一、sobel算子边缘检测理论
sobel算子是广泛应用的微分算子之一,可以计算图像处理中的边缘检测,计算图像的灰度地图。在技术上,它是一个离散的一阶差分算子,用来计算图像亮度函数的一阶梯度之近似值。在图像的任何一点使用此算子,将会产生该点对应的梯度矢量或是其法矢量原理就是基于图像的卷积来实现在水平方向与垂直方向检测对于方向上的边缘。
这个实验在有学过上述图像矩阵中值运算的基础上来做并不难,把中值改为一个固定的矩阵相乘,这一部分也是卷积操作,与之前老师让学习的神经网络的卷积是相同的运算,也是打神经网络的基础吧。
对于源图像与奇数Sobel水平核Gx,竖直核Gy进行卷积可计算水平核竖直变换,当内核大小为3x3时:
原图中的作用点像素值通过卷积之后为:
可以化简成,结果相差不大:
二、MATLAB实现
效果图:
三、FPGA实现
首先,sobel边缘检测依然是建立在灰度图输出Y分量的基础上:
Y分量输入3*3矩阵变化:
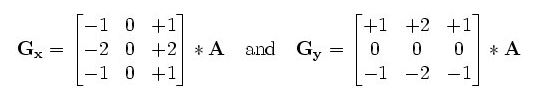
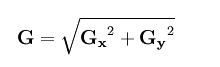
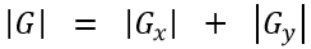


module matrix_3x3_8bit
(input wire clk ,
input wire rst_n ,
//input ---------------------------------------------
input wire din_vld ,
input wire [ 7:0] din ,
//output --------------------------------------------
output reg [ 7:0] matrix_11 ,
output reg [ 7:0] matrix_12 ,
output reg [ 7:0] matrix_13 ,
output reg [ 7:0] matrix_21 ,
output reg [ 7:0] matrix_22 ,
output reg [ 7:0] matrix_23 ,
output reg [ 7:0] matrix_31 ,
output reg [ 7:0] matrix_32 ,
output reg [ 7:0] matrix_33
);
/*************************************************/
wire wr_en_1 ;
wire wr_en_2 ;
wire rd_en_1 ;
wire rd_en_2 ;
wire [ 7:0] q_1 ;
wire [ 7:0] q_2 ;
reg [10:0] cnt_col ;
wire add_cnt_col ;
wire end_cnt_col ;
reg [10:0] cnt_row ;
wire add_cnt_row ;
wire end_cnt_row ;
//fifO_showahead模式
FIFO_show_2048_8bit u1(
.clock ( clk),
.data ( din),
.rdreq ( rd_en_1),
.wrreq ( wr_en_1),
.full ( ),
.q ( q_1)
);
FIFO_show_2048_8bit u2(
.clock ( clk),
.data ( din),
.rdreq ( rd_en_2),
.wrreq ( wr_en_1),
.full ( ),
.q ( q_2)
);
//对数据进行行列的划分
//列
always @(posedge clk or negedge rst_n) begin
if(!rst_n)
cnt_col <= 11'd0;
else if(add_cnt_col) begin //当使能时列计数器计数
if(end_cnt_col) //列计数器计数且记满时归零
cnt_col <= 11'd0;
else
cnt_col <= cnt_col + 11'd1;
end
end
assign add_cnt_col = din_vld;
assign end_cnt_col = add_cnt_col && cnt_col== COL-11'd1;
//行
always @(posedge clk or negedge rst_n) begin
if(!rst_n)
cnt_row <= 11'd0;
else if(add_cnt_row) begin
if(end_cnt_row)
cnt_row <= 11'd0;
else
cnt_row <= cnt_row + 11'd1;
end
end
assign add_cnt_row = end_cnt_col;
assign end_cnt_row = add_cnt_row && cnt_row== ROW-11'd1;
//fifo读写,第一个fifo从第一行读,但不写最后一行;第二个从第二行读,不写后两行,加上原输入的那一行,形成三行
assign wr_en_1 = (cnt_row < ROW - 11'd1) ? din_vld : 1'd0; //不写最后1行
assign rd_en_1 = (cnt_row > 11'd0 ) ? din_vld : 1'd0; //从第1行开始读
assign wr_en_2 = (cnt_row < ROW - 11'd2) ? din_vld : 1'd0; //不写最后2行
assign rd_en_2 = (cnt_row > 11'd1 ) ? din_vld : 1'd0; //从第2行开始读
//矩阵数据选取
assign row_1 = q_2;
assign row_2 = q_1;
assign row_3 = din; //原输入是没有延时最先输出的、最大的数据
//打拍形成矩阵数据,延时1个clk
//矩阵使用边界复制方法
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
{matrix_11, matrix_12, matrix_13} <= {8'd0, 8'd0, 8'd0};
{matrix_21, matrix_22, matrix_23} <= {8'd0, 8'd0, 8'd0};
{matrix_31, matrix_32, matrix_33} <= {8'd0, 8'd0, 8'd0};
end
//第一排
else if(cnt_row == 11'd0) begin
if(cnt_col == 11'd0) begin //第1个矩阵,清零的时候,矩阵全部为din数据
{matrix_11, matrix_12, matrix_13} <= {row_3, row_3, row_3};
{matrix_21, matrix_22, matrix_23} <= {row_3, row_3, row_3};
{matrix_31, matrix_32, matrix_33} <= {row_3, row_3, row_3};
end
else begin //剩余矩阵
{matrix_11, matrix_12, matrix_13} <= {matrix_12, matrix_13, row_3};
{matrix_21, matrix_22, matrix_23} <= {matrix_22, matrix_23, row_3};
{matrix_31, matrix_32, matrix_33} <= {matrix_32, matrix_33, row_3};
end
end
//------------------------------------------------------------------------- 第2排矩阵
else if(cnt_row == 11'd1) begin
if(cnt_col == 11'd0) begin //第1个矩阵,第二行有输入,矩阵由填充
{matrix_11, matrix_12, matrix_13} <= {row_2, row_2, row_2};
{matrix_21, matrix_22, matrix_23} <= {row_2, row_2, row_2};
{matrix_31, matrix_32, matrix_33} <= {row_3, row_3, row_3};
end
else begin //剩余矩阵
{matrix_11, matrix_12, matrix_13} <= {matrix_12, matrix_13, row_2};
{matrix_21, matrix_22, matrix_23} <= {matrix_22, matrix_23, row_2};
{matrix_31, matrix_32, matrix_33} <= {matrix_32, matrix_33, row_3};
end
end
//------------------------------------------------------------------------- 剩余矩阵
else begin
if(cnt_col == 11'd0) begin //第1个矩阵,第三行有输入,矩阵完成
{matrix_11, matrix_12, matrix_13} <= {row_1, row_1, row_1};
{matrix_21, matrix_22, matrix_23} <= {row_2, row_2, row_2};
{matrix_31, matrix_32, matrix_33} <= {row_3, row_3, row_3};
end
else begin //剩余矩阵
{matrix_11, matrix_12, matrix_13} <= {matrix_12, matrix_13, row_1};
{matrix_21, matrix_22, matrix_23} <= {matrix_22, matrix_23, row_2};
{matrix_31, matrix_32, matrix_33} <= {matrix_32, matrix_33, row_3};
end
end
end
endmodule
至此,得到sobel算子运算需要的矩阵,下一步进行处理:
//sobel处理
module sobel(
input wire clk,
input wire rst_n,
input wire Y_de,
input wire Y_hsync,
input wire Y_vsync,
input wire [ 7:0] Y_data,
output wire sobel_de,
output wire sobel_hsync,
output wire sobel_vsync,
output wire [15:0] sobel_data
);
//matrix_3x3 ----------------------------------------
wire [ 7:0] matrix_11 ;
wire [ 7:0] matrix_12 ;
wire [ 7:0] matrix_13 ;
wire [ 7:0] matrix_21 ;
wire [ 7:0] matrix_22 ;
wire [ 7:0] matrix_23 ;
wire [ 7:0] matrix_31 ;
wire [ 7:0] matrix_32 ;
wire [ 7:0] matrix_33 ;
//sobel ---------------------------------------------作为行列的寄存,最终取值
reg [ 9:0] Gx1,Gx3,Gy1,Gy3,Gx,Gy ;
reg [10:0] G ;
//阈值
wire [ 7:0] value ;
//信号同步 ----------------------------------------------
reg [ 3:0] Y_de_r ;
reg [ 3:0] Y_hsync_r ;
reg [ 3:0] Y_vsync_r ;
matrix_3x3_8bit u_matrix_3x3_8bit
(
.clk (clk ),
.rst_n (rst_n ),
.din_vld (Y_de ),
.din (Y_data ),
.matrix_11 (matrix_11 ),
.matrix_12 (matrix_12 ),
.matrix_13 (matrix_13 ),
.matrix_21 (matrix_21 ),
.matrix_22 (matrix_22 ),
.matrix_23 (matrix_23 ),
.matrix_31 (matrix_31 ),
.matrix_32 (matrix_32 ),
.matrix_33 (matrix_33 )
);
//sobel处理
/*
-1 0 +1 +1 +2 +1
gx = -2 0 +2 提取竖直分量边界 gy = 0 0 0
-1 0 +3 -1 -2 -1
*/
//延时1个clk
always @ (negedge rst_n or posedge clk)
begin
// Reset whenever the reset signal goes low, regardless of the clock
if (!rst_n)
begin
Gx1 <= 10'd0;
Gx3 <= 10'd0;
Gy1 <= 10'd0;
Gy3 <= 10'd0;
end
// If not resetting, update the register output on the clock's rising edge
else
begin
Gx1 <= matrix_11 + (matrix_21 << 1) + matrix_31; //矩阵相乘,第一列为x1+2x2+x1,
Gx3 <= matrix_13 + (matrix_23 << 1) + matrix_33;
Gy1 <= matrix_11 + (matrix_12 << 1) + matrix_13;
Gy3 <= matrix_31 + (matrix_32 << 1) + matrix_33;
end
end
// G = |Gx| + |Gy|
//延时1个clk
//取 Gx 、Gy的绝对值
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
Gx <= 10'd0;
Gy <= 10'd0;
end
else begin //也可判断bit[7]来确定
Gx <= (Gx1 > Gx3) ? (Gx1 - Gx3) : (Gx3 - Gx1);
Gy <= (Gy1 > Gy3) ? (Gy1 - Gy3) : (Gy3 - Gy1);
end
end
//得G
//延时1个clk
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
G <= 10'd0;
end
else begin
G <= Gx + Gy;
end
end
//设置判决阈值
assign value = 8'd120;
assign sobel_data = (G > value) ? 16'h0000 : 16'hFFFF;
//== 信号同步
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
Y_de_r <= 4'b0;
Y_hsync_r <= 4'b0;
Y_vsync_r <= 4'b0;
end
else begin
Y_de_r <= {Y_de_r[2:0], Y_de};
Y_hsync_r <= {Y_hsync_r[2:0], Y_hsync};
Y_vsync_r <= {Y_vsync_r[2:0], Y_vsync};
end
end
assign sobel_de = Y_de_r[3];
assign sobel_hsync = Y_hsync_r[3];
assign sobel_vsync = Y_vsync_r[3];
endmodule
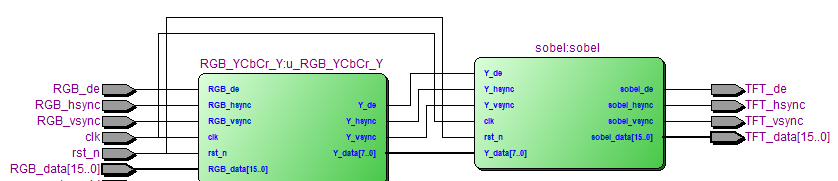
连接模块接口,接入顶层。
三、上板验证

