【图书介绍】《Spark SQL大数据分析快速上手》-CSDN博客
《Spark SQL大数据分析快速上手》【摘要 书评 试读】- 京东图书
本节主要介绍RDD的创建及其处理过程。本节所有实战均在Spark Shell命令行方式下进行。
Spark Shell是Spark提供的一个交互式分析工具,用于快速开发和调试Spark应用程序。它是一个集成了Scala解释器的交互式环境,允许用户直接在Shell中执行Spark操作,无须编写完整的Spark应用程序。
Spark Shell提供了许多内置的函数和变量,例如SparkContext和SparkSession对象,这些对象在启动Spark Shell时会自动创建。用户可以直接使用这些对象来访问Spark的功能,例如读取数据、转换数据、执行计算等。
要启动Spark Shell,首先打开终端或命令行界面,并导航到Spark的安装目录;然后,在终端中输入以下命令:
./bin/spark-shell该命令将启动一个交互式的Scala环境,并自动创建一个SparkContext和SparkSession对象。这样就可以在Shell中输入Scala代码来执行Spark操作。
除了基本的启动方式外,还可以通过指定一些参数来定制Spark Shell的行为。例如,可以使用--master参数来指定Spark集群的地址,使用--executor-memory和--total-executor-cores参数来指定每个执行器的内存和整个集群使用的CPU核数。这些参数可以更好地控制Spark应用程序在集群上的执行。
需要注意的是,如果启动Spark Shell时没有指定master地址,那么Spark Shell将默认启动本地模式,即仅在本机上启动一个进程,而不与集群建立联系。这对于简单的测试和调试非常有用。本节采用本地模式启动。
3.4.1 RDD的创建
Spark可以从Hadoop支持的任何存储源中加载数据去创建RDD,包括本地文件系统和HDFS等文件系统。下面通过Spark中的SparkContext对象调用textFile()方法来加载数据并创建RDD。
(1)从文件系统中加载数据并创建RDD:
scala> val test=sc.textFile("file:///export/data/test.txt")
test: org.apache.spark.rdd.RDD[String]=file:///export/data/test.txt MapPartitionsRDD[1] at textFile at <console>:24(2)从HDFS中加载数据并创建RDD:
scala> val testRDD=sc.textFile("/data/test.txt")
testRDD:org.apache.spark.rdd.RDD[String]=/data/test.txt MapPartitionsRDD[1] at textFile at <console>:24Spark还可以通过并行集合创建RDD,即在一个已经存在的集合数组上,通过SparkContext对象调用parallelize()方法来创建RDD:
scala> val array=Array(1,2,3,4,5)
array: Array[Int]=Array(1,2,3,4,5)
scala> val arrRDD=sc.parallelize(array)
arrRDD: org.apache.spark.rdd.RDD[Int]=ParallelcollectionRDD[6] at parallelize at <console>:263.4.2 RDD的处理过程
Spark用Scala语言实现了RDD的API,开发者可以通过调用这些API对RDD进行操作。RDD每完成一次转换操作,都会生成新的RDD,以供下一次“转换”操作使用。当最后一个RDD遇到“行动”操作时,Spark会根据所有转换操作的依赖关系进行计算,并将最终结果输出到外部数据源,如HDFS、数据库或文件系统等。如果在处理过程中需要复用中间数据结果,可以使用缓存机制将数据暂存于内存中,以提高后续操作的效率。整个处理过程如图3-5所示。
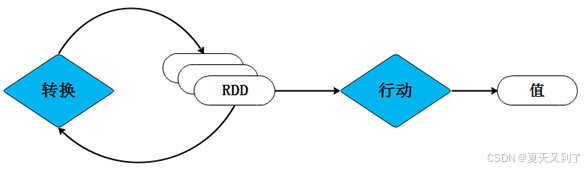
图3-5 RDD的处理过程
