大家好,我是数据分析小兵,小兵今天为大家介绍Flink及Spark两种大数据处理引擎的概念、特点与不同,本文重点是针对计算模式(流计算、批计算)和容错机制两个重要特性,尝试通过通俗易懂的文字举例分析,来讲清楚在什么情况下适合选择Flink和Spark。
01 Spark VS Flink概述
Apache Spark ,是一个统一的、快速的分布式计算引擎,能够同时支持批处理与流计算,充分利用内存做并行计算,官方给出Spark内存计算的速度比MapReduce快100倍。因此可以说作为当下最流行的计算框架,Spark已经足够优秀了。
Apache Flink 是一个分布式大数据计算引擎,是一个Stateful Computations Over Streams,即数据流上的有状态的计算,被定义为下一代大数据处理引擎,发展十分迅速并且在行业内已有很多最佳实践。
02 Spark VS Flink发展历史
Spark由加州大学伯克利分校AMPLab于2009年启动,并于2010年成立Apache开源基金会。Spark的目标是解决Hadoop的瓶颈问题,通过内存计算和数据分片处理等方法提高大数据处理的效率和性能。2014 年 2 月,Spark 成为 Apache 的顶级项目。
Flink是Apache软件基金会的一个顶级项目,是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架,并且可以同时支持实时计算和批量计算。Flink起源于Stratosphere 项目,该项目是在2010年到2014年间由柏林工业大学、柏林洪堡大学和哈索普拉特纳研究所联合开展的,开始是做批处理,后来转向了流计算。
2014年12月,Flink项目成为Apache软件基金会顶级项目。目前,Flink是Apache软件基金会的5个最大的大数据项目之一,在全球范围内拥有350多位开发人员,并在越来越多的企业中得到了应用。在国外,优步、网飞、微软和亚马逊等已经开始使用Flink。在国内,包括阿里巴巴、美团、滴滴等在内的知名互联网企业,都已经开始大规模使用Flink作为企业的分布式大数据处理引擎。
03 Spark VS Flink技术栈
Spark技术栈
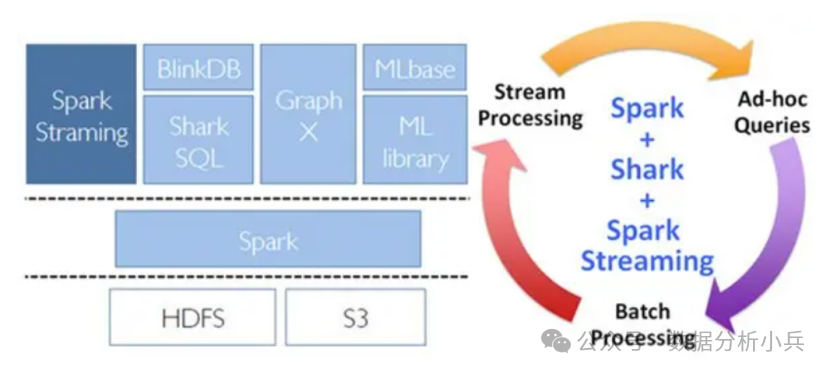
支持从多种数据源获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis 以及TCP sockets,从数据源获取数据之后,可以 使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果 存储到文件系统,数据库和现场 仪表盘。在“One Stack rule them all”的基础上,还可以使用Spark的其他子框架,如集群学习、图计算等,对流数据进行处理。
Flink技术栈
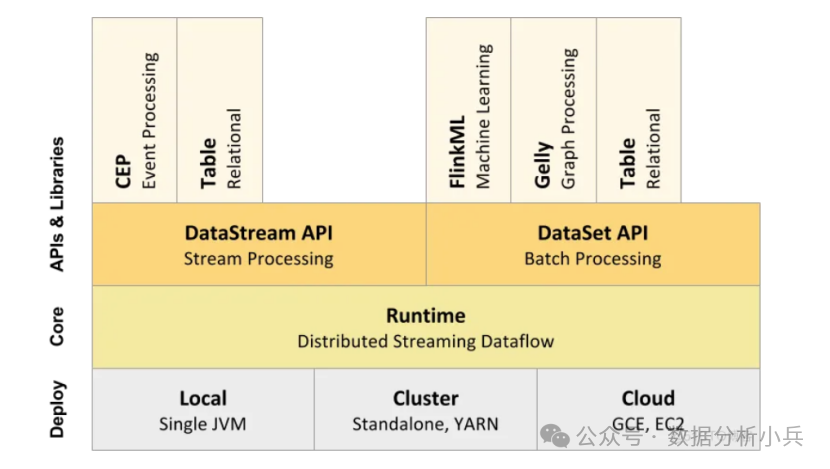
Flink与Spark类似,同样提供了多种编程模型,从流计算到批处理,再到结构化数据处理以及机器学习、图计算等。
lDataStreamAPl DataSetAP!:这是Fink核心的编程模型,这两套AP!分别面向流处理与批处理,是构建在有状态流处理以及Runtime之上的高级抽象,供大部分业务逻辑处理使用。
lTabIe API& SQL: Table API& SQL是以DataStream AP!和 DataSetAP!为基础面向结构化数据处理的高级抽象,提供类似于关系型数据库的Table和SQL查询功能,能够简单方便的操作数据流。
lCEP:是DataStream APl/DataSetAPI的另一个高级抽象,是一个面向复杂事件处理的库。
lFlinkML:Flink机器学习库,批处理API的高级封装,提供可扩展的ML算法、直观的API和工具。
lGelly:Flink图计算的库,也是在批处理API基础上做的一层封装,提供了创建、转换和修改图的方法以及图算法库。
04 Spark VS Flink技术特点
Spark特点:
l高性能,与 Hadoop 的 MapReduce 相比,Spark 基于内存的运算要快 100 倍以上,基于硬盘的运算也要快 10 倍以上。Spark 实现了高效的 DAG 执行引擎,可以通过基于内存来高效处理数据流。
l易用性,Spark 支持 Java、Python、R 和 Scala 的 API,还支持超过 80 种高级算法,使用户可以快速构建不同的应用。
l通用性,Spark 提供了统一的解决方案。Spark 可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。
l兼容性,Spark 可以非常方便地与其他的开源产品进行融合。比如,Spark 可以使用 Hadoop 的 YARN 和 Apache Mesos 作为它的资源管理和调度器,并且可以处理所有 Hadoop 支持的数据,包括 HDFS、HBase 和 Cassandra 等。这对于已经部署 Hadoop 集群的用户特别重要因为不需要做任何数据迁移就可以使用 Spark 的强大处理能力。
Flink特点:
l高容错性,Flink提供了容错机制,可以恢复数据流应用到一致状态。该机制确保在发生故障时,程序的状态最终将只反映数据流中的每个记录一次,也就是实现了“精确一次”(exactly -once)的容错性。Flink的容错机制不断地创建分布式数据流的快照,通过异步快照来确保数据状态的一致性。
l丰富的状态管理,流处理应用需要在一定时间内存储所接收到的事件或中间结果,以供后续某个时间点访问并进行后续处理。Flink提供了丰富的状态管理相关的特性支持。
l同时支持高吞吐、低延迟、高性能,高吞吐、高性能、低时延的实时流处理引擎,能够提供ms级时延处理能力。
l丰富的时间语义支持,时间是流处理应用的重要组成部分,对于实时流处理应用来说,基于时间语义的窗口聚合、检测、匹配等运算是非常常见的。Flink提供了丰富的时间语义支持。
05 Spark VS Flink应用场景分析
5.1 计算模式分析
首先我们先通过两个例子来介绍一下流计算和批计算的特点。
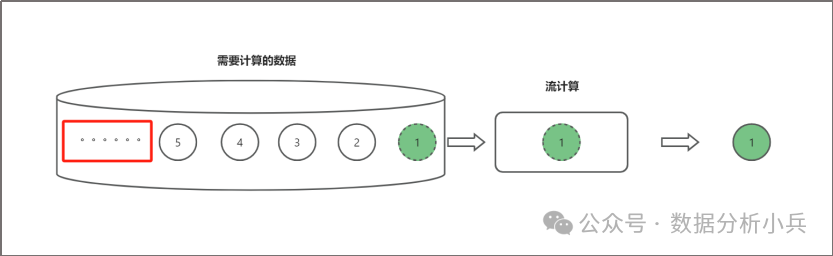
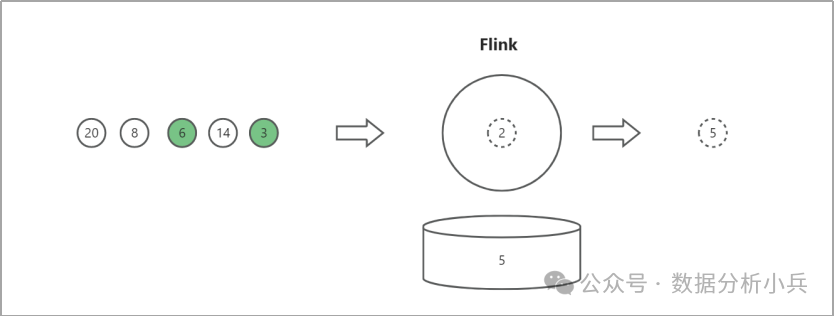
流计算的特点是我在处理一条数据的时候,无法预知未来还有多少数据,而且这个数据的总量是不确定的,有可能有无穷无尽的数据,也有可能到某个点就没有了。如上图所示,我们不知道数据“5”后面还有没有数据,还有多少条数据。
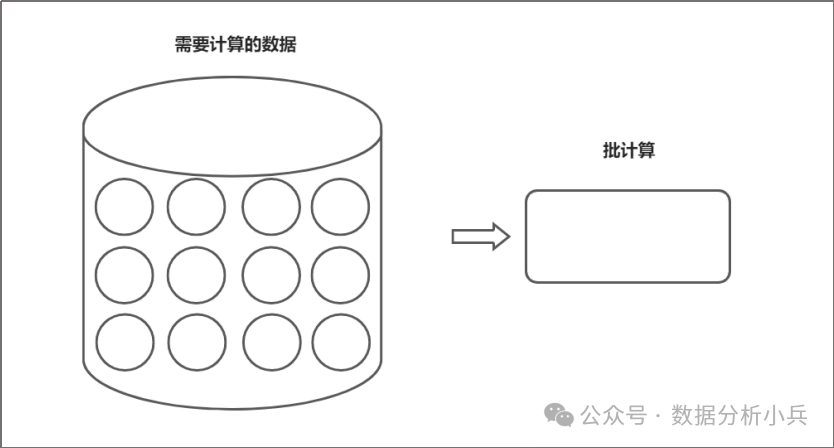
而批计算之所以叫批计算,就是因为在我处理的那一瞬间,或者说在我程序启动的那一瞬间有多少数据是已经确定了的,它是不会再变了的。如上图,需要计算的数据是12条,那在整个处理生命周期里面就是这12条数据,不会再改变。
这样的不同的特点带来的影响就是不同的计算模式,他的计算实现策略也不相同,我们举一个批计算的例子:我们来做一个分组聚合的计算,统计下图中有多少绿色球,多少白色球。
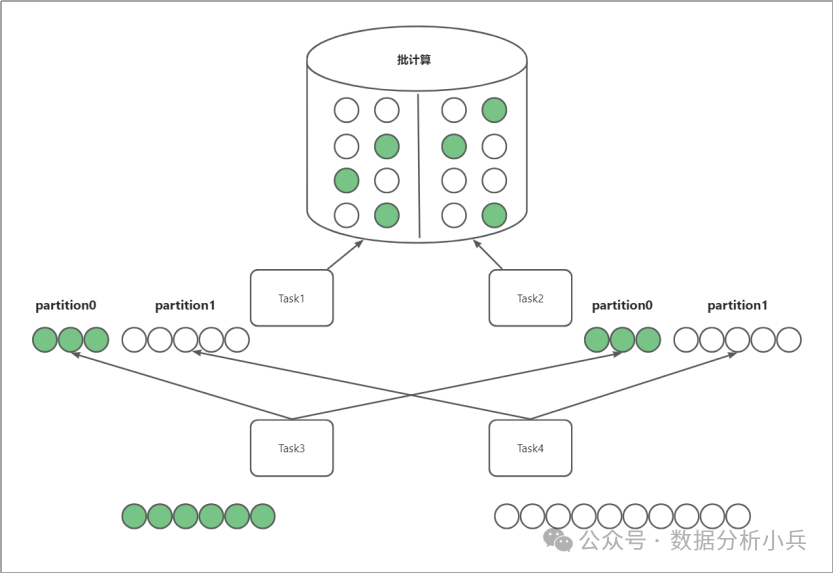
我们要怎么来实现呢?
-
因为是分布式批计算,所以这次计算任务他要计算的数量是固定且已知的,我们可以建立两个分布式任务Task1和Task2,分别去读左半边和右半边数据,将取到的绿色球存在partition0,白色球存在partition1,并落地存储为一个文件。
-
当Task1和Task2对所有的数据做完处理并存储为数据文件后,再让Task3和Task4分别去取partition0和partition1数据并求和,就算出了绿色球和白色球的数量。
-
注意一个细节,Task3和Task4是需要等他的上游任务将所有数据处理完并形成文件后再去读数据,但如果数据是动态的,我们不知道有多少数据,还能这样去计算么?答案显然是不能的。因为这样的特性,批计算可以在上游任务设计一些策略进行一些预处理,比如Task1和Task2在取完数据后,对绿色球和白色球分别做一个求和,提前计算出数量,通过这些策略来优化计算性能,但是流计算是不能采用这样的策略的。
总结:Spark和Flink都是批流一体的计算引擎,但是Spark更适合做批计算,而Flink更适合做流计算。Spark 适合于吞吐量比较大的场景,数据量非常大而且逻辑复杂的批数据处理,并且对计算效率有较高要求(比如用大数据分析来构建推荐系统进行个性化推荐、广告定点投放等)。Flink 主要用来处理要求低延时的任务,实时监控、实时报表、流数据分析和实时仓库。Flink可以用于事件驱动型应用,数据管道,数据流分析等。
5.2 容错机制分析
上面提到了,sparkstreaming也是可以做流计算的,包括Storm也可以,那我们为什么说Flink最适合做流计算呢,就是因为Flink提供了很强的容错机制,接下来我们就举几个简单的例子来分析一下Flink的容错机制,这也是Flink最为核心的特点之一。
-
复杂的计算需要记录变量
首先,我们做复杂计算时需要记录变量,举个例子,我们要分别统计白色数据和绿色数据的最大值,如下图所示:
当处理完白色数据“5”之后,因为“5”是处理的第一个数据,所以需要在缓存记录当前的最大值为5,这样再处理下一个数据“2”的时候,才能够就进行比较。
-
Flink采用STATE组件记录变量
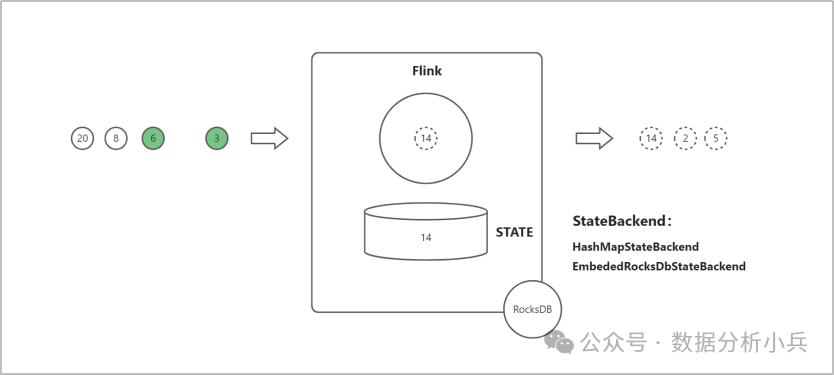
有的朋友可能会说了,不就是记录个变量么?其他的流计算引擎也可以,你为什么说Flink更强?那是因为Flink提供了非常强大的状态容错能力。还是上面的例子,大家想一下,虽然我记录了变量,但是如果是记录在内存里,系统一旦挂掉,这些变量是不是就没有了,这样再计算出来的结果很可能就是错误的。而Flink提供STATE组件来记录变量,如下图。
Flink的STATE组件提供了两种状态后端,分别是HashMapStateBackend和EmbededRocksDbStateBackend。
HashMapStateBackend,将变量记录在内存的一张数据表中;
EmbededRocksDbStateBackend,会将变量记录在Flink内嵌的一个数据库RocksDB中,而RocksDB会将变量存储在本地磁盘上。
-
Flink通过异步快照机制保证语义的一致性
有的朋友肯定又有疑惑了,你说的这HashMapStateBackend不也是存在内存里么?系统挂了还不是会丢失状态值?这里就要介绍一下Flink的checkpoint(快照)机制了。还是先来看一个例子,我们要求一组数据中的最大值,如下图:
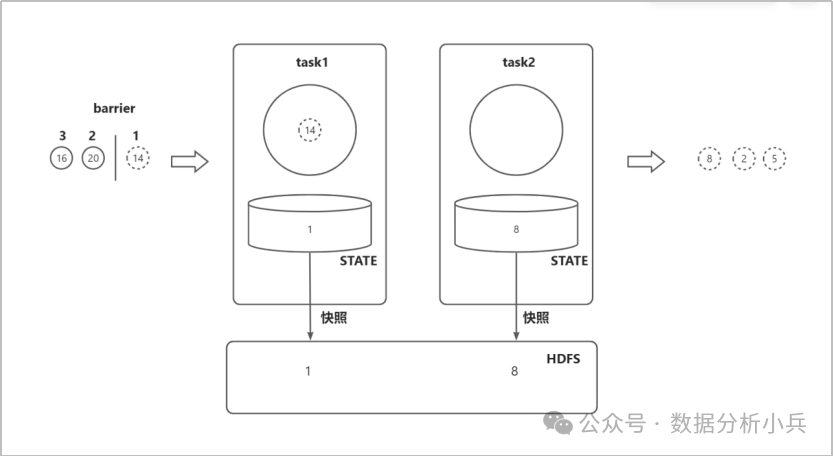
我们创建2个任务,task1负责读取数据,通过STATE记录数据偏移量后传送给task2,task2负责计算最大值。通过barrier和快照来保证语义的一致性。
-
首先,我们假设task1读取了数据“14”,那么task1的state偏移量将变为1;
-
接下来task2计算数据“14”,并将task2的state最大值更新为14。注意这个时候barrier被task1读取,会对state偏移量进行快照,将偏移量1的快照存入HDFS;
-
Task1继续读取数据“20”,将task1的state偏移量将变为2,而task2读取到了barrier,会对state最大值进行快照,将最大值14的快照存入HDFS,此时的状态如下图:
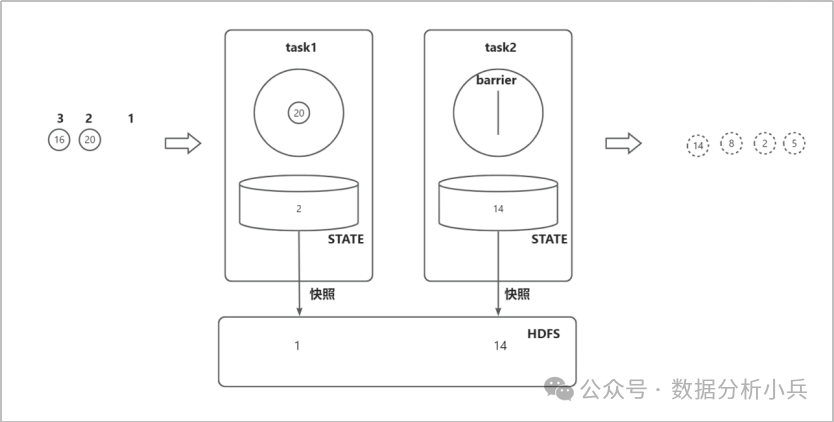
那我们假设这个时候系统挂掉了,重启后task1的state将加载偏移量1,而task2的state将加载最大值14。接下来task1将重新读取数据“20”,这样就确保了最后计算的最大值是没有问题的,因为task1和task2的state都是处理了相同的数字(“5”“2”“8”“14”)后的状态,这就是Flink通过异步快照机制实现的语义一致和高容错性。
小兵今天通过举例重点介绍了计算模式和容错机制两个特性,结论就是如果您的业务场景大部分是批计算,那就选择Spark;如果大部分场景需要流计算就选择Flink,Flink提供了更为强大的容错机制。
参考资料:
《Flink编程基础(Scala版)》--林子雨编著
Apache 流框架 Flink,Spark Streaming,Storm对比分析--网易数帆
大数据之Spark--浊酒南街
实战Flink+Doris实时数仓