==s2 | 相等则返回ture,否则返回false |
| !=,<,<=,>,>= | 保持这些操作符惯有的含义 |
十一、static数据成员和成员函数
static修饰类中成员,表示类的共享数据
11.1 static数据成员
static数据成员不像普通的类数据成员,static类数据成员独立于一切类对象。static类数据成员是与类关联的,但不与该类定义的对象有任何关系。即static不会像普通类数据成员一样每一个类对象都有一份,全部类对象是共享一个static类成员的。static 成员变量不占用对象的内存,而是在所有对象之外开辟内存,即使不创建对象也可以访问。
例如A类对象修改了static成员为1,那么B对象对应的static类对象成员的值也会是1。
使用static成员变量必须在类外进行初始化。静态成员变量在初始化时不能再加 static,但必须要有数据类型。被 private、protected、public 修饰的静态成员变量都可以用这种方式初始化:
int Martain::martain_count = 2;
使用static数据成员的好处:
用static修饰的成员变量在对象中是不占内存的,因为他不是跟对象一起在堆或者栈中生成,用static修饰的变量在静态存储区生成的。所以用static修饰一方面的好处是可以节省对象的内存空间。如同你创建100个Person对象,而这100个对象都有共有的一个变量,例如叫国籍变量,就是Person对象的国籍都是相同的。
那如果国籍变量用static修饰的话,即使有100个Person对象,也不会创建100个国籍变量,只需要有一个static修饰的国籍变量就可以了。这100个对象要用的时候,就会去调用static修饰的国籍变量。否则有100个Person变量,就会创建100个国籍变量,在国籍变量都是相同的情况下,就等于浪费空间了。
11.2 static成员函数
由于static修饰的类成员属于类,不属于对象,因此static类成员函数是没有this指针的(this指针是指向本对象的指针)。正因为没有this指针,所以static类成员函数不能访问非static的类成员,只能访问 static修饰的静态类成员。
普通成员函数可以通过对象名进行调用,而static成员函数必须通过类名进行调用(因为它与类关联):
class Martain {
plubic:
int func1();
static int func2();
}
main(){
Martain m1;
m1.func1();
Martain::func2();
}
注:本节其它内容见测试代码"004-static"
十二、动态内存分配
new/delete是运算符(关键字),malloc/free是函数调用。
int *p1 = new int;
int *p2 = new int[10]; //分配10个int型的内存空间
Student *pstu1 = new Student; //分配一个Student类的内存空间
Student *pstu2 = new Student(); //这两种用法都是可以的
delete p1;
delete[] p2;
十三、拷贝构造函数
Student(const Student& s); //拷贝构造函数的固定形式
13.1 调用时机
1、定义一个新对象并用一个同类型的对象进行初始化时
2、对象作为实参或函数返回对象时
实例代码:
Student s1("Jame");
printf("&s1 = %x\n", &s1);
//调用时机1:用一个对象初始化另一个对象
Student s2 = s1;
printf("&s2 = %x\n", &s2);
//调用时机2:对象作为实参或函数返回对象
foo(s1);
Student s4 = zoo();
printf("&s4 = %x\n", &s4);
13.2 浅拷贝和深拷贝
浅拷贝
如果不定义拷贝构造函数,则编译器会使用默认拷贝构造函数,是浅拷贝,浅拷贝过程如下:
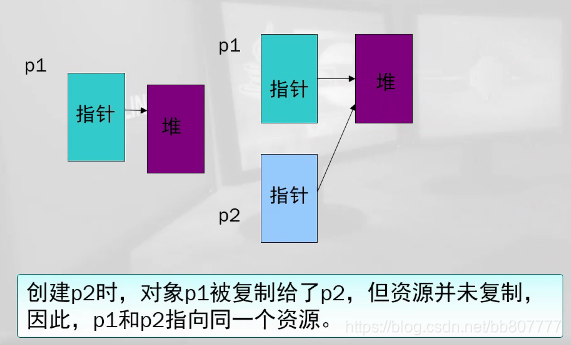
浅拷贝遇到含有指针的对象类型时很容易出问题,因为浅拷贝出来的对象和原对象的指针都指向同一个内存空间,当其中一个对象被析构后,另一个对象再使用时就会发生内存溢出。
深拷贝
深拷贝遇到指针时,会重新分配一块空间,因此不会有问题。
13.3 什么时候需要定义拷贝构造函数
1、类数据成员有指针
2、类数据成员管理资源(如打开一个文件)
3、一个类需要析构函数释放资源时,那它也需要一个拷贝构造函数
某些情况下想禁止调用拷贝构造函数、赋值运算符,那么可以将这两个函数放到private中。如下:
class Uncopyable {
private:
Uncopyable(const Uncopyable &); //阻止拷贝构造
Uncopyable &operator=(const Uncopyable &); //阻止赋值运算符
};
十四、const关键字
14.1 初始化列表
构造函数的初始化列表
初始化 const 成员变量的唯一方法就是使用初始化列表
14.2 const 和指针
const 也可以和指针变量一起使用,这样可以限制指针变量本身,也可以限制指针指向的数据。const 和指针一起使用会有几种不同的顺序,如下所示:
1. const int *p1;
2. int const *p2;
3. int * const p3;
在最后一种情况下,指针是只读的,也就是 p3 本身的值不能被修改;在前面两种情况下,指针所指向的数据是只读的,也就是 p1、p2 本身的值可以修改(指向不同的数据),但它们指向的数据不能被修改。
当然,指针本身和它指向的数据都有可能是只读的,下面的两种写法能够做到这一点:
1. const int * const p4;
2. int const * const p5;
const 和指针结合的写法——记忆:如果变量名和*号被分隔开,则const修饰的是[变量名](即指针),指针只读;如果没有被分割开,则修饰的是[*变量名](即指针指向的变量),也就是指针指向的变量只读。
14.3 const成员变量
初始化const成员变量的唯一方法是使用初始化列表(不能在构造函数的函数体中初始化)。
class Demo {
private:
const int m_len;
int *m_arr;
public:
Demo(int len) : m_len(len) { //通过初始化列表初始化const成员变量
m_arr = new int[len];
};
}
class Demo {
private:
const int m_len;
int *m_arr;
public:
Demo(int len){};
}
Demo:Demo(int len) {
m_len = len; //错误:不能在函数体内初始化
m_arr = new int[len];
}
14.4 const成员函数(常成员函数)
const 成员函数可以使用类中的所有成员变量,但是不能修改它们的值,这种措施主要还是为了保护数据而设置的。const 成员函数也称为常成员函数。
常成员函数需要在声明和定义的时候在函数头部的结尾加上 const 关键字
14.5 const对象(常对象)
在 C++ 中,const 也可以用来修饰对象,称为常对象。一旦将对象定义为常对象之后,就只能调用类的 const 成员(包括 const 成员变量和 const 成员函数)了。
定义常对象的语法和定义常量的语法类似:
const classnameobject(params);
classnameconst object(params);
两种方式定义出来的对象都是常对象。
当然也可以定义 const 指针:
const classname *p = new classname (params);
classname const *p = new classname (params);
classname为类名,object为对象名,params为实参列表,p为指针名。
十五、友元函数和友元类
15.1 友元函数
待补充
15.2 友元类
待补充
15.3 设计模式——单例设计模式
待补充
15.4 Valgrind内存检测工具
待补充
十六、运算符重载
运算符函数的格式:operator op(argument-list);
运算符重载可以选择使用成员函数或非成员函数来实现。
16.1 成员函数版本
Time operator+(const Time & t) const;
16.2 非成员函数版本
非成员函数应是友元函数,这样才可以直接访问类的私有数据。
friend Time operator+(const Time & t1, const Time & t2);注意:友元函数在定义时不要用关键字friend,在声明时采用。
16.3 运算符重载的使用方法
total = coding.operator+(fixing);
total = coding + fixing;
上述两种表示法都将调用operator+()方法。
另外,也可以这样用:
total = coding + fixing + morefixing;解释:由于+是从左向右结合的运算符,所以会先被转换成total = coding.operator+(fixing + morefixing);,然后函数参数被转换成一个函数调用,结果就是:total = coding.operator+( fixing.operator+(morefixing) );
16.4 运算符重载的限制
1、重载后的运算符必须至少有一个操作数是用户定义的类型,即不能将加法运算符重载成两个int型相加,这样限制是为了安全考虑;
2、不能违反运算符原来的句法规则,如不能修改运算符的优先级;
3、不能创建新的运算符;
4、不能重载:sizeof . .* :: ?: typeid const_cast synamic_cast reinterpret_cast static_cast;
5、大多数运算符都可以通过成员或非成员函数进行重载,但是这些运算符只能通过成员函数进行重载:= () [] ->
十七、继承
OOP三大特性
封装 继承 多态
17.1 类之间关系
is-a继承体现
has-a组合体现
17.2 继承的意义
代码重用
体现不同抽象层次
17.3 C++中继承三种方式
公有继承
私有继承
多重继承
公有继承形式:
class Teacher: public Person {
}
UML astah
父类 子类
基类 继承类
子类只能访问父类的public和protected成员,不能访问private成员。
在构造一个子类时,父类部分由父类的构造函数完成,子类的部分由子类的构造函数完成。
构造一个子类时,先构造父类,然后构造子类,析构时相反。
十八、多态
OOP三大特性:封装、继承、多态
多态:同样的方法调用而执行不同操作、运行不同代码。
LSP(里氏代换原则):子类型必须能够替换它们的基类。
18.1 虚函数与抽象类
虚函数 是在基类中使用关键字 virtual 声明的函数。在派生类中重新定义基类中定义的虚函数时,会告诉编译器不要静态链接到该函数。
虚函数是继承的,基类中声明为虚函数的函数,在子类中不可能再设置为非虚函数。
我们想要的是在程序中任意点可以根据所调用的对象类型来选择调用的函数,这种操作被称为动态链接,或后期绑定。
当一个类中含有虚函数时,这个类叫抽象类。
Class Animal {
virtual ~Animal();
virtual void makeSound();
}
扩展:
class Pet {
eat();
}
class Dog : public Pet {
eat();
}
int main() {
Pet * p = new Dog; //如果指针为Pet类型,则eat必须为虚方法,如果是Dog类型,则不需要。
p->eat();
}
p->eat()这里会调用Pet的eat方法,而不是Dog的。为了使编译器正确地链接到Dog的eat方法,需要在基类的eat()前加上Virtural保留字。
18.2 纯虚函数与接口类
您可能想要在基类中定义虚函数,以便在派生类中重新定义该函数更好地适用于对象,但是您在基类中又不能对虚函数给出有意义的实现,这个时候就会用到纯虚函数。
在虚函数后加上=0就是纯虚函数,纯虚函数没有主体。
Class Animal {
virtual ~Animal() = 0;
virtual void makeSound() = 0;
}
上面就是一个接口类,接口类不能实例化,不能生成对象实例。
必须为多态基类声明virtual析构函数,否则只会析构基类对象,不会析构子类对象。
编译时的多态性:通过重载实现
运行时的多态性:通过虚函数实现
十九、类模板
19.1
二十、STL
STL由一些集合类以及在这些数据集合上操作的算法构成,包括:容器、迭代器、算法、函数对象。
- 容器(Container):管理某类对象的集合
- 迭代器(Iterator):在对象集合上进行遍历
- 算法(Algorithm):处理集合内的元素
在C++标准中,STL包括这些头文件:<algorithm> <vector> <list> <map> <set> <memory> <functional> 等。
容器的类别:
- 序列式容器:vector、
- 关联式容器
20.1 Vector
动态数组,自动分配内存
API:push_back 、pop_back、begin、end、capacity、size
遍历方法:iterator、下标法
20.2 Iterator
迭代器是面向对象版本的指针,迭代器可以指向容器中的一个位置,用来遍历STL容器。
所有容器都提供两种迭代器:
1)Container::iterator 以读写模式遍历元素
vector<int>::iterator iter; //定义一个迭代器
*iter = 10; //ok
2)Container::const_interator 以只读模式遍历元素
vector<int>::const_iterator iter; //定义一个只读的迭代器
*iter = 10; //error
API:begin、end、
20.3 list
使用双向链表管理元素,时顺序访问的容器。
遍历方法:iterator
API:push_back、push_front、pop_back、begin、end、erase、size、sort
20.4 map
集合和映射时两种主要的非线性容器类,内部实现一般为平衡二叉树。
map是关联容器。
遍历方法:iterator
API:insert、begin、end
示例:
map<int,string> mymap;
//插入元素的方法:
mymap.insert(pair<int, string>(1,"one"));
mymap.insert(make_pair(2, "two"));
mymap.insert(map<int, string>::value_type(9, "nine"));
mymap[0] = "Zero";
//访问方法1(map的迭代器):
map<int, string>::iterator iter_map;
for (iter_map = mymap.begin(); iter_map != mymap.end(); ++iter_map)
{
cout << iter_map->first << " " << iter_map->second << endl;
}
//访问方法2(map下标):
cout << mymap[0] << endl;
二十一、设计模式
面向对象设计的第一原则:针对接口编程,而不是针对实现编程。
面向对象设计的第二原则:优先使用对象组合,而不是类继承。
继承和对象组合常一起使用。
21.1 观察者模式
观察者模式定义了对象间的一对多依赖关系,当一方的对象改变状态时,所有的依赖者都会被通知并自动被更新。被依赖的一方叫目标或主题(Subject),依赖方叫观察者(Observers)。
观察者模式也叫“发布-订阅模式”(Publish-Subscribe)。
21.2 策略模式
第二部分 进阶知识
一、重载<<操作符
operator<<()函数的原型:
std::ostream& operator<<(std::ostream &os, Score s);
第一个参数:是将要向它写入数据的那个流,以引用参数传递;
第二个参数:是要写入的数据。不用的operator<<()重载函数就是因为这个参数才相互区别的;
返回值:一般和第一个参数一样即可,返回写入的那个流。
class Score {
public:
Score(unsigned int score) : m_score(score) {};
friend std::ostream& operator<<(std::ostream & os, Score &s);
private:
unsigned int m_score;
};
std::ostream& operator<<(std::ostream & os, Score &s);
std::ostream& operator<<(std::ostream & os, Score &s)
{
os << s.m_score;
return os;
}
int main(int argc, char *argv[])
{
Score Fang(80);
cout << "Score:" << Fang << endl;
return 0;
}
二、捕获异常
2.1 基本语法
int exception_func(int num)
{
if (num == 0) {
cout << "before throw -1 " << endl;
throw -1;
cout << "after throw -1 " << endl;
}
else if (num == 1) {
throw -1.1;
}
else if (num == 2) {
throw string("a string exception");
}
else {
cout << "num = " << num << endl;
}
return num;
}
int main(int argc, char *argv[])
{
//捕获异常
try {
exception_func(2);
}
catch (int i) {
cout << "capture a exception: " << i << endl;
}
catch (double d) {
cout << "capture a exception: " << d << endl;
}
catch (string s) {
cout << "capture a exception: " << s << endl;
}
catch (...) {
cout << "capture a unknown exception. " << endl;
}
}
使用异常的原则是:应该只用来处理确实可能不正常的情况。
构造器、析构器不应该使用异常。
如果try语句块无法找到与之匹配的catch语句块,则它抛出的异常将中止程序的执行。
如果使用对象作为异常,以“值传递”方式抛出对象,以“引用传递”方式捕获对象。
2.2 函数的异常声明列表
为了增强程序的可读性和可维护性,使程序员在使用一个函数时就能看出这个函数可能会拋出哪些异常,C++ 允许在函数声明和定义时,加上它所能拋出的异常的列表,具体写法如下:
void func() throw (int, double, A, B, C);或
void func() throw (int, double, A, B, C){...}上面的写法表明 func 可能拋出 int 型、double 型以及 A、B、C 三种类型的异常。异常声明列表可以在函数声明时写,也可以在函数定义时写。如果两处都写,则两处应一致。
如果异常声明列表如下编写,则说明 func 函数不会拋出任何异常:
void func() throw ();
一个函数如果不交待能拋出哪些类型的异常,就可以拋出任何类型的异常。
函数如果拋出了其异常声明列表中没有的异常,在编译时不会引发错误,但在运行时, Dev C++ 编译出来的程序会出错;用 Visual Studio 2010 编译出来的程序则不会出错,异常声明列表不起实际作用。
2.3 C++标准异常类
C++ 标准库中有一些类代表异常,这些类都是从 exception 类派生而来的:
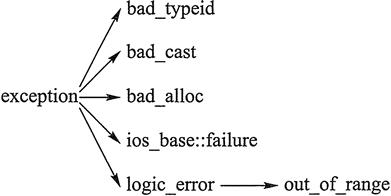
示例:
int main(int argc, char *argv[])
{
try {
vector<int> vec_int(10);
vec_int.at(11) = 1; //会抛出异常
//vec_int.assign(11, 1); //不会抛出异常
}
catch (out_of_range & e) {
cout << e.what() << endl;
}
catch (...) {
cout << "capture a unknown exception2. " << endl;
}
try {
char * p = new char[0x7fffffff];
}
catch (bad_alloc & e) {
cout << e.what() << endl;
}
catch (...) {
cout << "capture a unknown exception3. " << endl;
}
}
第三部分 其它零碎知识点
- const引用参数和临时变量
仅当函数形参为const引用时,才允许生成临时变量。分两种情况:
- 实参的类型正确,但不是左值,例如(x+0.3)就不是左值;
- 实参的类型不正确,但可以转换成正确的类型。
- 定义位于类声明中的函数将自动成为内联函数。
- 内联函数要求在每个使用它的文件中都对其进行定义,可以将内联定义放在定义类的头文件中。
- 变量作用域
- 当局部变量被定义时,系统不会对其初始化,您必须自行对其初始化。
- 在程序中,局部变量和全局变量的名称可以相同,但是在函数内,局部变量的值会覆盖全局变量的值。
- 在一个函数体内可以存在重名的变量,前提是它们的作用域不同:
#include <iostream>
using namespace std;
int main()
{
int b = 2;
{
int b = 1;
cout << "b = " << b << endl; // 1
}
cout << "b = " << b << endl; // 2
}
- 存储在静态数据区的变量会在程序刚开始运行时就完成初始化,也是唯一的一次初始化。共有两种变量存储在静态存储区:全局变量和 static 变量。
- 全局变量和和局部变量同名时,可通过域名在函数中引用到全局变量,不加域名解析则引用局部变量
#include<iostream>
using namespace std;
int a = 10;
int main()
{
int a = 20;
cout << ::a << endl; // 10
cout << a << endl; // 20
return 0;
}
- 在 VS2013 环境,对全局变量的引用以及重新赋值,直接用全局变量名会出现:count 变量不明确的问题。
在变量名前加上 :: 符号即可。
#include <iostream>
using namespace std;
int count = 10; //全局变量初始化
int main()
{
::count = 1; //全局变量重新赋值
for (;::count <= 10; ++::count)
{
cout <<"全局变量count="<< ::count << endl;
}
return 0;
}
- 变量在内存中的位置
(1)代码区(text segment):又称只读区。通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读,某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,比如字符串常量等。
(2)全局初始化数据区/静态数据区(Data Segment):用来存放程序已经初始化的全局变量,已经初始化的静态变量。位置位于可执行代码段后面,可以是不相连的。在程序运行之初就为数据段申请了空间,程序退出的时候释放空间,其生命周期是整个程序的运行时期。
(3)未初始化数据区(BSS):用来存放程序中未初始化的全局变量和静态变量,位置在数据段之后,可以不相连。其生命周期和数据段一样。(2)和(3)统称为静态存储区。
(4)栈区(Stack):又称堆栈,存放程序临时创建的局部变量,如函数的参数值、返回值、局部变量等。也就是我们函数括弧{}中定义的变量(但不包括static声明的静态变量,static意味着在数据段中存放的变量)。除此之外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且等到调用结束后,函数的返回值也会被存放回栈中。编译器自动分配释放,是向下有限扩展的。
(5)堆区(Heap):位于栈区的下面,是向上有限扩展的。用于存放进程运行中动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存的时候,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存的时候,被释放的内存从堆中被剔除(堆被缩减)。一般由程序员进行分配和释放,若不释放,在程序结束的时候,由OS负责回收。
const修饰的全局变量保存在代码区中,const修饰的局部变量保存在栈段中。