前言:
《Denoising Diffusion Probabilistic Models》
- 作者:Jonathan Ho, Ajay Jain, and Pieter Abbeel
一、模型原理
Diffusion Model的原理基于扩散过程,这个过程分为两个主要阶段:前向过程和反向过程。
- 前向过程:在前向过程中,模型对一张原始图片逐步施加噪声,直至图像被破坏变成完全的高斯噪声。这个过程中,每个时间步加入的噪声都是服从正态分布的。随着一步步加入噪声,每一步必须要加入更大的噪声才能看出加了噪声的效果。
- 反向过程:在反向过程中,模型学习从高斯噪声还原为原始图像的过程。这实际上是一个去噪过程,模型通过逐步去噪,最终得到一张清晰的图像。
二、模型架构
PyTorch Diffusion Model的模型架构通常包括一个神经网络,该网络学习从噪声到图片的映射。常见的模型架构包括U-Net、VAE等。这些模型通常由编码器和解码器组成:
- 编码器:编码器将输入的噪声逐步转换为更复杂的表示。
- 解码器:解码器则将编码器的输出逐步解码为最终的图片
三、训练过程
为了训练PyTorch Diffusion Model,需要准备一个数据集,其中包含大量真实图片和对应的噪声图片。噪声图片可以通过对真实图片添加高斯噪声来生成。数据集应该分为训练集、验证集和测试集。
在训练过程中,通过反向传播和优化器来更新模型的权重,使得模型能够从噪声图片生成真实的图片。训练过程中可以使用不同的损失函数,如重建损失、KL散度等来度量生成的图片与真实图片之间的差异。
四、应用与优化
PyTorch Diffusion Model在图像生成领域具有广泛的应用前景,如图像修复、超分辨率、风格迁移等。为了提高模型的性能和效率,可以进行以下优化:
- 参数调整:包括学习率、批量大小等关键参数的调整,以获得更好的收敛效果。
- 内存管理:通过优化内存使用,减少内存消耗,提高训练速度。
- 计算加速:利用GPU进行并行计算,可以显著提高模型训练和推理的速度。
- 混合精度训练:使用不同精度数据类型进行训练,减少内存消耗和计算时间。
目录:
- 简介
- Text- to -image 简介
一 简介
1.1 Diffusion Model 生成图片过程
这个过程叫做 Reverse Process
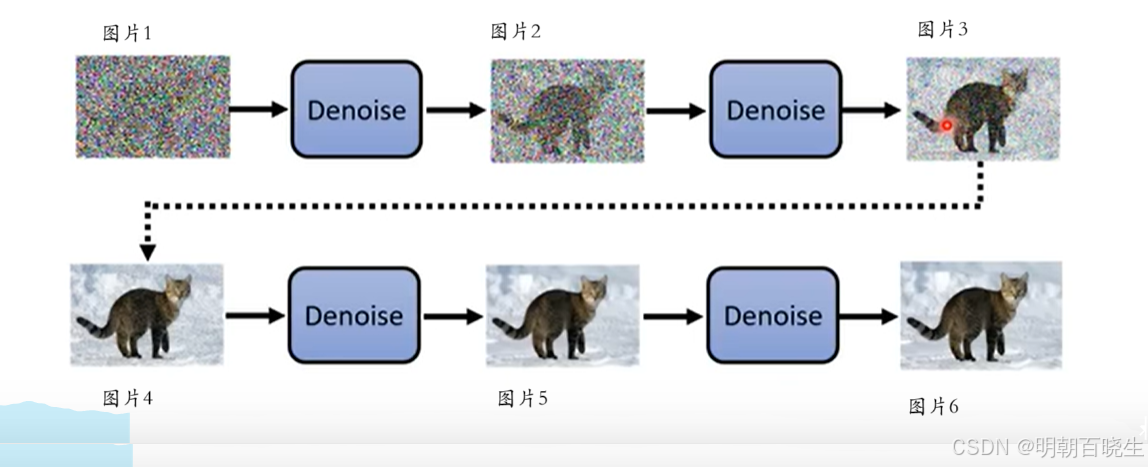
1 随机生成一张符合高斯分布的噪声图片1
2 把图片1输入Denoise 模型去除噪声,得到图片2
3 把图片2输入Denoise 模型去除噪声,输出图片3
4 依次迭代,不断的Denoise,最后生成图片
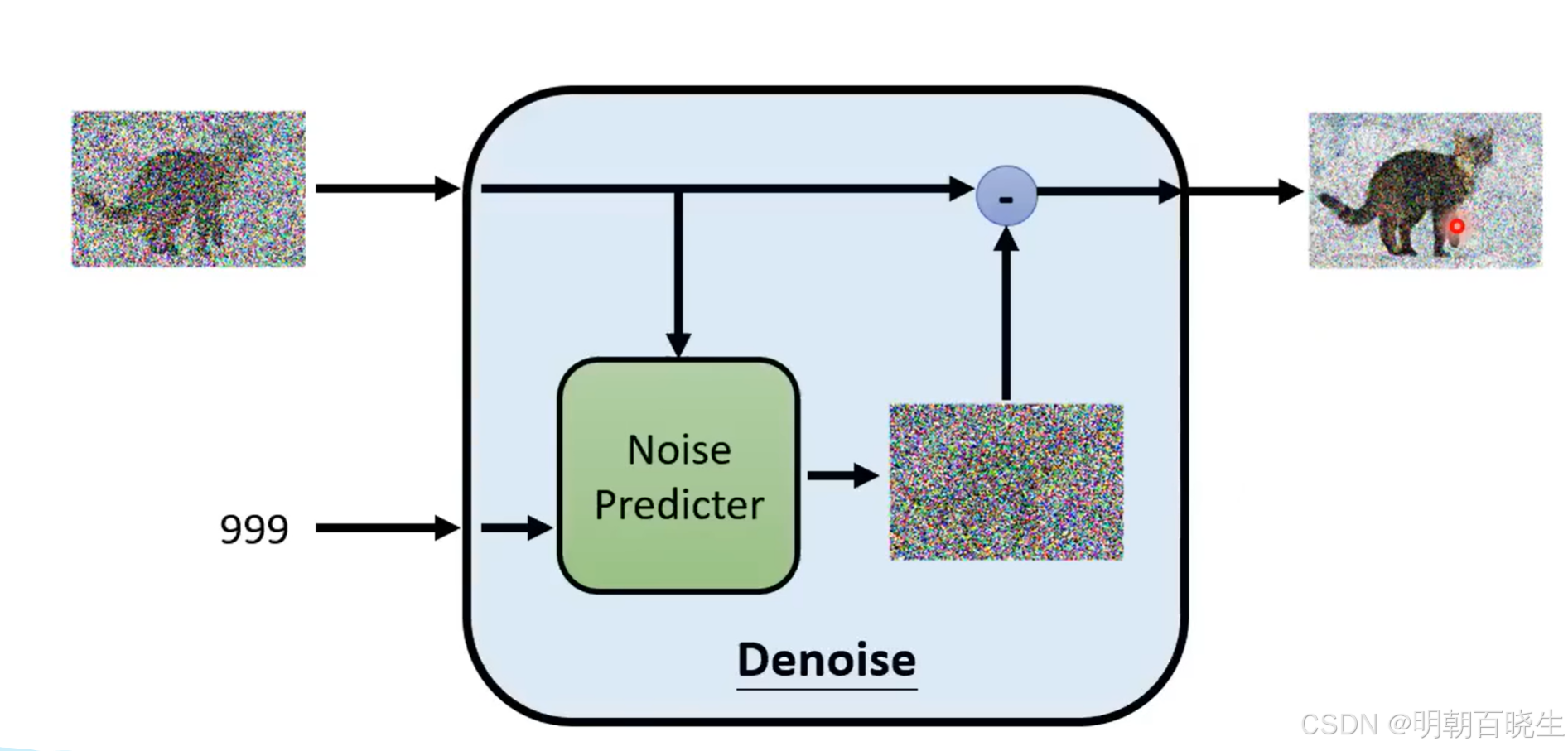
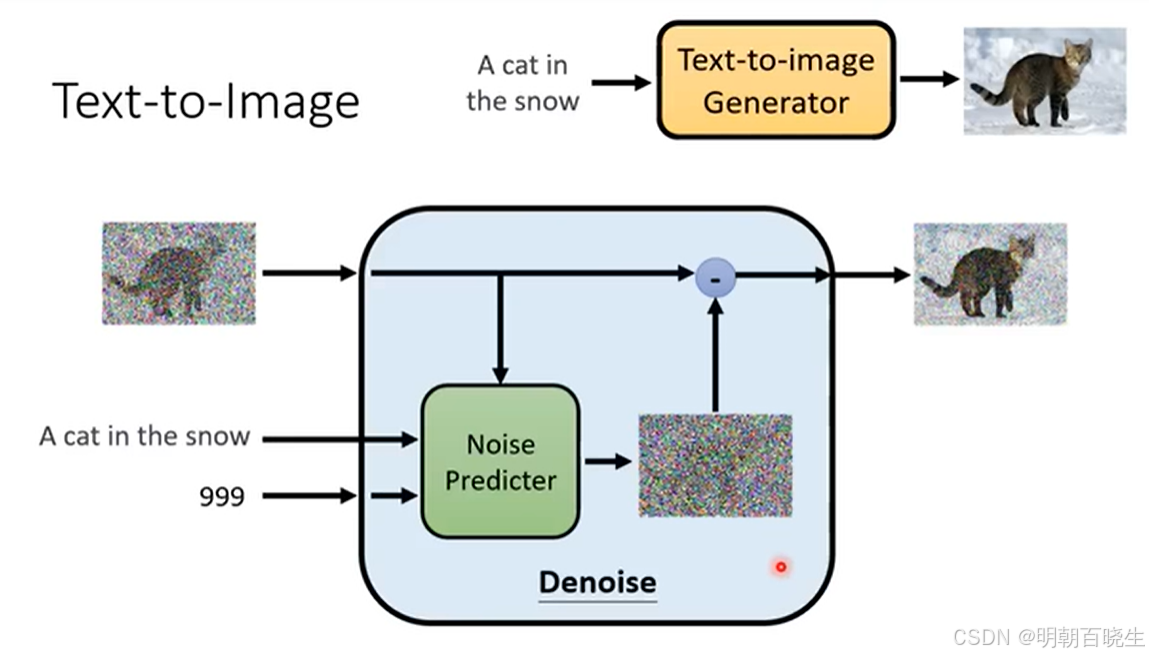
1.2 Denoise Model

输入:
图片X + step(噪声的严重程度)
内部架构
首先通过Noise Predicter 预测出噪声图片N,然后把输入图片X减去噪声图片N
得到输出
1.3 Noise Predicter 模块
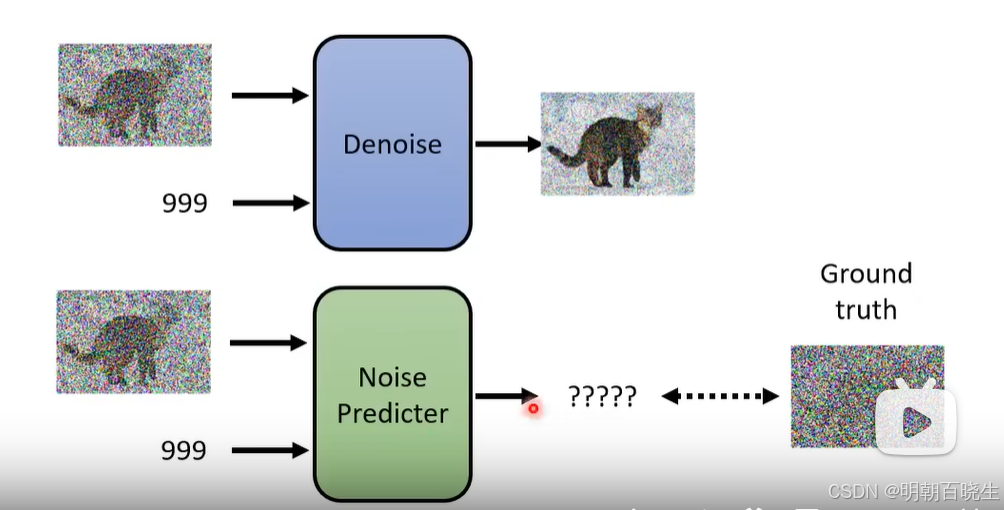
1.3.1 问题:
Noise Predicter 模型如何得到训练的数据集
1.3.2 解决方法:
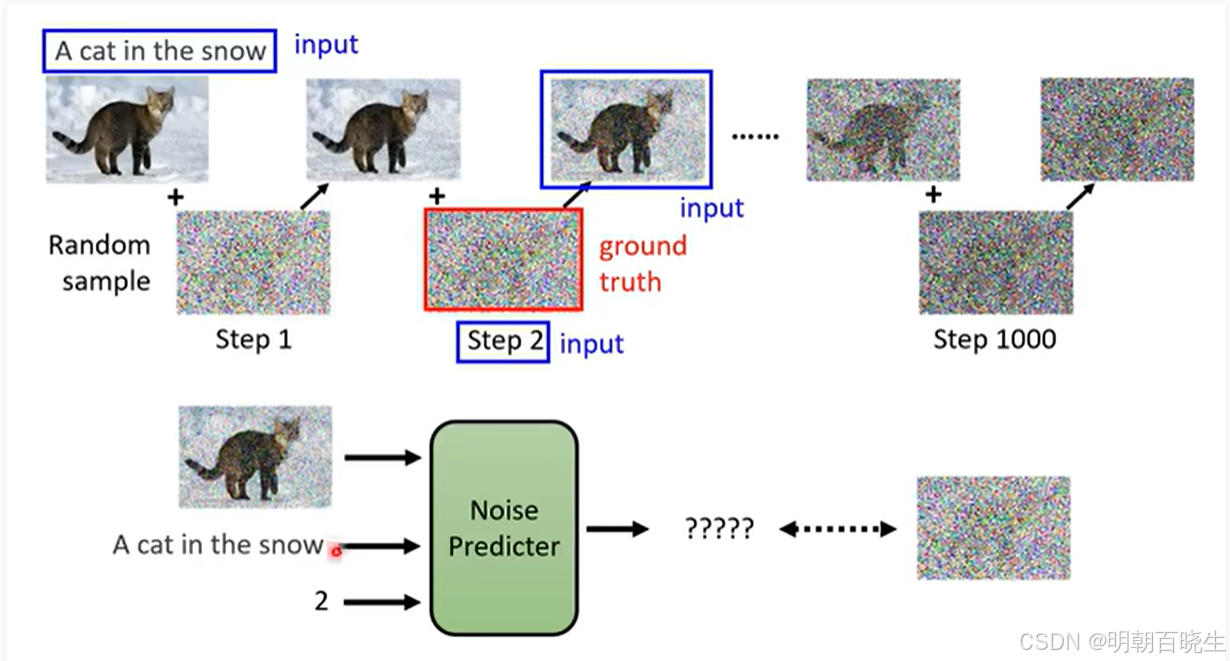
Forward Process or Diffusion Process
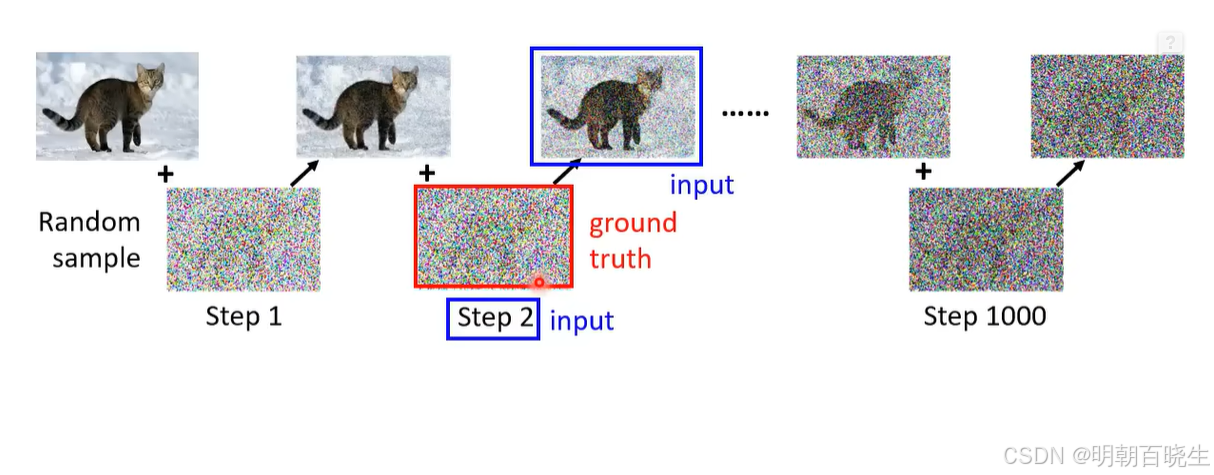
原始图片:
step1: 随机采样了噪声
, 输出
step2:随机采样了噪声
, 输出
Step3: 随机采样了噪声
, 输出
依次类推,得到对应的训练集
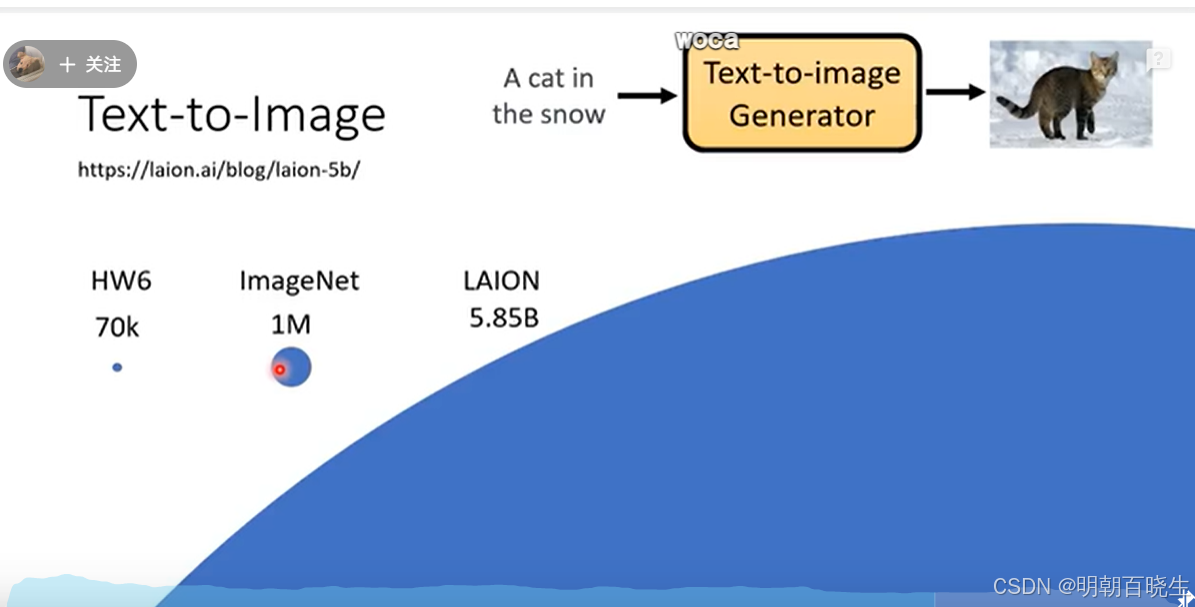
二 Text to Image
文字如何生成图片
2.1 数据集
ImageNet LAION
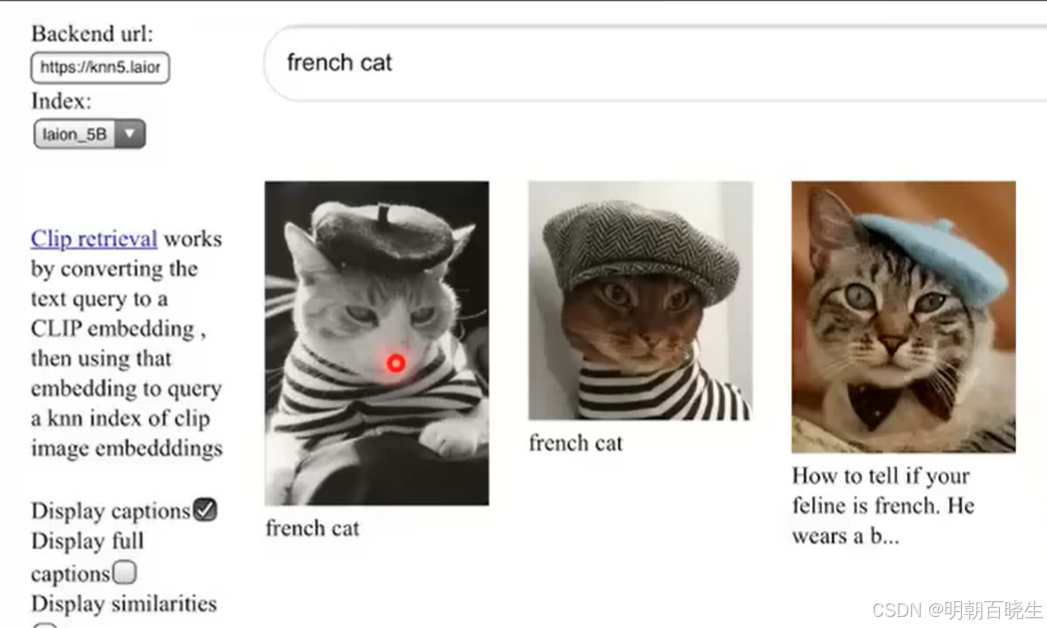
2.1 Denoise 流程
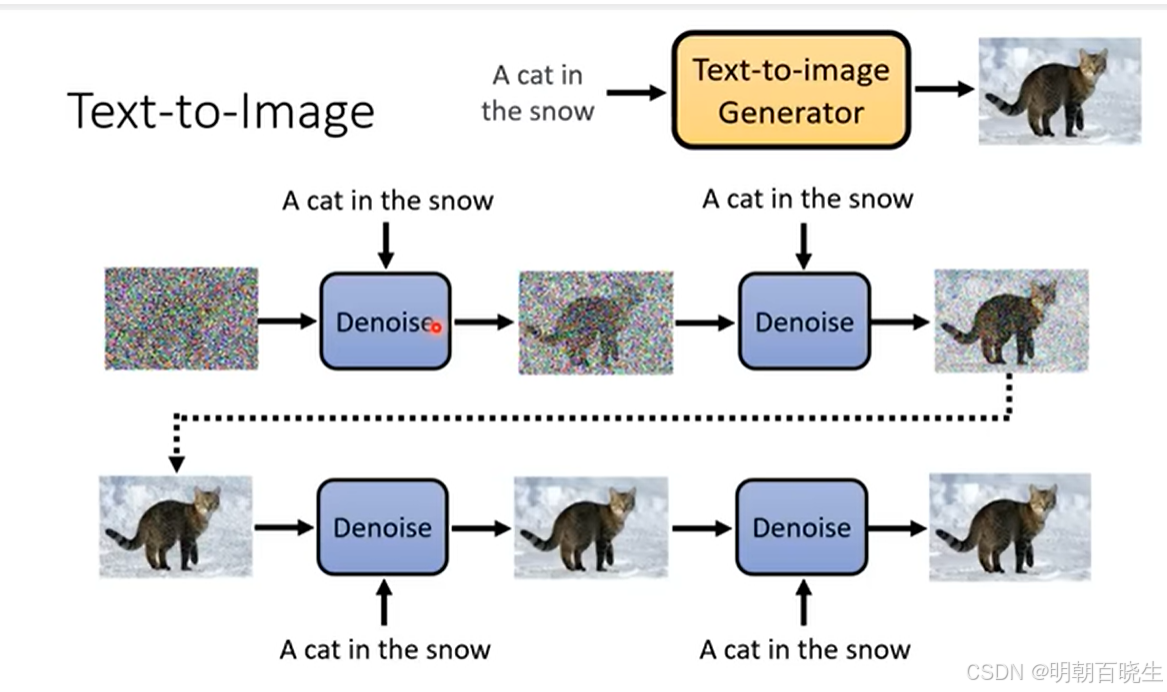
输入:
文字,step, 图片
输出:
迭代输出图片
2.2 Denoise 模型
2.3 算法

Diffusion Model:比“GAN"还要牛逼的图像生成模型!论文精读+公式推导,迪哥2小时带你吃透扩散模型!_哔哩哔哩_bilibili
论文研读之Diffusion+Transformer时序生成:用于一般时序生成的可解释扩散模型_哔哩哔哩_bilibili 扩散模型 - Diffusion Model【李宏毅2023】_哔哩哔哩_bilibili
【斯坦福吴恩达】2024公认的最好的扩散模型原理课程-How Diffusion Models Work~_哔哩哔哩_bilibili