
知识图谱三元组抽取是知识图谱构建的重要步骤之一,其目的是从文本或数据中提取出结构化的信息,以形成实体、属性和关系之间的联系。这些三元组(Subject-Predicate-Object)是知识图谱的基本单元,用于描述实体之间的语义关系。以下是对知识图谱三元组抽取的详细介绍:
1. 三元组的定义
三元组由三个部分组成:主语(Subject)、谓语(Predicate)和宾语(Object)。例如,“奥巴马是美国前总统”可以表示为三元组(奥巴马, 是, 美国前总统)。这种结构化表示方式便于计算机处理和存储。
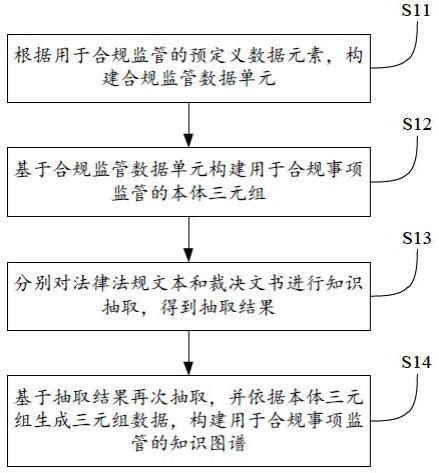
2. 三元组抽取的主要流程
知识图谱的三元组抽取通常包括以下几个步骤:
-
文本预处理:对输入的原始数据进行清洗和标准化,如去除停用词、转换为小写等。
-
候选三元组生成:通过自然语言处理技术(如命名实体识别、依存句法分析等)从文本中提取可能的主语、谓语和宾语组合,形成候选三元组。
-
实体/关系解析:将候选三元组中的实体和关系与已有的知识库进行匹配,验证其有效性。如果匹配成功,则保留该三元组;否则丢弃。
-
模式推断:基于已确认的有效三元组,推断出知识图谱的结构或模式,如确定实体之间的关系类型。
-
融合与优化:对抽取的三元组进行去重、消歧义和冗余信息过滤,确保数据质量。
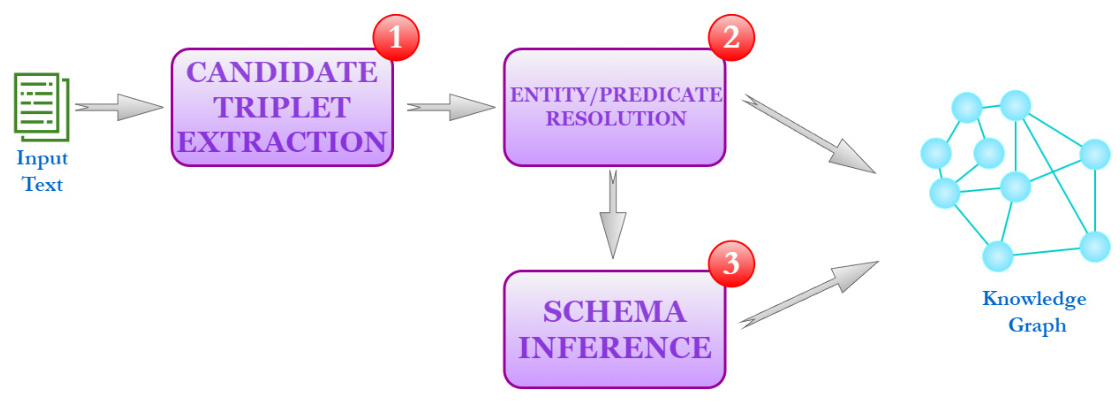
3. 常用技术与工具
(1) 自然语言处理技术
- 命名实体识别(NER):用于识别文本中的实体(如人名、地名、组织名)。
- 依存句法分析:用于分析句子结构,提取主谓宾关系。
- 关系抽取:通过机器学习模型(如条件随机场模型、最大生成树模型等)识别实体间的关系。
(2) 知识图谱构建工具
- OpenIE:用于从开放域文本中抽取三元组。
- RDFLib、GraphDB:用于存储和管理三元组数据。
- Protégé、Grapholith:可视化工具,帮助构建和编辑知识图谱。
(3) 深度学习方法
-
使用BERT等预训练模型进行微调,提升关系抽取的准确性。
-
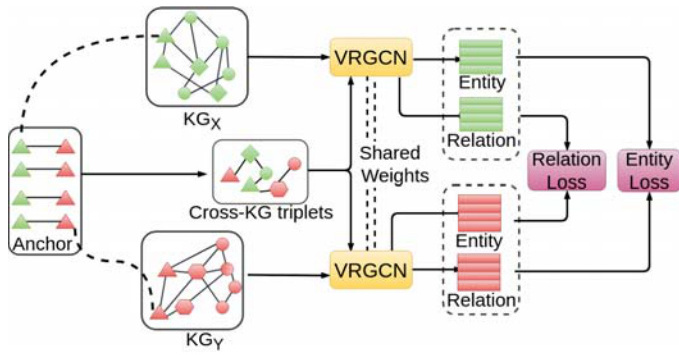
利用变分关系图卷积网络(VRGCN)等模型,从多源知识图谱中提取跨知识图谱的实体和关系。
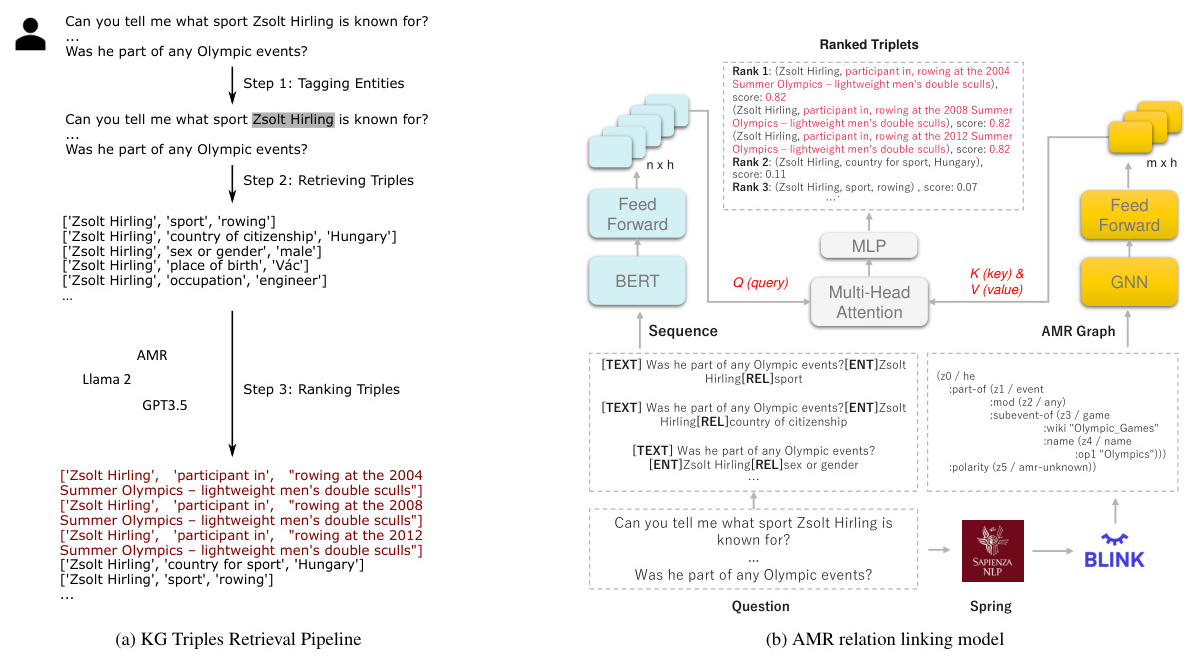
4. 应用场景
知识图谱三元组抽取广泛应用于多个领域:
-
问答系统:通过抽取知识图谱中的三元组,回答用户的问题。
-
语义搜索:利用三元组表示的知识,提高搜索引擎的语义理解能力。
-
智能推荐:基于用户行为和兴趣,结合知识图谱中的实体关系进行个性化推荐。
-
医疗诊断:从病历文本中抽取三元组,辅助医生诊断疾病。
5. 挑战与未来方向
尽管三元组抽取技术已取得显著进展,但仍面临以下挑战:
- 语义理解的复杂性:自然语言表达的模糊性和多样性导致抽取结果存在语义漂移。
- 大规模数据处理:如何高效处理海量数据并保证抽取效率。
- 动态更新:知识图谱需要不断更新以反映现实世界的最新变化。
未来的研究方向包括:
- 开发更高效的抽取算法,减少人工干预。
- 结合多模态数据(如图像、视频)提升抽取精度。
- 探索跨领域知识图谱的构建与融合技术。
知识图谱三元组抽取是知识图谱构建的核心环节,通过自动化技术从文本中提取结构化信息,为后续的知识推理、问答系统和智能应用提供基础支持。随着技术的发展,其应用范围和效率将进一步扩展和提升。
如何在三元组抽取中有效处理语义模糊性?
-
使用Transformer和BERT模型:
- Transformer和BERT模型在自然语言处理任务中表现出色,特别是在语义理解方面。这些模型可以通过预训练和微调来捕捉复杂的语义关系,从而减少语义模糊性的影响。例如,BERT通过双向Transformer架构预训练深度双向表示,可以更好地理解上下文中的语义关系。
-
模糊查询操作符:
- 在数据库查询中,模糊查询操作符如
%和_可以用于处理模糊匹配。虽然这些操作符主要用于文本匹配,但它们的概念可以借鉴到三元组抽取中,通过引入模糊匹配机制来处理语义模糊性。
- 在数据库查询中,模糊查询操作符如
-
三元组学习中的无歧义数据集:
- 在三元组学习中,创建无歧义的数据集是减少语义模糊性的关键步骤。通过预处理数据,去除不一致的探针决策和低周期率的决策,可以生成高质量的训练数据集,从而提高模型的鲁棒性和准确性。
-
模糊集合的置信度属性:
- 在模糊集合的定义中,可以使用置信度属性来处理模糊性。例如,三元划分(N、ZE、P)和七元模糊划分(NG、NM、NP、ZE、NM、PM、PG)可以帮助在语义分析中保持概念的连贯性和一致性。
-
选择性约束:
- 在三元组抽取中,使用选择性约束来区分文本中的有意义和无意义三元组。通过统计每个头函数三元组的频率,并根据这些频率进行加权排序,可以更准确地确定正确的解析。
面对大规模数据处理,目前有哪些高效的三元组抽取技术或算法?
-
聚类和随机采样方法:
- 一种基于聚类和随机采样的方法被提出用于生成特定结构的三元组。该方法首先通过聚类算法将数据集划分为多个簇,然后在每个簇中随机采样,以生成三元组。
-
DGCNN和概率图模型:
- 另一种方法结合了DGCNN(深度生成卷积神经网络)和概率图模型,用于中文信息抽取任务中的三元组抽取。该方法使用了词嵌入、位置嵌入和DGCNN编码器,并通过优化损失函数和调整超参数来提高模型性能。
-
改进的Apriori算法和GNNLP模型:
- 在泰迪杯数据挖掘挑战赛中,使用了改进的Apriori算法进行关联分析,并结合GNNLP(图神经网络关联预测)模型来提取三元组。这种方法在隐含关系抽取任务中表现出较高的效率和准确性。
-
DocBert模型:
- DocBert模型在多个行业的粗粒度三元组抽取任务中表现优异,特别是在小样本数据集上取得了显著的提升。该模型在公开数据集LIE上也表现良好,超过了最新的预训练模型。
-
难样本采样三元组损失(TriHard Loss):
- TriHard Loss是一种改进的三元组损失方法,通过在线难样本采样来提高模型的泛化能力。该方法在行人重识别任务中得到了验证,能够有效提升模型性能。
这些方法各有特点,适用于不同的应用场景和数据类型。