0.STL简介
C++的STL(Standard Template Library,标准模板库)是C++标准库的一部分,它提供了一套通用的类和函数模板,用于处理数据结构和算法。STL的主要组件包括:
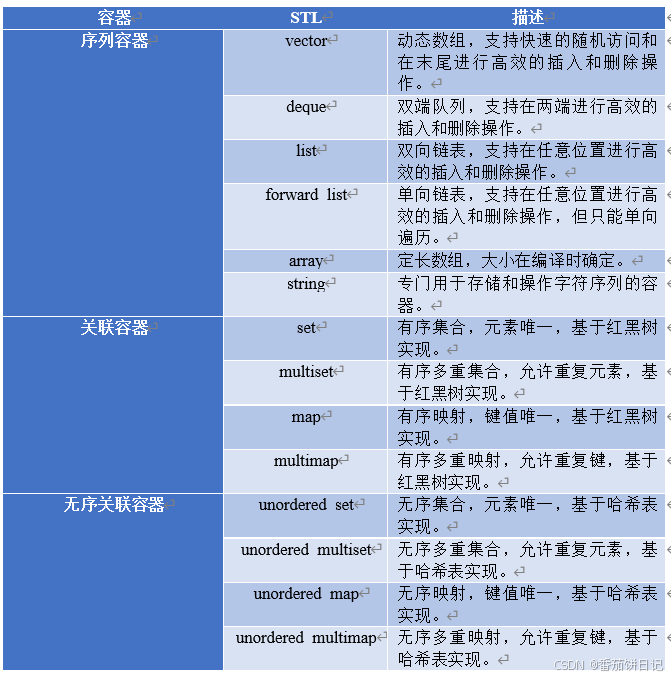
- 容器
- 分配器
- 算法
- 迭代器
- 适配器
- 仿函数
容器
容器是用于存储和管理数据元素的类模板。STL中的容器可以分为序列容器和关联容器
容器适配器
容器适配器是对其他容器进行封装,提供特定的接口,适配特定的使用场景。

1.vector
vector访问之前一定要预先定义大小!!!!!
vector(矢量)是一种变长数组,即自动改变数组长度的数组
vector可以用来以邻接表的方式存储图
1.1如何使用vector
1.1.1vector的定义
vector<类型名>变量名;
类型名:int ,double, char, struct, STL容器(vector,set,queue)
例:
vector<int> name;
vector<vector<int> >; // > >之间要加空格
vector数组就是一个一维数组,如果定义成vector数组的数组,就是二维数组
(低维是高维的地址)
二维数组中,一维形式就是地址。
# include<vector>
# include<iostream>
using namespace std;
int main()
{
int arr[3][2];
cout<<arr[0]<<endl; //输出arr第一行的地址
cout<<arr[1]<<endl;
cout<<arr[2]<<endl;
return 0;
}
1.1.2vector容器内元素的访问
- 通过下标访问
# include<iostream>
# include<vector>
using namespace std;
int main()
{
vector<int> vi;
vi.push_back(1);
cout<<vi[0]<<endl;
return 0;
}
- 通过迭代器访问
迭代器可以理解为指针
# include<iostream>
# include<vector>
using namespace std;
int main()
{
vector<int> v;
for (int i = 0; i < 5; i++)
{
v.push_back(i);
}
//v.begin()返回v的首元素地址
vector<int>::iterator it = v.begin();
for (int i = 0; i < v.size(); i++)
{
cout<<it[i]<<" ";
}
return 0;
}
其中it[i]可以写成*(it +i)
类似于字符串遍历的for循环写法
for (vector<int>::iterator it = v.begin(); it!=v.end(); it++)
{
cout<<*it<<" ";
}
1.2vetcor常用函数
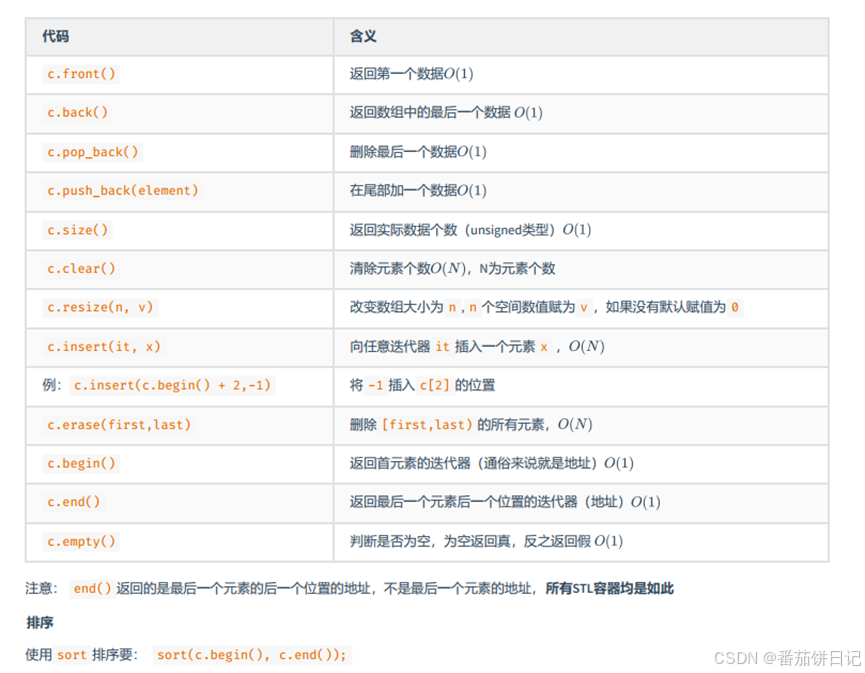
1.3vector常见用途
(1) 存储数据
Vector本身可以作为数组的使用,而且在一些元素个数不确定的场合可以节省空间
(2) 用邻接表存储图
用vector实现邻接表,更为简单
2.string
string是一个字符串类型,和char型字符串类似
- 头文件
#include<string>
- 初始化
string str1; //生成空字符串
string str2(“12345”,0,3)//结果为“123”,从0位置开始,长度为3
string str3(“12345678”)//生成12345678的复制品
string str4(“123456”,5)结果为12345,长度为5
2.1如何使用string
- 访问单个字符
#include<iostream>
#include<string>
using namespace std;
int main(void)
{
string s = "ni hao";
for (int i = 0; i < s.size(); i++)
{
cout << s[i] << " ";
}
return 0;
}
- string数组使用
# include<iostream>
# include<string>
using namespace std;
int main(void)
{
string s[10];
for (int i = 0; i < 10; i++)
{
s[i] = "loading...";
cout << s[i] << i << "\n";
}
}
2.2方法函数
2.2.1 获取字符串长度
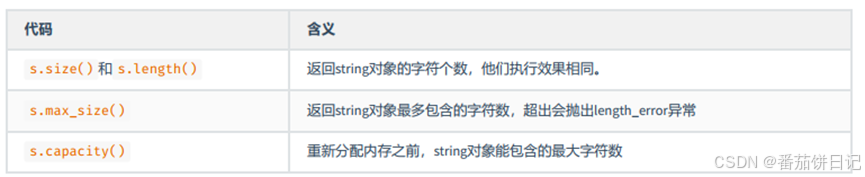
2.2.2 插入
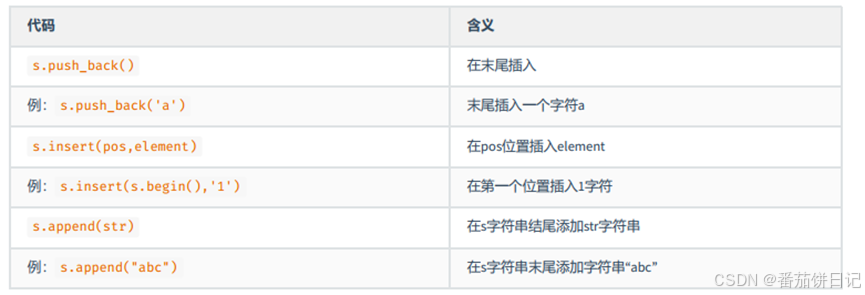
2.2.3 删除
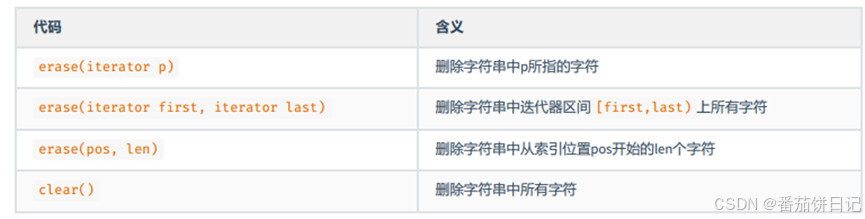
2.2.4 字符替换
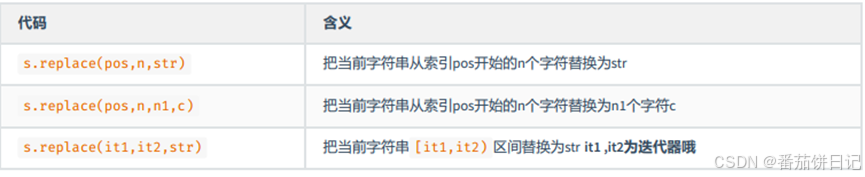
2.2.5 大小写转换
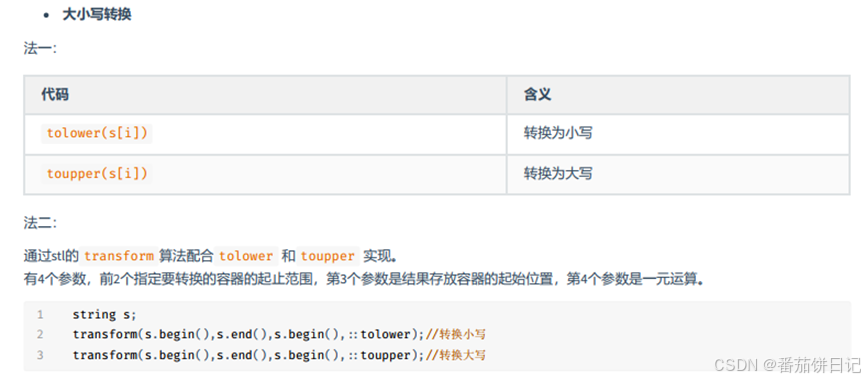
2.2.6 分割

2.2.7 查找
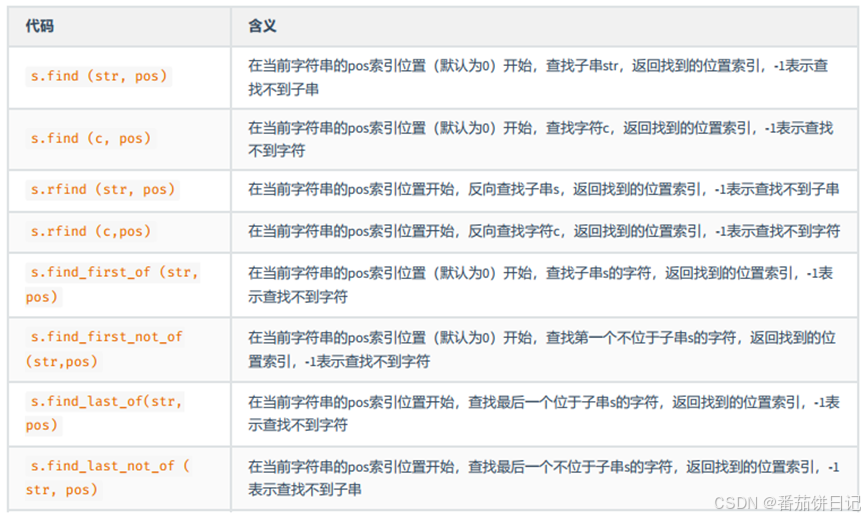
2.2.8 排序

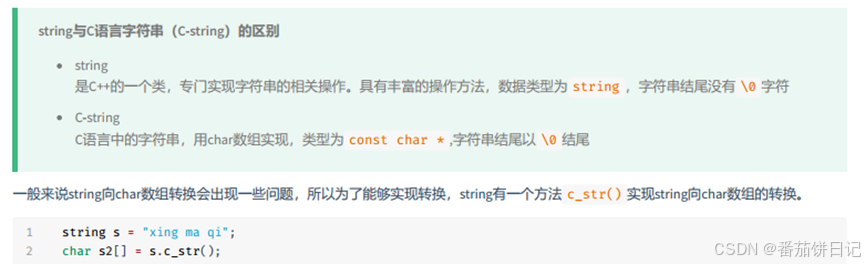
2.3C语言与C++的string区别
3.set
set是一个内部自动有序且不含重复元素的容器
set可以在需要去除重复元素的情况下节省时间,减少思维量
默认升序输出
3.1如何使用set
使用set需加头文件
#include <set>
using namespace std;
set的定义
set<类型名>变量名;
类型名可以是int, double, char, struct, 也可以是STL容器:vector,set,queue
例:
set<struct node> name;
set<set<int> > name; //> >之间有空格
set数组的定义和vector相同:
set<类型名> array[size];
set容器内元素的访问
- set只能通过迭代器访问
set<int> ::iterator it;
set<char>::iterator it;
得到了迭代器it,并可以通过*it来访问set里的元素
注意:除了vector和string之外的STL容器都不支持(it+i)的访问方式,因此只能按照如下方式枚举*
# include<iostream>
# include<set>
using namespace std;
int main(void)
{
set<int> st;
st.insert(5);
st.insert(2);
st.insert(6);
for (set<int>::iterator it = st.begin(); it != st.end(); it++)
{
cout<<*it<<" ";
}
return 0;
}
输出:2,5,6
3.2set的常用函数

3.2.1 insert()
#include <iostream>
#include <set>
using namespace std;
int main(void)
{
set<char> st;
st.insert('A');
st.insert('B');
st.insert('C');
for (set<char>::iterator it = st.begin(); it != st.end(); it++)
{
cout<<*it<<endl;
}
return 0;
}
3.2.2 find()
find(value)返回的是set中value所对应的迭代器,即value的指针(地址)
#include <iostream>
#include <set>
using namespace std;
int main(void)
{
set<int> st;
for (int i = 1; i <= 3; i++)
{
st.insert(i);
}
set<int>::iterator it = st.find(2);//在set中查找2,返回迭代器
cout<< *it<<endl;
cout<<*(st.find(2))<<endl;
return 0;
}
3.2.3 erase()
erase()有两种用法:
- 删除单个元素
- 删除一个区间内的所有元素
- 删除单个元素
删除单个元素的方法有两种
(1) st.erase(it),其中it为所需要删除元素的迭代器(地址)。可以集合find函数来使用
#include <iostream>
#include <set>
using namespace std;
int main(void)
{
set<int> st;
st.insert(100);
st.insert(200);
st.insert(300);
//删除单个元素
st.erase(st.find(100));
st.erase(st.find(200));
for (set<int>::iterator it = st.begin(); it != st.end(); it++)
{
cout<<*it<<" ";
}
return 0;
}
(2) st.erase(value),value为需要删除元素的值
2.删除一个区间内的所有元素
st.erase(iteratorBegin, iteratorEnd)可以删除一个区间内的所有元素
其中iteratorBegin为所需要删除区间的起始迭代器
iteratorEnd为需要删除区间的结束迭代器的下一个地址
也[iteratorBegin, iteratorEnd]
#include <iostream>
#include <set>
using namespace std;
int main(void)
{
set<int> st;
st.insert(100);
st.insert(200);
st.insert(300);
st.insert(400);
set<int>::iterator it = st.begin();
st.erase(it, st.find(300));
for (it = st.begin(); it !=st.end(); it++)
{
cout<<*it<<" ";
}
return 0;
}
3.3其他set
3.3.1multiset
multiset:元素可以重复,且元素有序
- 元素可以重复:允许多个相同的元素。
- 元素有序:内部使用红黑树实现,元素按键值升序排列。
当你需要一个有序的集合,并且允许重复元素时,使用multiset是一个好选择。
例:
#include <iostream>
#include <set>
int main() {
std::multiset<int> ms = {3, 1, 4, 1, 5, 9, 2, 6, 5, 3};
for (int num : ms) {
std::cout << num << " ";
}
return 0;
}
输出:1 1 2 3 3 4 5 5 6 9
3.3.2unrodered_set
元素无序且只能出现一次
- 元素无序:内部使用哈希表实现,元素无特定顺序。
- 元素唯一:不允许重复元素。
当你需要快速查找元素且不关心顺序,并且不需要重复元素时,unordered_set是一个理想选择。
例:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> us = {3, 1, 4, 1, 5, 9, 2, 6, 5, 3};
for (int num : us) {
std::cout << num << " ";
}
return 0;
}
输出:输出顺序不定,可能为6 5 4 3 2 9 1
3.3.3 unordered_multiset
- 元素无序:内部使用哈希表实现,元素无特定顺序。
- 元素可以重复:允许多个相同的元素。
例:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_multiset<int> ums = {3, 1, 4, 1, 5, 9, 2, 6, 5, 3};
for (int num : ums) {
std::cout << num << " ";
}
return 0;
}
输出:输出顺序不定,可能为5 6 5 4 3 3 2 9 1 1
4.map
映射类似于函数的对应关系,每一个x对应一个y,而map是每个键对应一个值,类似与Python的字典
- 头文件
#include<map>
- 声明函数
map<string, string> mp;
map<string,int> mp;
map<int, node>//node是结构体
map会按照键的顺序从小到大排序,键的类型必须是可以比较大小
- 元素有序:基于红黑树实现,元素按键值升序排列。
- 键唯一:不允许重复的键。
4.1如何使用map
访问map容器内的元素
- 正向遍历
# include<iostream>
using namespace std;
int main(void)
{
map<int, int> mp;
mp[1] = 2;
mp[2] = 3;
mp[3] = 4;
auto it = mp.begin();
while(it != mp.end())
{
cout << it->first << " " << it->second << "\n";
it++;
}
return 0;
}
- 反向遍历
# include<map>
# include<iostream>
using namespace std;
int main(void)
{
map<int, int> mp;
mp[1] = 2;
mp[2] = 3;
mp[3] = 4;
auto it = mp.rbegin();
while(it != mp.rend())
{
cout << it->first << " " << it->second << "\n";
it++;
}
return 0;
}
- 访问元素
#include<map>
using namespace std;
int main(void)
{
map<string, string> mp;
//方式一
mp["学习"] = "看书";
mp["玩耍"] = "打游戏";
//方式二 插入元素构造键值对
mp.insert(make_pair("vegetables","蔬菜"));
//方式三
mp.insert(pair<string, string>("fruit","水果"));
//方式四
mp.insert({"hahahahah","wawawaw"});
//下标访问
cout<<mp["学习"]<<"\n";
//迭代器访问
map<string, string>::iterator it;
for (it = mp.begin(); it != mp.end(); it++)
{
cout<<it->first<<" "<<it->second<<"\n";
}
//智能指针访问
for (auto i : mp)
{
cout<<i.first<<" "<<i.second<<endl;
}
//对指定的单个元素访问
map<string, string>::iterator it1 = mp.find("学习");
cout<<it1->first<<" "<<it1->second<<"\n";
}
4.2map常用函数
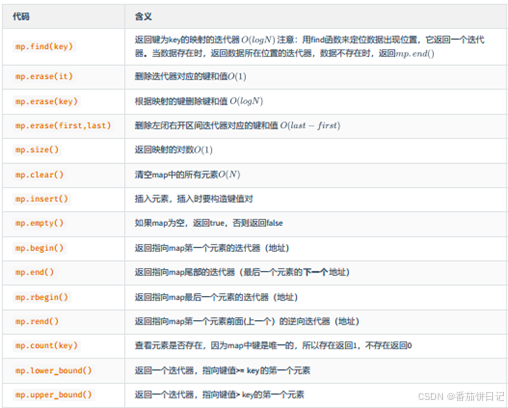
- 注意点
查找元素是否存在时,可以使用
- mp.find()
- mp.count()
- mp[key]
但是第三种情况,如果不存在对应的key时,会自动创建一个键值对(产生额外的键值对,为了不增加额外的空间负担,最好使用前两种方法)
二分查找lower_bound(), upper_bound()
# include<iostream>
# include<map>
using namespace std;
int main(void)
{
map<int, int> m{{1,2},{2,2},{1,2},{8,2},{6,2}};
map<int, int>::iterator it1 = m.lower_bound(2);
cout << it1->first << "\n"; //2
map<int, int>::iterator it2 = m.upper_bound(2);
cout << it2->first << "\n"; //6
return 0;
}
添加元素
# include<iostream>
# include<map>
using namespace std;
int main(void)
{
map<string, string> mp;
//方式一
mp["学习"] = "看书";
mp["玩耍"] = "打游戏";
//方式二 插入元素构造键值对
mp.insert(make_pair("vegetables","蔬菜"));
//方式三
mp.insert(pair<string, string>("fruit","水果"));
//方式四
mp.insert({"hahahahah","wawawaw"});
map<string, string>::iterator it = mp.begin();
while(it != mp.end())
{
cout<<it->first<<" "<<it->second<<"\n";
it++;
}
return 0;
}
4.3其他map
4.3.1multimap
- 元素有序:基于红黑树实现,元素按键值升序排列。
- 键可以重复:允许多个相同的键。
#include <iostream>
#include <map>
int main() {
std::multimap<int, std::string> mm;
mm.insert({1, "one"});
mm.insert({3, "three"});
mm.insert({2, "two"});
mm.insert({1, "uno"});
for (const auto& pair : mm) {
std::cout << pair.first << ": " << pair.second << "\n";
}
return 0;
}
输出:输出:1: one 1: uno 2: two 3: three
4.3.2unordered_map
- 元素无序:基于哈希表实现,元素无特定顺序。
- 键唯一:不允许重复的键。
- 快速访问:平均情况下,插入和查找操作的时间复杂度为O(1)。
例:
#include <iostream>
#include <unordered_map>
int main() {
std::unordered_map<int, std::string> um;
um[1] = "one";
um[3] = "three";
um[2] = "two";
for (const auto& pair : um) {
std::cout << pair.first << ": " << pair.second << "\n";
}
return 0;
}
输出:输出顺序不定,可能为2: two 1: one 3: three
4.3.3unordered_multimap
- 元素无序:基于哈希表实现,元素无特定顺序。
- 键可以重复:允许多个相同的键。
- 快速访问:平均情况下,插入和查找操作的时间复杂度为O(1)。
例:
#include <iostream>
#include <unordered_map>
int main() {
std::unordered_multimap<int, std::string> umm;
umm.insert({1, "one"});
umm.insert({3, "three"});
umm.insert({2, "two"});
umm.insert({1, "uno"});
for (const auto& pair : umm) {
std::cout << pair.first << ": " << pair.second << "\n";
}
return 0;
}
输出:输出顺序不定,可能为1: one 1: uno 2: two 3: three
5.pair
5.1介绍
pair只含有两个元素,可以看做是只有两个元素的结构体
头文件
#include<utility>
应用:
- 代替二元结构体
- 作为map的键值进行插入
#include<utility>
#include<iostream>
#include<map>
using namespace std;
int main(void)
{
map<string, int> mp;
mp.insert(pair<string, int>("xiaoming",11));
pair<string, int> p;
p = pair<string, int>("wang", 18);
p = make_pair("li", 16);
p = {"sun", 24};
return 0;
}
5.2访问
# include<iostream>
# include<utility>
using namespace std;
int main(void)
{
pair<int, int>p[20];
for (int i = 0; i < 20; i++)
{
cout << p[i].first << " " << p[i].second;
}
return 0;
}
6.queue
6.1介绍
队列是一种先进先出的数据结构
queue 仅允许访问队首(第一个元素)和队尾(最后一个元素),你无法通过索引直接访问中间元素
- 头文件
#include<queue>
- 声明
queue<int> q;
6.2queue常用函数
| 代码 | 含义 |
|---|---|
| q.front() | 返回队首元素 |
| q.back() | 返回队尾元素 |
| q.push(ele) | 尾部添加一个元素ele |
| q.pop() | 删除第一个元素 |
| q.size() | 返回队列中元素的个数,返回值类型unsigned int |
| q.empty() | 判断是否为空,队列为空,返回true |
6.3队列模拟
使用q[]数组模拟队列
hh表示队首元素的下标,初始值为0
tt表示队尾元素的下标,初始值为-1,表示队列刚开始为空
#include<iostream>
using namespace std;
const int N = 1e5 + 5;
int q[N];
int main(void)
{
int hh = 0;
int tt = -1;
//入队
q[++tt] = 1;
q[++tt] = 2;
while (hh <= tt)
{
int t = q[hh++];
printf("%d\n", t);
}
return 0;
}
7deque
7.1介绍
首尾都可插入和删除的队列为双端队列
- 头文件
#include<deque>
- 声明
deque<int> dq;
7.2函数

8.priority_queue
8.1介绍
优先队列是在正常队列的基础上加了优先级,保证每次的队首元素都是优先级最大的
可以实现每次从优先队列中取出的元素都是队列中优先级最大的
它的底层是通过堆来实现的
- 头文件
#include<queue>
- 声明函数
priority_queue<int> q;
8.2函数
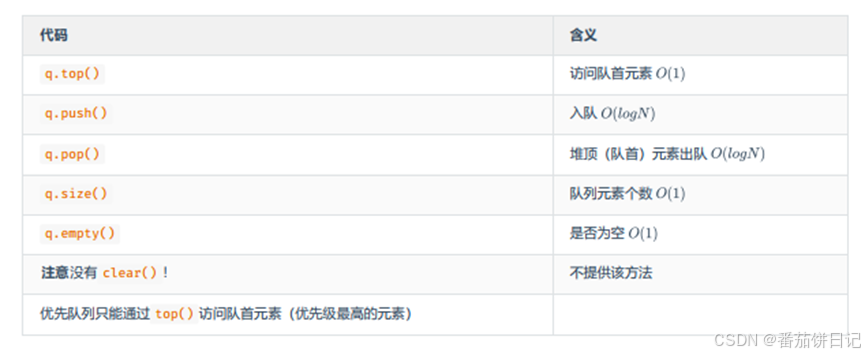
8.3设置优先级
基本数据类型的优先级
priority_queue<int> pq; // 默认大顶堆,即每次取出的元素是队列中的最大值
priority_queue<int, vector<int>, greater<int> > q; //小根堆。每次取出的元素是队列中的最小值
第一个参数:优先队列中存储的数据类型
第二个参数:是用来承载底层数据结构堆的容器,若优先队列中存放的是double类型,就要填vector ,总之存的是什么数据类型,就相应的填写对应的数据类型,同时要改动第三个参数的对应类型
第三个参数
less 数字大的优先级大,堆顶为最大的数字
greater数字小的优先级大,堆顶为最小的数字
高级数据类型(结构体)优先级
- 自定义全局比较规则
#include<queue>
#include<iostream>
using namespace std;
struct Point
{
int x;
};
struct cmp //自定义堆的排序规则
{
bool operator()(const Point& a, const Point& b)
{
return a.x < b.x;
}
};
priority_queue<Point, vector<Point>,cmp> q; //x大的在堆顶
- 直接在结构体里写
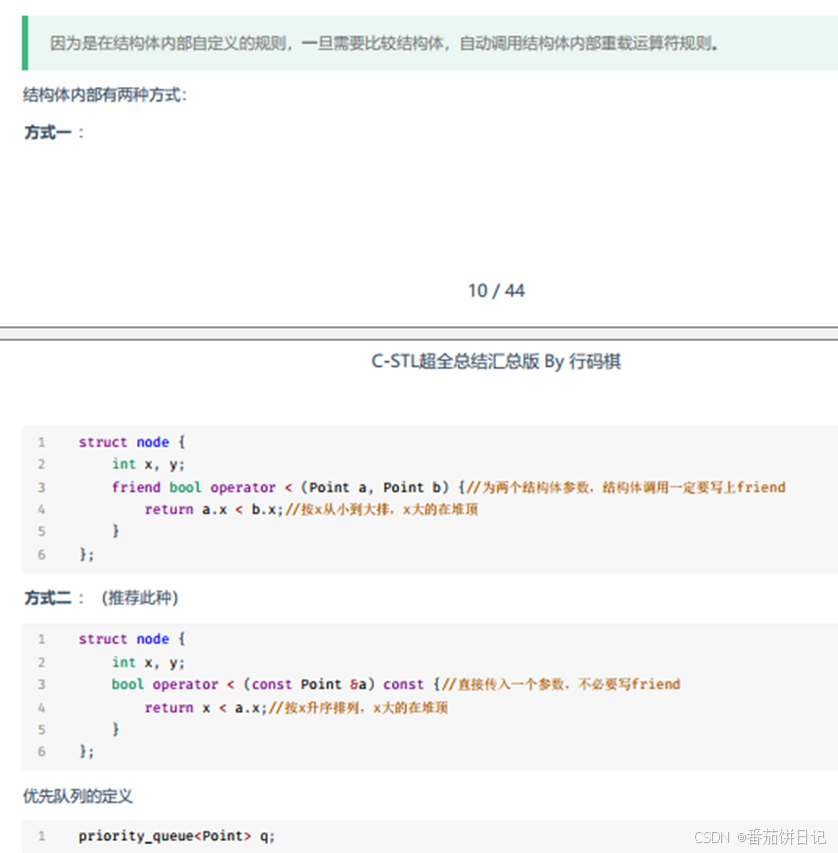
存储特殊类型的优先级
存储pair类型
排序规则:首先对pair的first进行降序排序,再对second降序排序
对first先排序,大的排在前面,如果first元素相同,在对second元素排序,保持大的在前面
# include<queue>
# include<iostream>
using namespace std;
int main(void)
{
priority_queue<pair<int, int> > q;
q.push({7,8});
q.push({7,9});
q.push(make_pair(8,7));
while (!q.empty())
{
cout << q.top().first << " "<<q.top().second << "\n";
q.pop();
}
return 0;
}
9.stack
9.1如何使用stack
定义
STL中实现的一个先进后出的容器
- 添加头文件
#include<stack>
- 声明
stack<int> s;
stack<string> s;
stack<node> s; //node是结构体类型
stack容器内元素的访问
栈提供push和pop等等接口,所有元素必须符合先进后出规则,所以栈不提供走访功能,也不提供迭代器(iterator)。不像set或map提供迭代器来遍历所有元素。
STL中栈往往不被归类为容器,而是容器适配器(container adapter),栈以底层容器完成所有的工作,对外提供统一的接口,底层容器是可插拔的(可以控制哪种容器来实现栈)。
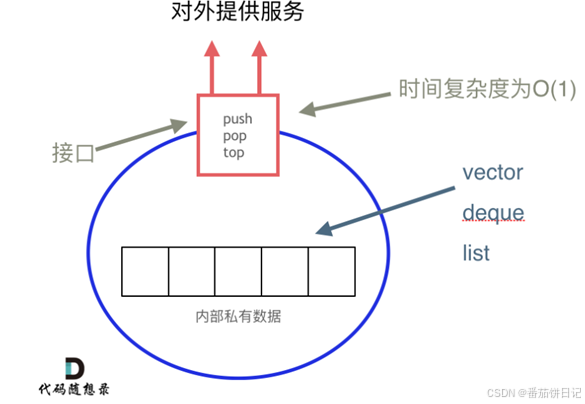
- 栈遍历
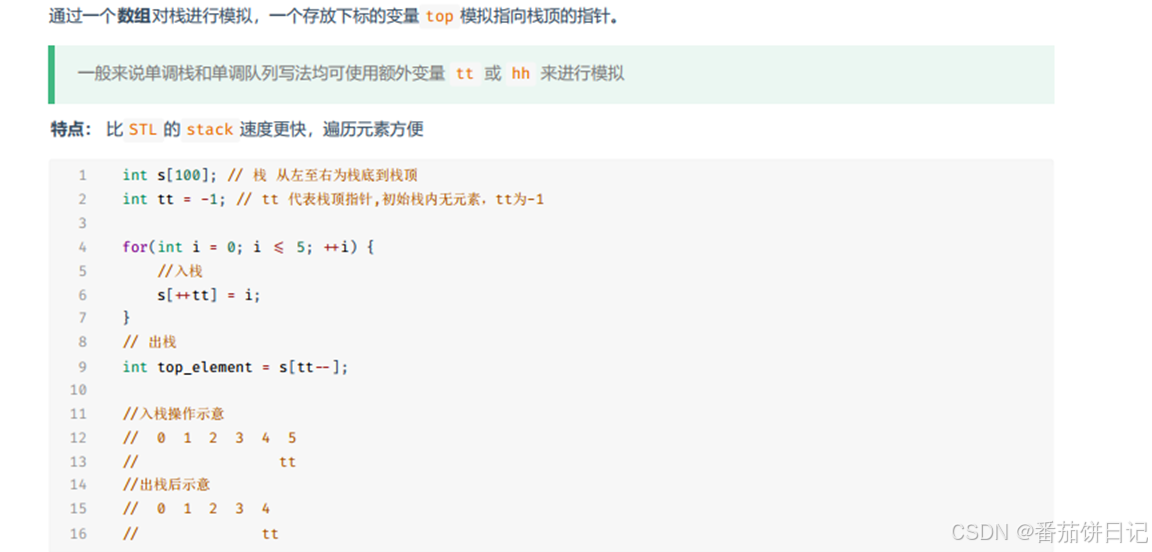
栈只能对栈顶元素进行操作,如果要进行遍历,只能将栈中元素一个个取出来存在数组中
- 数组模拟栈遍历
通过一个数组对栈进行模拟,一个存放下标的变量top模拟指向栈顶的指针
比STL的stack 更快,遍历元素方便
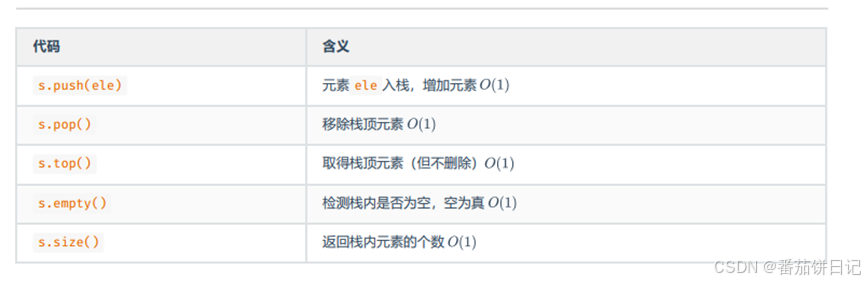
9.2stack常用函数
10.bitset
10.1如何使用bitset
定义
类似数组,每个元素只能是0或1,每个元素只占用1bit空间
- 头文件
#include<bitset>
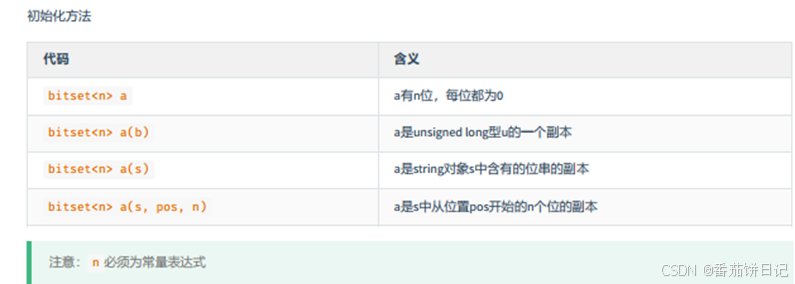
- 初始化定义
在这里插入代码片
# include<iostream>
# include<bitset>
using namespace std;
int main(void)
{
bitset<4> bitset1;
bitset<9> bitset2(12);
string s = "100101";
bitset<10> bitset3(s); //长度为10,前面用0补充
char s2[] = "10101";
bitset<13> bitset4(s2);
cout<<bitset1<<endl; //0000
cout<<bitset2<<endl; //000001100
cout<<bitset3<<endl;//0000100101
return 0;
}
特性
可进行位操作

访问
#include<iostream>
#include<bitset>
using namespace std;
int main(void)
{
bitset<4> f("1011");
for(int i = 0; i < 4; i++)
{
cout << f[i];
}
return 0;
}//输出1101
bitset优化
一般使用bitset来优化时间复杂度
bitset还有开动态空间的技巧,常用在01背包优化等算法中
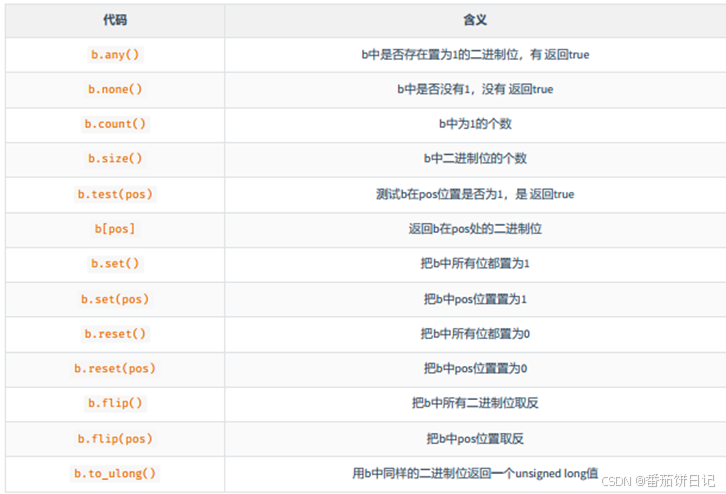
10.2bitset的常用函数
11.array
array是c++新增的容器,效率与普通数据相差无几,比vector效率要高,自身添加了一些成员函数,和其他容器相比,array容器的大小是固定的,无法动态地扩展和收缩,只允许访问或替换存储的元素
注意:array的使用要在std的命名空间里
11.1如何使用array
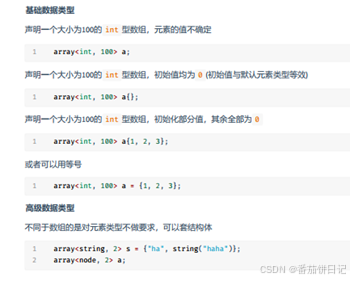
声明与初始化
存取元素
#include<iostream>
#include<array>
using namespace std;
int main(void)
{
//修改元素
array<int, 4> a = {1, 2, 3, 4};
a[0] = 4;
//访问元素
for (int i = 0; i < 4; i++)
{
cout << a[i] << "\n";
}
//auto访问
for (auto i : a)
{
cout << i <<" ";
}
//迭代器访问
auto it1 = a.begin();
for (; it1 != a.end(); it1++)
{
cout << *it1 <<" ";
}
//at函数访问
int res = a.at(1) + a.at(2);
cout<<res<<"\n"; //res=5;
//get方法访问
get<1>(a) = 100; //将数组下标为1的地方改成100
cout<<a[1];
}
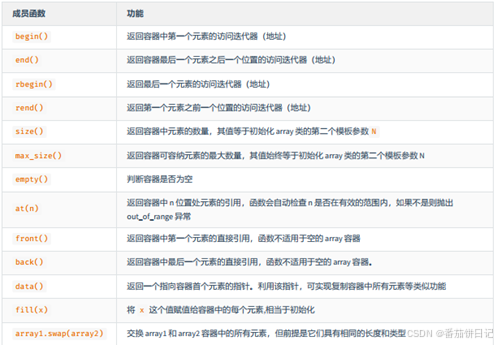
11.2array常用函数
12.tuple
tuple是pair的泛化,可以封装不同类型任意数量的对象
可以将tuple理解为pair的扩展,tuple可以声明二元组,也可以声明三元组
tuple可以等价为结构体使用
12.1定义
- 头文件
#include<tuple>
- 声明初始化
# include<tuple>
# include<iostream>
using namespace std;
int main(void)
{
tuple<int, int, string> t1;
//赋值
t1 = make_tuple(1,1,"hahha");
//创建的同时初始化
tuple<int, int, int, int>t2(1,2,3,4);
//使用pair对象构造tuple对象,但tuple对象必须是两个元素
auto p = make_pair("wang", 1);
tuple<string, int>t3{p}; //将pair对象赋给tuple对象
return 0;
}
12.2元素操作
# include<tuple>
# include<iostream>
using namespace std;
int main(void)
{
tuple<int, int, string> t1;
//赋值
t1 = make_tuple(1,1,"hahha");
//创建的同时初始化
tuple<int, int, int, int>t2(1,2,3,4);
//使用pair对象构造tuple对象,但tuple对象必须是两个元素
auto p = make_pair("wang", 1);
tuple<string, int>t3{p}; //将pair对象赋给tuple对象
int first = get<0>(t2); //获取t2的第一个元素
get<0>(t2) = 100;
cout<<get<0>(t2)<<"\n";
return 0;
}
12.3函数操作

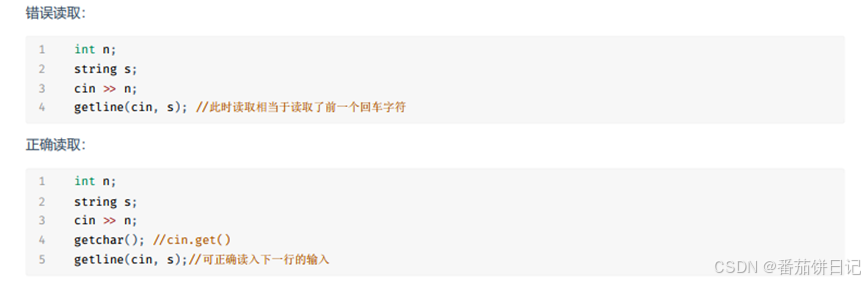
13 读入详解
cin
读入字符串,遇空格, 回车结束

getline
读入一行字符串(包括空格),遇到回车结束
注意getline(cin, s)会获取前一个输入的换行符,需要在前面添加读取换行符的语句,如getchar()或cin.get()
cin与getline()混用
cin输入完后,回车,cin遇到回车结束输入,但回车还在输入流中,cin不会清除,导致getline()读取回车,结束。需要在cin后面加cin.ignore();主动删除输入流中的换行符

cin与cout解锁
注意:cin与cout解锁使用时,不能与scanf,getchar,printf,cin,getline()混用,一定要注意,会出错


14智能指针
14.1auto
auto是自动推断元素的类型,一般用来遍历
例如vector num
for (auto &i :nums)
&i 表示 i 是 nums中每个元素的引用,而不是副本。使用引用可以避免不必要的拷贝,提高效率。
遍历二维数组
vector<vector<int>> res;
for (const auto& row : res)
{
for (int num : row)
{
cout << num << " ";
}
cout << endl;
}
使用const auto&
- auto可以自动判断数据类型, &是对数据进行引用,而不是拷贝,节省内存提高效率。
- const保证在遍历时不对res的数据做修改,安全。
智能指针详解