什么是RAG
RAG(Retrieval Augmented Generation,检索增强生成),LLM在回答问题或生成文本时,先会从大量文档中检索出相关的信息,然后基于这些信息生成回答或文本,从而提高预测质量。
R:检索器模块
在RAG中,R代表检索,其作用是从大量知识库中检索出最相关的前k个文档。然而,构建一个高质量的检索器是一项挑战。
如何获取准确的语义表示?
在RAG中,语义空间指的是查询和文档被映射的多维空间。以下是两种构建准确语义空间的方法;
- 块优化
处理外部文档的第一步是分块,已获得更加细致的特征。接着讲这些文档快嵌入。选择分块的策略时,需要考虑被索引内容的特点、使用的嵌入模型及其最适大小、用户查询的预期长度和复杂度、以及检索结果在特定应用中的使用方式。实际上,准确的查询结果是通过灵活应用多种分块策略来实现的,并没有最佳策略,只有最适合的策略。 - 微调嵌入模型
在确定了chunk的适合大小之后,我们需要通过一个嵌入模型将chunk和查询嵌入到的语音空间中。例如UAE、Voyage、BGE等;
如何协调查询和文档的语义空间?
在RAG应用中,有些检索器用同一个嵌入模型来处理查询和文档,而有些则使用不同的模型,此外,用户的原始查询可能表达不清晰或者缺少必要的语义信息。因此,协调用户的查询与文档的语义空间显得尤为重要。因此,协调用户的查询与文档的语义空间显得尤为重要。
1、查询重写
一种直接的方式是对查询进行重写。可以利用大预言模型的能力生成一个指导性的伪文档,形成一个新的查询;也可以通过文本标识符来建立查询向量,利用这些标识符生成一个相关但可能并不存在的“假想”文档,它的目的是捕捉到相关的模式。
2、嵌入变换
在查询编码器后加入一个特殊的适配器,并对其进行微调,从而优化查询的嵌入表示,使之更适合特定的任务。
如何对齐检索模型的输出和大语言模型的偏好?
在RAG流水线中,即使采用了上述技术来提高检索模型的命中率,任然可能无法改善RAG的最终效果,因为检索到的文档可能不符合大语言模型的需求。
大语言模型的监督训练:REPLUG使用检索模型和大语言模型计算检索到的文档的概率分布,然后通过计算KL散度进行训练监督训练。
这种简单而有效的训练方法利用大语言模型作为监督信号,提高了检索模型的性能,消除了特定的交叉注意力机制的需求。
此外,也有一些方法选择在检索模型上外部附加适配器来实现对齐,这是因为微调嵌入模型可能面临一些挑战,比如使用API实现嵌入功能或计算资源不足等。因此一些方法选择在检索模型上外部附加适配器来实现对齐。
除此之外,PKG通过指令微调将知识注入到白盒模型中,并直接替换检索模块,用于根据查询直接输出相关文档。
G:生成器模块
将检索到的信息转换为自己流畅的文本。在RAG中,生成组件的输入不仅包括传统的上下文信息,还有通过检索器得到的相关文本片段。这使得生成组件能够深入地理解问题背后的上下文,并产生更加丰富的回答。此外,生成组件还会根据检索到的文本来指导内容的生成,确保生成的内容与检索到的信息保持一致。
正是因为输入数据的多样性,我们针对生成阶段进行了一些列的有针对性的工作,以便更好的适应来自查询和文档的输入数据。
如何通过后检索处理提升检索结果?
后检索处理指的是,在通过检索器从大型文档数据中检索到相关信息后,对这些信息进行进一步的处理,过滤和优化;
主要的目的是提高检索结果的质量,更好地满足用户需求或为后续任务做准备。
主要的策略是包括信息压缩和结果的重新排列。
如何优化生成器对应的输入数据?
生成器工作:负责将检索到的信息转化为相关文本,形成模型的最终输出;
优化目的:在于确保生成文本即流畅又能有效利用检索文档,更好地回应用户的查询。
RAG的输入不仅包括查询,还涵盖了检索器找到的多种文档(无论是结构化还是非结构化)。一般在将输入提供给微调过的模型之前,需要对检索器找到的文档进行后续处理。
值的注意的是,RAG中对生成器的微调方式与大语言模型的普通微调方法大体相同,包括有通用优化过程以及运用对比学习等。
使用RAG的好处?
RAG方法使得开发者不必为每个塔顶任务重新训练整个大模型,只需要外挂上知识库,即可为模型提供额外的信息输入,提高其回答的准确性。RAG模型尤其适合知识密集型的任务。
- 可扩展性:减少模型大小和训练成本,并允许轻松扩展知识;
- 准确性:通过引入信息来源,用户可以核实答案的准确性,增强了人们对模型输出结果的信任;
- 可控性:允许更新或定制知识;
- 可解释性:检索到的项目作为模型预测中来源的参考;
- 多功能性:RAG可以针对多种任务进行微调和定制,包括QA、文本摘要、对话系统等;
- 及时性:使用检索技术能识别到最新的信息,这使RAG在保持回答的及时性和准确性方面,想驾驭只依赖训练数据的传统语言模型有着明显的优势。
- 定制性:通过索引与特定领域相关的文本语料库,RAG能够为不同领域提供专业的知识支持;
- 安全性:RAG通过数据库中设置角色和安全控制,实现了对数据使用的更好控制。相比之下,经过微调的模型在管理数据访问权限方面可能不够明确。
RAG VS SFT
| RAG | SFT | |
|---|---|---|
| Data | 动态数据;RAG不断查询外部源,确保信息保持最新,而无需频繁的模型重新训练 | 相对静态,并且在动态数据场景中肯呢个很快就会过时。SFT也不能保证记住这些知识 |
| 外部知识 | RAG擅长利用外部资源。通过子啊生成相应之前从知识源检索相关信息来增强LLM能力。它非常适合文档或其他结构化/非结构化数据库 | SFT可以对LLM进行微调以对齐预训练学到的外部知识,但对于频繁更改的数据源来说可能不太实用 |
| 模型定制 | RAG主要关注的信息检索,擅长整合外部知识,但可能无法完全定制模型的行为或写作风格 | SFT允许根据特定的语气或术语调整LLM的行为、写作风格或特定领域的知识 |
| 减少幻觉 | RAG本质上不太容易出现幻觉,因为每个回答都建立在检索到的证据上 | SFT可以通过将模型基于特定领域的训练数据来帮助减少幻觉。当然面对不熟悉的输入时,它任然可以产生幻觉 |
| 透明度 | RAG系统通过将相应生成分解为不同的阶段来提供透明度,提供对数据检索的匹配度以提高对输出的信任 | SFT就是一个黑匣子,使得响应背后的推理更加不透明 |
| 专业技术 | RAG需要高效的检索策略和大型数据库相关技术。另外还需要保持外部数据源集成以及数据更新 | SFT需要准备和整理高质量的训练数据集、定义微调目标以及相应的计算资源 |
介绍一下RAG典型的实现方法
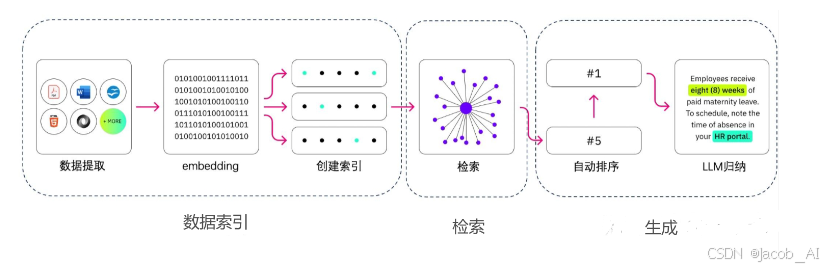
如何构建数据索引?
数据索引一般是一个离线的过程,主要是将私域数据向量化后构建索引并存入数据库的过程。主要包括:数据提取、文本分割、向量化(Embedding)及创建索引等环节。
1、数据获取
即从原始数据到便于处理的格式化数据的过程,具体工程包括:
- 数据获取:包括多格式数据加载、不同数据源获取等,根据数据自身情况,将数据处理为同一个范式;
Doc类:直接解析其实就能够得到文本到底是什么元素,比如标题、表格等,这部分直接将文本段及其对应的属性存储下来,用于后续切分的依据;
PDF类文档:
难点:如何完整的恢复图片、表格、标题、段落等内容,形成一个文字版的文档,
解决方法:使用了多个开源模型进行协同分析,例如版面分析使用了百度的PP-StructureV2,能够对text,title,Footer等进行检测,统一了OCR和文本属性分类两个任务;
PPT类文档:
难点:如何对PPT中大量的流程图,架构原图进行提取,因为这些图多以形状元素在PPT中呈现,如果光提取文字,大量潜藏的信息就完全丢失了;
解决方法:将PPT转换成PDF形式,然后用上述处理PDF的方式来进行解析;
- 数据清洗:对源数据进行去重、过滤、压缩和格式化等处理;
- 信息提取:提取数据中关键信息,包括文件名,时间,章节,图片等信息;
2、文本分割
分割的方式有:
- 句分割:以“句”的粒度进行切分,保留一个句子的完整语义。常见切分的符号包括:句号、感叹号、问号、换行符等等;
- 固定大小的分块方式:根据Embedding模型的token长度限制,将文本分割为固定长度,这种切分方式会损失很多的语义信息,一般通过在头尾增加一定的冗余量来缓解。
- 基于意图的分块方式
句分割:最简单的就是用过句号和换行符来做切分;
递归分割:通过分而治之的思想,用递归切分的方式切分到最小单元;
常用的工具:
LangChain。text_splitter库中的类 CharacterTextSplitter:可以指定分隔符、块大小、重叠和长度函数来拆分文本。
3、向量化
向量化的思想是将文本、图像、音频等转换成为向量矩阵的过程,也就是变成计算机可以理解的格式。
常见的Embedding模型有:chatGPT-embedding ERNIE-embeddingV1 M3E BGE
创建索引:
- 思路:数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程。
- 常用的工具:FAISS、Chroma
如何对数据进行检索?
思路:
- 元数据过滤:当我们把索引分成许多chunks的时候,检索效率会成为问题。这个时候,如果可以通过元数据先进行过滤,就会大大提升效率和相关度;
- 图关系检索:即引入知识图谱,将实体变成为node,把它们之间的关系变成relation,就可以利用知识之间的关系做更准确的回答。特别是针对一些多跳问题,利用图数据检索,让检索的相关度变得更高;
- 检索技术:
向量化相似度检索:相似度计算方式包括欧氏距离、曼哈顿距离、余弦相似等;
关键词检索:这是一种传统的检索方式,元数据过滤也是一种,还有一种就是先把chunk做摘要,在通过关键词检索找到可能相关的chunk,增肌检索的效率;
全文检索
SQL检索:更加传统的检索算法。
- 重排序(Rerank):相关度、匹配度等因素做一些重新的调整,得到更符合业务场景的排序;
- 查询轮换:这是查询检索的一种方式,一般会有几种方式:
子查询:可以再不同的场景中使用各种查询策略,比如可以使用LLaMAIndex等框架提供的自查询器,采用树查询chunks等;
HyDE:这是一种抄作业的方式,生成相似度或者更标准的Prompt模板;
RAG经典的案例
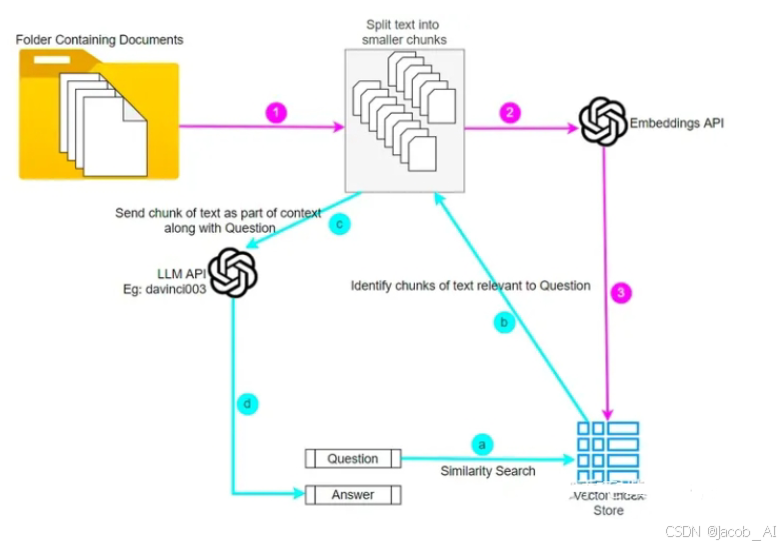
ChatPDF
其流程如下所示:
1、ChatPDF首先会对读取到PDF文件,将其准换为可处理的文本格式,例如条TXT等;
2、ChatPDF会对提取出来的文本进行清洗和标准化,例如去除特殊字符、分段、分句等,以便用于后续的处理。这一步可以使用自然语言处理技术,如正则表达式等;
3、ChatPDF使用OpenAI的Embedding API将每个分段转换为向量,这个向量将对文本中的语义进行编码,以便于与问题的向量进行比较;
4、当用户提出问题时,ChatPDF使用OpenAI的Embedding API将问题转换为一个向量,并于每个分段的向量进行比较,找到最相似的分段。这个相似度计算可以使用余弦相似度等常见的方法进行比较;
5、ChatPDF将找到的最相似的分段与问题作为Prompt,调用OpenAI的Completion API让ChatGPT 学习分段内容后在进行回答;
6、ChatPDF会将ChatGPT生成的答案返回给用户,完成一次查询。
RAG存在什么问题?
- 检索效果依赖Embedding和检索算法:目前可能检索到无关信息,反而对输出有负面影响;
- 大模型如何利用检索到的信息任然是黑盒的。可能存在不准确(甚至是生成的文本与检索信息相冲突);
- 对所有任务都无差别检索k个文本片段,效率不高,同时会大大增加模型输入的长度;
- 无法引用来源,也因此无法准确地查证事实,检索的真实性取决于数据源及检索算法;