本文参考这里
1. 事件循环
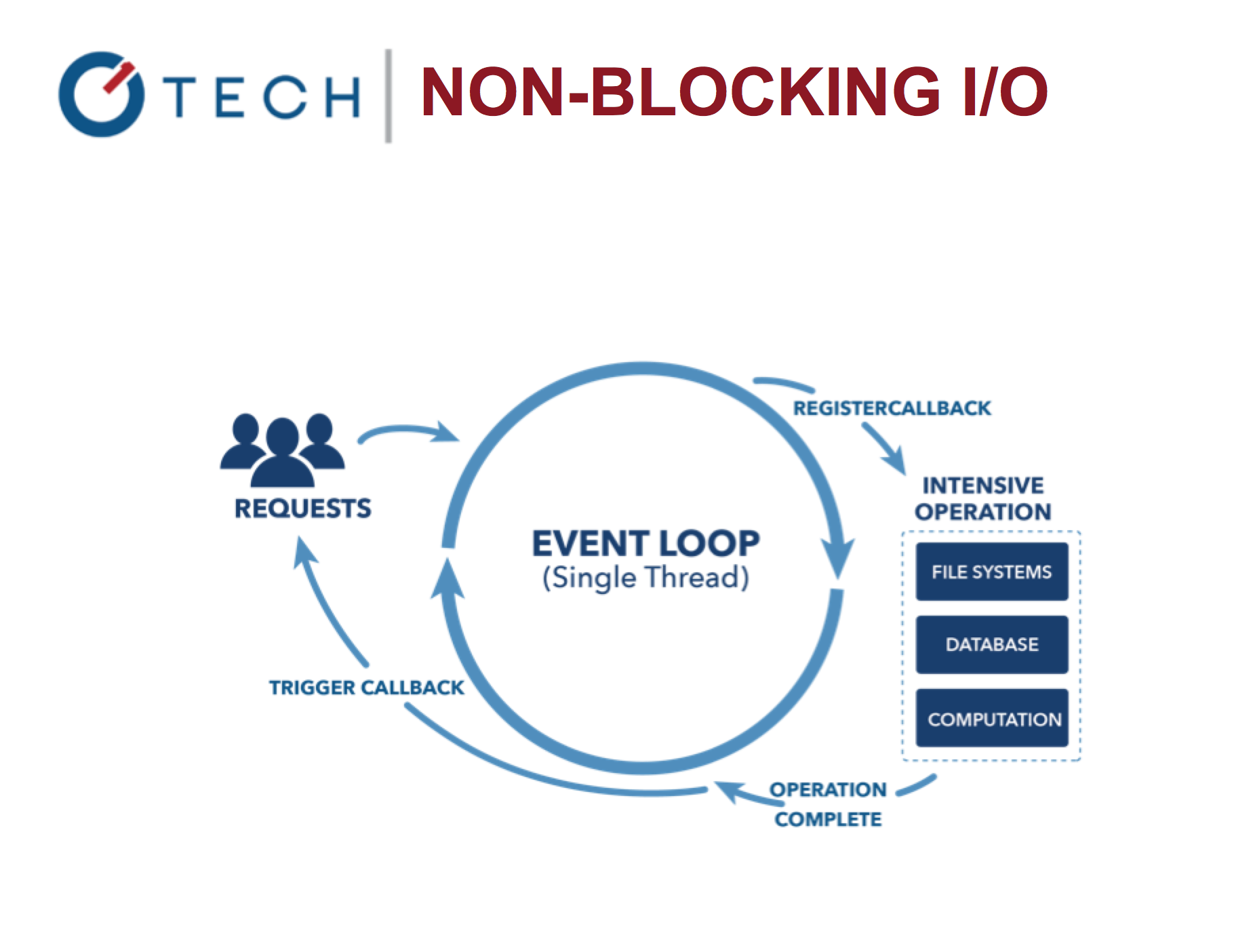
java的同步执行模式:
System.out.println("Step: 1");
System.out.println("Step: 2");
Thread.sleep(1000);
System.out.println("Step: 3");顺序执行1.2.3,并在输出3之前停顿1s。
对异步执行的node来说:
console.log('Step: 1')
setTimeout(function () {
console.log('Step: 3')
}, 1000)
console.log('Step: 2')不会停顿1s,输出顺序也不会只1,3,2.
setTimeout函数将其回调函数在1s之后放入事件队列上,供时间循环遍历。所以从时间队列遍历的顺序上看,执行顺序就是1,2,3.
2. 全局对象global
global.process:保存了一些process、system和环境相关的一些信息。global.__filename:当前执行脚本的文件名和路径。global.__dirname: 当前执行脚本的绝对路径。global.module: 当前模块导出的对象。global.require():导出模块的方法。
3. process对象
process对象保存了一些当前进程的一些信息:
* process.pid:进程id
* process.versions:node\v8和其他组建的版本号
* process.arch:系统架构
* process.argv:命令行接口参数
* process.env:环境变量
* process.uptime():获取uptime
* process.memoryUsage():获取占用内存
* process.cwd():获取当前工作目录
* process.exit():结束当前进程
* process.on():添加监听事件
4. 时间触发器
node中的时间触发器这么用:
var events = require('events');
var emitter = new events.EventEmitter();
emitter.on('knock', function() {
console.log('Who\'s there?')
})
emitter.on('knock', function() {
console.log('Go away!')
})
emitter.emit('knock')编写一个使用EventEmitter的job模块:
// job.js
var util = require('util')
var Job = function Job() {
var job = this
// ...
job.process = function() {
// ...
job.emit('done', { completedOn: new Date() })
}
}
util.inherits(Job, require('events').EventEmitter)
module.exports = Job使用job模块:
// weekly.js
var Job = require('./job.js')
var job = new Job()
job.on('done', function(details){
console.log('Job was completed at', details.completedOn)
job.removeAllListeners()
})
job.process()5. Streams流式读写
用node处理大数据时候会出现些问题。首先,速度降低,buffer限制在1Gb。再说了,如果有些读写资源一直持续,并不停止,node怎么工作?
流式读写可以解决这些问题。
先看一下标准的buffer读写机制:
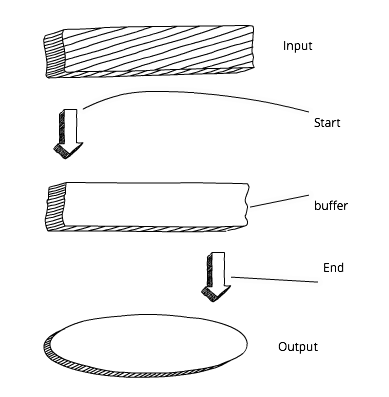
在进一步读取或者output之前,我们必须先等待buffer加载完所有的数据。相比之下,使用流式读取机制是这样的:
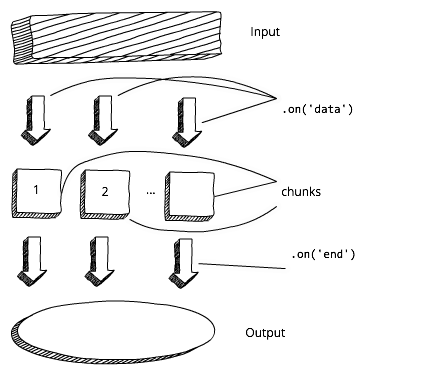
node中有4中流:
* Readable:可读
* Writable:可写
* Duplex:双工,可读可写
* Transform:转换数据
流式读写隐藏在node的各个地方:
* HTTP requests and responses
* Standard input/output
* File reads and writes
6. 可读流例子
标准输入流process.stdin就是一个可读流。
process.stdin.resume()
process.stdin.setEncoding('utf8')
process.stdin.on('data', function (chunk) {
console.log('chunk: ', chunk)
})
process.stdin.on('end', function () {
console.log('--- END ---')
})可读流有一个read()方法用来同步读取数据块。通常使用while(null != (chunk = readble.read())来循环读取数据:
var readable = getReadableStreamSomehow()
readable.on('readable', () => {
var chunk
while (null !== (chunk = readable.read())) {
console.log('got %d bytes of data', chunk.length)
}
})7. 可写流例子
使用write()方法往可写流中写入数据,process.stdout就是一个可写流:
process.stdout.write('hello world');8. 管道
下面的例子使用pipe()方法将一个文件读取后压缩,再写入压缩文件中:
var readable = getReadableStreamSomehow()
readable.on('readable', () => {
var chunk
while (null !== (chunk = readable.read())) {
console.log('got %d bytes of data', chunk.length)
}
})9. http流
http的请求和相应既是可读可写的流,也是event emitter。可以给请求添加data事件:
const http = require('http')
var server = http.createServer( (req, res) => {
var body = ''
req.setEncoding('utf8')
req.on('data', (chunk) => {
body += chunk
})
req.on('end', () => {
var data = JSON.parse(body)
res.write(typeof data)
res.end()
})
})
server.listen(1337)如果server端需要返回大数据,可以使用流式返回:
app.get('/non-stream', function(req, res) {
var file = fs.readFile(largeImagePath, function(error, data){
res.end(data)
})
})
app.get('/stream', function(req, res) {
var stream = fs.createReadStream(largeImagePath)
stream.pipe(res)
})10. buffers
浏览器端的javascript没有用来处理二进制数据的数据类型。但是node中有个buffer的数据类型可以用来处理二进制数据。
创建二进制数据类型可以这样:
* new Buffer(size)
* new Buffer(array)
* new Buffer(buffer)
* new Buffer(str[, encoding])
二进制数据令人看起来很费解,通常使用toString()方法转换成人读格式。
let buf = new Buffer(26)
for (var i = 0 ; i < 26 ; i++) {
buf[i] = i + 97 // 97 is ASCII a
}
console.log(buf) // <Buffer 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 78 79 7a>
buf.toString('utf8') // outputs: abcdefghijklmnopqrstuvwxyz
buf.toString('ascii') // outputs: abcdefghijklmnopqrstuvwxyz
buf.toString('ascii', 0, 5) // outputs: abcde
buf.toString('utf8', 0, 5) // outputs: abcde
buf.toString(undefined, 0, 5) // encoding defaults to 'utf8', outputs abcdefs模块读出的数据类型也是buffer类型的:
fs.readFile('/etc/passwd', function (err, data) {
if (err) return console.error(err)
console.log(data)
});11. clusters
javascript单线程利用不了多核cpu,但是node可以使用cluster模块充分利用多核cpu。
使用cluster模块的套路通常是这样的:
// cluster.js
var cluster = require('cluster')
if (cluster.isMaster) {
for (var i = 0; i < numCPUs; i++) {
cluster.fork()
}
} else if (cluster.isWorker) {
// your server code
})12. pm2工具
pm2工具可以充分利用多核,并且不用像上面使用cluster模块那样写那么恶心的代码。
下面写一个express server,使用pm2工具可以在不改变代码的情况下利用多核cpu。
var express = require('express')
var port = 3000
global.stats = {}
console.log('worker (%s) is now listening to http://localhost:%s',
process.pid, port)
var app = express()
app.get('*', function(req, res) {
if (!global.stats[process.pid]) global.stats[process.pid] = 1
else global.stats[process.pid] += 1;
var l ='cluser '
+ process.pid
+ ' responded \n';
console.log(l, global.stats)
res.status(200).send(l)
})
app.listen(port)使用pm2工具启动server:
pm2 start server.js -i 0
13. spawn vs fork vs exec
cluster模块使用fork()方法穿件新的node server实例,其实node中有3中方法穿件新的外部进程:spawn(), fork(), exec()。3种方法均来自于child_process模块。他们的不同之处总结起来如下:
* require('child_process').spawn():用来处理大数据,支持流式,支持任何命令,不会创建新的V8实例。
* require('child_process').fork():创建一个新的V8实例,包含多个workers线程,仅仅支持node命令。
* require('child_process').exec():使用buffer,所以不适合处理大数据,通过异步方式在回调函数中一次性处理数据。支持所有命令。
下面看一下使用spawn来执行node program.js的例子:
var fs = require('fs')
var process = require('child_process')
var p = process.spawn('node', 'program.js')
p.stdout.on('data', function(data)) {
console.log('stdout: ' + data)
})fork()的语法与spawn()类似,fork()进程执行的都是nodejs程序,所以fork()参数中不需要加node命令:
var fs = require('fs')
var process = require('child_process')
var p = process.fork('program.js')
p.stdout.on('data', function(data)) {
console.log('stdout: ' + data)
})exec()不支持data事件,只能回调:
var fs = require('fs')
var process = require('child_process')
var p = process.exec('node program.js', function (error, stdout, stderr) {
if (error) console.log(error.code)
})14. 异步错误处理
说到错误处理,nodejs和其他大部分语言都有try/catch语句。同步编程时候,使用try/catch很爽:
try {
throw new Error('Fail!')
} catch (e) {
console.log('Custom Error: ' + e.message)
}node的异步机制导致错误发生时的上下文丢失,从而无法捕捉error。所以使用node编写程序时候,回调函数的第一个参数往往是error参数,用来记录发生的错误,每次执行回调时候,开发者需要先检查一下error,并将error冒泡(将error传递给下一个回掉函数):
if (error) return callback(error)
// or
if (error) return console.error(error)
```
使用domain模块。将异常代码放入domain模块的run方法中,异常抛出后,程序不会崩溃,并且还能得到友好的错误提示。
```javascript
// domain-async.js:
var d = require('domain').create()
d.on('error', function(e) {
console.log('Custom Error: ' + e)
})
d.run(function() {
setTimeout(function () {
throw new Error('Failed!')
}, Math.round(Math.random()*100))
});