169期《YOLO-World Real-Time Open-Vocabulary Object Detection》
You Only Look Once (YOLO) 系列检测模型是目前最常用的检测模型之一。然而,它们通常是在预先定义好的目标类别上进行训练,很大程度上限制了它们在开放场景中的可用性。为了解决这一限制,本文引入了 YOLO-World,通过视觉语言建模和大规模数据集的预训练来增强 YOLO,具有开集检测能力。具体来说,本文提出了一种新的重参数化视觉语言路径聚合网络(RepVL-PAN)和区域-文本对比损失,以促进视觉和语言信息之间的交互。本文提出的方法在具有挑战性的LVIS数据集上取得了35.4AP的精度,V100上取得了52的FPS,在精度和速度方面都优于许多最先进的方法。此外,微调后的 YOLO-World 在几个下游任务(包括对象检测和开放词汇实例分割)上均取得了显著的性能。具体贡献可以总结为:
- YOLO-World 是下一代YOLO检测器,旨在实现实时开放词汇目标检测。
- YOLO-World 是在大型视觉语言数据集上进行预训练的,包括 Objects365、GQA、Flickr30K和CC3M,这为YOLO-World提供了强大的零样本开放词汇能力和图像基础能力。
- YOLO-World 实现了快速的推理速度,本文提出了重参数化技术,以在给定用户词汇的情况下实现更快的推理和部署。
- YOLO-World 项目链接:https://www.yoloworld.cc/
1. Framework
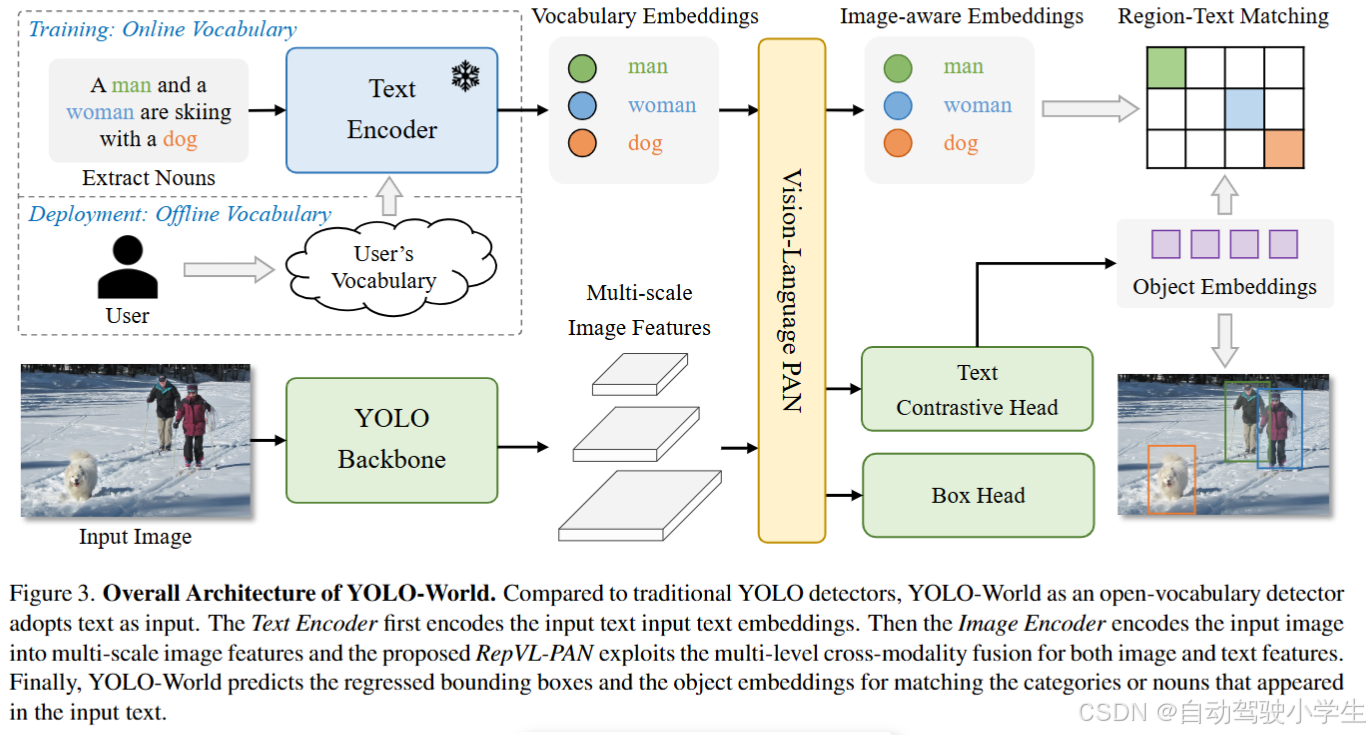
YOLO-World模型框图如下所示,可分为几个模块:
- YOLO-World 使用CLIP作为文本编码器构建YOLO检测器,用于从输入文本中提取文本嵌入,例如对象类别或名词短语。
- YOLO-World 包含一个重参数化的视觉语言路径聚合网络(RepVL-PAN),以促进多尺度图像特征和文本嵌入之间的交互。RepVL-PAN 可以将用户的离线词汇表重参数化为模型参数,以便快速推理和部署。
- YOLO-World在具有区域文本对比损失的大规模区域文本数据集上进行预训练,以学习视觉和语言之间的区域级对齐。对于正常的图像文本数据集,例如CC3M,本文采用自动标注方法来生成伪区域文本对。
2. Performance
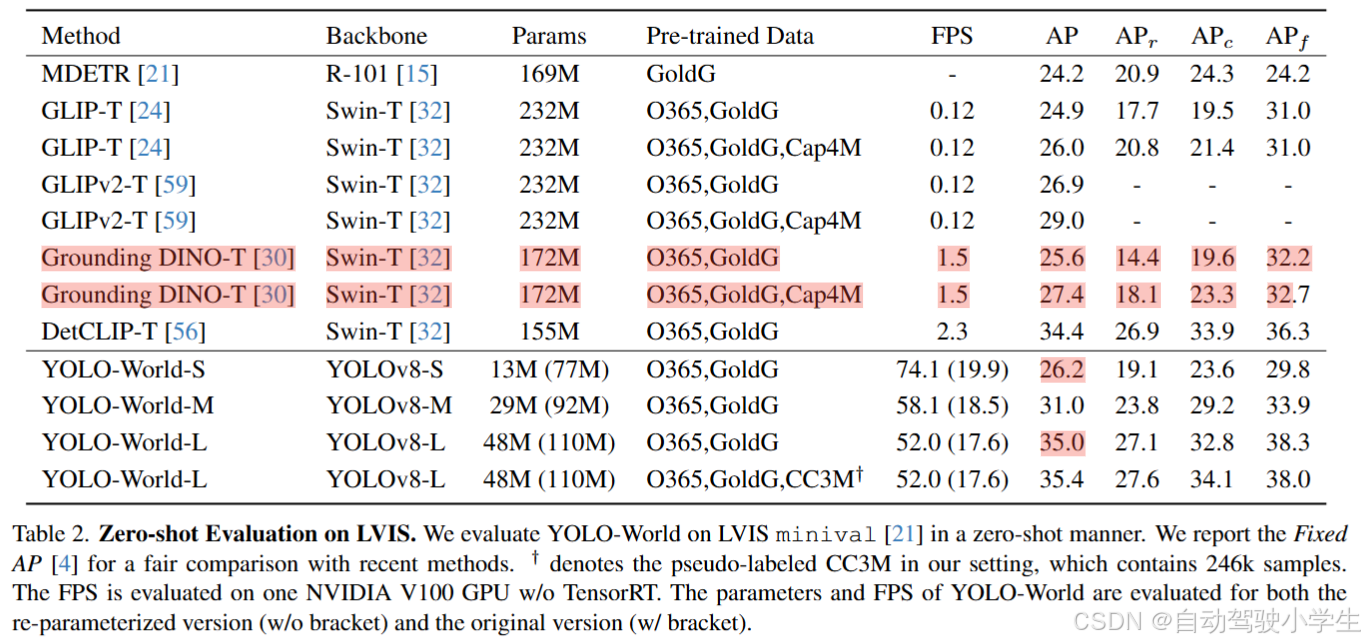
下表是YOLO-World模型在LVIS数据集上零样本检测能力,可以看到AP均超过先前的检测模型,而在运行速度上提高了几十倍,达到了实时性。
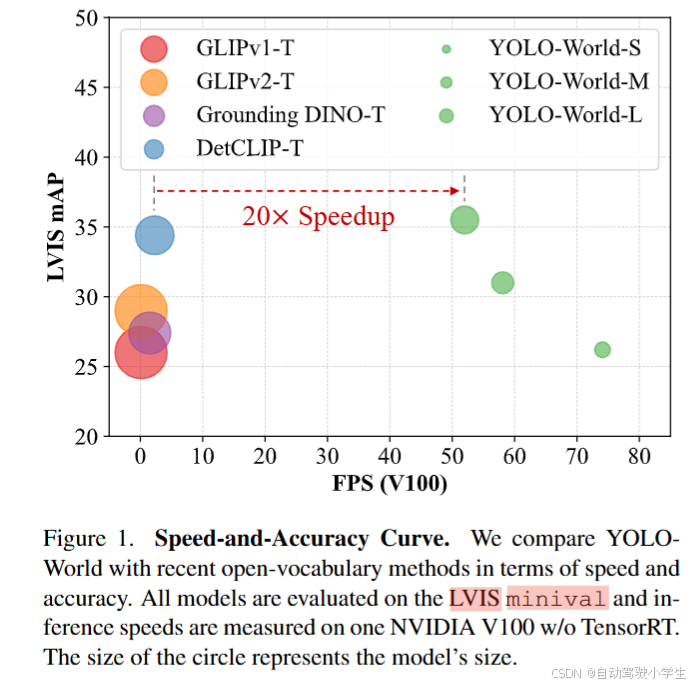
下面是YOLO-Wold检测模型和其它开集检测模型推理速度的对比。
下面是一些可视化效果展示:
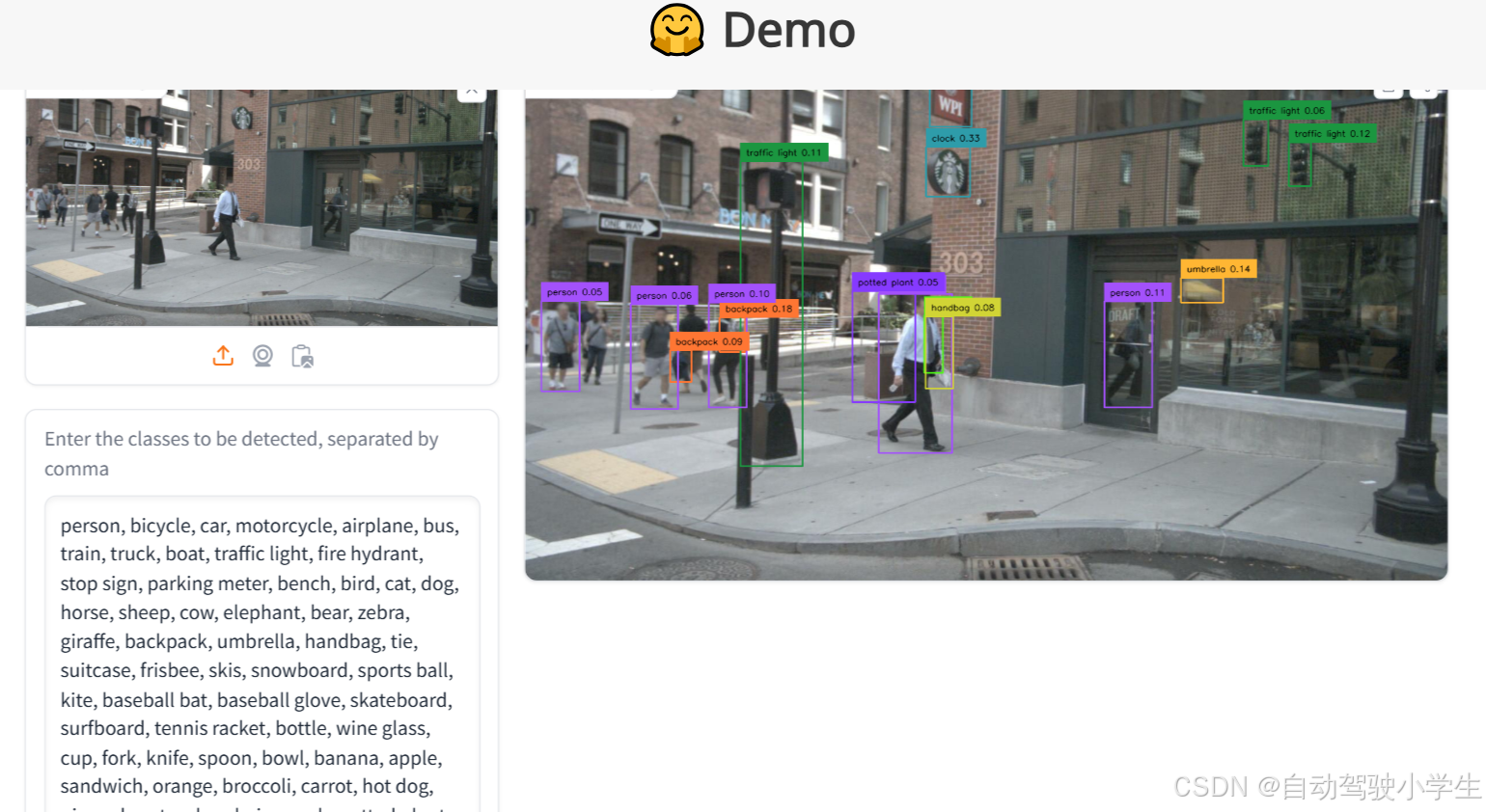
下面是网页在线Demo检测效果,大家可以在线体验下。