介绍
大家好,博主又来给大家分享知识了。一直以来,我都非常感激大家对我的支持与鼓励,大家的点赞、关注和收藏,不仅是对博主分享内容的认可,更是博主不断创作、坚持分享知识的永恒动力。
今天给大家分享的内容是使用LangChain进行大模型应用开发中的LangGraph,那么什么是LangGraph呢?我们直接进入正题。
LangGraph
LangGraph概述
LangGraph是一个用于借助大语言模型(LLMs)构建有状态的、多主体应用程序的库,可用于创建智能体和多智能体工作流程。
LangGraph的灵感源自Pregel和Apache Beam。其公开接口借鉴了NetworkX的设计思路。LangGraph由LangChain的开发者——LangChain公司所开发,但即便不使用LangChain,也能运用LangGraph。
大家可选看:
- Pregel:它是一种用于大规模图处理的分布式计算模型,由谷歌公司开发并在2010年左右提出,常用于处理超大规模的图数据,它为大规模图处理提供了一种高效、灵活且易于编程的解决方案,在许多领域都有广泛的应用。
- Apache Beam:它是一个统一的开源编程模型,用于定义和执行数据处理工作流,支持批处理和流处理,可在多种分布式执行环境中运行。Apache Beam为数据处理提供了一个强大、灵活且可移植的编程模型,适用于各种数据处理场景,无论是批处理还是流处理,都能帮助开发者高效地实现数据处理工作流。
- NetworkX:它是一个用Python语言编写的用于创建、操作和研究复杂网络的结构、动力学和功能的开源库。NetworkX为研究和分析复杂网络提供了一个强大而灵活的工具,广泛应用于各个领域的网络研究和分析中。
LangGraph优势
LangGraph使我们能够对智能体应用程序的流程和状态进行细粒度的控制。它实现了一个中央持久层,具备了大多数智能体架构共有的功能:
- 记忆功能:LangGraph可以持久保存应用程序状态的任意方面,支持保存对话的记忆,以及用户交互过程中及不同交互之间的其他更新内容。
- 人工介入:由于状态会被保存检查点,执行过程可以被中断和恢复,从而允许在关键阶段通过人工输入来进行决策、验证和修正。
LangGraph是LangChain的高级库,为大型语言模型(LLM)带来循环计算能力。它超越了LangChain的线性工作流,通过循环支持复杂的任务处理。
- 状态:维护计算过程中的上下文,实现基于累积数据的动态决策。
- 节点:代表计算步骤,执行特定任务,可定制以适应不同工作流。
- 边:连接节点,定义计算流程,支持条件逻辑,实现复杂工作流。
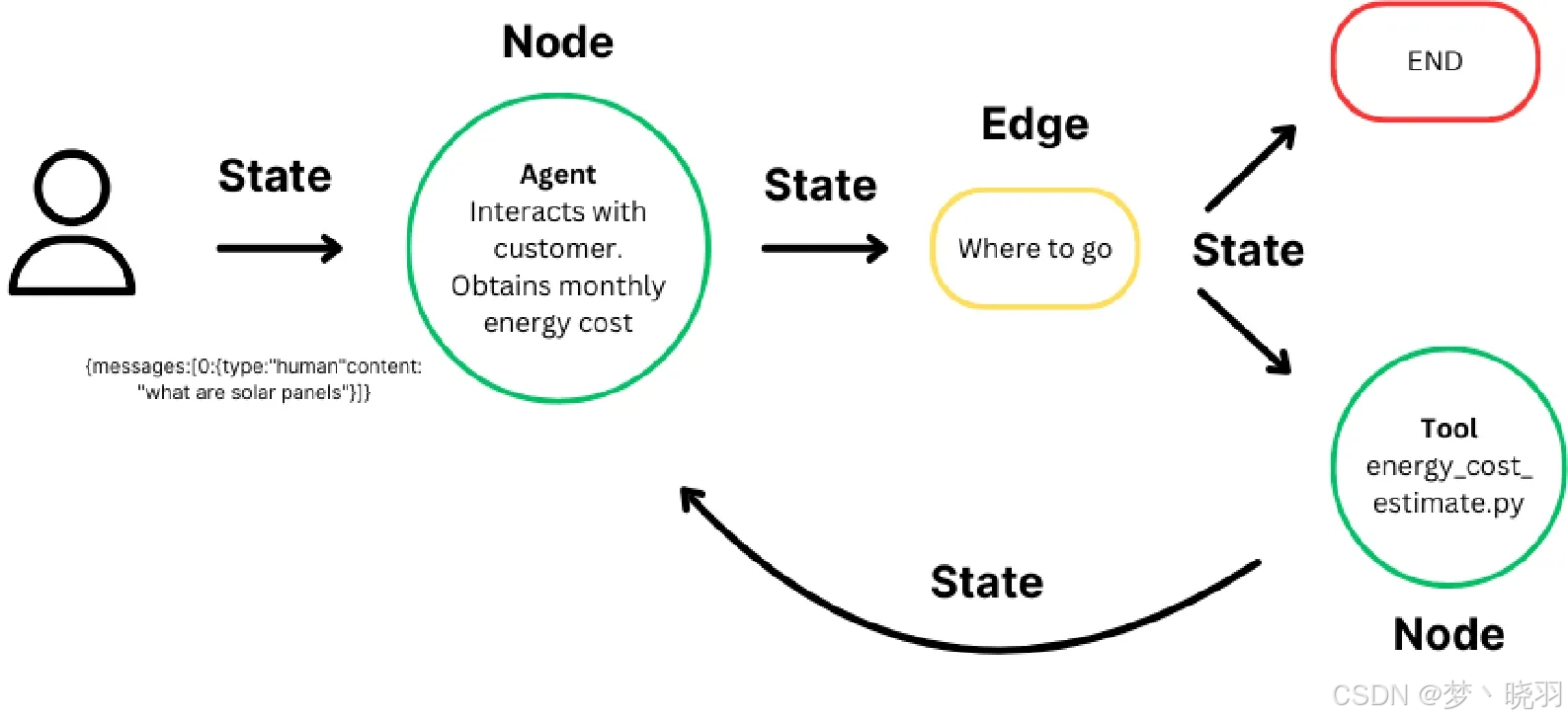
对这些组件进行标准化,能让个人和团队专注于智能体的行为本身,而非其支持性的基础设施。通过LangGraph平台,LangGraph还提供了用于开发、部署、调试和监控应用程序的工具。
LangGraph可与LangChain和LangSmith无缝集成(但并非必须使用它们)。
LangGraph平台
LangGraph平台是用于部署LangGraph智能体的基础设施。它是一个将智能体应用程序部署到生产环境的商业解决方案,构建在开源的LangGraph框架之上。
LangGraph平台由多个组件组成,这些组件协同工作,为LangGraph应用程序的开发、部署、调试和监控提供支持,包括:LangGraph服务器(提供应用程序编程接口)、LangGraph软件开发工具包(用于调用这些接口的客户端)、LangGraph命令行界面(用于构建服务器的命令行工具)以及LangGraph工作室(用户界面兼调试器)。
LangGraph平台的优势是它能够解决这些问题:
- 流式传输支持:LangGraph服务器提供多种流式传输模式,针对各种应用程序需求进行了优化。
- 后台运行:可在后台以异步方式运行智能体。
- 支持长时间运行的智能体:具备能够处理长时间运行进程的基础设施。
- 重复消息处理:处理在智能体做出响应之前收到用户两条消息的情况。
- 应对突发流量:设有任务队列,即使在高负载情况下也能确保请求得到一致处理而不丢失。
LangGraph安装
我们使用pip命令安装,安装命令为:
pip install langgraphLangGraph入门示例
我们利用LangGraph和LangChain构建了一个基于大语言模型的问答工作流应用,实现与用户进行多轮对话并根据用户问题调用工具查询信息的功能。
我们构建一个简单的问答系统,通过工作流的方式管理对话流程,根据用户问题调用工具获取信息,并使用语言模型生成回复。
完整代码
# 导入Literal类型,用于类型注解,指定方法返回值只能是特定的几个值
from typing import Literal
# 从langchain_core.messages模块导入HumanMessage类,用于表示人类输入的消息
from langchain_core.messages import HumanMessage
# 从langchain_core.tools模块导入tool装饰器,用于将方法转换为工具
from langchain_core.tools import tool
# 从langchain_openai模块导入ChatOpenAI类,用于调用OpenAI的聊天模型
from langchain_openai import ChatOpenAI
# 从langgraph.checkpoint.memory模块导入MemorySaver类,用于保存工作流的状态
from langgraph.checkpoint.memory import MemorySaver
# 从langgraph.graph模块导入END常量、StateGraph类和MessagesState类,用于构建工作流图和管理消息状态
from langgraph.graph import END, StateGraph, MessagesState
# 从langgraph.prebuilt模块导入ToolNode类,用于创建工具节点
from langgraph.prebuilt import ToolNode
# 使用tool装饰器将search方法转换为工具
@tool
def search(query: str):
"""模拟一个搜索工具"""
# 如果查询中包含“北京”或“Beijing”
if "北京" in query.lower() or "Beijing" in query.lower():
# 返回北京的天气信息
return "现在31度,有风."
# 否则返回默认的天气信息
return "现在是35度,万里无云。"
# 将search工具添加到列表中
tools = [search]
# 创建一个工具节点,用于处理工具调用
tool_node = ToolNode(tools)
# 初始化一个ChatOpenAI模型实例,使用gpt-3.5-turbo模型,设置temperature=0不考虑随机性,并将工具绑定到模型上
chat_model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0).bind_tools(tools)
# 定义一个方法,用于判断是否需要继续调用工具
def should_continue(state: MessagesState) -> Literal["tools", END]:
# 从状态中获取消息列表
messages = state['messages']
# 获取最后一条消息
last_message = messages[-1]
# 如果最后一条消息包含工具调用
if last_message.tool_calls:
# 返回"tools",表示需要继续调用工具
return "tools"
# 否则返回END,表示工作流结束
return END
# 定义一个方法,用于调用语言模型处理消息
def call_model(state: MessagesState):
# 从状态中获取消息列表
messages = state['messages']
# 调用语言模型处理消息
response = chat_model.invoke(messages)
# 返回包含模型响应的新状态
return {"messages": [response]}
# 创建一个StateGraph实例,用于定义工作流的状态转换
workflow = StateGraph(MessagesState)
# 向工作流中添加一个名为"agent"的节点,该节点执行call_model方法
workflow.add_node("agent", call_model)
# 向工作流中添加一个名为"tools"的节点,该节点执行tool_node
workflow.add_node("tools", tool_node)
# 设置"agent"节点为工作流的入口点
workflow.set_entry_point("agent")
# 为"agent"节点添加条件边,根据should_continue方法的返回值决定流向
workflow.add_conditional_edges(
"agent",
should_continue,
)
# 添加从"tools"节点到"agent"节点的边,使得工具调用完成后回到"agent"节点继续处理
workflow.add_edge("tools", 'agent')
# 创建一个MemorySaver实例,用于保存工作流的状态
checkpointer = MemorySaver()
# 使用checkpointer编译工作流,生成可执行的应用
app = workflow.compile(checkpointer=checkpointer)
# 调用应用,传入用户的问题和配置信息
final_state = app.invoke(
{"messages": [HumanMessage(content="北京的天气怎么样?")]},
config={"configurable": {"thread_id": 21}}
)
# 从最终状态中提取模型的回复内容
result = final_state["messages"][-1].content
# 打印模型的回复
print(result)
# 再次调用应用,传入新的用户问题和配置信息
final_state = app.invoke(
{"messages": [HumanMessage(content="我问的哪个城市?")]},
config={"configurable": {"thread_id": 21}}
)
# 从最终状态中提取模型的回复内容
result = final_state["messages"][-1].content
# 打印模型的回复
print(result)运行结果
北京的天气现在是31度,有风。
您问的是北京城市的天气情况。
进程已结束,退出代码为 0运行示例分析
定义工作流控制方法
def should_continue(state: MessagesState) -> Literal["tools", END]:
messages = state['messages']
last_message = messages[-1]
if last_message.tool_calls:
return "tools"
return END
def call_model(state: MessagesState):
messages = state['messages']
response = chat_model.invoke(messages)
return {"messages": [response]}- should_continue方法:根据当前对话状态判断是否需要继续调用工具。如果最后一条消息包含工具调用,则返回"tools"继续调用工具;否则返回END表示工作流结束。
- call_model方法:从传入的状态中获取消息列表,调用 chat_model 处理消息,并返回包含模型响应的新状态。
构建工作流
workflow = StateGraph(MessagesState)
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)
workflow.set_entry_point("agent")
workflow.add_conditional_edges(
"agent",
should_continue,
)
workflow.add_edge("tools", 'agent')- 创建一个StateGraph实例workflow,用于定义工作流的状态转换。
- 添加两个节点:"agent" 节点执行call_model函数,"tools"节点执行tool_node。
- 设置"agent"节点为工作流的入口点。
- 为"agent"节点添加条件边,根据should_continue函数的返回值决定流向。
- 添加从"tools"节点到"agent"节点的边,使工具调用完成后回到"agent"节点继续处理。
编译工作流并保存状态
checkpointer = MemorySaver()
app = workflow.compile(checkpointer=checkpointer)- 创建一个MemorySaver实例checkpointer,用于保存工作流的状态。
- 使用checkpointer编译工作流workflow,生成可执行的应用app。
处理用户问题
final_state = app.invoke(
{"messages": [HumanMessage(content="北京的天气怎么样?")]},
config={"configurable": {"thread_id": 21}}
)
result = final_state["messages"][-1].content
print(result)
final_state = app.invoke(
{"messages": [HumanMessage(content="我问的哪个城市?")]},
config={"configurable": {"thread_id": 21}}
)
result = final_state["messages"][-1].content
print(result)- 两次调用app的invoke方法,分别传入不同的用户问题和相同的配置信息,获取工作流的最终状态。
- 从最终状态中提取模型的回复内容并打印输出,实现与用户的交互。
LangGraph智能体工作流构建管理者
- 在上面代码中,config={"configurable": {"thread_id": 21}}中的"thread_id": 21起到唯一标识一次对话流程的作用。thread_id可理解为“对话线程ID”,如同专属编号,标记特定的对话线程,这里的21就是该对话线程对应的编号。
- 代码中两次调用app.invoke方法时都传入相同的thread_id(即21),这表明这两次调用属于同一轮对话。系统基于此thread_id保存和恢复对话状态,确保两次调用间的数据和上下文相互关联。
- 从运行结果可知,第二次app.invoke传入相同thread_id,系统能依据该标识找到对应的对话上下文,这些上下文通过保存的状态(即存储的消息列表)留存,从而让智能体根据上下文准确回答用户问题(如确定用户询问的城市是北京)。
结合实际应用,LangGraph的作用主要体现在以下几个方面:
- 构建工作流:通过StateGraph类构建工作流图,定义了节点(如 “agent” 节点用于调用语言模型处理消息,“tools”节点用于处理工具调用)和边(包括条件边和普通边,决定工作流的流向和执行顺序),清晰地描述了智能体应用的执行流程,实现了从用户输入到调用工具、语言模型,再到生成回复的有序操作。
- 管理对话状态:借助MessagesState管理消息状态,在工作流中传递和处理消息,同时使用MemorySaver保存工作流的状态,确保在应用运行过程中可以记录中间状态,方便后续恢复或调试,保障对话的连续性和上下文的关联。
- 创建工具节点:利用ToolNode创建工具节点,使得在工作流中可以调用各种工具(如模拟的搜索工具),辅助智能体完成任务,根据用户输入动态调用工具获取信息,增强了智能体处理复杂任务的能力。
- 实现应用架构可扩展可管理:通过定义节点、边和状态保存机制,搭建起一个可扩展、可管理的应用架构,使得智能体应用能够根据用户的输入灵活地调用工具和语言模型,完成复杂的任务,并且便于对整个应用进行管理和维护。
结束
好了,以上就是本次分享的全部内容了。希望大家对LangGraph有一定的了解和掌握,本次分享只是对LangGraph的一个入门讲解,让大家对它有个概念,然后通过示例代码来给大家演示如何去使用它的功能。
LangGraph是一个用于构建具有LLMs的有状态、多角色应用程序的库,用于创建智能体和多智能体工作流。与其他LLM框架相比,它提供了循环、可控性和持久性的核心优势。
LangGraph允许我们定义涉及循环的流程,这对于大多数智能体架构至关重要。作为一种非常底层的框架,它提供了对应用程序的流程和状态的精细控制,这对创建可靠的智能体至关重要。此外,LangGraph包含内置的持久性,可以实现高级的 “人机交互” 和内存功能。
那么本次分享就到这里了。最后,博主还是那句话:请大家多去大胆的尝试和使用,成功总是在不断的失败中试验出来的,敢于尝试就已经成功了一半。如果大家对博主分享的内容感兴趣或有帮助,请点赞和关注。大家的点赞和关注是博主持续分享的动力🤭,博主也希望让更多的人学习到新的知识。