说说React中onClick绑定后的工作原理
- 首先react有自己的事件系统,也是遵循w3c的,这个事件系统的名称叫做合成事件(SyntheticEvent),而其自定义事件系统的动机主要包含以下几个方面
- 抹平不同浏览器之间的兼容性差异。最主要的动机。
- 件合成既可以处理兼容性问题
- 提供一个抽象的跨平台事件机制
- 可以做更多优化
- 可以干预事件的分发
- 当给组件(元素)绑定
onClick事件之后- react会对事件先进行注册,将事件统一注册到
document上 - 根据组件
唯一的标识key来对事件函数进行存储 - 统一的指定
dispatchEvent回调函数 - 储存事件回调:
react会将click这个事件统一存到一个对象中,回调函数的存储采用键值对(key/value)的方式存储在对象中,key 是组件的唯一标识 id,value 对应的就是事件的回调函数,通过组件的key就能回调到相应的函数了
- react会对事件先进行注册,将事件统一注册到
说说react里面bind与箭头函数
- bind 由于在类中,采用的是
严格模式,所以事件回调的时候会丢失this指向,指向undefined,需要使用bind来给函数绑定上当前实例的this指向 箭头函数的this指向上下文,所以永久能拿到当前组件实例的this指向,我们可以完美的使用箭头函数来替代传统事件处理函数的回调
说说react中的性能优化
性能优化分为2个方面
- 使用shouldComponentUpdate来对state和props进行对比,如果两次的结果一直,那么就return false
- 使用纯净组件,pureComponent
高阶组件和高阶函数是什么
- 高阶函数:函数接收一个函数作为参数,或者将函数作为返回值的函数就是高阶函数 map some every filter reduce find forEach等等都属于高阶函数
- 高阶组价:接受一个组件,返回一个新组建的组件就是高阶组件,本质上和高阶函数的意思一样
- 高阶组件是用来复用react代码的一种方式
setState和repalceState的区别
setState 是修改其中的部分状态,相当于 Object. assign,只是覆盖,不会减少原来的状态; replaceState 是完全替换原来的状态,相当于赋值,将原来的 state 替换为另一个对象,如果新状态属性减少,那么 state 中就没有这个状态了
redux中核心组件有哪些,reducer的作用
redux 三大核心
- action action理解为动作,action的值一般为一个对象,格式如 { type: “”, data: “” },type是必须要的,因为reducer处理数据的时候要根据不同的type来进行不同的操作
- reducer reducer是初始化以及处理派发的action的纯函数
- store store是一个仓库,用来存储数据,它可以获取数据,也可以派发数据,还能监听到数据的变化
reducer的作用
接收旧的 state 和 action,返回新的 state
什么是受控组件
受控组件就是可以被 react 状态控制的组件
在 react 中,Input textarea 等组件默认是非受控组件(输入框内部的值是用户控制,和React无关)。但是也可以转化成受控组件,就是通过 onChange 事件获取当前输入内容,将当前输入内容作为 value 传入,此时就成为受控组件。
hooks+context和redux你是怎么选择的,都在什么场景下使用
如果项目体量较小,只是需要一个公共的store存储state,而不讲究使用action来管理state,那context完全可以胜任。反之,则是redux的优点。
使用场景:
如果你在组件间传递的数据逻辑比较复杂,可以使用redux;
如果组件层级不多,可以使用props;
如果层级较深,数据逻辑简单,可以使用context。
useffect 模拟生命周期
- 模拟componentDidMount
第二个参数为一个空数组,可以模拟componentDidMount
componentDidMount:useEffect(()=>{console.log('第一次渲染时调用')},[])
- 模拟componentDidUpdate
没有第二个参数代表监听所有的属性更新
useEffect(()=>{console.log('任意状态改变')})
监听多个属性的变化需要将属性作为数组传入第二个参数。
useEffect(()=>{console.log('指定状态改变')},[状态1,状态2...])
- 模拟componentWillUnmount
useEffect(()=>{ ... return()=>{ //组件卸载前} })
setsate更新之后和usestate的区别
-
setState( updater [,callback] )
updater:object/function - 用于更新数据
callback:function - 用于获取更新后最新的 state 值构造函数是唯一建议给 this.state 赋值的地方
不建议直接修改 state 的值,因为这样不会重新渲染组件
自动进行浅合并(只会合并第1层)
由于 setState() 异步更新的缘故,依赖 state 旧值更新 state 的时候建议采用传入函数的方式 -
useState(initState)
const [ state , setState ] = useState(initState)
state:状态
setState(updater) :修改状态的方法
updater:object/function - 用于更新数据
initState:状态的初始值
react父组件props变化的时候子组件怎么监听
当props发生变化时执行,初始化render时不执行,在这个回调函数里面,你可以根据属性的变化,通过调用this.setState()来更新你的组件状态,旧的属性还是可以通过this.props来获取,这里调用更新状态是安全的,并不会触发额外的render调用
//props发生变化时触发
componentWillReceiveProps(props) {
console.log(props)
this.setState({show: props.checked})
}
usememo在react中怎么使用
返回一个 memoized 值。
把“创建”函数和依赖项数组作为参数传入 useMemo,它仅会在某个依赖项改变时才重新计算 memoized 值。这种优化有助于避免在每次渲染时都进行高开销的计算。
传入 useMemo 的函数会在渲染期间执行。请不要在这个函数内部执行与渲染无关的操作,诸如副作用这类的操作属于 useEffect 的适用范畴,而不是 useMemo。
如果没有提供依赖项数组,useMemo 在每次渲染时都会计算新的值。
你可以把 useMemo 作为性能优化的手段,但不要把它当成语义上的保证。将来,React 可能会选择“遗忘”以前的一些 memoized 值,并在下次渲染时重新计算它们,比如为离屏组件释放内存。先编写在没有 useMemo 的情况下也可以执行的代码 —— 之后再在你的代码中添加 useMemo,以达到优化性能的目的。
React Hooks各种函数介绍
-
useState:
useState 是用于声明一个状态变量的,用于为函数组件引入状态.
useState 只接收一个参数,这个参数可以是数字、字符串、对象等任意值,用于初始化声明的状态变量。也可以是一个返回初始值的函数,最好是函数,可在渲染时减少不必要的计算。
返回一个长度为2的读写数组,数组的第一项是定义的状态变量本身,第二项是一个用来更新该状态变量的函数,约定是 set 前缀加上状态的变量名.
useState Hook 中返回的 setState 并不会帮我们自动合并对象状态的属性;
setState 中接收的对象参数如果地址没变的话会被 React 认为没有改变,因此不会引起视图的更新 -
useReducer:
useReducer 是 useState 的升级版。在 useState 中返回的写接口中,我们只能传递最终的结果,在 setN 的内部也只是简单的赋值操作。
创建初始状态值initialState,
创建包含所有操作的 reducer(state, action) 函数,每种操作类型均返回新的 state 值
根据 initialState 和 reducer 使用 const [state, dispatch] = useReducer(reducer, initialState) 得到读写 API
调用写接口,传递的参数均挂在 action 对象上
-
useContext:
context 是上下文的意思,上下文是局部的全局变量这个局部的范围由开发者自己指
-
useEffect:
effect 是副作用的意思,对环境的改变就是副作用。副作用是函数式编程里的一个概念
在 React 中,useEffect 就是在每次 render 后执行的操作,相当于 afterRender, 接收的第一个参数是回调函数,第二个参数是回调时机。可用在函数组件中模拟生命周期。如果同时出现多个 useEffect ,会按出现顺序依次执行
-
useLayoutEffect
useEffect 总是在浏览器渲染完视图过后才执行,如果 useEffect 里面的回调函数有对 DOM 视图的操作,则会出现一开始是初始化的视图,后来执行了 useEffect 里的回调后立马改变了视图的某一部分,会出现一个闪烁的状态。
为了避免这种闪烁,可以将副作用的回调函数提前到浏览器渲染视图的前面执行,当还没有将 DOM 挂载到页面显示前执行 Effect 中对 DOM 进行操作的回调函数,则在浏览器渲染到页面后不会出现闪烁的状态。layout 是视图的意思,useLayoutEffect 就是在视图显示出来前执行的副作用。
useEffect 和 useLayoutEffect 就是执行的时间点不同,useLayoutEffect 是在浏览器渲染前执行,useEffect 是在浏览器渲染后执行。但二者都是在 render 函数执行过程中运行,useEffect 是在 render 完毕后执行,useLayoutEffect 是在 render 完毕前(视图还没渲染到浏览器页面上)执行。
因此 useLayoutEffect 总是在 useEffect 前执行。
一般情况下,如果 Effect 中的回调函数中涉及到 DOM 视图的改变,就应该用 useLayoutEffect,如果没有,则用 useEffect。
-
useRef
useRef Hook 是用来定义一个在组件不断 render 时保持不变的变量。
组件每次 render 后都会返回一个虚拟 DOM,组件内对应的变量都只属于那个时刻的虚拟 DOM。
useRef Hook 就提供了创建贯穿整个虚拟 DOM 更新历史的属于这个组件的局部的全局变量。
为了确保每次 render 后使用 useRef 获得的变量都能是之前的同一个变量,只能使用引用做到,因此,useRef 就将这个局部的全局变量的值存储到了一个对象中,属性名为:currentuseRef 的 current 变化时不会自动 render
useRef 可以将创建的 Refs 对象通过 ref 属性的方式引用到 DOM 节点或者 React 实例。
-
useCallback
是将某个函数“放入到react底层原型链上,并返回该函数的索引”,而useMemo是将某个函数返回值“放入到react底层原型链上,并返回该返回值的索引”。一个是针对函数,一个是针对函数返回值。
-
useImperativeHandle
useImperativeHandle可以让父组件获取并执行子组件内某些自定义函数(方法)。本质上其实是子组件将自己内部的函数(方法)通过useImperativeHandle添加到父组件中useRef定义的对象中。
-
useMemo
useMemo可以将某些函数的计算结果(返回值)挂载到react底层原型链上,并返回该函数返回值的索引。当组件重新渲染时,如果useMemo依赖的数据变量未发生变化,那么直接使用原型链上保存的该函数计算结果,跳过本次无意义的重新计算,达到提高组件性能的目的。
React Component和Purecomponent区别
Component 没有直接实现 shouldComponentUpdate 这个方法;但是 PureComponent通过浅层的Porps 和 state 的对比,内部实现了这个生命周期函数。
PureComponent会跳过整个组件子树的props更新,要确保全部的子组件也是 pure 的形式。
Component 中需要手动执行的 shouldComponentUpdate 函数,在PureComponent中已经自动完成了(自动浅对比)。
PureComponent不仅会影响本身,而且会影响子组件,所以PureComponent最好用在数据展示组件中
PureCoponent 如果是复杂数据类型,这里会造成错误的显示(setState浅复制更新,但是界面不会重新渲染)
hooks相对于class的优化
类组件缺点一:复杂且不容易理解的“this”
Hooks解决方式:函数组件和普通JS函数非常相似,在普通JS函数中定义的变量、方法都可以不使用“this.”,而直接使用该变量或函数,因此你不再需要去关心“this”了。
类组件缺点二:组件数据状态逻辑不能重用
Hooks解决方式:
通过自定义Hook,可以数据状态逻辑从组件中抽离出去,这样同一个Hook可以被多个组件使用,解决组件数据状态逻辑并不能重用的问题。
类组件缺点三:组件之间传值过程复杂、缺点三:复杂场景下代码难以组织在一起
Hooks解决方式:
通过React内置的useState()函数,可以将不同数据分别从"this.state"中独立拆分出去。降低数据复杂度和可维护性,同时解决类组件缺点三中“内部state数据只能是整体,无法被拆分更细”的问题。
通过React内置的useEffect()函数,将componentDidMount、componentDidUpdate、componentWillUncount 3个生命周期函数通过Hook(钩子)关联成1个处理函数,解决事件订阅分散在多个生命周期函数的问题。
hooks父组件怎么调用子组件的方法
父组件使用 useRef 创建一个 ref 传入 子组件
子组件需要使用 useImperativeHandle 暴露 ref 自定义的实例值给父组件。这个需要用 forwardRef 包裹着。
讲一下react中的通信
1 父子通信, 使用的时候 在子组件上面自定义属性,子组件通过 this.props[累组件]或者props[函数组件]接收然后使用
子组件
class Son extends React.Component {
render(){
// this.props.til til 为父组件传递数据
return <div>...</div>
}
}
父组件
class Home extends React.Component {
render(){
return <>
<Son til="参数" />
</>
}
}
2 子父通信 ,使用的时候其实还是父传子,只不过这次将父组件的方法传递给子组件,然后子组件去调用父组件传递的方法,通过传递实参的我方式将子组件的数据传递过来
class Son extends React.Component {
render(){
// this.props.til til 为父组件传递数据
return <div onClick={()=>this.props.onData('传递的数据')}>...</div>
}
}
父组件
class Home extends React.Component {
getData=(data)=>{
//data就是接收的参数。可以在里面来使用
}
render(){
return <>
<Son onGetData={this.getData}/>
</>
}
}
3 状态提升,这种情况将两个组件通过同一个父组件来包裹,将数据绑定到父组件上,然后通过子父和父子进行通信
4 context传递 , 利用Context对象来传递,Context 提供了 Provider 和 Consumer 俩个组件,Provider负责提供数据,Consumer负责使用数据 , Provider需要包裹父组件,那么所有它的子代组件都可以获取到共享值,实际上react-router,react-redux 等等都在使用context
const Context = React.Contexxt('这里是默认值');
// App组件里面
class App extends React.Component {
render(){
return <>
<Context.Provider value={data ‘传递的数据’} >
<Home /> // 只要是home的组件的子代组件都可以获取到传餐
<Context.Provider>
</>
}
}
// Home 组件
class Home extends React.Component {
render(){
return <>
<Son />
<Context.Consumer>
{
data=> data就可以拿到数据
}
</Context.Consumer>
</>
}
}
// Son
class Son extends React.Component {
static contextType = Context. // 可以静态接收。接收完之后。可以使用 this.context来调用context的值
render(){
return <>
//Son组件里面可以获取到 context的值
<Context.Consumer>
{
data=> data就可以拿到数据
}
</Context.Consumer>
</>
}
}
5 reudx. 可以使用redux 来进行组件通信,适用于多个组件使用同一个数据 ,可以更好的维护和使用
react通过什么方法修改参数
类组件修改数据的方法, 通过setState , 注意setState的修改方法有两种,而且它是异步的
函数组件修改方式通过自定义的方法。需要通过 useState , 例如。const [count,setCount] = useState(0)
这里面setCount 可以修改count参数
说你对react native的了解
React native 基于 JavaScript 开发的一个 可以开发原生app的这么一个集成框架,它兼容开发 iOS 和 Android能够实现一套代码,两个系统都能使用,方便维护,相比于web前端的 react ,react-native更好的提供了一些调用手机硬件的API,可以更好的开发移动端,现在react-native它的生态环境也是越来越好,基本上可以完全实现原生开发,
但是现在好多的应用还是用它来套壳 (原生 + web前端),用它来做有些路由,和框架的搭建,然后里面内容来使用前端的react来实现,这样一来让维护更方便,开发更快捷
redux的实现原理
redux它是一个单独的状态管理工具,它是一个数据集中管理的方案,简单来说,就是将公用的数据,放在redux里面进行存储,修改的时候也是利用redux提供的方法来修改,让框架使用的数据的时候更方便,维护起来更容易,reudx提供了一下核心内容:
1 store.
store是redux的核心内容,整个redux的仓库,所有的应用方法都是由store提供
2 createStore
createStore用老创建store的,方法里面有三个参数,有reducer,有中间件,还有初始值,最重要的就是reducer函数,它提供了整个数据管理的逻辑
3 reducer(state, action)
reducer函数相当于数据加工厂,初始的数据,修改数据的 逻辑都统统的在这里完成,它让我们整个的数据走向更完成,维护更方便
4 action
action 本质是一个对象,它来告诉 redux 要执行什么任务
5 state
state它就是我们需要存储的redux的数据,所有的数据都将要在这里面存储
6 store.getState()
它就是用来获取数据的,每次修改前后的数据都可以用store.getState()来修改
7 store.dispatch(action)
用户通过dispatch出发要执行的任务,这个就是出发动作,然后reducer函数会执行,然后进行数据加工
8。store.subscribe(callback)
会自动的监听state,一旦有state发生改变,store.subscribe就会还行,利用它可以用来更新视图
react里的一个输入框每当用户输入文字就会触发onchange,我们怎么拿到他最后输入完的结果
1 第一种是通过受控组件,可以获取到state里面的值,获取修改结果
class Home extends React.Component {
state = {
val:""
}
//这是一个通用的写法,然后注意 name的值一定要与state定义的一直
changeInput = (e) =>{
let {name,value} = e.target
this.setState({
[name]:value
})
}
render(){
return <>
<input onChange="this.state.val" />
</>
}
}
2 第二种通过ref来获取里面的值
class Home extends React.Component {
render(){
// this.val 获取里面的真是dom
return <input ref={node=>this.val} />
}
}
react的render什么时候渲染
react生命周期有三个阶段。 两个阶段都会执行 render
主要从更新和挂载两个阶段来讲,挂载阶段都顺序,更新阶段一定要说 shouldComponentUpdate true 和false 分别对应后边是否执行render
1) 挂在阶段
constructor(){}
static getDerivedStateFromProps(){
return {}
}
render(){}. 挂载阶段会执行一次
componentDidMount(){}
2 ) 更新阶段
static getDerivedStateFromProps(props, state){rerturn {}}
shouldComponentUpdate(nextProps, nextState).{ return Boolean. 注意如果 false 则 不向下执行 ,true的时候会执行render}
return。true
render() ..
useEffect的依赖为引用类型如何处理
useEffect的依赖为饮用类型的时候,可能会导致监听不出发,原因就是监听的统一个地址的时候,对象本身地址没变,所以监听的结果就是认为数据并没有改变从而不直径调用
解决方案
1 如果数据是对象的话,可以监听对象的里面的值,值是基本类型,如果值改变了,那么可以监听执行
2 在去修改对象和数据的时候,使用参拷贝或者浅拷贝,这样地址发生改变可以监听执行
3 可以转成字符串,通过JSON.stringify() ,监听字符串这样的,这样改变也会执行
说说在使用Hooks的过程中,需要注意的
1 首先注意到就是 useState 里面方法是异步的,所以不要在后面连续调用,由于react方法是批量异步调用,并不是每次调用修改方法都执行,所以需要用到callback写法
const [count, setCount] = useState(0);
const add = () => {
setCount(count + 1);
setCount(count + 1);
setCount(count + 1);
setCount(count + 1); // 就算执行多次 其实还是会只执行一次
//class组件是用一样的
};
修改后
const add = () => {
setCount(count => count + 1); //这种回调函数的写法
setCount(count => count + 1);
setCount(count => count + 1);
setCount(count => count + 1);
// class组件
this.setState(prev=>({count: prev.count}))
};
2 由于 useState的是异步的,不要在修改后直接使用数据 , 可以先修改数据,判断数据,也可以利用useEffec,useMemo等等通过监听数据执行
const [count, setCount] = useState(0);
const add = () => {
setCount(count + 1);
if(count>=10) { // 一个逻辑 这样的写的话 会执行上一次吃结果}
};
正确使用 1
const add = () => {
let n = count +1
if(n){
//逻辑
}
setCount(n)
};
正确2 :
const add = () => [
setCount(count+1)
]
useEffect(()=>{
// 这里是逻辑
},[count])
3 useEffect 这个hook的使用,每一个消耗性能的内容都可以通过return 来消除
useEffect(()=>{
// 逻辑1
return ()=>{
// 清楚逻辑1的副作用
}
},[监听的值])
4 useRef 可以获取组件的数据,也可当常量的值来使用,注意获取数据使用的时候函数组件特别需要注意,如果子组件是函数组件需要利用 useImperativeHandle ,forWard
react组件的key说一下 key发生变化会发生什么 key 值不同销毁前会触发什么生命周期
1 react的key值给组件作为唯一标识,类似身份证,当数组发生增删改查的时候可以通过这个 标识来去对比虚拟dom的更改前后,如果相同标识的数据或者属性没有改变的话,讲直接略过,对比有改变的然后直接改变此项
2 如果给组件添加key,如果key值改变的时候,组件将会重新出创建会执行 挂在阶段的生命周期
constructor
static getDerivedStateFromProps()
render(){}
componentDidUpdate
知道react里面的createPortal么?说说使用场景。之前react没有这个的时候是怎么实现的,有他没他的区别
react.createPortal 这个方法是来使用做弹窗Modal组件的,在没有这个组件之前我们可以自己定义组件,然后去实现Modal效果
Modal.js
const styles = {
modal: {
position: 'fixed',
top: 0,
left: 0,
right: 0,
bottom: 0,
backgroundColor: 'rgba(0,0,0,0.3)',
display: 'flex',
justifyContent: 'center',
alignItems: 'center'
}
}
class Modal extends Component {
constructor(props) {
super(props);
}
render() {
return (
<div style={styles.modal}>
{this.props.children}
</div>
);
}
}
react.createPortal 这个来制作弹窗组件,它 在Modal 组件位置进行 fixed 定位,可以任意的挂载到某个dom元素上,使用后的管理更方便,但是注意需要预留html的挂载元素
react全家桶
真正意义上的react全家桶,其实指的是react,react-dom,react-native。
因为react核心库只是vDom的操作,无关dom(dom操作在react-dom中)——这意味着它天生就可以做到跨平台。
注意这里有误区,react-router,react-router-dom,react-dux只是社区的一些使用较多的解决方案,事实上它们各有缺陷。
如何理解fiber?
截止到当前版本(react17.0.2),react尚存在一个明显的缺陷——这是大多数vDom框架都需要面对的——“diff”。
要知道,render前后的两颗vDom tree进行diff,这个过程是不可中断的(以tree为单位,不可中断),这将造成当diff的两颗tree足够庞大的时候,js线程会被diff阻塞,无法对并发事件作出回应。
为了解决这个问题,react将vDom节点上添加了链表节点的特性,将其改造成了fiber节点(其实就是vdom节点结合了链表节点的特性),目的是为了后面的Fiber架构的实现,以实现应对并发事件的“并发模式”。
事实上,原计划是17版本上的,但最终定期在了18版本。
时间分片,任务分炼
fiber节点的改造是为了将diff的单位从不可中断的tree降级到可中断的单一vDom。这意味着每次一个vDom节点比对过后,可以轮训是否发生了优先级更高的并发事件(react将用户想更快得到反馈的事进行了优先级排序,比如js动画等)。
每个vDom的比对是一个时间片单位,因此基于fiber节点的Fiber架构,存在这样的特性:
“时间分片,任务分炼,异步渲染。”
hooks
你了解hooks吗?谈谈你对hooks的理解?聊聊hooks?
react-hooks提供给了函数式组件以业务逻辑抽离封装的能力,从单一组件单位进行UI与业务逻辑的分离,以此来保证函数式组件的UI纯净。
在此之前,我们只能通过状态提升的方式,将业务逻辑提升到容器组件的方式。
hooks使用规则?
-
只可以在顶层调用栈调用hooks
- 不可以在循环/条件/嵌套里调用hooks
-
只可以在react function或自定义hooks里调用hooks
- 原因见hooks调用记录表底层
hooks调用记录表底层_单链表结构
hooks的引用记录,是用单链表结构实现的;(可在力扣/leetcode网找一下实现单链表的算法)
每一个链表节点(node)都有一个next的指针指向下一个node;
如果中间有缺失,那么就无法找到下一个next;
因此hooks不可以在条件里调用(有可能丢失链表node,导致hooks遍历中断);
useEffect与副作用?什么是副作用?聊聊useEffect?
- 副作用函数
我们将跟UI渲染无关的业务逻辑称之为副作用。
useEffect是react在函数式组件里提供的副作用解决方案,它接受两个参数。
第一个是必传参数,类型为函数。
我们写在此函数中的业务逻辑代码就是我们所说的副作用。 - 消除副作用函数
默认情况下,useEffct会在每次render后执行传入的副作用函数。
然而有的时候我们需要在执行副作用前先去除掉上次render添加的副作用效果,我们可以在副作用函数里再返回一个函数———这个函数就是消除副作用,它会在每次reRender前和组件卸载时去执行。 - 监听器
与 useMemo, useCallback等一样,useEffect可以传入一个监听数组参数,这意味着副作用只有在数组中的监听值变化时才会执行。
我们借助它的这个参数特性,可以模拟类组件生命周期钩子————比如componentDidMount等。
生命周期模拟?
useEffect的本质作用,其实是将函数式组件中的业务逻辑副作用进行抽离封装。模拟生命周期并不是它的核心思想,但它当然能做到这个事:
https://github.com/melodyWxy/melody-core-utils/blob/master/src/lifeHooks/index.ts
useLayoutEffect?
与useEffect的区别是,useLayoutEffect中副作用的执行时间在组件render之前,这意味着它适用于比组件render更紧急的副作用。
正因为如此,多数情况下我们不会选择使用它,因为我们并不想阻塞render。
useRef
-
变量值存储功能
首先,函数式组件每次render就会重新执行一次,这意味着我们在函数组件中定义的变量都会重置,无法保留变更。
useRef可以解决这个问题——它会形成一个闭包作用域来记录这个值。 -
ref的通用功能
当然,我们也可以用它来标记dom和类组件,从而获取对应的实例。
useCallback
同样的,因为函数式组件每次render就会重新执行一次,因此我们在函数式组件中定义的方法都会重新定义————多数情况下这是不必要的,因此我们可以用useCallback来缓存它。
当然,我们也可以基于它第二个参数——一个监听数组,来控制它在何种时机进行重定义。
useMemo
同样的,因为函数式组件每次render就会重新执行一次,因此我们在定义的一些变量或者计算过后的变量,都会重新定义————多数情况下这是不必要的,因此我们可以用useCallback来缓存它。
当然,我们也可以基于它第二个参数——一个监听数组,来控制它在何种时机进行重定义。
redux
Flux
Flux 是一种 架构思想,简单来讲 就是:
状态提升到全局Store + Store内容分发给组件 + 组件交互updateStore然后更新组件。
就是这样一种 通过全局store同一管理数据(从而实现组件间数据共享)的架构思想。
redux与react-redux
基于这种思想,社区里已有各种各样成型的解决方案,其中,redux是通用性比较强的方案(兼容原生和绝大部分框架);
但它的使用较为麻烦,在react项目里,一般用 redux + react-redux + 配置中间件(根据项目需要配置) 这样的方式。
比如 dva = redux + react-redux + redux-saga + router (耦合了router也是dva的诟病所在);
在hooks出现之后,react提供了 useContext这样的钩子,实现了redux的功能。
react-redux 的核心:Provider 与 connect
Provider和connect的底层原理
Provider容器组件底层: 把store打入 contextconnect;
高阶组件底层: 从context拿到store,然后打入到参数组件的props;
- 什么是高阶组件?
高阶组件:接受一个组件为参数,return 出一个新的组件;
高阶函数:就是一个函数,接受一个函数为参数。 - redux的核心:
- createStore 与 disPatchcreateStore: 创建store
- disPatch: 更新store的方法disPatch的规范/更新store的流程
react-redux流程
- 状态提升到全局与分发
- createStore创建全局状态仓库
- Provider和connnect进行状态的分发
- 状态更新
- disPatch 一个 action (action就是一个对象,形如{type:‘xxx’,…prarams}),基于action.type,触发对应的reducer(reducer是具体更新store的方法,纯函数)逻辑,从而更新store;
react组件的概念(高阶组件,受控组件,非受控组件)
高阶组件:
高阶组件(HOC)是 React 中用于复用组件逻辑的一种高级技巧。HOC 自身不是 React API 的一部分,它是一种基于 React 的组合特性而形成的设计模式。
一 属性代理
1. 属性代理是最常见的实现方式,它本质上是使用组合的方式,通过将组件包装在容器组件中实现功能。
2. 属性代理方式实现的高阶组件和原组件的生命周期关系完全是React父子组件的生命周期关系,所以该方式实现的高阶组件会影响原组件某些生命周期等方法。
操作 props
抽象 state
获取 refs 引用
获取原组件的 static 方法
通过 props 实现条件渲染
二 反向继承
反向继承指的是使用一个函数接受一个组件作为参数传入,并返回一个继承了该传入组件的类组件,且在返回组件的 render() 方法中返回 super.render() 方法,最简单的实现如下:
受控组件
- 受控组件通过props获取其当前值,并通过回调函数(比如onChange)通知变化
- 表单状态发生变化时,都会通知React,将状态交给React进行处理,比如可以使用useState存储
- 受控组件中,组件渲染出的状态与它的value或checked属性相对应
- 受控组件会更新state的流程
非受控组件
非受控组件将数据存储在DOM中,而不是组件内,这比较类似于传统的HTML表单元素。
- 非受控组件的值不受组件自身的state和props控制
- 非受控组件使用ref从DOM中获取元素数据
react类组件中的生命周期,整体分几步,常用的有哪些
三大阶段,如图
实例期
存在期
销毁期

render里面为什么不能使用setState
setState会重新执行render函数,如果添加setState会导致死循环
子组件中修改状态时会不会影响父组件,会不会触发生命周期
如果父组件中没有依赖子组件的状态不会
如果父组件中依赖了子组件的状态,因为要执行setState会重新触发生命周期
父组件改变时会不会影响子组件
会,因为会重新执行render函数,如果不想更新子组件可以在shouldComponentUpdate中终止掉
react页面跳转路由传参方法
跳转路由,并向路由组件传递params参数
{tabItem.title}跳转路由,并向路由组件传递search参数
{tabItem.title}跳转路由,并向路由组件传递state参数
{tabItem.title} ### 使用redux时,setState修改状态的过程是异步还是同步类组件setState是同步还是异步
- 使用合成事件 setState是异步的,想要拿到最新数据需要去回调中
- 使用原生事件 setState是同步的
传值过程中,子传值能不能改变父组件,为什么?
不能,props为只读状态 单向数据流
hooks中常用的api有哪些
useState()
userContext()
userReducer()
useEffect()
useeffect中第二个参数有什么作用
如果想执行只运行一次的 effect(仅在组件挂载和卸载时执行),可以传递一个空数组([])作为第二个参数。这就告诉 React 你的 effect 不依赖于 props 或 state 中的任何值,所以它永远都不需要重复执行。
react常用的优化手段有哪些
- 属性传递优化
- 多组件优化
- Key
- memo
- purecomponent
- 生命周期
- 虚拟列表
- 使用纯组件
- 懒加载组件
- 使用 React Fragments 避免额外标记
- 不要使用内联函数定义
- 避免 componentWillMount() 中的异步请求
- 在 Constructor 的早期绑定函数
- 优化 React 中的条件渲染
- 不要在 render 方法中导出数据
- 为组件创建错误边界
- 组件的不可变数据结构
为什么要用redux,怎么修改数据
使用Redux的主要优势之一是它可以帮你处理应用的共享状态。如果两个组件需要访问同一状态,该怎么办?这种两个组件同时需要访问同一状态的现象称为“共享状态”。你可以将该状态提升到附近的父组件,但是如果该父组件在组件树中向上好几个组件的位置,那么将状态当做属性向下一个一个地传递,这项工作很快就会变得乏味。此外,在该父组件和该子组件之间的组件甚至根本不需要访问该状态!
在构建网络应用时,Redux不仅使我们能够以有条理的方式存储数据,而且使我们能够在应用的任何位置快速获取该数据。只需告诉Redux到底哪个组件需要哪个数据,它就会为你处理后续一切工作!
借助Redux,你可以控制状态改变的时间、原因和方式。
useEffect是干什么的
该 Hook 接收一个包含命令式、且可能有副作用代码的函数。
在函数组件主体内(这里指在 React 渲染阶段)改变 DOM、添加订阅、设置定时器、记录日志以及执行其他包含副作用的操作都是不被允许的,因为这可能会产生莫名其妙的 bug 并破坏 UI 的一致性。
使用 useEffect 完成副作用操作。赋值给 useEffect 的函数会在组件渲染到屏幕之后执行。你可以把 effect 看作从 React 的纯函数式世界通往命令式世界的逃生通道。
useEffect能完全模拟componentDidUpdate吗
不可以。 useEffect 并不完全等同于 componentWillUnMount 。当 useEffect 模拟 componentDidMount 和 componentDidUpdate 的时候,返回的函数并不完全等同于 componentWillUnMount。
useLayoutEffect和useEffect的区别
useEffect和useLayoutEffect作为组件的副作用,本质上是一样的。共用一套结构来存储effect链表。整体流程上都是先在render阶段,生成effect,并将它们拼接成链表,存到fiber.updateQueue上,最终带到commit阶段被处理。他们彼此的区别只是最终的执行时机不同,一个异步一个同步,这使得useEffect不会阻塞渲染,而useLayoutEffect会阻塞渲染。
react和vue的数据流,底层原理
React遵循从上到下的数据流向,即单向数据流。
1、单向数据流并非‘单向绑定’,甚至单向数据流与绑定没有‘任何关系’。对于React来说,单向数据流(从上到下)与单一数据源这两个原则,限定了React中要想在一个组件中更新另一个组件的状态
(类似于Vue的平行组件传参,或者是子组件向父组件传递参数),需要进行状态提升。即将状态提升到他们最近的祖先组件中。子组件中Change了状态,触发父组件状态的变更,父组件状态的变更,
影响到了另一个组件的显示(因为传递给另一个组件的状态变化了,这一点与Vue子组件的$emit()方法很相似)。
2、Vue也是单向数据流,只不过能实现双向绑定。
3、单向数据流中的‘单向’-- 数据从父组件到子组件这个流向叫单向。
4、绑定的单双向:View层与Module层之间的映射关系。
react路由和vue路由底层实现原理
eact-router和vue-router实现原理大同小异,都是通过两种方式,hash和history,首先看一下什么是hash和history:
- hash —— 即地址栏 URL 中的 # 符号(此 hash 不是密码学里的散列运算)。比如这个 URL:http://www.abc.com/#/hello,hash 的值为 #/hello。它的特点在于:hash 虽然出现在 URL 中,但不会被包括在 HTTP 请求中,对后端完全没有影响,因此改变 hash 不会重新加载页面。
- history —— 利用了 HTML5 History Interface 中新增的 pushState() 和 replaceState() 方法。(需要特定浏览器支持)这两个方法应用于浏览器的历史记录栈,在当前已有的 back、forward、go 的基础之上,它们提供了对历史记录进行修改的功能。只是当它们执行修改时,虽然改变了当前的 URL,但浏览器不会立即向后端发送请求。
- hash模式(vue-router默认hash模式)
hash模式背后的原理是onhashchange事件。
window.onhashchange=function(){
let hash=location.hash.slice(1);
document.body.style.color=hash;
}
(localtion是js里管理地址栏的内置对象,是window对象的一部分,可通过window.localtion访问,在w3cshool里的详细介绍)
由于hash发生变化的url都会被浏览器记录下来,使得浏览器的前进后退都可以使用了,尽管浏览器没有亲求服务器,但是页面状态和url关联起来。后来人们称其为前端路由,成为单页应用标配。
比如http://www.abc.com/#/index,hash值为#/index。hash模式的特点在于hash出现在url中,但是不会被包括在HTTP请求中,对后端没有影响,不会重新加载页面。
2.history模式
当使用history模式时,url就像正常的url,例如http://abc.com/user/id相比hash模式更加好看。特别注意,history模式需要后台配置支持。如果后台没有正确配置,访问时会返回404。
其中一事件触发用到了 onpopstate。
通过history api,我们丢弃了丑陋的#,但是有一个缺点,当刷新时,如果服务器中没有相应的相应或者资源,会分分钟刷出一个404来(刷新需要请求服务器)。所以history模式不怕前进,不怕后退,就怕刷新。
下述案例为实现的react-router的代码,来了解router大致实现原理
原理: 在dom渲染完成之后,给window 添加 “hashchange” 事件监听页面hash的变化,并且在state属性之中添加了 route属性,代表当前页面的路由。
1、当点击连接 页面hash改变时,触发绑定在window 上的 hashchange 事件,
2、在 hashchange 事件中改变组件的 state中的 route 属性,(react组件的state属性改变时,自动重新渲染页面)
3、页面 随着 state 中的route属性改变自动 根据 不停的hash 给 Child 变量赋值不通的组件,进行渲染
核心代码:
import React from 'react'
import { render } from 'react-dom'
const About = function () {
return <div>111</div>
}
const Inbox = function () {
return <div>222</div>
}
const Home = function () {
return <div>333</div>
}
class App extends React.Component {
state = {
route: window.location.hash.substr(1)
}
componentDidMount() {
window.addEventListener('hashchange', () => {
this.setState({
route: window.location.hash.substr(1)
})
})
}
render() {
let Child
switch (this.state.route) {
case '/about': Child = About; break;
case '/inbox': Child = Inbox; break;
default: Child = Home;
}
return (
<div>
<h1>App</h1>
<ul>
<li><a href="#/about">About</a></li>
<li><a href="#/inbox">Inbox</a></li>
</ul>
<Child />
</div>
)
}
}
render(<App />, document.body)
axios守卫(请求和响应守卫)
其实这个问题问的是axios请求封装种的请求拦截器和响应拦截器,比如如下的封装代码案例
import axios from 'axios'
import router from './../router'
// development 开发环境 production 生产环境
const isDev = process.env.NODE_ENV === 'development'
// baseURL 会自动加到所有的请求之前
const request = axios.create({
// http://121.89.205.189/api/pro/list ==> /pro/list
baseURL: isDev ? 'http://121.89.205.189/api' : 'http://121.89.205.189/api',
timeout: 6000
})
// 请求拦截器
request.interceptors.request.use(config => {
// 传入token验证登录状态
// 如果需要设置其他的信息也可以在这里
config.headers.common.token = localStorage.getItem('token')
return config
}, err => Promise.reject(err))
// 响应拦截器封装
request.interceptors.response.use(response => {
// 如果验证未登录,可以跳转到登录页面
if (response.data.code === '10119') {
router.push('/login')
}
return response
}, err => Promise.reject(err))
export default request
dva之前有了解吗
这个其实是支付宝整合的一套框架,集成了 (redux + react-router + redux-saga 等)的一层轻量封装。dva 是 framework,不是 library,类似 emberjs。
他最核心的是提供了 app.model 方法,用于把 reducer, initialState, action, saga 封装到一起。
app.model({
namespace: 'products',
state: {
list: [],
loading: false,
},
subscriptions: [
function(dispatch) {
dispatch({type: 'products/query'});
},
],
effects: {
['products/query']: function*() {
yield call(delay(800));
yield put({
type: 'products/query/success',
payload: ['ant-tool', 'roof'],
});
},
},
reducers: {
['products/query'](state) {
return { ...state, loading: true, };
},
['products/query/success'](state, { payload }) {
return { ...state, loading: false, list: payload };
},
},
});
-
namespace - 对应 reducer 在 combine 到 rootReducer 时的 key 值
-
state - 对应 reducer 的 initialState
-
subscription - [email protected] 的新概念,在 dom ready 后执行,这里不展开解释
-
effects - 对应 saga,并简化了使用
-
reducers - 相当于数据模型
// 如何创建一个dva项目
$ npm install dva-cli -g
$ dva new myapp && cd myapp
$ npm start
使用了Ant design ,如何自定义样式
方式1:添加global
可以在样式的外部添加:global
<Form onSubmit={this.handleSubmit} className="account-form">
</Form>
:global{
.account-form{
background-color: red;
}
}
方式2:定制主题
可以参考链接https://ant.design/docs/react/customize-theme-cn
我们以 webpack@4 为例进行说明,以下是一个 webpack.config.js 的典型例子,对 less-loader 的 options 属性进行相应配置。
// webpack.config.js
module.exports = {
rules: [{
test: /\.less$/,
use: [{
loader: 'style-loader',
}, {
loader: 'css-loader', // translates CSS into CommonJS
}, {
loader: 'less-loader', // compiles Less to CSS
+ options: {
+ lessOptions: { // 如果使用less-loader@5,请移除 lessOptions 这一级直接配置选项。
+ modifyVars: {
+ 'primary-color': '#1DA57A',
+ 'link-color': '#1DA57A',
+ 'border-radius-base': '2px',
+ },
+ javascriptEnabled: true,
+ },
+ },
}],
// ...other rules
}],
// ...other config
}
注意:
- less-loader 的处理范围不要过滤掉
node_modules下的 antd 包。 lessOptions的配置写法在 [email protected] 里支持。
React 组件传值的方法
- 父组件传递到子组件传值。又称正向传值 采用props进行数据的传递
- 子组件传递到父组件传值。又称逆向传值 通过在父组件引入的子组件中传递一个函数并传参,子组件去触发这个函数更改参数完成数据更新
- 同级组件传值。又称同胞传值 通过一款插件pubsub-js 这个可以采用发布订阅的方式实现组件间的传值 a组件通过publish进行发布数据。b组件通过subscribe订阅数据
- 跨层级传值 通过上下文对象的形式进行数据的传递 通过Provider生产数据 需要接受的组件使用consumer使用数据
- redux也可以完成上述传值方式
useEffect模拟生命周期
模拟componentDidMount
hooks 模拟 componentDidMount
useEffect 拥有两个参数,第一个参数作为回调函数会在浏览器布局和绘制完成后调用,因此它不会阻碍浏览器的渲染进程。
第二个参数是一个数组
- 当数组存在并有值时,如果数组中的任何值发生更改,则每次渲染后都会触发回调。
- 当它不存在时,每次渲染后都会触发回调。
- 当它是一个空列表时,回调只会被触发一次,类似于 componentDidMount。
useEffect(()=>{console.log('第一次渲染时调用')},[])
模拟componentDidUpdate
没有第二个参数代表监听所有的属性更新
useEffect(()=>{console.log('任意属性该改变')})
监听多个属性的变化需要将属性作为数组传入第二个参数。
useEffect(()=>{console.log('n变了')},[n,m])
模拟componentWillUnmount
通常,组件卸载时需要清除 effect 创建的诸如订阅或计时器 ID 等资源 useEffect函数返回的函数可以表示组件卸载了
useEffect(()=>{
const timer = setTimeout(()=>{
...
},1000)
return()=>{
console.log('组件卸载了')
clearTimerout(timer)
}
})
hooks模拟生命周期
在 React 16.8 之前,函数组件只能是无状态组件,也不能访问 react 生命周期。hook 做为 react 新增特性,可以让我们在不编写 class 的情况下使用 state 以及其他的 react 特性,例如生命周期。接下来我们便举例说明如何使用 hooks 来模拟比较常见的 class 组件生命周期。
-
hooks 模拟 componentDidMount
useEffect 拥有两个参数,第一个参数作为回调函数会在浏览器布局和绘制完成后调用,因此它不会阻碍浏览器的渲染进程。
第二个参数是一个数组- 当数组存在并有值时,如果数组中的任何值发生更改,则每次渲染后都会触发回调。
- 当它不存在时,每次渲染后都会触发回调。
- 当它是一个空列表时,回调只会被触发一次,类似于 componentDidMount。
useEffect(()=>{console.log('第一次渲染时调用')},[]) -
hooks 模拟 shouldComponentUpdate
React.memo 包裹一个组件来对它的 props 进行浅比较,但这不是一个 hooks,因为它的写法和 hooks 不同,其实React.memo 等效于 PureComponent,但它只比较 props。
const MyComponent = React.memo( _MyComponent, (prevProps, nextProps) => nextProps.count !== prevProps.count ) -
hooks 模拟 componentDidUpdate
没有第二个参数代表监听所有的属性更新
useEffect(()=>{console.log('任意属性该改变')})监听多个属性的变化需要将属性作为数组传入第二个参数。
useEffect(()=>{console.log('n变了')},[n,m]) -
hooks 模拟 componentWillUnmount
通常,组件卸载时需要清除 effect 创建的诸如订阅或计时器 ID 等资源 useEffect函数返回的函数可以表示组件卸载了
useEffect(()=>{ const timer = setTimeout(()=>{ ... },1000) return()=>{ console.log('组件卸载了') clearTimerout(timer) } })
react框架怎么做优化
1.render里面尽量减少新建变量和bind函数,传递参数时尽量减少传递参数的数量
第一种是在构造函数中绑定this,会在 构造函数 实例化的时候执行一次
第二种是在render()函数里面绑定this,在每次render()的时候都会重新执行一遍
第三种就是使用箭头函数,每一次render()的时候,都会生成一个新的箭头函数,即使两个箭头函数的内容是一样的。
2.shouldComponentUpdate是决定react组件什么时候能够不重新渲染的函数,但是这个函数默认的实现方式就是简单的返回一个true。也就是说,默认每次更新的时候都要调用所用的生命周期函数,包括render函数,重新渲染。
为了不做不必要的渲染,需要使用shouldComponentUpdate 加以判断
最新的react中,react给我们提供了React.PureComponent
3.使用key进行组件的唯一标识
react的虚拟dom怎么实现
虚拟DOM可以看做一棵模拟了DOM树的JavaScript对象树。在传统的 Web 应用中,我们往往会把数据的变化实时地更新到用户界面中,于是每次数据的微小变动都会引起 DOM 树的重新渲染。虚拟DOM的目的是将所有操作累加起来,统计计算出所有的变化后,统一更新一次DOM。
React会先将你的代码转换成一个javascript对象,然后再把这个javascript对象转换成真实的DOM。而这个javascript对象就是所谓的虚拟DOM。
1.基于babel-preset-react-app把JSX变成React.createElement(...)。可以理解为JSX只是React.createElement的语法糖。
<div className="box" style={{color: '#f00'}} index={0}>
123
<p>456</p>
</div>
经过babel转换成下面的样子:
React.createElement("div", {
className: "box",
style: {
color: '#f00'
},
index: 0
}, "123", React.createElement("p", null, "456")
);
2.执行React.createElement(...)会返回一个javascript对象,这个对象就是所谓的虚拟DOM。
createElement会返回一个虚拟对象 let VitrualDomObj = React.createElement(...)
3.把这个虚拟DOM通过render函数转换成真实的DOM
myrender( VitrualDomObj , document.getElementById('root'));
redux和mobx的区别?
1.共同点:
- 两者都是为了解决状态不好管理,无法有效同步的问题而产生的工具。
- 都是用来统一管理应用状态的工具
- 某一个状态只有一个可靠的数据来源
- 操作更新的方式是统一的,并且是可控的
- 都支持store与react组件,如react-redux,mobx-react;
2.不同点:
Redux每一次的dispatch都会从根reducer到子reducer嵌套递归的执行,所以效率相对较低;而Mobx的内部使用的是依赖收集,所以不会有这个问题,执行的代码较少,性能相对更高;
Redux核心是不可变对象,在Reducer中的操作都要比较小心,注意不能修改到state的属性,返回时必须是一个全新的对象;而Mobx采用不存在这个问题,操作比较随意;
Redux中写法固定,模板代码较多,Mobx中写法比较随意,但是因为写法随意的原因,如果没有规范性的话,维护性则不会像Redux那么高;
正因为Redux中的reducer更新时,每次return的都是不可变对象,所以时间旅行操作相对容易,而Mobx在这方面不占优势
Redux更加的轻量,但是一般来说都会配合中间件进行使用
react中跨级组件通信中的context是不推荐使用的,为什么?不使用redux还有其它方案吗?
1、Context目前还处于实验阶段,可能会在后面的发行版本中有很大的变化,事实上这种情况已经发生了,所以为了避免给今后升级带来大的影响和麻烦,不建议在app中使用context。
2、尽管不建议在app中使用context,但是独有组件而言,由于影响范围小于app,如果可以做到高内聚,不破坏组件树之间的依赖关系,可以考虑使用context
3、对于组件之间的数据通信或者状态管理,有效使用props或者state解决,然后再考虑使用第三方的成熟库进行解决,以上的方法都不是最佳的方案的时候,在考虑context。
4、context的更新需要通过setState()触发,但是这并不是很可靠的,Context支持跨组件的访问,但是如果中间的子组件通过一些方法不影响更新,比如 shouldComponentUpdate() 返回false 那么不能保证Context的更新一定可以使用Context的子组件,因此,Context的可靠性需要关注。
其他的解决方案可以使用
- mobx
- useContext + useReducer
react-router底层实现原理
顶层Router订阅history,history变化时,Router调用setState将location向下传递,并设置到RouterContext。Route组件匹配context中的location决定是否显示。Switch选择最先匹配到的显示,利用props children。Link组件阻止a标签默认事件,并调用history.push。NavLink通过匹配context中的location决定是否为active状态。Redirect组件匹配context里的location决定是否调用history.push(to),Switch组件会匹配location和from决定是否发起Redirect。
react为什么是单向数据流,react有什么特性
单向数据流就是:数据在某个节点被改动后,只会影响一个方向上的其他节点。数据只会影响到下一个层级的节点,不会影响上一个层级的节点。
在react中Props 为只读的,而不是可更改的。这也就是数据更新不能直接通过 this.state 操作,想要更新,就需要通过 React 提供的专门的 this.setState() 方法来做。
单向数据流其实就是一种框架本身对数据流向的限制。保证数据的可控性。
react使用的是jsx,模板的好处是什么?
JSX 是 JavaScript 的一种扩展,为函数调用和对象构造提供了语法糖,特别是 React.createElement()。JSX 看起来可能更像是模板引擎或 HTML,但它不是。JSX 生成 React 元素,同时允许你充分利用 JavaScript 的全部功能。
JSX 是编写 React 组件的极好方法,有以下优点:
改进的开发人员体验:代码更易读,因为它们更加形象,感谢类 XML 语法,从而可以更好地表示嵌套的声明式结构。
更具生产力的团队成员:非正式开发人员可以更容易地修改代码,因为 JSX 看起来像HTML,这正是他们所熟悉的。
更少的语法错误:开发人员需要敲入的代码量变得更少,这意味着他们犯错的概率降低了,能够减少重复性伤害。
antd常用的组件
- 常用组件有:Table、Form、Grid、Button、Menu、Upload、DatePicker、Pagination等。
antd弹出层的原理
- 弹出层组件使用了 ReactDOM.createPortal(child, container) 来实现的。
- React Portal 提供了一种将子节点渲染到存在于父组件以外的 DOM 节点的优秀的方案。
类组件和函数组件的区别
- 函数组件看似只是一个返回值是DOM结构的函数,其实它的背后是无状态组件(Stateless Components)的思想。函数组件中,你无法使用State,也无法使用组件的生命周期方法,这就决定了函数组件都是展示性组件(Presentational Components),接收Props,渲染DOM,而不关注其他逻辑。
- 函数组件中没有this。所以你再也不需要考虑this带来的烦恼。而在类组件中,你依然要记得绑定this这个琐碎的事情。如示例中的sayHi。
- 函数组件更容易理解。当你看到一个函数组件时,你就知道它的功能只是接收属性,渲染页面,它不执行与UI无关的逻辑处理,它只是一个纯函数。而不用在意它返回的DOM结构有多复杂。
- 性能。目前React还是会把函数组件在内部转换成类组件,所以使用函数组件和使用类组件在性能上并无大的差异。但是,React官方已承诺,未来将会优化函数组件的性能,因为函数组件不需要考虑组件状态和组件生命周期方法中的各种比较校验,所以有很大的性能提升空间。
- 函数组件迫使你思考最佳实践。这是最重要的一点。组件的主要职责是UI渲染,理想情况下,所有的组件都是展示性组件,每个页面都是由这些展示性组件组合而成。如果一个组件是函数组件,那么它当然满足这个要求。所以牢记函数组件的概念,可以让你在写组件时,先思考这个组件应不应该是展示性组件。更多的展示性组件意味着更多的组件有更简洁的结构,更多的组件能被更好的复用。
在React组件复用与组合 中我们会提到,应当避免在底层的展示性组件中混入对于状态的管理,而应该将状态托管于某个高阶组件或者其他的状态容器中。利用函数式声明组件可以彻底保证不会在组件中进行状态操作。
双向数据绑定和单向数据流的优缺点
- 单向数据流 数据流动方向可以跟踪,流动单一,追查问题的时候可以跟快捷。缺点就是写起来不太方便。要使UI发生变更就必须创建各种action来维护对应的state
- 单向数据流其实是没有状态的, 这使得单向绑定能够避免状态管理在复杂度上升时产生的各种问题, 程序的调试会变得相对容易, 但强制要求编码时设计思维的一致性。
- 双向流动值和UI双绑定,这种好处大家都懂。但是由于各种数据相互依赖相互绑定,导致数据问题的源头难以被跟踪到,子组件修改父组件,兄弟组件互相修改有有违设计原则。 但好处就是 太方便使用了。
- 双向数据流是自动管理状态的, 但是在实际应用中会有很多不得不手动处理状态变化的逻辑, 使得程序复杂度上升, 难以调试, 但程序各个部分自成一体, 不强制要求一致的编码。
如果你的程序需要一个统一的数据源, 应该选择单向数据流, 所有的数据变化都是可观测的, 数据自上而下流动, 即使出问题也很容易找到源头. - 如果你的程序本身有多个数据源, 或者是程序的逻辑本身会产生很多的副作用, 应该选择双向绑定的程序, 将大项目分化为小项目, 逐个击破。
- 单向绑定使得数据流也是单向的,对于复杂应用来说这是实施统一的状态管理(如redux)的前提。
双向绑定在一些需要实时反应用户输入的场合会非常方便(比如多级联动菜单)。但通常认为复杂应用中这种便利比不上引入状态管理带来的优势。
setState是同步还是异步
- 在 React 的 setState 函数实现中,会根据一个变量 isBatchingUpdates 判断是直接更新 this.state 还是放到一个updateQueue中延时更新,而 isBatchingUpdates 默认是 false,表示 setState 会同步更新 this.state;但是,有一个函数 batchedUpdates,该函数会把 isBatchingUpdates 修改为 true,而当 React 在调用事件处理函数之前就会先调用这个 batchedUpdates将isBatchingUpdates修改为true,这样由 React 控制的事件处理过程 setState 不会同步更新 this.state,而是异步的。
- 所以说setstate本身是同步的,一旦走了react内部的合并逻辑,放入了updateQueue队列中就变成异步了,而代码中的函数是react控制的,内部会走合并逻辑,所以这里的setState 不但是合并的也是异步的
- 上面说了,setState是异步的原因是因为走了react内部的合并逻辑,那只要能绕过react内部的合并逻辑,不让它进入到updateQueue中不就变成同步了吗?因为setState()本身就是同步的
- 利用setTimeout绕过react内部的合并逻辑
- 异步的情况:
由React控制的事件处理函数,以及生命周期函数调用setState时表现为异步 。大部分开发中用到的都是React封装的事件,比如onChange、onClick、onTouchMove等(合成事件中),这些事件处理函数中的setState都是异步处理的。
同步的情况:
React控制之外的事件中调用setState是同步更新的。比如原生js绑定的事件,setTimeout/setInterval,ajax,promise.then内等 React 无法掌控的 APIs情况下,setState是同步更新state的
redux和context+hooks优缺点
- 数据流对比
redux
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NQnPCpdb-1655685209074)(./pic/1.png)]
hooks
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GdD9566E-1655685209076)(./pic/2.png)]
-
简单分析
redux 的数据流程图画得比较简单,理解大概意思就好,毕竟它不是我要说的重点,和 hooks 的数据流程相比其实是大同小异。从 hooks 数据流能大致看出来,我们设计好 store 后,通过对应的 hooks 函数生成每个 store 的 Provider 和 Context。我们把所有的单个 Provider 糅合为一个整体的 Providers,作为所有 UI 的父组件。
在任何一个子 UI 组件内部,通过 hooks 函数得到对应 store 的 state、dispatch。UI 组件内,通过主动调用 dispatch 发送 action,然后经过 store 的数据处理中心 reducer,就能触发相应的数据改变。这个数据流程和 redux 几乎一模一样。
-
相同点
统一 store 数据管理
支持以发送 action 来修改数据
支持 action 处理中心:reducer -
异同点
hooks UI 层获取 store 和 dispatch 不需要用 HOC 依赖注入,而是用 useContext
redux 在 action 之后改变视图本质上还是 state 注入的方式修改的组件内部 state,而 hooks 则是一对一的数据触发
hooks 的 reducer 来自于 useReducer
hooks 还没有 middleware 的解决方案
react的生命周期
-
react旧版生命周期包含三个过程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-98ZYyCG7-1655685209079)(./pic/3.png)]
1、挂载过程
constructor()
componentWillMount()
componentDidMount()
2、更新过程
componentWillReceiveProps(nextProps)
shouldComponentUpdate(nextProps,nextState)
componentWillUpdate (nextProps,nextState)
render()
componentDidUpdate(prevProps,prevState)
3、卸载过程
componentWillUnmount()
其具体作用分别为:
1、constructor()
完成了React数据的初始化。
2、componentWillMount()
组件已经完成初始化数据,但是还未渲染DOM时执行的逻辑,主要用于服务端渲染。
3、componentDidMount()
组件第一次渲染完成时执行的逻辑,此时DOM节点已经生成了。
4、componentWillReceiveProps(nextProps)
接收父组件新的props时,重新渲染组件执行的逻辑。
5、shouldComponentUpdate(nextProps, nextState)
在setState以后,state发生变化,组件会进入重新渲染的流程时执行的逻辑。在这个生命周期中return false可以阻止组件的更新,主要用于性能优化。
6、componentWillUpdate(nextProps, nextState)
shouldComponentUpdate返回true以后,组件进入重新渲染的流程时执行的逻辑。
7、render()
页面渲染执行的逻辑,render函数把jsx编译为函数并生成虚拟dom,然后通过其diff算法比较更新前后的新旧DOM树,并渲染更改后的节点。
8、componentDidUpdate(prevProps, prevState)
重新渲染后执行的逻辑。
9、componentWillUnmount()
组件的卸载前执行的逻辑,比如进行“清除组件中所有的setTimeout、setInterval等计时器”或“移除所有组件中的监听器removeEventListener”等操作。
- react新版生命周期
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ucZdaSK9-1655685209080)(./pic/4.png)]
react16.4后使用了新的生命周期,使用getDerivedStateFromProps代替了旧的componentWillReceiveProps及componentWillMount。使用getSnapshotBeforeUpdate代替了旧的componentWillUpdate。
使用getDerivedStateFromProps(nextProps, prevState)的原因:
旧的React中componentWillReceiveProps方法是用来判断前后两个 props 是否相同,如果不同,则将新的 props 更新到相应的 state 上去。在这个过程中我们实际上是可以访问到当前props的,这样我们可能会对this.props做一些奇奇怪怪的操作,很可能会破坏 state 数据的单一数据源,导致组件状态变得不可预测。
而在 getDerivedStateFromProps 中禁止了组件去访问 this.props,强制让开发者去比较 nextProps 与 prevState 中的值,以确保当开发者用到 getDerivedStateFromProps 这个生命周期函数时,就是在根据当前的 props 来更新组件的 state,而不是去访问this.props并做其他一些让组件自身状态变得更加不可预测的事情。
使用getSnapshotBeforeUpdate(prevProps, prevState)的原因:
在 React 开启异步渲染模式后,在执行函数时读到的 DOM 元素状态并不总是渲染时相同,这就导致在 componentDidUpdate 中使用 componentWillUpdate 中读取到的 DOM 元素状态是不安全的,因为这时的值很有可能已经失效了。
而getSnapshotBeforeUpdate 会在最终的 render 之前被调用,也就是说在 getSnapshotBeforeUpdate 中读取到的 DOM 元素状态是可以保证与componentDidUpdate 中一致的。
React-redux中有个Context使用过吗?用来干什么的
这里再次提及下Redux的Store上的3个api,
store.getState() // 获得 store 上存储的所有状态
store.dispatch() // View 发出 Action 的唯一方法
store.subscribe() // 订阅 store上State 发生变化
虽然 Redux 应用全局就一个 Store 这样的直接导入依然有问题,因为在组件中直接导人 Store 是非常不利于组件复用的 。
所以,一个应用中,最好只有一个地方需要直接导人 Store ,这个位置当然应该是在调用最顶层 React 组件的位置 。 但是这样需要把Store,从顶层一层层往下传递,首先我们想到的就是props(父子组件通信方案)。这种方法有一个很大的缺陷,就是从上到下,所有的组件都要帮助传递这个 props 。
设想在一个嵌套多层的组件结构中,只有最里层的组件才需要使用 store ,但是为了把 store 从最外层传递到最里层,就要求中间所有的组件都需要增加对这个 store prop 的支持,即使根本不使用它,这无疑增加程序的耦合度,复杂度和不可维护性 。
React 提供了一个 叫 Context 的功能,能够完美地解决这个问题 。
redux-thunk是干什么的,为什么要用这个?具体怎么实现
-
什么是thunk?
thunk可以理解为函数的另一种称呼,但不是以前我们说的简单函数。Thunk代表的是一个被其他函数返回的函数。
-
那么它是怎么作用在redux上的呢?
Redux中有几个概念:”actions”,”action creators”,”reducer”,“middleware”
Actions就是普通对象,并且一定有一个type属性,除了这个,你可以在对象中自定义你想要描述该action的数据。
// 1. plain object
// 2. has a type
// 3. whatever else you want
{
type: "USER_LOGGED_IN",
username: "dave"
}
每次都要手写action对象会很麻烦,redux有一个“action creators”的概念来简化。
function userLoggedIn() {
return {
type: 'USER_LOGGED_IN',
username: 'dave'
};
}
你可以通过调用userLoggedIn函数来生成这个action,如果你在app中多次dispatch同样的action,使用action creators会大大简化工作。
- Action可以做点什么吗?
Action虽然叫action,但其实什么都不做,只是对象而已。它们可以自己做点什么吗?比如像调用api或是触发其他actions?
因为reducer必须是纯函数,我们不能在reducer里调用api或是触发其他actions。
如果我们希望action做些什么,就要把代码放进一个函数中去,这个函数就是thunk。
Action creators返回一个函数而不是一个action对象。
function getUser() {
return function() {
return axios.get('/current_user');
};
}
- 那么怎么让Redux处理actions是函数的情况呢?
我们就引入了redux-thunk,它是一个中间件,每次action都会经历它,如果action是一个函数,就调用这个函数,这就是redux-thunk做的事。
传递给thunk函数的就是两个参数:
-
Dispatch,如果它们需要,可以dispatch新的action。
-
getState,它们可以获取最新的state。
function logOutUser() { return function(dispatch, getState) { return axios.post('/logout').then(function() { // pretend we declared an action creator // called 'userLoggedOut', and now we can dispatch it dispatch(userLoggedOut()); }); }; }
- 如何使用redux-thunk
- 安装redux-thunk包
npm install --save redux-thunk - 导入redux-thunk并插入redux
import { createStore, applyMiddleware } from 'redux';
import thunk from 'redux-thunk';
import rootReducer from './reducers/index';
const store = createStore(
rootReducer,
applyMiddleware(thunk)
);
怎么用 React-redux 解决数据发生改变就会刷新页面这个问题
通常情况下,store 状态数据发生改变,会刷新页面这个问题是由于设计导致的,可能是组件定义时的问题。建议不要将页面中使用的组件都包装到一个大的容器组件中(如图1所示),而是将各相关的组件包装到一个较小的容器组件中(如图2所示):
图1 图2


图1中,当容器组件中订阅的 store 发生变化时,所有组件都会重新渲染。在图2中,由于将相关组件包装到了较小的容器组件中,当 container2 容器中订阅的 store 发生变化时,仅相关的组件重新渲染,其它组件不会导致重新渲染。
一般什么时候使用redux
在遇到如下情况时,可以考虑使用 redux:
- 某个状态需要在全局使用或共享(例如角色权限等信息)
- state并不总是以单向的方式线性流动
- UI 可以根据应用程序状态显著变化
- 许多不相关的组件以相同的方式更新状态
- 状态树结构复杂
redux有什么优缺点
优点:
- 纯粹,清晰易懂,让状态可预测,方便测试
缺点:
- 繁琐,要写大量的 action creator、reducer,所以即便想进行一个小的状态变化也会需要更改好几个地方
- 需要写大量
switch case分支判断,造成不小的负担 - 状态是存在于顶层的一棵树,通过 connect 和组件连在一起,单个组件是无法独立工作的。
- 对于各种异步的副作用,redux 本身是无能为力的,需要使用中间件
类组件有状态,为什么还要用 redux
类组件有 state,但 React 推荐组件间传递数据使用 props 自上而下流动,如果涉及到跨组件层级的通信,涉及到全局组件状态数据的共享及更新等,在各组件中都添加 props 来传递数据会显得非常繁琐,利用 redux 可以简化状态更新的繁琐度,提供统一的状态更新方式,使得状态更新可预测,也方便调试与维护。
shouldComponentUpdate 的作用
此方法仅作为性能优化的方式而存在,根据 shouldComponentUpdate() 的返回值,判断 React 组件的输出是否受当前 state 或 props 更改的影响,返回 false 以告知 React 可以跳过更新。
示例:

这是一个组件的子树。每个节点中,SCU 代表 shouldComponentUpdate 返回的值,而 vDOMEq 代表返回的 React 元素是否相同。最后,圆圈的颜色代表了该组件是否需要被调停。
节点 C2 的 shouldComponentUpdate 返回了 false,React 因而不会去渲染 C2,也因此 C4 和 C5 的 shouldComponentUpdate 不会被调用到。
对于 C1 和 C3,shouldComponentUpdate 返回了 true,所以 React 需要继续向下查询子节点。这里 C6 的 shouldComponentUpdate 返回了 true,同时由于渲染的元素与之前的不同使得 React 更新了该 DOM。
最后一个有趣的例子是 C8。React 需要渲染这个组件,但是由于其返回的 React 元素和之前渲染的相同,所以不需要更新 DOM。
显而易见,你看到 React 只改变了 C6 的 DOM。对于 C8,通过对比了渲染的 React 元素跳过了渲染。而对于 C2 的子节点和 C7,由于 shouldComponentUpdate 使得 render 并没有被调用。因此它们也不需要对比元素了。
react 中 ref 的作用
ref 是 React 提供的用来操纵 React 组件实例或者操作 DOM 元素的技术。
适合使用 ref 的几种情况:
- 管理焦点,文本选择或媒体播放
- 触发强制动画
- 集成第三方 DOM 库
示例1:
class CustomTextInput extends React.Component {
constructor(props) {
super(props);
// 创建一个 ref 来存储 textInput 的 DOM 元素
this.textInput = React.createRef();
this.focusTextInput = this.focusTextInput.bind(this);
}
focusTextInput() {
// 直接使用原生 API 使 text 输入框获得焦点
// 注意:我们通过 "current" 来访问 DOM 节点
this.textInput.current.focus();
}
render() {
// 告诉 React 我们想把 <input> ref 关联到
// 构造器里创建的 `textInput` 上
return (
<div>
<input
type="text"
ref={this.textInput} />
<input
type="button"
value="Focus the text input"
onClick={this.focusTextInput}
/>
</div>
);
}
}
这个例子是为 DOM 元素添加 ref,使用 ref 去存储 DOM 节点的引用,React 会在组件挂载时给 ref 对象的 current 属性传入 DOM 元素,并在组件卸载时传入 null 值。ref 会在 componentDidMount 或 componentDidUpdate 生命周期钩子触发前更新。
示例2:
class AutoFocusTextInput extends React.Component {
constructor(props) {
super(props);
this.textInput = React.createRef();
}
componentDidMount() {
this.textInput.current.focusTextInput();
}
render() {
return (
<CustomTextInput ref={this.textInput} />
);
}
}
这个示例是包装上面的 CustomTextInput,来模拟它挂载之后立即被点击的操作,我们可以使用 ref 来获取这个自定义的 input 组件并手动调用它的 focusTextInput 方法。
解释 redux 的工作流程
Redux工作流程:
- 在 View 中派发 action(dispatch(action))
- store 接收到派发的 action 对象
- 在 store 中,调用 reducer(),并传递之前的 state 与 action 作为参数
- 在 reducer 中按照 action.type 判断,运算并返回新的 state 给 store
- store 中更新最新的 state
- 执行由 subscribe() 注册的监听任务(这些任务订阅了 store 的变化)
redux 数据流向,比如点击按钮到状态修改,数据如何流向的

由上图我们可以看到,redux 数据流向大致步骤(以按钮点击修改状态为例):
- UI 首次呈现时,访问 redux 存储的当前状态 state,并使用该数据来决定初始呈现内容:显示提现
$0元。 - 在视图中触发点击事件:提现
- 事件处理程序中,触发 action 并传递给 store:dispatch(action)
- store 使用前一个
state和接收到的 action 经 reducer 函数处理,并将返回值保存为新的state - UI 根据新状态重新呈现
说一下 redux 的使用流程,dispash 是从哪里解构出来的
redux 使用流程:
- 创建 reducer() 纯函数,用于同步更新状态
- 将各独立的 reducer 合并为一个完整的根 reducer
- 创建 action creator 函数,用于生成 action 对象
- 基于根 reducer 创建 store,如果有异步更新状态数据操作,应用中间件(如 redux-thunk)
- 订阅 store 中的状态变化
- 在 UI 中根据 store 的状态初始渲染
- 在 UI 中触发 action 到 store 中更新状态
如果我们要在 View 中实现 store 中的状态更新,则需要 dispatch(action),这个 dispatch() 方法是从创建的 store 中解构出来的,在 store 中除了 dispatch 外,还可以解构诸如 getState、subscribe 等属性。
React性能为什么强于vue
对于框架之间我们并不是特别在意谁强谁弱, 而是要搞清楚框架真正值得我们学习的点:
像React框架, 它在 架构上融合了数据驱动视图、组件化、函数式编程、面向对象、Fiber 等经典设计“哲学”, 在底层技术选型上涉及了 JSX、虚拟 DOM等经典解决方案,在周边生态上至少涵盖了状态管理和前端路由两 大领域的最佳实践。此外,它还自建了状态管理机制与事件系统,创造性地在前端框架中引入了 Hooks 思 想… React 十年如一日的稳定输出背后,有太多值得我们去吸收和借鉴的东西.
- npm源码包大小, react 291kb, vue 2.97mb 更小的源码包, 更少的cpu消耗.
- 基于虚拟DOM, 减少重绘次数(将多次数据操作汇集成一次
DOM更新); 减少手动操作DOM操作(不用再像以前写jQuery那样,先获取DOM元素,再设置属性) - Fiber算法, React16提出了Fiber架构,其能够将任务分片,划分优先级,同时能够实现类似于操作系统中对线程的抢占式调度,非常强大, 对于因为JavaScript的单线程特性,单个同步任务耗时太长,出现卡顿的问题就可以得到解决, 这进一步弥补了React在组件更新机制方面的缺陷.
- Hooks, 创造性地在前端框架中引入了 Hooks , 这使得程序员有了除class component以外的界面构建方式, Hooks让复用代码这件事变得更容易, 结合函数式组件整体风格更清爽,更优雅, 更少的代码量, 这也使得项目更容易阅读和维护.
- 结合shouldComponentUpdate等方法, 可以避免不必要的组件更新, 实现更少的cpu消耗, 程序员可以从代码的角度介入到组件更新效率的控制过程中.
vue-router和react-router的区别
- 路由配置语法的差异
- vue-router是全局配置方式,react-router是全局组件方式。
- vue-router仅支持对象形式的配置,react-router支持对象形式和JSX语法的组件形式配置。
- vue-router任何路由组件都会被渲染到位置,react-router子组件作为children被传入父组件,而根组件被渲染到位置。
- 使用方式上的不同
- vue-router通过路由配置表 + router-link, router-view控制路由.
- react-router通过Link,NavLink, Route,Switch,Redirect等路由组件控制路由,
- 获取参数的方式不同
- vue-router借助this. r o u t e r 获 取 全 局 路 由 的 实 例 , t h i s . router获取全局路由的实例,this. router获取全局路由的实例,this.route获取当前路由信息
- react-router借助this.props.location, this.props.match获取路由参数
三、小程序
简单谈谈微信小程序
在结构和样式方面,小程序提供了一些常用的标签与控件,比如:
view,小程序主要的布局元素,类似于html标签的div,你也完全可以像控制div那样去控制view。
scroll-view,你要滚动内容的话,没必要用view去做overflow,scroll-view提供了更为强大的功能,通过参数的调整,你可以控制滚动方向,触发的事件等等
配置文件app.json平级的还有一个app.js文件,是小程序的脚本代码。我们可以在这个文件中监听并处理小程序的生命周期函数、声明全局变量,在每个page目录里的js做当前页面的业务操作。但是小程序的页面的脚本逻辑是在JsCore中运行,JsCore是一个没有窗口对象的环境,所以不能在脚本中使用window,也无法在脚本中操作组件,所以我们常用的zepto/jquery 等类库也是无法使用的。
另一个app.wxss文件,这个是全局的样式,所有的页面都会调用到,每个项目目录下面的wxss是局部样式文件,不会和其他目录产生污染,可以放心使用样式名。
他提供的WXSS(WeiXin Style Sheets)是一套样式语言,具有 CSS 大部分特性,可以看作一套简化版的css。
同时为了更适合开发微信小程序,还对 CSS 进行了扩充以及修改,直接帮我们把适配的一部分工作都做了,比如他的rpx(responsive pixel),可以根据屏幕宽度进行自适应,规定屏幕宽为750rpx。如在 iPhone6 上,屏幕宽度为375px,共有750个物理像素,则750rpx = 375px = 750物理像素,1rpx = 0.5px = 1物理像素。
在调用微信生态系统功能时,微信小程序提供了相应的api,比如你要修改一个头像,可以使用wx.chooseImage等
小程序的原生组件有哪些
以微信小程序为例,可以分成容器组件、基础组件、表单组件、媒体组件、开放能力组件等
小程序的安卓版和ios版是怎么开发出来
小程序开发基于html、css、javascript,与web开发一样具有跨平台特性,一次开发即可在安卓和iOS等平台访问,但与普通web开发不同,小程序运行环境并不是浏览器,而是依附于各自的软件App,如微信小程序必须在微信中访问,支付宝小程序必须在支付宝中访问等,小程序的开发流程也有所不同,需要经过申请小程序帐号、安装小程序开发者工具、配置项目、开发、调试、上线发布等过程方可完成
uni-app弹窗被覆盖怎么解决
如果弹窗被别的内容覆盖,且设置很大的z-index也无法解决,这种情况多半是被一些如map、video、textarea、canvas等原生组件遮盖,因为原生组件层级高于前端组件,我们可以使用cover-view组件解决
小程序生命周期
onReady 生命周期函数–监听页面初次渲染完成
onShow 生命周期函数–监听页面显示
onHide 生命周期函数–监听页面隐藏
onUnload 生命周期函数–监听页面卸载
onPullDownRefresh 页面相关事件处理函数–监听用户下拉动作
onReachBottom 页面上拉触底事件的处理函数
onShareAppMessage 用户点击右上角转发
onPageScroll 页面滚动触发事件的处理函数
onTabItemTap 当前是 tab 页时,点击 tab 时触发
小程序路由跳转
-
通过组件navigator跳转,设置url属性指定跳转的路径,设置open-type属性指定跳转的类型(可选),open-type的属性有 redirect, switchTab, navigateBack
// redirect 对应 API 中的 wx.redirect 方法 <navigator url="/page/redirect/redirect?title=redirect" open-type="redirect">在当前页打开</navigator> // navigator 组件默认的 open-type 为 navigate <navigator url="/page/navigate/navigate?title=navigate">跳转到新页面</navigator> // switchTab 对应 API 中的 wx.switchTab 方法 <navigator url="/page/index/index" open-type="switchTab">切换 Tab</navigator> // reLanch 对应 API 中的 wx.reLanch 方法 <navigator url="/page/redirect/redirect?title=redirect" open-type="redirect">//关闭所有页面,打开到应用内的某个页面 // navigateBack 对应 API 中的 wx.navigateBack 方法 <navigator url="/page/index/index" open-type="navigateBack">关闭当前页面,返回上一级页面或多级页面</navigator> -
通过api跳转,wx.navigateTo() , wx.navigateBack(), wx.redirectTo() , wx.switchTab(), wx.reLanch()
wx.navigateTo({ url: 'page/home/home?user_id=1' // 页面 A }) wx.navigateTo({ url: 'page/detail/detail?product_id=2' // 页面 B }) // 跳转到页面 A wx.navigateBack({ delta: 2 //返回指定页面 }) // 关闭当前页面,跳转到应用内的某个页面。 wx.redirectTo({ url: 'page/home/home?user_id=111' }) // 跳转到tabBar页面(在app.json中注册过的tabBar页面),同时关闭其他非tabBar页面。 wx.switchTab({ url: 'page/index/index' }) // 关闭所有页面,打开到应用内的某个页面。 wx.reLanch({ url: 'page/home/home?user_id=111' })
小程序的兼容问题有哪些
遇到的如下:
- 1,ios下的zIndex层级问题,主要发生在iphone7和iphoneX下 绝对定位必须有一个共同的父元素。
- 2,左右边框不生效 当边框的宽度设置为奇数的时候,可能会不生效 解决方法:将宽度设置为偶数的时候,在ios下就可以解决
- 3,还有尽量不要用margin-bottom ,当元素是在整个页面的最底部的时候,在ios下可能margin-bottom会失效,所以建议,都使用padding-bottom
new Date跨平台兼容性问题
在Andriod使用new Date(“2018-05-30 00:00:00”)木有问题,但是在ios下面识别不出来。
因为IOS下面不能识别这种格式,需要用2018/05/30 00:00:00格式。可以使用正则表达式对做字符串替换,将短横替换为斜杠。var iosDate= date.replace(/-/g, ‘/’);。
wx.getUserInfo()接口更改问题
微信小程序最近被吐槽最多的一个更改,就是用户使用wx.getUserInfo(开发和体验版)时不会弹出授权,正式版不受影响。现在授权方式是需要引导用户点击一个授权按钮,然后再弹出授权。
小程序框架都掌握哪一些,uniapp都会哪一些,平时开发遇到的困难
- Taro
- uni-app
- WeUI
- mpvue
- iView Weapp
开发uni-app遇到的坑
上传图片
小程序时必须要写header:{“Content-Type”: “multipart/form-data”}, h5是必须省略
uni-app h5 端的ios图片不能加载问题
uni-app h5端 ios只能加载https的图片
uni-app 使用deep 穿透微信小程序生效 h5无作用
需要在methods同级下加一个 :
options: { styleIsolation: ‘shared’ },
uni-app post请求如何传递数组 参数
在开发中我们接口上传图片是post请求 无法传递一个数组 解决方法如下
我们可以把数据转换成字符串 然后拼接到请求地址后后面
拼接字符串格式:image[]=arr[0]&image[]=arr[1]
imgURlClick(imgArr){
return '?images[]='+imgArr.join('&images[]=')
}
小程序怎么获取手机号
-
准备一个button组件, 将 button 组件
open-type的值设置为getPhoneNumber,当用户点击并同意之后,可以通过bindgetphonenumber事件回调获取到动态令牌code;<button open-type="getPhoneNumber" bindgetphonenumber="getPhoneNumber"></button>Page({ getPhoneNumber (e) { console.log(e.detail.code) } }) -
接着把
code传到开发者后台,并在开发者后台调用微信后台提供的 phonenumber.getPhoneNumber 接口,消费code来换取用户手机号。每个code有效期为5分钟,且只能消费一次。getPhoneNumber: function (e) { var that = this; console.log(e.detail.errMsg == "getPhoneNumber:ok"); if (e.detail.errMsg == "getPhoneNumber:ok") { wx.request({ url: 'http://localhost/index/users/decodePhone', data: { encryptedData: e.detail.encryptedData, iv: e.detail.iv, sessionKey: that.data.session_key, uid: "", }, method: "post", success: function (res) { console.log(res); } }) } }注:
getPhoneNumber返回的code与wx.login返回的code作用是不一样的,不能混用.注:从基础库 2.21.2 开始,对获取手机号的接口进行了安全升级, 需要用户主动触发才能发起获取手机号接口,所以该功能不由 API 来调用,需用 button 组件的点击来触发。另外,新版本接口不再需要提前调用
wx.login进行登录.
小程序的登录流程
登陆流程:
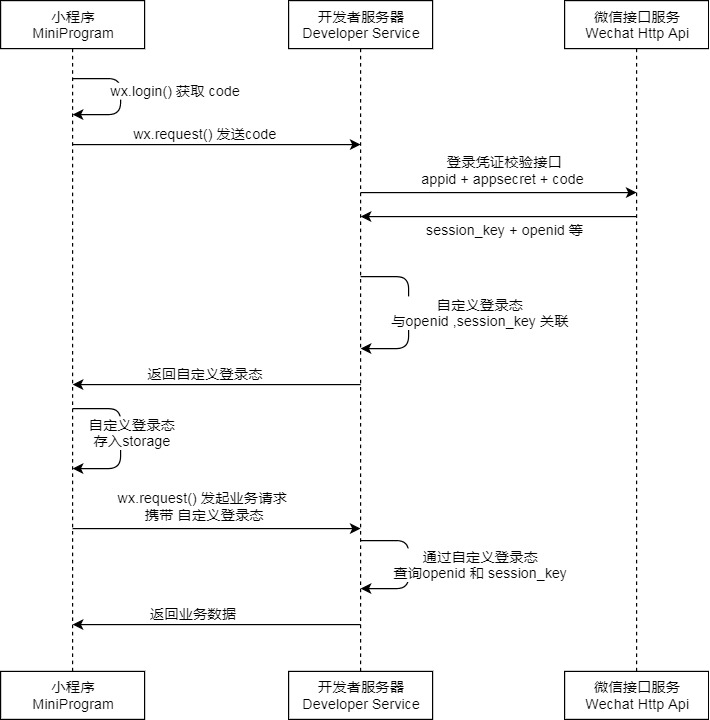
-
首次登录
-
调用小程序api接口
wx.login()获取 临时登录凭证code ,这个code是有过期时间的. -
将这个
code回传到开发者服务器(就是请求开发者服务器的登录接口,通过凭证进而换取用户登录态信息,包括用户的唯一标识(openid)及本次登录的会话密钥(session_key)等) -
拿到开发者服务器传回来的会话密钥(session_key)之后,前端需要保存起来.
wx.setStorageSync('sessionKey', 'value')
-
-
再次登录的时候,就要判断存储的session_key是否过期了
- 获取缓存中的session_key,
wx.getStorageSync('sessionKey') - 如果缓存中存在session_key,那么调用小程序api接口
wx.checkSession()来判断登录态是否过期,回调成功说明当前 session_key 未过期,回调失败说明 session_key 已过期。登录态过期后前端需要再调用 wx.login()获取新的用户的code,然后再向开发者服务器发起登录请求. - 一般在项目开发,开发者服务器也会对用户的登录态做过期限制,所以这时在判断完微信服务器中登录态如果没有过期之后还要判断开发者服务器的登录态是否过期。(请求开发者服务器给定的接口进行请求判断就好)
- 获取缓存中的session_key,
小程序如果版本更新了怎么通知用户
当小程序发布新的版本后,用户如果之前访问过该小程序,通过已打开的小程序进入(未手动删除),则会弹出提示,提醒用户更新新的版本。用户点击确定就可以自动重启更新,点击取消则关闭弹窗,不再更新.
-
核心步骤:
-
打开小程序, 检查小程序是否有新版本发布
updateManager.onCheckForUpdate(function (res) {}) -
小程序有新版本,则静默下载新版本,做好更新准备
updateManager.onUpdateReady(function () {}) -
新的版本已经下载好,调用
applyUpdate应用新版本并重启小程序updateManager.applyUpdate()
-
-
更新版本的模拟测试
微信开发者工具上可以通过「编译模式」下的「下次编译模拟更新」开关来调试.
点击编译模式设置下拉列表,然后点击“添加编译模式”,在自定义编译条件弹窗界面,点击下次编译时模拟更新,然后点击确定,重新编译就可以了.
注: 需要注意的是,这种方式模拟更新一次之后就失效了,后边再测试仍需要对这种编译模式进行重新设置才可以.
-
核心代码如下:
App({
onLaunch: function(options) {
this.autoUpdate()
},
autoUpdate:function(){
var self=this
// 获取小程序更新机制兼容
if (wx.canIUse('getUpdateManager')) {
const updateManager = wx.getUpdateManager()
//1. 检查小程序是否有新版本发布
updateManager.onCheckForUpdate(function (res) {
// 请求完新版本信息的回调
if (res.hasUpdate) {
//2. 小程序有新版本,则静默下载新版本,做好更新准备
updateManager.onUpdateReady(function () {
wx.showModal({
title: '更新提示',
content: '新版本已经准备好,是否重启应用?',
success: function (res) {
if (res.confirm) {
//3. 新的版本已经下载好,调用 applyUpdate 应用新版本并重启
updateManager.applyUpdate()
} else if (res.cancel) {
//不应用
}
}
})
})
updateManager.onUpdateFailed(function () {
// 新的版本下载失败
wx.showModal({
title: '已经有新版本了哟~',
content: '新版本已经上线啦~,请您删除当前小程序,重新搜索打开哟~',
})
})
}
})
} else {
// 如果希望用户在最新版本的客户端上体验您的小程序,可以这样子提示
wx.showModal({
title: '提示',
content: '当前微信版本过低,无法使用该功能,请升级到最新微信版本后重试。'
})
}
}
})
小程序嵌入H5页面怎么做
- 解决方式 :web-view
webview 指向网页的链接。可打开关联的公众号的文章,其它网页需登录小程序管理后台配置业务域名。
-
具体实现步骤:
-
登陆小程序管理后台, 配置服务器域名( h5页面所在的域名 )
-
在小程序里面嵌入h5
- 在小程序里面定义一个你想要的H5入口
<navigator url="/page/navigate/navigate" hover-class="navigator-hover">跳转到新页面</navigator>- 新建一个页面,放置 webview , src指向h5网页的链接.
<web-view src="{{url}}" bindmessage="getMessage"></web-view> </block>
注: 实际开发中在h5页面中有可能需要向小程序发送消息, 实现h5页面和小程序页面的通信
需要使用postMessage向小程序发送消息, 在h5中postMessage 注意,key必须叫做data,否则取不到.
-
小程序的生命周期函数有哪些?分别有什么作用?
小程序的生命周期函数大体分为三类:
-
小程序应用的生命周期
属性 说明 onLaunch 监听小程序初始化, 全局只触发一次 onShow 监听小程序启动或切前台。 onHide 监听小程序切后台。 参考官网: 应用的生命周期
-
小程序页面的生命周期
属性 说明 onLoad 监听页面加载, 获取其他页面传过来的参数, 发起网络请求 onShow 监听页面显示 onReady 监听页面初次渲染完成 onHide 监听页面隐藏 onUnload 监听页面卸载 参考官网: 页面的生命周期
-
小程序组件的生命周期
定义段 描述 created 在组件实例刚刚被创建时执行,注意此时不能调用 setData)attached 在组件实例进入页面节点树时执行) ready 在组件布局完成后执行) moved 在组件实例被移动到节点树另一个位置时执行) detached 在组件实例被从页面节点树移除时执行)
四、webpack
webpack了解吗,讲一讲原理,怎么压缩代码
- 需要读到入口文件里面的内容。
- 分析入口文件,递归的去读取模块所依赖的文件内容,生成AST语法树。
- 根据AST语法树,生成浏览器能够运行的代码
webpack怎么配置
主要配置5个核心文件
1. mode:通过选择 `development`, `production` 或 `none` 之中的一个,来设置 `mode` 参数,你可以启用 webpack 内置在相应环境下的优化。
2. entry:**入口起点(entry point)** 指示 webpack 应该使用哪个模块,来作为构建其内部 [依赖图(dependency graph)](https://webpack.docschina.org/concepts/dependency-graph/) 的开始。进入入口起点后,webpack 会找出有哪些模块和库是入口起点(直接和间接)依赖的。
3. output:**output** 属性告诉 webpack 在哪里输出它所创建的 *bundle*,以及如何命名这些文件。主要输出文件的默认值是 `./dist/main.js`,其他生成文件默认放置在 `./dist` 文件夹中。
4. loader:webpack 只能理解 JavaScript 和 JSON 文件,这是 webpack 开箱可用的自带能力。**loader** 让 webpack 能够去处理其他类型的文件,并将它们转换为有效 [模块](https://webpack.docschina.org/concepts/modules),以供应用程序使用,以及被添加到依赖图中。
5. plugin:loader 用于转换某些类型的模块,而插件则可以用于执行范围更广的任务。包括:打包优化,资源管理,注入环境变量。
webpack怎么打包
初始化参数:解析webpack配置参数,合并shell传入和webpack.config.js文件配置的参数,形成最后的配置结果;
开始编译:上一步得到的参数初始化compiler对象,注册所有配置的插件,插件 监听webpack构建生命周期的事件节点,做出相应的反应,执行对象的run方法开始执行编译;
确定入口:从配置的entry入口,开始解析文件构建AST语法树,找出依赖,递归下去;
编译模块:递归中根据文件类型和loader配置,调用所有配置的loader对文件进行转换,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理;
完成模块编译并输出:递归完事后,得到每个文件结果,包含每个模块以及他们之间的依赖关系,根据entry或分包配置生成代码块chunk;
输出完成:输出所有的chunk到文件系统;
vue打包内存过大,怎么使用webpack来进行优化
开放式题目
-
打包优化的目的
1、优化项目启动速度,和性能
2、必要的清理数据
3、性能优化的主要方向
cdn加载
-压缩js
减少项目在首次加载的时长(首屏加载优化)
4、目前的解决方向cdn加载不比多说,就是改为引入外部js路径
首屏加载优化方面主要其实就两点
第一:
尽可能的减少首次加载的文件体积,和进行分布加载第二:
首屏加载最好的解决方案就是ssr(服务端渲染),还利于seo
但是一般情况下没太多人选择ssr,因为只要不需要seo,ssr更多的是增加了项目开销和技术难度的。1、路由懒加载
在 Webpack 中,我们可以使用动态 import语法来定义代码分块点 (split point): import(’./Fee.vue’) // 返回 Promise如果您使用的是 Babel,你将需要添加 syntax-dynamic-import 插件,才能使 Babel 可以正确地解析语法。
结合这两者,这就是如何定义一个能够被 Webpack 自动代码分割的异步组件。const Fee = () => import(‘./Fee.vue’)
在路由配置中什么都不需要改变,只需要像往常一样使用 Foo:const router = new VueRouter({ routes: [ { path: '/fee', component: Fee } ] })2、服务器和webpack打包同时配置Gzip
Gzip是GNU zip的缩写,顾名思义是一种压缩技术。它将浏览器请求的文件先在服务器端进行压缩,然后传递给浏览器,浏览器解压之后再进行页面的解析工作。在服务端开启Gzip支持后,我们前端需要提供资源压缩包,通过Compression-Webpack-Plugin插件build提供压缩需要后端配置,这里提供nginx方式:
http:{ gzip on; #开启或关闭gzip on off gzip_disable "msie6"; #不使用gzip IE6 gzip_min_length 100k; #gzip压缩最小文件大小,超出进行压缩(自行调节) gzip_buffers 4 16k; #buffer 不用修改 gzip_comp_level 8; #压缩级别:1-10,数字越大压缩的越好,时间也越长 gzip_types text/plain application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png; # 压缩文件类型 }// 安装插件
$ cnpm i --save-dev compression-webpack-plugin
// 在vue-config.js 中加入
const CompressionWebpackPlugin = require('compression-webpack-plugin');
const productionGzipExtensions = [
"js",
"css",
"svg",
"woff",
"ttf",
"json",
"html"
];
const isProduction = process.env.NODE_ENV === 'production';
.....
module.exports = {
....
// 配置webpack
configureWebpack: config => {
if (isProduction) {
// 开启gzip压缩
config.plugins.push(new CompressionWebpackPlugin({
algorithm: 'gzip',
test: /\.js$|\.html$|\.json$|\.css/,
threshold: 10240,
minRatio: 0.8
}))
}
}
}
3、优化打包chunk-vendor.js文件体积过大
当我们运行项目并且打包的时候,会发现chunk-vendors.js这个文件非常大,那是因为webpack将所有的依赖全都压缩到了这个文件里面,这时我们可以将其拆分,将所有的依赖都打包成单独的js。
// 在vue-config.js 中加入
.....
module.exports = {
....
// 配置webpack
configureWebpack: config => {
if (isProduction) {
// 开启分离js
config.optimization = {
runtimeChunk: 'single',
splitChunks: {
chunks: 'all',
maxInitialRequests: Infinity,
minSize: 20000,
cacheGroups: {
vendor: {
test: /[\\/]node_modules[\\/]/,
name (module) {
// get the name. E.g. node_modules/packageName/not/this/part.js
// or node_modules/packageName
const packageName = module.context.match(/[\\/]node_modules[\\/](.*?)([\\/]|$)/)[1]
// npm package names are URL-safe, but some servers don't like @ symbols
return `npm.${packageName.replace('@', '')}`
}
}
}
}
};
}
}
}
// 至此,你会发现原先的vender文件没有了,同时多了好几个依赖的js文件
4、启用CDN加速
用Gzip已把文件的大小减少了三分之二了,但这个还是得不到满足。那我们就把那些不太可能改动的代码或者库分离出来,继续减小单个chunk-vendors,然后通过CDN加载进行加速加载资源。
// 修改vue.config.js 分离不常用代码库
// 如果不配置webpack也可直接在index.html引入
module.exports = {
configureWebpack: config => {
if (isProduction) {
config.externals = {
'vue': 'Vue',
'vue-router': 'VueRouter',
'moment': 'moment'
}
}
}
}
// 在public文件夹的index.html 加载
<script src="https://cdn.bootcss.com/vue/2.5.17-beta.0/vue.runtime.min.js"></script>
<script src="https://cdn.bootcss.com/vue-router/3.0.1/vue-router.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/moment.js/2.22.2/moment.min.js"></script>
5、完整vue.config.js代码
const path = require('path')
// 在vue-config.js 中加入
// 开启gzip压缩
const CompressionWebpackPlugin = require('compression-webpack-plugin');
// 判断开发环境
const isProduction = process.env.NODE_ENV === 'production';
const resolve = dir => {
return path.join(__dirname, dir)
}
// 项目部署基础
// 默认情况下,我们假设你的应用将被部署在域的根目录下,
// 例如:https://www.my-app.com/
// 默认:'/'
// 如果您的应用程序部署在子路径中,则需要在这指定子路径
// 例如:https://www.foobar.com/my-app/
// 需要将它改为'/my-app/'
// iview-admin线上演示打包路径: https://file.iviewui.com/admin-dist/
const BASE_URL = process.env.NODE_ENV === 'production'
? '/'
: '/'
module.exports = {
//webpack配置
configureWebpack:config => {
// 开启gzip压缩
if (isProduction) {
config.plugins.push(new CompressionWebpackPlugin({
algorithm: 'gzip',
test: /\.js$|\.html$|\.json$|\.css/,
threshold: 10240,
minRatio: 0.8
}));
// 开启分离js
config.optimization = {
runtimeChunk: 'single',
splitChunks: {
chunks: 'all',
maxInitialRequests: Infinity,
minSize: 20000,
cacheGroups: {
vendor: {
test: /[\\/]node_modules[\\/]/,
name (module) {
// get the name. E.g. node_modules/packageName/not/this/part.js
// or node_modules/packageName
const packageName = module.context.match(/[\\/]node_modules[\\/](.*?)([\\/]|$)/)[1]
// npm package names are URL-safe, but some servers don't like @ symbols
return `npm.${packageName.replace('@', '')}`
}
}
}
}
};
// 取消webpack警告的性能提示
config.performance = {
hints:'warning',
//入口起点的最大体积
maxEntrypointSize: 50000000,
//生成文件的最大体积
maxAssetSize: 30000000,
//只给出 js 文件的性能提示
assetFilter: function(assetFilename) {
return assetFilename.endsWith('.js');
}
}
}
},
// Project deployment base
// By default we assume your app will be deployed at the root of a domain,
// e.g. https://www.my-app.com/
// If your app is deployed at a sub-path, you will need to specify that
// sub-path here. For example, if your app is deployed at
// https://www.foobar.com/my-app/
// then change this to '/my-app/'
publicPath: BASE_URL,
// tweak internal webpack configuration.
// see https://github.com/vuejs/vue-cli/blob/dev/docs/webpack.md
devServer: {
host: 'localhost',
port: 8080, // 端口号
hotOnly: false,
https: false, // https:{type:Boolean}
open: true, //配置自动启动浏览器
proxy:null // 配置跨域处理,只有一个代理
},
// 如果你不需要使用eslint,把lintOnSave设为false即可
lintOnSave: true,
css:{
loaderOptions:{
less:{
javascriptEnabled:true
}
},
extract: true,// 是否使用css分离插件 ExtractTextPlugin
sourceMap: false,// 开启 CSS source maps
modules: false// 启用 CSS modules for all css / pre-processor files.
},
chainWebpack: config => {
config.resolve.alias
.set('@', resolve('src')) // key,value自行定义,比如.set('@@', resolve('src/components'))
.set('@c', resolve('src/components'))
},
// 打包时不生成.map文件
productionSourceMap: false
// 这里写你调用接口的基础路径,来解决跨域,如果设置了代理,那你本地开发环境的axios的baseUrl要写为 '' ,即空字符串
// devServer: {
// proxy: 'localhost:3000'
// }
}
webpack打包用过什么插件
1、HtmlWebpackPlugin
包名:html-webpack-plugin
该插件将为你生成一个 HTML 文件, 在 body 中使用 script 标签引入你所有 webpack 生成的 bundle。
官方传送门
2、CleanWebpackPlugin
包名:clean-webpack-plugin
用于在打包前清理上一次项目生成的
bundle文件。默认情况下,此插件将删除webpack的Output.Path目录中的所有文件,以及在每次成功重建后所有未使用的webpack资源(assets)。如果使用的webpack版本是 4 以上的,默认 清理<PROJECT_DIR>/dist/下的文件。
官方传送门
3、MiniCssExtractPlugin
包名:mini-css-extract-plugin
将 css 成生文件,而非内联 。该插件的主要是为了抽离 css 样式,防止将样式打包在 js 中引起页面样式加载错乱的现象。支持按需加载 css 和 sourceMap
官方传送门
4、HotModuleReplacementPlugin
包名:HotModuleReplacementPlugin
由
webpack 自带。在对CSS / JS文件进行修改时,可以立即更新浏览器(部分刷新)。依赖于webpack-dev-server
官方传送门
5、ImageminPlugin
包名:imagemin-webpack-plugin
批量压缩图片。
官方传送门
6、PurifyCSSPlugin
包名:purifycss-webpack
从CSS中删除未使用的选择器(删除多余的 css 代码)。和
extract-text-webpack-plugin一起使用
官方传送门
7、OptimizeCSSAssetsPlugin
包名:optimize-css-assets-webpack-plugin
压缩css文件。
官方传送门
8、CssMinimizerPlugin
包名: css-minimizer-webpack-plugin
压缩css文件。**用于 webpack 5 **。
官方传送门
9、UglifyJsPlugin
包名:uglifyjs-webpack-plugin
压缩js文件。
官方传送门
10、ProvidePlugin
包名:ProvidePlugin
由
webpack 自带。自动加载模块,而不必在任何地方import或require它们。例如:new webpack.ProvidePlugin({$: ‘jquery’,React: ‘react’})
官方传送门
11、SplitChunksPlugin
包名:-
在
webapck配置中的optimization字段中配置。cacheGroups是关键,将文件提取打包成公共模块,像 抽取node_modules里的文件。
官方传送门
12、CompressionPlugin
包名:compression-webpack-plugin
启用
gzip压缩。
官方传送门
13、CopyWebpackPlugin
包名: copy-webpack-plugin
将已存在的单个文件或整个目录复制到构建目录中。多用于 将静态文件 因在打包时 webpack 并不会帮我们拷贝到 dist 目录 拷贝到 dist 目录
官方传送门
14、DefinePlugin
包名:DefinePlugin
由
webpack 自带。设置全局变量。如:new webpack.DefinePlugin({‘process.env.NODE_ENV’: JSON.stringify(‘production’)})
官方传送门
1、DllPlugin
包名:DllPlugin
由
webpack 自带。dllplugin和dllreferenceplugin提供了拆分捆绑包的方法,这些方式可以大大提高构建时间性能。
官方传送门
2、DLLReferencePlugin
包名:DLLReferencePlugin
由
webpack 自带。它引用了仅需要预先构建的依赖项的DLL-only-Bundle。
官方传送门
3、ParallelUglifyPlugin
包名:webpack-parallel-uglify-plugin
开启多个子进程,把对多个文件压缩的工作分别给多个子进程去完成。减少构建时间。
官方传送门
4、HappyPack
包名:happypack
让 webpack 把任务分解给多个子进程去并发的执行,子进程处理完后再把结果发送给主进程。提升 构建 速度
官方传送门
说说gulp和webpack的区别
开放式题目
Gulp强调的是前端开发的工作流程。我们可以通过配置一系列的task,定义task处理的事务(例如文件压缩合并、雪碧图、启动server、版本控制等),然后定义执行顺序,来让Gulp执行这些task,从而构建项目的整个前端开发流程。通俗一点来说,“Gulp就像是一个产品的流水线,整个产品从无到有,都要受流水线的控制,在流水线上我们可以对产品进行管理。”
Webpack是一个前端模块化方案,更侧重模块打包。我们可以把开发中的所有资源(图片、js文件、css文件等)都看成模块,通过loader(加载器)和plugins(插件)对资源进行处理,打包成符合生产环境部署的前端资源。 Webpack就是需要通过其配置文件(Webpack.config.js)中 entry 配置的一个入口文件(JS文件),然后在解析过程中,发现其他的模块,如scss等文件,再调用配置的loader或者插件对相关文件进行解析处理。
虽然Gulp 和 Webpack都是前端自动化构建工具,但看2者的定位就知道不是对等的。Gulp严格上讲,模块化不是他强调的东西,旨在规范前端开发流程。Webpack更明显的强调模块化开发,而那些文件压缩合并、预处理等功能,不过是他附带的功能。
五、Typescript
了解过TS吗?
ts是一种基于静态类型检查的强类型语言那当然js就是一种弱类型语言
由于我们在浏览器中不能编译ts语言所以我们需要安装编译器
安装下载
使用npm install -g typescript进行下载
使用tsc进行检测是否安装成功
在文件中间一个js文件,然后在文件中见一个ts文件,但是直接去使用的时候会报错,需要在终端中使用tsc ./js/hello.ts,这样之后可以在当前的就是文件中自动编译一个同名js文件。
let num:number=20
console.log(num)
console.log("str")
ts支持的数据类型
数组
let arr:number[]=[1,2,3,4,5]
//将let定义为一个数组,每一项都是number
let arr:number[]=[1,2,3,4,5,"str"] //报错不能将类型string分配给类型number
let arr1:Array<number|string>=[1,2,3,4,5,"str"]//这样写就不会报错
//通过给范型添加多类型,让数组支持多种数据格式
元组Tuple
规定元素类型和规定元素数量和顺序的数组
特点:不要越界访问
定义的是什么类型写的就是什么类型,可以使用数组的下标取值,但是如果使用数组的push方法的话,虽然输出的数组中有,但是取值的话会报错可以打印出来但不建议这样写,这就说了元组的一个越界问题
let tu:[number,string]
tu=[1,"str"]
枚举
1.有限的可列举出来的命名和索引对应的类型
2枚举类型的优势:语义化可维护性
3原理:反向映射,互相指向
//定义了一个枚举
enum user{
admin,
guest,
develoment,
pm
}
console.log(user)
//使用user类型来定义枚举变量any
代表任意类型:
let t:any=10
t="str"
t=true
接口
跟另一个事物之间的一个媒介
interface userInfo{
name:string;
age:number;
address?:string//问号代表该属性可添加可不添加
}
function getUserInfo(u:userInfo){
console.log(u.name) //张三
}
let user1 = {name:"张三",age:24,address:"北京"}
getUserInfo(user1)
使用ts写一个对象属性约束
使用{useName:string, password:number}约束传入的userData参数(并将password置为可选参数)
class User{
useName:string;
password?:number|undefined;
//使用{useName:string, password?:number|undefined}约束传入的userData参数
constructor(userData:{useName:string, password?:number|undefined}){
this.useName=userData.useName;
if(userData.password)
this.password=userData.password;
}
}
let u1=new User( {useName:"小猪猪", password:12233} );
let u2=new User( {useName:"大猪猪"} )
console.log(u1);
console.log(u2);
说一下typescript中的泛型
泛型(Generics)是指在定义函数、接口或类的时候,不预先指定具体的类型,而在使用的时候再指定类型的一种特性。
通俗理解:泛型就是解决类 接口 方法的复用性、以及对不特定数据类型的支持
function getData(value:string):string{
return value //只能返回string类型的数据
}
//想要同时返回string和number类型
//1.通常: 代码冗余
function getData1(value:string):string{
return value
}
function getData2(value:number):number{
return value
}
//2.用any(可以解决,但是放弃了类型检查)
function getData(value:any):any{
return value //什么类型都可以
}
//传入什么返回什么。比如传入number类型,必须返回number类型。传入string必须返回string类型。用any就可以不一致。
//泛型,可以支持不特定的数据类型
//要求:传入参数和返回的参数一致
//这里的T指泛型,也可以用任意字母取代,但是前后要一致
function getData<T>(value:T):T{
return value
}
function getData<T>(value:T):T{
return 'xxxx' //错误写法。不能将任何任性分配给T
}
//调用
getData<number>(123); //123
getData<number>('xxx'); //错误写法
//可以调用的时候传一个泛型,返回的时候返回其他的类型(用的不多)
function getData<T>(value:T):any{
return 'xxx'
}
//调用
getData<number>(123); //xxx
getData<string>('xxx'); //xxx
//定义泛型是什么类型,就要传入什么类型的参数
如何在TS中对函数的返回值进行类型约束
ts中函数参数的类型定义
函数的参数可能是一个,也可能是多个,有可能是一个变量,一个对象,一个函数,一个数组等等。
1.函数的参数为单个或多个单一变量的类型定义
function fntA(one, two, three) {
// 参数 "two" 隐式具有 "any" 类型,但可以从用法中推断出更好的类型。
return one + two + three
}
const aResult = fntA(1, '3', true)
修改后:
function fntA(one: number, two: string, three: boolean) {
return one + two + three
}
const aResult1 = fntA(1, '3', true)
// 如果函数的参数为单个或者多个变量的时候,只需要为这些参数进行静态类型下的基础类型定义就行
2.函数的参数为数组的类型定义
function fntB(arr) {
//参数 "arr" 隐式具有 "any" 类型,但可以从用法中推断出更好的类型。
return arr[0]
}
const bResult = fntB([1, 3, 5])
修改后:
function fntB(arr: number[]) {
return arr[0]
}
const bResult1 = fntB([1, 3, 5])
// 如果参数是数组时,只需要为这些变量进行对象类型下的数组类型定义
3.函数的参数为对象的类型定义
function fntC({ one, two }) {
return one + two
}
const cResult = fntC({ one: 6, two: 10 })
修改后:
function fntC({ one, two }: { one: number, two: number }) {
return one + two
}
const cResult1 = fntC({ one: 6, two: 10 })
// 如果参数是对象,只需要为这些变量进行对象类型下的对象类型定义
4.函数的参数为函数的类型定义
function fntD(callback) {
//参数 "callback" 隐式具有 "any" 类型,但可以从用法中推断出更好的类型
callback(true)
}
function callback(bl: boolean): boolean {
console.log(bl)
return bl
}
const dResult = fntD(callback)
修改后:
function fntD(callback: (bl: boolean) => boolean) {
callback(true)
}
function callback(bl: boolean): boolean {
console.log(bl)
return bl
}
const dResult = fntD(callback)
// 如果参数是函数,只需要为参数进行对象类型下的函数类型定义即可
ts中函数返回值的类型定义
当函数有返回值时,根据返回值的类型在相应的函数位置进行静态类型定义即可
返回数字:
function getTotal2(one: number, two: number): number {
return one + two;
}
const total2 = getTotal(1, 2);
// 返回值为数字类型
返回布尔值
function getTotal2(one: number, two: number): boolean {
return Boolean(one + two);
}
const total2 = getTotal(1, 2);
// 返回值为布尔类型
返回字符串
function getTotal2(one: string, two: string): string{
return Bone + two;
}
const total2 = getTotal('1', '2');
// 返回值为字符串
返回对象
function getObj(name: string, age: number): { name: string, age: number } {
return {name,age}
}
getObj('小红',16)
// 返回值为对象
返回数组
function getArr(arr: number[]) :number[]{
let newArr = [...arr]
return newArr
}
getArr([1,2,3,4])
// 返回值为数组
函数返回值为underfinde,仅仅时为了在内部实现某个功能,我们就可以给他一个类型注解void,代表没有任何返回值,
function sayName() {
console.log('hello,world')
}
修改后:
function sayName1(): void {
console.log('无返回值')
}
当函数没有返回值时
// 因为总是抛出异常,所以 error 将不会有返回值
// never 类型表示永远不会有值的一种类型
function error(message: string): never {
throw new Error(message);
}
ts和js相比有什么区别
- 在ts中完全可以使用js
- ts是js的超集,并且ts比js多了一个类型检查功能
RX了解吗?
Rx 中强大的地方在于两处
- 管道思想,通过管道,我们订阅了数据的来源,并在数据源更新时响应 。
- 强大的操作符,通过操作符对流和流中的数据转换,拼接,以形成我们想要的数据模型 。
在 Rx 中,我们先预装好管道,通过管道流通数据 。这些管道的来源多种, create ,from, fromEvent, of …, 通过操作符将管道 拼接,合并,映射…形成最终的数据模型 。
对于管道来说,有两点非常重要
. 管道是懒执行的,只有订阅器 observer subscribe了 数据管道,这个管道才会有数据流通 。
. 整个节点组成一个完整的管道,订阅了后面的管道节点,也会同时订阅之前的管道节点 ,每个节点接受之前的值,并发出新值
Rx 如此高效和强大,得益于其强大的操作符 。
主要包含下面几类
创建操作符: create, range, of, from, fromEvent, fromPromise, empty …
组合 contact ,merge, startWith, zip …
时间 delay , throttle, dobounceTime, interval …
过滤: filter, first, last, skip, distinct, take …
转换: buffer,map, mapTo, mergeMap, switch, switchMap, reduce, scan .
六、nodejs
说说对nodejs的了解
- Node.js 是一个开源和跨平台的 JavaScript 运行时环境。 它几乎是任何类型项目的流行工具!
- Node.js 在浏览器之外运行 V8 JavaScript 引擎(Google Chrome 的内核)。 这使得 Node.js 的性能非常好。
- Node.js 应用程序在单个进程中运行,无需为每个请求创建新的线程。 Node.js 在其标准库中提供了一组异步的 I/O 原语,以防止 JavaScript 代码阻塞,通常,Node.js 中的库是使用非阻塞范式编写的,使得阻塞行为成为异常而不是常态。
- 当 Node.js 执行 I/O 操作时(比如从网络读取、访问数据库或文件系统),Node.js 将在响应返回时恢复操作(而不是阻塞线程和浪费 CPU 周期等待)。
这允许 Node.js 使用单个服务器处理数千个并发连接,而不会引入管理线程并发(这可能是错误的重要来源)的负担。 - Node.js 具有独特的优势,因为数百万为浏览器编写 JavaScript 的前端开发者现在无需学习完全不同的语言,就可以编写除客户端代码之外的服务器端代码。
- 在 Node.js 中,可以毫无问题地使用新的 ECMAScript 标准,因为你不必等待所有用户更新他们的浏览器,你负责通过更改 Node.js 版本来决定使用哪个 ECMAScript 版本,你还可以通过运行带有标志的 Node.js 来启用特定的实验性功能。
nodejs如何写接口,返回参数如何处理,有多少种方法
- nodejs的原生模块http可用于编写接口,但一般推荐使用express或koa2来设计restful api。
- 下面以 express 为例说明如何编写接口。
var express = require('express')
var app = express()
app.get('/', function (req, res) {
res.send('hello world')
})
- express响应客户端的方法有:end()/json()/render()/send()/jsonp()/sendFile()等。
websocket和http的区别
- WebSocket 是 HTML5 中的协议,支持持久连续,http 协议不支持持久性连接。
- Http1.0 和 HTTP1.1 都不支持持久性的链接,HTTP1.1 中的 keep-alive,将多个 http 请求合并为 1个。
常见的 HTTP Method 有哪些? GET/POST 区别?
1、常见的HTTP方法
- GET:获取资源
- POST:传输资源
- PUT:更新资源
- DELETE:删除资源
- HEAD:获得报文首部
2、GET/POST的区别
- GET在浏览器回退时是无害的,而POST会再次提交请求
- GET请求会被浏览器主动缓存,而POST不会,除非手动设置
- GET请求参数会被完整保留在浏览器的历史记录里,而POST中的参数不会被保留
- GET请求在URL中传送的参数是有长度限制的,而POST没有限制
- GET参数通过URL传递,POST放在Request body中
- GET请求只能进行 url 编码,而POST支持多种编码方式
- GET产生的URL地址可以被收藏,而POST不可以
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息
说一说Tcp三次握手,四次挥手
1、三次握手
- seq序号,用来标识从TCP源端向目的端发送的字节流,发起方发送数据时对此进行标记
- ack确认序号,只有ACK标志位为1时,确认序号字段才有效,ack=seq+1
2、四次挥手
关闭连接时,当服务器端收到FIN报文时,很可能并不会立即关闭链接,所以只能先回复一个ACK报文,告诉客户端:”你发的FIN报文我收到了”,只有等到服务器端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送,故需要四步握手。
阐述一下http1.0与http2.0的区别,及http和https区别
1、HTTP1.0和HTTP1.1的一些区别
- 缓存处理,HTTP1.0中主要使用Last-Modified,Expires 来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略:ETag,Cache-Control…
带宽优化及网络连接的使用,HTTP1.1支持断点续传,即返回码是206(Partial Content) - 错误通知的管理,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除…
- Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)
- 长连接,HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点
2、HTTP2.0和HTTP1.X相比的新特性
- 新的二进制格式(Binary Format),HTTP1.x的解析是基于文本,基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合,基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮
- header压缩,HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小
- 服务端推送(server push),例如我的网页有一个sytle.css的请求,在客户端收到sytle.css数据的同时,服务端会将sytle.js的文件推送给客户端,当客户端再次尝试获取sytle.js时就可以直接从缓存中获取到,不用再发请求了
node.js如何导出页面数据形成报表
生成报表并下载是作为web应用中的一个传统功能,在实际项目中有广范的应用,实现原理也很简单,以NodeJS导出数据的方法为例,就是拿到页面数据对应id,然后根据id查询数据库,拿到所需数据后格式化为特点格式的数据,最后导出文件。
在nodejs中,也提供了很多的第三方库来实现这一功能,以node-xlsx导出excel文件为例,实现步骤如下:
- 下载
node-xlsxnpm install node-xlsx - 编写接口
以下代码使用
express编写,调用接口实现下载功能const fs = require('fs'); const path = require('path'); const xlsx = require('node-xlsx'); const express = require('express'); const router = express.Router(); const mongo = require('../db'); router.post('/export', async (req, res) => { const { ids } = req.body; const query = { _id: { $in: ids } } // 查询数据库获取数据 let result = await mongo.find(colName, query); // 设置表头 const keys = Object.keys(Object.assign({}, ...result)); rows[0] = keys; // 设置表格数据 const rows = [] result.map(item => { const values = [] keys.forEach((key, idx) => { if (item[key] === undefined) { values[idx] = null; } else { values[idx] = item[key]; } }) rows.push(values); }); let data = xlsx.build([{ name: "商品列表", data: rows }]); const downloadPath = path.join(__dirname, '../../public/download'); const filePath = `${downloadPath}/goodslist.xlsx`; fs.writeFileSync(filePath, data); res.download(filePath, `商品列表.xlsx`, (err) => { console.log('download err', err); }); })
协商缓存和强缓存
浏览器缓存主要分为强强缓存(也称本地缓存)和协商缓存(也称弱缓存)。浏览器在第一次请求发生后,再次发送请求时:
- 浏览器请求某一资源时,会先获取该资源缓存的header信息,然后根据header中的
Cache-Control和Expires来判断是否过期。若没过期则直接从缓存中获取资源信息,包括缓存的header的信息,所以此次请求不会与服务器进行通信。这里判断是否过期,则是强缓存相关。后面会讲Cache-Control和Expires相关。 - 如果显示已过期,浏览器会向服务器端发送请求,这个请求会携带第一次请求返回的有关缓存的header字段信息,比如客户端会通过
If-None-Match头将先前服务器端发送过来的Etag发送给服务器,服务会对比这个客户端发过来的Etag是否与服务器的相同,若相同,就将If-None-Match的值设为false,返回状态304,客户端继续使用本地缓存,不解析服务器端发回来的数据,若不相同就将If-None-Match的值设为true,返回状态为200,客户端重新机械服务器端返回的数据;客户端还会通过If-Modified-Since头将先前服务器端发过来的最后修改时间戳发送给服务器,服务器端通过这个时间戳判断客户端的页面是否是最新的,如果不是最新的,则返回最新的内容,如果是最新的,则返回304,客户端继续使用本地缓存。
强缓存
强缓存是利用http头中的Expires和Cache-Control两个字段来控制的,用来表示资源的缓存时间。强缓存中,普通刷新会忽略它,但不会清除它,需要强制刷新。浏览器强制刷新,请求会带上Cache-Control:no-cache和Pragma:no-cache
Expires
Expires是http1.0的规范,它的值是一个绝对时间的GMT格式的时间字符串。如我现在这个网页的Expires值是:expires:Fri, 14 Apr 2017 10:47:02 GMT。这个时间代表这这个资源的失效时间,只要发送请求时间是在Expires之前,那么本地缓存始终有效,则在缓存中读取数据。所以这种方式有一个明显的缺点,由于失效的时间是一个绝对时间,所以当服务器与客户端时间偏差较大时,就会导致缓存混乱。如果同时出现Cache-Control:max-age和Expires,那么max-age优先级更高。如我主页的response headers部分如下:
cache-control:max-age=691200
expires:Fri, 14 Apr 2017 10:47:02 GMT
Cache-Control
Cache-Control是在http1.1中出现的,主要是利用该字段的max-age值来进行判断,它是一个相对时间,例如Cache-Control:max-age=3600,代表着资源的有效期是3600秒。cache-control除了该字段外,还有下面几个比较常用的设置值:
-
no-cache:不使用本地缓存。需要使用缓存协商,先与服务器确认返回的响应是否被更改,如果之前的响应中存在ETag,那么请求的时候会与服务端验证,如果资源未被更改,则可以避免重新下载。
-
no-store:直接禁止游览器缓存数据,每次用户请求该资源,都会向服务器发送一个请求,每次都会下载完整的资源。
-
public:可以被所有的用户缓存,包括终端用户和CDN等中间代理服务器。
-
private:只能被终端用户的浏览器缓存,不允许CDN等中继缓存服务器对其缓存。
Cache-Control与Expires可以在服务端配置同时启用,同时启用的时候Cache-Control优先级高。
协商缓存
协商缓存就是由服务器来确定缓存资源是否可用,所以客户端与服务器端要通过某种标识来进行通信,从而让服务器判断请求资源是否可以缓存访问。
普通刷新会启用弱缓存,忽略强缓存。只有在地址栏或收藏夹输入网址、通过链接引用资源等情况下,浏览器才会启用强缓存,这也是为什么有时候我们更新一张图片、一个js文件,页面内容依然是旧的,但是直接浏览器访问那个图片或文件,看到的内容却是新的。
这个主要涉及到两组header字段:Etag和If-None-Match、Last-Modified和If-Modified-Since。上面以及说得很清楚这两组怎么使用啦~复习一下:
Etag和If-None-Match
Etag/If-None-Match返回的是一个校验码。ETag可以保证每一个资源是唯一的,资源变化都会导致ETag变化。服务器根据浏览器上送的If-None-Match值来判断是否命中缓存。
与Last-Modified不一样的是,当服务器返回304 Not Modified的响应时,由于ETag重新生成过,response header中还会把这个ETag返回,即使这个ETag跟之前的没有变化。
Last-Modify/If-Modify-Since
浏览器第一次请求一个资源的时候,服务器返回的header中会加上Last-Modify,Last-modify是一个时间标识该资源的最后修改时间,例如Last-Modify: Thu,31 Dec 2037 23:59:59 GMT。
当浏览器再次请求该资源时,request的请求头中会包含If-Modify-Since,该值为缓存之前返回的Last-Modify。服务器收到If-Modify-Since后,根据资源的最后修改时间判断是否命中缓存。
如果命中缓存,则返回304,并且不会返回资源内容,并且不会返回Last-Modify。
为什么要有Etag
你可能会觉得使用Last-Modified已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要Etag呢?HTTP1.1中Etag的出现主要是为了解决几个Last-Modified比较难解决的问题:
- 一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新GET;
- 某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),If-Modified-Since能检查到的粒度是s级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒);
- 某些服务器不能精确的得到文件的最后修改时间。
Last-Modified与ETag是可以一起使用的,服务器会优先验证ETag,一致的情况下,才会继续比对Last-Modified,最后才决定是否返回304。
http常用状态码有哪一些,说一说他们的作用
常用的状态码: 200表示成功,301表示重定向,404表示资源未找到,500表示服务器内部错误
状态码分类:
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
http状态码列表
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
网络攻击方案有哪些,自己有写过什么安全性方面的东西吗?
- iframe
- opener
- CSRF(跨站请求伪造)
- XSS(跨站脚本攻击)
- ClickJacking(点击劫持)
- HSTS(HTTP严格传输安全)
- CND劫持
很难通过技术手段完全避免 XSS,但我们可以总结以下原则减少漏洞的产生:
- 利用模板引擎 开启模板引擎自带的 HTML 转义功能。例如: 在 ejs 中,尽量使用
<%= data %>而不是<%- data %>; 在 doT.js 中,尽量使用{{! data }而不是{{= data }; 在 FreeMarker 中,确保引擎版本高于 2.3.24,并且选择正确的freemarker.core.OutputFormat。 - 避免内联事件 尽量不要使用
onLoad="onload('{{data}}')"、onClick="go('{{action}}')"这种拼接内联事件的写法。在 JavaScript 中通过.addEventlistener()事件绑定会更安全。 - 避免拼接 HTML 前端采用拼接 HTML 的方法比较危险,如果框架允许,使用
createElement、setAttribute之类的方法实现。或者采用比较成熟的渲染框架,如 Vue/React 等。 - 时刻保持警惕 在插入位置为 DOM 属性、链接等位置时,要打起精神,严加防范。
- 增加攻击难度,降低攻击后果 通过 CSP、输入长度配置、接口安全措施等方法,增加攻击的难度,降低攻击的后果。
- 主动检测和发现 可使用 XSS 攻击字符串和自动扫描工具寻找潜在的 XSS 漏洞。
静态资源部署到哪?
-
存放静态资源文件到服务器
但这种形式在性能上也有缺陷:
-
受地理环境影响,离服务器越远资源加载越慢
-
频繁请求资源对服务器压力较大
-
-
存放静态资源文件到CDN
为了进一步提升性能,可以把动态网页(index.html)和静态资源(js、css、image…)分开部署。静态资源被放置于 CDN 上.
但是 CDN 也有缓存策略:新的静态资源发布后,需要一定的时间去覆盖各个边缘站点的旧资源。若某客户端获得了新的动态网页,但是附近的 CDN 节点尚未更新最近发布的静态资源,客户端即便放弃本地缓存,它加载的依旧是位于 CDN 上的“脏数据”。怎么办呢?干脆把文件名也给改了——让摘要信息成为文件名的一部分!具体实现可以仰仗 webpack,将
output.filename设为[name].[contenthash].js,输出文件和 html 模版都会帮你更改好.用摘要信息重命名后的资源文件,与旧资源就不同名了,不再需要以覆盖旧文件的形式主动更新各个地区的边缘站点。新版本发布后,浏览器首次请求资源,若 CDN 不存在该资源,便会向就近的边缘站点加载该文件,同时更新 CDN 缓存;这就彻底避免了 CDN 脏数据的问题.
说说你对nodejs的了解
我们从以下几方面来看nodejs.
-
什么是nodejs?
Node.js是一个开源与跨平台的JavaScript运行时环境, 在浏览器外运行 V8 JavaScript 引擎(Google Chrome 的内核),利用事件驱动、非阻塞和异步输入输出模型等技术提高性能.可以理解为
Node.js就是一个服务器端的、非阻塞式I/O的、事件驱动的JavaScript运行环境-
非阻塞异步
Nodejs采用了非阻塞型I/O机制,在做I/O操作的时候不会造成任何的阻塞,当完成之后,以时间的形式通知执行操作例如在执行了访问数据库的代码之后,将立即转而执行其后面的代码,把数据库返回结果的处理代码放在回调函数中,从而提高了程序的执行效率
-
事件驱动
事件驱动就是当进来一个新的请求的时,请求将会被压入一个事件队列中,然后通过一个循环来检测队列中的事件状态变化,如果检测到有状态变化的事件,那么就执行该事件对应的处理代码,一般都是回调函数
-
-
优缺点
优点:
- 处理高并发场景性能更佳
- 适合I/O密集型应用,指的是应用在运行极限时,CPU占用率仍然比较低,大部分时间是在做 I/O硬盘内存读写操作
因为
Nodejs是单线程,带来的缺点有:- 不适合CPU密集型应用
- 只支持单核CPU,不能充分利用CPU
- 可靠性低,一旦代码某个环节崩溃,整个系统都崩溃
-
应用场景
借助
Nodejs的特点和弊端,其应用场景分类如下:- 善于
I/O,不善于计算。因为Nodejs是一个单线程,如果计算(同步)太多,则会阻塞这个线程 - 大量并发的I/O,应用程序内部并不需要进行非常复杂的处理
- 与 websocket 配合,开发长连接的实时交互应用程序
具体场景可以表现为如下:
- 第一大类:用户表单收集系统、后台管理系统、实时交互系统、考试系统、联网软件、高并发量的web应用程序
- 第二大类:基于web、canvas等多人联网游戏
- 第三大类:基于web的多人实时聊天客户端、聊天室、图文直播
- 第四大类:单页面浏览器应用程序
- 第五大类:操作数据库、为前端和移动端提供基于
json的API
- 善于
七、GIT
git经常用哪些指令
-
产生代码库
-
新建一个git代码库
-
git init
-
-
下载远程项目和它的整个代码历史
-
git clone 远程仓库地址
-
-
-
配置
-
显示配置
-
git config --list [--global]
-
-
编辑配置
-
git config -e [--global]
-
-
设置用户信息
-
git config [--global] user.name "名" git config [--global] user.email "邮箱地址"
-
-
-
暂存区文件操作
-
增加文件到暂存区
-
# 1.添加当前目录的所有文件到暂存区 git add . # 2.添加指定目录到暂存区,包括子目录 git add [dir] # 3.添加指定文件到暂存区 git add [file1] [file2] ...
-
-
在暂存区中删除文件
-
# 删除工作区文件,并且将这次删除放入暂存区 git rm [file1] [file2] ... # 停止追踪指定文件,但该文件会保留在工作区 git rm --cached [file]
-
-
重命名暂存区文件
-
# 改名文件,并且将这个改名放入暂存区 git mv [file-original] [file-renamed]
-
-
-
代码提交
-
# 提交暂存区到仓库区 git commit -m [message]
-
-
分支操作
-
# 列出所有本地分支 git branch # 列出所有远程分支 git branch -r # 列出所有本地分支和远程分支 git branch -a # 新建一个分支,但依然停留在当前分支 git branch [branch-name] # 新建一个分支,并切换到该分支 git checkout -b [branch] # 新建一个分支,指向指定commit git branch [branch] [commit] # 新建一个分支,与指定的远程分支建立追踪关系 git branch --track [branch] [remote-branch] # 切换到指定分支,并更新工作区 git checkout [branch-name] # 切换到上一个分支 git checkout - # 建立追踪关系,在现有分支与指定的远程分支之间 git branch --set-upstream [branch] [remote-branch] # 合并指定分支到当前分支 git merge [branch] # 选择一个commit,合并进当前分支 git cherry-pick [commit] # 删除分支 git branch -d [branch-name] # 删除远程分支 git push origin --delete [branch-name] git branch -dr [remote/branch]
-
-
信息查看
-
# 显示有变更的文件 git status # 显示当前分支的版本历史 git log # 显示commit历史,以及每次commit发生变更的文件 git log --stat # 搜索提交历史,根据关键词 git log -S [keyword] # 显示某个commit之后的所有变动,每个commit占据一行 git log [tag] HEAD --pretty=format:%s # 显示某个commit之后的所有变动,其"提交说明"必须符合搜索条件 git log [tag] HEAD --grep feature # 显示过去5次提交 git log -5 --pretty --oneline
-
-
同步操作
-
# 增加一个新的远程仓库,并命名 git remote add [shortname] [url] # 取回远程仓库的变化,并与本地分支合并 git pull [remote] [branch] # 上传本地指定分支到远程仓库 git push [remote] [branch] # 强行推送当前分支到远程仓库,即使有冲突 git push [remote] --force # 推送所有分支到远程仓库 git push [remote] --all
-
-
撤销操作
-
# 恢复暂存区的指定文件到工作区 git checkout [file] # 恢复某个commit的指定文件到暂存区和工作区 git checkout [commit] [file] # 恢复暂存区的所有文件到工作区 git checkout . # 重置暂存区的指定文件,与上一次commit保持一致,但工作区不变 git reset [file] # 重置暂存区与工作区,与上一次commit保持一致 git reset --hard # 重置当前分支的指针为指定commit,同时重置暂存区,但工作区不变 git reset [commit] # 重置当前分支的HEAD为指定commit,同时重置暂存区和工作区,与指定commit一致 git reset --hard [commit] # 重置当前HEAD为指定commit,但保持暂存区和工作区不变 git reset --keep [commit] # 新建一个commit,用来撤销指定commit # 后者的所有变化都将被前者抵消,并且应用到当前分支 git revert [commit]
-
git出现代码冲突怎么解决
冲突合并一般是因为自己的本地做的提交和服务器上的提交有差异,并且这些差异中的文件改动,Git不能自动合并,那么就需要用户手动进行合并
如我这边执行git pull origin master
如果Git能够自动合并,那么过程看起来是这样的:

拉取的时候,Git自动合并,并产生了一次提交。
如果Git不能够自动合并,那么会提示:
这个时候我们就可以知道README.MD有冲突,需要我们手动解决,修改README.MD解决冲突:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F5DEAiz1-1655685209086)(https://storage.lynnn.cn/assets/markdown/91147/pictures/2021/12/7d37e41669c2572905b80640702251df80004482.png?sign=d0a69bfe47903bbe41f03166db81a88a&t=61c3e0b2)]
可以看出来,在1+1=几的这行代码上产生了冲突,解决冲突的目标是保留期望存在的代码,这里保留1+1=2,然后保存退出。

退出之后,确保所有的冲突都得以解决,然后就可以使用:
git add .
git commit -m "fixed conflicts"
git push origin master`
即可完成一次冲突的合并。
整个过程看起来是这样的:

你们团队是怎么管理git分支的
关于Git分支管理,每个团队在不同阶段都有自己的管理策略。我们团队以前采用的是版本分支管理策略,也就是每次上线新版本都会创建一个新的版本分支,而新的需求开发也从当前最新的版本分支迁出一个新的需求分支开发,线上bug则在版本分支上修改然后发布。
如何实现Git的免密操作
现在的远程仓库都提供了基于SSH协议的Git服务,在使用SSH协议访问仓库之前,需要先配置好账户/仓库的SSH公钥。
① 产生公私钥对
ssh-keygen -t rsa -C [email protected]
产生完毕后,公私玥对位于c/Users/用户名/.ssh/:
- id_rsa:私钥(私有的钥匙,不能公开)
- id_rsa.pub:公钥(可以公开的钥匙)
② 将公钥上传至远程仓库个人中心的设置里
以gitee为例,添加公钥请访问:https://gitee.com/profile/sshkeys
注:如果想用现在的免密登录,请使用ssh协议去关联本地与线上仓库。
八、其它
loadsh 了解过吗?
Lodash 是一个一致性、模块化、高性能的 JavaScript 实用工具库。
首先要明白的是lodash的所有函数都不会在原有的数据上进行操作,而是复制出一个新的数据而不改变原有数据。类似immutable.js的理念去处理。
Lodash 通过降低 array、number、objects、string 等等的使用难度从而让 JavaScript 变得更简单。 Lodash 的模块化方法 非常适用于:
- 遍历 array、object 和 string 对
- 值进行操作和检测
- 创建符合功能的函数
常用语法:cloneDeep深拷贝,uniq数组去重,compact 去除假值,filter和reject 过滤集合传入匿名函数, join 将 array 中的所有元素转换为由 separator 分隔的字符串等
是否用过混合APP开发
1.原生开发(NativeApp开发):像盖房子一样,先打地基然后浇地梁、房屋结构、一砖一瓦、钢筋水泥、电路走向等,原生APP同理:通过代码从每个页面、每个功能、每个效果、每个逻辑、每个步骤全部用代码写出来,一层层,一段段全用代码写出来
此种APP的数据都保存在本地,APP能及时调取,所以相应速度及流畅性有保障
2.混合开发(HTML5开发):这个就相当于一种框架开发,说白了就是网页;该模式通常由“HTML5云网站+APP应用客户端”两部份构成,APP应用客户端只需安装应用的框架部份,而应用的数据则是每次打开APP的时候,去云端取数据呈现给手机用户。
混合APP还有一种是套壳APP,套壳APP就是用H5的网页打包成APP,虽然是APP能安装到手机上,但是每个界面,全部是网页
混合APP开发优势:
时间短:基本都是模版拿来直接套上或打包成APP,会节省很大一部分时间。
价格便宜:代码不需要重新写,界面不用重新设计,都是固定的,可替换的地方很少,自己随便都能换上,所以价格相对便宜。
项目中的组件是如何使用的
可以使用第三方组件库以及自定义组件
vue项目中使用组件库为 vant / element-ui / iview / ant-design-vue
react常用组件库为 Ant Design / Ant Design Mobile
开发者也可以通过自定义实现组件的使用
hash和histoty的原理
- hash模式:在浏览器中符号“#”,#以及#后面的字符称之为hash,用 window.location.hash 读取。特点:hash虽然在URL中,但不被包括在HTTP请求中;用来指导浏览器动作,对服务端安全无用,hash不会重加载页面。
- history模式:history采用HTML5的新特性;且提供了两个新方法: pushState(), replaceState()可以对浏览器历史记录栈进行修改,以及popState事件的监听到状态变更
window.location.href和history.push的区别
- window.location.href 锚点跳转,不会加入路由栈。
- history.push 向由路由栈中添加新的路由信息,点击浏览器返回按钮时返回到上一页。
商城项目中有写到调用微信,支付宝支付,简单讲述一下这个支付与后台对接的过程,微信支付的原理
- 步骤1:用户在商户APP中选择商品,提交订单,选择微信支付。
- 步骤2:商户后台收到用户支付单,调用微信支付统一下单接口。参见【统一下单API】。
- 步骤3:统一下单接口返回正常的prepay_id,再按签名规范重新生成签名后,将数据传输给APP。参与签名的字段名为appid,partnerid,prepayid,noncestr,timestamp,package。注意:package的值格式为Sign=WXPay
- 步骤4:商户APP调起微信支付。api参见本章节【app端开发步骤说明】
- 步骤5:商户后台接收支付通知。api参见【支付结果通知API】
- 步骤6:商户后台查询支付结果。,api参见【查询订单API】(查单实现可参考:支付回调和查单实现指引)
混合开发知道吗?你是怎么理解混合开发的,在项目中用到过混合开发吗?
- 在APP应用中使用WebView嵌套H5页面,即为混合开发。
- Android、IOS、uniapp、ReactNative、小程序,都支持混合开发了。
平时工作中有是否有接触linux系统?说说常用到linux命令?
1、常用的目录操作命令
- 创建目录 mkdir <目录名称>
- 删除目录 rm <目录名称>
- 定位目录 cd <目录名称>
- 查看目录文件 ls ll
- 修改目录名 mv <目录名称> <新目录名称>
- 拷贝目录 cp <目录名称> <新目录名称>
2、常用的文件操作命令
- 创建文件 touch <文件名称> vi <文件名称>
- 删除文件 rm <文件名称>
- 修改文件名 mv <文件名称> <新文件名称>
- 拷贝文件 cp <文件名称> <新文件名称>
3、常用的文件内容操作命令
- 查看文件 cat <文件名称> head <文件名称> tail <文件名称>
- 编辑文件内容 vi <文件名称>
- 查找文件内容 grep ‘关键字’ <文件名称>
echarts是什么,怎么用
echarts是一个基于 JavaScript 的开源可视化图表库,可以流畅的运行在 PC 和移动设备上,兼容绝大部分的浏览器(IE9/10/11,Chrome,Firefox,Safari等),底层依赖矢量图形库 ZRender,提供20 多种图表和十几种组件,支持Canvas、SVG 双引擎并能一键切换,让移动端渲染更加流畅
echarts源自百度,现由Apache 开源社区维护,官方提供了完善的文档( https://echarts.apache.org ),使用也非常简单,步骤如下:
-
下载echarts
- 从 GitHub 获取
https://github.com/apache/echarts
- 从 npm 获取
npm install echarts --save - 从 CDN 获取
https://www.jsdelivr.com/package/npm/echarts
- 在线定制
https://echarts.apache.org//builder.html
- 从 GitHub 获取
-
引入echarts
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <script src="echarts.js"></script> </head> </html> -
添加一个div容器并设置宽高
注意:不设置宽高无法显示效果
<body> <div id="main" style="width: 600px;height:400px;"></div> </body> -
初始化一个 echarts 实例并通过
setOption方法生成一个图表(以柱状图为例)<script type="text/javascript"> // 基于准备好的dom,初始化echarts实例 var myChart = echarts.init(document.getElementById('main')); // 指定图表的配置项和数据 var option = { title: { text: 'ECharts 入门示例' }, tooltip: {}, legend: { data: ['销量'] }, xAxis: { data: ['衬衫', '羊毛衫', '雪纺衫', '裤子', '高跟鞋', '袜子'] }, yAxis: {}, series: [ { name: '销量', type: 'bar', data: [5, 20, 36, 10, 10, 20] } ] }; // 使用刚指定的配置项和数据显示图表。 myChart.setOption(option); </script>
Hash和history的区别
hash与history一般指Vue-router或React-router中的路由模式,Vue-router中通过mode配置选项设置,React-router中通过HashRouter与BrowerRouter组件设置,区别如下:
- 最直观的区别就是在浏览器url中hash 带了一个很丑的
#,而history是没有 - hash即浏览器地址栏 URL 中的 # 符号,hash 虽然出现在 URL 中,但不会被包括在 HTTP 请求中,因此改变 hash 不会重新加载页面
- history利用了 HTML5新增的
pushState()和replaceState()方法,在已有back()、forward()、go()的基础上,提供了对历史记录进行修改的功能。调用pushState()和replaceState()时,虽然改变了当前的 URL,但浏览器不会向后端发送请求,但如何用户刷新页面,会导致浏览器向服务器发起请求,如后端没有做出适当的响应,则会显示404页面
谈谈宏任务与微任务的理解,举一个宏任务与微任务的api
要理解宏任务(macrotask)与微任务(microtask),就必须了解javascript中的事件循环机制(event loop)以及js代码的运行方式
要了解js代码的运行方式,得先搞懂以下几个概念
-
JS是单线程执行
单线程指的是JS引擎线程
-
宿主环境
JS运行的环境,一般为浏览器或者Node
-
执行栈
是一个存储函数调用的栈结构,遵循先进后出的原则
JS引擎常驻于内存中,等待宿主将JS代码或函数传递给它执行,如何传递,这就是**事件循环(event loop)**所做的事情:当js执行栈空闲时,事件循环机制会从任务队列中提取第一个任务进入到执行栈执行,优先提取微任务(microtask),待微任务队列清空后,再提取宏任务(macrotask),并不断重复该过程
在实际应用中,宏任务(macrotask)与微任务(microtask)的API分别如下:
- 宏任务
- setTimeout/setInterval
- ajax
- setImmediate (Node 独有)
- requestAnimationFrame (浏览器独有)
- I/O
- UI rendering (浏览器独有)
- 微任务
- process.nextTick (Node 独有)
- Promise
- Object.observe
- MutationObserver
对Event loop的了解?
Javascript是单线程的,那么各个任务进程是按照什么样的规范来执行的呢?这就涉及到Event Loop的概念了,EventLoop是在html5规范中明确定义的;
何为eventloop,javascript中的一种运行机制,用来解决浏览器单线程的问题
Event Loop是一个程序结构,用于等待和发送消息和事件。同步任务、异步任务、微任务、宏任务
javascript单线程任务从时间上分为同步任务和异步任务,而异步任务又分为宏任务(macroTask)和微任务(microTask)
宏任务:主代码块、setTimeOut、setInterval、script、I/O操作、UI渲染
微任务:promise、async/await(返回的也是一个promise)、process.nextTick
在执行代码前,任务队列为空,所以会优先执行主代码块,再执行主代码块过程中,遇到同步任务则立即将任务放到调用栈执行任务,遇到宏任务则将任务放入宏任务队列中,遇到微任务则将任务放到微任务队列中。
主线程任务执行完之后,先检查微任务队列是否有任务,有的话则将按照先入先出的顺序将先放进来的微任务放入调用栈中执行,并将该任务从微任务队列中移除,执行完该任务后继续查看微任务队列中是否还有任务,有的话继续执行微任务,微任务队列null时,查看宏任务队列,有的话则按先进先出的顺序执行,将任务放入调用栈并将该任务从宏任务队列中移除,该任务执行完之后继续查看微任务队列,有的话则执行微任务队列,没有则继续执行宏任务队列中的任务。
需要注意的是:每次调用栈执行完一个宏任务之后,都会去查看微任务队列,如果microtask queue不为空,则会执行微任务队列中的任务,直到微任务队列为空再返回去查看执行宏任务队列中的任务
console.log('script start')
async function async1() {
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2 end')
}
async1()
setTimeout(function() {
console.log('setTimeout')
}, 0)
new Promise(resolve => {
console.log('Promise')
resolve()
})
.then(function() {
console.log('promise1')
})
.then(function() {
console.log('promise2')
})
console.log('script end')
最终输出 :
script start
VM70:8 async2 end
VM70:17 Promise
VM70:27 script end
VM70:5 async1 end
VM70:21 promise1
VM70:24 promise2
undefined
VM70:13 setTimeout
解析:
在说返回结果之前,先说一下async/await,async 返回的是一个promise,而await则等待一个promise对象执行,await之后的代码则相当于promise.then()
async function async1() {
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2 end')
}
//等价于
new Promise(resolve =>
resolve(console.log('async2 end'))
).then(res => {
console.log('async1 end')
})
整体分析:先执行同步任务 script start -> async2 end -> await之后的console被放入微任务队列中 -> setTimeOut被放入宏任务队列中 ->promise -> promise.then被放入微任务队列中 -> script end -> 同步任务执行完毕,查看微任务队列 --> async1 end -> promise1 -> promise2 --> 微任务队列执行完毕,执行宏任务队列打印setTimeout